弁言
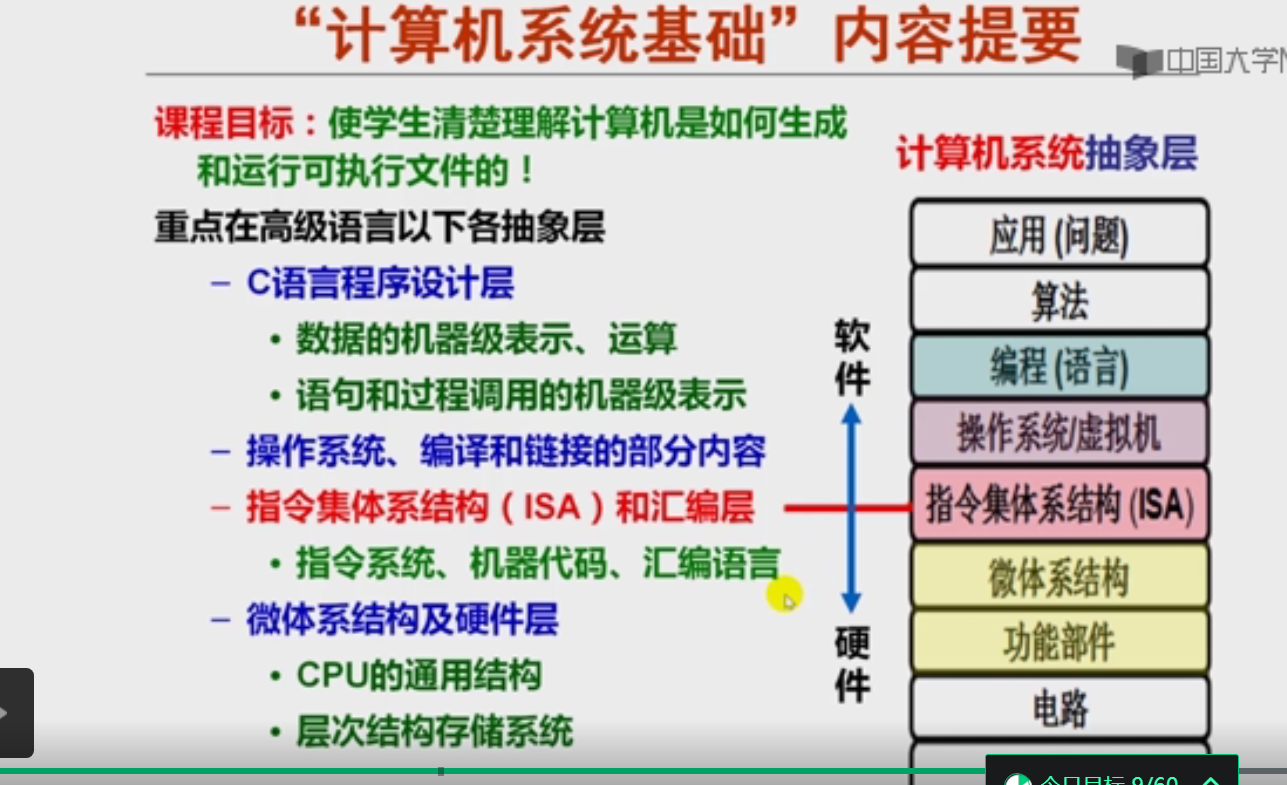
计算机系统基础一课程概述
主要介绍高级语言程序中的数据运算、语句和过程调用等如何在计算机系统中实现,包含:(1)数据、指针、指令等的表示和存储;(2)高级语言程序中语句与机器级代码间的对应关系;(3)静态链接和动态链接。 —— 课程团队
课程概述
本课程是“计算机系统基础”系列课程中的第一门,主要介绍高级语言程序中的数据类型及其运算、语句和过程调用等是如何在计算机系统中实现的。主要包含三个主题:(1)表示。不同数据类型(如带符号整数、无符号整数、浮点数、数组、结构等)数据在寄存器或存储器中的表示和存储;指令的格式、编码及其在存储器中的存储;存储地址(指针)的表示。(2)转换。高级语言程序中的过程(函数调用)、循环、选择等语句与机器级代码之间的对应关系。(3)链接。多个可重定位目标文件如何链接生成可执行目标文件并加载到系统中。
通过本课程的学习,使学习者能从程序员角度认识计算机系统,能够建立高级语言程序、ISA、OS、编译器、链接器等之间的相互关联,对指令在硬件上的执行过程和指令的底层硬件执行机制有一定的认识和理解,从而增强在程序调试、性能提升、程序移植和健壮性等方面的能力,并为后续的“计算机组成与设计”、“操作系统”、“编译原理”、“计算机体系结构”等课程打下坚实基础。
学完本课程后,学习者将对以下问题有比较深刻的认识,并能解决相关实际问题。
程序中处理的数据在机器中如何表示和运算?
程序中各类控制语句对应的机器级代码结构是怎样的?
多个程序模块是如何链接起来形成可执行目标文件的?
机器级代码及构成机器级代码的指令是如何在机器上执行的?
授课目标
通过本课程的学习,使学习者能从程序员角度认识计算机系统,能够建立高级语言程序、ISA、OS、编译器、链接器等之间的相互关联,对指令在硬件上的执行过程和指令的底层硬件执行机制有一定的认识和理解,从而增强在程序调试、性能提升、程序移植和健壮性等方面的能力,并为后续的“计算机组成与设计”、“操作系统”、“编译原理”、“计算机体系结构”等课程打下坚实基础。
课程大纲
第一周 计算机系统概述
第1讲 为什么要学习计算机系统基础
第2讲 计算机系统基本组成与基本功能
第3讲 程序开发和执行过程简介
第4讲 计算机系统层次结构
第5讲 本课程的主要学习内容
第一周小测验
第二周 数据的表示和存储
第1讲 数制和编码
第2讲 定点数的编码表示
第3讲 C语言中的整数
第4讲 浮点数的编码表示
第5讲 非数值数据的编码表示
第6讲 数据宽度和存储容量的单位
第7讲 数据存储时的字节排列
第二周小测验
第三周 运算电路基础
第1讲 数字逻辑电路基础
第2讲 从C表达式到逻辑电路
第3讲 C语言中的各类运算
第4讲 整数加减运算
第三周小测验
第四周 乘除运算及浮点数运算
第1讲 整数乘法运算
第2讲 整数除法运算
第3讲 浮点数运算
第四周小测验
第五周 IA-32指令系统概述
第1讲 程序转换概述
第2讲 IA-32指令系统概述
第五周小测验
第六周 IA-32指令类型
第1讲 传送指令
第2讲 定点算术运算指令
第3讲 按位运算指令
第4讲 控制转移指令
第5讲 x87浮点处理指令
第6讲 MMX及SSE指令集
第六周小测验
第七周 C语言语句的机器级表示
第1讲 过程(函数)调用的机器级表示
第2讲 选择和循环语句的机器级表示
第七周小测验
第八周 复杂数据类型的机器级表示
第1讲 数组和指针类型的分配和访问
第2讲 结构和联合数据类型的分配和访问
第3讲 数据的对齐存放
第4讲 越界访问和缓冲区溢出攻击
第八周小测验
第九周 x86-64指令系统
第1讲 x86-64指令系统概述
第2讲 x86-64的基本指令
第3讲 x86-64的过程调用
第九周小测验
第十周 链接概述和目标文件格式
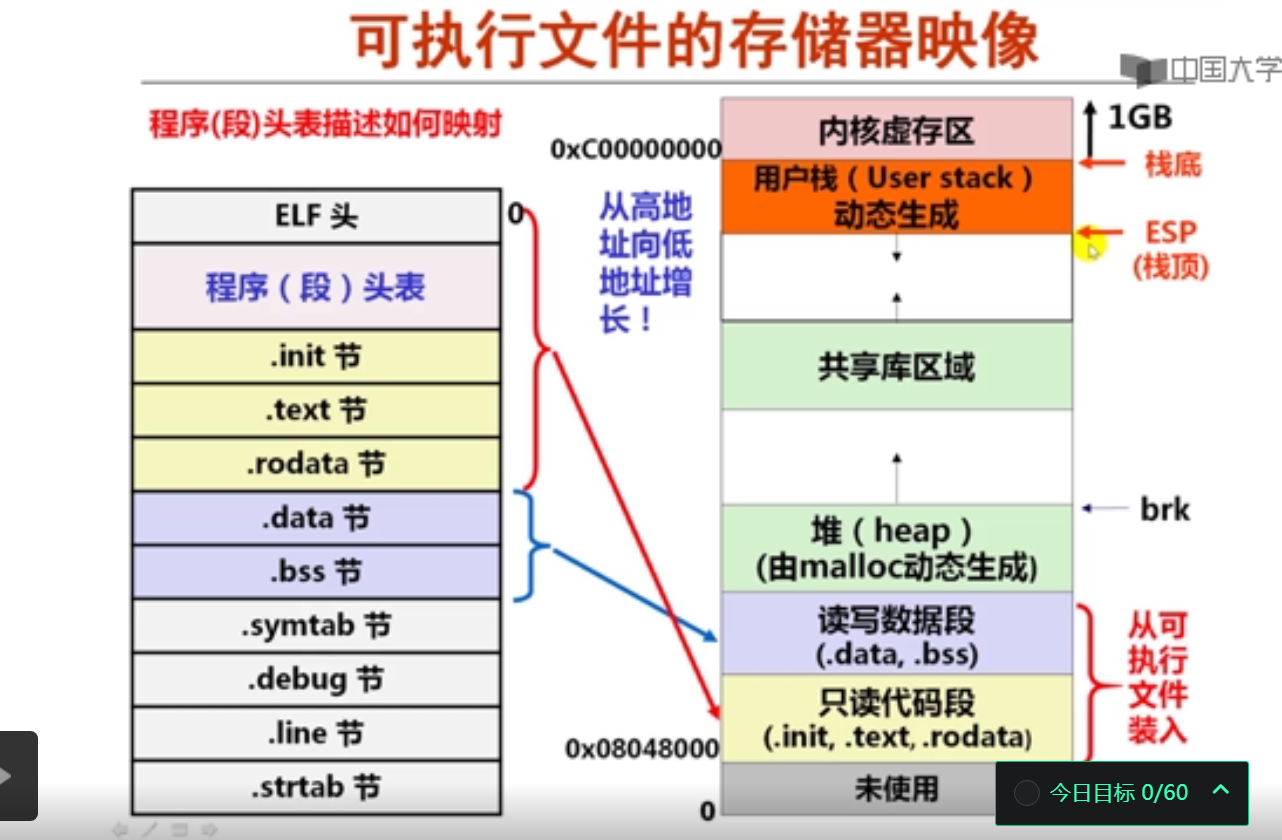
第1讲 可执行文件生成概述
第2讲 目标文件格式概述
第3讲 ELF可重定位目标文件
第4讲 ELF可执行目标文件
第十周小测验
第十一周 符号及符号解析
第1讲 符号及符号表
第2讲 静态链接和符号解析
第十一周小测验
第十二周 重定位及动态链接
第1讲 符号的重定位
第2讲 可执行文件的加载
第3讲 共享库和动态链接
第十二周小测验
预备知识
高级语言程序设计(最好有C语言程序设计的基础)
第一周计算机系统概述
第1讲 为什么要学习计算机系统基础
1.C语言程序举例(22分钟)







2. 为什么要学习计算机系统基础(6分钟)
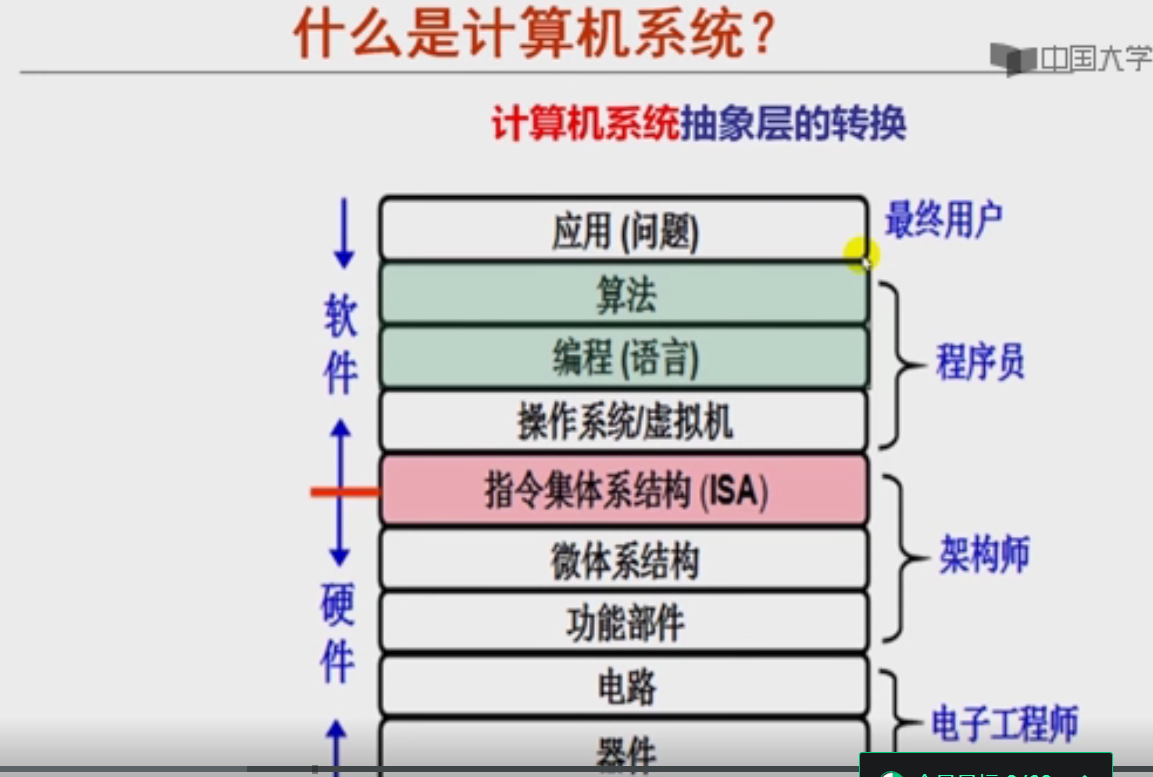
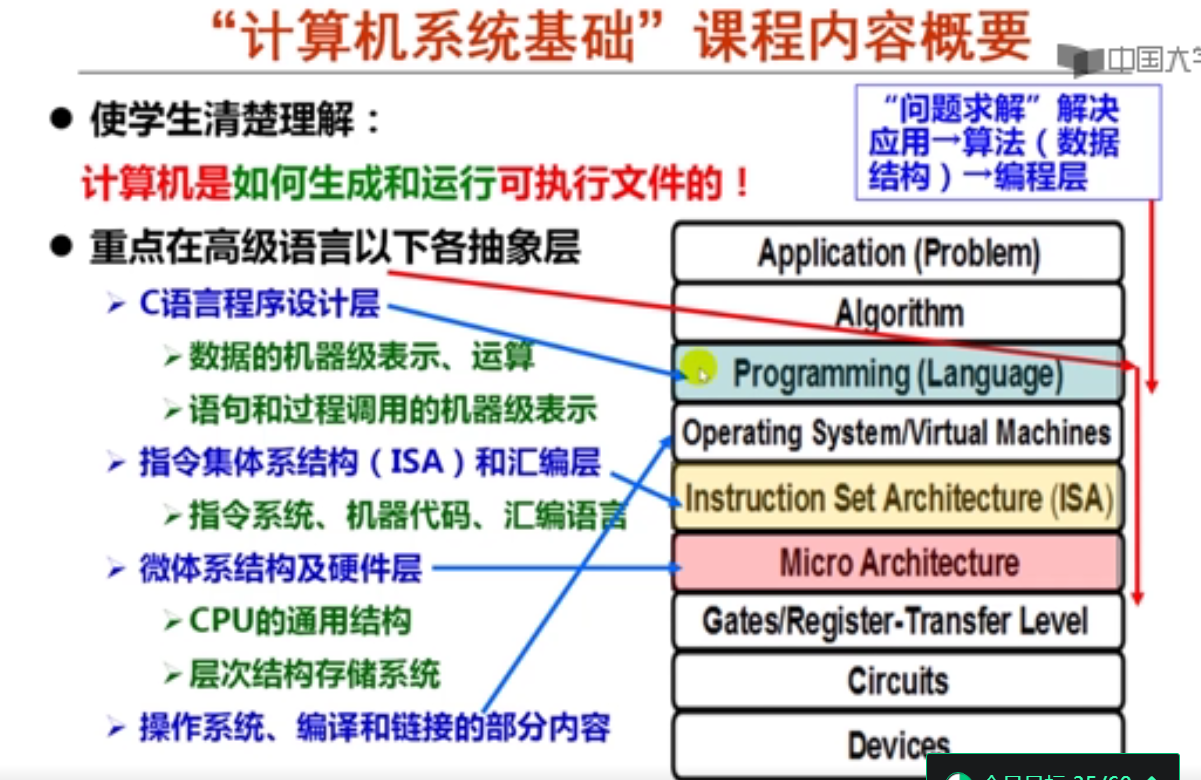
计算机系统层次中,从上层的应用到底层的硬件之间各个抽象层的顺序是应用(问题)-> 算法 -> 编程(语言)-> 操作系统 -> 指令集体系结构 -> 微体系结构 -> 硬件

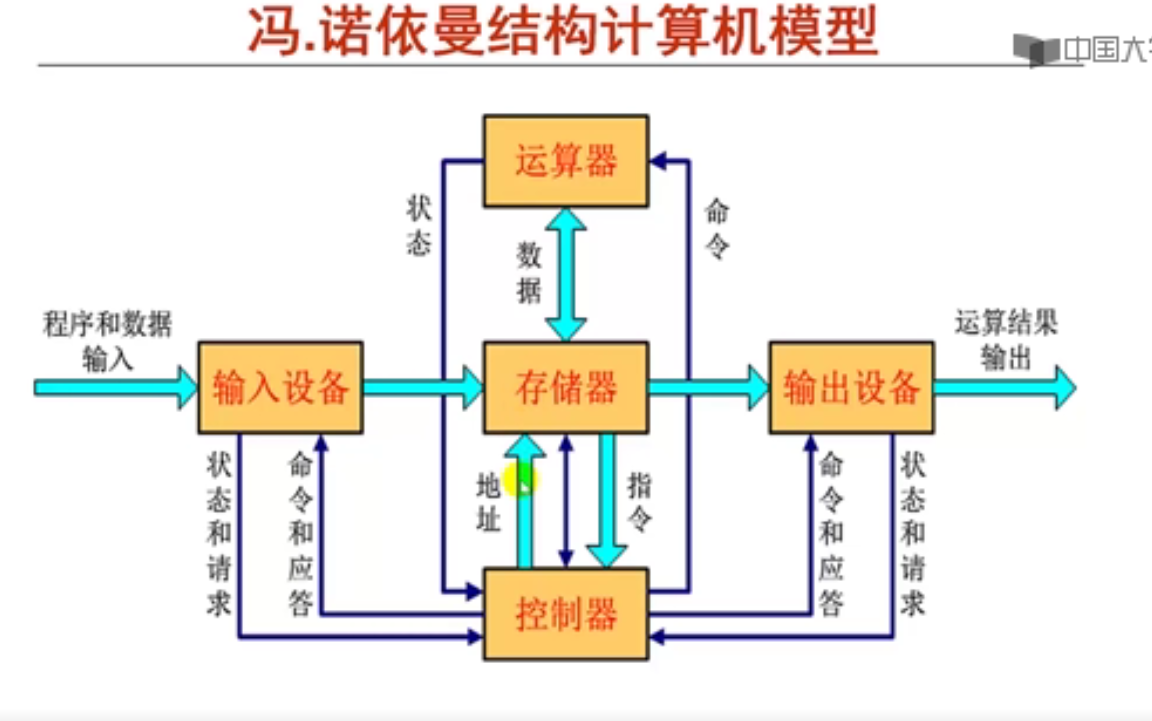
第2讲 计算机系统基本组成与基本功能
1. 冯•诺依曼结构主要思想((16分钟)


