前言
LeetCode刷题指南
题目分类及刷题顺序推荐
一、数组
| 题目分类 | 题目编号 |
|---|---|
| 数组的遍历 | 485、495、414、628 |
| 统计数组中的元素 | 645、697、448、442、41、274 |
| 数组的改变、移动 | 453、665、283 |
| 二维数组及滚动数组 | 118、119、661、598、419 |
| 数组的旋转 | 189、396 |
| 特定顺序遍历二维数组 | 54、59、498 |
| 二维数组变换 | 566、48、73、289 |
| 前缀和数组 | 303、304、238 |
二、字符串
| 题目分类 | 题目编号 |
|---|---|
| 字符 | 520 |
| 回文串的定义 | 125 |
| 公共前缀 | 14 |
| 单词 | 434、58 |
| 字符串的反转 | 344、541、557、151 |
| 字符的统计 | 387、389、383、242、49、451、423、657、551、696、467、535 |
| 数字与字符串间转换 | 299、412、506、539、553、537、592、640、38、443、8、13、12、273、165、481 |
| 子序列 | 392、524、521、522 |
| 高精度运算 | 66、67、415、43、306 |
| 字符串变换 | 482、6、68 |
| 字符串匹配 | 28、686、459、214 |
| 中心拓展法 | 5、647 |
三、数与位
| 题目分类 | 题目编号 |
|---|---|
| 数字的位操作 | 7、9、479、564、231、342、326、504、263、190、191、476、461、477、693、393、172、458、258、319、405、171、168、670、233、357、400 |
| 简单数学题 | 492、29、507 |
| 快速幂 | 50、372 |
四、栈与递归
| 题目分类 | 题目编号 |
|---|---|
| 用栈访问最后若干元素 | 682、71、388 |
| 栈与计算器 | 150、227、224 |
| 栈与括号匹配 | 20、636、591、32 |
| 递归 | 385、341、394 |
五、链表
| 题目分类 | 题目编号 |
|---|---|
| 链表的删除 | 203、237、19 |
| 链表的遍历 | 430 |
| 链表的旋转与反转 | 61、24、206、92、25 |
| 链表高精度加法 | 2、445 |
| 链表的合并 | 21、23 |
六、哈希表
| 题目分类 | 题目编号 |
|---|---|
| 哈希表的查找、插入及删除 | 217、633、349、128、202、500、290、532、205、166、466、138 |
| 哈希表与索引 | 1、167、599、219、220 |
| 哈希表与统计 | 594、350、554、609、454、18 |
| 哈希表与前缀和 | 560、523、525 |
七、贪心算法
| 题目分类 | 题目编号 |
|---|---|
| 数组与贪心算法 | 605、121、122、561、455、575、135、409、621、179、56、57、228、452、435、646、406、48、169、215、75、324、517、649、678、420 |
| 子数组与贪心算法 | 53、134、581、152 |
| 子序列与贪心算法 | 334、376、659 |
| 数字与贪心 | 343 |
| 单调栈法 | 496、503、456、316、402、321、84、85 |
八、双指针法
| 题目分类 | 题目编号 |
|---|---|
| 头尾指针 | 345、680、167、15、16、18、11、42 |
| 同向双指针、滑动窗口 | 27、26、80、83、82、611、187、643、674、209、3、438、567、424、76、30 |
| 分段双指针 | 86、328、160、88、475 |
| 快慢指针 | 141、142、143、234、457、287 |
九、树
| 题目分类 | 题目编号 |
|---|---|
| 树与递归 | 100、222、101、226、437、563、617、508、572、543、654、687、87 |
| 树的层次遍历 | 102、429、690、559、662、671、513、515、637、103、107、257、623、653、104、111、112、113、129、404、199、655、116、117 |
| 树的前序遍历 | 144、589 |
| 树的前序序列化 | 606、331、652、297、449 |
| 树的后序遍历 | 145、590 |
| 树的中序遍历与二叉搜索树 | 94、700、530、538、230、98、173、669、450、110、95、108、109 |
| 重构二叉树 | 105、106 |
| 二叉树的展开 | 114 |
| 最近公共祖先 | 235、236 |
| Morris中序遍历 | 501、99 |
| 四叉树 | 558、427 |
十、图与搜索
| 题目分类 | 题目编号 |
|---|---|
| 图的建立与应用 | 565 |
| 深度优先搜索 | 17、397 |
| 回溯法 | 526、401、36、37、51、52、77、39、216、40、46、47、31、556、60、491、78、90、79、93、332 |
| 回溯法与表达式 | 241、282、679 |
| 回溯法与括号 | 22、301 |
| 回溯法与贪心 | 488 |
| 广度优先搜索 | 133、200、695、463、542、130、417、529、127、126、433、675 |
| 并查集 | 547、684、685 |
| 拓扑排序 | 399、207、210 |
| 有限状态自动机 | 65、468 |
十一、二分查找
| 题目分类 | 题目编号 |
|---|---|
| 二分查找应用(简单) | 374、35、278、367、69、441 |
| 二分查找应用(中等) | 34、540、275、436、300、354、658、162、4 |
| 二分查找与旋转数组 | 153、154、33、81 |
| 二分查找与矩阵 | 74、240 |
| 二分答案法 | 378、668、410、483 |
十二、二进制运算的应用
| 题目分类 | 题目编号 |
|---|---|
| 异或的应用 | 89、136、137、260、268 |
| 与或非的应用 | 371、318、201 |
十三、动态规划
| 题目分类 | 题目编号 |
|---|---|
| 数组中的动态规划 | 509、70、338、45、55、198、213、650、91、639、552、123、188、309、32、264、313、403 |
| 子数组、子序列中的动态规划 | 689、413、446、368、416、279 |
| 背包问题 | 322、518、474、494、377 |
| 矩阵中的动态规划 | 62、63、64、120、576、688、221、629、174、96、329 |
| 动态规划与字符串匹配 | 583、72、97、115、516、132、131、139、140、514、10、44 |
| 状态压缩动态规划 | 464、691、698、638、473 |
| 区间中的动态规划 | 486、664、375、312、546 |
| 树形dp | 337、124 |
| 数位dp | 233、600 |
十四、数据结构
| 题目分类 | 题目编号 |
|---|---|
| 数据结构设计——栈与队列 | 225、232、284、622、641、155 |
| 数据结构设计——哈希表 | 676、355、380、381 |
| 数据结构设计——哈希与双向链表 | 432、146、460 |
| 前缀树 | 208、211、648、386、677、472、421、212、336、440 |
| 堆 | 23、373、378、632、347、692、502、630、407、295、480 |
| 树状数组 | 307、315、493、327、673 |
| 线段树 | 699 |
| 平衡树(set/map) | 352、218、363 |
十五、采样
| 题目分类 | 题目编号 |
|---|---|
| 按权值采样 | 528、497 |
| 蓄水池抽样 | 382、398 |
| 拒绝采样 | 470、478、519 |
十六、计算几何
| 题目分类 | 题目编号 |
|---|---|
| 计算几何基础 | 593、447、223、149 |
| 分类讨论法 | 335 |
| 凸包 | 587 |
| 覆盖问题 | 391 |
十七、常用技巧与算法
| 题目分类 | 题目编号 |
|---|---|
| 博弈论 | 292 |
| 分块 | 239、164 |
| 倍增法 | 330 |
| 拓展欧几里得算法 | 365 |
| 洗牌算法 | 384 |
| 找规律 | 390、672 |
| 分治法 | 395、667 |
| 排序算法 | 147、148 |
| 线性筛 | 204 |
| 摩尔投票法 | 229 |
数组
数组理论基础
数组是存放在连续内存空间上的相同类型数据的集合。
数组可以方便的通过下标索引的方式获取到下标对应的数据。
需要两点注意的是
- 数组下标都是从0开始的。
- 数组内存空间的地址是连续的
正是因为数组在内存空间的地址是连续的,所以我们在删除或者增添元素的时候,就难免要移动其他元素的地址。
数组的元素是不能删的,只能覆盖。
那么二维数组在内存的空间地址是连续的么?
不同编程语言的内存管理是不一样的,以C++为例,在C++中二维数组是连续分布的。
数组与双指针
- 26. Remove Duplicates from Sorted Array
- 27. Remove Element
- 88. Merge Sorted Array
- 977. Squares of a Sorted Array
26. Remove Duplicates from Sorted Array
Given an integer array nums sorted in non-decreasing order, remove the duplicates in-place such that each unique element appears only once. The relative order of the elements should be kept the same. Then return the number of unique elements in nums.
Consider the number of unique elements of nums to be k, to get accepted, you need to do the following things:
- Change the array
numssuch that the firstkelements ofnumscontain the unique elements in the order they were present innumsinitially. The remaining elements ofnumsare not important as well as the size ofnums. - Return
k.
Example 1:
**Input:** nums = [1,1,2]
**Output:** 2, nums = [1,2,_]
**Explanation:** Your function should return k = 2, with the first two elements of nums being 1 and 2 respectively.
It does not matter what you leave beyond the returned k (hence they are underscores).
Example 2:
**Input:** nums = [0,0,1,1,1,2,2,3,3,4]
**Output:** 5, nums = [0,1,2,3,4,_,_,_,_,_]
**Explanation:** Your function should return k = 5, with the first five elements of nums being 0, 1, 2, 3, and 4 respectively.
It does not matter what you leave beyond the returned k (hence they are underscores).
Constraints:
1 <= nums.length <= 3 * 104-100 <= nums[i] <= 100numsis sorted in non-decreasing order.
思路
仿照移除元素,使用快慢指针移除重复元素
C++解法
class Solution {
public:
int removeDuplicates(vector<int>& nums) {
int j = 1;
for(int i = 1; i < nums.size(); i++){
if(nums[i] != nums[i - 1]){
nums[j] = nums[i];
j++;
}
}
return j;
}
};
Java解法
class Solution {
public int removeDuplicates(int[] nums) {
int j = 1;
for (int i = 1; i < nums.length; i++) {
if (nums[i] != nums[i - 1]) {
nums[j] = nums[i];
j++;
}
}
return j;
}
}
Python3解法
class Solution:
def removeDuplicates(self, nums: List[int]) -> int:
j = 1
for i in range(1, len(nums)):
if nums[i] != nums[i - 1]:
nums[j] = nums[i]
j += 1
return j
Go解法
func removeDuplicates(nums []int) int {
slow := 1
for fast := 1; fast < len(nums); fast = fast + 1{
if nums[fast] != nums[fast - 1]{
nums[slow] = nums[fast]
slow = slow + 1
}
}
return slow
}
注意:这里LeetCode背后的数组格式是左闭右开的,即返回数组的索引范围是[0, slow-1]
27. Remove Element
Given an integer array nums and an integer val, remove all occurrences of val in nums in-place. The order of the elements may be changed. Then return the number of elements in nums which are not equal to val.
Consider the number of elements in nums which are not equal to val be k, to get accepted, you need to do the following things:
- Change the array
numssuch that the firstkelements ofnumscontain the elements which are not equal toval. The remaining elements ofnumsare not important as well as the size ofnums. - Return
k.
Example 1:
**Input:** nums = [3,2,2,3], val = 3
**Output:** 2, nums = [2,2,_,_]
**Explanation:** Your function should return k = 2, with the first two elements of nums being 2.
It does not matter what you leave beyond the returned k (hence they are underscores).
Example 2:
**Input:** nums = [0,1,2,2,3,0,4,2], val = 2
**Output:** 5, nums = [0,1,4,0,3,_,_,_]
**Explanation:** Your function should return k = 5, with the first five elements of nums containing 0, 0, 1, 3, and 4.
Note that the five elements can be returned in any order.
It does not matter what you leave beyond the returned k (hence they are underscores).
Constraints:
0 <= nums.length <= 1000 <= nums[i] <= 500 <= val <= 100
思路
双指针(快慢指针)
C++解法
class Solution {
public:
int removeElement(vector<int>& nums, int val) {
int size = nums.size();
int slow = 0;
for(int fast = 0; fast < size; fast++)
{
if(nums[fast] != val)
{
nums[slow++] = nums[fast];
}
}
return slow;
}
};
Java解法
class Solution {
public int removeElement(int[] nums, int val) {
int index = 0;
for (int i = 0; i < nums.length; i++) {
if (nums[i] != val) {
nums[index] = nums[i];
index++;
}
}
return index;
}
}
Python3解法
class Solution:
def removeElement(self, nums: List[int], val: int) -> int:
index = 0
for i in range(len(nums)):
if nums[i] != val:
nums[index] = nums[i]
index += 1
return index
Go解法
func removeElement(nums []int, val int) int {
slow := 0
for fast := 0; fast < len(nums); fast = fast + 1{
if nums[fast] != val{
nums[slow] = nums[fast]
slow = slow + 1
}
}
return slow
}
另一种解法:
func removeElement(nums []int, val int) int {
i := 0
for _, v := range nums {
if v != val {
nums[i] = v
i++
}
}
return i
}
88. Merge Sorted Array
You are given two integer arrays nums1 and nums2, sorted in non-decreasing order, and two integers m and n, representing the number of elements in nums1 and nums2 respectively.
Merge nums1 and nums2 into a single array sorted in non-decreasing order.
The final sorted array should not be returned by the function, but instead be stored inside the array nums1. To accommodate this, nums1 has a length of m + n, where the first m elements denote the elements that should be merged, and the last n elements are set to 0 and should be ignored. nums2 has a length of n.
Example 1:
**Input:** nums1 = [1,2,3,0,0,0], m = 3, nums2 = [2,5,6], n = 3
**Output:** [1,2,2,3,5,6]
**Explanation:** The arrays we are merging are [1,2,3] and [2,5,6].
The result of the merge is [1,2,2,3,5,6] with the underlined elements coming from nums1.
Example 2:
**Input:** nums1 = [1], m = 1, nums2 = [], n = 0
**Output:** [1]
**Explanation:** The arrays we are merging are [1] and [].
The result of the merge is [1].
Example 3:
**Input:** nums1 = [0], m = 0, nums2 = [1], n = 1
**Output:** [1]
**Explanation:** The arrays we are merging are [] and [1].
The result of the merge is [1].
Note that because m = 0, there are no elements in nums1. The 0 is only there to ensure the merge result can fit in nums1.
Constraints:
nums1.length == m + nnums2.length == n0 <= m, n <= 2001 <= m + n <= 200-10^9 <= nums1[i], nums2[j] <= 10^9
Follow up: Can you come up with an algorithm that runs in O(m + n) time?
思路
基本解法:复制nums2的内容到nums1中,然后排序,此时Time Complexity为
C++解法
class Solution {
public:
void merge(vector<int>& nums1, int m, vector<int>& nums2, int n) {
for(int i = m, j = 0; i< nums1.size() && j < n; i++, j++){
nums1[i] = nums2[j];
}
sort(nums1.begin(), nums1.end());
}
};
Java解法
class Solution {
public void merge(int[] nums1, int m, int[] nums2, int n) {
for (int j = 0, i = m; j < n; j++) {
nums1[i] = nums2[j];
i++;
}
Arrays.sort(nums1);
}
}
Python3解法
class Solution:
def merge(self, nums1: List[int], m: int, nums2: List[int], n: int) -> None:
"""
Do not return anything, modify nums1 in-place instead.
"""
for j in range(n):
nums1[m + j] = nums2[j]
nums1.sort()
Go解法
func merge(nums1 []int, m int, nums2 []int, n int) {
for i, j := m, 0; i < len(nums1) && j < n; i, j = i + 1, j + 1{
nums1[i] = nums2[j]
}
sort.Ints(nums1)
}
977. Squares of a Sorted Array
Given an integer array nums sorted in non-decreasing order, return an array of the squares of each number sorted in non-decreasing order.
Example 1:
**Input:** nums = [-4,-1,0,3,10]
**Output:** [0,1,9,16,100]
**Explanation:** After squaring, the array becomes [16,1,0,9,100].
After sorting, it becomes [0,1,9,16,100].
Example 2:
**Input:** nums = [-7,-3,2,3,11]
**Output:** [4,9,9,49,121]
Constraints:
1 <= nums.length <= 10^4-10^4 <= nums[i] <= 10^4numsis sorted in non-decreasing order.
思路
方法一:原地平方然后排序
方法二:双指针(左右指针)
C++解法
方法一:
class Solution {
public:
vector<int> sortedSquares(vector<int>& nums) {
for (int i = 0; i < nums.size(); i++) {
nums[i] *= nums[i];
}
sort(nums.begin(), nums.end());
return nums;
}
};
方法二:
class Solution {
public:
vector<int> sortedSquares(vector<int>& nums) {
vector<int> results(nums.size());
int k = nums.size() - 1;
int left = 0;
int right = nums.size() - 1;
while(left <= right)
{
if(nums[left] * nums[left] > nums[right] * nums[right])
{
results[k--] = nums[left] * nums[left];
left++;
}
else
{
results[k--] = nums[right] * nums[right];
right--;
}
}
return results;
}
};
Java解法
class Solution {
public int[] sortedSquares(int[] nums) {
int left = 0;
int right = nums.length - 1;
int[] result = new int[nums.length];
int index = nums.length - 1;
while(left <= right){
if(Math.abs(nums[left]) > Math.abs(nums[right])){
result[index--] = nums[left] * nums[left];
left++;
}else{
result[index--] = nums[right] * nums[right];
right--;
}
}
return result;
}
}
Python3解法
class Solution:
def sortedSquares(self, nums: List[int]) -> List[int]:
n = len(nums)
ans = [0] * n
start, end = 0, n - 1
for i in range(n - 1, -1, -1):
if abs(nums[start]) >= abs(nums[end]):
ans[i] = nums[start] * nums[start]
start += 1
else:
ans[i] = nums[end] * nums[end]
end -= 1
return ans
Go解法
func sortedSquares(nums []int) []int {
n := len(nums)
results := make([]int, n)
k := n-1
left, right := 0, n - 1
for left <= right {
if nums[left]*nums[left] > nums[right]*nums[right] {
results[k] = nums[left] * nums[left]
left++
} else {
results[k] = nums[right] * nums[right]
right--
}
k--
}
return results;
}
二分查找
- 来源说明
- 704. Binary Search
- 35. Search Insert Position
- 34. Find First and Last Position of Element in Sorted Array
- 162. Find Peak Element
来源说明
704. Binary Search
Given an array of integers nums which is sorted in ascending order, and an integer target, write a function to search target in nums. If target exists, then return its index. Otherwise, return -1.
You must write an algorithm with O(log n) runtime complexity.
Example 1:
Input: nums = [-1,0,3,5,9,12], target = 9 Output: 4 Explanation: 9 exists in nums and its index is 4
Example 2:
Input: nums = [-1,0,3,5,9,12], target = 2 Output: -1 Explanation: 2 does not exist in nums so return -1
Constraints:
1 <= nums.length <= 10^4-10^4 < nums[i], target < 10^4- All the integers in
numsare unique. numsis sorted in ascending order.
思路
这道题目的前提是数组为有序数组,同时题目还强调数组中无重复元素,因为一旦有重复元素,使用二分查找法返回的元素下标可能不是唯一的,这些都是使用二分法的前提条件,当大家看到题目描述满足如上条件的时候,可要想一想是不是可以用二分法了。
二分查找涉及的很多的边界条件,逻辑比较简单,但就是写不好。例如到底是 while(left < right) 还是 while(left <= right),到底是right = middle呢,还是要right = middle - 1呢?
大家写二分法经常写乱,主要是因为对区间的定义没有想清楚,区间的定义就是不变量。要在二分查找的过程中,保持不变量,就是在while寻找中每一次边界的处理都要坚持根据区间的定义来操作,这就是循环不变量规则。
写二分法,区间的定义一般为两种,左闭右闭即[left, right],或者左闭右开即[left, right)。
下面我用这两种区间的定义分别讲解两种不同的二分查找写法。
C++ 写法
二分查找第一种写法
第一种写法,我们定义 target 是在一个在左闭右闭的区间里,也就是[left, right] (这个很重要非常重要)。
区间的定义这就决定了二分法的代码应该如何写,因为定义target在[left, right]区间,所以有如下两点:
- while (left <= right) 要使用 <= ,因为left == right是有意义的,所以使用 <=
- if (nums[middle] > target) right 要赋值为 middle - 1,因为当前这个nums[middle]一定不是target,那么接下来要查找的左区间结束下标位置就是 middle - 1
代码如下:
// 版本一
class Solution {
public:
int search(vector<int>& nums, int target) {
int left = 0;
int right = nums.size() - 1; // 定义target在左闭右闭的区间里,[left, right]
while (left <= right) { // 当left==right,区间[left, right]依然有效,所以用 <=
int middle = left + ((right - left) / 2);// 防止溢出 等同于(left + right)/2
if (nums[middle] > target) {
right = middle - 1; // target 在左区间,所以[left, middle - 1]
} else if (nums[middle] < target) {
left = middle + 1; // target 在右区间,所以[middle + 1, right]
} else { // nums[middle] == target
return middle; // 数组中找到目标值,直接返回下标
}
}
// 未找到目标值
return -1;
}
};
- 时间复杂度:O(log n)
- 空间复杂度:O(1)
二分查找第二种写法
如果说定义 target 是在一个在左闭右开的区间里,也就是[left, right) ,那么二分法的边界处理方式则截然不同。
有如下两点:
- while (left < right),这里使用 < ,因为left == right在区间
[left, right)是没有意义的 - if (nums[middle] > target) right 更新为 middle,因为当前nums[middle]不等于target,去左区间继续寻找,而寻找区间是左闭右开区间,所以right更新为middle,即:下一个查询区间不会去比较nums[middle]
代码如下:(详细注释)
// 版本二
class Solution {
public:
int search(vector<int>& nums, int target) {
int left = 0;
int right = nums.size(); // 定义target在左闭右开的区间里,即:[left, right)
while (left < right) { // 因为left == right的时候,在[left, right)是无效的空间,所以使用 <
int middle = left + ((right - left) >> 1);
if (nums[middle] > target) {
right = middle; // target 在左区间,在[left, middle)中
} else if (nums[middle] < target) {
left = middle + 1; // target 在右区间,在[middle + 1, right)中
} else { // nums[middle] == target
return middle; // 数组中找到目标值,直接返回下标
}
}
// 未找到目标值
return -1;
}
};
- 时间复杂度:O(log n)
- 空间复杂度:O(1)
总结
二分法是非常重要的基础算法,为什么很多同学对于二分法都是一看就会,一写就废?
其实主要就是对区间的定义没有理解清楚,在循环中没有始终坚持根据查找区间的定义来做边界处理。
区间的定义就是不变量,那么在循环中坚持根据查找区间的定义来做边界处理,就是循环不变量规则。
本篇根据两种常见的区间定义,给出了两种二分法的写法,每一个边界为什么这么处理,都根据区间的定义做了详细介绍。
相信看完本篇应该对二分法有更深刻的理解了。
35. Search Insert Position
Given a sorted array of distinct integers and a target value, return the index if the target is found. If not, return the index where it would be if it were inserted in order.
You must write an algorithm with O(log n) runtime complexity.
Example 1:
Input: nums = [1,3,5,6], target = 5
Output: 2
Example 2:
Input: nums = [1,3,5,6], target = 2
Output: 1
Example 3:
Input: nums = [1,3,5,6], target = 7
Output: 4
Constraints:
1 <= nums.length <= 10^4-10^4 <= nums[i] <= 10^4numscontains distinct values sorted in ascending order.-10^4 <= target <= 10^4
思路
先看在不在数组里,在的话输出下标;不在的话看是不是比前一个大,比后一个小,注意数组越界的问题。
要是上来就比第一个数小就输出零,比最后一个大输出数组长度。
不管 target 是在一个左闭右闭的区间里还在在一个左闭右开的区间里,在数组中找不到 target 时,都需要return left。
C++ 解法
假设target 是在一个在左闭右闭的区间里,也就是[left, right]
class Solution {
public:
int searchInsert(vector<int>& nums, int target) {
int left = 0;
int right = nums.size() - 1;
while(left <= right){
int mid = (right + left) / 2;
if(nums[mid] < target){
left = mid + 1;
}else if(nums[mid] > target){
right = mid - 1;
}else{
return mid;
}
}
return left;
}
};
Java 解法
假设target 是在一个在左闭右闭的区间里,也就是[left, right]
class Solution {
public int searchInsert(int[] nums, int target) {
int left = 0;
int right = nums.length - 1;
while(left <= right){
int mid = left + (right - left) / 2;
if(nums[mid] < target){
left = mid + 1;
}else if(nums[mid] > target){
right = mid - 1;
}else{
return mid;
}
}
return left;
}
}
Python 解法
假设target 是在一个在左闭右闭的区间里,也就是[left, right]
class Solution:
def searchInsert(self, nums: List[int], target: int) -> int:
left = 0
right = len(nums) - 1
while left <= right:
mid = (left + right) // 2
if nums[mid] == target:
return mid
elif nums[mid] > target:
right = mid - 1
else:
left = mid + 1
return left
34. Find First and Last Position of Element in Sorted Array
Given an array of integers nums sorted in non-decreasing order, find the starting and ending position of a given target value.
If target is not found in the array, return [-1, -1].
You must write an algorithm with O(log n) runtime complexity.
Example 1:
Input: nums = [5,7,7,8,8,10], target = 8
Output: [3,4]
Example 2:
Input: nums = [5,7,7,8,8,10], target = 6
Output: [-1,-1]
Example 3:
Input: nums = [], target = 0
Output: [-1,-1]
Constraints:
0 <= nums.length <= 10^5-10^9 <= nums[i] <= 10^9numsis a non-decreasing array.-10^9 <= target <= 10^9
思路
寻找target在数组里的左右边界,有如下三种情况:
- 情况一:target 在数组范围的右边或者左边,例如数组{3, 4, 5},target为2或者数组{3, 4, 5},target为6,此时应该返回{-1, -1}
- 情况二:target 在数组范围中,且数组中不存在target,例如数组{3,6,7},target为5,此时应该返回{-1, -1}
- 情况三:target 在数组范围中,且数组中存在target,例如数组{3,6,7},target为6,此时应该返回{1, 1}
这三种情况都考虑到,说明就想的很清楚了。
接下来,在去寻找左边界,和右边界了。
方法1:一次二分查找,再扩展区间
方法2:使用两次二分查找,分别查找lower_bound和upper_bound。
刚刚接触二分搜索的同学不建议上来就想用一个二分来查找左右边界,很容易把自己绕进去,建议扎扎实实的写两个二分分别找左边界和右边界
确定好:计算出来的右边界是不包含target的右边界,左边界同理。
C++ 解法1
假设target 是在一个在左闭右闭的区间里,也就是[left, right]
class Solution {
public:
vector<int> searchRange(vector<int>& nums, int target) {
int leftBorder = getLeftBorder(nums, target);
int rightBorder = getRightBorder(nums, target);
// 情况一
if (leftBorder == -2 || rightBorder == -2) return {-1, -1};
// 情况三
if (rightBorder - leftBorder > 1) return {leftBorder + 1, rightBorder - 1};
// 情况二
return {-1, -1};
}
private:
int getRightBorder(vector<int>& nums, int target) {
int left = 0;
int right = nums.size() - 1;
int rightBorder = -2; // 记录一下rightBorder没有被赋值的情况
while (left <= right) {
int middle = left + ((right - left) / 2);
if (nums[middle] > target) {
right = middle - 1;
} else { // 寻找右边界,nums[middle] == target的时候更新left
left = middle + 1;
rightBorder = left;
}
}
return rightBorder;
}
int getLeftBorder(vector<int>& nums, int target) {
int left = 0;
int right = nums.size() - 1;
int leftBorder = -2; // 记录一下leftBorder没有被赋值的情况
while (left <= right) {
int middle = left + ((right - left) / 2);
if (nums[middle] >= target) { // 寻找左边界,nums[middle] == target的时候更新right
right = middle - 1;
leftBorder = right;
} else {
left = middle + 1;
}
}
return leftBorder;
}
};
C++ 解法2
lower_bound倾向于找左边的元素,所以只有nums[mid] < target时才移动左指针;而upper_bound倾向于找右边的元素,所以当nums[mid] <= target就向右移动左指针了。
lower_bound返回的是开始的第一个满足条件的位置,而upper_bound返回的是第一个不满足条件的位置。所以,当两个相等的时候代表没有找到,如果找到了的话,需要返回的是[left, right - 1]。
class Solution {
public:
int lower_bound(vector<int>& nums, int target) {
int left = 0;
int right = nums.size();
while(left < right){
int mid = (right + left) / 2;
if(nums[mid] < target){
left = mid + 1;
}else{
right = mid;
}
}
return left;
}
int upper_bound(vector<int>& nums, int target){
int left = 0;
int right = nums.size();
while(left < right){
int mid = (right + left) / 2;
if(nums[mid] <= target){
left = mid + 1;
}else {
right = mid;
}
}
return left;
}
vector<int> searchRange(vector<int>& nums, int target) {
int leftBorder = lower_bound(nums, target);
int rightBorder = upper_bound(nums, target);
if (leftBorder == rightBorder)
return {-1, -1};
else
return {leftBorder, rightBorder - 1};
}
};
Java 解法
假设target 是在一个在左闭右开的区间里,也就是[left, right)
先尝试找到一个target,找不到则返回{-1, -1},找到时则向两边扩展得结果
class Solution {
public int[] searchRange(int[] nums, int target) {
int[] result = {-1, -1};
int left = 0;
int right = nums.length;
boolean isExist = false;
while(left < right){
int mid = left + (right - left) / 2;
if(nums[mid] < target){
left = mid + 1;
}else if(nums[mid] > target){
right = mid;
}else{
isExist = true;
break;
}
}
if(isExist){
int mid = left + (right - left) / 2;
int i = mid;
int j = mid;
while(i >= 0 && nums[i] == target){
i--;
}
while(j < nums.length && nums[j] == target){
j++;
}
result[0] = i + 1;
result[1] = j - 1;
}
return result;
}
}
Python 解法
假设target 是在一个在左闭右开的区间里,也就是[left, right)
class Solution(object):
def searchRange(self, nums, target):
"""
:type nums: List[int]
:type target: int
:rtype: List[int]
"""
left = bisect.bisect_left(nums, target)
right = bisect.bisect_right(nums, target)
if left == right:
return [-1, -1]
return [left, right - 1]
162. Find Peak Element
A peak element is an element that is strictly greater than its neighbors.
Given a 0-indexed integer array nums, find a peak element, and return its index. If the array contains multiple peaks, return the index to any of the peaks.
You may imagine that nums[-1] = nums[n] = -∞. In other words, an element is always considered to be strictly greater than a neighbor that is outside the array.
You must write an algorithm that runs in O(log n) time.
Example 1:
Input: nums = [1,2,3,1]
Output: 2
Explanation: 3 is a peak element and your function should return the index number 2.
Example 2:
Input: nums = [1,2,1,3,5,6,4]
Output: 5
Explanation: Your function can return either index number 1 where the peak element is 2, or index number 5 where the peak element is 6.
Constraints:
1 <= nums.length <= 1000-2^31 <= nums[i] <= 2^31 - 1nums[i] != nums[i + 1]for all validi.
思路
给一个数组,找出其中的峰顶数据,就是大于两个邻居的数的index,如果有多个答案,任意一个都可以。
这个题可以直接使用最简单的暴力搜索,遍历整个数组,时间复杂度为O(n).虽然题目要求是log时间,但是这样也可以AC。
但是也可以实现O(logn)的时间复杂度。可以用binary search。每次寻找中间的数,如果恰好是峰顶数据,就返回index。如果不是,就查看其与中间元素相邻的左边和右边的值,选取大于中间元素的那边的一半数组继续遍历,如果两边都大于,就随便选一个。注意,这里是没有考虑相同的数据挨着的情况的。
C++ 解法
class Solution {
public:
int findPeakElement(vector<int>& nums) {
int size = nums.size();
if(size <= 1 || nums[0] > nums[1])
return 0;
if(nums[size - 2] < nums[size - 1]){
return size - 1;
}
for(int i = 1; i < nums.size() - 1; i++){
if(nums[i] > nums[i - 1] && nums[i] > nums[i + 1]){
return i;
}
}
return -1;
}
};
Java 解法
分治策略
二分查找区间类型为左闭右闭
class Solution {
public int findPeakElement(int[] nums) {
return binarySearchToFindPeakElement(nums, 0, nums.length - 1);
}
public int binarySearchToFindPeakElement(int[] nums, int left, int right){
if(left > right)
return -1;
if(left == right)
return left;
if(left + 1 == right)
return nums[left] > nums[right] ? left : right;
int mid = left + (right - left) / 2;
if(nums[mid] < nums[mid + 1]){
return binarySearchToFindPeakElement(nums, mid + 1, right);
}else if(nums[mid] < nums[mid - 1] ){
return binarySearchToFindPeakElement(nums, left, mid -1);
}else{
return mid;
}
}
}
Python 解法
二分查找区间类型为左闭右闭
class Solution:
def findPeakElement(self, nums: List[int]) -> int:
left, right = 0, len(nums) - 1
while left < right:
mid = (left + right) >> 1
if nums[mid - 1] <= nums[mid] >= nums[mid + 1]:
return mid
elif nums[mid] < nums[mid + 1]:
left = mid + 1
else:
right = mid
return left
更精简的写法如下:
class Solution:
def findPeakElement(self, nums: List[int]) -> int:
left, right = 0, len(nums) - 1
while left < right:
mid = (left + right) >> 1
if nums[mid] < nums[mid + 1]:
left = mid + 1
else:
right = mid
return right
最后返回right或left均可。
注意:这里和C++写法存在较大差异。
滑动窗口
209. Minimum Size Subarray Sum
Given an array of positive integers nums and a positive integer target, return the minimal length of a subarray whose sum is greater than or equal to target. If there is no such subarray, return 0 instead.
Example 1:
Input: target = 7, nums = [2,3,1,2,4,3]
Output: 2
Explanation: The subarray [4,3] has the minimal length under the problem constraint.
Example 2:
Input: target = 4, nums = [1,4,4]
Output: 1
Example 3:
Input: target = 11, nums = [1,1,1,1,1,1,1,1]
Output: 0
Constraints:
1 <= target <= 10^91 <= nums.length <= 10^51 <= nums[i] <= 10^4
Follow up: If you have figured out the O(n) solution, try coding another solution of which the time complexity is O(n log(n)).
思路
- 双重for循环暴力解决
- 单层for循环,滑动窗口
下面代码使用滑动窗口。
- Time complexity: O(n)
- Space complexity: O(1)
C++
滑动窗口解法:
class Solution {
public:
int minSubArrayLen(int target, vector<int>& nums) {
int minLen = numeric_limits<int>::max();
int left = 0;
int curSum = 0;
for (int right = 0; right < nums.size(); right++) {
curSum += nums[right];
while (curSum >= target) {
if (right - left + 1 < minLen) {
minLen = right - left + 1;
}
curSum -= nums[left];
left++;
}
}
return minLen != numeric_limits<int>::max() ? minLen : 0;
}
};
暴力解法:
class Solution {
public:
int minSubArrayLen(int s, vector<int>& nums) {
int result = INT32_MAX; // 最终的结果
int sum = 0; // 子序列的数值之和
int subLength = 0; // 子序列的长度
for (int i = 0; i < nums.size(); i++) { // 设置子序列起点为i
sum = 0;
for (int j = i; j < nums.size(); j++) { // 设置子序列终止位置为j
sum += nums[j];
if (sum >= s) { // 一旦发现子序列和超过了s,更新result
subLength = j - i + 1; // 取子序列的长度
result = result < subLength ? result : subLength;
break; // 因为我们是找符合条件最短的子序列,所以一旦符合条件就break
}
}
}
// 如果result没有被赋值的话,就返回0,说明没有符合条件的子序列
return result == INT32_MAX ? 0 : result;
}
};
- 时间复杂度:O(n^2)
- 空间复杂度:O(1)
后面力扣官方更新了数据,暴力解法已经超时了。
Java
class Solution {
public int minSubArrayLen(int target, int[] nums) {
int minLen = Integer.MAX_VALUE;
int left = 0;
int curSum = 0;
for (int right = 0; right < nums.length; right++) {
curSum += nums[right];
while (curSum >= target) {
if (right - left + 1 < minLen) {
minLen = right - left + 1;
}
curSum -= nums[left];
left++;
}
}
return minLen != Integer.MAX_VALUE ? minLen : 0;
}
}
Python
class Solution:
def minSubArrayLen(self, target: int, nums: List[int]) -> int:
min_len = float("inf")
left = 0
cur_sum = 0
for right in range(len(nums)):
cur_sum += nums[right]
while cur_sum >= target:
if right - left + 1 < min_len:
min_len = right - left + 1
cur_sum -= nums[left]
left += 1
return min_len if min_len != float("inf") else 0
Go
func minSubArrayLen(target int, nums []int) int {
i := 0
l := len(nums) // 数组长度
sum := 0 // 子数组之和
result := l + 1 // 初始化返回长度为l+1,目的是为了判断“不存在符合条件的子数组,返回0”的情况
for j := 0; j < l; j++ {
sum += nums[j]
for sum >= target {
subLength := j - i + 1
if subLength < result {
result = subLength
}
sum -= nums[i]
i++
}
}
if result == l+1 {
return 0
} else {
return result
}
}
注意:题目要求子数组的和要大于或等于target
3364. Minimum Positive Sum Subarray
You are given an integer array nums and two integers l and r. Your task is to find the minimum sum of a subarray whose size is between l and r (inclusive) and whose sum is greater than 0.
Return the minimum sum of such a subarray. If no such subarray exists, return -1.
A subarray is a contiguous non-empty sequence of elements within an array.
Example 1:
Input: nums = [3, -2, 1, 4], l = 2, r = 3
Output: 1
Explanation:
The subarrays of length between l = 2 and r = 3 where the sum is greater than 0 are:
[3, -2]with a sum of 1[1, 4]with a sum of 5[3, -2, 1]with a sum of 2[-2, 1, 4]with a sum of 3
Out of these, the subarray [3, -2] has a sum of 1, which is the smallest positive sum. Hence, the answer is 1.
Example 2:
Input: nums = [-2, 2, -3, 1], l = 2, r = 3
Output: -1
Explanation:
There is no subarray of length between l and r that has a sum greater than 0. So, the answer is -1.
Example 3:
Input: nums = [1, 2, 3, 4], l = 2, r = 4
Output: 3
Explanation:
The subarray [1, 2] has a length of 2 and the minimum sum greater than 0. So, the answer is 3.
Constraints:
1 <= nums.length <= 1001 <= l <= r <= nums.length-1000 <= nums[i] <= 1000
思路
方法一:暴力求解,二重循环
方法二:可变长度的滑动窗口
C++解法
Approach 1: Brute Force
Steps:
- Iterate through all possible subarrays of size ( k ) where ( l <= k <= r ).
- Compute the sum of each subarray.
- Check if the sum is greater than ( 0 ), and keep track of the minimum valid sum.
- Return the minimum valid sum or (-1) if no such subarray exists.
Complexity:
- Time Complexity: (O(n^2)) (since we calculate the sum for all subarrays).
- Space Complexity: (O(1)) (no extra space used).
Code:
class Solution {
public:
int minSumSubarray(vector<int>& nums, int l, int r) {
int n = nums.size();
int minSum = INT_MAX;
bool found = false;
for (int start = 0; start < n; ++start) {
int sum = 0;
for (int end = start; end < n; ++end) {
sum += nums[end];
int length = end - start + 1;
if (length >= l && length <= r && sum > 0) {
minSum = min(minSum, sum);
found = true;
}
}
}
return found ? minSum : -1;
}
};
Approach 2: Sliding Window (Optimized)
Steps:
- Use a sliding window of size ( l ) to ( r ).
- Maintain the sum of elements in the current window.
- Check if the sum is greater than ( 0 ), and update the minimum sum if valid.
- Slide the window one element at a time, updating the sum in ( O(1) ).
Complexity:
- Time Complexity: (O(n X (r - l + 1))) (for sliding windows of varying sizes).
- Space Complexity: (O(1)).
Code:
class Solution {
public:
int minSumSubarray(vector<int>& nums, int l, int r) {
int n = nums.size();
int minSum = INT_MAX;
bool found = false;
for (int k = l; k <= r; ++k) {
int sum = 0;
for (int i = 0; i < n; ++i) {
sum += nums[i];
if (i >= k - 1) {
if (sum > 0) {
minSum = min(minSum, sum);
found = true;
}
sum -= nums[i - k + 1];
}
}
}
return found ? minSum : -1;
}
};
Approach 3: Prefix Sum with Sliding Window
Steps
1. Precompute Prefix Sum
- Create a prefix sum array where each element at index (i) stores the sum of all elements from index (0) to (i - 1).
- Formula:
prefix[i] = prefix[i - 1] + nums[i - 1].
- Formula:
2. Iterate Over All Valid Subarray Sizes
- For each (k) in the range ([l, r]):
- Use the prefix sum array to calculate subarray sums in (O(1)).
- Compare each subarray sum with the current minimum.
3. Check Validity
- If the subarray sum is greater than (0), update the minimum sum.
4. Return the Result
- If a valid subarray is found, return the minimum sum. Otherwise, return (-1).
Complexity:
- Time Complexity: (O(n X (r - l + 1))) (for sliding windows of varying sizes).
- Space Complexity: (O(1)).
Code
class Solution {
public:
int minSumSubarray(vector<int>& nums, int l, int r) {
int n = nums.size();
vector<int> prefix(n + 1, 0);
// Step 1: Compute prefix sums
for (int i = 0; i < n; ++i) {
prefix[i + 1] = prefix[i] + nums[i];
}
int minSum = INT_MAX;
bool found = false;
// Step 2: Iterate over all window sizes
for (int k = l; k <= r; ++k) {
// Sliding window over prefix sum
for (int i = 0; i + k <= n; ++i) {
int sum = prefix[i + k] - prefix[i]; // Subarray sum from i to i+k-1
if (sum > 0) {
minSum = min(minSum, sum);
found = true;
}
}
}
// Step 3: Return result
return found ? minSum : -1;
}
};
Approach 4: Optimized Sliding Window with Fixed Size
The sliding window method allows us to efficiently calculate the sum of a subarray by updating the sum incrementally as we "slide" the window across the array. For every subarray of size (k), we:
- Add the element at the current end of the window.
- Remove the element at the start of the window if the window size exceeds (k).
Steps
1. Iterate over all window sizes ((k))
- Start by trying subarrays of size (l) (minimum valid size) and incrementally check sizes up to (r) (maximum valid size).
- For each (k), initialize the sliding window and calculate the sum dynamically as the window slides.
2. Use a sliding window of size (k)
- Start with the first (k) elements to initialize the sum.
- Slide the window one element at a time:
- Add the new element at the window's end.
- Remove the old element at the window's start.
- This ensures (O(1)) updates to the sum for each new position.
3. Check validity
- After updating the sum, check if it is greater than (0).
- If valid, compare it with the current minimum sum and update if smaller.
4. Return the result
- After evaluating all possible subarray sizes, return the smallest valid sum. If no valid subarray is found, return (-1).
Complexity:
- Time Complexity: (O(n X (r - l + 1))) (for sliding windows of varying sizes).
- Space Complexity: (O(1)).
class Solution {
public:
int minSumSubarray(vector<int>& nums, int l, int r) {
int n = nums.size();
int minSum = INT_MAX; // Stores the minimum valid sum
bool found = false; // Indicates if a valid subarray is found
// Iterate over all window sizes from l to r
for (int k = l; k <= r; ++k) {
int sum = 0;
// Initialize the sum for the first window of size k
for (int i = 0; i < k; ++i) {
sum += nums[i];
}
// Check the first window
if (sum > 0) {
minSum = min(minSum, sum);
found = true;
}
// Slide the window across the array
for (int i = k; i < n; ++i) {
sum += nums[i]; // Add the new element at the end of the window
sum -= nums[i - k]; // Remove the old element at the start of the window
// Check the current window
if (sum > 0) {
minSum = min(minSum, sum);
found = true;
}
}
}
// Return the result or -1 if no valid subarray was found
return found ? minSum : -1;
}
};
643. Maximum Average Subarray I
You are given an integer array nums consisting of n elements, and an integer k.
Find a contiguous subarray whose length is equal to k that has the maximum average value and return this value. Any answer with a calculation error less than 10^-5 will be accepted.
Example 1:
**Input:** nums = [1,12,-5,-6,50,3], k = 4
**Output:** 12.75000
**Explanation:** Maximum average is (12 - 5 - 6 + 50) / 4 = 51 / 4 = 12.75
Example 2:
**Input:** nums = [5], k = 1
**Output:** 5.00000
Constraints:
n == nums.length1 <= k <= n <= 10^5-10^4 <= nums[i] <= 10^4
思路
使用滑动窗口求特定长度的最大子列和
C++解法
class Solution {
public:
double findMaxAverage(vector<int>& nums, int k) {
int left = 0;
double result = -10000000.0;
double sum = 0;
for(int right = 0; right < nums.size(); right++){
sum += nums[right];
if(right - left + 1 == k){
double temp = sum / k;
result = result > temp ? result : temp;
sum -= nums[left];
left++;
}
}
return result;
}
};
Java解法
Python解法
Go解法
Matrix
- 48. Rotate Image
- 54. Spiral Matrix
- 59. Spiral Matrix II
- 73. Set Matrix Zeroes
- 240. Search a 2D Matrix II
48. Rotate Image
You are given an n x n 2D matrix representing an image, rotate the image by 90 degrees (clockwise).
You have to rotate the image in-place, which means you have to modify the input 2D matrix directly. DO NOT allocate another 2D matrix and do the rotation.
Example 1:
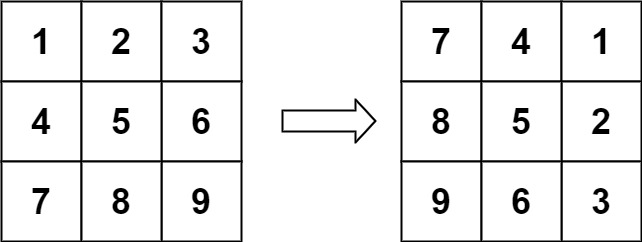
Input: matrix = [[1,2,3],[4,5,6],[7,8,9]]
Output: [[7,4,1],[8,5,2],[9,6,3]]
Example 2:
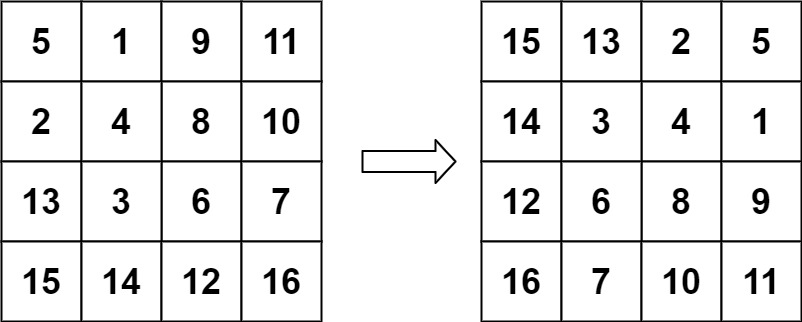
Input: matrix = [[5,1,9,11],[2,4,8,10],[13,3,6,7],[15,14,12,16]]
Output: [[15,13,2,5],[14,3,4,1],[12,6,8,9],[16,7,10,11]]
Constraints:
n == matrix.length == matrix[i].length1 <= n <= 20-1000 <= matrix[i][j] <= 1000
思路
Input: matrix = [[1,2,3],[4,5,6],[7,8,9]]
先以上下分界线对称交换两行,此时矩阵如下所示:
matrix = [[7,8,9],[4,5,6],[1,2,3]]
主对角线位置上的元素被放置到合适的位置
最后交换主对角线两侧的元素得到最终结果。
Output: [[7,4,1],[8,5,2],[9,6,3]]
核心操作
Vertical Flip:
- The first part of the algorithm vertically flips the matrix. It swaps the elements in the top row with the corresponding elements in the bottom row, moving towards the center row.
- Example before vertical flip (3x3 matrix):
1 2 3
4 5 6
7 8 9
- Example after vertical flip:
7 8 9
4 5 6
1 2 3
Transpose:
- The second part of the algorithm transposes the matrix. It swaps the elements at positions
[i][j]with the elements at[j][i], effectively turning rows into columns and vice versa. - Example after transpose:
7 4 1
8 5 2
9 6 3
Combining these two operations results in rotating the matrix by 90 degrees clockwise.
Summary
This algorithm efficiently rotates a matrix by 90 degrees clockwise by first flipping it vertically and then transposing it. This approach leverages the properties of matrix operations to achieve the desired transformation with minimal code complexity.
C++ 解法
Java 解法
class Solution {
public void rotate(int[][] matrix) {
int top = 0, bottom = matrix.length - 1;
while(top < bottom){
for(int i = 0; i < matrix[0].length; i++){
int temp = matrix[top][i];
matrix[top][i] = matrix[bottom][i];
matrix[bottom][i] = temp;
}
top++;
bottom--;
}
for(int row = 0; row < matrix.length; row++){
for(int col = row + 1; col < matrix[0].length; col++){
int temp = matrix[row][col];
matrix[row][col] = matrix[col][row];
matrix[col][row] = temp;
}
}
}
}
Python 解法
54. Spiral Matrix
Given an m x n matrix, return all elements of the matrix in spiral order.
Example 1:

Input: matrix = [[1,2,3],[4,5,6],[7,8,9]]
Output: [1,2,3,6,9,8,7,4,5]
Example 2:

Input: matrix = [[1,2,3,4],[5,6,7,8],[9,10,11,12]]
Output: [1,2,3,4,8,12,11,10,9,5,6,7]
Constraints:
m == matrix.lengthn == matrix[i].length1 <= m, n <= 10-100 <= matrix[i][j] <= 100
思路
注意:这里不一定是一个方阵
方法一:模拟
可以模拟螺旋矩阵的路径。初始位置是矩阵的左上角,初始方向是向右,当路径超出界限或者进入之前访问过的位置时,顺时针旋转,进入下一个方向。
判断路径是否进入之前访问过的位置需要使用一个与输入矩阵大小相同的辅助矩阵 visited,其中的每个元素表示该位置是否被访问过。当一个元素被访问时,将 visited 中的对应位置的元素设为已访问。
如何判断路径是否结束?由于矩阵中的每个元素都被访问一次,因此路径的长度即为矩阵中的元素数量,当路径的长度达到矩阵中的元素数量时即为完整路径,将该路径返回。
复杂度分析
时间复杂度:O(mn),其中 m 和 n 分别是输入矩阵的行数和列数。矩阵中的每个元素都要被访问一次。
空间复杂度:O(mn)。需要创建一个大小为 m×n 的矩阵 visited 记录每个位置是否被访问过。
方法二:按层模拟
可以将矩阵看成若干层,首先输出最外层的元素,其次输出次外层的元素,直到输出最内层的元素。
定义矩阵的第 k 层是到最近边界距离为 k 的所有顶点。例如,下图矩阵最外层元素都是第 1 层,次外层元素都是第 2 层,剩下的元素都是第 3 层。
[[1, 1, 1, 1, 1, 1, 1],
[1, 2, 2, 2, 2, 2, 1],
[1, 2, 3, 3, 3, 2, 1],
[1, 2, 2, 2, 2, 2, 1],
[1, 1, 1, 1, 1, 1, 1]]
对于每层,从左上方开始以顺时针的顺序遍历所有元素。假设当前层的左上角位于 (top,left),右下角位于 (bottom,right),按照如下顺序遍历当前层的元素。
从左到右遍历上侧元素,依次为 (top,left) 到 (top,right)。
从上到下遍历右侧元素,依次为 (top+1,right) 到 (bottom,right)。
如果 left<right 且 top<bottom,则从右到左遍历下侧元素,依次为 (bottom,right−1) 到 (bottom,left+1),以及从下到上遍历左侧元素,依次为 (bottom,left) 到 (top+1,left)。
遍历完当前层的元素之后,将 left 和 top 分别增加 1,将 right 和 bottom 分别减少 1,进入下一层继续遍历,直到遍历完所有元素为止。
复杂度分析
时间复杂度:O(mn),其中 m 和 n 分别是输入矩阵的行数和列数。矩阵中的每个元素都要被访问一次。
空间复杂度:O(1)。除了输出数组以外,空间复杂度是常数。
作者:力扣官方题解 链接: https://leetcode.cn/problems/spiral-matrix/solutions/275393/luo-xuan-ju-zhen-by-leetcode-solution/ 来源:力扣(LeetCode) 著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
C++ 解法
方法二:按层模拟
class Solution {
public:
vector<int> spiralOrder(vector<vector<int>>& matrix) {
if (matrix.size() == 0 || matrix[0].size() == 0) {
return {};
}
int rows = matrix.size(), columns = matrix[0].size();
vector<int> order;
int left = 0, right = columns - 1, top = 0, bottom = rows - 1;
while (left <= right && top <= bottom) {
for (int column = left; column <= right; column++) {
order.push_back(matrix[top][column]);
}
for (int row = top + 1; row <= bottom; row++) {
order.push_back(matrix[row][right]);
}
if (left < right && top < bottom) {
for (int column = right - 1; column > left; column--) {
order.push_back(matrix[bottom][column]);
}
for (int row = bottom; row > top; row--) {
order.push_back(matrix[row][left]);
}
}
left++;
right--;
top++;
bottom--;
}
return order;
}
};
Java 解法
方法二:按层模拟
class Solution {
public List<Integer> spiralOrder(int[][] matrix) {
List<Integer> order = new ArrayList<Integer>();
if (matrix == null || matrix.length == 0 || matrix[0].length == 0) {
return order;
}
int rows = matrix.length, columns = matrix[0].length;
int left = 0, right = columns - 1, top = 0, bottom = rows - 1;
while (left <= right && top <= bottom) {
for (int column = left; column <= right; column++) {
order.add(matrix[top][column]);
}
for (int row = top + 1; row <= bottom; row++) {
order.add(matrix[row][right]);
}
if (left < right && top < bottom) {
for (int column = right - 1; column > left; column--) {
order.add(matrix[bottom][column]);
}
for (int row = bottom; row > top; row--) {
order.add(matrix[row][left]);
}
}
left++;
right--;
top++;
bottom--;
}
return order;
}
}
Python3 解法
方法一:模拟
class Solution:
def spiralOrder(self, matrix: List[List[int]]) -> List[int]:
if not matrix or not matrix[0]:
return list()
rows, columns = len(matrix), len(matrix[0])
visited = [[False] * columns for _ in range(rows)]
total = rows * columns
order = [0] * total
directions = [[0, 1], [1, 0], [0, -1], [-1, 0]]
row, column = 0, 0
directionIndex = 0
for i in range(total):
order[i] = matrix[row][column]
visited[row][column] = True
nextRow, nextColumn = row + directions[directionIndex][0], column + directions[directionIndex][1]
if not (0 <= nextRow < rows and 0 <= nextColumn < columns and not visited[nextRow][nextColumn]):
directionIndex = (directionIndex + 1) % 4
row += directions[directionIndex][0]
column += directions[directionIndex][1]
return order
59. Spiral Matrix II
Given a positive integer n, generate an n x n matrix filled with elements from 1 to n2 in spiral order.
Example 1:
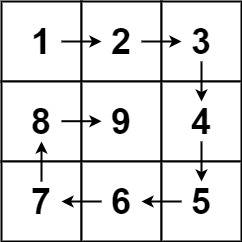
Input: n = 3
Output: [[1,2,3],[8,9,4],[7,6,5]]
Example 2:
Input: n = 1
Output: [[1]]
Constraints:
1 <= n <= 20
思路
坚持循环不变量原则
奇偶分开处理
圈数=n/2
C++
class Solution {
public:
vector<vector<int>> generateMatrix(int n) {
vector<vector<int>> result(n, vector<int>(n,0));
int startx = 0;
int starty = 0;
int offset = 1;
int count = 1;
int i;
int j;
int loop = n / 2;
while(loop--)
{
i = startx;
j = starty;
for(j = starty; j < n - offset; j++)
{
result[i][j] = count++;
}
for(i = startx; i < n - offset; i++)
{
result[i][j] = count++;
}
for(; j > starty; j--)
{
result[i][j] = count++;
}
for(; i > startx; i--)
{
result[i][j] = count++;
}
startx++;
starty++;
offset++;
}
if(n % 2 == 1)
result[n / 2][n / 2] = count;
return result;
}
};
Java
class Solution {
public int[][] generateMatrix(int n) {
int[][] result = new int[n][n];
int counter = 1;
int startx = 0;
int starty = 0;
int offset = 1;
int numOfLoop = n / 2;
while((numOfLoop--) > 0){
for(int j = starty; j < n - offset; j++){
result[startx][j] = counter++;
}
for(int i = starty; i < n - offset; i++){
result[i][n - offset] = counter++;
}
for(int j = n - offset; j > startx; j--){
result[n - offset][j] = counter++;
}
for(int i = n - offset; i > starty; i--){
result[i][starty] = counter++;
}
startx++;
starty++;
offset++;
}
if(n % 2 == 1){
result[n/2][n/2] = counter;
}
return result;
}
}
Python
class Solution(object):
def generateMatrix(self, n):
top, bottom, left, right = 0, n-1, 0, n - 1
val = 1
arr = [[0] * n for _ in range(n)]
while left <= right and top <= bottom:
for j in range(left, right + 1):
arr[top][j] = val
val += 1
top += 1
for i in range(top, bottom + 1):
arr[i][right] = val
val += 1
right -= 1
for j in range(right, left - 1, -1):
arr[bottom][j] = val
val += 1
bottom -= 1
for i in range(bottom, top - 1, -1):
arr[i][left] = val
val += 1
left += 1
return arr
73. Set Matrix Zeroes
Given an m x n integer matrix matrix, if an element is 0, set its entire row and column to 0's.
You must do it in place.
Example 1:
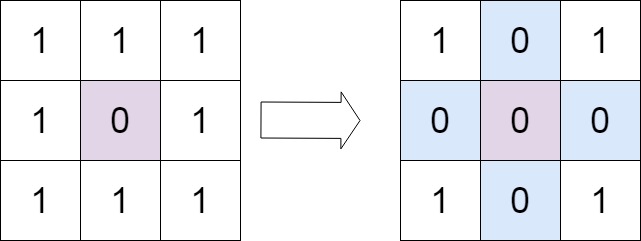
Input: matrix = [[1,1,1],[1,0,1],[1,1,1]]
Output: [[1,0,1],[0,0,0],[1,0,1]]
Example 2:
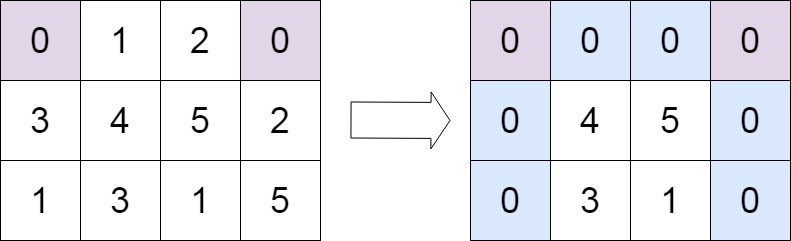
Input: matrix = [[0,1,2,0],[3,4,5,2],[1,3,1,5]]
Output: [[0,0,0,0],[0,4,5,0],[0,3,1,0]]
Constraints:
m == matrix.lengthn == matrix[0].length1 <= m, n <= 200-2^31 <= matrix[i][j] <= 2^31 - 1
Follow up:
- A straightforward solution using
O(mn)space is probably a bad idea. - A simple improvement uses
O(m + n)space, but still not the best solution. - Could you devise a constant space solution?
思路
方法一:使用两个标记数组
思路和算法
我们可以用两个标记数组分别记录每一行和每一列是否有零出现。
具体地,我们首先遍历该数组一次,如果某个元素为 0,那么就将该元素所在的行和列所对应标记数组的位置置为 true。最后我们再次遍历该数组,用标记数组更新原数组即可。
复杂度分析
时间复杂度:O(mn),其中 m 是矩阵的行数,n 是矩阵的列数。我们至多只需要遍历该矩阵两次。
空间复杂度:O(m+n),其中 m 是矩阵的行数,n 是矩阵的列数。我们需要分别记录每一行或每一列是否有零出现。
方法二:使用两个标记变量
思路和算法
我们可以用矩阵的第一行和第一列代替方法一中的两个标记数组,以达到 O(1) 的额外空间。但这样会导致原数组的第一行和第一列被修改,无法记录它们是否原本包含 0。因此我们需要额外使用两个标记变量分别记录第一行和第一列是否原本包含 0。
在实际代码中,我们首先预处理出两个标记变量,接着使用其他行与列去处理第一行与第一列,然后反过来使用第一行与第一列去更新其他行与列,最后使用两个标记变量更新第一行与第一列即可。
复杂度分析
时间复杂度:O(mn),其中 m 是矩阵的行数,n 是矩阵的列数。我们至多只需要遍历该矩阵两次。
空间复杂度:O(1)。我们只需要常数空间存储若干变量。
方法三:使用一个标记变量
思路和算法
我们可以对方法二进一步优化,只使用一个标记变量记录第一列是否原本存在 0。这样,第一列的第一个元素即可以标记第一行是否出现 0。但为了防止每一列的第一个元素被提前更新,我们需要从最后一行开始,倒序地处理矩阵元素。
复杂度分析
时间复杂度:O(mn),其中 m 是矩阵的行数,n 是矩阵的列数。我们至多只需要遍历该矩阵两次。
空间复杂度:O(1)。我们只需要常数空间存储若干变量。
作者:力扣官方题解 链接:https://leetcode.cn/problems/set-matrix-zeroes/solutions/669901/ju-zhen-zhi-ling-by-leetcode-solution-9ll7/ 来源:力扣(LeetCode) 著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
C++ 解法
方法二:使用两个标记变量
class Solution {
public:
void setZeroes(vector<vector<int>>& matrix) {
int m = matrix.size();
int n = matrix[0].size();
int flag_col0 = false, flag_row0 = false;
for (int i = 0; i < m; i++) {
if (!matrix[i][0]) {
flag_col0 = true;
}
}
for (int j = 0; j < n; j++) {
if (!matrix[0][j]) {
flag_row0 = true;
}
}
for(int i = 1; i < m; i++){
for(int j = 1; j < n; j++){
if(matrix[i][j] == 0){
matrix[i][0] = 0;
matrix[0][j] = 0;
}
}
}
for (int i = 1; i < m; i++) {
for (int j = 1; j < n; j++) {
if (!matrix[i][0] || !matrix[0][j]) {
matrix[i][j] = 0;
}
}
}
if (flag_col0) {
for (int i = 0; i < m; i++) {
matrix[i][0] = 0;
}
}
if (flag_row0) {
for (int j = 0; j < n; j++) {
matrix[0][j] = 0;
}
}
}
};
Java 解法
方法一:使用两个标记数组
class Solution {
public void setZeroes(int[][] matrix) {
int m = matrix.length;
int n = matrix[0].length;
boolean[] row = new boolean[m];
boolean[] col = new boolean[n];
for(int i = 0; i < m; i++){
for(int j = 0; j < n; j++){
if(matrix[i][j] == 0){
row[i] = true;
col[j] = true;
}
}
}
for(int i = 0; i < m; i++){
for(int j = 0; j < n; j++){
if(row[i] || col[j]){
matrix[i][j] = 0;
}
}
}
}
}
Python3 解法
方法三:使用一个标记变量
class Solution:
def setZeroes(self, matrix: List[List[int]]) -> None:
m, n = len(matrix), len(matrix[0])
flag_col0 = False
for i in range(m):
if matrix[i][0] == 0:
flag_col0 = True
for j in range(1, n):
if matrix[i][j] == 0:
matrix[i][0] = matrix[0][j] = 0
for i in range(m - 1, -1, -1):
for j in range(1, n):
if matrix[i][0] == 0 or matrix[0][j] == 0:
matrix[i][j] = 0
if flag_col0:
matrix[i][0] = 0
240. Search a 2D Matrix II
Write an efficient algorithm that searches for a value target in an m x n integer matrix matrix. This matrix has the following properties:
- Integers in each row are sorted in ascending from left to right.
- Integers in each column are sorted in ascending from top to bottom.
Example 1:
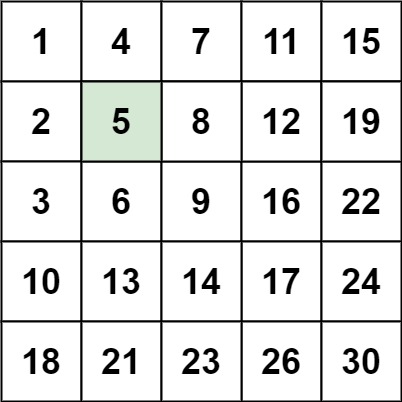
Input: matrix = [[1,4,7,11,15],[2,5,8,12,19],[3,6,9,16,22],[10,13,14,17,24],[18,21,23,26,30]], target = 5
Output: true
Example 2:
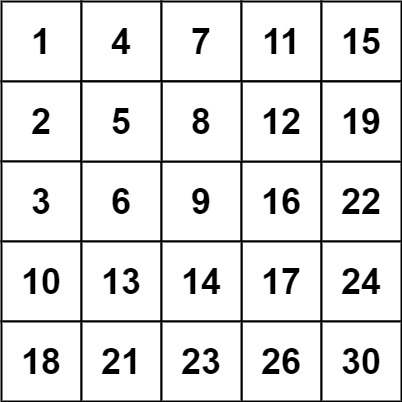
Input: matrix = [[1,4,7,11,15],[2,5,8,12,19],[3,6,9,16,22],[10,13,14,17,24],[18,21,23,26,30]], target = 20
Output: false
Constraints:
m == matrix.lengthn == matrix[i].length1 <= n, m <= 300-10^9 <= matrix[i][j] <= 10^9- All the integers in each row are sorted in ascending order.
- All the integers in each column are sorted in ascending order.
-10^9 <= target <= 10^9
思路
方法一:直接查找
思路与算法
我们直接遍历整个矩阵 matrix,判断 target 是否出现即可。
复杂度分析
时间复杂度:O(mn)。
空间复杂度:O(1)。
方法二:二分查找
思路与算法
由于矩阵 matrix 中每一行的元素都是升序排列的,因此我们可以对每一行都使用一次二分查找,判断 target 是否在该行中,从而判断 target 是否出现。
复杂度分析
时间复杂度:O(mlogn)。对一行使用二分查找的时间复杂度为 O(logn),最多需要进行 m 次二分查找。
空间复杂度:O(1)。
方法三:Z 字形查找
思路与算法
我们可以从矩阵 matrix 的右上角 (0,n−1) 进行搜索。在每一步的搜索过程中,如果我们位于位置 (x,y),那么我们希望在以 matrix 的左下角为左下角、以 (x,y) 为右上角的矩阵中进行搜索,即行的范围为 [x,m−1],列的范围为 [0,y]:
如果 matrix[x,y]=target,说明搜索完成;
如果 matrix[x,y]>target,由于每一列的元素都是升序排列的,那么在当前的搜索矩阵中,所有位于第 y 列的元素都是严格大于 target 的,因此我们可以将它们全部忽略,即将 y 减少 1;
如果 matrix[x,y]<target,由于每一行的元素都是升序排列的,那么在当前的搜索矩阵中,所有位于第 x 行的元素都是严格小于 target 的,因此我们可以将它们全部忽略,即将 x 增加 1。
在搜索的过程中,如果我们超出了矩阵的边界,那么说明矩阵中不存在 target。
复杂度分析
时间复杂度:O(m+n)。在搜索的过程中,如果我们没有找到 target,那么我们要么将 y 减少 1,要么将 x 增加 1。由于 (x,y) 的初始值分别为 (0,n−1),因此 y 最多能被减少 n 次,x 最多能被增加 m 次,总搜索次数为 m+n。在这之后,x 和 y 就会超出矩阵的边界。
空间复杂度:O(1)。
作者:力扣官方题解 链接: https://leetcode.cn/problems/search-a-2d-matrix-ii/solutions/1062538/sou-suo-er-wei-ju-zhen-ii-by-leetcode-so-9hcx/ 来源:力扣(LeetCode) 著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
C++ 解法
方法二:二分查找
class Solution {
public:
bool searchMatrix(vector<vector<int>>& matrix, int target) {
for (const auto& row: matrix) {
auto it = lower_bound(row.begin(), row.end(), target);
if (it != row.end() && *it == target) {
return true;
}
}
return false;
}
};
Java 解法
方法三:Z 字形查找
class Solution {
public boolean searchMatrix(int[][] matrix, int target) {
int m = matrix.length, n = matrix[0].length;
int x = 0, y = n - 1;
while (x < m && y >= 0) {
if (matrix[x][y] == target) {
return true;
}
if (matrix[x][y] > target) {
--y;
} else {
++x;
}
}
return false;
}
}
Python 解法
方法一:直接查找
class Solution:
def searchMatrix(self, matrix: List[List[int]], target: int) -> bool:
for row in matrix:
for element in row:
if element == target:
return True
return False
数与位
数字位操作
7. Reverse Integer
Given a signed 32-bit integer x, return x with its digits reversed. If reversing x causes the value to go outside the signed 32-bit integer range [-231, 231 - 1], then return 0.
Assume the environment does not allow you to store 64-bit integers (signed or unsigned).
Example 1:
Input: x = 123
Output: 321
Example 2:
Input: x = -123
Output: -321
Example 3:
Input: x = 120
Output: 21
Constraints:
-2^31 <= x <= 2^31 - 1
思路
x = -1230
第一次循环:pop = 0, x = -123, reversed = 0
第二次循环:pop = 3, x = -12, reversed = 3
第三次循环:pop = 2, x = -1, reversed = 32
第四次循环:pop = -1, x = 0, reversed = -321
Complexity Analysis
- Time Complexity: O(log(x)). There are roughly log10(x) digits in x.
- Space Complexity: O(1).
C++解法
#include <string> // 引入string库
#include <limits> // 引入limits库以处理溢出
class Solution {
public:
int reverse(int x) {
long long reversed = 0; // 使用long long以避免溢出
while (x != 0) {
// 取出最后一位
int pop = x % 10;
x /= 10; // 删除最后一位
// 加入到反转结果中
reversed = reversed * 10 + pop;
// 检查是否可能发生溢出
if (reversed > std::numeric_limits<int>::max() || reversed < std::numeric_limits<int>::min()) {
return 0; // 溢出时返回0
}
}
return static_cast<int>(reversed); // 转换为int并返回
}
};
class Solution {
public:
int reverse(int x) {
int rev = 0;
while (x != 0) {
int pop = x % 10;
x /= 10;
if (rev > INT_MAX / 10 || (rev == INT_MAX / 10 && pop > 7))
return 0;
if (rev < INT_MIN / 10 || (rev == INT_MIN / 10 && pop < -8))
return 0;
rev = rev * 10 + pop;
}
return rev;
}
};
Java解法
class Solution {
public int reverse(int x) {
int rev = 0;
while (x != 0) {
int pop = x % 10;
x /= 10;
if (
rev > Integer.MAX_VALUE / 10 ||
(rev == Integer.MAX_VALUE / 10 && pop > 7)
) return 0;
if (
rev < Integer.MIN_VALUE / 10 ||
(rev == Integer.MIN_VALUE / 10 && pop < -8)
) return 0;
rev = rev * 10 + pop;
}
return rev;
}
}
To explain, lets assume that rev is positive.
- If
temp=rev⋅10+popcauses overflow, then it must be thatrev≥INTMAX/10 - If
rev>INTMAX/10, then temp=rev⋅10+pop is guaranteed to overflow. - If
rev==INTMAX/10, thentemp=rev⋅10+popwill overflow if and only if pop>7
I think both two conditions are unneccessary
|| (rev == INT_MAX / 10 && pop > 7)
|| (rev == INT_MAX / 10 && pop > 7)
because when rev == INTMAX/10, pop then will be 0, 1, or 2 because the input is int.
Python3解法
class Solution:
def reverse(self, x: int) -> int:
sign = [1, -1][x < 0]
rev, x = 0, abs(x)
while x:
x, mod = divmod(x, 10)
rev = rev * 10 + mod
if rev > 2**31 - 1:
return 0
return sign * rev
9. Palindrome Number
Given an integer x, return true if x is a palindrome__, and false otherwise.
Example 1:
Input: x = 121
Output: true
Explanation: 121 reads as 121 from left to right and from right to left.
Example 2:
Input: x = -121
Output: false
Explanation: From left to right, it reads -121. From right to left, it becomes 121-. Therefore it is not a palindrome.
Example 3:
Input: x = 10
Output: false
Explanation: Reads 01 from right to left. Therefore it is not a palindrome.
Constraints:
-2^31 <= x <= 2^31 - 1
Follow up: Could you solve it without converting the integer to a string?
思路
方法一:判断是否为负数,如果是负数则返回false,如果不是负数就把参数反转一下比较
Beware of overflow when you reverse the integer.
方法二:转为字符串,然后调用反转函数比较
C++解法
class Solution {
public:
bool isPalindrome(int x) {
if(x < 0) return false;
return reverse(x) == x;
}
int reverse(int x) {
int rev = 0;
while (x != 0) {
int pop = x % 10;
x /= 10;
if (rev > INT_MAX / 10 || (rev == INT_MAX / 10 && pop > 7))
return 0;
if (rev < INT_MIN / 10 || (rev == INT_MIN / 10 && pop < -8))
return 0;
rev = rev * 10 + pop;
}
return rev;
}
};
测试用例为1234567899时,使用下面代码会报错terminate called after throwing an instance of 'std::out_of_range'
class Solution {
public:
bool isPalindrome(int x) {
if(x < 0) return false;
string s = to_string(x);
reverse(s.begin(), s.end());
return stoi(s) == x;
}
};
直接使用stoi函数会导致溢出,因为stoi函数会把字符串转换为整数,而字符串的长度是有限的,所以会导致溢出。
#include <string>
#include <algorithm>
class Solution {
public:
bool isPalindrome(int x) {
if (x < 0) return false; // 负数不是回文
string s = to_string(x); // 转换为字符串
string reversed_s = s; // 复制字符串
reverse(reversed_s.begin(), reversed_s.end()); // 反转字符串
return s == reversed_s; // 直接比较反转前后的字符串
}
};
链表
关于链表,你该了解这些!
什么是链表,链表是一种通过指针串联在一起的线性结构,每一个节点由两部分组成,一个是数据域一个是指针域(存放指向下一个节点的指针),最后一个节点的指针域指向null(空指针的意思)。
链表的入口节点称为链表的头结点也就是head。
如图所示: 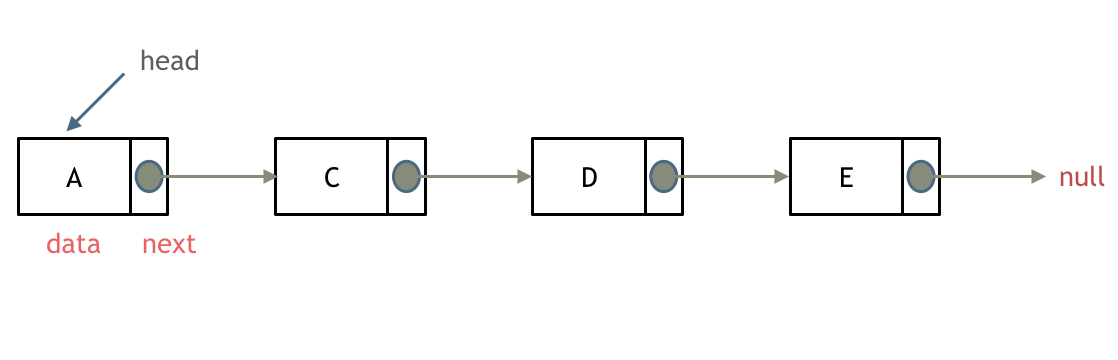
链表的类型
接下来说一下链表的几种类型:
单链表
刚刚说的就是单链表。
双链表
单链表中的指针域只能指向节点的下一个节点。
双链表:每一个节点有两个指针域,一个指向下一个节点,一个指向上一个节点。
双链表 既可以向前查询也可以向后查询。
如图所示: 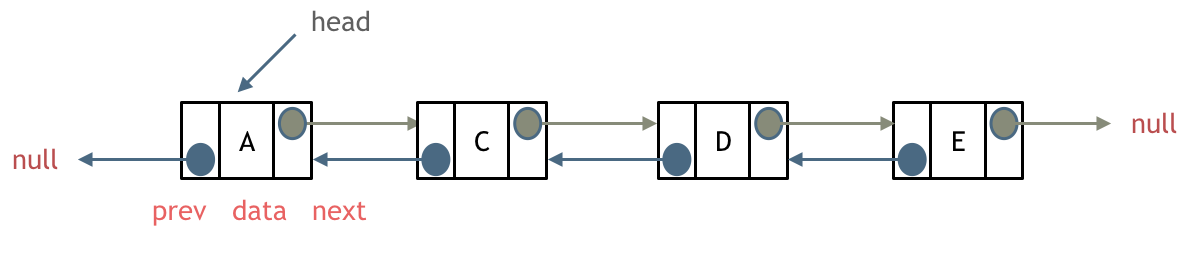
循环链表
循环链表,顾名思义,就是链表首尾相连。
循环链表可以用来解决约瑟夫环问题。
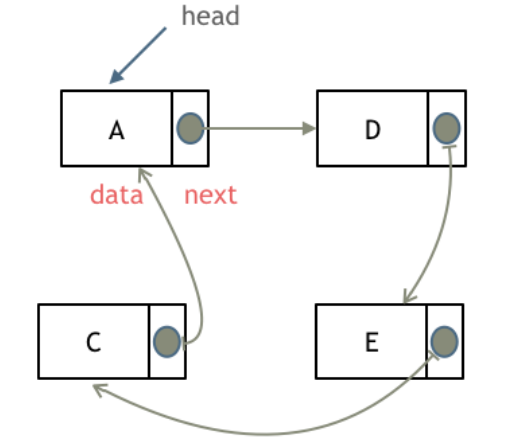
链表的存储方式
了解完链表的类型,再来说一说链表在内存中的存储方式。
数组是在内存中是连续分布的,但是链表在内存中可不是连续分布的。
链表是通过指针域的指针链接在内存中各个节点。
所以链表中的节点在内存中不是连续分布的 ,而是散乱分布在内存中的某地址上,分配机制取决于操作系统的内存管理。
如图所示:
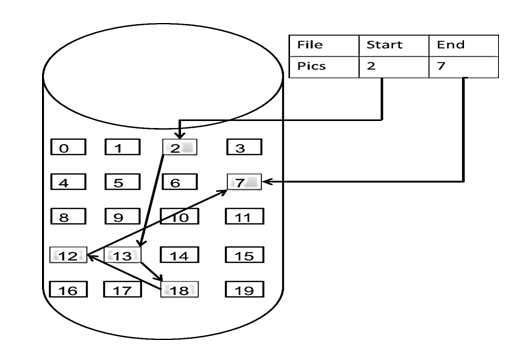
这个链表起始节点为2, 终止节点为7, 各个节点分布在内存的不同地址空间上,通过指针串联在一起。
链表的定义
接下来说一说链表的定义。
链表节点的定义,很多同学在面试的时候都写不好。
这是因为平时在刷leetcode的时候,链表的节点都默认定义好了,直接用就行了,所以同学们都没有注意到链表的节点是如何定义的。
而在面试的时候,一旦要自己手写链表,就写的错漏百出。
这里我给出C/C++的定义链表节点方式,如下所示:
// 单链表
struct ListNode {
int val; // 节点上存储的元素
ListNode *next; // 指向下一个节点的指针
ListNode(int x) : val(x), next(NULL) {} // 节点的构造函数
};
有同学说了,我不定义构造函数行不行,答案是可以的,C++默认生成一个构造函数。
但是这个构造函数不会初始化任何成员变量,下面我来举两个例子:
通过自己定义构造函数初始化节点:
ListNode* head = new ListNode(5);
使用默认构造函数初始化节点:
ListNode* head = new ListNode();
head->val = 5;
所以如果不定义构造函数使用默认构造函数的话,在初始化的时候就不能直接给变量赋值!
链表的操作
删除节点
删除D节点,如图所示:
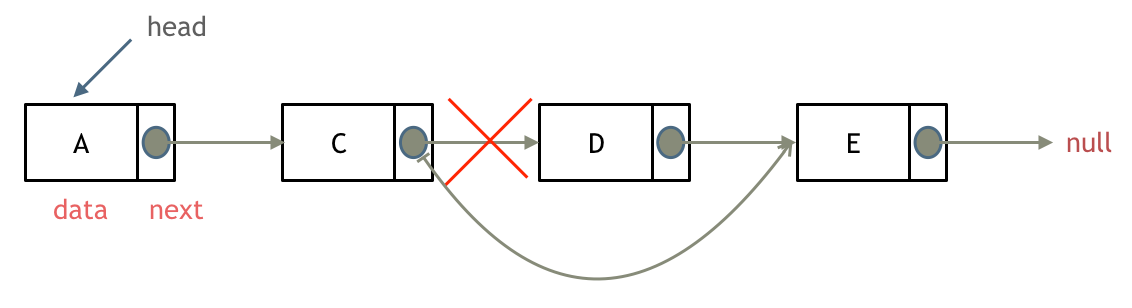
只要将C节点的next指针 指向E节点就可以了。
那有同学说了,D节点不是依然存留在内存里么?只不过是没有在这个链表里而已。
是这样的,所以在C++里最好是再手动释放这个D节点,释放这块内存。
其他语言例如Java、Python,就有自己的内存回收机制,就不用自己手动释放了。
添加节点
如图所示:
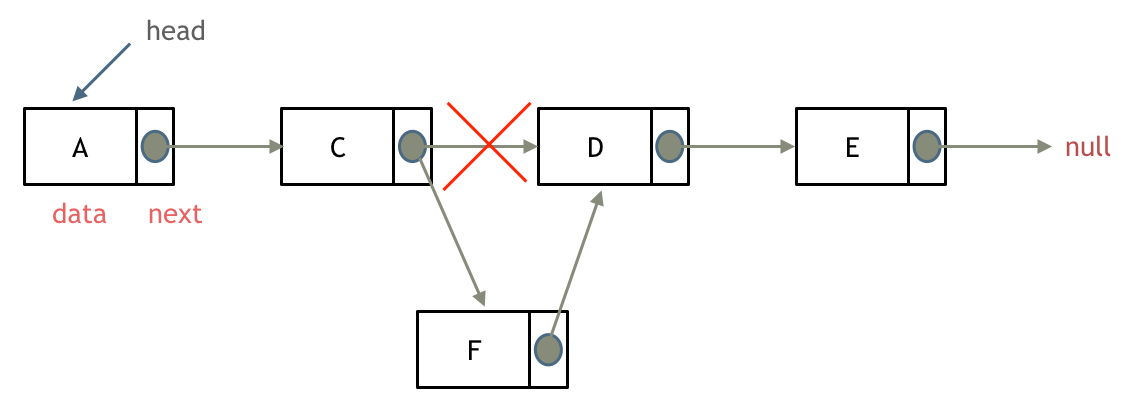
可以看出链表的增添和删除都是O(1)操作,也不会影响到其他节点。
但是要注意,要是删除第五个节点,需要从头节点查找到第四个节点通过next指针进行删除操作,查找的时间复杂度是O(n)。
性能分析
再把链表的特性和数组的特性进行一个对比,如图所示:
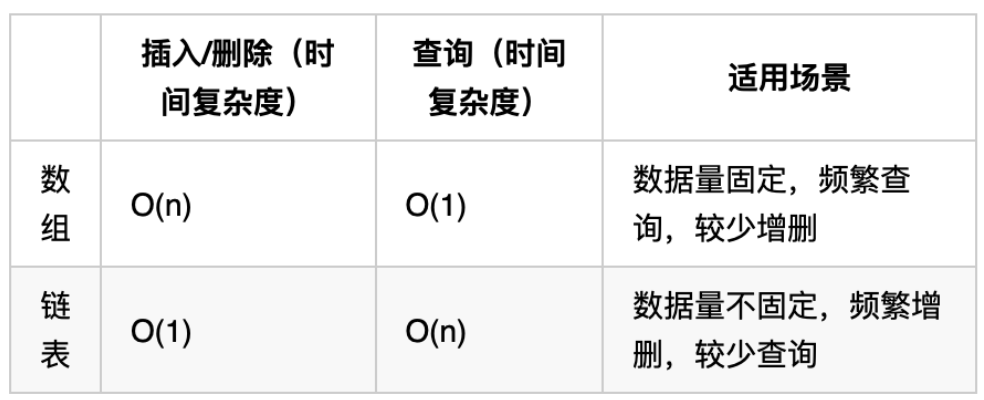
数组在定义的时候,长度就是固定的,如果想改动数组的长度,就需要重新定义一个新的数组。
链表的长度可以是不固定的,并且可以动态增删, 适合数据量不固定,频繁增删,较少查询的场景。
相信大家已经对链表足够的了解,后面我会讲解关于链表的高频面试题目,我们下期见!
链表经典题目
虚拟头结点
在链表:听说用虚拟头节点会方便很多? (opens new window)中,我们讲解了链表操作中一个非常重要的技巧:虚拟头节点。
链表的一大问题就是操作当前节点必须要找前一个节点才能操作。这就造成了,头结点的尴尬,因为头结点没有前一个节点了。
每次对应头结点的情况都要单独处理,所以使用虚拟头结点的技巧,就可以解决这个问题。
在链表:听说用虚拟头节点会方便很多? (opens new window)中,我给出了用虚拟头结点和没用虚拟头结点的代码,大家对比一下就会发现,使用虚拟头结点的好处。
链表的基本操作
在链表:一道题目考察了常见的五个操作! (opens new window)中,我们通过设计链表把链表常见的五个操作练习了一遍。
这是练习链表基础操作的非常好的一道题目,考察了:
- 获取链表第index个节点的数值
- 在链表的最前面插入一个节点
- 在链表的最后面插入一个节点
- 在链表第index个节点前面插入一个节点
- 删除链表的第index个节点的数值
可以说把这道题目做了,链表基本操作就OK了,再也不用担心链表增删改查整不明白了。
这里我依然使用了虚拟头结点的技巧,大家复习的时候,可以去看一下代码。
反转链表
在链表:听说过两天反转链表又写不出来了? (opens new window)中,讲解了如何反转链表。
因为反转链表的代码相对简单,有的同学可能直接背下来了,但一写还是容易出问题。
反转链表是面试中高频题目,很考察面试者对链表操作的熟练程度。
我在文章 (opens new window)中,给出了两种反转的方式,迭代法和递归法。
建议大家先学透迭代法,然后再看递归法,因为递归法比较绕,如果迭代还写不明白,递归基本也写不明白了。
可以先通过迭代法,彻底弄清楚链表反转的过程!
删除倒数第N个节点
在链表:删除链表倒数第N个节点,怎么删? (opens new window)中我们结合虚拟头结点 和 双指针法来移除链表倒数第N个节点。
链表相交
链表:链表相交 (opens new window)使用双指针来找到两个链表的交点(引用完全相同,即:内存地址完全相同的交点)
环形链表
在链表:环找到了,那入口呢? (opens new window)中,讲解了在链表如何找环,以及如何找环的入口位置。
这道题目可以说是链表的比较难的题目了。 但代码却十分简洁,主要在于一些数学证明。
设计链表
707. Design Linked List
Description
Design your implementation of the linked list. You can choose to use a singly or doubly linked list.
A node in a singly linked list should have two attributes: val and next. val is the value of the current node, and next is a pointer/reference to the next node.
If you want to use the doubly linked list, you will need one more attribute prev to indicate the previous node in the linked list. Assume all nodes in the linked list are 0-indexed.
Implement the MyLinkedList class:
MyLinkedList()Initializes theMyLinkedListobject.int get(int index)Get the value of theindexthnode in the linked list. If the index is invalid, return-1.void addAtHead(int val)Add a node of valuevalbefore the first element of the linked list. After the insertion, the new node will be the first node of the linked list.void addAtTail(int val)Append a node of valuevalas the last element of the linked list.void addAtIndex(int index, int val)Add a node of valuevalbefore theindexthnode in the linked list. Ifindexequals the length of the linked list, the node will be appended to the end of the linked list. Ifindexis greater than the length, the node will not be inserted.void deleteAtIndex(int index)Delete theindexthnode in the linked list, if the index is valid.
Example 1:
Input
["MyLinkedList", "addAtHead", "addAtTail", "addAtIndex", "get", "deleteAtIndex", "get"]
[[], [1], [3], [1, 2], [1], [1], [1]]
Output
[null, null, null, null, 2, null, 3]
Explanation
MyLinkedList myLinkedList = new MyLinkedList();
myLinkedList.addAtHead(1);
myLinkedList.addAtTail(3);
myLinkedList.addAtIndex(1, 2); // linked list becomes 1->2->3
myLinkedList.get(1); // return 2
myLinkedList.deleteAtIndex(1); // now the linked list is 1->3
myLinkedList.get(1); // return 3
Constraints:
0 <= index, val <= 1000- Please do not use the built-in LinkedList library.
- At most
2000calls will be made toget,addAtHead,addAtTail,addAtIndexanddeleteAtIndex.
思路
这道题目设计链表的五个接口:
- 获取链表第index个节点的数值
- 在链表的最前面插入一个节点
- 在链表的最后面插入一个节点
- 在链表第index个节点前面插入一个节点
- 删除链表的第index个节点
可以说这五个接口,已经覆盖了链表的常见操作,是练习链表操作非常好的一道题目
链表操作的两种方式:
- 直接使用原来的链表来进行操作。
- 设置一个虚拟头结点在进行操作。
下面采用的设置一个虚拟头结点(这样更方便一些,大家看代码就会感受出来)。
需要处理头结点时就要设置虚拟头节点。
C++解法
class MyLinkedList {
public:
// 定义链表节点结构体
struct LinkedNode {
int val;
LinkedNode* next;
LinkedNode(int val):val(val), next(nullptr){}
};
// 初始化链表
MyLinkedList() {
_dummyHead = new LinkedNode(0); // 这里定义的头结点 是一个虚拟头结点,而不是真正的链表头结点
_size = 0;
}
// 获取到第index个节点数值,如果index是非法数值直接返回-1, 注意index是从0开始的,第0个节点就是头结点
int get(int index) {
if (index > (_size - 1) || index < 0) {
return -1;
}
LinkedNode* cur = _dummyHead->next;
while(index--){ // 如果--index 就会陷入死循环
cur = cur->next;
}
return cur->val;
}
// 在链表最前面插入一个节点,插入完成后,新插入的节点为链表的新的头结点
void addAtHead(int val) {
LinkedNode* newNode = new LinkedNode(val);
newNode->next = _dummyHead->next;
_dummyHead->next = newNode;
_size++;
}
// 在链表最后面添加一个节点
void addAtTail(int val) {
LinkedNode* newNode = new LinkedNode(val);
LinkedNode* cur = _dummyHead;
while(cur->next != nullptr){
cur = cur->next;
}
cur->next = newNode;
_size++;
}
// 在第index个节点之前插入一个新节点,例如index为0,那么新插入的节点为链表的新头节点。
// 如果index 等于链表的长度,则说明是新插入的节点为链表的尾结点
// 如果index大于链表的长度,则返回空
// 如果index小于0,则在头部插入节点
void addAtIndex(int index, int val) {
if(index > _size) return;
if(index < 0) index = 0;
LinkedNode* newNode = new LinkedNode(val);
LinkedNode* cur = _dummyHead;
while(index--) {
cur = cur->next;
}
newNode->next = cur->next;
cur->next = newNode;
_size++;
}
// 删除第index个节点,如果index 大于等于链表的长度,直接return,注意index是从0开始的
void deleteAtIndex(int index) {
if (index >= _size || index < 0) {
return;
}
LinkedNode* cur = _dummyHead;
while(index--) {
cur = cur ->next;
}
LinkedNode* tmp = cur->next;
cur->next = cur->next->next;
delete tmp;
//delete命令指示释放了tmp指针原本所指的那部分内存,
//被delete后的指针tmp的值(地址)并非就是NULL,而是随机值。也就是被delete后,
//如果不再加上一句tmp=nullptr,tmp会成为乱指的野指针
//如果之后的程序不小心使用了tmp,会指向难以预想的内存空间
tmp=nullptr;
_size--;
}
// 打印链表
void printLinkedList() {
LinkedNode* cur = _dummyHead;
while (cur->next != nullptr) {
cout << cur->next->val << " ";
cur = cur->next;
}
cout << endl;
}
private:
int _size;
LinkedNode* _dummyHead;
};
Java解法
Python3解法
876. Middle of the Linked List
Given the head of a singly linked list, return the middle node of the linked list.
If there are two middle nodes, return the second middle node.
Example 1:

Input: head = [1,2,3,4,5]
Output: [3,4,5]
Explanation: The middle node of the list is node 3.
Example 2:

Input: head = [1,2,3,4,5,6]
Output: [4,5,6]
Explanation: Since the list has two middle nodes with values 3 and 4, we return the second one.
Constraints:
- The number of nodes in the list is in the range
[1, 100]. 1 <= Node.val <= 100
思路
双指针,快慢指针
C++解法
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode() : val(0), next(nullptr) {}
* ListNode(int x) : val(x), next(nullptr) {}
* ListNode(int x, ListNode *next) : val(x), next(next) {}
* };
*/
class Solution {
public:
ListNode* middleNode(ListNode* head) {
if(head == NULL){
return NULL;
}
ListNode* dummyHead = new ListNode(0);
dummyHead->next = head;
ListNode* slow = dummyHead;
ListNode* fast = head;
while(fast != NULL && fast->next != NULL){
fast = fast->next->next;
slow = slow->next;
}
return slow->next;
}
};
移除链表元素
- 19. Remove Nth Node From End of List
- 203. Remove Linked List Elements
- 237. Delete Node in a Linked List
- 2095. Delete the Middle Node of a Linked List
- 2487. Remove Nodes From Linked List
- 3217. Delete Nodes From Linked List Present in Array
要点:需要处理头节点时,使用虚拟头节点。如果要删除slow->next,则slow指针要慢一步。
19. Remove Nth Node From End of List
Given the head of a linked list, remove the nth node from the end of the list and return its head.
Example 1:

Input: head = [1,2,3,4,5], n = 2
Output: [1,2,3,5]
Example 2:
Input: head = [1], n = 1
Output: []
Example 3:
Input: head = [1,2], n = 1
Output: [1]
Constraints:
- The number of nodes in the list is
sz. 1 <= sz <= 300 <= Node.val <= 1001 <= n <= sz
Follow up: Could you do this in one pass?
思路
快慢指针求解,因为要删除slow->next,所以slow指针要慢一步。
Maintain two pointers and update one with a delay of n steps.
Complexity
- Time complexity: O(n)
- Space complexity: O(1)
C++解法
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode() : val(0), next(nullptr) {}
* ListNode(int x) : val(x), next(nullptr) {}
* ListNode(int x, ListNode *next) : val(x), next(next) {}
* };
*/
class Solution {
public:
ListNode* removeNthFromEnd(ListNode* head, int n) {
ListNode* dummyHead = new ListNode(0);
dummyHead->next = head;
ListNode* slow = dummyHead;
ListNode* fast = head;
for(int i = 0; i < n; i++){
fast = fast->next;
}
while(fast != NULL){
fast = fast->next;
slow = slow->next;
}
slow->next = slow->next->next;
return dummyHead->next;
}
};
Java解法
class Solution {
public ListNode removeNthFromEnd(ListNode head, int n) {
ListNode fast = head, slow = head;
for (int i = 0; i < n; i++) fast = fast.next;
if (fast == null) return head.next;
while (fast.next != null) {
fast = fast.next;
slow = slow.next;
}
slow.next = slow.next.next;
return head;
}
}
Python3解法
class Solution:
def removeNthFromEnd(self, head: ListNode, n: int) -> ListNode:
fast, slow = head, head
for _ in range(n): fast = fast.next
if not fast: return head.next
while fast.next: fast, slow = fast.next, slow.next
slow.next = slow.next.next
return head
203. Remove Linked List Elements
Description
Given the head of a linked list and an integer val, remove all the nodes of the linked list that has Node.val == val, and return the new head.
Example 1:
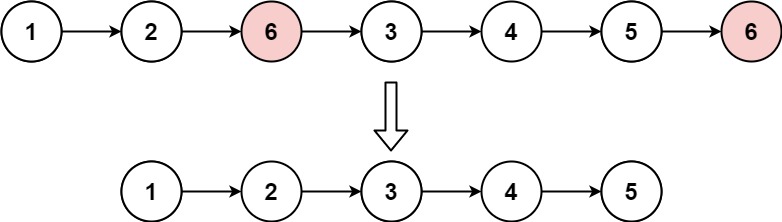
Input: head = [1,2,6,3,4,5,6], val = 6
Output: [1,2,3,4,5]
Example 2:
Input: head = [], val = 1
Output: []
Example 3:
Input: head = [7,7,7,7], val = 7
Output: []
Constraints:
- The number of nodes in the list is in the range
[0, 10^4]. 1 <= Node.val <= 500 <= val <= 50
思路
- 单独处理头节点
- 使用虚拟头节点
推荐使用虚拟头节点。
C++解法
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode() : val(0), next(nullptr) {}
* ListNode(int x) : val(x), next(nullptr) {}
* ListNode(int x, ListNode *next) : val(x), next(next) {}
* };
*/
class Solution {
public:
ListNode* removeElements(ListNode* head, int val) {
ListNode* dummyHead = new ListNode(0);
dummyHead->next = head;
ListNode* cur = dummyHead;
while(cur->next != NULL){
if(cur->next->val == val){
ListNode* temp = cur->next;
cur->next = cur->next->next;
delete temp;
}else{
cur = cur->next;
}
}
return dummyHead->next;
}
};
Java解法
/**
* Definition for singly-linked list.
* public class ListNode {
* int val;
* ListNode next;
* ListNode() {}
* ListNode(int val) { this.val = val; }
* ListNode(int val, ListNode next) { this.val = val; this.next = next; }
* }
*/
class Solution {
public ListNode removeElements(ListNode head, int val) {
ListNode dummyHead = new ListNode(0);
dummyHead.next = head;
ListNode cur = dummyHead;
while(cur.next != null){
if(cur.next.val == val){
cur.next = cur.next.next;
}else{
cur = cur.next;
}
}
return dummyHead.next;
}
}
Python3解法
# Definition for singly-linked list.
# class ListNode:
# def __init__(self, val=0, next=None):
# self.val = val
# self.next = next
class Solution:
def removeElements(self, head: Optional[ListNode], val: int) -> Optional[ListNode]:
temp = ListNode(0)
temp.next = head
prev, curr = temp, head
while curr:
if curr.val == val:
prev.next = curr.next
else:
prev = curr
curr = curr.next
return temp.next
Go解法
/**
* Definition for singly-linked list.
* type ListNode struct {
* Val int
* Next *ListNode
* }
*/
func removeElements(head *ListNode, val int) *ListNode {
dummyHead := &ListNode{Val:0, Next: head}
pre := dummyHead
cur := pre.Next
for cur != nil {
if cur.Val == val{
pre.Next = cur.Next
cur = pre.Next
}else{
pre = cur
cur = cur.Next
}
}
return dummyHead.Next
}
237. Delete Node in a Linked List
There is a singly-linked list head and we want to delete a node node in it.
You are given the node to be deleted node. You will not be given access to the first node of head.
All the values of the linked list are unique, and it is guaranteed that the given node node is not the last node in the linked list.
Delete the given node. Note that by deleting the node, we do not mean removing it from memory. We mean:
- The value of the given node should not exist in the linked list.
- The number of nodes in the linked list should decrease by one.
- All the values before
nodeshould be in the same order. - All the values after
nodeshould be in the same order.
Custom testing:
- For the input, you should provide the entire linked list
headand the node to be givennode.nodeshould not be the last node of the list and should be an actual node in the list. - We will build the linked list and pass the node to your function.
- The output will be the entire list after calling your function.
Example 1:
Input: head = [4,5,1,9], node = 5
Output: [4,1,9]
Explanation: You are given the second node with value 5, the linked list should become 4 -> 1 -> 9 after calling your function.
Example 2:
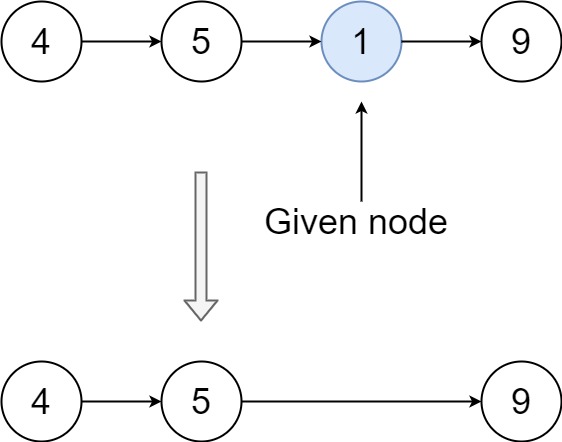
Input: head = [4,5,1,9], node = 1
Output: [4,5,9]
Explanation: You are given the third node with value 1, the linked list should become 4 -> 5 -> 9 after calling your function.
Constraints:
- The number of the nodes in the given list is in the range
[2, 1000]. -1000 <= Node.val <= 1000- The value of each node in the list is unique.
- The
nodeto be deleted is in the list and is not a tail node.
思路
Approach: Data Overwriting
Note: This method will not work if we need to delete the last node of the linked list since there is no immediate successor. However, the problem description explicitly states that the node to be deleted is not the tail node in the list.
Algorithm
- Copy the data from the successor node into the current node to be deleted.
- Update the
nextpointer of the current node to reference thenextpointer of the successor node.
用待删除结点下一个节点覆盖待删除结点,此时删除原待删除结点下一个节点即可
Complexity Analysis
-
Time Complexity: O(1)
- The method involves a constant number of operations: updating the data of the current node and altering its
nextpointer. Each of these operations requires a fixed amount of time, irrespective of the size of the linked list.
- The method involves a constant number of operations: updating the data of the current node and altering its
-
Space Complexity: O(1)
- This deletion technique does not necessitate any extra memory allocation, as it operates directly on the existing nodes without creating additional data structures.
C++解法
/**
* Definition for singly-linked list. //单链表的定义
* struct ListNode {
* int val; //当前结点的值(数据域)
* ListNode *next; //指向下一个结点的指针(指针域)
* ListNode(int x) : val(x), next(NULL) {} //初始化当前结点的值为x,指针为空
* };
*/
class Solution {
public:
void deleteNode(ListNode* node) {
// Overwrite data of next node on current node.
node->val = node->next->val;
// Make current node point to next of next node.
node->next = node->next->next;
}
};
Java解法
/**
* Definition for singly-linked list.
* public class ListNode {
* int val;
* ListNode next;
* ListNode(int x) { val = x; }
* }
*/
class Solution {
public void deleteNode(ListNode node) {
// Overwrite data of next node on current node.
node.val = node.next.val;
// Make current node point to next of next node.
node.next = node.next.next;
}
}
Python3解法
# Definition for singly-linked list.
# class ListNode:
# def __init__(self, x):
# self.val = x
# self.next = None
class Solution:
def deleteNode(self, node):
"""
:type node: ListNode
:rtype: void Do not return anything, modify node in-place instead.
"""
# Overwrite data of next node on current node.
node.val = node.next.val
# Make current node point to next of next node.
node.next = node.next.next
Go解法
2095. Delete the Middle Node of a Linked List
You are given the head of a linked list. Delete the middle node, and return the head of the modified linked list.
The middle node of a linked list of size n is the ⌊n / 2⌋th node from the start using 0-based indexing, where ⌊x⌋ denotes the largest integer less than or equal to x.
- For
n=1,2,3,4, and5, the middle nodes are0,1,1,2, and2, respectively.
Example 1:

Input: head = [1,3,4,7,1,2,6]
Output: [1,3,4,1,2,6]
Explanation:
The above figure represents the given linked list. The indices of the nodes are written below.
Since n = 7, node 3 with value 7 is the middle node, which is marked in red.
We return the new list after removing this node.
Example 2:

Input: head = [1,2,3,4]
Output: [1,2,4]
Explanation:
The above figure represents the given linked list.
For n = 4, node 2 with value 3 is the middle node, which is marked in red.
Example 3:

Input: head = [2,1]
Output: [2]
Explanation:
The above figure represents the given linked list.
For n = 2, node 1 with value 1 is the middle node, which is marked in red.
Node 0 with value 2 is the only node remaining after removing node 1.
Constraints:
- The number of nodes in the list is in the range
[1, 10^5]. 1 <= Node.val <= 10^5
思路
普通解法:求长度的一半然后遍历到这里并删除该节点,需要考虑只有一个节点的情况
双指针解法:快指针比慢指针的速度快一倍,快指针到头说明慢指针到达了一半的位置,跳过该节点即可。Complexity 👈
- Time complexity: O(n)
- Space complexity: O(1)
C++解法
双指针解法:
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode() : val(0), next(nullptr) {}
* ListNode(int x) : val(x), next(nullptr) {}
* ListNode(int x, ListNode *next) : val(x), next(next) {}
* };
*/
class Solution {
public:
ListNode* deleteMiddle(ListNode* head) {
if(head == NULL || head->next == NULL){
return NULL;
}
ListNode* dummyHead = new ListNode(0);
dummyHead->next = head;
ListNode* slow = dummyHead;
ListNode* fast = head;
while(fast != NULL && fast->next != NULL){
fast = fast->next->next;
slow = slow->next;
}
slow->next = slow->next->next;
return dummyHead->next;
}
};
普通解法:
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode() : val(0), next(nullptr) {}
* ListNode(int x) : val(x), next(nullptr) {}
* ListNode(int x, ListNode *next) : val(x), next(next) {}
* };
*/
class Solution {
public:
ListNode* deleteMiddle(ListNode* head) {
int length = 0;
ListNode* pMove = head;
while(pMove){
length += 1;
pMove = pMove->next;
}
if(length <= 1){
return NULL;
}
int index = length % 2 == 1 ? (length - 1) / 2 : length / 2;
ListNode* pre = NULL;
ListNode* cur = head;
for(; index > 0; index--){
pre = cur;
cur = cur->next;
}
if(pre->next){
pre->next = cur->next;
}
return head;
}
};
Java解法
/**
* Definition for singly-linked list.
* public class ListNode {
* int val;
* ListNode next;
* ListNode() {}
* ListNode(int val) { this.val = val; }
* ListNode(int val, ListNode next) { this.val = val; this.next = next; }
* }
*/
class Solution {
public ListNode deleteMiddle(ListNode head) {
if(head == null)return null;
ListNode prev = new ListNode(0);
prev.next = head;
ListNode slow = prev;
ListNode fast = head;
while(fast != null && fast.next != null){
slow = slow.next;
fast = fast.next.next;
}
slow.next = slow.next.next;
return prev.next;
}
}
Python解法
# Definition for singly-linked list.
# class ListNode(object):
# def __init__(self, val=0, next=None):
# self.val = val
# self.next = next
class Solution(object):
def deleteMiddle(self, head):
"""
:type head: Optional[ListNode]
:rtype: Optional[ListNode]
"""
if head == None :return None
prev = ListNode(0)
prev.next = head
slow = prev
fast = head
while fast != None and fast.next != None:
slow = slow.next
fast = fast.next.next
slow.next = slow.next.next
return prev.next
2487. Remove Nodes From Linked List
You are given the head of a linked list.
Remove every node which has a node with a greater value anywhere to the right side of it.
Return the head of the modified linked list.
Example 1:

Input: head = [5,2,13,3,8]
Output: [13,8]
Explanation: The nodes that should be removed are 5, 2 and 3.
- Node 13 is to the right of node 5.
- Node 13 is to the right of node 2.
- Node 8 is to the right of node 3.
Example 2:
Input: head = [1,1,1,1]
Output: [1,1,1,1]
Explanation: Every node has value 1, so no nodes are removed.
Constraints:
- The number of the nodes in the given list is in the range
[1, 10^5]. 1 <= Node.val <= 10^5
思路
Iterate on nodes in reversed order.
When iterating in reversed order, save the maximum value that was passed before.
Overview
Given the head of a linked list, the task is to remove every node that has a node with a greater value anywhere on its right side. This means that after processing the linked list, every node will only have nodes with smaller values to their right, or the linked list should be in decreasing order.
Key Observations
- The nodes in the linked list have positive values.
- There may be duplicate values.
- We manipulate the list by deleting values, not by sorting it.
Approach 1: Stack
Intuition
A challenge associated with this problem is that, for a given node, we need to not only delete the node directly to the right if it has a larger value but also delete all other nodes to the right that have larger values. The brute force approach involves iterating through the linked list using nested loops, comparing the value of each node with the nodes that follow it, and deleting any nodes whose values are smaller than the following nodes. However, this approach is inefficient, with a quadratic time complexity.
The resultant linked list should be in decreasing order. We can leverage this fact to develop a more efficient solution.
A list in decreasing order, if reversed, is in increasing order.
If we reverse the list, the node values should be in increasing order after deleting nodes. We can delete any nodes whose values are smaller than the nodes before them. This strategy ensures efficient deletion of all nodes that have nodes with a greater value to their right (in the original order) without using nested loops.
The list we are given is a singly linked list, so we can't easily traverse it in reverse from tail to head.
Whenever a problem requires reversing a sequence, it is worth considering using a stack.
Stacks are a First-In-Last-Out (FILO) data structure, meaning that the first items added to the stack are the last ones removed. Consequently, if you push a sequence of items into a stack and then remove them, the sequence will be reversed. Learn more about stacks by reading our Stack Explore Card.
We start by adding all of the nodes to a stack.
Next, we create a new linked list to store the result. We keep track of the maximum node value encountered so far using the variable maximum.
Then, we pop each node from the stack. If the node's value is not smaller than the maximum, we create a new node with that value and add it to the resultList. Since the linked list is reversed, we build the resultList from back to front, continuously adding new nodes to the beginning.
Algorithm
- Initialize an empty
stackto be used for reversing the nodes. - Set a pointer
currenttohead. - While
currentis notNull:- Add
currentto thestack. - Set
currenttocurrent.next.
- Add
- Pop the node from the top of the
stackand setcurrentto that node. - Initialize a variable
maximumtocurrent.val. - Create a new ListNode
resultListwithmaximumas its value. - While the
stackis not empty:- Pop the node from the top of the
stackand setcurrentto that node. - If
current.val<maximum:- Continue; this node does not need to be added to the
resultList.
- Continue; this node does not need to be added to the
- Otherwise, add a new node to the front of the
resultList:- Create a new ListNode
newNodewithcurrent.valas its value. - Set
newNode.nexttoresultList. - Set
resultListtonewNode. - Update
maximumtocurrent.val.
- Create a new ListNode
- Pop the node from the top of the
- Return
resultList.
Complexity Analysis
Let n be the length of the original linked list.
-
Time complexity: O(n)
Adding the nodes from the original linked list to the stack takes O(n).
Removing nodes from the stack and adding them to the result takes O(n), as each node is popped from the stack exactly once.
Therefore, the time complexity is O(2n), which simplifies to O(n).
-
Space complexity: O(n)
We add each of the nodes from the original linked list to the
stack, making its size n.We only use
resultListto store the result, so it does not contribute to the space complexity.Therefore, the space complexity is O(n).
Approach 2: Recursion
Intuition
The nodes we retain in the linked list must meet the following criteria: Each node's value is not smaller than the values of the following nodes.
Linked lists are often manipulated using recursion. This problem is an excellent candidate for recursion because it can be broken down into subproblems that collectively solve the main problem.
Consider a node B situated in the middle of the linked list, where all subsequent nodes have values less than or equal to B's value. If node B satisfies this criterion, its value is not smaller than the values of the following nodes. For the node A directly preceding B, if A is not smaller than B, then A is also not smaller than any nodes following B. This holds due to the transitive property: if a≥b and b≥c, then a≥c.
This means that if we've solved the subproblem for nodes to the right of a given node in the linked list, we can efficiently solve the problem for that node.
Let`s begin by discussing the base cases:
-
The linked list is empty:
- An empty list meets the criteria, so we return the
head.
- An empty list meets the criteria, so we return the
-
The linked list has only one node:
- A list with one node also meets the criteria, because there are no following nodes. Again, we return the
head.
- A list with one node also meets the criteria, because there are no following nodes. Again, we return the
We can develop a strategy for handling longer lists by thinking about handling a linked list with two nodes.
For a linked list with two nodes, there are two cases for the head node:
-
The
headnode's value is the same size or larger than the next node's value.- This linked list meets the criteria. Return the list.
-
The
headnode's value is smaller than the next node's value.- We need to delete
head. Return the next node.
- We need to delete
For linked lists with more than two nodes, the main adjustment we need to make is to check the rest of the linked list.
The challenge we face is ensuring that head.next is set to the correct next node. Does the next node also need to be deleted? Are there other nodes later in the linked list that have values that are greater than head?
Instead of simply setting head to head.next to progress to the next node, we recursively call removeNodes(head.next). This recursive function removes nodes with greater values anywhere to the right. This ensures that head is set to the correct node and that the rest of the linked list also meets the criteria.
Algorithm
- Base Case: If
headorhead.nextisNull, returnhead. - Recursive Call: Set
nextNodetoremoveNodes(head.next). - Comparison: If
head.valis less thannextNode.val, we need to removehead. ReturnnextNode. - Otherwise, set
headtohead.nextand then returnhead.
Complexity Analysis
Let n be the length of the original linked list.
-
Time complexity: O(n)
We call
removeNodes()once for each node in the original linked list. The other operations inside the function all take constant time, so the time complexity is dominated by the recursive calls. Thus, the time complexity is O(n). -
Space complexity: O(n)
Since we make n recursive calls to
removeNodes(), the call stack can grow up to size n. Therefore, the space complexity is O(n).
Approach 3: Reverse Twice
Intuition
The first approach used a stack to reverse the linked list, resulting in linear auxiliary space. However, instead of using a stack, we can write a function to reverse the nodes in place, avoiding the need for auxiliary space. This task is explored in the problem Reverse Linked List. The basic idea is to set each node's next field to point to the previous node.
After reversing the linked list, the node values will be in increasing order, allowing us to delete any nodes whose values are smaller than the nodes preceding them.
To facilitate this process, we maintain the maximum node value found so far using the variable maximum.
We traverse each node, current, in the reversed linked list and update the maximum value accordingly. If the value of the current node is smaller than the maximum, we delete current. Deleting nodes in place requires us to track the previous node so that we can correctly link it to the next node if we delete the current node.
Once we have traversed the linked list to delete the nodes, we have a linked list that is in increasing order.
However, since the desired result should be in decreasing order, we reverse the modified linked list and then return it.
Interview Tip: In-place Algorithms
This approach modifies the input. In-place algorithms overwrite the input to save space, but sometimes this can cause problems.
Here are a couple of situations where an in-place algorithm might not be suitable.
The algorithm needs to run in a multi-threaded environment, without exclusive access to the array. Other threads might need to read the array too, and might not expect it to be modified.
Even if there is only a single thread, or the algorithm has exclusive access to the array while running, the array might need to be reused later or by another thread once the lock has been released.
In an interview, you should always check whether the interviewer minds you overwriting the input. Be ready to explain the pros and cons of doing so if asked!
Algorithm
- Define a function
reverseListthat takes the head of a linked list as input and reverses it, returning the new head.- Initialize three pointers,
prevtonull,currenttohead, andnextTemptonull. - While
currentis notnull:- Set
nextTemptocurrent.next. - Reverse the order of the nodes by setting
current.nexttoprev. - Progress both pointers by setting
prevtocurrentandcurrenttonextTemp.
- Set
- Return
prev.
- Initialize three pointers,
- Reverse the original linked list using
reverseList(head). Setheadto the reversed linked list. - Initialize a variable
maximumto0. - Initialize two pointers,
prevtonullandcurrenttohead. - Delete the nodes that are smaller than the node before them. While
currentis notnull:- Update
maximumto the max betweenmaximumandcurrent.val. - If
current.valis less thanmaximum, deletecurrent.- Skip the current node by setting
prev.nexttocurrent.next. - Set a pointer
deletedtocurrent. - Move
currenttocurrent.nextto progress to the next node. - Set
deleted.nexttonullto remove any additional pointers to the newcurrentnode.
- Skip the current node by setting
- Otherwise, if
current.valis not less thanmaximum, retaincurrentand progress both pointers by settingprevtocurrentandcurrenttocurrent.next.
- Update
- Reverse and return the modified linked list using
reverseList(head).
Complexity Analysis
Let n be the length of the original linked list.
-
Time complexity: O(n)
Reversing the original linked list takes O(n).
Traversing the reversed original linked list and removing nodes takes O(n).
Reversing the modified linked list takes an additional O(n) time.
Therefore, the total time complexity is O(3n), which simplifies to O(n).
-
Space complexity: O(1)
We use a few variables and pointers that use constant extra space. Since we don't use any data structures that grow with input size, the space complexity remains O(1).
C++解法
Approach 3: Reverse Twice
class Solution {
private:
ListNode* reverseList(ListNode* head) {
ListNode* prev = nullptr;
ListNode* current = head;
ListNode* nextTemp = nullptr;
// Set each node's next pointer to the previous node
while (current != nullptr) {
nextTemp = current->next;
current->next = prev;
prev = current;
current = nextTemp;
}
return prev;
}
public:
ListNode* removeNodes(ListNode* head) {
// Reverse the original linked list
head = reverseList(head);
int maximum = 0;
ListNode* prev = nullptr;
ListNode* current = head;
// Traverse the list deleting nodes
while (current != nullptr) {
maximum = max(maximum, current->val);
// Delete nodes that are smaller than maximum
if (current->val < maximum) {
// Delete current by skipping
prev->next = current->next;
ListNode* deleted = current;
current = current->next;
deleted->next = nullptr;
}
// Current does not need to be deleted
else {
prev = current;
current = current->next;
}
}
// Reverse and return the modified linked list
return reverseList(head);
}
};
Approach 2: Recursion
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode() : val(0), next(nullptr) {}
* ListNode(int x) : val(x), next(nullptr) {}
* ListNode(int x, ListNode *next) : val(x), next(next) {}
* };
*/
class Solution {
public:
ListNode* removeNodes(ListNode* head) {
// Base case, reached end of the list
if (head == nullptr || head->next == nullptr) {
return head;
}
// Recursive call
ListNode* nextNode = removeNodes(head->next);
// If the next node has greater value than head delete the head
// Return next node, which removes the current head and makes next the new head
if (head->val < nextNode->val) {
return nextNode;
}
// Keep the head
head->next = nextNode;
return head;
}
};
Approach 1: Stack
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode() : val(0), next(nullptr) {}
* ListNode(int x) : val(x), next(nullptr) {}
* ListNode(int x, ListNode *next) : val(x), next(next) {}
* };
*/
class Solution {
public:
ListNode* removeNodes(ListNode* head) {
stack<ListNode*> stack;
ListNode* current = head;
// Add nodes to the stack
while (current != nullptr) {
stack.push(current);
current = current->next;
}
current = stack.top();
stack.pop();
int maximum = current->val;
ListNode* resultList = new ListNode(maximum);
// Remove nodes from the stack and add to result
while (!stack.empty()) {
current = stack.top();
stack.pop();
// Current should not be added to the result
if (current->val < maximum) {
continue;
}
// Add new node with current's value to front of the result
else {
ListNode* newNode = new ListNode(current->val);
newNode->next = resultList;
resultList = newNode;
maximum = current->val;
}
}
return resultList;
}
};
Java解法
Approach 2: Recursion
/**
* Definition for singly-linked list.
* public class ListNode {
* int val;
* ListNode next;
* ListNode() {}
* ListNode(int val) { this.val = val; }
* ListNode(int val, ListNode next) { this.val = val; this.next = next; }
* }
*/
class Solution {
public ListNode removeNodes(ListNode head) {
// Base case, reached end of the list
if (head == null || head.next == null) {
return head;
}
// Recursive call
ListNode nextNode = removeNodes(head.next);
// If the next node has greater value than head, delete the head
// Return next node, which removes the current head and makes next the new head
if (head.val < nextNode.val) {
return nextNode;
}
// Keep the head
head.next = nextNode;
return head;
}
}
Python3解法
Approach 1: Stack
# Definition for singly-linked list.
# class ListNode:
# def __init__(self, val=0, next=None):
# self.val = val
# self.next = next
class Solution:
def removeNodes(self, head: Optional[ListNode]) -> Optional[ListNode]:
stack = []
current = head
# Add nodes to the stack
while current:
stack.append(current)
current = current.next
current = stack.pop()
maximum = current.val
result_list = ListNode(maximum)
# Remove nodes from the stack and add to result
while stack:
current = stack.pop()
# Current should not be added to the result
if current.val < maximum:
continue
# Add new node with current's value to front of the result
else:
new_node = ListNode(current.val)
new_node.next = result_list
result_list = new_node
maximum = current.val
return result_list
Go解法
3217. Delete Nodes From Linked List Present in Array
You are given an array of integers nums and the head of a linked list. Return the head of the modified linked list after removing all nodes from the linked list that have a value that exists in nums.
Example 1:
Input: nums = [1,2,3], head = [1,2,3,4,5]
Output: [4,5]
Explanation:

Remove the nodes with values 1, 2, and 3.
Example 2:
Input: nums = [1], head = [1,2,1,2,1,2]
Output: [2,2,2]
Explanation:

Remove the nodes with value 1.
Example 3:
Input: nums = [5], head = [1,2,3,4]
Output: [1,2,3,4]
Explanation:
No node has value 5.
Constraints:
1 <= nums.length <= 10^51 <= nums[i] <= 10^5- All elements in
numsare unique. - The number of nodes in the given list is in the range
[1, 10^5]. 1 <= Node.val <= 10^5- The input is generated such that there is at least one node in the linked list that has a value not present in
nums.
思路
方法一:迭代处理数组中的元素,然后调用removeElements()函数,这种方法会超时。
方法二:哈希数组,遍历一遍链表
不要删除指针,否则容易出现悬挂指针问题,具体报错信息为ERROR: AddressSanitizer: heap-use-after-free on address
C++解法
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode() : val(0), next(nullptr) {}
* ListNode(int x) : val(x), next(nullptr) {}
* ListNode(int x, ListNode *next) : val(x), next(next) {}
* };
*/
class Solution {
public:
ListNode* modifiedList(vector<int>& nums, ListNode* head) {
if (nums.size() == 0 || head == NULL) {
return head;
}
bitset<100001> hasN = 0;
for(int x : nums){
hasN[x] = 1;
}
ListNode* dummyHead = new ListNode(0);
dummyHead->next = head;
ListNode* pre = dummyHead;
ListNode* cur = head;
while(cur){
if(hasN[cur->val]){
pre->next = cur->next;
cur = pre->next;
}else{
pre = cur;
cur = cur->next;
}
}
return dummyHead->next;
}
};
反转链表
206. Reverse Linked List
Description
Given the head of a singly linked list, reverse the list, and return the reversed list.
Example 1:

Input: head = [1,2,3,4,5]
Output: [5,4,3,2,1]
Example 2:

Input: head = [1,2]
Output: [2,1]
Example 3:
Input: head = []
Output: []
Constraints:
- The number of nodes in the list is the range
[0, 5000]. -5000 <= Node.val <= 5000
Follow up: A linked list can be reversed either iteratively or recursively. Could you implement both?
思路
双指针
迭代
递归
C++ 解法
递归
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode() : val(0), next(nullptr) {}
* ListNode(int x) : val(x), next(nullptr) {}
* ListNode(int x, ListNode *next) : val(x), next(next) {}
* };
*/
class Solution {
public:
ListNode* reverseList(ListNode* head) {
if(head == NULL || head->next == NULL)
return head;
ListNode* last = reverseList(head->next);
head->next->next = head;
head->next = NULL;
return last;
}
};
Java 解法
迭代
/**
* Definition for singly-linked list.
* public class ListNode {
* int val;
* ListNode next;
* ListNode() {}
* ListNode(int val) { this.val = val; }
* ListNode(int val, ListNode next) { this.val = val; this.next = next; }
* }
*/
class Solution {
public ListNode reverseList(ListNode head) {
ListNode pre = null;
ListNode cur = head;
while(cur != null){
ListNode temp = cur.next;
cur.next = pre;
pre = cur;
cur = temp;
}
return pre;
}
}
Python3 解法
迭代
# Definition for singly-linked list.
# class ListNode:
# def __init__(self, val=0, next=None):
# self.val = val
# self.next = next
class Solution:
def reverseList(self, head: Optional[ListNode]) -> Optional[ListNode]:
pre = None
cur = head
while cur != None:
temp = cur.next
cur.next = pre
pre = cur
cur = temp
return pre
递归
# Definition for singly-linked list.
# class ListNode:
# def __init__(self, val=0, next=None):
# self.val = val
# self.next = next
class Solution:
def reverseList(self, head: Optional[ListNode]) -> Optional[ListNode]:
if head == None or head.next == None:
return head
last = self.reverseList(head.next)
head.next.next = head
head.next = None
return last
92. Reverse Linked List II
Description
Given the head of a singly linked list and two integers left and right where left <= right, reverse the nodes of the list from position left to position right, and return the reversed list.
Example 1:
Input: head = [1,2,3,4,5], left = 2, right = 4
Output: [1,4,3,2,5]
Example 2:
Input: head = [5], left = 1, right = 1
Output: [5]
Constraints:
The number of nodes in the list is n.
- 1 <= n <= 500
- -500 <= Node.val <= 500
- 1 <= left <= right <= n
Follow up: Could you do it in one pass?
思路
链表的操作问题,一般而言面试(机试)的时候不允许我们修改节点的值,而只能修改节点的指向操作。
思路通常都不难,写对链表问题的技巧是:一定要先想清楚思路,并且必要的时候在草稿纸上画图,理清「穿针引线」的先后步骤,然后再编码。
方法一:穿针引线
我们以下图中黄色区域的链表反转为例。
使用「206. 反转链表」的解法,反转 left 到 right 部分以后,再拼接起来。我们还需要记录 left 的前一个节点,和 right 的后一个节点。如图所示:
算法步骤:
第 1 步:先将待反转的区域反转; 第 2 步:把 pre 的 next 指针指向反转以后的链表头节点,把反转以后的链表的尾节点的 next 指针指向 succ。
说明:编码细节我们不在题解中介绍了,请见下方代码。思路想明白以后,编码不是一件很难的事情。这里要提醒大家的是,链接什么时候切断,什么时候补上去,先后顺序一定要想清楚,如果想不清楚,可以在纸上模拟,让思路清晰。
复杂度分析
时间复杂度:O(N),其中 N 是链表总节点数。最坏情况下,需要遍历整个链表。
空间复杂度:O(1)。只使用到常数个变量。
方法二:一次遍历「穿针引线」反转链表(头插法)
方法一的缺点是:如果 left 和 right 的区域很大,恰好是链表的头节点和尾节点时,找到 left 和 right 需要遍历一次,反转它们之间的链表还需要遍历一次,虽然总的时间复杂度为 O(N),但遍历了链表 2 次,可不可以只遍历一次呢?答案是可以的。我们依然画图进行说明。
我们依然以方法一的示例为例进行说明。
整体思想是:在需要反转的区间里,每遍历到一个节点,让这个新节点来到反转部分的起始位置。下面的图展示了整个流程。
下面我们具体解释如何实现。使用三个指针变量 pre、curr、next 来记录反转的过程中需要的变量,它们的意义如下:
curr:指向待反转区域的第一个节点 left; next:永远指向 curr 的下一个节点,循环过程中,curr 变化以后 next 会变化; pre:永远指向待反转区域的第一个节点 left 的前一个节点,在循环过程中不变。 第 1 步,我们使用 ①、②、③ 标注「穿针引线」的步骤。
操作步骤:
先将 curr 的下一个节点记录为 next; 执行操作 ①:把 curr 的下一个节点指向 next 的下一个节点; 执行操作 ②:把 next 的下一个节点指向 pre 的下一个节点; 执行操作 ③:把 pre 的下一个节点指向 next。 第 1 步完成以后「拉直」的效果如下:
第 2 步,同理。同样需要注意 「穿针引线」操作的先后顺序。
第 2 步完成以后「拉直」的效果如下:
第 3 步,同理。
第 3 步完成以后「拉直」的效果如下:
复杂度分析:
时间复杂度:O(N),其中 N 是链表总节点数。最多只遍历了链表一次,就完成了反转。
空间复杂度:O(1)。只使用到常数个变量。
作者:力扣官方题解 链接:https://leetcode.cn/problems/reverse-linked-list-ii/solutions/634701/fan-zhuan-lian-biao-ii-by-leetcode-solut-teyq/ 来源:力扣(LeetCode) 著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
C++ 解法
方法一:穿针引线
class Solution {
private:
void reverseLinkedList(ListNode *head) {
// 也可以使用递归反转一个链表
ListNode *pre = nullptr;
ListNode *cur = head;
while (cur != nullptr) {
ListNode *next = cur->next;
cur->next = pre;
pre = cur;
cur = next;
}
}
public:
ListNode *reverseBetween(ListNode *head, int left, int right) {
// 因为头节点有可能发生变化,使用虚拟头节点可以避免复杂的分类讨论
ListNode *dummyNode = new ListNode(-1);
dummyNode->next = head;
ListNode *pre = dummyNode;
// 第 1 步:从虚拟头节点走 left - 1 步,来到 left 节点的前一个节点
// 建议写在 for 循环里,语义清晰
for (int i = 0; i < left - 1; i++) {
pre = pre->next;
}
// 第 2 步:从 pre 再走 right - left + 1 步,来到 right 节点
ListNode *rightNode = pre;
for (int i = 0; i < right - left + 1; i++) {
rightNode = rightNode->next;
}
// 第 3 步:切断出一个子链表(截取链表)
ListNode *leftNode = pre->next;
ListNode *curr = rightNode->next;
// 注意:切断链接
pre->next = nullptr;
rightNode->next = nullptr;
// 第 4 步:同第 206 题,反转链表的子区间
reverseLinkedList(leftNode);
// 第 5 步:接回到原来的链表中
pre->next = rightNode;
leftNode->next = curr;
return dummyNode->next;
}
};
方法二:一次遍历「穿针引线」反转链表(头插法)
class Solution {
public:
ListNode *reverseBetween(ListNode *head, int left, int right) {
// 设置 dummyNode 是这一类问题的一般做法
ListNode *dummyNode = new ListNode(-1);
dummyNode->next = head;
ListNode *pre = dummyNode;
for (int i = 0; i < left - 1; i++) {
pre = pre->next;
}
ListNode *cur = pre->next;
ListNode *next;
for (int i = 0; i < right - left; i++) {
next = cur->next;
cur->next = next->next;
next->next = pre->next;
pre->next = next;
}
return dummyNode->next;
}
};
Java 解法
方法一:穿针引线
/**
* Definition for singly-linked list.
* public class ListNode {
* int val;
* ListNode next;
* ListNode() {}
* ListNode(int val) { this.val = val; }
* ListNode(int val, ListNode next) { this.val = val; this.next = next; }
* }
*/
class Solution {
public void reverseLinkedList(ListNode head) {
ListNode pre = null;
ListNode cur = head;
while(cur != null){
ListNode temp = cur.next;
cur.next = pre;
pre = cur;
cur = temp;
}
}
public ListNode reverseBetween(ListNode head, int left, int right) {
ListNode dummyHead = new ListNode(-1);
dummyHead.next = head;
ListNode pre = dummyHead;
for(int i = 0; i < left - 1; i++){
pre = pre.next;
}
ListNode rightNode = pre;
for(int i = 0; i < right - left + 1; i++){
rightNode = rightNode.next;
}
ListNode leftNode = pre.next;
ListNode succ = rightNode.next;
rightNode.next = null;
pre.next = null;
reverseLinkedList(leftNode);
pre.next = rightNode;
leftNode.next = succ;
return dummyHead.next;
}
}
Python3 解法
环形链表
141. Linked List Cycle
Given head, the head of a linked list, determine if the linked list has a cycle in it.
There is a cycle in a linked list if there is some node in the list that can be reached again by continuously following the next pointer. Internally, pos is used to denote the index of the node that tail's next pointer is connected to. Note that pos is not passed as a parameter.
Return true if there is a cycle in the linked list. Otherwise, return false.
Example 1:

Input: head = [3,2,0,-4], pos = 1
Output: true
Explanation: There is a cycle in the linked list, where the tail connects to the 1st node (0-indexed).
Example 2:
Input: head = [1,2], pos = 0
Output: true
Explanation: There is a cycle in the linked list, where the tail connects to the 0th node.
Example 3:

Input: head = [1], pos = -1
Output: false
Explanation: There is no cycle in the linked list.
Constraints:
- The number of the nodes in the list is in the range
[0, 104]. -10^5 <= Node.val <= 10^5posis-1or a valid index in the linked-list.
Follow up: Can you solve it using O(1) (i.e. constant) memory?
思路
双指针,快指针比慢指针速度快一倍,有环则两者相遇,无环则自动跳出循环
C++解法
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode(int x) : val(x), next(NULL) {}
* };
*/
class Solution {
public:
bool hasCycle(ListNode *head) {
if(head == NULL || head->next == NULL)
return false;
ListNode* slow = head;
ListNode* fast = head;
while(fast && fast->next){
slow = slow->next;
fast = fast->next->next;
if(slow == fast)
return true;
}
return false;
}
};
142. Linked List Cycle II
Given the head of a linked list, return the node where the cycle begins. If there is no cycle, return null.
There is a cycle in a linked list if there is some node in the list that can be reached again by continuously following the next pointer. Internally, pos is used to denote the index of the node that tail's next pointer is connected to (0-indexed). It is -1 if there is no cycle. Note that pos is not passed as a parameter.
Do not modify the linked list.
Example 1:
Input: head = [3,2,0,-4], pos = 1
Output: tail connects to node index 1
Explanation: There is a cycle in the linked list, where tail connects to the second node.
Example 2:
Input: head = [1,2], pos = 0
Output: tail connects to node index 0
Explanation: There is a cycle in the linked list, where tail connects to the first node.
Example 3:
Input: head = [1], pos = -1
Output: no cycle
Explanation: There is no cycle in the linked list.
Constraints:
- The number of the nodes in the list is in the range
[0, 10^4]. -10^5 <= Node.val <= 10^5posis-1or a valid index in the linked-list.
Follow up: Can you solve it using O(1) (i.e. constant) memory?
思路
快慢指针相遇,相遇后新增一个指针ptr,由于距离关系,slow指针到环入口的距离与头指针相等,ptr和slow相遇处即为环入口。
Time Complexity: O(N)
Space Complexity: O(1)
C++解法
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode(int x) : val(x), next(NULL) {}
* };
*/
class Solution {
public:
ListNode *detectCycle(ListNode *head) {
if(head == NULL || head->next == NULL)
return NULL;
ListNode* slow = head;
ListNode* fast = head;
while(fast && fast->next){
slow = slow->next;
fast = fast->next->next;
if(slow == fast){
ListNode* ptr = head;
while(ptr != slow){
ptr = ptr->next;
slow = slow->next;
}
return ptr;
}
}
return NULL;
}
};
Java解法
public class Solution {
public ListNode detectCycle(ListNode head) {
ListNode slow = head, fast = head;
while (fast != null && fast.next != null) {
slow = slow.next;
fast = fast.next.next;
if (slow == fast) break;
}
if (fast == null || fast.next == null) return null;
while (head != slow) {
head = head.next;
slow = slow.next;
}
return head;
}
}
Python解法
class Solution(object):
def detectCycle(self, head):
slow = fast = head
while fast and fast.next:
slow, fast = slow.next, fast.next.next
if slow == fast: break
else: return None # if not (fast and fast.next): return None
while head != slow:
head, slow = head.next, slow.next
return head
交换节点
24. Swap Nodes in Pairs
Given a linked list, swap every two adjacent nodes and return its head. You must solve the problem without modifying the values in the list's nodes (i.e., only nodes themselves may be changed.)
Example 1:
Input: head = [1,2,3,4]
Output: [2,1,4,3]
Explanation:

Example 2:
Input: head = []
Output: []
Example 3:
Input: head = [1]
Output: [1]
Example 4:
Input: head = [1,2,3]
Output: [2,1,3]
Constraints:
- The number of nodes in the list is in the range
[0, 100]. 0 <= Node.val <= 100
思路
设置虚拟头节点,然后两两交换
Complexity
- Time complexity: O(n)
- Space complexity: O(1)
C++解法
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode() : val(0), next(nullptr) {}
* ListNode(int x) : val(x), next(nullptr) {}
* ListNode(int x, ListNode *next) : val(x), next(next) {}
* };
*/
class Solution {
public:
ListNode* swapPairs(ListNode* head) {
if(head == NULL || head->next == NULL){
return head;
}
ListNode* dummyHead = new ListNode(0);
dummyHead->next = head;
ListNode* pre = dummyHead;
ListNode* cur = head;
while(cur != NULL && cur->next != NULL){
ListNode* temp = cur->next->next;
cur->next->next = cur;
pre->next = cur->next;
cur->next = temp;
pre = cur;
cur = temp;
}
return dummyHead->next;
}
};
Java解法
class Solution {
public ListNode swapPairs(ListNode head) {
ListNode dummy = new ListNode(0, head);
ListNode prev = dummy, cur = head;
while (cur != null && cur.next != null) {
ListNode npn = cur.next.next;
ListNode second = cur.next;
second.next = cur;
cur.next = npn;
prev.next = second;
prev = cur;
cur = npn;
}
return dummy.next;
}
}
Python3解法
class Solution:
def swapPairs(self, head: Optional[ListNode]) -> Optional[ListNode]:
dummy = ListNode(0, head)
prev, cur = dummy, head
while cur and cur.next:
npn = cur.next.next
second = cur.next
second.next = cur
cur.next = npn
prev.next = second
prev = cur
cur = npn
return dummy.next
1721. Swapping Nodes in a Linked List
You are given the head of a linked list, and an integer k.
Return the head of the linked list after swapping the values of the kth node from the beginning and the kth node from the end (the list is 1-indexed).
Example 1:
Input: head = [1,2,3,4,5], k = 2
Output: [1,4,3,2,5]
Example 2:
Input: head = [7,9,6,6,7,8,3,0,9,5], k = 5
Output: [7,9,6,6,8,7,3,0,9,5]
Constraints:
- The number of nodes in the list is
n. 1 <= k <= n <= 10^50 <= Node.val <= 100
思路
方法一:
We can traverse the linked list and store the elements in an array.
Upon conversion to an array, we can swap the required elements by indexing the array.
We can rebuild the linked list using the order of the elements in the array.
方法二:
- To solve this problem in one pass, we can use a two-pointer approach.
- First, we can initialize two pointers, left_ptr and right_ptr, both pointing to the head of the linked list. We can then move the right_ptr k-2 steps forward.
- After this, we can move both left_ptr and right_ptr forward simultaneously until right_ptr reaches the end of the list.
- At this point, left_ptr will be pointing to the kth node from the beginning, and end_ptr will be pointing to the kth node from the end.
- We can then swap the values of these two nodes, and return the head of the linked list.
Complexity
- Time complexity: O(N)
- Space complexity: O(1)
C++解法
方法一:
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode() : val(0), next(nullptr) {}
* ListNode(int x) : val(x), next(nullptr) {}
* ListNode(int x, ListNode *next) : val(x), next(next) {}
* };
*/
class Solution {
public:
ListNode* swapNodes(ListNode* head, int k) {
vector<int> nums;
ListNode* cur = head;
while(cur != NULL){
nums.push_back(cur->val);
cur = cur->next;
}
swap(nums[k-1], nums[nums.size()-k]);
ListNode* dummyHead = new ListNode(0);
cur = dummyHead;
for(int i = 0; i < nums.size(); i++){
ListNode* newNode = new ListNode(nums[i]);
cur->next = newNode;
cur = newNode;
}
return dummyHead->next;
}
};
方法二:
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode() : val(0), next(nullptr) {}
* ListNode(int x) : val(x), next(nullptr) {}
* ListNode(int x, ListNode *next) : val(x), next(next) {}
* };
*/
class Solution {
public:
ListNode* swapNodes(ListNode* head, int k) {
ListNode* dummyHead = new ListNode(0);
dummyHead->next = head;
ListNode* fast = dummyHead;
ListNode* slow = dummyHead;
for(int i = 0; i < k; i++){
fast = fast->next;
}
ListNode* temp = fast;
while(fast != nullptr){
fast = fast->next;
slow = slow->next;
}
swap(slow->val, temp->val);
return dummyHead->next;
}
};
哈希法
哈希表
首先什么是哈希表,哈希表(英文名字为Hash table,国内也有一些算法书籍翻译为散列表,大家看到这两个名称知道都是指hash table就可以了)。
哈希表是根据关键码的值而直接进行访问的数据结构。
这么官方的解释可能有点懵,其实直白来讲其实数组就是一张哈希表。
哈希表中关键码就是数组的索引下标,然后通过下标直接访问数组中的元素,如下图所示:
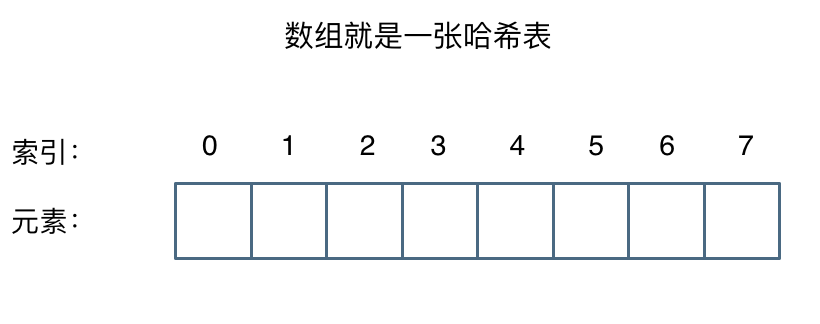
那么哈希表能解决什么问题呢,一般哈希表都是用来快速判断一个元素是否出现集合里。
例如要查询一个名字是否在这所学校里。
要枚举的话时间复杂度是O(n),但如果使用哈希表的话, 只需要O(1)就可以做到。
我们只需要初始化把这所学校里学生的名字都存在哈希表里,在查询的时候通过索引直接就可以知道这位同学在不在这所学校里了。
将学生姓名映射到哈希表上就涉及到了hash function ,也就是哈希函数。
哈希函数
哈希函数,把学生的姓名直接映射为哈希表上的索引,然后就可以通过查询索引下标快速知道这位同学是否在这所学校里了。
哈希函数如下图所示,通过hashCode把名字转化为数值,一般hashcode是通过特定编码方式,可以将其他数据格式转化为不同的数值,这样就把学生名字映射为哈希表上的索引数字了。
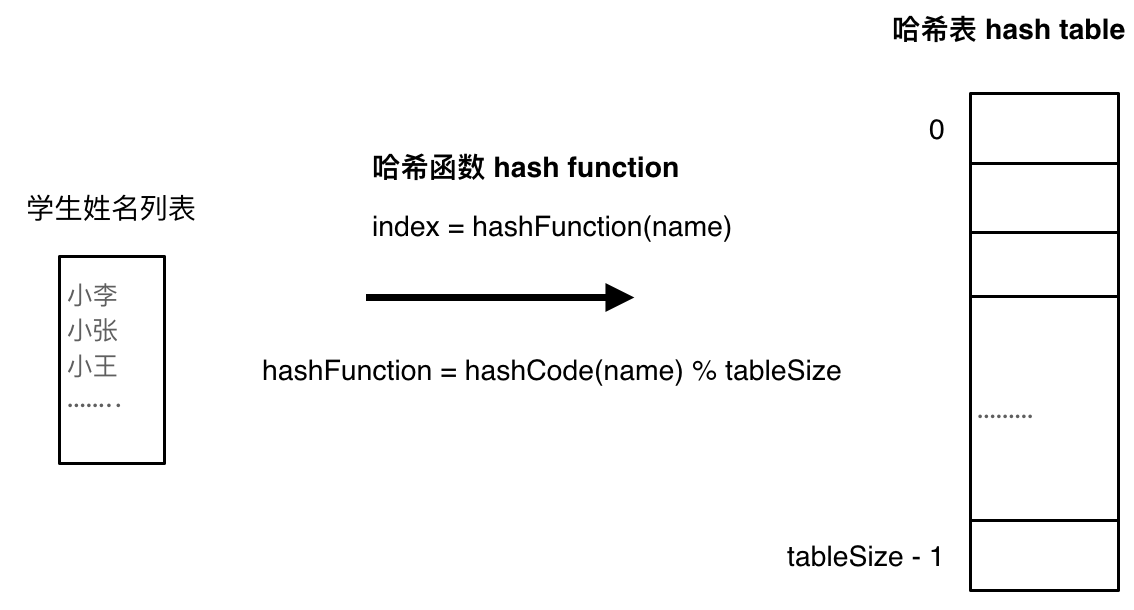
如果hashCode得到的数值大于 哈希表的大小了,也就是大于tableSize了,怎么办呢?
此时为了保证映射出来的索引数值都落在哈希表上,我们会在再次对数值做一个取模的操作,这样我们就保证了学生姓名一定可以映射到哈希表上了。
此时问题又来了,哈希表我们刚刚说过,就是一个数组。
如果学生的数量大于哈希表的大小怎么办,此时就算哈希函数计算的再均匀,也避免不了会有几位学生的名字同时映射到哈希表 同一个索引下标的位置。
接下来哈希碰撞登场
哈希碰撞
如图所示,小李和小王都映射到了索引下标 1 的位置,这一现象叫做哈希碰撞。
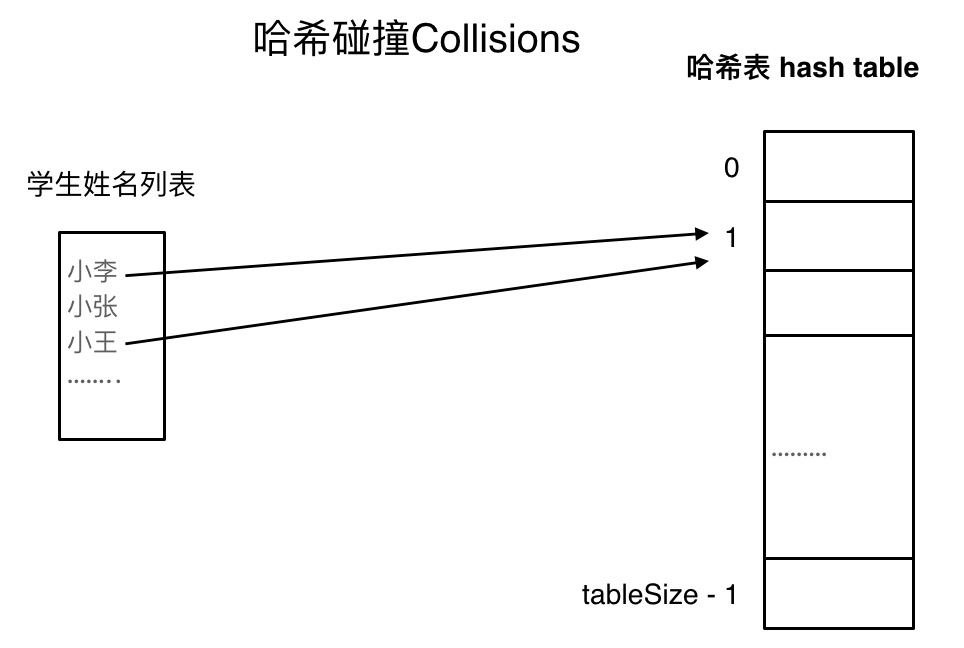
一般哈希碰撞有两种解决方法, 拉链法和线性探测法。
拉链法
刚刚小李和小王在索引1的位置发生了冲突,发生冲突的元素都被存储在链表中。 这样我们就可以通过索引找到小李和小王了
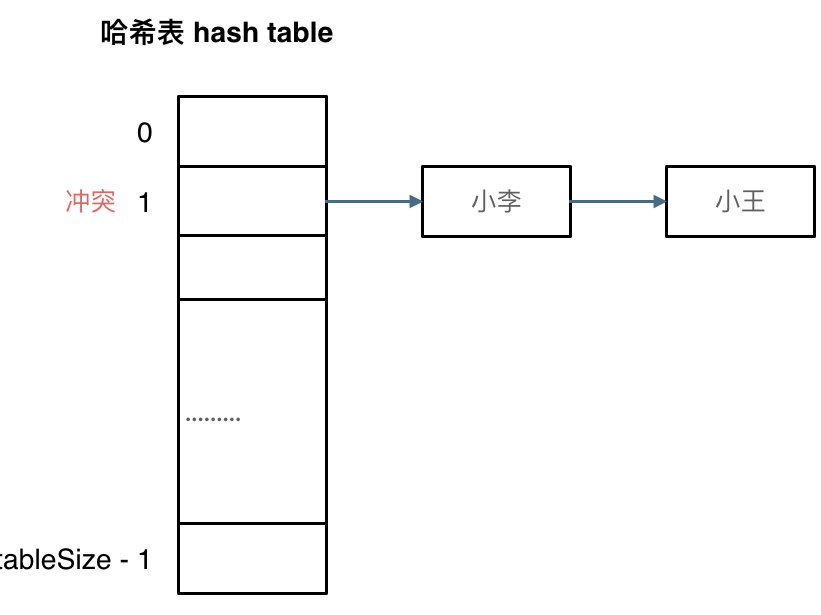
(数据规模是dataSize, 哈希表的大小为tableSize)
其实拉链法就是要选择适当的哈希表的大小,这样既不会因为数组空值而浪费大量内存,也不会因为链表太长而在查找上浪费太多时间。
线性探测法
使用线性探测法,一定要保证tableSize大于dataSize。 我们需要依靠哈希表中的空位来解决碰撞问题。
例如冲突的位置,放了小李,那么就向下找一个空位放置小王的信息。所以要求tableSize一定要大于dataSize ,要不然哈希表上就没有空置的位置来存放 冲突的数据了。如图所示:
其实关于哈希碰撞还有非常多的细节,感兴趣的同学可以再好好研究一下,这里我就不再赘述了。
常见的三种哈希结构
当我们想使用哈希法来解决问题的时候,我们一般会选择如下三种数据结构。
- 数组
- set (集合)
- map(映射)
这里数组就没啥可说的了,我们来看一下set。
在C++中,set 和 map 分别提供以下三种数据结构,其底层实现以及优劣如下表所示:
| 集合 | 底层实现 | 是否有序 | 数值是否可以重复 | 能否更改数值 | 查询效率 | 增删效率 |
|---|---|---|---|---|---|---|
| std::set | 红黑树 | 有序 | 否 | 否 | O(log n) | O(log n) |
| std::multiset | 红黑树 | 有序 | 是 | 否 | O(logn) | O(logn) |
| std::unordered_set | 哈希表 | 无序 | 否 | 否 | O(1) | O(1) |
std::unordered_set底层实现为哈希表,std::set 和std::multiset 的底层实现是红黑树,红黑树是一种平衡二叉搜索树,所以key值是有序的,但key不可以修改,改动key值会导致整棵树的错乱,所以只能删除和增加。
| 映射 | 底层实现 | 是否有序 | 数值是否可以重复 | 能否更改数值 | 查询效率 | 增删效率 |
|---|---|---|---|---|---|---|
| std::map | 红黑树 | key有序 | key不可重复 | key不可修改 | O(logn) | O(logn) |
| std::multimap | 红黑树 | key有序 | key可重复 | key不可修改 | O(log n) | O(log n) |
| std::unordered_map | 哈希表 | key无序 | key不可重复 | key不可修改 | O(1) | O(1) |
std::unordered_map 底层实现为哈希表,std::map 和std::multimap 的底层实现是红黑树。同理,std::map 和std::multimap 的key也是有序的(这个问题也经常作为面试题,考察对语言容器底层的理解)。
当我们要使用集合来解决哈希问题的时候,优先使用unordered_set,因为它的查询和增删效率是最优的,如果需要集合是有序的,那么就用set,如果要求不仅有序还要有重复数据的话,那么就用multiset。
那么再来看一下map ,在map 是一个key value 的数据结构,map中,对key是有限制,对value没有限制的,因为key的存储方式使用红黑树实现的。
其他语言例如:Java里的HashMap ,TreeMap 都是一样的原理。可以灵活贯通。
虽然std::set和std::multiset 的底层实现基于红黑树而非哈希表,它们通过红黑树来索引和存储数据。不过给我们的使用方式,还是哈希法的使用方式,即依靠键(key)来访问值(value)。所以使用这些数据结构来解决映射问题的方法,我们依然称之为哈希法。std::map也是一样的道理。
这里在说一下,一些C++的经典书籍上 例如STL源码剖析,说到了hash_set 和hash_map,这个与unordered_set,unordered_map又有什么关系呢?
实际上功能都是一样一样的, 但是unordered_set在C++11的时候被引入标准库了,而hash_set并没有,所以建议还是使用unordered_set比较好,这就好比一个是官方认证的,hash_set,hash_map 是C++11标准之前民间高手自发造的轮子。
哈希表经典题目
数组作为哈希表
一些应用场景就是为数组量身定做的。
在242.有效的字母异位词 中,我们提到了数组就是简单的哈希表,但是数组的大小是受限的!
这道题目包含小写字母,那么使用数组来做哈希最合适不过。
在383.赎金信 中同样要求只有小写字母,那么就给我们浓浓的暗示,用数组!
本题和242.有效的字母异位词 很像,242.有效的字母异位词 是求 字符串a 和 字符串b 是否可以相互组成,在383.赎金信 中是求字符串a能否组成字符串b,而不用管字符串b 能不能组成字符串a。
一些同学可能想,用数组干啥,都用map不就完事了。
上面两道题目用map确实可以,但使用map的空间消耗要比数组大一些,因为map要维护红黑树或者符号表,而且还要做哈希函数的运算。所以数组更加简单直接有效!
set作为哈希表
在349. 两个数组的交集 中我们给出了什么时候用数组就不行了,需要用set。
这道题目没有限制数值的大小,就无法使用数组来做哈希表了。
主要因为如下两点:
- 数组的大小是有限的,受到系统栈空间(不是数据结构的栈)的限制。
- 如果数组空间够大,但哈希值比较少、特别分散、跨度非常大,使用数组就造成空间的极大浪费。
所以此时一样的做映射的话,就可以使用set了。
关于set,C++ 给提供了如下三种可用的数据结构:(详情请看关于哈希表,你该了解这些! )
- std::set
- std::multiset
- std::unordered_set
std::set和std::multiset底层实现都是红黑树,std::unordered_set的底层实现是哈希, 使用unordered_set 读写效率是最高的,本题并不需要对数据进行排序,而且还不要让数据重复,所以选择unordered_set。
在202.快乐数 中,我们再次使用了unordered_set来判断一个数是否重复出现过。
map作为哈希表
在1.两数之和 中map正式登场。
来说一说:使用数组和set来做哈希法的局限。
- 数组的大小是受限制的,而且如果元素很少,而哈希值太大会造成内存空间的浪费。
- set是一个集合,里面放的元素只能是一个key,而两数之和这道题目,不仅要判断y是否存在而且还要记录y的下标位置,因为要返回x 和 y的下标。所以set 也不能用。
map是一种<key, value>的结构,本题可以用key保存数值,用value在保存数值所在的下标。所以使用map最为合适。
C++提供如下三种map:(详情请看关于哈希表,你该了解这些! )
- std::map
- std::multimap
- std::unordered_map
std::unordered_map 底层实现为哈希,std::map 和std::multimap 的底层实现是红黑树。
同理,std::map 和std::multimap 的key也是有序的(这个问题也经常作为面试题,考察对语言容器底层的理解),1.两数之和 中并不需要key有序,选择std::unordered_map 效率更高!
在454.四数相加 中我们提到了其实需要哈希的地方都能找到map的身影。
本题咋眼一看好像和18. 四数之和 ,15.三数之和 差不多,其实差很多!
关键差别是本题为四个独立的数组,只要找到A[i] + B[j] + C[k] + D[l] = 0就可以,不用考虑重复问题,而18. 四数之和 ,15.三数之和 是一个数组(集合)里找到和为0的组合,可就难很多了!
用哈希法解决了两数之和,很多同学会感觉用哈希法也可以解决三数之和,四数之和。
其实是可以解决,但是非常麻烦,需要去重导致代码效率很低。
在15.三数之和 中我给出了哈希法和双指针两个解法,大家就可以体会到,使用哈希法还是比较麻烦的。
所以18. 四数之和,15.三数之和都推荐使用双指针法!
总结
总结一下,当我们遇到了要快速判断一个元素是否出现集合里的时候,就要考虑哈希法。
但是哈希法也是牺牲了空间换取了时间,因为我们要使用额外的数组,set或者是map来存放数据,才能实现快速的查找。
如果在做面试题目的时候遇到需要判断一个元素是否出现过的场景也应该第一时间想到哈希法!
对于哈希表的知识相信很多同学都知道,但是没有成体系。
本篇我们从哈希表的理论基础到数组、set和map的经典应用,把哈希表的整个全貌完整的呈现给大家。
同时也强调虽然map是万能的,详细介绍了什么时候用数组,什么时候用set。
相信通过这个总结篇,大家可以对哈希表有一个全面的了解。
哈希数组
- 242. Valid Anagram
- 438. Find All Anagrams in a String
- 2273. Find Resultant Array After Removing Anagrams
- 268. Missing Number
- 287. Find the Duplicate Number
- 349. Intersection of Two Arrays
- 350. Intersection of Two Arrays II
- 383. Ransom Note
- 2215. Find the Difference of Two Arrays
- 2248. Intersection of Multiple Arrays
242. Valid Anagram
Given two strings s and t, return true if t is an anagram of s, and false otherwise.
An anagram is a word or phrase formed by rearranging the letters of a different word or phrase, using all the original letters exactly once.
Example 1:
Input: s = "anagram", t = "nagaram"
Output: true
Example 2:
Input: s = "rat", t = "car"
Output: false
Constraints:
1 <= s.length, t.length <= 5 * 10^4sandtconsist of lowercase English letters.
Follow up: What if the inputs contain Unicode characters? How would you adapt your solution to such a case?
思路
先判断两个字符串长度是否相等,然后使用哈希数组存储出现过的字母,一增一减,判断数组中元素是否全为0即可。
C++解法
class Solution {
public:
bool isAnagram(string s, string t) {
if(s.length() != t.length()){
return false;
}
int hash[26] = {0};
int i = 0;
while(s[i] != '\0')
{
hash[s[i] - 'a']++;
i++;
}
i = 0;
while(t[i] != '\0')
{
hash[t[i] - 'a']--;
i++;
}
for(int i = 0; i < 26; i++)
{
if(hash[i] != 0)
return false;
}
return true;
}
};
Java解法
以下是修改后的代码:
class Solution {
public boolean isAnagram(String s, String t) {
// 检查两个字符串的长度是否相同
if (s.length() != t.length()) {
return false;
}
// 创建一个大小为26的数组来计数
int[] chars = new int[26];
// 遍历第一个字符串,增加字符计数
for (char ch : s.toCharArray()) {
chars[ch - 'a']++;
}
// 遍历第二个字符串,减少字符计数
for (char ch : t.toCharArray()) {
chars[ch - 'a']--;
}
// 检查所有计数是否都为0
for (int count : chars) {
if (count != 0) {
return false;
}
}
return true;
}
}
说明:
- 长度检查: 首先检查两个字符串的长度,如果不同,直接返回
false。 - 使用数组: 使用
int[] chars = new int[26];来记录每个字母的计数,避免了动态大小带来的问题。 - 更新字符计数: 第一个字符串的字符计数增加,第二个字符串的字符计数减少,以便最终检查结果。
- 检查计数: 最后检查计数数组,如果所有元素都是0,则两个字符串是异位词。
438. Find All Anagrams in a String
Given two strings s and p, return an array of all the start indices of p's anagrams in s. You may return the answer in any order.
Example 1:
Input: s = "cbaebabacd", p = "abc"
Output: [0,6]
Explanation: The substring with start index = 0 is "cba", which is an anagram of "abc". The substring with start index = 6 is "bac", which is an anagram of "abc".
Example 2:
Input: s = "abab", p = "ab"
Output: [0,1,2]
Explanation: The substring with start index = 0 is "ab", which is an anagram of "ab". The substring with start index = 1 is "ba", which is an anagram of "ab". The substring with start index = 2 is "ab", which is an anagram of "ab".
Constraints:
1 <= s.length, p.length <= 3 * 10^4sandpconsist of lowercase English letters.
思路
方法一:遍历,截取子字符串,判断是否是anagram。这种方式效率低下。
方法二:滑动数组
C++解法
方法二:滑动数组
For 2 strings to be anagrams of each other, they should have the same elements with the same frequency.
vector<int> findAnagrams(string s, string p) {
int s_len = s.length();
int p_len = p.length();
if(s.size() < p.size()) return {};
vector<int> freq_p(26,0);
vector<int> window(26,0);
//first window
for(int i=0;i<p_len;i++){
freq_p[p[i]-'a']++;
window[s[i]-'a']++;
}
vector<int> ans;
if(freq_p == window) ans.push_back(0);
for(int i=p_len;i<s_len;i++){
window[s[i-p_len] - 'a']--;
window[s[i] - 'a']++;
if(freq_p == window) ans.push_back(i-p_len+1);
}
return ans;
}
**Time Complexity = O(n * 26) = O(n), n is the length of string s.
Space Complexity = O(26) = O(1)
这段 C++ 代码用于找到字符串 s 中所有与字符串 p 由字符组成的所有不同的字母异位词(anagrams)。下面是代码的详细解释:
代码结构解析
-
定义函数和参数:
vector<int> findAnagrams(string s, string p) {这里定义了一个函数
findAnagrams,接收两个字符串s和p,返回一个vector<int>结果,表示s中所有p的异位词的起始索引。 -
获取字符串长度并进行初步检查:
int s_len = s.length(); int p_len = p.length(); if(s.size() < p.size()) return {};s_len和p_len分别存储字符串s和p的长度。- 如果
s的长度小于p的长度,则s中不可能包含p的异位词,函数直接返回一个空的vector。
-
初始化频率数组:
vector<int> freq_p(26,0); vector<int> window(26,0);freq_p用于存储字符串p中各个字符的频率。window用于记录当前窗口(即s中的一个子串)内各个字符的频率。
-
计算第一个窗口的字符频率:
for(int i=0;i<p_len;i++){ freq_p[p[i]-'a']++; window[s[i]-'a']++; }- 遍历
p和s的前p_len个字符,更新freq_p和window中各个字符的频率。 p[i] - 'a'计算出字符p[i]对应的数组索引(以a为起始索引)。
- 遍历
-
检查第一个窗口:
vector<int> ans; if(freq_p == window) ans.push_back(0);- 如果
freq_p和window相等,则说明第一个窗口是p的一个异位词,索引 0 被加入到结果ans中。
- 如果
-
滑动窗口:
for(int i=p_len;i<s_len;i++){ window[s[i-p_len] - 'a']--; window[s[i] - 'a']++; if(freq_p == window) ans.push_back(i-p_len+1); }- 从
p_len开始,遍历s的后续字符。 - 每次滑动窗口时,移除左侧字符
s[i - p_len]的频率 (因为这个字符不再在窗口中),并 增加右侧字符s[i]的频率。 - 在每次滑动后,检查
freq_p和window是否相等,如果相等,则将当前窗口的起始索引 (i - p_len + 1) 加入ans中。
- 从
-
返回结果:
return ans;- 函数返回所有找到的索引的
vector。
- 函数返回所有找到的索引的
总结
这段代码使用了一个滑动窗口的技术,通过维护两个频率数组(一个用于 p 的字符频率,另一个用于 s 中当前窗口的字符频率)来高效地查找字符串 s 中所有 p 的异位词。每次窗口滑动时,只需更新频率数组,而不需要重新计算整个窗口的字符频率,从而提升了效率。整体时间复杂度为 O(n),其中 n 是字符串 s 的长度。
Java解法
方法一:
class Solution {
public List<Integer> findAnagrams(String s, String p) {
List<Integer> result = new ArrayList<>();
int pLength = p.length();
int sLength = s.length();
// 仅当s的长度大于或等于p的长度时才处理
if (sLength < pLength) return result;
for (int i = 0; i <= sLength - pLength; i++) { // 修改为 <= 确保包含最后一个可能的起点
String temp = s.substring(i, i + pLength); // 修正这一行
if (isAnagram(temp, p)) {
result.add(i);
}
}
return result;
}
public boolean isAnagram(String s, String t) {
// 检查两个字符串的长度是否相同
if (s.length() != t.length()) {
return false;
}
// 创建一个大小为26的数组来计数
int[] chars = new int[26];
// 遍历第一个字符串,增加字符计数
for (char ch : s.toCharArray()) {
chars[ch - 'a']++;
}
// 遍历第二个字符串,减少字符计数
for (char ch : t.toCharArray()) {
chars[ch - 'a']--;
}
// 检查所有计数是否都为0
for (int count : chars) {
if (count != 0) {
return false;
}
}
return true;
}
}
2273. Find Resultant Array After Removing Anagrams
You are given a 0-indexed string array words, where words[i] consists of lowercase English letters.
In one operation, select any index i such that 0 < i < words.length and words[i - 1] and words[i] are anagrams, and delete words[i] from words. Keep performing this operation as long as you can select an index that satisfies the conditions.
Return words after performing all operations. It can be shown that selecting the indices for each operation in any arbitrary order will lead to the same result.
An Anagram is a word or phrase formed by rearranging the letters of a different word or phrase using all the original letters exactly once. For example, "dacb" is an anagram of "abdc".
Example 1:
Input: words = ["abba","baba","bbaa","cd","cd"]
Output: ["abba","cd"]
Explanation:
One of the ways we can obtain the resultant array is by using the following operations:
- Since words[2] = "bbaa" and words[1] = "baba" are anagrams, we choose index 2 and delete words[2].
Now words = ["abba","baba","cd","cd"].
- Since words[1] = "baba" and words[0] = "abba" are anagrams, we choose index 1 and delete words[1].
Now words = ["abba","cd","cd"].
- Since words[2] = "cd" and words[1] = "cd" are anagrams, we choose index 2 and delete words[2].
Now words = ["abba","cd"].
We can no longer perform any operations, so ["abba","cd"] is the final answer.
Example 2:
Input: words = ["a","b","c","d","e"]
Output: ["a","b","c","d","e"]
Explanation:
No two adjacent strings in words are anagrams of each other, so no operations are performed.
Constraints:
1 <= words.length <= 1001 <= words[i].length <= 10words[i]consists of lowercase English letters.
思路
方法一:设定prev="",每个新元素都排序后转为字符串,然后和prev比较,不相同则加入结果集中
方法二:使用栈
C++解法
class Solution {
public:
vector<string> removeAnagrams(vector<string>& words) {
for(int i = 1;i<words.size();i++){
string x = words[i];
sort(x.begin(),x.end());
string y = words[i-1];
sort(y.begin(),y.end());
if(x == y){
words.erase(words.begin() + i);
i--;
}
}
return words;
}
};
Java解法
方法一完整测试代码:
import java.util.*;
class Solution {
public List<String> removeAnagrams(String[] words) {
String prev = "";
List<String> li = new ArrayList<>();
for (int i = 0; i < words.length; i++) {
char[] ch = words[i].toCharArray();
Arrays.sort(ch);
//System.out.println("ch: " + Arrays.toString(ch));
String curr = String.valueOf(ch);
//System.out.println("curr: " + curr);
if (!curr.equals(prev)) {
li.add(words[i]);
prev = curr;
}
}
return li;
}
}
public class Main {
public static void main(String[] args) {
Solution solution = new Solution();
String[] words1 = {"abba", "baba", "bbaa", "cd", "cd"};
System.out.println("Input: " + Arrays.toString(words1));
List<String> output = solution.removeAnagrams(words1);
System.out.println("Output: " + output);
}
}
使用栈的解法如下所示:
class Solution {
public List<String> removeAnagrams(String[] words) {
Stack<String> stack = new Stack<>();
for(int i = words.length-1;i>= 0;i--){
String s = words[i];
while(!stack.isEmpty() && anagram(stack.peek(),s) == true)stack.pop();
stack.push(s);
}
List<String> res = new ArrayList<>();
while(!stack.isEmpty())res.add(stack.pop());
return res;
}
public boolean anagram(String p,String q){
int arr[] = new int[26];
for(char i : p.toCharArray())arr[i-'a']+=1;
for(char i : q.toCharArray())arr[i-'a']-=1;
for(int i : arr)if(i != 0)return false;
return true;
}
}
268. Missing Number
Given an array nums containing n distinct numbers in the range [0, n], return the only number in the range that is missing from the array.
Example 1:
Input: nums = [3,0,1]
Output: 2
Explanation: n = 3 since there are 3 numbers, so all numbers are in the range [0,3]. 2 is the missing number in the range since it does not appear in nums.
Example 2:
Input: nums = [0,1]
Output: 2
Explanation: n = 2 since there are 2 numbers, so all numbers are in the range [0,2]. 2 is the missing number in the range since it does not appear in nums.
Example 3:
Input: nums = [9,6,4,2,3,5,7,0,1]
Output: 8
Explanation: n = 9 since there are 9 numbers, so all numbers are in the range [0,9]. 8 is the missing number in the range since it does not appear in nums.
Constraints:
n == nums.length1 <= n <= 10^40 <= nums[i] <= n- All the numbers of
numsare unique.
Follow up: Could you implement a solution using only O(1) extra space complexity and O(n) runtime complexity?
思路
用哈希数组判断数字是否出现过
C++解法
class Solution {
public:
int missingNumber(vector<int>& nums) {
vector<int> result(10001, 0);
int maxValue = -1;
for(int num : nums){
result[num]++;
if(num > maxValue){
maxValue = num;
}
}
for(int i = 0; i < maxValue; i++){
if(result[i] == 0){
return i;
}
}
return maxValue + 1;
}
};
287. Find the Duplicate Number
Given an array of integers nums containing n + 1 integers where each integer is in the range [1, n] inclusive.
There is only one repeated number in nums, return this repeated number.
You must solve the problem without modifying the array nums and using only constant extra space.
Example 1:
Input: nums = [1,3,4,2,2]
Output: 2
Example 2:
Input: nums = [3,1,3,4,2]
Output: 3
Example 3:
Input: nums = [3,3,3,3,3]
Output: 3
Constraints:
1 <= n <= 10^5nums.length == n + 11 <= nums[i] <= n- All the integers in
numsappear only once except for precisely one integer which appears two or more times.
Follow up:
- How can we prove that at least one duplicate number must exist in
nums? - Can you solve the problem in linear runtime complexity?
思路
设置一个哈希数组,遍历nums数组,设置哈希数组,如果某个数的频率大于1,则直接结束循环
C++解法
class Solution {
public:
int findDuplicate(vector<int>& nums) {
vector<int> result(100001, 0);
for(int num : nums){
result[num]++;
if(result[num] > 1){
return num;
}
}
return -1;
}
};
349. Intersection of Two Arrays
Given two integer arrays nums1 and nums2, return an array of their intersection. Each element in the result must be unique and you may return the result in any order.
Example 1:
Input: nums1 = [1,2,2,1], nums2 = [2,2]
Output: [2]
Example 2:
Input: nums1 = [4,9,5], nums2 = [9,4,9,8,4]
Output: [9,4]
Explanation: [4,9] is also accepted.
Constraints:
1 <= nums1.length, nums2.length <= 10000 <= nums1[i], nums2[i] <= 1000
思路
方法一:因为0 <= nums1[i], nums2[i] <= 1000,所以这里可以使用哈希数组
方法二:使用Hashset判断元素是否出现并去重
C++解法
方法一:
class Solution {
public:
vector<int> intersection(vector<int>& nums1, vector<int>& nums2) {
vector<int> result;
int hash1[1001] = {0};
int hash2[1001] = {0};
for(int num : nums1){
hash1[num]++;
}
for(int num : nums2){
hash2[num]++;
}
for(int i = 0; i < 1001; i++){
if(hash1[i] > 0 && hash2[i] > 0){
result.push_back(i);
}
}
return result;
}
};
方法二:
class Solution {
public:
vector<int> intersection(vector<int>& nums1, vector<int>& nums2) {
unordered_set<int> result_set; // 存放结果,之所以用set是为了给结果集去重
unordered_set<int> nums_set(nums1.begin(), nums1.end());
for (int num : nums2) {
// 发现nums2的元素 在nums_set里又出现过
if (nums_set.find(num) != nums_set.end()) {
result_set.insert(num);
}
}
return vector<int>(result_set.begin(), result_set.end());
}
};
- 时间复杂度: O(n + m) m 是最后要把 set转成vector
- 空间复杂度: O(n)
Java解法
方法二:
import java.util.*;
class Solution {
public int[] intersection(int[] nums1, int[] nums2) {
Set<Integer> resultSet = new HashSet<>();
Set<Integer> numsSet = new HashSet<>();
for (int num : nums1) {
numsSet.add(num);
}
for (int num : nums2) {
if (numsSet.contains(num)) {
resultSet.add(num);
}
}
return resultSet.stream().mapToInt(Integer::intValue).toArray();
}
}
Python解法
方法二:
from typing import List
class Solution:
def intersection(self, nums1: List[int], nums2: List[int]) -> List[int]:
result_set = set()
nums_set = set(nums1)
for num in nums2:
if num in nums_set:
result_set.add(num)
return list(result_set)
Go解法
方法二:
package main
import "fmt"
func intersection(nums1 []int, nums2 []int) []int {
resultSet := make(map[int]struct{})
numsSet := make(map[int]struct{})
for _, num := range nums1 {
numsSet[num] = struct{}{}
}
for _, num := range nums2 {
if _, exists := numsSet[num]; exists {
resultSet[num] = struct{}{}
}
}
result := make([]int, 0, len(resultSet))
for num := range resultSet {
result = append(result, num)
}
return result
}
func main() {
fmt.Println(intersection([]int{1, 2, 2, 1}, []int{2, 2})) // Example usage
}
Rust解法
方法二:
#![allow(unused)] fn main() { use std::collections::HashSet; pub struct Solution; impl Solution { pub fn intersection(nums1: Vec<i32>, nums2: Vec<i32>) -> Vec<i32> { let nums_set: HashSet<i32> = nums1.into_iter().collect(); let result_set: HashSet<i32> = nums2.into_iter().filter(|num| nums_set.contains(num)).collect(); result_set.into_iter().collect() } } }
350. Intersection of Two Arrays II
Given two integer arrays nums1 and nums2, return an array of their intersection. Each element in the result must appear as many times as it shows in both arrays and you may return the result in any order.
Example 1:
Input: nums1 = [1,2,2,1], nums2 = [2,2]
Output: [2,2]
Example 2:
Input: nums1 = [4,9,5], nums2 = [9,4,9,8,4]
Output:[4,9]
Explanation: [9,4] is also accepted.
Constraints:
1 <= nums1.length, nums2.length <= 10000 <= nums1[i], nums2[i] <= 1000
Follow up:
- What if the given array is already sorted? How would you optimize your algorithm?
- What if
nums1's size is small compared tonums2's size? Which algorithm is better? - What if elements of
nums2are stored on disk, and the memory is limited such that you cannot load all elements into the memory at once?
思路
因为0 <= nums1[i], nums2[i] <= 1000,所以这里可以使用哈希数组。对于每一个共同元素,计算其次数然后向结果中添加相应数量的元素。
C++解法
class Solution {
public:
vector<int> intersect(vector<int>& nums1, vector<int>& nums2) {
vector<int> result;
int hash1[1001] = {0};
int hash2[1001] = {0};
for(int num : nums1){
hash1[num]++;
}
for(int num : nums2){
hash2[num]++;
}
for(int i = 0; i < 1001; i++){
if(hash1[i] > 0 && hash2[i] > 0){
int times = min(hash1[i], hash2[i]);
for(int time = 0; time < times; time++){
result.push_back(i);
}
}
}
return result;
}
};
383. Ransom Note
Given two strings ransomNote and magazine, return true if ransomNote can be constructed by using the letters from magazine and false otherwise.
Each letter in magazine can only be used once in ransomNote.
Example 1:
Input: ransomNote = "a", magazine = "b"
Output: false
Example 2:
Input: ransomNote = "aa", magazine = "ab"
Output: false
Example 3:
Input: ransomNote = "aa", magazine = "aab"
Output: true
Constraints:
1 <= ransomNote.length, magazine.length <= 10^5ransomNoteandmagazineconsist of lowercase English letters.
思路
使用哈希数组存储可用的数字,使用magazine字符串存储字符,使用ransomNote字符串消耗字符,不够消耗时,返回false。否则返回true。
C++解法
class Solution {
public:
bool canConstruct(string ransomNote, string magazine) {
int record[26] = {0};
//add
if (ransomNote.size() > magazine.size()) {
return false;
}
for (int i = 0; i < magazine.length(); i++) {
// 通过record数据记录 magazine里各个字符出现次数
record[magazine[i]-'a'] ++;
}
for (int j = 0; j < ransomNote.length(); j++) {
// 遍历ransomNote,在record里对应的字符个数做--操作
record[ransomNote[j]-'a']--;
// 如果小于零说明ransomNote里出现的字符,magazine没有
if(record[ransomNote[j]-'a'] < 0) {
return false;
}
}
return true;
}
};
- 时间复杂度: O(n)
- 空间复杂度: O(1)
Java解法
class Solution {
public boolean canConstruct(String ransomNote, String magazine) {
// shortcut
if (ransomNote.length() > magazine.length()) {
return false;
}
// 定义一个哈希映射数组
int[] record = new int[26];
// 遍历
for(char c : magazine.toCharArray()){
record[c - 'a'] += 1;
}
for(char c : ransomNote.toCharArray()){
record[c - 'a'] -= 1;
}
// 如果数组中存在负数,说明ransomNote字符串中存在magazine中没有的字符
for(int i : record){
if(i < 0){
return false;
}
}
return true;
}
}
2215. Find the Difference of Two Arrays
Given two 0-indexed integer arrays nums1 and nums2, return a list answer of size 2 where:
answer[0]is a list of all distinct integers innums1which are not present innums2.answer[1]is a list of all distinct integers innums2which are not present innums1.
Note that the integers in the lists may be returned in any order.
Example 1:
Input: nums1 = [1,2,3], nums2 = [2,4,6]
Output: [[1,3],[4,6]]
Explanation:
For nums1, nums1[1] = 2 is present at index 0 of nums2, whereas nums1[0] = 1 and nums1[2] = 3 are not present in nums2. Therefore, answer[0] = [1,3].
For nums2, nums2[0] = 2 is present at index 1 of nums1, whereas nums2[1] = 4 and nums2[2] = 6 are not present in nums2. Therefore, answer[1] = [4,6].
Example 2:
Input: nums1 = [1,2,3,3], nums2 = [1,1,2,2]
Output: [[3],[]]
Explanation:
For nums1, nums1[2] and nums1[3] are not present in nums2. Since nums1[2] == nums1[3], their value is only included once and answer[0] = [3].
Every integer in nums2 is present in nums1. Therefore, answer[1] = [].
Constraints:
1 <= nums1.length, nums2.length <= 1000-1000 <= nums1[i], nums2[i] <= 1000
思路
注意到-1000 <= nums1[i], nums2[i] <= 1000,这里的哈希数组容量及数值需要调整。然后遍历两个哈希数组,找只在一个哈希数组中出现的元素即可。
C++解法
class Solution {
public:
vector<vector<int>> findDifference(vector<int>& nums1, vector<int>& nums2) {
vector<vector<int>> result;
int hash1[2001] = {0};
int hash2[2001] = {0};
for(int num : nums1){
hash1[num + 1000]++;
}
for(int num : nums2){
hash2[num + 1000]++;
}
vector<int> temp1;
vector<int> temp2;
for(int i = 0; i < 2001; i++){
if(hash1[i] > 0 && hash2[i] == 0){
temp1.push_back(i-1000);
}else if(hash1[i] == 0 && hash2[i] > 0){
temp2.push_back(i-1000);
}
}
result.push_back(temp1);
result.push_back(temp2);
return result;
}
};
2248. Intersection of Multiple Arrays
Given a 2D integer array nums where nums[i] is a non-empty array of distinct positive integers, return the list of integers that are present in each array of nums sorted in ascending order.
Example 1:
Input: nums = [[**3**,1,2,**4**,5],[1,2,**3**,**4**],[**3**,**4**,5,6]]
Output: [3,4]
Explanation:
The only integers present in each of nums[0] = [3,1,2,4,5], nums[1] = [1,2,3,4], and nums[2] = [3,4,5,6] are 3 and 4, so we return [3,4].
Example 2:
Input: nums = [[1,2,3],[4,5,6]]
Output: []
Explanation:
There does not exist any integer present both in nums[0] and nums[1], so we return an empty list [].
Constraints:
1 <= nums.length <= 10001 <= sum(nums[i].length) <= 10001 <= nums[i][j] <= 1000- All the values of
nums[i]are unique.
思路
用哈希数组保存元素出现次数,向结果中加入出现次数等于二维数组长度的元素
C++解法
class Solution {
public:
vector<int> intersection(vector<vector<int>>& nums) {
vector<int> result;
int hash[1001] = {0};
// 统计每个数字出现的次数
for (int i = 0; i < nums.size(); i++) {
for (int j = 0; j < nums[i].size(); j++) {
hash[nums[i][j]]++;
}
}
// 记录出现次数等于子数组数量的元素
for (int i = 0; i < 1001; i++) {
if (hash[i] == nums.size()) {
result.push_back(i);
}
}
return result;
}
};
哈希集合
349. Intersection of Two Arrays
Given two integer arrays nums1 and nums2, return an array of their intersection. Each element in the result must be unique and you may return the result in any order.
Example 1:
Input: nums1 = [1,2,2,1], nums2 = [2,2]
Output: [2]
Example 2:
Input: nums1 = [4,9,5], nums2 = [9,4,9,8,4]
Output: [9,4]
Explanation: [4,9] is also accepted.
Constraints:
1 <= nums1.length, nums2.length <= 10000 <= nums1[i], nums2[i] <= 1000
思路
方法一:因为0 <= nums1[i], nums2[i] <= 1000,所以这里可以使用哈希数组
方法二:使用Hashset判断元素是否出现并去重
C++解法
方法一:
class Solution {
public:
vector<int> intersection(vector<int>& nums1, vector<int>& nums2) {
vector<int> result;
int hash1[1001] = {0};
int hash2[1001] = {0};
for(int num : nums1){
hash1[num]++;
}
for(int num : nums2){
hash2[num]++;
}
for(int i = 0; i < 1001; i++){
if(hash1[i] > 0 && hash2[i] > 0){
result.push_back(i);
}
}
return result;
}
};
方法二:
class Solution {
public:
vector<int> intersection(vector<int>& nums1, vector<int>& nums2) {
unordered_set<int> result_set; // 存放结果,之所以用set是为了给结果集去重
unordered_set<int> nums_set(nums1.begin(), nums1.end());
for (int num : nums2) {
// 发现nums2的元素 在nums_set里又出现过
if (nums_set.find(num) != nums_set.end()) {
result_set.insert(num);
}
}
return vector<int>(result_set.begin(), result_set.end());
}
};
- 时间复杂度: O(n + m) m 是最后要把 set转成vector
- 空间复杂度: O(n)
Java解法
方法二:
import java.util.*;
class Solution {
public int[] intersection(int[] nums1, int[] nums2) {
Set<Integer> resultSet = new HashSet<>();
Set<Integer> numsSet = new HashSet<>();
for (int num : nums1) {
numsSet.add(num);
}
for (int num : nums2) {
if (numsSet.contains(num)) {
resultSet.add(num);
}
}
return resultSet.stream().mapToInt(Integer::intValue).toArray();
}
}
Python解法
方法二:
from typing import List
class Solution:
def intersection(self, nums1: List[int], nums2: List[int]) -> List[int]:
result_set = set()
nums_set = set(nums1)
for num in nums2:
if num in nums_set:
result_set.add(num)
return list(result_set)
Go解法
方法二:
package main
import "fmt"
func intersection(nums1 []int, nums2 []int) []int {
resultSet := make(map[int]struct{})
numsSet := make(map[int]struct{})
for _, num := range nums1 {
numsSet[num] = struct{}{}
}
for _, num := range nums2 {
if _, exists := numsSet[num]; exists {
resultSet[num] = struct{}{}
}
}
result := make([]int, 0, len(resultSet))
for num := range resultSet {
result = append(result, num)
}
return result
}
func main() {
fmt.Println(intersection([]int{1, 2, 2, 1}, []int{2, 2})) // Example usage
}
Rust解法
方法二:
#![allow(unused)] fn main() { use std::collections::HashSet; pub struct Solution; impl Solution { pub fn intersection(nums1: Vec<i32>, nums2: Vec<i32>) -> Vec<i32> { let nums_set: HashSet<i32> = nums1.into_iter().collect(); let result_set: HashSet<i32> = nums2.into_iter().filter(|num| nums_set.contains(num)).collect(); result_set.into_iter().collect() } } }
202. Happy Number
Write an algorithm to determine if a number n is happy.
A happy number is a number defined by the following process:
- Starting with any positive integer, replace the number by the sum of the squares of its digits.
- Repeat the process until the number equals 1 (where it will stay), or it loops endlessly in a cycle which does not include 1.
- Those numbers for which this process ends in 1 are happy.
Return true if n is a happy number, and false if not.
Example 1:
Input: n = 19
Output: true
Explanation:
1^2 + 9^2 = 82
8^2 + 2^2 = 68
6^2 + 8^2 = 100
1^2 + 0^2 + 0^2 = 1
Example 2:
Input: n = 2
Output: false
Constraints:
1 <= n <= 2^31 - 1
思路
判断某个元素是否出现过(是否有循环),使用unordered_set数据结构
这道题目看上去貌似一道数学问题,其实并不是!
题目中说了会 无限循环,那么也就是说求和的过程中,sum会重复出现,这对解题很重要!
当我们遇到了要快速判断一个元素是否出现集合里的时候,就要考虑哈希法了。
所以这道题目使用哈希法,来判断这个sum是否重复出现,如果重复了就是return false, 否则一直找到sum为1为止。
判断sum是否重复出现就可以使用unordered_set。
还有一个难点就是求和的过程,如果对取数值各个位上的单数操作不熟悉的话,做这道题也会比较艰难。
C++解法
class Solution {
public:
// 取数值各个位上的单数之和
int getSum(int n) {
int sum = 0;
while (n) {
sum += (n % 10) * (n % 10);
n /= 10;
}
return sum;
}
bool isHappy(int n) {
unordered_set<int> set;
while(1) {
int sum = getSum(n);
if (sum == 1) {
return true;
}
// 如果这个sum曾经出现过,说明已经陷入了无限循环了,立刻return false
if (set.find(sum) != set.end()) {
return false;
} else {
set.insert(sum);
}
n = sum;
}
}
};
- 时间复杂度: O(logn)
- 空间复杂度: O(logn)
Java解法
class Solution {
public boolean isHappy(int n) {
Set<Integer> record = new HashSet<>();
while (n != 1 && !record.contains(n)) {
record.add(n);
n = getNextNumber(n);
}
return n == 1;
}
private int getNextNumber(int n) {
int res = 0;
while (n > 0) {
int temp = n % 10;
res += temp * temp;
n = n / 10;
}
return res;
}
}
哈希映射
- 1. Two Sum
- 167. Two Sum II - Input Array Is Sorted
- 454. 4Sum II
- 15. 3Sum
- 18. 4Sum
- 49. Group Anagrams
1. Two Sum
Given an array of integers nums and an integer target, return indices of the two numbers such that they add up to target.
You may assume that each input would have exactly one solution, and you may not use the same element twice.
You can return the answer in any order.
Example 1:
Input: nums = [2,7,11,15], target = 9
Output: [0,1]
Explanation: Because nums[0] + nums[1] == 9, we return [0, 1].
Example 2:
Input: nums = [3,2,4], target = 6
Output: [1,2]
Example 3:
Input: nums = [3,3], target = 6
Output: [0,1]
Constraints:
2 <= nums.length <= 10^4-10^9 <= nums[i] <= 10^9-10^9 <= target <= 10^9- Only one valid answer exists.
Follow-up: Can you come up with an algorithm that is less than O(n2) time complexity?
思路
使用HashMap
本题其实有四个重点:
- 为什么会想到用哈希表
- 哈希表为什么用map
- 本题map是用来存什么的
- map中的key和value用来存什么的
把这四点想清楚了,本题才算是理解透彻了。
C++解法
class Solution {
public:
vector<int> twoSum(vector<int>& nums, int target) {
std::unordered_map <int,int> map;
for(int i = 0; i < nums.size(); i++) {
// 遍历当前元素,并在map中寻找是否有匹配的key
auto iter = map.find(target - nums[i]);
if(iter != map.end()) {
return {iter->second, i};
}
// 如果没找到匹配对,就把访问过的元素和下标加入到map中
map.insert(pair<int, int>(nums[i], i));
}
return {};
}
};
- 时间复杂度: O(n)
- 空间复杂度: O(n)
Java解法
class Solution {
public int[] twoSum(int[] nums, int target) {
Map<Integer, Integer> numMap = new HashMap<>();
int length = nums.length;
for(int i = 0; i < length; i++){
int complement = target - nums[i];
if(numMap.containsKey(complement)){
return new int[]{i, numMap.get(complement)};
}
numMap.put(nums[i], i);
}
return null;
}
}
167. Two Sum II - Input Array Is Sorted
Given a 1-indexed array of integers numbers that is already sorted in non-decreasing order, find two numbers such that they add up to a specific target number. Let these two numbers be numbers[index1] and numbers[index2] where 1 <= index1 < index2 <= numbers.length.
Return the indices of the two numbers, index1 and index2, added by one as an integer array [index1, index2] of length 2.
The tests are generated such that there is exactly one solution. You may not use the same element twice.
Your solution must use only constant extra space.
Example 1:
Input: numbers = [2,7,11,15], target = 9
Output: [1,2]
Explanation: The sum of 2 and 7 is 9. Therefore, index1 = 1, index2 = 2. We return [1, 2].
Example 2:
Input: numbers = [2,3,4], target = 6
Output: [1,3]
Explanation: The sum of 2 and 4 is 6. Therefore index1 = 1, index2 = 3. We return [1, 3].
Example 3:
Input: numbers = [-1,0], target = -1
Output: [1,2]
Explanation: The sum of -1 and 0 is -1. Therefore index1 = 1, index2 = 2. We return [1, 2].
Constraints:
2 <= numbers.length <= 3 * 10^4-1000 <= numbers[i] <= 1000numbersis sorted in non-decreasing order.-1000 <= target <= 1000- The tests are generated such that there is exactly one solution.
思路
方法一:在2Sum基础上修改索引即可,效率低下
方法二:双指针,左右指针,如果使用二分搜索确保numbers[right]<target程序效率会更高。
C++解法
方法一:
class Solution {
public:
vector<int> twoSum(vector<int>& numbers, int target) {
unordered_map<int, int> map;
for(int i = 0; i < numbers.size(); i++){
int temp = target - numbers[i];
auto iter = map.find(temp);
if(iter != map.end()){
return {iter->second, i + 1};
}
map.insert(pair<int, int>(numbers[i], i + 1));
}
return {};
}
};
Java解法
class Solution {
public int[] twoSum(int[] numbers, int target) {
int left = 0;
int right = numbers.length - 1;
while(left <= right){
if(numbers[left] + numbers[right] > target){
right--;
}else if(numbers[left] + numbers[right] < target){
left++;
}else{
return new int[]{left + 1, right + 1};
}
}
return null;
}
}
454. 4Sum II
Given four integer arrays nums1, nums2, nums3, and nums4 all of length n, return the number of tuples (i, j, k, l) such that:
0 <= i, j, k, l < nnums1[i] + nums2[j] + nums3[k] + nums4[l] == 0
Example 1:
Input: nums1 = [1,2], nums2 = [-2,-1], nums3 = [-1,2], nums4 = [0,2]
Output: 2
Explanation:
The two tuples are:
1. (0, 0, 0, 1) -> nums1[0] + nums2[0] + nums3[0] + nums4[1] = 1 + (-2) + (-1) + 2 = 0
2. (1, 1, 0, 0) -> nums1[1] + nums2[1] + nums3[0] + nums4[0] = 2 + (-1) + (-1) + 0 = 0
Example 2:
Input: nums1 = [0], nums2 = [0], nums3 = [0], nums4 = [0]
Output: 1
Constraints:
n == nums1.lengthn == nums2.lengthn == nums3.lengthn == nums4.length1 <= n <= 200-228 <= nums1[i], nums2[i], nums3[i], nums4[i] <= 228
思路
把四个数组变成两个数组,然后仿照2Sum问题找(a+b)和0-(c+d)。分步相乘。
本题不考虑去重的问题。
本题其实有四个重点:
- 为什么会想到用哈希表?
- 哈希表为什么用map?
- 本题map是用来存什么的?
- map中的key和value用来存什么的?
把这四点想清楚了,本题才算是理解透彻了。
map用来存前两个数组元素之和及频率
C++解法
class Solution {
public:
int fourSumCount(vector<int>& nums1, vector<int>& nums2, vector<int>& nums3, vector<int>& nums4) {
unordered_map<int, int> map;
int count = 0;
for(int a : nums1){
for(int b : nums2){
map[a + b]++;
}
}
for(int c : nums3){
for(int d : nums4){
auto iter = map.find(0 - c - d);
if(iter != map.end()){
count += iter->second;
}
}
}
return count;
}
};
Java解法
class Solution {
public int fourSumCount(int[] nums1, int[] nums2, int[] nums3, int[] nums4) {
Map<Integer, Integer> map = new HashMap<>();
int count = 0;
// 将 nums1 和 nums2 的所有和放入 map 中
for (int a : nums1) {
for (int b : nums2) {
map.put(a + b, map.getOrDefault(a + b, 0) + 1);
}
}
// 遍历 nums3 和 nums4,查找使得总和为 0 的组合
for (int c : nums3) {
for (int d : nums4) {
// 查找相应的负数和
count += map.getOrDefault(-(c + d), 0);
}
}
return count;
}
}
15. 3Sum
Given an integer array nums, return all the triplets [nums[i], nums[j], nums[k]] such that i != j, i != k, and j != k, and nums[i] + nums[j] + nums[k] == 0.
Notice that the solution set must not contain duplicate triplets.
Example 1:
Input: nums = [-1,0,1,2,-1,-4]
Output: [[-1,-1,2],[-1,0,1]]
Explanation:
nums[0] + nums[1] + nums[2] = (-1) + 0 + 1 = 0.
nums[1] + nums[2] + nums[4] = 0 + 1 + (-1) = 0.
nums[0] + nums[3] + nums[4] = (-1) + 2 + (-1) = 0.
The distinct triplets are [-1,0,1] and [-1,-1,2].
Notice that the order of the output and the order of the triplets does not matter.
Example 2:
Input: nums = [0,1,1]
Output: []
Explanation: The only possible triplet does not sum up to 0.
Example 3:
Input: nums = [0,0,0]
Output: [[0,0,0]]
Explanation: The only possible triplet sums up to 0.
Constraints:
3 <= nums.length <= 3000-10^5 <= nums[i] <= 10^5
思路
因为结果要去重,这里不方便使用哈希法。
收获一个结果后再进行去重操作。
哈希解法
两层for循环就可以确定 两个数值,可以使用哈希法来确定 第三个数 0-(a+b) 或者 0 - (a + c) 是否在 数组里出现过,其实这个思路是正确的,但是我们有一个非常棘手的问题,就是题目中说的不可以包含重复的三元组。
把符合条件的三元组放进vector中,然后再去重,这样是非常费时的,很容易超时,也是这道题目通过率如此之低的根源所在。
去重的过程不好处理,有很多小细节,如果在面试中很难想到位。
时间复杂度可以做到O(n^2),但还是比较费时的,因为不好做剪枝操作。
大家可以尝试使用哈希法写一写,就知道其困难的程度了。
双指针
其实这道题目使用哈希法并不十分合适,因为在去重的操作中有很多细节需要注意,在面试中很难直接写出没有bug的代码。
而且使用哈希法在使用两层for循环的时候,能做的剪枝操作很有限,虽然时间复杂度是O(n^2),也是可以在leetcode上通过,但是程序的执行时间依然比较长 。
接下来我来介绍另一个解法:双指针法,这道题目使用双指针法 要比哈希法高效一些,那么来讲解一下具体实现的思路。
动画效果如下:
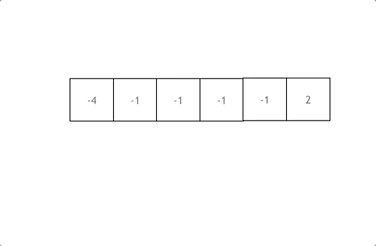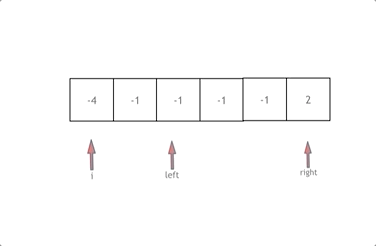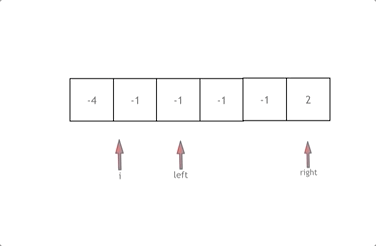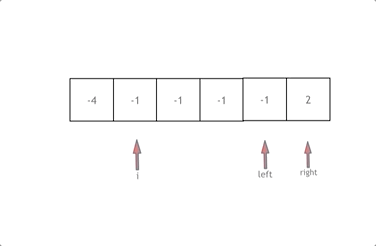
拿这个nums数组来举例,首先将数组排序,然后有一层for循环,i从下标0的地方开始,同时定一个下标left 定义在i+1的位置上,定义下标right 在数组结尾的位置上。
依然还是在数组中找到 abc 使得a + b +c =0,我们这里相当于 a = nums[i],b = nums[left],c = nums[right]。
接下来如何移动left 和right呢, 如果nums[i] + nums[left] + nums[right] > 0 就说明 此时三数之和大了,因为数组是排序后了,所以right下标就应该向左移动,这样才能让三数之和小一些。
如果 nums[i] + nums[left] + nums[right] < 0 说明 此时 三数之和小了,left 就向右移动,才能让三数之和大一些,直到left与right相遇为止。
时间复杂度:O(n^2)。
去重逻辑的思考
a的去重
说到去重,其实主要考虑三个数的去重。 a, b ,c, 对应的就是 nums[i],nums[left],nums[right]
a 如果重复了怎么办,a是nums里遍历的元素,那么应该直接跳过去。
但这里有一个问题,是判断 nums[i] 与 nums[i + 1]是否相同,还是判断 nums[i] 与 nums[i-1] 是否相同。
有同学可能想,这不都一样吗?
其实不一样!
都是和nums[i]进行比较,是比较它的前一个,还是比较它的后一个。
如果我们的写法是 这样:
if (nums[i] == nums[i + 1]) { // 去重操作
continue;
}
那我们就把三元组中出现重复元素的情况直接pass掉了。 例如{-1, -1 ,2} 这组数据,当遍历到第一个-1 的时候,判断 下一个也是-1,那这组数据就pass了。
我们要做的是不能有重复的三元组,但三元组内的元素是可以重复的!
所以这里是有两个重复的维度。
那么应该这么写:
if (i > 0 && nums[i] == nums[i - 1]) {
continue;
}
这么写就是当前使用nums[i],我们判断前一位是不是一样的元素,在看 {-1, -1 ,2} 这组数据,当遍历到第一个 -1 的时候,只要前一位没有-1,那么 {-1, -1 ,2} 这组数据一样可以收录到结果集里。
这是一个非常细节的思考过程。
b与c的去重
很多同学写本题的时候,去重的逻辑多加了对right 和left 的去重:(代码中注释部分)
while (right > left) {
if (nums[i] + nums[left] + nums[right] > 0) {
right--;
// 去重 right
while (left < right && nums[right] == nums[right + 1]) right--;
} else if (nums[i] + nums[left] + nums[right] < 0) {
left++;
// 去重 left
while (left < right && nums[left] == nums[left - 1]) left++;
} else {
}
}
但细想一下,这种去重其实对提升程序运行效率是没有帮助的。
拿right去重为例,即使不加这个去重逻辑,依然根据 while (right > left) 和 if (nums[i] + nums[left] + nums[right] > 0) 去完成right-- 的操作。
多加了 while (left < right && nums[right] == nums[right + 1]) right--; 这一行代码,其实就是把 需要执行的逻辑提前执行了,但并没有减少 判断的逻辑。
最直白的思考过程,就是right还是一个数一个数的减下去的,所以在哪里减的都是一样的。
所以这种去重是可以不加的。 仅仅是把去重的逻辑提前了而已。
既然三数之和可以使用双指针法,我们之前讲过的1.两数之和,可不可以使用双指针法呢?
如果不能,题意如何更改就可以使用双指针法呢?
两数之和 就不能使用双指针法,因为1.两数之和要求返回的是索引下标, 而双指针法一定要排序,一旦排序之后原数组的索引就被改变了。
如果1.两数之和要求返回的是数值的话,就可以使用双指针法了。
C++解法
哈希法C++代码:
class Solution {
public:
// 在一个数组中找到3个数形成的三元组,它们的和为0,不能重复使用(三数下标互不相同),且三元组不能重复。
// b(存储)== 0-(a+c)(检索)
vector<vector<int>> threeSum(vector<int>& nums) {
vector<vector<int>> result;
sort(nums.begin(), nums.end());
for (int i = 0; i < nums.size(); i++) {
// 如果a是正数,a<b<c,不可能形成和为0的三元组
if (nums[i] > 0)
break;
// [a, a, ...] 如果本轮a和上轮a相同,那么找到的b,c也是相同的,所以去重a
if (i > 0 && nums[i] == nums[i - 1])
continue;
// 这个set的作用是存储b
unordered_set<int> set;
for (int k = i + 1; k < nums.size(); k++) {
// 去重b=c时的b和c
if (k > i + 2 && nums[k] == nums[k - 1] && nums[k - 1] == nums[k - 2])
continue;
// a+b+c=0 <=> b=0-(a+c)
int target = 0 - (nums[i] + nums[k]);
if (set.find(target) != set.end()) {
result.push_back({nums[i], target, nums[k]}); // nums[k]成为c
set.erase(target);
}
else {
set.insert(nums[k]); // nums[k]成为b
}
}
}
return result;
}
};
- 时间复杂度: O(n^2)
- 空间复杂度: O(n),额外的 set 开销
双指针法C++代码如下:
class Solution {
public:
vector<vector<int>> threeSum(vector<int>& nums) {
vector<vector<int>> result;
sort(nums.begin(), nums.end());
// 找出a + b + c = 0
// a = nums[i], b = nums[left], c = nums[right]
for (int i = 0; i < nums.size(); i++) {
// 排序之后如果第一个元素已经大于零,那么无论如何组合都不可能凑成三元组,直接返回结果就可以了
if (nums[i] > 0) {
return result;
}
// 错误去重a方法,将会漏掉-1,-1,2 这种情况
/*
if (nums[i] == nums[i + 1]) {
continue;
}
*/
// 正确去重a方法
if (i > 0 && nums[i] == nums[i - 1]) {
continue;
}
int left = i + 1;
int right = nums.size() - 1;
while (right > left) {
// 去重复逻辑如果放在这里,0,0,0 的情况,可能直接导致 right<=left 了,从而漏掉了 0,0,0 这种三元组
/*
while (right > left && nums[right] == nums[right - 1]) right--;
while (right > left && nums[left] == nums[left + 1]) left++;
*/
if (nums[i] + nums[left] + nums[right] > 0) right--;
else if (nums[i] + nums[left] + nums[right] < 0) left++;
else {
result.push_back(vector<int>{nums[i], nums[left], nums[right]});
// 去重逻辑应该放在找到一个三元组之后,对b 和 c去重
while (right > left && nums[right] == nums[right - 1]) right--;
while (right > left && nums[left] == nums[left + 1]) left++;
// 找到答案时,双指针同时收缩
right--;
left++;
}
}
}
return result;
}
};
- 时间复杂度: O(n^2)
- 空间复杂度: O(1)
Java解法
(版本一) 双指针
class Solution {
public List<List<Integer>> threeSum(int[] nums) {
List<List<Integer>> result = new ArrayList<>();
Arrays.sort(nums);
// 找出a + b + c = 0
// a = nums[i], b = nums[left], c = nums[right]
for (int i = 0; i < nums.length; i++) {
// 排序之后如果第一个元素已经大于零,那么无论如何组合都不可能凑成三元组,直接返回结果就可以了
if (nums[i] > 0) {
return result;
}
if (i > 0 && nums[i] == nums[i - 1]) { // 去重a
continue;
}
int left = i + 1;
int right = nums.length - 1;
while (right > left) {
int sum = nums[i] + nums[left] + nums[right];
if (sum > 0) {
right--;
} else if (sum < 0) {
left++;
} else {
result.add(Arrays.asList(nums[i], nums[left], nums[right]));
// 去重逻辑应该放在找到一个三元组之后,对b 和 c去重
while (right > left && nums[right] == nums[right - 1]) right--;
while (right > left && nums[left] == nums[left + 1]) left++;
right--;
left++;
}
}
}
return result;
}
}
(版本二) 使用哈希集合
class Solution {
public List<List<Integer>> threeSum(int[] nums) {
List<List<Integer>> result = new ArrayList<>();
Arrays.sort(nums);
for (int i = 0; i < nums.length; i++) {
// 如果第一个元素大于零,不可能凑成三元组
if (nums[i] > 0) {
return result;
}
// 三元组元素a去重
if (i > 0 && nums[i] == nums[i - 1]) {
continue;
}
HashSet<Integer> set = new HashSet<>();
for (int j = i + 1; j < nums.length; j++) {
// 三元组元素b去重
if (j > i + 2 && nums[j] == nums[j - 1] && nums[j - 1] == nums[j - 2]) {
continue;
}
int c = -nums[i] - nums[j];
if (set.contains(c)) {
result.add(Arrays.asList(nums[i], nums[j], c));
set.remove(c); // 三元组元素c去重
} else {
set.add(nums[j]);
}
}
}
return result;
}
}
Python解法
(版本一) 双指针
class Solution:
def threeSum(self, nums: List[int]) -> List[List[int]]:
result = []
nums.sort()
for i in range(len(nums)):
# 如果第一个元素已经大于0,不需要进一步检查
if nums[i] > 0:
return result
# 跳过相同的元素以避免重复
if i > 0 and nums[i] == nums[i - 1]:
continue
left = i + 1
right = len(nums) - 1
while right > left:
sum_ = nums[i] + nums[left] + nums[right]
if sum_ < 0:
left += 1
elif sum_ > 0:
right -= 1
else:
result.append([nums[i], nums[left], nums[right]])
# 跳过相同的元素以避免重复
while right > left and nums[right] == nums[right - 1]:
right -= 1
while right > left and nums[left] == nums[left + 1]:
left += 1
right -= 1
left += 1
return result
(版本二) 使用字典
class Solution:
def threeSum(self, nums: List[int]) -> List[List[int]]:
result = []
nums.sort()
# 找出a + b + c = 0
# a = nums[i], b = nums[j], c = -(a + b)
for i in range(len(nums)):
# 排序之后如果第一个元素已经大于零,那么不可能凑成三元组
if nums[i] > 0:
break
if i > 0 and nums[i] == nums[i - 1]: #三元组元素a去重
continue
d = {}
for j in range(i + 1, len(nums)):
if j > i + 2 and nums[j] == nums[j-1] == nums[j-2]: # 三元组元素b去重
continue
c = 0 - (nums[i] + nums[j])
if c in d:
result.append([nums[i], nums[j], c])
d.pop(c) # 三元组元素c去重
else:
d[nums[j]] = j
return result
Go解法
(版本一) 双指针
func threeSum(nums []int) [][]int {
sort.Ints(nums)
res := [][]int{}
// 找出a + b + c = 0
// a = nums[i], b = nums[left], c = nums[right]
for i := 0; i < len(nums)-2; i++ {
// 排序之后如果第一个元素已经大于零,那么无论如何组合都不可能凑成三元组,直接返回结果就可以了
n1 := nums[i]
if n1 > 0 {
break
}
// 去重a
if i > 0 && n1 == nums[i-1] {
continue
}
l, r := i+1, len(nums)-1
for l < r {
n2, n3 := nums[l], nums[r]
if n1+n2+n3 == 0 {
res = append(res, []int{n1, n2, n3})
// 去重逻辑应该放在找到一个三元组之后,对b 和 c去重
for l < r && nums[l] == n2 {
l++
}
for l < r && nums[r] == n3 {
r--
}
} else if n1+n2+n3 < 0 {
l++
} else {
r--
}
}
}
return res
}
(版本二) 哈希解法
func threeSum(nums []int) [][]int {
res := make([][]int, 0)
sort.Ints(nums)
// 找出a + b + c = 0
// a = nums[i], b = nums[j], c = -(a + b)
for i := 0; i < len(nums); i++ {
// 排序之后如果第一个元素已经大于零,那么不可能凑成三元组
if nums[i] > 0 {
break
}
// 三元组元素a去重
if i > 0 && nums[i] == nums[i-1] {
continue
}
set := make(map[int]struct{})
for j := i + 1; j < len(nums); j++ {
// 三元组元素b去重
if j > i + 2 && nums[j] == nums[j-1] && nums[j-1] == nums[j-2] {
continue
}
c := -nums[i] - nums[j]
if _, ok := set[c]; ok {
res = append(res, []int{nums[i], nums[j], c})
// 三元组元素c去重
delete(set, c)
} else {
set[nums[j]] = struct{}{}
}
}
}
return res
}
Rust解法
#![allow(unused)] fn main() { // 哈希解法 use std::collections::HashSet; impl Solution { pub fn three_sum(nums: Vec<i32>) -> Vec<Vec<i32>> { let mut result: Vec<Vec<i32>> = Vec::new(); let mut nums = nums; nums.sort(); let len = nums.len(); for i in 0..len { if nums[i] > 0 { break; } if i > 0 && nums[i] == nums[i - 1] { continue; } let mut set = HashSet::new(); for j in (i + 1)..len { if j > i + 2 && nums[j] == nums[j - 1] && nums[j] == nums[j - 2] { continue; } let c = 0 - (nums[i] + nums[j]); if set.contains(&c) { result.push(vec![nums[i], nums[j], c]); set.remove(&c); } else { set.insert(nums[j]); } } } result } } }
#![allow(unused)] fn main() { // 双指针法 use std::cmp::Ordering; impl Solution { pub fn three_sum(nums: Vec<i32>) -> Vec<Vec<i32>> { let mut result: Vec<Vec<i32>> = Vec::new(); let mut nums = nums; nums.sort(); let len = nums.len(); for i in 0..len { if nums[i] > 0 { return result; } if i > 0 && nums[i] == nums[i - 1] { continue; } let (mut left, mut right) = (i + 1, len - 1); while left < right { match (nums[i] + nums[left] + nums[right]).cmp(&0){ Ordering::Equal =>{ result.push(vec![nums[i], nums[left], nums[right]]); left +=1; right -=1; while left < right && nums[left] == nums[left - 1]{ left += 1; } while left < right && nums[right] == nums[right+1]{ right -= 1; } } Ordering::Greater => right -= 1, Ordering::Less => left += 1, } } } result } } }
18. 4Sum
Given an array nums of n integers, return an array of all the unique quadruplets [nums[a], nums[b], nums[c], nums[d]] such that:
0 <= a, b, c, d < na,b,c, anddare distinct.nums[a] + nums[b] + nums[c] + nums[d] == target
You may return the answer in any order.
Example 1:
Input: nums = [1,0,-1,0,-2,2], target = 0
Output: [[-2,-1,1,2],[-2,0,0,2],[-1,0,0,1]]
Example 2:
Input: nums = [2,2,2,2,2], target = 8
Output: [[2,2,2,2]]
Constraints:
1 <= nums.length <= 200-10^9 <= nums[i] <= 10^9-10^9 <= target <= 10^9
思路
四数之和,和15.三数之和是一个思路,都是使用双指针法, 基本解法就是在15.三数之和的基础上再套一层for循环。
但是有一些细节需要注意,例如: 不要判断nums[k] > target 就返回了,三数之和 可以通过 nums[i] > 0 就返回了,因为 0 已经是确定的数了,四数之和这道题目 target是任意值。比如:数组是[-4, -3, -2, -1],target是-10,不能因为-4 > -10而跳过。但是我们依旧可以去做剪枝,逻辑变成nums[i] > target && (nums[i] >=0 || target >= 0)就可以了。
15.三数之和的双指针解法是一层for循环num[i]为确定值,然后循环内有left和right下标作为双指针,找到nums[i] + nums[left] + nums[right] == 0。
四数之和的双指针解法是两层for循环nums[k] + nums[i]为确定值,依然是循环内有left和right下标作为双指针,找出nums[k] + nums[i] + nums[left] + nums[right] == target的情况,三数之和的时间复杂度是O(n^2),四数之和的时间复杂度是O(n^3) 。
那么一样的道理,五数之和、六数之和等等都采用这种解法。
对于15.三数之和双指针法就是将原本暴力O(n^3)的解法,降为O(n^2)的解法,四数之和的双指针解法就是将原本暴力O(n^4)的解法,降为O(n^3)的解法。
之前我们讲过哈希表的经典题目:454.四数相加II,相对于本题简单很多,因为本题是要求在一个集合中找出四个数相加等于target,同时四元组不能重复。
而454.四数相加II是四个独立的数组,只要找到A[i] + B[j] + C[k] + D[l] = 0就可以,不用考虑有重复的四个元素相加等于0的情况,所以相对于本题还是简单了不少!
C++解法
class Solution {
public:
vector<vector<int>> fourSum(vector<int>& nums, int target) {
vector<vector<int>> result;
sort(nums.begin(), nums.end());
for (int k = 0; k < nums.size(); k++) {
// 剪枝处理
if (nums[k] > target && nums[k] >= 0) {
break; // 这里使用break,统一通过最后的return返回
}
// 对nums[k]去重
if (k > 0 && nums[k] == nums[k - 1]) {
continue;
}
for (int i = k + 1; i < nums.size(); i++) {
// 2级剪枝处理
if (nums[k] + nums[i] > target && nums[k] + nums[i] >= 0) {
break;
}
// 对nums[i]去重
if (i > k + 1 && nums[i] == nums[i - 1]) {
continue;
}
int left = i + 1;
int right = nums.size() - 1;
while (right > left) {
// nums[k] + nums[i] + nums[left] + nums[right] > target 会溢出
if ((long) nums[k] + nums[i] + nums[left] + nums[right] > target) {
right--;
// nums[k] + nums[i] + nums[left] + nums[right] < target 会溢出
} else if ((long) nums[k] + nums[i] + nums[left] + nums[right] < target) {
left++;
} else {
result.push_back(vector<int>{nums[k], nums[i], nums[left], nums[right]});
// 对nums[left]和nums[right]去重
while (right > left && nums[right] == nums[right - 1]) right--;
while (right > left && nums[left] == nums[left + 1]) left++;
// 找到答案时,双指针同时收缩
right--;
left++;
}
}
}
}
return result;
}
};
- 时间复杂度: O(n^3)
- 空间复杂度: O(1)
二级剪枝的部分:
if (nums[k] + nums[i] > target && nums[k] + nums[i] >= 0) {
break;
}
可以优化为:
if (nums[k] + nums[i] > target && nums[i] >= 0) {
break;
}
因为只要 nums[k] + nums[i] > target,那么 nums[i] 后面的数都是正数的话,就一定不符合条件了。
不过这种剪枝其实有点小绕,大家能够理解 文章给的完整代码的剪枝就够了。
Java解法
import java.util.*;
public class Solution {
public List<List<Integer>> fourSum(int[] nums, int target) {
Arrays.sort(nums); // 排序数组
List<List<Integer>> result = new ArrayList<>(); // 结果集
for (int k = 0; k < nums.length; k++) {
// 剪枝处理
if (nums[k] > target && nums[k] >= 0) {
break;
}
// 对nums[k]去重
if (k > 0 && nums[k] == nums[k - 1]) {
continue;
}
for (int i = k + 1; i < nums.length; i++) {
// 第二级剪枝
if (nums[k] + nums[i] > target && nums[k] + nums[i] >= 0) {
break;
}
// 对nums[i]去重
if (i > k + 1 && nums[i] == nums[i - 1]) {
continue;
}
int left = i + 1;
int right = nums.length - 1;
while (right > left) {
long sum = (long) nums[k] + nums[i] + nums[left] + nums[right];
if (sum > target) {
right--;
} else if (sum < target) {
left++;
} else {
result.add(Arrays.asList(nums[k], nums[i], nums[left], nums[right]));
// 对nums[left]和nums[right]去重
while (right > left && nums[right] == nums[right - 1]) right--;
while (right > left && nums[left] == nums[left + 1]) left++;
right--;
left++;
}
}
}
}
return result;
}
public static void main(String[] args) {
Solution solution = new Solution();
int[] nums = {1, 0, -1, 0, -2, 2};
int target = 0;
List<List<Integer>> results = solution.fourSum(nums, target);
for (List<Integer> result : results) {
System.out.println(result);
}
}
}
Python解法
(版本一) 双指针
class Solution:
def fourSum(self, nums: List[int], target: int) -> List[List[int]]:
nums.sort()
n = len(nums)
result = []
for i in range(n):
if nums[i] > target and nums[i] > 0 and target > 0:# 剪枝(可省)
break
if i > 0 and nums[i] == nums[i-1]:# 去重
continue
for j in range(i+1, n):
if nums[i] + nums[j] > target and target > 0: #剪枝(可省)
break
if j > i+1 and nums[j] == nums[j-1]: # 去重
continue
left, right = j+1, n-1
while left < right:
s = nums[i] + nums[j] + nums[left] + nums[right]
if s == target:
result.append([nums[i], nums[j], nums[left], nums[right]])
while left < right and nums[left] == nums[left+1]:
left += 1
while left < right and nums[right] == nums[right-1]:
right -= 1
left += 1
right -= 1
elif s < target:
left += 1
else:
right -= 1
return result
(版本二) 使用字典
class Solution(object):
def fourSum(self, nums, target):
"""
:type nums: List[int]
:type target: int
:rtype: List[List[int]]
"""
# 创建一个字典来存储输入列表中每个数字的频率
freq = {}
for num in nums:
freq[num] = freq.get(num, 0) + 1
# 创建一个集合来存储最终答案,并遍历4个数字的所有唯一组合
ans = set()
for i in range(len(nums)):
for j in range(i + 1, len(nums)):
for k in range(j + 1, len(nums)):
val = target - (nums[i] + nums[j] + nums[k])
if val in freq:
# 确保没有重复
count = (nums[i] == val) + (nums[j] == val) + (nums[k] == val)
if freq[val] > count:
ans.add(tuple(sorted([nums[i], nums[j], nums[k], val])))
return [list(x) for x in ans]
Go解法
func fourSum(nums []int, target int) [][]int {
if len(nums) < 4 {
return nil
}
sort.Ints(nums)
var res [][]int
for i := 0; i < len(nums)-3; i++ {
n1 := nums[i]
// if n1 > target { // 不能这样写,因为可能是负数
// break
// }
if i > 0 && n1 == nums[i-1] { // 对nums[i]去重
continue
}
for j := i + 1; j < len(nums)-2; j++ {
n2 := nums[j]
if j > i+1 && n2 == nums[j-1] { // 对nums[j]去重
continue
}
l := j + 1
r := len(nums) - 1
for l < r {
n3 := nums[l]
n4 := nums[r]
sum := n1 + n2 + n3 + n4
if sum < target {
l++
} else if sum > target {
r--
} else {
res = append(res, []int{n1, n2, n3, n4})
for l < r && n3 == nums[l+1] { // 去重
l++
}
for l < r && n4 == nums[r-1] { // 去重
r--
}
// 找到答案时,双指针同时靠近
r--
l++
}
}
}
}
return res
}
49. Group Anagrams
Given an array of strings strs, group the anagrams together. You can return the answer in any order.
Example 1:
Input: strs = ["eat","tea","tan","ate","nat","bat"]
Output: [["bat"],["nat","tan"],["ate","eat","tea"]]
Explanation:
- There is no string in strs that can be rearranged to form
"bat". - The strings
"nat"and"tan"are anagrams as they can be rearranged to form each other. - The strings
"ate","eat", and"tea"are anagrams as they can be rearranged to form each other.
Example 2:
Input: strs = [""]
Output: [[""]]
Example 3:
Input: strs = ["a"]
Output: [["a"]]
Constraints:
1 <= strs.length <= 10^40 <= strs[i].length <= 100strs[i]consists of lowercase English letters.
思路
- 头文件引入:引入必要的标准库,如
<iostream>,<vector>,<unordered_map>, 和<algorithm>。 - 类定义:定义一个名为
Solution的类,其中包含groupAnagrams方法,接受一个字符串向量并返回一个字符串向量的向量。 - unordered_map:使用
std::unordered_map来代替 Java 的HashMap。 - 字符串排序:利用
std::sort对字符串进行排序以创建一个唯一的键。 - 结果存储:通过遍历哈希表,将分组的单词存储到结果向量中。
C++解法
#include <iostream>
#include <vector>
#include <unordered_map>
#include <algorithm>
class Solution {
public:
std::vector<std::vector<std::string>> groupAnagrams(std::vector<std::string>& strs) {
std::unordered_map<std::string, std::vector<std::string>> map;
for (const auto& str : strs) {
std::string key = str; // Copy the string to a key
// Sort the string to create a key
std::sort(key.begin(), key.end());
// Add the original string to the map using the sorted key
map[key].push_back(str);
}
// Prepare the result using a vector of vectors
std::vector<std::vector<std::string>> result;
for (const auto& pair : map) {
result.push_back(pair.second);
}
return result;
}
};
Java解法
class Solution {
public List<List<String>> groupAnagrams(String[] strs) {
Map<String, List<String>> map = new HashMap<String, List<String>>();
for (String str : strs) {
char[] array = str.toCharArray();
Arrays.sort(array);
String key = new String(array);
List<String> list = map.getOrDefault(key, new ArrayList<String>());
list.add(str);
map.put(key, list);
}
return new ArrayList<List<String>>(map.values());
}
}
字符串
字符串:总结篇
其实我们已经学习了十天的字符串了,从字符串的定义到库函数的使用原则,从各种反转到KMP算法,相信大家应该对字符串有比较深刻的认识了。
那么这次我们来做一个总结。
什么是字符串
字符串是若干字符组成的有限序列,也可以理解为是一个字符数组,但是很多语言对字符串做了特殊的规定,接下来我来说一说C/C++中的字符串。
在C语言中,把一个字符串存入一个数组时,也把结束符 '\0'存入数组,并以此作为该字符串是否结束的标志。
例如这段代码:
char a[5] = "asd";
for (int i = 0; a[i] != '\0'; i++) {
}
在C++中,提供一个string类,string类会提供 size接口,可以用来判断string类字符串是否结束,就不用'\0'来判断是否结束。
例如这段代码:
string a = "asd";
for (int i = 0; i < a.size(); i++) {
}
那么vector< char > 和 string 又有什么区别呢?
其实在基本操作上没有区别,但是 string提供更多的字符串处理的相关接口,例如string 重载了+,而vector却没有。
所以想处理字符串,我们还是会定义一个string类型。
要不要使用库函数
在文章344.反转字符串中强调了打基础的时候,不要太迷恋于库函数。
甚至一些同学习惯于调用substr,split,reverse之类的库函数,却不知道其实现原理,也不知道其时间复杂度,这样实现出来的代码,如果在面试现场,面试官问:“分析其时间复杂度”的话,一定会一脸懵逼!
所以建议如果题目关键的部分直接用库函数就可以解决,建议不要使用库函数。
如果库函数仅仅是 解题过程中的一小部分,并且你已经很清楚这个库函数的内部实现原理的话,可以考虑使用库函数。
双指针法
在344.反转字符串,我们使用双指针法实现了反转字符串的操作,双指针法在数组,链表和字符串中很常用。
接着在字符串:替换空格,同样还是使用双指针法在时间复杂度O(n)的情况下完成替换空格。
其实很多数组填充类的问题,都可以先预先给数组扩容带填充后的大小,然后在从后向前进行操作。
那么针对数组删除操作的问题,其实在27. 移除元素中就已经提到了使用双指针法进行移除操作。
同样的道理在151.翻转字符串里的单词中我们使用O(n)的时间复杂度,完成了删除冗余空格。
一些同学会使用for循环里调用库函数erase来移除元素,这其实是O(n^2)的操作,因为erase就是O(n)的操作,所以这也是典型的不知道库函数的时间复杂度,上来就用的案例了。
反转系列
在反转上还可以在加一些玩法,其实考察的是对代码的掌控能力。
541. 反转字符串II中,一些同学可能为了处理逻辑:每隔2k个字符的前k的字符,写了一堆逻辑代码或者再搞一个计数器,来统计2k,再统计前k个字符。
其实当需要固定规律一段一段去处理字符串的时候,要想想在在for循环的表达式上做做文章。
只要让 i += (2 * k),i 每次移动 2 * k 就可以了,然后判断是否需要有反转的区间。
因为要找的也就是每2 * k 区间的起点,这样写程序会高效很多。
在151.翻转字符串里的单词中要求翻转字符串里的单词,这道题目可以说是综合考察了字符串的多种操作。是考察字符串的好题。
这道题目通过 先整体反转再局部反转,实现了反转字符串里的单词。
后来发现反转字符串还有一个牛逼的用处,就是达到左旋的效果。
在字符串:反转个字符串还有这个用处?中,我们通过先局部反转再整体反转达到了左旋的效果。
KMP
KMP的主要思想是当出现字符串不匹配时,可以知道一部分之前已经匹配的文本内容,可以利用这些信息避免从头再去做匹配了。
KMP的精髓所在就是前缀表,在KMP精讲中提到了,什么是KMP,什么是前缀表,以及为什么要用前缀表。
前缀表:起始位置到下标i之前(包括i)的子串中,有多大长度的相同前缀后缀。
那么使用KMP可以解决两类经典问题:
再一次强调了什么是前缀,什么是后缀,什么又是最长相等前后缀。
前缀:指不包含最后一个字符的所有以第一个字符开头的连续子串。
后缀:指不包含第一个字符的所有以最后一个字符结尾的连续子串。
然后针对前缀表到底要不要减一,这其实是不同KMP实现的方式,我们在KMP精讲中针对之前两个问题,分别给出了两个不同版本的的KMP实现。
其中主要理解j=next[x]这一步最为关键!
总结
字符串类类型的题目,往往想法比较简单,但是实现起来并不容易,复杂的字符串题目非常考验对代码的掌控能力。
双指针法是字符串处理的常客。
KMP算法是字符串查找最重要的算法,但彻底理解KMP并不容易,我们已经写了五篇KMP的文章,不断总结和完善,最终才把KMP讲清楚。
好了字符串相关的算法知识就介绍到了这里了,明天开始新的征程,大家加油!
字符串反转系列
- 344. Reverse String
- 345. Reverse Vowels of a String
- 541. Reverse String II
- 151. Reverse Words in a String
- 557. Reverse Words in a String III
- 917. Reverse Only Letters
- 2810. Faulty Keyboard
344. Reverse String
Write a function that reverses a string. The input string is given as an array of characters s.
You must do this by modifying the input array in-place with O(1) extra memory.
Example 1:
Input: s = ["h","e","l","l","o"]
Output: ["o","l","l","e","h"]
Example 2:
Input: s = ["H","a","n","n","a","h"]
Output: ["h","a","n","n","a","H"]
Constraints:
1 <= s.length <= 105s[i]is a printable ascii character.
思路
方法一:调包,使用String相关函数方法
方法二:双指针
The problem requires reversing a string in-place, which means directly modifying the input array without using additional memory for another array. A two-pointer approach works efficiently:
- Place one pointer at the beginning of the array and another at the end.
- Swap the characters at these two pointers.
- Move the pointers closer until they meet.
Complexity:
- Time Complexity: ( O(n) ), where ( n ) is the length of the array. Each element is processed once.
- Space Complexity: ( O(1) ), as no additional memory is used.
C++解法
class Solution {
public:
void reverseString(vector<char>& s) {
int left = 0;
int right = s.size() - 1;
while(left < right){
swap(s[left++], s[right--]);
}
}
};
Java解法
class Solution {
public void reverseString(char[] s) {
int left = 0, right = s.length - 1;
while (left < right) {
char temp = s[left];
s[left] = s[right];
s[right] = temp;
left++;
right--;
}
}
}
在Java中,字符串本身是不可变的,因此没有内置的 reverse 函数来直接反转字符串。不过,您可以使用 StringBuilder 或 StringBuffer 来实现字符串的反转,因为它们提供了一个 reverse() 方法。以下是两种实现方法的示例代码:
使用 StringBuilder
public class Main {
public static void main(String[] args) {
String original = "Hello, World!";
String reversed = new StringBuilder(original).reverse().toString();
System.out.println(reversed); // 输出: !dlroW ,olleH
}
}
使用 StringBuffer
public class Main {
public static void main(String[] args) {
String original = "Hello, World!";
String reversed = new StringBuffer(original).reverse().toString();
System.out.println(reversed); // 输出: !dlroW ,olleH
}
}
这些代码段通过 StringBuilder 或 StringBuffer 的 reverse() 方法反转给定的字符串,并将结果打印出来。
345. Reverse Vowels of a String
Given a string s, reverse only all the vowels in the string and return it.
The vowels are 'a', 'e', 'i', 'o', and 'u', and they can appear in both lower and upper cases, more than once.
Example 1:
Input: s = "IceCreAm"
Output: "AceCreIm"
Explanation:
The vowels in s are ['I', 'e', 'e', 'A']. On reversing the vowels, s becomes "AceCreIm".
Example 2:
Input: s = "leetcode"
Output: "leotcede"
Constraints:
1 <= s.length <= 3 * 10^5sconsist of printable ASCII characters.
思路
双指针,左右指针,找到元音字母就交换
C++解法
#include <string>
#include <unordered_set>
class Solution {
public:
std::string reverseVowels(std::string s) {
int left = 0;
int right = s.length() - 1;
// 定义元音字符集合
std::unordered_set<char> vowels{'a', 'e', 'i', 'o', 'u',
'A', 'E', 'I', 'O', 'U'};
while (left < right) {
// 找到左边的元音
while (left < right && vowels.find(s[left]) == vowels.end()) {
left++;
}
// 找到右边的元音
while (left < right && vowels.find(s[right]) == vowels.end()) {
right--;
}
// 如果左边的指针小于右边的指针,则交换元音字符
if (left < right) {
std::swap(s[left], s[right]);
left++;
right--;
}
}
return s; // 返回反转元音后的字符串
}
};
代码说明
-
头文件: 包含
<string>和<unordered_set>库,以便使用字符串和集合。 -
字符集合: 使用
std::unordered_set<char>来存储元音字符,这使得查找是否是元音字符的复杂度为 O(1),提高了效率。 -
使用
std::swap: C++ 已经提供了std::swap函数来交换变量,因此直接使用这个函数来交换左右指针指向的字符。 -
循环结构: 循环结构与 Java 代码保持相同,确保左右指针逐步向中间靠拢,直到找到元音字符并进行交换。
Java解法
class Solution {
public String reverseVowels(String s) {
int left = 0;
int right = s.length() - 1;
char[] chars = s.toCharArray(); // 将字符串转换为字符数组,以便交换字符
// 定义元音字符集合
String vowels = "aeiouAEIOU";
while (left < right) {
// 找到左边的元音
while (left < right && !vowels.contains(String.valueOf(chars[left]))) {
left++;
}
// 找到右边的元音
while (left < right && !vowels.contains(String.valueOf(chars[right]))) {
right--;
}
// 如果左边的指针小于右边的指针,则交换元音字符
if (left < right) {
char temp = chars[left];
chars[left] = chars[right];
chars[right] = temp;
left++;
right--;
}
}
return new String(chars); // 将字符数组转换回来为字符串
}
}
修正的内容:
-
字符访问方式: 原代码使用
s.charAt[left],正确的方法是使用小括号s.charAt(left)。 -
条件逻辑:
- 原来的条件使用了逻辑“或” (||),这会导致不正确的结果。应改为使用逻辑“与” (&&),要确保当前字符不是元音时才继续移动指针。
- 使用
!vowels.contains(...)更简洁地判断一个字符是否是元音。
-
字符交换:
- 原先代码尝试调用
swap函数,而在 Java 中没有直接对字符进行交换的函数,合理的做法是使用一个临时变量temp来进行手动交换。
- 原先代码尝试调用
-
字符串与字符数组转换:
- Java 的字符串是不可变的,因此需要将字符串先转换为字符数组,进行所需的修改后再转换回字符串。
-
边界检查: 添加了
left < right的检查,确保在交换之前左右指针仍然是有效的。
541. Reverse String II
Given a string s and an integer k, reverse the first k characters for every 2k characters counting from the start of the string.
If there are fewer than k characters left, reverse all of them. If there are less than 2k but greater than or equal to k characters, then reverse the first k characters and leave the other as original.
Example 1:
Input: s = "abcdefg", k = 2
Output: "bacdfeg"
Example 2:
Input: s = "abcd", k = 2
Output: "bacd"
Constraints:
1 <= s.length <= 10^4sconsists of only lowercase English letters.1 <= k <= 10^4
思路
以2k为单位跳转,但只反转前k个字符
C++解法
class Solution {
public:
string reverseStr(string s, int k) {
for(int i = 0; i < s.size(); i += 2 * k){
if(i + k <= s.size()){
reverse(s.begin() + i,s.begin() + i + k);
continue;
}
reverse(s.begin() + i, s.end());
}
return s;
}
};
Java解法
151. Reverse Words in a String
Given an input string s, reverse the order of the words.
A word is defined as a sequence of non-space characters. The words in s will be separated by at least one space.
Return a string of the words in reverse order concatenated by a single space.
Note that s may contain leading or trailing spaces or multiple spaces between two words. The returned string should only have a single space separating the words. Do not include any extra spaces.
Example 1:
Input: s = "the sky is blue"
Output: "blue is sky the"
Example 2:
Input: s = " hello world "
Output: "world hello"
Explanation: Your reversed string should not contain leading or trailing spaces.
Example 3:
Input: s = "a good example"
Output: "example good a"
Explanation: You need to reduce multiple spaces between two words to a single space in the reversed string.
Constraints:
1 <= s.length <= 10^4scontains English letters (upper-case and lower-case), digits, and spaces' '.- There is at least one word in
s.
Follow-up: If the string data type is mutable in your language, can you solve it in-place with O(1) extra space?
思路
先移除多余的空格然后再调整单词的位置
C++解法
class Solution {
public:
void reverse(string& s, int start, int end){ //翻转,区间写法:左闭右闭 []
for (int i = start, j = end; i < j; i++, j--) {
swap(s[i], s[j]);
}
}
void removeExtraSpaces(string& s) {//去除所有空格并在相邻单词之间添加空格, 快慢指针。
int slow = 0; //整体思想参考https://programmercarl.com/0027.移除元素.html
for (int i = 0; i < s.size(); ++i) { //
if (s[i] != ' ') { //遇到非空格就处理,即删除所有空格。
if (slow != 0) s[slow++] = ' '; //手动控制空格,给单词之间添加空格。slow != 0说明不是第一个单词,需要在单词前添加空格。
while (i < s.size() && s[i] != ' ') { //补上该单词,遇到空格说明单词结束。
s[slow++] = s[i++];
}
}
}
s.resize(slow); //slow的大小即为去除多余空格后的大小。
}
string reverseWords(string s) {
removeExtraSpaces(s); //去除多余空格,保证单词之间之只有一个空格,且字符串首尾没空格。
reverse(s, 0, s.size() - 1);
int start = 0; //removeExtraSpaces后保证第一个单词的开始下标一定是0。
for (int i = 0; i <= s.size(); ++i) {
if (i == s.size() || s[i] == ' ') { //到达空格或者串尾,说明一个单词结束。进行翻转。
reverse(s, start, i - 1); //翻转,注意是左闭右闭 []的翻转。
start = i + 1; //更新下一个单词的开始下标start
}
}
return s;
}
};
- 时间复杂度: O(n)
- 空间复杂度: O(1) 或 O(n),取决于语言中字符串是否可变
Java解法
class Solution {
/**
* 不使用Java内置方法实现
* <p>
* 1.去除首尾以及中间多余空格
* 2.反转整个字符串
* 3.反转各个单词
*/
public String reverseWords(String s) {
// System.out.println("ReverseWords.reverseWords2() called with: s = [" + s + "]");
// 1.去除首尾以及中间多余空格
StringBuilder sb = removeSpace(s);
// 2.反转整个字符串
reverseString(sb, 0, sb.length() - 1);
// 3.反转各个单词
reverseEachWord(sb);
return sb.toString();
}
private StringBuilder removeSpace(String s) {
// System.out.println("ReverseWords.removeSpace() called with: s = [" + s + "]");
int start = 0;
int end = s.length() - 1;
while (s.charAt(start) == ' ') start++;
while (s.charAt(end) == ' ') end--;
StringBuilder sb = new StringBuilder();
while (start <= end) {
char c = s.charAt(start);
if (c != ' ' || sb.charAt(sb.length() - 1) != ' ') {
sb.append(c);
}
start++;
}
// System.out.println("ReverseWords.removeSpace returned: sb = [" + sb + "]");
return sb;
}
/**
* 反转字符串指定区间[start, end]的字符
*/
public void reverseString(StringBuilder sb, int start, int end) {
// System.out.println("ReverseWords.reverseString() called with: sb = [" + sb + "], start = [" + start + "], end = [" + end + "]");
while (start < end) {
char temp = sb.charAt(start);
sb.setCharAt(start, sb.charAt(end));
sb.setCharAt(end, temp);
start++;
end--;
}
// System.out.println("ReverseWords.reverseString returned: sb = [" + sb + "]");
}
private void reverseEachWord(StringBuilder sb) {
int start = 0;
int end = 1;
int n = sb.length();
while (start < n) {
while (end < n && sb.charAt(end) != ' ') {
end++;
}
reverseString(sb, start, end - 1);
start = end + 1;
end = start + 1;
}
}
}
//解法二:创建新字符数组填充。时间复杂度O(n)
class Solution {
public String reverseWords(String s) {
//源字符数组
char[] initialArr = s.toCharArray();
//新字符数组
char[] newArr = new char[initialArr.length+1];//下面循环添加"单词 ",最终末尾的空格不会返回
int newArrPos = 0;
//i来进行整体对源字符数组从后往前遍历
int i = initialArr.length-1;
while(i>=0){
while(i>=0 && initialArr[i] == ' '){i--;} //跳过空格
//此时i位置是边界或!=空格,先记录当前索引,之后的while用来确定单词的首字母的位置
int right = i;
while(i>=0 && initialArr[i] != ' '){i--;}
//指定区间单词取出(由于i为首字母的前一位,所以这里+1,),取出的每组末尾都带有一个空格
for (int j = i+1; j <= right; j++) {
newArr[newArrPos++] = initialArr[j];
if(j == right){
newArr[newArrPos++] = ' ';//空格
}
}
}
//若是原始字符串没有单词,直接返回空字符串;若是有单词,返回0-末尾空格索引前范围的字符数组(转成String返回)
if(newArrPos == 0){
return "";
}else{
return new String(newArr,0,newArrPos-1);
}
}
}
//解法三:双反转+移位,String 的 toCharArray() 方法底层会 new 一个和原字符串相同大小的 char 数组,空间复杂度:O(n)
class Solution {
/**
* 思路:
* ①反转字符串 "the sky is blue " => " eulb si yks eht"
* ②遍历 " eulb si yks eht",每次先对某个单词进行反转再移位
* 这里以第一个单词进行为演示:" eulb si yks eht" ==反转=> " blue si yks eht" ==移位=> "blue si yks eht"
*/
public String reverseWords(String s) {
//步骤1:字符串整体反转(此时其中的单词也都反转了)
char[] initialArr = s.toCharArray();
reverse(initialArr, 0, s.length() - 1);
int k = 0;
for (int i = 0; i < initialArr.length; i++) {
if (initialArr[i] == ' ') {
continue;
}
int tempCur = i;
while (i < initialArr.length && initialArr[i] != ' ') {
i++;
}
for (int j = tempCur; j < i; j++) {
if (j == tempCur) { //步骤二:二次反转
reverse(initialArr, tempCur, i - 1);//对指定范围字符串进行反转,不反转从后往前遍历一个个填充有问题
}
//步骤三:移动操作
initialArr[k++] = initialArr[j];
if (j == i - 1) { //遍历结束
//避免越界情况,例如=> "asdasd df f",不加判断最后就会数组越界
if (k < initialArr.length) {
initialArr[k++] = ' ';
}
}
}
}
if (k == 0) {
return "";
} else {
//参数三:以防出现如"asdasd df f"=>"f df asdasd"正好凑满不需要省略空格情况
return new String(initialArr, 0, (k == initialArr.length) && (initialArr[k - 1] != ' ') ? k : k - 1);
}
}
public void reverse(char[] chars, int begin, int end) {
for (int i = begin, j = end; i < j; i++, j--) {
chars[i] ^= chars[j];
chars[j] ^= chars[i];
chars[i] ^= chars[j];
}
}
}
/*
* 解法四:时间复杂度 O(n)
* 参考卡哥 c++ 代码的三步骤:先移除多余空格,再将整个字符串反转,最后把单词逐个反转
* 有别于解法一 :没有用 StringBuilder 实现,而是对 String 的 char[] 数组操作来实现以上三个步骤
*/
class Solution {
//用 char[] 来实现 String 的 removeExtraSpaces,reverse 操作
public String reverseWords(String s) {
char[] chars = s.toCharArray();
//1.去除首尾以及中间多余空格
chars = removeExtraSpaces(chars);
//2.整个字符串反转
reverse(chars, 0, chars.length - 1);
//3.单词反转
reverseEachWord(chars);
return new String(chars);
}
//1.用 快慢指针 去除首尾以及中间多余空格,可参考数组元素移除的题解
public char[] removeExtraSpaces(char[] chars) {
int slow = 0;
for (int fast = 0; fast < chars.length; fast++) {
//先用 fast 移除所有空格
if (chars[fast] != ' ') {
//在用 slow 加空格。 除第一个单词外,单词末尾要加空格
if (slow != 0)
chars[slow++] = ' ';
//fast 遇到空格或遍历到字符串末尾,就证明遍历完一个单词了
while (fast < chars.length && chars[fast] != ' ')
chars[slow++] = chars[fast++];
}
}
//相当于 c++ 里的 resize()
char[] newChars = new char[slow];
System.arraycopy(chars, 0, newChars, 0, slow);
return newChars;
}
//双指针实现指定范围内字符串反转,可参考字符串反转题解
public void reverse(char[] chars, int left, int right) {
if (right >= chars.length) {
System.out.println("set a wrong right");
return;
}
while (left < right) {
chars[left] ^= chars[right];
chars[right] ^= chars[left];
chars[left] ^= chars[right];
left++;
right--;
}
}
//3.单词反转
public void reverseEachWord(char[] chars) {
int start = 0;
//end <= s.length() 这里的 = ,是为了让 end 永远指向单词末尾后一个位置,这样 reverse 的实参更好设置
for (int end = 0; end <= chars.length; end++) {
// end 每次到单词末尾后的空格或串尾,开始反转单词
if (end == chars.length || chars[end] == ' ') {
reverse(chars, start, end - 1);
start = end + 1;
}
}
}
}
Python解法
(版本一)先删除空白,然后整个反转,最后单词反转。 因为字符串是不可变类型,所以反转单词的时候,需要将其转换成列表,然后通过join函数再将其转换成列表,所以空间复杂度不是O(1)
class Solution:
def reverseWords(self, s: str) -> str:
# 反转整个字符串
s = s[::-1]
# 将字符串拆分为单词,并反转每个单词
# split()函数能够自动忽略多余的空白字符
s = ' '.join(word[::-1] for word in s.split())
return s
(版本二)使用双指针
class Solution:
def reverseWords(self, s: str) -> str:
# 将字符串拆分为单词,即转换成列表类型
words = s.split()
# 反转单词
left, right = 0, len(words) - 1
while left < right:
words[left], words[right] = words[right], words[left]
left += 1
right -= 1
# 将列表转换成字符串
return " ".join(words)
(版本三) 拆分字符串 + 反转列表
class Solution:
def reverseWords(self, s):
words = s.split() #type(words) --- list
words = words[::-1] # 反转单词
return ' '.join(words) #列表转换成字符串
(版本四) 将字符串转换为列表后,使用双指针去除空格
class Solution:
def single_reverse(self, s, start: int, end: int):
while start < end:
s[start], s[end] = s[end], s[start]
start += 1
end -= 1
def reverseWords(self, s: str) -> str:
result = ""
fast = 0
# 1. 首先将原字符串反转并且除掉空格, 并且加入到新的字符串当中
# 由于Python字符串的不可变性,因此只能转换为列表进行处理
s = list(s)
s.reverse()
while fast < len(s):
if s[fast] != " ":
if len(result) != 0:
result += " "
while s[fast] != " " and fast < len(s):
result += s[fast]
fast += 1
else:
fast += 1
# 2.其次将每个单词进行翻转操作
slow = 0
fast = 0
result = list(result)
while fast <= len(result):
if fast == len(result) or result[fast] == " ":
self.single_reverse(result, slow, fast - 1)
slow = fast + 1
fast += 1
else:
fast += 1
return "".join(result)
(版本五) 遇到空格就说明前面的是一个单词,把它加入到一个数组中。
class Solution:
def reverseWords(self, s: str) -> str:
words = []
word = ''
s += ' ' # 帮助处理最后一个字词
for char in s:
if char == ' ': # 遇到空格就说明前面的可能是一个单词
if word != '': # 确认是单词,把它加入到一个数组中
words.append(word)
word = '' # 清空当前单词
continue
word += char # 收集单词的字母
words.reverse()
return ' '.join(words)
Go解法
版本一:
func reverseWords(s string) string {
b := []byte(s)
// 移除前面、中间、后面存在的多余空格
slow := 0
for i := 0; i < len(b); i++ {
if b[i] != ' ' {
if slow != 0 {
b[slow] = ' '
slow++
}
for i < len(b) && b[i] != ' ' { // 复制逻辑
b[slow] = b[i]
slow++
i++
}
}
}
b = b[0:slow]
// 翻转整个字符串
reverse(b)
// 翻转每个单词
last := 0
for i := 0; i <= len(b); i++ {
if i == len(b) || b[i] == ' ' {
reverse(b[last:i])
last = i + 1
}
}
return string(b)
}
func reverse(b []byte) {
left := 0
right := len(b) - 1
for left < right {
b[left], b[right] = b[right], b[left]
left++
right--
}
}
版本二:
import (
"fmt"
)
func reverseWords(s string) string {
//1.使用双指针删除冗余的空格
slowIndex, fastIndex := 0, 0
b := []byte(s)
//删除头部冗余空格
for len(b) > 0 && fastIndex < len(b) && b[fastIndex] == ' ' {
fastIndex++
}
//删除单词间冗余空格
for ; fastIndex < len(b); fastIndex++ {
if fastIndex-1 > 0 && b[fastIndex-1] == b[fastIndex] && b[fastIndex] == ' ' {
continue
}
b[slowIndex] = b[fastIndex]
slowIndex++
}
//删除尾部冗余空格
if slowIndex-1 > 0 && b[slowIndex-1] == ' ' {
b = b[:slowIndex-1]
} else {
b = b[:slowIndex]
}
//2.反转整个字符串
reverse(b)
//3.反转单个单词 i单词开始位置,j单词结束位置
i := 0
for i < len(b) {
j := i
for ; j < len(b) && b[j] != ' '; j++ {
}
reverse(b[i:j])
i = j
i++
}
return string(b)
}
func reverse(b []byte) {
left := 0
right := len(b) - 1
for left < right {
b[left], b[right] = b[right], b[left]
left++
right--
}
}
557. Reverse Words in a String III
Given a string s, reverse the order of characters in each word within a sentence while still preserving whitespace and initial word order.
Example 1:
Input: s = "Let's take LeetCode contest"
Output: "s'teL ekat edoCteeL tsetnoc"
Example 2:
Input: s = "Mr Ding"
Output: "rM gniD"
Constraints:
1 <= s.length <= 5 * 10^4scontains printable ASCII characters.sdoes not contain any leading or trailing spaces.- There is at least one word in
s. - All the words in
sare separated by a single space.
思路
通过设置start变量确定反转范围
C++解法
class Solution {
public:
void reverse(string& s, int start, int end) {
for (int i = start, j = end; i < j; i++, j--) {
swap(s[i], s[j]);
}
}
string reverseWords(string s) {
int start = 0;
for (int i = 0; i <= s.size(); i++) {
if (i == s.size() || s[i] == ' ') {
reverse(s, start, i - 1);
start = i + 1;
}
}
return s;
}
};
917. Reverse Only Letters
Given a string s, reverse the string according to the following rules:
- All the characters that are not English letters remain in the same position.
- All the English letters (lowercase or uppercase) should be reversed.
Return s after reversing it.
Example 1:
Input: s = "ab-cd"
Output: "dc-ba"
Example 2:
Input: s = "a-bC-dEf-ghIj"
Output: "j-Ih-gfE-dCba"
Example 3:
Input: s = "Test1ng-Leet=code-Q!"
Output: "Qedo1ct-eeLg=ntse-T!"
Constraints:
1 <= s.length <= 100sconsists of characters with ASCII values in the range[33, 122].sdoes not contain'\"'or'\\'.
思路
This problem is exactly like reversing a normal string except that there are certain characters that we have to simply skip. That should be easy enough to do if you know how to reverse a string using the two-pointer approach.
C++解法
class Solution {
public:
string reverseOnlyLetters(string s) {
int left = 0;
int right = s.length() - 1;
while(left < right){
while(left < right && !isalpha(s[left])) left++;
while(left < right && !isalpha(s[right])) right--;
swap(s[left++], s[right--]);
}
return s;
}
};
2810. Faulty Keyboard
Your laptop keyboard is faulty, and whenever you type a character 'i' on it, it reverses the string that you have written. Typing other characters works as expected.
You are given a 0-indexed string s, and you type each character of s using your faulty keyboard.
Return the final string that will be present on your laptop screen.
Example 1:
Input: s = "string"
Output: "rtsng"
Explanation: After typing first character, the text on the screen is "s". After the second character, the text is "st". After the third character, the text is "str". Since the fourth character is an 'i', the text gets reversed and becomes "rts". After the fifth character, the text is "rtsn". After the sixth character, the text is "rtsng". Therefore, we return "rtsng".
Example 2:
Input: s = "poiinter"
Output: "ponter"
Explanation: After the first character, the text on the screen is "p". After the second character, the text is "po". Since the third character you type is an 'i', the text gets reversed and becomes "op". Since the fourth character you type is an 'i', the text gets reversed and becomes "po". After the fifth character, the text is "pon". After the sixth character, the text is "pont". After the seventh character, the text is "ponte". After the eighth character, the text is "ponter". Therefore, we return "ponter".
Constraints:
1 <= s.length <= 100sconsists of lowercase English letters.s[0] != 'i'
思路
Try to build a new string by traversing the given string and reversing whenever you get the character ‘i’.
注意:s[0] != 'i',reverse时注意不要发生数组越界问题
C++解法
class Solution {
public:
void reverse(string &s, int start, int end){
for(int i = start, j = end; i < j; i++, j--){
swap(s[i], s[j]);
}
}
string finalString(string s) {
string result = "";
for(int j = 0; j < s.length(); j++){
if(s[j] == 'i'){
reverse(result, 0, result.size() - 1);
}else{
result += s[j];
}
}
return result;
}
};
双指针
- 说明
- 905. Sort Array By Parity
- 922. Sort Array By Parity II
- 287. Find the Duplicate Number
- 42. Trapping Rain Water
- 881. Boats to Save People
- 11. Container With Most Water
- 475. Heaters
- 41. First Missing Positive
说明
前置知识:无
设置两个指针的技巧,其实这种说法很宽泛,似乎没什么可总结的
1)有时候所谓的双指针技巧,就单纯是代码过程用双指针的形式表达出来而已。
没有单调性(贪心)方面的考虑
2)有时候的双指针技巧包含单调性(贪心)方面的考虑,牵扯到可能性的取舍。
对分析能力的要求会变高。其实是先有的思考和优化,然后代码变成了双指针的形式。
3)所以,双指针这个“皮”不重要,分析题目单调性(贪心)方面的特征,这个能力才重要。
常见的双指针类型:
- 同向双指针
- 快慢双指针
- 从两头往中间的双指针
- 其他
左右指针
- 左右双指针通常用于解决数组或字符串相关问题,例如寻找两数之和、反转字符串等。
- 典型应用:求解数组或字符串相关问题。左右双指针可以在不同方向上同时进行移动,并通过特定条件来更新左右边界。
快慢指针
- 快慢指针法通常用于解决链表中的问题,如判定链表中是否有环、找到链表的中间节点等。快指针每次移动两步,慢指针每次移动一步。
- 典型应用:判断链表是否有环。当存在环时,快慢指针最终会相遇;找到链表中间节点时,快指针到达末尾时慢指针正好在中间位置。
总结来说,在编程中使用双指针法可帮助我们降低时间复杂度,并且适合处理循环、交错等特殊情况。
905. Sort Array By Parity
Given an integer array nums, move all the even integers at the beginning of the array followed by all the odd integers.
Return any array that satisfies this condition.
Example 1:
Input: nums = [3,1,2,4]
Output: [2,4,3,1]
Explanation: The outputs [4,2,3,1], [2,4,1,3], and [4,2,1,3] would also be accepted.
Example 2:
Input: nums = [0]
Output: [0]
Constraints:
1 <= nums.length <= 50000 <= nums[i] <= 5000
思路
双指针
Time Complexity: O(N)
C++解法
class Solution {
public:
vector<int> sortArrayByParity(vector<int>& nums) {
for(int i = 0, j = 0; j < nums.size(); j++){
if(nums[j] % 2 == 0){
swap(nums[i++], nums[j]);
}
}
return nums;
}
};
Java解法
class Solution {
public int[] sortArrayByParity(int[] nums) {
for (int i = 0, j = 0; j < nums.length; j++)
if (nums[j] % 2 == 0) {
int tmp = nums[i];
nums[i++] = nums[j];
nums[j] = tmp;;
}
return nums;
}
}
922. Sort Array By Parity II
Given an array of integers nums, half of the integers in nums are odd, and the other half are even.
Sort the array so that whenever nums[i] is odd, i is odd, and whenever nums[i] is even, i is even.
Return any answer array that satisfies this condition.
Example 1:
Input: nums = [4,2,5,7]
Output: [4,5,2,7]
Explanation: [4,7,2,5], [2,5,4,7], [2,7,4,5] would also have been accepted.
Example 2:
Input: nums = [2,3]
Output: [2,3]
Constraints:
2 <= nums.length <= 2 * 10^4nums.lengthis even.- Half of the integers in
numsare even. 0 <= nums[i] <= 1000
Follow Up: Could you solve it in-place?
思路
双指针
C++解法
class Solution {
public:
vector<int> sortArrayByParityII(vector<int>& nums) {
for(int odd = 1, even = 0; odd < nums.size() && even < nums.size(); ){
if(nums[nums.size() - 1] % 2 != 0){
swap(nums[odd], nums[nums.size() - 1]);
odd += 2;
}else{
swap(nums[even], nums[nums.size() - 1]);
even += 2;
}
}
return nums;
}
};
Java解法
// 按奇偶排序数组II
// 给定一个非负整数数组 nums。nums 中一半整数是奇数 ,一半整数是偶数
// 对数组进行排序,以便当 nums[i] 为奇数时,i也是奇数
// 当 nums[i] 为偶数时, i 也是 偶数
// 你可以返回 任何满足上述条件的数组作为答案
// 测试链接 : https://leetcode.cn/problems/sort-array-by-parity-ii/
public class Code01_SortArrayByParityII {
// 时间复杂度O(n),额外空间复杂度O(1)
public static int[] sortArrayByParityII(int[] nums) {
int n = nums.length;
for (int odd = 1, even = 0; odd < n && even < n;) {
if ((nums[n - 1] & 1) == 1) {
swap(nums, odd, n - 1);
odd += 2;
} else {
swap(nums, even, n - 1);
even += 2;
}
}
return nums;
}
public static void swap(int[] nums, int i, int j) {
int tmp = nums[i];
nums[i] = nums[j];
nums[j] = tmp;
}
}
287. Find the Duplicate Number
Given an array of integers nums containing n + 1 integers where each integer is in the range [1, n] inclusive.
There is only one repeated number in nums, return this repeated number.
You must solve the problem without modifying the array nums and using only constant extra space.
Example 1:
Input: nums = [1,3,4,2,2]
Output: 2
Example 2:
Input: nums = [3,1,3,4,2]
Output: 3
Example 3:
Input: nums = [3,3,3,3,3]
Output: 3
Constraints:
1 <= n <= 10^5nums.length == n + 11 <= nums[i] <= n- All the integers in
numsappear only once except for precisely one integer which appears two or more times.
Follow up:
- How can we prove that at least one duplicate number must exist in
nums? - Can you solve the problem in linear runtime complexity?
思路
快慢指针(类似循环链表)
C++解法
数组记录数量:
class Solution {
public:
int findDuplicate(vector<int>& nums) {
vector<int> result(100001, 0);
for(int num : nums){
result[num]++;
if(result[num] > 1){
return num;
}
}
return -1;
}
};
Java解法
// 寻找重复数
// 给定一个包含 n + 1 个整数的数组 nums ,其数字都在 [1, n] 范围内(包括 1 和 n)
// 可知至少存在一个重复的整数。
// 假设 nums 只有 一个重复的整数 ,返回 这个重复的数 。
// 你设计的解决方案必须 不修改 数组 nums 且只用常量级 O(1) 的额外空间。
// 测试链接 : https://leetcode.cn/problems/find-the-duplicate-number/
public class Code02_FindTheDuplicateNumber {
// 时间复杂度O(n),额外空间复杂度O(1)
public static int findDuplicate(int[] nums) {
if (nums == null || nums.length < 2) {
return -1;
}
int slow = nums[0];
int fast = nums[nums[0]];
while (slow != fast) {
slow = nums[slow];
fast = nums[nums[fast]];
}
// 相遇了,快指针回开头
fast = 0;
while (slow != fast) {
fast = nums[fast];
slow = nums[slow];
}
return slow;
}
}
42. Trapping Rain Water
Given n non-negative integers representing an elevation map where the width of each bar is 1, compute how much water it can trap after raining.
Example 1:

Input: height = [0,1,0,2,1,0,1,3,2,1,2,1]
Output: 6
Explanation: The above elevation map (black section) is represented by array [0,1,0,2,1,0,1,3,2,1,2,1]. In this case, 6 units of rain water (blue section) are being trapped.
Example 2:
Input: height = [4,2,0,3,2,5]
Output: 9
Constraints:
n == height.length1 <= n <= 2 * 10^40 <= height[i] <= 10^5
思路
方法一:单调栈
方法二:双指针
C++解法
单调栈解法
class Solution {
public:
int trap(vector<int>& height) {
if(height.size() <= 2) return 0;
int result = 0;
stack<int> st;
st.push(0);
for(int i = 1; i < height.size(); i++){
if(height[i] < height[st.top()]){
st.push(i);
}else if(height[i] == height[st.top()]){
st.push(i);
}else{
while(!st.empty() && height[i] > height[st.top()]){
int mid = st.top();
st.pop();
if(!st.empty()){
int h = min(height[i], height[st.top()]) - height[mid];
int w = i - st.top() - 1;
result += h * w;
}
}
st.push(i);
}
}
return result;
}
};
Java解法
双指针解法:
// 接雨水
// 给定 n 个非负整数表示每个宽度为 1 的柱子的高度图,计算按此排列的柱子,下雨之后能接多少雨水
// 测试链接 : https://leetcode.cn/problems/trapping-rain-water/
public class Code03_TrappingRainWater {
// 辅助数组的解法(不是最优解)
// 时间复杂度O(n),额外空间复杂度O(n)
// 提交时改名为trap
public static int trap1(int[] nums) {
int n = nums.length;
int[] lmax = new int[n];
int[] rmax = new int[n];
lmax[0] = nums[0];
// 0~i范围上的最大值,记录在lmax[i]
for (int i = 1; i < n; i++) {
lmax[i] = Math.max(lmax[i - 1], nums[i]);
}
rmax[n - 1] = nums[n - 1];
// i~n-1范围上的最大值,记录在rmax[i]
for (int i = n - 2; i >= 0; i--) {
rmax[i] = Math.max(rmax[i + 1], nums[i]);
}
int ans = 0;
// x x
// 0 1 2 3...n-2 n-1
for (int i = 1; i < n - 1; i++) {
ans += Math.max(0, Math.min(lmax[i - 1], rmax[i + 1]) - nums[i]);
}
return ans;
}
// 双指针的解法(最优解)
// 时间复杂度O(n),额外空间复杂度O(1)
// 提交时改名为trap
public static int trap2(int[] nums) {
int l = 1, r = nums.length - 2, lmax = nums[0], rmax = nums[nums.length - 1];
int ans = 0;
while (l <= r) {
if (lmax <= rmax) {
ans += Math.max(0, lmax - nums[l]);
lmax = Math.max(lmax, nums[l++]);
} else {
ans += Math.max(0, rmax - nums[r]);
rmax = Math.max(rmax, nums[r--]);
}
}
return ans;
}
}
881. Boats to Save People
You are given an array people where people[i] is the weight of the ith person, and an infinite number of boats where each boat can carry a maximum weight of limit. Each boat carries at most two people at the same time, provided the sum of the weight of those people is at most limit.
Return the minimum number of boats to carry every given person.
Example 1:
Input: people = [1,2], limit = 3
Output: 1
Explanation: 1 boat (1, 2)
Example 2:
Input: people = [3,2,2,1], limit = 3
Output: 3
Explanation: 3 boats (1, 2), (2) and (3)
Example 3:
Input: people = [3,5,3,4], limit = 5
Output: 4
Explanation: 4 boats (3), (3), (4), (5)
Constraints:
1 <= people.length <= 5 * 10^41 <= people[i] <= limit <= 3 * 10^4
思路
排序+双指针
C++解法
class Solution {
public:
int numRescueBoats(vector<int>& people, int limit) {
sort(people.begin(), people.end());
int left = 0;
int right = people.size() - 1;
int result = 0;
int sum = 0;
while(left <= right){
sum = left == right ? people[left] : people[left] + people[right];
if(sum > limit){
right--;
}else{
left++;
right--;
}
result++;
}
return result;
}
};
Java解法
// 救生艇
// 给定数组 people
// people[i]表示第 i 个人的体重 ,船的数量不限,每艘船可以承载的最大重量为 limit
// 每艘船最多可同时载两人,但条件是这些人的重量之和最多为 limit
// 返回 承载所有人所需的最小船数
// 测试链接 : https://leetcode.cn/problems/boats-to-save-people/
public class Code04_BoatsToSavePeople {
// 时间复杂度O(n * logn),因为有排序,额外空间复杂度O(1)
public static int numRescueBoats(int[] people, int limit) {
Arrays.sort(people);
int ans = 0;
int l = 0;
int r = people.length - 1;
int sum = 0;
while (l <= r) {
sum = l == r ? people[l] : people[l] + people[r];
if (sum > limit) {
r--;
} else {
l++;
r--;
}
ans++;
}
return ans;
}
}
11. Container With Most Water
You are given an integer array height of length n. There are n vertical lines drawn such that the two endpoints of the ith line are (i, 0) and (i, height[i]).
Find two lines that together with the x-axis form a container, such that the container contains the most water.
Return the maximum amount of water a container can store.
Notice that you may not slant the container.
Example 1:

Input: height = [1,8,6,2,5,4,8,3,7]
Output: 49
Explanation: The above vertical lines are represented by array [1,8,6,2,5,4,8,3,7]. In this case, the max area of water (blue section) the container can contain is 49.
Example 2:
Input: height = [1,1]
Output: 1
Constraints:
n == height.length2 <= n <= 10^50 <= height[i] <= 10^4
思路
双指针解法计算公式:result = max(result, min(leftMax, rightMax) * (right - left))
C++解法
class Solution {
public int maxArea(int[] height) {
int result = 0;
int left = 0;
int right = height.length - 1;
while(left <= right){
result = Math.max(result, Math.min(height[right],height[left])*(right-left));
if(height[right] < height[left]) right--;
else left++;
}
return result;
}
}
Java解法
// 盛最多水的容器
// 给定一个长度为 n 的整数数组 height 。有 n 条垂线,第 i 条线的两个端点是 (i, 0) 和 (i, height[i]) 。
// 找出其中的两条线,使得它们与 x 轴共同构成的容器可以容纳最多的水
// 返回容器可以储存的最大水量
// 说明:你不能倾斜容器
// 测试链接 : https://leetcode.cn/problems/container-with-most-water/
public class Code05_ContainerWithMostWater {
// 时间复杂度O(n),额外空间复杂度O(1)
public static int maxArea(int[] height) {
int ans = 0;
for (int l = 0, r = height.length - 1; l < r;) {
ans = Math.max(ans, Math.min(height[l], height[r]) * (r - l));
if (height[l] <= height[r]) {
l++;
} else {
r--;
}
}
return ans;
}
}
475. Heaters
Winter is coming! During the contest, your first job is to design a standard heater with a fixed warm radius to warm all the houses.
Every house can be warmed, as long as the house is within the heater's warm radius range.
Given the positions of houses and heaters on a horizontal line, return the minimum radius standard of heaters so that those heaters could cover all houses.
Notice that all the heaters follow your radius standard, and the warm radius will the same.
Example 1:
Input: houses = [1,2,3], heaters = [2]
Output: 1
Explanation: The only heater was placed in the position 2, and if we use the radius 1 standard, then all the houses can be warmed.
Example 2:
Input: houses = [1,2,3,4], heaters = [1,4]
Output: 1
Explanation: The two heaters were placed at positions 1 and 4. We need to use a radius 1 standard, then all the houses can be warmed.
Example 3:
Input: houses = [1,5], heaters = [2]
Output: 3
Constraints:
1 <= houses.length, heaters.length <= 3 * 10^41 <= houses[i], heaters[i] <= 10^9
思路
双指针,排序两个数组,然后为每间房子匹配最近的供暖器,计算最短距离的最大值。
C++解法
class Solution {
public:
int findRadius(vector<int>& houses, vector<int>& heaters) {
sort(houses.begin(), houses.end());
sort(heaters.begin(), heaters.end());
int result = 0;
for(int i = 0, j = 0; i < houses.size(); i++){
while(!isBest(houses, heaters, i, j)){
j++;
}
result = max(result, abs(houses[i] - heaters[j]));
}
return result;
}
bool isBest(vector<int>& houses, vector<int>& heaters, int i, int j){
if(j == heaters.size() - 1 || abs(houses[i] - heaters[j]) < abs(houses[i] - heaters[j + 1])){
return true;
}
return false;
}
};
Java解法
// 供暖器
// 冬季已经来临。 你的任务是设计一个有固定加热半径的供暖器向所有房屋供暖。
// 在加热器的加热半径范围内的每个房屋都可以获得供暖。
// 现在,给出位于一条水平线上的房屋 houses 和供暖器 heaters 的位置
// 请你找出并返回可以覆盖所有房屋的最小加热半径。
// 说明:所有供暖器都遵循你的半径标准,加热的半径也一样。
// 测试链接 : https://leetcode.cn/problems/heaters/
public class Code06_Heaters {
// 时间复杂度O(n * logn),因为有排序,额外空间复杂度O(1)
public static int findRadius(int[] houses, int[] heaters) {
Arrays.sort(houses);
Arrays.sort(heaters);
int ans = 0;
for (int i = 0, j = 0; i < houses.length; i++) {
// i号房屋
// j号供暖器
while (!best(houses, heaters, i, j)) {
j++;
}
ans = Math.max(ans, Math.abs(heaters[j] - houses[i]));
}
return ans;
}
// 这个函数含义:
// 当前的地点houses[i]由heaters[j]来供暖是最优的吗?
// 当前的地点houses[i]由heaters[j]来供暖,产生的半径是a
// 当前的地点houses[i]由heaters[j + 1]来供暖,产生的半径是b
// 如果a < b, 说明是最优,供暖不应该跳下一个位置
// 如果a >= b, 说明不是最优,应该跳下一个位置
public static boolean best(int[] houses, int[] heaters, int i, int j) {
return j == heaters.length - 1
||
Math.abs(heaters[j] - houses[i]) < Math.abs(heaters[j + 1] - houses[i]);
}
}
41. First Missing Positive
Given an unsorted integer array nums. Return the smallest positive integer that is not present in nums.
You must implement an algorithm that runs in O(n) time and uses O(1) auxiliary space.
Example 1:
Input: nums = [1,2,0]
Output: 3
Explanation: The numbers in the range [1,2] are all in the array.
Example 2:
Input: nums = [3,4,-1,1]
Output: 2
Explanation: 1 is in the array but 2 is missing.
Example 3:
Input: nums = [7,8,9,11,12]
Output: 1
Explanation: The smallest positive integer 1 is missing.
Constraints:
1 <= nums.length <= 10^5-2^31 <= nums[i] <= 2^31 - 1
思路
left满足nums[left] == left + 1的最大下标
right可能满足nums[left] == left + 1的最大下标,右侧为垃圾区
C++解法
class Solution {
public:
int firstMissingPositive(vector<int>& nums) {
int left = 0;
int right = nums.size();
while(left < right){
if(nums[left] == left + 1) left++;
else if(nums[left] > right || nums[left] <= left || nums[nums[left] - 1] == nums[left]){
swap(nums[left], nums[right - 1]);
right--;
}else{
swap(nums[left], nums[nums[left] - 1]);
}
}
return left + 1;
}
};
Java解法
// 缺失的第一个正数
// 给你一个未排序的整数数组 nums ,请你找出其中没有出现的最小的正整数。
// 请你实现时间复杂度为 O(n) 并且只使用常数级别额外空间的解决方案。
// 测试链接 : https://leetcode.cn/problems/first-missing-positive/
public class Code07_FirstMissingPositive {
// 时间复杂度O(n),额外空间复杂度O(1)
public static int firstMissingPositive(int[] arr) {
// l的左边,都是做到i位置上放着i+1的区域
// 永远盯着l位置的数字看,看能不能扩充(l++)
int l = 0;
// [r....]垃圾区
// 最好的状况下,认为1~r是可以收集全的,每个数字收集1个,不能有垃圾
// 有垃圾呢?预期就会变差(r--)
int r = arr.length;
while (l < r) {
if (arr[l] == l + 1) {
l++;
} else if (arr[l] <= l || arr[l] > r || arr[arr[l] - 1] == arr[l]) {
swap(arr, l, --r);
} else {
swap(arr, l, arr[l] - 1);
}
}
return l + 1;
}
public static void swap(int[] arr, int i, int j) {
int tmp = arr[i];
arr[i] = arr[j];
arr[j] = tmp;
}
}
移动元素
三数之和
接雨水
11. Container With Most Water
You are given an integer array height of length n. There are n vertical lines drawn such that the two endpoints of the ith line are (i, 0) and (i, height[i]).
Find two lines that together with the x-axis form a container, such that the container contains the most water.
Return the maximum amount of water a container can store.
Notice that you may not slant the container.
Example 1:
Input: height = [1,8,6,2,5,4,8,3,7]
Output: 49
Explanation: The above vertical lines are represented by array [1,8,6,2,5,4,8,3,7]. In this case, the max area of water (blue section) the container can contain is 49.
Example 2:
Input: height = [1,1]
Output: 1
Constraints:
n == height.length2 <= n <= 10^50 <= height[i] <= 10^4
思路
双指针,左低移左,右低移右
The two-pointer technique starts with the widest container and moves the pointers inward based on the comparison of heights.
Increasing the width of the container can only lead to a larger area if the height of the new boundary is greater. By moving the pointers towards the center, we explore containers with the potential for greater areas.
C++ 解法
class Solution {
public:
int maxArea(vector<int>& height) {
int left = 0;
int right = height.size() - 1;
int maxArea = 0;
while (left < right) {
int currentArea = min(height[left], height[right]) * (right - left);
maxArea = max(maxArea, currentArea);
if (height[left] < height[right]) {
left++;
} else {
right--;
}
}
return maxArea;
}
};
Java 解法
class Solution {
public int maxArea(int[] height) {
int result = 0;
int left = 0;
int right = height.length - 1;
while(left <= right){
result = Math.max(result, Math.min(height[right],height[left])*(right-left));
if(height[right] < height[left]) right--;
else left++;
}
return result;
}
}
Python 解法
class Solution:
def maxArea(self, height: List[int]) -> int:
left = 0
right = len(height) - 1
maxArea = 0
while left < right:
currentArea = min(height[left], height[right]) * (right - left)
maxArea = max(maxArea, currentArea)
if height[left] < height[right]:
left += 1
else:
right -= 1
return maxArea
42. Trapping Rain Water
Given n non-negative integers representing an elevation map where the width of each bar is 1, compute how much water it can trap after raining.
Example 1:
Input: height = [0,1,0,2,1,0,1,3,2,1,2,1]
Output: 6
Explanation: The above elevation map (black section) is represented by array [0,1,0,2,1,0,1,3,2,1,2,1]. In this case, 6 units of rain water (blue section) are being trapped.
Example 2:
Input: height = [4,2,0,3,2,5]
Output: 9
Constraints:
n == height.length1 <= n <= 2 * 10^40 <= height[i] <= 10^5
思路
一共三种解法:双指针、单调栈和动态规划。
C++ 解法
单调栈
class Solution {
public:
int trap(vector<int>& height) {
if(height.size() <= 2) return 0;
int result = 0;
stack<int> st;
st.push(0);
for(int i = 1; i < height.size(); i++){
if(height[i] < height[st.top()]){
st.push(i);
}else if(height[i] == height[st.top()]){
st.push(i);
}else{
while(!st.empty() && height[i] > height[st.top()]){
int mid = st.top();
st.pop();
if(!st.empty()){
int h = min(height[i], height[st.top()]) - height[mid];
int w = i - st.top() - 1;
result += h * w;
}
}
st.push(i);
}
}
return result;
}
};
Java 解法
双指针
class Solution {
public int trap(int[] height) {
int i=0,left_max=height[0];
int sum=0;
int j=height.length-1,right_max=height[j];
while(i < j){
if(left_max <= right_max){
sum += left_max - height[i];
i++;
left_max = Math.max(left_max, height[i]);
}else{
sum += right_max - height[j];
j--;
right_max = Math.max(right_max, height[j]);
}
}
return sum;
}
}
Python 解法
双指针
class Solution:
def trap(self, height: List[int]) -> int:
i = 0
left_max = height[0]
sum = 0
j = len(height) - 1
right_max = height[j]
while i < j:
if left_max <= right_max:
sum += left_max - height[i]
i += 1
left_max = max(left_max, height[i])
else:
sum += right_max - height[j]
j -= 1
right_max = max(right_max, height[j])
return sum
栈
栈和队列
灵魂四问:
- C++中stack,queue 是容器么?
- 我们使用的stack,queue是属于那个版本的STL?
- 我们使用的STL中stack,queue是如何实现的?
- stack,queue 提供迭代器来遍历空间么?
栈与队列是我们熟悉的不能再熟悉的数据结构,但它们的底层实现,很多同学都比较模糊,这其实就是基础所在。
可以出一道面试题:栈里面的元素在内存中是连续分布的么?
这个问题有两个陷阱:
- 陷阱1:栈是容器适配器,底层容器使用不同的容器,导致栈内数据在内存中不一定是连续分布的。
- 陷阱2:默认情况下,默认底层容器是deque,那么deque在内存中的数据分布是什么样的呢? 答案是:不连续的,下文也会提到deque。
我想栈和队列的原理大家应该很熟悉了,队列是先进先出,栈是先进后出。
如图所示:
那么我这里再列出四个关于栈的问题,大家可以思考一下。以下是以C++为例,使用其他编程语言的同学也对应思考一下,自己使用的编程语言里栈和队列是什么样的。
- C++中stack 是容器么?
- 我们使用的stack是属于哪个版本的STL?
- 我们使用的STL中stack是如何实现的?
- stack 提供迭代器来遍历stack空间么?
相信这四个问题并不那么好回答, 因为一些同学使用数据结构会停留在非常表面上的应用,稍稍往深一问,就会有好像懂,好像也不懂的感觉。
有的同学可能仅仅知道有栈和队列这么个数据结构,却不知道底层实现,也不清楚所使用栈和队列和STL是什么关系。
所以这里我再给大家扫一遍基础知识,
首先大家要知道 栈和队列是STL(C++标准库)里面的两个数据结构。
C++标准库是有多个版本的,要知道我们使用的STL是哪个版本,才能知道对应的栈和队列的实现原理。
那么来介绍一下,三个最为普遍的STL版本:
-
HP STL 其他版本的C++ STL,一般是以HP STL为蓝本实现出来的,HP STL是C++ STL的第一个实现版本,而且开放源代码。
-
P.J.Plauger STL 由P.J.Plauger参照HP STL实现出来的,被Visual C++编译器所采用,不是开源的。
-
SGI STL 由Silicon Graphics Computer Systems公司参照HP STL实现,被Linux的C++编译器GCC所采用,SGI STL是开源软件,源码可读性甚高。
接下来介绍的栈和队列也是SGI STL里面的数据结构, 知道了使用版本,才知道对应的底层实现。
来说一说栈,栈先进后出,如图所示:
栈提供push 和 pop 等等接口,所有元素必须符合先进后出规则,所以栈不提供走访功能,也不提供迭代器(iterator)。 不像是set 或者map 提供迭代器iterator来遍历所有元素。
栈是以底层容器完成其所有的工作,对外提供统一的接口,底层容器是可插拔的(也就是说我们可以控制使用哪种容器来实现栈的功能)。
所以STL中栈往往不被归类为容器,而被归类为container adapter(容器适配器)。
那么问题来了,STL 中栈是用什么容器实现的?
从下图中可以看出,栈的内部结构,栈的底层实现可以是vector,deque,list 都是可以的, 主要就是数组和链表的底层实现。
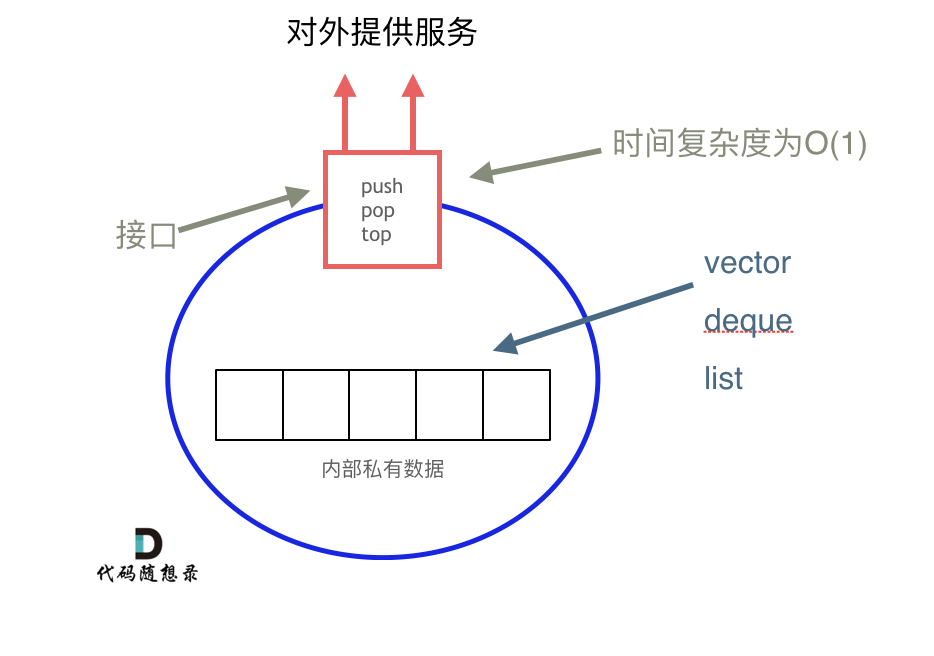
我们常用的SGI STL,如果没有指定底层实现的话,默认是以deque为栈的底层结构。
deque是一个双向队列,只要封住一段,只开通另一端就可以实现栈的逻辑了。
SGI STL中 队列底层实现缺省情况下一样使用deque实现的。
我们也可以指定vector为栈的底层实现,初始化语句如下:
std::stack<int, std::vector<int> > third; // 使用vector为底层容器的栈
刚刚讲过栈的特性,对应的队列的情况是一样的。
队列中先进先出的数据结构,同样不允许有遍历行为,不提供迭代器, SGI STL中队列一样是以deque为缺省情况下的底部结构。
也可以指定list 为起底层实现,初始化queue的语句如下:
std::queue<int, std::list<int>> third; // 定义以list为底层容器的队列
所以STL 队列也不被归类为容器,而被归类为container adapter( 容器适配器)。
我这里讲的都是C++ 语言中的情况, 使用其他语言的同学也要思考栈与队列的底层实现问题, 不要对数据结构的使用浅尝辄止,而要深挖其内部原理,才能夯实基础。
栈的实现
225. Implement Stack using Queues
Implement a last-in-first-out (LIFO) stack using only two queues. The implemented stack should support all the functions of a normal stack (push, top, pop, and empty).
Implement the MyStack class:
void push(int x)Pushes element x to the top of the stack.int pop()Removes the element on the top of the stack and returns it.int top()Returns the element on the top of the stack.boolean empty()Returnstrueif the stack is empty,falseotherwise.
Notes:
- You must use only standard operations of a queue, which means that only
push to back,peek/pop from front,sizeandis emptyoperations are valid. - Depending on your language, the queue may not be supported natively. You may simulate a queue using a list or deque (double-ended queue) as long as you use only a queue's standard operations.
Example 1:
Input
["MyStack", "push", "push", "top", "pop", "empty"]
[[], [1], [2], [], [], []]
Output
[null, null, null, 2, 2, false]
Explanation
MyStack myStack = new MyStack();
myStack.push(1);
myStack.push(2);
myStack.top(); // return 2
myStack.pop(); // return 2
myStack.empty(); // return False
Constraints:
1 <= x <= 9- At most
100calls will be made topush,pop,top, andempty. - All the calls to
popandtopare valid.
Follow-up: Can you implement the stack using only one queue?
思路
使用一个队列或两个队列都可以,使用一个队列时,弹出操作需要先弹出size-1个元素再加入,再弹出所要弹出的元素。
C++解法
class MyStack {
public:
queue<int> q;
MyStack() {
}
void push(int x) {
q.push(x);
}
int pop() {
int size = q.size();
size--;
while(size--){
q.push(q.front());
q.pop();
}
int result = q.front();
q.pop();
return result;
}
int top() {
return q.back();
}
bool empty() {
return q.size() == 0;
}
};
/**
* Your MyStack object will be instantiated and called as such:
* MyStack* obj = new MyStack();
* obj->push(x);
* int param_2 = obj->pop();
* int param_3 = obj->top();
* bool param_4 = obj->empty();
*/
Java解法
字符消消乐
- 20. Valid Parentheses
- 1047. Remove All Adjacent Duplicates In String
- 1209. Remove All Adjacent Duplicates in String II
- 2390. Removing Stars From a String
- 2716. Minimize String Length
20. Valid Parentheses
Given a string s containing just the characters '(', ')', '{', '}', '[' and ']', determine if the input string is valid.
An input string is valid if:
- Open brackets must be closed by the same type of brackets.
- Open brackets must be closed in the correct order.
- Every close bracket has a corresponding open bracket of the same type.
Example 1:
Input: s = "()"
Output: true
Example 2:
Input: s = "()[]{}"
Output: true
Example 3:
Input: s = "(]"
Output: false
Example 4:
Input: s = "([])"
Output: true
Constraints:
1 <= s.length <= 10^4sconsists of parentheses only'()[]{}'.
思路
使用栈数据结构,碰到左括号就压入右括号,碰到右括号就比较,相同则弹出,不同则结束程序。
Use a stack of characters.
When you encounter an opening bracket, push it to the top of the stack.
When you encounter a closing bracket, check if the top of the stack was the opening for it. If yes, pop it from the stack. Otherwise, return false.
C++解法
class Solution {
public:
bool isValid(string s) {
if (s.size() % 2 != 0) return false; // 如果s的长度为奇数,一定不符合要求
stack<char> st;
for (int i = 0; i < s.size(); i++) {
if (s[i] == '(') st.push(')');
else if (s[i] == '{') st.push('}');
else if (s[i] == '[') st.push(']');
// 第三种情况:遍历字符串匹配的过程中,栈已经为空了,没有匹配的字符了,说明右括号没有找到对应的左括号 return false
// 第二种情况:遍历字符串匹配的过程中,发现栈里没有我们要匹配的字符。所以return false
else if (st.empty() || st.top() != s[i]) return false;
else st.pop(); // st.top() 与 s[i]相等,栈弹出元素
}
// 第一种情况:此时我们已经遍历完了字符串,但是栈不为空,说明有相应的左括号没有右括号来匹配,所以return false,否则就return true
return st.empty();
}
};
时间复杂度: O(n)
空间复杂度: O(n)
下面的写法是错误的:
class Solution {
public:
bool isValid(string s) {
if(s.size() % 2 != 0) return false;
stack<char> st;
for(char ch : s){
if(ch == '('){
st.push(')');
}else if(ch == '['){
st.push(']');
}else if(ch == '{'){
st.push('}');
}else{
if(st.top() == ch){
st.pop();
}else{
return false;
}
}
}
return st.empty();
}
};
其中的if(st.top() == ch)会报错。
Java解法
class Solution {
public boolean isValid(String s) {
Deque<Character> deque = new LinkedList<>();
char ch;
for (int i = 0; i < s.length(); i++) {
ch = s.charAt(i);
//碰到左括号,就把相应的右括号入栈
if (ch == '(') {
deque.push(')');
}else if (ch == '{') {
deque.push('}');
}else if (ch == '[') {
deque.push(']');
} else if (deque.isEmpty() || deque.peek() != ch) {
return false;
}else {//如果是右括号判断是否和栈顶元素匹配
deque.pop();
}
}
//最后判断栈中元素是否匹配
return deque.isEmpty();
}
}
1047. Remove All Adjacent Duplicates In String
You are given a string s consisting of lowercase English letters. A duplicate removal consists of choosing two adjacent and equal letters and removing them.
We repeatedly make duplicate removals on s until we no longer can.
Return the final string after all such duplicate removals have been made. It can be proven that the answer is unique.
Example 1:
Input: s = "abbaca"
Output: "ca"
Explanation:
For example, in "abbaca" we could remove "bb" since the letters are adjacent and equal, and this is the only possible move. The result of this move is that the string is "aaca", of which only "aa" is possible, so the final string is "ca".
Example 2:
Input: s = "azxxzy"
Output: "ay"
Constraints:
1 <= s.length <= 10^5sconsists of lowercase English letters.
思路
本题也是用栈来解决的经典题目。
那么栈里应该放的是什么元素呢?
我们在删除相邻重复项的时候,其实就是要知道当前遍历的这个元素,我们在前一位是不是遍历过一样数值的元素,那么如何记录前面遍历过的元素呢?
所以就是用栈来存放,那么栈的目的,就是存放遍历过的元素,当遍历当前的这个元素的时候,去栈里看一下我们是不是遍历过相同数值的相邻元素。
然后再去做对应的消除操作。 如动画所示:

从栈中弹出剩余元素,此时是字符串ac,因为从栈里弹出的元素是倒序的,所以再对字符串进行反转一下,就得到了最终的结果。
C++解法
class Solution {
public:
string removeDuplicates(string S) {
stack<char> st;
for (char s : S) {
if (st.empty() || s != st.top()) {
st.push(s);
} else {
st.pop(); // s 与 st.top()相等的情况
}
}
string result = "";
while (!st.empty()) { // 将栈中元素放到result字符串汇总
result += st.top();
st.pop();
}
reverse (result.begin(), result.end()); // 此时字符串需要反转一下
return result;
}
};
- 时间复杂度: O(n)
- 空间复杂度: O(n)
当然可以拿字符串直接作为栈,这样省去了栈还要转为字符串的操作。
代码如下:
class Solution {
public:
string removeDuplicates(string S) {
string result;
for(char s : S) {
if(result.empty() || result.back() != s) {
result.push_back(s);
}
else {
result.pop_back();
}
}
return result;
}
};
- 时间复杂度: O(n)
- 空间复杂度: O(1),返回值不计空间复杂度
Java解法
使用 Deque 作为堆栈
class Solution {
public String removeDuplicates(String S) {
//ArrayDeque会比LinkedList在除了删除元素这一点外会快一点
//参考:https://stackoverflow.com/questions/6163166/why-is-arraydeque-better-than-linkedlist
ArrayDeque<Character> deque = new ArrayDeque<>();
char ch;
for (int i = 0; i < S.length(); i++) {
ch = S.charAt(i);
if (deque.isEmpty() || deque.peek() != ch) {
deque.push(ch);
} else {
deque.pop();
}
}
String str = "";
//剩余的元素即为不重复的元素
while (!deque.isEmpty()) {
str = deque.pop() + str;
}
return str;
}
}
拿字符串直接作为栈,省去了栈还要转为字符串的操作。
class Solution {
public String removeDuplicates(String s) {
// 将 res 当做栈
// 也可以用 StringBuilder 来修改字符串,速度更快
// StringBuilder res = new StringBuilder();
StringBuffer res = new StringBuffer();
// top为 res 的长度
int top = -1;
for (int i = 0; i < s.length(); i++) {
char c = s.charAt(i);
// 当 top >= 0,即栈中有字符时,当前字符如果和栈中字符相等,弹出栈顶字符,同时 top--
if (top >= 0 && res.charAt(top) == c) {
res.deleteCharAt(top);
top--;
// 否则,将该字符 入栈,同时top++
} else {
res.append(c);
top++;
}
}
return res.toString();
}
}
拓展:双指针
class Solution {
public String removeDuplicates(String s) {
char[] ch = s.toCharArray();
int fast = 0;
int slow = 0;
while(fast < s.length()){
// 直接用fast指针覆盖slow指针的值
ch[slow] = ch[fast];
// 遇到前后相同值的,就跳过,即slow指针后退一步,下次循环就可以直接被覆盖掉了
if(slow > 0 && ch[slow] == ch[slow - 1]){
slow--;
}else{
slow++;
}
fast++;
}
return new String(ch,0,slow);
}
}
Python解法
# 方法一,使用栈
class Solution:
def removeDuplicates(self, s: str) -> str:
res = list()
for item in s:
if res and res[-1] == item:
res.pop()
else:
res.append(item)
return "".join(res) # 字符串拼接
# 方法二,使用双指针模拟栈,如果不让用栈可以作为备选方法。
class Solution:
def removeDuplicates(self, s: str) -> str:
res = list(s)
slow = fast = 0
length = len(res)
while fast < length:
# 如果一样直接换,不一样会把后面的填在slow的位置
res[slow] = res[fast]
# 如果发现和前一个一样,就退一格指针
if slow > 0 and res[slow] == res[slow - 1]:
slow -= 1
else:
slow += 1
fast += 1
return ''.join(res[0: slow])
Go解法
使用栈
func removeDuplicates(s string) string {
stack := make([]rune, 0)
for _, val := range s {
if len(stack) == 0 || val != stack[len(stack)-1] {
stack = append(stack, val)
} else {
stack = stack[:len(stack)-1]
}
}
var res []rune
for len(stack) != 0 { // 将栈中元素放到result字符串汇总
res = append(res, stack[len(stack)-1])
stack = stack[:len(stack)-1]
}
// 此时字符串需要反转一下
l, r := 0, len(res)-1
for l < r {
res[l], res[r] = res[r], res[l]
l++
r--
}
return string(res)
}
拿字符串直接作为栈,省去了栈还要转为字符串的操作
func removeDuplicates(s string) string {
var stack []byte
for i := 0; i < len(s);i++ {
// 栈不空 且 与栈顶元素不等
if len(stack) > 0 && stack[len(stack)-1] == s[i] {
// 弹出栈顶元素 并 忽略当前元素(s[i])
stack = stack[:len(stack)-1]
}else{
// 入栈
stack = append(stack, s[i])
}
}
return string(stack)
}
1209. Remove All Adjacent Duplicates in String II
You are given a string s and an integer k, a k duplicate removal consists of choosing k adjacent and equal letters from s and removing them, causing the left and the right side of the deleted substring to concatenate together.
We repeatedly make k duplicate removals on s until we no longer can.
Return the final string after all such duplicate removals have been made. It is guaranteed that the answer is unique.
Example 1:
Input: s = "abcd", k = 2
Output: "abcd"
Explanation: There's nothing to delete.
Example 2:
Input: s = "deeedbbcccbdaa", k = 3
Output: "aa"
Explanation:
First delete "eee" and "ccc", get "ddbbbdaa"
Then delete "bbb", get "dddaa"
Finally delete "ddd", get "aa"
Example 3:
Input: s = "pbbcggttciiippooaais", k = 2
Output: "ps"
Constraints:
1 <= s.length <= 10^52 <= k <= 10^4sonly contains lowercase English letters.
思路
Solution 1: Two Pointers
Solution 2: Stack
Save the character c and its count to the stack.
If the next character c is same as the last one, increment the count.
Otherwise push a pair (c, 1) into the stack.
I used a dummy element ('#', 0) to avoid empty stack.
Complexity
Time O(N) for one pass
Space O(N)
C++解法
string removeDuplicates(string s, int k) {
int i = 0, n = s.length();
vector<int> count(n);
for (int j = 0; j < n; ++j, ++i) {
s[i] = s[j];
count[i] = i > 0 && s[i - 1] == s[j] ? count[i - 1] + 1 : 1;
if (count[i] == k) i -= k;
}
return s.substr(0, i);
}
string removeDuplicates(string s, int k) {
vector<pair<int, char>> stack = {{0, '#'}};
for (char c: s) {
if (stack.back().second != c) {
stack.push_back({1, c});
} else if (++stack.back().first == k)
stack.pop_back();
}
string res;
for (auto & p : stack) {
res.append(p.first, p.second);
}
return res;
}
Java解法
public String removeDuplicates(String s, int k) {
int[] count = new int[s.length()];
StringBuilder sb = new StringBuilder();
for(char c : s.toCharArray()) {
sb.append(c);
int last = sb.length()-1;
count[last] = 1 + (last > 0 && sb.charAt(last) == sb.charAt(last-1) ? count[last-1] : 0);
if(count[last] >= k) sb.delete(sb.length()-k, sb.length());
}
return sb.toString();
}
public String removeDuplicates(String s, int k) {
int i = 0, n = s.length(), count[] = new int[n];
char[] stack = s.toCharArray();
for (int j = 0; j < n; ++j, ++i) {
stack[i] = stack[j];
count[i] = i > 0 && stack[i - 1] == stack[j] ? count[i - 1] + 1 : 1;
if (count[i] == k) i -= k;
}
return new String(stack, 0, i);
}
Python解法
def removeDuplicates(self, s, k):
stack = [['#', 0]]
for c in s:
if stack[-1][0] == c:
stack[-1][1] += 1
if stack[-1][1] == k:
stack.pop()
else:
stack.append([c, 1])
return ''.join(c * k for c, k in stack)
2390. Removing Stars From a String
You are given a string s, which contains stars *.
In one operation, you can:
- Choose a star in
s. - Remove the closest non-star character to its left, as well as remove the star itself.
Return the string after all stars have been removed.
Note:
- The input will be generated such that the operation is always possible.
- It can be shown that the resulting string will always be unique.
Example 1:
Input: s = "leet**cod*e"
Output: "lecoe"
Explanation: Performing the removals from left to right:
- The closest character to the 1st star is 't' in
"lee**t****cod*e". s becomes"lee*cod*e". - The closest character to the 2nd star is 'e' in
"le**e***cod*e". s becomes"lecod*e". - The closest character to the 3rd star is 'd' in
"leco**d***e". s becomes"lecoe". There are no more stars, so we return "lecoe".
Example 2:
Input: s = "erase*****"
Output: ""
Explanation: The entire string is removed, so we return an empty string.
Constraints:
1 <= s.length <= 10^5sconsists of lowercase English letters and stars*.- The operation above can be performed on
s.
思路
What data structure could we use to efficiently perform these removals?
Use a stack to store the characters. Pop one character off the stack at each star. Otherwise, we push the character onto the stack.
当然可以拿字符串直接作为栈,这样省去了栈还要转为字符串的操作。
C++解法
class Solution {
public:
string removeStars(string s) {
string result;
for(char ch : s) {
if(result.empty() || ch != '*') {
result.push_back(ch);
}
else {
result.pop_back();
}
}
return result;
}
};
2716. Minimize String Length
Given a string s, you have two types of operation:
- Choose an index
iin the string, and letcbe the character in positioni. Delete the closest occurrence ofcto the left ofi(if exists). - Choose an index
iin the string, and letcbe the character in positioni. Delete the closest occurrence ofcto the right ofi(if exists).
Your task is to minimize the length of s by performing the above operations zero or more times.
Return an integer denoting the length of the minimized string.
Example 1:
Input: s = "aaabc"
Output: 3
Explanation:
- Operation 2: we choose
i = 1socis 'a', then we removes[2]as it is closest 'a' character to the right ofs[1].
sbecomes "aabc" after this. - Operation 1: we choose
i = 1socis 'a', then we removes[0]as it is closest 'a' character to the left ofs[1].
sbecomes "abc" after this.
Example 2:
Input: s = "cbbd"
Output: 3
Explanation:
- Operation 1: we choose
i = 2socis 'b', then we removes[1]as it is closest 'b' character to the left ofs[1].
sbecomes "cbd" after this.
Example 3:
Input: s = "baadccab"
Output: 4
Explanation:
- Operation 1: we choose
i = 6socis 'a', then we removes[2]as it is closest 'a' character to the left ofs[6].
sbecomes "badccab" after this. - Operation 2: we choose
i = 0socis 'b', then we removes[6]as it is closest 'b' character to the right ofs[0].
sbecomes "badcca" fter this. - Operation 2: we choose
i = 3socis 'c', then we removes[4]as it is closest 'c' character to the right ofs[3].
sbecomes "badca" after this. - Operation 1: we choose
i = 4socis 'a', then we removes[1]as it is closest 'a' character to the left ofs[4].
sbecomes "bdca" after this.
Constraints:
1 <= s.length <= 100scontains only lowercase English letters
思路
The minimized string will not contain duplicate characters.
The minimized string will contain all distinct characters of the original string.
C++解法
class Solution {
public:
int minimizedStringLength(string s) {
return unordered_set<char>(s.begin(), s.end()).size();
}
};
使用hash数组求解:
class Solution {
public:
int minimizedStringLength(string s) {
int hash[26] = {0};
for(char ch : s){
hash[ch - 'a']++;
}
int count = 0;
for(int i = 0; i < 26; i++){
if(hash[i] != 0){
count++;
}
}
return count;
}
};
注意:int hash[26] = {0};这行代码确保 hash 数组的所有元素都被初始化为零,避免了使用未初始化值的问题。
Java解法
class Solution {
public int minimizedStringLength(String s) {
return (int) s.chars().distinct().count();
}
}
Python3解法
class Solution:
def minimizedStringLength(self, s: str) -> int:
return len(set(s))
栈与计算器
150. Evaluate Reverse Polish Notation
You are given an array of strings tokens that represents an arithmetic expression in a Reverse Polish Notation.
Evaluate the expression. Return an integer that represents the value of the expression.
Note that:
- The valid operators are
'+','-','*', and'/'. - Each operand may be an integer or another expression.
- The division between two integers always truncates toward zero.
- There will not be any division by zero.
- The input represents a valid arithmetic expression in a reverse polish notation.
- The answer and all the intermediate calculations can be represented in a 32-bit integer.
Example 1:
Input: tokens = ["2","1","+","3","*"]
Output: 9
Explanation: ((2 + 1) * 3) = 9
Example 2:
Input: tokens = ["4","13","5","/","+"]
Output: 6
Explanation: (4 + (13 / 5)) = 6
Example 3:
Input: tokens = ["10","6","9","3","+","-11","*","/","*","17","+","5","+"]
Output: 22
Explanation: ((10 * (6 / ((9 + 3) * -11))) + 17) + 5
= ((10 * (6 / (12 * -11))) + 17) + 5
= ((10 * (6 / -132)) + 17) + 5
= ((10 * 0) + 17) + 5
= (0 + 17) + 5
= 17 + 5
= 22
Constraints:
1 <= tokens.length <= 10^4tokens[i]is either an operator:"+","-","*", or"/", or an integer in the range[-200, 200].
思路
遇到数字字符串就转为数字并入栈,遇到运算符就弹出两个数字计算,然后把结果压栈。
逆波兰表达式:是一种后缀表达式,所谓后缀就是指运算符写在后面。
平常使用的算式则是一种中缀表达式,如 ( 1 + 2 ) * ( 3 + 4 ) 。
该算式的逆波兰表达式写法为 ( ( 1 2 + ) ( 3 4 + ) * ) 。
逆波兰表达式主要有以下两个优点:
- 去掉括号后表达式无歧义,上式即便写成 1 2 + 3 4 + * 也可以依据次序计算出正确结果。
- 适合用栈操作运算:遇到数字则入栈;遇到运算符则取出栈顶两个数字进行计算,并将结果压入栈中。
C++解法
class Solution {
public:
int evalRPN(vector<string>& tokens) {
// 力扣修改了后台测试数据,需要用longlong
stack<long long> st;
for (int i = 0; i < tokens.size(); i++) {
if (tokens[i] == "+" || tokens[i] == "-" || tokens[i] == "*" || tokens[i] == "/") {
long long num1 = st.top();
st.pop();
long long num2 = st.top();
st.pop();
if (tokens[i] == "+") st.push(num2 + num1);
if (tokens[i] == "-") st.push(num2 - num1);
if (tokens[i] == "*") st.push(num2 * num1);
if (tokens[i] == "/") st.push(num2 / num1);
} else {
st.push(stoll(tokens[i]));
}
}
long long result = st.top();
st.pop(); // 把栈里最后一个元素弹出(其实不弹出也没事)
return result;
}
};
实测使用int可以AC。
- 时间复杂度: O(n)
- 空间复杂度: O(n)
Java解法
class Solution {
public int evalRPN(String[] tokens) {
Deque<Integer> stack = new LinkedList();
for (String s : tokens) {
if ("+".equals(s)) { // leetcode 内置jdk的问题,不能使用==判断字符串是否相等
stack.push(stack.pop() + stack.pop()); // 注意 - 和/ 需要特殊处理
} else if ("-".equals(s)) {
stack.push(-stack.pop() + stack.pop());
} else if ("*".equals(s)) {
stack.push(stack.pop() * stack.pop());
} else if ("/".equals(s)) {
int temp1 = stack.pop();
int temp2 = stack.pop();
stack.push(temp2 / temp1);
} else {
stack.push(Integer.valueOf(s));
}
}
return stack.pop();
}
}
Python3解法
from operator import add, sub, mul
def div(x, y):
# 使用整数除法的向零取整方式
return int(x / y) if x * y > 0 else -(abs(x) // abs(y))
class Solution(object):
op_map = {'+': add, '-': sub, '*': mul, '/': div}
def evalRPN(self, tokens: List[str]) -> int:
stack = []
for token in tokens:
if token not in {'+', '-', '*', '/'}:
stack.append(int(token))
else:
op2 = stack.pop()
op1 = stack.pop()
stack.append(self.op_map[token](op1, op2)) # 第一个出来的在运算符后面
return stack.pop()
另一种可行,但因为使用eval()相对较慢的方法:
class Solution(object):
def evalRPN(self, tokens: List[str]) -> int:
stack = []
for token in tokens:
# 判断是否为数字,因为isdigit()不识别负数,故需要排除第一位的符号
if token.isdigit() or (len(token)>1 and token[1].isdigit()):
stack.append(token)
else:
op2 = stack.pop()
op1 = stack.pop()
# 由题意"The division always truncates toward zero",所以使用int()可以天然取整
stack.append(str(int(eval(op1 + token + op2))))
return int(stack.pop())
Go
func evalRPN(tokens []string) int {
stack := []int{}
for _, token := range tokens {
val, err := strconv.Atoi(token)
if err == nil {
stack = append(stack, val)
} else { // 如果err不为nil说明不是数字
num1, num2 := stack[len(stack)-2], stack[(len(stack))-1]
stack = stack[:len(stack)-2]
switch token {
case "+":
stack = append(stack, num1+num2)
case "-":
stack = append(stack, num1-num2)
case "*":
stack = append(stack, num1*num2)
case "/":
stack = append(stack, num1/num2)
}
}
}
return stack[0]
}
224. Basic Calculator
Given a string s representing a valid expression, implement a basic calculator to evaluate it, and return the result of the evaluation.
Note: You are not allowed to use any built-in function which evaluates strings as mathematical expressions, such as eval().
Example 1:
Input: s = "1 + 1"
Output: 2
Example 2:
Input: s = " 2-1 + 2 "
Output: 3
Example 3:
Input: s = "(1+(4+5+2)-3)+(6+8)"
Output: 23
Constraints:
1 <= s.length <= 3 * 10^5sconsists of digits,'+','-','(',')', and' '.srepresents a valid expression.'+'is not used as a unary operation (i.e.,"+1"and"+(2 + 3)"is invalid).'-'could be used as a unary operation (i.e.,"-1"and"-(2 + 3)"is valid).- There will be no two consecutive operators in the input.
- Every number and running calculation will fit in a signed 32-bit integer.
思路
左括号前是运算符,所以需要存储。
sum = st.top().first + st.top().second * sum;其中sum是括号内数字和,st.top().first是括号前数字和,st.top().second是括号前运算符符号。
C++解法
class Solution {
public:
int calculate(string s) {
long long int sum = 0;
int sign = 1;
stack<pair<int,int>> st;
for(int i = 0; i < s.length(); i++){
if(isdigit(s[i])){
long long int num = 0;
while(i < s.size() && isdigit(s[i])){
num = num * 10 + (s[i] - '0');
i++;
}
i--;
sum += num * sign;
sign = 1;
}else if(s[i] == '('){
st.push({sum, sign});
sum = 0;
sign = 1;
}else if(s[i] == ')'){
sum = st.top().first + st.top().second * sum;
st.pop();
}else if(s[i] == '-'){
sign = -1 * sign;
}
}
return sum;
}
};
227. Basic Calculator II
Given a string s which represents an expression, evaluate this expression and return its value.
The integer division should truncate toward zero.
You may assume that the given expression is always valid. All intermediate results will be in the range of [-2^31, 2^31 - 1].
Note: You are not allowed to use any built-in function which evaluates strings as mathematical expressions, such as eval().
Example 1:
Input: s = "3+2*2"
Output: 7
Example 2:
Input: s = " 3/2 "
Output: 1
Example 3:
Input: s = " 3+5 / 2 "
Output: 5
Constraints:
1 <= s.length <= 3 * 10^5sconsists of integers and operators('+', '-', '*', '/')separated by some number of spaces.srepresents a valid expression.- All the integers in the expression are non-negative integers in the range
[0, 2^31 - 1]. - The answer is guaranteed to fit in a 32-bit integer.
思路
Approach 1: Using Stack
Intuition
We know that there could be 4 types of operations - addition (+), subtraction (-), multiplication (*) and division (/). Without parenthesis, we know that, multiplication (*) and (\) operations would always have higher precedence than addition (+) and subtraction (-) based on operator precedence rules.