2. 现代计算机结构模型及工作原理(19分钟)
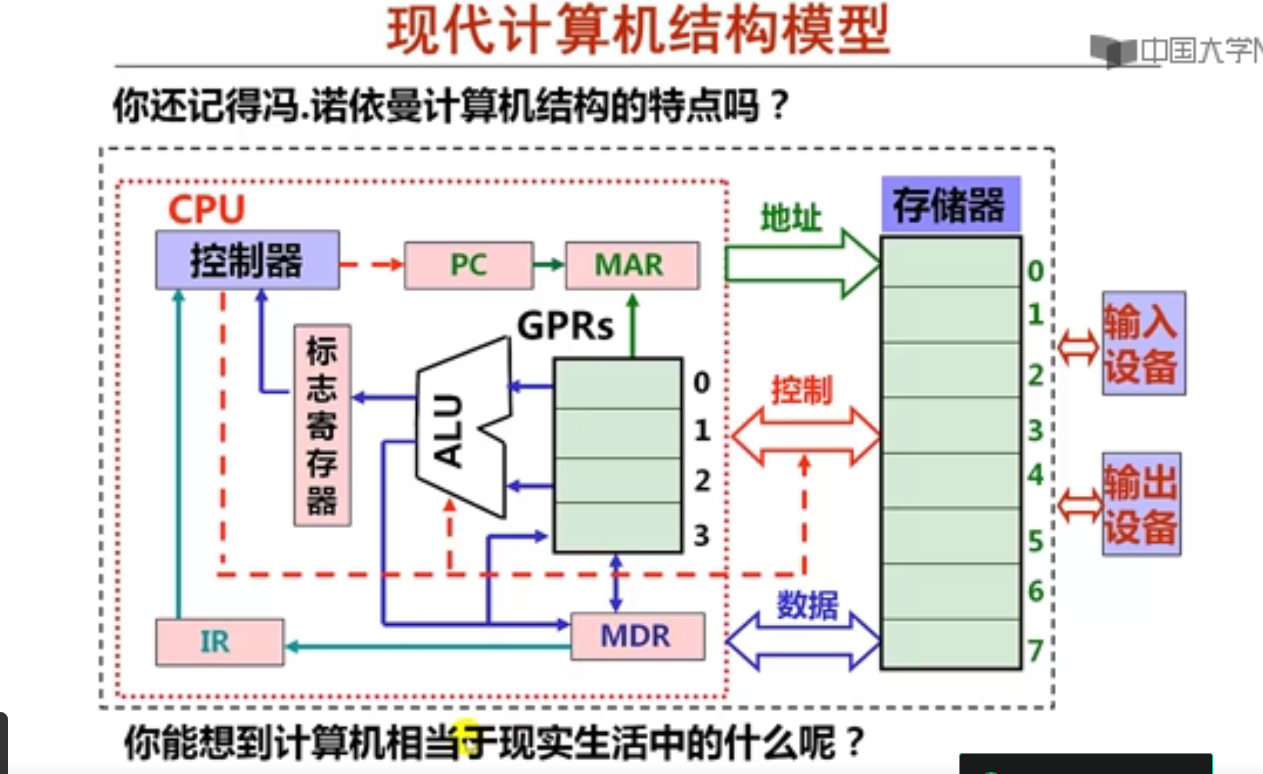
| 英文简写 | 英文全称 | 中文名称 |
|---|---|---|
| CPU | Central Processing Unit | 中央处理器 |
| PC | Program Counter | 程序计数器 |
| IR | Instruction Register | 指令寄存器 |
| ALU | Arithmetic Logic Unit | 算术逻辑单元 |
| MAR | Memory Address Register | 存储器地址寄存器 |
| MDR | Memory Data Register | 存储器数据寄存器 |
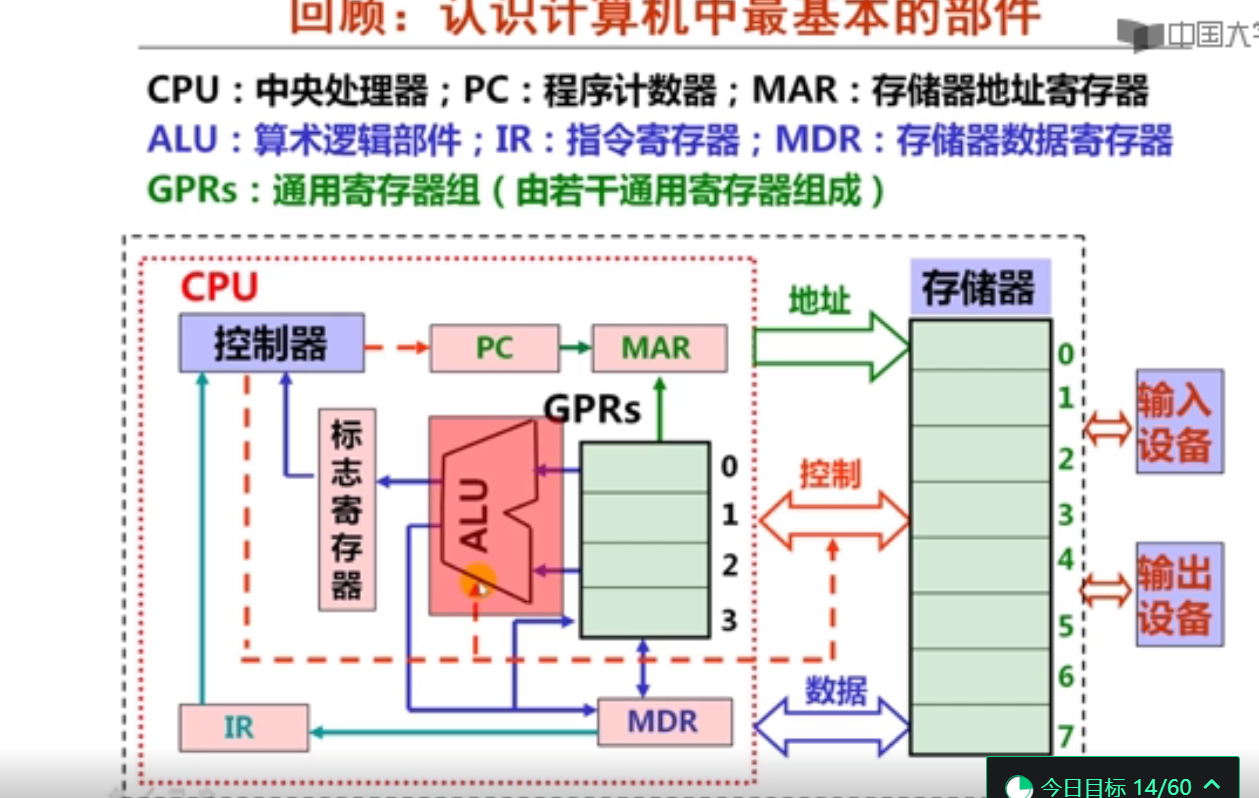
在ALU中运算的数据可以是通用寄存器组(GPRs)中某个寄存器的内容,也可以是存储器中某个存储单元的内容。


- 指令由操作码和操作数或操作数的地址码构成
- 指令操作码通过CPU中的控制器进行译码
- 将要执行的下条指令的地址总是在程序计数器PC中

第3讲 程序开发和执行过程简介
1. 从机器语言到高级编程语言(16分钟)

一条指令描述计算机中一个最基本的动作。
机器指令是一串0/1序列。
汇编指令是机器指令的符号表示,其功能和机器指令一一对应。

2. 程序的开发和执行及其支撑环境(16分钟)

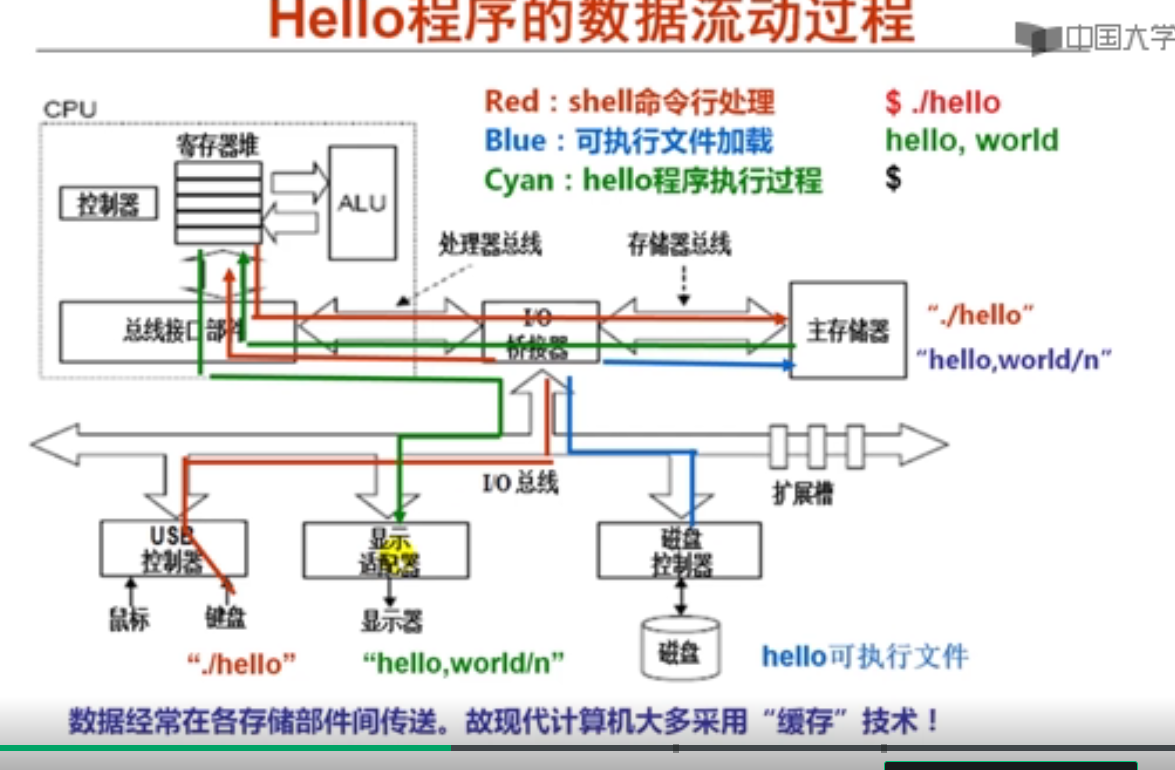
高级编程语言与具体的计算机结构没有关系
一条高级语言中的语句会对应很多条机器指令
高级语言程序必须被翻译成机器语言才能被执行


第4讲 计算机系统层次结构
1. 编程语言和计算机系统层次(8分钟)

2. 现代计算机系统的层次结构(20分钟)
下面几层是电子工程师所关注的器件和逻辑电路等层次
中间几层是计算机架构师所关注的ISA和微架构等层次
上面几层是程序员所关注的算法、编程和系统软件等层次
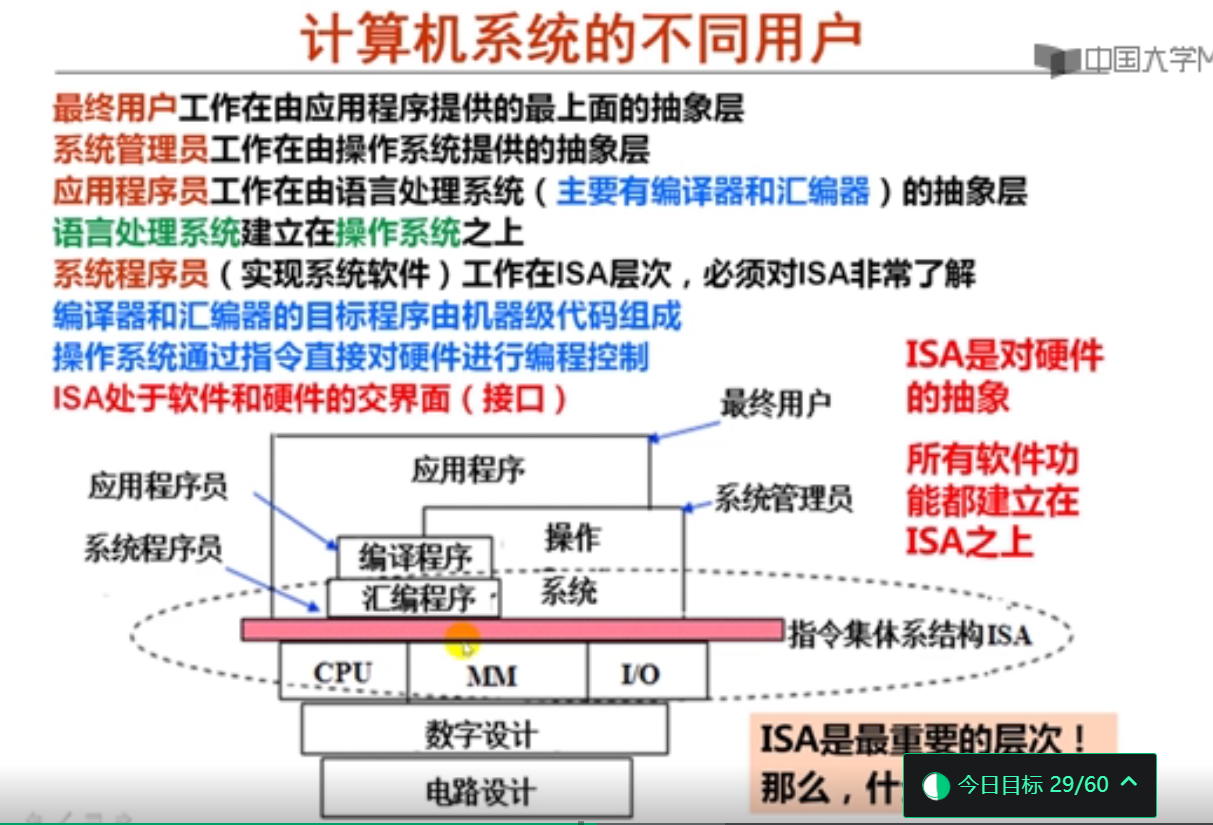

有没有乘法指令属于指令集体系结构(ISA)需考虑的问题,而如何实现乘法指令是微体系结构需要考虑的问题。
第5讲 本课程的主要学习内容
本课程主要学习内容(16分钟)


第一周小测验
1以下有关冯.诺依曼结构思想的叙述中,错误的是( B )。
A.程序由指令构成,计算机能自动执行程序中一条一条指令
B.指令和数据都放在存储器中,两者在形式上有差别
C.计算机由运算器、存储器、控制器和I/O设备组成
D.计算机内部以二进制形式表示指令和数据
2以下有关指令以及指令执行过程的叙述中,错误的是( A )。
A.指令中指定的操作数只能是存放在存储器中的数据
B.CPU中的控制器对指令操作码进行译码
C.指令由操作码和操作数或操作数的地址码构成
D.将要执行的下条指令的地址总是在程序计数器PC中
3以下有关编程语言的叙述中,错误的是( D )。
A.计算机不能直接执行高级语言程序和汇编语言程序
B.用高级编程语言编写程序比用汇编语言更方便
C.汇编语言和机器语言都与计算机系统结构相关
D.不能直接用机器语言(机器指令)编写程序
4以下有关机器指令和汇编指令的叙述中,错误的是( C )。
A.汇编指令中用十进制或十六进制表示立即数
B.汇编指令中用符号表示操作码和地址码
C.机器指令和汇编指令都能被计算机直接执行
D.机器指令和汇编指令一一对应,功能相同
5以下有关使用高级编程语言编写和开发软件的叙述中,错误的是( C )。
A.须有程序员与计算机交互的用户接口,即GUI或CUI
B.须有一个翻译或转换程序,即编译器或解释器
C.须程序员在应用程序中直接控制外设进行输入/输出
D.须有一套工具软件或集成开发环境,即语言处理系统
6一个完整的计算机系统包括硬件和软件。软件又分为( A )。
A.系统软件和应用软件
B.低级语言程序和高级语言程序
C.操作系统和语言处理程序
D.操作系统和高级语言
7以下给出的软件中,属于系统软件的是( A )。
A.Windows XP
B.MS Word
C.RealPlayer
D.金山词霸
8以下有关指令集体系结构的叙述中,错误的是( D )。
A.指令集体系结构位于计算机软件和硬件的交界面上
B.指令集体系结构的英文缩写是ISA
C.指令集体系结构是指低级语言程序员所看到的概念结构和功能特性
D.通用寄存器的长度、功能与编号不属于指令集体系结构的内容
9以下有关计算机系统层次结构的叙述中,错误的是( A )。
A.应用程序员工作在指令集体系结构层,需要对底层很熟悉
B.OS是对ISA和硬件的抽象,程序员通过OS使用系统资源
C.ISA是对硬件的抽象,软件通过ISA使用硬件提供的功能
D.最上层是提供给最终用户使用的应用程序(软件)层
10以下术语中,不属于计算机中硬件(即物理上实际存在的部件)的是( D )。
A.程序计数器(PC)
B.数据通路
C.算术逻辑部件
D.指令字
第二周 数据的表示和存储
- 第1讲 数制和编码
- 附录十进制转换为二进制、八进制、十六进制实例
- 第2讲 定点数的编码表示
- 第3讲 C语言中的整数
- 第4讲 浮点数的编码表示
- 第5讲 非数值数据的编码表示
- 第6讲 数据宽度和存储容量的单位
- 第7讲 数据存储时的字节排列
- 第二周小测验
第1讲 数制和编码
1. 10进制数和2进制数(19分钟)
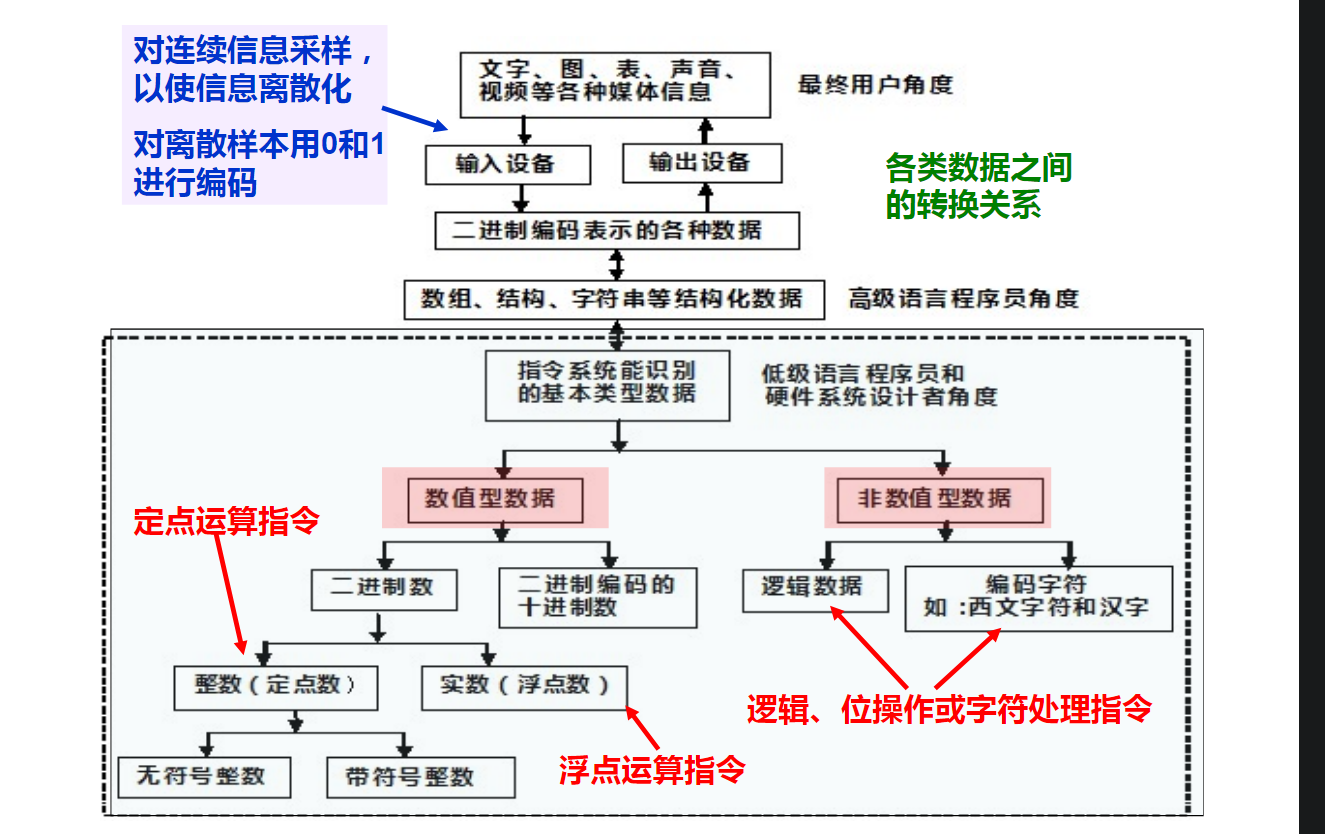
文字、音频和视频等感觉媒体信息通过某种数字化方法被输入到计算机中就变成了用0/1表示的数字信息
在高级语言程序中出现的数据(变量或字面量)都是一种用0/1表示的数字信息
浮点运算指令中的操作数一定是浮点数,定点运算指令中的操作数一定是定点数



2. 2/8/10/16进制数之间的转换(20分钟)

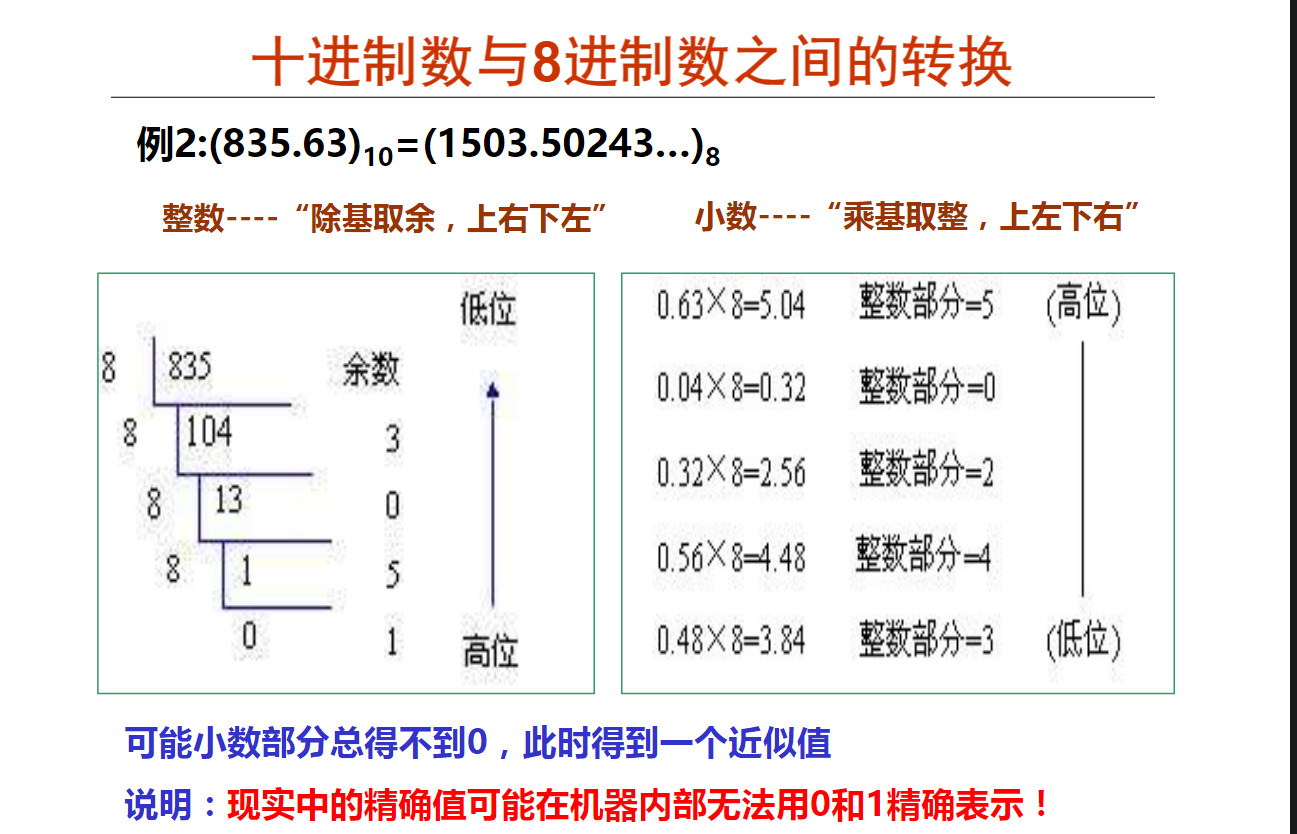
在计算机内部,一个浮点数可以用数的符号和两个定点数来表示。

附录十进制转换为二进制、八进制、十六进制实例
1、十进制转二进制
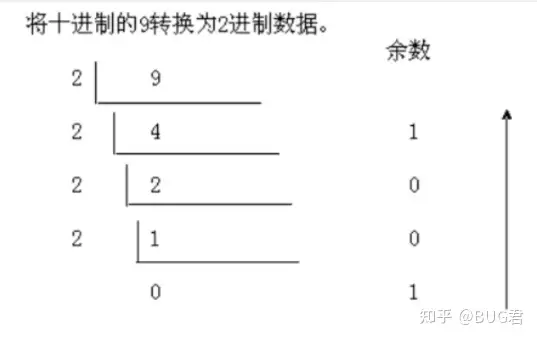
(1)十进制整数转二进制的转换原理:除以2,反向取余数,直到商为0终止。具体做法:
将某个十进制数除2得到的整数部分保留,作为第二次除2时的被除数,得到的余数依次记下,重复上述步骤,直到整数部分为0就结束,将所有得到的余数最终逆序输出,则为该十进制对应的二进制数。
例如:9(十进制)→1001(二进制)
(2)十进制小数转换成二进制小数采用 “乘2取整,顺序输出” 法。
例题: 0.68D = ______ B(精确到小数点后5位)
如下所示,0.68乘以2,取整,然后再将小数乘以2,取整,直到达到题目要求精度。得到结果:0.10101B.
例如:十进制小数0.68转换为二进制数
具体步骤:
0.68* 2=1.36 -->1
0.36* 2=0.72 -->0
0.72* 2=1.44 -->1
0.44* 2=0.88–>0
0.88* 2=1.76 -->1
已经达到了题目要求的精度,最后将取出的整数部分顺序输出即可
则为:0.68D–>0.10101B
2、十进制转八进制
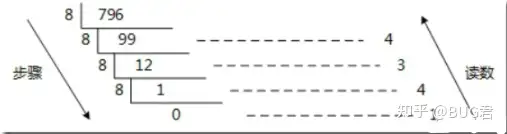
(1)十进制整数转八进制整数原理:除以8,反向取余数,直到商为0终止。具体步骤与二进制一样。例如:十进制数796转换成八进制数:
将796除8取得第一个余数为4,将除8得到的整数部分99作为第二次的被除数,重复上述步骤,直至最终整数部分为0就结束。将取得的所有余数逆序输出
则为:796–>1434
(2)十进制小数转换成八进制小数采用 “乘8取整,顺序输出” 法。思路和十进制转二进制一样,参考如下例题:
例题: 10.68D = ______ Q(精确到小数点后3位)
解析:如下图所示,整数部分除以8取余数,直到无法整除。小数部分0.68乘以8,取整,然后再将小数乘以8,取整,直到达到题目要求精度。得到结果:12.534Q.例如:十进制数10.68转换成八进制数,分为整数部分和小数部分求解
步骤:
(1)整数部分
10/8=1 -->2
1/8=0 -->1
倒序输出为12
(2)小数部分
0.68* 8=5.44 -->5
0.44* 8=3.52 -->3
0.52* 8=4.16 -->4
已经达到了题目要求的精度,即可结束
则小数部分为:0.68–>0.534
因此10.68D -->12.534Q
3、十进制转十六进制
(1)十进制整数转十六进制整数原理:除以16,反向取余数,直到商为0终止。具体步骤也和二进制、八进制一样,重复上述做法即可得到十六进制数。
例如:十进制数796转换为十六进制数,即为:796–>31c
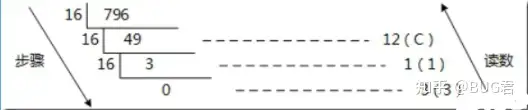
需要注意的是,十六进制数是由0-9和A-F(或者a-f)组成的,A相当于十进制中的10,B相当于11,依次类推,F相当与15,上述事例中取得的余数12即为十六进制中的c
总结:以上几种进制的整数部分转换原理都是除进制数取余数,倒序输出
(2)十进制小数转十六进制小数原理:十进制小数转换成十六进制小数采用 “乘16取整,顺序输出” 法。思路也是一样的,就不重复了。
例题: 25.68D = ______ H(精确到小数点后3位)
解析:如下图所示,整数部分除以16取余数,直到无法整除。小数部分0.68乘以16,取整,然后再将小数乘以16,取整,直到达到题目要求精度。得到结果:19.ae1H.
(1)整数部分
25/16=1 -->9
1/16=0 -->1
倒序输出为:19
(2)小数部分
0.68* 16=10.88 -->a(即十进制中的10)
0.88* 16=14.08 -->e
0.08* 16=1.28 -->1
已经达到了要求的精度,顺序输出为:ae1
则:25.68D -->19.ae1H
总结:小数部分转换原理都是乘进制数取整数部分,再将整数部分顺序输出。
第2讲 定点数的编码表示
1. 原码和移码表示 (10分钟)
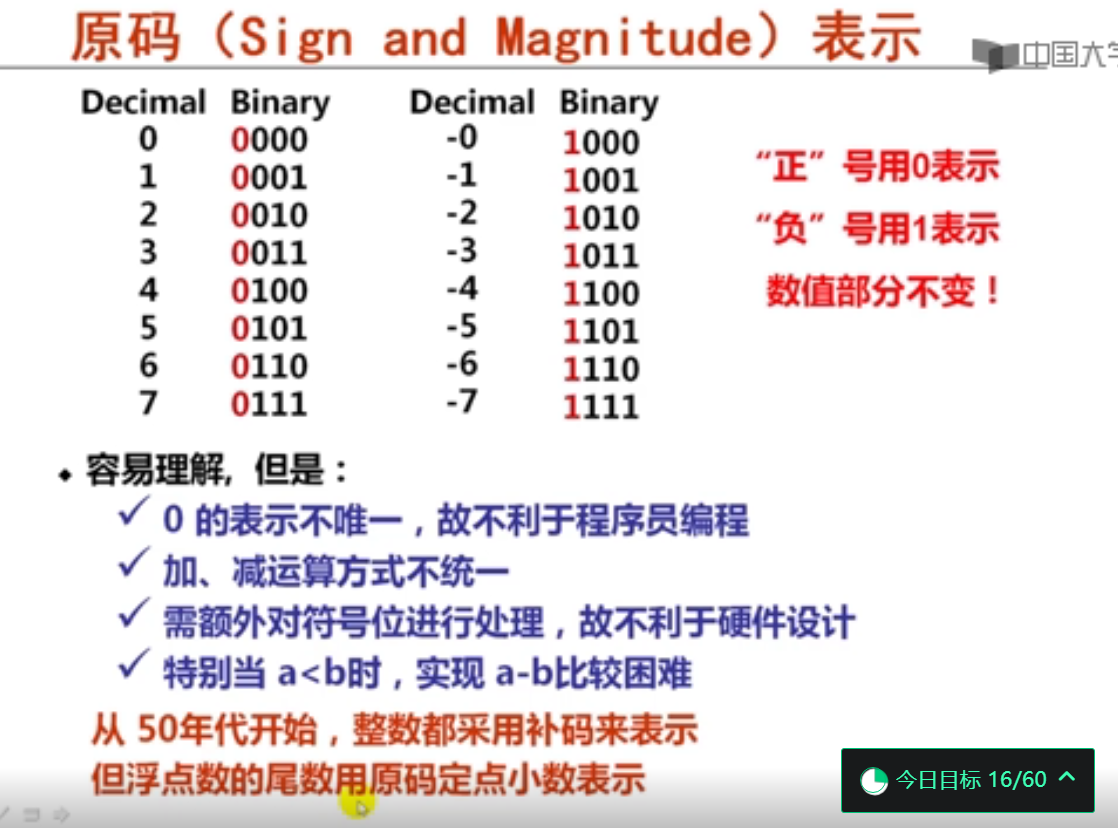

例如:1.01x2^{-5}+1.11x2^3中编码位数为4即阶数要加8
2. 模运算系统和补码表示(17分钟)

钟表系统的模是12,若当前时针指向11点,则顺时针拨动5格与逆时针拨动7格的结果相同,都是指向4点。
在只有4档的算盘中,若用加法实现减法运算的结果,则应该用6823加7044来实现6823-2956,结果为3867。
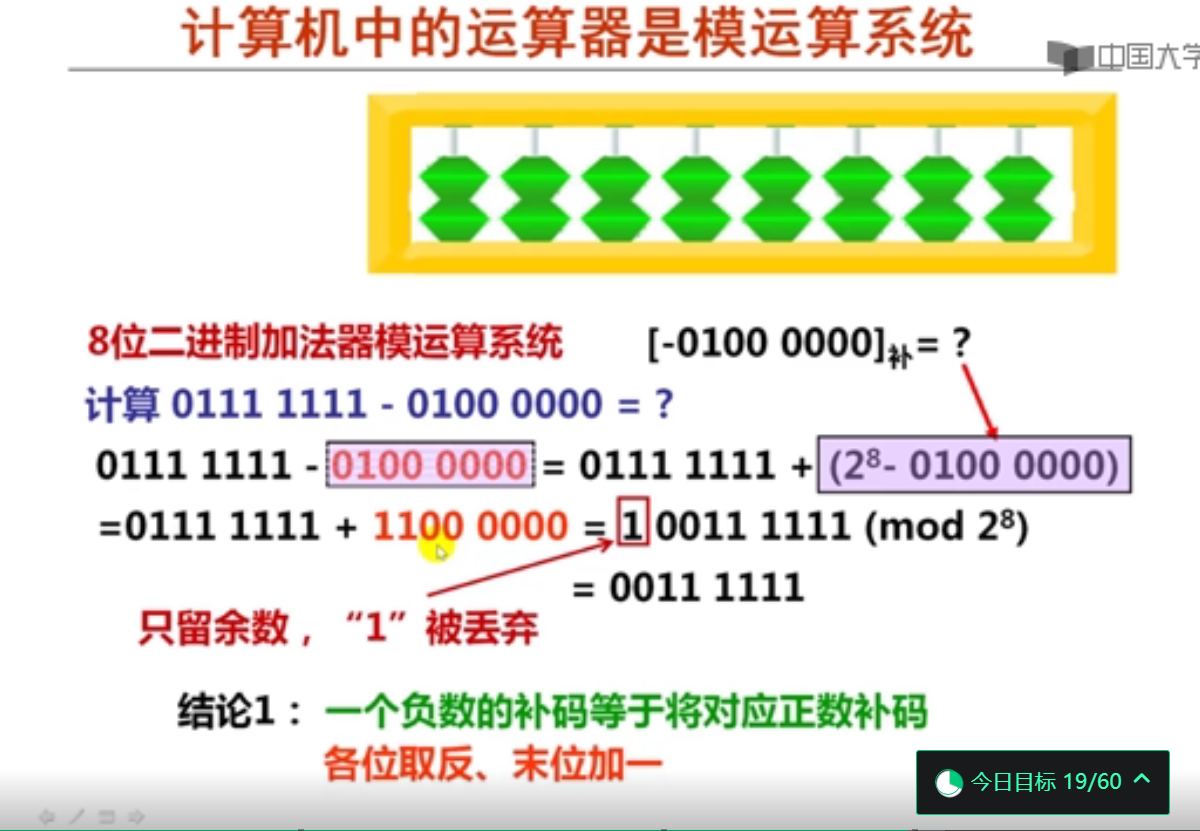
假定补码位数为8,二进制数-1000的补码表示为( 1111 1000 )。
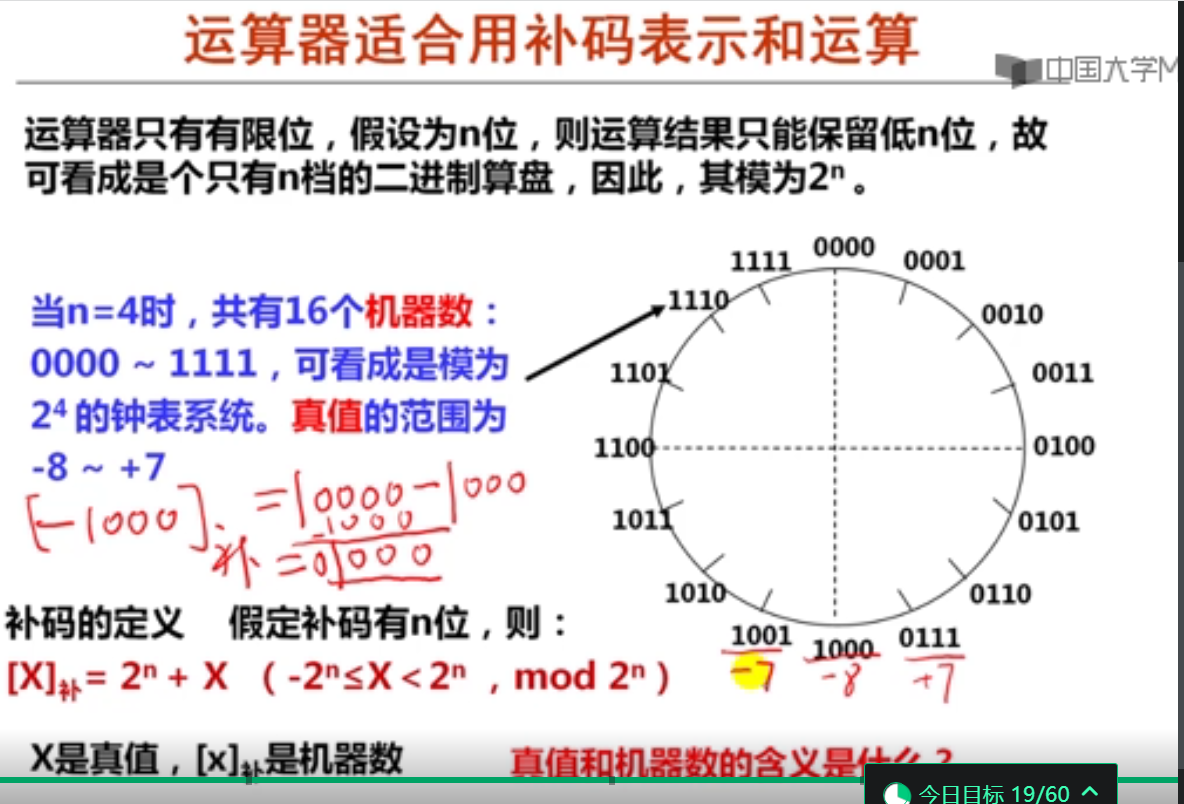
3. 补码和真值的对应关系(19分钟)

在32位机器中,一个int型变量的值为-1,则机器数为( 1111 1111 1111 1111 1111 1111 1111 1111 )。
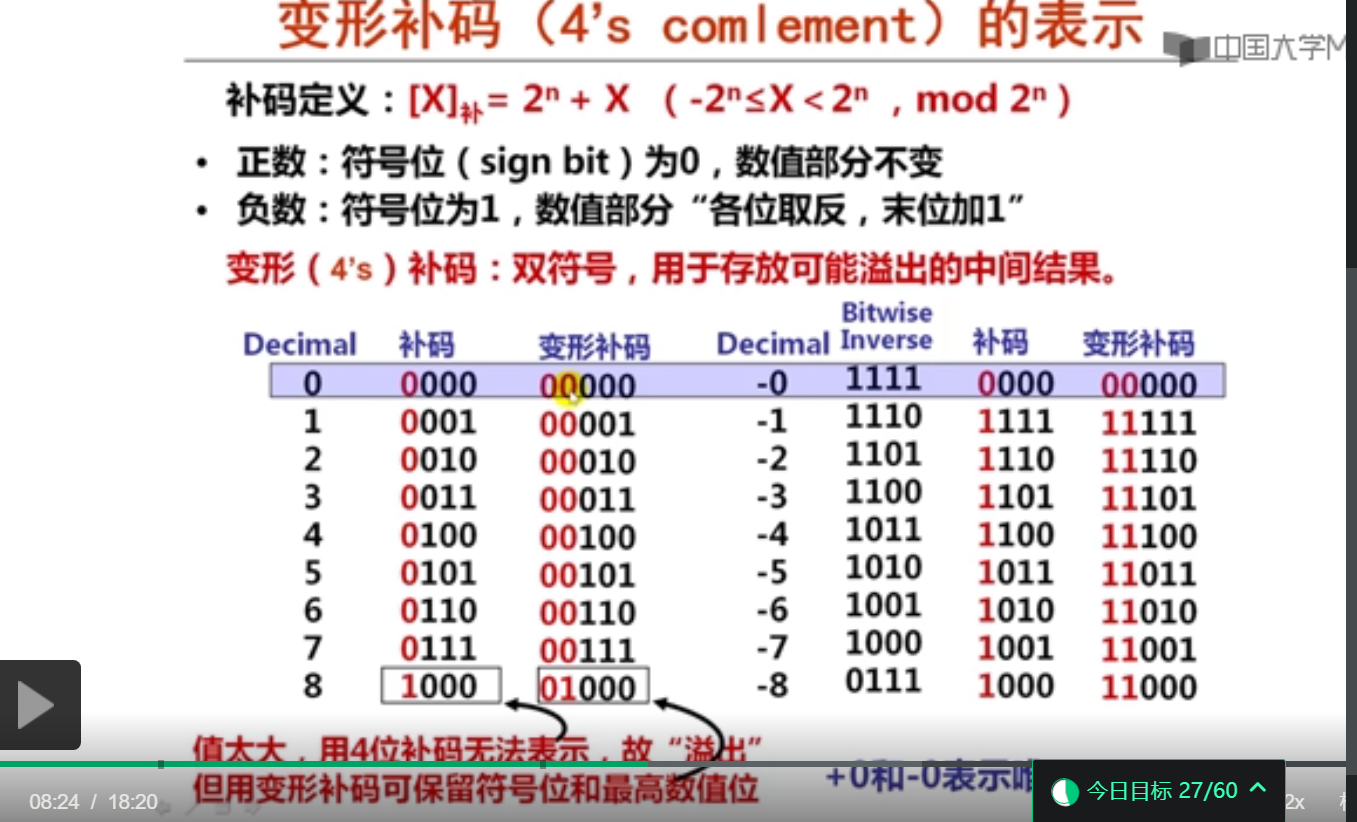
变形补码(4’ complement)采用双符号位表示。例如-100的8位变形补码表示为10011100。-100的8位变形补码高两位不同,是溢出形式。

-123的16位补码表示为( 1111 1111 1000 0101B 或FF85H )。

8位补码表示11010111对应的真值是( -41 )。
第3讲 C语言中的整数
1. 无符号整数和带符号整数 (15分钟)