If we look at the above examples, we can make the following observations -
- If the current operation is addition
(+)or subtraction(-), then the expression is evaluated based on the precedence of the next operation.
In example 1, 4+3 is evaluated later because the next operation is multiplication (3*5) which has higher precedence.
But, in example 2, 4+3 is evaluated first because the next operation is subtraction (3-5) which has equal precedence.
- If the current operator is multiplication
(*)or division(/), then the expression is evaluated irrespective of the next operation. This is because in the given set of operations(+,-,*,/), the*and/operations have the highest precedence and therefore must be evaluated first.
In the above examples 3 and 4, 4*3 is always evaluated first irrespective of the next operation.
Using this intuition let's look at the algorithm to implement the problem.
Algorithm
Scan the input string s from left to right and evaluate the expressions based on the following rules
- If the current character is a digit
0-9( operand ), add it to the numbercurrentNumber. - Otherwise, the current character must be an operation
(+,-,*, /). Evaluate the expression based on the type of operation.
- Addition
(+)or Subtraction(-): We must evaluate the expression later based on the next operation. So, we must store thecurrentNumberto be used later. Let's push the currentNumber in the Stack.
Stack data structure follows Last In First Out (LIFO) principle. Hence, the last pushed number in the stack would be popped out first for evaluation. In addition, when we pop from the stack and evaluate this expression in the future, we need a way to determine if the operation was Addition
(+)or Subtraction(-). To simplify our evaluation, we can push-currentNumberin a stack if the current operation is subtraction (-) and assume that the operation for all the values in the stack is addition(+). This works because(a - currentNumber)is equivalent to(a + (-currentNumber)).
- Multiplication
(*)or Division(/): Pop the top values from the stack and evaluate the current expression. Push the evaluated value back to the stack.
Once the string is scanned, pop from the stack and add to the result.
Implementation
Complexity Analysis
- Time Complexity: O(n), where n is the length of the string s. We iterate over the string s at most twice.
- Space Complexity: O(n), where n is the length of the string s.
Approach 2: Optimized Approach without the stack
Intuition
In the previous approach, we used a stack to track the values of the evaluated expressions. In the end, we pop all the values from the stack and add to the result. Instead of that, we could add the values to the result beforehand and keep track of the last calculated number, thus eliminating the need for the stack. Let's understand the algorithm in detail.
Algorithm
The approach works similar to Approach 1 with the following differences :
- Instead of using a
stack, we use a variablelastNumberto track the value of the last evaluated expression. - If the operation is Addition
(+)or Subtraction(-), add thelastNumberto the result instead of pushing it to the stack. ThecurrentNumberwould be updated tolastNumberfor the next iteration. - If the operation is Multiplication
(*)or Division(/), we must evaluate the expressionlastNumber * currentNumberand update thelastNumberwith the result of the expression. This would be added to the result after the entire string is scanned.
Implementation
Complexity Analysis
- Time Complexity: O(n), where n is the length of the string s.
- Space Complexity: O(1), as we use constant extra space to store
lastNumber,resultand so on.
C++解法
使用栈
class Solution {
public:
int calculate(string s) {
int len = s.length();
if (len == 0) return 0;
stack<int> stack;
int currentNumber = 0;
char operation = '+';
for (int i = 0; i < len; i++) {
char currentChar = s[i];
if (isdigit(currentChar)) {
currentNumber = (currentNumber * 10) + (currentChar - '0');
}
if (!isdigit(currentChar) && !iswspace(currentChar) || i == len - 1) {
if (operation == '-') {
stack.push(-currentNumber);
} else if (operation == '+') {
stack.push(currentNumber);
} else if (operation == '*') {
int stackTop = stack.top();
stack.pop();
stack.push(stackTop * currentNumber);
} else if (operation == '/') {
int stackTop = stack.top();
stack.pop();
stack.push(stackTop / currentNumber);
}
operation = currentChar;
currentNumber = 0;
}
}
int result = 0;
while (stack.size() != 0) {
result += stack.top();
stack.pop();
}
return result;
}
};
不用栈
class Solution {
public:
int calculate(string s) {
int length = s.length();
if (length == 0) return 0;
int currentNumber = 0, lastNumber = 0, result = 0;
char sign = '+';
for (int i = 0; i < length; i++) {
char currentChar = s[i];
if (isdigit(currentChar)) {
currentNumber = (currentNumber * 10) + (currentChar - '0');
}
if (!isdigit(currentChar) && !iswspace(currentChar) || i == length - 1) {
if (sign == '+' || sign == '-') {
result += lastNumber;
lastNumber = (sign == '+') ? currentNumber : -currentNumber;
} else if (sign == '*') {
lastNumber = lastNumber * currentNumber;
} else if (sign == '/') {
lastNumber = lastNumber / currentNumber;
}
sign = currentChar;
currentNumber = 0;
}
}
result += lastNumber;
return result;
}
};
Java解法
class Solution {
public int calculate(String s) {
if (s == null || s.isEmpty()) return 0;
int len = s.length();
Stack<Integer> stack = new Stack<Integer>();
int currentNumber = 0;
char operation = '+';
for (int i = 0; i < len; i++) {
char currentChar = s.charAt(i);
if (Character.isDigit(currentChar)) {
currentNumber = (currentNumber * 10) + (currentChar - '0');
}
if (!Character.isDigit(currentChar) && !Character.isWhitespace(currentChar) || i == len - 1) {
if (operation == '-') {
stack.push(-currentNumber);
}
else if (operation == '+') {
stack.push(currentNumber);
}
else if (operation == '*') {
stack.push(stack.pop() * currentNumber);
}
else if (operation == '/') {
stack.push(stack.pop() / currentNumber);
}
operation = currentChar;
currentNumber = 0;
}
}
int result = 0;
while (!stack.isEmpty()) {
result += stack.pop();
}
return result;
}
}
不用栈
class Solution {
public int calculate(String s) {
if (s == null || s.isEmpty()) return 0;
int length = s.length();
int currentNumber = 0, lastNumber = 0, result = 0;
char operation = '+';
for (int i = 0; i < length; i++) {
char currentChar = s.charAt(i);
if (Character.isDigit(currentChar)) {
currentNumber = (currentNumber * 10) + (currentChar - '0');
}
if (!Character.isDigit(currentChar) && !Character.isWhitespace(currentChar) || i == length - 1) {
if (operation == '+' || operation == '-') {
result += lastNumber;
lastNumber = (operation == '+') ? currentNumber : -currentNumber;
} else if (operation == '*') {
lastNumber = lastNumber * currentNumber;
} else if (operation == '/') {
lastNumber = lastNumber / currentNumber;
}
operation = currentChar;
currentNumber = 0;
}
}
result += lastNumber;
return result;
}
}
队列
栈和队列
灵魂四问:
- C++中stack,queue 是容器么?
- 我们使用的stack,queue是属于那个版本的STL?
- 我们使用的STL中stack,queue是如何实现的?
- stack,queue 提供迭代器来遍历空间么?
栈与队列是我们熟悉的不能再熟悉的数据结构,但它们的底层实现,很多同学都比较模糊,这其实就是基础所在。
可以出一道面试题:栈里面的元素在内存中是连续分布的么?
这个问题有两个陷阱:
- 陷阱1:栈是容器适配器,底层容器使用不同的容器,导致栈内数据在内存中不一定是连续分布的。
- 陷阱2:默认情况下,默认底层容器是deque,那么deque在内存中的数据分布是什么样的呢? 答案是:不连续的,下文也会提到deque。
我想栈和队列的原理大家应该很熟悉了,队列是先进先出,栈是先进后出。
如图所示:
那么我这里再列出四个关于栈的问题,大家可以思考一下。以下是以C++为例,使用其他编程语言的同学也对应思考一下,自己使用的编程语言里栈和队列是什么样的。
- C++中stack 是容器么?
- 我们使用的stack是属于哪个版本的STL?
- 我们使用的STL中stack是如何实现的?
- stack 提供迭代器来遍历stack空间么?
相信这四个问题并不那么好回答, 因为一些同学使用数据结构会停留在非常表面上的应用,稍稍往深一问,就会有好像懂,好像也不懂的感觉。
有的同学可能仅仅知道有栈和队列这么个数据结构,却不知道底层实现,也不清楚所使用栈和队列和STL是什么关系。
所以这里我再给大家扫一遍基础知识,
首先大家要知道 栈和队列是STL(C++标准库)里面的两个数据结构。
C++标准库是有多个版本的,要知道我们使用的STL是哪个版本,才能知道对应的栈和队列的实现原理。
那么来介绍一下,三个最为普遍的STL版本:
-
HP STL 其他版本的C++ STL,一般是以HP STL为蓝本实现出来的,HP STL是C++ STL的第一个实现版本,而且开放源代码。
-
P.J.Plauger STL 由P.J.Plauger参照HP STL实现出来的,被Visual C++编译器所采用,不是开源的。
-
SGI STL 由Silicon Graphics Computer Systems公司参照HP STL实现,被Linux的C++编译器GCC所采用,SGI STL是开源软件,源码可读性甚高。
接下来介绍的栈和队列也是SGI STL里面的数据结构, 知道了使用版本,才知道对应的底层实现。
来说一说栈,栈先进后出,如图所示:
栈提供push 和 pop 等等接口,所有元素必须符合先进后出规则,所以栈不提供走访功能,也不提供迭代器(iterator)。 不像是set 或者map 提供迭代器iterator来遍历所有元素。
栈是以底层容器完成其所有的工作,对外提供统一的接口,底层容器是可插拔的(也就是说我们可以控制使用哪种容器来实现栈的功能)。
所以STL中栈往往不被归类为容器,而被归类为container adapter(容器适配器)。
那么问题来了,STL 中栈是用什么容器实现的?
从下图中可以看出,栈的内部结构,栈的底层实现可以是vector,deque,list 都是可以的, 主要就是数组和链表的底层实现。
我们常用的SGI STL,如果没有指定底层实现的话,默认是以deque为栈的底层结构。
deque是一个双向队列,只要封住一段,只开通另一端就可以实现栈的逻辑了。
SGI STL中 队列底层实现缺省情况下一样使用deque实现的。
我们也可以指定vector为栈的底层实现,初始化语句如下:
std::stack<int, std::vector<int> > third; // 使用vector为底层容器的栈
刚刚讲过栈的特性,对应的队列的情况是一样的。
队列中先进先出的数据结构,同样不允许有遍历行为,不提供迭代器, SGI STL中队列一样是以deque为缺省情况下的底部结构。
也可以指定list 为起底层实现,初始化queue的语句如下:
std::queue<int, std::list<int>> third; // 定义以list为底层容器的队列
所以STL 队列也不被归类为容器,而被归类为container adapter( 容器适配器)。
我这里讲的都是C++ 语言中的情况, 使用其他语言的同学也要思考栈与队列的底层实现问题, 不要对数据结构的使用浅尝辄止,而要深挖其内部原理,才能夯实基础。
队列的实现
232. Implement Queue using Stacks
Implement a first in first out (FIFO) queue using only two stacks. The implemented queue should support all the functions of a normal queue (push, peek, pop, and empty).
Implement the MyQueue class:
void push(int x)Pushes element x to the back of the queue.int pop()Removes the element from the front of the queue and returns it.int peek()Returns the element at the front of the queue.boolean empty()Returnstrueif the queue is empty,falseotherwise.
Notes:
- You must use only standard operations of a stack, which means only
push to top,peek/pop from top,size, andis emptyoperations are valid. - Depending on your language, the stack may not be supported natively. You may simulate a stack using a list or deque (double-ended queue) as long as you use only a stack's standard operations.
Example 1:
Input
["MyQueue", "push", "push", "peek", "pop", "empty"]
[[], [1], [2], [], [], []]
Output
[null, null, null, 1, 1, false]
Explanation
MyQueue myQueue = new MyQueue();
myQueue.push(1); // queue is: [1]
myQueue.push(2); // queue is: [1, 2] (leftmost is front of the queue)
myQueue.peek(); // return 1
myQueue.pop(); // return 1, queue is [2]
myQueue.empty(); // return false
Constraints:
1 <= x <= 9- At most
100calls will be made topush,pop,peek, andempty. - All the calls to
popandpeekare valid.
Follow-up: Can you implement the queue such that each operation is amortized O(1) time complexity? In other words, performing n operations will take overall O(n) time even if one of those operations may take longer.
思路
用两个栈实现队列。当stackOut为空时就把stackIn中所有元素加入到stackOut中。
因为All the calls to pop and peek are valid.所以这里不再需要校验操作的合法性。
C++解法
class MyQueue {
public:
stack<int> stackIn;
stack<int> stackOut;
MyQueue() {}
void push(int x) { stackIn.push(x); }
int pop() {
if (stackOut.empty()) {
while (!stackIn.empty()) {
int x = stackIn.top();
stackIn.pop();
stackOut.push(x);
}
}
int result = stackOut.top();
stackOut.pop();
return result;
}
int peek() {
int result = this->pop();
stackOut.push(result);
return result;
}
bool empty() { return stackOut.empty() && stackIn.empty(); }
};
/**
* Your MyQueue object will be instantiated and called as such:
* MyQueue* obj = new MyQueue();
* obj->push(x);
* int param_2 = obj->pop();
* int param_3 = obj->peek();
* bool param_4 = obj->empty();
*/
Java解法
单调队列
239. Sliding Window Maximum
You are given an array of integers nums, there is a sliding window of size k which is moving from the very left of the array to the very right. You can only see the k numbers in the window. Each time the sliding window moves right by one position.
Return the max sliding window.
Example 1:
Input: nums = [1,3,-1,-3,5,3,6,7], k = 3
Output: [3,3,5,5,6,7]
Explanation:
Window position Max
--------------- -----
[1 3 -1] -3 5 3 6 7 **3**
1 [3 -1 -3] 5 3 6 7 **3**
1 3 [-1 -3 5] 3 6 7 ** 5**
1 3 -1 [-3 5 3] 6 7 **5**
1 3 -1 -3 [5 3 6] 7 **6**
1 3 -1 -3 5 [3 6 7] **7**
Example 2:
Input: nums = [1], k = 1
Output: [1]
Constraints:
1 <= nums.length <= 10^5-10^4 <= nums[i] <= 10^41 <= k <= nums.length
思路
不能使用普通队列,也不能使用优先级队列,需要自己实现特殊单调队列,特殊队列要有pop()、push()和getMaxValue()成员函数。
这是使用单调队列的经典题目。
难点是如何求一个区间里的最大值呢? (这好像是废话),暴力一下不就得了。
暴力方法,遍历一遍的过程中每次从窗口中再找到最大的数值,这样很明显是O(n × k)的算法。
有的同学可能会想用一个大顶堆(优先级队列)来存放这个窗口里的k个数字,这样就可以知道最大的最大值是多少了, 但是问题是这个窗口是移动的,而大顶堆每次只能弹出最大值,我们无法移除其他数值,这样就造成大顶堆维护的不是滑动窗口里面的数值了。所以不能用大顶堆。
此时我们需要一个队列,这个队列呢,放进去窗口里的元素,然后随着窗口的移动,队列也一进一出,每次移动之后,队列告诉我们里面的最大值是什么。
这个队列应该长这个样子:
class MyQueue {
public:
void pop(int value) {
}
void push(int value) {
}
int front() {
return que.front();
}
};
每次窗口移动的时候,调用que.pop(滑动窗口中移除元素的数值),que.push(滑动窗口添加元素的数值),然后que.front()就返回我们要的最大值。
这么个队列香不香,要是有现成的这种数据结构是不是更香了!
其实在C++中,可以使用 multiset 来模拟这个过程,文末提供这个解法仅针对C++,以下讲解我们还是靠自己来实现这个单调队列。
然后再分析一下,队列里的元素一定是要排序的,而且要最大值放在出队口,要不然怎么知道最大值呢。
但如果把窗口里的元素都放进队列里,窗口移动的时候,队列需要弹出元素。
那么问题来了,已经排序之后的队列 怎么能把窗口要移除的元素(这个元素可不一定是最大值)弹出呢。
大家此时应该陷入深思.....
其实队列没有必要维护窗口里的所有元素,只需要维护有可能成为窗口里最大值的元素就可以了,同时保证队列里的元素数值是由大到小的。
那么这个维护元素单调递减的队列就叫做单调队列,即单调递减或单调递增的队列。C++中没有直接支持单调队列,需要我们自己来实现一个单调队列
不要以为实现的单调队列就是 对窗口里面的数进行排序,如果排序的话,那和优先级队列又有什么区别了呢。
来看一下单调队列如何维护队列里的元素。
动画如下:
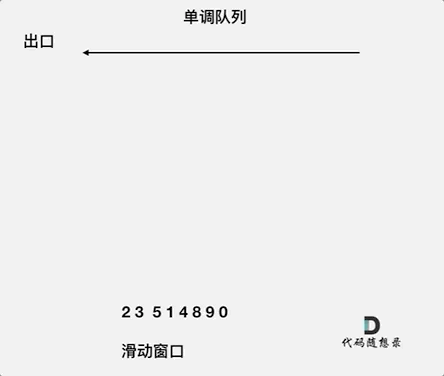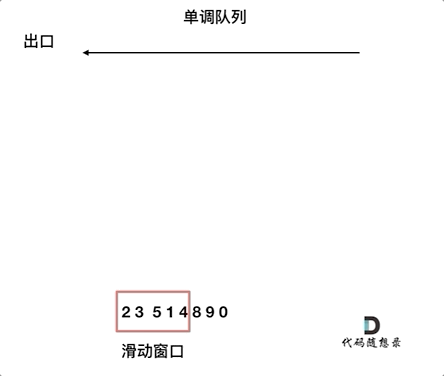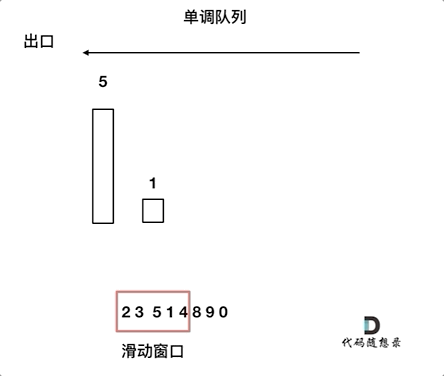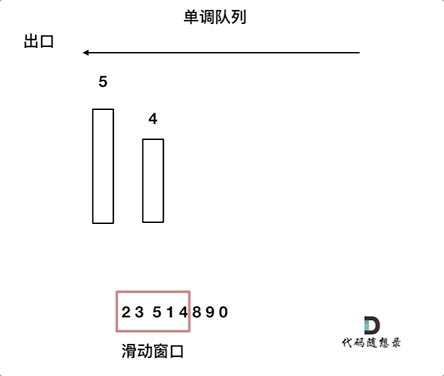
对于窗口里的元素{2, 3, 5, 1 ,4},单调队列里只维护{5, 4} 就够了,保持单调队列里单调递减,此时队列出口元素就是窗口里最大元素。
此时大家应该怀疑单调队列里维护着{5, 4} 怎么配合窗口进行滑动呢?
设计单调队列的时候,pop,和push操作要保持如下规则:
- pop(value):如果窗口移除的元素value等于单调队列的出口元素,那么队列弹出元素,否则不用任何操作
- push(value):如果push的元素value大于入口元素的数值,那么就将队列入口的元素弹出,直到push元素的数值小于等于队列入口元素的数值为止
保持如上规则,每次窗口移动的时候,只要问que.front()就可以返回当前窗口的最大值。
为了更直观的感受到单调队列的工作过程,以题目示例为例,输入: nums = [1,3,-1,-3,5,3,6,7], 和 k = 3,动画如下:
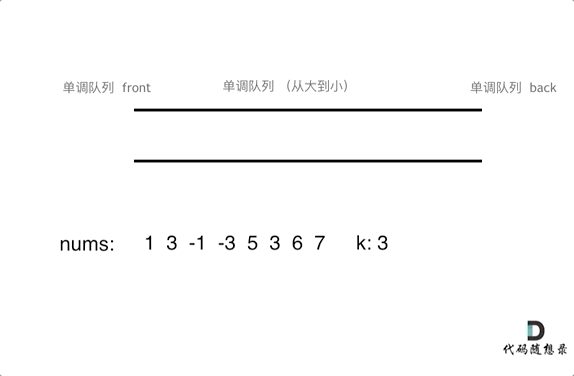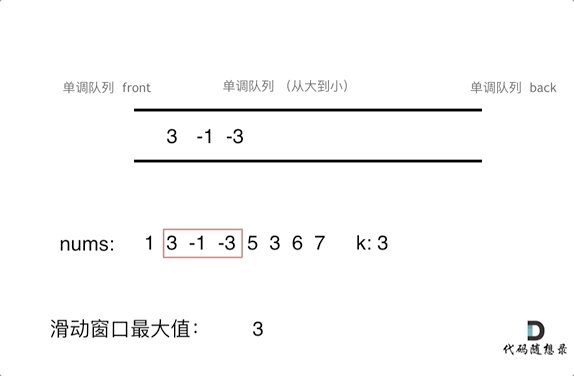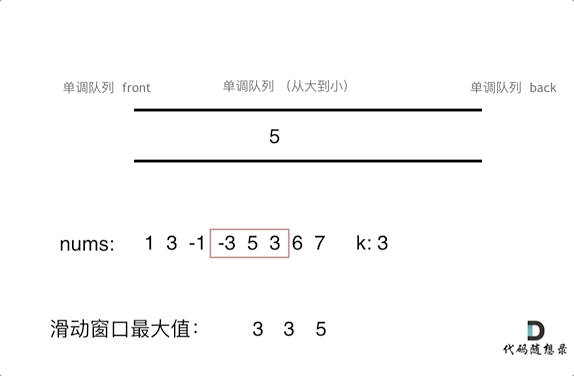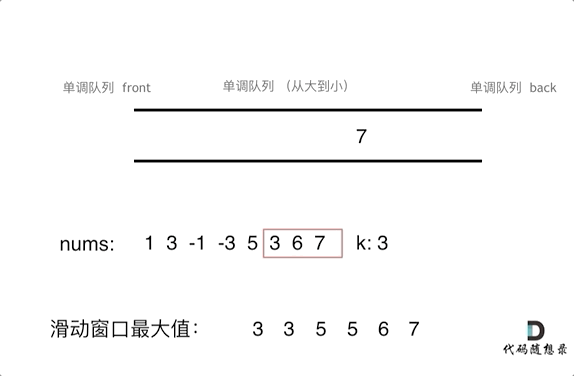
那么我们用什么数据结构来实现这个单调队列呢?
使用deque最为合适,在文章栈与队列:来看看栈和队列不为人知的一面中,我们就提到了常用的queue在没有指定容器的情况下,deque就是默认底层容器。
基于刚刚说过的单调队列pop和push的规则,代码不难实现,如下:
class MyQueue { //单调队列(从大到小)
public:
deque<int> que; // 使用deque来实现单调队列
// 每次弹出的时候,比较当前要弹出的数值是否等于队列出口元素的数值,如果相等则弹出。
// 同时pop之前判断队列当前是否为空。
void pop(int value) {
if (!que.empty() && value == que.front()) {
que.pop_front();
}
}
// 如果push的数值大于入口元素的数值,那么就将队列后端的数值弹出,直到push的数值小于等于队列入口元素的数值为止。
// 这样就保持了队列里的数值是单调从大到小的了。
void push(int value) {
while (!que.empty() && value > que.back()) {
que.pop_back();
}
que.push_back(value);
}
// 查询当前队列里的最大值 直接返回队列前端也就是front就可以了。
int front() {
return que.front();
}
};
这样我们就用deque实现了一个单调队列,接下来解决滑动窗口最大值的问题就很简单了,直接看代码吧。
C++解法
class Solution {
private:
class MyQueue { //单调队列(从大到小)
public:
deque<int> que; // 使用deque来实现单调队列
// 每次弹出的时候,比较当前要弹出的数值是否等于队列出口元素的数值,如果相等则弹出。
// 同时pop之前判断队列当前是否为空。
void pop(int value) {
if (!que.empty() && value == que.front()) {
que.pop_front();
}
}
// 如果push的数值大于入口元素的数值,那么就将队列后端的数值弹出,直到push的数值小于等于队列入口元素的数值为止。
// 这样就保持了队列里的数值是单调从大到小的了。
void push(int value) {
while (!que.empty() && value > que.back()) {
que.pop_back();
}
que.push_back(value);
}
// 查询当前队列里的最大值 直接返回队列前端也就是front就可以了。
int front() {
return que.front();
}
};
public:
vector<int> maxSlidingWindow(vector<int>& nums, int k) {
MyQueue que;
vector<int> result;
for (int i = 0; i < k; i++) { // 先将前k的元素放进队列
que.push(nums[i]);
}
result.push_back(que.front()); // result 记录前k的元素的最大值
for (int i = k; i < nums.size(); i++) {
que.pop(nums[i - k]); // 滑动窗口移除最前面元素
que.push(nums[i]); // 滑动窗口前加入最后面的元素
result.push_back(que.front()); // 记录对应的最大值
}
return result;
}
};
- 时间复杂度: O(n)
- 空间复杂度: O(k)
再来看一下时间复杂度,使用单调队列的时间复杂度是 O(n)。
有的同学可能想了,在队列中 push元素的过程中,还有pop操作呢,感觉不是纯粹的O(n)。
其实,大家可以自己观察一下单调队列的实现,nums 中的每个元素最多也就被 push_back 和 pop_back 各一次,没有任何多余操作,所以整体的复杂度还是 O(n)。
空间复杂度因为我们定义一个辅助队列,所以是O(k)。
大家貌似对单调队列 都有一些疑惑,首先要明确的是,题解中单调队列里的pop和push接口,仅适用于本题哈。单调队列不是一成不变的,而是不同场景不同写法,总之要保证队列里单调递减或递增的原则,所以叫做单调队列。 不要以为本题中的单调队列实现就是固定的写法哈。
大家貌似对deque也有一些疑惑,C++中deque是stack和queue默认的底层实现容器(这个我们之前已经讲过啦),deque是可以两边扩展的,而且deque里元素并不是严格的连续分布的。
Java解法
//解法一
//自定义数组
class MyQueue {
Deque<Integer> deque = new LinkedList<>();
//弹出元素时,比较当前要弹出的数值是否等于队列出口的数值,如果相等则弹出
//同时判断队列当前是否为空
void poll(int val) {
if (!deque.isEmpty() && val == deque.peek()) {
deque.poll();
}
}
//添加元素时,如果要添加的元素大于入口处的元素,就将入口元素弹出
//保证队列元素单调递减
//比如此时队列元素3,1,2将要入队,比1大,所以1弹出,此时队列:3,2
void add(int val) {
while (!deque.isEmpty() && val > deque.getLast()) {
deque.removeLast();
}
deque.add(val);
}
//队列队顶元素始终为最大值
int peek() {
return deque.peek();
}
}
class Solution {
public int[] maxSlidingWindow(int[] nums, int k) {
if (nums.length == 1) {
return nums;
}
int len = nums.length - k + 1;
//存放结果元素的数组
int[] res = new int[len];
int num = 0;
//自定义队列
MyQueue myQueue = new MyQueue();
//先将前k的元素放入队列
for (int i = 0; i < k; i++) {
myQueue.add(nums[i]);
}
res[num++] = myQueue.peek();
for (int i = k; i < nums.length; i++) {
//滑动窗口移除最前面的元素,移除是判断该元素是否放入队列
myQueue.poll(nums[i - k]);
//滑动窗口加入最后面的元素
myQueue.add(nums[i]);
//记录对应的最大值
res[num++] = myQueue.peek();
}
return res;
}
}
//解法二
//利用双端队列手动实现单调队列
/**
* 用一个单调队列来存储对应的下标,每当窗口滑动的时候,直接取队列的头部指针对应的值放入结果集即可
* 单调队列类似 (tail -->) 3 --> 2 --> 1 --> 0 (--> head) (右边为头结点,元素存的是下标)
*/
class Solution {
public int[] maxSlidingWindow(int[] nums, int k) {
ArrayDeque<Integer> deque = new ArrayDeque<>();
int n = nums.length;
int[] res = new int[n - k + 1];
int idx = 0;
for(int i = 0; i < n; i++) {
// 根据题意,i为nums下标,是要在[i - k + 1, i] 中选到最大值,只需要保证两点
// 1.队列头结点需要在[i - k + 1, i]范围内,不符合则要弹出
while(!deque.isEmpty() && deque.peek() < i - k + 1){
deque.poll();
}
// 2.既然是单调,就要保证每次放进去的数字要比末尾的都大,否则也弹出
while(!deque.isEmpty() && nums[deque.peekLast()] < nums[i]) {
deque.pollLast();
}
deque.offer(i);
// 因为单调,当i增长到符合第一个k范围的时候,每滑动一步都将队列头节点放入结果就行了
if(i >= k - 1){
res[idx++] = nums[deque.peek()];
}
}
return res;
}
}
Python解法
解法一:使用自定义的单调队列类
from collections import deque
class MyQueue: #单调队列(从大到小
def __init__(self):
self.queue = deque() #这里需要使用deque实现单调队列,直接使用list会超时
#每次弹出的时候,比较当前要弹出的数值是否等于队列出口元素的数值,如果相等则弹出。
#同时pop之前判断队列当前是否为空。
def pop(self, value):
if self.queue and value == self.queue[0]:
self.queue.popleft()#list.pop()时间复杂度为O(n),这里需要使用collections.deque()
#如果push的数值大于入口元素的数值,那么就将队列后端的数值弹出,直到push的数值小于等于队列入口元素的数值为止。
#这样就保持了队列里的数值是单调从大到小的了。
def push(self, value):
while self.queue and value > self.queue[-1]:
self.queue.pop()
self.queue.append(value)
#查询当前队列里的最大值 直接返回队列前端也就是front就可以了。
def front(self):
return self.queue[0]
class Solution:
def maxSlidingWindow(self, nums: List[int], k: int) -> List[int]:
que = MyQueue()
result = []
for i in range(k): #先将前k的元素放进队列
que.push(nums[i])
result.append(que.front()) #result 记录前k的元素的最大值
for i in range(k, len(nums)):
que.pop(nums[i - k]) #滑动窗口移除最前面元素
que.push(nums[i]) #滑动窗口前加入最后面的元素
result.append(que.front()) #记录对应的最大值
return result
解法二:直接用单调队列
from collections import deque
class Solution:
def maxSlidingWindow(self, nums: List[int], k: int) -> List[int]:
max_list = [] # 结果集合
kept_nums = deque() # 单调队列
for i in range(len(nums)):
update_kept_nums(kept_nums, nums[i]) # 右侧新元素加入
if i >= k and nums[i - k] == kept_nums[0]: # 左侧旧元素如果等于单调队列头元素,需要移除头元素
kept_nums.popleft()
if i >= k - 1:
max_list.append(kept_nums[0])
return max_list
def update_kept_nums(kept_nums, num): # num 是新加入的元素
# 所有小于新元素的队列尾部元素,在新元素出现后,都是没有价值的,都需要被移除
while kept_nums and num > kept_nums[-1]:
kept_nums.pop()
kept_nums.append(num)
Go解法
// 封装单调队列的方式解题
type MyQueue struct {
queue []int
}
func NewMyQueue() *MyQueue {
return &MyQueue{
queue: make([]int, 0),
}
}
func (m *MyQueue) Front() int {
return m.queue[0]
}
func (m *MyQueue) Back() int {
return m.queue[len(m.queue)-1]
}
func (m *MyQueue) Empty() bool {
return len(m.queue) == 0
}
func (m *MyQueue) Push(val int) {
for !m.Empty() && val > m.Back() {
m.queue = m.queue[:len(m.queue)-1]
}
m.queue = append(m.queue, val)
}
func (m *MyQueue) Pop(val int) {
if !m.Empty() && val == m.Front() {
m.queue = m.queue[1:]
}
}
func maxSlidingWindow(nums []int, k int) []int {
queue := NewMyQueue()
length := len(nums)
res := make([]int, 0)
// 先将前k个元素放入队列
for i := 0; i < k; i++ {
queue.Push(nums[i])
}
// 记录前k个元素的最大值
res = append(res, queue.Front())
for i := k; i < length; i++ {
// 滑动窗口移除最前面的元素
queue.Pop(nums[i-k])
// 滑动窗口添加最后面的元素
queue.Push(nums[i])
// 记录最大值
res = append(res, queue.Front())
}
return res
}
优先队列
347. Top K Frequent Elements
Given an integer array nums and an integer k, return the k most frequent elements. You may return the answer in any order.
Example 1:
Input: nums = [1,1,1,2,2,3], k = 2
Output: [1,2]
Example 2:
Input: nums = [1], k = 1
Output: [1]
Constraints:
1 <= nums.length <= 10^5-10^4 <= nums[i] <= 10^4kis in the range[1, the number of unique elements in the array].- It is guaranteed that the answer is unique.
Follow up: Your algorithm's time complexity must be better than O(n log n), where n is the array's size.
思路
使用map存储,使用value调整堆结构
使用小顶堆,每次弹出堆顶元素
这道题目主要涉及如下三块内容:
- 要统计元素出现频率
- 对频率排序
- 找出前K个高频元素
首先统计元素出现的频率,这一类的问题可以使用map来进行统计。
然后是对频率进行排序,这里我们可以使用一种 容器适配器就是优先级队列。
什么是优先级队列呢?
其实就是一个披着队列外衣的堆,因为优先级队列对外接口只是从队头取元素,从队尾添加元素,再无其他取元素的方式,看起来就是一个队列。
而且优先级队列内部元素是自动依照元素的权值排列。那么它是如何有序排列的呢?
缺省情况下priority_queue利用max-heap(大顶堆)完成对元素的排序,这个大顶堆是以vector为表现形式的complete binary tree(完全二叉树)。
什么是堆呢?
堆是一棵完全二叉树,树中每个结点的值都不小于(或不大于)其左右孩子的值。 如果父亲结点是大于等于左右孩子就是大顶堆,小于等于左右孩子就是小顶堆。
所以大家经常说的大顶堆(堆头是最大元素),小顶堆(堆头是最小元素),如果懒得自己实现的话,就直接用priority_queue(优先级队列)就可以了,底层实现都是一样的,从小到大排就是小顶堆,从大到小排就是大顶堆。
本题我们就要使用优先级队列来对部分频率进行排序。
为什么不用快排呢, 使用快排要将map转换为vector的结构,然后对整个数组进行排序, 而这种场景下,我们其实只需要维护k个有序的序列就可以了,所以使用优先级队列是最优的。
此时要思考一下,是使用小顶堆呢,还是大顶堆?
有的同学一想,题目要求前 K 个高频元素,那么果断用大顶堆啊。
那么问题来了,定义一个大小为k的大顶堆,在每次移动更新大顶堆的时候,每次弹出都把最大的元素弹出去了,那么怎么保留下来前K个高频元素呢。
而且使用大顶堆就要把所有元素都进行排序,那能不能只排序k个元素呢?
所以我们要用小顶堆,因为要统计最大前k个元素,只有小顶堆每次将最小的元素弹出,最后小顶堆里积累的才是前k个最大元素。
寻找前k个最大元素流程如图所示:(图中的频率只有三个,所以正好构成一个大小为3的小顶堆,如果频率更多一些,则用这个小顶堆进行扫描)
C++优先队列
priority_queue 是 C++ 标准库中的一个容器适配器,用于实现优先队列。在优先队列中,元素按照优先级的顺序被排列,通常最小或最大元素可以在常数时间内被访问。以下是关于 priority_queue 的详细讲解,包括用法、重要函数和一个简单的示例。
- 引入头文件
要使用 priority_queue,需要包含头文件:
#include <queue>
- 基本特性
- 底层数据结构:
priority_queue通常基于堆(heap)实现,主要使用最大堆或最小堆。 - 默认排序:默认情况下,
priority_queue是最大堆,即优先级最高的元素在顶部。如果需要最小堆,可以使用自定义比较函数。
- 主要构造函数
priority_queue 的构造函数可以接受以下参数:
std::vector<T>,std::deque<T>:指定存储容器的类型(默认为std::vector)。- 自定义比较函数(可选):确定优先级的自定义比较器。
- 常用操作
priority_queue 支持以下常用操作:
push(const T& value):插入一个新的元素。pop():移除堆顶元素。top():返回堆顶元素(最大或最小)。empty():判断是否为空。size():返回元素个数。
- 使用示例
以下是一个简单的示例,演示如何使用 priority_queue:
#include <iostream>
#include <queue>
#include <vector>
int main() {
// 创建一个最大优先队列
std::priority_queue<int> maxHeap;
// 插入元素
maxHeap.push(10);
maxHeap.push(20);
maxHeap.push(15);
// 输出并移除堆顶元素
std::cout << "最大元素: " << maxHeap.top() << std::endl; // 输出 20
maxHeap.pop();
std::cout << "新的最大元素: " << maxHeap.top() << std::endl; // 输出 15
// 最小优先队列示例
std::priority_queue<int, std::vector<int>, std::greater<int>> minHeap;
// 插入元素
minHeap.push(10);
minHeap.push(20);
minHeap.push(15);
// 输出并移除堆顶元素
std::cout << "最小元素: " << minHeap.top() << std::endl; // 输出 10
minHeap.pop();
std::cout << "新的最小元素: " << minHeap.top() << std::endl; // 输出 15
return 0;
}
- 常见应用场景
优先队列常用于以下场景:
- 调度算法:比如任务调度。
- Dijkstra 算法:用于寻找最短路径时的优先队列。
- 贪心算法:在处理最优解的构造过程中管理元素的优先级。
总结
priority_queue 是一个强大的数据结构,能够以高效的方式管理具有优先级的元素。通过自定义比较器,你可以灵活地对元素的排列进行控制。如果你有任何具体问题或者需要更深入的解释,请告诉我!
C++解法
class Solution {
public:
// 小顶堆
class mycomparison {
public:
bool operator()(const pair<int, int>& lhs, const pair<int, int>& rhs) {
return lhs.second > rhs.second;
}
};
vector<int> topKFrequent(vector<int>& nums, int k) {
// 要统计元素出现频率
unordered_map<int, int> map; // map<nums[i],对应出现的次数>
for (int i = 0; i < nums.size(); i++) {
map[nums[i]]++;
}
// 对频率排序
// 定义一个小顶堆,大小为k
priority_queue<pair<int, int>, vector<pair<int, int>>, mycomparison> pri_que;
// 用固定大小为k的小顶堆,扫面所有频率的数值
for (unordered_map<int, int>::iterator it = map.begin(); it != map.end(); it++) {
pri_que.push(*it);
if (pri_que.size() > k) { // 如果堆的大小大于了K,则队列弹出,保证堆的大小一直为k
pri_que.pop();
}
}
// 找出前K个高频元素,因为小顶堆先弹出的是最小的,所以倒序来输出到数组
vector<int> result(k);
for (int i = k - 1; i >= 0; i--) {
result[i] = pri_que.top().first;
pri_que.pop();
}
return result;
}
};
- 时间复杂度: O(nlogk)
- 空间复杂度: O(n)
大家对这个比较运算在建堆时是如何应用的,为什么左大于右就会建立小顶堆,反而建立大顶堆比较困惑。
确实 例如我们在写快排的cmp函数的时候,return left>right 就是从大到小,return left<right 就是从小到大。
优先级队列的定义正好反过来了,可能和优先级队列的源码实现有关(我没有仔细研究),我估计是底层实现上优先队列队首指向后面,队尾指向最前面的缘故!
Java解法
/*Comparator接口说明:
* 返回负数,形参中第一个参数排在前面;返回正数,形参中第二个参数排在前面
* 对于队列:排在前面意味着往队头靠
* 对于堆(使用PriorityQueue实现):从队头到队尾按从小到大排就是最小堆(小顶堆),
* 从队头到队尾按从大到小排就是最大堆(大顶堆)--->队头元素相当于堆的根节点
* */
class Solution {
//解法1:基于大顶堆实现
public int[] topKFrequent1(int[] nums, int k) {
Map<Integer,Integer> map = new HashMap<>(); //key为数组元素值,val为对应出现次数
for (int num : nums) {
map.put(num, map.getOrDefault(num,0) + 1);
}
//在优先队列中存储二元组(num, cnt),cnt表示元素值num在数组中的出现次数
//出现次数按从队头到队尾的顺序是从大到小排,出现次数最多的在队头(相当于大顶堆)
PriorityQueue<int[]> pq = new PriorityQueue<>((pair1, pair2) -> pair2[1] - pair1[1]);
for (Map.Entry<Integer, Integer> entry : map.entrySet()) {//大顶堆需要对所有元素进行排序
pq.add(new int[]{entry.getKey(), entry.getValue()});
}
int[] ans = new int[k];
for (int i = 0; i < k; i++) { //依次从队头弹出k个,就是出现频率前k高的元素
ans[i] = pq.poll()[0];
}
return ans;
}
//解法2:基于小顶堆实现
public int[] topKFrequent2(int[] nums, int k) {
Map<Integer,Integer> map = new HashMap<>(); //key为数组元素值,val为对应出现次数
for (int num : nums) {
map.put(num, map.getOrDefault(num, 0) + 1);
}
//在优先队列中存储二元组(num, cnt),cnt表示元素值num在数组中的出现次数
//出现次数按从队头到队尾的顺序是从小到大排,出现次数最低的在队头(相当于小顶堆)
PriorityQueue<int[]> pq = new PriorityQueue<>((pair1, pair2) -> pair1[1] - pair2[1]);
for (Map.Entry<Integer, Integer> entry : map.entrySet()) { //小顶堆只需要维持k个元素有序
if (pq.size() < k) { //小顶堆元素个数小于k个时直接加
pq.add(new int[]{entry.getKey(), entry.getValue()});
} else {
if (entry.getValue() > pq.peek()[1]) { //当前元素出现次数大于小顶堆的根结点(这k个元素中出现次数最少的那个)
pq.poll(); //弹出队头(小顶堆的根结点),即把堆里出现次数最少的那个删除,留下的就是出现次数多的了
pq.add(new int[]{entry.getKey(), entry.getValue()});
}
}
}
int[] ans = new int[k];
for (int i = k - 1; i >= 0; i--) { //依次弹出小顶堆,先弹出的是堆的根,出现次数少,后面弹出的出现次数多
ans[i] = pq.poll()[0];
}
return ans;
}
}
简化版代码:
class Solution {
public int[] topKFrequent(int[] nums, int k) {
// 优先级队列,为了避免复杂 api 操作,pq 存储数组
// lambda 表达式设置优先级队列从大到小存储 o1 - o2 为从小到大,o2 - o1 反之
PriorityQueue<int[]> pq = new PriorityQueue<>((o1, o2) -> o1[1] - o2[1]);
int[] res = new int[k]; // 答案数组为 k 个元素
Map<Integer, Integer> map = new HashMap<>(); // 记录元素出现次数
for (int num : nums) map.put(num, map.getOrDefault(num, 0) + 1);
for (var x : map.entrySet()) { // entrySet 获取 k-v Set 集合
// 将 kv 转化成数组
int[] tmp = new int[2];
tmp[0] = x.getKey();
tmp[1] = x.getValue();
pq.offer(tmp);
// 下面的代码是根据小根堆实现的,我只保留优先队列的最后的k个,只要超出了k我就将最小的弹出,剩余的k个就是答案
if(pq.size() > k) {
pq.poll();
}
}
for (int i = 0; i < k; i++) {
res[i] = pq.poll()[0]; // 获取优先队列里的元素
}
return res;
}
}
Python解法
解法一:
#时间复杂度:O(nlogk)
#空间复杂度:O(n)
import heapq
class Solution:
def topKFrequent(self, nums: List[int], k: int) -> List[int]:
#要统计元素出现频率
map_ = {} #nums[i]:对应出现的次数
for i in range(len(nums)):
map_[nums[i]] = map_.get(nums[i], 0) + 1
#对频率排序
#定义一个小顶堆,大小为k
pri_que = [] #小顶堆
#用固定大小为k的小顶堆,扫描所有频率的数值
for key, freq in map_.items():
heapq.heappush(pri_que, (freq, key))
if len(pri_que) > k: #如果堆的大小大于了K,则队列弹出,保证堆的大小一直为k
heapq.heappop(pri_que)
#找出前K个高频元素,因为小顶堆先弹出的是最小的,所以倒序来输出到数组
result = [0] * k
for i in range(k-1, -1, -1):
result[i] = heapq.heappop(pri_que)[1]
return result
解法二:
class Solution:
def topKFrequent(self, nums: List[int], k: int) -> List[int]:
# 使用字典统计数字出现次数
time_dict = defaultdict(int)
for num in nums:
time_dict[num] += 1
# 更改字典,key为出现次数,value为相应的数字的集合
index_dict = defaultdict(list)
for key in time_dict:
index_dict[time_dict[key]].append(key)
# 排序
key = list(index_dict.keys())
key.sort()
result = []
cnt = 0
# 获取前k项
while key and cnt != k:
result += index_dict[key[-1]]
cnt += len(index_dict[key[-1]])
key.pop()
return result[0: k]
Go解法
//方法一:小顶堆
func topKFrequent(nums []int, k int) []int {
map_num:=map[int]int{}
//记录每个元素出现的次数
for _,item:=range nums{
map_num[item]++
}
h:=&IHeap{}
heap.Init(h)
//所有元素入堆,堆的长度为k
for key,value:=range map_num{
heap.Push(h,[2]int{key,value})
if h.Len()>k{
heap.Pop(h)
}
}
res:=make([]int,k)
//按顺序返回堆中的元素
for i:=0;i<k;i++{
res[k-i-1]=heap.Pop(h).([2]int)[0]
}
return res
}
//构建小顶堆
type IHeap [][2]int
func (h IHeap) Len()int {
return len(h)
}
func (h IHeap) Less (i,j int) bool {
return h[i][1]<h[j][1]
}
func (h IHeap) Swap(i,j int) {
h[i],h[j]=h[j],h[i]
}
func (h *IHeap) Push(x interface{}){
*h=append(*h,x.([2]int))
}
func (h *IHeap) Pop() interface{}{
old:=*h
n:=len(old)
x:=old[n-1]
*h=old[0:n-1]
return x
}
//方法二:利用O(nlogn)排序
func topKFrequent(nums []int, k int) []int {
ans:=[]int{}
map_num:=map[int]int{}
for _,item:=range nums {
map_num[item]++
}
for key,_:=range map_num{
ans=append(ans,key)
}
//核心思想:排序
//可以不用包函数,自己实现快排
sort.Slice(ans,func (a,b int)bool{
return map_num[ans[a]]>map_num[ans[b]]
})
return ans[:k]
}
二叉树
题目分类
题目分类大纲如下:
说到二叉树,大家对于二叉树其实都很熟悉了,本文呢我也不想教科书式的把二叉树的基础内容再啰嗦一遍,所以以下我讲的都是一些比较重点的内容。
相信只要耐心看完,都会有所收获。
二叉树的种类
在我们解题过程中二叉树有两种主要的形式:满二叉树和完全二叉树。
满二叉树
满二叉树:如果一棵二叉树只有度为0的结点和度为2的结点,并且度为0的结点在同一层上,则这棵二叉树为满二叉树。
如图所示:
这棵二叉树为满二叉树,也可以说深度为k,有2^k-1个节点的二叉树。
完全二叉树
什么是完全二叉树?
完全二叉树的定义如下:在完全二叉树中,除了最底层节点可能没填满外,其余每层节点数都达到最大值,并且最下面一层的节点都集中在该层最左边的若干位置。若最底层为第 h 层(h从1开始),则该层包含 1~ 2^(h-1) 个节点。
大家要自己看完全二叉树的定义,很多同学对完全二叉树其实不是真正的懂了。
我来举一个典型的例子如题:
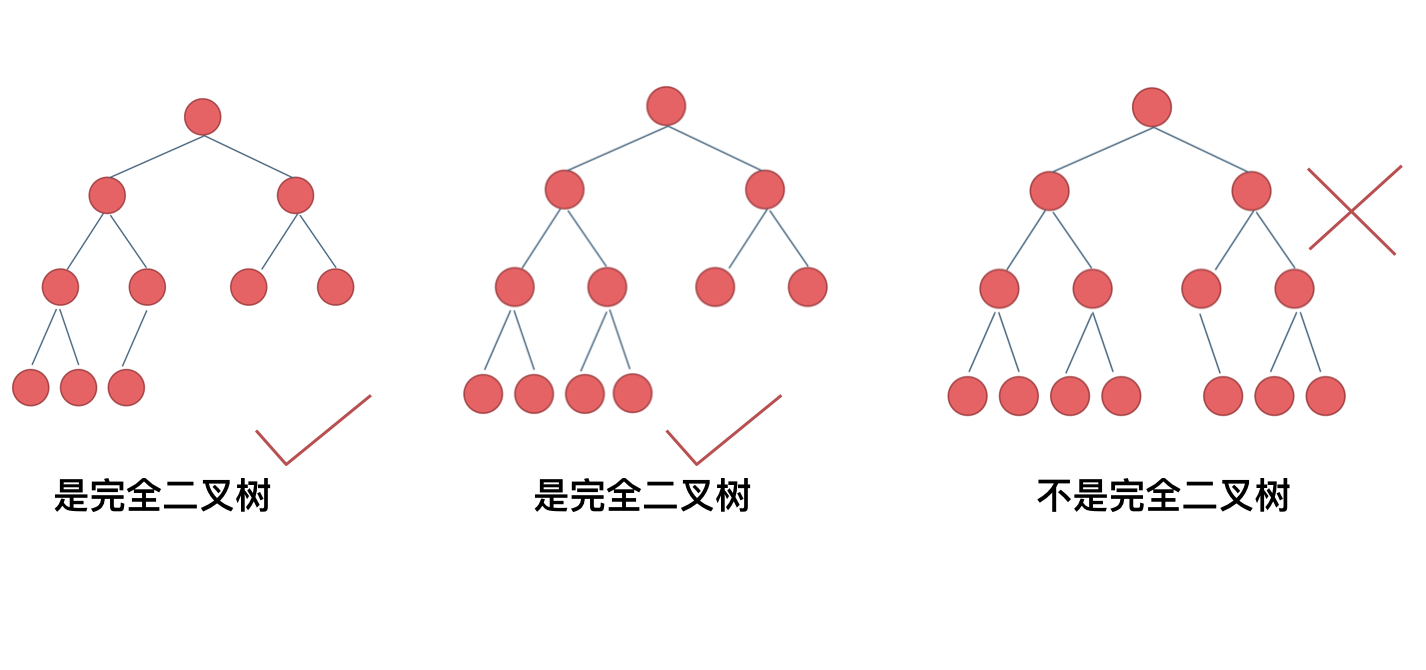
相信不少同学最后一个二叉树是不是完全二叉树都中招了。
之前我们刚刚讲过优先级队列其实是一个堆,堆就是一棵完全二叉树,同时保证父子节点的顺序关系。
二叉搜索树
前面介绍的树,都没有数值的,而二叉搜索树是有数值的了,二叉搜索树是一个有序树。
- 若它的左子树不空,则左子树上所有结点的值均小于它的根结点的值;
- 若它的右子树不空,则右子树上所有结点的值均大于它的根结点的值;
- 它的左、右子树也分别为二叉排序树
下面这两棵树都是搜索树
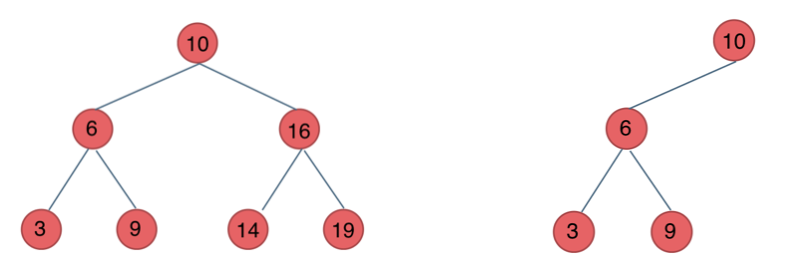
平衡二叉搜索树
平衡二叉搜索树:又被称为AVL(Adelson-Velsky and Landis)树,且具有以下性质:它是一棵空树或它的左右两个子树的高度差的绝对值不超过1,并且左右两个子树都是一棵平衡二叉树。
如图:
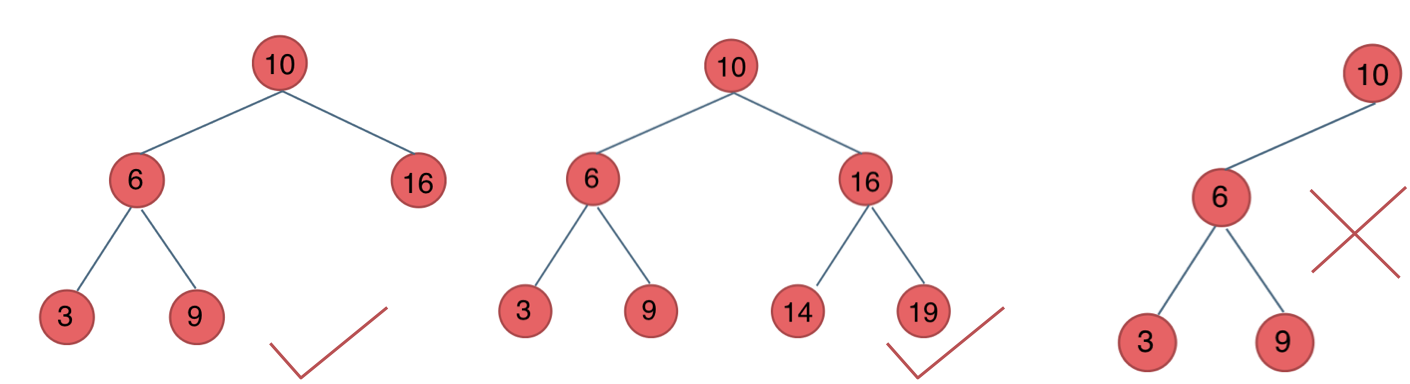
最后一棵 不是平衡二叉树,因为它的左右两个子树的高度差的绝对值超过了1。
C++中map、set、multimap,multiset的底层实现都是平衡二叉搜索树,所以map、set的增删操作时间时间复杂度是logn,注意我这里没有说unordered_map、unordered_set,unordered_map、unordered_set底层实现是哈希表。
所以大家使用自己熟悉的编程语言写算法,一定要知道常用的容器底层都是如何实现的,最基本的就是map、set等等,否则自己写的代码,自己对其性能分析都分析不清楚!
二叉树的存储方式
二叉树可以链式存储,也可以顺序存储。
那么链式存储方式就用指针, 顺序存储的方式就是用数组。
顾名思义就是顺序存储的元素在内存是连续分布的,而链式存储则是通过指针把分布在各个地址的节点串联一起。
链式存储如图:
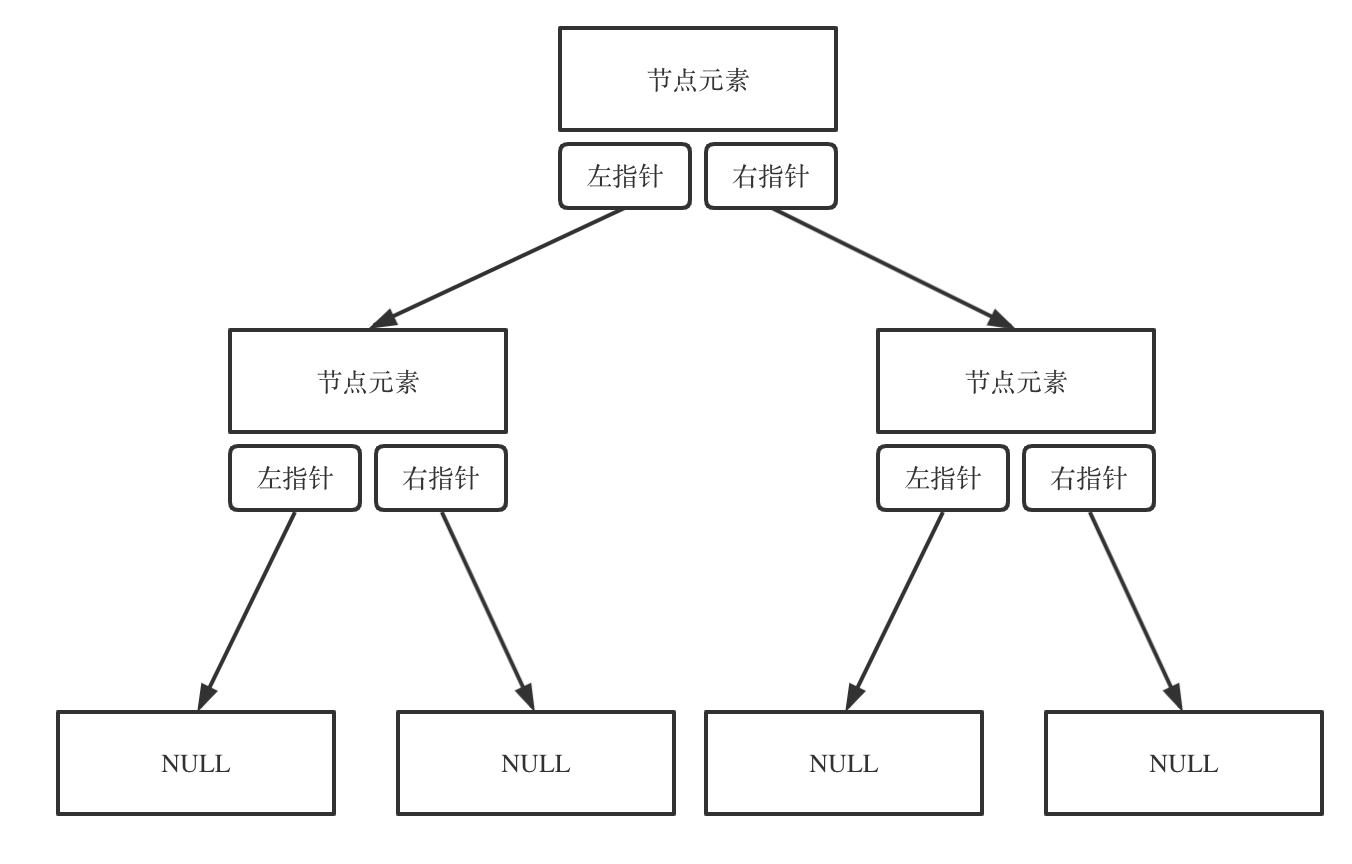
链式存储是大家很熟悉的一种方式,那么我们来看看如何顺序存储呢?
其实就是用数组来存储二叉树,顺序存储的方式如图:
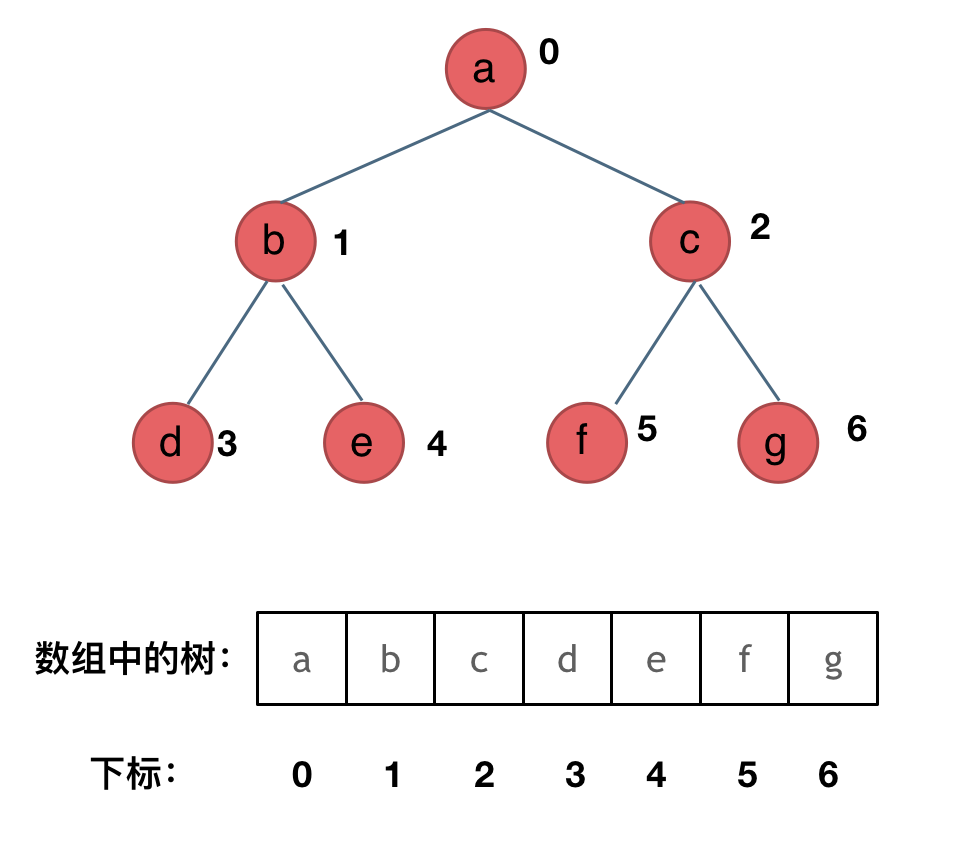
用数组来存储二叉树如何遍历的呢?
如果父节点的数组下标是 i,那么它的左孩子就是 i * 2 + 1,右孩子就是 i * 2 + 2。
但是用链式表示的二叉树,更有利于我们理解,所以一般我们都是用链式存储二叉树。
所以大家要了解,用数组依然可以表示二叉树。
二叉树的遍历方式
关于二叉树的遍历方式,要知道二叉树遍历的基本方式都有哪些。
一些同学用做了很多二叉树的题目了,可能知道前中后序遍历,可能知道层序遍历,但是却没有框架。
我这里把二叉树的几种遍历方式列出来,大家就可以一一串起来了。
二叉树主要有两种遍历方式:
- 深度优先遍历:先往深走,遇到叶子节点再往回走。
- 广度优先遍历:一层一层的去遍历。
这两种遍历是图论中最基本的两种遍历方式,后面在介绍图论的时候 还会介绍到。
那么从深度优先遍历和广度优先遍历进一步拓展,才有如下遍历方式:
- 深度优先遍历
- 前序遍历(递归法,迭代法)
- 中序遍历(递归法,迭代法)
- 后序遍历(递归法,迭代法)
- 广度优先遍历
- 层次遍历(迭代法)
在深度优先遍历中:有三个顺序,前中后序遍历, 有同学总分不清这三个顺序,经常搞混,我这里教大家一个技巧。
这里前中后,其实指的就是中间节点的遍历顺序,只要大家记住 前中后序指的就是中间节点的位置就可以了。
看如下中间节点的顺序,就可以发现,中间节点的顺序就是所谓的遍历方式
- 前序遍历:中左右
- 中序遍历:左中右
- 后序遍历:左右中
大家可以对着如下图,看看自己理解的前后中序有没有问题。
最后再说一说二叉树中深度优先和广度优先遍历实现方式,我们做二叉树相关题目,经常会使用递归的方式来实现深度优先遍历,也就是实现前中后序遍历,使用递归是比较方便的。
之前我们讲栈与队列的时候,就说过栈其实就是递归的一种实现结构,也就说前中后序遍历的逻辑其实都是可以借助栈使用递归的方式来实现的。
而广度优先遍历的实现一般使用队列来实现,这也是队列先进先出的特点所决定的,因为需要先进先出的结构,才能一层一层的来遍历二叉树。
这里其实我们又了解了栈与队列的一个应用场景了。
具体的实现我们后面都会讲的,这里大家先要清楚这些理论基础。
二叉树的定义
刚刚我们说过了二叉树有两种存储方式顺序存储,和链式存储,顺序存储就是用数组来存,这个定义没啥可说的,我们来看看链式存储的二叉树节点的定义方式。
C++代码如下:
struct TreeNode {
int val;
TreeNode *left;
TreeNode *right;
TreeNode(int x) : val(x), left(NULL), right(NULL) {}
};
Java
public class TreeNode {
int val;
TreeNode left;
TreeNode right;
TreeNode() {}
TreeNode(int val) { this.val = val; }
TreeNode(int val, TreeNode left, TreeNode right) {
this.val = val;
this.left = left;
this.right = right;
}
}
Python
class TreeNode:
def __init__(self, val, left = None, right = None):
self.val = val
self.left = left
self.right = right
Go
type TreeNode struct {
Val int
Left *TreeNode
Right *TreeNode
}
大家会发现二叉树的定义 和链表是差不多的,相对于链表 ,二叉树的节点里多了一个指针, 有两个指针,指向左右孩子。
这里要提醒大家要注意二叉树节点定义的书写方式。
在现场面试的时候面试官可能要求手写代码,所以数据结构的定义以及简单逻辑的代码一定要锻炼白纸写出来。
因为我们在刷leetcode的时候,节点的定义默认都定义好了,真到面试的时候,需要自己写节点定义的时候,有时候会一脸懵逼!
总结
二叉树是一种基础数据结构,在算法面试中都是常客,也是众多数据结构的基石。
本篇我们介绍了二叉树的种类、存储方式、遍历方式以及定义,比较全面的介绍了二叉树各个方面的重点,帮助大家扫一遍基础。
说到二叉树,就不得不说递归,很多同学对递归都是又熟悉又陌生,递归的代码一般很简短,但每次都是一看就会,一写就废。
二叉树前中后序遍历
- 说明
- 94. Binary Tree Inorder Traversal
- 144. Binary Tree Preorder Traversal
- 145. Binary Tree Postorder Traversal
说明
针对二叉树的问题,解题之前一定要想清楚究竟是前中后序遍历,还是层序遍历。
二叉树解题的大忌就是自己稀里糊涂的过了(因为这道题相对简单),但是也不知道自己是怎么遍历的。
这也是造成了二叉树的题目“一看就会,一写就废”的原因。
针对翻转二叉树,我给出了一种递归,三种迭代(两种模拟深度优先遍历,一种层序遍历)的写法,都是之前我们讲过的写法,融汇贯通一下而已。
大家一定也有自己的解法,但一定要成方法论,这样才能通用,才能举一反三!
递归思路
这次我们要好好谈一谈递归,为什么很多同学看递归算法都是“一看就会,一写就废”。
主要是对递归不成体系,没有方法论,每次写递归算法 ,都是靠玄学来写代码,代码能不能编过都靠运气。
本篇将介绍前后中序的递归写法,一些同学可能会感觉很简单,其实不然,我们要通过简单题目把方法论确定下来,有了方法论,后面才能应付复杂的递归。
这里帮助大家确定下来递归算法的三个要素。每次写递归,都按照这三要素来写,可以保证大家写出正确的递归算法!
-
确定递归函数的参数和返回值: 确定哪些参数是递归的过程中需要处理的,那么就在递归函数里加上这个参数, 并且还要明确每次递归的返回值是什么进而确定递归函数的返回类型。
-
确定终止条件: 写完了递归算法, 运行的时候,经常会遇到栈溢出的错误,就是没写终止条件或者终止条件写的不对,操作系统也是用一个栈的结构来保存每一层递归的信息,如果递归没有终止,操作系统的内存栈必然就会溢出。
-
确定单层递归的逻辑: 确定每一层递归需要处理的信息。在这里也就会重复调用自己来实现递归的过程。
好了,我们确认了递归的三要素,接下来就来练练手:
以下以前序遍历为例:
- 确定递归函数的参数和返回值:因为要打印出前序遍历节点的数值,所以参数里需要传入vector来放节点的数值,除了这一点就不需要再处理什么数据了也不需要有返回值,所以递归函数返回类型就是void,代码如下:
void traversal(TreeNode* cur, vector<int>& vec)
- 确定终止条件:在递归的过程中,如何算是递归结束了呢,当然是当前遍历的节点是空了,那么本层递归就要结束了,所以如果当前遍历的这个节点是空,就直接return,代码如下:
if (cur == NULL) return;
- 确定单层递归的逻辑:前序遍历是中左右的顺序,所以在单层递归的逻辑,是要先取中节点的数值,代码如下:
vec.push_back(cur->val); // 中
traversal(cur->left, vec); // 左
traversal(cur->right, vec); // 右
单层递归的逻辑就是按照中左右的顺序来处理的,这样二叉树的前序遍历,基本就写完了,再看一下完整代码:
前序遍历:
class Solution {
public:
void traversal(TreeNode* cur, vector<int>& vec) {
if (cur == NULL) return;
vec.push_back(cur->val); // 中
traversal(cur->left, vec); // 左
traversal(cur->right, vec); // 右
}
vector<int> preorderTraversal(TreeNode* root) {
vector<int> result;
traversal(root, result);
return result;
}
};
那么前序遍历写出来之后,中序和后序遍历就不难理解了,代码如下:
中序遍历:
void traversal(TreeNode* cur, vector<int>& vec) {
if (cur == NULL) return;
traversal(cur->left, vec); // 左
vec.push_back(cur->val); // 中
traversal(cur->right, vec); // 右
}
后序遍历:
void traversal(TreeNode* cur, vector<int>& vec) {
if (cur == NULL) return;
traversal(cur->left, vec); // 左
traversal(cur->right, vec); // 右
vec.push_back(cur->val); // 中
}
迭代思路
为什么可以用迭代法(非递归的方式)来实现二叉树的前后中序遍历呢?
我们在栈与队列:匹配问题都是栈的强项 (opens new window)中提到了,递归的实现就是:每一次递归调用都会把函数的局部变量、参数值和返回地址等压入调用栈中,然后递归返回的时候,从栈顶弹出上一次递归的各项参数,所以这就是递归为什么可以返回上一层位置的原因。
此时大家应该知道我们用栈也可以是实现二叉树的前后中序遍历了。
前序遍历(迭代法)
我们先看一下前序遍历。
前序遍历是中左右,每次先处理的是中间节点,那么先将根节点放入栈中,然后将右孩子加入栈,再加入左孩子。
为什么要先加入 右孩子,再加入左孩子呢? 因为这样出栈的时候才是中左右的顺序。
动画如下:

不难写出如下代码: (注意代码中空节点不入栈)
class Solution {
public:
vector<int> preorderTraversal(TreeNode* root) {
stack<TreeNode*> st;
vector<int> result;
if (root == NULL) return result;
st.push(root);
while (!st.empty()) {
TreeNode* node = st.top(); // 中
st.pop();
result.push_back(node->val);
if (node->right) st.push(node->right); // 右(空节点不入栈)
if (node->left) st.push(node->left); // 左(空节点不入栈)
}
return result;
}
};
此时会发现貌似使用迭代法写出前序遍历并不难,确实不难。
此时是不是想改一点前序遍历代码顺序就把中序遍历搞出来了?
其实还真不行!
但接下来,再用迭代法写中序遍历的时候,会发现套路又不一样了,目前的前序遍历的逻辑无法直接应用到中序遍历上。
中序遍历(迭代法)
为了解释清楚,我说明一下 刚刚在迭代的过程中,其实我们有两个操作:
- 处理:将元素放进result数组中
- 访问:遍历节点
分析一下为什么刚刚写的前序遍历的代码,不能和中序遍历通用呢,因为前序遍历的顺序是中左右,先访问的元素是中间节点,要处理的元素也是中间节点,所以刚刚才能写出相对简洁的代码,因为要访问的元素和要处理的元素顺序是一致的,都是中间节点。
那么再看看中序遍历,中序遍历是左中右,先访问的是二叉树顶部的节点,然后一层一层向下访问,直到到达树左面的最底部,再开始处理节点(也就是在把节点的数值放进result数组中),这就造成了处理顺序和访问顺序是不一致的。
那么在使用迭代法写中序遍历,就需要借用指针的遍历来帮助访问节点,栈则用来处理节点上的元素。
动画如下:
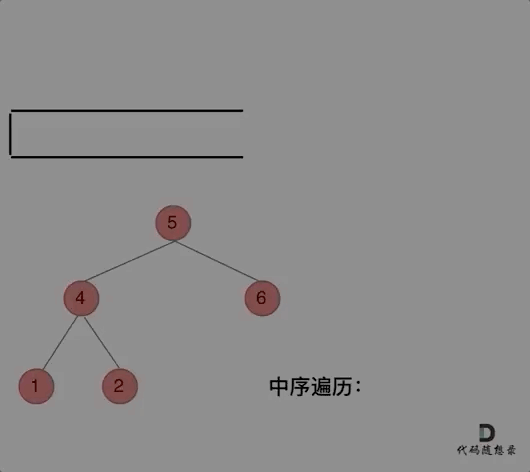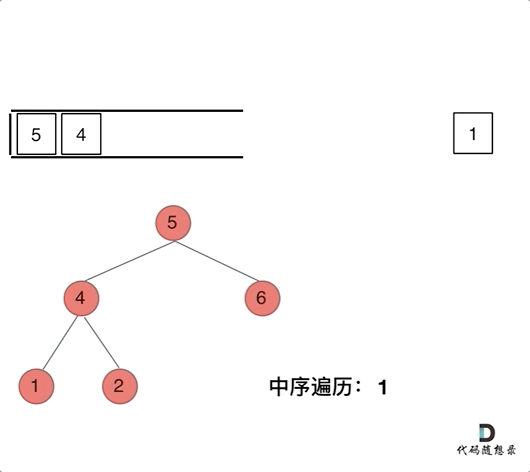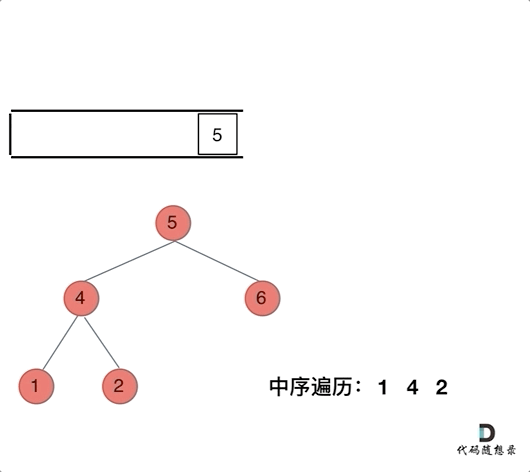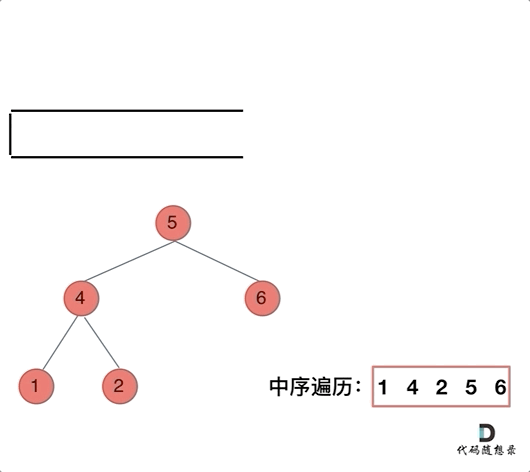
中序遍历,可以写出如下代码:
class Solution {
public:
vector<int> inorderTraversal(TreeNode* root) {
vector<int> result;
stack<TreeNode*> st;
TreeNode* cur = root;
while (cur != NULL || !st.empty()) {
if (cur != NULL) { // 指针来访问节点,访问到最底层
st.push(cur); // 将访问的节点放进栈
cur = cur->left; // 左
} else {
cur = st.top(); // 从栈里弹出的数据,就是要处理的数据(放进result数组里的数据)
st.pop();
result.push_back(cur->val); // 中
cur = cur->right; // 右
}
}
return result;
}
};
后序遍历(迭代法)
再来看后序遍历,先序遍历是中左右,后序遍历是左右中,那么我们只需要调整一下先序遍历的代码顺序,就变成中右左的遍历顺序,然后在反转result数组,输出的结果顺序就是左右中了,如下图:

所以后序遍历只需要前序遍历的代码稍作修改就可以了,代码如下:
class Solution {
public:
vector<int> postorderTraversal(TreeNode* root) {
stack<TreeNode*> st;
vector<int> result;
if (root == NULL) return result;
st.push(root);
while (!st.empty()) {
TreeNode* node = st.top();
st.pop();
result.push_back(node->val);
if (node->left) st.push(node->left); // 相对于前序遍历,这更改一下入栈顺序 (空节点不入栈)
if (node->right) st.push(node->right); // 空节点不入栈
}
reverse(result.begin(), result.end()); // 将结果反转之后就是左右中的顺序了
return result;
}
};
总结
此时我们用迭代法写出了二叉树的前后中序遍历,大家可以看出前序和中序是完全两种代码风格,并不像递归写法那样代码稍做调整,就可以实现前后中序。
这是因为前序遍历中访问节点(遍历节点)和处理节点(将元素放进result数组中)可以同步处理,但是中序就无法做到同步!
上面这句话,可能一些同学不太理解,建议自己亲手用迭代法,先写出来前序,再试试能不能写出中序,就能理解了。
那么问题又来了,难道二叉树前后中序遍历的迭代法实现,就不能风格统一么(即前序遍历改变代码顺序就可以实现中序 和 后序)?
94. Binary Tree Inorder Traversal
Given the root of a binary tree, return the inorder traversal of its nodes' values.
Example 1:
Input: root = [1,null,2,3]
Output: [1,3,2]
Explanation:
Example 2:
Input: root = [1,2,3,4,5,null,8,null,null,6,7,9]
Output: [4,2,6,5,7,1,3,9,8]
Explanation:
Example 3:
Input: root = []
Output: []
Example 4:
Input: root = [1]
Output: [1]
Constraints:
- The number of nodes in the tree is in the range
[0, 100]. -100 <= Node.val <= 100
Follow up: Recursive solution is trivial, could you do it iteratively?
C++解法
迭代
class Solution {
public:
vector<int> inorderTraversal(TreeNode* root) {
vector<int> result;
stack<TreeNode*> st;
TreeNode* cur = root;
while (cur != NULL || !st.empty()) {
if (cur != NULL) { // 指针来访问节点,访问到最底层
st.push(cur); // 将访问的节点放进栈
cur = cur->left; // 左
} else {
cur = st.top(); // 从栈里弹出的数据,就是要处理的数据(放进result数组里的数据)
st.pop();
result.push_back(cur->val); // 中
cur = cur->right; // 右
}
}
return result;
}
};
Java解法
迭代
// 中序遍历顺序: 左-中-右 入栈顺序: 左-右
class Solution {
public List<Integer> inorderTraversal(TreeNode root) {
List<Integer> result = new ArrayList<>();
if (root == null){
return result;
}
Stack<TreeNode> stack = new Stack<>();
TreeNode cur = root;
while (cur != null || !stack.isEmpty()){
if (cur != null){
stack.push(cur);
cur = cur.left;
}else{
cur = stack.pop();
result.add(cur.val);
cur = cur.right;
}
}
return result;
}
}
Python3解法
# 中序遍历-迭代-LC94_二叉树的中序遍历
class Solution:
def inorderTraversal(self, root: TreeNode) -> List[int]:
if not root:
return []
stack = [] # 不能提前将root节点加入stack中
result = []
cur = root
while cur or stack:
# 先迭代访问最底层的左子树节点
if cur:
stack.append(cur)
cur = cur.left
# 到达最左节点后处理栈顶节点
else:
cur = stack.pop()
result.append(cur.val)
# 取栈顶元素右节点
cur = cur.right
return result
Go解法
迭代法中序遍历
func inorderTraversal(root *TreeNode) []int {
ans := []int{}
if root == nil {
return ans
}
st := list.New()
cur := root
for cur != nil || st.Len() > 0 {
if cur != nil {
st.PushBack(cur)
cur = cur.Left
} else {
cur = st.Remove(st.Back()).(*TreeNode)
ans = append(ans, cur.Val)
cur = cur.Right
}
}
return ans
}
144. Binary Tree Preorder Traversal
Given the root of a binary tree, return the preorder traversal of its nodes' values.
Example 1:
Input: root = [1,null,2,3]
Output: [1,2,3]
Explanation:
Example 2:
Input: root = [1,2,3,4,5,null,8,null,null,6,7,9]
Output: [1,2,4,5,6,7,3,8,9]
Explanation:
Example 3:
Input: root = []
Output: []
Example 4:
Input: root = [1]
Output: [1]
Constraints:
- The number of nodes in the tree is in the range
[0, 100]. -100 <= Node.val <= 100
Follow up: Recursive solution is trivial, could you do it iteratively?
C++解法
递归
class Solution {
public:
void traversal(TreeNode* cur, vector<int>& vec) {
if (cur == NULL) return;
vec.push_back(cur->val); // 中
traversal(cur->left, vec); // 左
traversal(cur->right, vec); // 右
}
vector<int> preorderTraversal(TreeNode* root) {
vector<int> result;
traversal(root, result);
return result;
}
};
迭代
class Solution {
public:
vector<int> preorderTraversal(TreeNode* root) {
stack<TreeNode*> st;
vector<int> result;
if (root == NULL) return result;
st.push(root);
while (!st.empty()) {
TreeNode* node = st.top(); // 中
st.pop();
result.push_back(node->val);
if (node->right) st.push(node->right); // 右(空节点不入栈)
if (node->left) st.push(node->left); // 左(空节点不入栈)
}
return result;
}
};
Java解法
递归
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode() {}
* TreeNode(int val) { this.val = val; }
* TreeNode(int val, TreeNode left, TreeNode right) {
* this.val = val;
* this.left = left;
* this.right = right;
* }
* }
*/
class Solution {
public void traverse(TreeNode root, List<Integer> result){
if(root == null){
return;
}
result.add(root.val);
traverse(root.left, result);
traverse(root.right, result);
}
public List<Integer> preorderTraversal(TreeNode root) {
List<Integer> result = new ArrayList<>();
traverse(root, result);
return result;
}
}
迭代
// 前序遍历顺序:中-左-右,入栈顺序:中-右-左
class Solution {
public List<Integer> preorderTraversal(TreeNode root) {
List<Integer> result = new ArrayList<>();
if (root == null){
return result;
}
Stack<TreeNode> stack = new Stack<>();
stack.push(root);
while (!stack.isEmpty()){
TreeNode node = stack.pop();
result.add(node.val);
if (node.right != null){
stack.push(node.right);
}
if (node.left != null){
stack.push(node.left);
}
}
return result;
}
}
Python3解法
# 前序遍历-迭代-LC144_二叉树的前序遍历
class Solution:
def preorderTraversal(self, root: TreeNode) -> List[int]:
# 根节点为空则返回空列表
if not root:
return []
stack = [root]
result = []
while stack:
node = stack.pop()
# 中节点先处理
result.append(node.val)
# 右孩子先入栈
if node.right:
stack.append(node.right)
# 左孩子后入栈
if node.left:
stack.append(node.left)
return result
Go解法
迭代法前序遍历
func preorderTraversal(root *TreeNode) []int {
ans := []int{}
if root == nil {
return ans
}
st := list.New()
st.PushBack(root)
for st.Len() > 0 {
node := st.Remove(st.Back()).(*TreeNode)
ans = append(ans, node.Val)
if node.Right != nil {
st.PushBack(node.Right)
}
if node.Left != nil {
st.PushBack(node.Left)
}
}
return ans
}
145. Binary Tree Postorder Traversal
Given the root of a binary tree, return the postorder traversal of its nodes' values.
Example 1:
Input: root = [1,null,2,3]
Output: [3,2,1]
Explanation:
Example 2:
Input: root = [1,2,3,4,5,null,8,null,null,6,7,9]
Output: [4,6,7,5,2,9,8,3,1]
Explanation:
Example 3:
Input: root = []
Output: []
Example 4:
Input: root = [1]
Output: [1]
Constraints:
- The number of the nodes in the tree is in the range
[0, 100]. -100 <= Node.val <= 100
Follow up: Recursive solution is trivial, could you do it iteratively?
C++解法
class Solution {
public:
vector<int> postorderTraversal(TreeNode* root) {
stack<TreeNode*> st;
vector<int> result;
if (root == NULL) return result;
st.push(root);
while (!st.empty()) {
TreeNode* node = st.top();
st.pop();
result.push_back(node->val);
if (node->left) st.push(node->left); // 相对于前序遍历,这更改一下入栈顺序 (空节点不入栈)
if (node->right) st.push(node->right); // 空节点不入栈
}
reverse(result.begin(), result.end()); // 将结果反转之后就是左右中的顺序了
return result;
}
};
Java解法
迭代
// 后序遍历顺序 左-右-中 入栈顺序:中-左-右 出栈顺序:中-右-左, 最后翻转结果
class Solution {
public List<Integer> postorderTraversal(TreeNode root) {
List<Integer> result = new ArrayList<>();
if (root == null){
return result;
}
Stack<TreeNode> stack = new Stack<>();
stack.push(root);
while (!stack.isEmpty()){
TreeNode node = stack.pop();
result.add(node.val);
if (node.left != null){
stack.push(node.left);
}
if (node.right != null){
stack.push(node.right);
}
}
Collections.reverse(result);
return result;
}
}
Python3解法
# 后序遍历-迭代-LC145_二叉树的后序遍历
class Solution:
def postorderTraversal(self, root: TreeNode) -> List[int]:
if not root:
return []
stack = [root]
result = []
while stack:
node = stack.pop()
# 中节点先处理
result.append(node.val)
# 左孩子先入栈
if node.left:
stack.append(node.left)
# 右孩子后入栈
if node.right:
stack.append(node.right)
# 将最终的数组翻转
return result[::-1]
Go解法
迭代法后序遍历
func postorderTraversal(root *TreeNode) []int {
ans := []int{}
if root == nil {
return ans
}
st := list.New()
st.PushBack(root)
for st.Len() > 0 {
node := st.Remove(st.Back()).(*TreeNode)
ans = append(ans, node.Val)
if node.Left != nil {
st.PushBack(node.Left)
}
if node.Right != nil {
st.PushBack(node.Right)
}
}
reverse(ans)
return ans
}
func reverse(a []int) {
l, r := 0, len(a) - 1
for l < r {
a[l], a[r] = a[r], a[l]
l, r = l+1, r-1
}
}
二叉树层序遍历
- 102. Binary Tree Level Order Traversal
- 107. Binary Tree Level Order Traversal II
- 637. Average of Levels in Binary Tree
- 103. Binary Tree Zigzag Level Order Traversal
- 199. Binary Tree Right Side View
- 515. Find Largest Value in Each Tree Row
- 116. Populating Next Right Pointers in Each Node
- 117. Populating Next Right Pointers in Each Node II(同上)
- 104. Maximum Depth of Binary Tree
- 111. Minimum Depth of Binary Tree
102. Binary Tree Level Order Traversal
Given the root of a binary tree, return the level order traversal of its nodes' values. (i.e., from left to right, level by level).
Example 1:

Input: root = [3,9,20,null,null,15,7]
Output: [[3],[9,20],[15,7]]
Example 2:
Input: root = [1]
Output: [[1]]
Example 3:
Input: root = []
Output: []
Constraints:
- The number of nodes in the tree is in the range
[0, 2000]. -1000 <= Node.val <= 1000
思路
层序遍历一个二叉树。就是从左到右一层一层的去遍历二叉树。这种遍历的方式和我们之前讲过的都不太一样。
需要借用一个辅助数据结构即队列来实现,队列先进先出,符合一层一层遍历的逻辑,而用栈先进后出适合模拟深度优先遍历也就是递归的逻辑。
而这种层序遍历方式就是图论中的广度优先遍历,只不过我们应用在二叉树上。
使用队列实现二叉树广度优先遍历,动画如下:
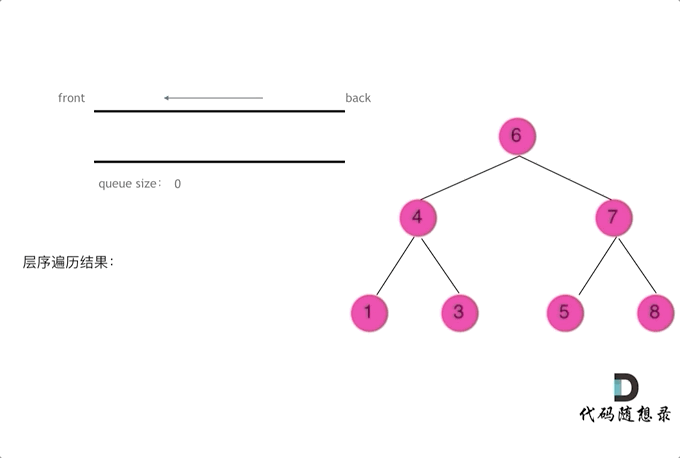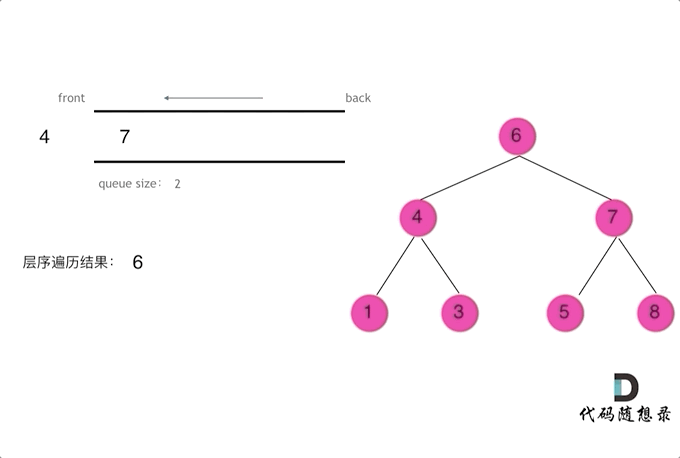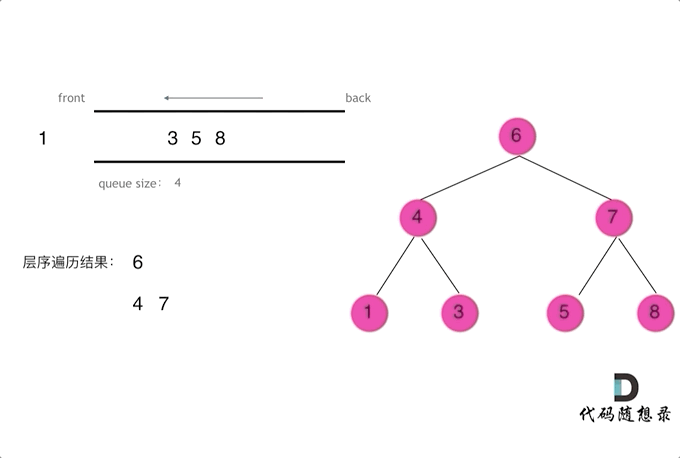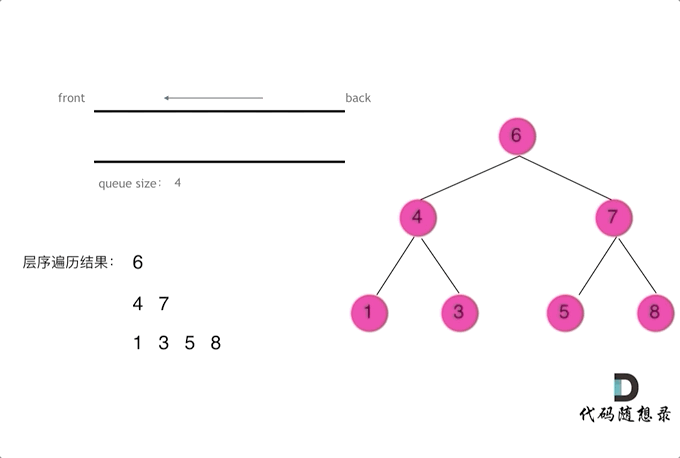
这样就实现了层序从左到右遍历二叉树。
代码如下:这份代码也可以作为二叉树层序遍历的模板,打十个就靠它了。
C++解法
使用队列实现二叉树广度优先遍历
class Solution {
public:
vector<vector<int>> levelOrder(TreeNode* root) {
queue<TreeNode*> que;
if (root != NULL) que.push(root);
vector<vector<int>> result;
while (!que.empty()) {
int size = que.size();
vector<int> vec;
// 这里一定要使用固定大小size,不要使用que.size(),因为que.size是不断变化的
for (int i = 0; i < size; i++) {
TreeNode* node = que.front();
que.pop();
vec.push_back(node->val);
if (node->left) que.push(node->left);
if (node->right) que.push(node->right);
}
result.push_back(vec);
}
return result;
}
};
递归法:
# 递归法
class Solution {
public:
void order(TreeNode* cur, vector<vector<int>>& result, int depth)
{
if (cur == nullptr) return;
if (result.size() == depth) result.push_back(vector<int>());
result[depth].push_back(cur->val);
order(cur->left, result, depth + 1);
order(cur->right, result, depth + 1);
}
vector<vector<int>> levelOrder(TreeNode* root) {
vector<vector<int>> result;
int depth = 0;
order(root, result, depth);
return result;
}
};
Java解法
// 102.二叉树的层序遍历
class Solution {
public List<List<Integer>> resList = new ArrayList<List<Integer>>();
public List<List<Integer>> levelOrder(TreeNode root) {
//checkFun01(root,0);
checkFun02(root);
return resList;
}
//BFS--递归方式
public void checkFun01(TreeNode node, Integer deep) {
if (node == null) return;
deep++;
if (resList.size() < deep) {
//当层级增加时,list的Item也增加,利用list的索引值进行层级界定
List<Integer> item = new ArrayList<Integer>();
resList.add(item);
}
resList.get(deep - 1).add(node.val);
checkFun01(node.left, deep);
checkFun01(node.right, deep);
}
//BFS--迭代方式--借助队列
public void checkFun02(TreeNode node) {
if (node == null) return;
Queue<TreeNode> que = new LinkedList<TreeNode>();
que.offer(node);
while (!que.isEmpty()) {
List<Integer> itemList = new ArrayList<Integer>();
int len = que.size();
while (len > 0) {
TreeNode tmpNode = que.poll();
itemList.add(tmpNode.val);
if (tmpNode.left != null) que.offer(tmpNode.left);
if (tmpNode.right != null) que.offer(tmpNode.right);
len--;
}
resList.add(itemList);
}
}
}
Python3解法
# 利用长度法
# Definition for a binary tree node.
# class TreeNode:
# def __init__(self, val=0, left=None, right=None):
# self.val = val
# self.left = left
# self.right = right
class Solution:
def levelOrder(self, root: Optional[TreeNode]) -> List[List[int]]:
if not root:
return []
queue = collections.deque([root])
result = []
while queue:
level = []
for _ in range(len(queue)):
cur = queue.popleft()
level.append(cur.val)
if cur.left:
queue.append(cur.left)
if cur.right:
queue.append(cur.right)
result.append(level)
return result
Go解法
/**
1. 二叉树的递归遍历
*/
func levelOrder(root *TreeNode) [][]int {
arr := [][]int{}
depth := 0
var order func(root *TreeNode, depth int)
order = func(root *TreeNode, depth int) {
if root == nil {
return
}
if len(arr) == depth {
arr = append(arr, []int{})
}
arr[depth] = append(arr[depth], root.Val)
order(root.Left, depth+1)
order(root.Right, depth+1)
}
order(root, depth)
return arr
}
107. Binary Tree Level Order Traversal II
Given the root of a binary tree, return the bottom-up level order traversal of its nodes' values. (i.e., from left to right, level by level from leaf to root).
Example 1:
Input: root = [3,9,20,null,null,15,7]
Output: [[15,7],[9,20],[3]]
Example 2:
Input: root = [1]
Output: [[1]]
Example 3:
Input: root = []
Output: []
Constraints:
- The number of nodes in the tree is in the range
[0, 2000]. -1000 <= Node.val <= 1000
思路
在上面基础上反转下即可
C++解法
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode() : val(0), left(nullptr), right(nullptr) {}
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
* };
*/
class Solution {
public:
vector<vector<int>> levelOrderBottom(TreeNode* root) {
queue<TreeNode*> que;
vector<vector<int>> result;
if(root == NULL) return result;
que.push(root);
while(!que.empty()){
vector<int> level;
int size = que.size();
for(int i = 0; i < size; i++){
TreeNode* cur = que.front();
level.push_back(cur->val);
que.pop();
if(cur->left) que.push(cur->left);
if(cur->right) que.push(cur->right);
}
result.push_back(level);
}
reverse(result.begin(), result.end());
return result;
}
};
637. Average of Levels in Binary Tree
Given the root of a binary tree, return the average value of the nodes on each level in the form of an array. Answers within 10-5 of the actual answer will be accepted.
Example 1:
Input: root = [3,9,20,null,null,15,7]
Output: [3.00000,14.50000,11.00000]
Explanation: The average value of nodes on level 0 is 3, on level 1 is 14.5, and on level 2 is 11.
Hence return [3, 14.5, 11].
Example 2:
Input: root = [3,9,20,15,7]
Output: [3.00000,14.50000,11.00000]
Constraints:
- The number of nodes in the tree is in the range
[1, 10^4]. -2^31 <= Node.val <= 2^31 - 1
思路
每层遍历时就计算下结果
C++解法
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode() : val(0), left(nullptr), right(nullptr) {}
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
* };
*/
class Solution {
public:
vector<double> averageOfLevels(TreeNode* root) {
vector<double> result;
queue<TreeNode*> que;
if(root == NULL) return result;
que.push(root);
while(!que.empty()){
double sum = 0.0;
int size = que.size();
for(int i = 0; i < size; i++){
TreeNode* cur = que.front();
que.pop();
sum += cur->val;
if(cur->left) que.push(cur->left);
if(cur->right) que.push(cur->right);
}
result.push_back(sum / size);
}
return result;
}
};
103. Binary Tree Zigzag Level Order Traversal
Given the root of a binary tree, return the zigzag level order traversal of its nodes' values. (i.e., from left to right, then right to left for the next level and alternate between).
Example 1:
Input: root = [3,9,20,null,null,15,7]
Output: [[3],[20,9],[15,7]]
Example 2:
Input: root = [1]
Output: [[1]]
Example 3:
Input: root = []
Output: []
Constraints:
- The number of nodes in the tree is in the range
[0, 2000]. -100 <= Node.val <= 100
思路
添加状态变量level判断是否需要反转,然后把每层遍历结果加入result
C++代码
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode() : val(0), left(nullptr), right(nullptr) {}
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
* };
*/
class Solution {
public:
vector<vector<int>> zigzagLevelOrder(TreeNode* root) {
queue<TreeNode*> que;
vector<vector<int>> result;
if(root == NULL) return result;
que.push(root);
int level = 0;
while(!que.empty()){
vector<int> nums;
int size = que.size();
for(int i = 0; i < size; i++){
TreeNode* cur = que.front();
nums.push_back(cur->val);
que.pop();
if(cur->left) que.push(cur->left);
if(cur->right) que.push(cur->right);
}
if(level % 2 == 1)
reverse(nums.begin(), nums.end());
level++;
result.push_back(nums);
}
return result;
}
};
199. Binary Tree Right Side View
Description
Given the root of a binary tree, imagine yourself standing on the right side of it, return the values of the nodes you can see ordered from top to bottom.
Example 1:

Input: root = [1,2,3,null,5,null,4]
Output: [1,3,4]
Example 2:
Input: root = [1,null,3]
Output: [1,3]
Example 3:
Input: root = []
Output: []
Constraints:
- The number of nodes in the tree is in the range
[0, 100]. -100 <= Node.val <= 100
思路
层次遍历,每层最后一个节点
由于树的形状无法提前知晓,不可能设计出优于 O(n) 的算法。因此,我们应该试着寻找线性时间解。带着这个想法,我们来考虑一些同等有效的方案。
方法一:深度优先搜索
思路
我们对树进行深度优先搜索,在搜索过程中,我们总是先访问右子树。那么对于每一层来说,我们在这层见到的第一个结点一定是最右边的结点。
算法
这样一来,我们可以存储在每个深度访问的第一个结点,一旦我们知道了树的层数,就可以得到最终的结果数组。
上图表示了问题的一个实例。红色结点自上而下组成答案,边缘以访问顺序标号。
复杂度分析
时间复杂度 : O(n)。深度优先搜索最多访问每个结点一次,因此是线性复杂度。
空间复杂度 : O(n)。最坏情况下,栈内会包含接近树高度的结点数量,占用 O(n) 的空间。
方法二:广度优先搜索
思路
我们可以对二叉树进行层次遍历,那么对于每层来说,最右边的结点一定是最后被遍历到的。二叉树的层次遍历可以用广度优先搜索实现。
算法
执行广度优先搜索,左结点排在右结点之前,这样,我们对每一层都从左到右访问。因此,只保留每个深度最后访问的结点,我们就可以在遍历完整棵树后得到每个深度最右的结点。除了将栈改成队列,并去除了 rightmost_value_at_depth 之前的检查外,算法没有别的改动。
上图表示了同一个示例,红色结点自上而下组成答案,边缘以访问顺序标号。
复杂度分析
时间复杂度 : O(n)。 每个节点最多进队列一次,出队列一次,因此广度优先搜索的复杂度为线性。
空间复杂度 : O(n)。每个节点最多进队列一次,所以队列长度最大不不超过 n,所以这里的空间代价为 O(n)。
作者:力扣官方题解
链接: https://leetcode.cn/problems/binary-tree-right-side-view/solutions/213494/er-cha-shu-de-you-shi-tu-by-leetcode-solution/
来源:力扣(LeetCode)
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
C++ 解法
dfs
class Solution {
public:
vector<int> rightSideView(TreeNode* root) {
unordered_map<int, int> rightmostValueAtDepth;
int max_depth = -1;
stack<TreeNode*> nodeStack;
stack<int> depthStack;
nodeStack.push(root);
depthStack.push(0);
while (!nodeStack.empty()) {
TreeNode* node = nodeStack.top();nodeStack.pop();
int depth = depthStack.top();depthStack.pop();
if (node != NULL) {
// 维护二叉树的最大深度
max_depth = max(max_depth, depth);
// 如果不存在对应深度的节点我们才插入
if (rightmostValueAtDepth.find(depth) == rightmostValueAtDepth.end()) {
rightmostValueAtDepth[depth] = node -> val;
}
nodeStack.push(node -> left);
nodeStack.push(node -> right);
depthStack.push(depth + 1);
depthStack.push(depth + 1);
}
}
vector<int> rightView;
for (int depth = 0; depth <= max_depth; ++depth) {
rightView.push_back(rightmostValueAtDepth[depth]);
}
return rightView;
}
};
bfs
class Solution {
public:
vector<int> rightSideView(TreeNode* root) {
unordered_map<int, int> rightmostValueAtDepth;
int max_depth = -1;
queue<TreeNode*> nodeQueue;
queue<int> depthQueue;
nodeQueue.push(root);
depthQueue.push(0);
while (!nodeQueue.empty()) {
TreeNode* node = nodeQueue.front();nodeQueue.pop();
int depth = depthQueue.front();depthQueue.pop();
if (node != NULL) {
// 维护二叉树的最大深度
max_depth = max(max_depth, depth);
// 由于每一层最后一个访问到的节点才是我们要的答案,因此不断更新对应深度的信息即可
rightmostValueAtDepth[depth] = node -> val;
nodeQueue.push(node -> left);
nodeQueue.push(node -> right);
depthQueue.push(depth + 1);
depthQueue.push(depth + 1);
}
}
vector<int> rightView;
for (int depth = 0; depth <= max_depth; ++depth) {
rightView.push_back(rightmostValueAtDepth[depth]);
}
return rightView;
}
};
Java 解法
dfs
class Solution {
public List<Integer> rightSideView(TreeNode root) {
Map<Integer, Integer> rightmostValueAtDepth = new HashMap<Integer, Integer>();
int max_depth = -1;
Deque<TreeNode> nodeStack = new LinkedList<TreeNode>();
Deque<Integer> depthStack = new LinkedList<Integer>();
nodeStack.push(root);
depthStack.push(0);
while (!nodeStack.isEmpty()) {
TreeNode node = nodeStack.pop();
int depth = depthStack.pop();
if (node != null) {
// 维护二叉树的最大深度
max_depth = Math.max(max_depth, depth);
// 如果不存在对应深度的节点我们才插入
if (!rightmostValueAtDepth.containsKey(depth)) {
rightmostValueAtDepth.put(depth, node.val);
}
nodeStack.push(node.left);
nodeStack.push(node.right);
depthStack.push(depth + 1);
depthStack.push(depth + 1);
}
}
List<Integer> rightView = new ArrayList<Integer>();
for (int depth = 0; depth <= max_depth; depth++) {
rightView.add(rightmostValueAtDepth.get(depth));
}
return rightView;
}
}
bfs
class Solution {
public List<Integer> rightSideView(TreeNode root) {
Map<Integer, Integer> rightmostValueAtDepth = new HashMap<Integer, Integer>();
int max_depth = -1;
Queue<TreeNode> nodeQueue = new LinkedList<TreeNode>();
Queue<Integer> depthQueue = new LinkedList<Integer>();
nodeQueue.add(root);
depthQueue.add(0);
while (!nodeQueue.isEmpty()) {
TreeNode node = nodeQueue.remove();
int depth = depthQueue.remove();
if (node != null) {
// 维护二叉树的最大深度
max_depth = Math.max(max_depth, depth);
// 由于每一层最后一个访问到的节点才是我们要的答案,因此不断更新对应深度的信息即可
rightmostValueAtDepth.put(depth, node.val);
nodeQueue.add(node.left);
nodeQueue.add(node.right);
depthQueue.add(depth + 1);
depthQueue.add(depth + 1);
}
}
List<Integer> rightView = new ArrayList<Integer>();
for (int depth = 0; depth <= max_depth; depth++) {
rightView.add(rightmostValueAtDepth.get(depth));
}
return rightView;
}
}
Python 解法
dfs
class Solution:
def rightSideView(self, root: TreeNode) -> List[int]:
rightmost_value_at_depth = dict() # 深度为索引,存放节点的值
max_depth = -1
stack = [(root, 0)]
while stack:
node, depth = stack.pop()
if node is not None:
# 维护二叉树的最大深度
max_depth = max(max_depth, depth)
# 如果不存在对应深度的节点我们才插入
rightmost_value_at_depth.setdefault(depth, node.val)
stack.append((node.left, depth + 1))
stack.append((node.right, depth + 1))
return [rightmost_value_at_depth[depth] for depth in range(max_depth + 1)]
bfs
class Solution:
def rightSideView(self, root: TreeNode) -> List[int]:
rightmost_value_at_depth = dict() # 深度为索引,存放节点的值
max_depth = -1
queue = deque([(root, 0)])
while queue:
node, depth = queue.popleft()
if node is not None:
# 维护二叉树的最大深度
max_depth = max(max_depth, depth)
# 由于每一层最后一个访问到的节点才是我们要的答案,因此不断更新对应深度的信息即可
rightmost_value_at_depth[depth] = node.val
queue.append((node.left, depth + 1))
queue.append((node.right, depth + 1))
return [rightmost_value_at_depth[depth] for depth in range(max_depth + 1)]
515. Find Largest Value in Each Tree Row
Given the root of a binary tree, return an array of the largest value in each row of the tree (0-indexed).
Example 1:
Input: root = [1,3,2,5,3,null,9]
Output: [1,3,9]
Example 2:
Input: root = [1,2,3]
Output: [1,3]
Constraints:
- The number of nodes in the tree will be in the range
[0, 10^4]. -2^31 <= Node.val <= 2^31 - 1
思路
每层计算一次最大值即可
C++解法
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode() : val(0), left(nullptr), right(nullptr) {}
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
* };
*/
class Solution {
public:
int getMax(vector<int> nums){
int maxVal = nums[0];
for(int num : nums){
if(num > maxVal){
maxVal = num;
}
}
return maxVal;
}
vector<int> largestValues(TreeNode* root) {
queue<TreeNode*> que;
vector<int> result;
if(root == NULL) return result;
que.push(root);
while(!que.empty()){
vector<int> nums;
int size = que.size();
for(int i = 0; i < size; i++){
TreeNode* cur = que.front();
nums.push_back(cur->val);
que.pop();
if(cur->left) que.push(cur->left);
if(cur->right) que.push(cur->right);
}
int maxVal = getMax(nums);
result.push_back(maxVal);
}
return result;
}
};
116. Populating Next Right Pointers in Each Node
You are given a perfect binary tree where all leaves are on the same level, and every parent has two children. The binary tree has the following definition:
struct Node {
int val;
Node *left;
Node *right;
Node *next;
}
Populate each next pointer to point to its next right node. If there is no next right node, the next pointer should be set to NULL.
Initially, all next pointers are set to NULL.
Example 1:

Input: root = [1,2,3,4,5,6,7]
Output: [1,#,2,3,#,4,5,6,7,#]
Explanation: Given the above perfect binary tree (Figure A), your function should populate each next pointer to point to its next right node, just like in Figure B. The serialized output is in level order as connected by the next pointers, with '#' signifying the end of each level.
Example 2:
Input: root = []
Output: []
Constraints:
- The number of nodes in the tree is in the range
[0, 2^{12} - 1]. -1000 <= Node.val <= 1000
Follow-up:
- You may only use constant extra space.
- The recursive approach is fine. You may assume implicit stack space does not count as extra space for this problem.
思路
本题依然是层序遍历,只不过在单层遍历的时候记录一下本层的头部节点,然后在遍历的时候让前一个节点指向本节点就可以了
C++代码
class Solution {
public:
Node* connect(Node* root) {
queue<Node*> que;
if (root != NULL) que.push(root);
while (!que.empty()) {
int size = que.size();
// vector<int> vec;
Node* nodePre;
Node* node;
for (int i = 0; i < size; i++) {
if (i == 0) {
nodePre = que.front(); // 取出一层的头结点
que.pop();
node = nodePre;
} else {
node = que.front();
que.pop();
nodePre->next = node; // 本层前一个节点next指向本节点
nodePre = nodePre->next;
}
if (node->left) que.push(node->left);
if (node->right) que.push(node->right);
}
nodePre->next = NULL; // 本层最后一个节点指向NULL
}
return root;
}
};
Java解法
class Solution {
public Node connect(Node root) {
Queue<Node> tmpQueue = new LinkedList<Node>();
if (root != null) tmpQueue.add(root);
while (tmpQueue.size() != 0){
int size = tmpQueue.size();
Node cur = tmpQueue.poll();
if (cur.left != null) tmpQueue.add(cur.left);
if (cur.right != null) tmpQueue.add(cur.right);
for (int index = 1; index < size; index++){
Node next = tmpQueue.poll();
if (next.left != null) tmpQueue.add(next.left);
if (next.right != null) tmpQueue.add(next.right);
cur.next = next;
cur = next;
}
}
return root;
}
}
Python3解法
"""
# Definition for a Node.
class Node:
def __init__(self, val: int = 0, left: 'Node' = None, right: 'Node' = None, next: 'Node' = None):
self.val = val
self.left = left
self.right = right
self.next = next
"""
class Solution:
def connect(self, root: 'Node') -> 'Node':
if not root:
return root
queue = collections.deque([root])
while queue:
level_size = len(queue)
prev = None
for i in range(level_size):
node = queue.popleft()
if prev:
prev.next = node
prev = node
if node.left:
queue.append(node.left)
if node.right:
queue.append(node.right)
return root
Go解法
/**
1. 填充每个节点的下一个右侧节点指针
2. 填充每个节点的下一个右侧节点指针 II
*/
func connect(root *Node) *Node {
if root == nil { //防止为空
return root
}
queue := list.New()
queue.PushBack(root)
tmpArr := make([]*Node, 0)
for queue.Len() > 0 {
length := queue.Len() //保存当前层的长度,然后处理当前层(十分重要,防止添加下层元素影响判断层中元素的个数)
for i := 0; i < length; i++ {
node := queue.Remove(queue.Front()).(*Node) //出队列
if node.Left != nil {
queue.PushBack(node.Left)
}
if node.Right != nil {
queue.PushBack(node.Right)
}
tmpArr = append(tmpArr, node) //将值加入本层切片中
}
if len(tmpArr) > 1 {
// 遍历每层元素,指定next
for i := 0; i < len(tmpArr)-1; i++ {
tmpArr[i].Next = tmpArr[i+1]
}
}
tmpArr = []*Node{} //清空层的数据
}
return root
}
117. Populating Next Right Pointers in Each Node II(同上)
Given a binary tree
struct Node {
int val;
Node *left;
Node *right;
Node *next;
}
Populate each next pointer to point to its next right node. If there is no next right node, the next pointer should be set to NULL.
Initially, all next pointers are set to NULL.
Example 1:
Input: root = [1,2,3,4,5,null,7]
Output: [1,#,2,3,#,4,5,7,#]
Explanation: Given the above binary tree (Figure A), your function should populate each next pointer to point to its next right node, just like in Figure B. The serialized output is in level order as connected by the next pointers, with '#' signifying the end of each level.
Example 2:
Input: root = []
Output: []
Constraints:
- The number of nodes in the tree is in the range
[0, 6000]. -100 <= Node.val <= 100
Follow-up:
- You may only use constant extra space.
- The recursive approach is fine. You may assume implicit stack space does not count as extra space for this problem.
思路
这道题目说是二叉树,但116题目说是完整二叉树,其实没有任何差别,一样的代码一样的逻辑一样的味道
C++解法
class Solution {
public:
Node* connect(Node* root) {
queue<Node*> que;
if (root != NULL) que.push(root);
while (!que.empty()) {
int size = que.size();
vector<int> vec;
Node* nodePre;
Node* node;
for (int i = 0; i < size; i++) {
if (i == 0) {
nodePre = que.front(); // 取出一层的头结点
que.pop();
node = nodePre;
} else {
node = que.front();
que.pop();
nodePre->next = node; // 本层前一个节点next指向本节点
nodePre = nodePre->next;
}
if (node->left) que.push(node->left);
if (node->right) que.push(node->right);
}
nodePre->next = NULL; // 本层最后一个节点指向NULL
}
return root;
}
};
104. Maximum Depth of Binary Tree
Given the root of a binary tree, return its maximum depth.
A binary tree's maximum depth is the number of nodes along the longest path from the root node down to the farthest leaf node.
Example 1:
Input: root = [3,9,20,null,null,15,7]
Output: 3
Example 2:
Input: root = [1,null,2]
Output: 2
Constraints:
- The number of nodes in the tree is in the range
[0, 10^4]. -100 <= Node.val <= 100
思路
递归
C++解法
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode() : val(0), left(nullptr), right(nullptr) {}
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
* };
*/
class Solution {
public:
int maxDepth(TreeNode* root) {
if(root == NULL){
return 0;
}
return max(maxDepth(root->left), maxDepth(root->right)) + 1;
}
};
Java解法
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode() {}
* TreeNode(int val) { this.val = val; }
* TreeNode(int val, TreeNode left, TreeNode right) {
* this.val = val;
* this.left = left;
* this.right = right;
* }
* }
*/
class Solution {
public int maxDepth(TreeNode root) {
if(root == null) return 0;
if(root.left == null && root.right == null) return 1;
return Math.max(maxDepth(root.left), maxDepth(root.right)) + 1;
}
}
Python3解法
Go解法
111. Minimum Depth of Binary Tree
Given a binary tree, find its minimum depth.
The minimum depth is the number of nodes along the shortest path from the root node down to the nearest leaf node.
Note: A leaf is a node with no children.
Example 1:
Input: root = [3,9,20,null,null,15,7]
Output: 2
Example 2:
Input: root = [2,null,3,null,4,null,5,null,6]
Output: 5
Constraints:
- The number of nodes in the tree is in the range
[0, 10^5]. -1000 <= Node.val <= 1000
思路
递归
C++解法
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode() : val(0), left(nullptr), right(nullptr) {}
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
* };
*/
class Solution {
public:
int minDepth(TreeNode* root) {
if(root == NULL){
return 0;
}
if(root->left == NULL && root->right != NULL){
return minDepth(root->right) + 1;
}
if(root->right == NULL && root->left != NULL){
return minDepth(root->left) + 1;
}
return 1 + min(minDepth(root->left), minDepth(root->right));
}
};
Java解法
Python3解法
Go解法
二叉树路径
- 257. Binary Tree Paths
- 404. Sum of Left Leaves
- 513. Find Bottom Left Tree Value
- 112. Path Sum
- 113. Path Sum II
- 129. Sum Root to Leaf Numbers
- 437. Path Sum III
257. Binary Tree Paths
Given the root of a binary tree, return all root-to-leaf paths in any order.
A leaf is a node with no children.
Example 1:
Input: root = [1,2,3,null,5]
Output: ["1->2->5","1->3"]
Example 2:
Input: root = [1]
Output: ["1"]
Constraints:
- The number of nodes in the tree is in the range
[1, 100]. -100 <= Node.val <= 100
思路
这道题目要求从根节点到叶子的路径,所以需要前序遍历,这样才方便让父节点指向孩子节点,找到对应的路径。
在这道题目中将第一次涉及回溯,因为我们要把路径记录下来,需要回溯来回退一个路径再进入另一个路径。
前序遍历以及回溯的过程如图:
我们先使用递归的方式,来做前序遍历。要知道递归和回溯就是一家的,本题也需要回溯。
递归
- 递归函数参数以及返回值
要传入根节点,记录每一条路径的path,和存放结果集的result,这里递归不需要返回值,代码如下:
void traversal(TreeNode* cur, vector<int>& path, vector<string>& result)
- 确定递归终止条件
在写递归的时候都习惯了这么写:
if (cur == NULL) {
终止处理逻辑
}
但是本题的终止条件这样写会很麻烦,因为本题要找到叶子节点,就开始结束的处理逻辑了(把路径放进result里)。
那么什么时候算是找到了叶子节点? 是当 cur不为空,其左右孩子都为空的时候,就找到叶子节点。
所以本题的终止条件是:
if (cur->left == NULL && cur->right == NULL) {
终止处理逻辑
}
为什么没有判断cur是否为空呢,因为下面的逻辑可以控制空节点不入循环。
再来看一下终止处理的逻辑。
这里使用vector 结构path来记录路径,所以要把vector 结构的path转为string格式,再把这个string 放进 result里。
那么为什么使用了vector 结构来记录路径呢? 因为在下面处理单层递归逻辑的时候,要做回溯,使用vector方便来做回溯。
可能有的同学问了,我看有些人的代码也没有回溯啊。
其实是有回溯的,只不过隐藏在函数调用时的参数赋值里,下文我还会提到。
这里我们先使用vector结构的path容器来记录路径,那么终止处理逻辑如下:
if (cur->left == NULL && cur->right == NULL) { // 遇到叶子节点
string sPath;
for (int i = 0; i < path.size() - 1; i++) { // 将path里记录的路径转为string格式
sPath += to_string(path[i]);
sPath += "->";
}
sPath += to_string(path[path.size() - 1]); // 记录最后一个节点(叶子节点)
result.push_back(sPath); // 收集一个路径
return;
}
- 确定单层递归逻辑
因为是前序遍历,需要先处理中间节点,中间节点就是我们要记录路径上的节点,先放进path中。
path.push_back(cur->val);
然后是递归和回溯的过程,上面说过没有判断cur是否为空,那么在这里递归的时候,如果为空就不进行下一层递归了。
所以递归前要加上判断语句,下面要递归的节点是否为空,如下
if (cur->left) {
traversal(cur->left, path, result);
}
if (cur->right) {
traversal(cur->right, path, result);
}
此时还没完,递归完,要做回溯啊,因为path 不能一直加入节点,它还要删节点,然后才能加入新的节点。
那么回溯要怎么回溯呢,一些同学会这么写,如下:
if (cur->left) {
traversal(cur->left, path, result);
}
if (cur->right) {
traversal(cur->right, path, result);
}
path.pop_back();
这个回溯就有很大的问题,我们知道,回溯和递归是一一对应的,有一个递归,就要有一个回溯,这么写的话相当于把递归和回溯拆开了, 一个在花括号里,一个在花括号外。
所以回溯要和递归永远在一起,世界上最遥远的距离是你在花括号里,而我在花括号外!
那么代码应该这么写:
if (cur->left) {
traversal(cur->left, path, result);
path.pop_back(); // 回溯
}
if (cur->right) {
traversal(cur->right, path, result);
path.pop_back(); // 回溯
}
那么本题整体代码如下:
// 版本一
class Solution {
private:
void traversal(TreeNode* cur, vector<int>& path, vector<string>& result) {
path.push_back(cur->val); // 中,中为什么写在这里,因为最后一个节点也要加入到path中
// 这才到了叶子节点
if (cur->left == NULL && cur->right == NULL) {
string sPath;
for (int i = 0; i < path.size() - 1; i++) {
sPath += to_string(path[i]);
sPath += "->";
}
sPath += to_string(path[path.size() - 1]);
result.push_back(sPath);
return;
}
if (cur->left) { // 左
traversal(cur->left, path, result);
path.pop_back(); // 回溯
}
if (cur->right) { // 右
traversal(cur->right, path, result);
path.pop_back(); // 回溯
}
}
public:
vector<string> binaryTreePaths(TreeNode* root) {
vector<string> result;
vector<int> path;
if (root == NULL) return result;
traversal(root, path, result);
return result;
}
};
如上的C++代码充分体现了回溯。
那么如上代码可以精简成如下代码:
class Solution {
private:
void traversal(TreeNode* cur, string path, vector<string>& result) {
path += to_string(cur->val); // 中
if (cur->left == NULL && cur->right == NULL) {
result.push_back(path);
return;
}
if (cur->left) traversal(cur->left, path + "->", result); // 左
if (cur->right) traversal(cur->right, path + "->", result); // 右
}
public:
vector<string> binaryTreePaths(TreeNode* root) {
vector<string> result;
string path;
if (root == NULL) return result;
traversal(root, path, result);
return result;
}
};
如上代码精简了不少,也隐藏了不少东西。
注意在函数定义的时候void traversal(TreeNode* cur, string path, vector<string>& result) ,定义的是string path,每次都是复制赋值,不用使用引用,否则就无法做到回溯的效果。(这里涉及到C++语法知识)
那么在如上代码中,貌似没有看到回溯的逻辑,其实不然,回溯就隐藏在traversal(cur->left, path + "->", result);中的 path + "->"。 每次函数调用完,path依然是没有加上"->" 的,这就是回溯了。
为了把这份精简代码的回溯过程展现出来,大家可以试一试把:
if (cur->left) traversal(cur->left, path + "->", result); // 左 回溯就隐藏在这里
改成如下代码:
path += "->";
traversal(cur->left, path, result); // 左
即:
if (cur->left) {
path += "->";
traversal(cur->left, path, result); // 左
}
if (cur->right) {
path += "->";
traversal(cur->right, path, result); // 右
}
此时就没有回溯了,这个代码就是通过不了的了。
如果想把回溯加上,就要 在上面代码的基础上,加上回溯,就可以AC了。
if (cur->left) {
path += "->";
traversal(cur->left, path, result); // 左
path.pop_back(); // 回溯 '>'
path.pop_back(); // 回溯 '-'
}
if (cur->right) {
path += "->";
traversal(cur->right, path, result); // 右
path.pop_back(); // 回溯 '>'
path.pop_back(); // 回溯 '-'
}
整体代码如下:
//版本二
class Solution {
private:
void traversal(TreeNode* cur, string path, vector<string>& result) {
path += to_string(cur->val); // 中,中为什么写在这里,因为最后一个节点也要加入到path中
if (cur->left == NULL && cur->right == NULL) {
result.push_back(path);
return;
}
if (cur->left) {
path += "->";
traversal(cur->left, path, result); // 左
path.pop_back(); // 回溯 '>'
path.pop_back(); // 回溯 '-'
}
if (cur->right) {
path += "->";
traversal(cur->right, path, result); // 右
path.pop_back(); // 回溯'>'
path.pop_back(); // 回溯 '-'
}
}
public:
vector<string> binaryTreePaths(TreeNode* root) {
vector<string> result;
string path;
if (root == NULL) return result;
traversal(root, path, result);
return result;
}
};
大家应该可以感受出来,如果把 path + "->"作为函数参数就是可以的,因为并没有改变path的数值,执行完递归函数之后,path依然是之前的数值(相当于回溯了)
综合以上,第二种递归的代码虽然精简但把很多重要的点隐藏在了代码细节里,第一种递归写法虽然代码多一些,但是把每一个逻辑处理都完整的展现出来了。
C++解法
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode() : val(0), left(nullptr), right(nullptr) {}
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
* };
*/
class Solution {
public:
void traversal(TreeNode* cur, vector<int>& path, vector<string>& result){
path.push_back(cur->val);
if(cur->left == NULL && cur->right == NULL){
string strPath;
for(int i = 0; i < path.size() - 1; i++){
strPath += to_string(path[i]);
strPath += "->";
}
strPath += to_string(path[path.size() - 1]);
result.push_back(strPath);
return;
}
if(cur->left){
traversal(cur->left, path, result);
path.pop_back();
}
if(cur->right){
traversal(cur->right, path, result);
path.pop_back();
}
}
vector<string> binaryTreePaths(TreeNode* root) {
vector<int> path;
vector<string> result;
if(root == NULL){
return result;
}
traversal(root, path, result);
return result;
}
};
Java解法
//解法一
//方式一
class Solution {
/**
* 递归法
*/
public List<String> binaryTreePaths(TreeNode root) {
List<String> res = new ArrayList<>();// 存最终的结果
if (root == null) {
return res;
}
List<Integer> paths = new ArrayList<>();// 作为结果中的路径
traversal(root, paths, res);
return res;
}
private void traversal(TreeNode root, List<Integer> paths, List<String> res) {
paths.add(root.val);// 前序遍历,中
// 遇到叶子结点
if (root.left == null && root.right == null) {
// 输出
StringBuilder sb = new StringBuilder();// StringBuilder用来拼接字符串,速度更快
for (int i = 0; i < paths.size() - 1; i++) {
sb.append(paths.get(i)).append("->");
}
sb.append(paths.get(paths.size() - 1));// 记录最后一个节点
res.add(sb.toString());// 收集一个路径
return;
}
// 递归和回溯是同时进行,所以要放在同一个花括号里
if (root.left != null) { // 左
traversal(root.left, paths, res);
paths.remove(paths.size() - 1);// 回溯
}
if (root.right != null) { // 右
traversal(root.right, paths, res);
paths.remove(paths.size() - 1);// 回溯
}
}
}
//方式二
class Solution {
List<String> result = new ArrayList<>();
public List<String> binaryTreePaths(TreeNode root) {
deal(root, "");
return result;
}
public void deal(TreeNode node, String s) {
if (node == null)
return;
if (node.left == null && node.right == null) {
result.add(new StringBuilder(s).append(node.val).toString());
return;
}
String tmp = new StringBuilder(s).append(node.val).append("->").toString();
deal(node.left, tmp);
deal(node.right, tmp);
}
}
// 解法二
class Solution {
/**
* 迭代法
*/
public List<String> binaryTreePaths(TreeNode root) {
List<String> result = new ArrayList<>();
if (root == null)
return result;
Stack<Object> stack = new Stack<>();
// 节点和路径同时入栈
stack.push(root);
stack.push(root.val + "");
while (!stack.isEmpty()) {
// 节点和路径同时出栈
String path = (String) stack.pop();
TreeNode node = (TreeNode) stack.pop();
// 若找到叶子节点
if (node.left == null && node.right == null) {
result.add(path);
}
//右子节点不为空
if (node.right != null) {
stack.push(node.right);
stack.push(path + "->" + node.right.val);
}
//左子节点不为空
if (node.left != null) {
stack.push(node.left);
stack.push(path + "->" + node.left.val);
}
}
return result;
}
}
Python3解法
递归法+回溯
# Definition for a binary tree node.
class Solution:
def traversal(self, cur, path, result):
path.append(cur.val) # 中
if not cur.left and not cur.right: # 到达叶子节点
sPath = '->'.join(map(str, path))
result.append(sPath)
return
if cur.left: # 左
self.traversal(cur.left, path, result)
path.pop() # 回溯
if cur.right: # 右
self.traversal(cur.right, path, result)
path.pop() # 回溯
def binaryTreePaths(self, root):
result = []
path = []
if not root:
return result
self.traversal(root, path, result)
return result
Go解法
递归法:
func binaryTreePaths(root *TreeNode) []string {
res := make([]string, 0)
var travel func(node *TreeNode, s string)
travel = func(node *TreeNode, s string) {
if node.Left == nil && node.Right == nil {
v := s + strconv.Itoa(node.Val)
res = append(res, v)
return
}
s = s + strconv.Itoa(node.Val) + "->"
if node.Left != nil {
travel(node.Left, s)
}
if node.Right != nil {
travel(node.Right, s)
}
}
travel(root, "")
return res
}
迭代法
func binaryTreePaths(root *TreeNode) []string {
stack := []*TreeNode{}
paths := make([]string, 0)
res := make([]string, 0)
if root != nil {
stack = append(stack, root)
paths = append(paths, "")
}
for len(stack) > 0 {
l := len(stack)
node := stack[l-1]
path := paths[l-1]
stack = stack[:l-1]
paths = paths[:l-1]
if node.Left == nil && node.Right == nil {
res = append(res, path+strconv.Itoa(node.Val))
continue
}
if node.Right != nil {
stack = append(stack, node.Right)
paths = append(paths, path+strconv.Itoa(node.Val)+"->")
}
if node.Left != nil {
stack = append(stack, node.Left)
paths = append(paths, path+strconv.Itoa(node.Val)+"->")
}
}
return res
}
404. Sum of Left Leaves
Given the root of a binary tree, return the sum of all left leaves.
A leaf is a node with no children. A left leaf is a leaf that is the left child of another node.
Example 1:
Input: root = [3,9,20,null,null,15,7]
Output: 24
Explanation: There are two left leaves in the binary tree, with values 9 and 15 respectively.
Example 2:
Input: root = [1]
Output: 0
Constraints:
- The number of nodes in the tree is in the range
[1, 1000]. -1000 <= Node.val <= 1000
思路
首先要注意是判断左叶子,不是二叉树左侧节点,所以不要上来想着层序遍历。
因为题目中其实没有说清楚左叶子究竟是什么节点,那么我来给出左叶子的明确定义:节点A的左孩子不为空,且左孩子的左右孩子都为空(说明是叶子节点),那么A节点的左孩子为左叶子节点
大家思考一下如下图中二叉树,左叶子之和究竟是多少?
 其实是0,因为这棵树根本没有左叶子!
其实是0,因为这棵树根本没有左叶子!
但看这个图的左叶子之和是多少?
相信通过这两个图,大家对最左叶子的定义有明确理解了。
那么判断当前节点是不是左叶子是无法判断的,必须要通过节点的父节点来判断其左孩子是不是左叶子。
如果该节点的左节点不为空,该节点的左节点的左节点为空,该节点的左节点的右节点为空,则找到了一个左叶子,判断代码如下:
if (node->left != NULL && node->left->left == NULL && node->left->right == NULL) {
左叶子节点处理逻辑
}
递归的遍历顺序为后序遍历(左右中),是因为要通过递归函数的返回值来累加求取左叶子数值之和。
递归三部曲:
- 确定递归函数的参数和返回值
判断一个树的左叶子节点之和,那么一定要传入树的根节点,递归函数的返回值为数值之和,所以为int
使用题目中给出的函数就可以了。
- 确定终止条件
如果遍历到空节点,那么左叶子值一定是0
if (root == NULL) return 0;
注意,只有当前遍历的节点是父节点,才能判断其子节点是不是左叶子。 所以如果当前遍历的节点是叶子节点,那其左叶子也必定是0,那么终止条件为:
if (root == NULL) return 0;
if (root->left == NULL && root->right== NULL) return 0; //其实这个也可以不写,如果不写不影响结果,但就会让递归多进行了一层。
- 确定单层递归的逻辑
当遇到左叶子节点的时候,记录数值,然后通过递归求取左子树左叶子之和,和 右子树左叶子之和,相加便是整个树的左叶子之和。
代码如下:
int leftValue = sumOfLeftLeaves(root->left); // 左
if (root->left && !root->left->left && !root->left->right) {
leftValue = root->left->val;
}
int rightValue = sumOfLeftLeaves(root->right); // 右
int sum = leftValue + rightValue; // 中
return sum;
C++解法
整体递归代码如下:
class Solution {
public:
int sumOfLeftLeaves(TreeNode* root) {
if (root == NULL) return 0;
if (root->left == NULL && root->right== NULL) return 0;
int leftValue = sumOfLeftLeaves(root->left); // 左
if (root->left && !root->left->left && !root->left->right) { // 左子树就是一个左叶子的情况
leftValue = root->left->val;
}
int rightValue = sumOfLeftLeaves(root->right); // 右
int sum = leftValue + rightValue; // 中
return sum;
}
};
以上代码精简之后如下:
class Solution {
public:
int sumOfLeftLeaves(TreeNode* root) {
if (root == NULL) return 0;
int leftValue = 0;
if (root->left != NULL && root->left->left == NULL && root->left->right == NULL) {
leftValue = root->left->val;
}
return leftValue + sumOfLeftLeaves(root->left) + sumOfLeftLeaves(root->right);
}
};
精简之后的代码其实看不出来用的是什么遍历方式了,对于算法初学者以上根据第一个版本来学习。
后序遍历求和解法:
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode() : val(0), left(nullptr), right(nullptr) {}
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
* };
*/
class Solution {
public:
void traversal(TreeNode* root, vector<int>& vals){
if(root == NULL){
return;
}
traversal(root->left, vals);
traversal(root->right, vals);
if(root->left != NULL && root->left->left == NULL && root->left->right == NULL){
vals.push_back(root->left->val);
}
}
int sumOfLeftLeaves(TreeNode* root) {
vector<int> vals;
traversal(root, vals);
int sum = 0;
for(int val : vals){
sum += val;
}
return sum;
}
};
Java解法
// 层序遍历迭代法
class Solution {
public int sumOfLeftLeaves(TreeNode root) {
int sum = 0;
if (root == null) return 0;
Queue<TreeNode> queue = new LinkedList<>();
queue.offer(root);
while (!queue.isEmpty()) {
int size = queue.size();
while (size -- > 0) {
TreeNode node = queue.poll();
if (node.left != null) { // 左节点不为空
queue.offer(node.left);
if (node.left.left == null && node.left.right == null){ // 左叶子节点
sum += node.left.val;
}
}
if (node.right != null) queue.offer(node.right);
}
}
return sum;
}
}
Python3解法
递归精简版
# Definition for a binary tree node.
# class TreeNode:
# def __init__(self, val=0, left=None, right=None):
# self.val = val
# self.left = left
# self.right = right
class Solution:
def sumOfLeftLeaves(self, root):
if root is None:
return 0
leftValue = 0
if root.left is not None and root.left.left is None and root.left.right is None:
leftValue = root.left.val
return leftValue + self.sumOfLeftLeaves(root.left) + self.sumOfLeftLeaves(root.right)
Go解法
迭代法(前序遍历)
func sumOfLeftLeaves(root *TreeNode) int {
st := make([]*TreeNode, 0)
if root == nil {
return 0
}
st = append(st, root)
result := 0
for len(st) != 0 {
node := st[len(st)-1]
st = st[:len(st)-1]
if node.Left != nil && node.Left.Left == nil && node.Left.Right == nil {
result += node.Left.Val
}
if node.Right != nil {
st = append(st, node.Right)
}
if node.Left != nil {
st = append(st, node.Left)
}
}
return result
}
513. Find Bottom Left Tree Value
Given the root of a binary tree, return the leftmost value in the last row of the tree.
Example 1:
Input: root = [2,1,3]
Output: 1
Example 2:
Input: root = [1,2,3,4,null,5,6,null,null,7]
Output: 7
Constraints:
- The number of nodes in the tree is in the range
[1, 10^4]. -2^31 <= Node.val <= 2^31 - 1
思路
本题要找出树的最后一行的最左边的值。此时大家应该想起用层序遍历是非常简单的了,反而用递归的话会比较难一点。
我们依然还是先介绍递归法。
递归
咋眼一看,这道题目用递归的话就就一直向左遍历,最后一个就是答案呗?
没有这么简单,一直向左遍历到最后一个,它未必是最后一行啊。
我们来分析一下题目:在树的最后一行找到最左边的值。
首先要是最后一行,然后是最左边的值。
如果使用递归法,如何判断是最后一行呢,其实就是深度最大的叶子节点一定是最后一行。
如果对二叉树深度和高度还有点疑惑的话,请看:110.平衡二叉树 (opens new window)。
所以要找深度最大的叶子节点。
那么如何找最左边的呢?可以使用前序遍历(当然中序,后序都可以,因为本题没有 中间节点的处理逻辑,只要左优先就行),保证优先左边搜索,然后记录深度最大的叶子节点,此时就是树的最后一行最左边的值。
递归三部曲:
- 确定递归函数的参数和返回值
参数必须有要遍历的树的根节点,还有就是一个int型的变量用来记录最长深度。 这里就不需要返回值了,所以递归函数的返回类型为void。
本题还需要类里的两个全局变量,maxDepth用来记录最大深度,result记录最大深度最左节点的数值。
代码如下:
int maxDepth = INT_MIN; // 全局变量 记录最大深度
int result; // 全局变量 最大深度最左节点的数值
void traversal(TreeNode* root, int depth)
- 确定终止条件
当遇到叶子节点的时候,就需要统计一下最大的深度了,所以需要遇到叶子节点来更新最大深度。
代码如下:
if (root->left == NULL && root->right == NULL) {
if (depth > maxDepth) {
maxDepth = depth; // 更新最大深度
result = root->val; // 最大深度最左面的数值
}
return;
}
- 确定单层递归的逻辑
在找最大深度的时候,递归的过程中依然要使用回溯,代码如下:
// 中
if (root->left) { // 左
depth++; // 深度加一
traversal(root->left, depth);
depth--; // 回溯,深度减一
}
if (root->right) { // 右
depth++; // 深度加一
traversal(root->right, depth);
depth--; // 回溯,深度减一
}
return;
迭代法
本题使用层序遍历再合适不过了,比递归要好理解得多!
只需要记录最后一行第一个节点的数值就可以了。
如果对层序遍历不了解,看这篇二叉树:层序遍历登场! (opens new window),这篇里也给出了层序遍历的模板,稍作修改就一过刷了这道题了。
总结
本题涉及如下几点:
- 递归求深度的写法,我们在110.平衡二叉树 (opens new window)中详细的分析了深度应该怎么求,高度应该怎么求。
- 递归中其实隐藏了回溯,在257. 二叉树的所有路径 (opens new window)中讲解了究竟哪里使用了回溯,哪里隐藏了回溯。
- 层次遍历,在二叉树:层序遍历登场! (opens new window)深度讲解了二叉树层次遍历。 所以本题涉及到的点,我们之前都讲解过,这些知识点需要同学们灵活运用,这样就举一反三了。
C++解法
递归法完整代码如下:
class Solution {
public:
int maxDepth = INT_MIN;
int result;
void traversal(TreeNode* root, int depth) {
if (root->left == NULL && root->right == NULL) {
if (depth > maxDepth) {
maxDepth = depth;
result = root->val;
}
return;
}
if (root->left) {
depth++;
traversal(root->left, depth);
depth--; // 回溯
}
if (root->right) {
depth++;
traversal(root->right, depth);
depth--; // 回溯
}
return;
}
int findBottomLeftValue(TreeNode* root) {
traversal(root, 0);
return result;
}
};
当然回溯的地方可以精简,精简代码如下:
class Solution {
public:
int maxDepth = INT_MIN;
int result;
void traversal(TreeNode* root, int depth) {
if (root->left == NULL && root->right == NULL) {
if (depth > maxDepth) {
maxDepth = depth;
result = root->val;
}
return;
}
if (root->left) {
traversal(root->left, depth + 1); // 隐藏着回溯
}
if (root->right) {
traversal(root->right, depth + 1); // 隐藏着回溯
}
return;
}
int findBottomLeftValue(TreeNode* root) {
traversal(root, 0);
return result;
}
};
如果对回溯部分精简的代码不理解的话,可以看这篇257. 二叉树的所有路径(opens new window)
迭代法代码如下:
class Solution {
public:
int findBottomLeftValue(TreeNode* root) {
queue<TreeNode*> que;
if (root != NULL) que.push(root);
int result = 0;
while (!que.empty()) {
int size = que.size();
for (int i = 0; i < size; i++) {
TreeNode* node = que.front();
que.pop();
if (i == 0) result = node->val; // 记录该行第一个元素
if (node->left) que.push(node->left);
if (node->right) que.push(node->right);
}
}
return result;
}
};
Java解法
// 递归法
class Solution {
private int Deep = -1;
private int value = 0;
public int findBottomLeftValue(TreeNode root) {
value = root.val;
findLeftValue(root,0);
return value;
}
private void findLeftValue (TreeNode root,int deep) {
if (root == null) return;
if (root.left == null && root.right == null) {
if (deep > Deep) {
value = root.val;
Deep = deep;
}
}
if (root.left != null) findLeftValue(root.left,deep + 1);
if (root.right != null) findLeftValue(root.right,deep + 1);
}
}
//迭代法
class Solution {
public int findBottomLeftValue(TreeNode root) {
Queue<TreeNode> queue = new LinkedList<>();
queue.offer(root);
int res = 0;
while (!queue.isEmpty()) {
int size = queue.size();
for (int i = 0; i < size; i++) {
TreeNode poll = queue.poll();
if (i == 0) {
res = poll.val;
}
if (poll.left != null) {
queue.offer(poll.left);
}
if (poll.right != null) {
queue.offer(poll.right);
}
}
}
return res;
}
}
Python3解法
递归法+精简
class Solution:
def findBottomLeftValue(self, root: TreeNode) -> int:
self.max_depth = float('-inf')
self.result = None
self.traversal(root, 0)
return self.result
def traversal(self, node, depth):
if not node.left and not node.right:
if depth > self.max_depth:
self.max_depth = depth
self.result = node.val
return
if node.left:
self.traversal(node.left, depth+1)
if node.right:
self.traversal(node.right, depth+1)
Go解法
迭代法
func findBottomLeftValue(root *TreeNode) int {
var gradation int
queue := list.New()
queue.PushBack(root)
for queue.Len() > 0 {
length := queue.Len()
for i := 0; i < length; i++ {
node := queue.Remove(queue.Front()).(*TreeNode)
if i == 0 {
gradation = node.Val
}
if node.Left != nil {
queue.PushBack(node.Left)
}
if node.Right != nil {
queue.PushBack(node.Right)
}
}
}
return gradation
}
112. Path Sum
Given the root of a binary tree and an integer targetSum, return true if the tree has a root-to-leaf path such that adding up all the values along the path equals targetSum.
A leaf is a node with no children.
Example 1:
Input: root = [5,4,8,11,null,13,4,7,2,null,null,null,1], targetSum = 22
Output: true
Explanation: The root-to-leaf path with the target sum is shown.
Example 2:
Input: root = [1,2,3], targetSum = 5
Output: false
Explanation: There are two root-to-leaf paths in the tree:
(1 --> 2): The sum is 3.
(1 --> 3): The sum is 4.
There is no root-to-leaf path with sum = 5.
Example 3:
Input: root = [], targetSum = 0
Output: false
Explanation: Since the tree is empty, there are no root-to-leaf paths.
Constraints:
- The number of nodes in the tree is in the range
[0, 5000]. -1000 <= Node.val <= 1000-1000 <= targetSum <= 1000
思路
改造Binary Tree Paths代码
递归
可以使用深度优先遍历的方式(本题前中后序都可以,无所谓,因为中节点也没有处理逻辑)来遍历二叉树
- 确定递归函数的参数和返回类型
参数:需要二叉树的根节点,还需要一个计数器,这个计数器用来计算二叉树的一条边之和是否正好是目标和,计数器为int型。
再来看返回值,递归函数什么时候需要返回值?什么时候不需要返回值?这里总结如下三点:
- 如果需要搜索整棵二叉树且不用处理递归返回值,递归函数就不要返回值。(这种情况就是本文下半部分介绍的113.路径总和ii)
- 如果需要搜索整棵二叉树且需要处理递归返回值,递归函数就需要返回值。 (这种情况我们在236. 二叉树的最近公共祖先 (opens new window)中介绍)
- 如果要搜索其中一条符合条件的路径,那么递归一定需要返回值,因为遇到符合条件的路径了就要及时返回。(本题的情况)
而本题我们要找一条符合条件的路径,所以递归函数需要返回值,及时返回,那么返回类型是什么呢?
如图所示:
图中可以看出,遍历的路线,并不要遍历整棵树,所以递归函数需要返回值,可以用bool类型表示。
所以代码如下:
bool traversal(treenode* cur, int count) // 注意函数的返回类型
- 确定终止条件
首先计数器如何统计这一条路径的和呢?
不要去累加然后判断是否等于目标和,那么代码比较麻烦,可以用递减,让计数器count初始为目标和,然后每次减去遍历路径节点上的数值。
如果最后count == 0,同时到了叶子节点的话,说明找到了目标和。
如果遍历到了叶子节点,count不为0,就是没找到。
递归终止条件代码如下:
if (!cur->left && !cur->right && count == 0) return true; // 遇到叶子节点,并且计数为0
if (!cur->left && !cur->right) return false; // 遇到叶子节点而没有找到合适的边,直接返回
- 确定单层递归的逻辑
因为终止条件是判断叶子节点,所以递归的过程中就不要让空节点进入递归了。
递归函数是有返回值的,如果递归函数返回true,说明找到了合适的路径,应该立刻返回。
代码如下:
if (cur->left) { // 左 (空节点不遍历)
// 遇到叶子节点返回true,则直接返回true
if (traversal(cur->left, count - cur->left->val)) return true; // 注意这里有回溯的逻辑
}
if (cur->right) { // 右 (空节点不遍历)
// 遇到叶子节点返回true,则直接返回true
if (traversal(cur->right, count - cur->right->val)) return true; // 注意这里有回溯的逻辑
}
return false;
以上代码中是包含着回溯的,没有回溯,如何后撤重新找另一条路径呢。
回溯隐藏在traversal(cur->left, count - cur->left->val)这里, 因为把count - cur->left->val 直接作为参数传进去,函数结束,count的数值没有改变。
为了把回溯的过程体现出来,可以改为如下代码:
if (cur->left) { // 左
count -= cur->left->val; // 递归,处理节点;
if (traversal(cur->left, count)) return true;
count += cur->left->val; // 回溯,撤销处理结果
}
if (cur->right) { // 右
count -= cur->right->val;
if (traversal(cur->right, count)) return true;
count += cur->right->val;
}
return false;
整体代码如下:
class Solution {
private:
bool traversal(TreeNode* cur, int count) {
if (!cur->left && !cur->right && count == 0) return true; // 遇到叶子节点,并且计数为0
if (!cur->left && !cur->right) return false; // 遇到叶子节点直接返回
if (cur->left) { // 左
count -= cur->left->val; // 递归,处理节点;
if (traversal(cur->left, count)) return true;
count += cur->left->val; // 回溯,撤销处理结果
}
if (cur->right) { // 右
count -= cur->right->val; // 递归,处理节点;
if (traversal(cur->right, count)) return true;
count += cur->right->val; // 回溯,撤销处理结果
}
return false;
}
public:
bool hasPathSum(TreeNode* root, int sum) {
if (root == NULL) return false;
return traversal(root, sum - root->val);
}
};
以上代码精简之后如下:
class Solution {
public:
bool hasPathSum(TreeNode* root, int sum) {
if (!root) return false;
if (!root->left && !root->right && sum == root->val) {
return true;
}
return hasPathSum(root->left, sum - root->val) || hasPathSum(root->right, sum - root->val);
}
};
是不是发现精简之后的代码,已经完全看不出分析的过程了,所以我们要把题目分析清楚之后,再追求代码精简。 这一点我已经强调很多次了!
迭代
如果使用栈模拟递归的话,那么如果做回溯呢?
此时栈里一个元素不仅要记录该节点指针,还要记录从头结点到该节点的路径数值总和。
c++就我们用pair结构来存放这个栈里的元素。
定义为:pair<TreeNode*, int> pair<节点指针,路径数值>
这个为栈里的一个元素。
如下代码是使用栈模拟的前序遍历,如下:(详细注释)
class solution {
public:
bool haspathsum(TreeNode* root, int sum) {
if (root == null) return false;
// 此时栈里要放的是pair<节点指针,路径数值>
stack<pair<TreeNode*, int>> st;
st.push(pair<TreeNode*, int>(root, root->val));
while (!st.empty()) {
pair<TreeNode*, int> node = st.top();
st.pop();
// 如果该节点是叶子节点了,同时该节点的路径数值等于sum,那么就返回true
if (!node.first->left && !node.first->right && sum == node.second) return true;
// 右节点,压进去一个节点的时候,将该节点的路径数值也记录下来
if (node.first->right) {
st.push(pair<TreeNode*, int>(node.first->right, node.second + node.first->right->val));
}
// 左节点,压进去一个节点的时候,将该节点的路径数值也记录下来
if (node.first->left) {
st.push(pair<TreeNode*, int>(node.first->left, node.second + node.first->left->val));
}
}
return false;
}
};
C++解法
改造Binary Tree Paths代码的结果如下所示:
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode() : val(0), left(nullptr), right(nullptr) {}
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left),
* right(right) {}
* };
*/
class Solution {
public:
void traversal(TreeNode* root, vector<int>& path, vector<int>& result) {
path.push_back(root->val);
if (root->left == NULL && root->right == NULL) {
int size = path.size();
int sum = 0;
for (int i = 0; i < size; i++) {
sum += path[i];
}
result.push_back(sum);
return;
}
if (root->left != NULL) {
traversal(root->left, path, result);
path.pop_back();
}
if (root->right != NULL) {
traversal(root->right, path, result);
path.pop_back();
}
}
bool hasPathSum(TreeNode* root, int targetSum) {
vector<int> path;
vector<int> result;
if(root == NULL){
return false;
}
traversal(root, path, result);
for(int res : result){
if(res == targetSum){
return true;
}
}
return false;
}
};
遍历时就判断结果
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode() : val(0), left(nullptr), right(nullptr) {}
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left),
* right(right) {}
* };
*/
class Solution {
public:
bool traversal(TreeNode* root, vector<int>& path,int targetSum) {
path.push_back(root->val);
if (root->left == NULL && root->right == NULL) {
int size = path.size();
int sum = 0;
for (int i = 0; i < size; i++) {
sum += path[i];
}
if(sum == targetSum){
return true;
}
}
if (root->left != NULL) {
if(!traversal(root->left, path, targetSum))
path.pop_back();
else
return true;
}
if (root->right != NULL) {
if(!traversal(root->right, path, targetSum))
path.pop_back();
else
return true;
}
return false;
}
bool hasPathSum(TreeNode* root, int targetSum) {
vector<int> path;
if(root == NULL){
return false;
}
return traversal(root, path, targetSum);
}
};
Java解法
Python3解法
Go解法
113. Path Sum II
Given the root of a binary tree and an integer targetSum, return all root-to-leaf paths where the sum of the node values in the path equals targetSum. Each path should be returned as a list of the node values, not node references.
A root-to-leaf path is a path starting from the root and ending at any leaf node. A leaf is a node with no children.
Example 1:
Input: root = [5,4,8,11,null,13,4,7,2,null,null,5,1], targetSum = 22
Output: [[5,4,11,2],[5,8,4,5]]
Explanation: There are two paths whose sum equals targetSum:
5 + 4 + 11 + 2 = 22
5 + 8 + 4 + 5 = 22
Example 2:
Input: root = [1,2,3], targetSum = 5
Output: []
Example 3:
Input: root = [1,2], targetSum = 0
Output: []
Constraints:
- The number of nodes in the tree is in the range
[0, 5000]. -1000 <= Node.val <= 1000-1000 <= targetSum <= 1000
思路
改造PathSum代码
C++解法
改造PathSum代码的结果如下所示:
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode() : val(0), left(nullptr), right(nullptr) {}
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
* };
*/
class Solution {
public:
void traversal(TreeNode* root, vector<int>& path, vector<vector<int>>& result, int targetSum) {
path.push_back(root->val);
if (root->left == NULL && root->right == NULL) {
int size = path.size();
int sum = 0;
for (int i = 0; i < size; i++) {
sum += path[i];
}
if(sum == targetSum){
result.push_back(path);
}
return;
}
if (root->left != NULL) {
traversal(root->left, path, result, targetSum);
path.pop_back();
}
if (root->right != NULL) {
traversal(root->right, path, result, targetSum);
path.pop_back();
}
}
vector<vector<int>> pathSum(TreeNode* root, int targetSum) {
vector<int> path;
vector<vector<int>> result;
if(root == NULL){
return result;
}
traversal(root, path, result, targetSum);
return result;
}
};
代码随想录解法:
class solution {
private:
vector<vector<int>> result;
vector<int> path;
// 递归函数不需要返回值,因为我们要遍历整个树
void traversal(TreeNode* cur, int count) {
if (!cur->left && !cur->right && count == 0) { // 遇到了叶子节点且找到了和为sum的路径
result.push_back(path);
return;
}
if (!cur->left && !cur->right) return ; // 遇到叶子节点而没有找到合适的边,直接返回
if (cur->left) { // 左 (空节点不遍历)
path.push_back(cur->left->val);
count -= cur->left->val;
traversal(cur->left, count); // 递归
count += cur->left->val; // 回溯
path.pop_back(); // 回溯
}
if (cur->right) { // 右 (空节点不遍历)
path.push_back(cur->right->val);
count -= cur->right->val;
traversal(cur->right, count); // 递归
count += cur->right->val; // 回溯
path.pop_back(); // 回溯
}
return ;
}
public:
vector<vector<int>> pathSum(TreeNode* root, int sum) {
result.clear();
path.clear();
if (root == NULL) return result;
path.push_back(root->val); // 把根节点放进路径
traversal(root, sum - root->val);
return result;
}
};
Java解法
Python3解法
Go解法
129. Sum Root to Leaf Numbers
You are given the root of a binary tree containing digits from 0 to 9 only.
Each root-to-leaf path in the tree represents a number.
- For example, the root-to-leaf path
1 -> 2 -> 3represents the number123.
Return the total sum of all root-to-leaf numbers. Test cases are generated so that the answer will fit in a 32-bit integer.
A leaf node is a node with no children.
Example 1:
Input: root = [1,2,3]
Output: 25
Explanation:
The root-to-leaf path 1->2 represents the number 12.
The root-to-leaf path 1->3 represents the number 13.
Therefore, sum = 12 + 13 = 25.
Example 2:
Input: root = [4,9,0,5,1]
Output: 1026
Explanation:
The root-to-leaf path 4->9->5 represents the number 495.
The root-to-leaf path 4->9->1 represents the number 491.
The root-to-leaf path 4->0 represents the number 40.
Therefore, sum = 495 + 491 + 40 = 1026.
Constraints:
- The number of nodes in the tree is in the range
[1, 1000]. 0 <= Node.val <= 9- The depth of the tree will not exceed
10.
思路
改造PathSum代码
C++解法
改造PathSum代码的结果如下所示:
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode() : val(0), left(nullptr), right(nullptr) {}
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
* };
*/
class Solution {
public:
void traversal(TreeNode* root, vector<int>& path, vector<int>& result) {
path.push_back(root->val);
if(root->left == NULL && root->right == NULL){
int size = path.size();
string strPath;
for(int i = 0; i < size; i++){
strPath += to_string(path[i]);
}
result.push_back(stoi(strPath));
return;
}
if(root->left != NULL){
traversal(root->left, path, result);
path.pop_back();
}
if(root->right != NULL){
traversal(root->right, path, result);
path.pop_back();
}
}
int sumNumbers(TreeNode* root) {
vector<int> path;
vector<int> result;
int sum = 0;
if(root == NULL){
return sum;
}
traversal(root, path, result);
for(int res : result){
sum += res;
}
return sum;
}
};
Java解法
Python3解法
Go解法
437. Path Sum III
Given the root of a binary tree and an integer targetSum, return the number of paths where the sum of the values along the path equals targetSum.
The path does not need to start or end at the root or a leaf, but it must go downwards (i.e., traveling only from parent nodes to child nodes).
Example 1:
Input: root = [10,5,-3,3,2,null,11,3,-2,null,1], targetSum = 8
Output: 3
Explanation: The paths that sum to 8 are shown.
Example 2:
Input: root = [5,4,8,11,null,13,4,7,2,null,null,5,1], targetSum = 22
Output: 3
Constraints:
- The number of nodes in the tree is in the range
[0, 1000]. -10^9 <= Node.val <= 10^9-1000 <= targetSum <= 1000
思路
方法一:深度优先搜索
思路与算法
我们首先想到的解法是穷举所有的可能,我们访问每一个节点 node,检测以 node 为起始节点且向下延深的路径有多少种。我们递归遍历每一个节点的所有可能的路径,然后将这些路径数目加起来即为返回结果。
- 我们首先定义 rootSum(p,val) 表示以节点 p 为起点向下且满足路径总和为 val 的路径数目。我们对二叉树上每个节点 p 求出 rootSum(p,targetSum),然后对这些路径数目求和即为返回结果。
- 我们对节点 p 求 rootSum(p,targetSum) 时,以当前节点 p 为目标路径的起点递归向下进行搜索。假设当前的节点 p 的值为 val,我们对左子树和右子树进行递归搜索,对节点 p 的左孩子节点 pl 求出 rootSum(pl,targetSum−val),以及对右孩子节点 pr求出 rootSum(pr ,targetSum−val)。节点 p 的 rootSum(p,targetSum) 即等于 rootSum(pl,targetSum−val) 与 rootSum(p,targetSum−val) 之和,同时我们还需要判断一下当前节点 p 的值是否刚好等于 targetSum。
- 我们采用递归遍历二叉树的每个节点 p,对节点 p 求 rootSum(p,val),然后将每个节点所有求的值进行相加求和返回。
复杂度分析
时间复杂度:O(N^2 ),其中 N 为该二叉树节点的个数。对于每一个节点,求以该节点为起点的路径数目时,则需要遍历以该节点为根节点的子树的所有节点,因此求该路径所花费的最大时间为 O(N),我们会对每个节点都求一次以该节点为起点的路径数目,因此时间复杂度为 O(N^2)。
空间复杂度:O(N),考虑到递归需要在栈上开辟空间。
方法二: 前缀和
思路与算法
我们仔细思考一下,解法一中应该存在许多重复计算。我们定义节点的前缀和为:由根结点到当前结点的路径上所有节点的和。我们利用先序遍历二叉树,记录下根节点 root 到当前节点 p 的路径上除当前节点以外所有节点的前缀和,在已保存的路径前缀和中查找是否存在前缀和刚好等于当前节点到根节点的前缀和 curr 减去 targetSum。
- 对于空路径我们也需要保存预先处理一下,此时因为空路径不经过任何节点,因此它的前缀和为 0。
- 假设根节点为 root,我们当前刚好访问节点 node,则此时从根节点 root 到节点 node 的路径(无重复节点)刚好为 root→p1→p2→…→pk→node,此时我们可以已经保存了节点 p1,p2,p3 ,…,pk的前缀和,并且计算出了节点 node 的前缀和。
- 假设当前从根节点 root 到节点 node 的前缀和为 curr,则此时我们在已保存的前缀和查找是否存在前缀和刚好等于 curr−targetSum。假设从根节点 root 到节点 node 的路径中存在节点 pi到根节点 root 的前缀和为 curr−targetSum,则节点 pi+1到 node 的路径上所有节点的和一定为 targetSum。
- 我们利用深度搜索遍历树,当我们退出当前节点时,我们需要及时更新已经保存的前缀和。
复杂度分析
时间复杂度:O(N),其中 N 为二叉树中节点的个数。利用前缀和只需遍历一次二叉树即可。
空间复杂度:O(N)。
作者:力扣官方题解 链接: https://leetcode.cn/problems/path-sum-iii/solutions/1021296/lu-jing-zong-he-iii-by-leetcode-solution-z9td/ 来源:力扣(LeetCode) 著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
C++ 解法
深度优先搜索
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode() : val(0), left(nullptr), right(nullptr) {}
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
* };
*/
class Solution {
public:
int rootSum(TreeNode* root, long targetSum){
if(!root) return 0;
int ret = 0;
if(root->val == targetSum) ret++;
ret += rootSum(root->left, targetSum - root->val);
ret += rootSum(root->right, targetSum - root->val);
return ret;
}
int pathSum(TreeNode* root, long targetSum) {
if(!root) return 0;
int ret = rootSum(root, targetSum);
ret += pathSum(root->left, targetSum);
ret += pathSum(root->right, targetSum);
return ret;
}
};
Java 解法
Python 解法
二叉树物理性质
- # 958. Check Completeness of a Binary Tree
- 543. Diameter of Binary Tree
- 199. Binary Tree Right Side View
- 226. Invert Binary Tree
- 655. Print Binary Tree
# 958. Check Completeness of a Binary Tree
Given the root of a binary tree, determine if it is a complete binary tree.
In a complete binary tree, every level, except possibly the last, is completely filled, and all nodes in the last level are as far left as possible. It can have between 1 and 2h nodes inclusive at the last level h.
Example 1:

Input: root = [1,2,3,4,5,6]
Output: true
Explanation: Every level before the last is full (ie. levels with node-values {1} and {2, 3}), and all nodes in the last level ({4, 5, 6}) are as far left as possible.
Example 2:

Input: root = [1,2,3,4,5,null,7]
Output: false
Explanation: The node with value 7 isn't as far left as possible.
Constraints:
- The number of nodes in the tree is in the range
[1, 100]. 1 <= Node.val <= 1000
思路
Intuition :
Given the root of a binary tree, determine if it is a complete binary tree.
Approach : Breadth First Search
Traverse the tree in level-order using a queue. At each level, we add the left and right child nodes of each node to the queue.
If we encounter a null node, we still add it to the queue so that we can check if there are any more nodes left in the next step.
Once we have traversed the entire tree, we check if there are any remaining nodes in the queue. If there are, it means the tree is not complete, and we return false.
Otherwise, the tree is complete, and we return true.
Complexity :
Time complexity : O(n)
Space complexity: O(n)
C++解法
// Define the Solution class
class Solution {
public:
// Define the isCompleteTree function that takes a TreeNode pointer as input and returns a boolean
bool isCompleteTree(TreeNode* root) {
// Check if the root node is null, if so, return true (an empty tree is complete)
if (root == nullptr)
return true;
// Create a queue to store the nodes of the tree in level order
queue<TreeNode*> q{{root}};
// Traverse the tree in level order
while (q.front() != nullptr) {
// Remove the first node from the queue
TreeNode* node = q.front();
q.pop();
// Add the left and right child nodes of the current node to the queue
q.push(node->left);
q.push(node->right);
}
// Remove any remaining null nodes from the front of the queue
while (!q.empty() && q.front() == nullptr)
q.pop();
// Check if there are any remaining nodes in the queue
// If so, the tree is not complete, so return false
// Otherwise, the tree is complete, so return true
return q.empty();
}
};
Java解法
// Define the Solution class
class Solution {
// Define the isCompleteTree function that takes a TreeNode as input and returns a boolean
public boolean isCompleteTree(TreeNode root) {
// Check if the root node is null, if so, return true (an empty tree is complete)
if (root == null)
return true;
// Create a queue to store the nodes of the tree in level order
Queue<TreeNode> q = new LinkedList<>(Arrays.asList(root));
// Traverse the tree in level order
while (q.peek() != null) {
// Remove the first node from the queue
TreeNode node = q.poll();
// Add the left and right child nodes of the current node to the queue
q.offer(node.left);
q.offer(node.right);
}
// Remove any remaining null nodes from the end of the queue
while (!q.isEmpty() && q.peek() == null)
q.poll();
// Check if there are any remaining nodes in the queue
// If so, the tree is not complete, so return false
// Otherwise, the tree is complete, so return true
return q.isEmpty();
}
}
Python3解法
from collections import deque
class Solution:
def isCompleteTree(self, root: TreeNode) -> bool:
# Check if the root node is None, if so, return True (an empty tree is complete)
if not root:
return True
# Create a deque to store the nodes of the tree in level order
q = deque([root])
# Traverse the tree in level order
while q[0] is not None:
# Remove the first node from the deque
node = q.popleft()
# Add the left and right child nodes of the current node to the deque
q.append(node.left)
q.append(node.right)
# Remove any remaining None nodes from the beginning of the deque
while q and q[0] is None:
q.popleft()
# Check if there are any remaining nodes in the deque
# If so, the tree is not complete, so return False
# Otherwise, the tree is complete, so return True
return not bool(q)
Go解法
543. Diameter of Binary Tree
Description
Given the root of a binary tree, return the length of the diameter of the tree.
The diameter of a binary tree is the length of the longest path between any two nodes in a tree. This path may or may not pass through the root.
The length of a path between two nodes is represented by the number of edges between them.
Example 1:
Input: root = [1,2,3,4,5]
Output: 3
Explanation: 3 is the length of the path [4,2,1,3] or [5,2,1,3].
Example 2:
Input: root = [1,2]
Output: 1
Constraints:
- The number of nodes in the tree is in the range
[1, 10^4]. -100 <= Node.val <= 100
思路
方法一:深度优先搜索
首先我们知道一条路径的长度为该路径经过的节点数减一,所以求直径(即求路径长度的最大值)等效于求路径经过节点数的最大值减一。
而任意一条路径均可以被看作由某个节点为起点,从其左儿子和右儿子向下遍历的路径拼接得到。
如图我们可以知道路径 [9, 4, 2, 5, 7, 8] 可以被看作以 2 为起点,从其左儿子向下遍历的路径 [2, 4, 9] 和从其右儿子向下遍历的路径 [2, 5, 7, 8] 拼接得到。
假设我们知道对于该节点的左儿子向下遍历经过最多的节点数 L (即以左儿子为根的子树的深度) 和其右儿子向下遍历经过最多的节点数 R (即以右儿子为根的子树的深度),那么以该节点为起点的路径经过节点数的最大值即为 L+R+1 。
我们记节点 node 为起点的路径经过节点数的最大值为 dnode,那么二叉树的直径就是所有节点 dnode的最大值减一。
最后的算法流程为:我们定义一个递归函数 depth(node) 计算 dnode ,函数返回该节点为根的子树的深度。先递归调用左儿子和右儿子求得它们为根的子树的深度 L 和 R ,则该节点为根的子树的深度即为max(L,R)+1
该节点的 dnode值为L+R+1
递归搜索每个节点并设一个全局变量 ans 记录 dnode的最大值,最后返回 ans-1 即为树的直径。
作者:力扣官方题解 链接: https://leetcode.cn/problems/diameter-of-binary-tree/solutions/139683/er-cha-shu-de-zhi-jing-by-leetcode-solution/ 来源:力扣(LeetCode) 著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
C++ 解法
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode() : val(0), left(nullptr), right(nullptr) {}
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
* };
*/
class Solution {
public:
int diameterOfBinaryTree(TreeNode* root) {
int result = INT_MIN;
getMaxHeight(root, result);
return result;
}
int getMaxHeight(TreeNode* root, int& result){
if(root == NULL){
return 0;
}
int left = getMaxHeight(root->left, result);
int right = getMaxHeight(root->right, result);
result = max(result, left + right);
return max(left, right) + 1;
}
};
优化版本:
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode() : val(0), left(nullptr), right(nullptr) {}
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
* };
*/
class Solution {
public:
int diameterOfBinaryTree(TreeNode* root) {
int result = INT_MIN;
getMaxHeight(root, result);
return result;
}
int getMaxHeight(TreeNode* root, int& result){
if(root == NULL){
return 0;
}
if (map.count(root)) return map[root];
int left = getMaxHeight(root->left, result);
int right = getMaxHeight(root->right, result);
result = max(result, left + right);
return map[root] = max(left, right) + 1;
}
private:
unordered_map<TreeNode*, int> map;
};
Java 解法
Python 解法
199. Binary Tree Right Side View
Description
Given the root of a binary tree, imagine yourself standing on the right side of it, return the values of the nodes you can see ordered from top to bottom.
Example 1:
Input: root = [1,2,3,null,5,null,4]
Output: [1,3,4]
Example 2:
Input: root = [1,null,3]
Output: [1,3]
Example 3:
Input: root = []
Output: []
Constraints:
- The number of nodes in the tree is in the range
[0, 100]. -100 <= Node.val <= 100
思路
层次遍历,每层最后一个节点
由于树的形状无法提前知晓,不可能设计出优于 O(n) 的算法。因此,我们应该试着寻找线性时间解。带着这个想法,我们来考虑一些同等有效的方案。
方法一:深度优先搜索
思路
我们对树进行深度优先搜索,在搜索过程中,我们总是先访问右子树。那么对于每一层来说,我们在这层见到的第一个结点一定是最右边的结点。
算法
这样一来,我们可以存储在每个深度访问的第一个结点,一旦我们知道了树的层数,就可以得到最终的结果数组。
上图表示了问题的一个实例。红色结点自上而下组成答案,边缘以访问顺序标号。
复杂度分析
时间复杂度 : O(n)。深度优先搜索最多访问每个结点一次,因此是线性复杂度。
空间复杂度 : O(n)。最坏情况下,栈内会包含接近树高度的结点数量,占用 O(n) 的空间。
方法二:广度优先搜索
思路
我们可以对二叉树进行层次遍历,那么对于每层来说,最右边的结点一定是最后被遍历到的。二叉树的层次遍历可以用广度优先搜索实现。
算法
执行广度优先搜索,左结点排在右结点之前,这样,我们对每一层都从左到右访问。因此,只保留每个深度最后访问的结点,我们就可以在遍历完整棵树后得到每个深度最右的结点。除了将栈改成队列,并去除了 rightmost_value_at_depth 之前的检查外,算法没有别的改动。
上图表示了同一个示例,红色结点自上而下组成答案,边缘以访问顺序标号。
复杂度分析
时间复杂度 : O(n)。 每个节点最多进队列一次,出队列一次,因此广度优先搜索的复杂度为线性。
空间复杂度 : O(n)。每个节点最多进队列一次,所以队列长度最大不不超过 n,所以这里的空间代价为 O(n)。
作者:力扣官方题解
链接: https://leetcode.cn/problems/binary-tree-right-side-view/solutions/213494/er-cha-shu-de-you-shi-tu-by-leetcode-solution/
来源:力扣(LeetCode)
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
C++ 解法
dfs
class Solution {
public:
vector<int> rightSideView(TreeNode* root) {
unordered_map<int, int> rightmostValueAtDepth;
int max_depth = -1;
stack<TreeNode*> nodeStack;
stack<int> depthStack;
nodeStack.push(root);
depthStack.push(0);
while (!nodeStack.empty()) {
TreeNode* node = nodeStack.top();nodeStack.pop();
int depth = depthStack.top();depthStack.pop();
if (node != NULL) {
// 维护二叉树的最大深度
max_depth = max(max_depth, depth);
// 如果不存在对应深度的节点我们才插入
if (rightmostValueAtDepth.find(depth) == rightmostValueAtDepth.end()) {
rightmostValueAtDepth[depth] = node -> val;
}
nodeStack.push(node -> left);
nodeStack.push(node -> right);
depthStack.push(depth + 1);
depthStack.push(depth + 1);
}
}
vector<int> rightView;
for (int depth = 0; depth <= max_depth; ++depth) {
rightView.push_back(rightmostValueAtDepth[depth]);
}
return rightView;
}
};
bfs
class Solution {
public:
vector<int> rightSideView(TreeNode* root) {
unordered_map<int, int> rightmostValueAtDepth;
int max_depth = -1;
queue<TreeNode*> nodeQueue;
queue<int> depthQueue;
nodeQueue.push(root);
depthQueue.push(0);
while (!nodeQueue.empty()) {
TreeNode* node = nodeQueue.front();nodeQueue.pop();
int depth = depthQueue.front();depthQueue.pop();
if (node != NULL) {
// 维护二叉树的最大深度
max_depth = max(max_depth, depth);
// 由于每一层最后一个访问到的节点才是我们要的答案,因此不断更新对应深度的信息即可
rightmostValueAtDepth[depth] = node -> val;
nodeQueue.push(node -> left);
nodeQueue.push(node -> right);
depthQueue.push(depth + 1);
depthQueue.push(depth + 1);
}
}
vector<int> rightView;
for (int depth = 0; depth <= max_depth; ++depth) {
rightView.push_back(rightmostValueAtDepth[depth]);
}
return rightView;
}
};
Java 解法
dfs
class Solution {
public List<Integer> rightSideView(TreeNode root) {
Map<Integer, Integer> rightmostValueAtDepth = new HashMap<Integer, Integer>();
int max_depth = -1;
Deque<TreeNode> nodeStack = new LinkedList<TreeNode>();
Deque<Integer> depthStack = new LinkedList<Integer>();
nodeStack.push(root);
depthStack.push(0);
while (!nodeStack.isEmpty()) {
TreeNode node = nodeStack.pop();
int depth = depthStack.pop();
if (node != null) {
// 维护二叉树的最大深度
max_depth = Math.max(max_depth, depth);
// 如果不存在对应深度的节点我们才插入
if (!rightmostValueAtDepth.containsKey(depth)) {
rightmostValueAtDepth.put(depth, node.val);
}
nodeStack.push(node.left);
nodeStack.push(node.right);
depthStack.push(depth + 1);
depthStack.push(depth + 1);
}
}
List<Integer> rightView = new ArrayList<Integer>();
for (int depth = 0; depth <= max_depth; depth++) {
rightView.add(rightmostValueAtDepth.get(depth));
}
return rightView;
}
}
bfs
class Solution {
public List<Integer> rightSideView(TreeNode root) {
Map<Integer, Integer> rightmostValueAtDepth = new HashMap<Integer, Integer>();
int max_depth = -1;
Queue<TreeNode> nodeQueue = new LinkedList<TreeNode>();
Queue<Integer> depthQueue = new LinkedList<Integer>();
nodeQueue.add(root);
depthQueue.add(0);
while (!nodeQueue.isEmpty()) {
TreeNode node = nodeQueue.remove();
int depth = depthQueue.remove();
if (node != null) {
// 维护二叉树的最大深度
max_depth = Math.max(max_depth, depth);
// 由于每一层最后一个访问到的节点才是我们要的答案,因此不断更新对应深度的信息即可
rightmostValueAtDepth.put(depth, node.val);
nodeQueue.add(node.left);
nodeQueue.add(node.right);
depthQueue.add(depth + 1);
depthQueue.add(depth + 1);
}
}
List<Integer> rightView = new ArrayList<Integer>();
for (int depth = 0; depth <= max_depth; depth++) {
rightView.add(rightmostValueAtDepth.get(depth));
}
return rightView;
}
}
Python 解法
dfs
class Solution:
def rightSideView(self, root: TreeNode) -> List[int]:
rightmost_value_at_depth = dict() # 深度为索引,存放节点的值
max_depth = -1
stack = [(root, 0)]
while stack:
node, depth = stack.pop()
if node is not None:
# 维护二叉树的最大深度
max_depth = max(max_depth, depth)
# 如果不存在对应深度的节点我们才插入
rightmost_value_at_depth.setdefault(depth, node.val)
stack.append((node.left, depth + 1))
stack.append((node.right, depth + 1))
return [rightmost_value_at_depth[depth] for depth in range(max_depth + 1)]
bfs
class Solution:
def rightSideView(self, root: TreeNode) -> List[int]:
rightmost_value_at_depth = dict() # 深度为索引,存放节点的值
max_depth = -1
queue = deque([(root, 0)])
while queue:
node, depth = queue.popleft()
if node is not None:
# 维护二叉树的最大深度
max_depth = max(max_depth, depth)
# 由于每一层最后一个访问到的节点才是我们要的答案,因此不断更新对应深度的信息即可
rightmost_value_at_depth[depth] = node.val
queue.append((node.left, depth + 1))
queue.append((node.right, depth + 1))
return [rightmost_value_at_depth[depth] for depth in range(max_depth + 1)]
226. Invert Binary Tree
Given the root of a binary tree, invert the tree, and return its root.
Example 1:
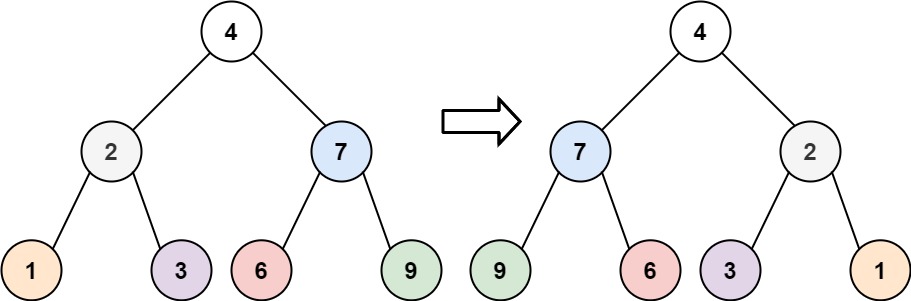
Input: root = [4,2,7,1,3,6,9]
Output: [4,7,2,9,6,3,1]
Example 2:
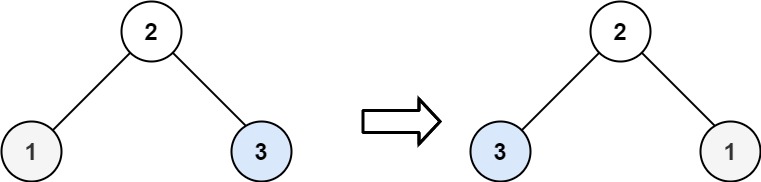
Input: root = [2,1,3]
Output: [2,3,1]
Example 3:
Input: root = []
Output: []
Constraints:
- The number of nodes in the tree is in the range
[0, 100]. -100 <= Node.val <= 100
思路
-
先序遍历,左右交换
-
左右交换,后序遍历
C++ 解法
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode() : val(0), left(nullptr), right(nullptr) {}
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
* };
*/
class Solution {
public:
TreeNode* invertTree(TreeNode* root) {
if(root == nullptr){
return root;
}
invertTree(root->left);
invertTree(root->right);
swap(root->left, root->right);
return root;
}
};
Java 解法
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode() {}
* TreeNode(int val) { this.val = val; }
* TreeNode(int val, TreeNode left, TreeNode right) {
* this.val = val;
* this.left = left;
* this.right = right;
* }
* }
*/
class Solution {
public TreeNode invertTree(TreeNode root) {
if(root == null){
return null;
}
if(root.left == null && root.right == null){
return root;
}
TreeNode temp = root.left;
root.left = root.right;
root.right = temp;
root.left = invertTree(root.left);
root.right = invertTree(root.right);
return root;
}
}
Python 解法
# Definition for a binary tree node.
# class TreeNode:
# def __init__(self, val=0, left=None, right=None):
# self.val = val
# self.left = left
# self.right = right
class Solution:
def invertTree(self, root: Optional[TreeNode]) -> Optional[TreeNode]:
if not root:
return
temp = root.left
root.left = root.right
root.right = temp
self.invertTree(root.left)
self.invertTree(root.right)
return root
655. Print Binary Tree
Given the root of a binary tree, construct a 0-indexed m x n string matrix res that represents a formatted layout of the tree. The formatted layout matrix should be constructed using the following rules:
- The height of the tree is
heightand the number of rowsmshould be equal toheight + 1. - The number of columns
nshould be equal to2^{height+1} - 1. - Place the root node in the middle of the top row (more formally, at location
res[0][(n-1)/2]). - For each node that has been placed in the matrix at position
res[r][c], place its left child atres[r+1][c-2height-r-1]and its right child atres[r+1][c+2^{height-r-1}]. - Continue this process until all the nodes in the tree have been placed.
- Any empty cells should contain the empty string
"".
Return the constructed matrix res.
Example 1:
Input: root = [1,2]
Output:
[["","1",""],
["2","",""]]
Example 2:
Input: root = [1,2,3,null,4]
Output:
[["","","","1","","",""],
["","2","","","","3",""],
["","","4","","","",""]]
Constraints:
- The number of nodes in the tree is in the range
[1, 210]. -99 <= Node.val <= 99- The depth of the tree will be in the range
[1, 10].
思路
C++解法
Java解法
public List<List<String>> printTree(TreeNode root) {
List<List<String>> res = new LinkedList<>();
int height = root == null ? 1 : getHeight(root);
int rows = height, columns = (int) (Math.pow(2, height) - 1);
List<String> row = new ArrayList<>();
for(int i = 0; i < columns; i++) row.add("");
for(int i = 0; i < rows; i++) res.add(new ArrayList<>(row));
populateRes(root, res, 0, rows, 0, columns - 1);
return res;
}
public void populateRes(TreeNode root, List<List<String>> res, int row, int totalRows, int i, int j) {
if (row == totalRows || root == null) return;
res.get(row).set((i+j)/2, Integer.toString(root.val));
populateRes(root.left, res, row+1, totalRows, i, (i+j)/2 - 1);
populateRes(root.right, res, row+1, totalRows, (i+j)/2+1, j);
}
public int getHeight(TreeNode root) {
if (root == null) return 0;
return 1 + Math.max(getHeight(root.left), getHeight(root.right));
}
这段代码定义了一个树的打印逻辑,用于将二叉树的结构输出为一个二维字符串列表。下面我们将详细讲解该代码,包括类TreeNode及Solution类中的各个方法,特别是populateRes函数的具体实现逻辑。
getHeight 方法
public int getHeight(TreeNode root) {
if (root == null) return 0;
else return 1 + Math.max(getHeight(root.left), getHeight(root.right));
}
- 该方法用于计算二叉树的高度。树的高度从0开始计数。
- 如果节点为空,返回0;否则,返回1加上左子树和右子树的最大高度。
- 这有助于确定打印树结构时所需的行数。
populateRes 方法
public void populateRes(TreeNode root, List<List<String>> res, int row, int totalRows, int i, int j) {
if (row == totalRows || root == null) return;
res.get(row).set((i + j) / 2, Integer.toString(root.val));
populateRes(root.left, res, row + 1, totalRows, i, (i + j) / 2 - 1);
populateRes(root.right, res, row + 1, totalRows, (i + j) / 2 + 1, j);
}
-
目的: 该方法递归地在结果列表中填充节点值。它基于树的结构定位每个节点的位置。
-
参数:
TreeNode root:当前处理的节点。List<List<String>> res:存储结果的二维列表。int row:当前的树层级。int totalRows:树的总层数。int i和int j:表示节点在当前行的索引范围。
-
逻辑:
- 基础条件:
- 如果当前层数已经达到总层数,或者当前节点为空,则返回。
- 填写当前节点值:
- 使用
res.get(row).set((i + j) / 2, Integer.toString(root.val));将当前节点的值存储在对应的二维列表中的正确位置。这里的(i + j) / 2计算出当前层节点的中间列索引,确保二叉树的节点以正确的对称方式排列。
- 使用
- 递归调用:
- 递归填充左子树和右子树:
- 左子树的调用范围是当前行的左半部分:
populateRes(root.left, res, row + 1, totalRows, i, (i + j) / 2 - 1); - 右子树的调用范围是当前行的右半部分:
populateRes(root.right, res, row + 1, totalRows, (i + j) / 2 + 1, j);
- 左子树的调用范围是当前行的左半部分:
- 递归填充左子树和右子树:
- 基础条件:
printTree 方法
public List<List<String>> printTree(TreeNode root) {
List<List<String>> result = new LinkedList<>();
int row = getHeight(root);
int col = (int) (Math.pow(2, row) - 1);
List<String> rowRes = new ArrayList<>();
for (int i = 0; i < col; i++) rowRes.add("");
for (int i = 0; i < row; i++) result.add(new ArrayList<>(rowRes));
populateRes(root, result, 0, row, 0, col);
return result;
}
- 目的: 该方法用于生成表示二叉树的二维列表。
- 逻辑:
- 计算树的高度
row和列数col。列数是基于树的高度计算得来的,最大列数是2^height - 1。 - 创建一行的初始结果,即包含所有列的空字符串(
rowRes)。 - 用内层循环初始化结果列表
result,使其中每一行的结构一致。 - 调用
populateRes来填充结果列表。 - 返回填充后的
result。
- 计算树的高度
Python3解法
Go解法
二叉树反转对称
226. Invert Binary Tree
Given the root of a binary tree, invert the tree, and return its root.
Example 1:
Input: root = [4,2,7,1,3,6,9]
Output: [4,7,2,9,6,3,1]
Example 2:
Input: root = [2,1,3]
Output: [2,3,1]
Example 3:
Input: root = []
Output: []
Constraints:
- The number of nodes in the tree is in the range
[0, 100]. -100 <= Node.val <= 100
思路
确定遍历顺序,推荐使用前序遍历和后序遍历。
C++解法
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode() : val(0), left(nullptr), right(nullptr) {}
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
* };
*/
class Solution {
public:
TreeNode* invertTree(TreeNode* root) {
if(root == nullptr){
return root;
}
invertTree(root->left);
invertTree(root->right);
swap(root->left, root->right);
return root;
}
};
Java解法
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode() {}
* TreeNode(int val) { this.val = val; }
* TreeNode(int val, TreeNode left, TreeNode right) {
* this.val = val;
* this.left = left;
* this.right = right;
* }
* }
*/
class Solution {
public TreeNode invertTree(TreeNode root) {
if(root == null){
return null;
}
if(root.left == null && root.right == null){
return root;
}
TreeNode temp = root.left;
root.left = root.right;
root.right = temp;
root.left = invertTree(root.left);
root.right = invertTree(root.right);
return root;
}
}
Python3解法
# Definition for a binary tree node.
# class TreeNode:
# def __init__(self, val=0, left=None, right=None):
# self.val = val
# self.left = left
# self.right = right
class Solution:
def invertTree(self, root: Optional[TreeNode]) -> Optional[TreeNode]:
if not root:
return
temp = root.left
root.left = root.right
root.right = temp
self.invertTree(root.left)
self.invertTree(root.right)
return root
Go解法
101. Symmetric Tree
Given the root of a binary tree, check whether it is a mirror of itself (i.e., symmetric around its center).
Example 1:
Input: root = [1,2,2,3,4,4,3]
Output: true
Example 2:
Input: root = [1,2,2,null,3,null,3]
Output: false
Constraints:
- The number of nodes in the tree is in the range
[1, 1000]. -100 <= Node.val <= 100
Follow up: Could you solve it both recursively and iteratively?
思路
只能使用后序遍历
C++解法
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode() : val(0), left(nullptr), right(nullptr) {}
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
* };
*/
class Solution {
public:
bool compare(TreeNode* left, TreeNode* right){
if(left == NULL && right == NULL){
return true;
}else if(left == NULL || right == NULL){
return false;
}else if(left->val == right->val){
return compare(left->right, right->left) && compare(left->left, right->right);
}else{
return false;
}
}
bool isSymmetric(TreeNode* root) {
if(root == NULL){
return true;
}
return compare(root->left, root->right);
}
};
Java解法
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode() {}
* TreeNode(int val) { this.val = val; }
* TreeNode(int val, TreeNode left, TreeNode right) {
* this.val = val;
* this.left = left;
* this.right = right;
* }
* }
*/
class Solution {
public boolean isSymmetric(TreeNode root) {
if(root == null) return true;
return isMirror(root.left, root.right);
}
public boolean isMirror(TreeNode left, TreeNode right){
if(left == null && right == null) return true;
else if(left == null || right == null) return false;
else if(left.val != right.val) return false;
return isMirror(left.left, right.right) && isMirror(left.right, right.left);
}
}
Python3解法
# Definition for a binary tree node.
# class TreeNode(object):
# def __init__(self, val=0, left=None, right=None):
# self.val = val
# self.left = left
# self.right = right
class Solution(object):
def isSymmetric(self, root):
"""
:type root: TreeNode
:rtype: bool
"""
if not root:
return True
return self.isMirror(root.left, root.right)
def isMirror(self, left, right):
if not left and not right:
return True
if not left or not right:
return False
return left.val == right.val and self.isMirror(left.left, right.right) and self.isMirror(left.right, right.left)
Go解法
二叉树深度高度节点数
- 104. Maximum Depth of Binary Tree
- 111. Minimum Depth of Binary Tree
- 222. Count Complete Tree Nodes
- 110. Balanced Binary Tree
104. Maximum Depth of Binary Tree
Given the root of a binary tree, return its maximum depth.
A binary tree's maximum depth is the number of nodes along the longest path from the root node down to the farthest leaf node.
Example 1:
Input: root = [3,9,20,null,null,15,7]
Output: 3
Example 2:
Input: root = [1,null,2]
Output: 2
Constraints:
- The number of nodes in the tree is in the range
[0, 10^4]. -100 <= Node.val <= 100
思路
递归
C++解法
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode() : val(0), left(nullptr), right(nullptr) {}
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
* };
*/
class Solution {
public:
int maxDepth(TreeNode* root) {
if(root == NULL){
return 0;
}
return max(maxDepth(root->left), maxDepth(root->right)) + 1;
}
};
Java解法
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode() {}
* TreeNode(int val) { this.val = val; }
* TreeNode(int val, TreeNode left, TreeNode right) {
* this.val = val;
* this.left = left;
* this.right = right;
* }
* }
*/
class Solution {
public int maxDepth(TreeNode root) {
if(root == null) return 0;
if(root.left == null && root.right == null) return 1;
return Math.max(maxDepth(root.left), maxDepth(root.right)) + 1;
}
}
Python3解法
Go解法
111. Minimum Depth of Binary Tree
Given a binary tree, find its minimum depth.
The minimum depth is the number of nodes along the shortest path from the root node down to the nearest leaf node.
Note: A leaf is a node with no children.
Example 1:
Input: root = [3,9,20,null,null,15,7]
Output: 2
Example 2:
Input: root = [2,null,3,null,4,null,5,null,6]
Output: 5
Constraints:
- The number of nodes in the tree is in the range
[0, 10^5]. -1000 <= Node.val <= 1000
思路
递归
C++解法
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode() : val(0), left(nullptr), right(nullptr) {}
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
* };
*/
class Solution {
public:
int minDepth(TreeNode* root) {
if(root == NULL){
return 0;
}
if(root->left == NULL && root->right != NULL){
return minDepth(root->right) + 1;
}
if(root->right == NULL && root->left != NULL){
return minDepth(root->left) + 1;
}
return 1 + min(minDepth(root->left), minDepth(root->right));
}
};
Java解法
Python3解法
Go解法
222. Count Complete Tree Nodes
Given the root of a complete binary tree, return the number of the nodes in the tree.
According to Wikipedia, every level, except possibly the last, is completely filled in a complete binary tree, and all nodes in the last level are as far left as possible. It can have between 1 and 2h nodes inclusive at the last level h.
Design an algorithm that runs in less than O(n) time complexity.
Example 1:

Input: root = [1,2,3,4,5,6]
Output: 6
Example 2:
Input: root = []
Output: 0
Example 3:
Input: root = [1]
Output: 1
Constraints:
- The number of nodes in the tree is in the range
[0, 5 * 10^4]. 0 <= Node.val <= 5 * 10^4- The tree is guaranteed to be complete.
思路
递归,从根节点出发统计的节点数=从根节点左节点出发统计的节点数+从根节点右节点出发统计的节点数+1
C++解法
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode() : val(0), left(nullptr), right(nullptr) {}
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
* };
*/
class Solution {
public:
int countNodes(TreeNode* root) {
if(root == NULL){
return 0;
}
return countNodes(root->left) + countNodes(root->right) + 1;
}
};
Java解法
Python3解法
Go解法
110. Balanced Binary Tree
Given a binary tree, determine if it is height-balanced.
Example 1:
Input: root = [3,9,20,null,null,15,7]
Output: true
Example 2:
Input: root = [1,2,2,3,3,null,null,4,4]
Output: false
Example 3:
Input: root = []
Output: true
Constraints:
- The number of nodes in the tree is in the range
[0, 5000]. -10^4 <= Node.val <= 10^4
思路
递归
C++解法
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode() : val(0), left(nullptr), right(nullptr) {}
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
* };
*/
class Solution {
public:
int getHeight(TreeNode* root){
if(root == NULL){
return 0;
}
int leftHeight = getHeight(root->left);
if(leftHeight == -1){
return -1;
}
int rightHeight = getHeight(root->right);
if(rightHeight == -1){
return -1;
}
if(abs(leftHeight - rightHeight) > 1){
return -1;
}else{
return 1 + max(leftHeight, rightHeight);
}
}
bool isBalanced(TreeNode* root) {
return getHeight(root) == -1 ? false : true;
}
};
Java解法
Python3解法
Go解法
二叉树构造(前序遍历)
- 105. Construct Binary Tree from Preorder and Inorder Traversal
- 106. Construct Binary Tree from Inorder and Postorder Traversal
- 654. Maximum Binary Tree
- 617. Merge Two Binary Trees
105. Construct Binary Tree from Preorder and Inorder Traversal
Given two integer arrays preorder and inorder where preorder is the preorder traversal of a binary tree and inorder is the inorder traversal of the same tree, construct and return the binary tree.
Example 1:

Input: preorder = [3,9,20,15,7], inorder = [9,3,15,20,7]
Output: [3,9,20,null,null,15,7]
Example 2:
Input: preorder = [-1], inorder = [-1]
Output: [-1]
Constraints:
1 <= preorder.length <= 3000inorder.length == preorder.length-3000 <= preorder[i], inorder[i] <= 3000preorderandinorderconsist of unique values.- Each value of
inorderalso appears inpreorder. preorderis guaranteed to be the preorder traversal of the tree.inorderis guaranteed to be the inorder traversal of the tree.
思路
C++解法
class Solution {
private:
TreeNode* traversal (vector<int>& inorder, int inorderBegin, int inorderEnd, vector<int>& preorder, int preorderBegin, int preorderEnd) {
if (preorderBegin == preorderEnd) return NULL;
int rootValue = preorder[preorderBegin]; // 注意用preorderBegin 不要用0
TreeNode* root = new TreeNode(rootValue);
if (preorderEnd - preorderBegin == 1) return root;
int delimiterIndex;
for (delimiterIndex = inorderBegin; delimiterIndex < inorderEnd; delimiterIndex++) {
if (inorder[delimiterIndex] == rootValue) break;
}
// 切割中序数组
// 中序左区间,左闭右开[leftInorderBegin, leftInorderEnd)
int leftInorderBegin = inorderBegin;
int leftInorderEnd = delimiterIndex;
// 中序右区间,左闭右开[rightInorderBegin, rightInorderEnd)
int rightInorderBegin = delimiterIndex + 1;
int rightInorderEnd = inorderEnd;
// 切割前序数组
// 前序左区间,左闭右开[leftPreorderBegin, leftPreorderEnd)
int leftPreorderBegin = preorderBegin + 1;
int leftPreorderEnd = preorderBegin + 1 + delimiterIndex - inorderBegin; // 终止位置是起始位置加上中序左区间的大小size
// 前序右区间, 左闭右开[rightPreorderBegin, rightPreorderEnd)
int rightPreorderBegin = preorderBegin + 1 + (delimiterIndex - inorderBegin);
int rightPreorderEnd = preorderEnd;
root->left = traversal(inorder, leftInorderBegin, leftInorderEnd, preorder, leftPreorderBegin, leftPreorderEnd);
root->right = traversal(inorder, rightInorderBegin, rightInorderEnd, preorder, rightPreorderBegin, rightPreorderEnd);
return root;
}
public:
TreeNode* buildTree(vector<int>& preorder, vector<int>& inorder) {
if (inorder.size() == 0 || preorder.size() == 0) return NULL;
// 参数坚持左闭右开的原则
return traversal(inorder, 0, inorder.size(), preorder, 0, preorder.size());
}
};
Java解法
class Solution {
Map<Integer, Integer> map;
public TreeNode buildTree(int[] preorder, int[] inorder) {
map = new HashMap<>();
for (int i = 0; i < inorder.length; i++) { // 用map保存中序序列的数值对应位置
map.put(inorder[i], i);
}
return findNode(preorder, 0, preorder.length, inorder, 0, inorder.length); // 前闭后开
}
public TreeNode findNode(int[] preorder, int preBegin, int preEnd, int[] inorder, int inBegin, int inEnd) {
// 参数里的范围都是前闭后开
if (preBegin >= preEnd || inBegin >= inEnd) { // 不满足左闭右开,说明没有元素,返回空树
return null;
}
int rootIndex = map.get(preorder[preBegin]); // 找到前序遍历的第一个元素在中序遍历中的位置
TreeNode root = new TreeNode(inorder[rootIndex]); // 构造结点
int lenOfLeft = rootIndex - inBegin; // 保存中序左子树个数,用来确定前序数列的个数
root.left = findNode(preorder, preBegin + 1, preBegin + lenOfLeft + 1,
inorder, inBegin, rootIndex);
root.right = findNode(preorder, preBegin + lenOfLeft + 1, preEnd,
inorder, rootIndex + 1, inEnd);
return root;
}
}
Python3解法
class Solution:
def buildTree(self, preorder: List[int], inorder: List[int]) -> TreeNode:
# 第一步: 特殊情况讨论: 树为空. 或者说是递归终止条件
if not preorder:
return None
# 第二步: 前序遍历的第一个就是当前的中间节点.
root_val = preorder[0]
root = TreeNode(root_val)
# 第三步: 找切割点.
separator_idx = inorder.index(root_val)
# 第四步: 切割inorder数组. 得到inorder数组的左,右半边.
inorder_left = inorder[:separator_idx]
inorder_right = inorder[separator_idx + 1:]
# 第五步: 切割preorder数组. 得到preorder数组的左,右半边.
# ⭐️ 重点1: 中序数组大小一定跟前序数组大小是相同的.
preorder_left = preorder[1:1 + len(inorder_left)]
preorder_right = preorder[1 + len(inorder_left):]
# 第六步: 递归
root.left = self.buildTree(preorder_left, inorder_left)
root.right = self.buildTree(preorder_right, inorder_right)
# 第七步: 返回答案
return root
Go解法
/**
* Definition for a binary tree node.
* type TreeNode struct {
* Val int
* Left *TreeNode
* Right *TreeNode
* }
*/
var (
hash map[int]int
)
func buildTree(preorder []int, inorder []int) *TreeNode {
hash = make(map[int]int, len(inorder))
for i, v := range inorder {
hash[v] = i
}
root := build(preorder, inorder, 0, 0, len(inorder)-1) // l, r 表示构造的树在中序遍历数组中的范围
return root
}
func build(pre []int, in []int, root int, l, r int) *TreeNode {
if l > r {
return nil
}
rootVal := pre[root] // 找到本次构造的树的根节点
index := hash[rootVal] // 根节点在中序数组中的位置
node := &TreeNode {Val: rootVal}
node.Left = build(pre, in, root + 1, l, index-1)
node.Right = build(pre, in, root + (index-l) + 1, index+1, r)
return node
}
106. Construct Binary Tree from Inorder and Postorder Traversal
Given two integer arrays inorder and postorder where inorder is the inorder traversal of a binary tree and postorder is the postorder traversal of the same tree, construct and return the binary tree.
Example 1:
Input: inorder = [9,3,15,20,7], postorder = [9,15,7,20,3]
Output: [3,9,20,null,null,15,7]
Example 2:
Input: inorder = [-1], postorder = [-1]
Output: [-1]
Constraints:
1 <= inorder.length <= 3000postorder.length == inorder.length-3000 <= inorder[i], postorder[i] <= 3000inorderandpostorderconsist of unique values.- Each value of
postorderalso appears ininorder. inorderis guaranteed to be the inorder traversal of the tree.postorderis guaranteed to be the postorder traversal of the tree.****
思路
首先回忆一下如何根据两个顺序构造一个唯一的二叉树,相信理论知识大家应该都清楚,就是以 后序数组的最后一个元素为切割点,先切中序数组,根据中序数组,反过来再切后序数组。一层一层切下去,每次后序数组最后一个元素就是节点元素。
如果让我们肉眼看两个序列,画一棵二叉树的话,应该分分钟都可以画出来。
流程如图:
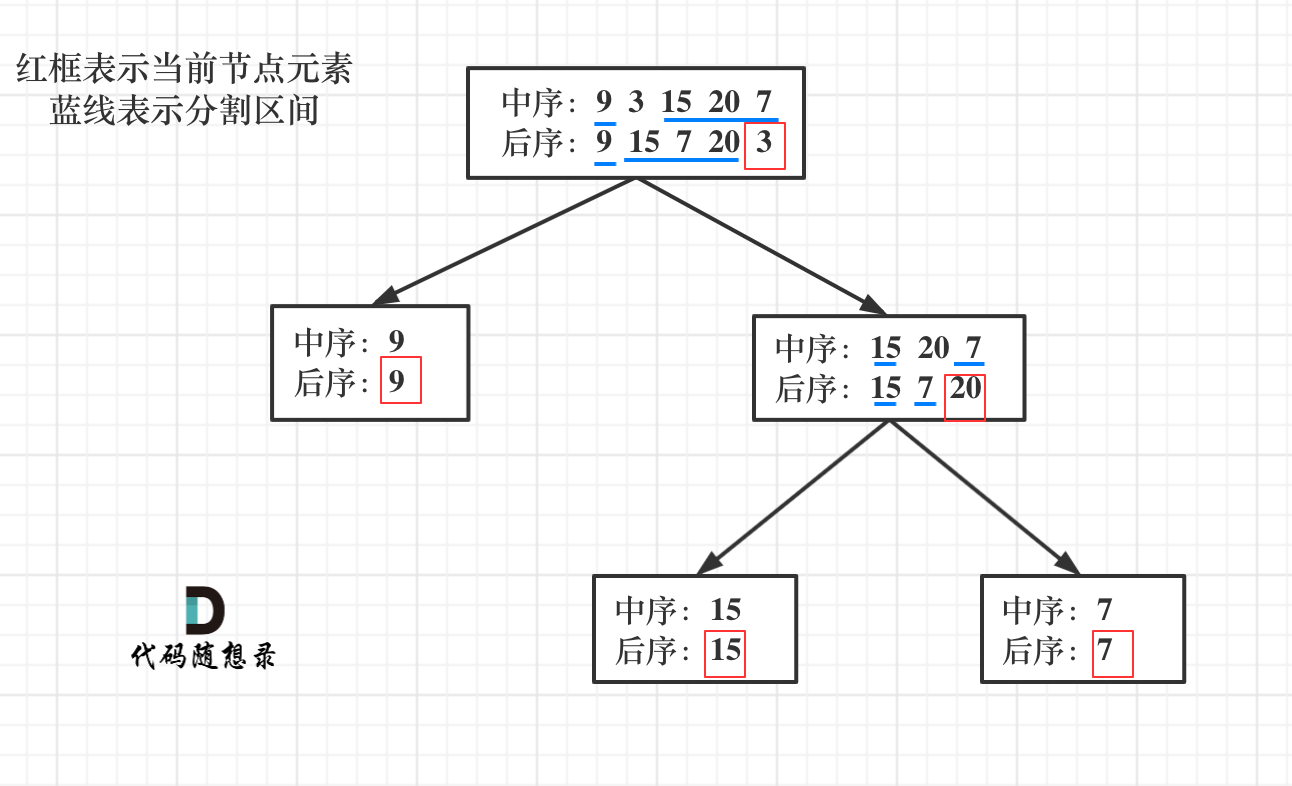
那么代码应该怎么写呢?
说到一层一层切割,就应该想到了递归。
来看一下一共分几步:
- 第一步:如果数组大小为零的话,说明是空节点了。
- 第二步:如果不为空,那么取后序数组最后一个元素作为节点元素。
- 第三步:找到后序数组最后一个元素在中序数组的位置,作为切割点
- 第四步:切割中序数组,切成中序左数组和中序右数组 (顺序别搞反了,一定是先切中序数组)
- 第五步:切割后序数组,切成后序左数组和后序右数组
- 第六步:递归处理左区间和右区间
不难写出如下代码:(先把框架写出来)
TreeNode* traversal (vector<int>& inorder, vector<int>& postorder) {
// 第一步
if (postorder.size() == 0) return NULL;
// 第二步:后序遍历数组最后一个元素,就是当前的中间节点
int rootValue = postorder[postorder.size() - 1];
TreeNode* root = new TreeNode(rootValue);
// 叶子节点
if (postorder.size() == 1) return root;
// 第三步:找切割点
int delimiterIndex;
for (delimiterIndex = 0; delimiterIndex < inorder.size(); delimiterIndex++) {
if (inorder[delimiterIndex] == rootValue) break;
}
// 第四步:切割中序数组,得到 中序左数组和中序右数组
// 第五步:切割后序数组,得到 后序左数组和后序右数组
// 第六步
root->left = traversal(中序左数组, 后序左数组);
root->right = traversal(中序右数组, 后序右数组);
return root;
}
难点大家应该发现了,就是如何切割,以及边界值找不好很容易乱套。
此时应该注意确定切割的标准,是左闭右开,还有左开右闭,还是左闭右闭,这个就是不变量,要在递归中保持这个不变量。
在切割的过程中会产生四个区间,把握不好不变量的话,一会左闭右开,一会左闭右闭,必然乱套!
我在数组:每次遇到二分法,都是一看就会,一写就废 (opens new window)和数组:这个循环可以转懵很多人! (opens new window)中都强调过循环不变量的重要性,在二分查找以及螺旋矩阵的求解中,坚持循环不变量非常重要,本题也是。
首先要切割中序数组,为什么先切割中序数组呢?
切割点在后序数组的最后一个元素,就是用这个元素来切割中序数组的,所以必要先切割中序数组。
中序数组相对比较好切,找到切割点(后序数组的最后一个元素)在中序数组的位置,然后切割,如下代码中我坚持左闭右开的原则:
// 找到中序遍历的切割点
int delimiterIndex;
for (delimiterIndex = 0; delimiterIndex < inorder.size(); delimiterIndex++) {
if (inorder[delimiterIndex] == rootValue) break;
}
// 左闭右开区间:[0, delimiterIndex)
vector<int> leftInorder(inorder.begin(), inorder.begin() + delimiterIndex);
// [delimiterIndex + 1, end)
vector<int> rightInorder(inorder.begin() + delimiterIndex + 1, inorder.end() );
接下来就要切割后序数组了。
首先后序数组的最后一个元素指定不能要了,这是切割点 也是 当前二叉树中间节点的元素,已经用了。
后序数组的切割点怎么找?
后序数组没有明确的切割元素来进行左右切割,不像中序数组有明确的切割点,切割点左右分开就可以了。
此时有一个很重的点,就是中序数组大小一定是和后序数组的大小相同的(这是必然)。
中序数组我们都切成了左中序数组和右中序数组了,那么后序数组就可以按照左中序数组的大小来切割,切成左后序数组和右后序数组。
代码如下:
// postorder 舍弃末尾元素,因为这个元素就是中间节点,已经用过了
postorder.resize(postorder.size() - 1);
// 左闭右开,注意这里使用了左中序数组大小作为切割点:[0, leftInorder.size)
vector<int> leftPostorder(postorder.begin(), postorder.begin() + leftInorder.size());
// [leftInorder.size(), end)
vector<int> rightPostorder(postorder.begin() + leftInorder.size(), postorder.end());
此时,中序数组切成了左中序数组和右中序数组,后序数组切割成左后序数组和右后序数组。
接下来可以递归了,代码如下:
root->left = traversal(leftInorder, leftPostorder);
root->right = traversal(rightInorder, rightPostorder);
相信大家自己就算是思路清晰, 代码写出来一定是各种问题,所以一定要加日志来调试,看看是不是按照自己思路来切割的,不要大脑模拟,那样越想越糊涂。
此时应该发现了,如上的代码性能并不好,因为每层递归定义了新的vector(就是数组),既耗时又耗空间,但上面的代码是最好理解的,为了方便读者理解,所以用如上的代码来讲解。
C++解法
完整代码如下:
class Solution {
private:
TreeNode* traversal (vector<int>& inorder, vector<int>& postorder) {
if (postorder.size() == 0) return NULL;
// 后序遍历数组最后一个元素,就是当前的中间节点
int rootValue = postorder[postorder.size() - 1];
TreeNode* root = new TreeNode(rootValue);
// 叶子节点
if (postorder.size() == 1) return root;
// 找到中序遍历的切割点
int delimiterIndex;
for (delimiterIndex = 0; delimiterIndex < inorder.size(); delimiterIndex++) {
if (inorder[delimiterIndex] == rootValue) break;
}
// 切割中序数组
// 左闭右开区间:[0, delimiterIndex)
vector<int> leftInorder(inorder.begin(), inorder.begin() + delimiterIndex);
// [delimiterIndex + 1, end)
vector<int> rightInorder(inorder.begin() + delimiterIndex + 1, inorder.end() );
// postorder 舍弃末尾元素
postorder.resize(postorder.size() - 1);
// 切割后序数组
// 依然左闭右开,注意这里使用了左中序数组大小作为切割点
// [0, leftInorder.size)
vector<int> leftPostorder(postorder.begin(), postorder.begin() + leftInorder.size());
// [leftInorder.size(), end)
vector<int> rightPostorder(postorder.begin() + leftInorder.size(), postorder.end());
root->left = traversal(leftInorder, leftPostorder);
root->right = traversal(rightInorder, rightPostorder);
return root;
}
public:
TreeNode* buildTree(vector<int>& inorder, vector<int>& postorder) {
if (inorder.size() == 0 || postorder.size() == 0) return NULL;
return traversal(inorder, postorder);
}
};
下面给出用下标索引写出的代码版本:(思路是一样的,只不过不用重复定义vector了,每次用下标索引来分割)
class Solution {
private:
// 中序区间:[inorderBegin, inorderEnd),后序区间[postorderBegin, postorderEnd)
TreeNode* traversal (vector<int>& inorder, int inorderBegin, int inorderEnd, vector<int>& postorder, int postorderBegin, int postorderEnd) {
if (postorderBegin == postorderEnd) return NULL;
int rootValue = postorder[postorderEnd - 1];
TreeNode* root = new TreeNode(rootValue);
if (postorderEnd - postorderBegin == 1) return root;
int delimiterIndex;
for (delimiterIndex = inorderBegin; delimiterIndex < inorderEnd; delimiterIndex++) {
if (inorder[delimiterIndex] == rootValue) break;
}
// 切割中序数组
// 左中序区间,左闭右开[leftInorderBegin, leftInorderEnd)
int leftInorderBegin = inorderBegin;
int leftInorderEnd = delimiterIndex;
// 右中序区间,左闭右开[rightInorderBegin, rightInorderEnd)
int rightInorderBegin = delimiterIndex + 1;
int rightInorderEnd = inorderEnd;
// 切割后序数组
// 左后序区间,左闭右开[leftPostorderBegin, leftPostorderEnd)
int leftPostorderBegin = postorderBegin;
int leftPostorderEnd = postorderBegin + delimiterIndex - inorderBegin; // 终止位置是 需要加上 中序区间的大小size
// 右后序区间,左闭右开[rightPostorderBegin, rightPostorderEnd)
int rightPostorderBegin = postorderBegin + (delimiterIndex - inorderBegin);
int rightPostorderEnd = postorderEnd - 1; // 排除最后一个元素,已经作为节点了
root->left = traversal(inorder, leftInorderBegin, leftInorderEnd, postorder, leftPostorderBegin, leftPostorderEnd);
root->right = traversal(inorder, rightInorderBegin, rightInorderEnd, postorder, rightPostorderBegin, rightPostorderEnd);
return root;
}
public:
TreeNode* buildTree(vector<int>& inorder, vector<int>& postorder) {
if (inorder.size() == 0 || postorder.size() == 0) return NULL;
// 左闭右开的原则
return traversal(inorder, 0, inorder.size(), postorder, 0, postorder.size());
}
};
Java解法
class Solution {
Map<Integer, Integer> map; // 方便根据数值查找位置
public TreeNode buildTree(int[] inorder, int[] postorder) {
map = new HashMap<>();
for (int i = 0; i < inorder.length; i++) { // 用map保存中序序列的数值对应位置
map.put(inorder[i], i);
}
return findNode(inorder, 0, inorder.length, postorder,0, postorder.length); // 前闭后开
}
public TreeNode findNode(int[] inorder, int inBegin, int inEnd, int[] postorder, int postBegin, int postEnd) {
// 参数里的范围都是前闭后开
if (inBegin >= inEnd || postBegin >= postEnd) { // 不满足左闭右开,说明没有元素,返回空树
return null;
}
int rootIndex = map.get(postorder[postEnd - 1]); // 找到后序遍历的最后一个元素在中序遍历中的位置
TreeNode root = new TreeNode(inorder[rootIndex]); // 构造结点
int lenOfLeft = rootIndex - inBegin; // 保存中序左子树个数,用来确定后序数列的个数
root.left = findNode(inorder, inBegin, rootIndex,
postorder, postBegin, postBegin + lenOfLeft);
root.right = findNode(inorder, rootIndex + 1, inEnd,
postorder, postBegin + lenOfLeft, postEnd - 1);
return root;
}
}
Python3解法
class Solution:
def buildTree(self, inorder: List[int], postorder: List[int]) -> TreeNode:
# 第一步: 特殊情况讨论: 树为空. (递归终止条件)
if not postorder:
return None
# 第二步: 后序遍历的最后一个就是当前的中间节点.
root_val = postorder[-1]
root = TreeNode(root_val)
# 第三步: 找切割点.
separator_idx = inorder.index(root_val)
# 第四步: 切割inorder数组. 得到inorder数组的左,右半边.
inorder_left = inorder[:separator_idx]
inorder_right = inorder[separator_idx + 1:]
# 第五步: 切割postorder数组. 得到postorder数组的左,右半边.
# ⭐️ 重点1: 中序数组大小一定跟后序数组大小是相同的.
postorder_left = postorder[:len(inorder_left)]
postorder_right = postorder[len(inorder_left): len(postorder) - 1]
# 第六步: 递归
root.left = self.buildTree(inorder_left, postorder_left)
root.right = self.buildTree(inorder_right, postorder_right)
# 第七步: 返回答案
return root
Go解法
/**
* Definition for a binary tree node.
* type TreeNode struct {
* Val int
* Left *TreeNode
* Right *TreeNode
* }
*/
var (
hash map[int]int
)
func buildTree(inorder []int, postorder []int) *TreeNode {
hash = make(map[int]int)
for i, v := range inorder { // 用map保存中序序列的数值对应位置
hash[v] = i
}
// 以左闭右闭的原则进行切分
root := rebuild(inorder, postorder, len(postorder)-1, 0, len(inorder)-1)
return root
}
// rootIdx表示根节点在后序数组中的索引,l, r 表示在中序数组中的前后切分点
func rebuild(inorder []int, postorder []int, rootIdx int, l, r int) *TreeNode {
if l > r { // 说明没有元素,返回空树
return nil
}
if l == r { // 只剩唯一一个元素,直接返回
return &TreeNode{Val : inorder[l]}
}
rootV := postorder[rootIdx] // 根据后序数组找到根节点的值
rootIn := hash[rootV] // 找到根节点在对应的中序数组中的位置
root := &TreeNode{Val : rootV} // 构造根节点
// 重建左节点和右节点
root.Left = rebuild(inorder, postorder, rootIdx-(r-rootIn)-1, l, rootIn-1)
root.Right = rebuild(inorder, postorder, rootIdx-1, rootIn+1, r)
return root
}
654. Maximum Binary Tree
You are given an integer array nums with no duplicates. A maximum binary tree can be built recursively from nums using the following algorithm:
- Create a root node whose value is the maximum value in
nums. - Recursively build the left subtree on the subarray prefix to the left of the maximum value.
- Recursively build the right subtree on the subarray suffix to the right of the maximum value.
Return the maximum binary tree built from nums.
Example 1:

Input: nums = [3,2,1,6,0,5]
Output: [6,3,5,null,2,0,null,null,1]
Explanation: The recursive calls are as follow:
- The largest value in [3,2,1,6,0,5] is 6. Left prefix is [3,2,1] and right suffix is [0,5].
- The largest value in [3,2,1] is 3. Left prefix is [] and right suffix is [2,1].
- Empty array, so no child.
- The largest value in [2,1] is 2. Left prefix is [] and right suffix is [1].
- Empty array, so no child.
- Only one element, so child is a node with value 1.
- The largest value in [0,5] is 5. Left prefix is [0] and right suffix is [].
- Only one element, so child is a node with value 0.
- Empty array, so no child.
- The largest value in [3,2,1] is 3. Left prefix is [] and right suffix is [2,1].
Example 2:

Input: nums = [3,2,1]
Output: [3,null,2,null,1]
Constraints:
1 <= nums.length <= 10000 <= nums[i] <= 1000- All integers in
numsare unique.
思路
前序遍历,区间分割要考虑循环不变量,这里是左闭右开。
最大二叉树的构建过程如下:

构造树一般采用的是前序遍历,因为先构造中间节点,然后递归构造左子树和右子树。
- 确定递归函数的参数和返回值
参数传入的是存放元素的数组,返回该数组构造的二叉树的头结点,返回类型是指向节点的指针。
- 确定终止条件
题目中说了输入的数组大小一定是大于等于1的,所以我们不用考虑小于1的情况,那么当递归遍历的时候,如果传入的数组大小为1,说明遍历到了叶子节点了。
那么应该定义一个新的节点,并把这个数组的数值赋给新的节点,然后返回这个节点。 这表示一个数组大小是1的时候,构造了一个新的节点,并返回。
- 确定单层递归的逻辑
这里有三步工作
-
先要找到数组中最大的值和对应的下标, 最大的值构造根节点,下标用来下一步分割数组。
-
最大值所在的下标左区间 构造左子树
这里要判断maxValueIndex > 0,因为要保证左区间至少有一个数值。
- 最大值所在的下标右区间 构造右子树
判断maxValueIndex < (nums.size() - 1),确保右区间至少有一个数值。
注意类似用数组构造二叉树的题目,每次分隔尽量不要定义新的数组,而是通过下标索引直接在原数组上操作,这样可以节约时间和空间上的开销。
一些同学也会疑惑,什么时候递归函数前面加if,什么时候不加if,这个问题我在最后也给出了解释。
其实就是不同代码风格的实现,一般情况来说:如果让空节点(空指针)进入递归,就不加if,如果不让空节点进入递归,就加if限制一下, 终止条件也会相应的调整。
C++解法
新建数组
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode() : val(0), left(nullptr), right(nullptr) {}
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
* };
*/
class Solution {
public:
TreeNode* constructMaximumBinaryTree(vector<int>& nums) {
TreeNode* node = new TreeNode(0);
if (nums.size() == 1) {
node->val = nums[0];
return node;
}
// 找到数组中最大的值和对应的下标
int maxValue = 0;
int maxValueIndex = 0;
for (int i = 0; i < nums.size(); i++) {
if (nums[i] > maxValue) {
maxValue = nums[i];
maxValueIndex = i;
}
}
node->val = maxValue;
// 最大值所在的下标左区间 构造左子树
if (maxValueIndex > 0) {
vector<int> newVec(nums.begin(), nums.begin() + maxValueIndex);
node->left = constructMaximumBinaryTree(newVec);
}
// 最大值所在的下标右区间 构造右子树
if (maxValueIndex < (nums.size() - 1)) {
vector<int> newVec(nums.begin() + maxValueIndex + 1, nums.end());
node->right = constructMaximumBinaryTree(newVec);
}
return node;
}
};
直接使用索引
class Solution {
private:
// 在左闭右开区间[left, right),构造二叉树
TreeNode* traversal(vector<int>& nums, int left, int right) {
if (left >= right) return nullptr;
// 分割点下标:maxValueIndex
int maxValueIndex = left;
for (int i = left + 1; i < right; ++i) {
if (nums[i] > nums[maxValueIndex]) maxValueIndex = i;
}
TreeNode* root = new TreeNode(nums[maxValueIndex]);
// 左闭右开:[left, maxValueIndex)
root->left = traversal(nums, left, maxValueIndex);
// 左闭右开:[maxValueIndex + 1, right)
root->right = traversal(nums, maxValueIndex + 1, right);
return root;
}
public:
TreeNode* constructMaximumBinaryTree(vector<int>& nums) {
return traversal(nums, 0, nums.size());
}
};
Java解法
class Solution {
public TreeNode constructMaximumBinaryTree(int[] nums) {
return constructMaximumBinaryTree1(nums, 0, nums.length);
}
public TreeNode constructMaximumBinaryTree1(int[] nums, int leftIndex, int rightIndex) {
if (rightIndex - leftIndex < 1) {// 没有元素了
return null;
}
if (rightIndex - leftIndex == 1) {// 只有一个元素
return new TreeNode(nums[leftIndex]);
}
int maxIndex = leftIndex;// 最大值所在位置
int maxVal = nums[maxIndex];// 最大值
for (int i = leftIndex + 1; i < rightIndex; i++) {
if (nums[i] > maxVal){
maxVal = nums[i];
maxIndex = i;
}
}
TreeNode root = new TreeNode(maxVal);
// 根据maxIndex划分左右子树
root.left = constructMaximumBinaryTree1(nums, leftIndex, maxIndex);
root.right = constructMaximumBinaryTree1(nums, maxIndex + 1, rightIndex);
return root;
}
}
Python3解法
class Solution:
def traversal(self, nums: List[int], left: int, right: int) -> TreeNode:
if left >= right:
return None
maxValueIndex = left
for i in range(left + 1, right):
if nums[i] > nums[maxValueIndex]:
maxValueIndex = i
root = TreeNode(nums[maxValueIndex])
root.left = self.traversal(nums, left, maxValueIndex)
root.right = self.traversal(nums, maxValueIndex + 1, right)
return root
def constructMaximumBinaryTree(self, nums: List[int]) -> TreeNode:
return self.traversal(nums, 0, len(nums))
Go解法
func constructMaximumBinaryTree(nums []int) *TreeNode {
if len(nums) == 0 {
return nil
}
// 找到最大值
index := findMax(nums)
// 构造二叉树
root := &TreeNode {
Val: nums[index],
Left: constructMaximumBinaryTree(nums[:index]), //左半边
Right: constructMaximumBinaryTree(nums[index+1:]),//右半边
}
return root
}
func findMax(nums []int) (index int) {
for i, v := range nums {
if nums[index] < v {
index = i
}
}
return
}
617. Merge Two Binary Trees
You are given two binary trees root1 and root2.
Imagine that when you put one of them to cover the other, some nodes of the two trees are overlapped while the others are not. You need to merge the two trees into a new binary tree. The merge rule is that if two nodes overlap, then sum node values up as the new value of the merged node. Otherwise, the NOT null node will be used as the node of the new tree.
Return the merged tree.
Note: The merging process must start from the root nodes of both trees.
Example 1:

Input: root1 = [1,3,2,5], root2 = [2,1,3,null,4,null,7]
Output: [3,4,5,5,4,null,7] ``
Example 2:
Input: root1 = [1], root2 = [1,2]
Output: [2,2]
Constraints:
- The number of nodes in both trees is in the range
[0, 2000]. -104 <= Node.val <= 10^4
思路
如何同时遍历两个二叉树呢?
其实和遍历一个树逻辑是一样的,只不过传入两个树的节点,同时操作。
递归
二叉树使用递归,就要想使用前中后哪种遍历方式?
本题使用哪种遍历都是可以的!
我们下面以前序遍历为例。
动画如下:
那么我们来按照递归三部曲来解决:
- 确定递归函数的参数和返回值:
首先要合入两个二叉树,那么参数至少是要传入两个二叉树的根节点,返回值就是合并之后二叉树的根节点。
- 确定终止条件:
因为是传入了两个树,那么就有两个树遍历的节点t1 和 t2,如果t1 == NULL 了,两个树合并就应该是 t2 了(如果t2也为NULL也无所谓,合并之后就是NULL)。
反过来如果t2 == NULL,那么两个数合并就是t1(如果t1也为NULL也无所谓,合并之后就是NULL)。
- 确定单层递归的逻辑:
单层递归的逻辑就比较好写了,这里我们重复利用一下t1这个树,t1就是合并之后树的根节点(就是修改了原来树的结构)。
那么单层递归中,就要把两棵树的元素加到一起。
接下来t1 的左子树是:合并 t1左子树 t2左子树之后的左子树。
t1 的右子树:是 合并 t1右子树 t2右子树之后的右子树。
最终t1就是合并之后的根节点。
但是前序遍历是最好理解的,我建议大家用前序遍历来做就OK。
可以修改t1的结构作为合并结果,当然也可以不修改t1和t2的结构,重新定义一个树。
迭代法
使用迭代法,如何同时处理两棵树呢?
求二叉树对称的时候就是把两个树的节点同时加入队列进行比较。
本题我们也使用队列,模拟的层序遍历
C++解法
前序遍历,递归,重新定义一棵树
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode() : val(0), left(nullptr), right(nullptr) {}
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
* };
*/
class Solution {
public:
TreeNode* mergeTrees(TreeNode* root1, TreeNode* root2) {
if(root1 == NULL) return root2;
if(root2 == NULL) return root1;
TreeNode* root = new TreeNode(root1->val + root2->val);
root->left = mergeTrees(root1->left, root2->left);
root->right = mergeTrees(root1->right, root2->right);
return root;
}
};
迭代法
class Solution {
public:
TreeNode* mergeTrees(TreeNode* t1, TreeNode* t2) {
if (t1 == NULL) return t2;
if (t2 == NULL) return t1;
queue<TreeNode*> que;
que.push(t1);
que.push(t2);
while(!que.empty()) {
TreeNode* node1 = que.front(); que.pop();
TreeNode* node2 = que.front(); que.pop();
// 此时两个节点一定不为空,val相加
node1->val += node2->val;
// 如果两棵树左节点都不为空,加入队列
if (node1->left != NULL && node2->left != NULL) {
que.push(node1->left);
que.push(node2->left);
}
// 如果两棵树右节点都不为空,加入队列
if (node1->right != NULL && node2->right != NULL) {
que.push(node1->right);
que.push(node2->right);
}
// 当t1的左节点 为空 t2左节点不为空,就赋值过去
if (node1->left == NULL && node2->left != NULL) {
node1->left = node2->left;
}
// 当t1的右节点 为空 t2右节点不为空,就赋值过去
if (node1->right == NULL && node2->right != NULL) {
node1->right = node2->right;
}
}
return t1;
}
};
Java解法
class Solution {
// 递归
public TreeNode mergeTrees(TreeNode root1, TreeNode root2) {
if (root1 == null) return root2;
if (root2 == null) return root1;
root1.val += root2.val;
root1.left = mergeTrees(root1.left,root2.left);
root1.right = mergeTrees(root1.right,root2.right);
return root1;
}
}
Python3解法
# Definition for a binary tree node.
# class TreeNode:
# def __init__(self, val=0, left=None, right=None):
# self.val = val
# self.left = left
# self.right = right
class Solution:
def mergeTrees(self, root1: TreeNode, root2: TreeNode) -> TreeNode:
# 递归终止条件:
# 但凡有一个节点为空, 就立刻返回另外一个. 如果另外一个也为None就直接返回None.
if not root1:
return root2
if not root2:
return root1
# 上面的递归终止条件保证了代码执行到这里root1, root2都非空.
root = TreeNode() # 创建新节点
root.val += root1.val + root2.val# 中
root.left = self.mergeTrees(root1.left, root2.left) #左
root.right = self.mergeTrees(root1.right, root2.right) # 右
return root # ⚠️ 注意: 本题我们创建了新节点.
Go解法
// 前序遍历
func mergeTrees(root1 *TreeNode, root2 *TreeNode) *TreeNode {
if root1 == nil {
return root2
}
if root2 == nil {
return root1
}
root1.Val += root2.Val
root1.Left = mergeTrees(root1.Left, root2.Left)
root1.Right = mergeTrees(root1.Right, root2.Right)
return root1
}
二叉搜索树
- 700. Search in a Binary Search Tree
- 98. Validate Binary Search Tree
- 530. Minimum Absolute Difference in BST
- 783. Minimum Distance Between BST Nodes(同上)
- 501. Find Mode in Binary Search Tree
- 235. Lowest Common Ancestor of a Binary Search Tree
- 701. Insert into a Binary Search Tree
- 450. Delete Node in a BST
- 669. Trim a Binary Search Tree
- 108. Convert Sorted Array to Binary Search Tree
- 109. Convert Sorted List to Binary Search Tree
- 538. Convert BST to Greater Tree
- 1038. Binary Search Tree to Greater Sum Tree(同上)
700. Search in a Binary Search Tree
You are given the root of a binary search tree (BST) and an integer val.
Find the node in the BST that the node's value equals val and return the subtree rooted with that node. If such a node does not exist, return null.
Example 1:
Input: root = [4,2,7,1,3], val = 2
Output: [2,1,3]
Example 2:
Input: root = [4,2,7,1,3], val = 5
Output: []
Constraints:
- The number of nodes in the tree is in the range
[1, 5000]. 1 <= Node.val <= 10^7rootis a binary search tree.1 <= val <= 10^7
思路
二叉搜索树是一个有序树:
- 若它的左子树不空,则左子树上所有结点的值均小于它的根结点的值;
- 若它的右子树不空,则右子树上所有结点的值均大于它的根结点的值;
- 它的左、右子树也分别为二叉搜索树
这就决定了,二叉搜索树,递归遍历和迭代遍历和普通二叉树都不一样。
本题,其实就是在二叉搜索树中搜索一个节点。那么我们来看看应该如何遍历。
递归法
- 确定递归函数的参数和返回值
递归函数的参数传入的就是根节点和要搜索的数值,返回的就是以这个搜索数值所在的节点。
- 确定终止条件
如果root为空,或者找到这个数值了,就返回root节点。
- 确定单层递归的逻辑
看看二叉搜索树的单层递归逻辑有何不同。
因为二叉搜索树的节点是有序的,所以可以有方向的去搜索。
如果root->val > val,搜索左子树,如果root->val < val,就搜索右子树,最后如果都没有搜索到,就返回NULL。
很多录友写递归函数的时候 习惯直接写 searchBST(root->left, val),却忘了递归函数还有返回值。
递归函数的返回值是什么? 是 左子树如果搜索到了val,要将该节点返回。 如果不用一个变量将其接住,那么返回值不就没了。
所以要 result = searchBST(root->left, val)。
迭代法
一提到二叉树遍历的迭代法,可能立刻想起使用栈来模拟深度遍历,使用队列来模拟广度遍历。
对于二叉搜索树可就不一样了,因为二叉搜索树的特殊性,也就是节点的有序性,可以不使用辅助栈或者队列就可以写出迭代法。
对于一般二叉树,递归过程中还有回溯的过程,例如走一个左方向的分支走到头了,那么要调头,在走右分支。
而对于二叉搜索树,不需要回溯的过程,因为节点的有序性就帮我们确定了搜索的方向。
例如要搜索元素为3的节点,我们不需要搜索其他节点,也不需要做回溯,查找的路径已经规划好了。
中间节点如果大于3就向左走,如果小于3就向右走,如图:
C++解法
递归法整体代码如下:
class Solution {
public:
TreeNode* searchBST(TreeNode* root, int val) {
if (root == NULL || root->val == val) return root;
TreeNode* result = NULL;
if (root->val > val) result = searchBST(root->left, val);
if (root->val < val) result = searchBST(root->right, val);
return result;
}
};
或者我们也可以这么写
class Solution {
public:
TreeNode* searchBST(TreeNode* root, int val) {
if (root == NULL || root->val == val) return root;
if (root->val > val) return searchBST(root->left, val);
if (root->val < val) return searchBST(root->right, val);
return NULL;
}
};
迭代法代码如下:
class Solution {
public:
TreeNode* searchBST(TreeNode* root, int val) {
while (root != NULL) {
if (root->val > val) root = root->left;
else if (root->val < val) root = root->right;
else return root;
}
return NULL;
}
};
Java解法
class Solution {
// 迭代,利用二叉搜索树特点,优化,可以不需要栈
public TreeNode searchBST(TreeNode root, int val) {
while (root != null)
if (val < root.val) root = root.left;
else if (val > root.val) root = root.right;
else return root;
return null;
}
}
Python3解法
class Solution:
def searchBST(self, root: TreeNode, val: int) -> TreeNode:
# 为什么要有返回值:
# 因为搜索到目标节点就要立即return,
# 这样才是找到节点就返回(搜索某一条边),如果不加return,就是遍历整棵树了。
if not root or root.val == val:
return root
if root.val > val:
return self.searchBST(root.left, val)
if root.val < val:
return self.searchBST(root.right, val)
Go解法
//递归法
func searchBST(root *TreeNode, val int) *TreeNode {
if root == nil || root.Val == val {
return root
}
if root.Val > val {
return searchBST(root.Left, val)
}
return searchBST(root.Right, val)
}
//迭代法
func searchBST(root *TreeNode, val int) *TreeNode {
for root != nil {
if root.Val > val {
root = root.Left
} else if root.Val < val {
root = root.Right
} else {
return root
}
}
return nil
}
98. Validate Binary Search Tree
Given the root of a binary tree, determine if it is a valid binary search tree (BST).
A valid BST is defined as follows:
- The left subtree of a node contains only nodes with keys less than the node's key.
- The right subtree of a node contains only nodes with keys greater than the node's key.
- Both the left and right subtrees must also be binary search trees.
Example 1:

Input: root = [2,1,3]
Output: true
Example 2:

Input: root = [5,1,4,null,null,3,6]
Output: false
Explanation: The root node's value is 5 but its right child's value is 4.
Constraints:
- The number of nodes in the tree is in the range
[1, 10^4]. -2^31 <= Node.val <= 2^31 - 1
思路
要知道中序遍历下,输出的二叉搜索树节点的数值是有序序列。
有了这个特性,验证二叉搜索树,就相当于变成了判断一个序列是不是递增的了。
递归法
可以递归中序遍历将二叉搜索树转变成一个数组,代码如下:
vector<int> vec;
void traversal(TreeNode* root) {
if (root == NULL) return;
traversal(root->left);
vec.push_back(root->val); // 将二叉搜索树转换为有序数组
traversal(root->right);
}
然后只要比较一下,这个数组是否是有序的,注意二叉搜索树中不能有重复元素。
traversal(root);
for (int i = 1; i < vec.size(); i++) {
// 注意要小于等于,搜索树里不能有相同元素
if (vec[i] <= vec[i - 1]) return false;
}
return true;
以上代码中,我们把二叉树转变为数组来判断,是最直观的,但其实不用转变成数组,可以在递归遍历的过程中直接判断是否有序。
这道题目比较容易陷入两个陷阱:
- 陷阱1
不能单纯的比较左节点小于中间节点,右节点大于中间节点就完事了。
写出了类似这样的代码:
if (root->val > root->left->val && root->val < root->right->val) {
return true;
} else {
return false;
}
我们要比较的是 左子树所有节点小于中间节点,右子树所有节点大于中间节点。所以以上代码的判断逻辑是错误的。
例如: [10,5,15,null,null,6,20] 这个case:
节点10大于左节点5,小于右节点15,但右子树里出现了一个6 这就不符合了!
- 陷阱2
样例中最小节点 可能是int的最小值,如果这样使用最小的int来比较也是不行的。
此时可以初始化比较元素为longlong的最小值。
问题可以进一步演进:如果样例中根节点的val 可能是longlong的最小值又要怎么办呢?文中会解答。
了解这些陷阱之后我们来看一下代码应该怎么写:
递归三部曲:
- 确定递归函数,返回值以及参数
要定义一个longlong的全局变量,用来比较遍历的节点是否有序,因为后台测试数据中有int最小值,所以定义为longlong的类型,初始化为longlong最小值。
注意递归函数要有bool类型的返回值, 我们在二叉树:递归函数究竟什么时候需要返回值,什么时候不要返回值? (opens new window)中讲了,只有寻找某一条边(或者一个节点)的时候,递归函数会有bool类型的返回值。
其实本题是同样的道理,我们在寻找一个不符合条件的节点,如果没有找到这个节点就遍历了整个树,如果找到不符合的节点了,立刻返回。
代码如下:
long long maxVal = LONG_MIN; // 因为后台测试数据中有int最小值
bool isValidBST(TreeNode* root)
- 确定终止条件
如果是空节点是不是二叉搜索树呢?
是的,二叉搜索树也可以为空!
代码如下:
if (root == NULL) return true;
- 确定单层递归的逻辑
中序遍历,一直更新maxVal,一旦发现maxVal >= root->val,就返回false,注意元素相同时候也要返回false。
代码如下:
bool left = isValidBST(root->left); // 左
// 中序遍历,验证遍历的元素是不是从小到大
if (maxVal < root->val) maxVal = root->val; // 中
else return false;
bool right = isValidBST(root->right); // 右
return left && right;
以上代码是因为后台数据有int最小值测试用例,所以都把maxVal改成了longlong最小值。
如果测试数据中有 longlong的最小值,怎么办?
不可能在初始化一个更小的值了吧。 建议避免初始化最小值,如下方法取到最左面节点的数值来比较。代码如下:
class Solution {
public:
TreeNode* pre = NULL; // 用来记录前一个节点
bool isValidBST(TreeNode* root) {
if (root == NULL) return true;
bool left = isValidBST(root->left);
if (pre != NULL && pre->val >= root->val) return false;
pre = root; // 记录前一个节点
bool right = isValidBST(root->right);
return left && right;
}
};
最后这份代码看上去整洁一些,思路也清晰。
迭代法
可以用迭代法模拟二叉树中序遍历,对前中后序迭代法生疏的同学可以看这两篇二叉树:听说递归能做的,栈也能做! (opens new window),二叉树:前中后序迭代方式统一写法(opens new window)
迭代法中序遍历稍加改动就可以了,代码如下:
class Solution {
public:
bool isValidBST(TreeNode* root) {
stack<TreeNode*> st;
TreeNode* cur = root;
TreeNode* pre = NULL; // 记录前一个节点
while (cur != NULL || !st.empty()) {
if (cur != NULL) {
st.push(cur);
cur = cur->left; // 左
} else {
cur = st.top(); // 中
st.pop();
if (pre != NULL && cur->val <= pre->val)
return false;
pre = cur; //保存前一个访问的结点
cur = cur->right; // 右
}
}
return true;
}
};
在二叉树:二叉搜索树登场! (opens new window)中我们分明写出了痛哭流涕的简洁迭代法,怎么在这里不行了呢,因为本题是要验证二叉搜索树啊。
总结
这道题目是一个简单题,但对于没接触过的同学还是有难度的。
所以初学者刚开始学习算法的时候,看到简单题目没有思路很正常,千万别怀疑自己智商,学习过程都是这样的,大家智商都差不多。
只要把基本类型的题目都做过,总结过之后,思路自然就开阔了,加油💪
C++解法
将二叉搜索树转换为有序数组整体代码如下:
class Solution {
private:
vector<int> vec;
void traversal(TreeNode* root) {
if (root == NULL) return;
traversal(root->left);
vec.push_back(root->val); // 将二叉搜索树转换为有序数组
traversal(root->right);
}
public:
bool isValidBST(TreeNode* root) {
vec.clear(); // 不加这句在leetcode上也可以过,但最好加上
traversal(root);
for (int i = 1; i < vec.size(); i++) {
// 注意要小于等于,搜索树里不能有相同元素
if (vec[i] <= vec[i - 1]) return false;
}
return true;
}
};
不转变成数组,可以在递归遍历的过程中直接判断是否有序。整体代码如下:
class Solution {
public:
long long maxVal = LONG_MIN; // 因为后台测试数据中有int最小值
bool isValidBST(TreeNode* root) {
if (root == NULL) return true;
bool left = isValidBST(root->left);
// 中序遍历,验证遍历的元素是不是从小到大
if (maxVal < root->val) maxVal = root->val;
else return false;
bool right = isValidBST(root->right);
return left && right;
}
};
不可能在初始化一个更小的值了吧。 建议避免初始化最小值,如下方法取到最左面节点的数值来比较。代码如下:
class Solution {
public:
TreeNode* pre = NULL; // 用来记录前一个节点
bool isValidBST(TreeNode* root) {
if (root == NULL) return true;
bool left = isValidBST(root->left);
if (pre != NULL && pre->val >= root->val) return false;
pre = root; // 记录前一个节点
bool right = isValidBST(root->right);
return left && right;
}
};
最后这份代码看上去整洁一些,思路也清晰。
Java解法
// 简洁实现·中序遍历
class Solution {
private long prev = Long.MIN_VALUE;
public boolean isValidBST(TreeNode root) {
if (root == null) {
return true;
}
if (!isValidBST(root.left)) {
return false;
}
if (root.val <= prev) { // 不满足二叉搜索树条件
return false;
}
prev = root.val;
return isValidBST(root.right);
}
}
Python3解法
递归法(版本三)直接取该树的最小值
# Definition for a binary tree node.
# class TreeNode:
# def __init__(self, val=0, left=None, right=None):
# self.val = val
# self.left = left
# self.right = right
class Solution:
def __init__(self):
self.pre = None # 用来记录前一个节点
def isValidBST(self, root):
if root is None:
return True
left = self.isValidBST(root.left)
if self.pre is not None and self.pre.val >= root.val:
return False
self.pre = root # 记录前一个节点
right = self.isValidBST(root.right)
return left and right
Go解法
// 中序遍历解法
func isValidBST(root *TreeNode) bool {
// 保存上一个指针
var prev *TreeNode
var travel func(node *TreeNode) bool
travel = func(node *TreeNode) bool {
if node == nil {
return true
}
leftRes := travel(node.Left)
// 当前值小于等于前一个节点的值,返回false
if prev != nil && node.Val <= prev.Val {
return false
}
prev = node
rightRes := travel(node.Right)
return leftRes && rightRes
}
return travel(root)
}
530. Minimum Absolute Difference in BST
Given the root of a Binary Search Tree (BST), return the minimum absolute difference between the values of any two different nodes in the tree.
Example 1:
Input: root = [4,2,6,1,3]
Output: 1
Example 2:
Input: root = [1,0,48,null,null,12,49]
Output: 1
Constraints:
- The number of nodes in the tree is in the range
[2, 10^4]. 0 <= Node.val <= 10^5
Note: This question is the same as 783: https://leetcode.com/problems/minimum-distance-between-bst-nodes/
思路
方法一:中序遍历转为有序数组
方法二:中序遍历,双指针,直接计算差值
题目中要求在二叉搜索树上任意两节点的差的绝对值的最小值。
注意是二叉搜索树,二叉搜索树可是有序的。
遇到在二叉搜索树上求什么最值啊,差值之类的,就把它想成在一个有序数组上求最值,求差值,这样就简单多了。
递归
那么二叉搜索树采用中序遍历,其实就是一个有序数组。
在一个有序数组上求两个数最小差值,这是不是就是一道送分题了。
最直观的想法,就是把二叉搜索树转换成有序数组,然后遍历一遍数组,就统计出来最小差值了。
代码如下:
class Solution {
private:
vector<int> vec;
void traversal(TreeNode* root) {
if (root == NULL) return;
traversal(root->left);
vec.push_back(root->val); // 将二叉搜索树转换为有序数组
traversal(root->right);
}
public:
int getMinimumDifference(TreeNode* root) {
vec.clear();
traversal(root);
if (vec.size() < 2) return 0;
int result = INT_MAX;
for (int i = 1; i < vec.size(); i++) { // 统计有序数组的最小差值
result = min(result, vec[i] - vec[i-1]);
}
return result;
}
};
以上代码是把二叉搜索树转化为有序数组了,其实在二叉搜素树中序遍历的过程中,我们就可以直接计算了。
需要用一个pre节点记录一下cur节点的前一个节点。
如图:
一些同学不知道在递归中如何记录前一个节点的指针,其实实现起来是很简单的,大家只要看过一次,写过一次,就掌握了。
代码如下:
class Solution {
private:
int result = INT_MAX;
TreeNode* pre = NULL;
void traversal(TreeNode* cur) {
if (cur == NULL) return;
traversal(cur->left); // 左
if (pre != NULL){ // 中
result = min(result, cur->val - pre->val);
}
pre = cur; // 记录前一个
traversal(cur->right); // 右
}
public:
int getMinimumDifference(TreeNode* root) {
traversal(root);
return result;
}
};
是不是看上去也并不复杂!
迭代
看过这两篇二叉树:听说递归能做的,栈也能做! (opens new window),二叉树:前中后序迭代方式的写法就不能统一一下么? (opens new window)文章之后,不难写出两种中序遍历的迭代法。
下面我给出其中的一种中序遍历的迭代法,代码如下:
class Solution {
public:
int getMinimumDifference(TreeNode* root) {
stack<TreeNode*> st;
TreeNode* cur = root;
TreeNode* pre = NULL;
int result = INT_MAX;
while (cur != NULL || !st.empty()) {
if (cur != NULL) { // 指针来访问节点,访问到最底层
st.push(cur); // 将访问的节点放进栈
cur = cur->left; // 左
} else {
cur = st.top();
st.pop();
if (pre != NULL) { // 中
result = min(result, cur->val - pre->val);
}
pre = cur;
cur = cur->right; // 右
}
}
return result;
}
};
总结
遇到在二叉搜索树上求什么最值,求差值之类的,都要思考一下二叉搜索树可是有序的,要利用好这一特点。
同时要学会在递归遍历的过程中如何记录前后两个指针,这也是一个小技巧,学会了还是很受用的。
后面我将继续介绍一系列利用二叉搜索树特性的题目。
C++解法
方法二:中序遍历,双指针,直接计算差值
代码如下:
class Solution {
private:
int result = INT_MAX;
TreeNode* pre = NULL;
void traversal(TreeNode* cur) {
if (cur == NULL) return;
traversal(cur->left); // 左
if (pre != NULL){ // 中
result = min(result, cur->val - pre->val);
}
pre = cur; // 记录前一个
traversal(cur->right); // 右
}
public:
int getMinimumDifference(TreeNode* root) {
traversal(root);
return result;
}
};
Java解法
迭代法-中序遍历
class Solution {
TreeNode pre;
Stack<TreeNode> stack;
public int getMinimumDifference(TreeNode root) {
if (root == null) return 0;
stack = new Stack<>();
TreeNode cur = root;
int result = Integer.MAX_VALUE;
while (cur != null || !stack.isEmpty()) {
if (cur != null) {
stack.push(cur); // 将访问的节点放进栈
cur = cur.left; // 左
}else {
cur = stack.pop();
if (pre != null) { // 中
result = Math.min(result, cur.val - pre.val);
}
pre = cur;
cur = cur.right; // 右
}
}
return result;
}
}
Python3解法
递归法(版本二)利用中序递增,找到该树最小值
class Solution:
def __init__(self):
self.result = float('inf')
self.pre = None
def traversal(self, cur):
if cur is None:
return
self.traversal(cur.left) # 左
if self.pre is not None: # 中
self.result = min(self.result, cur.val - self.pre.val)
self.pre = cur # 记录前一个
self.traversal(cur.right) # 右
def getMinimumDifference(self, root):
self.traversal(root)
return self.result
Go解法
中序遍历,然后计算最小差值
// 中序遍历的同时计算最小值
func getMinimumDifference(root *TreeNode) int {
// 保留前一个节点的指针
var prev *TreeNode
// 定义一个比较大的值
min := math.MaxInt64
var travel func(node *TreeNode)
travel = func(node *TreeNode) {
if node == nil {
return
}
travel(node.Left)
if prev != nil && node.Val - prev.Val < min {
min = node.Val - prev.Val
}
prev = node
travel(node.Right)
}
travel(root)
return min
}
783. Minimum Distance Between BST Nodes(同上)
Given the root of a Binary Search Tree (BST), return the minimum absolute difference between the values of any two different nodes in the tree.
Example 1:
Input: root = [4,2,6,1,3]
Output: 1
Example 2:
Input: root = [1,0,48,null,null,12,49]
Output: 1
Constraints:
- The number of nodes in the tree is in the range
[2, 10^4]. 0 <= Node.val <= 10^5
思路
方法一:中序遍历转为有序数组,再计算差值
方法二:中序遍历,双指针,直接计算差值
C++解法
方法一:中序遍历转为有序数组,再计算差值
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode() : val(0), left(nullptr), right(nullptr) {}
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
* };
*/
class Solution {
public:
vector<int> diffs;
void traversal(TreeNode* cur){
if(cur == NULL) return;
traversal(cur->left);
diffs.push_back(cur->val);
traversal(cur->right);
}
int minDiffInBST(TreeNode* root) {
traversal(root);
int result = INT_MAX;
for(int i = 0; i < diffs.size() - 1; i++){
result = min(result, diffs[i + 1] - diffs[i]);
}
return result;
}
};
501. Find Mode in Binary Search Tree
Given the root of a binary search tree (BST) with duplicates, return all the mode(s) (i.e., the most frequently occurred element) in it.
If the tree has more than one mode, return them in any order.
Assume a BST is defined as follows:
- The left subtree of a node contains only nodes with keys less than or equal to the node's key.
- The right subtree of a node contains only nodes with keys greater than or equal to the node's key.
- Both the left and right subtrees must also be binary search trees.
Example 1:
Input: root = [1,null,2,2]
Output: [2]
Example 2:
Input: root = [0]
Output: [0]
Constraints:
- The number of nodes in the tree is in the range
[1, 10^4]. -10^5 <= Node.val <= 10^5
Follow up: Could you do that without using any extra space? (Assume that the implicit stack space incurred due to recursion does not count).
思路
这道题目呢,递归法我从两个维度来讲。
首先如果不是二叉搜索树的话,应该怎么解题,是二叉搜索树,又应该如何解题,两种方式做一个比较,可以加深大家对二叉树的理解。
递归法
如果不是二叉搜索树,最直观的方法一定是把这个树都遍历了,用map统计频率,把频率排个序,最后取前面高频的元素的集合。
具体步骤如下:
- 这个树都遍历了,用map统计频率
至于用前中后序哪种遍历也不重要,因为就是要全遍历一遍,怎么个遍历法都行,层序遍历都没毛病!
这里采用前序遍历,代码如下:
// map<int, int> key:元素,value:出现频率
void searchBST(TreeNode* cur, unordered_map<int, int>& map) { // 前序遍历
if (cur == NULL) return ;
map[cur->val]++; // 统计元素频率
searchBST(cur->left, map);
searchBST(cur->right, map);
return ;
}
- 把统计的出来的出现频率(即map中的value)排个序
有的同学可能可以想直接对map中的value排序,还真做不到,C++中如果使用std::map或者std::multimap可以对key排序,但不能对value排序。
所以要把map转化数组即vector,再进行排序,当然vector里面放的也是pair<int, int>类型的数据,第一个int为元素,第二个int为出现频率。
代码如下:
bool static cmp (const pair<int, int>& a, const pair<int, int>& b) {
return a.second > b.second; // 按照频率从大到小排序
}
vector<pair<int, int>> vec(map.begin(), map.end());
sort(vec.begin(), vec.end(), cmp); // 给频率排个序
- 取前面高频的元素
此时数组vector中已经是存放着按照频率排好序的pair,那么把前面高频的元素取出来就可以了。
代码如下:
result.push_back(vec[0].first);
for (int i = 1; i < vec.size(); i++) {
// 取最高的放到result数组中
if (vec[i].second == vec[0].second) result.push_back(vec[i].first);
else break;
}
return result;
所以如果本题没有说是二叉搜索树的话,那么就按照上面的思路写!
既然是搜索树,它中序遍历就是有序的。
如图:
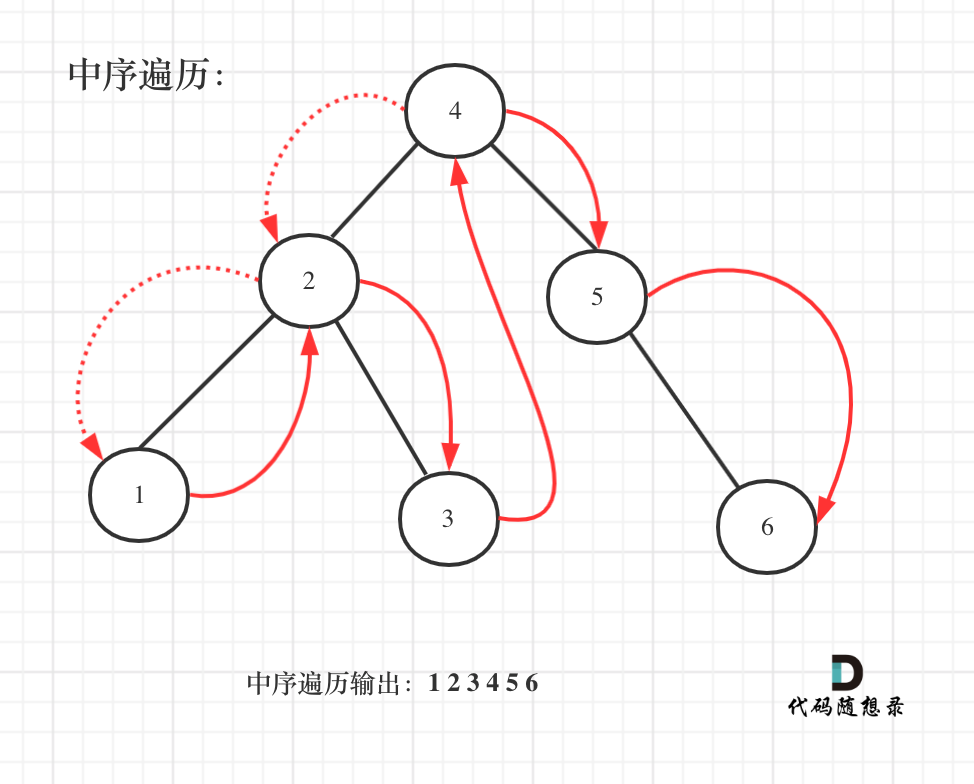
中序遍历代码如下:
void searchBST(TreeNode* cur) {
if (cur == NULL) return ;
searchBST(cur->left); // 左
(处理节点) // 中
searchBST(cur->right); // 右
return ;
}
遍历有序数组的元素出现频率,从头遍历,那么一定是相邻两个元素作比较,然后就把出现频率最高的元素输出就可以了。
关键是在有序数组上的话,好搞,在树上怎么搞呢?
这就考察对树的操作了。
在二叉树:搜索树的最小绝对差 (opens new window)中我们就使用了pre指针和cur指针的技巧,这次又用上了。
弄一个指针指向前一个节点,这样每次cur(当前节点)才能和pre(前一个节点)作比较。
而且初始化的时候pre = NULL,这样当pre为NULL时候,我们就知道这是比较的第一个元素。
代码如下:
if (pre == NULL) { // 第一个节点
count = 1; // 频率为1
} else if (pre->val == cur->val) { // 与前一个节点数值相同
count++;
} else { // 与前一个节点数值不同
count = 1;
}
pre = cur; // 更新上一个节点
此时又有问题了,因为要求最大频率的元素集合(注意是集合,不是一个元素,可以有多个众数),如果是数组上大家一般怎么办?
应该是先遍历一遍数组,找出最大频率(maxCount),然后再重新遍历一遍数组把出现频率为maxCount的元素放进集合。(因为众数有多个)
这种方式遍历了两遍数组。
那么我们遍历两遍二叉搜索树,把众数集合算出来也是可以的。
但这里其实只需要遍历一次就可以找到所有的众数。
那么如何只遍历一遍呢?
如果 频率count 等于 maxCount(最大频率),当然要把这个元素加入到结果集中(以下代码为result数组),代码如下:
if (count == maxCount) { // 如果和最大值相同,放进result中
result.push_back(cur->val);
}
是不是感觉这里有问题,result怎么能轻易就把元素放进去了呢,万一,这个maxCount此时还不是真正最大频率呢。
所以下面要做如下操作:
频率count 大于 maxCount的时候,不仅要更新maxCount,而且要清空结果集(以下代码为result数组),因为结果集之前的元素都失效了。
if (count > maxCount) { // 如果计数大于最大值
maxCount = count; // 更新最大频率
result.clear(); // 很关键的一步,不要忘记清空result,之前result里的元素都失效了
result.push_back(cur->val);
}
迭代法
只要把中序遍历转成迭代,中间节点的处理逻辑完全一样。
二叉树前中后序转迭代,传送门:
下面我给出其中的一种中序遍历的迭代法,其中间处理逻辑一点都没有变(我从递归法直接粘过来的代码,连注释都没改)
代码如下:
class Solution {
public:
vector<int> findMode(TreeNode* root) {
stack<TreeNode*> st;
TreeNode* cur = root;
TreeNode* pre = NULL;
int maxCount = 0; // 最大频率
int count = 0; // 统计频率
vector<int> result;
while (cur != NULL || !st.empty()) {
if (cur != NULL) { // 指针来访问节点,访问到最底层
st.push(cur); // 将访问的节点放进栈
cur = cur->left; // 左
} else {
cur = st.top();
st.pop(); // 中
if (pre == NULL) { // 第一个节点
count = 1;
} else if (pre->val == cur->val) { // 与前一个节点数值相同
count++;
} else { // 与前一个节点数值不同
count = 1;
}
if (count == maxCount) { // 如果和最大值相同,放进result中
result.push_back(cur->val);
}
if (count > maxCount) { // 如果计数大于最大值频率
maxCount = count; // 更新最大频率
result.clear(); // 很关键的一步,不要忘记清空result,之前result里的元素都失效了
result.push_back(cur->val);
}
pre = cur;
cur = cur->right; // 右
}
}
return result;
}
};
总结
本题在递归法中,我给出了如果是普通二叉树,应该怎么求众数。
知道了普通二叉树的做法时候,我再进一步给出二叉搜索树又应该怎么求众数,这样鲜明的对比,相信会对二叉树又有更深层次的理解了。
在递归遍历二叉搜索树的过程中,我还介绍了一个统计最高出现频率元素集合的技巧, 要不然就要遍历两次二叉搜索树才能把这个最高出现频率元素的集合求出来。
为什么没有这个技巧一定要遍历两次呢? 因为要求的是集合,会有多个众数,如果规定只有一个众数,那么就遍历一次稳稳的了。
最后我依然给出对应的迭代法,其实就是迭代法中序遍历的模板加上递归法中中间节点的处理逻辑,分分钟就可以写出来,中间逻辑的代码我都是从递归法中直接粘过来的。
求二叉搜索树中的众数其实是一道简单题,但大家可以发现我写了这么一大篇幅的文章来讲解,主要是为了尽量从各个角度对本题进剖析,帮助大家更快更深入理解二叉树。
需要强调的是 leetcode上的耗时统计是非常不准确的,看个大概就行,一样的代码耗时可以差百分之50以上,所以leetcode的耗时统计别太当回事,知道理论上的效率优劣就行了。
C++解法
普通二叉树处理方式完整代码如下所示:
class Solution {
private:
void searchBST(TreeNode* cur, unordered_map<int, int>& map) { // 前序遍历
if (cur == NULL) return ;
map[cur->val]++; // 统计元素频率
searchBST(cur->left, map);
searchBST(cur->right, map);
return ;
}
bool static cmp (const pair<int, int>& a, const pair<int, int>& b) {
return a.second > b.second;
}
public:
vector<int> findMode(TreeNode* root) {
unordered_map<int, int> map; // key:元素,value:出现频率
vector<int> result;
if (root == NULL) return result;
searchBST(root, map);
vector<pair<int, int>> vec(map.begin(), map.end());
sort(vec.begin(), vec.end(), cmp); // 给频率排个序
result.push_back(vec[0].first);
for (int i = 1; i < vec.size(); i++) {
// 取最高的放到result数组中
if (vec[i].second == vec[0].second) result.push_back(vec[i].first);
else break;
}
return result;
}
};
双指针处理方式完整代码如下:(只需要遍历一遍二叉搜索树,就求出了众数的集合)
class Solution {
private:
int maxCount = 0; // 最大频率
int count = 0; // 统计频率
TreeNode* pre = NULL;
vector<int> result;
void searchBST(TreeNode* cur) {
if (cur == NULL) return ;
searchBST(cur->left); // 左
// 中
if (pre == NULL) { // 第一个节点
count = 1;
} else if (pre->val == cur->val) { // 与前一个节点数值相同
count++;
} else { // 与前一个节点数值不同
count = 1;
}
pre = cur; // 更新上一个节点
if (count == maxCount) { // 如果和最大值相同,放进result中
result.push_back(cur->val);
}
if (count > maxCount) { // 如果计数大于最大值频率
maxCount = count; // 更新最大频率
result.clear(); // 很关键的一步,不要忘记清空result,之前result里的元素都失效了
result.push_back(cur->val);
}
searchBST(cur->right); // 右
return ;
}
public:
vector<int> findMode(TreeNode* root) {
count = 0;
maxCount = 0;
pre = NULL; // 记录前一个节点
result.clear();
searchBST(root);
return result;
}
};
Java解法
迭代法
class Solution {
public int[] findMode(TreeNode root) {
TreeNode pre = null;
Stack<TreeNode> stack = new Stack<>();
List<Integer> result = new ArrayList<>();
int maxCount = 0;
int count = 0;
TreeNode cur = root;
while (cur != null || !stack.isEmpty()) {
if (cur != null) {
stack.push(cur);
cur =cur.left;
}else {
cur = stack.pop();
// 计数
if (pre == null || cur.val != pre.val) {
count = 1;
}else {
count++;
}
// 更新结果
if (count > maxCount) {
maxCount = count;
result.clear();
result.add(cur.val);
}else if (count == maxCount) {
result.add(cur.val);
}
pre = cur;
cur = cur.right;
}
}
return result.stream().mapToInt(Integer::intValue).toArray();
}
}
Python3解法
递归法(版本二)利用二叉搜索树性质
class Solution:
def __init__(self):
self.maxCount = 0 # 最大频率
self.count = 0 # 统计频率
self.pre = None
self.result = []
def searchBST(self, cur):
if cur is None:
return
self.searchBST(cur.left) # 左
# 中
if self.pre is None: # 第一个节点
self.count = 1
elif self.pre.val == cur.val: # 与前一个节点数值相同
self.count += 1
else: # 与前一个节点数值不同
self.count = 1
self.pre = cur # 更新上一个节点
if self.count == self.maxCount: # 如果与最大值频率相同,放进result中
self.result.append(cur.val)
if self.count > self.maxCount: # 如果计数大于最大值频率
self.maxCount = self.count # 更新最大频率
self.result = [cur.val] # 很关键的一步,不要忘记清空result,之前result里的元素都失效了
self.searchBST(cur.right) # 右
return
def findMode(self, root):
self.count = 0
self.maxCount = 0
self.pre = None # 记录前一个节点
self.result = []
self.searchBST(root)
return self.result
Go解法
计数法,不使用额外空间,利用二叉树性质,中序遍历
func findMode(root *TreeNode) []int {
res := make([]int, 0)
count := 1
max := 1
var prev *TreeNode
var travel func(node *TreeNode)
travel = func(node *TreeNode) {
if node == nil {
return
}
travel(node.Left)
if prev != nil && prev.Val == node.Val {
count++
} else {
count = 1
}
if count >= max {
if count > max && len(res) > 0 {
res = []int{node.Val}
} else {
res = append(res, node.Val)
}
max = count
}
prev = node
travel(node.Right)
}
travel(root)
return res
}
235. Lowest Common Ancestor of a Binary Search Tree
Given a binary search tree (BST), find the lowest common ancestor (LCA) node of two given nodes in the BST.
According to the definition of LCA on Wikipedia: “The lowest common ancestor is defined between two nodes p and q as the lowest node in T that has both p and q as descendants (where we allow a node to be a descendant of itself).”
Example 1:
Input: root = [6,2,8,0,4,7,9,null,null,3,5], p = 2, q = 8
Output: 6
Explanation: The LCA of nodes 2 and 8 is 6.
Example 2:
Input: root = [6,2,8,0,4,7,9,null,null,3,5], p = 2, q = 4
Output: 2
Explanation: The LCA of nodes 2 and 4 is 2, since a node can be a descendant of itself according to the LCA definition.
Example 3:
Input: root = [2,1], p = 2, q = 1
Output: 2
Constraints:
- The number of nodes in the tree is in the range
[2, 10^5]. -10^9 <= Node.val <= 10^9- All
Node.valare unique. p != qpandqwill exist in the BST.
思路
做过二叉树:公共祖先问题 (opens new window)题目的同学应该知道,利用回溯从底向上搜索,遇到一个节点的左子树里有p,右子树里有q,那么当前节点就是最近公共祖先。
那么本题是二叉搜索树,二叉搜索树是有序的,那得好好利用一下这个特点。
在有序树里,如果判断一个节点的左子树里有p,右子树里有q呢?
因为是有序树,所以 如果 中间节点是 q 和 p 的公共祖先,那么 中节点的数组 一定是在 [p, q]区间的。即 中节点 > p && 中节点 < q 或者 中节点 > q && 中节点 < p。
那么只要从上到下去遍历,遇到 cur节点是数值在[p, q]区间中则一定可以说明该节点cur就是p 和 q的公共祖先。 那问题来了,一定是最近公共祖先吗?
如图,我们从根节点搜索,第一次遇到 cur节点是数值在[q, p]区间中,即 节点5,此时可以说明 q 和 p 一定分别存在于 节点 5的左子树,和右子树中。
此时节点5是不是最近公共祖先? 如果 从节点5继续向左遍历,那么将错过成为p的祖先, 如果从节点5继续向右遍历则错过成为q的祖先。
所以当我们从上向下去递归遍历,第一次遇到 cur节点是数值在[q, p]区间中,那么cur就是 q和p的最近公共祖先。
理解这一点,本题就很好解了。
而递归遍历顺序,本题就不涉及到 前中后序了(这里没有中节点的处理逻辑,遍历顺序无所谓了)。
如图所示:p为节点6,q为节点9
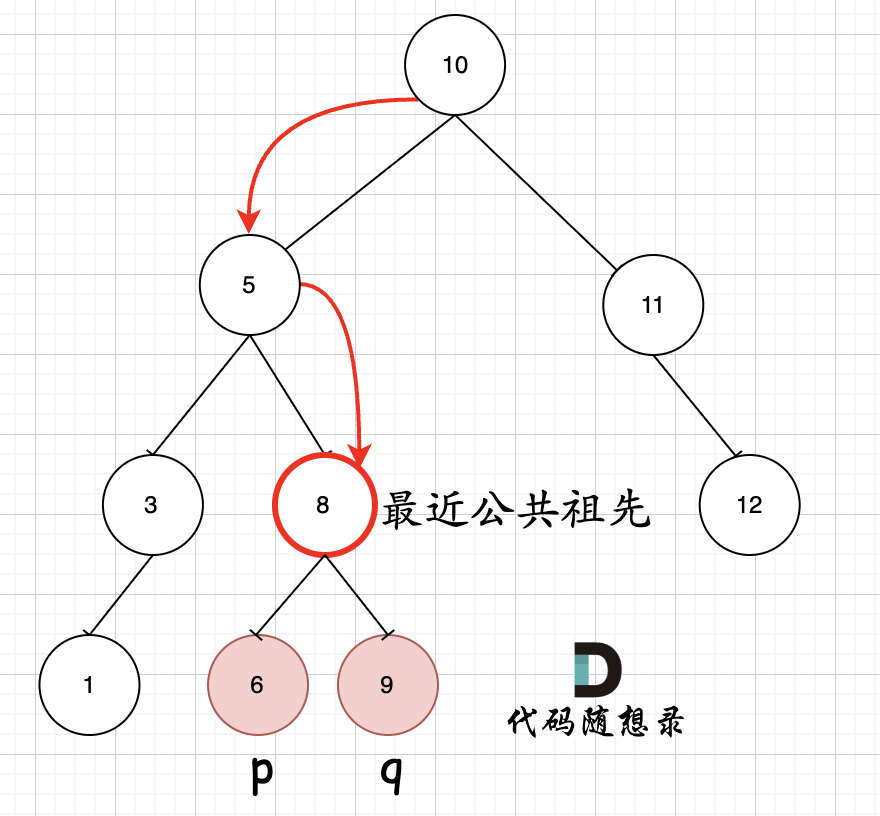
可以看出直接按照指定的方向,就可以找到节点8,为最近公共祖先,而且不需要遍历整棵树,找到结果直接返回!
递归法
递归三部曲如下:
- 确定递归函数返回值以及参数
参数就是当前节点,以及两个结点 p、q。
返回值是要返回最近公共祖先,所以是TreeNode * 。
代码如下:
TreeNode* traversal(TreeNode* cur, TreeNode* p, TreeNode* q)
- 确定终止条件
遇到空返回就可以了,代码如下:
if (cur == NULL) return cur;
其实都不需要这个终止条件,因为题目中说了p、q 为不同节点且均存在于给定的二叉搜索树中。也就是说一定会找到公共祖先的,所以并不存在遇到空的情况。
- 确定单层递归的逻辑
在遍历二叉搜索树的时候就是寻找区间[p->val, q->val](注意这里是左闭又闭)
那么如果 cur->val 大于 p->val,同时 cur->val 大于q->val,那么就应该向左遍历(说明目标区间在左子树上)。
需要注意的是此时不知道p和q谁大,所以两个都要判断
代码如下:
if (cur->val > p->val && cur->val > q->val) {
TreeNode* left = traversal(cur->left, p, q);
if (left != NULL) {
return left;
}
}
细心的同学会发现,在这里调用递归函数的地方,把递归函数的返回值left,直接return。
在二叉树:公共祖先问题 (opens new window)中,如果递归函数有返回值,如何区分要搜索一条边,还是搜索整个树。
搜索一条边的写法:
if (递归函数(root->left)) return ;
if (递归函数(root->right)) return ;
搜索整个树写法:
left = 递归函数(root->left);
right = 递归函数(root->right);
left与right的逻辑处理;
本题就是标准的搜索一条边的写法,遇到递归函数的返回值,如果不为空,立刻返回。
如果 cur->val 小于 p->val,同时 cur->val 小于 q->val,那么就应该向右遍历(目标区间在右子树)。
if (cur->val < p->val && cur->val < q->val) {
TreeNode* right = traversal(cur->right, p, q);
if (right != NULL) {
return right;
}
}
剩下的情况,就是cur节点在区间(p->val <= cur->val && cur->val <= q->val)或者 (q->val <= cur->val && cur->val <= p->val)中,那么cur就是最近公共祖先了,直接返回cur。
代码如下:
return cur;
迭代法
对于二叉搜索树的迭代法,大家应该在二叉树:二叉搜索树登场! (opens new window)就了解了。
利用其有序性,迭代的方式还是比较简单的,解题思路在递归中已经分析了。
总结
对于二叉搜索树的最近祖先问题,其实要比普通二叉树公共祖先问题 (opens new window)简单的多。
不用使用回溯,二叉搜索树自带方向性,可以方便的从上向下查找目标区间,遇到目标区间内的节点,直接返回。
最后给出了对应的迭代法,二叉搜索树的迭代法甚至比递归更容易理解,也是因为其有序性(自带方向性),按照目标区间找就行了。
C++解法
那么整体递归代码如下:
class Solution {
private:
TreeNode* traversal(TreeNode* cur, TreeNode* p, TreeNode* q) {
if (cur == NULL) return cur;
// 中
if (cur->val > p->val && cur->val > q->val) { // 左
TreeNode* left = traversal(cur->left, p, q);
if (left != NULL) {
return left;
}
}
if (cur->val < p->val && cur->val < q->val) { // 右
TreeNode* right = traversal(cur->right, p, q);
if (right != NULL) {
return right;
}
}
return cur;
}
public:
TreeNode* lowestCommonAncestor(TreeNode* root, TreeNode* p, TreeNode* q) {
return traversal(root, p, q);
}
};
精简后代码如下:
class Solution {
public:
TreeNode* lowestCommonAncestor(TreeNode* root, TreeNode* p, TreeNode* q) {
if (root->val > p->val && root->val > q->val) {
return lowestCommonAncestor(root->left, p, q);
} else if (root->val < p->val && root->val < q->val) {
return lowestCommonAncestor(root->right, p, q);
} else return root;
}
};
迭代代码如下:
class Solution {
public:
TreeNode* lowestCommonAncestor(TreeNode* root, TreeNode* p, TreeNode* q) {
while(root) {
if (root->val > p->val && root->val > q->val) {
root = root->left;
} else if (root->val < p->val && root->val < q->val) {
root = root->right;
} else return root;
}
return NULL;
}
};
灵魂拷问:是不是又被简单的迭代法感动到痛哭流涕?
Java解法
迭代法
class Solution {
public TreeNode lowestCommonAncestor(TreeNode root, TreeNode p, TreeNode q) {
while (true) {
if (root.val > p.val && root.val > q.val) {
root = root.left;
} else if (root.val < p.val && root.val < q.val) {
root = root.right;
} else {
break;
}
}
return root;
}
}
Python3解法
递归法(版本一)
class Solution:
def traversal(self, cur, p, q):
if cur is None:
return cur
# 中
if cur.val > p.val and cur.val > q.val: # 左
left = self.traversal(cur.left, p, q)
if left is not None:
return left
if cur.val < p.val and cur.val < q.val: # 右
right = self.traversal(cur.right, p, q)
if right is not None:
return right
return cur
def lowestCommonAncestor(self, root, p, q):
return self.traversal(root, p, q)
递归法(版本二)精简
class Solution:
def lowestCommonAncestor(self, root, p, q):
if root.val > p.val and root.val > q.val:
return self.lowestCommonAncestor(root.left, p, q)
elif root.val < p.val and root.val < q.val:
return self.lowestCommonAncestor(root.right, p, q)
else:
return root
Go解法
递归法
func lowestCommonAncestor(root, p, q *TreeNode) *TreeNode {
if root.Val > p.Val && root.Val > q.Val {
return lowestCommonAncestor(root.Left, p, q)
} else if root.Val < p.Val && root.Val < q.Val {
return lowestCommonAncestor(root.Right, p, q)
} else {
return root
}
}
701. Insert into a Binary Search Tree
You are given the root node of a binary search tree (BST) and a value to insert into the tree. Return the root node of the BST after the insertion. It is guaranteed that the new value does not exist in the original BST.
Notice that there may exist multiple valid ways for the insertion, as long as the tree remains a BST after insertion. You can return any of them.
Example 1:
Input: root = [4,2,7,1,3], val = 5
Output: [4,2,7,1,3,5]
Explanation: Another accepted tree is:
Example 2:
Input: root = [40,20,60,10,30,50,70], val = 25
Output: [40,20,60,10,30,50,70,null,null,25]
Example 3:
Input: root = [4,2,7,1,3,null,null,null,null,null,null], val = 5
Output: [4,2,7,1,3,5]
Constraints:
- The number of nodes in the tree will be in the range
[0, 10^4]. -10^8 <= Node.val <= 10^8- All the values
Node.valare unique. -10^8 <= val <= 10^8- It's guaranteed that
valdoes not exist in the original BST.
思路
这道题目其实是一道简单题目,但是题目中的提示:有多种有效的插入方式,还可以重构二叉搜索树,一下子吓退了不少人,瞬间感觉题目复杂了很多。
其实可以不考虑题目中提示所说的改变树的结构的插入方式。
如下演示视频中可以看出:只要按照二叉搜索树的规则去遍历,遇到空节点就插入节点就可以了。
例如插入元素10 ,需要找到末尾节点插入便可,一样的道理来插入元素15,插入元素0,插入元素6,需要调整二叉树的结构么? 并不需要。。
只要遍历二叉搜索树,找到空节点 插入元素就可以了,那么这道题其实就简单了。
接下来就是遍历二叉搜索树的过程了。
递归
递归三部曲:
- 确定递归函数参数以及返回值
参数就是根节点指针,以及要插入元素,这里递归函数要不要有返回值呢?
可以有,也可以没有,但递归函数如果没有返回值的话,实现是比较麻烦的,下面也会给出其具体实现代码。
有返回值的话,可以利用返回值完成新加入的节点与其父节点的赋值操作。(下面会进一步解释)
递归函数的返回类型为节点类型TreeNode * 。
代码如下:
TreeNode* insertIntoBST(TreeNode* root, int val)
- 确定终止条件
终止条件就是找到遍历的节点为null的时候,就是要插入节点的位置了,并把插入的节点返回。
代码如下:
if (root == NULL) {
TreeNode* node = new TreeNode(val);
return node;
}
这里把添加的节点返回给上一层,就完成了父子节点的赋值操作了,详细再往下看。
- 确定单层递归的逻辑
此时要明确,需要遍历整棵树么?
别忘了这是搜索树,遍历整棵搜索树简直是对搜索树的侮辱。
搜索树是有方向了,可以根据插入元素的数值,决定递归方向。
代码如下:
if (root->val > val) root->left = insertIntoBST(root->left, val);
if (root->val < val) root->right = insertIntoBST(root->right, val);
return root;
到这里,大家应该能感受到,如何通过递归函数返回值完成了新加入节点的父子关系赋值操作了,下一层将加入节点返回,本层用root->left或者root->right将其接住。
刚刚说了递归函数不用返回值也可以,找到插入的节点位置,直接让其父节点指向插入节点,结束递归,也是可以的。
迭代
再来看看迭代法,对二叉搜索树迭代写法不熟悉,可以看这篇:二叉树:二叉搜索树登场!(opens new window)
在迭代法遍历的过程中,需要记录一下当前遍历的节点的父节点,这样才能做插入节点的操作。
在二叉树:搜索树的最小绝对差 (opens new window)和二叉树:我的众数是多少? (opens new window)中,都是用了记录pre和cur两个指针的技巧,本题也是一样的。
总结
首先在二叉搜索树中的插入操作,大家不用恐惧其重构搜索树,其实根本不用重构。
然后在递归中,我们重点讲了如何通过递归函数的返回值完成新加入节点和其父节点的赋值操作,并强调了搜索树的有序性。
最后依然给出了迭代的方法,迭代的方法就需要记录当前遍历节点的父节点了,这个和没有返回值的递归函数实现的代码逻辑是一样的。
C++解法
递归法整体代码如下:
class Solution {
public:
TreeNode* insertIntoBST(TreeNode* root, int val) {
if (root == NULL) {
TreeNode* node = new TreeNode(val);
return node;
}
if (root->val > val) root->left = insertIntoBST(root->left, val);
if (root->val < val) root->right = insertIntoBST(root->right, val);
return root;
}
};
那么递归函数定义如下:
TreeNode* parent; // 记录遍历节点的父节点
void traversal(TreeNode* cur, int val)
没有返回值,需要记录上一个节点(parent),遇到空节点了,就让parent左孩子或者右孩子指向新插入的节点。然后结束递归。
代码如下:
class Solution {
private:
TreeNode* parent;
void traversal(TreeNode* cur, int val) {
if (cur == NULL) {
TreeNode* node = new TreeNode(val);
if (val > parent->val) parent->right = node;
else parent->left = node;
return;
}
parent = cur;
if (cur->val > val) traversal(cur->left, val);
if (cur->val < val) traversal(cur->right, val);
return;
}
public:
TreeNode* insertIntoBST(TreeNode* root, int val) {
parent = new TreeNode(0);
if (root == NULL) {
root = new TreeNode(val);
}
traversal(root, val);
return root;
}
};
可以看出还是麻烦一些的。
我之所以举这个例子,是想说明通过递归函数的返回值完成父子节点的赋值是可以带来便利的。
网上千篇一律的代码,可能会误导大家认为通过递归函数返回节点 这样的写法是天经地义,其实这里是有优化的!
迭代法代码如下:
class Solution {
public:
TreeNode* insertIntoBST(TreeNode* root, int val) {
if (root == NULL) {
TreeNode* node = new TreeNode(val);
return node;
}
TreeNode* cur = root;
TreeNode* parent = root; // 这个很重要,需要记录上一个节点,否则无法赋值新节点
while (cur != NULL) {
parent = cur;
if (cur->val > val) cur = cur->left;
else cur = cur->right;
}
TreeNode* node = new TreeNode(val);
if (val < parent->val) parent->left = node;// 此时是用parent节点的进行赋值
else parent->right = node;
return root;
}
};
Java解法
递归法
class Solution {
public TreeNode insertIntoBST(TreeNode root, int val) {
if (root == null) // 如果当前节点为空,也就意味着val找到了合适的位置,此时创建节点直接返回。
return new TreeNode(val);
if (root.val < val){
root.right = insertIntoBST(root.right, val); // 递归创建右子树
}else if (root.val > val){
root.left = insertIntoBST(root.left, val); // 递归创建左子树
}
return root;
}
}
Python3解法
递归法(版本二)
class Solution:
def insertIntoBST(self, root: Optional[TreeNode], val: int) -> Optional[TreeNode]:
if root is None or root.val == val:
return TreeNode(val)
elif root.val > val:
if root.left is None:
root.left = TreeNode(val)
else:
self.insertIntoBST(root.left, val)
elif root.val < val:
if root.right is None:
root.right = TreeNode(val)
else:
self.insertIntoBST(root.right, val)
return root
Go解法
递归法
func insertIntoBST(root *TreeNode, val int) *TreeNode {
if root == nil {
root = &TreeNode{Val: val}
return root
}
if root.Val > val {
root.Left = insertIntoBST(root.Left, val)
} else {
root.Right = insertIntoBST(root.Right, val)
}
return root
}
450. Delete Node in a BST
Given a root node reference of a BST and a key, delete the node with the given key in the BST. Return the root node reference (possibly updated) of the BST.
Basically, the deletion can be divided into two stages:
- Search for a node to remove.
- If the node is found, delete the node.
Example 1:
Input: root = [5,3,6,2,4,null,7], key = 3
Output: [5,4,6,2,null,null,7]
Explanation: Given key to delete is 3. So we find the node with value 3 and delete it.
One valid answer is [5,4,6,2,null,null,7], shown in the above BST.
Please notice that another valid answer is [5,2,6,null,4,null,7] and it's also accepted.
Example 2:
Input: root = [5,3,6,2,4,null,7], key = 0
Output: [5,3,6,2,4,null,7]
Explanation: The tree does not contain a node with value = 0.
Example 3:
Input: root = [], key = 0
Output: []
Constraints:
- The number of nodes in the tree is in the range
[0, 10^4]. -10^5 <= Node.val <= 10^5- Each node has a unique value.
rootis a valid binary search tree.-10^5 <= key <= 10^5
Follow up: Could you solve it with time complexity O(height of tree)?
思路
搜索树的节点删除要比节点增加复杂的多,有很多情况需要考虑,做好心理准备。
递归
递归三部曲:
- 确定递归函数参数以及返回值
说到递归函数的返回值,在二叉树:搜索树中的插入操作 (opens new window)中通过递归返回值来加入新节点, 这里也可以通过递归返回值删除节点。
代码如下:
TreeNode* deleteNode(TreeNode* root, int key)
- 确定终止条件
遇到空返回,其实这也说明没找到删除的节点,遍历到空节点直接返回了
if (root == nullptr) return root;
- 确定单层递归的逻辑
这里就把二叉搜索树中删除节点遇到的情况都搞清楚。
有以下五种情况:
- 第一种情况:没找到删除的节点,遍历到空节点直接返回了
- 找到删除的节点
- 第二种情况:左右孩子都为空(叶子节点),直接删除节点, 返回NULL为根节点
- 第三种情况:删除节点的左孩子为空,右孩子不为空,删除节点,右孩子补位,返回右孩子为根节点
- 第四种情况:删除节点的右孩子为空,左孩子不为空,删除节点,左孩子补位,返回左孩子为根节点
- 第五种情况:左右孩子节点都不为空,则将删除节点的左子树头结点(左孩子)放到删除节点的右子树的最左面节点的左孩子上,返回删除节点右孩子为新的根节点。
第五种情况有点难以理解,看下面动画:
动画中的二叉搜索树中,删除元素7, 那么删除节点(元素7)的左孩子就是5,删除节点(元素7)的右子树的最左面节点是元素8。
将删除节点(元素7)的左孩子放到删除节点(元素7)的右子树的最左面节点(元素8)的左孩子上,就是把5为根节点的子树移到了8的左孩子的位置。
要删除的节点(元素7)的右孩子(元素9)为新的根节点。.
这样就完成删除元素7的逻辑,最好动手画一个图,尝试删除一个节点试试。
代码如下:
if (root->val == key) {
// 第二种情况:左右孩子都为空(叶子节点),直接删除节点, 返回NULL为根节点
// 第三种情况:其左孩子为空,右孩子不为空,删除节点,右孩子补位 ,返回右孩子为根节点
if (root->left == nullptr) return root->right;
// 第四种情况:其右孩子为空,左孩子不为空,删除节点,左孩子补位,返回左孩子为根节点
else if (root->right == nullptr) return root->left;
// 第五种情况:左右孩子节点都不为空,则将删除节点的左子树放到删除节点的右子树的最左面节点的左孩子的位置
// 并返回删除节点右孩子为新的根节点。
else {
TreeNode* cur = root->right; // 找右子树最左面的节点
while(cur->left != nullptr) {
cur = cur->left;
}
cur->left = root->left; // 把要删除的节点(root)左子树放在cur的左孩子的位置
TreeNode* tmp = root; // 把root节点保存一下,下面来删除
root = root->right; // 返回旧root的右孩子作为新root
delete tmp; // 释放节点内存(这里不写也可以,但C++最好手动释放一下吧)
return root;
}
}
这里相当于把新的节点返回给上一层,上一层就要用 root->left 或者 root->right接住,代码如下:
if (root->val > key) root->left = deleteNode(root->left, key);
if (root->val < key) root->right = deleteNode(root->right, key);
return root;
普通二叉树的删除方式
这里我在介绍一种通用的删除,普通二叉树的删除方式(没有使用搜索树的特性,遍历整棵树),用交换值的操作来删除目标节点。
代码中目标节点(要删除的节点)被操作了两次:
- 第一次是和目标节点的右子树最左面节点交换。
- 第二次直接被NULL覆盖了。
思路有点绕,感兴趣的同学可以画图自己理解一下。
代码如下:(关键部分已经注释)
class Solution {
public:
TreeNode* deleteNode(TreeNode* root, int key) {
if (root == nullptr) return root;
if (root->val == key) {
if (root->right == nullptr) { // 这里第二次操作目标值:最终删除的作用
return root->left;
}
TreeNode *cur = root->right;
while (cur->left) {
cur = cur->left;
}
swap(root->val, cur->val); // 这里第一次操作目标值:交换目标值其右子树最左面节点。
}
root->left = deleteNode(root->left, key);
root->right = deleteNode(root->right, key);
return root;
}
};
这个代码是简短一些,思路也巧妙,但是不太好想,实操性不强,推荐第一种写法!
迭代法
删除节点的迭代法还是复杂一些的,但其本质我在递归法里都介绍了,最关键就是删除节点的操作(动画模拟的过程)
总结
读完本篇,大家会发现二叉搜索树删除节点比增加节点复杂的多。
因为二叉搜索树添加节点只需要在叶子上添加就可以的,不涉及到结构的调整,而删除节点操作涉及到结构的调整。
这里我们依然使用递归函数的返回值来完成把节点从二叉树中移除的操作。
这里最关键的逻辑就是第五种情况(删除一个左右孩子都不为空的节点),这种情况一定要想清楚。
而且就算想清楚了,对应的代码也未必可以写出来,所以这道题目既考察思维逻辑,也考察代码能力。
递归中我给出了两种写法,推荐大家学会第一种(利用搜索树的特性)就可以了,第二种递归写法其实是比较绕的。
最后我也给出了相应的迭代法,就是模拟递归法中的逻辑来删除节点,但需要一个pre记录cur的父节点,方便做删除操作。
迭代法其实不太容易写出来,所以如果是初学者的话,彻底掌握第一种递归写法就够了。
C++解法
递归法整体代码如下:(注释中:情况1,2,3,4,5和上面分析严格对应)
class Solution {
public:
TreeNode* deleteNode(TreeNode* root, int key) {
if (root == nullptr) return root; // 第一种情况:没找到删除的节点,遍历到空节点直接返回了
if (root->val == key) {
// 第二种情况:左右孩子都为空(叶子节点),直接删除节点, 返回NULL为根节点
if (root->left == nullptr && root->right == nullptr) {
///! 内存释放
delete root;
return nullptr;
}
// 第三种情况:其左孩子为空,右孩子不为空,删除节点,右孩子补位 ,返回右孩子为根节点
else if (root->left == nullptr) {
auto retNode = root->right;
///! 内存释放
delete root;
return retNode;
}
// 第四种情况:其右孩子为空,左孩子不为空,删除节点,左孩子补位,返回左孩子为根节点
else if (root->right == nullptr) {
auto retNode = root->left;
///! 内存释放
delete root;
return retNode;
}
// 第五种情况:左右孩子节点都不为空,则将删除节点的左子树放到删除节点的右子树的最左面节点的左孩子的位置
// 并返回删除节点右孩子为新的根节点。
else {
TreeNode* cur = root->right; // 找右子树最左面的节点
while(cur->left != nullptr) {
cur = cur->left;
}
cur->left = root->left; // 把要删除的节点(root)左子树放在cur的左孩子的位置
TreeNode* tmp = root; // 把root节点保存一下,下面来删除
root = root->right; // 返回旧root的右孩子作为新root
delete tmp; // 释放节点内存(这里不写也可以,但C++最好手动释放一下吧)
return root;
}
}
if (root->val > key) root->left = deleteNode(root->left, key);
if (root->val < key) root->right = deleteNode(root->right, key);
return root;
}
};
迭代法代码如下:
class Solution {
private:
// 将目标节点(删除节点)的左子树放到 目标节点的右子树的最左面节点的左孩子位置上
// 并返回目标节点右孩子为新的根节点
// 是动画里模拟的过程
TreeNode* deleteOneNode(TreeNode* target) {
if (target == nullptr) return target;
if (target->right == nullptr) return target->left;
TreeNode* cur = target->right;
while (cur->left) {
cur = cur->left;
}
cur->left = target->left;
return target->right;
}
public:
TreeNode* deleteNode(TreeNode* root, int key) {
if (root == nullptr) return root;
TreeNode* cur = root;
TreeNode* pre = nullptr; // 记录cur的父节点,用来删除cur
while (cur) {
if (cur->val == key) break;
pre = cur;
if (cur->val > key) cur = cur->left;
else cur = cur->right;
}
if (pre == nullptr) { // 如果搜索树只有头结点
return deleteOneNode(cur);
}
// pre 要知道是删左孩子还是右孩子
if (pre->left && pre->left->val == key) {
pre->left = deleteOneNode(cur);
}
if (pre->right && pre->right->val == key) {
pre->right = deleteOneNode(cur);
}
return root;
}
};
Java解法
// 解法1(最好理解的版本)
class Solution {
public TreeNode deleteNode(TreeNode root, int key) {
if (root == null) return root;
if (root.val == key) {
if (root.left == null) {
return root.right;
} else if (root.right == null) {
return root.left;
} else {
TreeNode cur = root.right;
while (cur.left != null) {
cur = cur.left;
}
cur.left = root.left;
root = root.right;
return root;
}
}
if (root.val > key) root.left = deleteNode(root.left, key);
if (root.val < key) root.right = deleteNode(root.right, key);
return root;
}
}
Python3解法
递归法(版本二)
class Solution:
def deleteNode(self, root, key):
if root is None: # 如果根节点为空,直接返回
return root
if root.val == key: # 找到要删除的节点
if root.right is None: # 如果右子树为空,直接返回左子树作为新的根节点
return root.left
cur = root.right
while cur.left: # 找到右子树中的最左节点
cur = cur.left
root.val, cur.val = cur.val, root.val # 将要删除的节点值与最左节点值交换
root.left = self.deleteNode(root.left, key) # 在左子树中递归删除目标节点
root.right = self.deleteNode(root.right, key) # 在右子树中递归删除目标节点
return root
Go解法
// 递归版本
func deleteNode(root *TreeNode, key int) *TreeNode {
if root == nil {
return nil
}
if key < root.Val {
root.Left = deleteNode(root.Left, key)
return root
}
if key > root.Val {
root.Right = deleteNode(root.Right, key)
return root
}
if root.Right == nil {
return root.Left
}
if root.Left == nil{
return root.Right
}
minnode := root.Right
for minnode.Left != nil {
minnode = minnode.Left
}
root.Val = minnode.Val
root.Right = deleteNode1(root.Right)
return root
}
func deleteNode1(root *TreeNode)*TreeNode {
if root.Left == nil {
pRight := root.Right
root.Right = nil
return pRight
}
root.Left = deleteNode1(root.Left)
return root
}
669. Trim a Binary Search Tree
Given the root of a binary search tree and the lowest and highest boundaries as low and high, trim the tree so that all its elements lies in [low, high]. Trimming the tree should not change the relative structure of the elements that will remain in the tree (i.e., any node's descendant should remain a descendant). It can be proven that there is a unique answer.
Return the root of the trimmed binary search tree. Note that the root may change depending on the given bounds.
Example 1:
Input: root = [1,0,2], low = 1, high = 2
Output: [1,null,2]
Example 2:
Input: root = [3,0,4,null,2,null,null,1], low = 1, high = 3
Output: [3,2,null,1]
Constraints:
- The number of nodes in the tree is in the range
[1, 10^4]. 0 <= Node.val <= 10^4- The value of each node in the tree is unique.
rootis guaranteed to be a valid binary search tree.0 <= low <= high <= 10^4
思路
相信看到这道题目大家都感觉是一道简单题(事实上leetcode上也标明是简单)。
但还真的不简单!
递归法
直接想法就是:递归处理,然后遇到 root->val < low || root->val > high 的时候直接return NULL,一波修改,赶紧利落。
不难写出如下代码:
class Solution {
public:
TreeNode* trimBST(TreeNode* root, int low, int high) {
if (root == nullptr || root->val < low || root->val > high) return nullptr;
root->left = trimBST(root->left, low, high);
root->right = trimBST(root->right, low, high);
return root;
}
};
然而[1, 3]区间在二叉搜索树的中可不是单纯的节点3和左孩子节点0就决定的,还要考虑节点0的右子树。
我们在重新关注一下第二个示例,如图:
所以以上的代码是不可行的!
从图中可以看出需要重构二叉树,想想是不是本题就有点复杂了。
其实不用重构那么复杂。
在上图中我们发现节点0并不符合区间要求,那么将节点0的右孩子 节点2 直接赋给 节点3的左孩子就可以了(就是把节点0从二叉树中移除),如图:
理解了最关键部分了我们再递归三部曲:
- 确定递归函数的参数以及返回值
这里我们为什么需要返回值呢?
因为是要遍历整棵树,做修改,其实不需要返回值也可以,我们也可以完成修剪(其实就是从二叉树中移除节点)的操作。
但是有返回值,更方便,可以通过递归函数的返回值来移除节点。
这样的做法在二叉树:搜索树中的插入操作 (opens new window)和二叉树:搜索树中的删除操作 (opens new window)中大家已经了解过了。
代码如下:
TreeNode* trimBST(TreeNode* root, int low, int high)
- 确定终止条件
修剪的操作并不是在终止条件上进行的,所以就是遇到空节点返回就可以了。
if (root == nullptr ) return nullptr;
- 确定单层递归的逻辑
如果root(当前节点)的元素小于low的数值,那么应该递归右子树,并返回右子树符合条件的头结点。
代码如下:
if (root->val < low) {
TreeNode* right = trimBST(root->right, low, high); // 寻找符合区间[low, high]的节点
return right;
}
如果root(当前节点)的元素大于high的,那么应该递归左子树,并返回左子树符合条件的头结点。
代码如下:
if (root->val > high) {
TreeNode* left = trimBST(root->left, low, high); // 寻找符合区间[low, high]的节点
return left;
}
接下来要将下一层处理完左子树的结果赋给root->left,处理完右子树的结果赋给root->right。
最后返回root节点,代码如下:
root->left = trimBST(root->left, low, high); // root->left接入符合条件的左孩子
root->right = trimBST(root->right, low, high); // root->right接入符合条件的右孩子
return root;
此时大家是不是还没发现这多余的节点究竟是如何从二叉树中移除的呢?
在回顾一下上面的代码,针对下图中二叉树的情况:
如下代码相当于把节点0的右孩子(节点2)返回给上一层,
if (root->val < low) {
TreeNode* right = trimBST(root->right, low, high); // 寻找符合区间[low, high]的节点
return right;
}
然后如下代码相当于用节点3的左孩子 把下一层返回的 节点0的右孩子(节点2) 接住。
root->left = trimBST(root->left, low, high);
此时节点3的左孩子就变成了节点2,将节点0从二叉树中移除了。
迭代法
因为二叉搜索树的有序性,不需要使用栈模拟递归的过程。
在剪枝的时候,可以分为三步:
- 将root移动到
[L, R]范围内,注意是左闭右闭区间 - 剪枝左子树
- 剪枝右子树
总结
修剪二叉搜索树其实并不难,但在递归法中大家可看出我费了很大的功夫来讲解如何删除节点的,这个思路其实是比较绕的。
最终的代码倒是很简洁。
如果不对递归有深刻的理解,这道题目还是有难度的!
本题我依然给出递归法和迭代法,初学者掌握递归就可以了,如果想进一步学习,就把迭代法也写一写。
C++解法
递归法最后整体代码如下:
class Solution {
public:
TreeNode* trimBST(TreeNode* root, int low, int high) {
if (root == nullptr ) return nullptr;
if (root->val < low) {
TreeNode* right = trimBST(root->right, low, high); // 寻找符合区间[low, high]的节点
return right;
}
if (root->val > high) {
TreeNode* left = trimBST(root->left, low, high); // 寻找符合区间[low, high]的节点
return left;
}
root->left = trimBST(root->left, low, high); // root->left接入符合条件的左孩子
root->right = trimBST(root->right, low, high); // root->right接入符合条件的右孩子
return root;
}
};
精简之后代码如下:
class Solution {
public:
TreeNode* trimBST(TreeNode* root, int low, int high) {
if (root == nullptr) return nullptr;
if (root->val < low) return trimBST(root->right, low, high);
if (root->val > high) return trimBST(root->left, low, high);
root->left = trimBST(root->left, low, high);
root->right = trimBST(root->right, low, high);
return root;
}
};
只看代码,其实不太好理解节点是如何移除的,这一块大家可以自己再模拟模拟!
迭代法代码如下:
class Solution {
public:
TreeNode* trimBST(TreeNode* root, int L, int R) {
if (!root) return nullptr;
// 处理头结点,让root移动到[L, R] 范围内,注意是左闭右闭
while (root != nullptr && (root->val < L || root->val > R)) {
if (root->val < L) root = root->right; // 小于L往右走
else root = root->left; // 大于R往左走
}
TreeNode *cur = root;
// 此时root已经在[L, R] 范围内,处理左孩子元素小于L的情况
while (cur != nullptr) {
while (cur->left && cur->left->val < L) {
cur->left = cur->left->right;
}
cur = cur->left;
}
cur = root;
// 此时root已经在[L, R] 范围内,处理右孩子大于R的情况
while (cur != nullptr) {
while (cur->right && cur->right->val > R) {
cur->right = cur->right->left;
}
cur = cur->right;
}
return root;
}
};
Java解法
递归法
class Solution {
public TreeNode trimBST(TreeNode root, int low, int high) {
if (root == null) {
return null;
}
if (root.val < low) {
return trimBST(root.right, low, high);
}
if (root.val > high) {
return trimBST(root.left, low, high);
}
// root在[low,high]范围内
root.left = trimBST(root.left, low, high);
root.right = trimBST(root.right, low, high);
return root;
}
}
Python3解法
递归法
class Solution:
def trimBST(self, root: TreeNode, low: int, high: int) -> TreeNode:
if root is None:
return None
if root.val < low:
# 寻找符合区间 [low, high] 的节点
return self.trimBST(root.right, low, high)
if root.val > high:
# 寻找符合区间 [low, high] 的节点
return self.trimBST(root.left, low, high)
root.left = self.trimBST(root.left, low, high) # root.left 接入符合条件的左孩子
root.right = self.trimBST(root.right, low, high) # root.right 接入符合条件的右孩子
return root
Go解法
// 递归
func trimBST(root *TreeNode, low int, high int) *TreeNode {
if root == nil {
return nil
}
if root.Val < low { //如果该节点值小于最小值,则该节点更换为该节点的右节点值,继续遍历
right := trimBST(root.Right, low, high)
return right
}
if root.Val > high { //如果该节点的值大于最大值,则该节点更换为该节点的左节点值,继续遍历
left := trimBST(root.Left, low, high)
return left
}
root.Left = trimBST(root.Left, low, high)
root.Right = trimBST(root.Right, low, high)
return root
}
108. Convert Sorted Array to Binary Search Tree
Given an integer array nums where the elements are sorted in ascending order, convert it to a height-balanced binary search tree.
Example 1:
Input: nums = [-10,-3,0,5,9]
Output: [0,-3,9,-10,null,5]
Explanation: [0,-10,5,null,-3,null,9] is also accepted:

Example 2:
Input: nums = [1,3]
Output: [3,1]
Explanation: [1,null,3] and [3,1] are both height-balanced BSTs.
Constraints:
1 <= nums.length <= 10^4-10^4 <= nums[i] <= 10^4numsis sorted in a strictly increasing order.
思路
题目中说要转换为一棵高度平衡二叉搜索树。为什么强调要平衡呢?
因为只要给我们一个有序数组,如果不强调平衡,都可以以线性结构来构造二叉搜索树。
上图中,是符合二叉搜索树的特性吧,如果要这么做的话,是不是本题意义就不大了,所以才强调是平衡二叉搜索树。
其实数组构造二叉树,构成平衡树是自然而然的事情,因为大家默认都是从数组中间位置取值作为节点元素,一般不会随机取。所以想构成不平衡的二叉树是自找麻烦。
在二叉树:构造二叉树登场! (opens new window)和二叉树:构造一棵最大的二叉树 (opens new window)中其实已经讲过了,如果根据数组构造一棵二叉树。
本质就是寻找分割点,分割点作为当前节点,然后递归左区间和右区间。
本题其实要比二叉树:构造二叉树登场! (opens new window)和 二叉树:构造一棵最大的二叉树 (opens new window)简单一些,因为有序数组构造二叉搜索树,寻找分割点就比较容易了。
分割点就是数组中间位置的节点。
那么为问题来了,如果数组长度为偶数,中间节点有两个,取哪一个?
取哪一个都可以,只不过构成了不同的平衡二叉搜索树。
例如:输入:[-10,-3,0,5,9]
如下两棵树,都是这个数组的平衡二叉搜索树:
如果要分割的数组长度为偶数的时候,中间元素为两个,是取左边元素 就是树1,取右边元素就是树2。
这也是题目中强调答案不是唯一的原因。 理解这一点,这道题目算是理解到位了。
递归
递归三部曲:
- 确定递归函数返回值及其参数
删除二叉树节点,增加二叉树节点,都是用递归函数的返回值来完成,这样是比较方便的。
相信大家如果仔细看了二叉树:搜索树中的插入操作 (opens new window)和二叉树:搜索树中的删除操作 (opens new window),一定会对递归函数返回值的作用深有感触。
那么本题要构造二叉树,依然用递归函数的返回值来构造中节点的左右孩子。
再来看参数,首先是传入数组,然后就是左下标left和右下标right,我们在二叉树:构造二叉树登场! (opens new window)中提过,在构造二叉树的时候尽量不要重新定义左右区间数组,而是用下标来操作原数组。
所以代码如下:
// 左闭右闭区间[left, right]
TreeNode* traversal(vector<int>& nums, int left, int right)
这里注意,我这里定义的是左闭右闭区间,在不断分割的过程中,也会坚持左闭右闭的区间,这又涉及到我们讲过的循环不变量。
在二叉树:构造二叉树登场! (opens new window),35.搜索插入位置 (opens new window)和59.螺旋矩阵II (opens new window)都详细讲过循环不变量。
- 确定递归终止条件
这里定义的是左闭右闭的区间,所以当区间 left > right的时候,就是空节点了。
代码如下:
if (left > right) return nullptr;
- 确定单层递归的逻辑
首先取数组中间元素的位置,不难写出int mid = (left + right) / 2;,这么写其实有一个问题,就是数值越界,例如left和right都是最大int,这么操作就越界了,在二分法 (opens new window)中尤其需要注意!
所以可以这么写:int mid = left + ((right - left) / 2);
但本题leetcode的测试数据并不会越界,所以怎么写都可以。但需要有这个意识!
取了中间位置,就开始以中间位置的元素构造节点,代码:TreeNode* root = new TreeNode(nums[mid]);。
接着划分区间,root的左孩子接住下一层左区间的构造节点,右孩子接住下一层右区间构造的节点。
最后返回root节点,单层递归整体代码如下:
int mid = left + ((right - left) / 2);
TreeNode* root = new TreeNode(nums[mid]);
root->left = traversal(nums, left, mid - 1);
root->right = traversal(nums, mid + 1, right);
return root;
这里int mid = left + ((right - left) / 2);的写法相当于是如果数组长度为偶数,中间位置有两个元素,取靠左边的。
迭代法
迭代法可以通过三个队列来模拟,一个队列放遍历的节点,一个队列放左区间下标,一个队列放右区间下标。
总结
在二叉树:构造二叉树登场! (opens new window)和 二叉树:构造一棵最大的二叉树 (opens new window)之后,我们顺理成章的应该构造一下二叉搜索树了,一不小心还是一棵平衡二叉搜索树。
其实思路也是一样的,不断中间分割,然后递归处理左区间,右区间,也可以说是分治。
此时相信大家应该对通过递归函数的返回值来增删二叉树很熟悉了,这也是常规操作。
在定义区间的过程中我们又一次强调了循环不变量的重要性。
最后依然给出迭代的方法,其实就是模拟取中间元素,然后不断分割去构造二叉树的过程。
C++解法
递归整体代码如下:
class Solution {
private:
TreeNode* traversal(vector<int>& nums, int left, int right) {
if (left > right) return nullptr;
int mid = left + ((right - left) / 2);
TreeNode* root = new TreeNode(nums[mid]);
root->left = traversal(nums, left, mid - 1);
root->right = traversal(nums, mid + 1, right);
return root;
}
public:
TreeNode* sortedArrayToBST(vector<int>& nums) {
TreeNode* root = traversal(nums, 0, nums.size() - 1);
return root;
}
};
注意:在调用traversal的时候传入的left和right为什么是0和nums.size() - 1,因为定义的区间为左闭右闭。
迭代法模拟的就是不断分割的过程,C++代码如下:(我已经详细注释)
class Solution {
public:
TreeNode* sortedArrayToBST(vector<int>& nums) {
if (nums.size() == 0) return nullptr;
TreeNode* root = new TreeNode(0); // 初始根节点
queue<TreeNode*> nodeQue; // 放遍历的节点
queue<int> leftQue; // 保存左区间下标
queue<int> rightQue; // 保存右区间下标
nodeQue.push(root); // 根节点入队列
leftQue.push(0); // 0为左区间下标初始位置
rightQue.push(nums.size() - 1); // nums.size() - 1为右区间下标初始位置
while (!nodeQue.empty()) {
TreeNode* curNode = nodeQue.front();
nodeQue.pop();
int left = leftQue.front(); leftQue.pop();
int right = rightQue.front(); rightQue.pop();
int mid = left + ((right - left) / 2);
curNode->val = nums[mid]; // 将mid对应的元素给中间节点
if (left <= mid - 1) { // 处理左区间
curNode->left = new TreeNode(0);
nodeQue.push(curNode->left);
leftQue.push(left);
rightQue.push(mid - 1);
}
if (right >= mid + 1) { // 处理右区间
curNode->right = new TreeNode(0);
nodeQue.push(curNode->right);
leftQue.push(mid + 1);
rightQue.push(right);
}
}
return root;
}
};
Java解法
递归: 左闭右开 [left,right)
class Solution {
public TreeNode sortedArrayToBST(int[] nums) {
return sortedArrayToBST(nums, 0, nums.length);
}
public TreeNode sortedArrayToBST(int[] nums, int left, int right) {
if (left >= right) {
return null;
}
if (right - left == 1) {
return new TreeNode(nums[left]);
}
int mid = left + (right - left) / 2;
TreeNode root = new TreeNode(nums[mid]);
root.left = sortedArrayToBST(nums, left, mid);
root.right = sortedArrayToBST(nums, mid + 1, right);
return root;
}
}
Python3解法
递归 精简(自身调用)
class Solution:
def sortedArrayToBST(self, nums: List[int]) -> Optional[TreeNode]:
if not nums:
return
mid = len(nums) // 2
root = TreeNode(nums[mid])
root.left = self.sortedArrayToBST(nums[:mid])
root.right = self.sortedArrayToBST(nums[mid + 1 :])
return root
Go解法
递归(隐含回溯)
func sortedArrayToBST(nums []int) *TreeNode {
if len(nums) == 0 { //终止条件,最后数组为空则可以返回
return nil
}
idx := len(nums)/2
root := &TreeNode{Val: nums[idx]}
root.Left = sortedArrayToBST(nums[:idx])
root.Right = sortedArrayToBST(nums[idx+1:])
return root
}
109. Convert Sorted List to Binary Search Tree
Given the head of a singly linked list where elements are sorted in ascending order, convert it to aheight-balanced binary search tree.
Example 1:
Input: head = [-10,-3,0,5,9]
Output: [0,-3,9,-10,null,5]
Explanation: One possible answer is [0,-3,9,-10,null,5], which represents the shown height balanced BST.
Example 2:
Input: head = []
Output: []
Constraints:
- The number of nodes in
headis in the range[0, 2 * 10^4]. -10^5 <= Node.val <= 10^5
思路
方法一:转为数组然后处理
方法二:双指针找中间位置,再分区处理
Intuition
The problem requires converting a sorted linked list into a height-balanced binary search tree (BST). Since the linked list is sorted, the middle element naturally serves as the root, ensuring balance.
Approach
Find the Middle Node:
Use the slow and fast pointer method to locate the middle element.
This middle node becomes the root of the BST.
Recursively Construct the Left and Right Subtrees:
The left half of the list (before the middle node) forms theleft subtree.
The right half of the list (after the middle node) forms theright subtree.
Base Case:
If head == tail, return nullptr, as there are no elements to process.
Complexity Analysis
Time Complexity:O(nlogn)
Finding the middle element takesO(n), and we perform thislog ntimes.
Space Complexity:O(logn)
Due to recursive stack space.
C++解法
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode() : val(0), next(nullptr) {}
* ListNode(int x) : val(x), next(nullptr) {}
* ListNode(int x, ListNode *next) : val(x), next(next) {}
* };
*/
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode() : val(0), left(nullptr), right(nullptr) {}
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
* };
*/
class Solution {
public:
TreeNode* sortedArrayToBST(vector<int>& nums) {
if(nums.size() == 0){
return NULL;
}
if(nums.size() == 1){
return new TreeNode(nums[0]);
}
int rootVal = nums[nums.size() / 2];
TreeNode* root = new TreeNode(rootVal);
vector<int> left(nums.begin(), nums.begin() + nums.size() / 2);
root->left = sortedArrayToBST(left);
vector<int> right(nums.begin() + nums.size() / 2 + 1 , nums.end());
root->right = sortedArrayToBST(right);
return root;
}
TreeNode* sortedListToBST(ListNode* head) {
vector<int> nums;
ListNode* cur = head;
while(cur){
nums.push_back(cur->val);
cur = cur->next;
}
return sortedArrayToBST(nums);
}
};
方法二:
class Solution {
public:
ListNode* find_middle(ListNode* head, ListNode* tail) {
if (!head)
return nullptr;
ListNode *slow = head, *fast = head;
while (fast != tail && fast->next != tail) {
slow = slow->next;
fast = fast->next->next;
}
return slow;
}
TreeNode* helper(ListNode* head, ListNode* tail) {
if (head == tail)
return nullptr;
ListNode* middle = find_middle(head, tail);
TreeNode* root = new TreeNode(middle->val);
root->left = helper(head, middle);
root->right = helper(middle->next, tail);
return root;
}
TreeNode* sortedListToBST(ListNode* head) {
if (!head)
return nullptr;
return helper(head, nullptr);
}
};
Java解法
Python3解法
Go解法
538. Convert BST to Greater Tree
Given the root of a Binary Search Tree (BST), convert it to a Greater Tree such that every key of the original BST is changed to the original key plus the sum of all keys greater than the original key in BST.
As a reminder, a binary search tree is a tree that satisfies these constraints:
- The left subtree of a node contains only nodes with keys less than the node's key.
- The right subtree of a node contains only nodes with keys greater than the node's key.
- Both the left and right subtrees must also be binary search trees.
Example 1:

Input: root = [4,1,6,0,2,5,7,null,null,null,3,null,null,null,8]
Output: [30,36,21,36,35,26,15,null,null,null,33,null,null,null,8]
Example 2:
Input: root = [0,null,1]
Output: [1,null,1]
Constraints:
- The number of nodes in the tree is in the range
[0, 10^4]. -10^4 <= Node.val <= 10^4- All the values in the tree are unique.
rootis guaranteed to be a valid binary search tree.
Note: This question is the same as 1038: https://leetcode.com/problems/binary-search-tree-to-greater-sum-tree/
思路
一看到累加树,相信很多小伙伴都会疑惑:如何累加?遇到一个节点,然后再遍历其他节点累加?怎么一想这么麻烦呢。
然后再发现这是一棵二叉搜索树,二叉搜索树啊,这是有序的啊。
那么有序的元素如何求累加呢?
其实这就是一棵树,大家可能看起来有点别扭,换一个角度来看,这就是一个有序数组[2, 5, 13],求从后到前的累加数组,也就是[20, 18, 13],是不是感觉这就简单了。
为什么变成数组就是感觉简单了呢?
因为数组大家都知道怎么遍历啊,从后向前,挨个累加就完事了,这换成了二叉搜索树,看起来就别扭了一些是不是。
那么知道如何遍历这个二叉树,也就迎刃而解了,从树中可以看出累加的顺序是右中左,所以我们需要反中序遍历这个二叉树,然后顺序累加就可以了。
递归
遍历顺序如图所示:
本题依然需要一个pre指针记录当前遍历节点cur的前一个节点,这样才方便做累加。
pre指针的使用技巧,我们在二叉树:搜索树的最小绝对差 (opens new window)和二叉树:我的众数是多少? (opens new window)都提到了,这是常用的操作手段。
- 递归函数参数以及返回值
这里很明确了,不需要递归函数的返回值做什么操作了,要遍历整棵树。
同时需要定义一个全局变量pre,用来保存cur节点的前一个节点的数值,定义为int型就可以了。
代码如下:
int pre = 0; // 记录前一个节点的数值
void traversal(TreeNode* cur)
- 确定终止条件
遇空就终止。
if (cur == NULL) return;
- 确定单层递归的逻辑
注意要右中左来遍历二叉树, 中节点的处理逻辑就是让cur的数值加上前一个节点的数值。
代码如下:
traversal(cur->right); // 右
cur->val += pre; // 中
pre = cur->val;
traversal(cur->left); // 左
迭代法
迭代法其实就是中序模板题了,在二叉树:前中后序迭代法 (opens new window)和二叉树:前中后序统一方式迭代法 (opens new window)可以选一种自己习惯的写法。
C++解法
递归法整体代码如下:
class Solution {
private:
int pre = 0; // 记录前一个节点的数值
void traversal(TreeNode* cur) { // 右中左遍历
if (cur == NULL) return;
traversal(cur->right);
cur->val += pre;
pre = cur->val;
traversal(cur->left);
}
public:
TreeNode* convertBST(TreeNode* root) {
pre = 0;
traversal(root);
return root;
}
};
迭代法的一种代码如下:
class Solution {
private:
int pre; // 记录前一个节点的数值
void traversal(TreeNode* root) {
stack<TreeNode*> st;
TreeNode* cur = root;
while (cur != NULL || !st.empty()) {
if (cur != NULL) {
st.push(cur);
cur = cur->right; // 右
} else {
cur = st.top(); // 中
st.pop();
cur->val += pre;
pre = cur->val;
cur = cur->left; // 左
}
}
}
public:
TreeNode* convertBST(TreeNode* root) {
pre = 0;
traversal(root);
return root;
}
};
Java解法
递归法
class Solution {
int sum;
public TreeNode convertBST(TreeNode root) {
sum = 0;
convertBST1(root);
return root;
}
// 按右中左顺序遍历,累加即可
public void convertBST1(TreeNode root) {
if (root == null) {
return;
}
convertBST1(root.right);
sum += root.val;
root.val = sum;
convertBST1(root.left);
}
}
Python3解法
迭代法(版本一)
class Solution:
def __init__(self):
self.pre = 0 # 记录前一个节点的数值
def traversal(self, root):
stack = []
cur = root
while cur or stack:
if cur:
stack.append(cur)
cur = cur.right # 右
else:
cur = stack.pop() # 中
cur.val += self.pre
self.pre = cur.val
cur = cur.left # 左
def convertBST(self, root):
self.pre = 0
self.traversal(root)
return root
Go解法
弄一个sum暂存其和值
var pre int
func convertBST(root *TreeNode) *TreeNode {
pre = 0
traversal(root)
return root
}
func traversal(cur *TreeNode) {
if cur == nil {
return
}
traversal(cur.Right)
cur.Val += pre
pre = cur.Val
traversal(cur.Left)
}
1038. Binary Search Tree to Greater Sum Tree(同上)
Given the root of a Binary Search Tree (BST), convert it to a Greater Tree such that every key of the original BST is changed to the original key plus the sum of all keys greater than the original key in BST.
As a reminder, a binary search tree is a tree that satisfies these constraints:
- The left subtree of a node contains only nodes with keys less than the node's key.
- The right subtree of a node contains only nodes with keys greater than the node's key.
- Both the left and right subtrees must also be binary search trees.
Example 1:
Input: root = [4,1,6,0,2,5,7,null,null,null,3,null,null,null,8]
Output: [30,36,21,36,35,26,15,null,null,null,33,null,null,null,8]
Example 2:
Input: root = [0,null,1]
Output: [1,null,1]
Constraints:
- The number of nodes in the tree is in the range
[0, 10^4]. -10^4 <= Node.val <= 10^4- All the values in the tree are unique.
rootis guaranteed to be a valid binary search tree.
Note: This question is the same as 538: https://leetcode.com/problems/convert-bst-to-greater-tree/
公共祖先
N叉树基本操作
- 589. N-ary Tree Preorder Traversal
- 590. N-ary Tree Postorder Traversal
- 429. N-ary Tree Level Order Traversal
- 310. Minimum Height Trees
589. N-ary Tree Preorder Traversal
Given the root of an n-ary tree, return the preorder traversal of its nodes' values.
Nary-Tree input serialization is represented in their level order traversal. Each group of children is separated by the null value (See examples)
Example 1:
Input: root = [1,null,3,2,4,null,5,6]
Output: [1,3,5,6,2,4]
Example 2:
Input: root = [1,null,2,3,4,5,null,null,6,7,null,8,null,9,10,null,null,11,null,12,null,13,null,null,14]
Output: [1,2,3,6,7,11,14,4,8,12,5,9,13,10]
Constraints:
- The number of nodes in the tree is in the range
[0, 10^4]. 0 <= Node.val <= 10^4- The height of the n-ary tree is less than or equal to
1000.
Follow up: Recursive solution is trivial, could you do it iteratively?
思路
递归或迭代求解
C++解法
递归法完整代码如下所示:
/*
// Definition for a Node.
class Node {
public:
int val;
vector<Node*> children;
Node() {}
Node(int _val) {
val = _val;
}
Node(int _val, vector<Node*> _children) {
val = _val;
children = _children;
}
};
*/
class Solution {
public:
void traversal(Node* root, vector<int>& result){
if(root == NULL){
return;
}
result.push_back(root->val);
for(Node* child : root->children){
traversal(child, result);
}
}
vector<int> preorder(Node* root) {
vector<int> result;
traversal(root, result);
return result;
}
};
迭代法完整代码如下所示:
/*
// Definition for a Node.
class Node {
public:
int val;
vector<Node*> children;
Node() {}
Node(int _val) {
val = _val;
}
Node(int _val, vector<Node*> _children) {
val = _val;
children = _children;
}
};
*/
class Solution {
public:
vector<int> preorder(Node* root) {
vector<int> result;
if(root == NULL) return result;
stack<Node*> st;
st.push(root);
while(!st.empty()){
Node* node = st.top();
st.pop();
result.push_back(node->val);
int size = node->children.size();
for(int i = size - 1; i >= 0; i--){
st.push(node->children[i]);
}
}
return result;
}
};
590. N-ary Tree Postorder Traversal
Given the root of an n-ary tree, return the postorder traversal of its nodes' values.
Nary-Tree input serialization is represented in their level order traversal. Each group of children is separated by the null value (See examples)
Example 1:
Input: root = [1,null,3,2,4,null,5,6]
Output: [5,6,3,2,4,1]
Example 2:
Input: root = [1,null,2,3,4,5,null,null,6,7,null,8,null,9,10,null,null,11,null,12,null,13,null,null,14]
Output: [2,6,14,11,7,3,12,8,4,13,9,10,5,1]
Constraints:
- The number of nodes in the tree is in the range
[0, 10^4]. 0 <= Node.val <= 10^4- The height of the n-ary tree is less than or equal to
1000.
Follow up: Recursive solution is trivial, could you do it iteratively?
思路
递归或迭代
C++解法
递归法完整代码如下所示:
/*
// Definition for a Node.
class Node {
public:
int val;
vector<Node*> children;
Node() {}
Node(int _val) {
val = _val;
}
Node(int _val, vector<Node*> _children) {
val = _val;
children = _children;
}
};
*/
class Solution {
public:
void traversal(Node* root, vector<int>& result){
if(root == NULL){
return;
}
for(Node* child : root->children){
traversal(child, result);
}
result.push_back(root->val);
}
vector<int> postorder(Node* root) {
vector<int> result;
traversal(root, result);
return result;
}
};
迭代法完整代码如下所示:
/*
// Definition for a Node.
class Node {
public:
int val;
vector<Node*> children;
Node() {}
Node(int _val) {
val = _val;
}
Node(int _val, vector<Node*> _children) {
val = _val;
children = _children;
}
};
*/
class Solution {
public:
vector<int> postorder(Node* root) {
vector<int> result;
if(root == NULL) return result;
stack<Node*> st;
st.push(root);
while(!st.empty()){
Node* node = st.top();
st.pop();
int size = node->children.size();
for(int i = 0; i < size; i++){
st.push(node->children[i]);
}
result.push_back(node->val);
}
reverse(result.begin(), result.end());
return result;
}
};
429. N-ary Tree Level Order Traversal
Given an n-ary tree, return the level order traversal of its nodes' values.
Nary-Tree input serialization is represented in their level order traversal, each group of children is separated by the null value (See examples).
Example 1:
Input: root = [1,null,3,2,4,null,5,6]
Output: [[1],[3,2,4],[5,6]]
Example 2:
Input: root = [1,null,2,3,4,5,null,null,6,7,null,8,null,9,10,null,null,11,null,12,null,13,null,null,14]
Output: [[1],[2,3,4,5],[6,7,8,9,10],[11,12,13],[14]]
Constraints:
- The height of the n-ary tree is less than or equal to
1000 - The total number of nodes is between
[0, 10^4]
思路
改写层序遍历代码即可
C++解法
/*
// Definition for a Node.
class Node {
public:
int val;
vector<Node*> children;
Node() {}
Node(int _val) {
val = _val;
}
Node(int _val, vector<Node*> _children) {
val = _val;
children = _children;
}
};
*/
class Solution {
public:
vector<vector<int>> levelOrder(Node* root) {
vector<vector<int>> result;
queue<Node*> que;
if(root == NULL) return result;
que.push(root);
while(!que.empty()){
vector<int> nums;
int size = que.size();
for(int i = 0; i < size; i++){
Node* cur = que.front();
que.pop();
nums.push_back(cur->val);
for(Node* node : cur->children){
que.push(node);
}
}
result.push_back(nums);
}
return result;
}
};
310. Minimum Height Trees
A tree is an undirected graph in which any two vertices are connected by exactly one path. In other words, any connected graph without simple cycles is a tree.
Given a tree of n nodes labelled from 0 to n - 1, and an array of n - 1 edges where edges[i] = [ai, bi] indicates that there is an undirected edge between the two nodes ai and bi in the tree, you can choose any node of the tree as the root. When you select a node x as the root, the result tree has height h. Among all possible rooted trees, those with minimum height (i.e. min(h)) are called minimum height trees (MHTs).
Return a list of all MHTs' root labels. You can return the answer in any order.
The height of a rooted tree is the number of edges on the longest downward path between the root and a leaf.
Example 1:
Input: n = 4, edges = [[1,0],[1,2],[1,3]]
Output: [1]
Explanation: As shown, the height of the tree is 1 when the root is the node with label 1 which is the only MHT.
Example 2:
Input: n = 6, edges = [[3,0],[3,1],[3,2],[3,4],[5,4]]
Output: [3,4]
Constraints:
1 <= n <= 2 * 10^4edges.length == n - 10 <= ai, bi < nai != bi- All the pairs
(ai, bi)are distinct. - The given input is guaranteed to be a tree and there will be no repeated edges.
思路
C++解法
class Solution {
public:
vector<int> findMinHeightTrees(int n, vector<vector<int>>& edges) {
if (n == 1) return {0};
std::vector<std::list<int>> adjacency_list(n);
std::vector<int> degree(n, 0);
for (auto& edge : edges) {
int u = edge[0], v = edge[1];
adjacency_list[u].push_back(v);
adjacency_list[v].push_back(u);
degree[u]++;
degree[v]++;
}
std::queue<int> leaves;
for (int i = 0; i < n; ++i) {
if (degree[i] == 1) leaves.push(i);
}
int remainingNodes = n;
while (remainingNodes > 2) {
int leavesCount = leaves.size();
remainingNodes -= leavesCount;
for (int i = 0; i < leavesCount; ++i) {
int leaf = leaves.front();
leaves.pop();
for (int neighbor : adjacency_list[leaf]) {
if (--degree[neighbor] == 1) {
leaves.push(neighbor);
}
}
}
}
std::vector<int> result;
while (!leaves.empty()) {
result.push_back(leaves.front());
leaves.pop();
}
return result;
}
};
Java解法
class Solution {
public List<Integer> findMinHeightTrees(int n, int[][] edges) {
if (n == 1) return Collections.singletonList(0);
int[] degree = new int[n];
Map<Integer, List<Integer>> adjacencyList = new HashMap<>();
for (int[] edge : edges) {
degree[edge[0]]++;
degree[edge[1]]++;
adjacencyList.computeIfAbsent(edge[0], x -> new ArrayList<>()).add(edge[1]);
adjacencyList.computeIfAbsent(edge[1], x -> new ArrayList<>()).add(edge[0]);
}
Queue<Integer> leaves = new LinkedList<>();
for (int i = 0; i < degree.length; i++) {
if (degree[i] == 1) {
leaves.add(i);
}
}
int remainingNodes = n;
while (remainingNodes > 2) {
int size = leaves.size();
remainingNodes -= size;
for (int i = 0; i < size; i++) {
int leaf = leaves.poll();
for (int neighbor : adjacencyList.get(leaf)) {
if (--degree[neighbor] == 1) {
leaves.add(neighbor);
}
}
}
}
return new ArrayList<>(leaves);
}
}
Python3解法
class Solution:
def findMinHeightTrees(self, n: int, edges: List[List[int]]) -> List[int]:
if n == 1:
return [0]
# Initialize the adjacency list and degree of each node
adjacency_list = defaultdict(list)
degree = [0] * n
for u, v in edges:
adjacency_list[u].append(v)
adjacency_list[v].append(u)
degree[u] += 1
degree[v] += 1
# Initialize leaves queue
leaves = deque([i for i in range(n) if degree[i] == 1])
# Trim leaves until 2 or fewer nodes remain
remaining_nodes = n
while remaining_nodes > 2:
leaves_count = len(leaves)
remaining_nodes -= leaves_count
for _ in range(leaves_count):
leaf = leaves.popleft()
for neighbor in adjacency_list[leaf]:
degree[neighbor] -= 1
if degree[neighbor] == 1:
leaves.append(neighbor)
return list(leaves)
回溯算法
理论基础
什么是回溯法
回溯法也可以叫做回溯搜索法,它是一种搜索的方式。
在二叉树系列中,我们已经不止一次,提到了回溯,例如二叉树:以为使用了递归,其实还隐藏着回溯。
回溯是递归的副产品,只要有递归就会有回溯。
所以以下讲解中,回溯函数也就是递归函数,指的都是一个函数。
回溯法的效率
回溯法的性能如何呢,这里要和大家说清楚了,虽然回溯法很难,很不好理解,但是回溯法并不是什么高效的算法。
因为回溯的本质是穷举,穷举所有可能,然后选出我们想要的答案,如果想让回溯法高效一些,可以加一些剪枝的操作,但也改不了回溯法就是穷举的本质。
那么既然回溯法并不高效为什么还要用它呢?
因为没得选,一些问题能暴力搜出来就不错了,撑死了再剪枝一下,还没有更高效的解法。
此时大家应该好奇了,都什么问题,这么牛逼,只能暴力搜索。
回溯法解决的问题
回溯法,一般可以解决如下几种问题:
- 组合问题:N个数里面按一定规则找出k个数的集合
- 切割问题:一个字符串按一定规则有几种切割方式
- 子集问题:一个N个数的集合里有多少符合条件的子集
- 排列问题:N个数按一定规则全排列,有几种排列方式
- 棋盘问题:N皇后,解数独等等
相信大家看着这些之后会发现,每个问题,都不简单!
另外,会有一些同学可能分不清什么是组合,什么是排列?
组合是不强调元素顺序的,排列是强调元素顺序。
例如:{1, 2} 和 {2, 1} 在组合上,就是一个集合,因为不强调顺序,而要是排列的话,{1, 2} 和 {2, 1} 就是两个集合了。
记住组合无序,排列有序,就可以了。
如何理解回溯法
回溯法解决的问题都可以抽象为树形结构,是的,我指的是所有回溯法的问题都可以抽象为树形结构!
因为回溯法解决的都是在集合中递归查找子集,集合的大小就构成了树的宽度,递归的深度就构成了树的深度。
递归就要有终止条件,所以必然是一棵高度有限的树(N叉树)。
这块可能初学者还不太理解,后面的回溯算法解决的所有题目中,我都会强调这一点并画图举相应的例子,现在有一个印象就行。
回溯法模板
这里给出Carl总结的回溯算法模板。
在讲二叉树的递归中我们说了递归三部曲,这里我再给大家列出回溯三部曲。
- 回溯函数模板返回值以及参数
在回溯算法中,我的习惯是函数起名字为backtracking,这个起名大家随意。
回溯算法中函数返回值一般为void。
再来看一下参数,因为回溯算法需要的参数可不像二叉树递归的时候那么容易一次性确定下来,所以一般是先写逻辑,然后需要什么参数,就填什么参数。
但后面的回溯题目的讲解中,为了方便大家理解,我在一开始就帮大家把参数确定下来。
回溯函数伪代码如下:
void backtracking(参数)
- 回溯函数终止条件
既然是树形结构,那么我们在讲解二叉树的递归的时候,就知道遍历树形结构一定要有终止条件。
所以回溯也有要终止条件。
什么时候达到了终止条件,树中就可以看出,一般来说搜到叶子节点了,也就找到了满足条件的一条答案,把这个答案存放起来,并结束本层递归。
所以回溯函数终止条件伪代码如下:
if (终止条件) {
存放结果;
return;
}
- 回溯搜索的遍历过程
在上面我们提到了,回溯法一般是在集合中递归搜索,集合的大小构成了树的宽度,递归的深度构成的树的深度。
如图:
注意图中,我特意举例集合大小和孩子的数量是相等的!
回溯函数遍历过程伪代码如下:
for (选择:本层集合中元素(树中节点孩子的数量就是集合的大小)) {
处理节点;
backtracking(路径,选择列表); // 递归
回溯,撤销处理结果
}
for循环就是遍历集合区间,可以理解一个节点有多少个孩子,这个for循环就执行多少次。
backtracking这里自己调用自己,实现递归。
大家可以从图中看出for循环可以理解是横向遍历,backtracking(递归)就是纵向遍历,这样就把这棵树全遍历完了,一般来说,搜索叶子节点就是找的其中一个结果了。
分析完过程,回溯算法模板框架如下:
void backtracking(参数) {
if (终止条件) {
存放结果;
return;
}
for (选择:本层集合中元素(树中节点孩子的数量就是集合的大小)) {
处理节点;
backtracking(路径,选择列表); // 递归
回溯,撤销处理结果
}
}
这份模板很重要,后面做回溯法的题目都靠它了!
如果从来没有学过回溯算法的录友们,看到这里会有点懵,后面开始讲解具体题目的时候就会好一些了,已经做过回溯法题目的录友,看到这里应该会感同身受了。
总结
本篇我们讲解了,什么是回溯算法,知道了回溯和递归是相辅相成的。
接着提到了回溯法的效率,回溯法其实就是暴力查找,并不是什么高效的算法。
然后列出了回溯法可以解决几类问题,可以看出每一类问题都不简单。
最后我们讲到回溯法解决的问题都可以抽象为树形结构(N叉树),并给出了回溯法的模板。
组合
- 77. Combinations
- 216. Combination Sum III
- 17. Letter Combinations of a Phone Number
- 39. Combination Sum
- 40. Combination Sum II
77. Combinations
Given two integers n and k, return all possible combinations of k numbers chosen from the range [1, n].
You may return the answer in any order.
Example 1:
Input: n = 4, k = 2
Output: [[1,2],[1,3],[1,4],[2,3],[2,4],[3,4]]
Explanation: There are 4 choose 2 = 6 total combinations.
Note that combinations are unordered, i.e., [1,2] and [2,1] are considered to be the same combination.
Example 2:
Input: n = 1, k = 1
Output: [[1]]
Explanation: There is 1 choose 1 = 1 total combination.
Constraints:
1 <= n <= 201 <= k <= n
思路
通过path的大小控制递归深度。
本题是回溯法的经典题目。
直接的解法当然是使用for循环,例如示例中k为2,很容易想到 用两个for循环,这样就可以输出和示例中一样的结果。
如果n为100,k为50呢,那就50层for循环,是不是开始窒息。
此时就会发现虽然想暴力搜索,但是用for循环嵌套连暴力都写不出来!
咋整?
回溯搜索法来了,虽然回溯法也是暴力,但至少能写出来,不像for循环嵌套k层让人绝望。
那么回溯法怎么暴力搜呢?
上面我们说了要解决 n为100,k为50的情况,暴力写法需要嵌套50层for循环,那么回溯法就用递归来解决嵌套层数的问题。
递归来做层叠嵌套(可以理解是开k层for循环),每一次的递归中嵌套一个for循环,那么递归就可以用于解决多层嵌套循环的问题了。
此时递归的层数大家应该知道了,例如:n为100,k为50的情况下,就是递归50层。
一些同学本来对递归就懵,回溯法中递归还要嵌套for循环,可能就直接晕倒了!
如果脑洞模拟回溯搜索的过程,绝对可以让人窒息,所以需要抽象图形结构来进一步理解。
我们在关于回溯算法,你该了解这些!中说到回溯法解决的问题都可以抽象为树形结构(N叉树),用树形结构来理解回溯就容易多了。
那么我把组合问题抽象为如下树形结构:
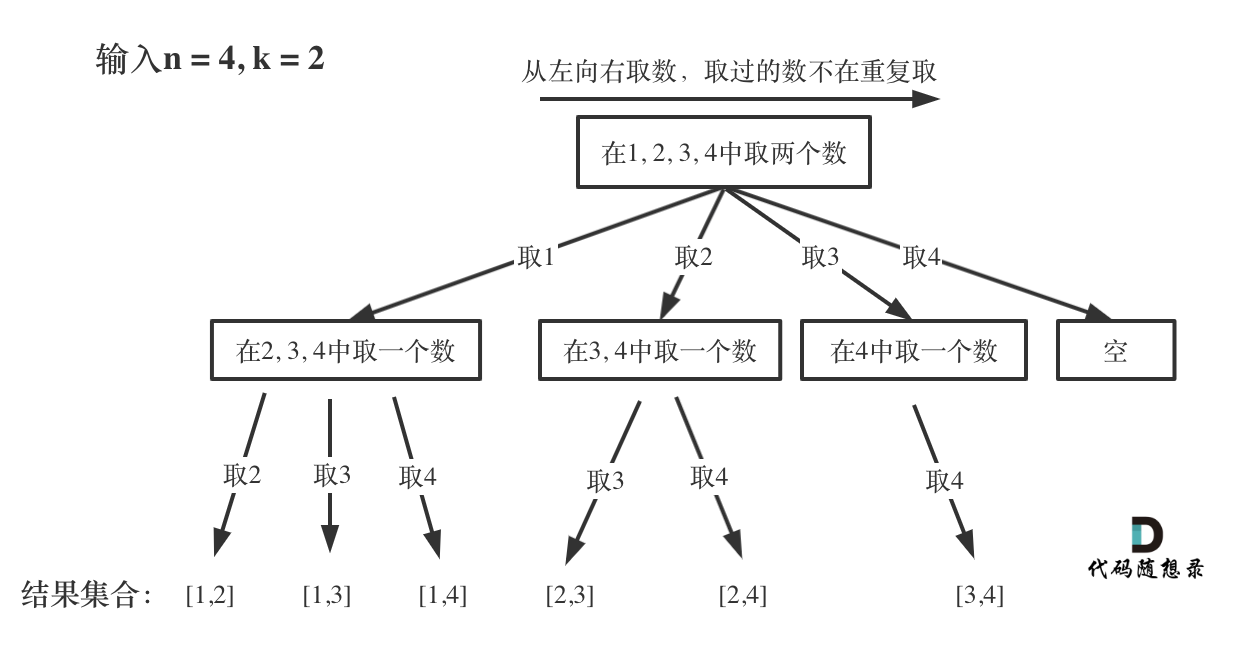
可以看出这棵树,一开始集合是 1,2,3,4, 从左向右取数,取过的数,不再重复取。
第一次取1,集合变为2,3,4 ,因为k为2,我们只需要再取一个数就可以了,分别取2,3,4,得到集合[1,2] [1,3] [1,4],以此类推。
每次从集合中选取元素,可选择的范围随着选择的进行而收缩,调整可选择的范围。
图中可以发现n相当于树的宽度,k相当于树的深度。
那么如何在这个树上遍历,然后收集到我们要的结果集呢?
图中每次搜索到了叶子节点,我们就找到了一个结果。
相当于只需要把达到叶子节点的结果收集起来,就可以求得 n个数中k个数的组合集合。
在关于回溯算法,你该了解这些!中我们提到了回溯法三部曲,那么我们按照回溯法三部曲开始正式讲解代码了。
- 递归函数的返回值以及参数
在这里要定义两个全局变量,一个用来存放符合条件单一结果,一个用来存放符合条件结果的集合。
代码如下:
vector<vector<int>> result; // 存放符合条件结果的集合
vector<int> path; // 用来存放符合条件结果
其实不定义这两个全局变量也是可以的,把这两个变量放进递归函数的参数里,但函数里参数太多影响可读性,所以我定义全局变量了。
函数里一定有两个参数,既然是集合n里面取k个数,那么n和k是两个int型的参数。
然后还需要一个参数,为int型变量startIndex,这个参数用来记录本层递归的中,集合从哪里开始遍历(集合就是[1,...,n] )。
为什么要有这个startIndex呢?
建议在77.组合视频讲解中,07:36的时候开始听,startIndex 就是防止出现重复的组合。
从下图中红线部分可以看出,在集合[1,2,3,4]取1之后,下一层递归,就要在[2,3,4]中取数了,那么下一层递归如何知道从[2,3,4]中取数呢,靠的就是startIndex。
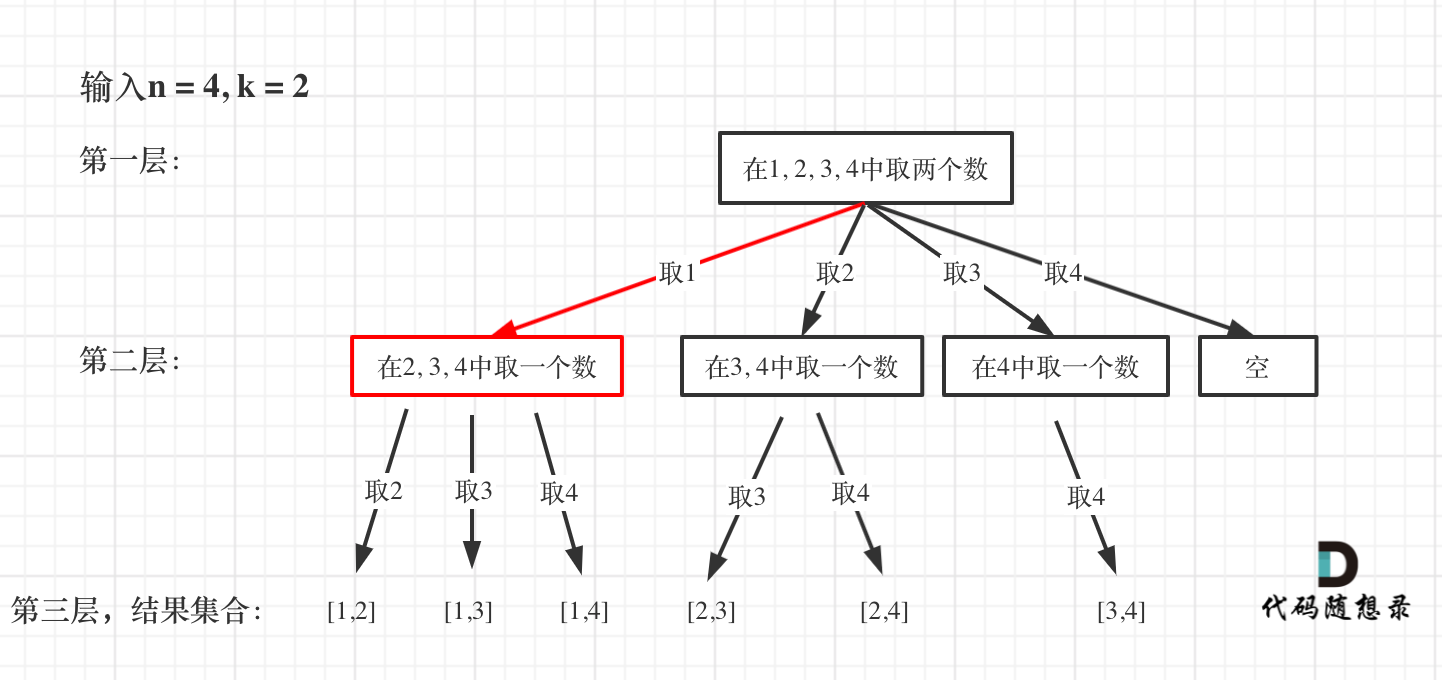
所以需要startIndex来记录下一层递归,搜索的起始位置。
那么整体代码如下:
vector<vector<int>> result; // 存放符合条件结果的集合
vector<int> path; // 用来存放符合条件单一结果
void backtracking(int n, int k, int startIndex)
- 回溯函数终止条件
什么时候到达所谓的叶子节点了呢?
path这个数组的大小如果达到k,说明我们找到了一个子集大小为k的组合了,在图中path存的就是根节点到叶子节点的路径。
如图红色部分:
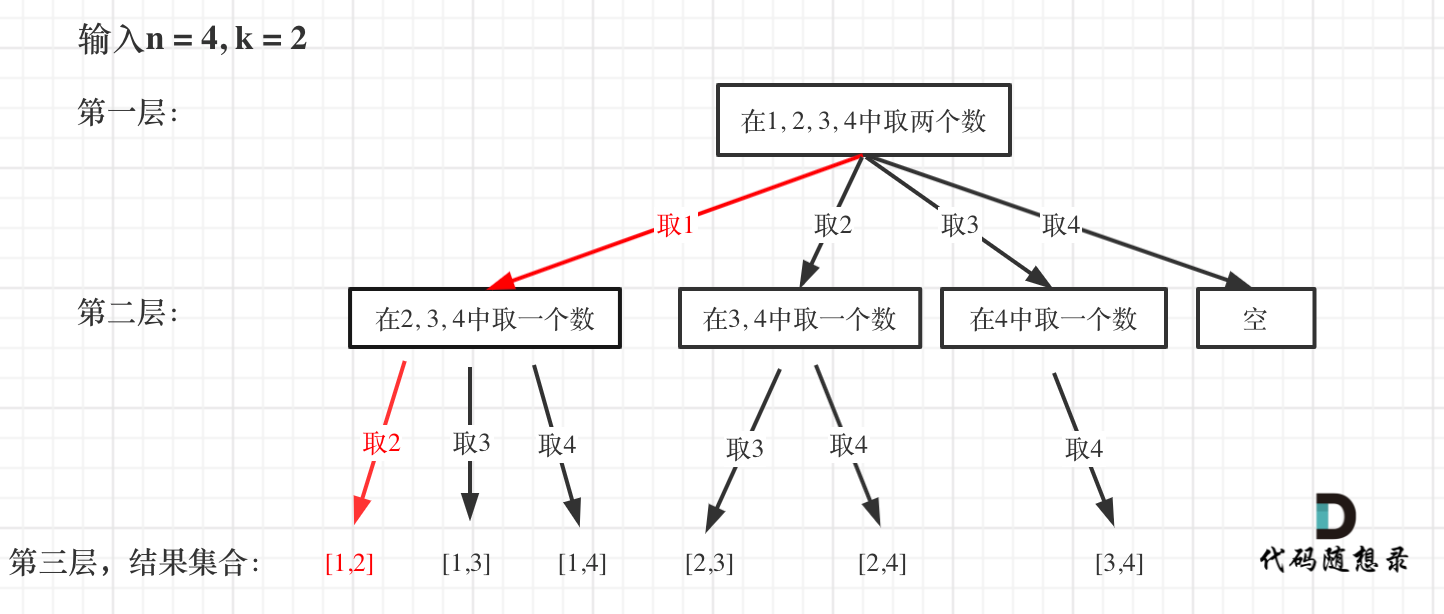
此时用result二维数组,把path保存起来,并终止本层递归。
所以终止条件代码如下:
if (path.size() == k) {
result.push_back(path);
return;
}
- 单层搜索的过程
回溯法的搜索过程就是一个树型结构的遍历过程,在如下图中,可以看出for循环用来横向遍历,递归的过程是纵向遍历。
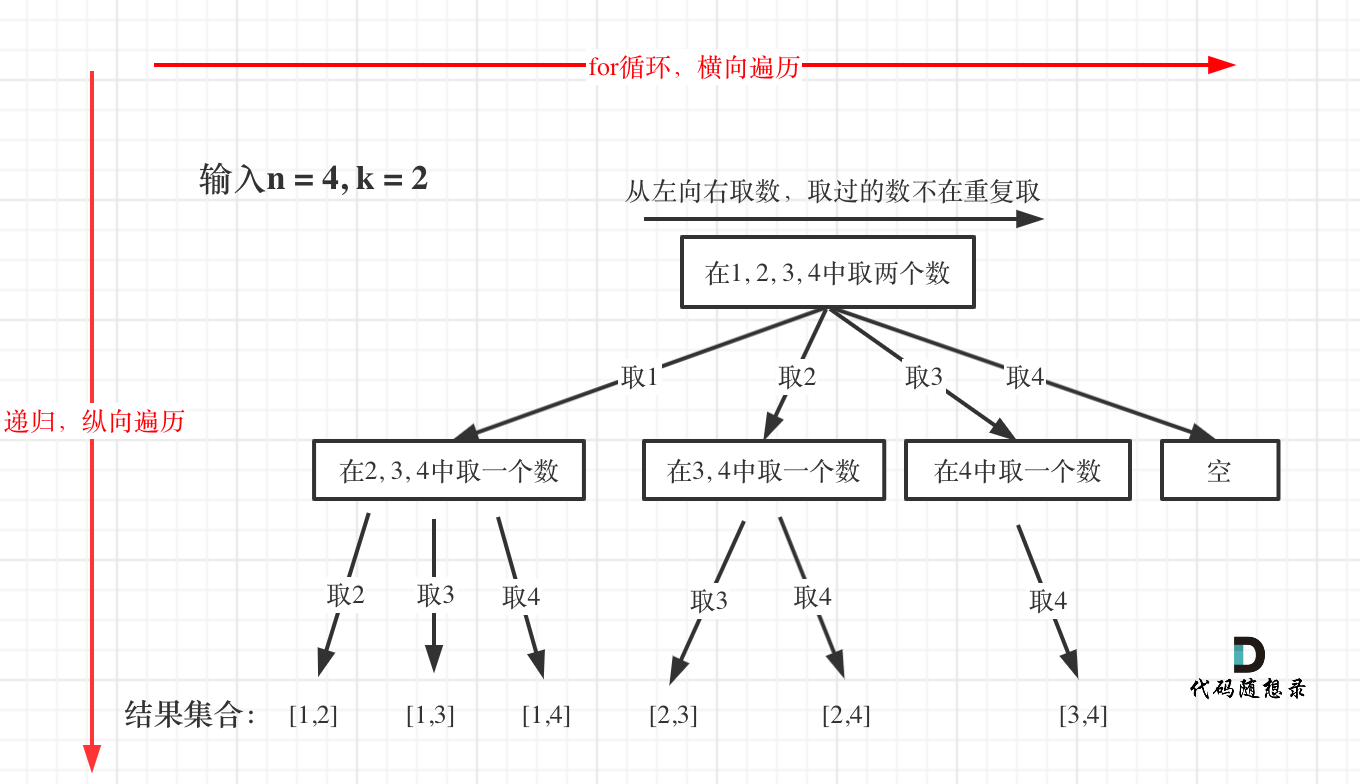
如此我们才遍历完图中的这棵树。
for循环每次从startIndex开始遍历,然后用path保存取到的节点i。
代码如下:
for (int i = startIndex; i <= n; i++) { // 控制树的横向遍历
path.push_back(i); // 处理节点
backtracking(n, k, i + 1); // 递归:控制树的纵向遍历,注意下一层搜索要从i+1开始
path.pop_back(); // 回溯,撤销处理的节点
}
可以看出backtracking(递归函数)通过不断调用自己一直往深处遍历,总会遇到叶子节点,遇到了叶子节点就要返回。
backtracking的下面部分就是回溯的操作了,撤销本次处理的结果。
C++解法
class Solution {
private:
vector<vector<int>> result; // 存放符合条件结果的集合
vector<int> path; // 用来存放符合条件结果
void backtracking(int n, int k, int startIndex) {
if (path.size() == k) {
result.push_back(path);
return;
}
for (int i = startIndex; i <= n; i++) {
path.push_back(i); // 处理节点
backtracking(n, k, i + 1); // 递归
path.pop_back(); // 回溯,撤销处理的节点
}
}
public:
vector<vector<int>> combine(int n, int k) {
result.clear(); // 可以不写
path.clear(); // 可以不写
backtracking(n, k, 1);
return result;
}
};
- 时间复杂度: O(n * 2^n)
- 空间复杂度: O(n)
216. Combination Sum III
Find all valid combinations of k numbers that sum up to n such that the following conditions are true:
- Only numbers
1through9are used. - Each number is used at most once.
Return a list of all possible valid combinations. The list must not contain the same combination twice, and the combinations may be returned in any order.
Example 1:
Input: k = 3, n = 7
Output: [[1,2,4]]
Explanation:
1 + 2 + 4 = 7
There are no other valid combinations.
Example 2:
Input: k = 3, n = 9
Output: [[1,2,6],[1,3,5],[2,3,4]]
Explanation:
1 + 2 + 6 = 9
1 + 3 + 5 = 9
2 + 3 + 4 = 9
There are no other valid combinations.
Example 3:
Input: k = 4, n = 1
Output: []
Explanation: There are no valid combinations.
Using 4 different numbers in the range [1,9], the smallest sum we can get is 1+2+3+4 = 10 and since 10 > 1, there are no valid combination.
Constraints:
2 <= k <= 91 <= n <= 60
思路
本题就是在[1,2,3,4,5,6,7,8,9]这个集合中找到和为n的k个数的组合。
相对于77. 组合,无非就是多了一个限制,本题是要找到和为n的k个数的组合,而整个集合已经是固定的了[1,...,9]。
想到这一点了,做过77. 组合之后,本题是简单一些了。
本题k相当于树的深度,9(因为整个集合就是9个数)就是树的宽度。
例如 k = 2,n = 4的话,就是在集合[1,2,3,4,5,6,7,8,9]中求 k(个数) = 2, n(和) = 4的组合。
选取过程如图:
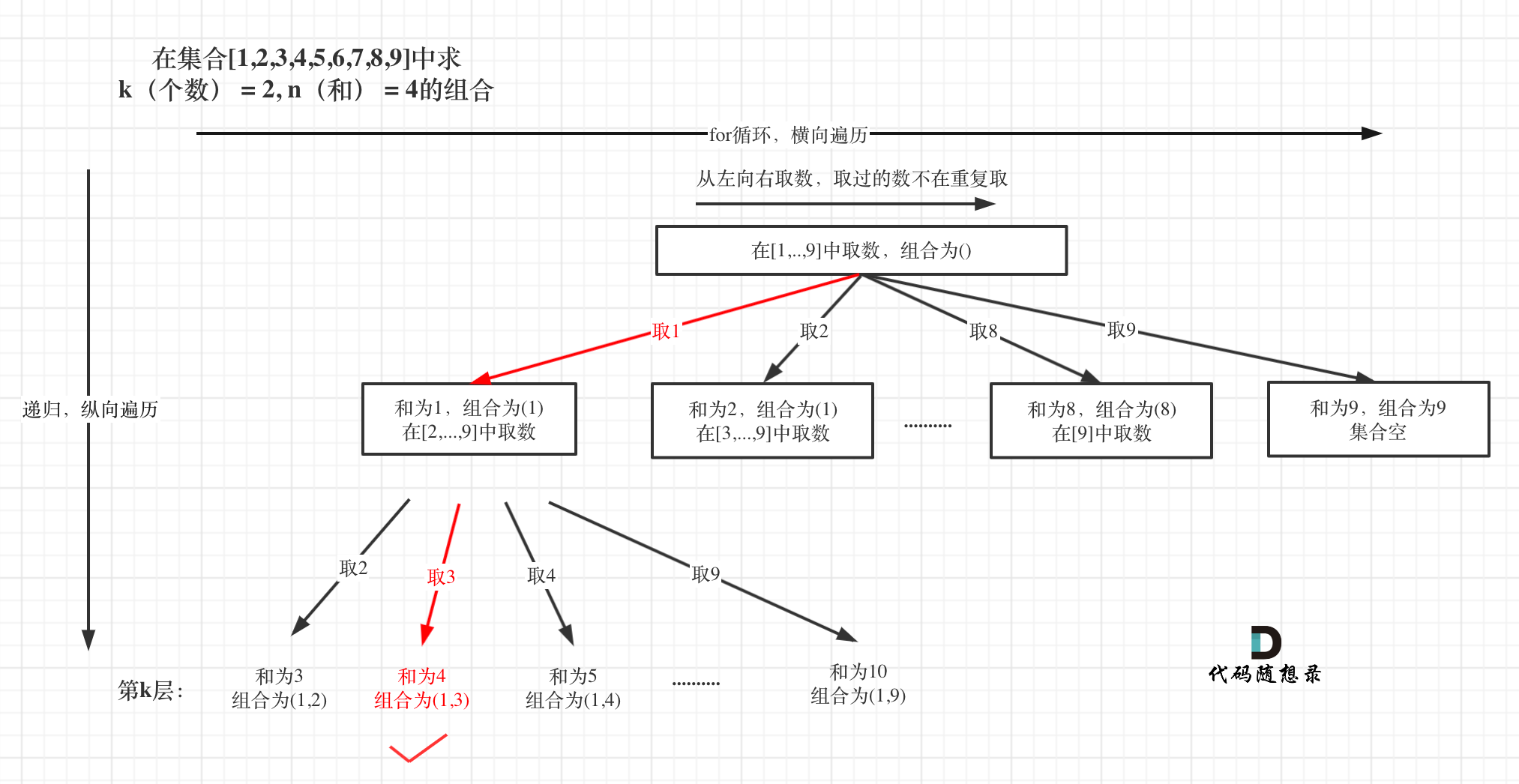
图中,可以看出,只有最后取到集合(1,3)和为4 符合条件。
- 确定递归函数参数
和77. 组合一样,依然需要一维数组path来存放符合条件的结果,二维数组result来存放结果集。
这里我依然定义path 和 result为全局变量。
至于为什么取名为path?从上面树形结构中,可以看出,结果其实就是一条根节点到叶子节点的路径。
vector<vector<int>> result; // 存放结果集
vector<int> path; // 符合条件的结果
接下来还需要如下参数:
- targetSum(int)目标和,也就是题目中的n。
- k(int)就是题目中要求k个数的集合。
- sum(int)为已经收集的元素的总和,也就是path里元素的总和。
- startIndex(int)为下一层for循环搜索的起始位置。
所以代码如下:
vector<vector<int>> result;
vector<int> path;
void backtracking(int targetSum, int k, int sum, int startIndex)
其实这里sum这个参数也可以省略,每次targetSum减去选取的元素数值,然后判断如果targetSum为0了,说明收集到符合条件的结果了,我这里为了直观便于理解,还是加一个sum参数。
还要强调一下,回溯法中递归函数参数很难一次性确定下来,一般先写逻辑,需要啥参数了,填什么参数。
- 确定终止条件
什么时候终止呢?
在上面已经说了,k其实就已经限制树的深度,因为就取k个元素,树再往下深了没有意义。
所以如果path.size() 和 k相等了,就终止。
如果此时path里收集到的元素和(sum) 和targetSum(就是题目描述的n)相同了,就用result收集当前的结果。
所以 终止代码如下:
if (path.size() == k) {
if (sum == targetSum) result.push_back(path);
return; // 如果path.size() == k 但sum != targetSum 直接返回
}
- 单层搜索过程
本题和77. 组合区别之一就是集合固定的就是9个数[1,...,9],所以for循环固定i<=9
如图: 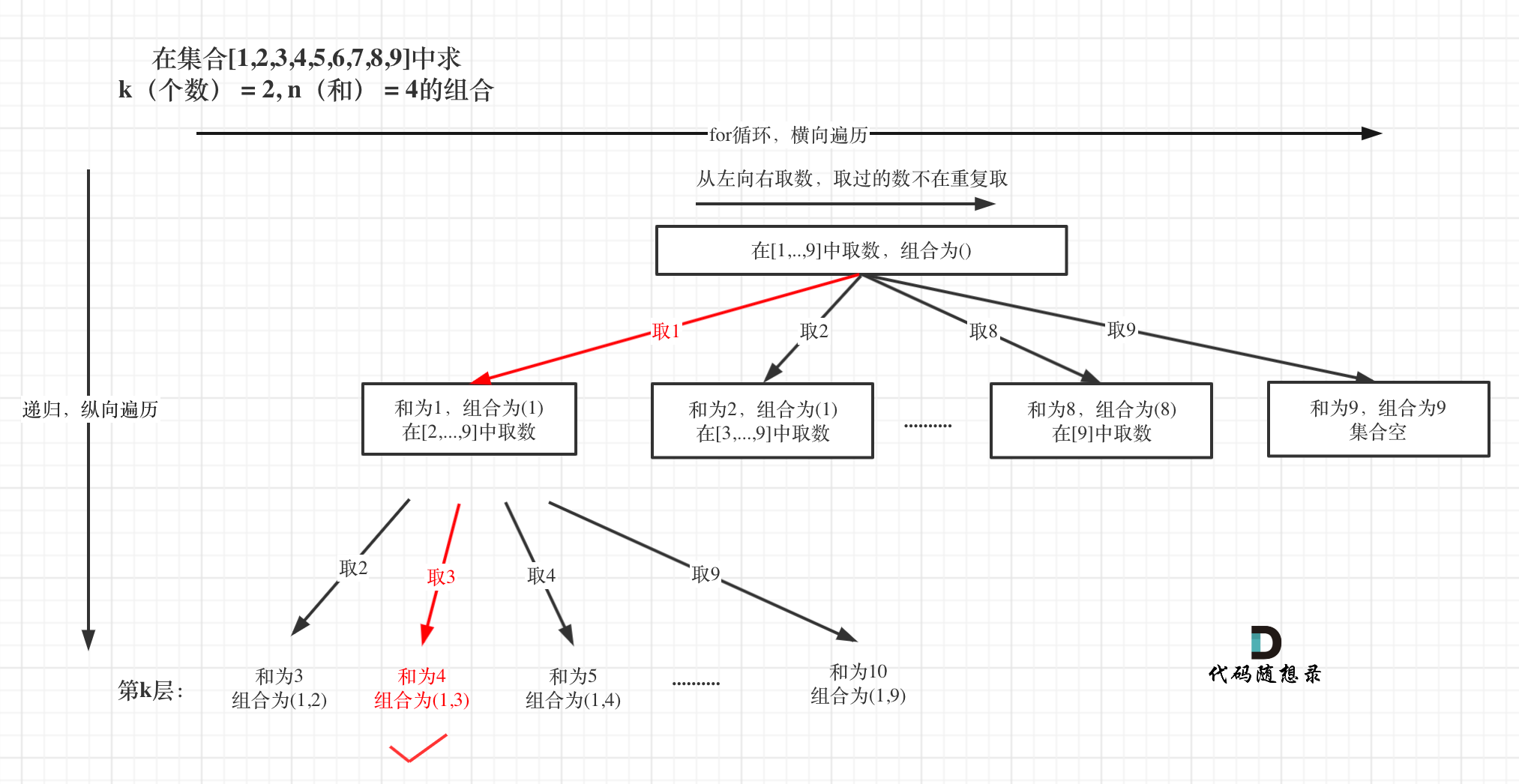
处理过程就是 path收集每次选取的元素,相当于树型结构里的边,sum来统计path里元素的总和。
代码如下:
for (int i = startIndex; i <= 9; i++) {
sum += i;
path.push_back(i);
backtracking(targetSum, k, sum, i + 1); // 注意i+1调整startIndex
sum -= i; // 回溯
path.pop_back(); // 回溯
}
别忘了处理过程 和 回溯过程是一一对应的,处理有加,回溯就要有减!
剪枝
这道题目,剪枝操作其实是很容易想到了,想必大家看上面的树形图的时候已经想到了。
如图: 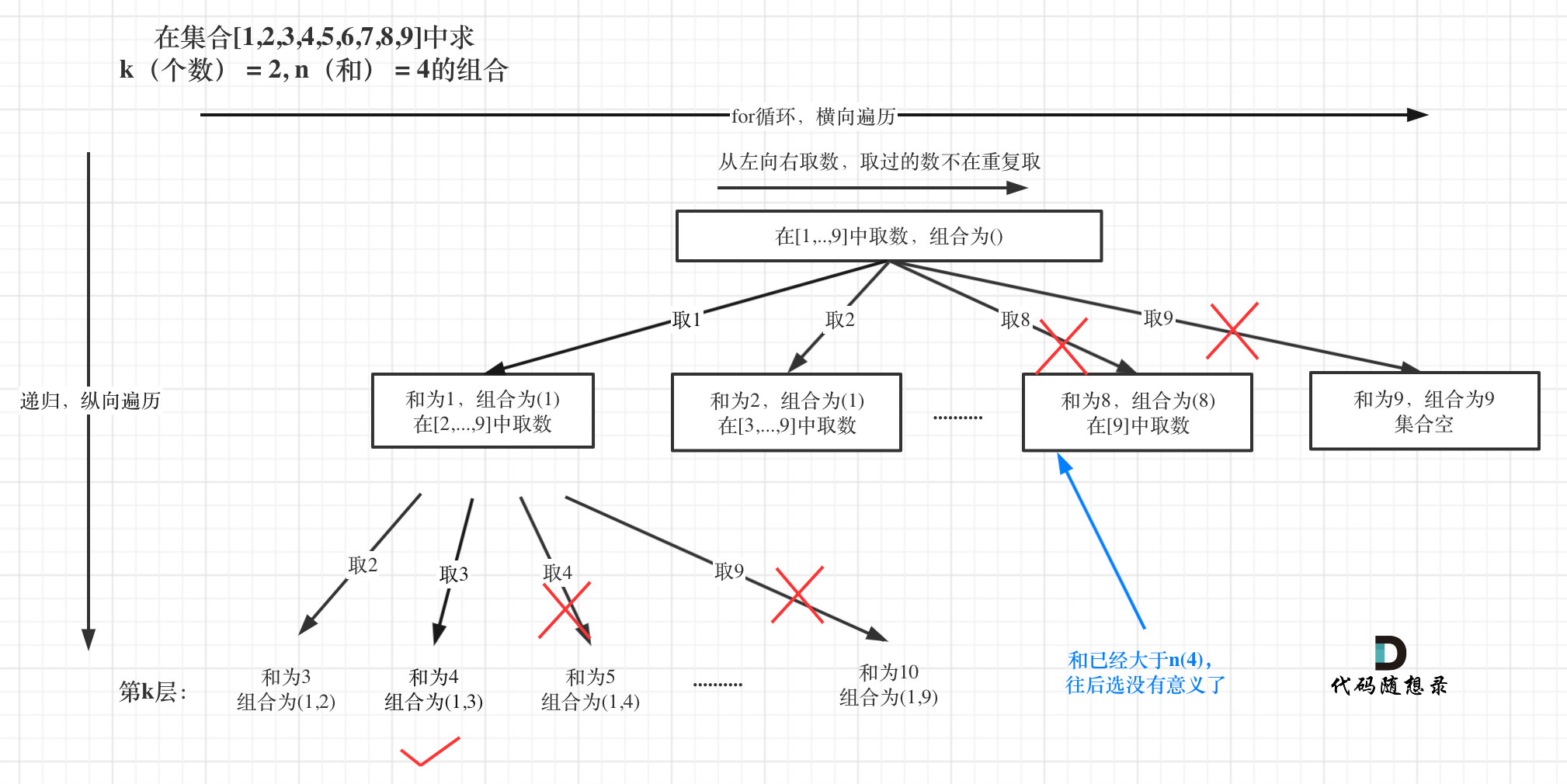
已选元素总和如果已经大于n(图中数值为4)了,那么往后遍历就没有意义了,直接剪掉。
那么剪枝的地方可以放在递归函数开始的地方,剪枝代码如下:
if (sum > targetSum) { // 剪枝操作
return;
}
当然这个剪枝也可以放在 调用递归之前,即放在这里,只不过要记得 要回溯操作给做了。
for (int i = startIndex; i <= 9 - (k - path.size()) + 1; i++) { // 剪枝
sum += i; // 处理
path.push_back(i); // 处理
if (sum > targetSum) { // 剪枝操作
sum -= i; // 剪枝之前先把回溯做了
path.pop_back(); // 剪枝之前先把回溯做了
return;
}
backtracking(targetSum, k, sum, i + 1); // 注意i+1调整startIndex
sum -= i; // 回溯
path.pop_back(); // 回溯
}
和回溯算法:组合问题再剪剪枝 一样,for循环的范围也可以剪枝,i <= 9 - (k - path.size()) + 1就可以了。
C++解法
class Solution {
private:
vector<vector<int>> result; // 存放结果集
vector<int> path; // 符合条件的结果
void backtracking(int targetSum, int k, int sum, int startIndex) {
if (sum > targetSum) { // 剪枝操作
return;
}
if (path.size() == k) {
if (sum == targetSum) result.push_back(path);
return; // 如果path.size() == k 但sum != targetSum 直接返回
}
for (int i = startIndex; i <= 9 - (k - path.size()) + 1; i++) { // 剪枝
sum += i; // 处理
path.push_back(i); // 处理
backtracking(targetSum, k, sum, i + 1); // 注意i+1调整startIndex
sum -= i; // 回溯
path.pop_back(); // 回溯
}
}
public:
vector<vector<int>> combinationSum3(int k, int n) {
result.clear(); // 可以不加
path.clear(); // 可以不加
backtracking(n, k, 0, 1);
return result;
}
};
- 时间复杂度: O(n * 2^n)
- 空间复杂度: O(n)
17. Letter Combinations of a Phone Number
Given a string containing digits from 2-9 inclusive, return all possible letter combinations that the number could represent. Return the answer in any order.
A mapping of digits to letters (just like on the telephone buttons) is given below. Note that 1 does not map to any letters.

Example 1:
Input: digits = "23"
Output: ["ad","ae","af","bd","be","bf","cd","ce","cf"]
Example 2:
Input: digits = ""
Output: []
Example 3:
Input: digits = "2"
Output: ["a","b","c"]
Constraints:
0 <= digits.length <= 4digits[i]is a digit in the range['2', '9'].
思路
不同集合,使用index,不需要使用startIndex去重。
从示例上来说,输入"23",最直接的想法就是两层for循环遍历了吧,正好把组合的情况都输出了。
如果输入"233"呢,那么就三层for循环,如果"2333"呢,就四层for循环.......
大家应该感觉出和77.组合遇到的一样的问题,就是这for循环的层数如何写出来,此时又是回溯法登场的时候了。
理解本题后,要解决如下三个问题:
- 数字和字母如何映射
- 两个字母就两个for循环,三个字符我就三个for循环,以此类推,然后发现代码根本写不出来
- 输入
1 * #按键等等异常情况
数字和字母如何映射
可以使用map或者定义一个二维数组,例如:string letterMap[10],来做映射,我这里定义一个二维数组,代码如下:
const string letterMap[10] = {
"", // 0
"", // 1
"abc", // 2
"def", // 3
"ghi", // 4
"jkl", // 5
"mno", // 6
"pqrs", // 7
"tuv", // 8
"wxyz", // 9
};
回溯法来解决n个for循环的问题
对于回溯法还不了解的同学看这篇:关于回溯算法,你该了解这些!
例如:输入:"23",抽象为树形结构,如图所示:
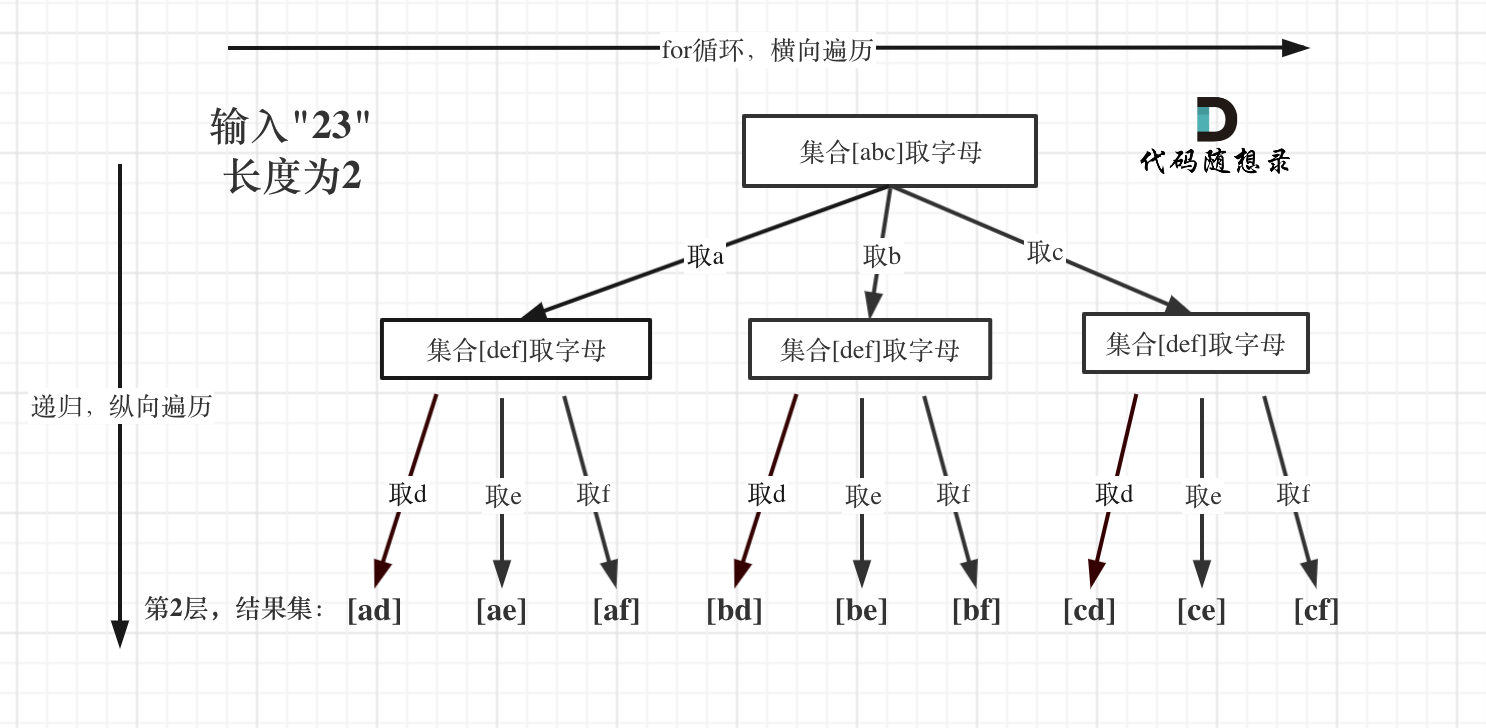
图中可以看出遍历的深度,就是输入"23"的长度,而叶子节点就是我们要收集的结果,输出["ad", "ae", "af", "bd", "be", "bf", "cd", "ce", "cf"]。
回溯三部曲:
- 确定回溯函数参数
首先需要一个字符串s来收集叶子节点的结果,然后用一个字符串数组result保存起来,这两个变量我依然定义为全局。
再来看参数,参数指定是有题目中给的string digits,然后还要有一个参数就是int型的index。
注意这个index可不是 77.组合和216.组合总和III中的startIndex了。
这个index是记录遍历第几个数字了,就是用来遍历digits的(题目中给出数字字符串),同时index也表示树的深度。
代码如下:
vector<string> result;
string s;
void backtracking(const string& digits, int index)
- 确定终止条件
例如输入用例"23",两个数字,那么根节点往下递归两层就可以了,叶子节点就是要收集的结果集。
那么终止条件就是如果index 等于 输入的数字个数(digits.size)了(本来index就是用来遍历digits的)。
然后收集结果,结束本层递归。
代码如下:
if (index == digits.size()) {
result.push_back(s);
return;
}
- 确定单层遍历逻辑
首先要取index指向的数字,并找到对应的字符集(手机键盘的字符集)。
然后for循环来处理这个字符集,代码如下:
int digit = digits[index] - '0'; // 将index指向的数字转为int
string letters = letterMap[digit]; // 取数字对应的字符集
for (int i = 0; i < letters.size(); i++) {
s.push_back(letters[i]); // 处理
backtracking(digits, index + 1); // 递归,注意index+1,一下层要处理下一个数字了
s.pop_back(); // 回溯
}
注意这里for循环,可不像是在回溯算法:求组合问题!和回溯算法:求组合总和!中从startIndex开始遍历的。
因为本题每一个数字代表的是不同集合,也就是求不同集合之间的组合,而77. 组合和216.组合总和III都是求同一个集合中的组合!
注意:输入1 * #按键等等异常情况
代码中最好考虑这些异常情况,但题目的测试数据中应该没有异常情况的数据,所以我就没有加了。
但是要知道会有这些异常,如果是现场面试中,一定要考虑到!
C++解法
// 版本一
class Solution {
private:
const string letterMap[10] = {
"", // 0
"", // 1
"abc", // 2
"def", // 3
"ghi", // 4
"jkl", // 5
"mno", // 6
"pqrs", // 7
"tuv", // 8
"wxyz", // 9
};
public:
vector<string> result;
string s;
void backtracking(const string& digits, int index) {
if (index == digits.size()) { //写成if (digits.size() == path.size())也行
result.push_back(s);
return;
}
int digit = digits[index] - '0'; // 将index指向的数字转为int
string letters = letterMap[digit]; // 取数字对应的字符集
for (int i = 0; i < letters.size(); i++) {
s.push_back(letters[i]); // 处理
backtracking(digits, index + 1); // 递归,注意index+1,一下层要处理下一个数字了
s.pop_back(); // 回溯
}
}
vector<string> letterCombinations(string digits) {
s.clear();
result.clear();
if (digits.size() == 0) {
return result;
}
backtracking(digits, 0);
return result;
}
};
- 时间复杂度: O(3^m * 4^n),其中 m 是对应四个字母的数字个数,n 是对应三个字母的数字个数
- 空间复杂度: O(3^m * 4^n)
39. Combination Sum
Given an array of distinct integers candidates and a target integer target, return a list of all unique combinations of candidates where the chosen numbers sum to target. You may return the combinations in any order.
The same number may be chosen from candidates an unlimited number of times. Two combinations are unique if the frequency of at least one of the chosen numbers is different.
The test cases are generated such that the number of unique combinations that sum up to target is less than 150 combinations for the given input.
Example 1:
Input: candidates = [2,3,6,7], target = 7
Output: [[2,2,3],[7]]
Explanation:
2 and 3 are candidates, and 2 + 2 + 3 = 7. Note that 2 can be used multiple times.
7 is a candidate, and 7 = 7.
These are the only two combinations.
Example 2:
Input: candidates = [2,3,5], target = 8
Output: [[2,2,2,2],[2,3,3],[3,5]]
Example 3:
Input: candidates = [2], target = 1
Output: []
Constraints:
1 <= candidates.length <= 302 <= candidates[i] <= 40- All elements of
candidatesare distinct. 1 <= target <= 40
思路
题目中的无限制重复被选取,吓得我赶紧想想出现0可咋办,然后看到下面提示:1 <= candidates[i] <= 200,我就放心了。
本题和77.组合,216.组合总和III的区别是:本题没有数量要求,可以无限重复,但是有总和的限制,所以间接的也是有个数的限制。
本题搜索的过程抽象成树形结构如下:
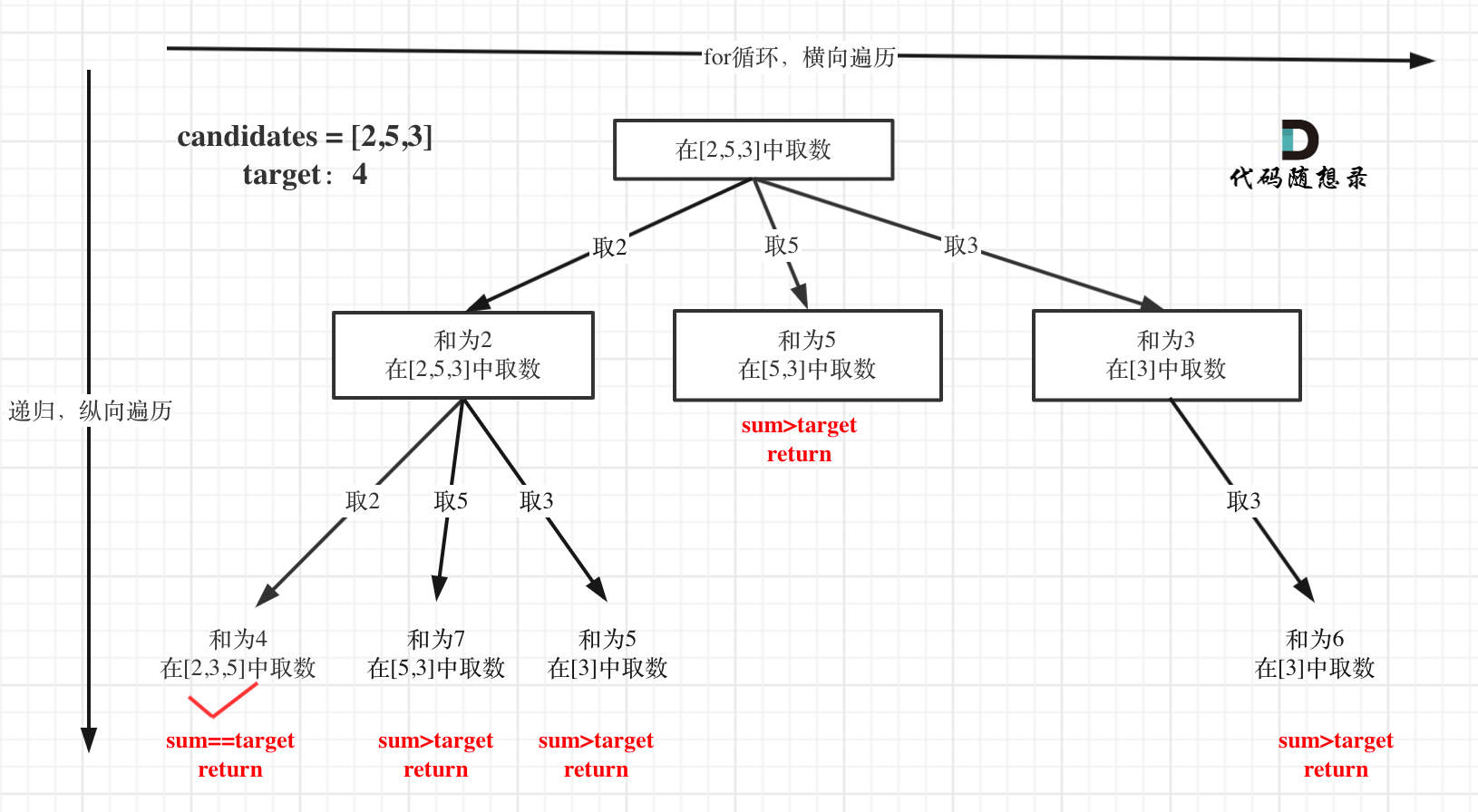 注意图中叶子节点的返回条件,因为本题没有组合数量要求,仅仅是总和的限制,所以递归没有层数的限制,只要选取的元素总和超过target,就返回!
注意图中叶子节点的返回条件,因为本题没有组合数量要求,仅仅是总和的限制,所以递归没有层数的限制,只要选取的元素总和超过target,就返回!
而在77.组合和216.组合总和III 中都可以知道要递归K层,因为要取k个元素的组合。
- 递归函数参数
这里依然是定义两个全局变量,二维数组result存放结果集,数组path存放符合条件的结果。(这两个变量可以作为函数参数传入)
首先是题目中给出的参数,集合candidates, 和目标值target。
此外我还定义了int型的sum变量来统计单一结果path里的总和,其实这个sum也可以不用,用target做相应的减法就可以了,最后如何target==0就说明找到符合的结果了,但为了代码逻辑清晰,我依然用了sum。
本题还需要startIndex来控制for循环的起始位置,对于组合问题,什么时候需要startIndex呢?
我举过例子,如果是一个集合来求组合的话,就需要startIndex,例如:77.组合,216.组合总和III。
如果是多个集合取组合,各个集合之间相互不影响,那么就不用startIndex,例如:17.电话号码的字母组合
注意以上我只是说求组合的情况,如果是排列问题,又是另一套分析的套路,后面我在讲解排列的时候会重点介绍。
代码如下:
vector<vector<int>> result;
vector<int> path;
void backtracking(vector<int>& candidates, int target, int sum, int startIndex)
- 递归终止条件
在如下树形结构中:
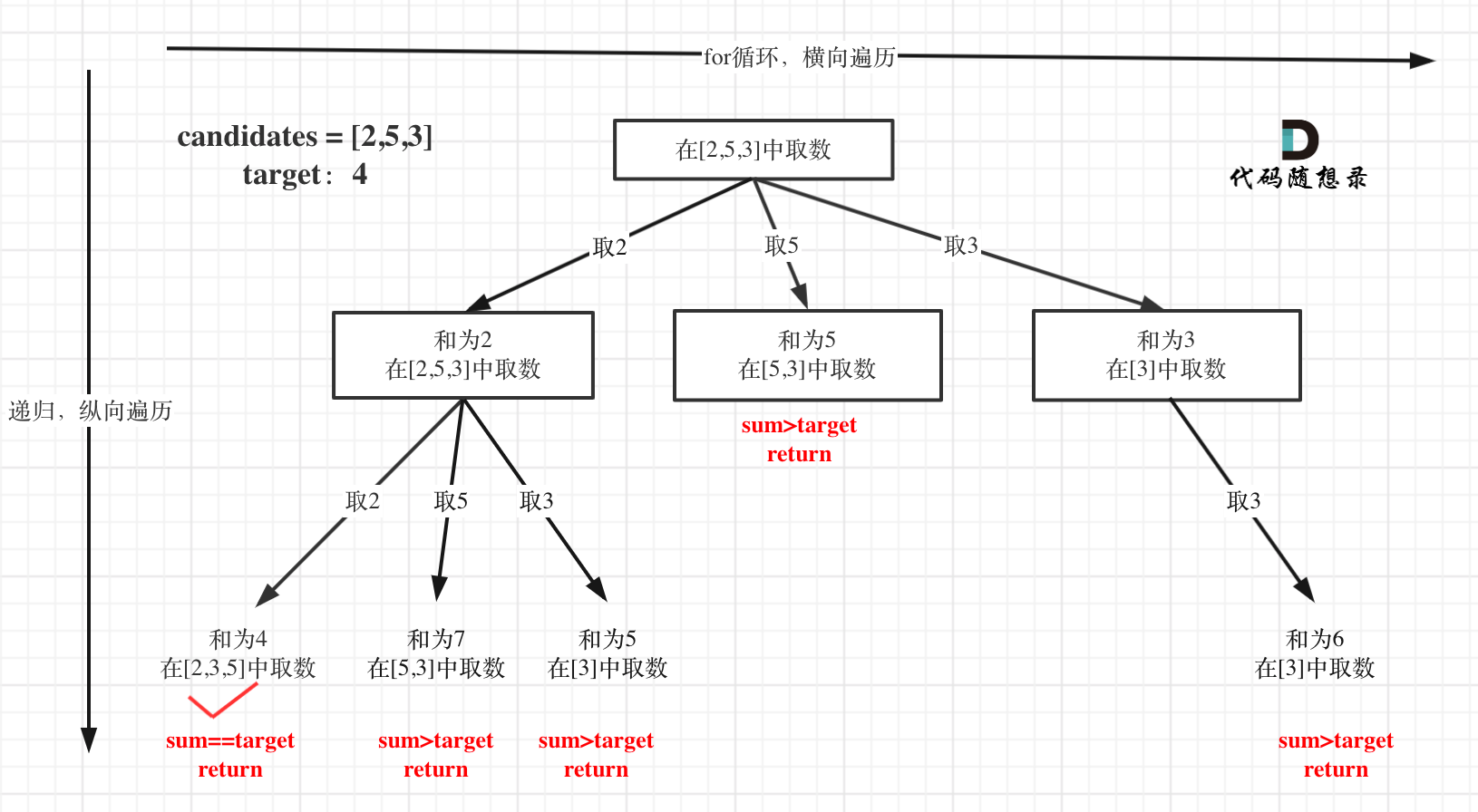
从叶子节点可以清晰看到,终止只有两种情况,sum大于target和sum等于target。
sum等于target的时候,需要收集结果,代码如下:
if (sum > target) {
return;
}
if (sum == target) {
result.push_back(path);
return;
}
- 单层搜索的逻辑
单层for循环依然是从startIndex开始,搜索candidates集合。
注意本题和77.组合、216.组合总和III的一个区别是:本题元素为可重复选取的。
如何重复选取呢,看代码,注释部分:
for (int i = startIndex; i < candidates.size(); i++) {
sum += candidates[i];
path.push_back(candidates[i]);
backtracking(candidates, target, sum, i); // 关键点:不用i+1了,表示可以重复读取当前的数
sum -= candidates[i]; // 回溯
path.pop_back(); // 回溯
}
剪枝优化
在这个树形结构中:
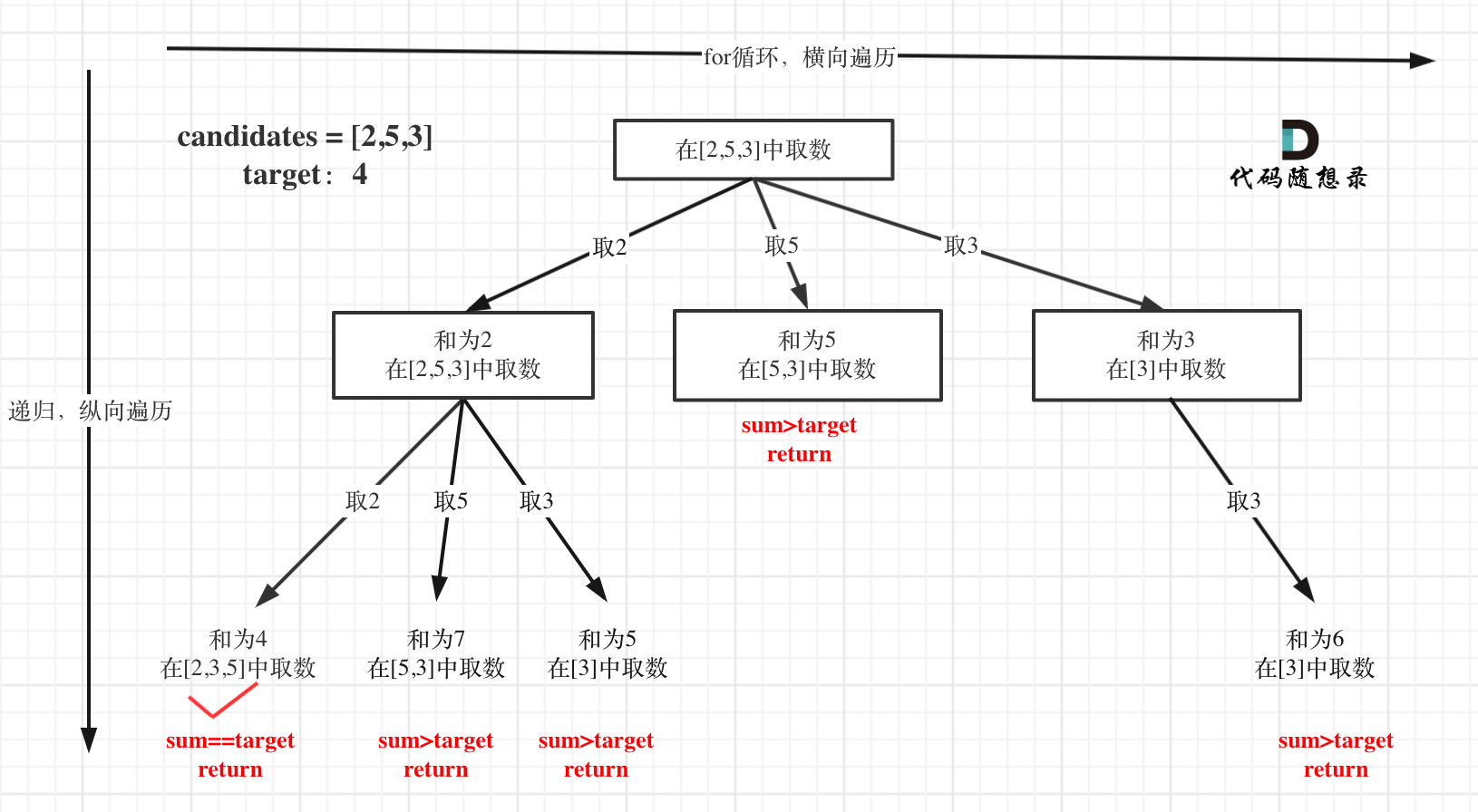
以及上面的版本一的代码大家可以看到,对于sum已经大于target的情况,其实是依然进入了下一层递归,只是下一层递归结束判断的时候,会判断sum > target的话就返回。
其实如果已经知道下一层的sum会大于target,就没有必要进入下一层递归了。
那么可以在for循环的搜索范围上做做文章了。
对总集合排序之后,如果下一层的sum(就是本层的 sum + candidates[i])已经大于target,就可以结束本轮for循环的遍历。
如图:
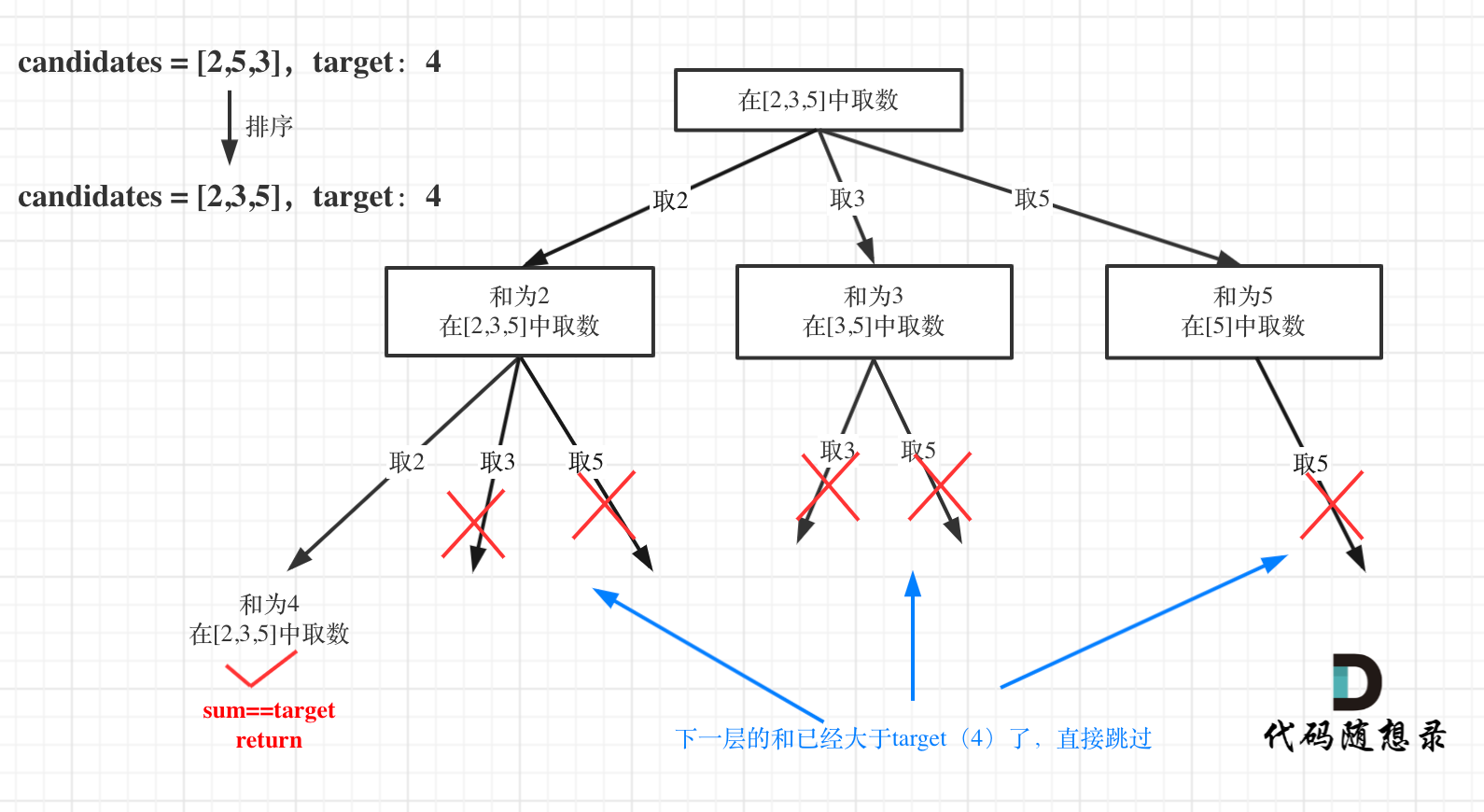
for循环剪枝代码如下:
for (int i = startIndex; i < candidates.size() && sum + candidates[i] <= target; i++)
C++解法
// 版本一
class Solution {
private:
vector<vector<int>> result;
vector<int> path;
void backtracking(vector<int>& candidates, int target, int sum, int startIndex) {
if (sum > target) {
return;
}
if (sum == target) {
result.push_back(path);
return;
}
for (int i = startIndex; i < candidates.size(); i++) {
sum += candidates[i];
path.push_back(candidates[i]);
backtracking(candidates, target, sum, i); // 不用i+1了,表示可以重复读取当前的数
sum -= candidates[i];
path.pop_back();
}
}
public:
vector<vector<int>> combinationSum(vector<int>& candidates, int target) {
result.clear();
path.clear();
backtracking(candidates, target, 0, 0);
return result;
}
};
剪枝操作
class Solution {
private:
vector<vector<int>> result;
vector<int> path;
void backtracking(vector<int>& candidates, int target, int sum, int startIndex) {
if (sum == target) {
result.push_back(path);
return;
}
// 如果 sum + candidates[i] > target 就终止遍历
for (int i = startIndex; i < candidates.size() && sum + candidates[i] <= target; i++) {
sum += candidates[i];
path.push_back(candidates[i]);
backtracking(candidates, target, sum, i);
sum -= candidates[i];
path.pop_back();
}
}
public:
vector<vector<int>> combinationSum(vector<int>& candidates, int target) {
result.clear();
path.clear();
sort(candidates.begin(), candidates.end()); // 需要排序
backtracking(candidates, target, 0, 0);
return result;
}
};
- 时间复杂度: O(n * 2^n),注意这只是复杂度的上界,因为剪枝的存在,真实的时间复杂度远小于此
- 空间复杂度: O(target)
40. Combination Sum II
Given a collection of candidate numbers (candidates) and a target number (target), find all unique combinations in candidates where the candidate numbers sum to target.
Each number in candidates may only be used once in the combination.
Note: The solution set must not contain duplicate combinations.
Example 1:
Input: candidates = [10,1,2,7,6,1,5], target = 8
Output:
[
[1,1,6],
[1,2,5],
[1,7],
[2,6]
]
Example 2:
Input: candidates = [2,5,2,1,2], target = 5
Output:
[
[1,2,2],
[5]
]
Constraints:
1 <= candidates.length <= 1001 <= candidates[i] <= 501 <= target <= 30
思路
这道题目和39.组合总和如下区别:
- 本题candidates 中的每个数字在每个组合中只能使用一次。
- 本题数组candidates的元素是有重复的,而39.组合总和是无重复元素的数组candidates
最后本题和39.组合总和要求一样,解集不能包含重复的组合。
本题的难点在于区别2中:集合(数组candidates)有重复元素,但还不能有重复的组合。
一些同学可能想了:我把所有组合求出来,再用set或者map去重,这么做很容易超时!
所以要在搜索的过程中就去掉重复组合。
很多同学在去重的问题上想不明白,其实很多题解也没有讲清楚,反正代码是能过的,感觉是那么回事,稀里糊涂的先把题目过了。
这个去重为什么很难理解呢,所谓去重,其实就是使用过的元素不能重复选取。 这么一说好像很简单!
都知道组合问题可以抽象为树形结构,那么“使用过”在这个树形结构上是有两个维度的,一个维度是同一树枝上使用过,一个维度是同一树层上使用过。没有理解这两个层面上的“使用过” 是造成大家没有彻底理解去重的根本原因。
那么问题来了,我们是要同一树层上使用过,还是同一树枝上使用过呢?
回看一下题目,元素在同一个组合内是可以重复的,怎么重复都没事,但两个组合不能相同。
所以我们要去重的是同一树层上的“使用过”,同一树枝上的都是一个组合里的元素,不用去重。
为了理解去重我们来举一个例子,candidates = [1, 1, 2], target = 3,(方便起见candidates已经排序了)
强调一下,树层去重的话,需要对数组排序!
选择过程树形结构如图所示:
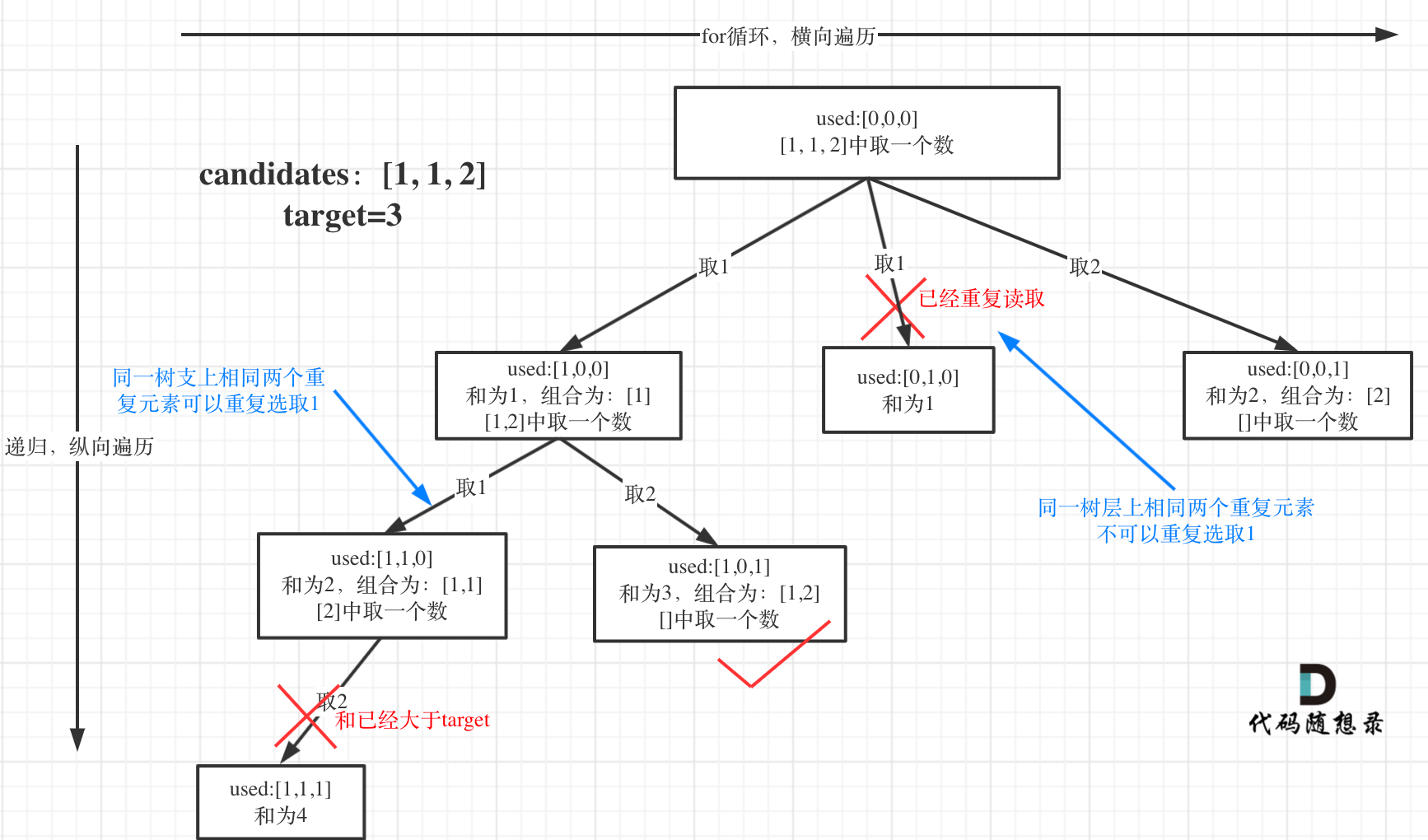
可以看到图中,每个节点相对于 39.组合总和我多加了used数组,这个used数组下面会重点介绍。
- 递归函数参数
与39.组合总和套路相同,此题还需要加一个bool型数组used,用来记录同一树枝上的元素是否使用过。
这个集合去重的重任就是used来完成的。
代码如下:
vector<vector<int>> result; // 存放组合集合
vector<int> path; // 符合条件的组合
void backtracking(vector<int>& candidates, int target, int sum, int startIndex, vector<bool>& used) {}
- 递归终止条件
与39.组合总和相同,终止条件为 sum > target 和 sum == target。
代码如下:
if (sum > target) { // 这个条件其实可以省略
return;
}
if (sum == target) {
result.push_back(path);
return;
}
sum > target 这个条件其实可以省略,因为在递归单层遍历的时候,会有剪枝的操作,下面会介绍到。
- 单层搜索的逻辑
这里与39.组合总和最大的不同就是要去重了。
前面我们提到:要去重的是“同一树层上的使用过”,如何判断同一树层上元素(相同的元素)是否使用过了呢。
如果candidates[i] == candidates[i - 1] 并且 used[i - 1] == false,就说明:前一个树枝,使用了candidates[i - 1],也就是说同一树层使用过candidates[i - 1]。
此时for循环里就应该做continue的操作。
这块比较抽象,如图:
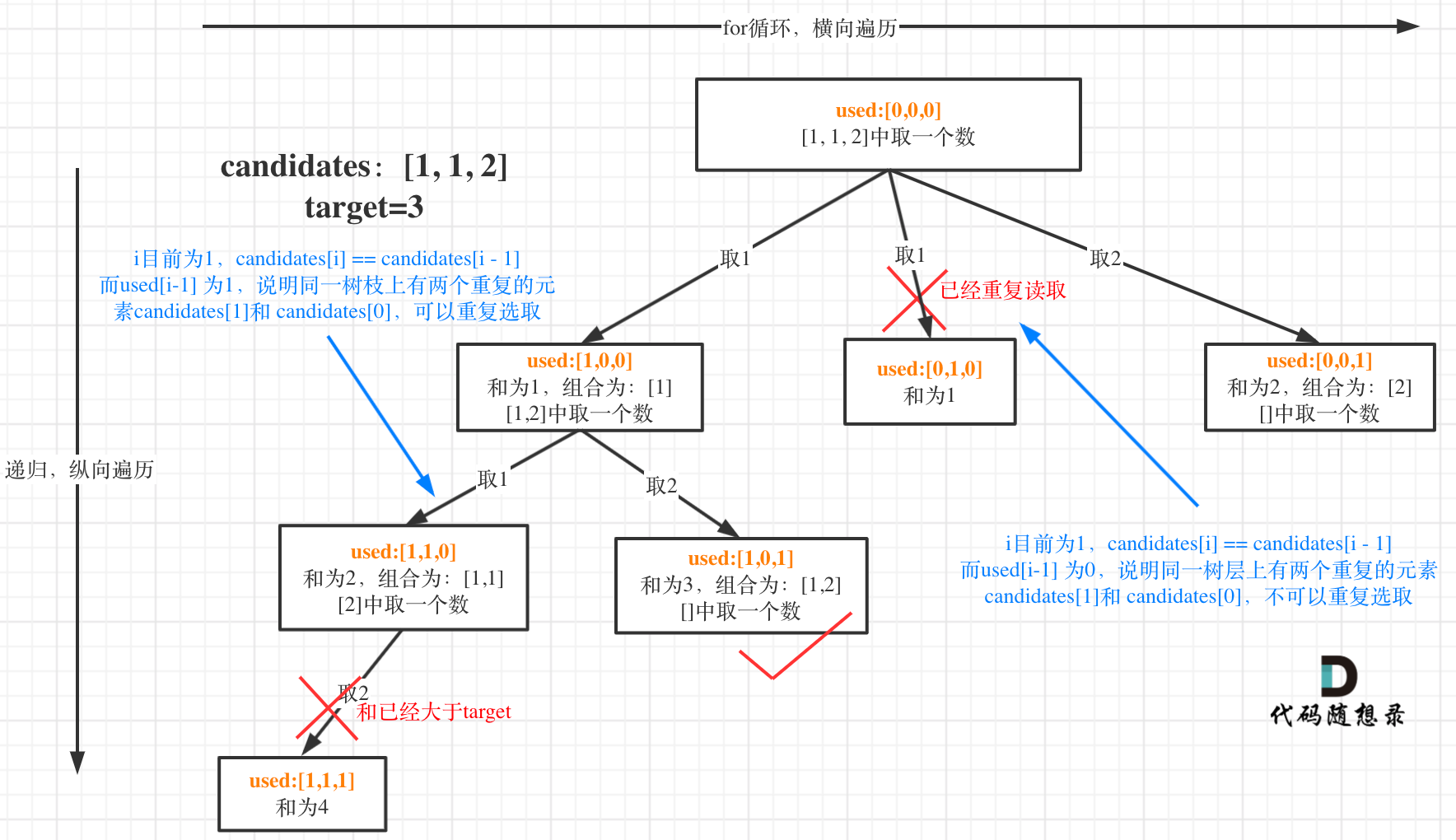
我在图中将used的变化用橘黄色标注上,可以看出在candidates[i] == candidates[i - 1]相同的情况下:
- used[i - 1] == true,说明同一树枝candidates[i - 1]使用过
- used[i - 1] == false,说明同一树层candidates[i - 1]使用过
可能有的录友想,为什么 used[i - 1] == false 就是同一树层呢,因为同一树层,used[i - 1] == false 才能表示,当前取的 candidates[i] 是从 candidates[i - 1] 回溯而来的。
而 used[i - 1] == true,说明是进入下一层递归,去下一个数,所以是树枝上,如图所示:
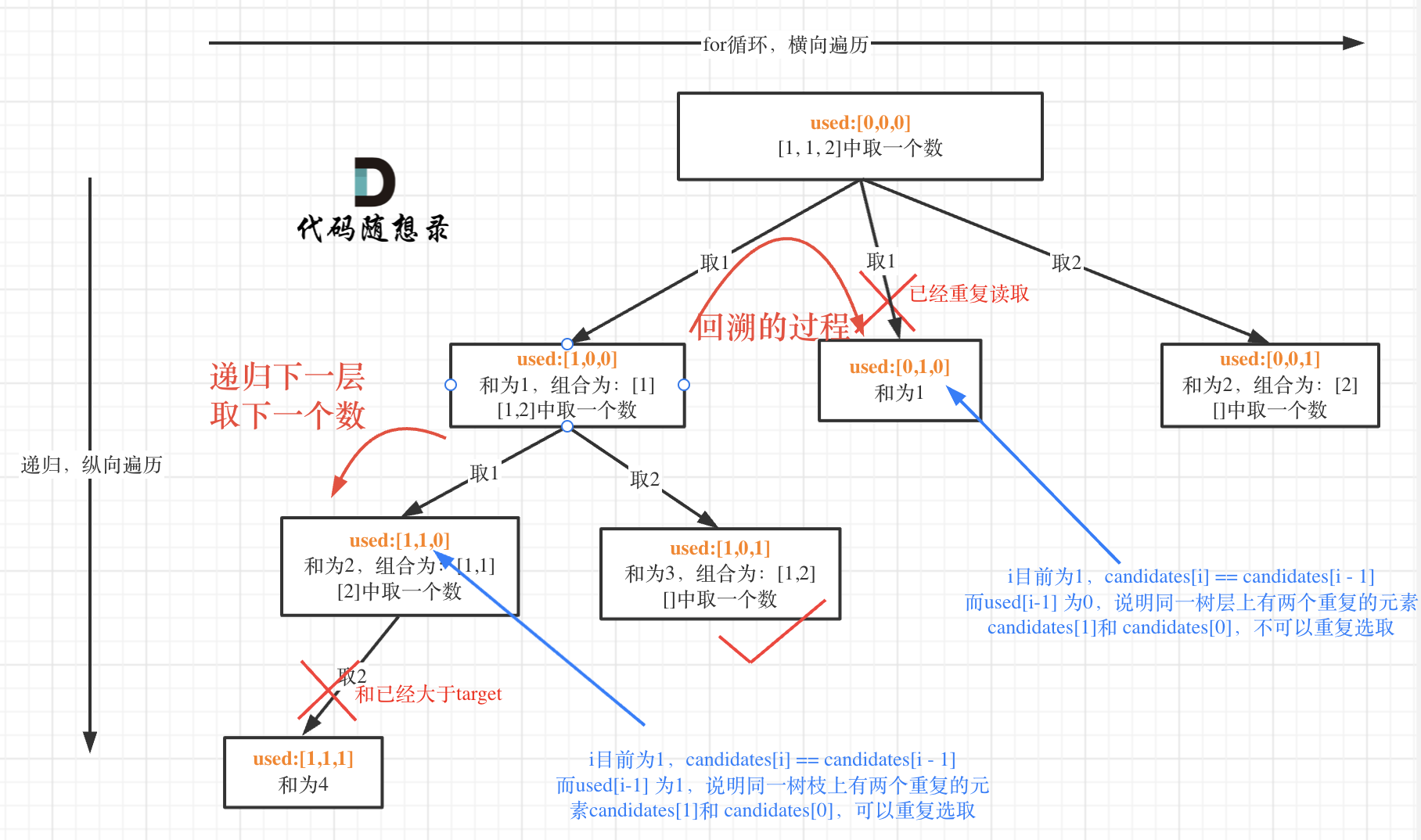
这块去重的逻辑很抽象,网上搜的题解基本没有能讲清楚的,如果大家之前思考过这个问题或者刷过这道题目,看到这里一定会感觉通透了很多!
那么单层搜索的逻辑代码如下:
for (int i = startIndex; i < candidates.size() && sum + candidates[i] <= target; i++) {
// used[i - 1] == true,说明同一树枝candidates[i - 1]使用过
// used[i - 1] == false,说明同一树层candidates[i - 1]使用过
// 要对同一树层使用过的元素进行跳过
if (i > 0 && candidates[i] == candidates[i - 1] && used[i - 1] == false) {
continue;
}
sum += candidates[i];
path.push_back(candidates[i]);
used[i] = true;
backtracking(candidates, target, sum, i + 1, used); // 和39.组合总和的区别1:这里是i+1,每个数字在每个组合中只能使用一次
used[i] = false;
sum -= candidates[i];
path.pop_back();
}
注意sum + candidates[i] <= target为剪枝操作,在39.组合总和有讲解过!
C++解法
class Solution {
private:
vector<vector<int>> result;
vector<int> path;
void backtracking(vector<int>& candidates, int target, int sum, int startIndex, vector<bool>& used) {
if (sum == target) {
result.push_back(path);
return;
}
for (int i = startIndex; i < candidates.size() && sum + candidates[i] <= target; i++) {
// used[i - 1] == true,说明同一树枝candidates[i - 1]使用过
// used[i - 1] == false,说明同一树层candidates[i - 1]使用过
// 要对同一树层使用过的元素进行跳过
if (i > 0 && candidates[i] == candidates[i - 1] && used[i - 1] == false) {
continue;
}
sum += candidates[i];
path.push_back(candidates[i]);
used[i] = true;
backtracking(candidates, target, sum, i + 1, used); // 和39.组合总和的区别1,这里是i+1,每个数字在每个组合中只能使用一次
used[i] = false;
sum -= candidates[i];
path.pop_back();
}
}
public:
vector<vector<int>> combinationSum2(vector<int>& candidates, int target) {
vector<bool> used(candidates.size(), false);
path.clear();
result.clear();
// 首先把给candidates排序,让其相同的元素都挨在一起。
sort(candidates.begin(), candidates.end());
backtracking(candidates, target, 0, 0, used);
return result;
}
};
- 时间复杂度: O(n * 2^n)
- 空间复杂度: O(n)
这里直接用startIndex来去重也是可以的, 就不用used数组了。
class Solution {
private:
vector<vector<int>> result;
vector<int> path;
void backtracking(vector<int>& candidates, int target, int sum, int startIndex) {
if (sum == target) {
result.push_back(path);
return;
}
for (int i = startIndex; i < candidates.size() && sum + candidates[i] <= target; i++) {
// 要对同一树层使用过的元素进行跳过
if (i > startIndex && candidates[i] == candidates[i - 1]) {
continue;
}
sum += candidates[i];
path.push_back(candidates[i]);
backtracking(candidates, target, sum, i + 1); // 和39.组合总和的区别1,这里是i+1,每个数字在每个组合中只能使用一次
sum -= candidates[i];
path.pop_back();
}
}
public:
vector<vector<int>> combinationSum2(vector<int>& candidates, int target) {
path.clear();
result.clear();
// 首先把给candidates排序,让其相同的元素都挨在一起。
sort(candidates.begin(), candidates.end());
backtracking(candidates, target, 0, 0);
return result;
}
};
分割
131. Palindrome Partitioning
Given a string s, partition s such that every substring of the partition is a palindrome. Return all possible palindrome partitioning of s.
Example 1:
Input: s = "aab"
Output: [["a","a","b"],["aa","b"]]
Example 2:
Input: s = "a"
Output: [["a"]]
Constraints:
1 <= s.length <= 16scontains only lowercase English letters.
思路
本题这涉及两个关键问题:
- 切割问题,有不同的切割方式
- 判断回文
相信这里不同的切割方式可以搞懵很多同学了。
这种题目,想用for循环暴力解法,可能都不那么容易写出来,所以要换一种暴力的方式,就是回溯。
一些同学可能想不清楚 回溯究竟是如何切割字符串呢?
我们来分析一下切割,其实切割问题类似组合问题。
例如对于字符串abcdef:
- 组合问题:选取一个a之后,在bcdef中再去选取第二个,选取b之后在cdef中再选取第三个.....。
- 切割问题:切割一个a之后,在bcdef中再去切割第二段,切割b之后在cdef中再切割第三段.....。
感受出来了不?
所以切割问题,也可以抽象为一棵树形结构,如图:
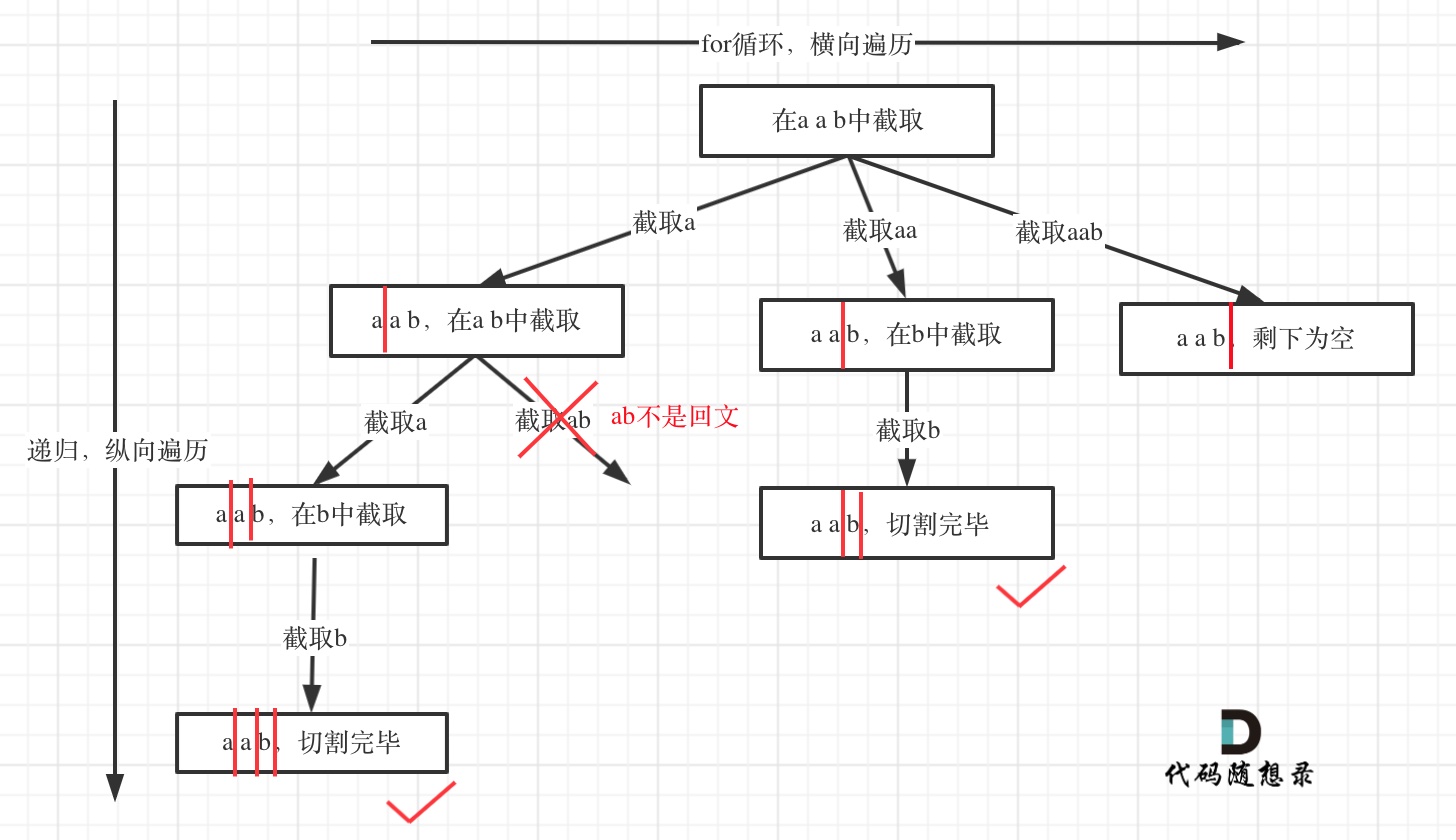
递归用来纵向遍历,for循环用来横向遍历,切割线(就是图中的红线)切割到字符串的结尾位置,说明找到了一个切割方法。
此时可以发现,切割问题的回溯搜索的过程和组合问题的回溯搜索的过程是差不多的。
- 递归函数参数
全局变量数组path存放切割后回文的子串,二维数组result存放结果集。 (这两个参数可以放到函数参数里)
本题递归函数参数还需要startIndex,因为切割过的地方,不能重复切割,和组合问题也是保持一致的。
在回溯算法:求组合总和(二)中我们深入探讨了组合问题什么时候需要startIndex,什么时候不需要startIndex。
代码如下:
vector<vector<string>> result;
vector<string> path; // 放已经回文的子串
void backtracking (const string& s, int startIndex) {}
- 递归函数终止条件
从树形结构的图中可以看出:切割线切到了字符串最后面,说明找到了一种切割方法,此时就是本层递归的终止条件。
那么在代码里什么是切割线呢?
在处理组合问题的时候,递归参数需要传入startIndex,表示下一轮递归遍历的起始位置,这个startIndex就是切割线。
所以终止条件代码如下:
void backtracking (const string& s, int startIndex) {
// 如果起始位置已经大于s的大小,说明已经找到了一组分割方案了
if (startIndex >= s.size()) {
result.push_back(path);
return;
}
}
- 单层搜索的逻辑
来看看在递归循环中如何截取子串呢?
在for (int i = startIndex; i < s.size(); i++)循环中,我们 定义了起始位置startIndex,那么 [startIndex, i] 就是要截取的子串。
首先判断这个子串是不是回文,如果是回文,就加入在vector<string> path中,path用来记录切割过的回文子串。
代码如下:
for (int i = startIndex; i < s.size(); i++) {
if (isPalindrome(s, startIndex, i)) { // 是回文子串
// 获取[startIndex,i]在s中的子串
string str = s.substr(startIndex, i - startIndex + 1);
path.push_back(str);
} else { // 如果不是则直接跳过
continue;
}
backtracking(s, i + 1); // 寻找i+1为起始位置的子串
path.pop_back(); // 回溯过程,弹出本次已经添加的子串
}
注意切割过的位置,不能重复切割,所以,backtracking(s, i + 1); 传入下一层的起始位置为i + 1。
判断回文子串
最后我们看一下回文子串要如何判断了,判断一个字符串是否是回文。
可以使用双指针法,一个指针从前向后,一个指针从后向前,如果前后指针所指向的元素是相等的,就是回文字符串了。
那么判断回文的C++代码如下:
bool isPalindrome(const string& s, int start, int end) {
for (int i = start, j = end; i < j; i++, j--) {
if (s[i] != s[j]) {
return false;
}
}
return true;
}
如果大家对双指针法有生疏了,传送门:双指针法:总结篇!
优化
上面的代码还存在一定的优化空间, 在于如何更高效的计算一个子字符串是否是回文字串。上述代码isPalindrome函数运用双指针的方法来判定对于一个字符串s, 给定起始下标和终止下标, 截取出的子字符串是否是回文字串。但是其中有一定的重复计算存在:
例如给定字符串"abcde", 在已知"bcd"不是回文字串时, 不再需要去双指针操作"abcde"而可以直接判定它一定不是回文字串。
具体来说, 给定一个字符串s, 长度为n, 它成为回文字串的充分必要条件是s[0] == s[n-1]且s[1:n-1]是回文字串。
大家如果熟悉动态规划这种算法的话, 我们可以高效地事先一次性计算出, 针对一个字符串s, 它的任何子串是否是回文字串, 然后在我们的回溯函数中直接查询即可, 省去了双指针移动判定这一步骤。
总结
这道题目在leetcode上是中等,但可以说是hard的题目了,但是代码其实就是按照模板的样子来的。
那么难究竟难在什么地方呢?
我列出如下几个难点:
- 切割问题可以抽象为组合问题
- 如何模拟那些切割线
- 切割问题中递归如何终止
- 在递归循环中如何截取子串
- 如何判断回文
我们平时在做难题的时候,总结出来难究竟难在哪里也是一种需要锻炼的能力。
一些同学可能遇到题目比较难,但是不知道题目难在哪里,反正就是很难。其实这样还是思维不够清晰,这种总结的能力需要多接触多锻炼。
本题我相信很多同学主要卡在了第一个难点上:就是不知道如何切割,甚至知道要用回溯法,也不知道如何用。也就是没有体会到按照求组合问题的套路就可以解决切割。
如果意识到这一点,算是重大突破了。接下来就可以对着模板照葫芦画瓢。
但接下来如何模拟切割线,如何终止,如何截取子串,其实都不好想,最后判断回文算是最简单的了。
关于模拟切割线,其实就是index是上一层已经确定了的分割线,i是这一层试图寻找的新分割线
除了这些难点,本题还有细节,例如:切割过的地方不能重复切割所以递归函数需要传入i + 1。
所以本题应该是一道hard题目了。
可能刷过这道题目的录友都没感受到自己原来克服了这么多难点,就把这道题目AC了,这应该叫做无招胜有招,人码合一。
C++解法
回溯解法:
class Solution {
private:
vector<vector<string>> result;
vector<string> path; // 放已经回文的子串
void backtracking (const string& s, int startIndex) {
// 如果起始位置已经大于s的大小,说明已经找到了一组分割方案了
if (startIndex >= s.size()) {
result.push_back(path);
return;
}
for (int i = startIndex; i < s.size(); i++) {
if (isPalindrome(s, startIndex, i)) { // 是回文子串
// 获取[startIndex,i]在s中的子串
string str = s.substr(startIndex, i - startIndex + 1);
path.push_back(str);
} else { // 不是回文,跳过
continue;
}
backtracking(s, i + 1); // 寻找i+1为起始位置的子串
path.pop_back(); // 回溯过程,弹出本次已经添加的子串
}
}
bool isPalindrome(const string& s, int start, int end) {
for (int i = start, j = end; i < j; i++, j--) {
if (s[i] != s[j]) {
return false;
}
}
return true;
}
public:
vector<vector<string>> partition(string s) {
result.clear();
path.clear();
backtracking(s, 0);
return result;
}
};
- 时间复杂度: O(n * 2^n)
- 空间复杂度: O(n^2)
动态规划解法:
具体参考代码如下:
class Solution {
private:
vector<vector<string>> result;
vector<string> path; // 放已经回文的子串
vector<vector<bool>> isPalindrome; // 放事先计算好的是否回文子串的结果
void backtracking (const string& s, int startIndex) {
// 如果起始位置已经大于s的大小,说明已经找到了一组分割方案了
if (startIndex >= s.size()) {
result.push_back(path);
return;
}
for (int i = startIndex; i < s.size(); i++) {
if (isPalindrome[startIndex][i]) { // 是回文子串
// 获取[startIndex,i]在s中的子串
string str = s.substr(startIndex, i - startIndex + 1);
path.push_back(str);
} else { // 不是回文,跳过
continue;
}
backtracking(s, i + 1); // 寻找i+1为起始位置的子串
path.pop_back(); // 回溯过程,弹出本次已经添加的子串
}
}
void computePalindrome(const string& s) {
// isPalindrome[i][j] 代表 s[i:j](双边包括)是否是回文字串
isPalindrome.resize(s.size(), vector<bool>(s.size(), false)); // 根据字符串s, 刷新布尔矩阵的大小
for (int i = s.size() - 1; i >= 0; i--) {
// 需要倒序计算, 保证在i行时, i+1行已经计算好了
for (int j = i; j < s.size(); j++) {
if (j == i) {isPalindrome[i][j] = true;}
else if (j - i == 1) {isPalindrome[i][j] = (s[i] == s[j]);}
else {isPalindrome[i][j] = (s[i] == s[j] && isPalindrome[i+1][j-1]);}
}
}
}
public:
vector<vector<string>> partition(string s) {
result.clear();
path.clear();
computePalindrome(s);
backtracking(s, 0);
return result;
}
};
Java解法
class Solution {
//保持前几题一贯的格式, initialization
List<List<String>> res = new ArrayList<>();
List<String> cur = new ArrayList<>();
public List<List<String>> partition(String s) {
backtracking(s, 0, new StringBuilder());
return res;
}
private void backtracking(String s, int start, StringBuilder sb){
//因为是起始位置一个一个加的,所以结束时start一定等于s.length,因为进入backtracking时一定末尾也是回文,所以cur是满足条件的
if (start == s.length()){
//注意创建一个新的copy
res.add(new ArrayList<>(cur));
return;
}
//像前两题一样从前往后搜索,如果发现回文,进入backtracking,起始位置后移一位,循环结束照例移除cur的末位
for (int i = start; i < s.length(); i++){
sb.append(s.charAt(i));
if (check(sb)){
cur.add(sb.toString());
backtracking(s, i + 1, new StringBuilder());
cur.remove(cur.size() -1 );
}
}
}
//helper method, 检查是否是回文
private boolean check(StringBuilder sb){
for (int i = 0; i < sb.length()/ 2; i++){
if (sb.charAt(i) != sb.charAt(sb.length() - 1 - i)){return false;}
}
return true;
}
}
93. Restore IP Addresses
A valid IP address consists of exactly four integers separated by single dots. Each integer is between 0 and 255 (inclusive) and cannot have leading zeros.
- For example,
"0.1.2.201"and"192.168.1.1"are valid IP addresses, but"0.011.255.245","192.168.1.312"and"192.168@1.1"are invalid IP addresses.
Given a string s containing only digits, return all possible valid IP addresses that can be formed by inserting dots into s. You are not allowed to reorder or remove any digits in s. You may return the valid IP addresses in any order.
Example 1:
Input: s = "25525511135"
Output: ["255.255.11.135","255.255.111.35"]
Example 2:
Input: s = "0000"
Output: ["0.0.0.0"]
Example 3:
Input: s = "101023"
Output: ["1.0.10.23","1.0.102.3","10.1.0.23","10.10.2.3","101.0.2.3"]
Constraints:
1 <= s.length <= 20sconsists of digits only.
思路
做这道题目之前,最好先把131.分割回文串这个做了。
这道题目相信大家刚看的时候,应该会一脸茫然。
其实只要意识到这是切割问题,切割问题就可以使用回溯搜索法把所有可能性搜出来,和刚做过的131.分割回文串就十分类似了。
切割问题可以抽象为树型结构,如图:
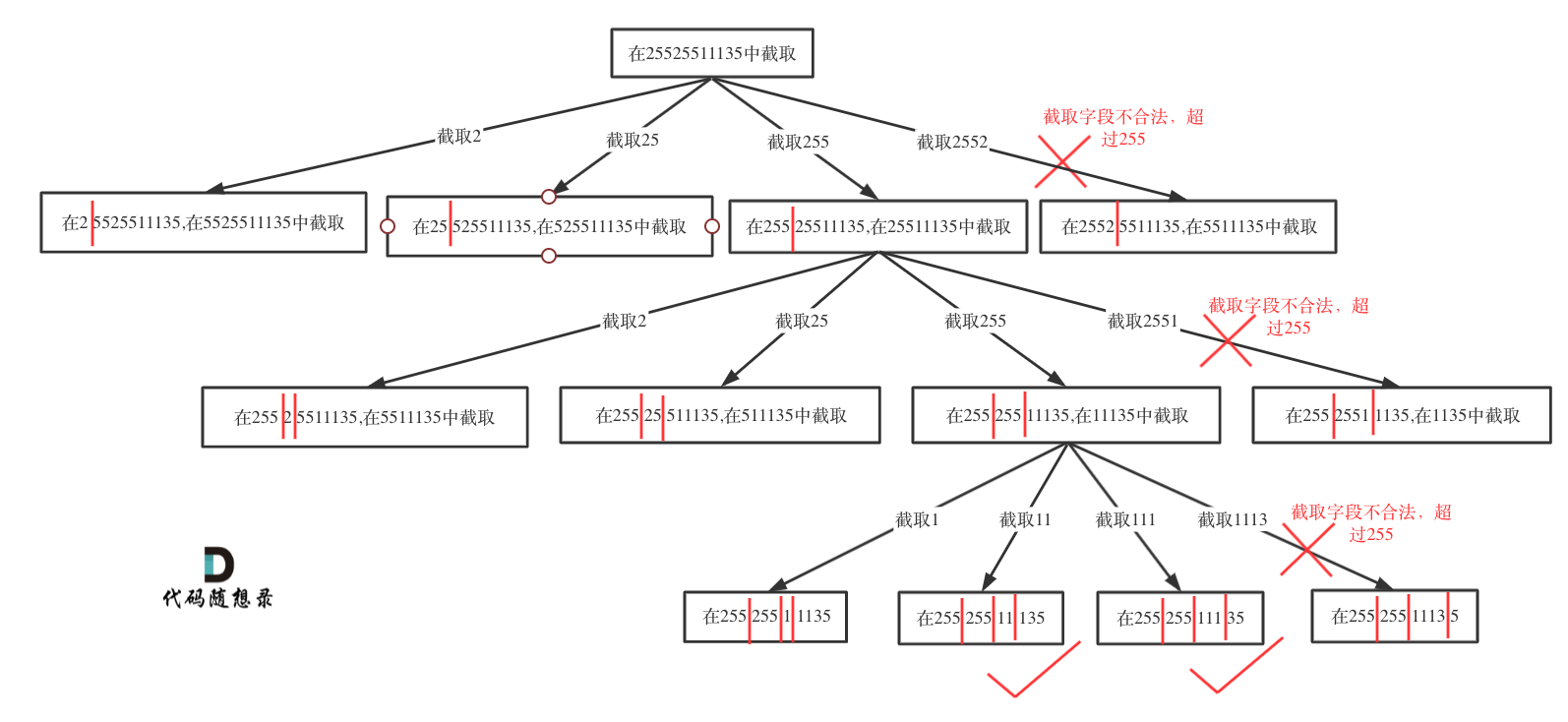
- 递归参数
在131.分割回文串中我们就提到切割问题类似组合问题。
startIndex一定是需要的,因为不能重复分割,记录下一层递归分割的起始位置。
本题我们还需要一个变量pointNum,记录添加逗点的数量。
所以代码如下:
vector<string> result;// 记录结果
// startIndex: 搜索的起始位置,pointNum:添加逗点的数量
void backtracking(string& s, int startIndex, int pointNum) {}
- 递归终止条件
终止条件和131.分割回文串情况就不同了,本题明确要求只会分成4段,所以不能用切割线切到最后作为终止条件,而是分割的段数作为终止条件。
pointNum表示逗点数量,pointNum为3说明字符串分成了4段了。
然后验证一下第四段是否合法,如果合法就加入到结果集里
代码如下:
if (pointNum == 3) { // 逗点数量为3时,分隔结束
// 判断第四段子字符串是否合法,如果合法就放进result中
if (isValid(s, startIndex, s.size() - 1)) {
result.push_back(s);
}
return;
}
- 单层搜索的逻辑
在131.分割回文串中已经讲过在循环遍历中如何截取子串。
在for (int i = startIndex; i < s.size(); i++)循环中 [startIndex, i] 这个区间就是截取的子串,需要判断这个子串是否合法。
如果合法就在字符串后面加上符号.表示已经分割。
如果不合法就结束本层循环,如图中剪掉的分支:
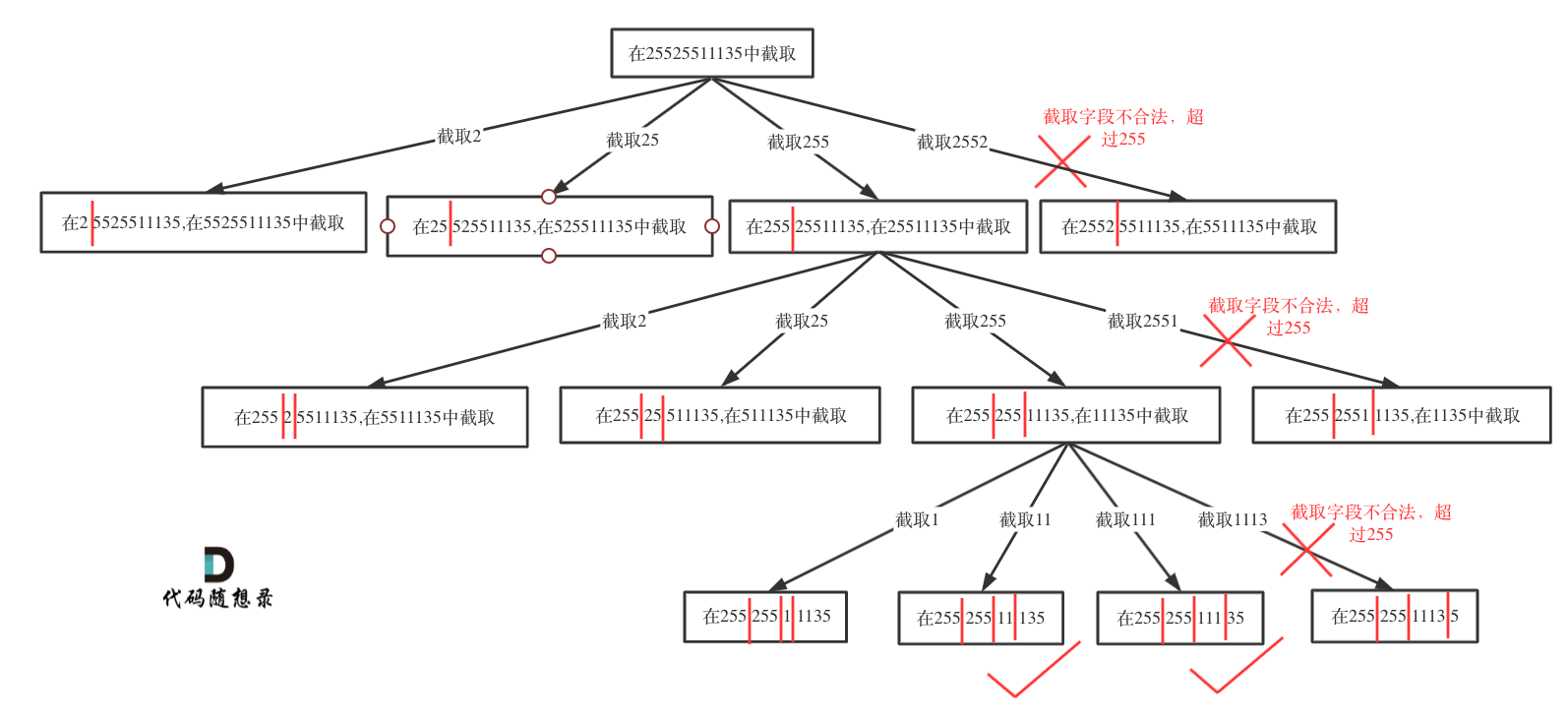
然后就是递归和回溯的过程:
递归调用时,下一层递归的startIndex要从i+2开始(因为需要在字符串中加入了分隔符.),同时记录分割符的数量pointNum 要 +1。
回溯的时候,就将刚刚加入的分隔符. 删掉就可以了,pointNum也要-1。
代码如下:
for (int i = startIndex; i < s.size(); i++) {
if (isValid(s, startIndex, i)) { // 判断 [startIndex,i] 这个区间的子串是否合法
s.insert(s.begin() + i + 1 , '.'); // 在i的后面插入一个逗点
pointNum++;
backtracking(s, i + 2, pointNum); // 插入逗点之后下一个子串的起始位置为i+2
pointNum--; // 回溯
s.erase(s.begin() + i + 1); // 回溯删掉逗点
} else break; // 不合法,直接结束本层循环
}
判断子串是否合法
最后就是在写一个判断段位是否是有效段位了。
主要考虑到如下三点:
- 段位以0为开头的数字不合法
- 段位里有非正整数字符不合法
- 段位如果大于255了不合法
代码如下:
// 判断字符串s在左闭又闭区间[start, end]所组成的数字是否合法
bool isValid(const string& s, int start, int end) {
if (start > end) {
return false;
}
if (s[start] == '0' && start != end) { // 0开头的数字不合法
return false;
}
int num = 0;
for (int i = start; i <= end; i++) {
if (s[i] > '9' || s[i] < '0') { // 遇到非数字字符不合法
return false;
}
num = num * 10 + (s[i] - '0');
if (num > 255) { // 如果大于255了不合法
return false;
}
}
return true;
}
C++解法
回溯解法:
class Solution {
private:
vector<string> result;// 记录结果
// startIndex: 搜索的起始位置,pointNum:添加逗点的数量
void backtracking(string& s, int startIndex, int pointNum) {
if (pointNum == 3) { // 逗点数量为3时,分隔结束
// 判断第四段子字符串是否合法,如果合法就放进result中
if (isValid(s, startIndex, s.size() - 1)) {
result.push_back(s);
}
return;
}
for (int i = startIndex; i < s.size(); i++) {
if (isValid(s, startIndex, i)) { // 判断 [startIndex,i] 这个区间的子串是否合法
s.insert(s.begin() + i + 1 , '.'); // 在i的后面插入一个逗点
pointNum++;
backtracking(s, i + 2, pointNum); // 插入逗点之后下一个子串的起始位置为i+2
pointNum--; // 回溯
s.erase(s.begin() + i + 1); // 回溯删掉逗点
} else break; // 不合法,直接结束本层循环
}
}
// 判断字符串s在左闭右闭区间[start, end]所组成的数字是否合法
bool isValid(const string& s, int start, int end) {
if (start > end) {
return false;
}
if (s[start] == '0' && start != end) { // 0开头的数字不合法
return false;
}
int num = 0;
for (int i = start; i <= end; i++) {
if (s[i] > '9' || s[i] < '0') { // 遇到非数字字符不合法
return false;
}
num = num * 10 + (s[i] - '0');
if (num > 255) { // 如果大于255了不合法
return false;
}
}
return true;
}
public:
vector<string> restoreIpAddresses(string s) {
result.clear();
if (s.size() < 4 || s.size() > 12) return result; // 算是剪枝了
backtracking(s, 0, 0);
return result;
}
};
- 时间复杂度: O(3^4),IP地址最多包含4个数字,每个数字最多有3种可能的分割方式,则搜索树的最大深度为4,每个节点最多有3个子节点。
- 空间复杂度: O(n)
子集
78. Subsets
Given an integer array nums of unique elements, return all possible subsets (the power set).
The solution set must not contain duplicate subsets. Return the solution in any order.
Example 1:
Input: nums = [1,2,3]
Output: [[],[1],[2],[1,2],[3],[1,3],[2,3],[1,2,3]]
Example 2:
Input: nums = [0]
Output: [[],[0]]
Constraints:
1 <= nums.length <= 10-10 <= nums[i] <= 10- All the numbers of
numsare unique.
思路
如果把 子集问题、组合问题、分割问题都抽象为一棵树的话,那么组合问题和分割问题都是收集树的叶子节点,而子集问题是找树的所有节点!
其实子集也是一种组合问题,因为它的集合是无序的,子集{1,2} 和 子集{2,1}是一样的。
那么既然是无序,取过的元素不会重复取,写回溯算法的时候,for就要从startIndex开始,而不是从0开始!
有同学问了,什么时候for可以从0开始呢?
求排列问题的时候,就要从0开始,因为集合是有序的,{1, 2} 和{2, 1}是两个集合,排列问题我们后续的文章就会讲到的。
以示例中nums = [1,2,3]为例把求子集抽象为树型结构,如下:
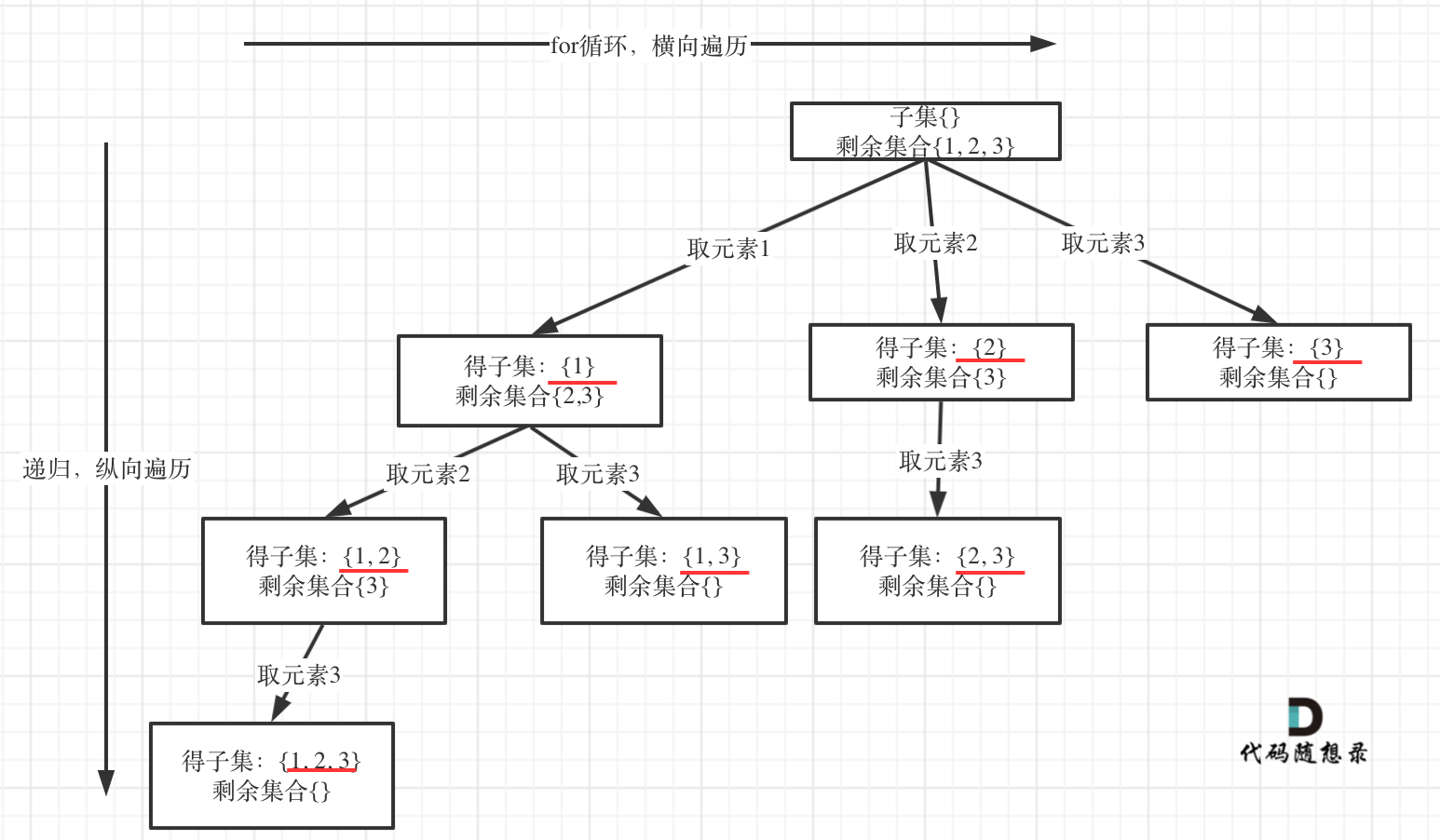
从图中红线部分,可以看出遍历这个树的时候,把所有节点都记录下来,就是要求的子集集合。
- 递归函数参数
全局变量数组path为子集收集元素,二维数组result存放子集组合。(也可以放到递归函数参数里)
递归函数参数在上面讲到了,需要startIndex。
代码如下:
vector<vector<int>> result;
vector<int> path;
void backtracking(vector<int>& nums, int startIndex) {}
递归终止条件
从图中可以看出:
剩余集合为空的时候,就是叶子节点。
那么什么时候剩余集合为空呢?
就是startIndex已经大于数组的长度了,就终止了,因为没有元素可取了,代码如下:
if (startIndex >= nums.size()) {
return;
}
其实可以不需要加终止条件,因为startIndex >= nums.size(),本层for循环本来也结束了。
- 单层搜索逻辑
求取子集问题,不需要任何剪枝!因为子集就是要遍历整棵树。
那么单层递归逻辑代码如下:
for (int i = startIndex; i < nums.size(); i++) {
path.push_back(nums[i]); // 子集收集元素
backtracking(nums, i + 1); // 注意从i+1开始,元素不重复取
path.pop_back(); // 回溯
}
C++解法
class Solution {
private:
vector<vector<int>> result;
vector<int> path;
void backtracking(vector<int>& nums, int startIndex) {
result.push_back(path); // 收集子集,要放在终止添加的上面,否则会漏掉自己
if (startIndex >= nums.size()) { // 终止条件可以不加
return;
}
for (int i = startIndex; i < nums.size(); i++) {
path.push_back(nums[i]);
backtracking(nums, i + 1);
path.pop_back();
}
}
public:
vector<vector<int>> subsets(vector<int>& nums) {
result.clear();
path.clear();
backtracking(nums, 0);
return result;
}
};
- 时间复杂度: O(n * 2^n)
- 空间复杂度: O(n)
在注释中,可以发现可以不写终止条件,因为本来我们就要遍历整棵树。
有的同学可能担心不写终止条件会不会无限递归?
并不会,因为每次递归的下一层就是从i+1开始的。
90. Subsets II
Given an integer array nums that may contain duplicates, return all possible subsets (the power set).
The solution set must not contain duplicate subsets. Return the solution in any order.
Example 1:
Input: nums = [1,2,2]
Output: [[],[1],[1,2],[1,2,2],[2],[2,2]]
Example 2:
Input: nums = [0]
Output: [[],[0]]
Constraints:
1 <= nums.length <= 10-10 <= nums[i] <= 10
思路
树层去重需要先排序
做本题之前一定要先做78.子集。
这道题目和78.子集区别就是集合里有重复元素了,而且求取的子集要去重。
那么关于回溯算法中的去重问题,在40.组合总和II中已经详细讲解过了,和本题是一个套路。
剧透一下,后期要讲解的排列问题里去重也是这个套路,所以理解“树层去重”和“树枝去重”非常重要。
用示例中的[1, 2, 2] 来举例,如图所示: (注意去重需要先对集合排序)
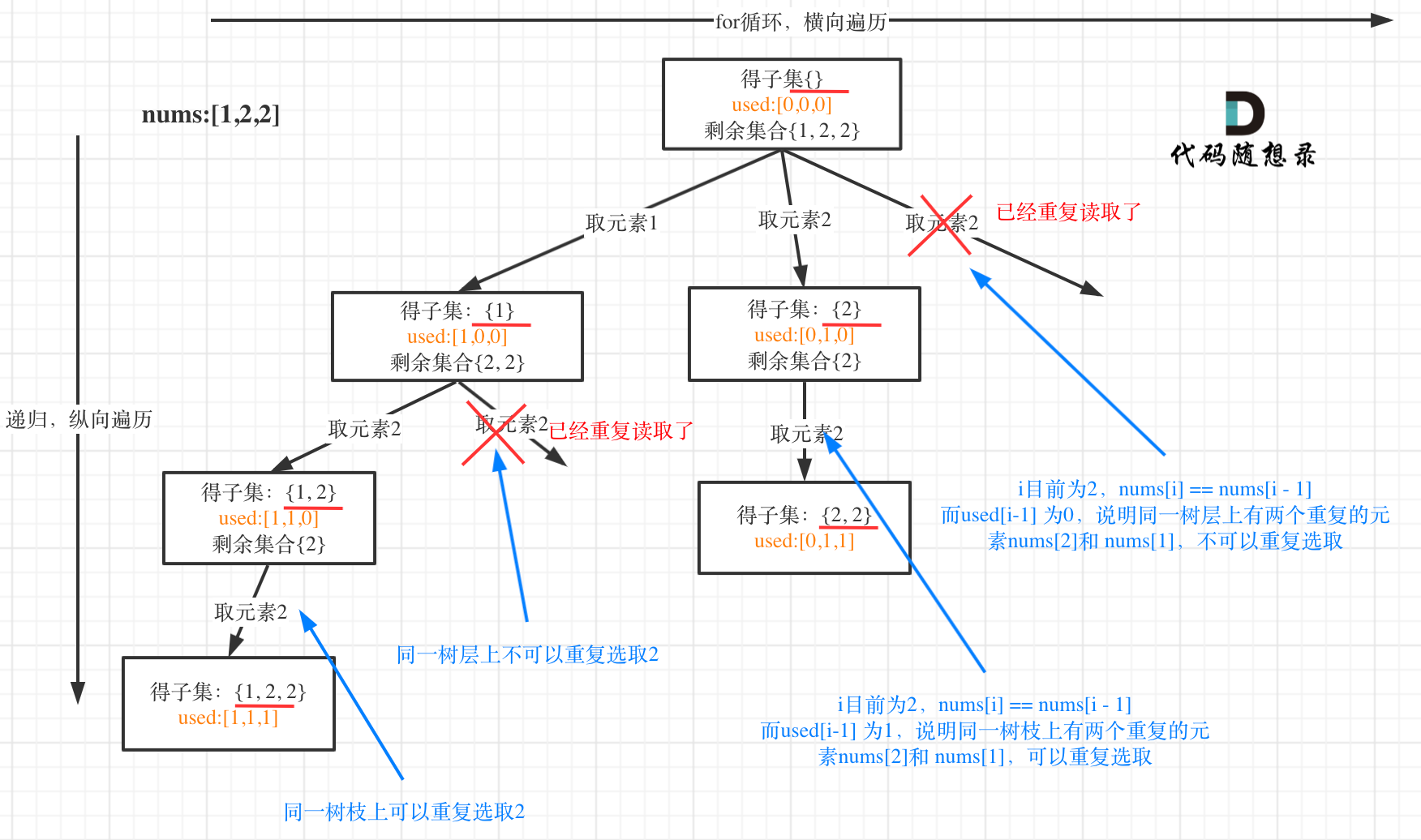
从图中可以看出,同一树层上重复取2 就要过滤掉,同一树枝上就可以重复取2,因为同一树枝上元素的集合才是唯一子集!
C++解法
class Solution {
private:
vector<vector<int>> result;
vector<int> path;
void backtracking(vector<int>& nums, int startIndex, vector<bool>& used) {
result.push_back(path);
for (int i = startIndex; i < nums.size(); i++) {
// used[i - 1] == true,说明同一树枝nums[i - 1]使用过
// used[i - 1] == false,说明同一树层nums[i - 1]使用过
// 而我们要对同一树层使用过的元素进行跳过
if (i > 0 && nums[i] == nums[i - 1] && used[i - 1] == false) {
continue;
}
path.push_back(nums[i]);
used[i] = true;
backtracking(nums, i + 1, used);
used[i] = false;
path.pop_back();
}
}
public:
vector<vector<int>> subsetsWithDup(vector<int>& nums) {
result.clear();
path.clear();
vector<bool> used(nums.size(), false);
sort(nums.begin(), nums.end()); // 去重需要排序
backtracking(nums, 0, used);
return result;
}
};
- 时间复杂度: O(n * 2^n)
- 空间复杂度: O(n)
使用set去重的版本。
class Solution {
private:
vector<vector<int>> result;
vector<int> path;
void backtracking(vector<int>& nums, int startIndex) {
result.push_back(path);
unordered_set<int> uset;
for (int i = startIndex; i < nums.size(); i++) {
if (uset.find(nums[i]) != uset.end()) {
continue;
}
uset.insert(nums[i]);
path.push_back(nums[i]);
backtracking(nums, i + 1);
path.pop_back();
}
}
public:
vector<vector<int>> subsetsWithDup(vector<int>& nums) {
result.clear();
path.clear();
sort(nums.begin(), nums.end()); // 去重需要排序
backtracking(nums, 0);
return result;
}
};
本题也可以不使用used数组来去重,因为递归的时候下一个startIndex是i+1而不是0。
如果要是全排列的话,每次要从0开始遍历,为了跳过已入栈的元素,需要使用used。
完整代码如下所示:
class Solution {
private:
vector<vector<int>> result;
vector<int> path;
void backtracking(vector<int>& nums, int startIndex) {
result.push_back(path);
for (int i = startIndex; i < nums.size(); i++) {
// 而我们要对同一树层使用过的元素进行跳过
if (i > startIndex && nums[i] == nums[i - 1] ) { // 注意这里使用i > startIndex
continue;
}
path.push_back(nums[i]);
backtracking(nums, i + 1);
path.pop_back();
}
}
public:
vector<vector<int>> subsetsWithDup(vector<int>& nums) {
result.clear();
path.clear();
sort(nums.begin(), nums.end()); // 去重需要排序
backtracking(nums, 0);
return result;
}
};
491. Non-decreasing Subsequences
Given an integer array nums, return all the different possible non-decreasing subsequences of the given array with at least two elements. You may return the answer in any order.
Example 1:
Input: nums = [4,6,7,7]
Output: [[4,6],[4,6,7],[4,6,7,7],[4,7],[4,7,7],[6,7],[6,7,7],[7,7]]
Example 2:
Input: nums = [4,4,3,2,1]
Output: [[4,4]]
Constraints:
1 <= nums.length <= 15-100 <= nums[i] <= 100
思路
这个递增子序列比较像是取有序的子集。而且本题也要求不能有相同的递增子序列。
这又是子集,又是去重,是不是不由自主的想起了刚刚讲过的90.子集II。
就是因为太像了,更要注意差别所在,要不就掉坑里了!
在90.子集II中我们是通过排序,再加一个标记数组来达到去重的目的。
而本题求自增子序列,是不能对原数组进行排序的,排完序的数组都是自增子序列了。
所以不能使用之前的去重逻辑!
本题给出的示例,还是一个有序数组 [4, 6, 7, 7],这更容易误导大家按照排序的思路去做了。
为了有鲜明的对比,我用[4, 7, 6, 7]这个数组来举例,抽象为树形结构如图:
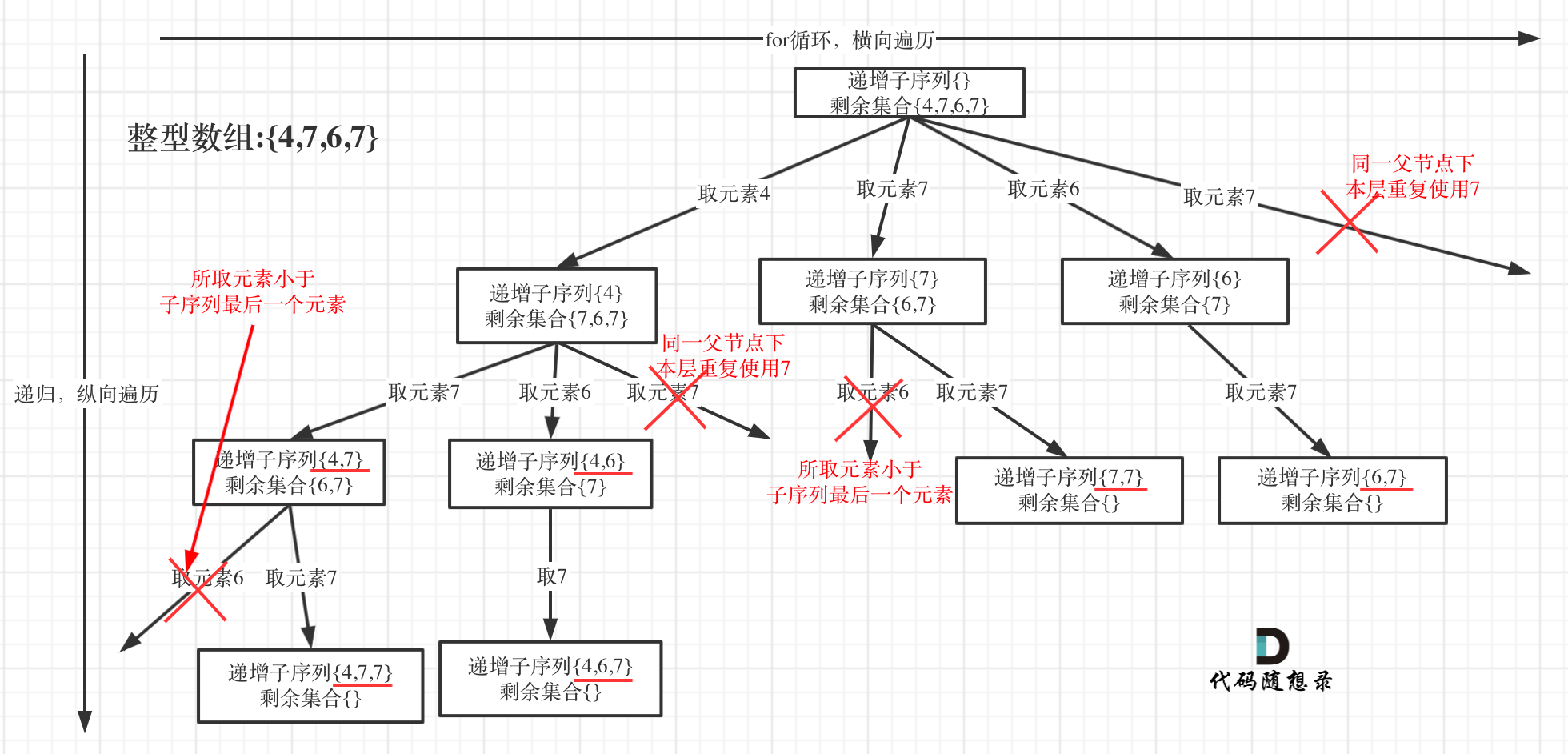
- 递归函数参数
本题求子序列,很明显一个元素不能重复使用,所以需要startIndex,调整下一层递归的起始位置。
代码如下:
vector<vector<int>> result;
vector<int> path;
void backtracking(vector<int>& nums, int startIndex)
- 终止条件
本题其实类似求子集问题,也是要遍历树形结构找每一个节点,所以和回溯算法:求子集问题!一样,可以不加终止条件,startIndex每次都会加1,并不会无限递归。
但本题收集结果有所不同,题目要求递增子序列大小至少为2,所以代码如下:
if (path.size() > 1) {
result.push_back(path);
// 注意这里不要加return,因为要取树上的所有节点
}
- 单层搜索逻辑
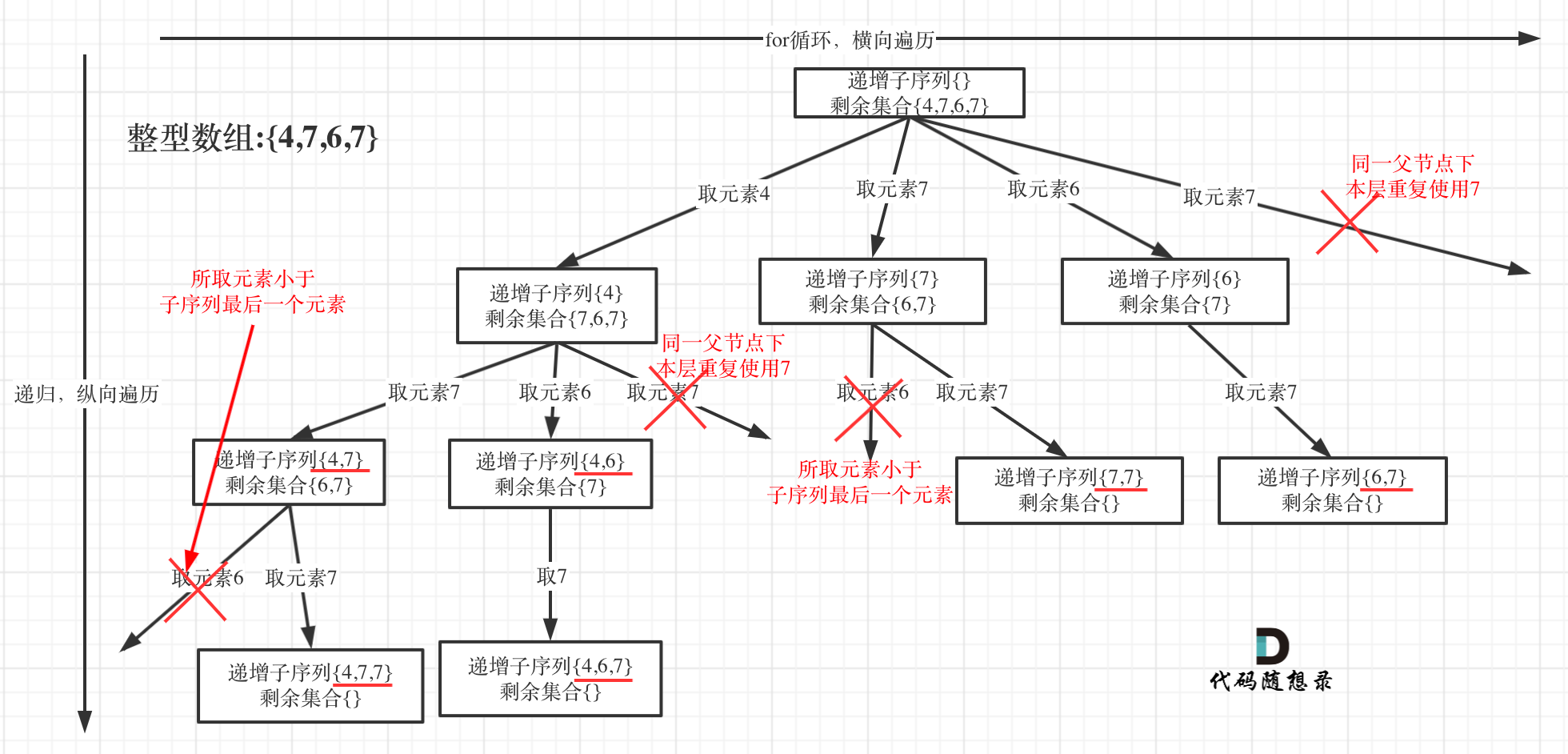
在图中可以看出,同一父节点下的同层上使用过的元素就不能再使用了
那么单层搜索代码如下:
unordered_set<int> uset; // 使用set来对本层元素进行去重
for (int i = startIndex; i < nums.size(); i++) {
if ((!path.empty() && nums[i] < path.back())
|| uset.find(nums[i]) != uset.end()) {
continue;
}
uset.insert(nums[i]); // 记录这个元素在本层用过了,本层后面不能再用了
path.push_back(nums[i]);
backtracking(nums, i + 1);
path.pop_back();
}
对于已经习惯写回溯的同学,看到递归函数上面的uset.insert(nums[i]);,下面却没有对应的pop之类的操作,应该很不习惯吧
这也是需要注意的点,unordered_set<int> uset; 是记录本层元素是否重复使用,新的一层uset都会重新定义(清空),所以要知道uset只负责本层!
优化
以上代码用我用了unordered_set<int>来记录本层元素是否重复使用。
其实用数组来做哈希,效率就高了很多。
注意题目中说了,数值范围[-100,100],所以完全可以用数组来做哈希。
程序运行的时候对unordered_set 频繁的insert,unordered_set需要做哈希映射(也就是把key通过hash function映射为唯一的哈希值)相对费时间,而且每次重新定义set,insert的时候其底层的符号表也要做相应的扩充,也是费事的。
C++解法
使用unordered_set
// 版本一
class Solution {
private:
vector<vector<int>> result;
vector<int> path;
void backtracking(vector<int>& nums, int startIndex) {
if (path.size() > 1) {
result.push_back(path);
// 注意这里不要加return,要取树上的节点
}
unordered_set<int> uset; // 使用set对本层元素进行去重
for (int i = startIndex; i < nums.size(); i++) {
if ((!path.empty() && nums[i] < path.back())
|| uset.find(nums[i]) != uset.end()) {
continue;
}
uset.insert(nums[i]); // 记录这个元素在本层用过了,本层后面不能再用了
path.push_back(nums[i]);
backtracking(nums, i + 1);
path.pop_back();
}
}
public:
vector<vector<int>> findSubsequences(vector<int>& nums) {
result.clear();
path.clear();
backtracking(nums, 0);
return result;
}
};
使用数组
// 版本二
class Solution {
private:
vector<vector<int>> result;
vector<int> path;
void backtracking(vector<int>& nums, int startIndex) {
if (path.size() > 1) {
result.push_back(path);
}
int used[201] = {0}; // 这里使用数组来进行去重操作,题目说数值范围[-100, 100]
for (int i = startIndex; i < nums.size(); i++) {
if ((!path.empty() && nums[i] < path.back())
|| used[nums[i] + 100] == 1) {
continue;
}
used[nums[i] + 100] = 1; // 记录这个元素在本层用过了,本层后面不能再用了
path.push_back(nums[i]);
backtracking(nums, i + 1);
path.pop_back();
}
}
public:
vector<vector<int>> findSubsequences(vector<int>& nums) {
result.clear();
path.clear();
backtracking(nums, 0);
return result;
}
};
这份代码在leetcode上提交,要比版本一耗时要好的多。
所以正如在哈希表:总结篇!(每逢总结必经典)中说的那样,数组,set,map都可以做哈希表,而且数组干的活,map和set都能干,但如果数值范围小的话能用数组尽量用数组。
排列
46. Permutations
Given an array nums of distinct integers, return all the possible permutations. You can return the answer in any order.
Example 1:
Input: nums = [1,2,3]
Output: [[1,2,3],[1,3,2],[2,1,3],[2,3,1],[3,1,2],[3,2,1]]
Example 2:
Input: nums = [0,1]
Output: [[0,1],[1,0]]
Example 3:
Input: nums = [1]
Output: [[1]]
Constraints:
1 <= nums.length <= 6-10 <= nums[i] <= 10- All the integers of
numsare unique.
思路
新增一个used数组记录数字是否被使用过,如果被使用过就重新进入循环。
C++解法
class Solution {
public:
vector<vector<int>> result;
vector<int> path;
void backtracking (vector<int>& nums, vector<bool>& used) {
// 此时说明找到了一组
if (path.size() == nums.size()) {
result.push_back(path);
return;
}
for (int i = 0; i < nums.size(); i++) {
if (used[i] == true) continue; // path里已经收录的元素,直接跳过
used[i] = true;
path.push_back(nums[i]);
backtracking(nums, used);
path.pop_back();
used[i] = false;
}
}
vector<vector<int>> permute(vector<int>& nums) {
result.clear();
path.clear();
vector<bool> used(nums.size(), false);
backtracking(nums, used);
return result;
}
};
- 时间复杂度: O(n! * n)
- 空间复杂度: O(n)
47. Permutations II
Given a collection of numbers, nums, that might contain duplicates, return all possible unique permutations in any order.
Example 1:
Input: nums = [1,1,2]
Output:
[[1,1,2],
[1,2,1],
[2,1,1]]
Example 2:
Input: nums = [1,2,3]
Output: [[1,2,3],[1,3,2],[2,1,3],[2,3,1],[3,1,2],[3,2,1]]
Constraints:
1 <= nums.length <= 8-10 <= nums[i] <= 10
思路
注意去重
C++解法
class Solution {
private:
vector<vector<int>> result;
vector<int> path;
void backtracking (vector<int>& nums, vector<bool>& used) {
// 此时说明找到了一组
if (path.size() == nums.size()) {
result.push_back(path);
return;
}
for (int i = 0; i < nums.size(); i++) {
// used[i - 1] == true,说明同一树枝nums[i - 1]使用过
// used[i - 1] == false,说明同一树层nums[i - 1]使用过
// 如果同一树层nums[i - 1]使用过则直接跳过
if (i > 0 && nums[i] == nums[i - 1] && used[i - 1] == false) {
continue;
}
if (used[i] == false) {
used[i] = true;
path.push_back(nums[i]);
backtracking(nums, used);
path.pop_back();
used[i] = false;
}
}
}
public:
vector<vector<int>> permuteUnique(vector<int>& nums) {
result.clear();
path.clear();
sort(nums.begin(), nums.end()); // 排序
vector<bool> used(nums.size(), false);
backtracking(nums, used);
return result;
}
};
时间复杂度: 最差情况所有元素都是唯一的。复杂度和全排列1都是 O(n! * n)
对于 n 个元素一共有 n! 中排列方案。而对于每一个答案,我们需要 O(n) 去复制最终放到 result 数组
空间复杂度: O(n)
回溯树的深度取决于我们有多少个元素
784. Letter Case Permutation
Given a string s, you can transform every letter individually to be lowercase or uppercase to create another string.
Return a list of all possible strings we could create. Return the output in any order.
Example 1:
Input: s = "a1b2"
Output: ["a1b2","a1B2","A1b2","A1B2"]
Example 2:
Input: s = "3z4"
Output: ["3z4","3Z4"]
Constraints:
1 <= s.length <= 12sconsists of lowercase English letters, uppercase English letters, and digits.
思路
Consider the below recursion tree for input string S="a1b2"
Initially OUTPUT = "".
By observing the above recursion tree, we come to the below conclusion.
There are two main cases which needs to be solved recursively:
-
The element at the given index is a digit
- Append the digit to the end of
currand go to next index(i+1).curr.push_back(s[i]); solve(curr,s,i+1);
- Append the digit to the end of
-
The element at the given index is an alphabet, this case has two sub cases:
-
Append
tolower(s[i])tocurrand go to next index (i+1).//sub case 1, considering lower case string c1=curr; c1.push_back(tolower(s[i])); solve(c1,s,i+1); -
Append
toupper(s[i])tocurrand go to next index (i+1).//sub case 2, considering upper case string c2=curr; c2.push_back(toupper(s[i])); solve(c2,s,i+1);
-
If at any function call, the index = S.length(), then curr string has one of our output, so save it in ans vector,
// if end of the string is reached
if(i==s.length()){
ans.push_back(curr); // push the current "curr" string to ans
return;
}
At the end of the recursion return ans.
C++解法
class Solution {
private:
vector<string> result;
void backtracking(string s, string path, int index){
if(index == s.size()){
result.push_back(path);
return;
}
if(isdigit(s[index])){
path.push_back(s[index]);
backtracking(s, path, index + 1);
}else{
string lowerpath = path;
lowerpath.push_back(tolower(s[index]));
backtracking(s, lowerpath, index + 1);
string upperpath = path;
upperpath.push_back(toupper(s[index]));
backtracking(s, upperpath, index + 1);
}
}
public:
vector<string> letterCasePermutation(string s) {
backtracking(s, "", 0);
return result;
}
};
31. Next Permutation
A permutation of an array of integers is an arrangement of its members into a sequence or linear order.
For example, for arr = [1,2,3], the following are all the permutations of arr: [1,2,3], [1,3,2], [2, 1, 3], [2, 3, 1], [3,1,2], [3,2,1].
The next permutation of an array of integers is the next lexicographically greater permutation of its integer. More formally, if all the permutations of the array are sorted in one container according to their lexicographical order, then the next permutation of that array is the permutation that follows it in the sorted container. If such arrangement is not possible, the array must be rearranged as the lowest possible order (i.e., sorted in ascending order).
- For example, the next permutation of
arr = [1,2,3]is[1,3,2]. - Similarly, the next permutation of
arr = [2,3,1]is[3,1,2]. - While the next permutation of
arr = [3,2,1]is[1,2,3]because[3,2,1]does not have a lexicographical larger rearrangement.
Given an array of integers nums, find the next permutation of nums.
The replacement must be in place and use only constant extra memory.
Example 1:
Input: nums = [1,2,3]
Output: [1,3,2]
Example 2:
Input: nums = [3,2,1]
Output: [1,2,3]
Example 3:
Input: nums = [1,1,5]
Output: [1,5,1]
Constraints:
1 <= nums.length <= 1000 <= nums[i] <= 100
思路
先找breakpoint(从右向左第一个小于右边相邻元素的数字),
C++解法
class Solution {
public:
void nextPermutation(vector<int>& nums) {
int n = nums.size(), i = n - 2;
// Step 1: Find the breakpoint
while (i >= 0 && nums[i] >= nums[i + 1]) {
i--;
}
if (i >= 0) {
// Step 2: Find the smallest element larger than nums[i]
int j = n - 1;
while (nums[j] <= nums[i]) {
j--;
}
swap(nums[i], nums[j]);
}
// Step 3: Reverse the subarray to the right of i
reverse(nums.begin() + i + 1, nums.end());
}
};
Java解法
class Solution {
public void reverse(int[] nums, int i, int j) {
while (i < j) {
int temp = nums[j];
nums[j] = nums[i];
nums[i] = temp;
i++; // 更新 i
j--; // 更新 j
}
}
public void nextPermutation(int[] nums) {
int length = nums.length;
int i = length - 2;
// 找到第一个下降的元素
while (i >= 0 && nums[i] >= nums[i + 1]) i--;
if (i >= 0) {
int j = length - 1;
// 找到比 nums[i] 大的最右边元素
while (j >= 0 && nums[j] <= nums[i]) j--;
// 交换元素
int temp = nums[j];
nums[j] = nums[i];
nums[i] = temp;
}
// 反转后面的元素
reverse(nums, i + 1, length - 1);
}
}
Python3解法
Go解法
棋盘
51. N-Queens
The n-queens puzzle is the problem of placing n queens on an n x n chessboard such that no two queens attack each other.
Given an integer n, return all distinct solutions to the n-queens puzzle. You may return the answer in any order.
Each solution contains a distinct board configuration of the n-queens' placement, where 'Q' and '.' both indicate a queen and an empty space, respectively.
Example 1:

Input: n = 4
Output: [[".Q..","...Q","Q...","..Q."],["..Q.","Q...","...Q",".Q.."]]
Explanation: There exist two distinct solutions to the 4-queens puzzle as shown above
Example 2:
Input: n = 1
Output: [["Q"]]
Constraints:
1 <= n <= 9
思路
都知道n皇后问题是回溯算法解决的经典问题,但是用回溯解决多了组合、切割、子集、排列问题之后,遇到这种二维矩阵还会有点不知所措。
首先来看一下皇后们的约束条件:
- 不能同行
- 不能同列
- 不能同斜线
确定完约束条件,来看看究竟要怎么去搜索皇后们的位置,其实搜索皇后的位置,可以抽象为一棵树。
下面我用一个 3 * 3 的棋盘,将搜索过程抽象为一棵树,如图:
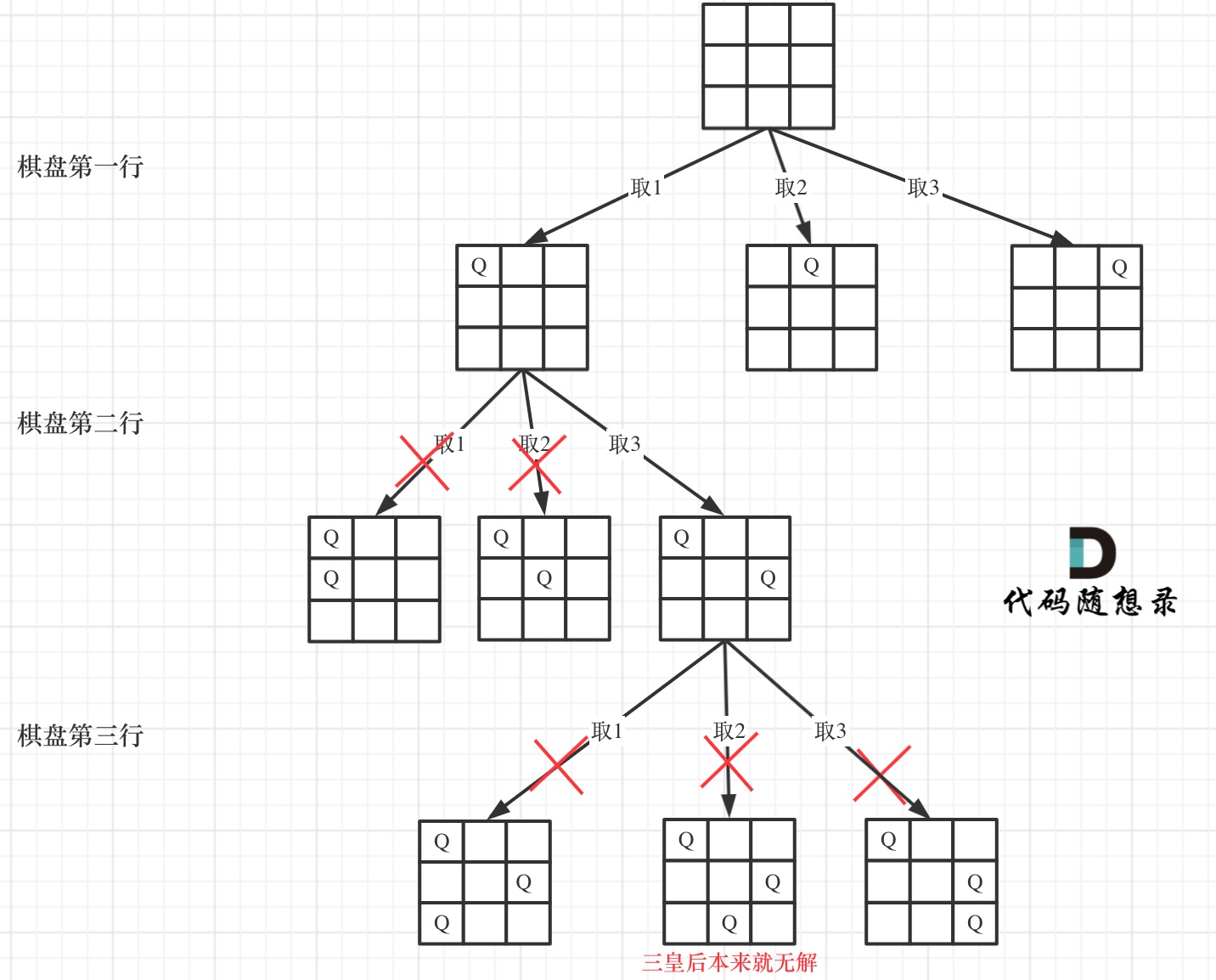
从图中,可以看出,二维矩阵中矩阵的高就是这棵树的高度,矩阵的宽就是树形结构中每一个节点的宽度。
那么我们用皇后们的约束条件,来回溯搜索这棵树,只要搜索到了树的叶子节点,说明就找到了皇后们的合理位置了。
按照我总结的如下回溯模板,我们来依次分析:
void backtracking(参数) {
if (终止条件) {
存放结果;
return;
}
for (选择:本层集合中元素(树中节点孩子的数量就是集合的大小)) {
处理节点;
backtracking(路径,选择列表); // 递归
回溯,撤销处理结果
}
}
- 递归函数参数
我依然是定义全局变量二维数组result来记录最终结果。
参数n是棋盘的大小,然后用row来记录当前遍历到棋盘的第几层了。
代码如下:
vector<vector<string>> result;
void backtracking(int n, int row, vector<string>& chessboard) {}
- 递归终止条件
在如下树形结构中:
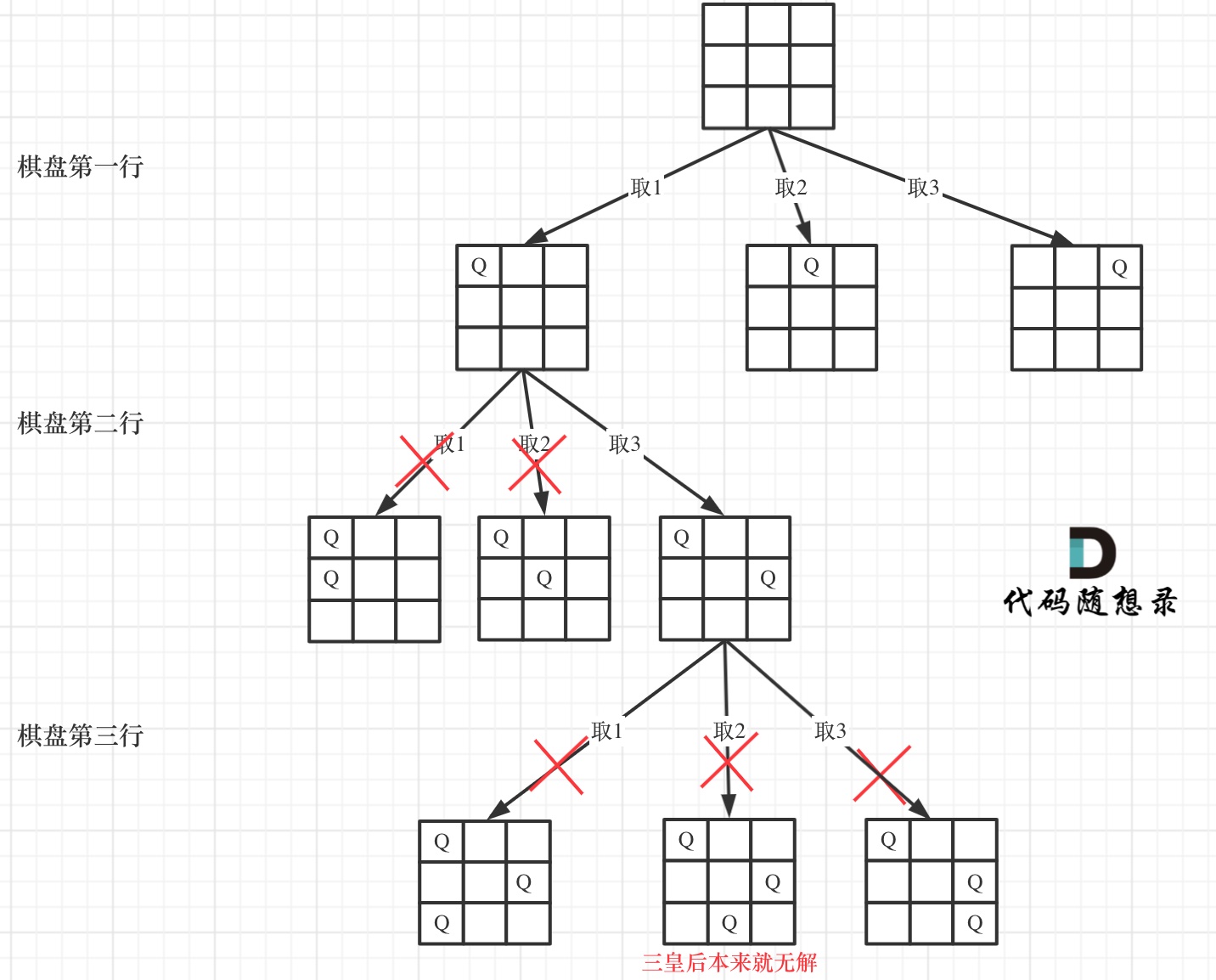
可以看出,当递归到棋盘最底层(也就是叶子节点)的时候,就可以收集结果并返回了。
代码如下:
if (row == n) {
result.push_back(chessboard);
return;
}
- 单层搜索的逻辑
递归深度就是row控制棋盘的行,每一层里for循环的col控制棋盘的列,一行一列,确定了放置皇后的位置。
每次都是要从新的一行的起始位置开始搜,所以都是从0开始。
代码如下:
for (int col = 0; col < n; col++) {
if (isValid(row, col, chessboard, n)) { // 验证合法就可以放
chessboard[row][col] = 'Q'; // 放置皇后
backtracking(n, row + 1, chessboard);
chessboard[row][col] = '.'; // 回溯,撤销皇后
}
}
- 验证棋盘是否合法
按照如下标准去重:
- 不能同行
- 不能同列
- 不能同斜线 (45度和135度角)
代码如下:
bool isValid(int row, int col, vector<string>& chessboard, int n) {
// 检查列
for (int i = 0; i < row; i++) { // 这是一个剪枝
if (chessboard[i][col] == 'Q') {
return false;
}
}
// 检查 135 度角是否有皇后
for (int i = row - 1, j = col - 1; i >=0 && j >= 0; i--, j--) {
if (chessboard[i][j] == 'Q') {
return false;
}
}
// 检查 45 度角是否有皇后
for(int i = row - 1, j = col + 1; i >= 0 && j < n; i--, j++) {
if (chessboard[i][j] == 'Q') {
return false;
}
}
return true;
}
在这份代码中,细心的同学可以发现为什么没有在同行进行检查呢?
因为在单层搜索的过程中,每一层递归,只会选for循环(也就是同一行)里的一个元素,所以不用去重了。
如果从来没有接触过N皇后问题的同学看着这样的题会感觉无从下手,可能知道要用回溯法,但也不知道该怎么去搜。
这里我明确给出了棋盘的宽度就是for循环的长度,递归的深度就是棋盘的高度,这样就可以套进回溯法的模板里了。
C++解法
class Solution {
private:
vector<vector<string>> result;
// n 为输入的棋盘大小
// row 是当前递归到棋盘的第几行了
void backtracking(int n, int row, vector<string>& chessboard) {
if (row == n) {
result.push_back(chessboard);
return;
}
for (int col = 0; col < n; col++) {
if (isValid(row, col, chessboard, n)) { // 验证合法就可以放
chessboard[row][col] = 'Q'; // 放置皇后
backtracking(n, row + 1, chessboard);
chessboard[row][col] = '.'; // 回溯,撤销皇后
}
}
}
bool isValid(int row, int col, vector<string>& chessboard, int n) {
// 检查列
for (int i = 0; i < row; i++) { // 这是一个剪枝
if (chessboard[i][col] == 'Q') {
return false;
}
}
// 检查135度角是否有皇后
for (int i = row - 1, j = col - 1; i >=0 && j >= 0; i--, j--) {
if (chessboard[i][j] == 'Q') {
return false;
}
}
// 检查45度角是否有皇后
for(int i = row - 1, j = col + 1; i >= 0 && j < n; i--, j++) {
if (chessboard[i][j] == 'Q') {
return false;
}
}
return true;
}
public:
vector<vector<string>> solveNQueens(int n) {
result.clear();
std::vector<std::string> chessboard(n, std::string(n, '.'));
backtracking(n, 0, chessboard);
return result;
}
};
- 时间复杂度: O(n!)
- 空间复杂度: O(n)
52. N-Queens II
The n-queens puzzle is the problem of placing n queens on an n x n chessboard such that no two queens attack each other.
Given an integer n, return the number of distinct solutions to the n-queens puzzle.
Example 1:
Input: n = 4
Output: 2
Explanation: There are two distinct solutions to the 4-queens puzzle as shown.
Example 2:
Input: n = 1
Output: 1
Constraints:
1 <= n <= 9
思路
和上面一样,计算result中的元素个数作为最终结果即可。
C++解法
class Solution {
public:
vector<vector<string>> result;
void backtracking(vector<string>& chessBoard, int n, int row){
if(row == n){
result.push_back(chessBoard);
return;
}
for(int i = 0; i < chessBoard[row].size(); i++){
if(isValid(chessBoard, n, row, i) && chessBoard[row][i] == '.'){
chessBoard[row][i] = 'Q';
backtracking(chessBoard, n, row + 1);
chessBoard[row][i] = '.';
}
}
}
bool isValid(vector<string>& chessBoard, int n, int row, int col){
// 检查列
for (int i = 0; i < row; i++) { // 这是一个剪枝
if (chessBoard[i][col] == 'Q') {
return false;
}
}
// 检查135度角是否有皇后
for (int i = row - 1, j = col - 1; i >=0 && j >= 0; i--, j--) {
if (chessBoard[i][j] == 'Q') {
return false;
}
}
// 检查45度角是否有皇后
for(int i = row - 1, j = col + 1; i >= 0 && j < n; i--, j++) {
if (chessBoard[i][j] == 'Q') {
return false;
}
}
return true;
}
int totalNQueens(int n) {
vector<string> chessBoard(n, string(n, '.'));
backtracking(chessBoard, n, 0);
return result.size();
}
};
37. Sudoku Solver
Write a program to solve a Sudoku puzzle by filling the empty cells.
A sudoku solution must satisfy all of the following rules:
- Each of the digits
1-9must occur exactly once in each row. - Each of the digits
1-9must occur exactly once in each column. - Each of the digits
1-9must occur exactly once in each of the 93x3sub-boxes of the grid.
The '.' character indicates empty cells.
Example 1:

Input: board = [["5","3",".",".","7",".",".",".","."],["6",".",".","1","9","5",".",".","."],[".","9","8",".",".",".",".","6","."],["8",".",".",".","6",".",".",".","3"],["4",".",".","8",".","3",".",".","1"],["7",".",".",".","2",".",".",".","6"],[".","6",".",".",".",".","2","8","."],[".",".",".","4","1","9",".",".","5"],[".",".",".",".","8",".",".","7","9"]]
Output: [["5","3","4","6","7","8","9","1","2"],["6","7","2","1","9","5","3","4","8"],["1","9","8","3","4","2","5","6","7"],["8","5","9","7","6","1","4","2","3"],["4","2","6","8","5","3","7","9","1"],["7","1","3","9","2","4","8","5","6"],["9","6","1","5","3","7","2","8","4"],["2","8","7","4","1","9","6","3","5"],["3","4","5","2","8","6","1","7","9"]]
Explanation: The input board is shown above and the only valid solution is shown below:

Constraints:
board.length == 9board[i].length == 9board[i][j]is a digit or'.'.- It is guaranteed that the input board has only one solution.
思路
棋盘搜索问题可以使用回溯法暴力搜索,只不过这次我们要做的是二维递归。
怎么做二维递归呢?
N皇后问题是因为每一行每一列只放一个皇后,只需要一层for循环遍历一行,递归来遍历列,然后一行一列确定皇后的唯一位置。
本题就不一样了,本题中棋盘的每一个位置都要放一个数字(而N皇后是一行只放一个皇后),并检查数字是否合法,解数独的树形结构要比N皇后更宽更深。
因为这个树形结构太大了,我抽取一部分,如图所示:
- 递归函数以及参数
递归函数的返回值需要是bool类型,为什么呢?
因为解数独找到一个符合的条件(就在树的叶子节点上)立刻就返回,相当于找从根节点到叶子节点一条唯一路径,所以需要使用bool返回值。
代码如下:
bool backtracking(vector<vector<char>>& board)
- 递归终止条件
本题递归不用终止条件,解数独是要遍历整个树形结构寻找可能的叶子节点就立刻返回。
不用终止条件会不会死循环?
递归的下一层的棋盘一定比上一层的棋盘多一个数,等数填满了棋盘自然就终止(填满当然好了,说明找到结果了),所以不需要终止条件!
那么有没有永远填不满的情况呢?
这个问题我在递归单层搜索逻辑里再来讲!
- 递归单层搜索逻辑
在树形图中可以看出我们需要的是一个二维的递归 (一行一列)
一个for循环遍历棋盘的行,一个for循环遍历棋盘的列,一行一列确定下来之后,递归遍历这个位置放9个数字的可能性!
代码如下:(详细看注释)
bool backtracking(vector<vector<char>>& board) {
for (int i = 0; i < board.size(); i++) { // 遍历行
for (int j = 0; j < board[0].size(); j++) { // 遍历列
if (board[i][j] != '.') continue;
for (char k = '1'; k <= '9'; k++) { // (i, j) 这个位置放k是否合适
if (isValid(i, j, k, board)) {
board[i][j] = k; // 放置k
if (backtracking(board)) return true; // 如果找到合适一组立刻返回
board[i][j] = '.'; // 回溯,撤销k
}
}
return false; // 9个数都试完了,都不行,那么就返回false
}
}
return true; // 遍历完没有返回false,说明找到了合适棋盘位置了
}
注意这里return false的地方,这里放return false 是有讲究的。
因为如果一行一列确定下来了,这里尝试了9个数都不行,说明这个棋盘找不到解决数独问题的解!
那么会直接返回, 这也就是为什么没有终止条件也不会永远填不满棋盘而无限递归下去!
判断棋盘是否合法有如下三个维度:
- 同行是否重复
- 同列是否重复
- 9宫格里是否重复
代码如下:
bool isValid(int row, int col, char val, vector<vector<char>>& board) {
for (int i = 0; i < 9; i++) { // 判断行里是否重复
if (board[row][i] == val) {
return false;
}
}
for (int j = 0; j < 9; j++) { // 判断列里是否重复
if (board[j][col] == val) {
return false;
}
}
int startRow = (row / 3) * 3;
int startCol = (col / 3) * 3;
for (int i = startRow; i < startRow + 3; i++) { // 判断9方格里是否重复
for (int j = startCol; j < startCol + 3; j++) {
if (board[i][j] == val ) {
return false;
}
}
}
return true;
}
C++解法
class Solution {
private:
bool backtracking(vector<vector<char>>& board) {
for (int i = 0; i < board.size(); i++) { // 遍历行
for (int j = 0; j < board[0].size(); j++) { // 遍历列
if (board[i][j] == '.') {
for (char k = '1'; k <= '9'; k++) { // (i, j) 这个位置放k是否合适
if (isValid(i, j, k, board)) {
board[i][j] = k; // 放置k
if (backtracking(board)) return true; // 如果找到合适一组立刻返回
board[i][j] = '.'; // 回溯,撤销k
}
}
return false; // 9个数都试完了,都不行,那么就返回false
}
}
}
return true; // 遍历完没有返回false,说明找到了合适棋盘位置了
}
bool isValid(int row, int col, char val, vector<vector<char>>& board) {
for (int i = 0; i < 9; i++) { // 判断行里是否重复
if (board[row][i] == val) {
return false;
}
}
for (int j = 0; j < 9; j++) { // 判断列里是否重复
if (board[j][col] == val) {
return false;
}
}
int startRow = (row / 3) * 3;
int startCol = (col / 3) * 3;
for (int i = startRow; i < startRow + 3; i++) { // 判断9方格里是否重复
for (int j = startCol; j < startCol + 3; j++) {
if (board[i][j] == val ) {
return false;
}
}
}
return true;
}
public:
void solveSudoku(vector<vector<char>>& board) {
backtracking(board);
}
};
36. Valid Sudoku
Determine if a 9 x 9 Sudoku board is valid. Only the filled cells need to be validated according to the following rules:
- Each row must contain the digits
1-9without repetition. - Each column must contain the digits
1-9without repetition. - Each of the nine
3 x 3sub-boxes of the grid must contain the digits1-9without repetition.
Note:
- A Sudoku board (partially filled) could be valid but is not necessarily solvable.
- Only the filled cells need to be validated according to the mentioned rules.
Example 1:
**Input:** board =
[["5","3",".",".","7",".",".",".","."]
,["6",".",".","1","9","5",".",".","."]
,[".","9","8",".",".",".",".","6","."]
,["8",".",".",".","6",".",".",".","3"]
,["4",".",".","8",".","3",".",".","1"]
,["7",".",".",".","2",".",".",".","6"]
,[".","6",".",".",".",".","2","8","."]
,[".",".",".","4","1","9",".",".","5"]
,[".",".",".",".","8",".",".","7","9"]]
Output: true
Example 2:
**Input:** board =
[["8","3",".",".","7",".",".",".","."]
,["6",".",".","1","9","5",".",".","."]
,[".","9","8",".",".",".",".","6","."]
,["8",".",".",".","6",".",".",".","3"]
,["4",".",".","8",".","3",".",".","1"]
,["7",".",".",".","2",".",".",".","6"]
,[".","6",".",".",".",".","2","8","."]
,[".",".",".","4","1","9",".",".","5"]
,[".",".",".",".","8",".",".","7","9"]]
Output: false
Explanation: Same as Example 1, except with the 5 in the top left corner being modified to 8. Since there are two 8's in the top left 3x3 sub-box, it is invalid.
Constraints:
board.length == 9board[i].length == 9board[i][j]is a digit1-9or'.'.
思路
遍历棋盘,分别处理每个不是.的位置,先保存,然后切换成.,最后尝试重新插入。如果不能重新插入,说明原来的棋盘不是合法的。
C++解法
class Solution {
public:
bool backtracking(vector<vector<char>>& board){
for(int i = 0; i < board.size(); i++){
for(int j = 0; j < board[i].size(); j++){
if (board[i][j] != '.'){
char val = board[i][j];
board[i][j] = '.';
if(!isValid(board, i, j, val)){
return false;
}
board[i][j] = val;
}
}
}
return true;
}
bool isValid(vector<vector<char>>& board, int row, int col, char val){
for (int i = 0; i < 9; i++) { // 判断行里是否重复
if (board[row][i] == val) {
return false;
}
}
for (int j = 0; j < 9; j++) { // 判断列里是否重复
if (board[j][col] == val) {
return false;
}
}
int startRow = (row / 3) * 3;
int startCol = (col / 3) * 3;
for (int i = startRow; i < startRow + 3; i++) { // 判断9方格里是否重复
for (int j = startCol; j < startCol + 3; j++) {
if (board[i][j] == val ) {
return false;
}
}
}
return true;
}
bool isValidSudoku(vector<vector<char>>& board) {
return backtracking(board);
}
};
贪心算法
局部最优推出全局最优
| 题目分类 | 题目编号 |
|---|---|
| 数组与贪心算法 | 605、121、122、561、455、575、135、409、621、179、56、57、228、452、435、646、406、48、169、215、75、324、517、649、678、420 |
| 子数组与贪心算法 | 53、134、581、152 |
| 子序列与贪心算法 | 334、376、659 |
| 数字与贪心 | 343 |
| 单调栈法 | 496、503、456、316、402、321、84、85 |
数组与贪心
子数组与贪心算法
53. Maximum Subarray
Given an integer array nums, find the subarray with the largest sum, and return its sum.
Example 1:
Input: nums = [-2,1,-3,4,-1,2,1,-5,4]
Output: 6
Explanation: The subarray [4,-1,2,1] has the largest sum 6.
Example 2:
Input: nums = [1]
Output: 1
Explanation: The subarray [1] has the largest sum 1.
Example 3:
Input: nums = [5,4,-1,7,8]
Output: 23
Explanation: The subarray [5,4,-1,7,8] has the largest sum 23.
Constraints:
1 <= nums.length <= 10^5-10^4 <= nums[i] <= 10^4
Follow up: If you have figured out the O(n) solution, try coding another solution using the divide and conquer approach, which is more subtle.
思路
贪心
贪心贪的是哪里呢?
如果 -2 1 在一起,计算起点的时候,一定是从 1 开始计算,因为负数只会拉低总和,这就是贪心贪的地方!
局部最优:当前“连续和”为负数的时候立刻放弃,从下一个元素重新计算“连续和”,因为负数加上下一个元素 “连续和”只会越来越小。
全局最优:选取最大“连续和”
局部最优的情况下,并记录最大的“连续和”,可以推出全局最优。
从代码角度上来讲:遍历 nums,从头开始用 count 累积,如果 count 一旦加上 nums[i]变为负数,那么就应该从 nums[i+1]开始从 0 累积 count 了,因为已经变为负数的 count,只会拖累总和。
这相当于是暴力解法中的不断调整最大子序和区间的起始位置。
那有同学问了,区间终止位置不用调整么? 如何才能得到最大“连续和”呢?
区间的终止位置,其实就是如果 count 取到最大值了,及时记录下来了。例如如下代码:
if (count > result) result = count;
这样相当于是用 result 记录最大子序和区间和(变相的算是调整了终止位置)。
如动画所示:
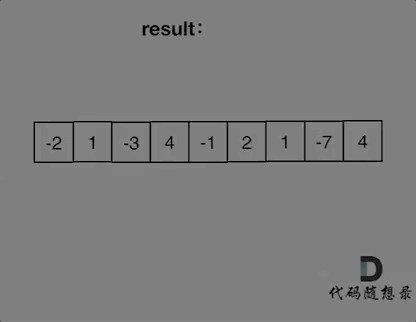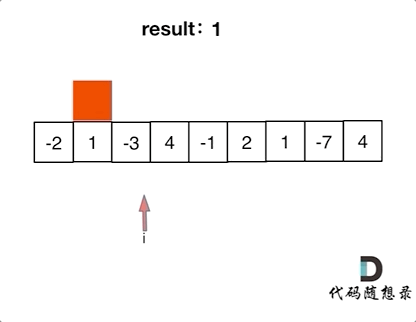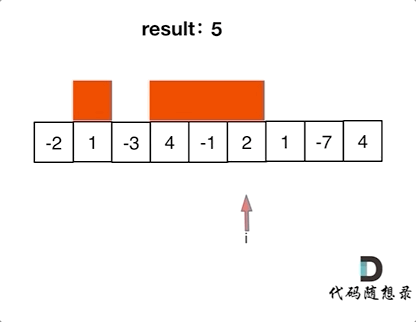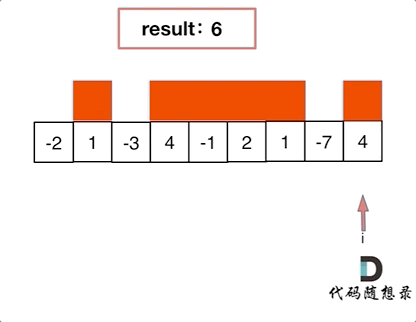
红色的起始位置就是贪心每次取 count 为正数的时候,开始一个区间的统计。
当然题目没有说如果数组为空,应该返回什么,所以数组为空的话返回啥都可以了。
常见误区一:
不少同学认为 如果输入用例都是-1,或者都是负数,这个贪心算法跑出来的结果是 0, 这是又一次证明脑洞模拟不靠谱的经典案例,建议大家把代码运行一下试一试,就知道了,也会理解为什么 result 要初始化为最小负数了。
常见误区二:
大家在使用贪心算法求解本题,经常陷入的误区,就是分不清,是遇到 负数就选择起始位置,还是连续和为负选择起始位置。
在动画演示用,大家可以发现, 4,遇到 -1 的时候,我们依然累加了,为什么呢?
因为和为 3,只要连续和还是正数就会 对后面的元素 起到增大总和的作用。 所以只要连续和为正数我们就保留。
这里也会有录友疑惑,那 4 + -1 之后 不就变小了吗? 会不会错过 4 成为最大连续和的可能性?
其实并不会,因为还有一个变量 result 一直在更新最大的连续和,只要有更大的连续和出现,result 就更新了,那么 result 已经把 4 更新了,后面连续和变成 3,也不会对最后结果有影响。
动态规划
这次我们用动态规划的思路再来分析一次。
动规五部曲如下:
- 确定dp数组(dp table)以及下标的含义
dp[i]:包括下标i(以nums[i]为结尾)的最大连续子序列和为dp[i]。
- 确定递推公式
dp[i]只有两个方向可以推出来:
- dp[i - 1] + nums[i],即:nums[i]加入当前连续子序列和
- nums[i],即:从头开始计算当前连续子序列和
一定是取最大的,所以dp[i] = max(dp[i - 1] + nums[i], nums[i]);
- dp数组如何初始化
从递推公式可以看出来dp[i]是依赖于dp[i - 1]的状态,dp[0]就是递推公式的基础。
dp[0]应该是多少呢?
根据dp[i]的定义,很明显dp[0]应为nums[0]即dp[0] = nums[0]。
- 确定遍历顺序
递推公式中dp[i]依赖于dp[i - 1]的状态,需要从前向后遍历。
- 举例推导dp数组
以示例一为例,输入:nums = [-2,1,-3,4,-1,2,1,-5,4],对应的dp状态如下:
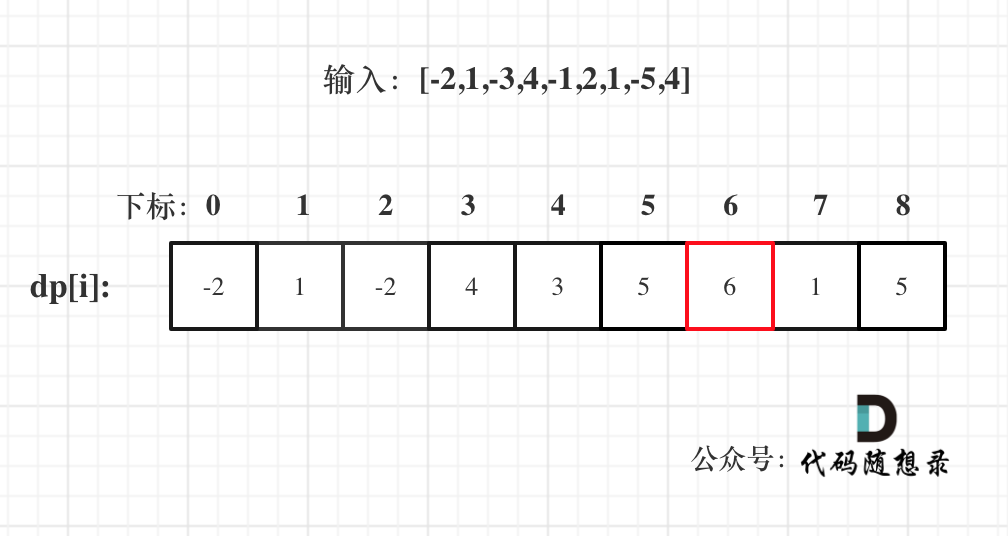
注意最后的结果可不是dp[nums.size() - 1]! ,而是dp[6]。
在回顾一下dp[i]的定义:包括下标i之前的最大连续子序列和为dp[i]。
那么我们要找最大的连续子序列,就应该找每一个i为终点的连续最大子序列。
所以在递推公式的时候,可以直接选出最大的dp[i]。
C++解法
贪心解法:
class Solution {
public:
int maxSubArray(vector<int>& nums) {
int result = INT32_MIN;
int count = 0;
for (int i = 0; i < nums.size(); i++) {
count += nums[i];
if (count > result) { // 取区间累计的最大值(相当于不断确定最大子序终止位置)
result = count;
}
if (count <= 0) count = 0; // 相当于重置最大子序起始位置,因为遇到负数一定是拉低总和
}
return result;
}
};
- 时间复杂度:O(n)
- 空间复杂度:O(1)
动态规划解法:
class Solution {
public:
int maxSubArray(vector<int>& nums) {
if (nums.size() == 0) return 0;
vector<int> dp(nums.size());
dp[0] = nums[0];
int result = dp[0];
for (int i = 1; i < nums.size(); i++) {
dp[i] = max(dp[i - 1] + nums[i], nums[i]); // 状态转移公式
if (dp[i] > result) result = dp[i]; // result 保存dp[i]的最大值
}
return result;
}
};
- 时间复杂度:O(n)
- 空间复杂度:O(n)
Java解法
贪心算法:
class Solution {
public int maxSubArray(int[] nums) {
int currSum = 0;
int maxSum = Integer.MIN_VALUE; // 修正这里的MIN_VALUE
for (int i = 0; i < nums.length; i++) {
currSum += nums[i];
if (currSum > maxSum) {
maxSum = currSum;
}
if (currSum < 0) {
currSum = 0;
}
}
return maxSum;
}
}
子序列与贪心算法
376. Wiggle Subsequence
A wiggle sequence is a sequence where the differences between successive numbers strictly alternate between positive and negative. The first difference (if one exists) may be either positive or negative. A sequence with one element and a sequence with two non-equal elements are trivially wiggle sequences.
- For example,
[1, 7, 4, 9, 2, 5]is a wiggle sequence because the differences(6, -3, 5, -7, 3)alternate between positive and negative. - In contrast,
[1, 4, 7, 2, 5]and[1, 7, 4, 5, 5]are not wiggle sequences. The first is not because its first two differences are positive, and the second is not because its last difference is zero.
A subsequence is obtained by deleting some elements (possibly zero) from the original sequence, leaving the remaining elements in their original order.
Given an integer array nums, return the length of the longest wiggle subsequence of nums.
Example 1:
Input: nums = [1,7,4,9,2,5]
Output: 6
Explanation: The entire sequence is a wiggle sequence with differences (6, -3, 5, -7, 3).
Example 2:
Input: nums = [1,17,5,10,13,15,10,5,16,8]
Output: 7
Explanation: There are several subsequences that achieve this length.
One is [1, 17, 10, 13, 10, 16, 8] with differences (16, -7, 3, -3, 6, -8).
Example 3:
Input: nums = [1,2,3,4,5,6,7,8,9]
Output: 2
Constraints:
1 <= nums.length <= 10000 <= nums[i] <= 1000
Follow up: Could you solve this in O(n) time?
思路
思路 1(贪心解法)
本题要求通过从原始序列中删除一些(也可以不删除)元素来获得子序列,剩下的元素保持其原始顺序。
相信这么一说吓退不少同学,这要求最大摆动序列又可以修改数组,这得如何修改呢?
来分析一下,要求删除元素使其达到最大摆动序列,应该删除什么元素呢?
用示例二来举例,如图所示:
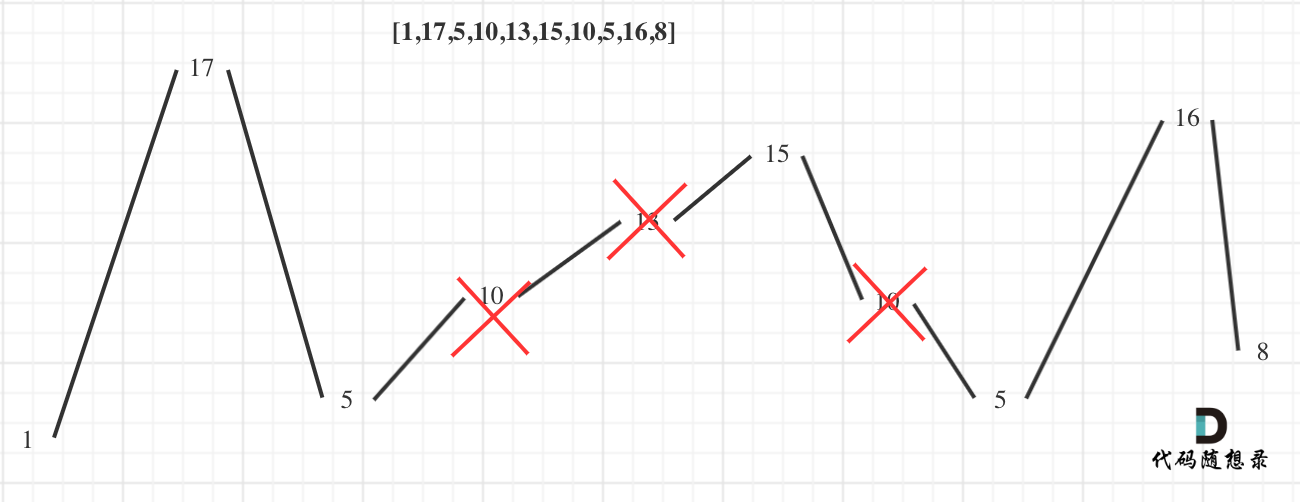
局部最优:删除单调坡度上的节点(不包括单调坡度两端的节点),那么这个坡度就可以有两个局部峰值。
整体最优:整个序列有最多的局部峰值,从而达到最长摆动序列。
局部最优推出全局最优,并举不出反例,那么试试贪心!
(为方便表述,以下说的峰值都是指局部峰值)
实际操作上,其实连删除的操作都不用做,因为题目要求的是最长摆动子序列的长度,所以只需要统计数组的峰值数量就可以了(相当于是删除单一坡度上的节点,然后统计长度)
这就是贪心所贪的地方,让峰值尽可能的保持峰值,然后删除单一坡度上的节点
在计算是否有峰值的时候,大家知道遍历的下标 i ,计算 prediff(nums[i] - nums[i-1]) 和 curdiff(nums[i+1] - nums[i],如果prediff < 0 && curdiff > 0 或者 prediff > 0 && curdiff < 0 此时就有波动就需要统计。
这是我们思考本题的一个大体思路,但本题要考虑三种情况:
- 情况一:上下坡中有平坡
- 情况二:数组首尾两端
- 情况三:单调坡中有平坡
情况一:上下坡中有平坡
例如 [1,2,2,2,1]这样的数组,如图:
它的摇摆序列长度是多少呢? 其实是长度是 3,也就是我们在删除的时候 要不删除左面的三个 2,要不就删除右边的三个 2。
如图,可以统一规则,删除左边的三个 2:
在图中,当 i 指向第一个 2 的时候,prediff > 0 && curdiff = 0 ,当 i 指向最后一个 2 的时候 prediff = 0 && curdiff < 0。
如果我们采用,删左面三个 2 的规则,那么 当 prediff = 0 && curdiff < 0 也要记录一个峰值,因为他是把之前相同的元素都删掉留下的峰值。
所以我们记录峰值的条件应该是: (preDiff <= 0 && curDiff > 0) || (preDiff >= 0 && curDiff < 0),为什么这里允许 prediff == 0 ,就是为了 上面我说的这种情况。
情况二:数组首尾两端
所以本题统计峰值的时候,数组最左面和最右面如何统计呢?
题目中说了,如果只有两个不同的元素,那摆动序列也是 2。
例如序列[2,5],如果靠统计差值来计算峰值个数就需要考虑数组最左面和最右面的特殊情况。
因为我们在计算 prediff(nums[i] - nums[i-1]) 和 curdiff(nums[i+1] - nums[i])的时候,至少需要三个数字才能计算,而数组只有两个数字。
这里我们可以写死,就是 如果只有两个元素,且元素不同,那么结果为 2。
不写死的话,如何和我们的判断规则结合在一起呢?
可以假设,数组最前面还有一个数字,那这个数字应该是什么呢?
之前我们在 讨论 情况一:相同数字连续 的时候, prediff = 0 ,curdiff < 0 或者 >0 也记为波谷。
那么为了规则统一,针对序列[2,5],可以假设为[2,2,5],这样它就有坡度了即 preDiff = 0,如图:
针对以上情形,result 初始为 1(默认最右面有一个峰值),此时 curDiff > 0 && preDiff <= 0,那么 result++(计算了左面的峰值),最后得到的 result 就是 2(峰值个数为 2 即摆动序列长度为 2)
经过以上分析后,我们可以写出如下代码:
// 版本一
class Solution {
public:
int wiggleMaxLength(vector<int>& nums) {
if (nums.size() <= 1) return nums.size();
int curDiff = 0; // 当前一对差值
int preDiff = 0; // 前一对差值
int result = 1; // 记录峰值个数,序列默认序列最右边有一个峰值
for (int i = 0; i < nums.size() - 1; i++) {
curDiff = nums[i + 1] - nums[i];
// 出现峰值
if ((preDiff <= 0 && curDiff > 0) || (preDiff >= 0 && curDiff < 0)) {
result++;
}
preDiff = curDiff;
}
return result;
}
};
- 时间复杂度:O(n)
- 空间复杂度:O(1)
此时大家是不是发现 以上代码提交也不能通过本题?
所以此时我们要讨论情况三!
情况三:单调坡度有平坡
在版本一中,我们忽略了一种情况,即 如果在一个单调坡度上有平坡,例如[1,2,2,2,3,4],如图:
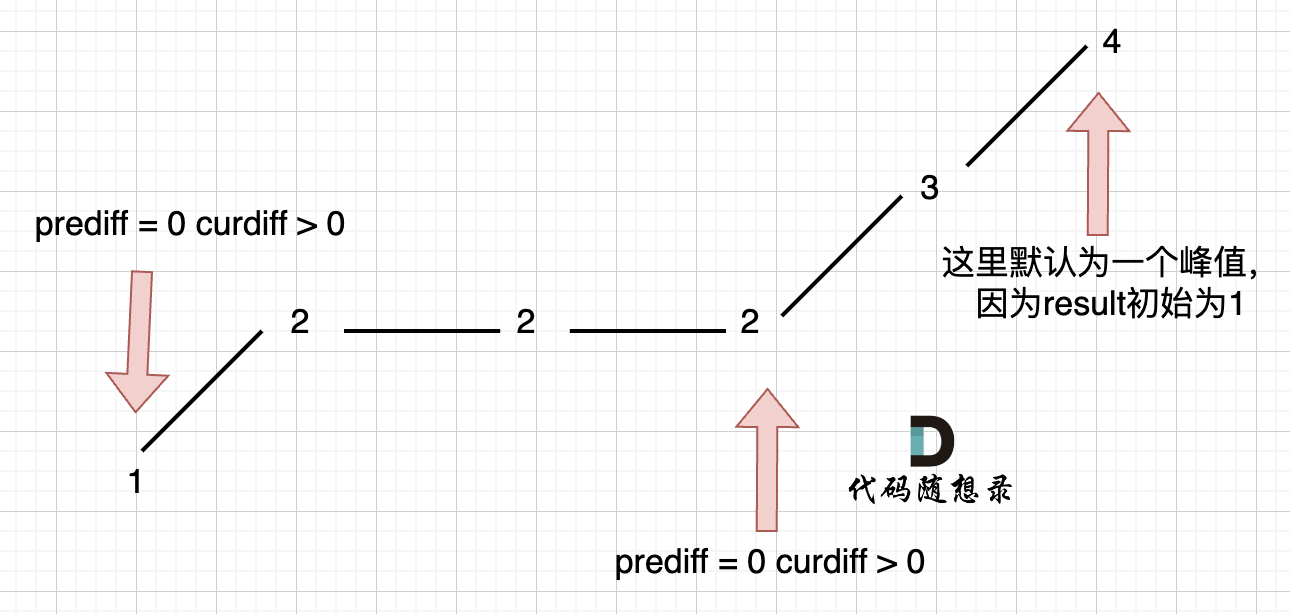
图中,我们可以看出,版本一的代码在三个地方记录峰值,但其实结果因为是 2,因为 单调中的平坡 不能算峰值(即摆动)。
之所以版本一会出问题,是因为我们实时更新了 prediff。
那么我们应该什么时候更新 prediff 呢?
我们只需要在 这个坡度 摆动变化的时候,更新 prediff 就行,这样 prediff 在 单调区间有平坡的时候 就不会发生变化,造成我们的误判。
所以本题的最终代码为:
// 版本二
class Solution {
public:
int wiggleMaxLength(vector<int>& nums) {
if (nums.size() <= 1) return nums.size();
int curDiff = 0; // 当前一对差值
int preDiff = 0; // 前一对差值
int result = 1; // 记录峰值个数,序列默认序列最右边有一个峰值
for (int i = 0; i < nums.size() - 1; i++) {
curDiff = nums[i + 1] - nums[i];
// 出现峰值
if ((preDiff <= 0 && curDiff > 0) || (preDiff >= 0 && curDiff < 0)) {
result++;
preDiff = curDiff; // 注意这里,只在摆动变化的时候更新prediff
}
}
return result;
}
};
其实本题看起来好像简单,但需要考虑的情况还是很复杂的,而且很难一次性想到位。
本题异常情况的本质,就是要考虑平坡, 平坡分两种,一个是 上下中间有平坡,一个是单调有平坡,如图:
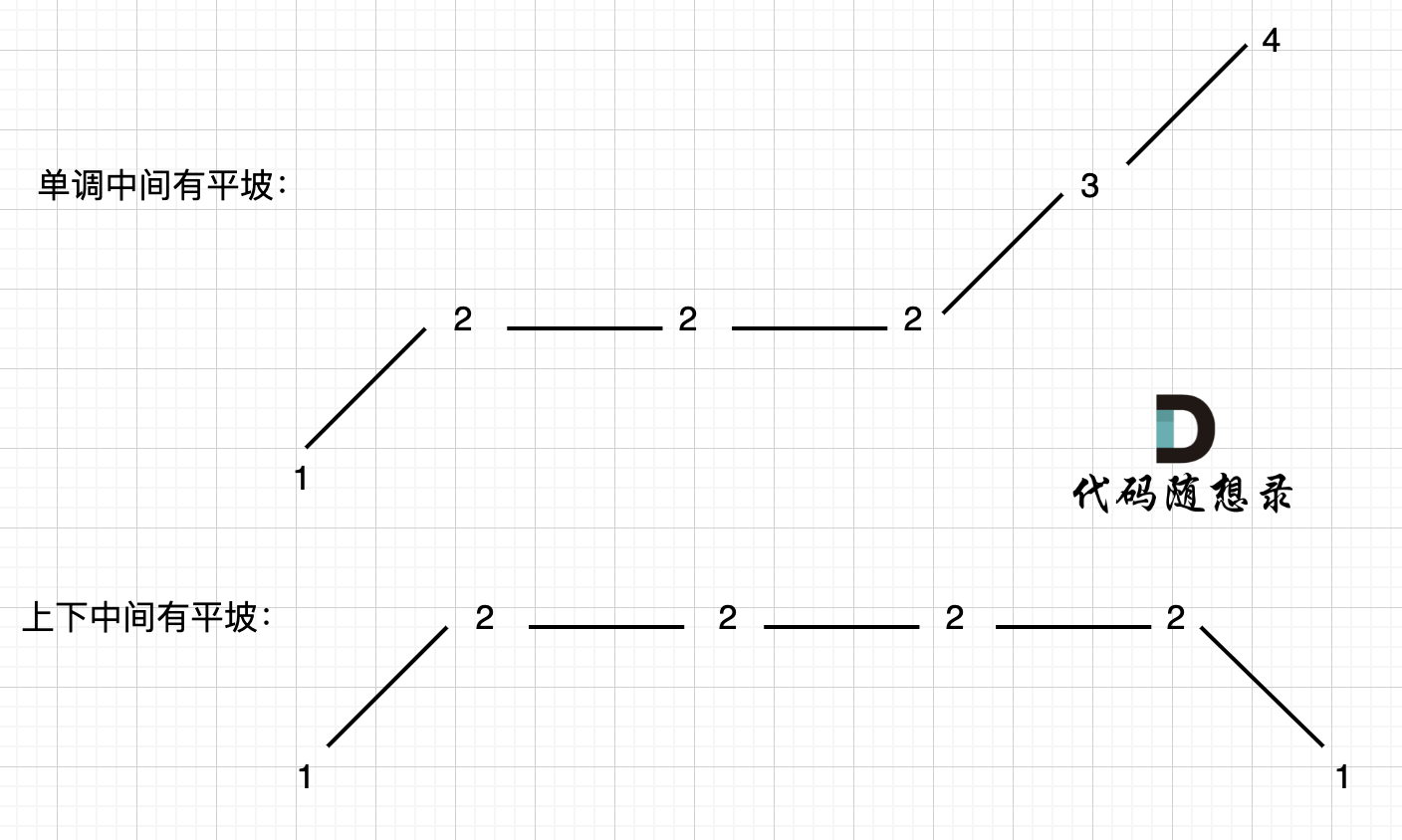
思路 2(动态规划)
考虑用动态规划的思想来解决这个问题。
很容易可以发现,对于我们当前考虑的这个数,要么是作为山峰(即 nums[i] > nums[i-1]),要么是作为山谷(即 nums[i] < nums[i - 1])。
- 设 dp 状态
dp[i][0],表示考虑前 i 个数,第 i 个数作为山峰的摆动子序列的最长长度 - 设 dp 状态
dp[i][1],表示考虑前 i 个数,第 i 个数作为山谷的摆动子序列的最长长度
则转移方程为:
dp[i][0] = max(dp[i][0], dp[j][1] + 1),其中0 < j < i且nums[j] < nums[i],表示将 nums[i]接到前面某个山谷后面,作为山峰。dp[i][1] = max(dp[i][1], dp[j][0] + 1),其中0 < j < i且nums[j] > nums[i],表示将 nums[i]接到前面某个山峰后面,作为山谷。
初始状态:
由于一个数可以接到前面的某个数后面,也可以以自身为子序列的起点,所以初始状态为:dp[0][0] = dp[0][1] = 1。
C++代码如下:
class Solution {
public:
int dp[1005][2];
int wiggleMaxLength(vector<int>& nums) {
memset(dp, 0, sizeof dp);
dp[0][0] = dp[0][1] = 1;
for (int i = 1; i < nums.size(); ++i) {
dp[i][0] = dp[i][1] = 1;
for (int j = 0; j < i; ++j) {
if (nums[j] > nums[i]) dp[i][1] = max(dp[i][1], dp[j][0] + 1);
}
for (int j = 0; j < i; ++j) {
if (nums[j] < nums[i]) dp[i][0] = max(dp[i][0], dp[j][1] + 1);
}
}
return max(dp[nums.size() - 1][0], dp[nums.size() - 1][1]);
}
};
- 时间复杂度:O(n^2)
- 空间复杂度:O(n)
进阶
可以用两棵线段树来维护区间的最大值
- 每次更新
dp[i][0],则在tree1的nums[i]位置值更新为dp[i][0] - 每次更新
dp[i][1],则在tree2的nums[i]位置值更新为dp[i][1] - 则 dp 转移方程中就没有必要 j 从 0 遍历到 i-1,可以直接在线段树中查询指定区间的值即可。
时间复杂度:O(nlog n)
空间复杂度:O(n)
C++解法
本题使用贪心算法的最终代码为:
// 版本二
class Solution {
public:
int wiggleMaxLength(vector<int>& nums) {
if (nums.size() <= 1) return nums.size();
int curDiff = 0; // 当前一对差值
int preDiff = 0; // 前一对差值
int result = 1; // 记录峰值个数,序列默认序列最右边有一个峰值
for (int i = 0; i < nums.size() - 1; i++) {
curDiff = nums[i + 1] - nums[i];
// 出现峰值
if ((preDiff <= 0 && curDiff > 0) || (preDiff >= 0 && curDiff < 0)) {
result++;
preDiff = curDiff; // 注意这里,只在摆动变化的时候更新prediff
}
}
return result;
}
};
数字与贪心
860. Lemonade Change
At a lemonade stand, each lemonade costs $5. Customers are standing in a queue to buy from you and order one at a time (in the order specified by bills). Each customer will only buy one lemonade and pay with either a $5, $10, or $20 bill. You must provide the correct change to each customer so that the net transaction is that the customer pays $5.
Note that you do not have any change in hand at first.
Given an integer array bills where bills[i] is the bill the ith customer pays, return true if you can provide every customer with the correct change, or false otherwise.
Example 1:
Input: bills = [5,5,5,10,20]
Output: true
Explanation:
From the first 3 customers, we collect three 10 bill and give back a 10 bill and a 5 bills.
For the next two customers in order, we collect a 5 bill.
For the last customer, we can not give the change of 10 bills.
Since not every customer received the correct change, the answer is false.
Constraints:
1 <= bills.length <= 10^5bills[i]is either5,10, or20.
思路
这道题目刚一看,可能会有点懵,这要怎么找零才能保证完成全部账单的找零呢?
但仔细一琢磨就会发现,可供我们做判断的空间非常少!
只需要维护三种金额的数量,5,10和20。
有如下三种情况:
- 情况一:账单是5,直接收下。
- 情况二:账单是10,消耗一个5,增加一个10
- 情况三:账单是20,优先消耗一个10和一个5,如果不够,再消耗三个5
此时大家就发现 情况一,情况二,都是固定策略,都不用我们来做分析了,而唯一不确定的其实在情况三。
而情况三逻辑也不复杂甚至感觉纯模拟就可以了,其实情况三这里是有贪心的。
账单是20的情况,为什么要优先消耗一个10和一个5呢?
因为美元10只能给账单20找零,而美元5可以给账单10和账单20找零,美元5更万能!
所以局部最优:遇到账单20,优先消耗美元10,完成本次找零。全局最优:完成全部账单的找零。
局部最优可以推出全局最优,并找不出反例,那么就试试贪心算法!
C++解法
C++代码如下:
class Solution {
public:
bool lemonadeChange(vector<int>& bills) {
int five = 0, ten = 0, twenty = 0;
for (int bill : bills) {
// 情况一
if (bill == 5) five++;
// 情况二
if (bill == 10) {
if (five <= 0) return false;
ten++;
five--;
}
// 情况三
if (bill == 20) {
// 优先消耗10美元,因为5美元的找零用处更大,能多留着就多留着
if (five > 0 && ten > 0) {
five--;
ten--;
twenty++; // 其实这行代码可以删了,因为记录20已经没有意义了,不会用20来找零
} else if (five >= 3) {
five -= 3;
twenty++; // 同理,这行代码也可以删了
} else return false;
}
}
return true;
}
};
- 时间复杂度: O(n)
- 空间复杂度: O(1)
跳跃游戏
55. Jump Game
You are given an integer array nums. You are initially positioned at the array's first index, and each element in the array represents your maximum jump length at that position.
Return true if you can reach the last index, or false otherwise.
Example 1:
Input: nums = [2,3,1,1,4]
Output: true
Explanation: Jump 1 step from index 0 to 1, then 3 steps to the last index.
Example 2:
Input: nums = [3,2,1,0,4]
Output: false
Explanation: You will always arrive at index 3 no matter what. Its maximum jump length is 0, which makes it impossible to reach the last index.
Constraints:
1 <= nums.length <= 10^40 <= nums[i] <= 10^5
思路
刚看到本题一开始可能想:当前位置元素如果是 3,我究竟是跳一步呢,还是两步呢,还是三步呢,究竟跳几步才是最优呢?
其实跳几步无所谓,关键在于可跳的覆盖范围!
不一定非要明确一次究竟跳几步,每次取最大的跳跃步数,这个就是可以跳跃的覆盖范围。
这个范围内,别管是怎么跳的,反正一定可以跳过来。
那么这个问题就转化为跳跃覆盖范围究竟可不可以覆盖到终点!
每次移动取最大跳跃步数(得到最大的覆盖范围),每移动一个单位,就更新最大覆盖范围。
贪心算法局部最优解:每次取最大跳跃步数(取最大覆盖范围),整体最优解:最后得到整体最大覆盖范围,看是否能到终点。
局部最优推出全局最优,找不出反例,试试贪心!
如图:
i 每次移动只能在 cover 的范围内移动,每移动一个元素,cover 得到该元素数值(新的覆盖范围)的补充,让 i 继续移动下去。
而 cover 每次只取 max(该元素数值补充后的范围, cover 本身范围)。
如果 cover 大于等于了终点下标,直接 return true 就可以了。
这道题目关键点在于:不用拘泥于每次究竟跳几步,而是看覆盖范围,覆盖范围内一定是可以跳过来的,不用管是怎么跳的。
C++解法
C++代码如下:
class Solution {
public:
bool canJump(vector<int>& nums) {
int cover = 0;
if (nums.size() == 1) return true; // 只有一个元素,就是能达到
for (int i = 0; i <= cover; i++) { // 注意这里是小于等于cover
cover = max(i + nums[i], cover);
if (cover >= nums.size() - 1) return true; // 说明可以覆盖到终点了
}
return false;
}
};
- 时间复杂度: O(n)
- 空间复杂度: O(1)
Java解法
45. Jump Game II
You are given a 0-indexed array of integers nums of length n. You are initially positioned at nums[0].
Each element nums[i] represents the maximum length of a forward jump from index i. In other words, if you are at nums[i], you can jump to any nums[i + j] where:
0 <= j <= nums[i]andi + j < n
Return the minimum number of jumps to reach nums[n - 1]. The test cases are generated such that you can reach nums[n - 1].
Example 1:
Input: nums = [2,3,1,1,4]
Output: 2
Explanation: The minimum number of jumps to reach the last index is 2. Jump 1 step from index 0 to 1, then 3 steps to the last index.
Example 2:
Input: nums = [2,3,0,1,4]
Output: 2
Constraints:
1 <= nums.length <= 10^40 <= nums[i] <= 1000- It's guaranteed that you can reach
nums[n - 1].
思路
本题要看最大覆盖范围。
本题要计算最少步数,那么就要想清楚什么时候步数才一定要加一呢?
贪心的思路,局部最优:当前可移动距离尽可能多走,如果还没到终点,步数再加一。整体最优:一步尽可能多走,从而达到最少步数。
思路虽然是这样,但在写代码的时候还不能真的能跳多远就跳多远,那样就不知道下一步最远能跳到哪里了。
所以真正解题的时候,要从覆盖范围出发,不管怎么跳,覆盖范围内一定是可以跳到的,以最小的步数增加覆盖范围,覆盖范围一旦覆盖了终点,得到的就是最少步数!
这里需要统计两个覆盖范围,当前这一步的最大覆盖和下一步最大覆盖。
如果移动下标达到了当前这一步的最大覆盖最远距离了,还没有到终点的话,那么就必须再走一步来增加覆盖范围,直到覆盖范围覆盖了终点。
如图:
图中覆盖范围的意义在于,只要红色的区域,最多两步一定可以到!(不用管具体怎么跳,反正一定可以跳到)
理解本题的关键在于:以最小的步数增加最大的覆盖范围,直到覆盖范围覆盖了终点,这个范围内最少步数一定可以跳到,不用管具体是怎么跳的,不纠结于一步究竟跳一个单位还是两个单位。
C++解法
方法一
从图中可以看出来,就是移动下标达到了当前覆盖的最远距离下标时,步数就要加一,来增加覆盖距离。最后的步数就是最少步数。
这里还是有个特殊情况需要考虑,当移动下标达到了当前覆盖的最远距离下标时:
- 如果当前覆盖最远距离下标不是集合终点,步数就加一,还需要继续走。
- 如果当前覆盖最远距离下标就是集合终点,步数不用加一,因为不能再往后走了。
C++代码如下:(详细注释)
// 版本一
class Solution {
public:
int jump(vector<int>& nums) {
if (nums.size() == 1) return 0;
int curDistance = 0; // 当前覆盖最远距离下标
int ans = 0; // 记录走的最大步数
int nextDistance = 0; // 下一步覆盖最远距离下标
for (int i = 0; i < nums.size(); i++) {
nextDistance = max(nums[i] + i, nextDistance); // 更新下一步覆盖最远距离下标
if (i == curDistance) { // 遇到当前覆盖最远距离下标
ans++; // 需要走下一步
curDistance = nextDistance; // 更新当前覆盖最远距离下标(相当于加油了)
if (nextDistance >= nums.size() - 1) break; // 当前覆盖最远距到达集合终点,不用做ans++操作了,直接结束
}
}
return ans;
}
};
- 时间复杂度: O(n)
- 空间复杂度: O(1)
方法二
依然是贪心,思路和方法一差不多,代码可以简洁一些。
针对于方法一的特殊情况,可以统一处理,即:移动下标只要遇到当前覆盖最远距离的下标,直接步数加一,不考虑是不是终点的情况。
想要达到这样的效果,只要让移动下标,最大只能移动到 nums.size - 2 的地方就可以了。
因为当移动下标指向 nums.size - 2 时:
-
如果移动下标等于当前覆盖最大距离下标, 需要再走一步(即 ans++),因为最后一步一定是可以到的终点。(题目假设总是可以到达数组的最后一个位置),如图:
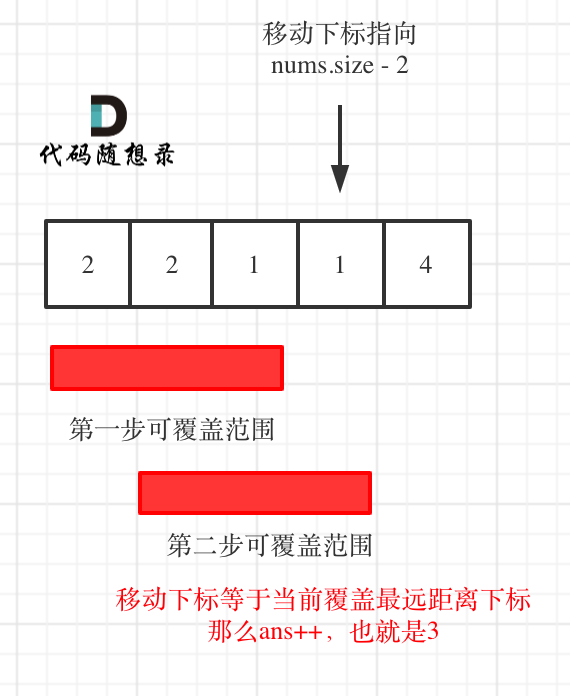
-
如果移动下标不等于当前覆盖最大距离下标,说明当前覆盖最远距离就可以直接达到终点了,不需要再走一步。如图:
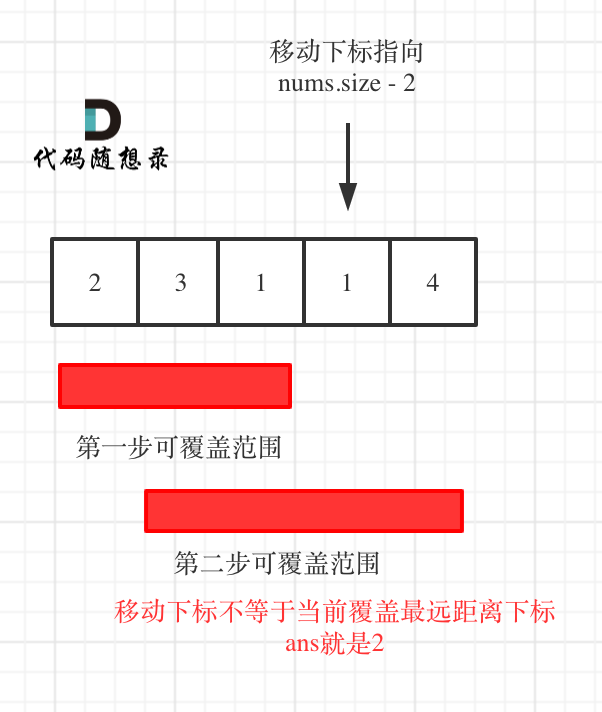
代码如下:
// 版本二
class Solution {
public:
int jump(vector<int>& nums) {
int curDistance = 0; // 当前覆盖的最远距离下标
int ans = 0; // 记录走的最大步数
int nextDistance = 0; // 下一步覆盖的最远距离下标
for (int i = 0; i < nums.size() - 1; i++) { // 注意这里是小于nums.size() - 1,这是关键所在
nextDistance = max(nums[i] + i, nextDistance); // 更新下一步覆盖的最远距离下标
if (i == curDistance) { // 遇到当前覆盖的最远距离下标
curDistance = nextDistance; // 更新当前覆盖的最远距离下标
ans++;
}
}
return ans;
}
};
- 时间复杂度: O(n)
- 空间复杂度: O(1)
可以看出版本二的代码相对于版本一简化了不少!
其精髓在于控制移动下标 i 只移动到 nums.size() - 2 的位置,所以移动下标只要遇到当前覆盖最远距离的下标,直接步数加一,不用考虑别的了。
Java解法
区间和贪心算法
452. Minimum Number of Arrows to Burst Balloons
There are some spherical balloons taped onto a flat wall that represents the XY-plane. The balloons are represented as a 2D integer array points where points[i] = [xstart, xend] denotes a balloon whose horizontal diameter stretches between xstart and xend. You do not know the exact y-coordinates of the balloons.
Arrows can be shot up directly vertically (in the positive y-direction) from different points along the x-axis. A balloon with xstart and xend is burst by an arrow shot at x if xstart <= x <= xend. There is no limit to the number of arrows that can be shot. A shot arrow keeps traveling up infinitely, bursting any balloons in its path.
Given the array points, return the minimum number of arrows that must be shot to burst all balloons.
Example 1:
Input: points = [[10,16],[2,8],[1,6],[7,12]]
Output: 2
Explanation: The balloons can be burst by 2 arrows:
- Shoot an arrow at x = 6, bursting the balloons [2,8] and [1,6].
- Shoot an arrow at x = 11, bursting the balloons [10,16] and [7,12].
Example 2:
Input: points = [[1,2],[3,4],[5,6],[7,8]]
Output: 4
Explanation: One arrow needs to be shot for each balloon for a total of 4 arrows.
Example 3:
Input: points = [[1,2],[2,3],[3,4],[4,5]]
Output: 2
Explanation: The balloons can be burst by 2 arrows:
- Shoot an arrow at x = 2, bursting the balloons [1,2] and [2,3].
- Shoot an arrow at x = 4, bursting the balloons [3,4] and [4,5].
Constraints:
1 <= points.length <= 10^5points[i].length == 2-2^31 <= xstart < xend <= 2^31 - 1
思路
如何使用最少的弓箭呢?
直觉上来看,貌似只射重叠最多的气球,用的弓箭一定最少,那么有没有当前重叠了三个气球,我射两个,留下一个和后面的一起射这样弓箭用的更少的情况呢?
尝试一下举反例,发现没有这种情况。
那么就试一试贪心吧!局部最优:当气球出现重叠,一起射,所用弓箭最少。全局最优:把所有气球射爆所用弓箭最少。
算法确定下来了,那么如何模拟气球射爆的过程呢?是在数组中移除元素还是做标记呢?
如果真实的模拟射气球的过程,应该射一个,气球数组就remove一个元素,这样最直观,毕竟气球被射了。
但仔细思考一下就发现:如果把气球排序之后,从前到后遍历气球,被射过的气球仅仅跳过就行了,没有必要让气球数组remove气球,只要记录一下箭的数量就可以了。
以上为思考过程,已经确定下来使用贪心了,那么开始解题。
为了让气球尽可能的重叠,需要对数组进行排序。
那么按照气球起始位置排序,还是按照气球终止位置排序呢?
其实都可以!只不过对应的遍历顺序不同,我就按照气球的起始位置排序了。
既然按照起始位置排序,那么就从前向后遍历气球数组,靠左尽可能让气球重复。
从前向后遍历遇到重叠的气球了怎么办?
如果气球重叠了,重叠气球中右边边界的最小值 之前的区间一定需要一个弓箭。
以题目示例: [[10,16],[2,8],[1,6],[7,12]]为例,如图:(方便起见,已经排序)
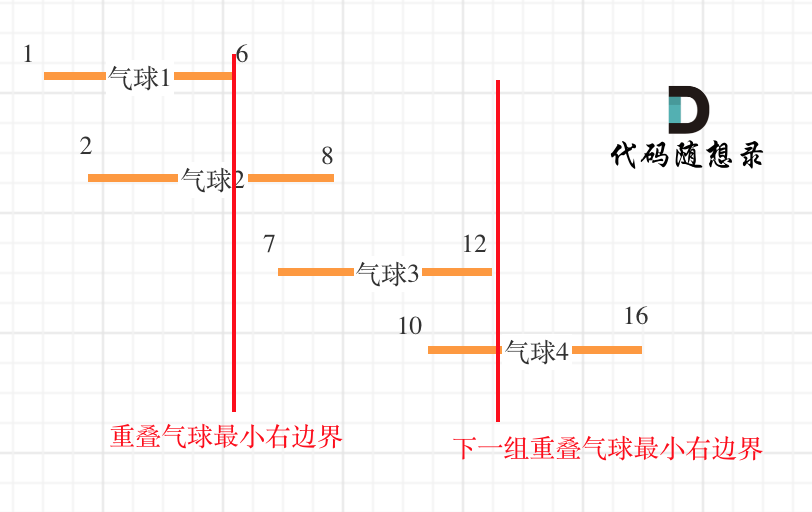
可以看出首先第一组重叠气球,一定是需要一个箭,气球3的左边界大于了第一组重叠气球的最小右边界,所以再需要一支箭来射气球3了。
注意事项
注意题目中说的是:满足 xstart ≤ x ≤ xend,则该气球会被引爆。那么说明两个气球挨在一起不重叠也可以一起射爆,
所以代码中 if (points[i][0] > points[i - 1][1]) 不能是>=
总结
这道题目贪心的思路很简单也很直接,就是重复的一起射了,但本题我认为是有难度的。
就算思路都想好了,模拟射气球的过程,很多同学真的要去模拟了,实时把气球从数组中移走,这么写的话就复杂了。
而且寻找重复的气球,寻找重叠气球最小右边界,其实都有代码技巧。
贪心题目有时候就是这样,看起来很简单,思路很直接,但是一写代码就感觉贼复杂无从下手。
这里其实是需要代码功底的,那代码功底怎么练?
多看多写多总结!
C++解法
C++代码如下:
class Solution {
private:
static bool cmp(const vector<int>& a, const vector<int>& b) {
return a[0] < b[0];
}
public:
int findMinArrowShots(vector<vector<int>>& points) {
if (points.size() == 0) return 0;
sort(points.begin(), points.end(), cmp);
int result = 1; // points 不为空至少需要一支箭
for (int i = 1; i < points.size(); i++) {
if (points[i][0] > points[i - 1][1]) { // 气球i和气球i-1不挨着,注意这里不是>=
result++; // 需要一支箭
}
else { // 气球i和气球i-1挨着
points[i][1] = min(points[i - 1][1], points[i][1]); // 更新重叠气球最小右边界
}
}
return result;
}
};
- 时间复杂度:,因为有一个快排
- 空间复杂度:,有一个快排,最差情况(倒序)时,需要n次递归调用。因此确实需要O(n)的栈空间
Java解法
import java.util.Arrays;
import java.util.Comparator;
class Solution {
public int findMinArrowShots(int[][] points) {
if (points == null || points.length == 0) {
return 0;
}
// 使用Comparator接口实现自定义排序,按照气球的右边界升序排列
Arrays.sort(points, Comparator.comparingInt(a -> a[1]));
int num = 1; // 至少需要一支箭
int end = points[0][1]; // 第一支箭射击的位置,初始化为第一个气球的右边界
for (int i = 1; i < points.length; i++) {
// 如果当前气球的左边界大于之前的最小右边界,则需要一支新的箭
if (points[i][0] > end) {
num++; // 增加箭的数量
end = points[i][1]; // 更新箭的射击位置为当前气球的右边界
}
}
return num;
}
}
代码逻辑:
- 对气球按照右边界进行升序排序。
- 初始化箭的数量为1,第一支箭射击的位置为第一个气球的右边界。
- 遍历剩余的气球,如果当前气球的左边界大于当前箭可以射爆的最远右边界,则需要一支新的箭,并更新箭的射击位置为当前气球的右边界。
- 返回箭的数量。
435. Non-overlapping Intervals
Given an array of intervals intervals where intervals[i] = [starti, endi], return the minimum number of intervals you need to remove to make the rest of the intervals non-overlapping.
Note that intervals which only touch at a point are non-overlapping. For example, [1, 2] and [2, 3] are non-overlapping.
Example 1:
Input: intervals = [[1,2],[2,3],[3,4],[1,3]]
Output: 1
Explanation: [1,3] can be removed and the rest of the intervals are non-overlapping.
Example 2:
Input: intervals = [[1,2],[1,2],[1,2]]
Output: 2
Explanation: You need to remove two [1,2] to make the rest of the intervals non-overlapping.
Example 3:
Input: intervals = [[1,2],[2,3]]
Output: 0
Explanation: You don't need to remove any of the intervals since they're already non-overlapping.
Constraints:
1 <= intervals.length <= 10^5intervals[i].length == 2-5 * 10^4 <= starti < endi <= 5 * 10^4
思路
相信很多同学看到这道题目都冥冥之中感觉要排序,但是究竟是按照右边界排序,还是按照左边界排序呢?
其实都可以。主要就是为了让区间尽可能的重叠。
我来按照右边界排序,从左向右记录非交叉区间的个数。最后用区间总数减去非交叉区间的个数就是需要移除的区间个数了。
此时问题就是要求非交叉区间的最大个数。
这里记录非交叉区间的个数还是有技巧的,如图:

区间,1,2,3,4,5,6都按照右边界排好序。
当确定区间 1 和 区间2 重叠后,如何确定是否与 区间3 也重贴呢?
就是取 区间1 和 区间2 右边界的最小值,因为这个最小值之前的部分一定是 区间1 和区间2 的重合部分,如果这个最小值也触达到区间3,那么说明 区间 1,2,3都是重合的。
接下来就是找大于区间1结束位置的区间,是从区间4开始。那有同学问了为什么不从区间5开始?别忘了已经是按照右边界排序的了。
区间4结束之后,再找到区间6,所以一共记录非交叉区间的个数是三个。
总共区间个数为6,减去非交叉区间的个数3。移除区间的最小数量就是3。
C++解法
C++代码如下:
class Solution {
public:
// 按照区间右边界排序
static bool cmp (const vector<int>& a, const vector<int>& b) {
return a[1] < b[1];
}
int eraseOverlapIntervals(vector<vector<int>>& intervals) {
if (intervals.size() == 0) return 0;
sort(intervals.begin(), intervals.end(), cmp);
int count = 1; // 记录非交叉区间的个数
int end = intervals[0][1]; // 记录区间分割点
for (int i = 1; i < intervals.size(); i++) {
if (end <= intervals[i][0]) {
end = intervals[i][1];
count++;
}
}
return intervals.size() - count;
}
};
- 时间复杂度: ,有一个快排
- 空间复杂度:,有一个快排,最差情况(倒序)时,需要n次递归调用。因此确实需要$O(n)的栈空间
Java解法
修改后的代码:
import java.util.Arrays;
import java.util.Comparator;
class Solution {
public int eraseOverlapIntervals(int[][] intervals) {
if (intervals == null || intervals.length == 0) {
return 0;
}
// 按照区间的结束时间升序排序
Arrays.sort(intervals, Comparator.comparingInt(a -> a[1]));
int num = 0; // 需要移除的区间数量
int end = intervals[0][1]; // 初始化为第一个区间的结束时间
for (int i = 1; i < intervals.length; i++) {
if (intervals[i][0] < end) {
// 发现重叠区间,需要移除一个
num++;
} else {
// 没有重叠,更新 end 为当前区间的结束时间
end = intervals[i][1];
}
}
return num;
}
}
代码解释:
-
排序: 首先,我们按照每个区间的结束时间对所有区间进行排序。这样做是为了确保我们总是优先选择结束时间最早的区间,这样可以尽可能多地保留不重叠的区间。
-
贪心选择:
- 我们初始化
num为0,表示需要移除的区间数量。 end变量用来记录当前已选择的、不重叠的区间的结束时间。初始值设置为第一个区间的结束时间。- 然后,我们遍历排序后的区间。对于每个区间,我们检查它是否与当前已选择的区间重叠(即,当前区间的开始时间是否小于
end)。 - 如果重叠,则
num加1,表示需要移除当前区间。 - 如果不重叠,则更新
end为当前区间的结束时间。
- 我们初始化
-
返回结果: 最后,返回需要移除的区间数量
num。
56. Merge Intervals
Given an array of intervals where intervals[i] = [starti, endi], merge all overlapping intervals, and return an array of the non-overlapping intervals that cover all the intervals in the input.
Example 1:
Input: intervals = [[1,3],[2,6],[8,10],[15,18]]
Output: [[1,6],[8,10],[15,18]]
Explanation: Since intervals [1,3] and [2,6] overlap, merge them into [1,6].
Example 2:
Input: intervals = [[1,4],[4,5]]
Output: [[1,5]]
Explanation: Intervals [1,4] and [4,5] are considered overlapping.
Constraints:
1 <= intervals.length <= 10^4intervals[i].length == 20 <= starti <= endi <= 10^4
思路
本题的本质其实还是判断重叠区间问题。
大家如果认真做题的话,话发现和我们刚刚讲过的452. 用最少数量的箭引爆气球 和 435. 无重叠区间 都是一个套路。
这几道题都是判断区间重叠,区别就是判断区间重叠后的逻辑,本题是判断区间重贴后要进行区间合并。
所以一样的套路,先排序,让所有的相邻区间尽可能的重叠在一起,按左边界,或者右边界排序都可以,处理逻辑稍有不同。
按照左边界从小到大排序之后,如果 intervals[i][0] <= intervals[i - 1][1] 即intervals[i]的左边界 <= intervals[i - 1]的右边界,则一定有重叠。(本题相邻区间也算重贴,所以是<=)
这么说有点抽象,看图:(注意图中区间都是按照左边界排序之后了)
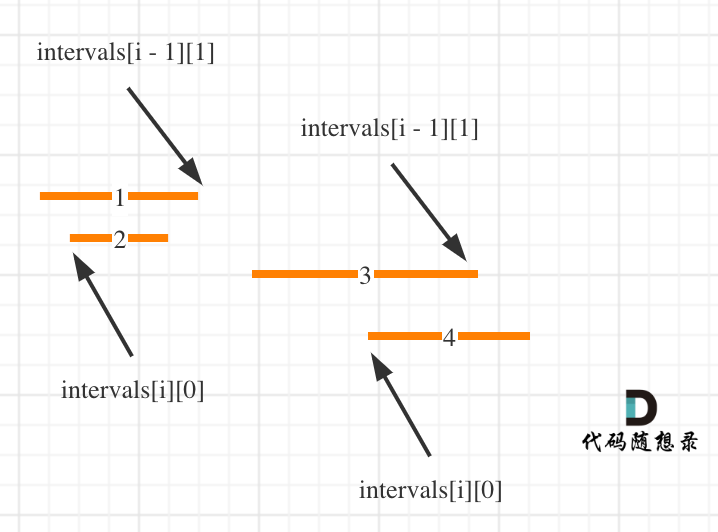
知道如何判断重复之后,剩下的就是合并了,如何去模拟合并区间呢?
其实就是用合并区间后左边界和右边界,作为一个新的区间,加入到result数组里就可以了。如果没有合并就把原区间加入到result数组。
C++解法
C++代码如下:
class Solution {
public:
vector<vector<int>> merge(vector<vector<int>>& intervals) {
vector<vector<int>> result;
if (intervals.size() == 0) return result; // 区间集合为空直接返回
// 排序的参数使用了lambda表达式
sort(intervals.begin(), intervals.end(), [](const vector<int>& a, const vector<int>& b){return a[0] < b[0];});
// 第一个区间就可以放进结果集里,后面如果重叠,在result上直接合并
result.push_back(intervals[0]);
for (int i = 1; i < intervals.size(); i++) {
if (result.back()[1] >= intervals[i][0]) { // 发现重叠区间
// 合并区间,只更新右边界就好,因为result.back()的左边界一定是最小值,因为我们按照左边界排序的
result.back()[1] = max(result.back()[1], intervals[i][1]);
} else {
result.push_back(intervals[i]); // 区间不重叠
}
}
return result;
}
};
- 时间复杂度: O(nlogn)
- 空间复杂度: O(logn),排序需要的空间开销
Java解法
下面是修改后的代码:
import java.util.ArrayList;
import java.util.Arrays;
import java.util.Comparator;
import java.util.List;
class Solution {
public int[][] merge(int[][] intervals) {
if (intervals == null || intervals.length <= 1) {
return intervals; // 如果为空或只有一个区间,则直接返回
}
// 按照区间的起始位置排序
Arrays.sort(intervals, Comparator.comparingInt(a -> a[0]));
List<int[]> result = new ArrayList<>();
int start = intervals[0][0];
int end = intervals[0][1];
for (int i = 1; i < intervals.length; i++) {
if (intervals[i][0] <= end) {
// 如果当前区间的起始位置小于等于end,则合并区间
end = Math.max(end, intervals[i][1]); //end取最大值,考虑[1,5][2,3]这种情况
} else {
// 否则,将当前区间添加到结果列表中
result.add(new int[]{start, end});
start = intervals[i][0];
end = intervals[i][1];
}
}
// 添加最后一个区间
result.add(new int[]{start, end});
// 将List<int[]>转换为int[][]
return result.toArray(new int[result.size()][]);
}
}
代码解释和改进:
- 空值和单区间检查: 添加了对
intervals为空或只有一个区间的检查,直接返回原数组,避免了后续的空指针异常和不必要的处理。 - 使用
ArrayList: 使用ArrayList<int[]>来动态存储合并后的区间。 - 正确的添加方式: 使用
result.add(new int[]{start, end})来添加新的区间到ArrayList中。 - 处理最后一个区间: 在循环结束后,将最后一个合并的区间添加到
result中。 - 转换为
int[][]: 使用result.toArray(new int[result.size()][])将ArrayList<int[]>转换为int[][]并返回。 - 合并区间时的
end更新: 使用end = Math.max(end, intervals[i][1]);确保end总是包含到目前为止的最远位置。 考虑类似[1,5]和[2,3]这样的例子,合并后应该是[1,5]。 - 注释: 添加了更详细的注释,方便理解代码的逻辑。
字符串和贪心算法
- 763. Partition Labels
- 316. Remove Duplicate Letters
- 1081. Smallest Subsequence of Distinct Characters(同上)
- 738. Monotone Increasing Digits
763. Partition Labels
You are given a string s. We want to partition the string into as many parts as possible so that each letter appears in at most one part. For example, the string "ababcc" can be partitioned into ["abab", "cc"], but partitions such as ["aba", "bcc"] or ["ab", "ab", "cc"] are invalid.
Note that the partition is done so that after concatenating all the parts in order, the resultant string should be s.
Return a list of integers representing the size of these parts.
Example 1:
Input: s = "ababcbacadefegdehijhklij"
Output: [9,7,8]
Explanation:
The partition is "ababcbaca", "defegde", "hijhklij".
This is a partition so that each letter appears in at most one part.
A partition like "ababcbacadefegde", "hijhklij" is incorrect, because it splits s into less parts.
Example 2:
Input: s = "eccbbbbdec"
Output: [10]
Constraints:
1 <= s.length <= 500sconsists of lowercase English letters.
思路
Try to greedily choose the smallest partition that includes the first letter. If you have something like "abaccbdeffed", then you might need to add b. You can use an map like "last['b'] = 5" to help you expand the width of your partition.
一想到分割字符串就想到了回溯,但本题其实不用回溯去暴力搜索。
题目要求同一字母最多出现在一个片段中,那么如何把同一个字母的都圈在同一个区间里呢?
如果没有接触过这种题目的话,还挺有难度的。
在遍历的过程中相当于是要找每一个字母的边界,如果找到之前遍历过的所有字母的最远边界,说明这个边界就是分割点了。此时前面出现过所有字母,最远也就到这个边界了。
可以分为如下两步:
- 统计每一个字符最后出现的位置
- 从头遍历字符,并更新字符的最远出现下标,如果找到字符最远出现位置下标和当前下标相等了,则找到了分割点
如图:
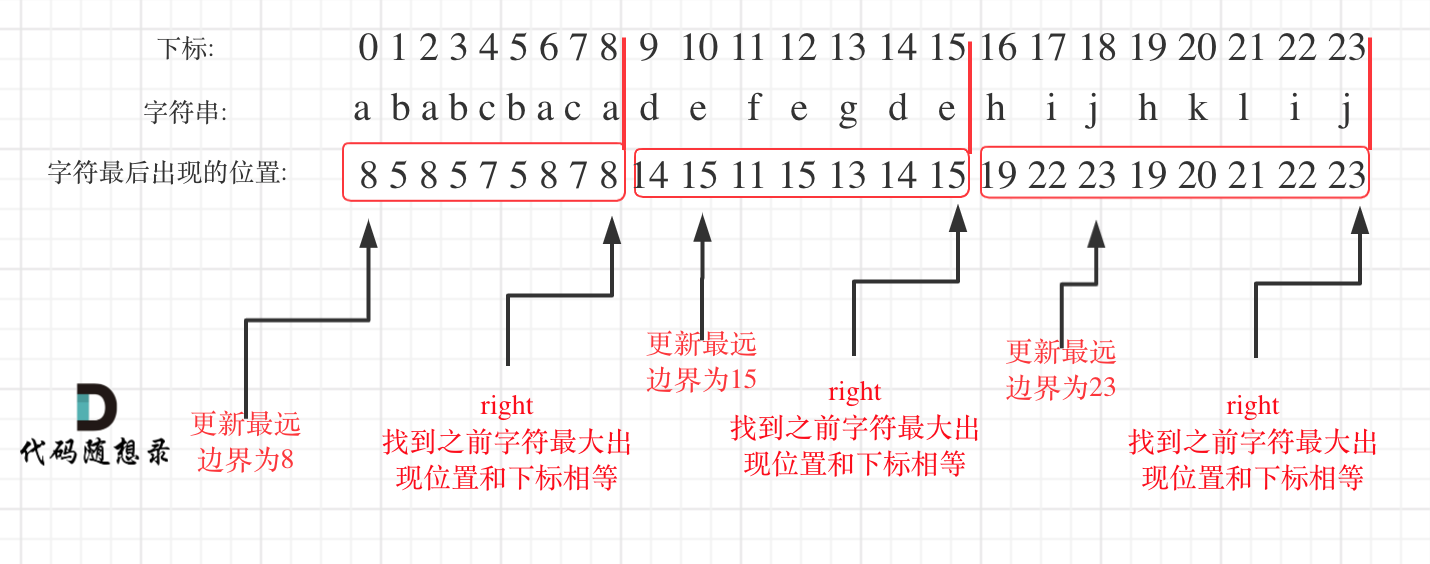
C++解法
明白原理之后,代码并不复杂,如下:
class Solution {
public:
vector<int> partitionLabels(string S) {
int hash[27] = {0}; // i为字符,hash[i]为字符出现的最后位置
for (int i = 0; i < S.size(); i++) { // 统计每一个字符最后出现的位置
hash[S[i] - 'a'] = i;
}
vector<int> result;
int left = 0;
int right = 0;
for (int i = 0; i < S.size(); i++) {
right = max(right, hash[S[i] - 'a']); // 找到字符出现的最远边界
if (i == right) {
result.push_back(right - left + 1);
left = i + 1;
}
}
return result;
}
};
- 时间复杂度:O(n)
- 空间复杂度:O(1),使用的hash数组是固定大小
Java解法
class Solution {
public List<Integer> partitionLabels(String S) {
List<Integer> list = new LinkedList<>();
int[] edge = new int[26];
char[] chars = S.toCharArray();
for (int i = 0; i < chars.length; i++) {
edge[chars[i] - 'a'] = i;
}
int idx = 0;
int last = -1;
for (int i = 0; i < chars.length; i++) {
idx = Math.max(idx,edge[chars[i] - 'a']);
if (i == idx) {
list.add(i - last);
last = i;
}
}
return list;
}
}
316. Remove Duplicate Letters
Given a string s, remove duplicate letters so that every letter appears once and only once. You must make sure your result is the smallest in lexicographical order among all possible results.
Example 1:
Input: s = "bcabc"
Output: "abc"
Example 2:
Input: s = "cbacdcbc"
Output: "acdb"
Constraints:
1 <= s.length <= 10^4sconsists of lowercase English letters.
Note: This question is the same as 1081: https://leetcode.com/problems/smallest-subsequence-of-distinct-characters/
思路
Greedily try to add one missing character. How to check if adding some character will not cause problems ? Use bit-masks to check whether you will be able to complete the sub-sequence if you add the character at some index i.
Approach: Stack and Greedy
To address the "Remove Duplicate Letters" problem using a stack and greedy algorithm, we lean on the properties of the stack to maintain lexicographical order:
Key Data Structures:
- stack: A dynamic data structure to hold characters in the desired order.
- seen: A set to track characters already in the stack.
- last_occurrence: A dictionary to track the last occurrence of each character in the string.
Enhanced Breakdown:
- Initialization: Initialize the stack, seen set, and last_occurrence dictionary.
- Iterate through the string:
- For each character, if it's in the seen set, skip it.
- If it's not in the seen set, add it to the stack. While adding, compare it with the top character of the stack. If the current character is smaller and the top character appears later in the string, pop the top character.
- Output: Convert the stack to a string and return.
Time Complexity:
- The solution iterates over each character in the string once, leading to a time complexity of O(n), where
nis the length of the strings.
Space Complexity:
- The space complexity is O(n) due to the stack, seen set, and last_occurrence dictionary.
C++解法
class Solution {
public:
string removeDuplicateLetters(string s) {
vector<int> lastIndex(26, 0);
for (int i = 0; i < s.length(); i++){
lastIndex[s[i] - 'a'] = i; // track the lastIndex of character presence
}
vector<bool> seen(26, false); // keep track seen
stack<char> st;
for (int i = 0; i < s.size(); i++) {
int curr = s[i] - 'a';
if (seen[curr]) continue; // if seen continue as we need to pick one char only
while(st.size() > 0 && st.top() > s[i] && i < lastIndex[st.top() - 'a']){
seen[st.top() - 'a'] = false; // pop out and mark unseen
st.pop();
}
st.push(s[i]); // add into stack
seen[curr] = true; // mark seen
}
string ans = "";
while (st.size() > 0){
ans += st.top();
st.pop();
}
reverse(ans.begin(), ans.end());
return ans;
}
};
Java解法
class Solution {
public String removeDuplicateLetters(String s) {
int[] lastIndex = new int[26];
for (int i = 0; i < s.length(); i++){
lastIndex[s.charAt(i) - 'a'] = i; // track the lastIndex of character presence
}
boolean[] seen = new boolean[26]; // keep track seen
Stack<Integer> st = new Stack();
for (int i = 0; i < s.length(); i++) {
int curr = s.charAt(i) - 'a';
if (seen[curr]) continue; // if seen continue as we need to pick one char only
while (!st.isEmpty() && st.peek() > curr && i < lastIndex[st.peek()]){
seen[st.pop()] = false; // pop out and mark unseen
}
st.push(curr); // add into stack
seen[curr] = true; // mark seen
}
StringBuilder sb = new StringBuilder();
while (!st.isEmpty())
sb.append((char) (st.pop() + 'a'));
return sb.reverse().toString();
}
}
1081. Smallest Subsequence of Distinct Characters(同上)
738. Monotone Increasing Digits
An integer has monotone increasing digits if and only if each pair of adjacent digits x and y satisfy x <= y.
Given an integer n, return the largest number that is less than or equal to n with monotone increasing digits.
Example 1:
Input: n = 10
Output: 9
Example 2:
Input: n = 1234
Output: 1234
Example 3:
Input: n = 332
Output: 299
Constraints:
0 <= n <= 10^9
思考
Build the answer digit by digit, adding the largest possible one that would make the number still less than or equal to N.
暴力解法
题意很简单,那么首先想的就是暴力解法了,来我替大家暴力一波,结果自然是超时!
代码如下:
class Solution {
private:
// 判断一个数字的各位上是否是递增
bool checkNum(int num) {
int max = 10;
while (num) {
int t = num % 10;
if (max >= t) max = t;
else return false;
num = num / 10;
}
return true;
}
public:
int monotoneIncreasingDigits(int N) {
for (int i = N; i > 0; i--) { // 从大到小遍历
if (checkNum(i)) return i;
}
return 0;
}
};
- 时间复杂度:O(n × m) m为n的数字长度
- 空间复杂度:O(1)
贪心算法
题目要求小于等于N的最大单调递增的整数,那么拿一个两位的数字来举例。
例如:98,一旦出现strNum[i - 1] > strNum[i]的情况(非单调递增),首先想让strNum[i - 1]--,然后strNum[i]变为9,这样这个整数就是89,即小于98的最大的单调递增整数。
这一点如果想清楚了,这道题就好办了。
此时是从前向后遍历还是从后向前遍历呢?
从前向后遍历的话,遇到strNum[i - 1] > strNum[i]的情况,让strNum[i - 1]减一,但此时如果strNum[i - 1]减一了,可能又小于strNum[i - 2]。
这么说有点抽象,举个例子,数字:332,从前向后遍历的话,那么就把变成了329,此时2又小于了第一位的3了,真正的结果应该是299。
那么从后向前遍历,就可以重复利用上次比较得出的结果了,从后向前遍历332的数值变化为:332 -> 329 -> 299
确定了遍历顺序之后,那么此时局部最优就可以推出全局,找不出反例,试试贪心。
C++解法
本题只要想清楚个例,例如98,一旦出现strNum[i - 1] > strNum[i]的情况(非单调递增),首先想让strNum[i - 1]减一,strNum[i]赋值9,这样这个整数就是89。就可以很自然想到对应的贪心解法了。
想到了贪心,还要考虑遍历顺序,只有从后向前遍历才能重复利用上次比较的结果。
最后代码实现的时候,也需要一些技巧,例如用一个flag来标记从哪里开始赋值9。
C++代码如下:
class Solution {
public:
int monotoneIncreasingDigits(int N) {
string strNum = to_string(N);
// flag用来标记赋值9从哪里开始
// 设置为这个默认值,为了防止第二个for循环在flag没有被赋值的情况下执行
int flag = strNum.size();
for (int i = strNum.size() - 1; i > 0; i--) {
if (strNum[i - 1] > strNum[i] ) {
flag = i;
strNum[i - 1]--;
}
}
for (int i = flag; i < strNum.size(); i++) {
strNum[i] = '9';
}
return stoi(strNum);
}
};
- 时间复杂度:O(n),n 为数字长度
- 空间复杂度:O(n),需要一个字符串,转化为字符串操作更方便
Java解法
class Solution {
public int monotoneIncreasingDigits(int n) {
String s = Integer.toString(n); // 将整数转换为字符串
char[] arr = s.toCharArray(); // 将字符串转换为字符数组,方便修改
int flag = arr.length;
for(int i = arr.length - 1; i > 0; i--){
if(arr[i] < arr[i - 1]){
arr[i - 1]--; // 字符自减
flag = i;
}
}
for(int i = flag; i < arr.length; i++){
arr[i] = '9'; // 将后面的所有字符设置为 '9'
}
return Integer.parseInt(new String(arr)); // 将字符数组转换回字符串,再转换为整数
}
}
主要修改说明:
- 类型转换:
Integer.toString(n): 将整数n转换为字符串,因为 Java 中没有直接名为toString的全局函数来转换整数。s.toCharArray(): 将字符串s转换为字符数组。这样可以方便地修改字符串中的字符。Integer.parseInt(new String(arr)): 将修改后的字符数组转换回字符串,然后再将字符串解析为整数,作为结果返回。
- 字符自减:
arr[i - 1]--: 字符数组中的元素是char类型,可以直接进行自减操作。
- 使用字符数组:
- 使用
char[] arr代替string s,因为 Java 的 String 类型是不可变的。为了能够修改字符串中的字符,我们需要将其转换为字符数组。
- 使用
- valueOf() 方法:
String类没有valueOf()实例方法。应该使用new String(arr)从字符数组创建一个新的字符串。
这段代码的思路是找到从右到左第一个降序的位置,将该位置的数字减 1,然后将该位置之后的所有数字都置为 9,以保证结果是单调递增的。
二叉树和贪心算法
968. Binary Tree Cameras
You are given the root of a binary tree. We install cameras on the tree nodes where each camera at a node can monitor its parent, itself, and its immediate children.
Return the minimum number of cameras needed to monitor all nodes of the tree.
Example 1:

Input: root = [0,0,null,0,0]
Output: 1
Explanation: One camera is enough to monitor all nodes if placed as shown.
Example 2:

Input: root = [0,0,null,0,null,0,null,null,0]
Output: 2
Explanation: At least two cameras are needed to monitor all nodes of the tree. The above image shows one of the valid configurations of camera placement.
Constraints:
- The number of nodes in the tree is in the range
[1, 1000]. Node.val == 0
思路
这道题目首先要想,如何放置,才能让摄像头最小的呢?
从题目中示例,其实可以得到启发,我们发现题目示例中的摄像头都没有放在叶子节点上!
这是很重要的一个线索,摄像头可以覆盖上中下三层,如果把摄像头放在叶子节点上,就浪费的一层的覆盖。
所以把摄像头放在叶子节点的父节点位置,才能充分利用摄像头的覆盖面积。
那么有同学可能问了,为什么不从头结点开始看起呢,为啥要从叶子节点看呢?
因为头结点放不放摄像头也就省下一个摄像头, 叶子节点放不放摄像头省下了的摄像头数量是指数阶别的。
所以我们要从下往上看,局部最优:让叶子节点的父节点安摄像头,所用摄像头最少,整体最优:全部摄像头数量所用最少!
局部最优推出全局最优,找不出反例,那么就按照贪心来!
此时,大体思路就是从低到上,先给叶子节点父节点放个摄像头,然后隔两个节点放一个摄像头,直至到二叉树头结点。
此时这道题目还有两个难点:
- 二叉树的遍历
- 如何隔两个节点放一个摄像头
确定遍历顺序
在二叉树中如何从低向上推导呢?
可以使用后序遍历也就是左右中的顺序,这样就可以在回溯的过程中从下到上进行推导了。
后序遍历代码如下:
int traversal(TreeNode* cur) {
// 空节点,该节点有覆盖
if (终止条件) return ;
int left = traversal(cur->left); // 左
int right = traversal(cur->right); // 右
逻辑处理 // 中
return ;
}
注意在以上代码中我们取了左孩子的返回值,右孩子的返回值,即left 和 right, 以后推导中间节点的状态
如何隔两个节点放一个摄像头
此时需要状态转移的公式,大家不要和动态的状态转移公式混到一起,本题状态转移没有择优的过程,就是单纯的状态转移!
来看看这个状态应该如何转移,先来看看每个节点可能有几种状态:
有如下三种:
- 该节点无覆盖
- 本节点有摄像头
- 本节点有覆盖
我们分别有三个数字来表示:
- 0:该节点无覆盖
- 1:本节点有摄像头
- 2:本节点有覆盖
大家应该找不出第四个节点的状态了。
一些同学可能会想有没有第四种状态:本节点无摄像头,其实无摄像头就是 无覆盖 或者 有覆盖的状态,所以一共还是三个状态。
因为在遍历树的过程中,就会遇到空节点,那么问题来了,空节点究竟是哪一种状态呢? 空节点表示无覆盖? 表示有摄像头?还是有覆盖呢?
回归本质,为了让摄像头数量最少,我们要尽量让叶子节点的父节点安装摄像头,这样才能摄像头的数量最少。
那么空节点不能是无覆盖的状态,这样叶子节点就要放摄像头了,空节点也不能是有摄像头的状态,这样叶子节点的父节点就没有必要放摄像头了,而是可以把摄像头放在叶子节点的爷爷节点上。
所以空节点的状态只能是有覆盖,这样就可以在叶子节点的父节点放摄像头了
接下来就是递推关系。
那么递归的终止条件应该是遇到了空节点,此时应该返回2(有覆盖),原因上面已经解释过了。
代码如下:
// 空节点,该节点有覆盖
if (cur == NULL) return 2;
递归的函数,以及终止条件已经确定了,再来看单层逻辑处理。
主要有如下四类情况:
- 情况1:左右节点都有覆盖
左孩子有覆盖,右孩子有覆盖,那么此时中间节点应该就是无覆盖的状态了。
如图:
代码如下:
// 左右节点都有覆盖
if (left == 2 && right == 2) return 0;
- 情况2:左右节点至少有一个无覆盖的情况
如果是以下情况,则中间节点(父节点)应该放摄像头:
- left == 0 && right == 0 左右节点无覆盖
- left == 1 && right == 0 左节点有摄像头,右节点无覆盖
- left == 0 && right == 1 左节点有无覆盖,右节点摄像头
- left == 0 && right == 2 左节点无覆盖,右节点覆盖
- left == 2 && right == 0 左节点覆盖,右节点无覆盖
这个不难理解,毕竟有一个孩子没有覆盖,父节点就应该放摄像头。
此时摄像头的数量要加一,并且return 1,代表中间节点放摄像头。
代码如下:
if (left == 0 || right == 0) {
result++;
return 1;
}
- 情况3:左右节点至少有一个有摄像头
如果是以下情况,其实就是 左右孩子节点有一个有摄像头了,那么其父节点就应该是2(覆盖的状态)
- left == 1 && right == 2 左节点有摄像头,右节点有覆盖
- left == 2 && right == 1 左节点有覆盖,右节点有摄像头
- left == 1 && right == 1 左右节点都有摄像头
代码如下:
if (left == 1 || right == 1) return 2;
从这个代码中,可以看出,如果left == 1, right == 0 怎么办?其实这种条件在情况2中已经判断过了,如图:
这种情况也是大多数同学容易迷惑的情况。
- 情况4:头结点没有覆盖
以上都处理完了,递归结束之后,可能头结点 还有一个无覆盖的情况,如图:
所以递归结束之后,还要判断根节点,如果没有覆盖,result++,代码如下:
int minCameraCover(TreeNode* root) {
result = 0;
if (traversal(root) == 0) { // root 无覆盖
result++;
}
return result;
}
C++解法
C++代码如下:
// 版本一
class Solution {
private:
int result;
int traversal(TreeNode* cur) {
// 空节点,该节点有覆盖
if (cur == NULL) return 2;
int left = traversal(cur->left); // 左
int right = traversal(cur->right); // 右
// 情况1
// 左右节点都有覆盖
if (left == 2 && right == 2) return 0;
// 情况2
// left == 0 && right == 0 左右节点无覆盖
// left == 1 && right == 0 左节点有摄像头,右节点无覆盖
// left == 0 && right == 1 左节点有无覆盖,右节点摄像头
// left == 0 && right == 2 左节点无覆盖,右节点覆盖
// left == 2 && right == 0 左节点覆盖,右节点无覆盖
if (left == 0 || right == 0) {
result++;
return 1;
}
// 情况3
// left == 1 && right == 2 左节点有摄像头,右节点有覆盖
// left == 2 && right == 1 左节点有覆盖,右节点有摄像头
// left == 1 && right == 1 左右节点都有摄像头
// 其他情况前段代码均已覆盖
if (left == 1 || right == 1) return 2;
// 以上代码我没有使用else,主要是为了把各个分支条件展现出来,这样代码有助于读者理解
// 这个 return -1 逻辑不会走到这里。
return -1;
}
public:
int minCameraCover(TreeNode* root) {
result = 0;
// 情况4
if (traversal(root) == 0) { // root 无覆盖
result++;
}
return result;
}
};
在以上代码的基础上,再进行精简,代码如下:
// 版本二
class Solution {
private:
int result;
int traversal(TreeNode* cur) {
if (cur == NULL) return 2;
int left = traversal(cur->left); // 左
int right = traversal(cur->right); // 右
if (left == 2 && right == 2) return 0;
else if (left == 0 || right == 0) {
result++;
return 1;
} else return 2;
}
public:
int minCameraCover(TreeNode* root) {
result = 0;
if (traversal(root) == 0) { // root 无覆盖
result++;
}
return result;
}
};
- 时间复杂度: O(n),需要遍历二叉树上的每个节点
- 空间复杂度: O(n)
大家可能会惊讶,居然可以这么简短,其实就是在版本一的基础上,使用else把一些情况直接覆盖掉了。
在网上关于这道题解可以搜到很多这种神级别的代码,但都没讲不清楚,如果直接看代码的话,指定越看越晕,所以建议大家对着版本一的代码一步一步来,版本二中看不中用!。
单调栈法
动态规划
动态规划理论基础
动态规划刷题大纲
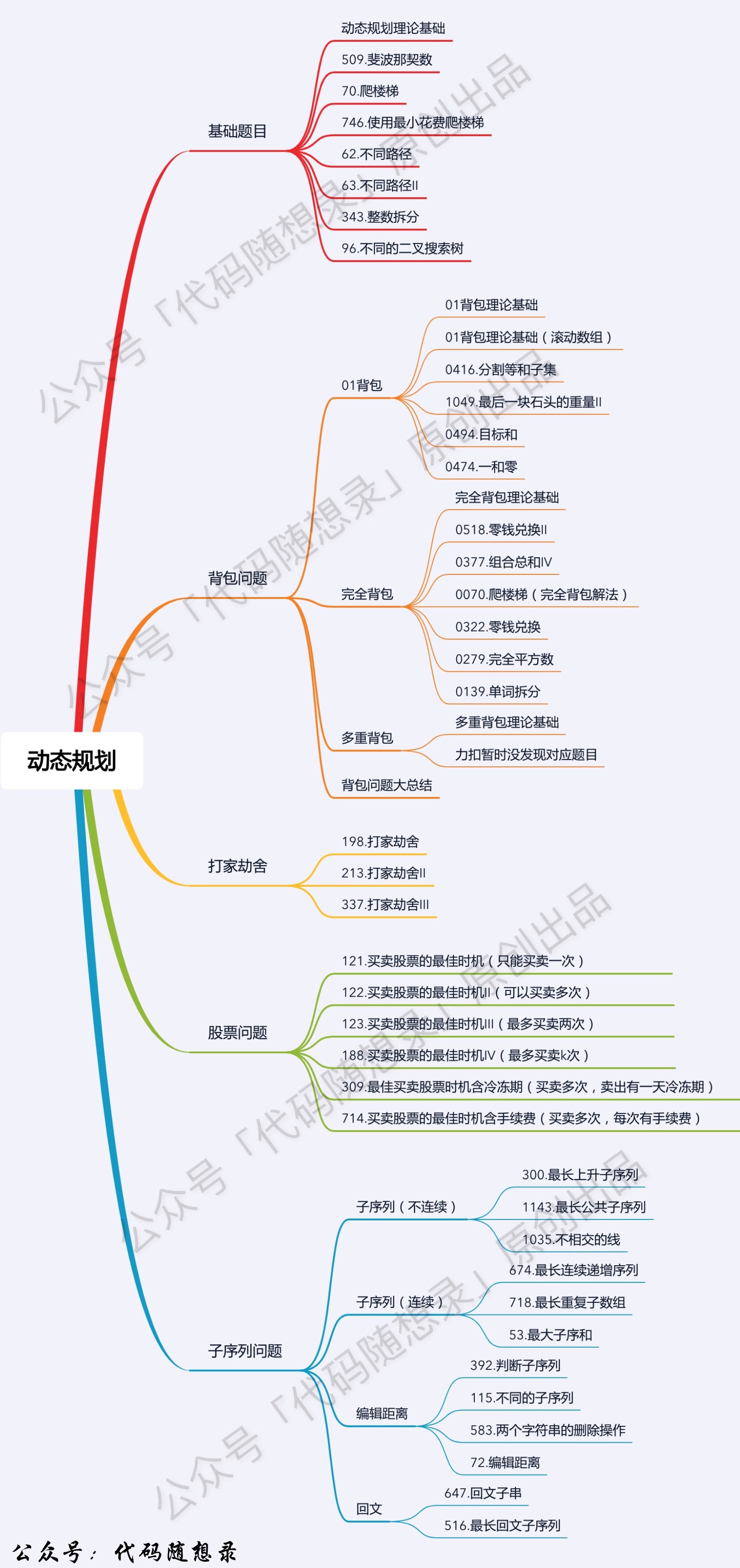
什么是动态规划
动态规划,英文:Dynamic Programming,简称DP,如果某一问题有很多重叠子问题,使用动态规划是最有效的。
所以动态规划中每一个状态一定是由上一个状态推导出来的,这一点就区分于贪心,贪心没有状态推导,而是从局部直接选最优的,
在关于贪心算法,你该了解这些!中我举了一个背包问题的例子。
例如:有N件物品和一个最多能背重量为W 的背包。第i件物品的重量是weight[i],得到的价值是value[i] 。每件物品只能用一次,求解将哪些物品装入背包里物品价值总和最大。
动态规划中dp[j]是由dp[j-weight[i]]推导出来的,然后取max(dp[j], dp[j - weight[i]] + value[i])。
但如果是贪心呢,每次拿物品选一个最大的或者最小的就完事了,和上一个状态没有关系。
所以贪心解决不了动态规划的问题。
其实大家也不用死扣动规和贪心的理论区别,后面做做题目自然就知道了。
而且很多讲解动态规划的文章都会讲最优子结构啊和重叠子问题啊这些,这些东西都是教科书的上定义,晦涩难懂而且不实用。
大家知道动规是由前一个状态推导出来的,而贪心是局部直接选最优的,对于刷题来说就够用了。
上述提到的背包问题,后序会详细讲解。
动态规划的解题步骤
做动规题目的时候,很多同学会陷入一个误区,就是以为把状态转移公式背下来,照葫芦画瓢改改,就开始写代码,甚至把题目AC之后,都不太清楚dp[i]表示的是什么。
这就是一种朦胧的状态,然后就把题给过了,遇到稍稍难一点的,可能直接就不会了,然后看题解,然后继续照葫芦画瓢陷入这种恶性循环中。
状态转移公式(递推公式)是很重要,但动规不仅仅只有递推公式。
对于动态规划问题,我将拆解为如下五步曲,这五步都搞清楚了,才能说把动态规划真的掌握了!
- 确定dp数组(dp table)以及下标的含义
- 确定递推公式
- dp数组如何初始化
- 确定遍历顺序
- 举例推导dp数组
一些同学可能想为什么要先确定递推公式,然后在考虑初始化呢?
因为一些情况是递推公式决定了dp数组要如何初始化!
后面的讲解中我都是围绕着这五点来进行讲解。
可能刷过动态规划题目的同学可能都知道递推公式的重要性,感觉确定了递推公式这道题目就解出来了。
其实 确定递推公式 仅仅是解题里的一步而已!
一些同学知道递推公式,但搞不清楚dp数组应该如何初始化,或者正确的遍历顺序,以至于记下来公式,但写的程序怎么改都通过不了。
后序的讲解的大家就会慢慢感受到这五步的重要性了。
动态规划应该如何debug
相信动规的题目,很大部分同学都是这样做的。
看一下题解,感觉看懂了,然后照葫芦画瓢,如果能正好画对了,万事大吉,一旦要是没通过,就怎么改都通过不了,对 dp数组的初始化,递推公式,遍历顺序,处于一种黑盒的理解状态。
写动规题目,代码出问题很正常!
找问题的最好方式就是把dp数组打印出来,看看究竟是不是按照自己思路推导的!
一些同学对于dp的学习是黑盒的状态,就是不清楚dp数组的含义,不懂为什么这么初始化,递推公式背下来了,遍历顺序靠习惯就是这么写的,然后一鼓作气写出代码,如果代码能通过万事大吉,通过不了的话就凭感觉改一改。
这是一个很不好的习惯!
做动规的题目,写代码之前一定要把状态转移在dp数组的上具体情况模拟一遍,心中有数,确定最后推出的是想要的结果。
然后再写代码,如果代码没通过就打印dp数组,看看是不是和自己预先推导的哪里不一样。
如果打印出来和自己预先模拟推导是一样的,那么就是自己的递归公式、初始化或者遍历顺序有问题了。
如果和自己预先模拟推导的不一样,那么就是代码实现细节有问题。
这样才是一个完整的思考过程,而不是一旦代码出问题,就毫无头绪的东改改西改改,最后过不了,或者说是稀里糊涂的过了。
这也是我为什么在动规五步曲里强调推导dp数组的重要性。
举个例子哈:在「代码随想录」刷题小分队微信群里,一些录友可能代码通过不了,会把代码抛到讨论群里问:我这里代码都已经和题解一模一样了,为什么通过不了呢?
发出这样的问题之前,其实可以自己先思考这三个问题:
- 这道题目我举例推导状态转移公式了么?
- 我打印dp数组的日志了么?
- 打印出来了dp数组和我想的一样么?
如果这灵魂三问自己都做到了,基本上这道题目也就解决了,或者更清晰的知道自己究竟是哪一点不明白,是状态转移不明白,还是实现代码不知道该怎么写,还是不理解遍历dp数组的顺序。
然后在问问题,目的性就很强了,群里的小伙伴也可以快速知道提问者的疑惑了。
注意这里不是说不让大家问问题哈, 而是说问问题之前要有自己的思考,问题要问到点子上!
大家工作之后就会发现,特别是大厂,问问题是一个专业活,是的,问问题也要体现出专业!
如果问同事很不专业的问题,同事们会懒的回答,领导也会认为你缺乏思考能力,这对职场发展是很不利的。
所以大家在刷题的时候,就锻炼自己养成专业提问的好习惯。
总结
这一篇是动态规划的整体概述,讲解了什么是动态规划,动态规划的解题步骤,以及如何debug。
动态规划是一个很大的领域,今天这一篇讲解的内容是整个动态规划系列中都会使用到的一些理论基础。
在后序讲解中针对某一具体问题,还会讲解其对应的理论基础,例如背包问题中的01背包,leetcode上的题目都是01背包的应用,而没有纯01背包的问题,那么就需要在把对应的理论知识讲解一下。
大家会发现,我讲解的理论基础并不是教科书上各种动态规划的定义,错综复杂的公式。
这里理论基础篇已经是非常偏实用的了,每个知识点都是在解题实战中非常有用的内容,大家要重视起来哈。
听说背包问题很难? 这篇总结篇来拯救你了
年前我们已经把背包问题都讲完了,那么现在我们要对背包问题进行总结一番。
背包问题是动态规划里的非常重要的一部分,所以我把背包问题单独总结一下,等动态规划专题更新完之后,我们还会在整体总结一波动态规划。
关于这几种常见的背包,其关系如下:
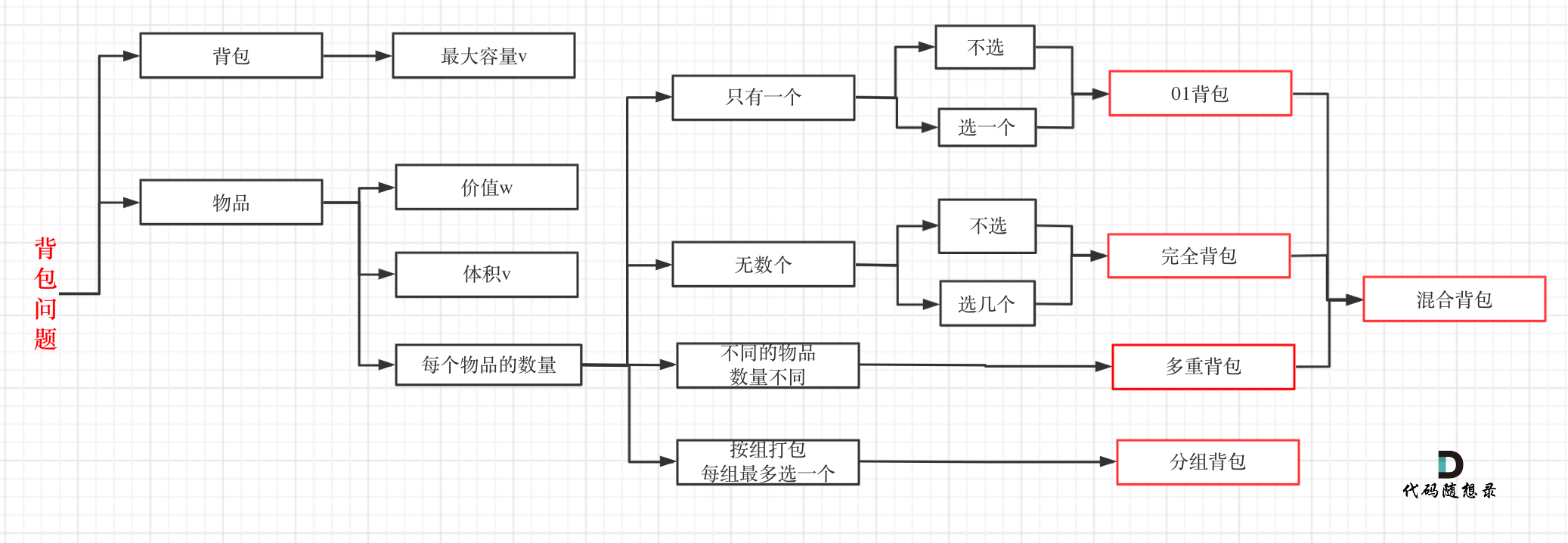
通过这个图,可以很清晰分清这几种常见背包之间的关系。
在讲解背包问题的时候,我们都是按照如下五部来逐步分析,相信大家也体会到,把这五部都搞透了,算是对动规来理解深入了。
- 确定dp数组(dp table)以及下标的含义
- 确定递推公式
- dp数组如何初始化
- 确定遍历顺序
- 举例推导dp数组
其实这五部里哪一步都很关键,但确定递推公式和确定遍历顺序都具有规律性和代表性,所以下面我从这两点来对背包问题做一做总结。
背包递推公式
问能否能装满背包(或者最多装多少):dp[j] = max(dp[j], dp[j - nums[i]] + nums[i]); ,对应题目如下:
问装满背包有几种方法:dp[j] += dp[j - nums[i]] ,对应题目如下:
问背包装满最大价值:dp[j] = max(dp[j], dp[j - weight[i]] + value[i]); ,对应题目如下:
问装满背包所有物品的最小个数:dp[j] = min(dp[j - coins[i]] + 1, dp[j]); ,对应题目如下:
遍历顺序
01背包
在动态规划:关于01背包问题,你该了解这些!中我们讲解二维dp数组01背包先遍历物品还是先遍历背包都是可以的,且第二层for循环是从小到大遍历。
和动态规划:关于01背包问题,你该了解这些!(滚动数组)中,我们讲解一维dp数组01背包只能先遍历物品再遍历背包容量,且第二层for循环是从大到小遍历。
一维dp数组的背包在遍历顺序上和二维dp数组实现的01背包其实是有很大差异的,大家需要注意!
完全背包
说完01背包,再看看完全背包。
在动态规划:关于完全背包,你该了解这些!中,讲解了纯完全背包的一维dp数组实现,先遍历物品还是先遍历背包都是可以的,且第二层for循环是从小到大遍历。
但是仅仅是纯完全背包的遍历顺序是这样的,题目稍有变化,两个for循环的先后顺序就不一样了。
如果求组合数就是外层for循环遍历物品,内层for遍历背包。
如果求排列数就是外层for遍历背包,内层for循环遍历物品。
相关题目如下:
如果求最小数,那么两层for循环的先后顺序就无所谓了,相关题目如下:
对于背包问题,其实递推公式算是容易的,难是难在遍历顺序上,如果把遍历顺序搞透,才算是真正理解了。
总结
这篇背包问题总结篇是对背包问题的高度概括,讲最关键的两部:递推公式和遍历顺序,结合力扣上的题目全都抽象出来了。
而且每一个点,我都给出了对应的力扣题目。
最后如果你想了解多重背包,可以看这篇动态规划:关于多重背包,你该了解这些!,力扣上还没有多重背包的题目,也不是面试考察的重点。
如果把我本篇总结出来的内容都掌握的话,可以说对背包问题理解的就很深刻了,用来对付面试中的背包问题绰绰有余!
背包问题总结:
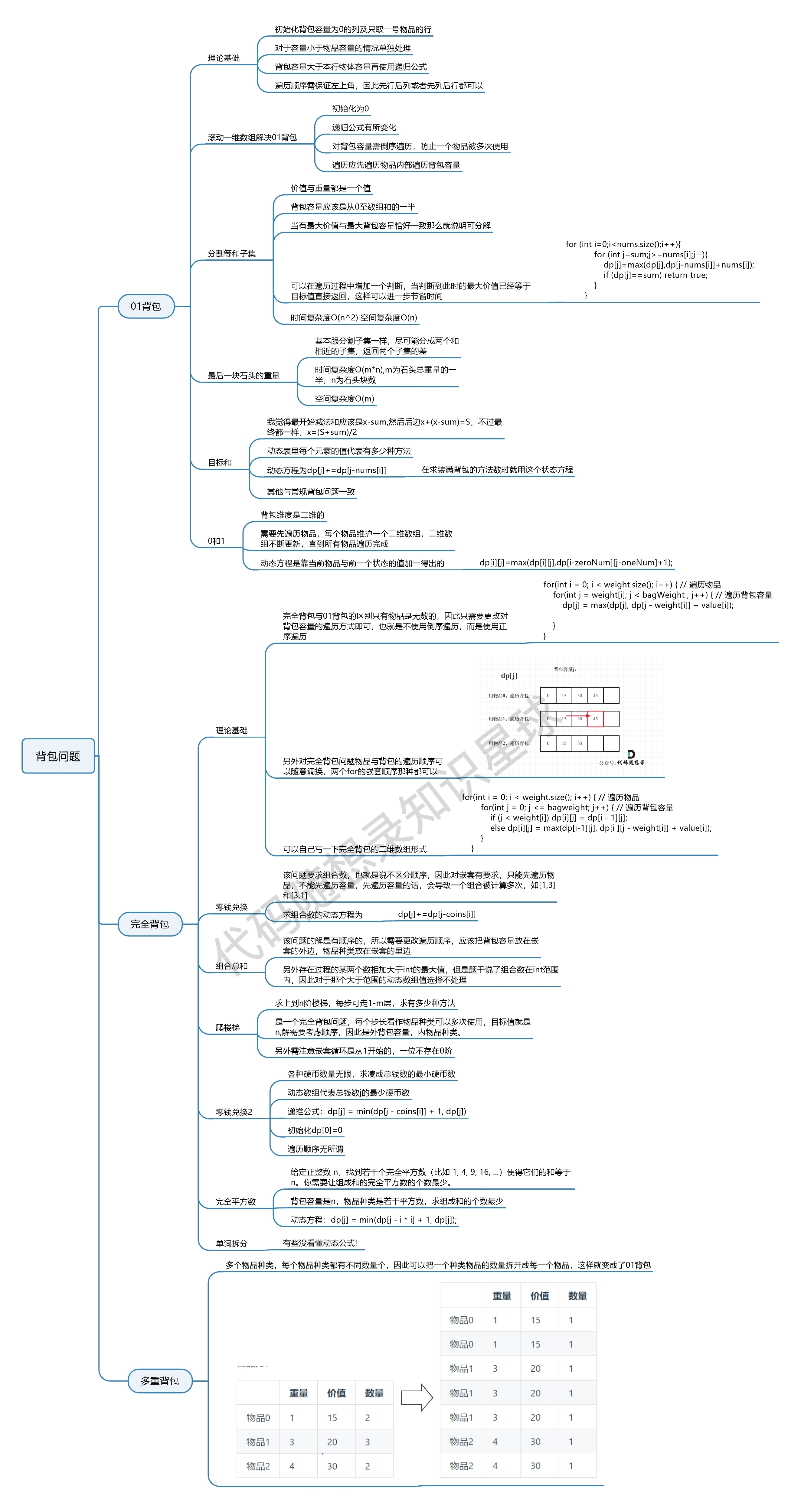
518. Coin Change II
You are given an integer array coins representing coins of different denominations and an integer amount representing a total amount of money.
Return the number of combinations that make up that amount. If that amount of money cannot be made up by any combination of the coins, return 0.
You may assume that you have an infinite number of each kind of coin.
The answer is guaranteed to fit into a signed 32-bit integer.
Example 1:
Input: amount = 5, coins = [1,2,5]
Output: 4
Explanation: there are four ways to make up the amount:
5=5
5=2+2+1
5=2+1+1+1
5=1+1+1+1+1
Example 2:
Input: amount = 3, coins = [2]
Output: 0
Explanation: the amount of 3 cannot be made up just with coins of 2.
Example 3:
Input: amount = 10, coins = [10]
Output: 1
Constraints:
1 <= coins.length <= 3001 <= coins[i] <= 5000- All the values of
coinsare unique. 0 <= amount <= 5000
思路
这是一道典型的背包问题,一看到钱币数量不限,就知道这是一个完全背包。
对完全背包还不了解的同学,可以看这篇:动态规划:关于完全背包,你该了解这些!
但本题和纯完全背包不一样,纯完全背包是凑成背包最大价值是多少,而本题是要求凑成总金额的物品组合个数!
注意题目描述中是凑成总金额的硬币组合数,为什么强调是组合数呢?
例如示例一:
5 = 2 + 2 + 1
5 = 2 + 1 + 2
这是一种组合,都是 2 2 1。
如果问的是排列数,那么上面就是两种排列了。
组合不强调元素之间的顺序,排列强调元素之间的顺序。 其实这一点我们在讲解回溯算法专题的时候就讲过了哈。
那我为什么要介绍这些呢,因为这和下文讲解遍历顺序息息相关!
回归本题,动规五步曲来分析如下:
- 确定dp数组以及下标的含义
dp[j]:凑成总金额j的货币组合数为dp[j]
- 确定递推公式
dp[j] 就是所有的dp[j - coins[i]](考虑coins[i]的情况)相加。
所以递推公式:dp[j] += dp[j - coins[i]];
这个递推公式大家应该不陌生了,我在讲解01背包题目的时候在这篇494. 目标和中就讲解了,求装满背包有几种方法,公式都是:dp[j] += dp[j - nums[i]];
- dp数组如何初始化
首先dp[0]一定要为1,dp[0] = 1是 递归公式的基础。如果dp[0] = 0 的话,后面所有推导出来的值都是0了。
那么 dp[0] = 1 有没有含义,其实既可以说 凑成总金额0的货币组合数为1,也可以说 凑成总金额0的货币组合数为0,好像都没有毛病。
但题目描述中,也没明确说 amount = 0 的情况,结果应该是多少。
这里我认为题目描述还是要说明一下,因为后台测试数据是默认,amount = 0 的情况,组合数为1的。
下标非0的dp[j]初始化为0,这样累计加dp[j - coins[i]]的时候才不会影响真正的dp[j]
dp[0]=1还说明了一种情况:如果正好选了coins[i]后,也就是j-coins[i] == 0的情况表示这个硬币刚好能选,此时dp[0]为1表示只选coins[i]存在这样的一种选法。
- 确定遍历顺序
本题中我们是外层for循环遍历物品(钱币),内层for遍历背包(金钱总额),还是外层for遍历背包(金钱总额),内层for循环遍历物品(钱币)呢?
我在动态规划:关于完全背包,你该了解这些!中讲解了完全背包的两个for循环的先后顺序都是可以的。
但本题就不行了!
因为纯完全背包求得装满背包的最大价值是多少,和凑成总和的元素有没有顺序没关系,即:有顺序也行,没有顺序也行!
而本题要求凑成总和的组合数,元素之间明确要求没有顺序。
所以纯完全背包是能凑成总和就行,不用管怎么凑的。
本题是求凑出来的方案个数,且每个方案个数是为组合数。
那么本题,两个for循环的先后顺序可就有说法了。
我们先来看 外层for循环遍历物品(钱币),内层for遍历背包(金钱总额)的情况。
代码如下:
for (int i = 0; i < coins.size(); i++) { // 遍历物品
for (int j = coins[i]; j <= amount; j++) { // 遍历背包容量
dp[j] += dp[j - coins[i]];
}
}
假设:coins[0] = 1,coins[1] = 5。
那么就是先把1加入计算,然后再把5加入计算,得到的方法数量只有{1, 5}这种情况。而不会出现{5, 1}的情况。
所以这种遍历顺序中dp[j]里计算的是组合数!
如果把两个for交换顺序,代码如下:
for (int j = 0; j <= amount; j++) { // 遍历背包容量
for (int i = 0; i < coins.size(); i++) { // 遍历物品
if (j - coins[i] >= 0) dp[j] += dp[j - coins[i]];
}
}
背包容量的每一个值,都是经过 1 和 5 的计算,包含了{1, 5} 和 {5, 1}两种情况。
此时dp[j]里算出来的就是排列数!
可能这里很多同学还不是很理解,建议动手把这两种方案的dp数组数值变化打印出来,对比看一看!(实践出真知)
- 举例推导dp数组
输入: amount = 5, coins = [1, 2, 5] ,dp状态图如下:
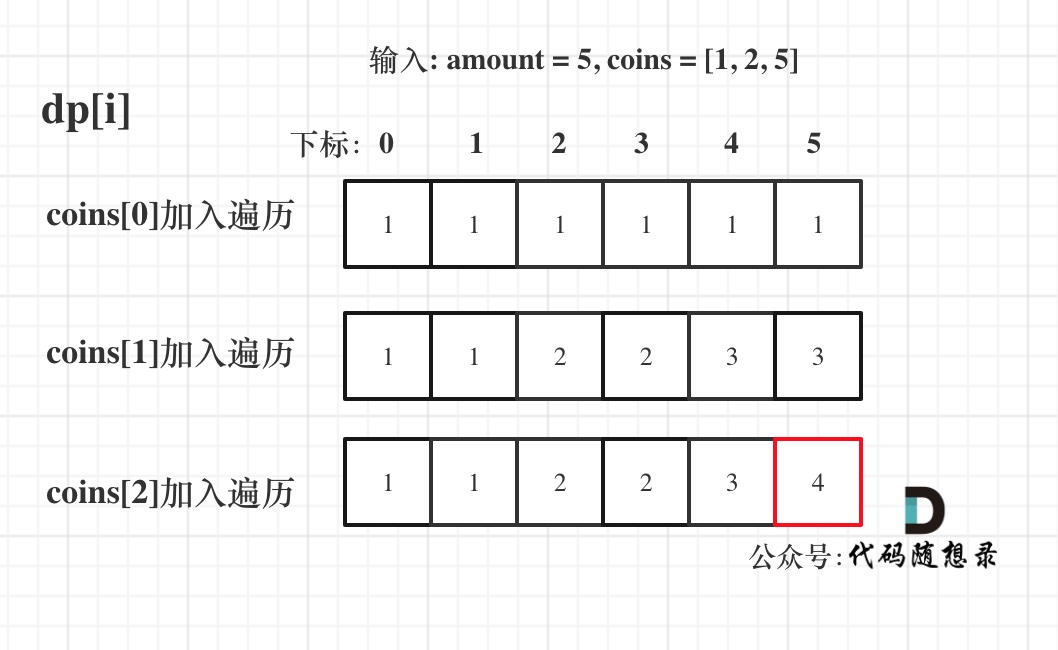
最后红色框dp[amount]为最终结果。
C++解法
以上分析完毕,C++代码如下:
class Solution {
public:
int change(int amount, vector<int>& coins) {
vector<int> dp(amount + 1, 0);
dp[0] = 1;
for (int i = 0; i < coins.size(); i++) { // 遍历物品
for (int j = coins[i]; j <= amount; j++) { // 遍历背包
dp[j] += dp[j - coins[i]];
}
}
return dp[amount];
}
};
- 时间复杂度: O(mn),其中 m 是amount,n 是 coins 的长度
- 空间复杂度: O(m)
Java解法
class Solution {
public int change(int amount, int[] coins) {
//递推表达式
int[] dp = new int[amount + 1];
//初始化dp数组,表示金额为0时只有一种情况,也就是什么都不装
dp[0] = 1;
for (int i = 0; i < coins.length; i++) {
for (int j = coins[i]; j <= amount; j++) {
dp[j] += dp[j - coins[i]];
}
}
return dp[amount];
}
}
322. Coin Change
You are given an integer array coins representing coins of different denominations and an integer amount representing a total amount of money.
Return the fewest number of coins that you need to make up that amount. If that amount of money cannot be made up by any combination of the coins, return -1.
You may assume that you have an infinite number of each kind of coin.
Example 1:
Input: coins = [1,2,5], amount = 11
Output: 3
Explanation: 11 = 5 + 5 + 1
Example 2:
Input: coins = [2], amount = 3
Output: -1
Example 3:
Input: coins = [1], amount = 0
Output: 0
Constraints:
1 <= coins.length <= 121 <= coins[i] <= 2^31 - 10 <= amount <= 10^4
思路
在动态规划:518.零钱兑换II中我们已经兑换一次零钱了,这次又要兑换,套路不一样!
题目中说每种硬币的数量是无限的,可以看出是典型的完全背包问题。
动规五部曲分析如下:
- 确定dp数组以及下标的含义
dp[j]:凑足总额为j所需钱币的最少个数为dp[j]
- 确定递推公式
凑足总额为j - coins[i]的最少个数为dp[j - coins[i]],那么只需要加上一个钱币coins[i]即dp[j - coins[i]] + 1就是dp[j](考虑coins[i])
所以dp[j] 要取所有 dp[j - coins[i]] + 1 中最小的。
递推公式:dp[j] = min(dp[j - coins[i]] + 1, dp[j]);
- dp数组如何初始化
首先凑足总金额为0所需钱币的个数一定是0,那么dp[0] = 0;
其他下标对应的数值呢?
考虑到递推公式的特性,dp[j]必须初始化为一个最大的数,否则就会在min(dp[j - coins[i]] + 1, dp[j])比较的过程中被初始值覆盖。
所以下标非0的元素都是应该是最大值。
代码如下:
vector<int> dp(amount + 1, INT_MAX);
dp[0] = 0;
- 确定遍历顺序
本题求钱币最小个数,那么钱币有顺序和没有顺序都可以,都不影响钱币的最小个数。
所以本题并不强调集合是组合还是排列。
如果求组合数就是外层for循环遍历物品,内层for遍历背包。
如果求排列数就是外层for遍历背包,内层for循环遍历物品。
在动态规划专题我们讲过了求组合数是动态规划:518.零钱兑换II,求排列数是动态规划:377. 组合总和 Ⅳ。
所以本题的两个for循环的关系是:外层for循环遍历物品,内层for遍历背包或者外层for遍历背包,内层for循环遍历物品都是可以的!
那么我采用coins放在外循环,target在内循环的方式。
本题钱币数量可以无限使用,那么是完全背包。所以遍历的内循环是正序
综上所述,遍历顺序为:coins(物品)放在外循环,target(背包)在内循环。且内循环正序。
- 举例推导dp数组
以输入:coins = [1, 2, 5], amount = 5为例
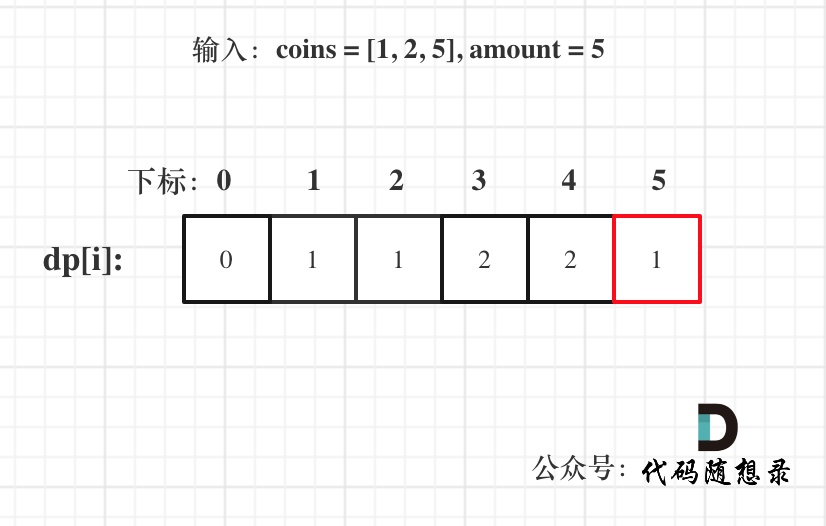
dp[amount]为最终结果。
C++解法
以上分析完毕,C++ 代码如下:
// 版本一
class Solution {
public:
int coinChange(vector<int>& coins, int amount) {
vector<int> dp(amount + 1, INT_MAX);
dp[0] = 0;
for (int i = 0; i < coins.size(); i++) { // 遍历物品
for (int j = coins[i]; j <= amount; j++) { // 遍历背包
if (dp[j - coins[i]] != INT_MAX) { // 如果dp[j - coins[i]]是初始值则跳过
dp[j] = min(dp[j - coins[i]] + 1, dp[j]);
}
}
}
if (dp[amount] == INT_MAX) return -1;
return dp[amount];
}
};
- 时间复杂度: O(n * amount),其中 n 为 coins 的长度
- 空间复杂度: O(amount)
对于遍历方式遍历背包放在外循环,遍历物品放在内循环也是可以的,我就直接给出代码了
// 版本二
class Solution {
public:
int coinChange(vector<int>& coins, int amount) {
vector<int> dp(amount + 1, INT_MAX);
dp[0] = 0;
for (int i = 1; i <= amount; i++) { // 遍历背包
for (int j = 0; j < coins.size(); j++) { // 遍历物品
if (i - coins[j] >= 0 && dp[i - coins[j]] != INT_MAX ) {
dp[i] = min(dp[i - coins[j]] + 1, dp[i]);
}
}
}
if (dp[amount] == INT_MAX) return -1;
return dp[amount];
}
};
- 时间复杂度: O(n * amount),其中 n 为 coins 的长度
- 空间复杂度: O(amount)
Java解法
class Solution {
public int coinChange(int[] coins, int amount) {
int max = Integer.MAX_VALUE;
int[] dp = new int[amount + 1];
//初始化dp数组为最大值
for (int j = 0; j < dp.length; j++) {
dp[j] = max;
}
//当金额为0时需要的硬币数目为0
dp[0] = 0;
for (int i = 0; i < coins.length; i++) {
//正序遍历:完全背包每个硬币可以选择多次
for (int j = coins[i]; j <= amount; j++) {
//只有dp[j-coins[i]]不是初始最大值时,该位才有选择的必要
if (dp[j - coins[i]] != max) {
//选择硬币数目最小的情况
dp[j] = Math.min(dp[j], dp[j - coins[i]] + 1);
}
}
}
return dp[amount] == max ? -1 : dp[amount];
}
}
279. Perfect Squares
Given an integer n, return the least number of perfect square numbers that sum to n.
A perfect square is an integer that is the square of an integer; in other words, it is the product of some integer with itself. For example, 1, 4, 9, and 16 are perfect squares while 3 and 11 are not.
Example 1:
Input: n = 12
Output: 3
Explanation: 12 = 4 + 4 + 4.
Example 2:
Input: n = 13
Output: 2
Explanation: 13 = 4 + 9.
Constraints:
1 <= n <= 10^4
思路
可能刚看这种题感觉没啥思路,又平方和的,又最小数的。
我来把题目翻译一下:完全平方数就是物品(可以无限件使用),凑个正整数n就是背包,问凑满这个背包最少有多少物品?
感受出来了没,这么浓厚的完全背包氛围,而且和昨天的题目动态规划:322. 零钱兑换就是一样一样的!
动规五部曲分析如下:
- 确定dp数组(dp table)以及下标的含义
dp[j]:和为j的完全平方数的最少数量为dp[j]
- 确定递推公式
dp[j] 可以由dp[j - i * i]推出, dp[j - i * i] + 1 便可以凑成dp[j]。
此时我们要选择最小的dp[j],所以递推公式:dp[j] = min(dp[j - i * i] + 1, dp[j]);
- dp数组如何初始化
dp[0]表示 和为0的完全平方数的最小数量,那么dp[0]一定是0。
有同学问题,那0 * 0 也算是一种啊,为啥dp[0] 就是 0呢?
看题目描述,找到若干个完全平方数(比如 1, 4, 9, 16, ...),题目描述中可没说要从0开始,dp[0]=0完全是为了递推公式。
非0下标的dp[j]应该是多少呢?
从递归公式dp[j] = min(dp[j - i * i] + 1, dp[j]);中可以看出每次dp[j]都要选最小的,所以非0下标的dp[j]一定要初始为最大值,这样dp[j]在递推的时候才不会被初始值覆盖。
- 确定遍历顺序
我们知道这是完全背包,
如果求组合数就是外层for循环遍历物品,内层for遍历背包。
如果求排列数就是外层for遍历背包,内层for循环遍历物品。
在动态规划:322. 零钱兑换中我们就深入探讨了这个问题,本题也是一样的,是求最小数!
所以本题外层for遍历背包,内层for遍历物品,还是外层for遍历物品,内层for遍历背包,都是可以的!
我这里先给出外层遍历背包,内层遍历物品的代码:
vector<int> dp(n + 1, INT_MAX);
dp[0] = 0;
for (int i = 0; i <= n; i++) { // 遍历背包
for (int j = 1; j * j <= i; j++) { // 遍历物品
dp[i] = min(dp[i - j * j] + 1, dp[i]);
}
}
- 举例推导dp数组
已输入n为5例,dp状态图如下:
dp[0] = 0 dp[1] = min(dp[0] + 1) = 1 dp[2] = min(dp[1] + 1) = 2 dp[3] = min(dp[2] + 1) = 3 dp[4] = min(dp[3] + 1, dp[0] + 1) = 1 dp[5] = min(dp[4] + 1, dp[1] + 1) = 2
最后的dp[n]为最终结果。
C++解法
以上动规五部曲分析完毕C++代码如下:
// 版本一
class Solution {
public:
int numSquares(int n) {
vector<int> dp(n + 1, INT_MAX);
dp[0] = 0;
for (int i = 0; i <= n; i++) { // 遍历背包
for (int j = 1; j * j <= i; j++) { // 遍历物品
dp[i] = min(dp[i - j * j] + 1, dp[i]);
}
}
return dp[n];
}
};
- 时间复杂度: O(n * √n)
- 空间复杂度: O(n)
同样我在给出先遍历物品,在遍历背包的代码,一样的可以AC的。
// 版本二
class Solution {
public:
int numSquares(int n) {
vector<int> dp(n + 1, INT_MAX);
dp[0] = 0;
for (int i = 1; i * i <= n; i++) { // 遍历物品
for (int j = i * i; j <= n; j++) { // 遍历背包
dp[j] = min(dp[j - i * i] + 1, dp[j]);
}
}
return dp[n];
}
};
爬楼梯
509. Fibonacci Number
The Fibonacci numbers, commonly denoted F(n) form a sequence, called the Fibonacci sequence, such that each number is the sum of the two preceding ones, starting from 0 and 1. That is,
F(0) = 0, F(1) = 1
F(n) = F(n - 1) + F(n - 2), for n > 1.
Given n, calculate F(n).
Example 1:
Input: n = 2
Output: 1
Explanation: F(2) = F(1) + F(0) = 1 + 0 = 1.
Example 2:
Input: n = 3
Output: 2
Explanation: F(3) = F(2) + F(1) = 1 + 1 = 2.
Example 3:
Input: n = 4
Output: 3
Explanation: F(4) = F(3) + F(2) = 2 + 1 = 3.
Constraints:
0 <= n <= 30
思路
动态规划五部曲:
这里我们要用一个一维dp数组来保存递归的结果
- 确定dp数组以及下标的含义
dp[i]的定义为:第i个数的斐波那契数值是dp[i]
- 确定递推公式
为什么这是一道非常简单的入门题目呢?
因为题目已经把递推公式直接给我们了:状态转移方程 dp[i] = dp[i - 1] + dp[i - 2];
- dp数组如何初始化
题目中把如何初始化也直接给我们了,如下:
dp[0] = 0;
dp[1] = 1;
- 确定遍历顺序
从递归公式dp[i] = dp[i - 1] + dp[i - 2];中可以看出,dp[i]是依赖 dp[i - 1] 和 dp[i - 2],那么遍历的顺序一定是从前到后遍历的
- 举例推导dp数组
按照这个递推公式dp[i] = dp[i - 1] + dp[i - 2],我们来推导一下,当N为10的时候,dp数组应该是如下的数列:
0 1 1 2 3 5 8 13 21 34 55
如果代码写出来,发现结果不对,就把dp数组打印出来看看和我们推导的数列是不是一致的。
C++解法
当然可以发现,我们只需要维护两个数值就可以了,不需要记录整个序列。
状态压缩版代码如下:
class Solution {
public:
int fib(int N) {
if (N <= 1) return N;
int dp[2];
dp[0] = 0;
dp[1] = 1;
for (int i = 2; i <= N; i++) {
int sum = dp[0] + dp[1];
dp[0] = dp[1];
dp[1] = sum;
}
return dp[1];
}
};
- 时间复杂度:O(n)
- 空间复杂度:O(1)
Java解法
class Solution {
public int fib(int n) {
if(n <= 1) return n;
int[] dp = new int[n + 1];
dp[0] = 0;
dp[1] = 1;
for(int i = 2; i <= n; i++){
dp[i] = dp[i - 1] + dp[i - 2];
}
return dp[n];
}
}
70. Climbing Stairs
You are climbing a staircase. It takes n steps to reach the top.
Each time you can either climb 1 or 2 steps. In how many distinct ways can you climb to the top?
Example 1:
Input: n = 2
Output: 2
Explanation: There are two ways to climb to the top.
- 1 step + 1 step
- 2 steps
Example 2:
Input: n = 3
Output: 3
Explanation: There are three ways to climb to the top.
- 1 step + 1 step + 1 step
- 1 step + 2 steps
- 2 steps + 1 step
Constraints:
1 <= n <= 45
思路
本题大家如果没有接触过的话,会感觉比较难,多举几个例子,就可以发现其规律。
爬到第一层楼梯有一种方法,爬到二层楼梯有两种方法。
那么第一层楼梯再跨两步就到第三层 ,第二层楼梯再跨一步就到第三层。
所以到第三层楼梯的状态可以由第二层楼梯和到第一层楼梯状态推导出来,那么就可以想到动态规划了。
我们来分析一下,动规五部曲:
定义一个一维数组来记录不同楼层的状态
- 确定dp数组以及下标的含义
dp[i]: 爬到第i层楼梯,有dp[i]种方法
- 确定递推公式
如何可以推出dp[i]呢?
从dp[i]的定义可以看出,dp[i] 可以有两个方向推出来。
首先是dp[i - 1],上i-1层楼梯,有dp[i - 1]种方法,那么再一步跳一个台阶不就是dp[i]了么。
还有就是dp[i - 2],上i-2层楼梯,有dp[i - 2]种方法,那么再一步跳两个台阶不就是dp[i]了么。
那么dp[i]就是 dp[i - 1]与dp[i - 2]之和!
所以dp[i] = dp[i - 1] + dp[i - 2] 。
在推导dp[i]的时候,一定要时刻想着dp[i]的定义,否则容易跑偏。
这体现出确定dp数组以及下标的含义的重要性!
- dp数组如何初始化
再回顾一下dp[i]的定义:爬到第i层楼梯,有dp[i]种方法。
那么i为0,dp[i]应该是多少呢,这个可以有很多解释,但基本都是直接奔着答案去解释的。
例如强行安慰自己爬到第0层,也有一种方法,什么都不做也就是一种方法即:dp[0] = 1,相当于直接站在楼顶。
但总有点牵强的成分。
那还这么理解呢:我就认为跑到第0层,方法就是0啊,一步只能走一个台阶或者两个台阶,然而楼层是0,直接站楼顶上了,就是不用方法,dp[0]就应该是0.
其实这么争论下去没有意义,大部分解释说dp[0]应该为1的理由其实是因为dp[0]=1的话在递推的过程中i从2开始遍历本题就能过,然后就往结果上靠去解释dp[0] = 1。
从dp数组定义的角度上来说,dp[0] = 0 也能说得通。
需要注意的是:题目中说了n是一个正整数,题目根本就没说n有为0的情况。
所以本题其实就不应该讨论dp[0]的初始化!
我相信dp[1] = 1,dp[2] = 2,这个初始化大家应该都没有争议的。
所以我的原则是:不考虑dp[0]如何初始化,只初始化dp[1] = 1,dp[2] = 2,然后从i = 3开始递推,这样才符合dp[i]的定义。
- 确定遍历顺序
从递推公式dp[i] = dp[i - 1] + dp[i - 2];中可以看出,遍历顺序一定是从前向后遍历的
- 举例推导dp数组
举例当n为5的时候,dp table(dp数组)应该是这样的
如果代码出问题了,就把dp table 打印出来,看看究竟是不是和自己推导的一样。
此时大家应该发现了,这不就是斐波那契数列么!
唯一的区别是,没有讨论dp[0]应该是什么,因为dp[0]在本题没有意义!
C++解法
以上五部分析完之后,C++代码如下:
// 版本一
class Solution {
public:
int climbStairs(int n) {
if (n <= 1) return n; // 因为下面直接对dp[2]操作了,防止空指针
vector<int> dp(n + 1);
dp[1] = 1;
dp[2] = 2;
for (int i = 3; i <= n; i++) { // 注意i是从3开始的
dp[i] = dp[i - 1] + dp[i - 2];
}
return dp[n];
}
};
- 时间复杂度:
- 空间复杂度:
当然依然也可以,优化一下空间复杂度,代码如下:
// 版本二
class Solution {
public:
int climbStairs(int n) {
if (n <= 1) return n;
int dp[3];
dp[1] = 1;
dp[2] = 2;
for (int i = 3; i <= n; i++) {
int sum = dp[1] + dp[2];
dp[1] = dp[2];
dp[2] = sum;
}
return dp[2];
}
};
- 时间复杂度:
- 空间复杂度:
后面将讲解的很多动规的题目其实都是当前状态依赖前两个,或者前三个状态,都可以做空间上的优化,但我个人认为面试中能写出版本一就够了哈,清晰明了,如果面试官要求进一步优化空间的话,我们再去优化。
因为版本一才能体现出动规的思想精髓,递推的状态变化。
Java解法
class Solution {
public int climbStairs(int n) {
if(n <= 3) return n;
int[] dp = new int[n + 1];
dp[2] = 2;
dp[3] = 3;
for(int i = 4; i <= n; i++){
dp[i] = dp[i - 1] + dp[i - 2];
}
return dp[n];
}
}
746. Min Cost Climbing Stairs
You are given an integer array cost where cost[i] is the cost of ith step on a staircase. Once you pay the cost, you can either climb one or two steps.
You can either start from the step with index 0, or the step with index 1.
Return the minimum cost to reach the top of the floor.
Example 1:
Input: cost = [10,15,20]
Output: 15
Explanation: You will start at index 1.
- Pay 15 and climb two steps to reach the top. The total cost is 15.
Example 2:
Input: cost = [1,100,1,1,1,100,1,1,100,1]
Output: 6
Explanation: You will start at index 0.
- Pay 1 and climb two steps to reach index 2.
- Pay 1 and climb two steps to reach index 4.
- Pay 1 and climb two steps to reach index 6.
- Pay 1 and climb one step to reach index 7.
- Pay 1 and climb two steps to reach index 9.
- Pay 1 and climb one step to reach the top. The total cost is 6.
Constraints:
2 <= cost.length <= 10000 <= cost[i] <= 999
思路
修改之后的题意就比较明确了,题目中说 “你可以选择从下标为 0 或下标为 1 的台阶开始爬楼梯” 也就是相当于 跳到 下标 0 或者 下标 1 是不花费体力的, 从 下标 0 下标1 开始跳就要花费体力了。
- 确定dp数组以及下标的含义
使用动态规划,就要有一个数组来记录状态,本题只需要一个一维数组dp[i]就可以了。
dp[i]的定义:到达第i台阶所花费的最少体力为dp[i]。
对于dp数组的定义,大家一定要清晰!
- 确定递推公式
可以有两个途径得到dp[i],一个是dp[i-1] 一个是dp[i-2]。
dp[i - 1] 跳到 dp[i] 需要花费 dp[i - 1] + cost[i - 1]。
dp[i - 2] 跳到 dp[i] 需要花费 dp[i - 2] + cost[i - 2]。
那么究竟是选从dp[i - 1]跳还是从dp[i - 2]跳呢?
一定是选最小的,所以dp[i] = min(dp[i - 1] + cost[i - 1], dp[i - 2] + cost[i - 2]);
- dp数组如何初始化
看一下递归公式,dp[i]由dp[i - 1],dp[i - 2]推出,既然初始化所有的dp[i]是不可能的,那么只初始化dp[0]和dp[1]就够了,其他的最终都是dp[0]dp[1]推出。
那么 dp[0] 应该是多少呢? 根据dp数组的定义,到达第0台阶所花费的最小体力为dp[0],那么有同学可能想,那dp[0] 应该是 cost[0],例如 cost = [1, 100, 1, 1, 1, 100, 1, 1, 100, 1] 的话,dp[0] 就是 cost[0] 应该是1。
这里就要说明本题力扣为什么改题意,而且修改题意之后 就清晰很多的原因了。
新题目描述中明确说了 “你可以选择从下标为 0 或下标为 1 的台阶开始爬楼梯。” 也就是说 到达 第 0 个台阶是不花费的,但从 第0 个台阶 往上跳的话,需要花费 cost[0]。
所以初始化 dp[0] = 0,dp[1] = 0;
- 确定遍历顺序
最后一步,递归公式有了,初始化有了,如何遍历呢?
本题的遍历顺序其实比较简单,简单到很多同学都忽略了思考这一步直接就把代码写出来了。
因为是模拟台阶,而且dp[i]由dp[i-1]dp[i-2]推出,所以是从前到后遍历cost数组就可以了。
但是稍稍有点难度的动态规划,其遍历顺序并不容易确定下来。 例如:01背包,都知道两个for循环,一个for遍历物品嵌套一个for遍历背包容量,那么为什么不是一个for遍历背包容量嵌套一个for遍历物品呢? 以及在使用一维dp数组的时候遍历背包容量为什么要倒序呢?
这些都与遍历顺序息息相关。当然背包问题后续「代码随想录」都会重点讲解的!
- 举例推导dp数组
拿示例2:cost = [1, 100, 1, 1, 1, 100, 1, 1, 100, 1] ,来模拟一下dp数组的状态变化,如下:
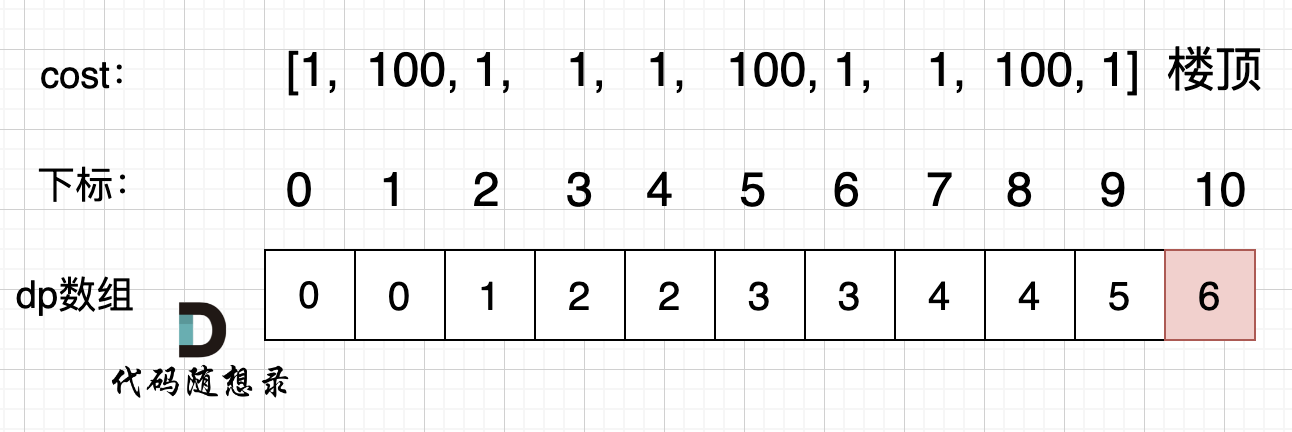
如果大家代码写出来有问题,就把dp数组打印出来,看看和如上推导的是不是一样的。
C++解法
以上分析完毕,整体C++代码如下:
class Solution {
public:
int minCostClimbingStairs(vector<int>& cost) {
vector<int> dp(cost.size() + 1);
dp[0] = 0; // 默认第一步都是不花费体力的
dp[1] = 0;
for (int i = 2; i <= cost.size(); i++) {
dp[i] = min(dp[i - 1] + cost[i - 1], dp[i - 2] + cost[i - 2]);
}
return dp[cost.size()];
}
};
- 时间复杂度:O(n)
- 空间复杂度:O(n)
还可以优化空间复杂度,因为dp[i]就是由前两位推出来的,那么也不用dp数组了,C++代码如下:
class Solution {
public:
int minCostClimbingStairs(vector<int>& cost) {
int dp0 = 0;
int dp1 = 0;
for (int i = 2; i <= cost.size(); i++) {
int dpi = min(dp1 + cost[i - 1], dp0 + cost[i - 2]);
dp0 = dp1; // 记录一下前两位
dp1 = dpi;
}
return dp1;
}
};
- 时间复杂度:O(n)
- 空间复杂度:O(1)
当然如果在面试中,能写出版本一就行,除非面试官额外要求空间复杂度,那么再去思考版本二,因为版本二还是有点绕。版本一才是正常思路。
70. 爬楼梯(进阶版)
假设你正在爬楼梯。需要 n 阶你才能到达楼顶。
每次你可以爬至多m (1 <= m < n)个台阶。你有多少种不同的方法可以爬到楼顶呢?
注意:给定 n 是一个正整数。
输入描述:输入共一行,包含两个正整数,分别表示n, m
输出描述:输出一个整数,表示爬到楼顶的方法数。
输入示例:3 2
输出示例:3
提示:
当 m = 2,n = 3 时,n = 3 这表示一共有三个台阶,m = 2 代表你每次可以爬一个台阶或者两个台阶。
此时你有三种方法可以爬到楼顶。
- 1 阶 + 1 阶 + 1 阶段
- 1 阶 + 2 阶
- 2 阶 + 1 阶
思路
之前讲这道题目的时候,因为还没有讲背包问题,所以就只是讲了一下爬楼梯最直接的动规方法(斐波那契)。
这次终于讲到了背包问题,我选择带录友们再爬一次楼梯!
这道题目 我们在动态规划:爬楼梯 中已经讲过一次了,这次我又给本题加点料,力扣上没有原题,所以可以在卡码网57. 爬楼梯上来刷这道题目。
我们之前做的 爬楼梯 是只能至多爬两个台阶。
这次改为:一步一个台阶,两个台阶,三个台阶,.......,直到 m个台阶。问有多少种不同的方法可以爬到楼顶呢?
这又有难度了,这其实是一个完全背包问题。
1阶,2阶,.... m阶就是物品,楼顶就是背包。
每一阶可以重复使用,例如跳了1阶,还可以继续跳1阶。
问跳到楼顶有几种方法其实就是问装满背包有几种方法。
此时大家应该发现这就是一个完全背包问题了!
和昨天的题目动态规划:377. 组合总和 Ⅳ基本就是一道题了。
动规五部曲分析如下:
- 确定dp数组以及下标的含义
dp[i]:爬到有i个台阶的楼顶,有dp[i]种方法。
- 确定递推公式
在动态规划:494.目标和 、 动态规划:518.零钱兑换II、动态规划:377. 组合总和 Ⅳ中我们都讲过了,求装满背包有几种方法,递推公式一般都是dp[i] += dp[i - nums[j]];
本题呢,dp[i]有几种来源,dp[i - 1],dp[i - 2],dp[i - 3] 等等,即:dp[i - j]
那么递推公式为:dp[i] += dp[i - j]
- dp数组如何初始化
既然递归公式是 dp[i] += dp[i - j],那么dp[0] 一定为1,dp[0]是递归中一切数值的基础所在,如果dp[0]是0的话,其他数值都是0了。
下标非0的dp[i]初始化为0,因为dp[i]是靠dp[i-j]累计上来的,dp[i]本身为0这样才不会影响结果
- 确定遍历顺序
这是背包里求排列问题,即:1、2 步 和 2、1 步都是上三个台阶,但是这两种方法不一样!
所以需将target放在外循环,将nums放在内循环。
每一步可以走多次,这是完全背包,内循环需要从前向后遍历。
- 举例来推导dp数组
介于本题和动态规划:377. 组合总和 Ⅳ几乎是一样的,这里我就不再重复举例了。
总结
本题看起来是一道简单题目,稍稍进阶一下其实就是一个完全背包!
如果我来面试的话,我就会先给候选人出一个本题原题,看其表现,如果顺利写出来,进而在要求每次可以爬[1 - m]个台阶应该怎么写。
顺便再考察一下两个for循环的嵌套顺序,为什么target放外面,nums放里面。
这就能考察对背包问题本质的掌握程度,候选人是不是刷题背公式,一眼就看出来了。
这么一连套下来,如果候选人都能答出来,相信任何一位面试官都是非常满意的。
本题代码不长,题目也很普通,但稍稍一进阶就可以考察完全背包,而且题目进阶的内容在leetcode上并没有原题,一定程度上就可以排除掉刷题党了,简直是面试题目的绝佳选择!
C++解法
以上分析完毕,C++代码如下:
#include <iostream>
#include <vector>
using namespace std;
int main() {
int n, m;
while (cin >> n >> m) {
vector<int> dp(n + 1, 0);
dp[0] = 1;
for (int i = 1; i <= n; i++) { // 遍历背包
for (int j = 1; j <= m; j++) { // 遍历物品
if (i - j >= 0) dp[i] += dp[i - j];
}
}
cout << dp[n] << endl;
}
}
- 时间复杂度: O(n * m)
- 空间复杂度: O(n)
代码中m表示最多可以爬m个台阶,代码中把m改成2就是 力扣:70.爬楼梯的解题思路。
当然注意 力扣是 核心代码模式,卡码网是ACM模式
Java解法
import java.util.Scanner;
class climbStairs{
public static void main(String [] args){
Scanner sc = new Scanner(System.in);
int m, n;
while (sc.hasNextInt()) {
// 从键盘输入参数,中间用空格隔开
n = sc.nextInt();
m = sc.nextInt();
// 求排列问题,先遍历背包再遍历物品
int[] dp = new int[n + 1];
dp[0] = 1;
for (int j = 1; j <= n; j++) {
for (int i = 1; i <= m; i++) {
if (j - i >= 0) dp[j] += dp[j - i];
}
}
System.out.println(dp[n]);
}
}
}
不同路径
62. Unique Paths
There is a robot on an m x n grid. The robot is initially located at the top-left corner (i.e., grid[0][0]). The robot tries to move to the bottom-right corner (i.e., grid[m - 1][n - 1]). The robot can only move either down or right at any point in time.
Given the two integers m and n, return the number of possible unique paths that the robot can take to reach the bottom-right corner.
The test cases are generated so that the answer will be less than or equal to 2 * 10^9.
Example 1:
Input: m = 3, n = 7
Output: 28
Example 2:
Input: m = 3, n = 2
Output: 3
Explanation: From the top-left corner, there are a total of 3 ways to reach the bottom-right corner:
- Right -> Down -> Down
- Down -> Down -> Right
- Down -> Right -> Down
Constraints:
1 <= m, n <= 100
思路
深搜
这道题目,刚一看最直观的想法就是用图论里的深搜,来枚举出来有多少种路径。
注意题目中说机器人每次只能向下或者向右移动一步,那么其实机器人走过的路径可以抽象为一棵二叉树,而叶子节点就是终点!
如图举例:
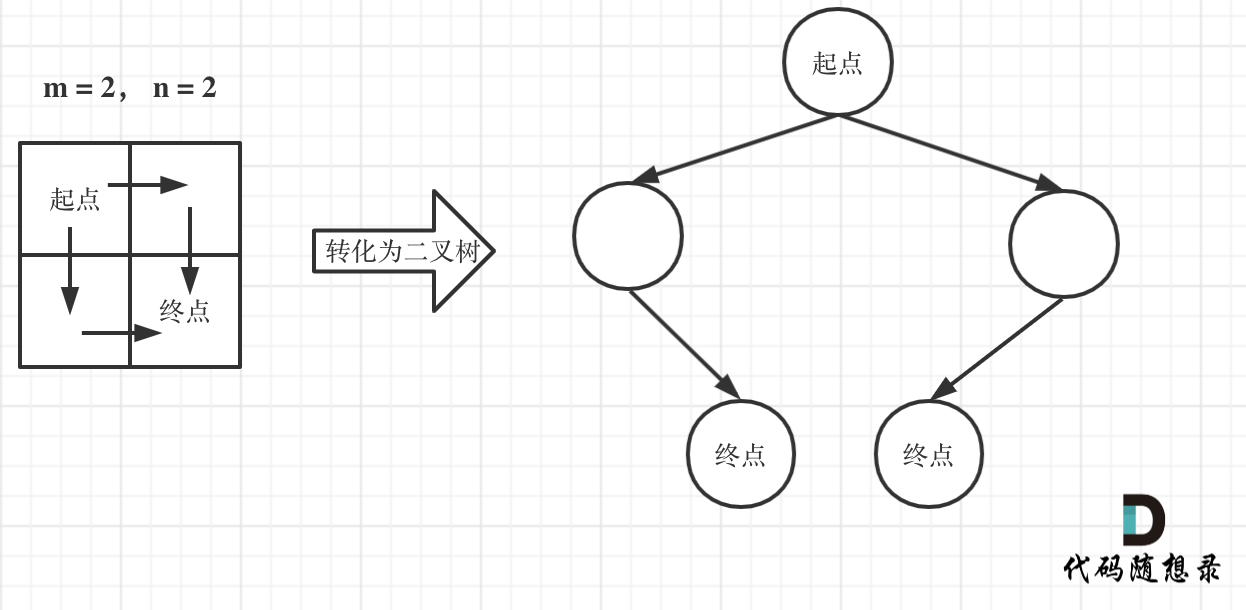
此时问题就可以转化为求二叉树叶子节点的个数,代码如下:
class Solution {
private:
int dfs(int i, int j, int m, int n) {
if (i > m || j > n) return 0; // 越界了
if (i == m && j == n) return 1; // 找到一种方法,相当于找到了叶子节点
return dfs(i + 1, j, m, n) + dfs(i, j + 1, m, n);
}
public:
int uniquePaths(int m, int n) {
return dfs(1, 1, m, n);
}
};
大家如果提交了代码就会发现超时了!
来分析一下时间复杂度,这个深搜的算法,其实就是要遍历整个二叉树。
这棵树的深度其实就是m+n-1(深度按从1开始计算)。
那二叉树的节点个数就是 。可以理解深搜的算法就是遍历了整个满二叉树(其实没有遍历整个满二叉树,只是近似而已)
所以上面深搜代码的时间复杂度为,可以看出,这是指数级别的时间复杂度,是非常大的。
动态规划
机器人从(0 , 0) 位置出发,到(m - 1, n - 1)终点。
按照动规五部曲来分析:
- 确定dp数组(dp table)以及下标的含义
dp[i][j]:表示从(0 ,0)出发,到(i, j) 有dp[i][j]条不同的路径。
- 确定递推公式
想要求dp[i][j],只能有两个方向来推导出来,即dp[i - 1][j] 和 dp[i][j - 1]。
此时在回顾一下 dp[i - 1][j] 表示啥,是从(0, 0)的位置到(i - 1, j)有几条路径,dp[i][j]同理。
那么很自然,dp[i][j] = dp[i - 1][j] + dp[i][j - 1],因为dp[i][j]只有这两个方向过来。
- dp数组的初始化
如何初始化呢,首先dp[i][j]一定都是1,因为从(0, 0)的位置到(i, 0)的路径只有一条,那么dp0也同理。
所以初始化代码为:
for (int i = 0; i < m; i++) dp[i][0] = 1;
for (int j = 0; j < n; j++) dp[0][j] = 1;
- 确定遍历顺序
这里要看一下递推公式dp[i][j] = dp[i - 1][j] + dp[i][j - 1],dp[i][j]都是从其上方和左方推导而来,那么从左到右一层一层遍历就可以了。
- 举例推导dp数组
如图所示:
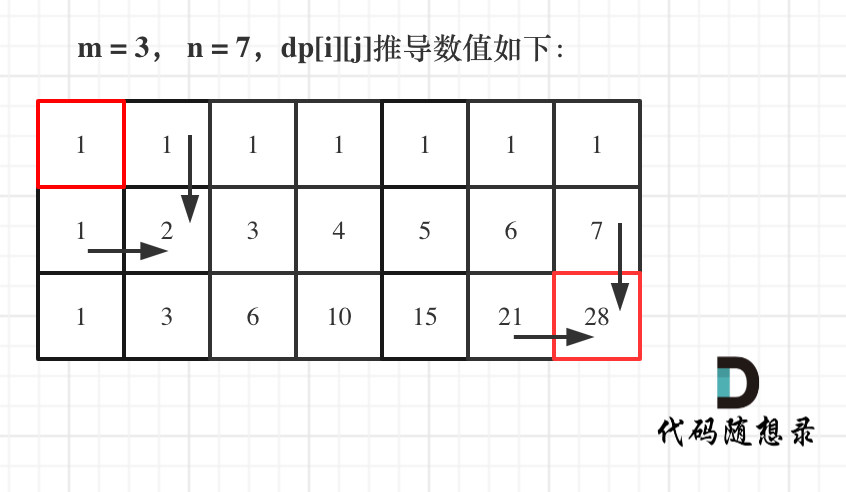
数论方法
在这个图中,可以看出一共m,n的话,无论怎么走,走到终点都需要 m + n - 2 步。
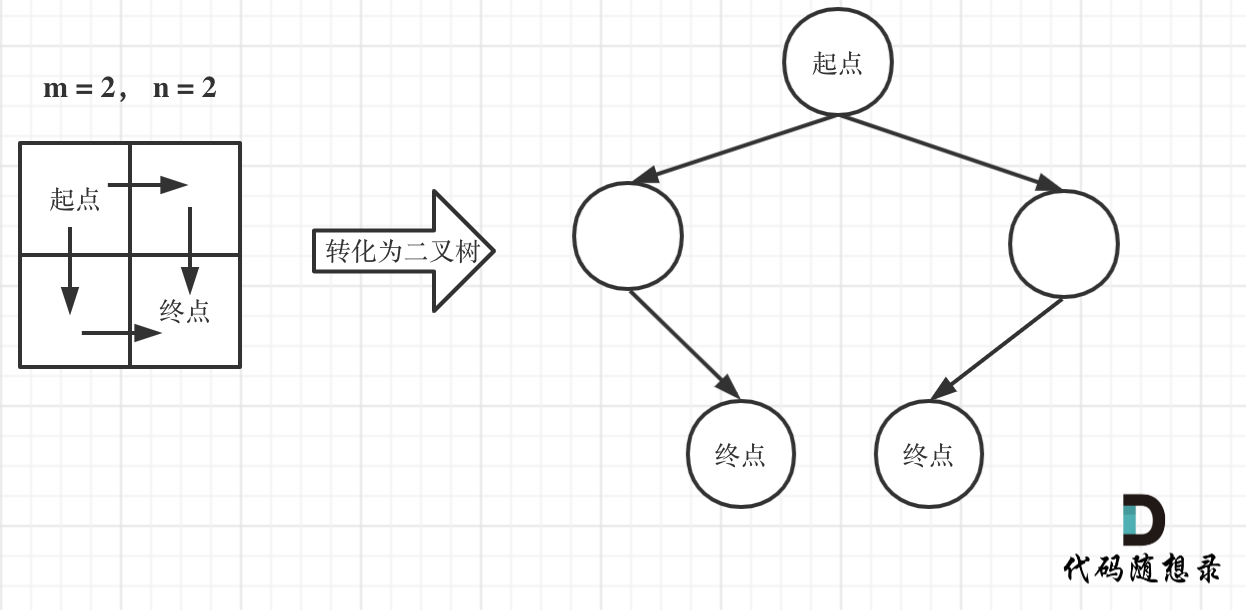
在这m + n - 2 步中,一定有 m - 1 步是要向下走的,不用管什么时候向下走。
那么有几种走法呢? 可以转化为,给你m + n - 2个不同的数,随便取m - 1个数,有几种取法。
那么这就是一个组合问题了。
那么答案,如图所示:
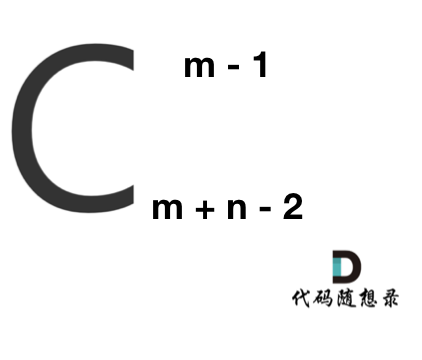
求组合的时候,要防止两个int相乘溢出! 所以不能把算式的分子都算出来,分母都算出来再做除法。
例如如下代码是不行的。
class Solution {
public:
int uniquePaths(int m, int n) {
int numerator = 1, denominator = 1;
int count = m - 1;
int t = m + n - 2;
while (count--) numerator *= (t--); // 计算分子,此时分子就会溢出
for (int i = 1; i <= m - 1; i++) denominator *= i; // 计算分母
return numerator / denominator;
}
};
需要在计算分子的时候,不断除以分母,代码如下:
class Solution {
public:
int uniquePaths(int m, int n) {
long long numerator = 1; // 分子
int denominator = m - 1; // 分母
int count = m - 1;
int t = m + n - 2;
while (count--) {
numerator *= (t--);
while (denominator != 0 && numerator % denominator == 0) {
numerator /= denominator;
denominator--;
}
}
return numerator;
}
};
- 时间复杂度:O(m)
- 空间复杂度:O(1)
计算组合问题的代码还是有难度的,特别是处理溢出的情况!
C++解法
以上动规五部曲分析完毕,C++代码如下:
class Solution {
public:
int uniquePaths(int m, int n) {
vector<vector<int>> dp(m, vector<int>(n, 0));
for (int i = 0; i < m; i++) dp[i][0] = 1;
for (int j = 0; j < n; j++) dp[0][j] = 1;
for (int i = 1; i < m; i++) {
for (int j = 1; j < n; j++) {
dp[i][j] = dp[i - 1][j] + dp[i][j - 1];
}
}
return dp[m - 1][n - 1];
}
};
- 时间复杂度:O(m × n)
- 空间复杂度:O(m × n)
其实用一个一维数组(也可以理解是滚动数组)就可以了,但是不利于理解,可以优化点空间,建议先理解了二维,在理解一维,C++代码如下:
class Solution {
public:
int uniquePaths(int m, int n) {
vector<int> dp(n);
for (int i = 0; i < n; i++) dp[i] = 1;
for (int j = 1; j < m; j++) {
for (int i = 1; i < n; i++) {
dp[i] += dp[i - 1];
}
}
return dp[n - 1];
}
};
- 时间复杂度:O(m × n)
- 空间复杂度:O(n)
Java解法
/**
* 1. 确定dp数组下标含义 dp[i][j] 到每一个坐标可能的路径种类
* 2. 递推公式 dp[i][j] = dp[i-1][j] dp[i][j-1]
* 3. 初始化 dp[i][0]=1 dp[0][i]=1 初始化横竖就可
* 4. 遍历顺序 一行一行遍历
* 5. 推导结果 。。。。。。。。
*
* @param m
* @param n
* @return
*/
public static int uniquePaths(int m, int n) {
int[][] dp = new int[m][n];
//初始化
for (int i = 0; i < m; i++) {
dp[i][0] = 1;
}
for (int i = 0; i < n; i++) {
dp[0][i] = 1;
}
for (int i = 1; i < m; i++) {
for (int j = 1; j < n; j++) {
dp[i][j] = dp[i-1][j]+dp[i][j-1];
}
}
return dp[m-1][n-1];
}
63. Unique Paths II
You are given an m x n integer array grid. There is a robot initially located at the top-left corner (i.e., grid[0][0]). The robot tries to move to the bottom-right corner (i.e., grid[m - 1][n - 1]). The robot can only move either down or right at any point in time.
An obstacle and space are marked as 1 or 0 respectively in grid. A path that the robot takes cannot include any square that is an obstacle.
Return the number of possible unique paths that the robot can take to reach the bottom-right corner.
The testcases are generated so that the answer will be less than or equal to 2 * 10^9.
Example 1:

Input: obstacleGrid = [[0,0,0],[0,1,0],[0,0,0]]
Output: 2
Explanation: There is one obstacle in the middle of the 3x3 grid above.
There are two ways to reach the bottom-right corner:
- Right -> Right -> Down -> Down
- Down -> Down -> Right -> Right
Example 2:

Input: obstacleGrid = [[0,1],[0,0]]
Output: 1
Constraints:
m == obstacleGrid.lengthn == obstacleGrid[i].length1 <= m, n <= 100obstacleGrid[i][j]is0or1.
思路
62.不同路径中我们已经详细分析了没有障碍的情况,有障碍的话,其实就是标记对应的dp table(dp数组)保持初始值(0)就可以了。
动规五部曲:
- 确定dp数组(dp table)以及下标的含义
dp[i][j] :表示从(0 ,0)出发,到(i, j) 有dp[i][j]条不同的路径。
- 确定递推公式
递推公式和62.不同路径一样,dp[i][j] = dp[i - 1][j] + dp[i][j - 1]
但这里需要注意一点,因为有了障碍,(i, j)如果就是障碍的话应该就保持初始状态(初始状态为0)。
所以代码为:
if (obstacleGrid[i][j] == 0) { // 当(i, j)没有障碍的时候,再推导dp[i][j]
dp[i][j] = dp[i - 1][j] + dp[i][j - 1];
}
- dp数组如何初始化
在62.不同路径不同路径中我们给出如下的初始化:
vector<vector<int>> dp(m, vector<int>(n, 0)); // 初始值为0
for (int i = 0; i < m; i++) dp[i][0] = 1;
for (int j = 0; j < n; j++) dp[0][j] = 1;
因为从(0, 0)的位置到(i, 0)的路径只有一条,所以dp[i][j]一定为1,dp0也同理。
但如果(i, 0) 这条边有了障碍之后,障碍之后(包括障碍)都是走不到的位置了,所以障碍之后的dp[i][j]应该还是初始值0。
如图:
下标(0, j)的初始化情况同理。
所以本题初始化代码为:
vector<vector<int>> dp(m, vector<int>(n, 0));
for (int i = 0; i < m && obstacleGrid[i][0] == 0; i++) dp[i][0] = 1;
for (int j = 0; j < n && obstacleGrid[0][j] == 0; j++) dp[0][j] = 1;
注意代码里for循环的终止条件,一旦遇到obstacleGrid[i][0] == 1的情况就停止dp[i][j]的赋值1的操作,dp[0][j]同理
- 确定遍历顺序
从递归公式dp[i][j] = dp[i - 1][j] + dp[i][j - 1]中可以看出,一定是从左到右一层一层遍历,这样保证推导dp[i][j]的时候,dp[i - 1][j]和 dp[i][j - 1]一定是有数值。
代码如下:
for (int i = 1; i < m; i++) {
for (int j = 1; j < n; j++) {
if (obstacleGrid[i][j] == 1) continue;
dp[i][j] = dp[i - 1][j] + dp[i][j - 1];
}
}
- 举例推导dp数组
拿示例1来举例如题:
对应的dp table 如图:
如果这个图看不懂,建议再理解一下递归公式,然后照着文章中说的遍历顺序,自己推导一下!
C++解法
动规五部分分析完毕,对应C++代码如下:
class Solution {
public:
int uniquePathsWithObstacles(vector<vector<int>>& obstacleGrid) {
int m = obstacleGrid.size();
int n = obstacleGrid[0].size();
if (obstacleGrid[m - 1][n - 1] == 1 || obstacleGrid[0][0] == 1) //如果在起点或终点出现了障碍,直接返回0
return 0;
vector<vector<int>> dp(m, vector<int>(n, 0));
for (int i = 0; i < m && obstacleGrid[i][0] == 0; i++) dp[i][0] = 1;
for (int j = 0; j < n && obstacleGrid[0][j] == 0; j++) dp[0][j] = 1;
for (int i = 1; i < m; i++) {
for (int j = 1; j < n; j++) {
if (obstacleGrid[i][j] == 1) continue;
dp[i][j] = dp[i - 1][j] + dp[i][j - 1];
}
}
return dp[m - 1][n - 1];
}
};
- 时间复杂度:O(n × m),n、m 分别为obstacleGrid 长度和宽度
- 空间复杂度:O(n × m)
同样我们给出空间优化版本:
class Solution {
public:
int uniquePathsWithObstacles(vector<vector<int>>& obstacleGrid) {
if (obstacleGrid[0][0] == 1)
return 0;
vector<int> dp(obstacleGrid[0].size());
for (int j = 0; j < dp.size(); ++j)
if (obstacleGrid[0][j] == 1)
dp[j] = 0;
else if (j == 0)
dp[j] = 1;
else
dp[j] = dp[j-1];
for (int i = 1; i < obstacleGrid.size(); ++i)
for (int j = 0; j < dp.size(); ++j){
if (obstacleGrid[i][j] == 1)
dp[j] = 0;
else if (j != 0)
dp[j] = dp[j] + dp[j-1];
}
return dp.back();
}
};
- 时间复杂度:O(n × m),n、m 分别为obstacleGrid 长度和宽度
- 空间复杂度:O(m)
Java解法
// 空间优化版本
class Solution {
public int uniquePathsWithObstacles(int[][] obstacleGrid) {
int m = obstacleGrid.length;
int n = obstacleGrid[0].length;
int[] dp = new int[n];
for (int j = 0; j < n && obstacleGrid[0][j] == 0; j++) {
dp[j] = 1;
}
for (int i = 1; i < m; i++) {
for (int j = 0; j < n; j++) {
if (obstacleGrid[i][j] == 1) {
dp[j] = 0;
} else if (j != 0) {
dp[j] += dp[j - 1];
}
}
}
return dp[n - 1];
}
}
64. Minimum Path Sum
Given a m x n grid filled with non-negative numbers, find a path from top left to bottom right, which minimizes the sum of all numbers along its path.
Note: You can only move either down or right at any point in time.
Example 1:
Input: grid = [[1,3,1],[1,5,1],[4,2,1]]
Output: 7
Explanation: Because the path 1 → 3 → 1 → 1 → 1 minimizes the sum.
Example 2:
Input: grid = [[1,2,3],[4,5,6]]
Output: 12
Constraints:
m == grid.lengthn == grid[i].length1 <= m, n <= 2000 <= grid[i][j] <= 200
思路
二维DP
C++解法
class Solution {
public:
int minPathSum(vector<vector<int>>& grid) {
int m = grid.size();
int n = grid[0].size();
vector<vector<int>> dp(m, vector<int>(n, 0));
// 初始化起点
dp[0][0] = grid[0][0];
// 初始化第一列
for (int i = 1; i < m; i++) {
dp[i][0] = dp[i - 1][0] + grid[i][0];
}
// 初始化第一行
for (int j = 1; j < n; j++) {
dp[0][j] = dp[0][j - 1] + grid[0][j];
}
// 计算其他位置的最小路径和
for (int i = 1; i < m; i++) {
for (int j = 1; j < n; j++) {
dp[i][j] = min(dp[i - 1][j], dp[i][j - 1]) + grid[i][j];
}
}
return dp[m - 1][n - 1];
}
};
980. Unique Paths III(回溯)
You are given an m x n integer array grid where grid[i][j] could be:
1representing the starting square. There is exactly one starting square.2representing the ending square. There is exactly one ending square.0representing empty squares we can walk over.-1representing obstacles that we cannot walk over.
Return the number of 4-directional walks from the starting square to the ending square, that walk over every non-obstacle square exactly once.
Example 1:

Input: grid = [[1,0,0,0],[0,0,0,0],[0,0,2,-1]]
Output: 2
Explanation: We have the following two paths:
- (0,0),(0,1),(0,2),(0,3),(1,3),(1,2),(1,1),(1,0),(2,0),(2,1),(2,2)
- (0,0),(1,0),(2,0),(2,1),(1,1),(0,1),(0,2),(0,3),(1,3),(1,2),(2,2)
Example 2:
Input: grid = [[1,0,0,0],[0,0,0,0],[0,0,0,2]]
Output: 4
Explanation: We have the following four paths:
- (0,0),(0,1),(0,2),(0,3),(1,3),(1,2),(1,1),(1,0),(2,0),(2,1),(2,2),(2,3)
- (0,0),(0,1),(1,1),(1,0),(2,0),(2,1),(2,2),(1,2),(0,2),(0,3),(1,3),(2,3)
- (0,0),(1,0),(2,0),(2,1),(2,2),(1,2),(1,1),(0,1),(0,2),(0,3),(1,3),(2,3)
- (0,0),(1,0),(2,0),(2,1),(1,1),(0,1),(0,2),(0,3),(1,3),(1,2),(2,2),(2,3)
Example 3:

Input: grid = [[0,1],[2,0]]
Output: 0
Explanation: There is no path that walks over every empty square exactly once.
Note that the starting and ending square can be anywhere in the grid.
Constraints:
m == grid.lengthn == grid[i].length1 <= m, n <= 201 <= m * n <= 20-1 <= grid[i][j] <= 2- There is exactly one starting cell and one ending cell.
思路
Brute Force Backtracking
First, find out where the start and end points are.
We also need to know the number of empty cells.
When we try to explore a cell, it will change 0 to -2 and perform a DFS in 4 directions.
If we hit the target and have passed all the empty cells, we increment the result.
The time complexity is comparable to dynamic programming, but it takes up less space and is easier to implement.
In the first step, we need to identify the starting point. We also want to know the number of empty cells.
Next, we iterate through the grid to count the empty cells and save the starting point as start_x and start_y.
Now, we perform a classic DFS, marking the visited cells with -1 and counting the cells we have traversed. If we reach the ending point and have passed the specified number of empty cells, it means we have visited every non-obstacle cell.
暴力回溯法
首先,找出起点和终点的位置。
我们还需要知道空单元格的数量。
当我们尝试探索一个单元格时,它将把0变为-2,并在四个方向上执行深度优先搜索(DFS)。
如果我们到达目标并经过了所有空单元格,我们就会增加结果计数。
时间复杂度与动态规划相当,但所需空间更少,且实现较为简单。
第一步,我们需要确定起点的位置。我们还想知道空单元格的数量。
接下来,我们遍历网格,计算空单元格的数量,并保存起点 start_x 和 start_y。
现在,我们执行经典的DFS,标记访问过的单元格为-1,并计算我们经过的单元格数。 如果我们到达终点并经过了指定数量的空单元格,这意味着我们访问了每个非障碍物单元格。
C++解法
class Solution {
public:
int res = 0, empty = 1;
void dfs(vector<vector<int>>& grid, int x, int y, int count) {
if (x < 0 || x >= grid.size() || y < 0 || y >= grid[0].size() || grid[x][y] == -1) return;
if (grid[x][y] == 2) {
if(empty == count) res++;
return;
}
grid[x][y] = -1;
dfs(grid, x+1, y, count+1);
dfs(grid, x-1, y, count+1);
dfs(grid, x, y+1, count+1);
dfs(grid, x, y-1, count+1);
grid[x][y] = 0;
}
int uniquePathsIII(vector<vector<int>>& grid) {
int start_x, start_y;
for (int i = 0; i < grid.size(); i++) {
for (int j = 0; j < grid[0].size(); j++) {
if (grid[i][j] == 1) start_x = i, start_y = j;
else if (grid[i][j] == 0) empty++;
}
}
dfs(grid, start_x, start_y, 0);
return res;
}
};
Java解法
int res = 0, empty = 1, sx, sy, ex, ey;
public int uniquePathsIII(int[][] grid) {
int m = grid.length, n = grid[0].length;
for (int i = 0; i < m; ++i) {
for (int j = 0; j < n; ++j) {
if (grid[i][j] == 0) empty++;
else if (grid[i][j] == 1) {
sx = i;
sy = j;
}
}
}
dfs(grid, sx, sy);
return res;
}
public void dfs(int[][] grid, int x, int y) {
if (x < 0 || x >= grid.length || y < 0 || y >= grid[0].length || grid[x][y] < 0)
return;
if (grid[x][y] == 2) {
if (empty == 0) res++;
return;
}
grid[x][y] = -2;
empty--;
dfs(grid, x + 1, y);
dfs(grid, x - 1, y);
dfs(grid, x, y + 1);
dfs(grid, x, y - 1);
grid[x][y] = 0;
empty++;
}
不同二叉搜索树
96. Unique Binary Search Trees
Given an integer n, return the number of structurally unique BST' s (binary search trees) which has exactly n nodes of unique values from 1 to n.
Example 1:

Input: n = 3
Output: 5
Example 2:
Input: n = 1
Output: 1
Constraints:
1 <= n <= 19
思路
这道题目描述很简短,但估计大部分同学看完都是懵懵的状态,这得怎么统计呢?
关于什么是二叉搜索树,我们之前在讲解二叉树专题的时候已经详细讲解过了,也可以看看这篇二叉树:二叉搜索树登场!再回顾一波。
了解了二叉搜索树之后,我们应该先举几个例子,画画图,看看有没有什么规律,如图:
n为1的时候有一棵树,n为2有两棵树,这个是很直观的。
来看看n为3的时候,有哪几种情况。
当1为头结点的时候,其右子树有两个节点,看这两个节点的布局,是不是和 n 为2的时候两棵树的布局是一样的啊!
(可能有同学问了,这布局不一样啊,节点数值都不一样。别忘了我们就是求不同树的数量,并不用把搜索树都列出来,所以不用关心其具体数值的差异)
当3为头结点的时候,其左子树有两个节点,看这两个节点的布局,是不是和n为2的时候两棵树的布局也是一样的啊!
当2为头结点的时候,其左右子树都只有一个节点,布局是不是和n为1的时候只有一棵树的布局也是一样的啊!
发现到这里,其实我们就找到了重叠子问题了,其实也就是发现可以通过dp[1] 和 dp[2] 来推导出来dp[3]的某种方式。
思考到这里,这道题目就有眉目了。
dp[3],就是 元素1为头结点搜索树的数量 + 元素2为头结点搜索树的数量 + 元素3为头结点搜索树的数量
元素1为头结点搜索树的数量 = 右子树有2个元素的搜索树数量 * 左子树有0个元素的搜索树数量
元素2为头结点搜索树的数量 = 右子树有1个元素的搜索树数量 * 左子树有1个元素的搜索树数量
元素3为头结点搜索树的数量 = 右子树有0个元素的搜索树数量 * 左子树有2个元素的搜索树数量
有2个元素的搜索树数量就是dp[2]。
有1个元素的搜索树数量就是dp[1]。
有0个元素的搜索树数量就是dp[0]。
所以dp[3] = dp[2] * dp[0] + dp[1] * dp[1] + dp[0] * dp[2]
如图所示:
此时我们已经找到递推关系了,那么可以用动规五部曲再系统分析一遍。
- 确定dp数组(dp table)以及下标的含义
dp[i] : 1到i为节点组成的二叉搜索树的个数为dp[i]。
也可以理解是i个不同元素节点组成的二叉搜索树的个数为dp[i] ,都是一样的。
以下分析如果想不清楚,就来回想一下dp[i]的定义
- 确定递推公式
在上面的分析中,其实已经看出其递推关系, dp[i] += dp[以j为头结点左子树节点数量] * dp[以j为头结点右子树节点数量]
j相当于是头结点的元素,从1遍历到i为止。
所以递推公式:dp[i] += dp[j - 1] * dp[i - j]; ,j-1 为j为头结点左子树节点数量,i-j 为以j为头结点右子树节点数量
- dp数组如何初始化
初始化,只需要初始化dp[0]就可以了,推导的基础,都是dp[0]。
那么dp[0]应该是多少呢?
从定义上来讲,空节点也是一棵二叉树,也是一棵二叉搜索树,这是可以说得通的。
从递归公式上来讲,dp[以j为头结点左子树节点数量] * dp[以j为头结点右子树节点数量] 中以j为头结点左子树节点数量为0,也需要dp[以j为头结点左子树节点数量] = 1, 否则乘法的结果就都变成0了。
所以初始化dp[0] = 1
- 确定遍历顺序
首先一定是遍历节点数,从递归公式:dp[i] += dp[j - 1] * dp[i - j]可以看出,节点数为i的状态是依靠 i之前节点数的状态。
那么遍历i里面每一个数作为头结点的状态,用j来遍历。
代码如下:
for (int i = 1; i <= n; i++) {
for (int j = 1; j <= i; j++) {
dp[i] += dp[j - 1] * dp[i - j];
}
}
- 举例推导dp数组
n为5时候的dp数组状态如图:
当然如果自己画图举例的话,基本举例到n为3就可以了,n为4的时候,画图已经比较麻烦了。
我这里列到了n为5的情况,是为了方便大家 debug代码的时候,把dp数组打出来,看看哪里有问题。
C++解法
综上分析完毕,C++代码如下:
class Solution {
public:
int numTrees(int n) {
vector<int> dp(n + 1);
dp[0] = 1;
for (int i = 1; i <= n; i++) {
for (int j = 1; j <= i; j++) {
dp[i] += dp[j - 1] * dp[i - j];
}
}
return dp[n];
}
};
- 时间复杂度:
- 空间复杂度:
Java解法
class Solution {
public int numTrees(int n) {
//初始化 dp 数组
int[] dp = new int[n + 1];
//初始化0个节点和1个节点的情况
dp[0] = 1;
dp[1] = 1;
for (int i = 2; i <= n; i++) {
for (int j = 1; j <= i; j++) {
//对于第i个节点,需要考虑1作为根节点直到i作为根节点的情况,所以需要累加
//一共i个节点,对于根节点j时,左子树的节点个数为j-1,右子树的节点个数为i-j
dp[i] += dp[j - 1] * dp[i - j];
}
}
return dp[n];
}
}
95. Unique Binary Search Trees II
Given an integer n, return all the structurally unique **BST'**s (binary search trees), which has exactly n nodes of unique values from 1 to n. Return the answer in any order.
Example 1:
Input: n = 3
Output: [[1,null,2,null,3],[1,null,3,2],[2,1,3],[3,1,null,null,2],[3,2,null,1]]
Example 2:
Input: n = 1
Output: [[1]]
Constraints:
1 <= n <= 8
思路
https://leetcode.com/problems/unique-binary-search-trees-ii/solutions/3667682/unique-binary-search-trees-ii/
C++解法
class Solution {
public:
vector<TreeNode*> allPossibleBST(
int start, int end, map<pair<int, int>, vector<TreeNode*>>& memo) {
vector<TreeNode*> res;
if (start > end) {
res.push_back(nullptr);
return res;
}
if (memo.find(make_pair(start, end)) != memo.end()) {
return memo[make_pair(start, end)];
}
// Iterate through all values from start to end to construct left and
// right subtrees recursively.
for (int i = start; i <= end; ++i) {
vector<TreeNode*> leftSubTrees = allPossibleBST(start, i - 1, memo);
vector<TreeNode*> rightSubTrees = allPossibleBST(i + 1, end, memo);
// Loop through all left and right subtrees and connect them to the
// ith root.
for (auto left : leftSubTrees) {
for (auto right : rightSubTrees) {
TreeNode* root = new TreeNode(i, left, right);
res.push_back(root);
}
}
}
return memo[make_pair(start, end)] = res;
}
vector<TreeNode*> generateTrees(int n) {
map<pair<int, int>, vector<TreeNode*>> memo;
return allPossibleBST(1, n, memo);
}
};
拆分系列
139. Word Break
Given a string s and a dictionary of strings wordDict, return true if s can be segmented into a space-separated sequence of one or more dictionary words.
Note that the same word in the dictionary may be reused multiple times in the segmentation.
Example 1:
Input: s = "leetcode", wordDict = ["leet","code"]
Output: true
Explanation: Return true because "leetcode" can be segmented as "leet code".
Example 2:
Input: s = "applepenapple", wordDict = ["apple","pen"]
Output: true
Explanation: Return true because "applepenapple" can be segmented as "apple pen apple".
Note that you are allowed to reuse a dictionary word.
Example 3:
Input: s = "catsandog", wordDict = ["cats","dog","sand","and","cat"]
Output: false
Constraints:
1 <= s.length <= 3001 <= wordDict.length <= 10001 <= wordDict[i].length <= 20sandwordDict[i]consist of only lowercase English letters.- All the strings of
wordDictare unique.
思路
动态规划,字符串拆分,使用布尔型数组
C++解法
class Solution {
public:
bool wordBreak(string s, vector<string>& wordDict) {
unordered_set<string> wordSet(wordDict.begin(), wordDict.end());
vector<bool> dp(s.size() + 1, false);
dp[0] = true;
for(int j = 1; j <= s.size(); j++){
for(int i = 0; i < j; i++){
string tempStr = s.substr(i, j - i);
if(wordSet.find(tempStr) != wordSet.end() && dp[i] == true){
dp[j] = true;
}
}
}
return dp[s.size()];
}
};
Java解法
class Solution {
public boolean wordBreak(String s, List<String> wordDict) {
HashSet<String> set = new HashSet<>(wordDict); // 优化:直接用构造函数初始化
boolean[] dp = new boolean[s.length() + 1];
dp[0] = true; // 空字符串可以被分割
for (int j = 1; j <= s.length(); j++) {
for (int i = 0; i < j; i++) {
String temp = s.substring(i, j); // 取子串 s[i, j)
if (set.contains(temp) && dp[i]) {
dp[j] = true;
break; // 一旦满足条件,跳出内层循环
}
}
}
return dp[s.length()];
}
}
343. Integer Break
Given an integer n, break it into the sum of k positive integers, where k >= 2, and maximize the product of those integers.
Return the maximum product you can get.
Example 1:
Input: n = 2
Output: 1
Explanation: 2 = 1 + 1, 1 × 1 = 1.
Example 2:
Input: n = 10
Output: 36
Explanation: 10 = 3 + 3 + 4, 3 × 3 × 4 = 36.
Constraints:
2 <= n <= 58
思路
看到这道题目,都会想拆成两个呢,还是三个呢,还是四个....
我们来看一下如何使用动态规划来解决。
动规五部曲,分析如下:
- 确定dp数组(dp table)以及下标的含义
dp[i]:分拆数字i,可以得到的最大乘积为dp[i]。
dp[i]的定义将贯彻整个解题过程,下面哪一步想不懂了,就想想dp[i]究竟表示的是啥!
- 确定递推公式
可以想 dp[i]最大乘积是怎么得到的呢?
其实可以从1遍历j,然后有两种渠道得到dp[i].
一个是j * (i - j) 直接相乘。
一个是j * dp[i - j],相当于是拆分(i - j),对这个拆分不理解的话,可以回想dp数组的定义。
那有同学问了,j怎么就不拆分呢?
j是从1开始遍历,拆分j的情况,在遍历j的过程中其实都计算过了。那么从1遍历j,比较(i - j) * j和dp[i - j] * j 取最大的。递推公式:dp[i] = max(dp[i], max((i - j) * j, dp[i - j] * j));
也可以这么理解,j * (i - j) 是单纯的把整数拆分为两个数相乘,而j * dp[i - j]是拆分成两个以及两个以上的个数相乘。
如果定义dp[i - j] * dp[j] 也是默认将一个数强制拆成4份以及4份以上了。
所以递推公式:dp[i] = max({dp[i], (i - j) * j, dp[i - j] * j});
那么在取最大值的时候,为什么还要比较dp[i]呢?
因为在递推公式推导的过程中,每次计算dp[i],取最大的而已。
- dp的初始化
不少同学应该疑惑,dp[0] dp[1]应该初始化多少呢?
有的题解里会给出dp[0] = 1,dp[1] = 1的初始化,但解释比较牵强,主要还是因为这么初始化可以把题目过了。
严格从dp[i]的定义来说,dp[0] dp[1] 就不应该初始化,也就是没有意义的数值。
拆分0和拆分1的最大乘积是多少?
这是无解的。
这里我只初始化dp[2] = 1,从dp[i]的定义来说,拆分数字2,得到的最大乘积是1,这个没有任何异议!
- 确定遍历顺序
确定遍历顺序,先来看看递归公式:dp[i] = max(dp[i], max((i - j) * j, dp[i - j] * j));
dp[i] 是依靠 dp[i - j]的状态,所以遍历i一定是从前向后遍历,先有dp[i - j]再有dp[i]。
所以遍历顺序为:
for (int i = 3; i <= n ; i++) {
for (int j = 1; j < i - 1; j++) {
dp[i] = max(dp[i], max((i - j) * j, dp[i - j] * j));
}
}
注意 枚举j的时候,是从1开始的。从0开始的话,那么让拆分一个数拆个0,求最大乘积就没有意义了。
j的结束条件是 j < i - 1 ,其实 j < i 也是可以的,不过可以节省一步,例如让j = i - 1,的话,其实在 j = 1的时候,这一步就已经拆出来了,重复计算,所以 j < i - 1
至于 i是从3开始,这样dp[i - j]就是dp[2]正好可以通过我们初始化的数值求出来。
更优化一步,可以这样:
for (int i = 3; i <= n ; i++) {
for (int j = 1; j <= i / 2; j++) {
dp[i] = max(dp[i], max((i - j) * j, dp[i - j] * j));
}
}
因为拆分一个数n 使之乘积最大,那么一定是拆分成m个近似相同的子数相乘才是最大的。
例如 6 拆成 3 * 3, 10 拆成 3 * 3 * 4。 100的话 也是拆成m个近似数组的子数 相乘才是最大的。
只不过我们不知道m究竟是多少而已,但可以明确的是m一定大于等于2,既然m大于等于2,也就是 最差也应该是拆成两个相同的 可能是最大值。
那么 j 遍历,只需要遍历到 n/2 就可以,后面就没有必要遍历了,一定不是最大值。
至于 “拆分一个数n 使之乘积最大,那么一定是拆分成m个近似相同的子数相乘才是最大的” 这个我就不去做数学证明了,感兴趣的同学,可以自己证明。
- 举例推导dp数组
C++解法
以上动规五部曲分析完毕,C++代码如下:
class Solution {
public:
int integerBreak(int n) {
vector<int> dp(n + 1);
dp[2] = 1;
for (int i = 3; i <= n ; i++) {
for (int j = 1; j <= i / 2; j++) {
dp[i] = max(dp[i], max((i - j) * j, dp[i - j] * j));
}
}
return dp[n];
}
};
- 时间复杂度:O(n^2)
- 空间复杂度:O(n)
Java解法
class Solution {
public int integerBreak(int n) {
//dp[i] 为正整数 i 拆分后的结果的最大乘积
int[] dp = new int[n+1];
dp[2] = 1;
for(int i = 3; i <= n; i++) {
for(int j = 1; j <= i-j; j++) {
// 这里的 j 其实最大值为 i-j,再大只不过是重复而已,
//并且,在本题中,我们分析 dp[0], dp[1]都是无意义的,
//j 最大到 i-j,就不会用到 dp[0]与dp[1]
dp[i] = Math.max(dp[i], Math.max(j*(i-j), j*dp[i-j]));
// j * (i - j) 是单纯的把整数 i 拆分为两个数 也就是 i,i-j ,再相乘
//而j * dp[i - j]是将 i 拆分成两个以及两个以上的个数,再相乘。
}
}
return dp[n];
}
}
279. Perfect Squares
Given an integer n, return the least number of perfect square numbers that sum to n.
A perfect square is an integer that is the square of an integer; in other words, it is the product of some integer with itself. For example, 1, 4, 9, and 16 are perfect squares while 3 and 11 are not.
Example 1:
Input: n = 12
Output: 3
Explanation: 12 = 4 + 4 + 4.
Example 2:
Input: n = 13
Output: 2
Explanation: 13 = 4 + 9.
Constraints:
1 <= n <= 10^4
思路
动态规划,拆分数字,递推公式为dp[j] = min(dp[j], dp[j - i * i] + 1);
C++解法
class Solution {
public:
int numSquares(int n) {
vector<int> dp(n + 1, INT_MAX);
dp[0] = 0;
for(int i = 1; i <= sqrt(n); i++){
for(int j = i * i; j <= n; j++){
if((dp[j - i * i] + i * i) != INT_MAX){
dp[j] = min(dp[j], dp[j - i * i] + 1);
}
}
}
return dp[n];
}
};
Java解法
class Solution {
public int numSquares(int n) {
int[] dp = new int[n + 1];
Arrays.fill(dp, Integer.MAX_VALUE);
dp[0] = 0;
for (int i = 1; i <= n; i++) {
for (int j = 1; j * j <= i; j++) {
dp[i] = Math.min(dp[i], dp[i - j * j] + 1);
}
}
return dp[n];
}
}
Go解法
func numSquares(amount int) int {
dp := make([]int, amount + 1);
for i := 0; i < len(dp); i++ {
dp[i] = math.MaxInt32;
}
dp[0] = 0;
for j := 1; j <= amount; j++ {
for i := 1; i * i <= j; i++ {
dp[j] = min(dp[j], dp[j - i * i] + 1);
}
}
return dp[amount];
}
01背包
- 理论基础
- 416. Partition Equal Subset Sum
- 1049. Last Stone Weight II
- 494. Target Sum
- 474. Ones and Zeroes
理论基础
前言
对于面试的话,其实掌握01背包,和完全背包,就够用了,最多可以再来一个多重背包。
至于背包九讲其他背包,面试几乎不会问,都是竞赛级别的了,leetcode上连多重背包的题目都没有,所以题库也告诉我们,01背包和完全背包就够用了。
而完全背包又是也是01背包稍作变化而来,即:完全背包的物品数量是无限的。
所以背包问题的理论基础重中之重是01背包,一定要理解透!
leetcode上没有纯01背包的问题,都是01背包应用方面的题目,也就是需要转化为01背包问题。
所以我先通过纯01背包问题,把01背包原理讲清楚,后续再讲解leetcode题目的时候,重点就是讲解如何转化为01背包问题了。
之前可能有些录友已经可以熟练写出背包了,但只要把这个文章仔细看完,相信你会意外收获!
01 背包:有n件物品和一个最多能背重量为w 的背包。第i件物品的重量是weight[i],得到的价值是value[i] 。每件物品只能用一次,求解将哪些物品装入背包里物品价值总和最大。

这是标准的背包问题,以至于很多同学看了这个自然就会想到背包,甚至都不知道暴力的解法应该怎么解了。
这样其实是没有从底向上去思考,而是习惯性想到了背包,那么暴力的解法应该是怎么样的呢?
每一件物品其实只有两个状态,取或者不取,所以可以使用回溯法搜索出所有的情况,那么时间复杂度就是,这里的n表示物品数量。
所以暴力的解法是指数级别的时间复杂度。进而才需要动态规划的解法来进行优化!
在下面的讲解中,我举一个例子:
背包最大重量为4。
物品为:
| - | 重量 | 价值 |
|---|---|---|
| 物品0 | 1 | 15 |
| 物品1 | 3 | 20 |
| 物品2 | 4 | 30 |
问背包能背的物品最大价值是多少?
以下讲解和图示中出现的数字都是以这个例子为例。
二维dp数组01背包
依然动规五部曲分析一波。
- 确定dp数组以及下标的含义
对于背包问题,有一种写法, 是使用二维数组,即dp[i][j] 表示从下标为[0-i]的物品里任意取,放进容量为j的背包,价值总和最大是多少。
只看这个二维数组的定义,大家一定会有点懵,看下面这个图:
要时刻记着这个dp数组的含义,下面的一些步骤都围绕这dp数组的含义进行的,如果哪里看懵了,就来回顾一下i代表什么,j又代表什么。
- 确定递推公式
再回顾一下dp[i][j]的含义:从下标为[0-i]的物品里任意取,放进容量为j的背包,价值总和最大是多少。
那么可以有两个方向推出来dp[i][j],
- 不放物品i:由
dp[i-1][j]推出,即背包容量为j,里面不放物品i的最大价值,此时dp[i][j]就是dp[i-1][j]。(其实就是当物品i的重量大于背包j的重量时,物品i无法放进背包中,所以背包内的价值依然和前面相同。) - 放物品i:由
dp[i-1][j]推出,dp[i-1][j]为背包容量为j - weight[i]的时候不放物品i的最大价值,那么dp[i-1][j]+ value[i] (物品i的价值),就是背包放物品i得到的最大价值
所以递归公式: dp[i][j] = max(dp[i-1][j], dp[i-1][j] + value[i]);
- dp数组如何初始化
关于初始化,一定要和dp数组的定义吻合,否则到递推公式的时候就会越来越乱。
首先从dp[i][j]的定义出发,如果背包容量j为0的话,即dp[i][j],无论是选取哪些物品,背包价值总和一定为0。如图:
在看其他情况。
状态转移方程 dp[i][j] = max(dp[i-1][j], dp[i-1][j] + value[i]); 可以看出i 是由 i-1 推导出来,那么i为0的时候就一定要初始化。
dp[0][0],即:i为0,存放编号0的物品的时候,各个容量的背包所能存放的最大价值。
那么很明显当 j < weight[0]的时候,dp[0][j]应该是 0,因为背包容量比编号0的物品重量还小。
当j >= weight[0]时,dp[0][j]应该是value[0],因为背包容量放足够放编号0物品。
代码初始化如下:
for (int j = 0 ; j < weight[0]; j++) { // 当然这一步,如果把dp数组预先初始化为0了,这一步就可以省略,但很多同学应该没有想清楚这一点。
dp[0][j] = 0;
}
// 正序遍历
for (int j = weight[0]; j <= bagweight; j++) {
dp[0][j] = value[0];
}
dp[0][j] 和 dp[i][0] 都已经初始化了,那么其他下标应该初始化多少呢?
其实从递归公式: dp[i][j] = max(dp[i-1][j], dp[i-1][j] + value[i]); 可以看出dp[i][j] 是由左上方数值推导出来了,那么 其他下标初始为什么数值都可以,因为都会被覆盖。
初始-1,初始-2,初始100,都可以!
但只不过一开始就统一把dp数组统一初始为0,更方便一些。
如图:
最后初始化代码如下:
// 初始化 dp
vector<vector<int>> dp(weight.size(), vector<int>(bagweight + 1, 0));
for (int j = weight[0]; j <= bagweight; j++) {
dp[0][j] = value[0];
}
费了这么大的功夫,才把如何初始化讲清楚,相信不少同学平时初始化dp数组是凭感觉来的,但有时候感觉是不靠谱的。
- 确定遍历顺序
在如下图中,可以看出,有两个遍历的维度:物品与背包重量
那么问题来了,先遍历 物品还是先遍历背包重量呢?
其实都可以!! 但是先遍历物品更好理解。
那么我先给出先遍历物品,然后遍历背包重量的代码。
// weight数组的大小 就是物品个数
for(int i = 1; i < weight.size(); i++) { // 遍历物品
for(int j = 0; j <= bagweight; j++) { // 遍历背包容量
if (j < weight[i]) dp[i][j] = dp[i - 1][j];
else dp[i][j] = max(dp[i - 1][j], dp[i - 1][j - weight[i]] + value[i]);
}
}
先遍历背包,再遍历物品,也是可以的!(注意我这里使用的二维dp数组)
例如这样:
// weight数组的大小 就是物品个数
for(int j = 0; j <= bagweight; j++) { // 遍历背包容量
for(int i = 1; i < weight.size(); i++) { // 遍历物品
if (j < weight[i]) dp[i][j] = dp[i - 1][j];
else dp[i][j] = max(dp[i - 1][j], dp[i - 1][j - weight[i]] + value[i]);
}
}
为什么也是可以的呢?
要理解递归的本质和递推的方向。
递归公式:dp[i][j] = max(dp[i - 1][j], dp[i - 1][j - weight[i]] + value[i]);
大家可以看出,虽然两个for循环遍历的次序不同,但是dp[i][j]所需要的数据就是左上角,根本不影响dp[i][j]公式的推导!
但先遍历物品再遍历背包这个顺序更好理解。
其实背包问题里,两个for循环的先后循序是非常有讲究的,理解遍历顺序其实比理解推导公式难多了。
- 举例推导dp数组
来看一下对应的dp数组的数值,如图:
最终结果就是dp[2](#)。
建议大家此时自己在纸上推导一遍,看看dp数组里每一个数值是不是这样的。
做动态规划的题目,最好的过程就是自己在纸上举一个例子把对应的dp数组的数值推导一下,然后再动手写代码!
很多同学做dp题目,遇到各种问题,然后凭感觉东改改西改改,怎么改都不对,或者稀里糊涂就改过了。
主要就是自己没有动手推导一下dp数组的演变过程,如果推导明白了,代码写出来就算有问题,只要把dp数组打印出来,对比一下和自己推导的有什么差异,很快就可以发现问题了。
void test_2_wei_bag_problem1() {
vector<int> weight = {1, 3, 4};
vector<int> value = {15, 20, 30};
int bagweight = 4;
// 二维数组
vector<vector<int>> dp(weight.size(), vector<int>(bagweight + 1, 0));
// 初始化
for (int j = weight[0]; j <= bagweight; j++) {
dp[0][j] = value[0];
}
// weight数组的大小 就是物品个数
for(int i = 1; i < weight.size(); i++) { // 遍历物品
for(int j = 0; j <= bagweight; j++) { // 遍历背包容量
if (j < weight[i]) dp[i][j] = dp[i - 1][j];
else dp[i][j] = max(dp[i - 1][j], dp[i - 1][j - weight[i]] + value[i]);
}
}
cout << dp[weight.size() - 1][bagweight] << endl;
}
int main() {
test_2_wei_bag_problem1();
}
本题力扣上没有原题,大家可以去卡码网第46题去练习,题意是一样的,代码如下:
//二维dp数组实现
#include <bits/stdc++.h>
using namespace std;
int n, bagweight;// bagweight代表行李箱空间
void solve() {
vector<int> weight(n, 0); // 存储每件物品所占空间
vector<int> value(n, 0); // 存储每件物品价值
for(int i = 0; i < n; ++i) {
cin >> weight[i];
}
for(int j = 0; j < n; ++j) {
cin >> value[j];
}
// dp数组, dp[i][j]代表行李箱空间为j的情况下,从下标为[0, i]的物品里面任意取,能达到的最大价值
vector<vector<int>> dp(weight.size(), vector<int>(bagweight + 1, 0));
// 初始化, 因为需要用到dp[i - 1]的值
// j < weight[0]已在上方被初始化为0
// j >= weight[0]的值就初始化为value[0]
for (int j = weight[0]; j <= bagweight; j++) {
dp[0][j] = value[0];
}
for(int i = 1; i < weight.size(); i++) { // 遍历科研物品
for(int j = 0; j <= bagweight; j++) { // 遍历行李箱容量
// 如果装不下这个物品,那么就继承dp[i - 1][j]的值
if (j < weight[i]) dp[i][j] = dp[i - 1][j];
// 如果能装下,就将值更新为 不装这个物品的最大值 和 装这个物品的最大值 中的 最大值
// 装这个物品的最大值由容量为j - weight[i]的包任意放入序号为[0, i - 1]的最大值 + 该物品的价值构成
else dp[i][j] = max(dp[i - 1][j], dp[i - 1][j - weight[i]] + value[i]);
}
}
cout << dp[weight.size() - 1][bagweight] << endl;
}
int main() {
while(cin >> n >> bagweight) {
solve();
}
return 0;
}
一维dp数组(滚动数组)
对于背包问题其实状态都是可以压缩的。
在使用二维数组的时候,递推公式:dp[i] = max(dp[i - 1], dp[i - 1] + value[i]);
其实可以发现如果把dp[i - 1]那一层拷贝到dp[i]上,表达式完全可以是:dp[i] = max(dp[i], dp[i] + value[i]);
与其把dp[i - 1]这一层拷贝到dp[i]上,不如只用一个一维数组了,只用dp[j](一维数组,也可以理解是一个滚动数组)。
这就是滚动数组的由来,需要满足的条件是上一层可以重复利用,直接拷贝到当前层。
读到这里估计大家都忘了 dp[i]里的i和j表达的是什么了,i是物品,j是背包容量。
dp[i] 表示从下标为[0-i]的物品里任意取,放进容量为j的背包,价值总和最大是多少。
一定要时刻记住这里i和j的含义,要不然很容易看懵了。
动规五部曲分析如下:
- 确定dp数组的定义
在一维dp数组中,dp[j]表示:容量为j的背包,所背的物品价值可以最大为dp[j]。
- 一维dp数组的递推公式
dp[j]为 容量为j的背包所背的最大价值,那么如何推导dp[j]呢?
dp[j]可以通过dp[j - weight[i]]推导出来,dp[j - weight[i]]表示容量为j - weight[i]的背包所背的最大价值。
dp[j - weight[i]] + value[i] 表示 容量为 j - 物品i重量 的背包 加上 物品i的价值。(也就是容量为j的背包,放入物品i了之后的价值即:dp[j])
此时dp[j]有两个选择,一个是取自己dp[j] 相当于 二维dp数组中的dpi-1,即不放物品i,一个是取dp[j - weight[i]] + value[i],即放物品i,指定是取最大的,毕竟是求最大价值,
所以递归公式为:
dp[j] = max(dp[j], dp[j - weight[i]] + value[i]);
可以看出相对于二维dp数组的写法,就是把dpi中i的维度去掉了。
- 一维dp数组如何初始化
关于初始化,一定要和dp数组的定义吻合,否则到递推公式的时候就会越来越乱。
dp[j]表示:容量为j的背包,所背的物品价值可以最大为dp[j],那么dp[0]就应该是0,因为背包容量为0所背的物品的最大价值就是0。
那么dp数组除了下标0的位置,初始为0,其他下标应该初始化多少呢?
看一下递归公式:dp[j] = max(dp[j], dp[j - weight[i]] + value[i]);
dp数组在推导的时候一定是取价值最大的数,如果题目给的价值都是正整数那么非0下标都初始化为0就可以了。
这样才能让dp数组在递归公式的过程中取的最大的价值,而不是被初始值覆盖了。
那么我假设物品价值都是大于0的,所以dp数组初始化的时候,都初始为0就可以了。
- 一维dp数组遍历顺序
代码如下:
for(int i = 0; i < weight.size(); i++) { // 遍历物品
for(int j = bagWeight; j >= weight[i]; j--) { // 遍历背包容量
dp[j] = max(dp[j], dp[j - weight[i]] + value[i]);
}
}
这里大家发现和二维dp的写法中,遍历背包的顺序是不一样的!
二维dp遍历的时候,背包容量是从小到大,而一维dp遍历的时候,背包是从大到小。
为什么呢?
倒序遍历是为了保证物品i只被放入一次!。但如果一旦正序遍历了,那么物品0就会被重复加入多次!
举一个例子:物品0的重量weight[0] = 1,价值value[0] = 15
如果正序遍历
dp[1] = dp[1 - weight[0]] + value[0] = 15
dp[2] = dp[2 - weight[0]] + value[0] = 30
此时dp[2]就已经是30了,意味着物品0,被放入了两次,所以不能正序遍历。
为什么倒序遍历,就可以保证物品只放入一次呢?
倒序就是先算dp[2]
dp[2] = dp[2 - weight[0]] + value[0] = 15 (dp数组已经都初始化为0)
dp[1] = dp[1 - weight[0]] + value[0] = 15
所以从后往前循环,每次取得状态不会和之前取得状态重合,这样每种物品就只取一次了。
那么问题又来了,为什么二维dp数组遍历的时候不用倒序呢?
因为对于二维dp,dp[i]都是通过上一层即dp[i - 1]计算而来,本层的dp[i]并不会被覆盖!
(如何这里读不懂,大家就要动手试一试了,空想还是不靠谱的,实践出真知!)
再来看看两个嵌套for循环的顺序,代码中是先遍历物品嵌套遍历背包容量,那可不可以先遍历背包容量嵌套遍历物品呢?
不可以!
因为一维dp的写法,背包容量一定是要倒序遍历(原因上面已经讲了),如果遍历背包容量放在上一层,那么每个dp[j]就只会放入一个物品,即:背包里只放入了一个物品。
倒序遍历的原因是,本质上还是一个对二维数组的遍历,并且右下角的值依赖上一层左上角的值,因此需要保证左边的值仍然是上一层的,从右向左覆盖。
(这里如果读不懂,就再回想一下dp[j]的定义,或者就把两个for循环顺序颠倒一下试试!)
所以一维dp数组的背包在遍历顺序上和二维其实是有很大差异的!,这一点大家一定要注意。
- 举例推导dp数组
一维dp,分别用物品0,物品1,物品2 来遍历背包,最终得到结果如下:
C++代码如下:
void test_1_wei_bag_problem() {
vector<int> weight = {1, 3, 4};
vector<int> value = {15, 20, 30};
int bagWeight = 4;
// 初始化
vector<int> dp(bagWeight + 1, 0);
for(int i = 0; i < weight.size(); i++) { // 遍历物品
for(int j = bagWeight; j >= weight[i]; j--) { // 遍历背包容量
dp[j] = max(dp[j], dp[j - weight[i]] + value[i]);
}
}
cout << dp[bagWeight] << endl;
}
int main() {
test_1_wei_bag_problem();
}
本题力扣上没有原题,大家可以去卡码网第46题去练习,题意是一样的,代码如下:
// 一维dp数组实现
#include <iostream>
#include <vector>
using namespace std;
int main() {
// 读取 M 和 N
int M, N;
cin >> M >> N;
vector<int> costs(M);
vector<int> values(M);
for (int i = 0; i < M; i++) {
cin >> costs[i];
}
for (int j = 0; j < M; j++) {
cin >> values[j];
}
// 创建一个动态规划数组dp,初始值为0
vector<int> dp(N + 1, 0);
// 外层循环遍历每个类型的研究材料
for (int i = 0; i < M; ++i) {
// 内层循环从 N 空间逐渐减少到当前研究材料所占空间
for (int j = N; j >= costs[i]; --j) {
// 考虑当前研究材料选择和不选择的情况,选择最大值
dp[j] = max(dp[j], dp[j - costs[i]] + values[i]);
}
}
// 输出dp[N],即在给定 N 行李空间可以携带的研究材料最大价值
cout << dp[N] << endl;
return 0;
}
可以看出,一维dp 的01背包,要比二维简洁的多! 初始化 和 遍历顺序相对简单了。
所以我倾向于使用一维dp数组的写法,比较直观简洁,而且空间复杂度还降了一个数量级!
在后面背包问题的讲解中,我都直接使用一维dp数组来进行推导。
总结
以上的讲解可以开发一道面试题目(毕竟力扣上没原题)。
就是本文中的题目,要求先实现一个纯二维的01背包,如果写出来了,然后再问为什么两个for循环的嵌套顺序这么写?反过来写行不行?再讲一讲初始化的逻辑。
然后要求实现一个一维数组的01背包,最后再问,一维数组的01背包,两个for循环的顺序反过来写行不行?为什么?
注意以上问题都是在候选人把代码写出来的情况下才问的。
就是纯01背包的题目,都不用考01背包应用类的题目就可以看出候选人对算法的理解程度了。
相信大家读完这篇文章,应该对以上问题都有了答案!
此时01背包理论基础就讲完了,我用了两篇文章把01背包的dp数组定义、递推公式、初始化、遍历顺序从二维数组到一维数组统统深度剖析了一遍,没有放过任何难点。
大家可以发现其实信息量还是挺大的。
如果把动态规划:关于01背包问题,你该了解这些!和本篇的内容都理解了,后面我们在做01背包的题目,就会发现非常简单了。
不用再凭感觉或者记忆去写背包,而是有自己的思考,了解其本质,代码的方方面面都在自己的掌控之中。
即使代码没有通过,也会有自己的逻辑去debug,这样就思维清晰了。
接下来就要开始用这两天的理论基础去做力扣上的背包面试题目了,录友们握紧扶手,我们要上高速啦!
416. Partition Equal Subset Sum
Given an integer array nums, return true if you can partition the array into two subsets such that the sum of the elements in both subsets is equal or false otherwise.
Example 1:
Input: nums = [1,5,11,5]
Output: true
Explanation: The array can be partitioned as [1, 5, 5] and [11].
Example 2:
Input: nums = [1,2,3,5]
Output: false
Explanation: The array cannot be partitioned into equal sum subsets.
Constraints:
1 <= nums.length <= 2001 <= nums[i] <= 100
思路
这道题目是要找是否可以将这个数组分割成两个子集,使得两个子集的元素和相等。
那么只要找到集合里能够出现 sum / 2 的子集总和,就算是可以分割成两个相同元素和子集了。
本题是可以用回溯暴力搜索出所有答案的,但最后超时了,也不想再优化了,放弃回溯,直接上01背包吧。
要明确本题中我们要使用的是01背包,因为元素我们只能用一次。
回归主题:首先,本题要求集合里能否出现总和为 sum / 2 的子集。
那么来一一对应一下本题,看看背包问题如何来解决。
只有确定了如下四点,才能把01背包问题套到本题上来。
- 背包的体积为sum / 2
- 背包要放入的商品(集合里的元素)重量为 元素的数值,价值也为元素的数值
- 背包如果正好装满,说明找到了总和为 sum / 2 的子集。
- 背包中每一个元素是不可重复放入。
以上分析完,我们就可以套用01背包,来解决这个问题了。
动规五部曲分析如下:
- 确定dp数组以及下标的含义
01背包中,dp[j] 表示: 容量为j的背包,所背的物品价值最大可以为dp[j]。
本题中每一个元素的数值既是重量,也是价值。
套到本题,dp[j]表示 背包总容量(所能装的总重量)是j,放进物品后,背的最大重量为dp[j]。
那么如果背包容量为target, dp[target]就是装满 背包之后的重量,所以当dp[target] == target的时候,背包就装满了。
有录友可能想,那还有装不满的时候?
拿输入数组 [1, 5, 11, 5],举例, dp[7] 只能等于 6,因为只能放进 1 和 5。
而dp[6] 就可以等于6了,放进1 和 5,那么dp[6] == 6,说明背包装满了。
- 确定递推公式
01背包的递推公式为:dp[j] = max(dp[j], dp[j - weight[i]] + value[i]);
本题,相当于背包里放入数值,那么物品i的重量是nums[i],其价值也是nums[i]。
所以递推公式:dp[j] = max(dp[j], dp[j - nums[i]] + nums[i]);
- dp数组如何初始化
在01背包,一维dp如何初始化,已经讲过,
从dp[j]的定义来看,首先dp[0]一定是0。
如果题目给的价值都是正整数那么非0下标都初始化为0就可以了,如果题目给的价值有负数,那么非0下标就要初始化为负无穷。
这样才能让dp数组在递推的过程中取得最大的价值,而不是被初始值覆盖了。
本题题目中 只包含正整数的非空数组,所以非0下标的元素初始化为0就可以了。
代码如下:
// 题目中说:每个数组中的元素不会超过 100,数组的大小不会超过 200
// 总和不会大于20000,背包最大只需要其中一半,所以10001大小就可以了
vector<int> dp(10001, 0);
- 确定遍历顺序
在动态规划:关于01背包问题,你该了解这些!(滚动数组)中就已经说明:如果使用一维dp数组,物品遍历的for循环放在外层,遍历背包的for循环放在内层,且内层for循环倒序遍历!
代码如下:
// 开始 01背包
for(int i = 0; i < nums.size(); i++) {
for(int j = target; j >= nums[i]; j--) { // 每一个元素一定是不可重复放入,所以从大到小遍历
dp[j] = max(dp[j], dp[j - nums[i]] + nums[i]);
}
}
- 举例推导dp数组
dp[j]的数值一定是小于等于j的。
如果dp[j] == j说明,集合中的子集总和正好可以凑成总和j,理解这一点很重要。
用例1,输入[1,5,11,5] 为例,最后dp[11] == 11,说明可以将这个数组分割成两个子集,使得两个子集的元素和相等。
C++解法
综上分析完毕,C++代码如下:
class Solution {
public:
bool canPartition(vector<int>& nums) {
int sum = 0;
// dp[i]中的i表示背包内总和
// 题目中说:每个数组中的元素不会超过 100,数组的大小不会超过 200
// 总和不会大于20000,背包最大只需要其中一半,所以10001大小就可以了
vector<int> dp(10001, 0);
for (int i = 0; i < nums.size(); i++) {
sum += nums[i];
}
// 也可以使用库函数一步求和
// int sum = accumulate(nums.begin(), nums.end(), 0);
if (sum % 2 == 1) return false;
int target = sum / 2;
// 开始 01背包
for(int i = 0; i < nums.size(); i++) {
for(int j = target; j >= nums[i]; j--) { // 每一个元素一定是不可重复放入,所以从大到小遍历
dp[j] = max(dp[j], dp[j - nums[i]] + nums[i]);
}
}
// 集合中的元素正好可以凑成总和target
if (dp[target] == target) return true;
return false;
}
};
- 时间复杂度:O(n^2)
- 空间复杂度:O(n),虽然dp数组大小为一个常数,但是大常数
Java解法
class Solution {
public boolean canPartition(int[] nums) {
int total = 0;
for(int num : nums){
total += num;
}
if(total % 2 == 1) return false;
int capacity = total / 2;
int[] dp = new int[capacity + 1];
for(int i = 1; i < nums.length; i++){
for(int j = capacity; j >= nums[i]; j--){
dp[j] = Math.max(dp[j], dp[j - nums[i]] + nums[i]);
if(dp[capacity] == capacity){
return true;
}
}
}
return false;
}
}
1049. Last Stone Weight II
You are given an array of integers stones where stones[i] is the weight of the ith stone.
We are playing a game with the stones. On each turn, we choose any two stones and smash them together. Suppose the stones have weights x and y with x <= y. The result of this smash is:
- If
x == y, both stones are destroyed, and - If
x != y, the stone of weightxis destroyed, and the stone of weightyhas new weighty - x.
At the end of the game, there is at most one stone left.
Return the smallest possible weight of the left stone. If there are no stones left, return 0.
Example 1:
Input: stones = [2,7,4,1,8,1]
Output: 1
Explanation:
We can combine 2 and 4 to get 2, so the array converts to [2,7,1,8,1] then,
we can combine 7 and 8 to get 1, so the array converts to [2,1,1,1] then,
we can combine 2 and 1 to get 1, so the array converts to [1,1,1] then,
we can combine 1 and 1 to get 0, so the array converts to [1], then that's the optimal value.
Example 2:
Input: stones = [31,26,33,21,40]
Output: 5
Constraints:
1 <= stones.length <= 301 <= stones[i] <= 100
思路
本题其实就是尽量让石头分成重量相同的两堆,相撞之后剩下的石头最小,这样就化解成01背包问题了。
是不是感觉和昨天讲解的416. 分割等和子集非常像了。
本题物品的重量为stones[i],物品的价值也为stones[i]。
对应着01背包里的物品重量weight[i]和 物品价值value[i]。
接下来进行动规五步曲:
- 确定dp数组以及下标的含义
dp[j]表示容量(这里说容量更形象,其实就是重量)为j的背包,最多可以背最大重量为dp[j]。
可以回忆一下01背包中,dp[j]的含义,容量为j的背包,最多可以装的价值为 dp[j]。
相对于 01背包,本题中,石头的重量是 stones[i],石头的价值也是 stones[i] ,可以 “最多可以装的价值为 dp[j]” == “最多可以背的重量为dp[j]”
- 确定递推公式
01背包的递推公式为:dp[j] = max(dp[j], dp[j - weight[i]] + value[i]);
本题则是:dp[j] = max(dp[j], dp[j - stones[i]] + stones[i]);
一些同学可能看到这dp[j - stones[i]] + stones[i]中 又有- stones[i] 又有+stones[i],看着有点晕乎。
大家可以再去看 dp[j]的含义。
- dp数组如何初始化
既然 dp[j]中的j表示容量,那么最大容量(重量)是多少呢,就是所有石头的重量和。
因为提示中给出1 <= stones.length <= 30,1 <= stones[i] <= 1000,所以最大重量就是30 * 1000 。
而我们要求的target其实只是最大重量的一半,所以dp数组开到15000大小就可以了。
当然也可以把石头遍历一遍,计算出石头总重量 然后除2,得到dp数组的大小。
我这里就直接用15000了。
接下来就是如何初始化dp[j]呢,因为重量都不会是负数,所以dp[j]都初始化为0就可以了,这样在递归公式dp[j] = max(dp[j], dp[j - stones[i]] + stones[i]);中dp[j]才不会初始值所覆盖。
代码为:
vector<int> dp(15001, 0);
- 确定遍历顺序
在动态规划:关于01背包问题,你该了解这些!(滚动数组)中就已经说明:如果使用一维dp数组,物品遍历的for循环放在外层,遍历背包的for循环放在内层,且内层for循环倒序遍历!
代码如下:
for (int i = 0; i < stones.size(); i++) { // 遍历物品
for (int j = target; j >= stones[i]; j--) { // 遍历背包
dp[j] = max(dp[j], dp[j - stones[i]] + stones[i]);
}
}
- 举例推导dp数组
举例,输入:[2,4,1,1],此时target = (2 + 4 + 1 + 1)/2 = 4 ,dp数组状态图如下:
最后dp[target]里是容量为target的背包所能背的最大重量。
那么分成两堆石头,一堆石头的总重量是dp[target],另一堆就是sum - dp[target]。
在计算target的时候,target = sum / 2 因为是向下取整,所以sum - dp[target] 一定是大于等于dp[target]的。
那么相撞之后剩下的最小石头重量就是 (sum - dp[target]) - dp[target]。
C++解法
以上分析完毕,C++代码如下:
class Solution {
public:
int lastStoneWeightII(vector<int>& stones) {
vector<int> dp(15001, 0);
int sum = 0;
for (int i = 0; i < stones.size(); i++) sum += stones[i];
int target = sum / 2;
for (int i = 0; i < stones.size(); i++) { // 遍历物品
for (int j = target; j >= stones[i]; j--) { // 遍历背包
dp[j] = max(dp[j], dp[j - stones[i]] + stones[i]);
}
}
return sum - dp[target] - dp[target];
}
};
- 时间复杂度:O(m × n) , m是石头总重量(准确的说是总重量的一半),n为石头块数
- 空间复杂度:O(m)
Java解法
class Solution {
public int lastStoneWeightII(int[] stones) {
Arrays.sort(stones);
int sum = 0;
for(int stone : stones){
sum += stone;
}
int bagSize = sum / 2;
int[] dp = new int[1501];
dp[0] = 0;
for(int i = 0; i < stones.length; i++){
for(int j = bagSize; j >= stones[i]; j--){
dp[j] = Math.max(dp[j], dp[j - stones[i]] + stones[i]);
}
}
return sum - dp[bagSize] * 2;
}
}
494. Target Sum
You are given an integer array nums and an integer target.
You want to build an expression out of nums by adding one of the symbols '+' and '-' before each integer in nums and then concatenate all the integers.
- For example, if
nums = [2, 1], you can add a'+'before2and a'-'before1and concatenate them to build the expression"+2-1".
Return the number of different expressions that you can build, which evaluates to target.
Example 1:
Input: nums = [1,1,1,1,1], target = 3
Output: 5
Explanation: There are 5 ways to assign symbols to make the sum of nums be target 3.
-1 + 1 + 1 + 1 + 1 = 3
+1 - 1 + 1 + 1 + 1 = 3
+1 + 1 - 1 + 1 + 1 = 3
+1 + 1 + 1 - 1 + 1 = 3
+1 + 1 + 1 + 1 - 1 = 3
Example 2:
Input: nums = [1], target = 1
Output: 1
Constraints:
1 <= nums.length <= 200 <= nums[i] <= 10000 <= sum(nums[i]) <= 1000-1000 <= target <= 1000
思路
本题要如何使表达式结果为target,
既然为target,那么就一定有 left组合 - right组合 = target。
left + right = sum,而sum是固定的。right = sum - left
公式来了, left - (sum - left) = target 推导出 left = (target + sum)/2 。
target是固定的,sum是固定的,left就可以求出来。
此时问题就是在集合nums中找出和为left的组合。
如何转化为01背包问题呢?
假设加法的总和为x,那么减法对应的总和就是sum - x。
所以我们要求的是 x - (sum - x) = target
x = (target + sum) / 2
此时问题就转化为,装满容量为x的背包,有几种方法。
这里的x,就是bagSize,也就是我们后面要求的背包容量。
大家看到(target + sum) / 2 应该担心计算的过程中向下取整有没有影响。
这么担心就对了,例如sum 是5,S是2的话其实就是无解的,所以:
(C++代码中,输入的S 就是题目描述的 target)
if ((S + sum) % 2 == 1) return 0; // 此时没有方案
同时如果 S的绝对值已经大于sum,那么也是没有方案的。
(C++代码中,输入的S 就是题目描述的 target)
if (abs(S) > sum) return 0; // 此时没有方案
再回归到01背包问题,为什么是01背包呢?
因为每个物品(题目中的1)只用一次!
这次和之前遇到的背包问题不一样了,之前都是求容量为j的背包,最多能装多少。
本题则是装满有几种方法。其实这就是一个组合问题了。
- 确定dp数组以及下标的含义
dp[j] 表示:填满j(包括j)这么大容积的包,有dp[j]种方法
其实也可以使用二维dp数组来求解本题,dp[i][j]:使用 下标为[0, i]的nums[i]能够凑满j(包括j)这么大容量的包,有dp[i][j]种方法。
下面我都是统一使用一维数组进行讲解, 二维降为一维(滚动数组),其实就是上一层拷贝下来,这个我在动态规划:关于01背包问题,你该了解这些!(滚动数组)也有介绍。
- 确定递推公式
有哪些来源可以推出dp[j]呢?
只要搞到nums[i],凑成dp[j]就有dp[j - nums[i]] 种方法。
例如:dp[j],j 为5,
- 已经有一个1(nums[i]) 的话,有 dp[4]种方法凑成容量为5的背包。
- 已经有一个2(nums[i]) 的话,有 dp[3]种方法凑成容量为5的背包。
- 已经有一个3(nums[i]) 的话,有 dp[2]中方法凑成容量为5的背包
- 已经有一个4(nums[i]) 的话,有 dp[1]中方法凑成容量为5的背包
- 已经有一个5 (nums[i])的话,有 dp[0]中方法凑成容量为5的背包
那么凑整dp[5]有多少方法呢,也就是把所有的dp[j - nums[i]]累加起来。
所以求组合类问题的公式,都是类似这种:
dp[j] += dp[j - nums[i]]
这个公式在后面在讲解背包解决排列组合问题的时候还会用到!
- dp数组如何初始化
从递推公式可以看出,在初始化的时候dp[0] 一定要初始化为1,因为dp[0]是在公式中一切递推结果的起源,如果dp[0]是0的话,递推结果将都是0。
这里有录友可能认为从dp数组定义来说 dp[0] 应该是0,也有录友认为dp[0]应该是1。
其实不要硬去解释它的含义,咱就把 dp[0]的情况带入本题看看应该等于多少。
如果数组[0] ,target = 0,那么 bagSize = (target + sum) / 2 = 0。 dp[0]也应该是1, 也就是说给数组里的元素 0 前面无论放加法还是减法,都是 1 种方法。
所以本题我们应该初始化 dp[0] 为 1。
可能有同学想了,那 如果是 数组[0,0,0,0,0] target = 0 呢。
其实此时最终的dp[0] = 32,也就是这五个零子集的所有组合情况,但此dp[0]非彼dp[0],dp[0]能算出32,其基础是因为dp[0] = 1 累加起来的。
dp[j]其他下标对应的数值也应该初始化为0,从递推公式也可以看出,dp[j]要保证是0的初始值,才能正确的由dp[j - nums[i]]推导出来。
- 确定遍历顺序
在动态规划:关于01背包问题,你该了解这些!(滚动数组)中,我们讲过对于01背包问题一维dp的遍历,nums放在外循环,target在内循环,且内循环倒序。
- 举例推导dp数组
输入:nums: [1, 1, 1, 1, 1], S: 3
bagSize = (S + sum) / 2 = (3 + 5) / 2 = 4
C++解法
C++代码如下:
class Solution {
public:
int findTargetSumWays(vector<int>& nums, int S) {
int sum = 0;
for (int i = 0; i < nums.size(); i++) sum += nums[i];
if (abs(S) > sum) return 0; // 此时没有方案
if ((S + sum) % 2 == 1) return 0; // 此时没有方案
int bagSize = (S + sum) / 2;
vector<int> dp(bagSize + 1, 0);
dp[0] = 1;
for (int i = 0; i < nums.size(); i++) {
for (int j = bagSize; j >= nums[i]; j--) {
dp[j] += dp[j - nums[i]];
}
}
return dp[bagSize];
}
};
- 时间复杂度:O(n × m),n为正数个数,m为背包容量
- 空间复杂度:O(m),m为背包容量
Java解法
class Solution {
public int findTargetSumWays(int[] nums, int target) {
int sum = 0;
for(int num : nums){
sum += num;
}
if(Math.abs(target) > sum) return 0;
if((sum + target) % 2 == 1) return 0;
int bagSize = (sum + target) / 2;
int[] dp = new int[bagSize + 1];
dp[0] = 1;
for(int i = 0; i < nums.length; i++){
for(int j = bagSize; j >= nums[i]; j--){
dp[j] += dp[j - nums[i]];
}
}
return dp[bagSize];
}
}
474. Ones and Zeroes
You are given an array of binary strings strs and two integers m and n.
Return the size of the largest subset of strs such that there are at most m 0's and n 1's in the subset.
A set x is a subset of a set y if all elements of x are also elements of y.
Example 1:
Input: strs = ["10","0001","111001","1","0"], m = 5, n = 3
Output: 4
Explanation: The largest subset with at most 5 0's and 3 1's is {"10", "0001", "1", "0"}, so the answer is 4.
Other valid but smaller subsets include {"0001", "1"} and {"10", "1", "0"}.
{"111001"} is an invalid subset because it contains 4 1's, greater than the maximum of 3.
Example 2:
Input: strs = ["10","0","1"], m = 1, n = 1
Output: 2
Explanation: The largest subset is {"0", "1"}, so the answer is 2.
Constraints:
1 <= strs.length <= 6001 <= strs[i].length <= 100strs[i]consists only of digits'0'and'1'.1 <= m, n <= 100
思路
多重背包是每个物品,数量不同的情况。
本题中strs 数组里的元素就是物品,每个物品都是一个!
而m 和 n相当于是一个背包,两个维度的背包。
理解成多重背包的同学主要是把m和n混淆为物品了,感觉这是不同数量的物品,所以以为是多重背包。
但本题其实是01背包问题!
只不过这个背包有两个维度,一个是m 一个是n,而不同长度的字符串就是不同大小的待装物品。
开始动规五部曲:
- 确定dp数组(dp table)以及下标的含义
dp[i][j]:最多有i个0和j个1的strs的最大子集的大小为dp[i][j]。
- 确定递推公式
dp[i][j] 可以由前一个strs里的字符串推导出来,strs里的字符串有zeroNum个0,oneNum个1。
dp[i][j] 就可以是 dp[i - zeroNum][j - oneNum] + 1。
然后我们在遍历的过程中,取dp[i][j]的最大值。
所以递推公式:dp[i][j] = max(dp[i][j], dp[i - zeroNum][j - oneNum] + 1);
此时大家可以回想一下01背包的递推公式:dp[j] = max(dp[j], dp[j - weight[i]] + value[i]);
对比一下就会发现,字符串的zeroNum和oneNum相当于物品的重量(weight[i]),字符串本身的个数相当于物品的价值(value[i])。
这就是一个典型的01背包! 只不过物品的重量有了两个维度而已。
- dp数组如何初始化
在动态规划:关于01背包问题,你该了解这些!(滚动数组)中已经讲解了,01背包的dp数组初始化为0就可以。
因为物品价值不会是负数,初始为0,保证递推的时候dp[i][j]不会被初始值覆盖。
- 确定遍历顺序
在动态规划:关于01背包问题,你该了解这些!(滚动数组)中,我们讲到了01背包为什么一定是外层for循环遍历物品,内层for循环遍历背包容量且从后向前遍历!
那么本题也是,物品就是strs里的字符串,背包容量就是题目描述中的m和n。
代码如下:
for (string str : strs) { // 遍历物品
int oneNum = 0, zeroNum = 0;
for (char c : str) {
if (c == '0') zeroNum++;
else oneNum++;
}
for (int i = m; i >= zeroNum; i--) { // 遍历背包容量且从后向前遍历!
for (int j = n; j >= oneNum; j--) {
dp[i][j] = max(dp[i][j], dp[i - zeroNum][j - oneNum] + 1);
}
}
}
有同学可能想,那个遍历背包容量的两层for循环先后循序有没有什么讲究?
没讲究,都是物品重量的一个维度,先遍历哪个都行!
- 举例推导dp数组
C++解法
以上动规五部曲分析完毕,C++代码如下:
class Solution {
public:
int findMaxForm(vector<string>& strs, int m, int n) {
vector<vector<int>> dp(m + 1, vector<int> (n + 1, 0)); // 默认初始化0
for (string str : strs) { // 遍历物品
int oneNum = 0, zeroNum = 0;
for (char c : str) {
if (c == '0') zeroNum++;
else oneNum++;
}
for (int i = m; i >= zeroNum; i--) { // 遍历背包容量且从后向前遍历!
for (int j = n; j >= oneNum; j--) {
dp[i][j] = max(dp[i][j], dp[i - zeroNum][j - oneNum] + 1);
}
}
}
return dp[m][n];
}
};
- 时间复杂度: O(kmn),k 为strs的长度
- 空间复杂度: O(mn)
Java解法
class Solution {
public int findMaxForm(String[] strs, int m, int n) {
int[][] dp = new int[m + 1][n + 1];
for(String str : strs){
int x = 0;
int y = 0;
char[] array = str.toCharArray();
for(char c : array){
if(c == '0') x++;
if(c == '1') y++;
}
for(int i = m; i >= x; i--){
for(int j = n; j >= y; j--){
dp[i][j] = Math.max(dp[i][j], dp[i - x][j - y] + 1);
}
}
}
return dp[m][n];
}
}
完全背包问题
理论基础
前言
有N件物品和一个最多能背重量为W的背包。第i件物品的重量是weight[i],得到的价值是value[i] 。每件物品都有无限个(也就是可以放入背包多次),求解将哪些物品装入背包里物品价值总和最大。
完全背包和01背包问题唯一不同的地方就是,每种物品有无限件。
同样leetcode上没有纯完全背包问题,都是需要完全背包的各种应用,需要转化成完全背包问题,所以我这里还是以纯完全背包问题进行讲解理论和原理。
在下面的讲解中,我依然举这个例子:
背包最大重量为4。
物品为:
| - | 重量 | 价值 |
|---|---|---|
| 物品0 | 1 | 15 |
| 物品1 | 3 | 20 |
| 物品2 | 4 | 30 |
每件商品都有无限个!
问背包能背的物品最大价值是多少?
01背包和完全背包唯一不同就是体现在遍历顺序上,所以本文就不去做动规五部曲了,我们直接针对遍历顺序经行分析!
首先再回顾一下01背包的核心代码
for(int i = 0; i < weight.size(); i++) { // 遍历物品
for(int j = bagWeight; j >= weight[i]; j--) { // 遍历背包容量
dp[j] = max(dp[j], dp[j - weight[i]] + value[i]);
}
}
我们知道01背包内嵌的循环是从大到小遍历,为了保证每个物品仅被添加一次。
而完全背包的物品是可以添加多次的,所以要从小到大去遍历,即:
// 先遍历物品,再遍历背包
for(int i = 0; i < weight.size(); i++) { // 遍历物品
for(int j = weight[i]; j <= bagWeight ; j++) { // 遍历背包容量
dp[j] = max(dp[j], dp[j - weight[i]] + value[i]);
}
}
至于为什么,我在动态规划:关于01背包问题,你该了解这些!(滚动数组)中也做了讲解。
相信很多同学看网上的文章,关于完全背包介绍基本就到为止了。
其实还有一个很重要的问题,为什么遍历物品在外层循环,遍历背包容量在内层循环?
这个问题很多题解关于这里都是轻描淡写就略过了,大家都默认 遍历物品在外层,遍历背包容量在内层,好像本应该如此一样,那么为什么呢?
难道就不能遍历背包容量在外层,遍历物品在内层?
01背包中二维dp数组的两个for遍历的先后循序是可以颠倒了,一维dp数组的两个for循环先后循序一定是先遍历物品,再遍历背包容量。
在完全背包中,对于一维dp数组来说,其实两个for循环嵌套顺序是无所谓的!
因为dp[j] 是根据 下标j之前所对应的dp[j]计算出来的。 只要保证下标j之前的dp[j]都是经过计算的就可以了。
遍历物品在外层循环,遍历背包容量在内层循环,状态如图:
遍历背包容量在外层循环,遍历物品在内层循环,状态如图:
看了这两个图,大家就会理解,完全背包中,两个for循环的先后循序,都不影响计算dp[j]所需要的值(这个值就是下标j之前所对应的dp[j])。
先遍历背包在遍历物品,代码如下:
// 先遍历背包,再遍历物品
for(int j = 0; j <= bagWeight; j++) { // 遍历背包容量
for(int i = 0; i < weight.size(); i++) { // 遍历物品
if (j - weight[i] >= 0) dp[j] = max(dp[j], dp[j - weight[i]] + value[i]);
}
cout << endl;
}
完整的C++测试代码如下:
// 先遍历物品,在遍历背包
void test_CompletePack() {
vector<int> weight = {1, 3, 4};
vector<int> value = {15, 20, 30};
int bagWeight = 4;
vector<int> dp(bagWeight + 1, 0);
for(int i = 0; i < weight.size(); i++) { // 遍历物品
for(int j = weight[i]; j <= bagWeight; j++) { // 遍历背包容量
dp[j] = max(dp[j], dp[j - weight[i]] + value[i]);
}
}
cout << dp[bagWeight] << endl;
}
int main() {
test_CompletePack();
}
// 先遍历背包,再遍历物品
void test_CompletePack() {
vector<int> weight = {1, 3, 4};
vector<int> value = {15, 20, 30};
int bagWeight = 4;
vector<int> dp(bagWeight + 1, 0);
for(int j = 0; j <= bagWeight; j++) { // 遍历背包容量
for(int i = 0; i < weight.size(); i++) { // 遍历物品
if (j - weight[i] >= 0) dp[j] = max(dp[j], dp[j - weight[i]] + value[i]);
}
}
cout << dp[bagWeight] << endl;
}
int main() {
test_CompletePack();
}
本题力扣上没有原题,大家可以去卡码网第52题去练习,题意是一样的,C++代码如下:
#include <iostream>
#include <vector>
using namespace std;
// 先遍历背包,再遍历物品
void test_CompletePack(vector<int> weight, vector<int> value, int bagWeight) {
vector<int> dp(bagWeight + 1, 0);
for(int j = 0; j <= bagWeight; j++) { // 遍历背包容量
for(int i = 0; i < weight.size(); i++) { // 遍历物品
if (j - weight[i] >= 0) dp[j] = max(dp[j], dp[j - weight[i]] + value[i]);
}
}
cout << dp[bagWeight] << endl;
}
int main() {
int N, V;
cin >> N >> V;
vector<int> weight;
vector<int> value;
for (int i = 0; i < N; i++) {
int w;
int v;
cin >> w >> v;
weight.push_back(w);
value.push_back(v);
}
test_CompletePack(weight, value, V);
return 0;
}
遍历顺序和排列组合
在动态规划:关于完全背包,你该了解这些!中,讲解了纯完全背包的一维dp数组实现,先遍历物品还是先遍历背包都是可以的,且第二层for循环是从小到大遍历。
但是仅仅是纯完全背包的遍历顺序是这样的,题目稍有变化,两个for循环的先后顺序就不一样了。
如果求组合数就是外层for循环遍历物品,内层for遍历背包。
如果求排列数就是外层for遍历背包,内层for循环遍历物品。
相关题目如下:
如果求最小数,那么两层for循环的先后顺序就无所谓了,相关题目如下:
对于背包问题,其实递推公式算是容易的,难是难在遍历顺序上,如果把遍历顺序搞透,才算是真正理解了。
总结
细心的同学可能发现,全文我说的都是对于纯完全背包问题,其for循环的先后循环是可以颠倒的!
但如果题目稍稍有点变化,就会体现在遍历顺序上。
如果问装满背包有几种方式的话? 那么两个for循环的先后顺序就有很大区别了,而leetcode上的题目都是这种稍有变化的类型。
这个区别,我将在后面讲解具体leetcode题目中给大家介绍,因为这块如果不结合具题目,单纯的介绍原理估计很多同学会越看越懵!
别急,下一篇就是了!
最后,又可以出一道面试题了,就是纯完全背包,要求先用二维dp数组实现,然后再用一维dp数组实现,最后再问,两个for循环的先后是否可以颠倒?为什么?
这个简单的完全背包问题,估计就可以难住不少候选人了。
多重背包
动态规划:关于多重背包,你该了解这些!
本题力扣上没有原题,大家可以去卡码网第56题去练习,题意是一样的。
多重背包
对于多重背包,我在力扣上还没发现对应的题目,所以这里就做一下简单介绍,大家大概了解一下。
有N种物品和一个容量为V 的背包。第i种物品最多有Mi件可用,每件耗费的空间是Ci ,价值是Wi 。求解将哪些物品装入背包可使这些物品的耗费的空间 总和不超过背包容量,且价值总和最大。
多重背包和01背包是非常像的, 为什么和01背包像呢?
每件物品最多有Mi件可用,把Mi件摊开,其实就是一个01背包问题了。
例如:
背包最大重量为10。
物品为:
| - | 重量 | 价值 | 数量 |
|---|---|---|---|
| 物品0 | 1 | 15 | 2 |
| 物品1 | 3 | 20 | 3 |
| 物品2 | 4 | 30 | 2 |
问背包能背的物品最大价值是多少?
和如下情况有区别么?
| - | 重量 | 价值 | 数量 |
|---|---|---|---|
| 物品0 | 1 | 15 | 1 |
| 物品0 | 1 | 15 | 1 |
| 物品1 | 3 | 20 | 1 |
| 物品1 | 3 | 20 | 1 |
| 物品1 | 3 | 20 | 1 |
| 物品2 | 4 | 30 | 1 |
| 物品2 | 4 | 30 | 1 |
毫无区别,这就转成了一个01背包问题了,且每个物品只用一次。
练习题目:卡码网第56题,多重背包
代码如下:
// 超时了
#include<iostream>
#include<vector>
using namespace std;
int main() {
int bagWeight,n;
cin >> bagWeight >> n;
vector<int> weight(n, 0);
vector<int> value(n, 0);
vector<int> nums(n, 0);
for (int i = 0; i < n; i++) cin >> weight[i];
for (int i = 0; i < n; i++) cin >> value[i];
for (int i = 0; i < n; i++) cin >> nums[i];
for (int i = 0; i < n; i++) {
while (nums[i] > 1) { // 物品数量不是一的,都展开
weight.push_back(weight[i]);
value.push_back(value[i]);
nums[i]--;
}
}
vector<int> dp(bagWeight + 1, 0);
for(int i = 0; i < weight.size(); i++) { // 遍历物品,注意此时的物品数量不是n
for(int j = bagWeight; j >= weight[i]; j--) { // 遍历背包容量
dp[j] = max(dp[j], dp[j - weight[i]] + value[i]);
}
}
cout << dp[bagWeight] << endl;
}
大家去提交之后,发现这个解法超时了,为什么呢,哪里耗时呢?
耗时就在这段代码:
for (int i = 0; i < n; i++) {
while (nums[i] > 1) { // 物品数量不是一的,都展开
weight.push_back(weight[i]);
value.push_back(value[i]);
nums[i]--;
}
}
如果物品数量很多的话,C++中,这种操作十分费时,主要消耗在vector的动态底层扩容上。(其实这里也可以优化,先把 所有物品数量都计算好,一起申请vector的空间。
这里也有另一种实现方式,就是把每种商品遍历的个数放在01背包里面在遍历一遍。
代码如下:(详看注释)
#include<iostream>
#include<vector>
using namespace std;
int main() {
int bagWeight,n;
cin >> bagWeight >> n;
vector<int> weight(n, 0);
vector<int> value(n, 0);
vector<int> nums(n, 0);
for (int i = 0; i < n; i++) cin >> weight[i];
for (int i = 0; i < n; i++) cin >> value[i];
for (int i = 0; i < n; i++) cin >> nums[i];
vector<int> dp(bagWeight + 1, 0);
for(int i = 0; i < n; i++) { // 遍历物品
for(int j = bagWeight; j >= weight[i]; j--) { // 遍历背包容量
// 以上为01背包,然后加一个遍历个数
for (int k = 1; k <= nums[i] && (j - k * weight[i]) >= 0; k++) { // 遍历个数
dp[j] = max(dp[j], dp[j - k * weight[i]] + k * value[i]);
}
}
}
cout << dp[bagWeight] << endl;
}
时间复杂度:O(m × n × k),m:物品种类个数,n背包容量,k单类物品数量
从代码里可以看出是01背包里面在加一个for循环遍历一个每种商品的数量。 和01背包还是如出一辙的。
当然还有那种二进制优化的方法,其实就是把每种物品的数量,打包成一个个独立的包。
和以上在循环遍历上有所不同,因为是分拆为各个包最后可以组成一个完整背包,具体原理我就不做过多解释了,大家了解一下就行,面试的话基本不会考完这个深度了,感兴趣可以自己深入研究一波。
总结
多重背包在面试中基本不会出现,力扣上也没有对应的题目,大家对多重背包的掌握程度知道它是一种01背包,并能在01背包的基础上写出对应代码就可以了。
至于背包九讲里面还有混合背包,二维费用背包,分组背包等等这些,大家感兴趣可以自己去学习学习,这里也不做介绍了,面试也不会考。
打家劫舍
198. House Robber
You are a professional robber planning to rob houses along a street. Each house has a certain amount of money stashed, the only constraint stopping you from robbing each of them is that adjacent houses have security systems connected and it will automatically contact the police if two adjacent houses were broken into on the same night.
Given an integer array nums representing the amount of money of each house, return the maximum amount of money you can rob tonight without alerting the police.
Example 1:
Input: nums = [1,2,3,1]
Output: 4
Explanation: Rob house 1 (money = 1) and then rob house 3 (money = 3).
Total amount you can rob = 1 + 3 = 4.
Example 2:
Input: nums = [2,7,9,3,1]
Output: 12
Explanation: Rob house 1 (money = 2), rob house 3 (money = 9) and rob house 5 (money = 1).
Total amount you can rob = 2 + 9 + 1 = 12.
Constraints:
1 <= nums.length <= 1000 <= nums[i] <= 400
思路
大家如果刚接触这样的题目,会有点困惑,当前的状态我是偷还是不偷呢?
仔细一想,当前房屋偷与不偷取决于前一个房屋和前两个房屋是否被偷了。
所以这里就更感觉到,当前状态和前面状态会有一种依赖关系,那么这种依赖关系都是动规的递推公式。
当然以上是大概思路,打家劫舍是dp解决的经典问题,接下来我们来动规五部曲分析如下:
- 确定dp数组(dp table)以及下标的含义
dp[i]:考虑下标i(包括i)以内的房屋,最多可以偷窃的金额为dp[i]。
- 确定递推公式
决定dp[i]的因素就是第i房间偷还是不偷。
如果偷第i房间,那么dp[i] = dp[i - 2] + nums[i] ,即:第i-1房一定是不考虑的,找出 下标i-2(包括i-2)以内的房屋,最多可以偷窃的金额为dp[i-2] 加上第i房间偷到的钱。
如果不偷第i房间,那么dp[i] = dp[i - 1],即考虑i-1房,(注意这里是考虑,并不是一定要偷i-1房,这是很多同学容易混淆的点)
然后dp[i]取最大值,即dp[i] = max(dp[i - 2] + nums[i], dp[i - 1]);
- dp数组如何初始化
从递推公式dp[i] = max(dp[i - 2] + nums[i], dp[i - 1]);可以看出,递推公式的基础就是dp[0] 和 dp[1]
从dp[i]的定义上来讲,dp[0] 一定是 nums[0],dp[1]就是nums[0]和nums[1]的最大值即:dp[1] = max(nums[0], nums[1]);
代码如下:
vector<int> dp(nums.size());
dp[0] = nums[0];
dp[1] = max(nums[0], nums[1]);
- 确定遍历顺序
dp[i] 是根据dp[i - 2] 和 dp[i - 1] 推导出来的,那么一定是从前到后遍历!
代码如下:
for (int i = 2; i < nums.size(); i++) {
dp[i] = max(dp[i - 2] + nums[i], dp[i - 1]);
}
- 举例推导dp数组
以示例二,输入[2,7,9,3,1]为例。
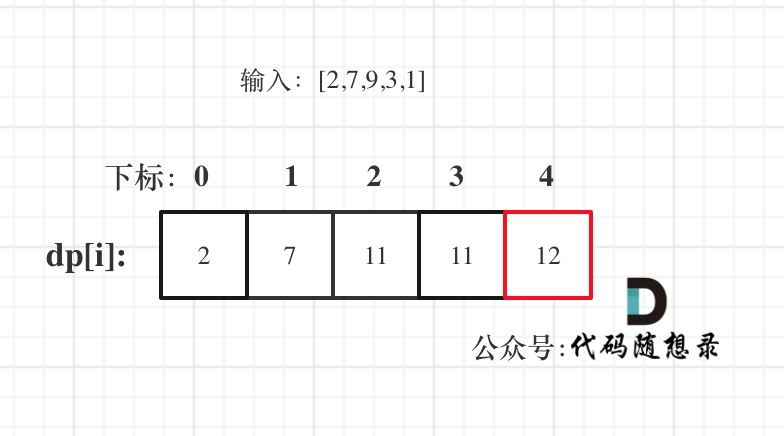
红框dp[nums.size() - 1]为结果。
C++解法
以上分析完毕,C++代码如下:
class Solution {
public:
int rob(vector<int>& nums) {
if (nums.size() == 0) return 0;
if (nums.size() == 1) return nums[0];
vector<int> dp(nums.size());
dp[0] = nums[0];
dp[1] = max(nums[0], nums[1]);
for (int i = 2; i < nums.size(); i++) {
dp[i] = max(dp[i - 2] + nums[i], dp[i - 1]);
}
return dp[nums.size() - 1];
}
};
- 时间复杂度: O(n)
- 空间复杂度: O(n)
Java解法
// 动态规划
class Solution {
public int rob(int[] nums) {
if (nums == null || nums.length == 0) return 0;
if (nums.length == 1) return nums[0];
int[] dp = new int[nums.length];
dp[0] = nums[0];
dp[1] = Math.max(dp[0], nums[1]);
for (int i = 2; i < nums.length; i++) {
dp[i] = Math.max(dp[i - 1], dp[i - 2] + nums[i]);
}
return dp[nums.length - 1];
}
}
// 使用滚动数组思想,优化空间
// 分析本题可以发现,所求结果仅依赖于前两种状态,此时可以使用滚动数组思想将空间复杂度降低为3个空间
class Solution {
public int rob(int[] nums) {
int len = nums.length;
if (len == 0) return 0;
else if (len == 1) return nums[0];
else if (len == 2) return Math.max(nums[0],nums[1]);
int[] result = new int[3]; //存放选择的结果
result[0] = nums[0];
result[1] = Math.max(nums[0],nums[1]);
for(int i=2;i<len;i++){
result[2] = Math.max(result[0]+nums[i],result[1]);
result[0] = result[1];
result[1] = result[2];
}
return result[2];
}
}
// 进一步对滚动数组的空间优化 dp数组只存与计算相关的两次数据
class Solution {
public int rob(int[] nums) {
if (nums.length == 1) {
return nums[0];
}
// 初始化dp数组
// 优化空间 dp数组只用2格空间 只记录与当前计算相关的前两个结果
int[] dp = new int[2];
dp[0] = nums[0];
dp[1] = Math.max(nums[0],nums[1]);
int res = 0;
// 遍历
for (int i = 2; i < nums.length; i++) {
res = Math.max((dp[0] + nums[i]) , dp[1] );
dp[0] = dp[1];
dp[1] = res;
}
// 输出结果
return dp[1];
}
}
213. House Robber II
You are a professional robber planning to rob houses along a street. Each house has a certain amount of money stashed. All houses at this place are arranged in a circle. That means the first house is the neighbor of the last one. Meanwhile, adjacent houses have a security system connected, and it will automatically contact the police if two adjacent houses were broken into on the same night.
Given an integer array nums representing the amount of money of each house, return the maximum amount of money you can rob tonight without alerting the police.
Example 1:
Input: nums = [2,3,2]
Output: 3
Explanation: You cannot rob house 1 (money = 2) and then rob house 3 (money = 2), because they are adjacent houses.
Example 2:
Input: nums = [1,2,3,1]
Output: 4
Explanation: Rob house 1 (money = 1) and then rob house 3 (money = 3).
Total amount you can rob = 1 + 3 = 4.
Example 3:
Input: nums = [1,2,3]
Output: 3
Constraints:
1 <= nums.length <= 1000 <= nums[i] <= 1000
思路
这道题目和198.打家劫舍是差不多的,唯一区别就是成环了。
对于一个数组,成环的话主要有如下三种情况:
- 情况一:考虑不包含首尾元素
-
情况二:考虑包含首元素,不包含尾元素
-
情况三:考虑包含尾元素,不包含首元素
注意我这里用的是"考虑",例如情况三,虽然是考虑包含尾元素,但不一定要选尾部元素! 对于情况三,取nums[1] 和 nums[3]就是最大的。
而情况二 和 情况三 都包含了情况一了,所以只考虑情况二和情况三就可以了。
分析到这里,本题其实比较简单了。 剩下的和198.打家劫舍就是一样的了。
C++解法
注意注释中的情况二情况三,以及把198.打家劫舍的代码抽离出来了。完整代码如下:
class Solution {
public:
int rob(vector<int>& nums) {
if (nums.size() == 0) return 0;
if (nums.size() == 1) return nums[0];
int result1 = robRange(nums, 0, nums.size() - 2); // 情况二
int result2 = robRange(nums, 1, nums.size() - 1); // 情况三
return max(result1, result2);
}
// 198.打家劫舍的逻辑
int robRange(vector<int>& nums, int start, int end) {
if (end == start) return nums[start];
vector<int> dp(nums.size());
dp[start] = nums[start];
dp[start + 1] = max(nums[start], nums[start + 1]);
for (int i = start + 2; i <= end; i++) {
dp[i] = max(dp[i - 2] + nums[i], dp[i - 1]);
}
return dp[end];
}
};
- 时间复杂度: O(n)
- 空间复杂度: O(n)
Java解法
class Solution {
public int robLinearArray(int[] nums) {
int[] dp = new int[nums.length + 1];
dp[0] = nums[0];
if(nums.length == 1){
return dp[0];
}
if(nums.length > 1){
dp[1] = Math.max(nums[0], nums[1]);
for(int j = 2; j < nums.length; j++){
dp[j] = Math.max(dp[j - 1], dp[j - 2] + nums[j]);
}
}
return dp[nums.length - 1];
}
public int rob(int[] nums) {
if(nums.length == 1){
return nums[0];
}
int[] resultWithoutFirst = Arrays.copyOfRange(nums, 1, nums.length);
int[] resultWithoutLast = Arrays.copyOfRange(nums, 0, nums.length - 1);
int maxLeft = robLinearArray(resultWithoutFirst);
int maxRight = robLinearArray(resultWithoutLast);
return Math.max(maxLeft, maxRight);
}
}
337. House Robber III
The thief has found himself a new place for his thievery again. There is only one entrance to this area, called root.
Besides the root, each house has one and only one parent house. After a tour, the smart thief realized that all houses in this place form a binary tree. It will automatically contact the police if two directly-linked houses were broken into on the same night.
Given the root of the binary tree, return the maximum amount of money the thief can rob without alerting the police.
Example 1:

Input: root = [3,2,3,null,3,null,1]
Output: 7
Explanation: Maximum amount of money the thief can rob = 3 + 3 + 1 = 7.
Example 2:

Input: root = [3,4,5,1,3,null,1]
Output: 9
Explanation: Maximum amount of money the thief can rob = 4 + 5 = 9.
Constraints:
- The number of nodes in the tree is in the range
[1, 10^4]. 0 <= Node.val <= 10^4
思路
对于树的话,首先就要想到遍历方式,前中后序(深度优先搜索)还是层序遍历(广度优先搜索)。
本题一定是要后序遍历,因为通过递归函数的返回值来做下一步计算。
与198.打家劫舍,213.打家劫舍II一样,关键是要讨论当前节点抢还是不抢。
如果抢了当前节点,两个孩子就不能动,如果没抢当前节点,就可以考虑抢左右孩子(注意这里说的是“考虑”)
动态规划其实就是使用状态转移容器来记录状态的变化,这里可以使用一个长度为2的数组,记录当前节点偷与不偷所得到的的最大金钱。
这道题目算是树形dp的入门题目,因为是在树上进行状态转移,我们在讲解二叉树的时候说过递归三部曲,那么下面我以递归三部曲为框架,其中融合动规五部曲的内容来进行讲解。
- 确定递归函数的参数和返回值
这里我们要求一个节点 偷与不偷的两个状态所得到的金钱,那么返回值就是一个长度为2的数组。
参数为当前节点,代码如下:
vector<int> robTree(TreeNode* cur) {
其实这里的返回数组就是dp数组。
所以dp数组(dp table)以及下标的含义:下标为0记录不偷该节点所得到的的最大金钱,下标为1记录偷该节点所得到的的最大金钱。
所以本题dp数组就是一个长度为2的数组!
那么有同学可能疑惑,长度为2的数组怎么标记树中每个节点的状态呢?
别忘了在递归的过程中,系统栈会保存每一层递归的参数。
如果还不理解的话,就接着往下看,看到代码就理解了哈。
- 确定终止条件
在遍历的过程中,如果遇到空节点的话,很明显,无论偷还是不偷都是0,所以就返回
if (cur == NULL) return vector<int>{0, 0};
这也相当于dp数组的初始化
- 确定遍历顺序
首先明确的是使用后序遍历。 因为要通过递归函数的返回值来做下一步计算。
通过递归左节点,得到左节点偷与不偷的金钱。
通过递归右节点,得到右节点偷与不偷的金钱。
代码如下:
// 下标0:不偷,下标1:偷
vector<int> left = robTree(cur->left); // 左
vector<int> right = robTree(cur->right); // 右
// 中
4. 确定单层递归的逻辑
如果是偷当前节点,那么左右孩子就不能偷,val1 = cur->val + left[0] + right[0]; (如果对下标含义不理解就再回顾一下dp数组的含义)
如果不偷当前节点,那么左右孩子就可以偷,至于到底偷不偷一定是选一个最大的,所以:val2 = max(left[0], left[1]) + max(right[0], right[1]);
最后当前节点的状态就是{val2, val1}; 即:{不偷当前节点得到的最大金钱,偷当前节点得到的最大金钱}
代码如下:
vector<int> left = robTree(cur->left); // 左
vector<int> right = robTree(cur->right); // 右
// 偷cur
int val1 = cur->val + left[0] + right[0];
// 不偷cur
int val2 = max(left[0], left[1]) + max(right[0], right[1]);
return {val2, val1};
- 举例推导dp数组
以示例1为例,dp数组状态如下:(注意用后序遍历的方式推导)
最后头结点就是取下标0 和下标1的最大值就是偷得的最大金钱。
C++解法
暴力递归代码如下:
class Solution {
public:
int rob(TreeNode* root) {
if (root == NULL) return 0;
if (root->left == NULL && root->right == NULL) return root->val;
// 偷父节点
int val1 = root->val;
if (root->left) val1 += rob(root->left->left) + rob(root->left->right); // 跳过root->left,相当于不考虑左孩子了
if (root->right) val1 += rob(root->right->left) + rob(root->right->right); // 跳过root->right,相当于不考虑右孩子了
// 不偷父节点
int val2 = rob(root->left) + rob(root->right); // 考虑root的左右孩子
return max(val1, val2);
}
};
- 时间复杂度:O(n^2),这个时间复杂度不太标准,也不容易准确化,例如越往下的节点重复计算次数就越多
- 空间复杂度:O(log n),算上递推系统栈的空间
当然以上代码超时了,这个递归的过程中其实是有重复计算了。
我们计算了root的四个孙子(左右孩子的孩子)为头结点的子树的情况,又计算了root的左右孩子为头结点的子树的情况,计算左右孩子的时候其实又把孙子计算了一遍。
记忆化递推
所以可以使用一个map把计算过的结果保存一下,这样如果计算过孙子了,那么计算孩子的时候可以复用孙子节点的结果。
代码如下:
class Solution {
public:
unordered_map<TreeNode* , int> umap; // 记录计算过的结果
int rob(TreeNode* root) {
if (root == NULL) return 0;
if (root->left == NULL && root->right == NULL) return root->val;
if (umap[root]) return umap[root]; // 如果umap里已经有记录则直接返回
// 偷父节点
int val1 = root->val;
if (root->left) val1 += rob(root->left->left) + rob(root->left->right); // 跳过root->left
if (root->right) val1 += rob(root->right->left) + rob(root->right->right); // 跳过root->right
// 不偷父节点
int val2 = rob(root->left) + rob(root->right); // 考虑root的左右孩子
umap[root] = max(val1, val2); // umap记录一下结果
return max(val1, val2);
}
};
- 时间复杂度:O(n)
- 空间复杂度:O(log n),算上递推系统栈的空间
动态规划
递归三部曲与动规五部曲分析完毕,C++代码如下:
class Solution {
public:
int rob(TreeNode* root) {
vector<int> result = robTree(root);
return max(result[0], result[1]);
}
// 长度为2的数组,0:不偷,1:偷
vector<int> robTree(TreeNode* cur) {
if (cur == NULL) return vector<int>{0, 0};
vector<int> left = robTree(cur->left);
vector<int> right = robTree(cur->right);
// 偷cur,那么就不能偷左右节点。
int val1 = cur->val + left[0] + right[0];
// 不偷cur,那么可以偷也可以不偷左右节点,则取较大的情况
int val2 = max(left[0], left[1]) + max(right[0], right[1]);
return {val2, val1};
}
};
- 时间复杂度:O(n),每个节点只遍历了一次
- 空间复杂度:O(log n),算上递推系统栈的空间
Java解法
class Solution {
// 1.递归去偷,超时
public int rob(TreeNode root) {
if (root == null)
return 0;
int money = root.val;
if (root.left != null) {
money += rob(root.left.left) + rob(root.left.right);
}
if (root.right != null) {
money += rob(root.right.left) + rob(root.right.right);
}
return Math.max(money, rob(root.left) + rob(root.right));
}
// 2.递归去偷,记录状态
// 执行用时:3 ms , 在所有 Java 提交中击败了 56.24% 的用户
public int rob1(TreeNode root) {
Map<TreeNode, Integer> memo = new HashMap<>();
return robAction(root, memo);
}
int robAction(TreeNode root, Map<TreeNode, Integer> memo) {
if (root == null)
return 0;
if (memo.containsKey(root))
return memo.get(root);
int money = root.val;
if (root.left != null) {
money += robAction(root.left.left, memo) + robAction(root.left.right, memo);
}
if (root.right != null) {
money += robAction(root.right.left, memo) + robAction(root.right.right, memo);
}
int res = Math.max(money, robAction(root.left, memo) + robAction(root.right, memo));
memo.put(root, res);
return res;
}
// 3.状态标记递归
// 执行用时:0 ms , 在所有 Java 提交中击败了 100% 的用户
// 不偷:Max(左孩子不偷,左孩子偷) + Max(右孩子不偷,右孩子偷)
// root[0] = Math.max(rob(root.left)[0], rob(root.left)[1]) +
// Math.max(rob(root.right)[0], rob(root.right)[1])
// 偷:左孩子不偷+ 右孩子不偷 + 当前节点偷
// root[1] = rob(root.left)[0] + rob(root.right)[0] + root.val;
public int rob3(TreeNode root) {
int[] res = robAction1(root);
return Math.max(res[0], res[1]);
}
int[] robAction1(TreeNode root) {
int res[] = new int[2];
if (root == null)
return res;
int[] left = robAction1(root.left);
int[] right = robAction1(root.right);
res[0] = Math.max(left[0], left[1]) + Math.max(right[0], right[1]);
res[1] = root.val + left[0] + right[0];
return res;
}
}
2560. House Robber IV
There are several consecutive houses along a street, each of which has some money inside. There is also a robber, who wants to steal money from the homes, but he refuses to steal from adjacent homes.
The capability of the robber is the maximum amount of money he steals from one house of all the houses he robbed.
You are given an integer array nums representing how much money is stashed in each house. More formally, the ith house from the left has nums[i] dollars.
You are also given an integer k, representing the minimum number of houses the robber will steal from. It is always possible to steal at least k houses.
Return the minimum capability of the robber out of all the possible ways to steal at least k houses.
Example 1:
Input: nums = [2,3,5,9], k = 2
Output: 5
Explanation:
There are three ways to rob at least 2 houses:
- Rob the houses at indices 0 and 2. Capability is max(nums[0], nums[2]) = 5.
- Rob the houses at indices 0 and 3. Capability is max(nums[0], nums[3]) = 9.
- Rob the houses at indices 1 and 3. Capability is max(nums[1], nums[3]) = 9. Therefore, we return min(5, 9, 9) = 5.
Example 2:
Input: nums = [2,7,9,3,1], k = 2
Output: 2
Explanation: There are 7 ways to rob the houses. The way which leads to minimum capability is to rob the house at index 0 and 4. Return max(nums[0], nums[4]) = 2.
Constraints:
1 <= nums.length <= 10^51 <= nums[i] <= 10^91 <= k <= (nums.length + 1)/2
思路
Can we use binary search to find the minimum value of a non-contiguous subsequence of a given size k?
Initialize the search range with the minimum and maximum elements of the input array.
Use a check function to determine if it is possible to select k non-consecutive elements that are less than or equal to the current "guess" value.
Adjust the search range based on the outcome of the check function, until the range converges and the minimum value is found.
方法一:二分查找
二分查找答案:找到最小的 x ,使得数组 nums 存在至少 k 个不超过 x 的数。
题目需要获取窃取至少 k 间房屋时小偷的最小窃取能力,属于常见的最小化最大值问题。
记当前偷取的房屋数目为 count,遍历数组 nums,假设当前遍历的房屋的金额为 x,如果 x≤y 成立,且上一遍历的房屋没有被偷取,那么令偷取的房屋数目 count 加 1,表示该房屋被偷取。 遍历结束后 f(y)=count,显然 f(y) 是非递减函数。
那么我们可以使用二分查找的方法,找到满足 f(y)≥k 的最小 y,即题目所求的小偷最小窃取能力。
C++解法
具体二分查找算法如下:
初始时 lower=numsmin,upper=numsmax。
令 middle=⌊(lower+upper)/2⌋,如果 f(middle)≥k,那么 upper=middle−1;否则 lower=middle+1。
当 lower≤upper 时,继续执行步骤 2;否则返回 lower 为结果。
class Solution {
public:
int minCapability(vector<int>& nums, int k) {
int lower = *min_element(nums.begin(), nums.end());
int upper = *max_element(nums.begin(), nums.end());
while (lower <= upper) {
int middle = (lower + upper) / 2;
int count = 0;
bool visited = false;
for (int x : nums) {
if (x <= middle && !visited) {
count++;
visited = true;
} else {
visited = false;
}
}
if (count >= k) {
upper = middle - 1;
} else {
lower = middle + 1;
}
}
return lower;
}
};
复杂度分析
时间复杂度:O(nlogT),其中 n 是数组 nums 的长度,T 是数组最大值与最小值之差。二分查找的次数为 O(logT),每次查找需要 O(n)。
空间复杂度:O(1)。
另一种解法如下所示:
class Solution {
public:
bool canRob(vector<int>& nums, int mid, int k) {
int count = 0, n = nums.size();
for (int i = 0; i < n; i++) {
if (nums[i] <= mid) {
count++;
i++;
}
}
return count >= k;
}
int minCapability(vector<int>& nums, int k) {
int left = 1, right = *max_element(nums.begin(), nums.end()), ans = right;
while (left <= right) {
int mid = (left + right) / 2;
if (canRob(nums, mid, k)) {
ans = mid;
right = mid - 1;
} else {
left = mid + 1;
}
}
return ans;
}
};
Java解法
class Solution {
public boolean canRob(int[] nums, int mid, int k) {
int count = 0, n = nums.length;
for (int i = 0; i < n; i++) {
if (nums[i] <= mid) {
count++;
i++;
}
}
return count >= k;
}
public int minCapability(int[] nums, int k) {
int left = 1, right = Arrays.stream(nums).max().getAsInt(), ans = right;
while (left <= right) {
int mid = (left + right) / 2;
if (canRob(nums, mid, k)) {
ans = mid;
right = mid - 1;
} else {
left = mid + 1;
}
}
return ans;
}
}
买卖股票
- 121. Best Time to Buy and Sell Stock
- 122. Best Time to Buy and Sell Stock II
- 123. Best Time to Buy and Sell Stock III
- 188. Best Time to Buy and Sell Stock IV
- 309. Best Time to Buy and Sell Stock with Cooldown
- 714. Best Time to Buy and Sell Stock with Transaction Fee
121. Best Time to Buy and Sell Stock
You are given an array prices where prices[i] is the price of a given stock on the ith day.
You want to maximize your profit by choosing a single day to buy one stock and choosing a different day in the future to sell that stock.
Return the maximum profit you can achieve from this transaction. If you cannot achieve any profit, return 0.
Example 1:
Input: prices = [7,1,5,3,6,4]
Output: 5
Explanation: Buy on day 2 (price = 1) and sell on day 5 (price = 6), profit = 6-1 = 5.
Note that buying on day 2 and selling on day 1 is not allowed because you must buy before you sell.
Example 2:
Input: prices = [7,6,4,3,1]
Output: 0
Explanation: In this case, no transactions are done and the max profit = 0.
Constraints:
1 <= prices.length <= 10^50 <= prices[i] <= 10^4
思路
动规五部曲分析如下:
- 确定dp数组(dp table)以及下标的含义
dp[i][j] 表示第i天持有股票所得最多现金 ,这里可能有同学疑惑,本题中只能买卖一次,持有股票之后哪还有现金呢?
其实一开始现金是0,那么加入第i天买入股票现金就是 -prices[i], 这是一个负数。
dp[i][j] 表示第i天不持有股票所得最多现金
注意这里说的是“持有”,“持有”不代表就是当天“买入”!也有可能是昨天就买入了,今天保持持有的状态
很多同学把“持有”和“买入”没区分清楚。
在下面递推公式分析中,我会进一步讲解。
- 确定递推公式
如果第i天持有股票即dp[i][j], 那么可以由两个状态推出来
- 第i-1天就持有股票,那么就保持现状,所得现金就是昨天持有股票的所得现金 即:
dp[i-1][j] - 第i天买入股票,所得现金就是买入今天的股票后所得现金即:-prices[i]
那么dp[i][j]应该选所得现金最大的,所以dp[i][j] = max(dp[i-1][j], -prices[i]);
如果第i天不持有股票即dp[i][j], 也可以由两个状态推出来
- 第i-1天就不持有股票,那么就保持现状,所得现金就是昨天不持有股票的所得现金 即:
dp[i-1][j] - 第i天卖出股票,所得现金就是按照今天股票价格卖出后所得现金即:prices[i] +
dp[i-1][j]
同样dp[i][j]取最大的,dp[i][j] = max(dp[i-1][j], prices[i] + dp[i-1][j]);
这样递推公式我们就分析完了
- dp数组如何初始化
由递推公式 dp[i][j] = max(dp[i-1][j], -prices[i]); 和 dp[i][j] = max(dp[i-1][j], prices[i] + dp[i-1][j]);可以看出
其基础都是要从dp[0][0]和dp[0][1]推导出来。
那么dp[0][1]表示第0天持有股票,此时的持有股票就一定是买入股票了,因为不可能有前一天推出来,所以dp[0][1] -= prices[0];
dp[0][0]表示第0天不持有股票,不持有股票那么现金就是0,所以dp[0][0] = 0;
- 确定遍历顺序
从递推公式可以看出dp[i]都是由dp[i - 1]推导出来的,那么一定是从前向后遍历。
- 举例推导dp数组
以示例1,输入:[7,1,5,3,6,4]为例,dp数组状态如下:
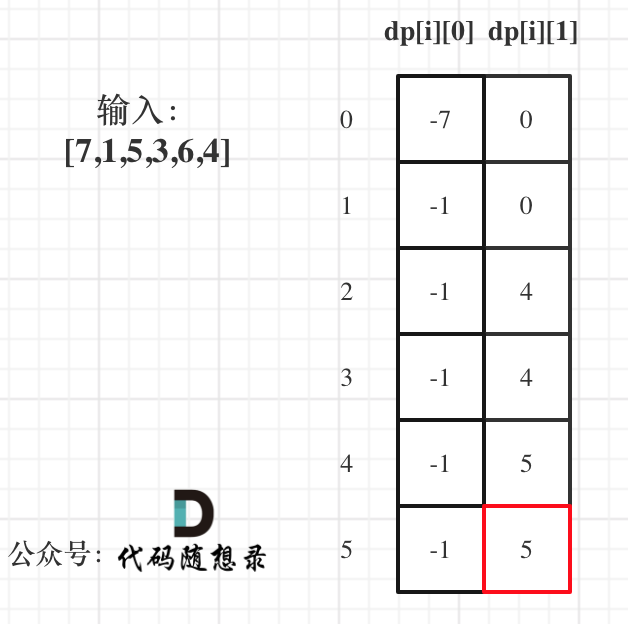
`dp[5][1]就是最终结果。
为什么不是dp[5][0]呢?
因为本题中不持有股票状态所得金钱一定比持有股票状态得到的多!
C++解法
动态规划
以上分析完毕,C++代码如下:
// 版本一
class Solution {
public:
int maxProfit(vector<int>& prices) {
int len = prices.size();
if (len == 0) return 0;
vector<vector<int>> dp(len, vector<int>(2));
dp[0][0] -= prices[0];
dp[0][1] = 0;
for (int i = 1; i < len; i++) {
dp[i][0] = max(dp[i - 1][0], -prices[i]);
dp[i][1] = max(dp[i - 1][1], prices[i] + dp[i - 1][0]);
}
return dp[len - 1][1];
}
};
- 时间复杂度:O(n)
- 空间复杂度:O(n)
从递推公式可以看出,dp[i]只是依赖于dp[i - 1]的状态。
dp[i][0] = max(dp[i - 1][0], -prices[i]);
dp[i][1] = max(dp[i - 1][1], prices[i] + dp[i - 1][0]);
那么我们只需要记录 当前天的dp状态和前一天的dp状态就可以了,可以使用滚动数组来节省空间,代码如下:
// 版本二
class Solution {
public:
int maxProfit(vector<int>& prices) {
int len = prices.size();
vector<vector<int>> dp(2, vector<int>(2)); // 注意这里只开辟了一个2 * 2大小的二维数组
dp[0][0] -= prices[0];
dp[0][1] = 0;
for (int i = 1; i < len; i++) {
dp[i % 2][0] = max(dp[(i - 1) % 2][0], -prices[i]);
dp[i % 2][1] = max(dp[(i - 1) % 2][1], prices[i] + dp[(i - 1) % 2][0]);
}
return dp[(len - 1) % 2][1];
}
};
- 时间复杂度:O(n)
- 空间复杂度:O(1)
这里能写出版本一就可以了,版本二虽然原理都一样,但是想直接写出版本二还是有点麻烦,容易自己给自己找bug。
所以建议是先写出版本一,然后在版本一的基础上优化成版本二,而不是直接就写出版本二。
暴力
这道题目最直观的想法,就是暴力,找最优间距了。
class Solution {
public:
int maxProfit(vector<int>& prices) {
int result = 0;
for (int i = 0; i < prices.size(); i++) {
for (int j = i + 1; j < prices.size(); j++){
result = max(result, prices[j] - prices[i]);
}
}
return result;
}
};
- 时间复杂度:O(n^2)
- 空间复杂度:O(1)
当然该方法超时了。
贪心
因为股票就买卖一次,那么贪心的想法很自然就是取最左最小值,取最右最大值,那么得到的差值就是最大利润。
C++代码如下:
class Solution {
public:
int maxProfit(vector<int>& prices) {
int low = INT_MAX;
int result = 0;
for (int i = 0; i < prices.size(); i++) {
low = min(low, prices[i]); // 取最左最小价格
result = max(result, prices[i] - low); // 直接取最大区间利润
}
return result;
}
};
- 时间复杂度:O(n)
- 空间复杂度:O(1)
Java解法
// 优化空间
class Solution {
public int maxProfit(int[] prices) {
int[] dp = new int[2];
// 0表示持有,1表示卖出
dp[0] = -prices[0];
dp[1] = 0;
for(int i = 1; i <= prices.length; i++){
// 前一天持有; 既然不限制交易次数,那么再次买股票时,要加上之前的收益
dp[0] = Math.max(dp[0], dp[1] - prices[i-1]);
// 前一天卖出; 或当天卖出,当天卖出,得先持有
dp[1] = Math.max(dp[1], dp[0] + prices[i-1]);
}
return dp[1];
}
}
122. Best Time to Buy and Sell Stock II
You are given an integer array prices where prices[i] is the price of a given stock on the ith day.
On each day, you may decide to buy and/or sell the stock. You can only hold at most one share of the stock at any time. However, you can buy it then immediately sell it on the same day.
Find and return the maximum profit you can achieve.
Example 1:
Input: prices = [7,1,5,3,6,4]
Output: 7
Explanation: Buy on day 2 (price = 1) and sell on day 3 (price = 5), profit = 5-1 = 4.
Then buy on day 4 (price = 3) and sell on day 5 (price = 6), profit = 6-3 = 3.
Total profit is 4 + 3 = 7.
Example 2:
Input: prices = [1,2,3,4,5]
Output: 4
Explanation: Buy on day 1 (price = 1) and sell on day 5 (price = 5), profit = 5-1 = 4.
Total profit is 4.
Example 3:
Input: prices = [7,6,4,3,1]
Output: 0
Explanation: There is no way to make a positive profit, so we never buy the stock to achieve the maximum profit of 0.
Constraints:
1 <= prices.length <= 3 * 10^40 <= prices[i] <= 10^4
思路
本题我们在讲解贪心专题的时候就已经讲解过了贪心算法:买卖股票的最佳时机II,只不过没有深入讲解动态规划的解法,那么这次我们再好好分析一下动规的解法。
本题和121. 买卖股票的最佳时机的唯一区别是本题股票可以买卖多次了(注意只有一只股票,所以再次购买前要出售掉之前的股票)
在动规五部曲中,这个区别主要是体现在递推公式上,其他都和121. 买卖股票的最佳时机一样一样的。
所以我们重点讲一讲递推公式。
这里重申一下dp数组的含义:
dp[i][j]表示第i天持有股票所得现金。dp[i][j]表示第i天不持有股票所得最多现金
如果第i天持有股票即dp[i][j], 那么可以由两个状态推出来
- 第i-1天就持有股票,那么就保持现状,所得现金就是昨天持有股票的所得现金 即:
dp[i-1][j] - 第i天买入股票,所得现金就是昨天不持有股票的所得现金减去 今天的股票价格 即:
dp[i-1][j]- prices[i]
注意这里和121. 买卖股票的最佳时机唯一不同的地方,就是推导dp[i][j]的时候,第i天买入股票的情况。
在121. 买卖股票的最佳时机中,因为股票全程只能买卖一次,所以如果买入股票,那么第i天持有股票即dp[i][j]一定就是 -prices[i]。
而本题,因为一只股票可以买卖多次,所以当第i天买入股票的时候,所持有的现金可能有之前买卖过的利润。
那么第i天持有股票即dp[i][j],如果是第i天买入股票,所得现金就是昨天不持有股票的所得现金 减去 今天的股票价格 即:dp[i-1][j] - prices[i]。
再来看看如果第i天不持有股票即dp[i][j]的情况, 依然可以由两个状态推出来
- 第i-1天就不持有股票,那么就保持现状,所得现金就是昨天不持有股票的所得现金 即:
dp[i-1][j] - 第i天卖出股票,所得现金就是按照今天股票价格卖出后所得现金即:prices[i] +
dp[i-1][j]
注意这里和121. 买卖股票的最佳时机就是一样的逻辑,卖出股票收获利润(可能是负值)天经地义!
C++解法
代码如下:(注意代码中的注释,标记了和121.买卖股票的最佳时机唯一不同的地方)
class Solution {
public:
int maxProfit(vector<int>& prices) {
int len = prices.size();
vector<vector<int>> dp(len, vector<int>(2, 0));
dp[0][0] -= prices[0];
dp[0][1] = 0;
for (int i = 1; i < len; i++) {
dp[i][0] = max(dp[i - 1][0], dp[i - 1][1] - prices[i]); // 注意这里是和121. 买卖股票的最佳时机唯一不同的地方。
dp[i][1] = max(dp[i - 1][1], dp[i - 1][0] + prices[i]);
}
return dp[len - 1][1];
}
};
- 时间复杂度:O(n)
- 空间复杂度:O(n)
大家可以本题和121. 买卖股票的最佳时机的代码几乎一样,唯一的区别在:
dp[i][0] = max(dp[i - 1][0], dp[i - 1][1] - prices[i]);
这正是因为本题的股票可以买卖多次! 所以买入股票的时候,可能会有之前买卖的利润即:dp[i-1][j],所以dp[i-1][j] - prices[i]。
想到到这一点,对这两道题理解的就比较深刻了。
这里我依然给出滚动数组的版本,C++代码如下:
// 版本二
class Solution {
public:
int maxProfit(vector<int>& prices) {
int len = prices.size();
vector<vector<int>> dp(2, vector<int>(2)); // 注意这里只开辟了一个2 * 2大小的二维数组
dp[0][0] -= prices[0];
dp[0][1] = 0;
for (int i = 1; i < len; i++) {
dp[i % 2][0] = max(dp[(i - 1) % 2][0], dp[(i - 1) % 2][1] - prices[i]);
dp[i % 2][1] = max(dp[(i - 1) % 2][1], prices[i] + dp[(i - 1) % 2][0]);
}
return dp[(len - 1) % 2][1];
}
};
- 时间复杂度:O(n)
- 空间复杂度:O(1)
Java解法
// 动态规划
class Solution
// 实现1:二维数组存储
// 可以将每天持有与否的情况分别用 dp[i][0] 和 dp[i][1] 来进行存储
// 时间复杂度:O(n),空间复杂度:O(n)
public int maxProfit(int[] prices) {
int n = prices.length;
int[][] dp = new int[n][2]; // 创建二维数组存储状态
dp[0][0] = 0; // 初始状态
dp[0][1] = -prices[0];
for (int i = 1; i < n; ++i) {
dp[i][0] = Math.max(dp[i - 1][0], dp[i - 1][1] + prices[i]); // 第 i 天,没有股票
dp[i][1] = Math.max(dp[i - 1][1], dp[i - 1][0] - prices[i]); // 第 i 天,持有股票
}
return dp[n - 1][0]; // 卖出股票收益高于持有股票收益,因此取[0]
}
}
贪心解法:
class Solution {
public int maxProfit(int[] prices) {
int result = 0;
for(int i = 1; i < prices.length; i++){
result += Math.max(prices[i] - prices[i - 1], 0);
}
return result;
}
}
123. Best Time to Buy and Sell Stock III
You are given an array prices where prices[i] is the price of a given stock on the ith day.
Find the maximum profit you can achieve. You may complete at most two transactions.
Note: You may not engage in multiple transactions simultaneously (i.e., you must sell the stock before you buy again).
Example 1:
Input: prices = [3,3,5,0,0,3,1,4]
Output: 6
Explanation: Buy on day 4 (price = 0) and sell on day 6 (price = 3), profit = 3-0 = 3.
Then buy on day 7 (price = 1) and sell on day 8 (price = 4), profit = 4-1 = 3.
Example 2:
Input: prices = [1,2,3,4,5]
Output: 4
Explanation: Buy on day 1 (price = 1) and sell on day 5 (price = 5), profit = 5-1 = 4.
Note that you cannot buy on day 1, buy on day 2 and sell them later, as you are engaging multiple transactions at the same time. You must sell before buying again.
Example 3:
Input: prices = [7,6,4,3,1]
Output: 0
Explanation: In this case, no transaction is done, i.e. max profit = 0.
Constraints:
1 <= prices.length <= 10^50 <= prices[i] <= 10^5
思路
这道题目相对 121.买卖股票的最佳时机 和 122.买卖股票的最佳时机II 难了不少。
关键在于至多买卖两次,这意味着可以买卖一次,可以买卖两次,也可以不买卖。
接来下我用动态规划五部曲详细分析一下:
- 确定dp数组以及下标的含义
一天一共就有五个状态,
- 没有操作 (其实我们也可以不设置这个状态)
- 第一次持有股票
- 第一次不持有股票
- 第二次持有股票
- 第二次不持有股票
dp[i][j]中 i表示第i天,j为 [0 - 4] 五个状态,dp[i][j]表示第i天状态j所剩最大现金。
需要注意:dp[i][j],表示的是第i天,买入股票的状态,并不是说一定要第i天买入股票,这是很多同学容易陷入的误区。
例如 dp[i][j] ,并不是说 第i天一定买入股票,有可能 第 i-1天 就买入了,那么 dp[i][j] 延续买入股票的这个状态。
- 确定递推公式
达到dp[i][j]状态,有两个具体操作:
- 操作一:第i天买入股票了,那么
dp[i][j] = dp[i-1][j] - prices[i] - 操作二:第i天没有操作,而是沿用前一天买入的状态,即:
dp[i][j]=dp[i-1][j]
那么dp[i][j]究竟选 dp[i-1][j] - prices[i],还是dp[i-1][j]呢?
一定是选最大的,所以 dp[i][j] = max(dp[i-1][j] - prices[i], dp[i-1][j]);
同理dp[i][j]也有两个操作:
- 操作一:第i天卖出股票了,那么
dp[i][j] = dp[i-1][j] + prices[i] - 操作二:第i天没有操作,沿用前一天卖出股票的状态,即:
dp[i][j]=dp[i-1][j]
所以dp[i][j] = max(dp[i-1][j] + prices[i], dp[i-1][j])
同理可推出剩下状态部分:
dp[i][j] = max(dp[i-1][j], dp[i-1][j] - prices[i]);
dp[i][j] = max(dp[i-1][j], dp[i-1][j] + prices[i]);
- dp数组如何初始化
第0天没有操作,这个最容易想到,就是0,即:dp[0][0] = 0;
第0天做第一次买入的操作,dp[0][1] = -prices[0];
第0天做第一次卖出的操作,这个初始值应该是多少呢?
此时还没有买入,怎么就卖出呢? 其实大家可以理解当天买入,当天卖出,所以dp[0][2] = 0;
第0天第二次买入操作,初始值应该是多少呢?应该不少同学疑惑,第一次还没买入呢,怎么初始化第二次买入呢?
第二次买入依赖于第一次卖出的状态,其实相当于第0天第一次买入了,第一次卖出了,然后再买入一次(第二次买入),那么现在手头上没有现金,只要买入,现金就做相应的减少。
所以第二次买入操作,初始化为:dp[0][3] = -prices[0];
同理第二次卖出初始化dp[0][4] = 0;
- 确定遍历顺序
从递归公式其实已经可以看出,一定是从前向后遍历,因为dp[i],依靠dp[i - 1]的数值。
- 举例推导dp数组
以输入[1,2,3,4,5]为例
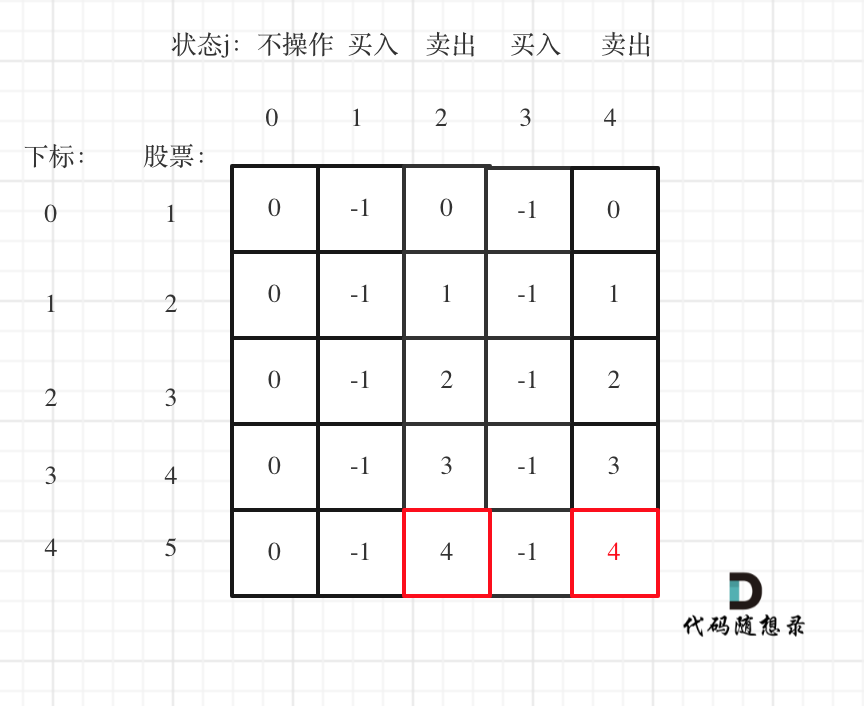
大家可以看到红色框为最后两次卖出的状态。
现在最大的时候一定是卖出的状态,而两次卖出的状态现金最大一定是最后一次卖出。如果想不明白的录友也可以这么理解:如果第一次卖出已经是最大值了,那么我们可以在当天立刻买入再立刻卖出。所以dp[4][4]已经包含了dp[4][4]的情况。也就是说第二次卖出手里所剩的钱一定是最多的。
所以最终最大利润是dp[4][4]
C++解法
以上五部都分析完了,不难写出如下代码:
// 版本一
class Solution {
public:
int maxProfit(vector<int>& prices) {
if (prices.size() == 0) return 0;
vector<vector<int>> dp(prices.size(), vector<int>(5, 0));
dp[0][1] = -prices[0];
dp[0][3] = -prices[0];
for (int i = 1; i < prices.size(); i++) {
dp[i][0] = dp[i - 1][0];
dp[i][1] = max(dp[i - 1][1], dp[i - 1][0] - prices[i]);
dp[i][2] = max(dp[i - 1][2], dp[i - 1][1] + prices[i]);
dp[i][3] = max(dp[i - 1][3], dp[i - 1][2] - prices[i]);
dp[i][4] = max(dp[i - 1][4], dp[i - 1][3] + prices[i]);
}
return dp[prices.size() - 1][4];
}
};
- 时间复杂度:O(n)
- 空间复杂度:O(n × 5)
当然,大家可以看到力扣官方题解里的一种优化空间写法,我这里给出对应的C++版本:
// 版本二
class Solution {
public:
int maxProfit(vector<int>& prices) {
if (prices.size() == 0) return 0;
vector<int> dp(5, 0);
dp[1] = -prices[0];
dp[3] = -prices[0];
for (int i = 1; i < prices.size(); i++) {
dp[1] = max(dp[1], dp[0] - prices[i]);
dp[2] = max(dp[2], dp[1] + prices[i]);
dp[3] = max(dp[3], dp[2] - prices[i]);
dp[4] = max(dp[4], dp[3] + prices[i]);
}
return dp[4];
}
};
- 时间复杂度:O(n)
- 空间复杂度:O(1)
大家会发现dp[2]利用的是当天的dp[1]。 但结果也是对的。
我来简单解释一下:
dp[1] = max(dp[1], dp[0] - prices[i]); 如果dp[1]取dp[1],即保持买入股票的状态,那么 dp[2] = max(dp[2], dp[1] + prices[i]);中dp[1] + prices[i] 就是今天卖出。
如果dp[1]取dp[0] - prices[i],今天买入股票,那么dp[2] = max(dp[2], dp[1] + prices[i]);中的dp[1] + prices[i]相当于是今天再卖出股票,一买一卖收益为0,对所得现金没有影响。相当于今天买入股票又卖出股票,等于没有操作,保持昨天卖出股票的状态了。
这种写法看上去简单,其实思路很绕,不建议大家这么写,这么思考,很容易把自己绕进去!
对于本题,把版本一的写法研究明白,足以!
Java解法
// 版本一
class Solution {
public int maxProfit(int[] prices) {
int len = prices.length;
// 边界判断, 题目中 length >= 1, 所以可省去
if (prices.length == 0) return 0;
/*
* 定义 5 种状态:
* 0: 没有操作, 1: 第一次买入, 2: 第一次卖出, 3: 第二次买入, 4: 第二次卖出
*/
int[][] dp = new int[len][5];
dp[0][1] = -prices[0];
// 初始化第二次买入的状态是确保 最后结果是最多两次买卖的最大利润
dp[0][3] = -prices[0];
for (int i = 1; i < len; i++) {
dp[i][1] = Math.max(dp[i - 1][1], -prices[i]);
dp[i][2] = Math.max(dp[i - 1][2], dp[i - 1][1] + prices[i]);
dp[i][3] = Math.max(dp[i - 1][3], dp[i - 1][2] - prices[i]);
dp[i][4] = Math.max(dp[i - 1][4], dp[i - 1][3] + prices[i]);
}
return dp[len - 1][4];
}
}
// 版本二: 空间优化
class Solution {
public int maxProfit(int[] prices) {
int[] dp = new int[4];
// 存储两次交易的状态就行了
// dp[0]代表第一次交易的买入
dp[0] = -prices[0];
// dp[1]代表第一次交易的卖出
dp[1] = 0;
// dp[2]代表第二次交易的买入
dp[2] = -prices[0];
// dp[3]代表第二次交易的卖出
dp[3] = 0;
for(int i = 1; i <= prices.length; i++){
// 要么保持不变,要么没有就买,有了就卖
dp[0] = Math.max(dp[0], -prices[i-1]);
dp[1] = Math.max(dp[1], dp[0]+prices[i-1]);
// 这已经是第二次交易了,所以得加上前一次交易卖出去的收获
dp[2] = Math.max(dp[2], dp[1]-prices[i-1]);
dp[3] = Math.max(dp[3], dp[2]+ prices[i-1]);
}
return dp[3];
}
}
188. Best Time to Buy and Sell Stock IV
You are given an integer array prices where prices[i] is the price of a given stock on the ith day, and an integer k.
Find the maximum profit you can achieve. You may complete at most k transactions: i.e. you may buy at most k times and sell at most k times.
Note: You may not engage in multiple transactions simultaneously (i.e., you must sell the stock before you buy again).
Example 1:
Input: k = 2, prices = [2,4,1]
Output: 2
Explanation: Buy on day 1 (price = 2) and sell on day 2 (price = 4), profit = 4-2 = 2.
Example 2:
Input: k = 2, prices = [3,2,6,5,0,3]
Output: 7
Explanation: Buy on day 2 (price = 2) and sell on day 3 (price = 6), profit = 6-2 = 4. Then buy on day 5 (price = 0) and sell on day 6 (price = 3), profit = 3-0 = 3.
Constraints:
1 <= k <= 1001 <= prices.length <= 10000 <= prices[i] <= 1000
思路
这道题目可以说是动态规划:123.买卖股票的最佳时机III的进阶版,这里要求至多有k次交易。
动规五部曲,分析如下:
- 确定dp数组以及下标的含义
在动态规划:123.买卖股票的最佳时机III中,我是定义了一个二维dp数组,本题其实依然可以用一个二维dp数组。
使用二维数组 dp[i][j] :第i天的状态为j,所剩下的最大现金是dp[i][j]
j的状态表示为:
- 0 表示不操作
- 1 第一次买入
- 2 第一次卖出
- 3 第二次买入
- 4 第二次卖出
- .....
大家应该发现规律了吧 ,除了0以外,偶数就是卖出,奇数就是买入。
题目要求是至多有K笔交易,那么j的范围就定义为 2 * k + 1 就可以了。
所以二维dp数组的C++定义为:
vector<vector<int>> dp(prices.size(), vector<int>(2 * k + 1, 0));
- 确定递推公式
还要强调一下:dp[i][j],表示的是第i天,买入股票的状态,并不是说一定要第i天买入股票,这是很多同学容易陷入的误区。
达到dp[i][j]状态,有两个具体操作:
- 操作一:第i天买入股票了,那么
dp[i][j]=dp[i-1][j]- prices[i] - 操作二:第i天没有操作,而是沿用前一天买入的状态,即:
dp[i][j]=dp[i-1][j]
选最大的,所以 dp[i][j] = max(dp[i-1][j] - prices[i], dp[i-1][j]);
同理dp[i][j]也有两个操作:
- 操作一:第i天卖出股票了,那么
dp[i][j]=dp[i-1][j]+ prices[i] - 操作二:第i天没有操作,沿用前一天卖出股票的状态,即:
dp[i][j]=dp[i-1][j]
所以``dp[i][j] = max(dp[i-1][j]+ prices[i],dp[i-1][j])
同理可以类比剩下的状态,代码如下:
for (int j = 0; j < 2 * k - 1; j += 2) {
dp[i][j + 1] = max(dp[i - 1][j + 1], dp[i - 1][j] - prices[i]);
dp[i][j + 2] = max(dp[i - 1][j + 2], dp[i - 1][j + 1] + prices[i]);
}
本题和动态规划:123.买卖股票的最佳时机III最大的区别就是这里要类比j为奇数是买,偶数是卖的状态。
- dp数组如何初始化
第0天没有操作,这个最容易想到,就是0,即:dp[0][0] = 0;
第0天做第一次买入的操作,dp[0][1] = -prices[0];
第0天做第一次卖出的操作,这个初始值应该是多少呢?
此时还没有买入,怎么就卖出呢? 其实大家可以理解当天买入,当天卖出,所以dp[0][2] = 0;
第0天第二次买入操作,初始值应该是多少呢?应该不少同学疑惑,第一次还没买入呢,怎么初始化第二次买入呢?
第二次买入依赖于第一次卖出的状态,其实相当于第0天第一次买入了,第一次卖出了,然后在买入一次(第二次买入),那么现在手头上没有现金,只要买入,现金就做相应的减少。
所以第二次买入操作,初始化为:dp[0][1] = -prices[0];
第二次卖出初始化dp[0][2] = 0;
所以同理可以推出dp[0][1]当j为奇数的时候都初始化为 -prices[0]
代码如下:
for (int j = 1; j < 2 * k; j += 2) {
dp[0][j] = -prices[0];
}
在初始化的地方同样要类比j为偶数是卖、奇数是买的状态。
- 确定遍历顺序
从递归公式其实已经可以看出,一定是从前向后遍历,因为dp[i],依靠dp[i - 1]的数值。
- 举例推导dp数组
以输入[1,2,3,4,5],k=2为例。
最后一次卖出,一定是利润最大的,dp[prices.size() - 1][2 * k]即红色部分就是最后求解。
C++解法
以上分析完毕,C++代码如下:
class Solution {
public:
int maxProfit(int k, vector<int>& prices) {
if (prices.size() == 0) return 0;
vector<vector<int>> dp(prices.size(), vector<int>(2 * k + 1, 0));
for (int j = 1; j < 2 * k; j += 2) {
dp[0][j] = -prices[0];
}
for (int i = 1;i < prices.size(); i++) {
for (int j = 0; j < 2 * k - 1; j += 2) {
dp[i][j + 1] = max(dp[i - 1][j + 1], dp[i - 1][j] - prices[i]);
dp[i][j + 2] = max(dp[i - 1][j + 2], dp[i - 1][j + 1] + prices[i]);
}
}
return dp[prices.size() - 1][2 * k];
}
};
- 时间复杂度: O(n * k),其中 n 为 prices 的长度
- 空间复杂度: O(n * k)
当然有的解法是定义一个三维数组dp[i][j][k],第i天,第j次买卖,k表示买还是卖的状态,从定义上来讲是比较直观。
但感觉三维数组操作起来有些麻烦,我是直接用二维数组来模拟三维数组的情况,代码看起来也清爽一些。
Java解法
// 版本二: 二维 dp数组
class Solution {
public int maxProfit(int k, int[] prices) {
if (prices.length == 0) return 0;
// [天数][股票状态]
// 股票状态: 奇数表示第 k 次交易持有/买入, 偶数表示第 k 次交易不持有/卖出, 0 表示没有操作
int len = prices.length;
int[][] dp = new int[len][k*2 + 1];
// dp数组的初始化, 与版本一同理
for (int i = 1; i < k*2; i += 2) {
dp[0][i] = -prices[0];
}
for (int i = 1; i < len; i++) {
for (int j = 0; j < k*2 - 1; j += 2) {
dp[i][j + 1] = Math.max(dp[i - 1][j + 1], dp[i - 1][j] - prices[i]);
dp[i][j + 2] = Math.max(dp[i - 1][j + 2], dp[i - 1][j + 1] + prices[i]);
}
}
return dp[len - 1][k*2];
}
}
309. Best Time to Buy and Sell Stock with Cooldown
You are given an array prices where prices[i] is the price of a given stock on the ith day.
Find the maximum profit you can achieve. You may complete as many transactions as you like (i.e., buy one and sell one share of the stock multiple times) with the following restrictions:
- After you sell your stock, you cannot buy stock on the next day (i.e., cooldown one day).
Note: You may not engage in multiple transactions simultaneously (i.e., you must sell the stock before you buy again).
Example 1:
Input: prices = [1,2,3,0,2]
Output: 3
Explanation: transactions = [buy, sell, cooldown, buy, sell]
Example 2:
Input: prices = [1]
Output: 0
Constraints:
1 <= prices.length <= 50000 <= prices[i] <= 1000
思路
相对于动态规划:122.买卖股票的最佳时机II,本题加上了一个冷冻期
在动态规划:122.买卖股票的最佳时机II 中有两个状态,持有股票后的最多现金,和不持有股票的最多现金。
动规五部曲,分析如下:
- 确定dp数组以及下标的含义
dp[i][j],第i天状态为j,所剩的最多现金为dp[i][j]。
其实本题很多同学搞的比较懵,是因为出现冷冻期之后,状态其实是比较复杂度,例如今天买入股票、今天卖出股票、今天是冷冻期,都是不能操作股票的。
具体可以区分出如下四个状态:
-
状态一:持有股票状态(今天买入股票,或者是之前就买入了股票然后没有操作,一直持有)
-
不持有股票状态,这里就有两种卖出股票状态
-
状态二:保持卖出股票的状态(两天前就卖出了股票,度过一天冷冻期。或者是前一天就是卖出股票状态,一直没操作)
-
状态三:今天卖出股票
-
-
状态四:今天为冷冻期状态,但冷冻期状态不可持续,只有一天!
j的状态为:
- 0:状态一
- 1:状态二
- 2:状态三
- 3:状态四
很多题解为什么讲的比较模糊,是因为把这四个状态合并成三个状态了,其实就是把状态二和状态四合并在一起了。
从代码上来看确实可以合并,但从逻辑上分析合并之后就很难理解了,所以我下面的讲解是按照这四个状态来的,把每一个状态分析清楚。
「今天卖出股票」我是没有单独列出一个状态的归类为「不持有股票的状态」,而本题为什么要单独列出「今天卖出股票」 一个状态呢?
因为本题我们有冷冻期,而冷冻期的前一天,只能是 「今天卖出股票」状态,如果是 「不持有股票状态」那么就很模糊,因为不一定是 卖出股票的操作。
注意这里的每一个状态,例如状态一,是持有股票股票状态并不是说今天一定就买入股票,而是说保持买入股票的状态即:可能是前几天买入的,之后一直没操作,所以保持买入股票的状态。
- 确定递推公式
达到买入股票状态(状态一)即:dp[i][j],有两个具体操作:
-
操作一:前一天就是持有股票状态(状态一),
dp[i][j]=dp[i-1][j] -
操作二:今天买入了,有两种情况
-
前一天是冷冻期(状态四),
dp[i-1][j]- prices[i] -
前一天是保持卖出股票的状态(状态二),
dp[i-1][j]- prices[i]
-
那么dp[i][j] = max(dp[i-1][j], dp[i-1][j] - prices[i], dp[i-1][j] - prices[i]);
达到保持卖出股票状态(状态二)即:dp[i][j],有两个具体操作:
- 操作一:前一天就是状态二
- 操作二:前一天是冷冻期(状态四)
dp[i][j] = max(dp[i-1][j], dp[i-1][j]);
达到今天就卖出股票状态(状态三),即:dp[i][j] ,只有一个操作:
昨天一定是持有股票状态(状态一),今天卖出
即:dp[i][j] = dp[i-1][j] + prices[i];
达到冷冻期状态(状态四),即:dp[i][j],只有一个操作:
昨天卖出了股票(状态三)
dp[i][j] = dp[i-1][j];
综上分析,递推代码如下:
dp[i][0] = max(dp[i - 1][0], max(dp[i - 1][3], dp[i - 1][1]) - prices[i]);
dp[i][1] = max(dp[i - 1][1], dp[i - 1][3]);
dp[i][2] = dp[i - 1][0] + prices[i];
dp[i][3] = dp[i - 1][2];
- dp数组如何初始化
这里主要讨论一下第0天如何初始化。
如果是持有股票状态(状态一)那么:dp[0][0] = -prices[0],一定是当天买入股票。
保持卖出股票状态(状态二),这里其实从 「状态二」的定义来说 ,很难明确应该初始多少,这种情况我们就看递推公式需要我们给他初始成什么数值。
如果i为1,第1天买入股票,那么递归公式中需要计算 dp[i-1][j] - prices[i] ,即 dp[0][j] - prices[1],那么大家感受一下dp[0][2] (即第0天的状态二)应该初始成多少,只能初始为0。想一想如果初始为其他数值,是我们第1天买入股票后 手里还剩的现金数量是不是就不对了。
今天卖出了股票(状态三),同上分析,dp[0][2]初始化为0,dp[0][3]也初始为0。
- 确定遍历顺序
从递归公式上可以看出,dp[i] 依赖于 dp[i-1],所以是从前向后遍历。
- 举例推导dp数组
以 [1,2,3,0,2] 为例,dp数组如下:
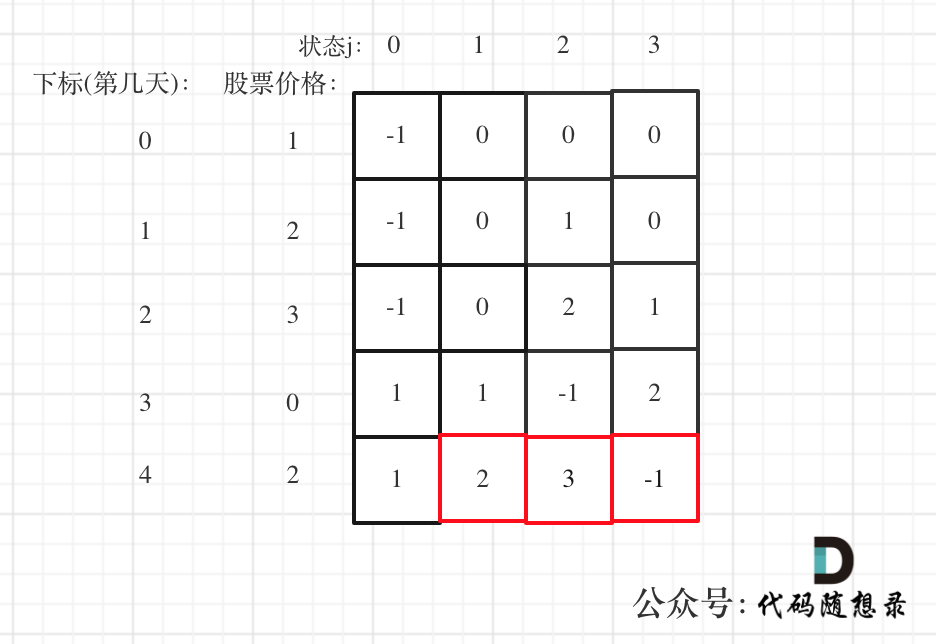
最后结果是取状态二,状态三和状态四的最大值,不少同学会把状态四忘了,状态四是冷冻期,最后一天如果是冷冻期也可能是最大值。
C++解法
代码如下:
class Solution {
public:
int maxProfit(vector<int>& prices) {
int n = prices.size();
if (n == 0) return 0;
vector<vector<int>> dp(n, vector<int>(4, 0));
dp[0][0] -= prices[0]; // 持股票
for (int i = 1; i < n; i++) {
dp[i][0] = max(dp[i - 1][0], max(dp[i - 1][3] - prices[i], dp[i - 1][1] - prices[i]));
dp[i][1] = max(dp[i - 1][1], dp[i - 1][3]);
dp[i][2] = dp[i - 1][0] + prices[i];
dp[i][3] = dp[i - 1][2];
}
return max(dp[n - 1][3], max(dp[n - 1][1], dp[n - 1][2]));
}
};
- 时间复杂度:O(n)
- 空间复杂度:O(n)
当然,空间复杂度可以优化,定义一个dp[2][4]大小的数组就可以了,就保存前一天的当前的状态,感兴趣的同学可以自己去写一写,思路是一样的。
Java解法
class Solution {
public int maxProfit(int[] prices) {
if (prices == null || prices.length < 2) {
return 0;
}
int[][] dp = new int[prices.length][2];
// bad case
dp[0][0] = 0;
dp[0][1] = -prices[0];
dp[1][0] = Math.max(dp[0][0], dp[0][1] + prices[1]);
dp[1][1] = Math.max(dp[0][1], -prices[1]);
for (int i = 2; i < prices.length; i++) {
// dp公式
dp[i][0] = Math.max(dp[i - 1][0], dp[i - 1][1] + prices[i]);
dp[i][1] = Math.max(dp[i - 1][1], dp[i - 2][0] - prices[i]);
}
return dp[prices.length - 1][0];
}
}
714. Best Time to Buy and Sell Stock with Transaction Fee
You are given an array prices where prices[i] is the price of a given stock on the ith day, and an integer fee representing a transaction fee.
Find the maximum profit you can achieve. You may complete as many transactions as you like, but you need to pay the transaction fee for each transaction.
Note:
- You may not engage in multiple transactions simultaneously (i.e., you must sell the stock before you buy again).
- The transaction fee is only charged once for each stock purchase and sale.
Example 1:
Input: prices = [1,3,2,8,4,9], fee = 2
Output: 8
Explanation: The maximum profit can be achieved by:
- Buying at prices[0] = 1
- Selling at prices[3] = 8
- Buying at prices[4] = 4
- Selling at prices[5] = 9 The total profit is ((8 - 1) - 2) + ((9 - 4) - 2) = 8.
Example 2:
Input: prices = [1,3,7,5,10,3], fee = 3
Output: 6
Constraints:
1 <= prices.length <= 5 * 10^41 <= prices[i] < 5 * 10^40 <= fee < 5 * 10^4
思路
本题贪心解法:贪心算法:买卖股票的最佳时机含手续费
性能是:
- 时间复杂度:O(n)
- 空间复杂度:O(1)
本题使用贪心算法并不好理解,也很容易出错,那么我们再来看看是使用动规的方法如何解题。
相对于动态规划:122.买卖股票的最佳时机II,本题只需要在计算卖出操作的时候减去手续费就可以了,代码几乎是一样的。
唯一差别在于递推公式部分,所以本篇也就不按照动规五部曲详细讲解了,主要讲解一下递推公式部分。
这里重申一下dp数组的含义:
dp[i][j] 表示第i天持有股票所省最多现金。 dp[i][j] 表示第i天不持有股票所得最多现金
如果第i天持有股票即dp[i][j], 那么可以由两个状态推出来
- 第i-1天就持有股票,那么就保持现状,所得现金就是昨天持有股票的所得现金 即:
dp[i-1][j] - 第i天买入股票,所得现金就是昨天不持有股票的所得现金减去 今天的股票价格 即:
dp[i-1][j]- prices[i]
所以:dp[i][j] = max(dp[i-1][j], dp[i-1][j] - prices[i]);
在来看看如果第i天不持有股票即dp[i][j]的情况, 依然可以由两个状态推出来
- 第i-1天就不持有股票,那么就保持现状,所得现金就是昨天不持有股票的所得现金 即:
dp[i-1][j] - 第i天卖出股票,所得现金就是按照今天股票价格卖出后所得现金,注意这里需要有手续费了即:
dp[i-1][j]+ prices[i] - fee
所以:dp[i][j] = max(dp[i-1][j], dp[i-1][j] + prices[i] - fee);
本题和动态规划:122.买卖股票的最佳时机II的区别就是这里需要多一个减去手续费的操作。
C++解法
以上分析完毕,C++代码如下:
class Solution {
public:
int maxProfit(vector<int>& prices, int fee) {
int n = prices.size();
vector<vector<int>> dp(n, vector<int>(2, 0));
dp[0][0] -= prices[0]; // 持股票
for (int i = 1; i < n; i++) {
dp[i][0] = max(dp[i - 1][0], dp[i - 1][1] - prices[i]);
dp[i][1] = max(dp[i - 1][1], dp[i - 1][0] + prices[i] - fee);
}
return max(dp[n - 1][0], dp[n - 1][1]);
}
};
- 时间复杂度:O(n)
- 空间复杂度:O(n)
Java解法
/**
* 买入时支付手续费
* @param prices
* @param fee
* @return
*/
public int maxProfit(int[] prices, int fee) {
int len = prices.length;
// 0 : 持股(买入)
// 1 : 不持股(售出)
// dp 定义第i天持股/不持股 所得最多现金
int[][] dp = new int[len][2];
// 考虑买入的时候就支付手续费
dp[0][0] = -prices[0] - fee;
for (int i = 1; i < len; i++) {
dp[i][0] = Math.max(dp[i - 1][0], dp[i - 1][1] - prices[i] - fee);
dp[i][1] = Math.max(dp[i - 1][0] + prices[i], dp[i - 1][1]);
}
return Math.max(dp[len - 1][0], dp[len - 1][1]);
}
子序列
- 300. Longest Increasing Subsequence
- 674. Longest Continuous Increasing Subsequence
- 718. Maximum Length of Repeated Subarray
- 1143. Longest Common Subsequence
- 1035. Uncrossed Lines
- 53. Maximum Subarray
300. Longest Increasing Subsequence
Given an integer array nums, return the length of the longest strictly increasing subsequence.
Example 1:
Input: nums = [10,9,2,5,3,7,101,18]
Output: 4
Explanation: The longest increasing subsequence is [2,3,7,101], therefore the length is 4.
Example 2:
Input: nums = [0,1,0,3,2,3]
Output: 4
Example 3:
Input: nums = [7,7,7,7,7,7,7]
Output: 1
Constraints:
1 <= nums.length <= 2500-10^4 <= nums[i] <= 10^4
Follow up: Can you come up with an algorithm that runs in O(n log(n)) time complexity?
思路
首先通过本题大家要明确什么是子序列,“子序列是由数组派生而来的序列,删除(或不删除)数组中的元素而不改变其余元素的顺序”。
本题也是代码随想录中子序列问题的第一题,如果没接触过这种题目的话,本题还是很难的,甚至想暴力去搜索也不知道怎么搜。 子序列问题是动态规划解决的经典问题,当前下标i的递增子序列长度,其实和i之前的下表j的子序列长度有关系,那又是什么样的关系呢。
接下来,我们依然用动规五部曲来详细分析一波:
- dp[i]的定义
本题中,正确定义dp数组的含义十分重要。
dp[i]表示i之前包括i的以nums[i]结尾的最长递增子序列的长度
为什么一定表示 “以nums[i]结尾的最长递增子序” ,因为我们在 做 递增比较的时候,如果比较 nums[j] 和 nums[i] 的大小,那么两个递增子序列一定分别以nums[j]为结尾 和 nums[i]为结尾, 要不然这个比较就没有意义了,不是尾部元素的比较那么 如何算递增呢。
- 状态转移方程
位置i的最长升序子序列等于j从0到i-1各个位置的最长升序子序列 + 1 的最大值。
所以:if (nums[i] > nums[j]) dp[i] = max(dp[i], dp[j] + 1);
注意这里不是要dp[i] 与 dp[j] + 1进行比较,而是我们要取dp[j] + 1的最大值。
- dp[i]的初始化
每一个i,对应的dp[i](即最长递增子序列)起始大小至少都是1.
- 确定遍历顺序
dp[i] 是有0到i-1各个位置的最长递增子序列 推导而来,那么遍历i一定是从前向后遍历。
j其实就是遍历0到i-1,那么是从前到后,还是从后到前遍历都无所谓,只要吧 0 到 i-1 的元素都遍历了就行了。 所以默认习惯 从前向后遍历。
遍历i的循环在外层,遍历j则在内层,代码如下:
for (int i = 1; i < nums.size(); i++) {
for (int j = 0; j < i; j++) {
if (nums[i] > nums[j]) dp[i] = max(dp[i], dp[j] + 1);
}
if (dp[i] > result) result = dp[i]; // 取长的子序列
}
- 举例推导dp数组
输入:[0,1,0,3,2],dp数组的变化如下:
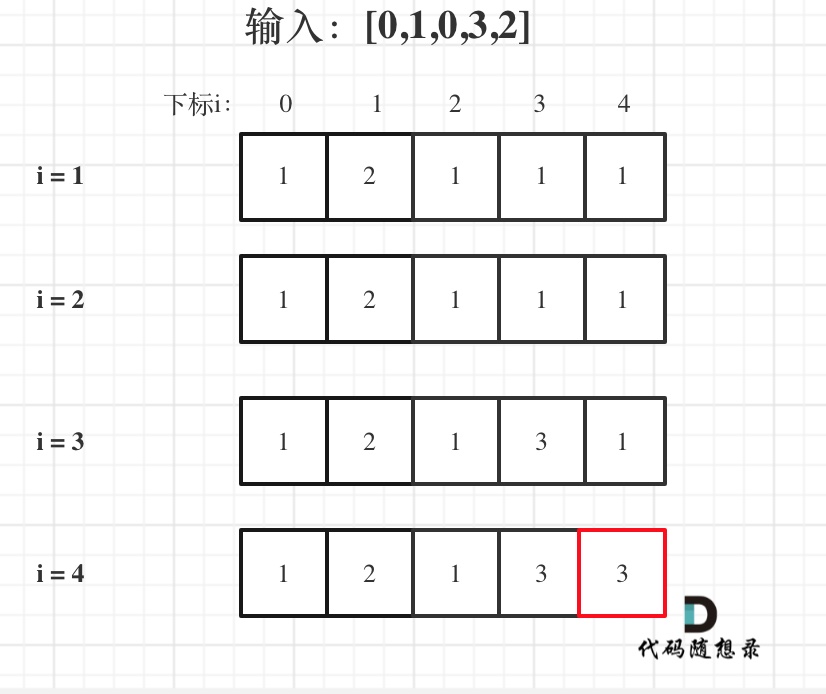
如果代码写出来,但一直AC不了,那么就把dp数组打印出来,看看对不对!
C++解法
以上五部分析完毕,C++代码如下:
class Solution {
public:
int lengthOfLIS(vector<int>& nums) {
if (nums.size() <= 1) return nums.size();
vector<int> dp(nums.size(), 1);
int result = 0;
for (int i = 1; i < nums.size(); i++) {
for (int j = 0; j < i; j++) {
if (nums[i] > nums[j]) dp[i] = max(dp[i], dp[j] + 1);
}
if (dp[i] > result) result = dp[i]; // 取长的子序列
}
return result;
}
};
- 时间复杂度: O(n^2)
- 空间复杂度: O(n)
Java解法
class Solution {
public int lengthOfLIS(int[] nums) {
int[] dp = new int[nums.length];
int res = 1;
Arrays.fill(dp, 1);
for (int i = 1; i < dp.length; i++) {
for (int j = 0; j < i; j++) {
if (nums[i] > nums[j]) {
dp[i] = Math.max(dp[i], dp[j] + 1);
}
res = Math.max(res, dp[i]);
}
}
return res;
}
}
674. Longest Continuous Increasing Subsequence
Given an unsorted array of integers nums, return the length of the longest continuous increasing subsequence (i.e. subarray). The subsequence must be strictly increasing.
A continuous increasing subsequence is defined by two indices l and r (l < r) such that it is [nums[l], nums[l + 1], ..., nums[r - 1], nums[r]] and for each l <= i < r, nums[i] < nums[i + 1].
Example 1:
Input: nums = [1,3,5,4,7]
Output: 3
Explanation: The longest continuous increasing subsequence is [1,3,5] with length 3.
Even though [1,3,5,7] is an increasing subsequence, it is not continuous as elements 5 and 7 are separated by element
4.
Example 2:
Input: nums = [2,2,2,2,2]
Output: 1
Explanation: The longest continuous increasing subsequence is [2] with length 1. Note that it must be strictly
increasing.
Constraints:
1 <= nums.length <= 10^4-10^9 <= nums[i] <= 10^9
思路
本题相对于昨天的动态规划:300.最长递增子序列最大的区别在于“连续”。
本题要求的是最长连续递增序列
动规五部曲分析如下:
- 确定dp数组(dp table)以及下标的含义
dp[i]:以下标i为结尾的连续递增的子序列长度为dp[i]。
注意这里的定义,一定是以下标i为结尾,并不是说一定以下标0为起始位置。
- 确定递推公式
如果 nums[i] > nums[i - 1],那么以 i 为结尾的连续递增的子序列长度 一定等于 以i - 1为结尾的连续递增的子序列长度 + 1 。
即:dp[i] = dp[i - 1] + 1;
注意这里就体现出和动态规划:300.最长递增子序列的区别!
因为本题要求连续递增子序列,所以就只要比较nums[i]与nums[i - 1],而不用去比较nums[j]与nums[i] (j是在0到i之间遍历)。
既然不用j了,那么也不用两层for循环,本题一层for循环就行,比较nums[i] 和 nums[i - 1]。
这里大家要好好体会一下!
- dp数组如何初始化
以下标i为结尾的连续递增的子序列长度最少也应该是1,即就是nums[i]这一个元素。
所以dp[i]应该初始1;
- 确定遍历顺序
从递推公式上可以看出, dp[i + 1]依赖dp[i],所以一定是从前向后遍历。
本文在确定递推公式的时候也说明了为什么本题只需要一层for循环,代码如下:
for (int i = 1; i < nums.size(); i++) {
if (nums[i] > nums[i - 1]) { // 连续记录
dp[i] = dp[i - 1] + 1;
}
}
- 举例推导dp数组
已输入nums = [1,3,5,4,7]为例,dp数组状态如下:
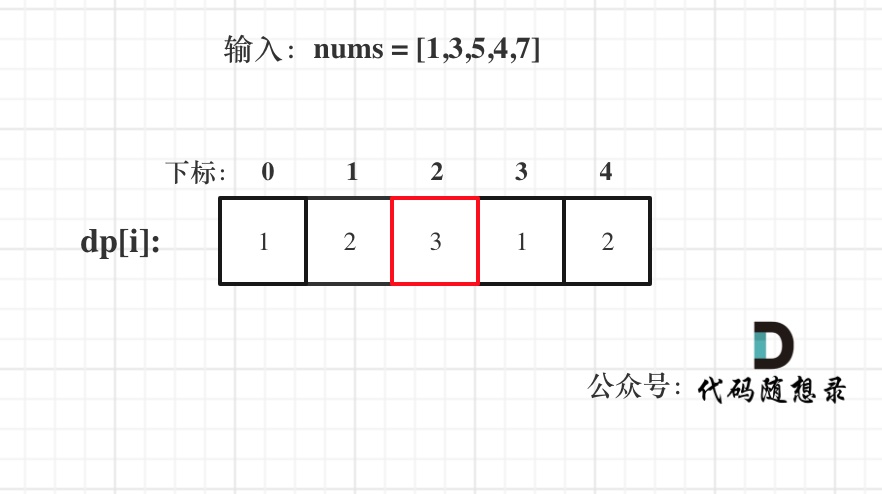
注意这里要取dp[i]里的最大值,所以dp[2]才是结果!
本题也是动规里子序列问题的经典题目,但也可以用贪心来做,大家也会发现贪心好像更简单一点,而且空间复杂度仅是O(1)。
在动规分析中,关键是要理解和动态规划:300.最长递增子序列的区别。
要联动起来,才能理解递增子序列怎么求,递增连续子序列又要怎么求。
概括来说:不连续递增子序列的跟前0-i 个状态有关,连续递增的子序列只跟前一个状态有关
C++解法
以上分析完毕,C++代码如下:
class Solution {
public:
int findLengthOfLCIS(vector<int>& nums) {
if (nums.size() == 0) return 0;
int result = 1;
vector<int> dp(nums.size() ,1);
for (int i = 1; i < nums.size(); i++) {
if (nums[i] > nums[i - 1]) { // 连续记录
dp[i] = dp[i - 1] + 1;
}
if (dp[i] > result) result = dp[i];
}
return result;
}
};
- 时间复杂度:O(n)
- 空间复杂度:O(n)
这道题目也可以用贪心来做,也就是遇到nums[i] > nums[i - 1]的情况,count就++,否则count为1,记录count的最大值就可以了。
代码如下:
class Solution {
public:
int findLengthOfLCIS(vector<int>& nums) {
if (nums.size() == 0) return 0;
int result = 1; // 连续子序列最少也是1
int count = 1;
for (int i = 1; i < nums.size(); i++) {
if (nums[i] > nums[i - 1]) { // 连续记录
count++;
} else { // 不连续,count从头开始
count = 1;
}
if (count > result) result = count;
}
return result;
}
};
- 时间复杂度:O(n)
- 空间复杂度:O(1)
Java解法
动态规划:
/**
* 1.dp[i] 代表当前下标最大连续值
* 2.递推公式 if(nums[i+1]>nums[i]) dp[i+1] = dp[i]+1
* 3.初始化 都为1
* 4.遍历方向,从其那往后
* 5.结果推导 。。。。
* @param nums
* @return
*/
public static int findLengthOfLCIS(int[] nums) {
int[] dp = new int[nums.length];
for (int i = 0; i < dp.length; i++) {
dp[i] = 1;
}
int res = 1;
//可以注意到,這邊的 i 是從 0 開始,所以會出現和卡哥的C++ code有差異的地方,在一些地方會看到有 i + 1 的偏移。
for (int i = 0; i < nums.length - 1; i++) {
if (nums[i + 1] > nums[i]) {
dp[i + 1] = dp[i] + 1;
}
res = res > dp[i + 1] ? res : dp[i + 1];
}
return res;
}
动态规划状态压缩
class Solution {
public int findLengthOfLCIS(int[] nums) {
// 记录以 前一个元素结尾的最长连续递增序列的长度 和 以当前 结尾的......
int beforeOneMaxLen = 1, currentMaxLen = 0;
// res 赋最小值返回的最小值1
int res = 1;
for (int i = 1; i < nums.length; i ++) {
currentMaxLen = nums[i] > nums[i - 1] ? beforeOneMaxLen + 1 : 1;
beforeOneMaxLen = currentMaxLen;
res = Math.max(res, currentMaxLen);
}
return res;
}
}
贪心法:
public static int findLengthOfLCIS(int[] nums) {
if (nums.length == 0) return 0;
int res = 1; // 连续子序列最少也是1
int count = 1;
for (int i = 0; i < nums.length - 1; i++) {
if (nums[i + 1] > nums[i]) { // 连续记录
count++;
} else { // 不连续,count从头开始
count = 1;
}
if (count > res) res = count;
}
return res;
}
718. Maximum Length of Repeated Subarray
Given two integer arrays nums1 and nums2, return the maximum length of a subarray that appears in both arrays.
Example 1:
Input: nums1 = [1,2,3,2,1], nums2 = [3,2,1,4,7]
Output: 3
Explanation: The repeated subarray with maximum length is [3,2,1].
Example 2:
Input: nums1 = [0,0,0,0,0], nums2 = [0,0,0,0,0]
Output: 5
Explanation: The repeated subarray with maximum length is [0,0,0,0,0].
Constraints:
1 <= nums1.length, nums2.length <= 10000 <= nums1[i], nums2[i] <= 100
思路
注意题目中说的子数组,其实就是连续子序列。
要求两个数组中最长重复子数组,如果是暴力的解法 只需要先两层for循环确定两个数组起始位置,然后再来一个循环可以是for或者while,来从两个起始位置开始比较,取得重复子数组的长度。
本题其实是动规解决的经典题目,我们只要想到 用二维数组可以记录两个字符串的所有比较情况,这样就比较好推 递推公式了。 动规五部曲分析如下:
- 确定dp数组(dp table)以及下标的含义
dp[i][j] :以下标i - 1为结尾的A,和以下标j - 1为结尾的B,最长重复子数组长度为dp[i][j]。 (特别注意: “以下标i - 1为结尾的A” 标明一定是 以A[i-1]为结尾的字符串 )
此时细心的同学应该发现,那dp[0][j]是什么含义呢?总不能是以下标-1为结尾的A数组吧。
其实dp[i][j]的定义也就决定着,我们在遍历dp[i][j]的时候i 和 j都要从1开始。
那有同学问了,我就定义dp[i][j]为 以下标i为结尾的A,和以下标j 为结尾的B,最长重复子数组长度。不行么?
行倒是行! 但实现起来就麻烦一点,需要单独处理初始化部分,在本题解下面的拓展内容里,我给出了 第二种 dp数组的定义方式所对应的代码和讲解,大家比较一下就了解了。
- 确定递推公式
根据dp[i][j]的定义,dp[i][j]的状态只能由dp[i - 1][j]推导出来。
即当A[i - 1] 和B[j - 1]相等的时候,dp[i][j] = dp[i - 1][j] + 1;
根据递推公式可以看出,遍历i 和 j 要从1开始!
- dp数组如何初始化
根据dp[i][j]的定义,dp[i][0] 和dp[0][j]其实都是没有意义的!
但dp[i][0] 和dp[0][j]要初始值,因为为了方便递归公式dp[i][j] = dp[i - 1][j] + 1;
所以dp[i][0] 和dp[0][j]初始化为0。
举个例子A[0]如果和B[0]相同的话,dp[1][1] = dp[0][j] + 1,只有dp[0][j]初始为0,正好符合递推公式逐步累加起来。
- 确定遍历顺序
外层for循环遍历A,内层for循环遍历B。
那又有同学问了,外层for循环遍历B,内层for循环遍历A。不行么?
也行,一样的,我这里就用外层for循环遍历A,内层for循环遍历B了。
同时题目要求长度最长的子数组的长度。所以在遍历的时候顺便把dp[i][j]的最大值记录下来。
代码如下:
for (int i = 1; i <= nums1.size(); i++) {
for (int j = 1; j <= nums2.size(); j++) {
if (nums1[i - 1] == nums2[j - 1]) {
dp[i][j] = dp[i - 1][j - 1] + 1;
}
if (dp[i][j] > result) result = dp[i][j];
}
}
- 举例推导dp数组
拿示例1中,A: [1,2,3,2,1],B: [3,2,1,4,7]为例,画一个dp数组的状态变化,如下:
C++解法
以上五部曲分析完毕,C++代码如下:
// 版本一
class Solution {
public:
int findLength(vector<int>& nums1, vector<int>& nums2) {
vector<vector<int>> dp (nums1.size() + 1, vector<int>(nums2.size() + 1, 0));
int result = 0;
for (int i = 1; i <= nums1.size(); i++) {
for (int j = 1; j <= nums2.size(); j++) {
if (nums1[i - 1] == nums2[j - 1]) {
dp[i][j] = dp[i - 1][j - 1] + 1;
}
if (dp[i][j] > result) result = dp[i][j];
}
}
return result;
}
};
- 时间复杂度:O(n × m),n 为A长度,m为B长度
- 空间复杂度:O(n × m)
滚动数组方法在如下图中:
我们可以看出dp[i][j]都是由dp[i - 1][j]推出。那么压缩为一维数组,也就是dp[j]都是由dp[j - 1]推出。
也就是相当于可以把上一层dp[i - 1][j]拷贝到下一层dp[i][j]来继续用。
此时遍历B数组的时候,就要从后向前遍历,这样避免重复覆盖。
// 版本二
class Solution {
public:
int findLength(vector<int>& A, vector<int>& B) {
vector<int> dp(vector<int>(B.size() + 1, 0));
int result = 0;
for (int i = 1; i <= A.size(); i++) {
for (int j = B.size(); j > 0; j--) {
if (A[i - 1] == B[j - 1]) {
dp[j] = dp[j - 1] + 1;
} else dp[j] = 0; // 注意这里不相等的时候要有赋0的操作
if (dp[j] > result) result = dp[j];
}
}
return result;
}
};
- 时间复杂度:,n 为A长度,m为B长度
- 空间复杂度:
Java解法
// 版本一
class Solution {
public int findLength(int[] nums1, int[] nums2) {
int result = 0;
int[][] dp = new int[nums1.length + 1][nums2.length + 1];
for (int i = 1; i < nums1.length + 1; i++) {
for (int j = 1; j < nums2.length + 1; j++) {
if (nums1[i - 1] == nums2[j - 1]) {
dp[i][j] = dp[i - 1][j - 1] + 1;
result = Math.max(result, dp[i][j]);
}
}
}
return result;
}
}
// 版本二: 滚动数组
class Solution {
public int findLength(int[] nums1, int[] nums2) {
int[] dp = new int[nums2.length + 1];
int result = 0;
for (int i = 1; i <= nums1.length; i++) {
for (int j = nums2.length; j > 0; j--) {
if (nums1[i - 1] == nums2[j - 1]) {
dp[j] = dp[j - 1] + 1;
} else {
dp[j] = 0;
}
result = Math.max(result, dp[j]);
}
}
return result;
}
}
1143. Longest Common Subsequence
Given two strings text1 and text2, return the length of their longest common subsequence. If there is no common subsequence, return 0.
A subsequence of a string is a new string generated from the original string with some characters (can be none) deleted without changing the relative order of the remaining characters.
- For example,
"ace"is a subsequence of"abcde".
A common subsequence of two strings is a subsequence that is common to both strings.
Example 1:
Input: text1 = "abcde", text2 = "ace"
Output: 3
Explanation: The longest common subsequence is "ace" and its length is 3.
Example 2:
Input: text1 = "abc", text2 = "abc"
Output: 3
Explanation: The longest common subsequence is "abc" and its length is 3.
Example 3:
Input: text1 = "abc", text2 = "def"
Output: 0
Explanation: There is no such common subsequence, so the result is 0.
Constraints:
1 <= text1.length, text2.length <= 1000text1andtext2consist of only lowercase English characters.
思路
本题和动态规划:718. 最长重复子数组区别在于这里不要求是连续的了,但要有相对顺序,即:"ace" 是 "abcde" 的子序列,但 "aec" 不是 "abcde" 的子序列。
继续动规五部曲分析如下:
- 确定dp数组(dp table)以及下标的含义
dp[i][j]:长度为[0, i - 1]的字符串text1与长度为[0, j - 1]的字符串text2的最长公共子序列为dp[i][j]
有同学会问:为什么要定义长度为[0, i - 1]的字符串text1,定义为长度为[0, i]的字符串text1不香么?
这样定义是为了后面代码实现方便,如果非要定义为长度为[0, i]的字符串text1也可以,我在 动态规划:718. 最长重复子数组 中的「拓展」里 详细讲解了区别所在,其实就是简化了dp数组第一行和第一列的初始化逻辑。
- 确定递推公式
主要就是两大情况: text1[i - 1] 与 text2[j - 1]相同,text1[i - 1] 与 text2[j - 1]不相同
如果text1[i - 1] 与 text2[j - 1]相同,那么找到了一个公共元素,所以dp[i][j] = dp[i - 1][j] + 1;
如果text1[i - 1] 与 text2[j - 1]不相同,那就看看text1[0, i - 2]与text2[0, j - 1]的最长公共子序列 和 text1[0, i - 1]与text2[0, j - 2]的最长公共子序列,取最大的。
即:dp[i][j] = max(dp[i - 1][j], dp[i][j - 1]);
代码如下:
if (text1[i - 1] == text2[j - 1]) {
dp[i][j] = dp[i - 1][j - 1] + 1;
} else {
dp[i][j] = max(dp[i - 1][j], dp[i][j - 1]);
}
- dp数组如何初始化
先看看dp[i][j]应该是多少呢?
test1[0, i-1]和空串的最长公共子序列自然是0,所以dp[i][0] = 0;
同理dp[0][j]也是0。
其他下标都是随着递推公式逐步覆盖,初始为多少都可以,那么就统一初始为0。
代码:
vector<vector<int>> dp(text1.size() + 1, vector<int>(text2.size() + 1, 0));
- 确定遍历顺序
从递推公式,可以看出,有三个方向可以推出dp[i][j],如图:
那么为了在递推的过程中,这三个方向都是经过计算的数值,所以要从前向后,从上到下来遍历这个矩阵。
- 举例推导dp数组
以输入:text1 = "abcde", text2 = "ace" 为例,dp状态如图:
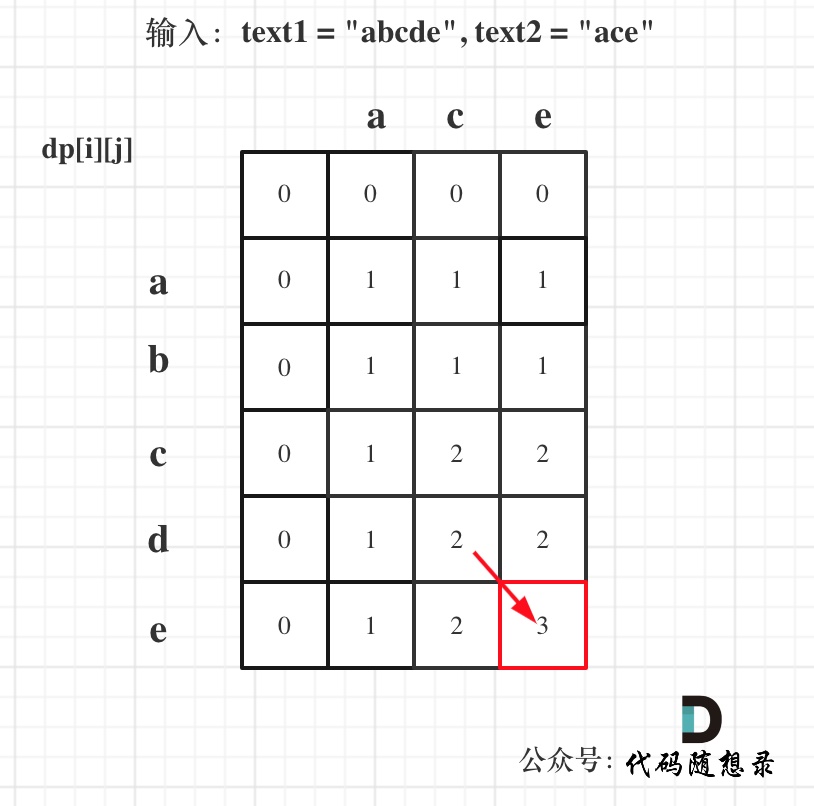
最后红框dptext1.size()为最终结果。
C++解法
以上分析完毕,C++代码如下:
class Solution {
public:
int longestCommonSubsequence(string text1, string text2) {
vector<vector<int>> dp(text1.size() + 1, vector<int>(text2.size() + 1, 0));
for (int i = 1; i <= text1.size(); i++) {
for (int j = 1; j <= text2.size(); j++) {
if (text1[i - 1] == text2[j - 1]) {
dp[i][j] = dp[i - 1][j - 1] + 1;
} else {
dp[i][j] = max(dp[i - 1][j], dp[i][j - 1]);
}
}
}
return dp[text1.size()][text2.size()];
}
};
- 时间复杂度: O(n * m),其中 n 和 m 分别为 text1 和 text2 的长度
- 空间复杂度: O(n * m)
Java解法
/*
二维dp数组
*/
class Solution {
public int longestCommonSubsequence(String text1, String text2) {
// char[] char1 = text1.toCharArray();
// char[] char2 = text2.toCharArray();
// 可以在一開始的時候就先把text1, text2 轉成char[],之後就不需要有這麼多爲了處理字串的調整
// 就可以和卡哥的code更一致
int[][] dp = new int[text1.length() + 1][text2.length() + 1]; // 先对dp数组做初始化操作
for (int i = 1 ; i <= text1.length() ; i++) {
char char1 = text1.charAt(i - 1);
for (int j = 1; j <= text2.length(); j++) {
char char2 = text2.charAt(j - 1);
if (char1 == char2) { // 开始列出状态转移方程
dp[i][j] = dp[i - 1][j - 1] + 1;
} else {
dp[i][j] = Math.max(dp[i - 1][j], dp[i][j - 1]);
}
}
}
return dp[text1.length()][text2.length()];
}
}
/**
一维dp数组
*/
class Solution {
public int longestCommonSubsequence(String text1, String text2) {
int n1 = text1.length();
int n2 = text2.length();
// 多从二维dp数组过程分析
// 关键在于 如果记录 dp[i - 1][j - 1]
// 因为 dp[i - 1][j - 1] <!=> dp[j - 1] <=> dp[i][j - 1]
int [] dp = new int[n2 + 1];
for(int i = 1; i <= n1; i++){
// 这里pre相当于 dp[i - 1][j - 1]
int pre = dp[0];
for(int j = 1; j <= n2; j++){
//用于给pre赋值
int cur = dp[j];
if(text1.charAt(i - 1) == text2.charAt(j - 1)){
//这里pre相当于dp[i - 1][j - 1] 千万不能用dp[j - 1] !!
dp[j] = pre + 1;
} else{
// dp[j] 相当于 dp[i - 1][j]
// dp[j - 1] 相当于 dp[i][j - 1]
dp[j] = Math.max(dp[j], dp[j - 1]);
}
//更新dp[i - 1][j - 1], 为下次使用做准备
pre = cur;
}
}
return dp[n2];
}
}
1035. Uncrossed Lines
You are given two integer arrays nums1 and nums2. We write the integers of nums1 and nums2 (in the order they are given) on two separate horizontal lines.
We may draw connecting lines: a straight line connecting two numbers nums1[i] and nums2[j] such that:
nums1[i] == nums2[j], and- the line we draw does not intersect any other connecting (non-horizontal) line.
Note that a connecting line cannot intersect even at the endpoints (i.e., each number can only belong to one connecting line).
Return the maximum number of connecting lines we can draw in this way.
Example 1:
Input: nums1 = [1,4,2], nums2 = [1,2,4]
Output: 2
Explanation: We can draw 2 uncrossed lines as in the diagram.
We cannot draw 3 uncrossed lines, because the line from nums1[1] = 4 to nums2[2] = 4 will intersect the line from nums1[2]=2 to nums2[1]=2.
Example 2:
Input: nums1 = [2,5,1,2,5], nums2 = [10,5,2,1,5,2]
Output: 3
Example 3:
Input: nums1 = [1,3,7,1,7,5], nums2 = [1,9,2,5,1]
Output: 2
Constraints:
1 <= nums1.length, nums2.length <= 5001 <= nums1[i], nums2[j] <= 2000
思路
绘制一些连接两个数字 A[i] 和 B[j] 的直线,只要 A[i] == B[j],且直线不能相交!
直线不能相交,这就是说明在字符串A中 找到一个与字符串B相同的子序列,且这个子序列不能改变相对顺序,只要相对顺序不改变,链接相同数字的直线就不会相交。
拿示例一A = [1,4,2], B = [1,2,4]为例,相交情况如图:
其实也就是说A和B的最长公共子序列是[1,4],长度为2。 这个公共子序列指的是相对顺序不变(即数字4在字符串A中数字1的后面,那么数字4也应该在字符串B数字1的后面)
这么分析完之后,大家可以发现:本题说是求绘制的最大连线数,其实就是求两个字符串的最长公共子序列的长度!
那么本题就和我们刚刚讲过的这道题目动态规划:1143.最长公共子序列就是一样一样的了。
一样到什么程度呢? 把字符串名字改一下,其他代码都不用改,直接copy过来就行了。
其实本题就是求最长公共子序列的长度,介于我们刚刚讲过动态规划:1143.最长公共子序列,所以本题我就不再做动规五部曲分析了。
如果大家有点遗忘了最长公共子序列,就再看一下这篇:动态规划:1143.最长公共子序列
C++解法
本题代码如下:
class Solution {
public:
int maxUncrossedLines(vector<int>& A, vector<int>& B) {
vector<vector<int>> dp(A.size() + 1, vector<int>(B.size() + 1, 0));
for (int i = 1; i <= A.size(); i++) {
for (int j = 1; j <= B.size(); j++) {
if (A[i - 1] == B[j - 1]) {
dp[i][j] = dp[i - 1][j - 1] + 1;
} else {
dp[i][j] = max(dp[i - 1][j], dp[i][j - 1]);
}
}
}
return dp[A.size()][B.size()];
}
};
- 时间复杂度: O(n * m)
- 空间复杂度: O(n * m)
Java解法
class Solution {
public int maxUncrossedLines(int[] nums1, int[] nums2) {
int len1 = nums1.length;
int len2 = nums2.length;
int[][] dp = new int[len1 + 1][len2 + 1];
for (int i = 1; i <= len1; i++) {
for (int j = 1; j <= len2; j++) {
if (nums1[i - 1] == nums2[j - 1]) {
dp[i][j] = dp[i - 1][j - 1] + 1;
} else {
dp[i][j] = Math.max(dp[i - 1][j], dp[i][j - 1]);
}
}
}
return dp[len1][len2];
}
}
53. Maximum Subarray
Given an integer array nums, find the subarray with the largest sum, and return its sum.
Example 1:
Input: nums = [-2,1,-3,4,-1,2,1,-5,4]
Output: 6
Explanation: The subarray [4,-1,2,1] has the largest sum 6.
Example 2:
Input: nums = [1]
Output: 1
Explanation: The subarray [1] has the largest sum 1.
Example 3:
Input: nums = [5,4,-1,7,8]
Output: 23
Explanation: The subarray [5,4,-1,7,8] has the largest sum 23.
Constraints:
1 <= nums.length <= 10^5-10^4 <= nums[i] <= 10^4
Follow up: If you have figured out the O(n) solution, try coding another solution using the divide and conquer approach, which is more subtle.
思路
这道题之前我们在讲解贪心专题的时候用贪心算法解决过一次,贪心算法:最大子序和。
这次我们用动态规划的思路再来分析一次。
动规五部曲如下:
- 确定dp数组(dp table)以及下标的含义
dp[i]:包括下标i(以nums[i]为结尾)的最大连续子序列和为dp[i]。
- 确定递推公式
dp[i]只有两个方向可以推出来:
- dp[i - 1] + nums[i],即:nums[i]加入当前连续子序列和
- nums[i],即:从头开始计算当前连续子序列和
一定是取最大的,所以dp[i] = max(dp[i - 1] + nums[i], nums[i]);
- dp数组如何初始化
从递推公式可以看出来dp[i]是依赖于dp[i - 1]的状态,dp[0]就是递推公式的基础。
dp[0]应该是多少呢?
根据dp[i]的定义,很明显dp[0]应为nums[0]即dp[0] = nums[0]。
- 确定遍历顺序
递推公式中dp[i]依赖于dp[i - 1]的状态,需要从前向后遍历。
- 举例推导dp数组
以示例一为例,输入:nums = [-2,1,-3,4,-1,2,1,-5,4],对应的dp状态如下:
注意最后的结果可不是dp[nums.size() - 1]! ,而是dp[6]。
在回顾一下dp[i]的定义:包括下标i之前的最大连续子序列和为dp[i]。
那么我们要找最大的连续子序列,就应该找每一个i为终点的连续最大子序列。
所以在递推公式的时候,可以直接选出最大的dp[i]。
C++解法
以上动规五部曲分析完毕,完整代码如下:
class Solution {
public:
int maxSubArray(vector<int>& nums) {
if (nums.size() == 0) return 0;
vector<int> dp(nums.size());
dp[0] = nums[0];
int result = dp[0];
for (int i = 1; i < nums.size(); i++) {
dp[i] = max(dp[i - 1] + nums[i], nums[i]); // 状态转移公式
if (dp[i] > result) result = dp[i]; // result 保存dp[i]的最大值
}
return result;
}
};
- 时间复杂度:O(n)
- 空间复杂度:O(n)
编辑距离
- 392. Is Subsequence
- 115. Distinct Subsequences
- 583. Delete Operation for Two Strings
- 72. Edit Distance
392. Is Subsequence
Given two strings s and t, return true if s is a subsequence of t, or false otherwise.
A subsequence of a string is a new string that is formed from the original string by deleting some (can be none) of the characters without disturbing the relative positions of the remaining characters. (i.e., "ace" is a subsequence of "abcde" while "aec" is not).
Example 1:
Input: s = "abc", t = "ahbgdc"
Output: true
Example 2:
Input: s = "axc", t = "ahbgdc"
Output: false
Constraints:
0 <= s.length <= 1000 <= t.length <= 10^4sandtconsist only of lowercase English letters.
Follow up: Suppose there are lots of incoming s, say s1, s2, ..., sk where k >= 109, and you want to check one by one to see if t has its subsequence. In this scenario, how would you change your code?
思路
(这道题也可以用双指针的思路来实现,时间复杂度也是O(n))
这道题应该算是编辑距离的入门题目,因为从题意中我们也可以发现,只需要计算删除的情况,不用考虑增加和替换的情况。
所以掌握本题的动态规划解法是对后面要讲解的编辑距离的题目打下基础。
动态规划五部曲分析如下:
- 确定dp数组(dp table)以及下标的含义
dp[i][j] 表示以下标i-1为结尾的字符串s,和以下标j-1为结尾的字符串t,相同子序列的长度为dp[i][j]。
注意这里是判断s是否为t的子序列。即t的长度是大于等于s的。
有同学问了,为啥要表示下标i-1为结尾的字符串呢,为啥不表示下标i为结尾的字符串呢?
为什么这么定义我在 718. 最长重复子数组 中做了详细的讲解。
其实用i来表示也可以!
但我统一以下标i-1为结尾的字符串来计算,这样在下面的递归公式中会容易理解一些,如果还有疑惑,可以继续往下看。
- 确定递推公式
在确定递推公式的时候,首先要考虑如下两种操作,整理如下:
-
if (s[i - 1] == t[j - 1])
- t中找到了一个字符在s中也出现了
-
if (s[i - 1] != t[j - 1])
- 相当于t要删除元素,继续匹配
if(s[i - 1] == t[j - 1]),那么dp[i][j] = dp[i - 1][j - 1] + 1;,因为找到了一个相同的字符,相同子序列长度自然要在dp[i-1][j-1]的基础上加1(如果不理解,在回看一下dp[i][j]的定义)
if(s[i - 1] != t[j - 1]),此时相当于t要删除元素,t如果把当前元素t[j - 1]删除,那么dp[i][j] 的数值就是 看s[i - 1]与 t[j - 2]的比较结果了,即:dp[i][j] = dp[i][j - 1];
其实这里大家可以发现和 1143.最长公共子序列 的递推公式基本那就是一样的,区别就是本题如果删元素一定是字符串t,而 1143.最长公共子序列是两个字符串都可以删元素。
- dp数组如何初始化
从递推公式可以看出dp[i][j]都是依赖于dp[i - 1][j - 1] 和 dp[i][j - 1],所以dp[0][j]和dp[i][0]是一定要初始化的。
这里大家已经可以发现,在定义dp[i][j]含义的时候为什么要表示以下标i-1为结尾的字符串s,和以下标j-1为结尾的字符串t,相同子序列的长度为dp[i][j]。
因为这样的定义在dp二维矩阵中可以留出初始化的区间,如图:
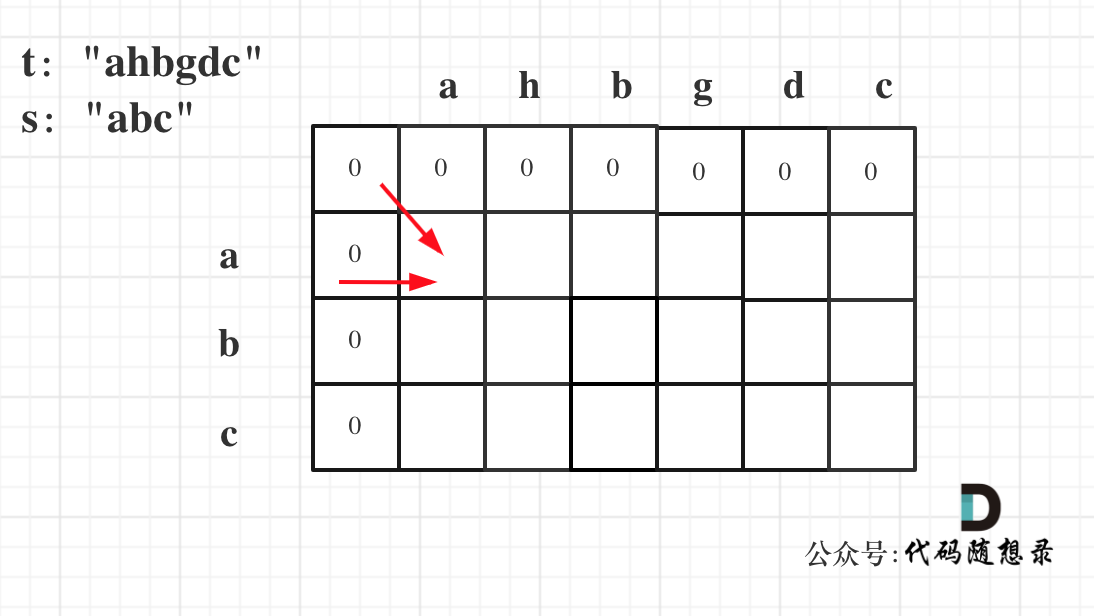
如果要是定义的dp[i][j]是以下标i为结尾的字符串s和以下标j为结尾的字符串t,初始化就比较麻烦了。
dp[i][j] 表示以下标i-1为结尾的字符串,与空字符串的相同子序列长度,所以为0. dp[0][j]同理。
vector<vector<int>> dp(s.size() + 1, vector<int>(t.size() + 1, 0));
- 确定遍历顺序
同理从递推公式可以看出dp[i][j]都是依赖于dp[i - 1][j - 1] 和 dp[i][j - 1],那么遍历顺序也应该是从上到下,从左到右
如图所示:
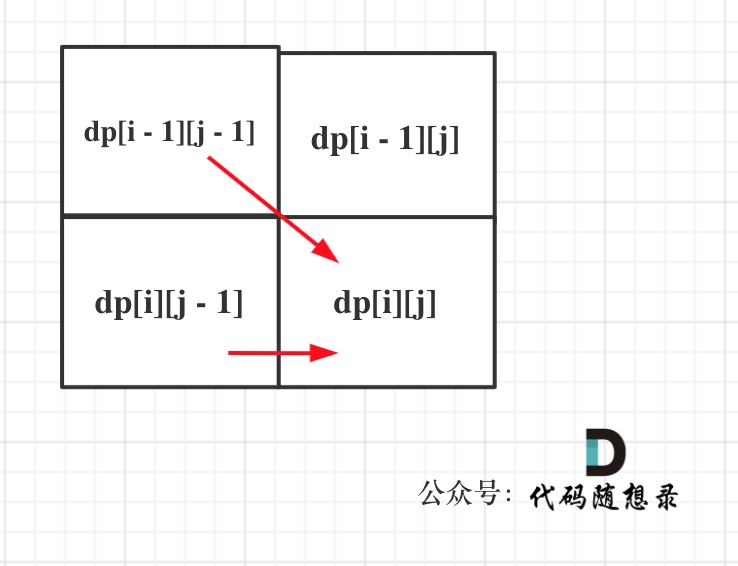
- 举例推导dp数组
以示例一为例,输入:s = "abc", t = "ahbgdc",dp状态转移图如下:
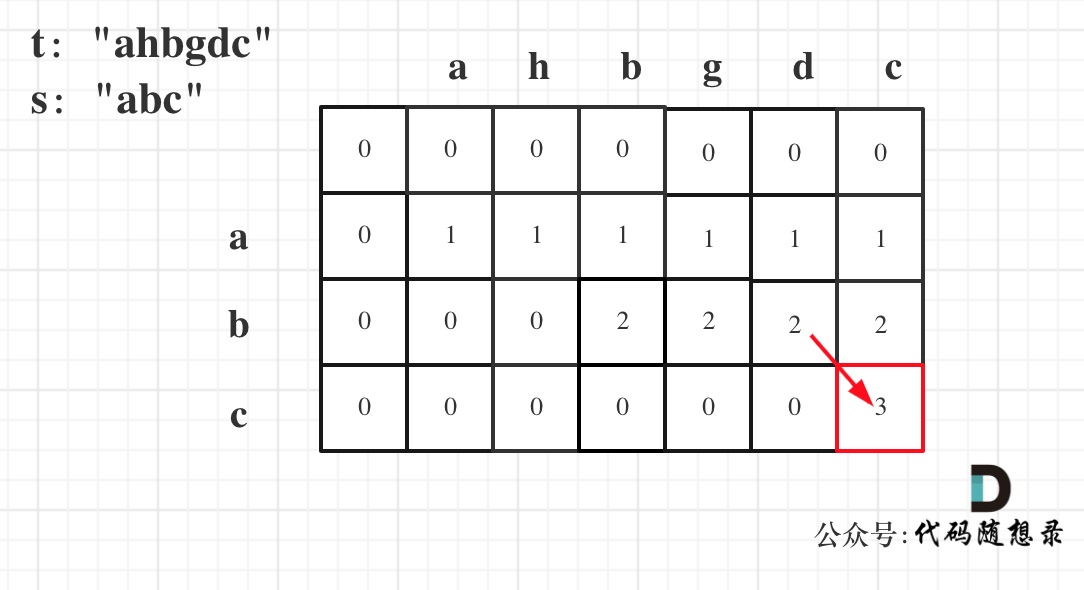
dp[i][j]表示以下标i-1为结尾的字符串s和以下标j-1为结尾的字符串t 相同子序列的长度,所以如果dp[s.size()][t.size()] 与 字符串s的长度相同说明:s与t的最长相同子序列就是s,那么s 就是 t 的子序列。
图中dp[s.size()][t.size()]=3, 而s.size() 也为3。所以s是t 的子序列,返回true。
C++解法
动规五部曲分析完毕,C++代码如下:
class Solution {
public:
bool isSubsequence(string s, string t) {
vector<vector<int>> dp(s.size() + 1, vector<int>(t.size() + 1, 0));
for (int i = 1; i <= s.size(); i++) {
for (int j = 1; j <= t.size(); j++) {
if (s[i - 1] == t[j - 1]) dp[i][j] = dp[i - 1][j - 1] + 1;
else dp[i][j] = dp[i][j - 1];
}
}
if (dp[s.size()][t.size()] == s.size()) return true;
return false;
}
};
- 时间复杂度:O(n × m)
- 空间复杂度:O(n × m)
Java解法
class Solution {
public boolean isSubsequence(String s, String t) {
int length1 = s.length(); int length2 = t.length();
int[][] dp = new int[length1+1][length2+1];
for(int i = 1; i <= length1; i++){
for(int j = 1; j <= length2; j++){
if(s.charAt(i-1) == t.charAt(j-1)){
dp[i][j] = dp[i-1][j-1] + 1;
}else{
dp[i][j] = dp[i][j-1];
}
}
}
if(dp[length1][length2] == length1){
return true;
}else{
return false;
}
}
}
> 修改遍历顺序后,可以利用滚动数组,对dp数组进行压缩
class Solution {
public boolean isSubsequence(String s, String t) {
// 修改遍历顺序,外圈遍历t,内圈遍历s。使得dp的推算只依赖正上方和左上方,方便压缩。
int[][] dp = new int[t.length() + 1][s.length() + 1];
for (int i = 1; i < dp.length; i++) { // 遍历t字符串
for (int j = 1; j < dp[i].length; j++) { // 遍历s字符串
if (t.charAt(i - 1) == s.charAt(j - 1)) {
dp[i][j] = dp[i - 1][j - 1] + 1;
} else {
dp[i][j] = dp[i - 1][j];
}
}
System.out.println(Arrays.toString(dp[i]));
}
return dp[t.length()][s.length()] == s.length();
}
}
> 状态压缩
class Solution {
public boolean isSubsequence(String s, String t) {
int[] dp = new int[s.length() + 1];
for (int i = 0; i < t.length(); i ++) {
// 需要使用上一轮的dp[j - 1],所以使用倒序遍历
for (int j = dp.length - 1; j > 0; j --) {
// i遍历的是t字符串,j遍历的是dp数组,dp数组的长度比s的大1,因此需要减1。
if (t.charAt(i) == s.charAt(j - 1)) {
dp[j] = dp[j - 1] + 1;
}
}
}
return dp[s.length()] == s.length();
}
}
> 将dp定义为boolean类型,dp[i]直接表示s.substring(0, i)是否为t的子序列
class Solution {
public boolean isSubsequence(String s, String t) {
boolean[] dp = new boolean[s.length() + 1];
// 表示 “” 是t的子序列
dp[0] = true;
for (int i = 0; i < t.length(); i ++) {
for (int j = dp.length - 1; j > 0; j --) {
if (t.charAt(i) == s.charAt(j - 1)) {
dp[j] = dp[j - 1];
}
}
}
return dp[dp.length - 1];
}
}
115. Distinct Subsequences
Given two strings s and t, return the number of distinct subsequences of s which equals t.
The test cases are generated so that the answer fits on a 32-bit signed integer.
Example 1:
Input: s = "rabbbit", t = "rabbit"
Output: 3
Explanation:
As shown below, there are 3 ways you can generate "rabbit" from s.
`**rabb**b**it**`
`**ra**b**bbit**`
`**rab**b**bit**`
Example 2:
Input: s = "babgbag", t = "bag"
Output: 5
Explanation:
As shown below, there are 5 ways you can generate "bag" from s.
`**ba**b**g**bag`
`**ba**bgba**g**`
`**b**abgb**ag**`
`ba**b**gb**ag**`
`babg**bag**`
Constraints:
1 <= s.length, t.length <= 1000sandtconsist of English letters.
思路
这道题目如果不是子序列,而是要求连续序列的,那就可以考虑用KMP。
这道题目相对于72. 编辑距离,简单了不少,因为本题相当于只有删除操作,不用考虑替换增加之类的。
但相对于刚讲过的动态规划:392.判断子序列就有难度了,这道题目双指针法可就做不了了,来看看动规五部曲分析如下:
- 确定dp数组(dp table)以及下标的含义
dp[i][j]:以i-1为结尾的s子序列中出现以j-1为结尾的t的个数为dp[i][j]。
为什么i-1,j-1 这么定义我在 718. 最长重复子数组 中做了详细的讲解。
- 确定递推公式
这一类问题,基本是要分析两种情况
- s[i - 1] 与 t[j - 1]相等
- s[i - 1] 与 t[j - 1] 不相等
当s[i - 1] 与 t[j - 1]相等时,dp[i][j]可以有两部分组成。
一部分是用s[i - 1]来匹配,那么个数为dp[i][j]。即不需要考虑当前s子串和t子串的最后一位字母,所以只需要dp[i][j]。
一部分是不用s[i - 1]来匹配,个数为dp[i - 1][j]。
这里可能有录友不明白了,为什么还要考虑不用s[i - 1]来匹配,都相同了指定要匹配啊。
例如: s:bagg 和 t:bag ,s[3] 和 t[2]是相同的,但是字符串s也可以不用s[3]来匹配,即用s[0]s[1]s[2]组成的bag。
当然也可以用s[3]来匹配,即:s[0]s[1]s[3]组成的bag。
所以当s[i - 1] 与 t[j - 1]相等时,dp[i][j] = dp[i - 1][j - 1] + dp[i - 1][j];
当s[i - 1] 与 t[j - 1]不相等时,dp[i][j]只有一部分组成,不用s[i - 1]来匹配(就是模拟在s中删除这个元素),即:dp[i - 1][j]
所以递推公式为:dp[i][j] = dp[i - 1][j];
这里可能有录友还疑惑,为什么只考虑 “不用s[i - 1]来匹配” 这种情况, 不考虑 “不用t[j - 1]来匹配” 的情况呢。
这里大家要明确,我们求的是 s 中有多少个 t,而不是 求t中有多少个s,所以只考虑 s中删除元素的情况,即 不用s[i - 1]来匹配 的情况。
- dp数组如何初始化
从递推公式dp[i][j] = dp[i - 1][j] + dp[i - 1][j]; 和 dp[i][j] = dp[i - 1][j]; 中可以看出dp[i][j] 是从上方和左上方推导而来,如图:,那么 dp[i][j] 和dp[0][j]是一定要初始化的。
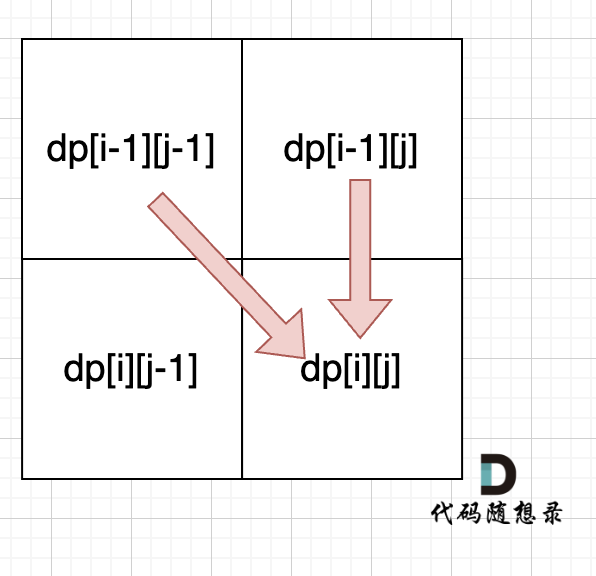
每次当初始化的时候,都要回顾一下dp[i][j]的定义,不要凭感觉初始化。
dp[i][0]表示什么呢?
dp[i][0] 表示:以i-1为结尾的s可以随便删除元素,出现空字符串的个数。
那么dp[i][0]一定都是1,因为也就是把以i-1为结尾的s,删除所有元素,出现空字符串的个数就是1。
再来看dp[0][j],dp[0][j]:空字符串s可以随便删除元素,出现以j-1为结尾的字符串t的个数。
那么dp[0][j]一定都是0,s如论如何也变成不了t。
最后就要看一个特殊位置了,即:dp[0][0] 应该是多少。
dp[0][j]应该是1,空字符串s,可以删除0个元素,变成空字符串t。
初始化分析完毕,代码如下:
vector<vector<long long>> dp(s.size() + 1, vector<long long>(t.size() + 1));
for (int i = 0; i <= s.size(); i++) dp[i][0] = 1;
for (int j = 1; j <= t.size(); j++) dp[0][j] = 0;
// 其实这行代码可以和dp数组初始化的时候放在一起,但我为了凸显初始化的逻辑,所以还是加上了。
4. 确定遍历顺序
从递推公式dp[i][j] = dp[i - 1][j] + dp[i - 1][j]; 和 dp[i][j] = dp[i - 1][j]; 中可以看出dp[i][j]都是根据左上方和正上方推出来的。
所以遍历的时候一定是从上到下,从左到右,这样保证dp[i][j]可以根据之前计算出来的数值进行计算。
代码如下:
for (int i = 1; i <= s.size(); i++) {
for (int j = 1; j <= t.size(); j++) {
if (s[i - 1] == t[j - 1]) {
dp[i][j] = dp[i - 1][j - 1] + dp[i - 1][j];
} else {
dp[i][j] = dp[i - 1][j];
}
}
}
- 举例推导dp数组
以s:"baegg",t:"bag"为例,推导dp数组状态如下:
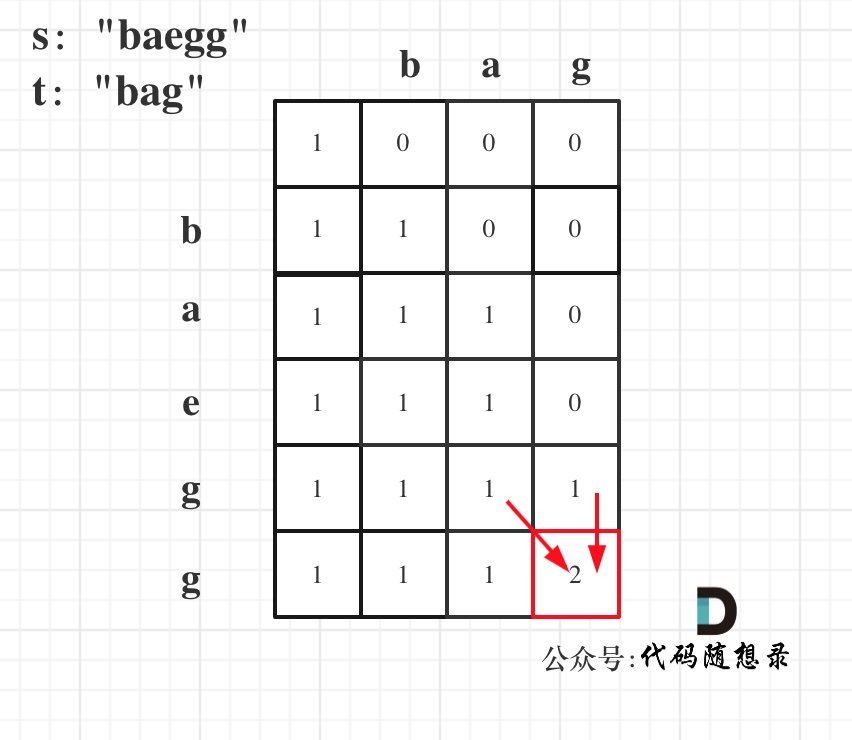
如果写出来的代码怎么改都通过不了,不妨把dp数组打印出来,看一看,是不是这样的。
C++解法
动规五部曲分析完毕,代码如下:
class Solution {
public:
int numDistinct(string s, string t) {
vector<vector<uint64_t>> dp(s.size() + 1, vector<uint64_t>(t.size() + 1));
for (int i = 0; i < s.size(); i++) dp[i][0] = 1;
for (int j = 1; j < t.size(); j++) dp[0][j] = 0;
for (int i = 1; i <= s.size(); i++) {
for (int j = 1; j <= t.size(); j++) {
if (s[i - 1] == t[j - 1]) {
dp[i][j] = dp[i - 1][j - 1] + dp[i - 1][j];
} else {
dp[i][j] = dp[i - 1][j];
}
}
}
return dp[s.size()][t.size()];
}
};
- 时间复杂度: O(n * m)
- 空间复杂度: O(n * m)
Java解法
class Solution {
public int numDistinct(String s, String t) {
int[][] dp = new int[s.length() + 1][t.length() + 1];
for (int i = 0; i < s.length() + 1; i++) {
dp[i][0] = 1;
}
for (int i = 1; i < s.length() + 1; i++) {
for (int j = 1; j < t.length() + 1; j++) {
if (s.charAt(i - 1) == t.charAt(j - 1)) {
dp[i][j] = dp[i - 1][j - 1] + dp[i - 1][j];
}else{
dp[i][j] = dp[i - 1][j];
}
}
}
return dp[s.length()][t.length()];
}
}
583. Delete Operation for Two Strings
Given two strings word1 and word2, return the minimum number of steps required to make word1 and word2 the same.
In one step, you can delete exactly one character in either string.
Example 1:
Input: word1 = "sea", word2 = "eat"
Output: 2
Explanation: You need one step to make "sea" to "ea" and another step to make "eat" to "ea".
Example 2:
Input: word1 = "leetcode", word2 = "etco"
Output: 4
Constraints:
1 <= word1.length, word2.length <= 500word1andword2consist of only lowercase English letters.
思路
本题和动态规划:115.不同的子序列相比,其实就是两个字符串都可以删除了,情况虽说复杂一些,但整体思路是不变的。
这次是两个字符串可以相互删了,这种题目也知道用动态规划的思路来解,动规五部曲,分析如下:
- 确定dp数组(dp table)以及下标的含义
dp[i][j]:以i-1为结尾的字符串word1,和以j-1位结尾的字符串word2,想要达到相等,所需要删除元素的最少次数。
这里dp数组的定义有点点绕,大家要撸清思路。
- 确定递推公式
- 当word1[i - 1] 与 word2[j - 1]相同的时候
- 当word1[i - 1] 与 word2[j - 1]不相同的时候
当word1[i - 1] 与 word2[j - 1]相同的时候,dp[i][j] = dp[i - 1][j - 1];
当word1[i - 1] 与 word2[j - 1]不相同的时候,有三种情况:
情况一:删word1[i - 1],最少操作次数为dp[i - 1][j] + 1
情况二:删word2[j - 1],最少操作次数为dp[i][j - 1] + 1
情况三:同时删word1[i - 1]和word2[j - 1],操作的最少次数为dp[i - 1][j - 1] + 2
那最后当然是取最小值,所以当word1[i - 1] 与 word2[j - 1]不相同的时候,递推公式:dp[i][j] = min({dp[i - 1][j - 1] + 2, dp[i - 1][j] + 1, dp[i][j - 1] + 1});
因为 dp[i][j] + 1 = dp[i - 1][j] + 2,所以递推公式可简化为:dp[i][j] = min(dp[i - 1][j] + 1, dp[i][j - 1] + 1);
这里可能不少录友有点迷糊,从字面上理解 就是 当同时删word1[i - 1]和word2[j - 1],dp[i][j] 本来就不考虑 word2[j - 1]了,那么我在删 word1[i - 1],是不是就达到两个元素都删除的效果,即 dp[i][j] + 1。
- dp数组如何初始化
从递推公式中,可以看出来,dp[i][j] 和 dp[0][j]是一定要初始化的。
dp[i][j]:word2为空字符串,以i-1为结尾的字符串word1要删除多少个元素,才能和word2相同呢,很明显dp[i][j] = i。
dp[0][j]的话同理,所以代码如下:
vector<vector<int>> dp(word1.size() + 1, vector<int>(word2.size() + 1));
for (int i = 0; i <= word1.size(); i++) dp[i][0] = i;
for (int j = 0; j <= word2.size(); j++) dp[0][j] = j;
- 确定遍历顺序
从递推公式 dp[i][j] = min(dp[i - 1][j - 1] + 2, min(dp[i - 1][j], dp[i][j - 1]) + 1); 和dp[i][j] = dp[i - 1][j - 1]可以看出dp[i][j]都是根据左上方、正上方、正左方推出来的。
所以遍历的时候一定是从上到下,从左到右,这样保证dp[i][j]可以根据之前计算出来的数值进行计算。
- 举例推导dp数组
以word1:"sea",word2:"eat"为例,推导dp数组状态图如下:
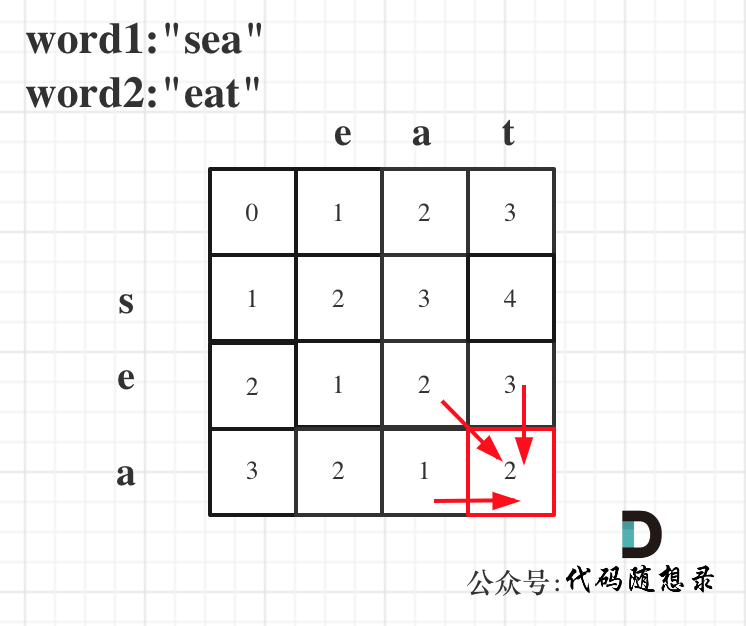
C++解法
以上分析完毕,代码如下:
class Solution {
public:
int minDistance(string word1, string word2) {
vector<vector<int>> dp(word1.size() + 1, vector<int>(word2.size() + 1));
for (int i = 0; i <= word1.size(); i++) dp[i][0] = i;
for (int j = 0; j <= word2.size(); j++) dp[0][j] = j;
for (int i = 1; i <= word1.size(); i++) {
for (int j = 1; j <= word2.size(); j++) {
if (word1[i - 1] == word2[j - 1]) {
dp[i][j] = dp[i - 1][j - 1];
} else {
dp[i][j] = min(dp[i - 1][j] + 1, dp[i][j - 1] + 1);
}
}
}
return dp[word1.size()][word2.size()];
}
};
- 时间复杂度: O(n * m)
- 空间复杂度: O(n * m)
本题和动态规划:1143.最长公共子序列基本相同,只要求出两个字符串的最长公共子序列长度即可,那么除了最长公共子序列之外的字符都是必须删除的,最后用两个字符串的总长度减去两个最长公共子序列的长度就是删除的最少步数。
代码如下:
class Solution {
public:
int minDistance(string word1, string word2) {
vector<vector<int>> dp(word1.size()+1, vector<int>(word2.size()+1, 0));
for (int i=1; i<=word1.size(); i++){
for (int j=1; j<=word2.size(); j++){
if (word1[i-1] == word2[j-1]) dp[i][j] = dp[i-1][j-1] + 1;
else dp[i][j] = max(dp[i-1][j], dp[i][j-1]);
}
}
return word1.size()+word2.size()-dp[word1.size()][word2.size()]*2;
}
};
- 时间复杂度: O(n * m)
- 空间复杂度: O(n * m)
Java解法
class Solution {
public int minDistance(String word1, String word2) {
int[][] dp = new int[word1.length() + 1][word2.length() + 1];
for(int i = 0; i <= word1.length(); i++){
dp[i][0] = i;
}
for(int j = 0; j <= word2.length(); j++){
dp[0][j] = j;
}
dp[0][0] = 0;
for(int i = 1; i <= word1.length(); i++){
for(int j = 1; j <= word2.length(); j++){
if(word1.charAt(i - 1) != word2.charAt(j - 1)){
dp[i][j] = Math.min(dp[i - 1][j], dp[i][j - 1]) + 1;
}else{
dp[i][j] = dp[i - 1][j - 1];
}
}
}
return dp[word1.length()][word2.length()];
}
}
// dp数组中存储word1和word2最长相同子序列的长度
class Solution {
public int minDistance(String word1, String word2) {
int len1 = word1.length();
int len2 = word2.length();
int[][] dp = new int[len1 + 1][len2 + 1];
for (int i = 1; i <= len1; i++) {
for (int j = 1; j <= len2; j++) {
if (word1.charAt(i - 1) == word2.charAt(j - 1)) {
dp[i][j] = dp[i - 1][j - 1] + 1;
} else {
dp[i][j] = Math.max(dp[i - 1][j], dp[i][j - 1]);
}
}
}
return len1 + len2 - dp[len1][len2] * 2;
}
}
// dp数组中存储需要删除的字符个数
class Solution {
public int minDistance(String word1, String word2) {
int[][] dp = new int[word1.length() + 1][word2.length() + 1];
for (int i = 0; i < word1.length() + 1; i++) dp[i][0] = i;
for (int j = 0; j < word2.length() + 1; j++) dp[0][j] = j;
for (int i = 1; i < word1.length() + 1; i++) {
for (int j = 1; j < word2.length() + 1; j++) {
if (word1.charAt(i - 1) == word2.charAt(j - 1)) {
dp[i][j] = dp[i - 1][j - 1];
}else{
dp[i][j] = Math.min(dp[i - 1][j - 1] + 2,
Math.min(dp[i - 1][j] + 1, dp[i][j - 1] + 1));
}
}
}
return dp[word1.length()][word2.length()];
}
}
//DP - longest common subsequence (用最長公共子序列反推)
class Solution {
public int minDistance(String word1, String word2) {
char[] char1 = word1.toCharArray();
char[] char2 = word2.toCharArray();
int len1 = char1.length;
int len2 = char2.length;
int dp[][] = new int [len1 + 1][len2 + 1];
for(int i = 1; i <= len1; i++){
for(int j = 1; j <= len2; j++){
if(char1[i - 1] == char2[j - 1])
dp[i][j] = dp[i - 1][j - 1] + 1;
else
dp[i][j] = Math.max(dp[i - 1][j], dp[i][j - 1]);
}
}
return len1 + len2 - (2 * dp[len1][len2]);//和leetcode 1143只差在這一行。
}
}
72. Edit Distance
Given two strings word1 and word2, return the minimum number of operations required to convert word1 to word2.
You have the following three operations permitted on a word:
- Insert a character
- Delete a character
- Replace a character
Example 1:
Input: word1 = "horse", word2 = "ros"
Output: 3
Explanation:
horse -> rorse (replace 'h' with 'r')
rorse -> rose (remove 'r')
rose -> ros (remove 'e')
Example 2:
Input: word1 = "intention", word2 = "execution"
Output: 5
Explanation:
intention -> inention (remove 't')
inention -> enention (replace 'i' with 'e')
enention -> exention (replace 'n' with 'x')
exention -> exection (replace 'n' with 'c')
exection -> execution (insert 'u')
Constraints:
0 <= word1.length, word2.length <= 500word1andword2consist of lowercase English letters.
思路
编辑距离是用动规来解决的经典题目,这道题目看上去好像很复杂,但用动规可以很巧妙的算出最少编辑距离。
接下来我依然使用动规五部曲,对本题做一个详细的分析:
- 确定dp数组(dp table)以及下标的含义
dp[i][j] 表示以下标i-1为结尾的字符串word1,和以下标j-1为结尾的字符串word2,最近编辑距离为dp[i][j]。
有同学问了,为啥要表示下标i-1为结尾的字符串呢,为啥不表示下标i为结尾的字符串呢?
为什么这么定义我在 718. 最长重复子数组 中做了详细的讲解。
其实用i来表示也可以! 用i-1就是为了方便后面dp数组初始化的。
- 确定递推公式
在确定递推公式的时候,首先要考虑清楚编辑的几种操作,整理如下:
if (word1[i - 1] == word2[j - 1]) 不操作
if (word1[i - 1] != word2[j - 1]) 增、删、换
也就是如上4种情况。
if (word1[i - 1] == word2[j - 1]) 那么说明不用任何编辑,dp[i][j] 就应该是 dp[i - 1][j - 1],即dp[i][j] = dp[i - 1][j - 1];
此时可能有同学有点不明白,为啥要即dp[i][j] = dp[i - 1][j - 1]呢?
那么就在回顾上面讲过的dp[i][j]的定义,word1[i - 1] 与 word2[j - 1]相等了,那么就不用编辑了,以下标i-2为结尾的字符串word1和以下标j-2为结尾的字符串word2的最近编辑距离dp[i - 1][j - 1]就是 dp[i][j]了。
在下面的讲解中,如果哪里看不懂,就回想一下dp[i][j]的定义,就明白了。
在整个动规的过程中,最为关键就是正确理解dp[i][j]的定义!
if (word1[i - 1] != word2[j - 1]),此时就需要编辑了,如何编辑呢?
- 操作一:word1删除一个元素,那么就是以下标i - 2为结尾的word1 与 j-1为结尾的word2的最近编辑距离 再加上一个操作。
即 dp[i][j] = dp[i - 1][j] + 1;
- 操作二:word2删除一个元素,那么就是以下标i - 1为结尾的word1 与 j-2为结尾的word2的最近编辑距离 再加上一个操作。
即 dp[i][j] = dp[i][j - 1] + 1;
这里有同学发现了,怎么都是删除元素,添加元素去哪了。
word2添加一个元素,相当于word1删除一个元素,例如 word1 = "ad" ,word2 = "a",word1删除元素'd' 和 word2添加一个元素'd',变成word1="a", word2="ad", 最终的操作数是一样! dp数组如下图所示意的:
a a d
+-----+-----+ +-----+-----+-----+
| 0 | 1 | | 0 | 1 | 2 |
+-----+-----+ ===> +-----+-----+-----+
a | 1 | 0 | a | 1 | 0 | 1 |
+-----+-----+ +-----+-----+-----+
d | 2 | 1 |
+-----+-----+
操作三:替换元素,word1替换word1[i - 1],使其与word2[j - 1]相同,此时不用增删加元素。
可以回顾一下,if (word1[i - 1] == word2[j - 1])的时候我们的操作 是 dp[i][j] = dp[i - 1][j - 1] 对吧。
那么只需要一次替换的操作,就可以让 word1[i - 1] 和 word2[j - 1] 相同。
所以 dp[i][j] = dp[i - 1][j - 1] + 1;
综上,当 if (word1[i - 1] != word2[j - 1]) 时取最小的,即:dp[i][j] = min({dp[i - 1][j - 1], dp[i - 1][j], dp[i][j - 1]}) + 1;
递归公式代码如下:
if (word1[i - 1] == word2[j - 1]) {
dp[i][j] = dp[i - 1][j - 1];
}
else {
dp[i][j] = min({dp[i - 1][j - 1], dp[i - 1][j], dp[i][j - 1]}) + 1;
}
- dp数组如何初始化
再回顾一下dp[i][j]的定义:
dp[i][j] 表示以下标i-1为结尾的字符串word1,和以下标j-1为结尾的字符串word2,最近编辑距离为dp[i][j]。
那么dp[i][j] 和 dp[0][j] 表示什么呢?
dp[i][j] :以下标i-1为结尾的字符串word1,和空字符串word2,最近编辑距离为dp[i][j]。
那么dp[i][j]就应该是i,对word1里的元素全部做删除操作,即:dp[i][j] = i;
同理dp[0][j] = j;
所以C++代码如下:
for (int i = 0; i <= word1.size(); i++) dp[i][0] = i;
for (int j = 0; j <= word2.size(); j++) dp[0][j] = j;
4. 确定遍历顺序
从如下四个递推公式:
dp[i][j] = dp[i - 1][j - 1]dp[i][j] = dp[i - 1][j - 1] + 1dp[i][j] = dp[i][j - 1] + 1dp[i][j] = dp[i - 1][j] + 1
可以看出dp[i][j]是依赖左方,上方和左上方元素的,如图:
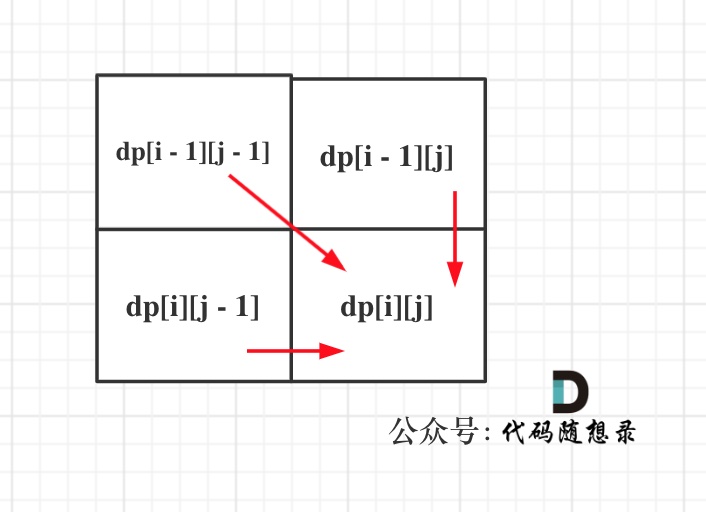
所以在dp矩阵中一定是从左到右从上到下去遍历。
代码如下:
for (int i = 1; i <= word1.size(); i++) {
for (int j = 1; j <= word2.size(); j++) {
if (word1[i - 1] == word2[j - 1]) {
dp[i][j] = dp[i - 1][j - 1];
}
else {
dp[i][j] = min({dp[i - 1][j - 1], dp[i - 1][j], dp[i][j - 1]}) + 1;
}
}
}
- 举例推导dp数组
以示例1为例,输入:word1 = "horse", word2 = "ros"为例,dp矩阵状态图如下:
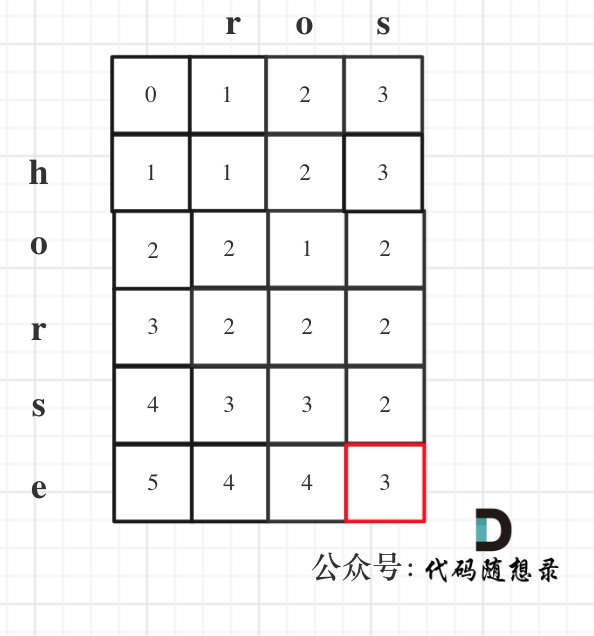
C++解法
以上动规五部分析完毕,C++代码如下:
class Solution {
public:
int minDistance(string word1, string word2) {
vector<vector<int>> dp(word1.size() + 1, vector<int>(word2.size() + 1, 0));
for (int i = 0; i <= word1.size(); i++) dp[i][0] = i;
for (int j = 0; j <= word2.size(); j++) dp[0][j] = j;
for (int i = 1; i <= word1.size(); i++) {
for (int j = 1; j <= word2.size(); j++) {
if (word1[i - 1] == word2[j - 1]) {
dp[i][j] = dp[i - 1][j - 1];
}
else {
dp[i][j] = min({dp[i - 1][j - 1], dp[i - 1][j], dp[i][j - 1]}) + 1;
}
}
}
return dp[word1.size()][word2.size()];
}
};
- 时间复杂度: O(n * m)
- 空间复杂度: O(n * m)
Java解法
public int minDistance(String word1, String word2) {
int m = word1.length();
int n = word2.length();
int[][] dp = new int[m + 1][n + 1];
// 初始化
for (int i = 1; i <= m; i++) {
dp[i][0] = i;
}
for (int j = 1; j <= n; j++) {
dp[0][j] = j;
}
for (int i = 1; i <= m; i++) {
for (int j = 1; j <= n; j++) {
// 因为dp数组有效位从1开始
// 所以当前遍历到的字符串的位置为i-1 | j-1
if (word1.charAt(i - 1) == word2.charAt(j - 1)) {
dp[i][j] = dp[i - 1][j - 1];
} else {
dp[i][j] = Math.min(Math.min(dp[i - 1][j - 1], dp[i][j - 1]), dp[i - 1][j]) + 1;
}
}
}
return dp[m][n];
}
回文串
647. Palindromic Substrings
Given a string s, return the number of palindromic substrings in it.
A string is a palindrome when it reads the same backward as forward.
A substring is a contiguous sequence of characters within the string.
Example 1:
Input: s = "abc"
Output: 3
Explanation: Three palindromic strings: "a", "b", "c".
Example 2:
Input: s = "aaa"
Output: 6
Explanation: Six palindromic strings: "a", "a", "a", "aa", "aa", "aaa".
Constraints:
1 <= s.length <= 1000sconsists of lowercase English letters.
思路
暴力解法
两层for循环,遍历区间起始位置和终止位置,然后还需要一层遍历判断这个区间是不是回文。所以时间复杂度:O(n^3)
动态规划
动规五部曲:
- 确定dp数组(dp table)以及下标的含义
如果大家做了很多这种子序列相关的题目,在定义dp数组的时候 很自然就会想题目求什么,我们就如何定义dp数组。
绝大多数题目确实是这样,不过本题如果我们定义,dp[i] 为 下标i结尾的字符串有 dp[i]个回文串的话,我们会发现很难找到递归关系。
dp[i] 和 dp[i-1] ,dp[i + 1] 看上去都没啥关系。
所以我们要看回文串的性质。 如图:
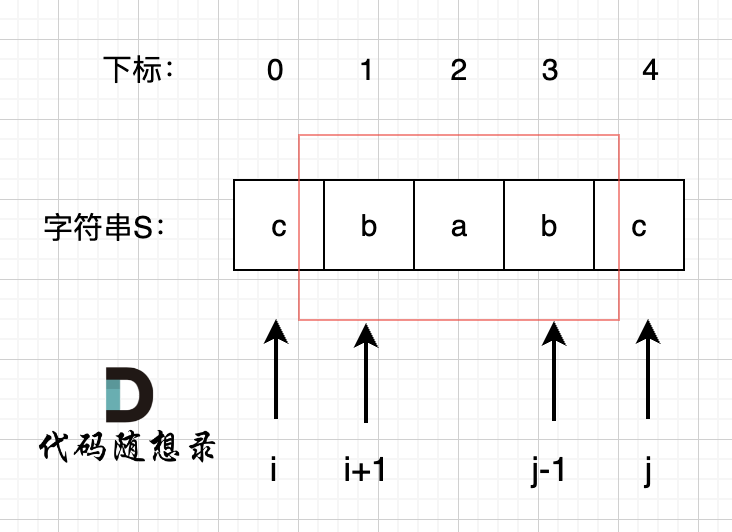
我们在判断字符串S是否是回文,那么如果我们知道 s[1],s[2],s[3] 这个子串是回文的,那么只需要比较 s[0]和s[4]这两个元素是否相同,如果相同的话,这个字符串s 就是回文串。
那么此时我们是不是能找到一种递归关系,也就是判断一个子字符串(字符串的下表范围[i,j])是否回文,依赖于,子字符串(下表范围[i + 1, j - 1])) 是否是回文。
所以为了明确这种递归关系,我们的dp数组是要定义成一位二维dp数组。
布尔类型的dp[i][j]:表示区间范围[i,j] (注意是左闭右闭)的子串是否是回文子串,如果是dp[i][j]为true,否则为false。
- 确定递推公式
在确定递推公式时,就要分析如下几种情况。
整体上是两种,就是s[i]与s[j]相等,s[i]与s[j]不相等这两种。
当s[i]与s[j]不相等,那没啥好说的了,dp[i][j]一定是false。
当s[i]与s[j]相等时,这就复杂一些了,有如下三种情况
- 情况一:下标i 与 j相同,同一个字符例如a,当然是回文子串
- 情况二:下标i 与 j相差为1,例如aa,也是回文子串
- 情况三:下标:i 与 j相差大于1的时候,例如cabac,此时s[i]与s[j]已经相同了,我们看i到j区间是不是回文子串就看aba是不是回文就可以了,那么aba的区间就是 i+1 与 j-1区间,这个区间是不是回文就看
dp[i + 1][j - 1]是否为true。
以上三种情况分析完了,那么递归公式如下:
if (s[i] == s[j]) {
if (j - i <= 1) { // 情况一 和 情况二
result++;
dp[i][j] = true;
} else if (dp[i + 1][j - 1]) { // 情况三
result++;
dp[i][j] = true;
}
}
result就是统计回文子串的数量。
注意这里我没有列出当s[i]与s[j]不相等的时候,因为在下面dp[i][j]初始化的时候,就初始为false。
- dp数组如何初始化
dp[i][j]可以初始化为true么? 当然不行,怎能刚开始就全都匹配上了。
所以dp[i][j]初始化为false。
- 确定遍历顺序
遍历顺序可有有点讲究了。
首先从递推公式中可以看出,情况三是根据dp[i + 1][j - 1]是否为true,在对dp[i][j]进行赋值true的。
dp[i + 1][j - 1]在 dp[i][j]的左下角,如图:
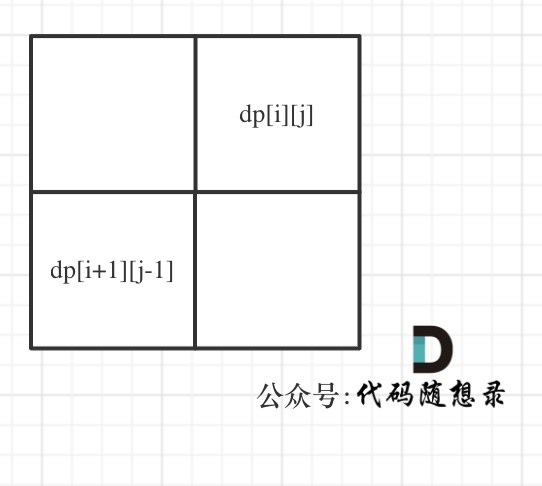
如果这矩阵是从上到下,从左到右遍历,那么会用到没有计算过的dp[i + 1][j - 1],也就是根据不确定是不是回文的区间[i+1,j-1],来判断了[i,j]是不是回文,那结果一定是不对的。
所以一定要从下到上,从左到右遍历,这样保证dp[i + 1][j - 1]都是经过计算的。
有的代码实现是优先遍历列,然后遍历行,其实也是一个道理,都是为了保证dp[i + 1][j - 1]都是经过计算的。
代码如下:
for (int i = s.size() - 1; i >= 0; i--) { // 注意遍历顺序
for (int j = i; j < s.size(); j++) {
if (s[i] == s[j]) {
if (j - i <= 1) { // 情况一 和 情况二
result++;
dp[i][j] = true;
} else if (dp[i + 1][j - 1]) { // 情况三
result++;
dp[i][j] = true;
}
}
}
}
- 举例推导dp数组
举例,输入:"aaa",dp[i][j]状态如下:
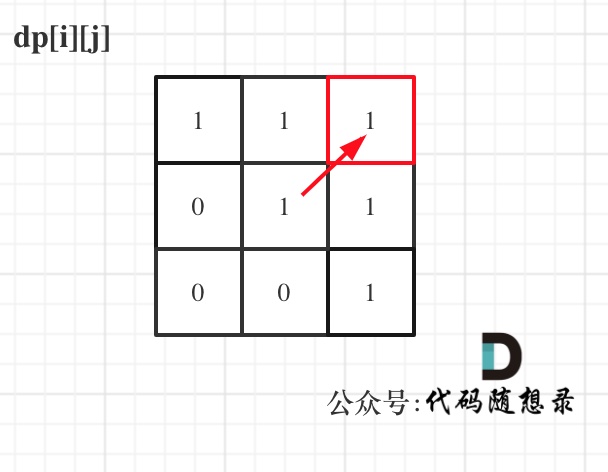
图中有6个true,所以就是有6个回文子串。
注意因为dp[i][j]的定义,所以j一定是大于等于i的,那么在填充dp[i][j]的时候一定是只填充右上半部分。
C++解法
以上分析完毕,C++代码如下:
class Solution {
public:
int countSubstrings(string s) {
vector<vector<bool>> dp(s.size(), vector<bool>(s.size(), false));
int result = 0;
for (int i = s.size() - 1; i >= 0; i--) { // 注意遍历顺序
for (int j = i; j < s.size(); j++) {
if (s[i] == s[j]) {
if (j - i <= 1) { // 情况一 和 情况二
result++;
dp[i][j] = true;
} else if (dp[i + 1][j - 1]) { // 情况三
result++;
dp[i][j] = true;
}
}
}
}
return result;
}
};
以上代码是为了凸显情况一二三,当然是可以简洁一下的,如下:
class Solution {
public:
int countSubstrings(string s) {
vector<vector<bool>> dp(s.size(), vector<bool>(s.size(), false));
int result = 0;
for (int i = s.size() - 1; i >= 0; i--) {
for (int j = i; j < s.size(); j++) {
if (s[i] == s[j] && (j - i <= 1 || dp[i + 1][j - 1])) {
result++;
dp[i][j] = true;
}
}
}
return result;
}
};
- 时间复杂度:O(n^2)
- 空间复杂度:O(n^2)
双指针法
动态规划的空间复杂度是偏高的,我们再看一下双指针法。
首先确定回文串,就是找中心然后向两边扩散看是不是对称的就可以了。
在遍历中心点的时候,要注意中心点有两种情况。
一个元素可以作为中心点,两个元素也可以作为中心点。
那么有人同学问了,三个元素还可以做中心点呢。其实三个元素就可以由一个元素左右添加元素得到,四个元素则可以由两个元素左右添加元素得到。
所以我们在计算的时候,要注意一个元素为中心点和两个元素为中心点的情况。
这两种情况可以放在一起计算,但分别计算思路更清晰,我倾向于分别计算,代码如下:
class Solution {
public:
int countSubstrings(string s) {
int result = 0;
for (int i = 0; i < s.size(); i++) {
result += extend(s, i, i, s.size()); // 以i为中心
result += extend(s, i, i + 1, s.size()); // 以i和i+1为中心
}
return result;
}
int extend(const string& s, int i, int j, int n) {
int res = 0;
while (i >= 0 && j < n && s[i] == s[j]) {
i--;
j++;
res++;
}
return res;
}
};
- 时间复杂度:O(n^2)
- 空间复杂度:O(1)
Java解法
动态规划:
class Solution {
public int countSubstrings(String s) {
char[] chars = s.toCharArray();
int len = chars.length;
boolean[][] dp = new boolean[len][len];
int result = 0;
for (int i = len - 1; i >= 0; i--) {
for (int j = i; j < len; j++) {
if (chars[i] == chars[j]) {
if (j - i <= 1) { // 情况一 和 情况二
result++;
dp[i][j] = true;
} else if (dp[i + 1][j - 1]) { //情况三
result++;
dp[i][j] = true;
}
}
}
}
return result;
}
}
动态规划:简洁版
class Solution {
public int countSubstrings(String s) {
boolean[][] dp = new boolean[s.length()][s.length()];
int res = 0;
for (int i = s.length() - 1; i >= 0; i--) {
for (int j = i; j < s.length(); j++) {
if (s.charAt(i) == s.charAt(j) && (j - i <= 1 || dp[i + 1][j - 1])) {
res++;
dp[i][j] = true;
}
}
}
return res;
}
}
中心扩散法:
class Solution {
public int countSubstrings(String s) {
int len, ans = 0;
if (s == null || (len = s.length()) < 1) return 0;
//总共有2 * len - 1个中心点
for (int i = 0; i < 2 * len - 1; i++) {
//通过遍历每个回文中心,向两边扩散,并判断是否回文字串
//有两种情况,left == right,right = left + 1,这两种回文中心是不一样的
int left = i / 2, right = left + i % 2;
while (left >= 0 && right < len && s.charAt(left) == s.charAt(right)) {
//如果当前是一个回文串,则记录数量
ans++;
left--;
right++;
}
}
return ans;
}
}
5. Longest Palindromic Substring
Given a string s, return the longest palindromic substring in s.
Example 1:
Input: s = "babad"
Output: "bab"
Explanation: "aba" is also a valid answer.
Example 2:
Input: s = "cbbd"
Output: "bb"
Constraints:
1 <= s.length <= 1000sconsist of only digits and English letters.
思路
Approach 1: Check All Substrings
Approach 2: Dynamic Programming
Approach 3: Expand From Centers
Approach 4: Manacher's Algorithm
C++解法
Approach 4: Manacher's Algorithm
Believe it or not, this problem can be solved in linear time.
Manacher's algorithm finds the longest palindromic substring in O(n) time and space.
Note: this algorithm is completely out of scope for coding interviews. Because of this, we will not be talking about the algorithm in detail. This approach has been included for the sake of completeness and for those who are curious about algorithms beyond the scope of interviews.
class Solution {
public:
string longestPalindrome(string s) {
string s_prime = "#";
for (char c : s) {
s_prime += c;
s_prime += "#";
}
int n = s_prime.length();
vector<int> palindrome_radii(n, 0);
int center = 0;
int radius = 0;
for (int i = 0; i < n; i++) {
int mirror = 2 * center - i;
if (i < radius) {
palindrome_radii[i] = min(radius - i, palindrome_radii[mirror]);
}
while (i + 1 + palindrome_radii[i] < n &&
i - 1 - palindrome_radii[i] >= 0 &&
s_prime[i + 1 + palindrome_radii[i]] ==
s_prime[i - 1 - palindrome_radii[i]]) {
palindrome_radii[i]++;
}
if (i + palindrome_radii[i] > radius) {
center = i;
radius = i + palindrome_radii[i];
}
}
int max_length = 0;
int center_index = 0;
for (int i = 0; i < n; i++) {
if (palindrome_radii[i] > max_length) {
max_length = palindrome_radii[i];
center_index = i;
}
}
int start_index = (center_index - max_length) / 2;
string longest_palindrome = s.substr(start_index, max_length);
return longest_palindrome;
}
};
Java解法
你的Java代码有一些小错误,导致在构建最长回文子串时无法正确返回结果。主要问题在于以下几点:
StringBuilder result需要初始化为一个空对象,或者可以使用String直接保存最长回文子串。- 在更新
result时,你应该使用str.substring(i, j + 1),而不是str.substring(i, j - i + 1)。 - 在更新
result时,应该在循环外声明并保存最长的回文子串,而不是每次都更新。
以下是修正后的代码:
class Solution {
public String longestPalindrome(String s) {
if (s == null || s.length() < 1) return "";
int start = 0, end = 0;
boolean[][] dp = new boolean[s.length()][s.length()];
for (int j = 0; j < s.length(); j++) {
for (int i = 0; i <= j; i++) {
if (s.charAt(i) == s.charAt(j) && (j - i <= 2 || dp[i + 1][j - 1])) {
dp[i][j] = true;
if (j - i > end - start) {
start = i;
end = j;
}
}
}
}
return s.substring(start, end + 1);
}
}
主要改动:
- 使用
start和end变量来追踪最长回文子串的起始和结束索引。 - 使用
dp[i + 1][j - 1]来判断当前的子串是否是回文,并在条件成立时更新start和end。 - 最后返回
s.substring(start, end + 1)获取正确的回文子串。
这段代码在性能上也是优化了,因为现在它只在必要时更新 start 和 end,使得代码更简洁高效。
516. Longest Palindromic Subsequence
Given a string s, find the longest palindromic subsequence's length in s.
A subsequence is a sequence that can be derived from another sequence by deleting some or no elements without changing the order of the remaining elements.
Example 1:
Input: s = "bbbab"
Output: 4
Explanation: One possible longest palindromic subsequence is "bbbb".
Example 2:
Input: s = "cbbd"
Output: 2
Explanation: One possible longest palindromic subsequence is "bb".
Constraints:
1 <= s.length <= 1000sconsists only of lowercase English letters.
思路
我们刚刚做过了 动态规划:回文子串,求的是回文子串,而本题要求的是回文子序列, 要搞清楚这两者之间的区别。
回文子串是要连续的,回文子序列可不是连续的! 回文子串,回文子序列都是动态规划经典题目。
回文子串,可以做这两题:
- 647.回文子串
- 5.最长回文子串
思路其实是差不多的,但本题要比求回文子串简单一点,因为情况少了一点。
动规五部曲分析如下:
- 确定dp数组(dp table)以及下标的含义
dp[i][j]:字符串s在[i, j]范围内最长的回文子序列的长度为dp[i][j]。
- 确定递推公式
在判断回文子串的题目中,关键逻辑就是看s[i]与s[j]是否相同。
如果s[i]与s[j]相同,那么``dp[i][j] = dp[i + 1][j - 1] + 2;
如图: 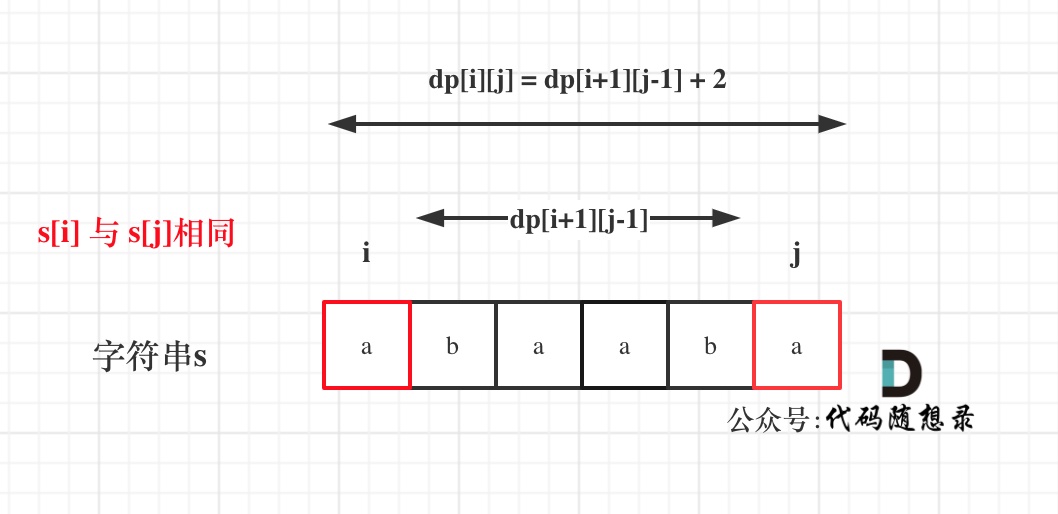
(如果这里看不懂,回忆一下dpi的定义)
如果s[i]与s[j]不相同,说明s[i]和s[j]的同时加入 并不能增加[i,j]区间回文子序列的长度,那么分别加入s[i]、s[j]看看哪一个可以组成最长的回文子序列。
加入s[j]的回文子序列长度为dp[i + 1][j]。
加入s[i]的回文子序列长度为`dp[i][j - 1]。
那么dpi一定是取最大的,即:dp[i][j] = max(dp[i + 1][j], dp[i][j - 1];
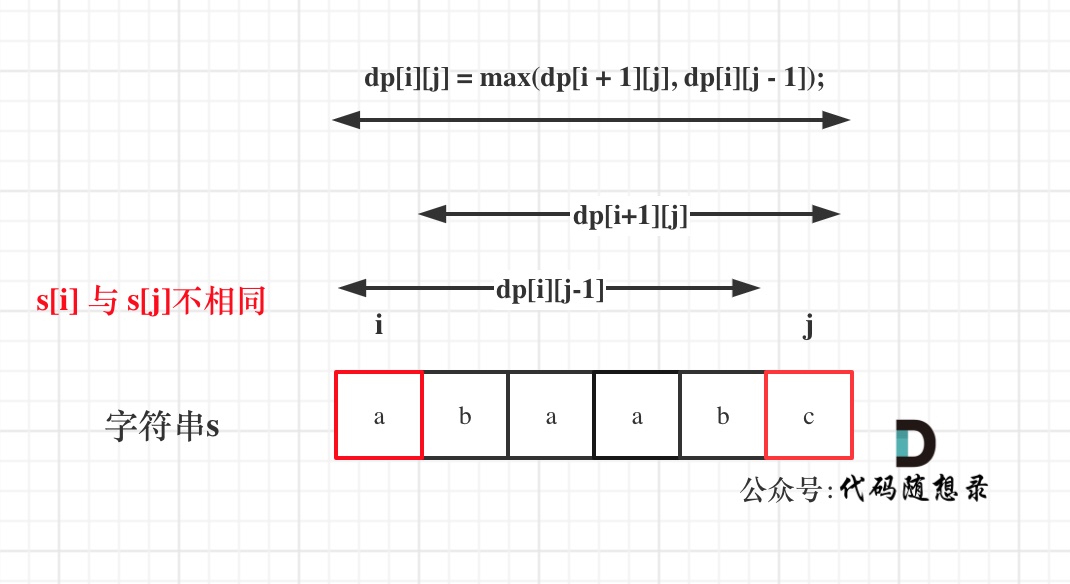
代码如下:
if (s[i] == s[j]) {
dp[i][j] = dp[i + 1][j - 1] + 2;
} else {
dp[i][j] = max(dp[i + 1][j], dp[i][j - 1]);
}
- dp数组如何初始化
首先要考虑当i 和j 相同的情况,从递推公式:dp[i][j] =dp[i + 1][j - 1] + 2; 可以看出 递推公式是计算不到 i 和j相同时候的情况。
所以需要手动初始化一下,当i与j相同,那么dp[i][j]一定是等于1的,即:一个字符的回文子序列长度就是1。
其他情况dp[i][j]初始为0就行,这样递推公式:dp[i][j] = max(dp[i + 1][j], dp[i][j - 1]); 中dp[i][j]才不会被初始值覆盖。
vector<vector<int>> dp(s.size(), vector<int>(s.size(), 0));
for (int i = 0; i < s.size(); i++) dp[i][i] = 1;
- 确定遍历顺序
从递归公式中,可以看出,dp[i][j]依赖于 dp[i][j - 1],dp[i + 1][j]和 dp[i + 1][j - 1],如图:
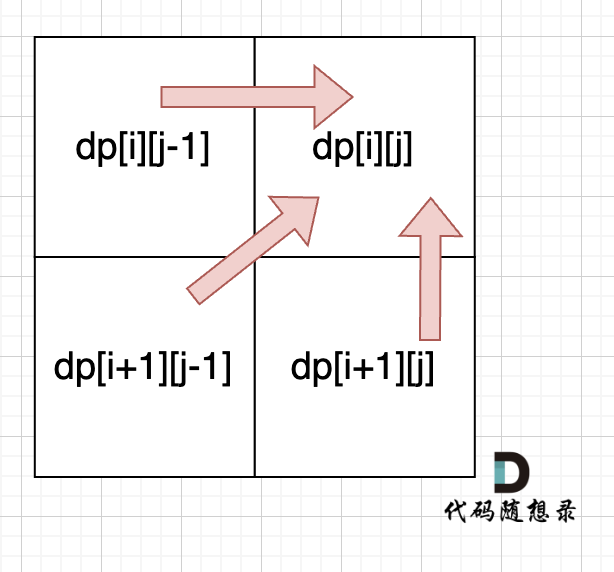
所以遍历i的时候一定要从下到上遍历,这样才能保证下一行的数据是经过计算的。
j的话,可以正常从左向右遍历。
代码如下:
for (int i = s.size() - 1; i >= 0; i--) {
for (int j = i + 1; j < s.size(); j++) {
if (s[i] == s[j]) {
dp[i][j] = dp[i + 1][j - 1] + 2;
} else {
dp[i][j] = max(dp[i + 1][j], dp[i][j - 1]);
}
}
}
- 举例推导dp数组
输入s:"cbbd" 为例,dp数组状态如图:
红色框即:dp[0][s.size() - 1]; 为最终结果。
C++解法
以上分析完毕,C++代码如下:
class Solution {
public:
int longestPalindromeSubseq(string s) {
vector<vector<int>> dp(s.size(), vector<int>(s.size(), 0));
for (int i = 0; i < s.size(); i++) dp[i][i] = 1;
for (int i = s.size() - 1; i >= 0; i--) {
for (int j = i + 1; j < s.size(); j++) {
if (s[i] == s[j]) {
dp[i][j] = dp[i + 1][j - 1] + 2;
} else {
dp[i][j] = max(dp[i + 1][j], dp[i][j - 1]);
}
}
}
return dp[0][s.size() - 1];
}
};
- 时间复杂度: O(n^2)
- 空间复杂度: O(n^2)
Java解法
public class Solution {
public int longestPalindromeSubseq(String s) {
int len = s.length();
int[][] dp = new int[len + 1][len + 1];
for (int i = len - 1; i >= 0; i--) { // 从后往前遍历 保证情况不漏
dp[i][i] = 1; // 初始化
for (int j = i + 1; j < len; j++) {
if (s.charAt(i) == s.charAt(j)) {
dp[i][j] = dp[i + 1][j - 1] + 2;
} else {
dp[i][j] = Math.max(dp[i + 1][j], Math.max(dp[i][j], dp[i][j - 1]));
}
}
}
return dp[0][len - 1];
}
}