16位无符号整数中的最大数是( 65535 )。


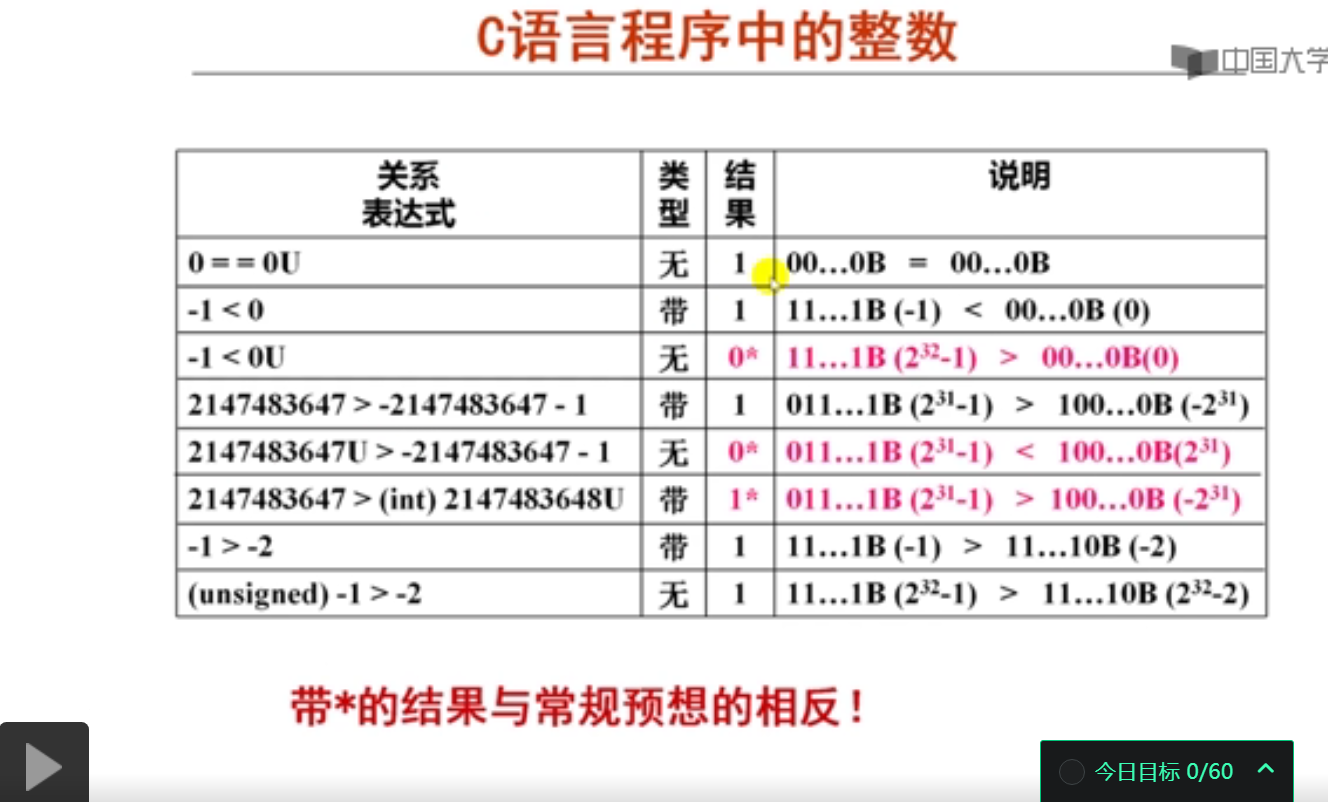
已知2147483647为2^31-1, C语言中的关系表达式"2147483647U>-2147483647-1"的结果是( 假 )。
测试代码:
#include <stdio.h>
int main()
{
printf("%d",(unsigned)-1>-2);//输出1
return 0;
}
#include <stdio.h>
int main()
{
printf("%d",-1<0u);//输出0
return 0;
}
#include <stdio.h>
int main()
{
printf("%d",2147483647>-2147483647-1);//输出1
printf("%d",2147483647u>-2147483647-1);//输出0
printf("%d",2147483647>(int)2147483648u);//输出1
return 0;
}
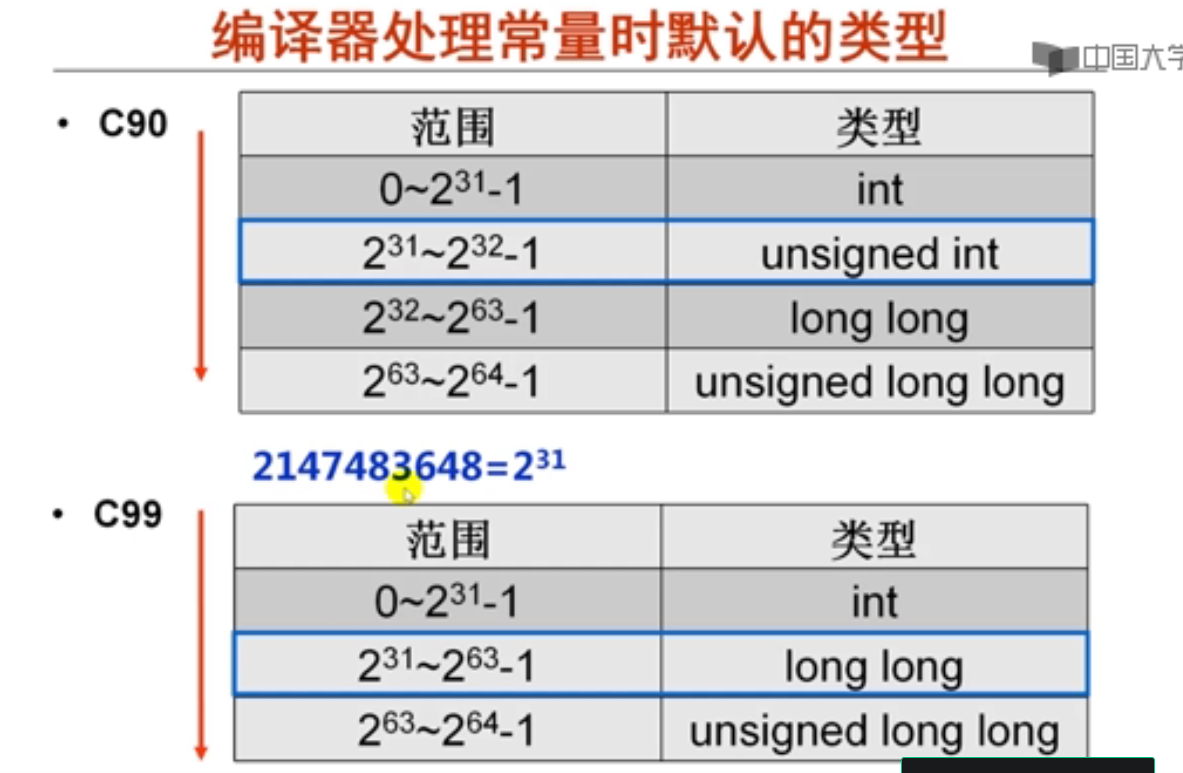
2. C语言程序中整数举例(16分钟)

4294967295=2^32-1
2147483647=2^31-1
最小负数这里表示需要用到4's complement方式。
测试实例:
#include <stdio.h>
int main()
{
int x=-1;
unsigned u=2147483647;
printf("%d\n",2147483647>-1);
printf("x=%u=%d\n",x,x);
printf("u=%u=%d\n",u,u);
return 0;
}
1
x=4294967295=-1
u=2147483647=2147483647
#include <stdio.h>
int main()
{
int x=-1;
unsigned u=2147483648;
printf("%d\n",2147483648>-1);
printf("%d\n",u>x);
printf("x=%u=%d\n",x,x);
printf("u=%u=%d\n",u,u);
return 0;
}
1
0
x=4294967295=-1
u=2147483648=-2147483648

#include <stdio.h>
int main()
{
printf("%d\n",-2147483648>2147483647);//输出0
return 0;
}
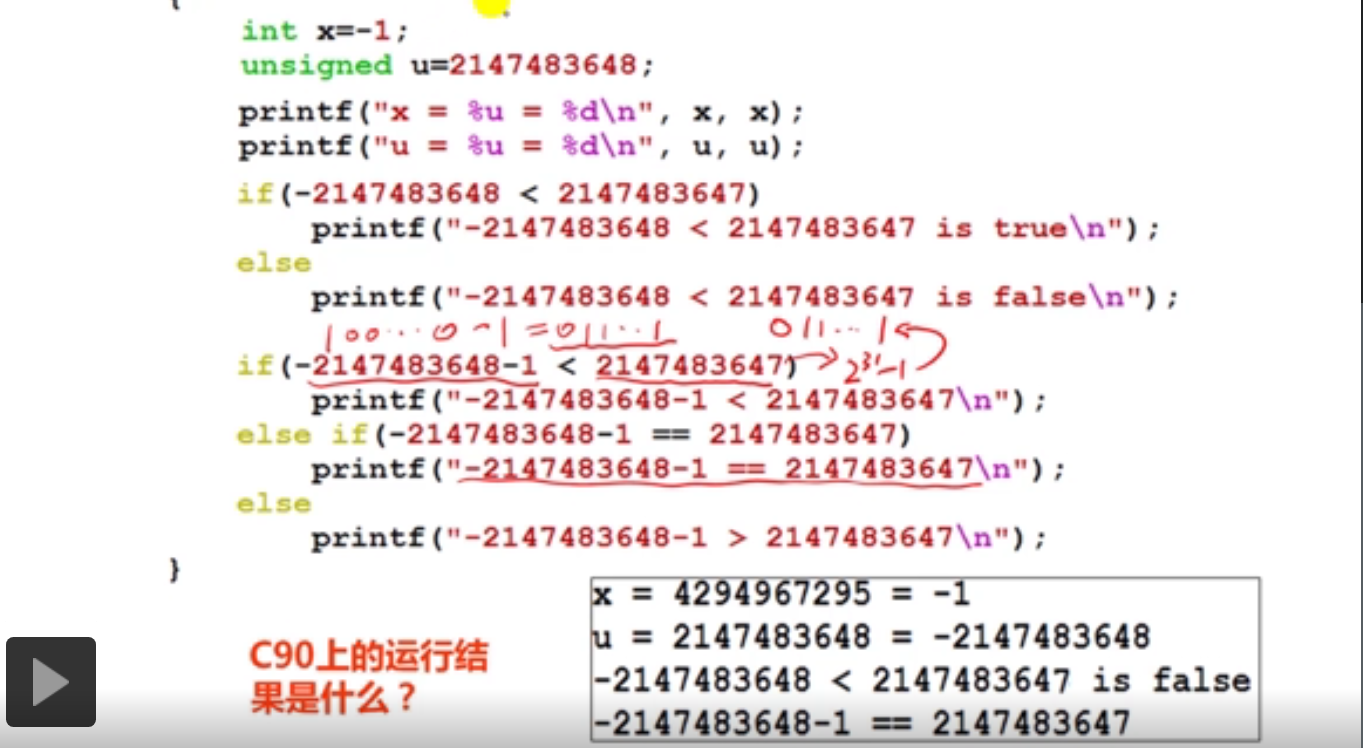
在c99上测试结果如下:
#include <stdio.h>
int main()
{
int x=-1;
unsigned u=2147483648;
printf("x=%u=%d\n",x,x);
printf("u=%u=%d\n",u,u);
if(-2147483648<2147483647)
printf("-2147483648<2147483647 is true\n");
else
printf("-2147483648<2147483647 is false\n");
if(-2147483648-1<2147483647)
printf("-2147483648-1<2147483647 is true\n");
else if(-2147483648-1==2147483647)
printf("-2147483648-1==2147483647 is true\n");
else
printf("-2147483648-1<2147483647 is false\n");
return 0;
}
x=4294967295=-1
u=2147483648=-2147483648
-2147483648<2147483647 is true
-2147483648-1<2147483647 is true
#include <stdio.h>
int main()
{
int x=-2;
unsigned u=2147483648;
printf("x=%u=%d\n",x,x);
printf("u=%u=%d\n",u,u);
return 0;
}
x=4294967294=-2
u=2147483648=-2147483648
产生u=2147483648=-2147483648的原因是2^31的二进制表示为1+31个0,按位取反最后加1,得到的补码也为1+31个0。由补码转为有符号真值时先取出符号位1,数值位按位取反最后加一,结合4's complement表示为1+1+31个0,即为-2^31。
第4讲 浮点数的编码表示
1. 浮点数的表示范围(17分钟)

浮点数由一个定点整数加一个定点小数表示。


以下关于浮点数表示格式的叙述中,错误的是( C )。
A.浮点数的表示范围主要由其阶码E的位数确定
B.浮点数的表示精度主要由其尾数M的位数确定
C.若运算的结果位于浮点数表示的上溢区,则说明其值大于最大可表示数
D.若运算的结果位于浮点数表示的下溢区,则说明其值位于0的附近,可近似表示成0
注:
补码规格化数的符号位和最高有效位相反
补码表示尾数时,“1”而以后各位全为“0”刚好代表 -1/2
为了机器判断方便,往往不把-1/2列入规格化的数,因此,机器只要判断运算结果的尾数最高位(数符)与尾数次高位(第一有效位)是否相同,便可以判断是否是规格化的数。
1.1000是个特例,不把它作为规格化数,是为了方便机器判断。
我们规定负数的补码表示形式为1.0xxxxx的形式,因为这种表示方式便于计算机判断它是否规格化了。
因为浮点数的加减运算都用补码,双符号位比单符号位更加利于检验,所以双符号位的补码形式常用于规格化中。
浮点数的尾数规格化规则
| - | 单符号位 | 双符号位 |
|---|---|---|
| 正数原码 | 0.1xxx | 00.1xxx |
| 正数补码 | 0.1xxx | 00.1xxx |
| 负数原码 | 1.1xxx | 11.1xxx |
| 负数补码 | 1.0xxx | 11.0xxx |
双符号位满足:原码部分第一个数值位都是1,补码的话符号位和第一个数值位都相反。
规格化的尾数必须保证尾数的最高数位必须是一个有效值(除去符号位)
所以按照如下法则判断即可。
原码表示的尾数判断浮点数是否规格化:第一个数值位是否为“1”,是,规格化;否,非规格化
**补码表示的尾数判断浮点数是否规格化:符号位与第一个数值位是否相异,是,规格化;否,非规格化(-1/2除外) **
例题:10、下面尾数(1位符号位)的表示中,不是规格化的尾数的是D 。
A、010011101(原码) B、110011110(原码)
C、010111111 (补码) D、110111001(补码)
由于负数的补码是除符号位其他值按位取反最后加1所以由此可见,D的原码除符号位首位应该是0,并不符合尾数规格化。

早期,不同体系结构计算机所用的浮点数表示格式是不一样的,在不同计算机之间进行程序移植时,需要考虑浮点数格式之间的转换。
2. IEEE 754中规格化数的表示(19分钟)


课堂测试:假定某数采用IEEE 754单精度浮点数格式表示为4510 0000H,则该数的值是( 1.125×2^11 )。
实例测试:
#include <stdio.h>
#include <stdlib.h>
void getFloatBin(float num,char bin[])
{
int t=1; //用来进行按位与运算
int *f=(int*)(&num); //将float解释成int,即把float的地址转换成int*
for(int i=0;i<32;i++)
{
//从最高位开始按位与,如果结果为1,则bin[i]=1,如果为0,则bin[i]=0
//这里没有在bin存入字符,而是数字1,0
bin[i]=(*f)&(t<<31-i)?1:0;
}
}
int main()
{
float test=100;
char c[32];
printf("测试的float数为:%f\n",test);
printf("二进制表示为:");
getFloatBin(test,c);
for(int i=0;i<32;i++)
{
printf("%d",c[i]);
if(i==0)
printf(", ");
if(i==8)
printf(", ");
}
return 0;
}
测试的float数为:100.000000
二进制表示为:0, 10000101, 10010000000000000000000
Process returned 0 (0x0) execution time : 0.055 s
当输入数据为-12.75时,输出结果如下:
测试的float数为:-12.750000
二进制表示为:1, 10000010, 10011000000000000000000
Process returned 0 (0x0) execution time : 0.055 s
Press any key to continue.
3. IEEE 754中特殊数的表示(15分钟)
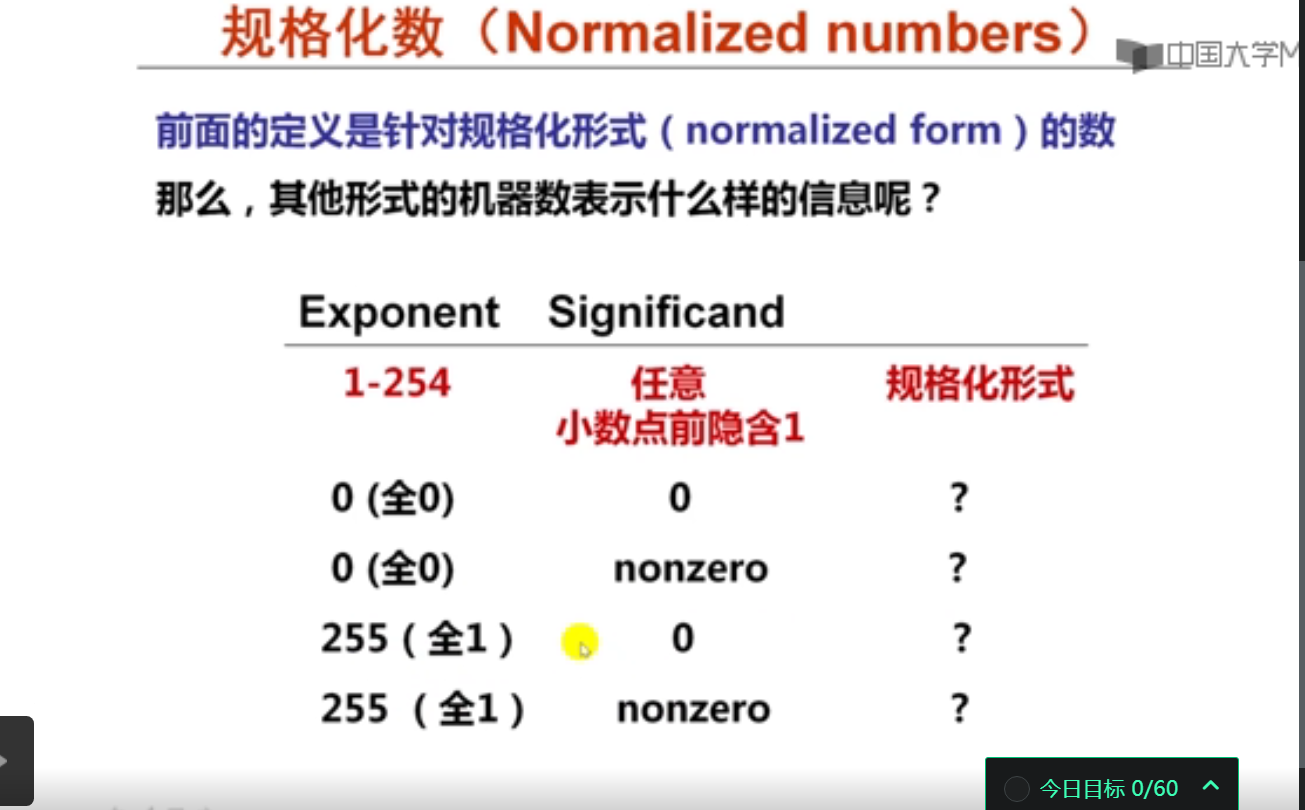
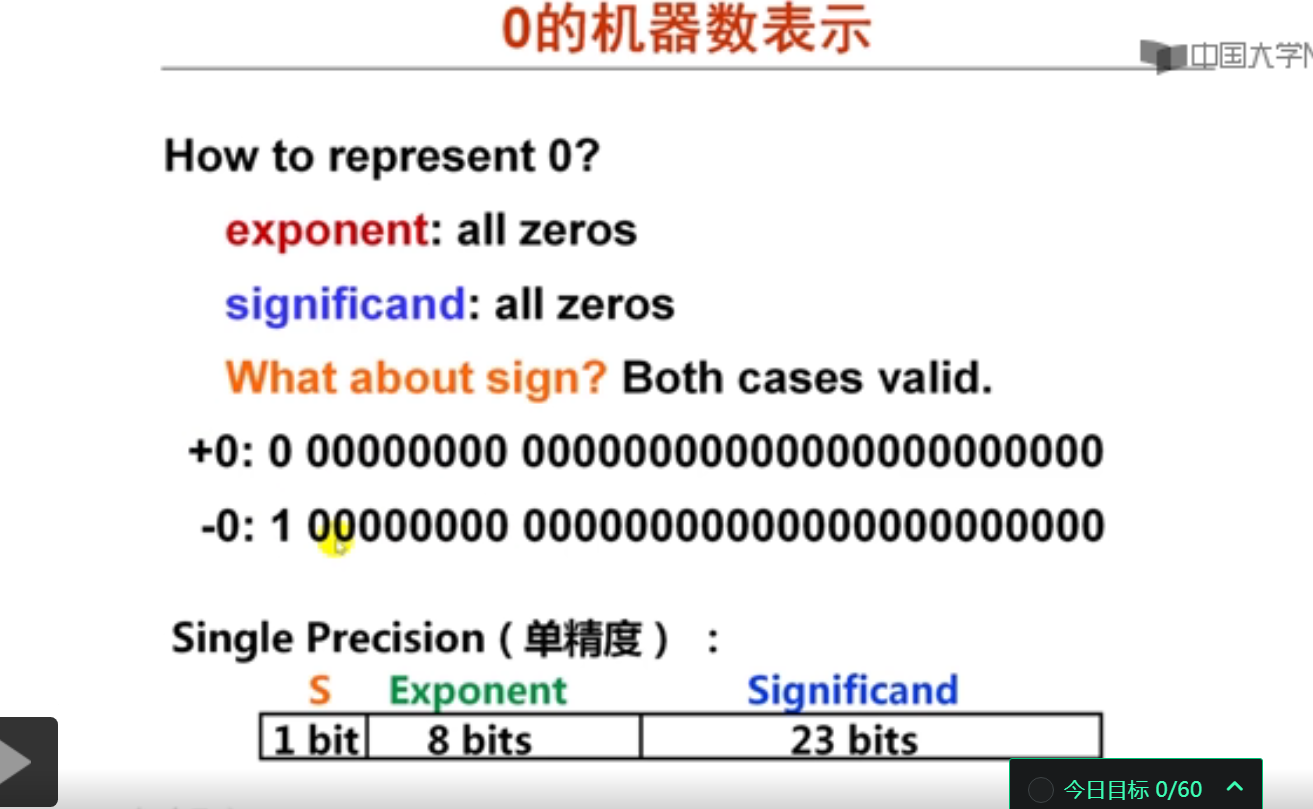

实例测试:
#include <stdio.h>
#include <stdlib.h>
int main()
{
float a=1.0,b=1000.0;
printf("%d\n",a/0>b); //输出1
printf("%d\n",a/0<b); //输出0
return 0;
}

若float型变量x=8.0,则x/0.0的值为+∞,若x=0.0,则x/0.0的值为非数(NaN)。
#include <iostream>
#include <cmath>
using namespace std;
int main()
{
cout<<"nan:"<<sqrt(-1)<<endl;
cout<<"nan:"<<log(-1.0)<<endl;
cout<<"nan:"<<0.0/0.0<<endl;
cout<<"nan:"<<0.0*sqrt(-1)<<endl;
cout<<"nan:"<<sqrt(-1)/sqrt(-1)<<endl;
cout<<"nan:"<<sqrt(-1)-sqrt(-1)<<endl;
cout<<"inf:"<<1/0.0<<endl;
cout<<"-inf:"<<-1/0.0<<endl;
cout<<"inf:"<<0.0+1/0.0<<endl;
cout<<"-inf:"<<log(0)<<endl;
cout<<"isfinite:0"<<isfinite(0.0/0.0)<<endl;
cout<<"isfinite:0"<<isfinite(1/0.0)<<endl;
cout<<"isfinite:0"<<isfinite(1.1)<<endl;
cout<<"isnormal:0"<<isnormal(0.0/0.0)<<endl;
cout<<"isnormal:0"<<isnormal(1/0.0)<<endl;
cout<<"isnormal:0"<<isnormal(1.1)<<endl;
cout<<"isinf:0"<<isinf(0.0/0.0)<<endl;
cout<<"isinf:1"<<isinf(1/0.0)<<endl;
cout<<"isinf:0"<<isinf(1.1)<<endl;
return 0;
}
nan:nan
nan:nan
nan:nan
nan:nan
nan:nan
nan:nan
inf:inf
-inf:-inf
inf:inf
-inf:-inf
isfinite:00
isfinite:00
isfinite:01
isnormal:00
isnormal:00
isnormal:01
isinf:00
isinf:11
isinf:00

阶码用移码表示,对于规格化数偏置为127,对于非规格化数偏置为126。
IEEE 754浮点数标准中,对于单精度浮点数(32位)和双精度浮点数(64位),其阶码值(exponent)的范围是一个固定长度的无符号二进制数所能表示的范围。对于单精度,阶码是8位,能表示的值的范围是0~255。对于双精度,阶码是11位,能表示的值的范围是0~2047。
然而,在IEEE 754浮点数中,阶码的0和最大值(对于单精度是255,对于双精度是2047)被保留了出来,用于表示特殊值,如无穷大、零和非规格化数等。所以,实际上,用于表示正常的浮点数的阶码范围是1~254(对于单精度)和1~2046(对于双精度)。
然后,这个范围被设计成了以一个"偏移值"(bias)为中心的负数和正数的范围。对于单精度,偏移值是127,所以实际的阶码范围是-126 ~ 127。对于双精度,偏移值是1023,所以实际的阶码范围是-1022 ~ 1023。
非规格化数是用来表示接近于0的非常小的浮点数的,其阶码被设计为0,然后根据这个偏移值的设计,它实际表示的阶码就是-126(对于单精度)或-1022(对于双精度)。这样设计的目的是为了能表示更接近于0的数。如果阶码是-127或-1023,那么这个范围就会被"浪费"在表示非常接近于0但是又不是非常接近于0的数上,这样就达不到最大化利用阶码范围的目的。
为了让非规格化单精度浮点数能够平缓过渡到规格化单精度浮点数,即,让这两大类单精度浮点数的衔接不至于“突兀”。
如果非规格化数采用-127为阶,那么对于大小在{1.000...(23 个0)~1.111...(23个1)}乘以2^-127之间的数。你就只能把他们归结到规格化的数那里去,但是这样你就发现数的定义出现了歧义,对于阶码是0,尾数非0的数,我们根本不知道他是规格化还是非规格化;同理对于0的表达也出现冲突,所以设计者把不大于【1.111...(23个)乘以2^-127】的数全部归结到非规格化数。这样可以避免阶码为0的情况下不能确定是规格化数还是非规格化数的冲突;同时对于阶码为0,尾数为0的情况,你也能知道它一定是0,而不是一个规格化数1.0000(23个0)乘以2^-127。


关于浮点数精度的一个例子:
#include <iostream>
using namespace std;
int main()
{
float heads;
cout.setf(ios::fixed,ios::floatfield);
while(1)
{
cout<<"Please input a number:";
cin>>heads;
cout<<heads<<endl;
}
}
Please input a number:61.419997
61.419998
Please input a number:61.419998
61.419998
Please input a number:61.419999
61.419998
Please input a number:61.42
61.419998
Please input a number:61.420001
61.420002
Please input a number:
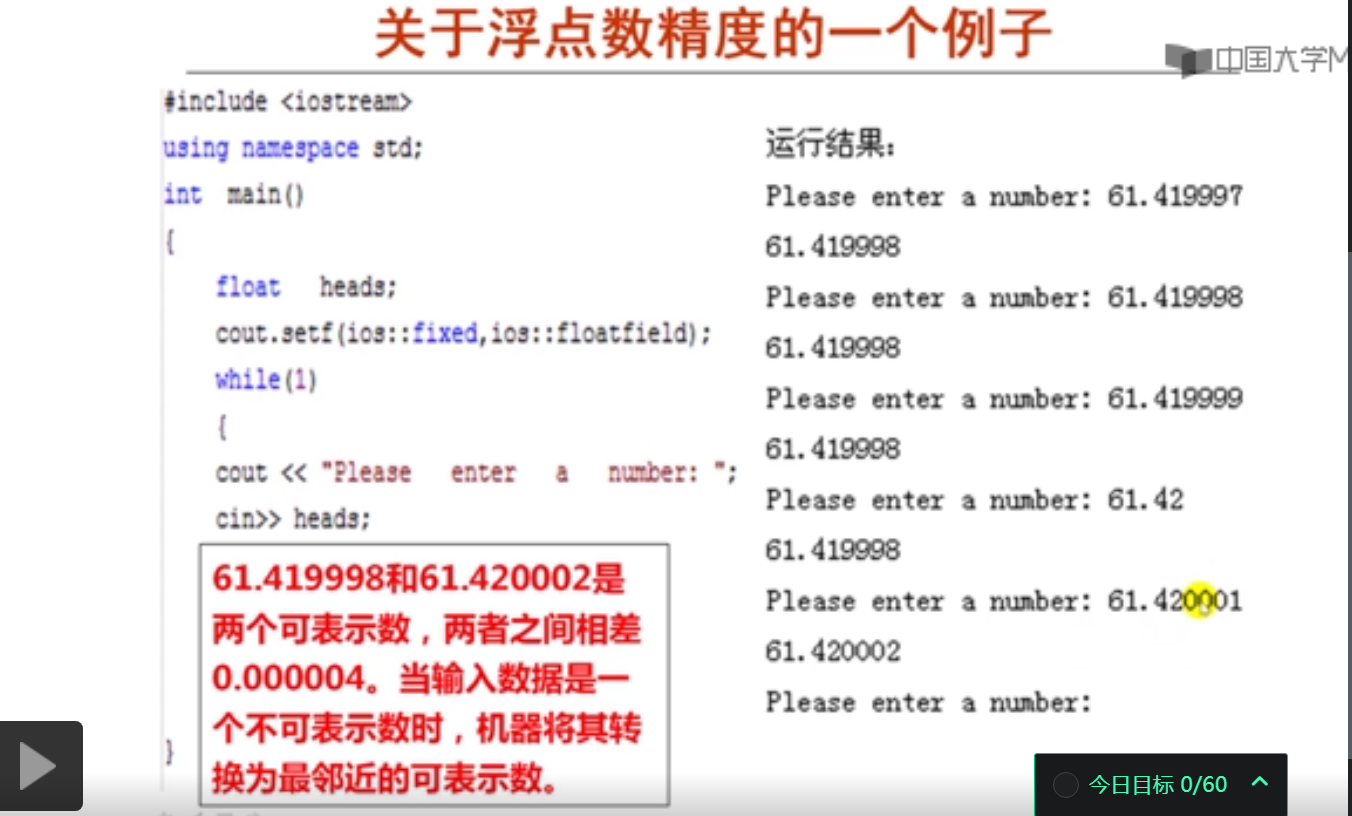
从键盘上输入61.420001赋值给一个float型变量x,再打印输出x时,其结果为61.420002。以下描述的是由此推断出的一些结论,下面三个都是正确结论。
- 由此说明能精确表示的float型数据的有效位数最多为7位。
- 由此说明32位IEEE 754单浮点数格式无法精确表示61.420001。
- 由此说明32位IEEE 754单浮点数格式能精确表示61.420002。
第5讲 非数值数据的编码表示
非数值数据的编码表示(19分钟)



西文字符没有输入码,但有内码(ASCII码),也有字模点阵和轮廓描述。

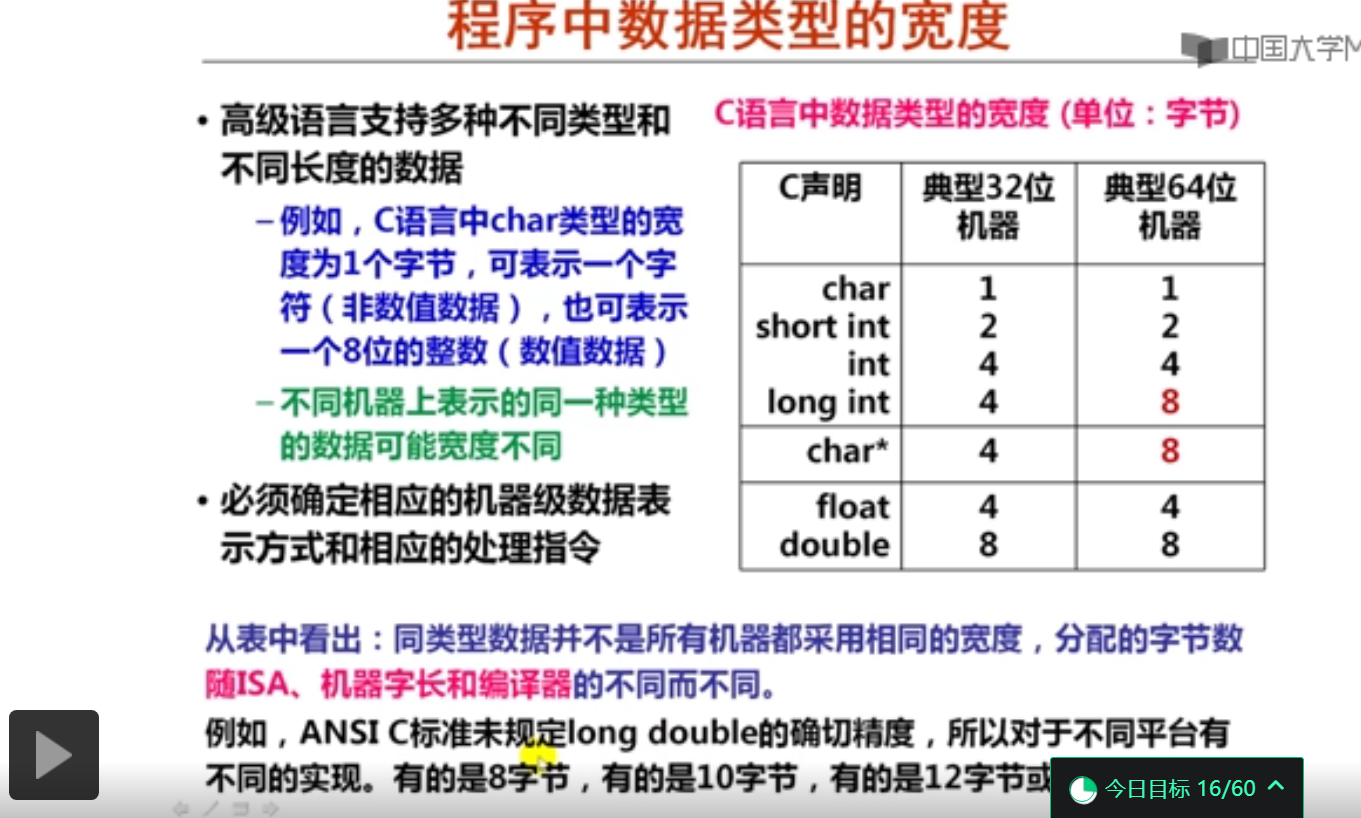
第6讲 数据宽度和存储容量的单位
数据宽度和存储容量的单位(12分钟)



第7讲 数据存储时的字节排列
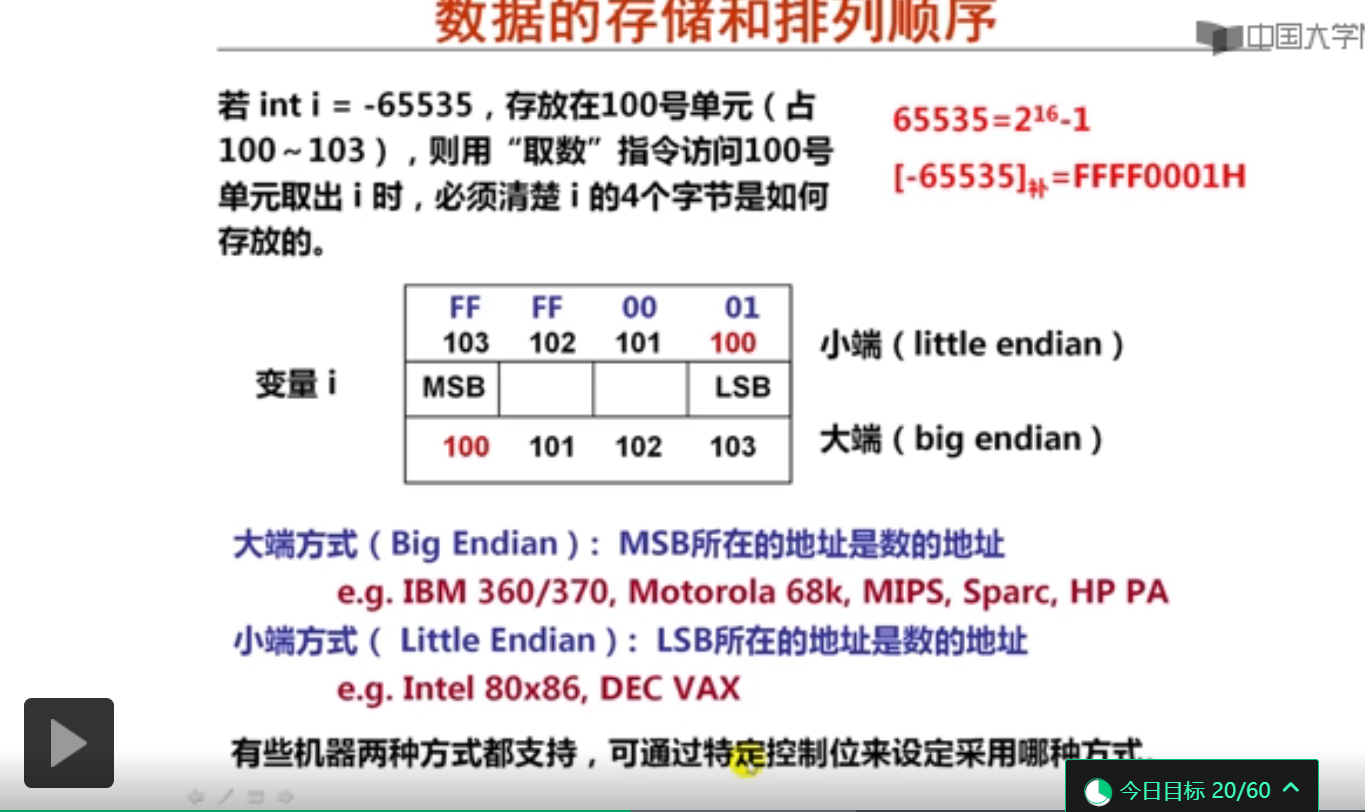
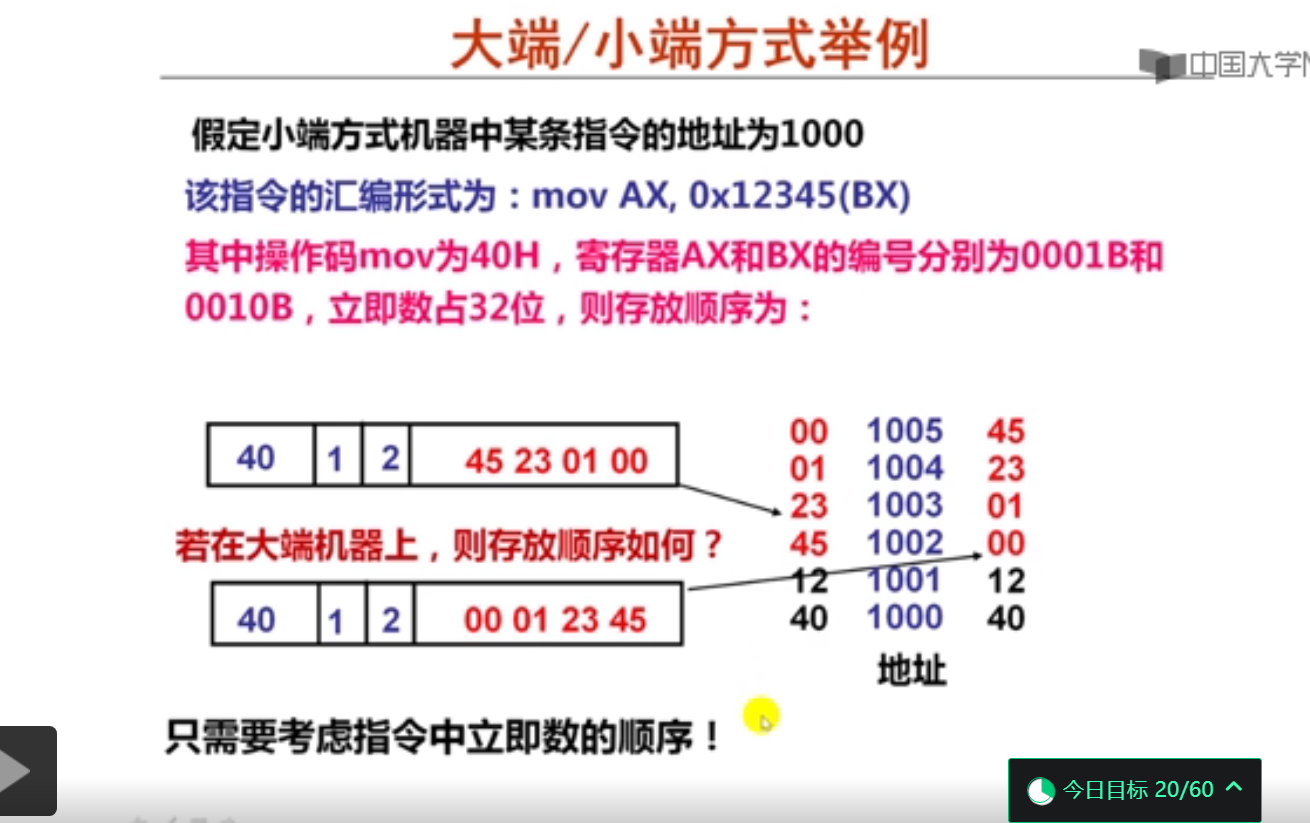
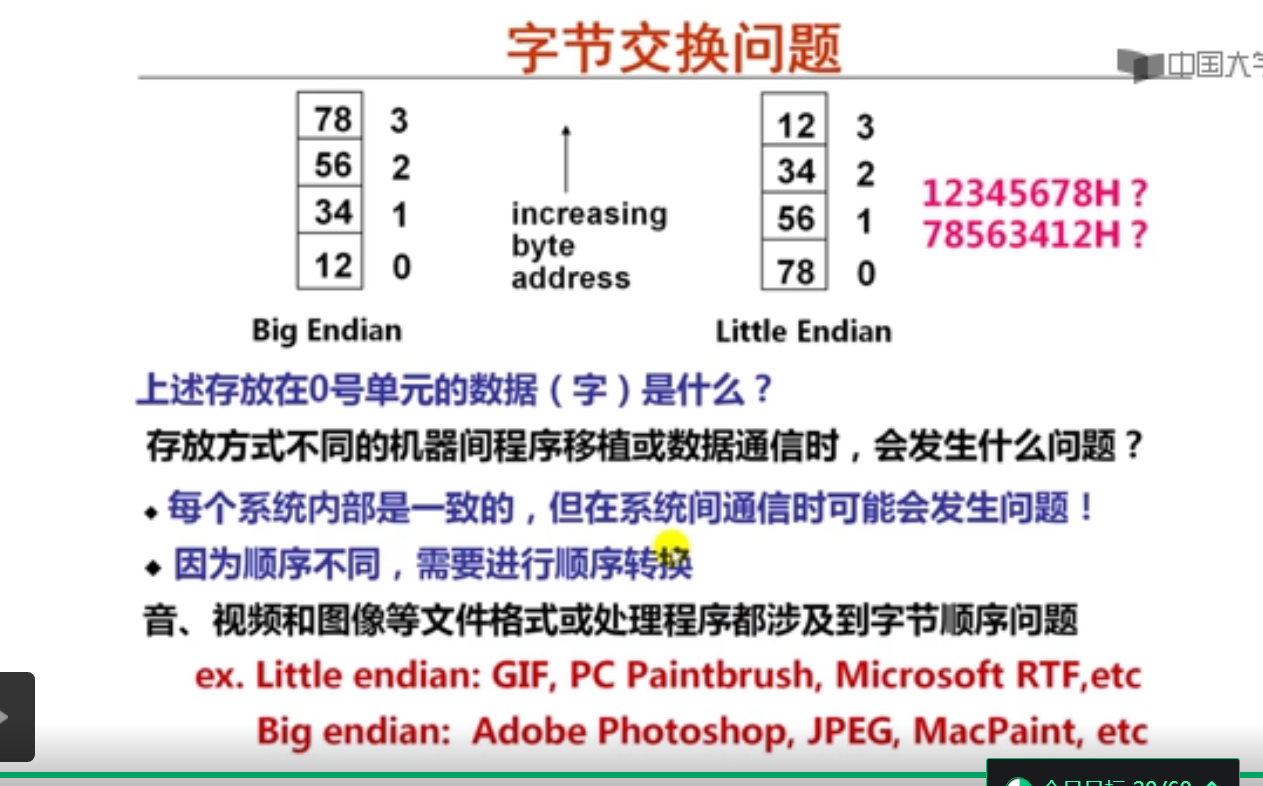
数据存储时的字节排列(20分钟)

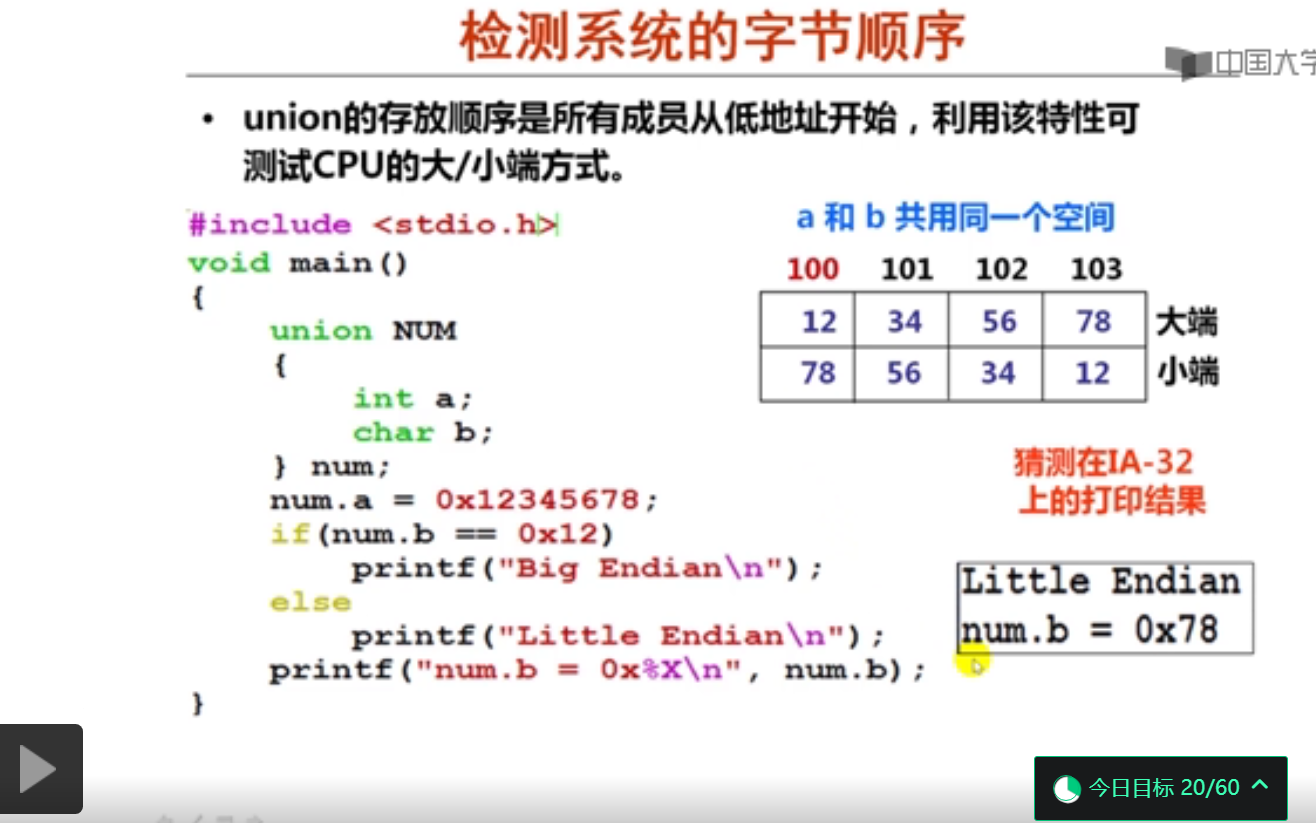
#include <stdio.h>
using namespace std;
int main()
{
union NUM
{
int a;
char b;
} num;
num.a=0x12345678;
if(num.b==0x12)
printf("Big endian!\n");
else
printf("Little endian!\n");
printf("num.b=0x%X\n",num.b);
return 0;
}
Little endian!
num.b=0x78

第二周小测验
1 108对应的十六进制形式是( B )。
A.63H
B.6CH
C.B4H
D.5CH
2 –1029的16位补码用十六进制表示为( C )。
A.0405H
B.7BFBH
C.FBFBH
D.8405H
3考虑以下C语言代码:
short si=–8196;
unsigned short usi=si;
执行上述程序段后,usi的值是( A )。
A.57340
B.8196
C.34572
D.57339
解析: A、-8196=-(8192+4)=-10 0000 0000 0100B,因此,si和usi的机器数都为1101 1111 1111 1100,按无符号整数解释,其值为65535-3-8192=65535-8195=57340。
4考虑以下C语言代码:
short si=–32768;
unsigned short usi=si;
执行上述程序段后,usi的值是( C )。
A.65536
B.–32768
C.32768
D.65535
解析: C、-32768=-1000 0000 0000 0000B,因此,si和usi的机器数都为1000 0000 0000 0000,按无符号整数解释,其值为32768。
5考虑以下C语言代码:
unsigned short usi=65535;
short si=usi;
执行上述程序段后,si的值是( D )。
A.1
B.–65535
C.65535
D.–1
解析: D、65535=1111 1111 1111 1111B,因此,usi和si的机器数都为1111 1111 1111 1111,按带符号整数解释,其值为-1。
6在ISO C90标准下执行以下关系表达式,结果为“真”的是( A )。
A.(unsigned) –1 > –2
B.2147483647 > –2147483648
C.–1 < 0U
D.2147483647 < (int) 2147483648U
解析: A、-1的机器数为全1,-2的机器数为11┅10,按无符号整数比较,显然全1比任何数大,即结果为“真”。 B、2147483647的机器数为011┅1,在C90中为int型;2147483648的机器数为100┅0,在C90中为unsigned型,-2147483648的机器数通过对100┅0各位取反末位加一得到,因此,机器数还是100┅0。011┅1和100┅0按无符号整数比较,显然011┅1比100┅0小,即结果为“假”。 C、-1的机器数为全1,按无符号整数比较,全1是最大的数,显然比0大,即结果为“假”。 D、2147483647的机器数为011┅1,在C90中为int型;2147483648的机器数为100┅0,在C90中为unsigned型,强制类型转换为int后,按带符号整数比较,显然011┅1比100┅0大,即结果为“假”。
7 –1028采用IEEE 754单精度浮点数格式表示的结果(十六进制形式)是( A)。
A.C4808000H
B.44C04000H
C.C4C04000H
D.44808000H
8假定变量i、f的数据类型分别是int、float。已知i=12345,f=1.2345e3,则在一个32位机器中执行下列表达式时,结果为“假”的是( B )。
A.f==(float)(double)f
B.f==(float)(int)f
C.i==(int)(float)i
D.i==(int)(double)i
解析: A、double型数的有效位数比float型数大得多,因而f转换为double类型后不会发生有效数字丢失。 B、f=1234.5,转换为int型数后,小数点后面的数字被丢失,因此与原来的f不相等。 C、12345<1024x16=2^14,因此,12345对应的二进制数的有效位数一定小于14,更小于IEEE 754单精度格式的有效位数24,因而转换为float型后,不会发生有效数字丢失,也即能够精确表示为float型,再转换为int型后,数值是一样的。 D、任何int型数的有效位数不会超过31位,因此都能精确转换为具有53位有效位数的double型。
9假定某计算机按字节编址,采用小端方式,有一个float型变量x的地址为0xffffc000,x=12345678H,则在内存单元0xffffc001中存放的内容是( A )。
A.01010110B
B.0101B
C.0001001000110100B
D.00110100B
解析: A、01010110B=56H,小端方式下,78H存在0xffffc000单元中,56H存在0xffffc001单元中,即结果正确。 B、因为按字节编址,所以某一个单元内存放一个8位数字。 C、因为按字节编址,所以某一个单元内只能存放8位数字。 D、00110100B=34H,小端方式下,78H存在0xffffc000单元中,34H存在0xffffc002单元中,即结果错误。
10下面是关于计算机中存储器容量单位的叙述,其中错误的是( D )。
A.最小的计量单位为位(bit),表示一位“0”或“1”
B.最基本的计量单位是字节(Byte),一个字节等于8bit
C.“主存容量为1KB”的含义是指主存中能存放1024个字节的二进制信息
D.一台计算机的编址单位、指令字长和数据字长都一样,且是字节的整数倍
第三周运算电路基础
- 第1讲 数字逻辑电路基础
- 1. 布尔代数和基本逻辑电路(16分钟)
- 2. 无符号数加法器(15分钟)
- 3. 整数加/减运算器和ALU(12分钟)
- 第2讲 从C表达式到逻辑电路
- 第3讲 C语言中的各类运算
- 第4讲 整数加减运算
- 第三周小测验
第1讲 数字逻辑电路基础
1. 布尔代数和基本逻辑电路(16分钟)
最基本的逻辑运算有与、或、非运算,异或运算表示所有变量中有奇数个1,则结果为1。
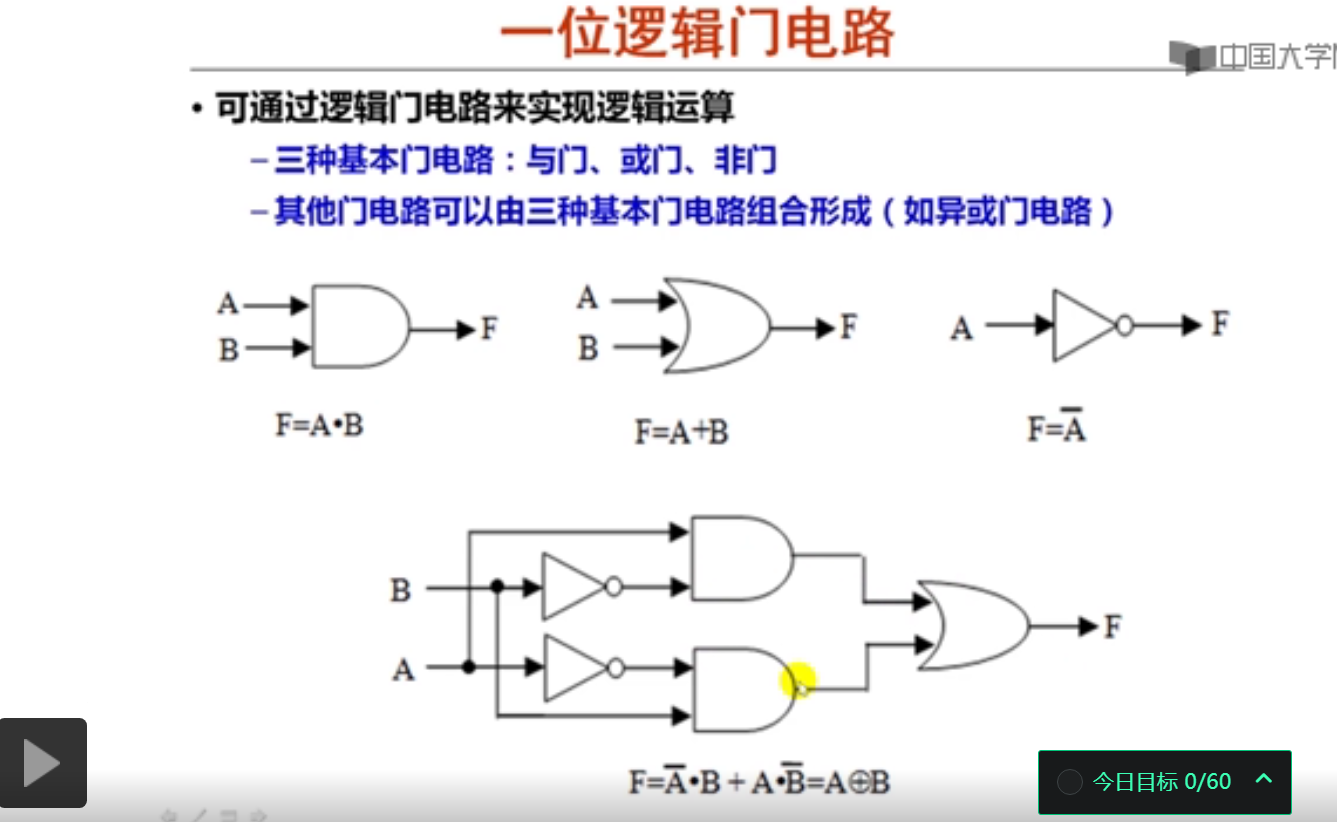

视频后面介绍的是多路复用器。
2. 无符号数加法器(15分钟)
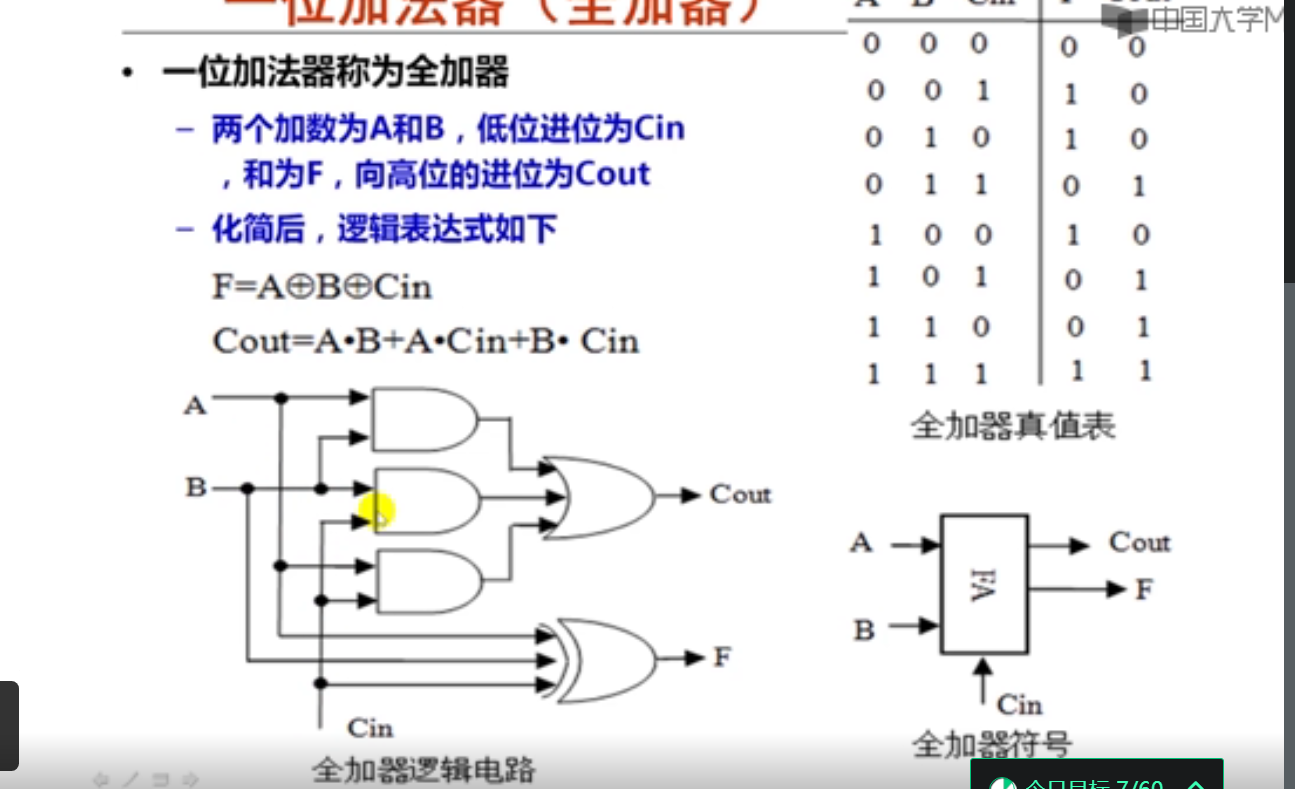
全加器(Fully adder)实现一位加运算。
只要两个输入A、B和低位进位Cin中有两个以上为1,本位向高位的进位Cout就为1。
只有当两个输入A、B和低位进位Cin中有奇数个1,本位和F才为1。
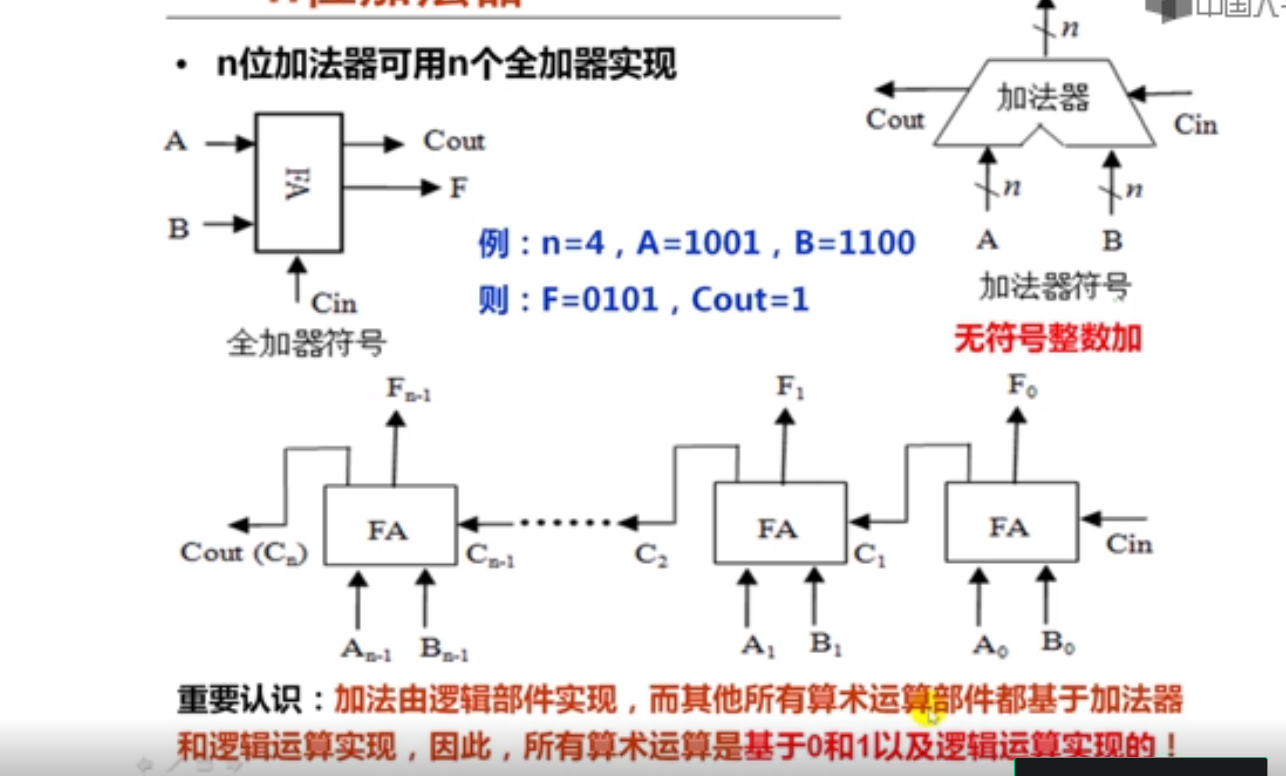
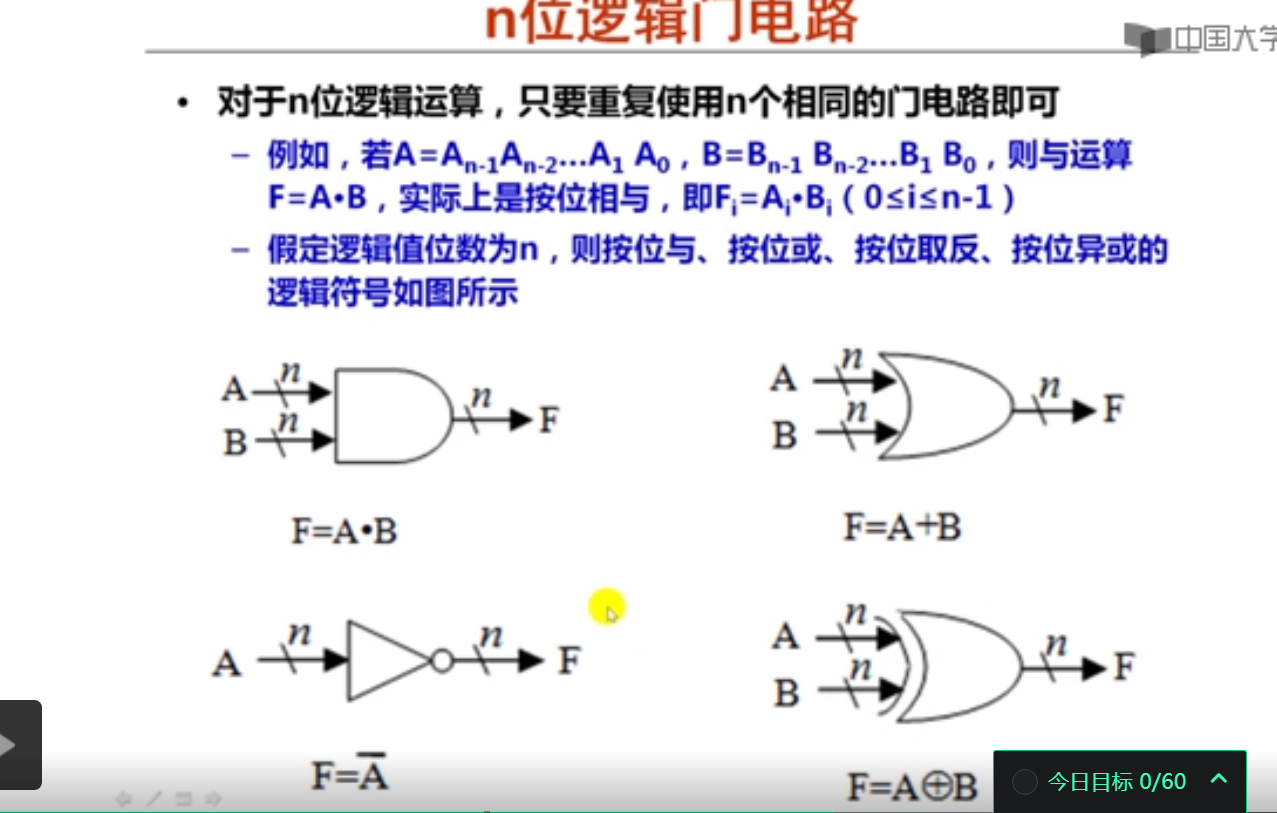
n位加法器实现的是n位无符号数的加运算。
n位加法器的输入包括一位低位进位Cin和两个n位的加数A、B。
n位加法器的输出包括一个n位的和数F和一位高位进位Cout。
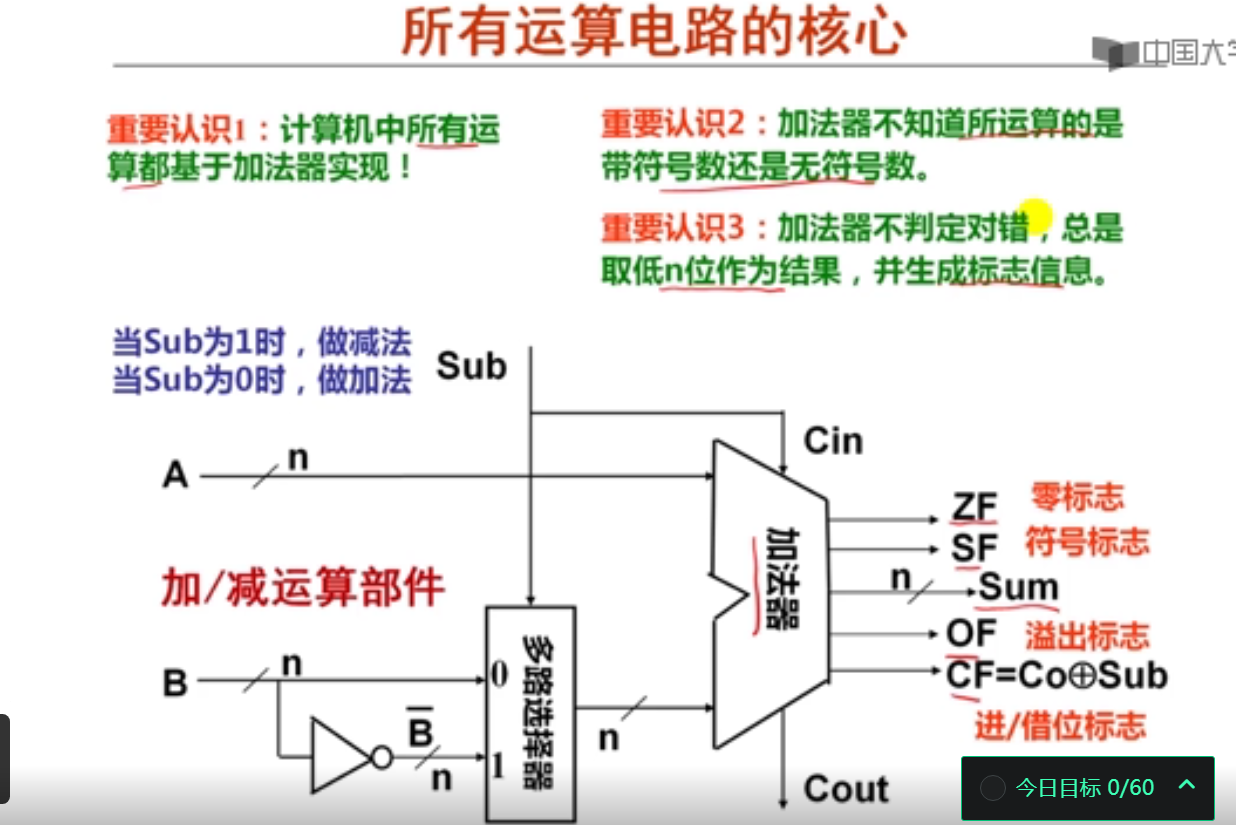
所有算术运算部件都是基于n位加法器构建的。
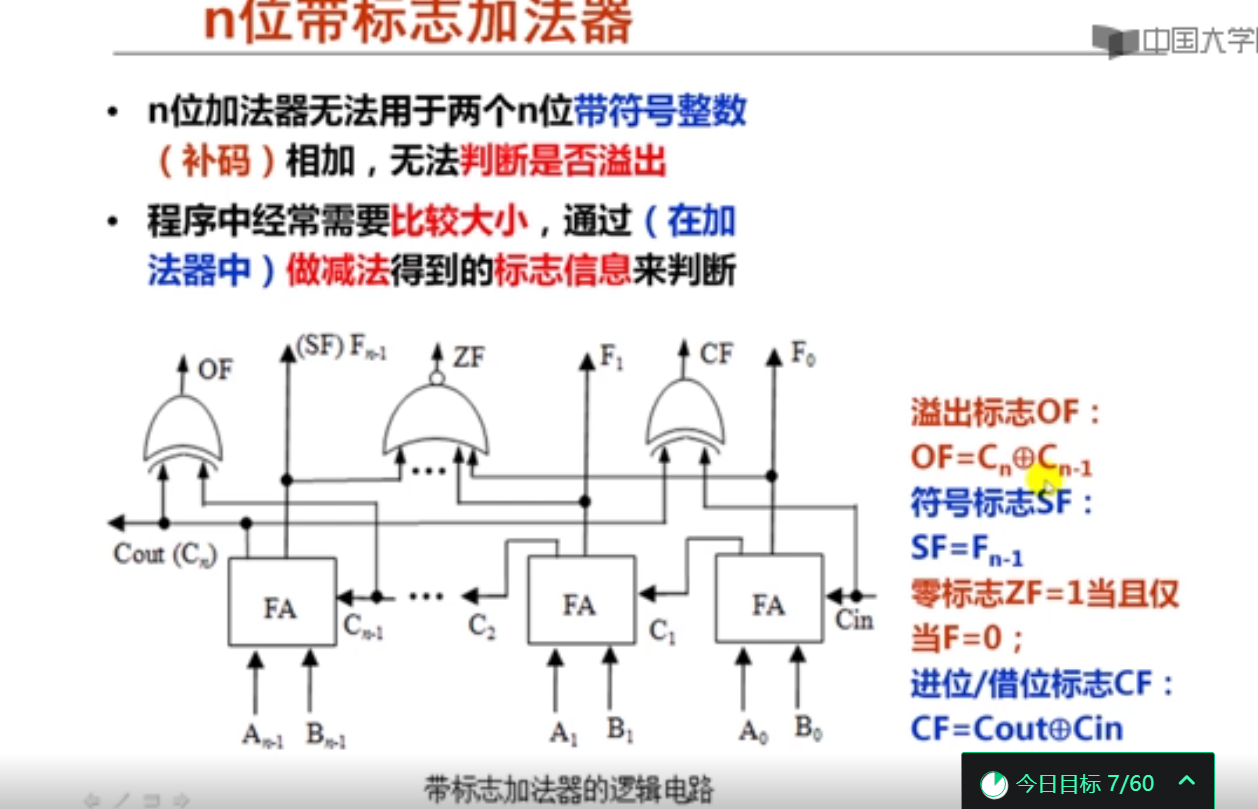
以下关于n位带标志加法器的叙述中,错误的是( D )。
A.n位带标志加法器和n位加法器一样,都可用于实现两个n位无符号数的加运算。
B.n位带标志加法器的输入与n位加法器的输入完全一样,包含两个n位加数和一位低位进位。
C.n位带标志加法器的输出比n位加法器的输出多了几个标志信息。
D.通常的标志信息包括溢出标志OF、符号标志ZF、零标志SF和进位/借位标志CF。
正确说法:通常的标志信息包括溢出标志OF、符号标志SF、零标志ZF和进位/借位标志CF。
3. 整数加/减运算器和ALU(12分钟)

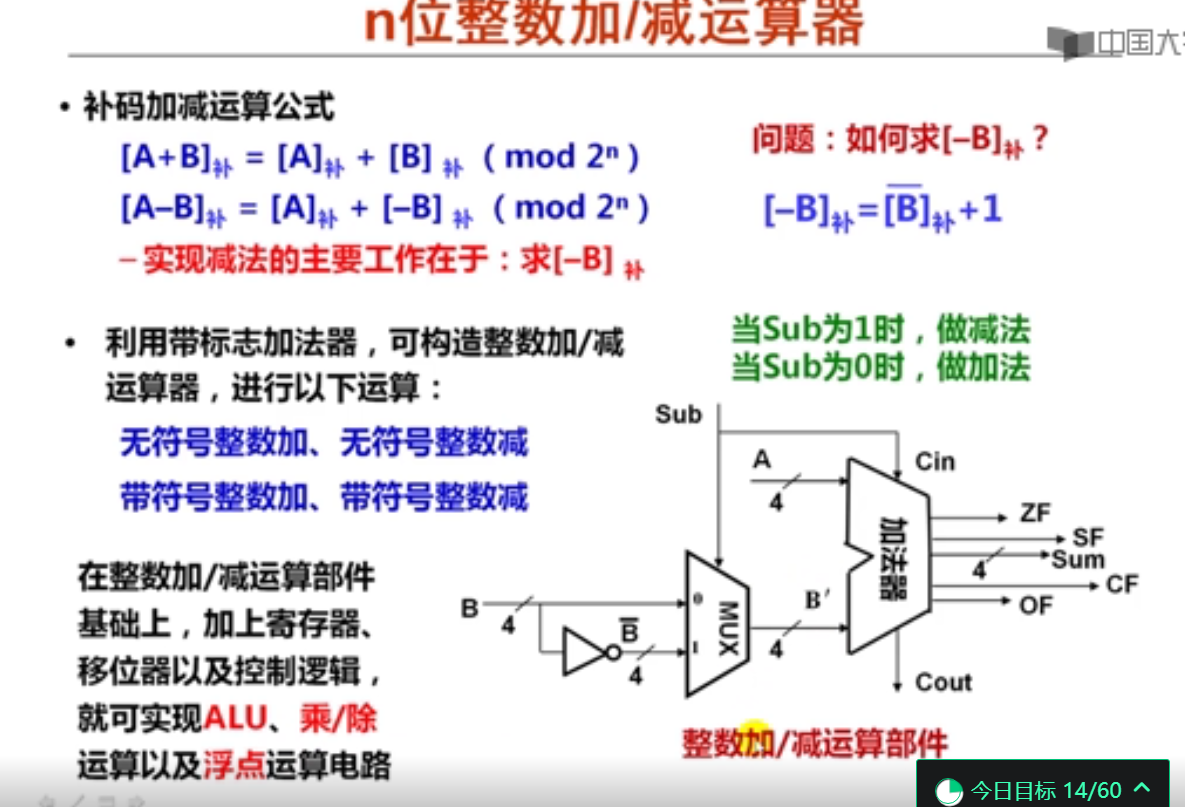
以下关于整数加/减运算器的叙述中,错误的是(B )。
A.整数加/减运算器可以实现两个补码的加/减运算。
B.整数加/减运算器不可以实现两个无符号数的加/减运算。
C.整数加/减运算器的输入为两个运算的操作数和一位控制信号sub。
D.整数加/减运算器通过输出的标志信息确定运算结果是否正确。
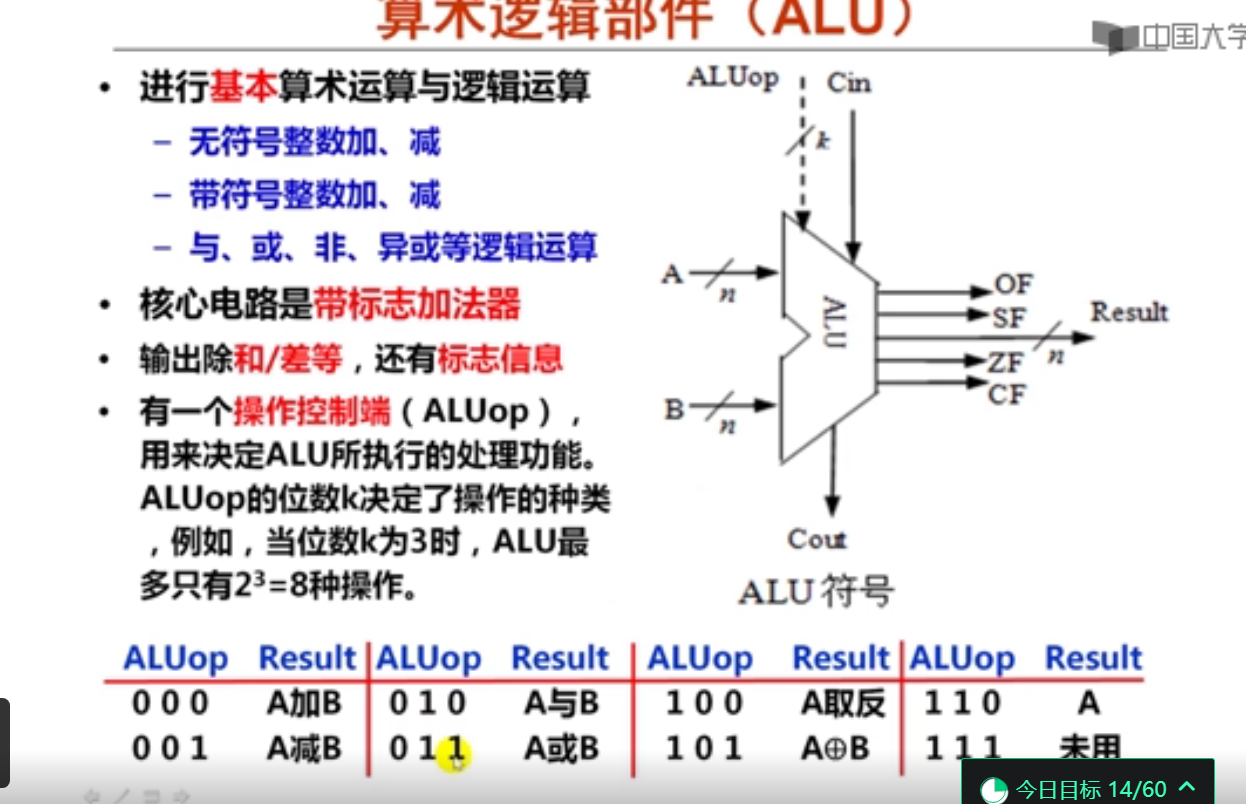
ALU可以实现与、或、非等逻辑运算。
控制端ALUop可以控制ALU实现哪种运算。
ALU是CPU中的主要运算部件之一。
第2讲 从C表达式到逻辑电路
从C表达式到逻辑电路(10分钟)


以下对运算类指令的叙述中,错误的是(D )。
A.指令系统中有专门的带符号整数乘和带符号整数除运算指令。
B.指令系统中有专门的无符号整数乘和无符号整数除运算指令。
C.指令系统中有专门的无符号整数移位和带符号整数移位运算指令。
D.指令系统中有专门的浮点数左移和右移运算指令。

第3讲 C语言中的各类运算
C语言中的各类运算(25分钟)

8位无符号整数1001 0101右移一位后的结果为( 0100 1010 )。
若8位带符号整数的补码表示为1001 0101,则右移一位后的结果为( 1100 1010 )。


#include <stdio.h>
#include <stdlib.h>
int main()
{
int x = -65535;
//(3)x的最低有效字节全变为0,其余各位取反。
printf("%d",((x^~0xFF)>>8)<<8);
//写成(~x)>>8<<8也可
}
print(bin(-65535))
print(bin(65280))
-0b1111111111111111
0b1111111100000000


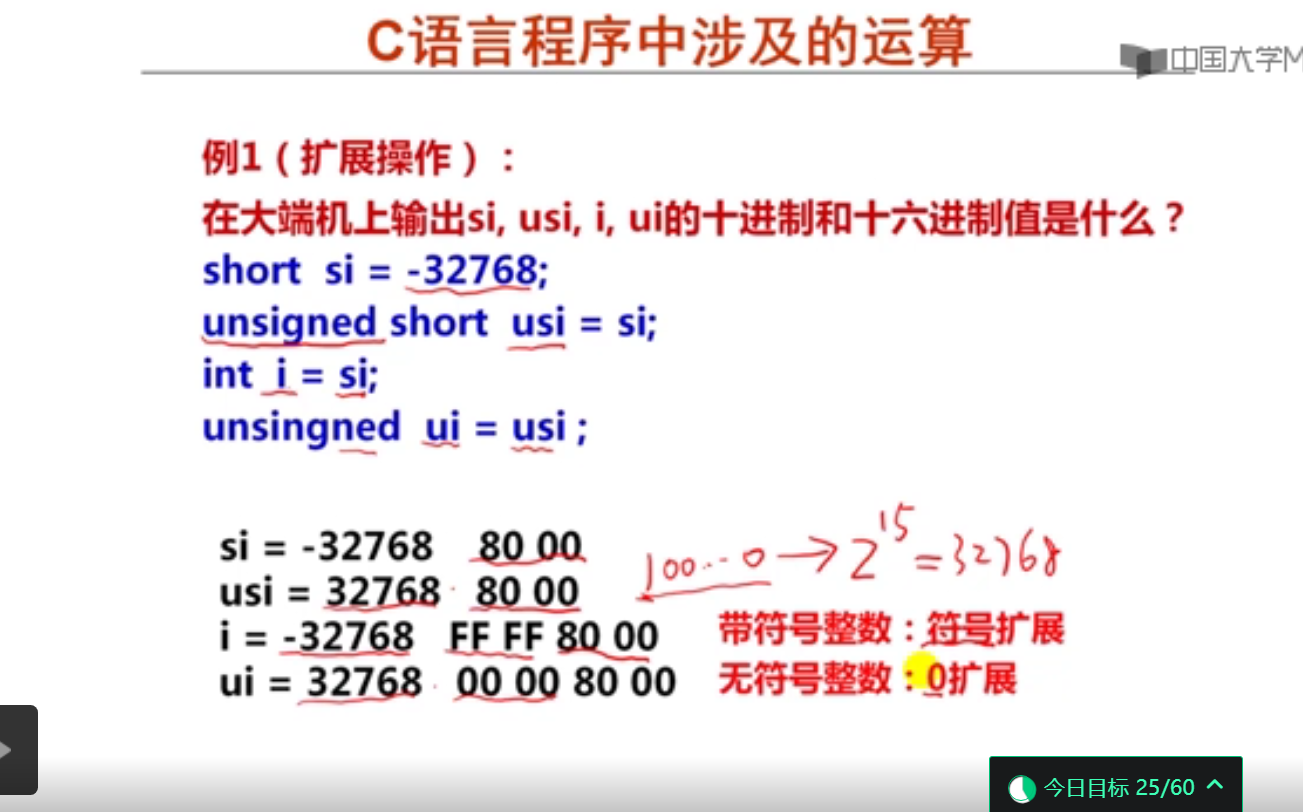

#include <stdio.h>
#include <stdlib.h>
int main()
{
int i = 32768;
short si = (short)i;
int j = si;
printf("%hd\n",si);
printf("%d\n",j);
}
-32768
-32768
一、前提: (1)本博客所有内容均指在8位机器下的整数转换及表示; (2)-128的绝对值在无符号整型下的表示:128D = 1000 0000B; (3)溢出丢弃进位法则:在用有符号整型表示二进制数时,当后面的非符号位发生溢出时,符号位不变,直接丢弃溢出的进位。
二、开始转换:
-
-128原码 = 1000 0000 说明:最高位1表示符号位,后7位发生了溢出,进位丢弃,符号位不变。
-
-128反码 = 1111 1111 说明:除符号位外,其余各位对原码取反。
-
-128补码 = 1000 0000 说明:在反码的末位加1,从而使后7位再次发生溢出,进位丢弃,符号位不变。
同理,-32768的补码是1000 0000 0000 0000。
第4讲 整数加减运算
1. 加减运算生成的标志信息(16分钟)

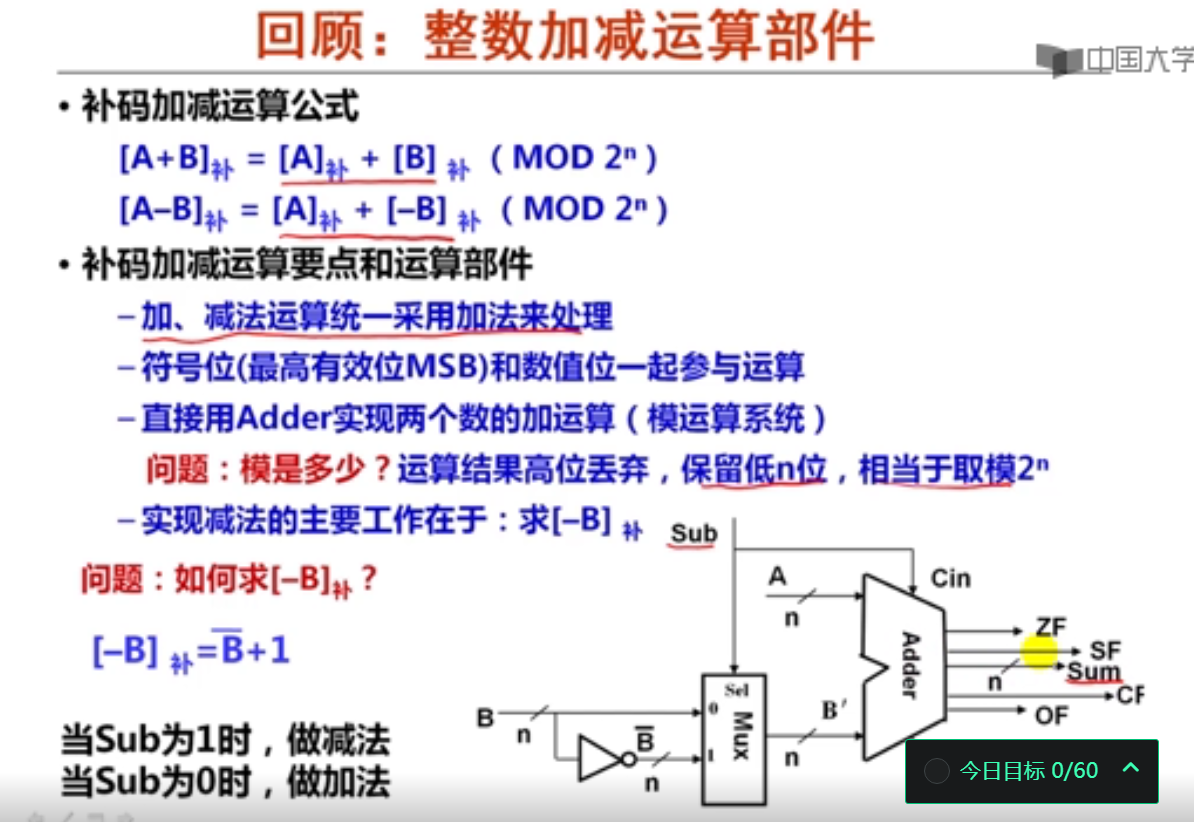
假定整数加/减运算器的两个输入端分别是A和B,以下关于整数加/减运算器的叙述中,错误的是( C)。
A.当控制端Sub为1时,执行的是A加B的反码加1,因此进行的是减运算。
B.当需要比较两个整数的大小时,编译器生成定点数减法指令,因此在整数加/减运算器中执行减运算。
C.不管是带符号整数还是无符号整数,做减运算时,只要借位标志CF=1,就说明有借位,即A小于B。
D.整数加/减运算器生成的所有标志信息通常会记录在一个专门用于记录机器状态信息的寄存器中。
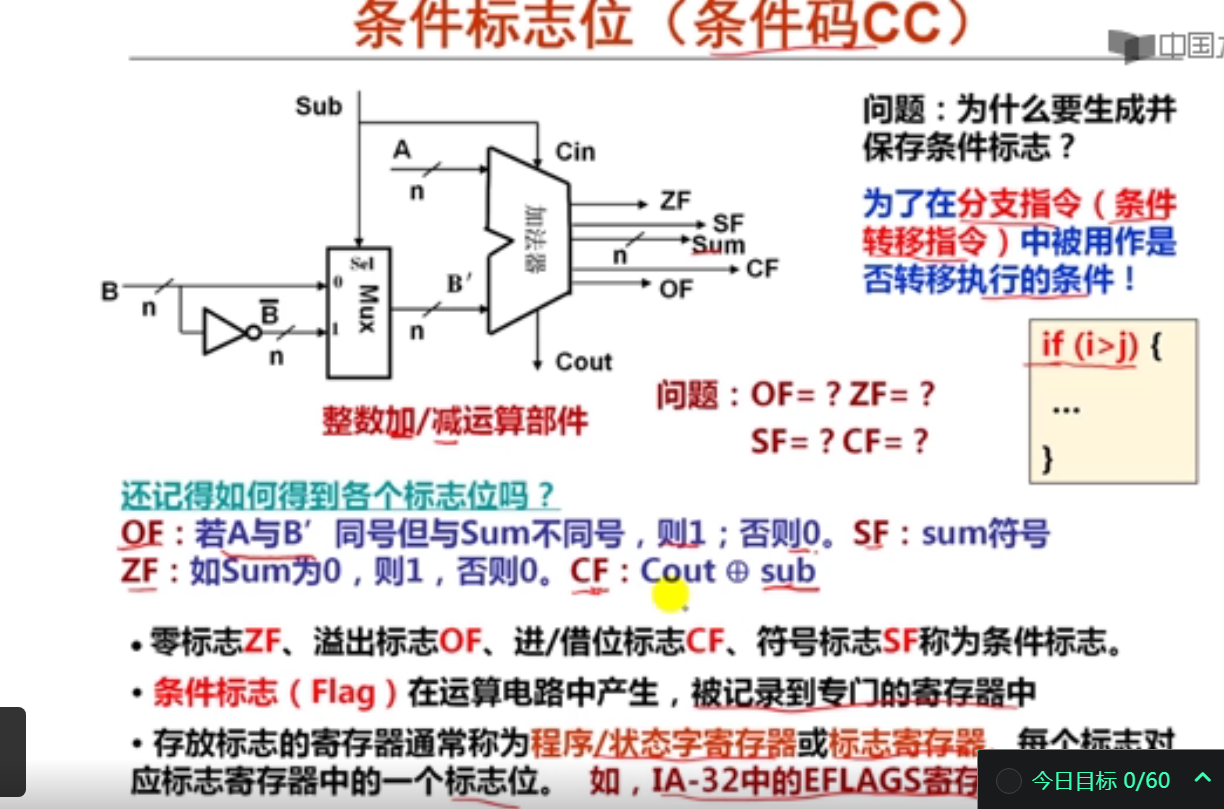
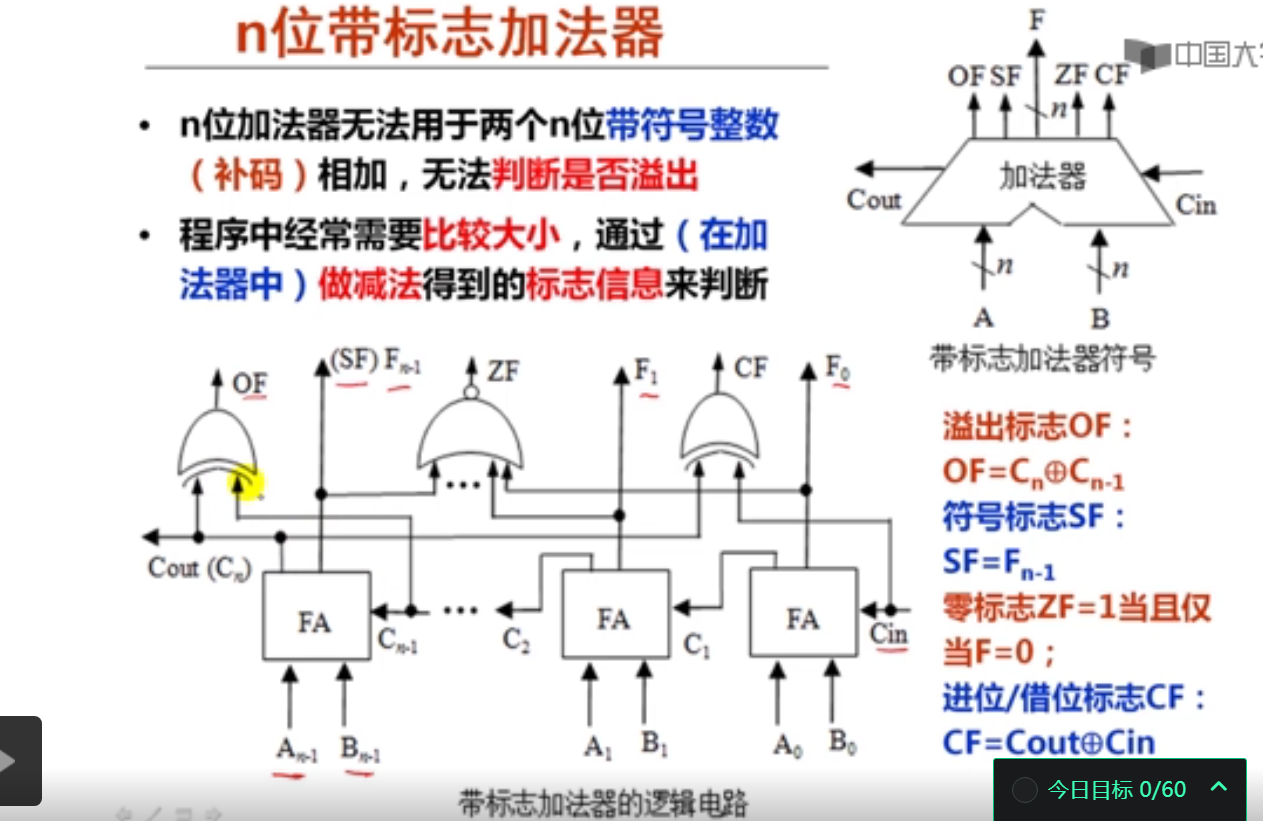
以下关于n位带标志加法器的叙述中,错误的是( C )。
A.在整数加/减运算器中的加法器是n位带标志加法器。
B.符号标志SF与和的符号位Fn-1相同。
C.进位标志CF等于加法器的进位输出Cout。
D.当两个加数的符号相同且不同于和的符号,则溢出标志OF=1。
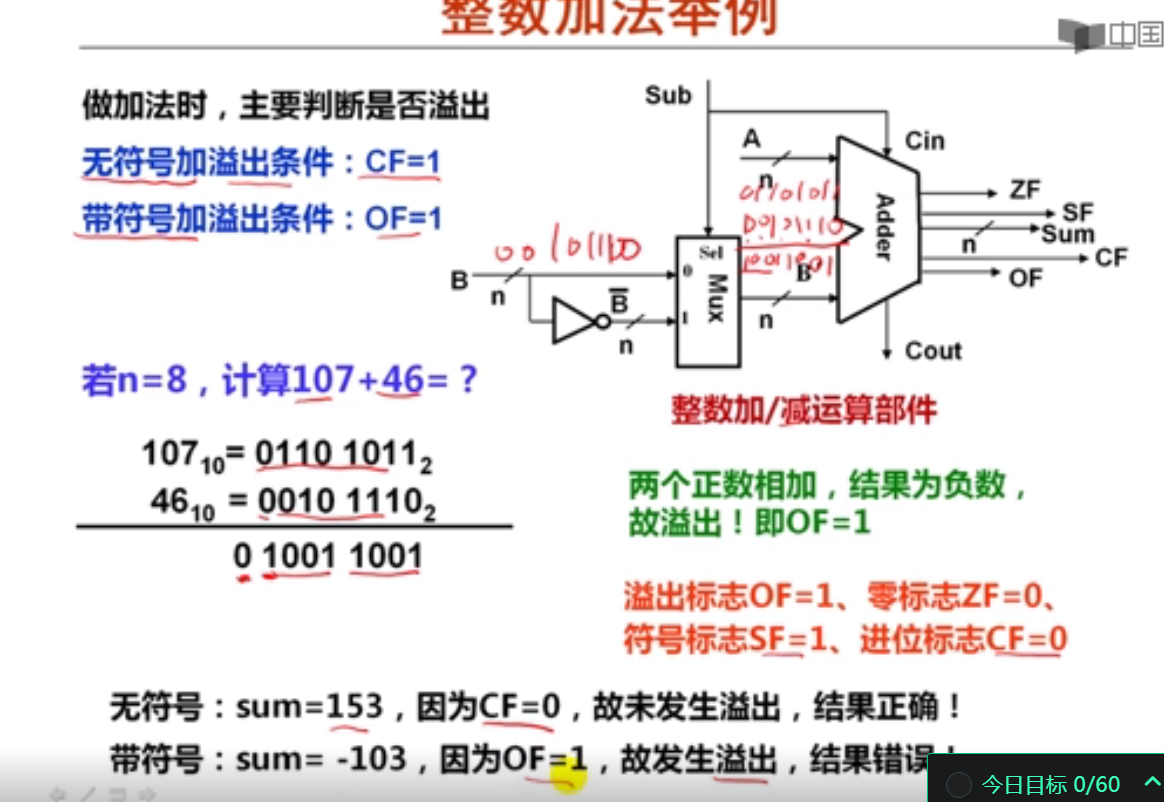

2. 加减运算溢出公式及举例(17分钟)
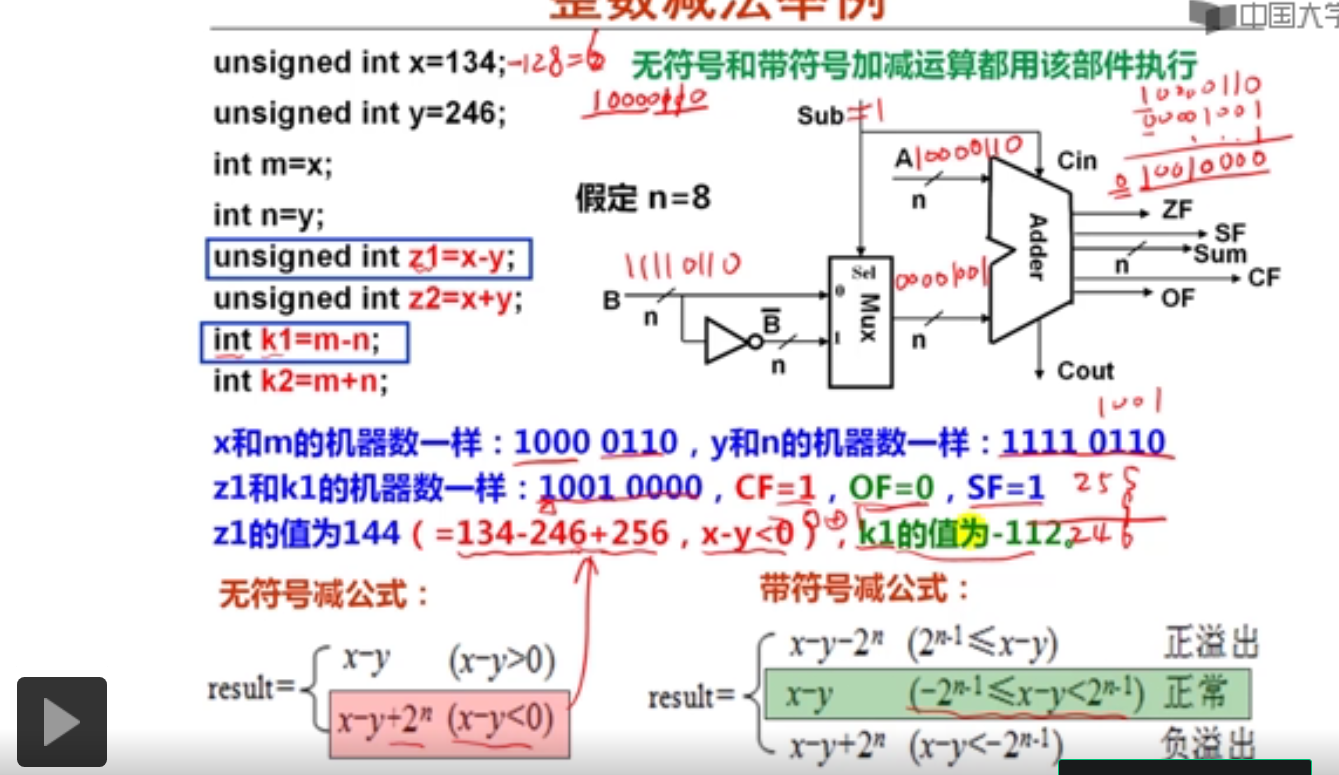
#include <stdio.h>
#include <stdlib.h>
int main()
{
unsigned int x = 134;
unsigned int y = 246;
int m = x;
int n = y;
unsigned int z1 = x-y;
unsigned int z2 = x+y;
printf("%u\n",z1);
printf("%u\n",z2);
int k1 = m-n;
int k2 = m+n;
printf("%d\n",k1);
printf("%d\n",k2);
}
4294967184
380
-112
380





第三周小测验
1CPU中能进行算术运算和逻辑运算的最基本运算部件是( A )。
A.ALU
B.移位器
C.多路选择器
D.加法器
2ALU有一个操作控制端ALUop,ALU在ALUop的控制下执行相应的运算。以下给出的运算中,( B )运算不能由ALUop直接控制完成。
A.传送(ALU输入直送为输出)
B.乘法和除法
C.加法和减法
D.与、或、非等逻辑运算
解析: B、ALU通常仅用于进行加、减以及各类逻辑运算和传送操作,乘法和除法运算可以利用ALU分步骤进行加/减和移位来完成,因此,在进行乘或除运算时,每个步骤送到ALUop的控制信号可以控制进行加/减和移位操作,但不能用一个控制信息直接使ALU完成乘或除运算。
3假设变量x的位数为n(n>=8),x的最低有效字节不变,其余各位全变为0,则对应C语言表达式为( B )。
A.x | ~ 0xFF
B. x & 0xFF
C.x ^ 0xFF
D.x | 0xFF
4假设变量x的位数为n(n>=8),x的最高有效字节不变,其余各位全变为0,则对应C语言表达式为( C )。
A.((x&0xFF)<<(n-8))>>(n-8)
B.((x&0xFF)>>(n-8))<<(n-8)
C.(x>>(n-8))<<(n-8)
D.(x<<(n-8))>>(n-8)
5考虑以下C语言代码:
short si = –8196;
int i = si;
执行上述程序段后,i的机器数表示为( C )。
A.0000 DFFCH
B.FFFF 9FFCH
C.FFFF DFFCH
D.0000 9FFCH
6若在一个8位整数加/减运算器中完成x–y的运算,已知带符号整数x=–69,y=–38,则加法器的两个输入端和输入的低位进位分别为( A )。
A.1011 1011、0010 0101、1
B.1011 1011、1101 1010、1
C.1011 1011、0010 0110、1
D.1011 1011、1101 1010、0
解析: A、–69和–38的机器数分别是1011 1011、1101 1010,因为是做x-y,所以,整数加/减运算器中的控制端sub为1,即低位进位为1,并控制加法器的第二个输入端各位取反,为0010 0101。
7若在一个8位整数加/减运算器中完成x+y的运算,已知无符号整数x=69,y=38,则加法器的两个输入端和输入的低位进位分别为( C )。
A.0100 0101、1101 1010、0
B. 0100 0101、1101 1010、1
C.C.0100 0101、0010 0110、0
D.0100 0101、0010 0110、1
解析: C、69和38的机器数分别是0100 0101、0010 0110,因为是做加法,所以,整数加/减运算器中的控制端sub为0,即低位进位为0。
8若在一个8位整数加/减运算器中完成x+y的运算,已知x=63,y= –31,则x+y的机器数及相应的溢出标志OF分别是( B )。
A.20H、1
B.20H、0
C.1FH、1
D.1FH、0
解析: B、63和–31的机器数分别是0011 1111、1110 0001,因为是做x+y,所以,在加法器中将两个机器数直接相加,得到结果为0010 0000(20H),并生成进位Cout=1,因为两个加数符号位相异,因此,不会发生溢出,即OF=0。
9若在一个8位整数加/减运算器中完成x+y的运算,假定变量x和y的机器数用补码表示为[x]补=F5H,[y]补=7EH,则x+y的值及相应的溢出标志OF分别是( D )。
A.119、0
B.119、1
C.115、1
D.115、0
解析: D、x和y的机器数是用补码表示的,分别是1111 0101、0111 1110,因为是做x+y,所以,sub=0,即1111 0101 + 0111 1110 +0 = 0111 0011,其真值为127-12=115。因为两个加数符号位相异,所以不会发生溢出,即OF=0。
10若在一个8位整数加/减运算器中完成x–y的运算,假定变量x和y的机器数用补码表示为[x]补=F5H,[y]补=7EH,则x–y的值及相应的溢出标志OF分别是( A )。
A.119、1
B.115、1
C. 115、0
D.119、0
解析: A、x和y的机器数是用补码表示的,分别是1111 0101、0111 1110,因为是做x-y,所以,sub=1,y对应的机器数各位取反,即1111 0101 + 1000 0001 +1 = 0111 0111,其真值为127-8=119。因为两个加数符号位为1,而结果符号为0,所以发生了溢出,即OF=1。
第四周乘除运算及浮点数运算
第1讲 整数乘法运算
对于C语言程序中的表达式z=x*y,其中x,y和z都是32位的int型整数,z的取值为x*y的64位乘积中的低32位。
在计算机内部,一个整数x的平方可能是负数,这是因为在计算机中其结果取的是x*x的低n位乘积而高n位中的有效数位被丢弃而造成的。

以下是关于整数乘运算(z=x*y)结果溢出判断规则的描述,其中错误的是( A )。
A.如果是C语言程序员,可以采用"若(y!=0 || x==z/y),则结果z不溢出"的规则。
B.若x,y,z为无符号整数,则编译器可以采用"若z的高n为全0,则不溢出,否则溢出"的规则。
C.若x,y,z为带符号整数,则编译器可以采用"若z的高n+1位为全0或全1,则不溢出,否则溢出"的规则。
D.高级语言程序员使用高级语言语句实现溢出判断,而编译器使用若干条指令进行溢出判断。

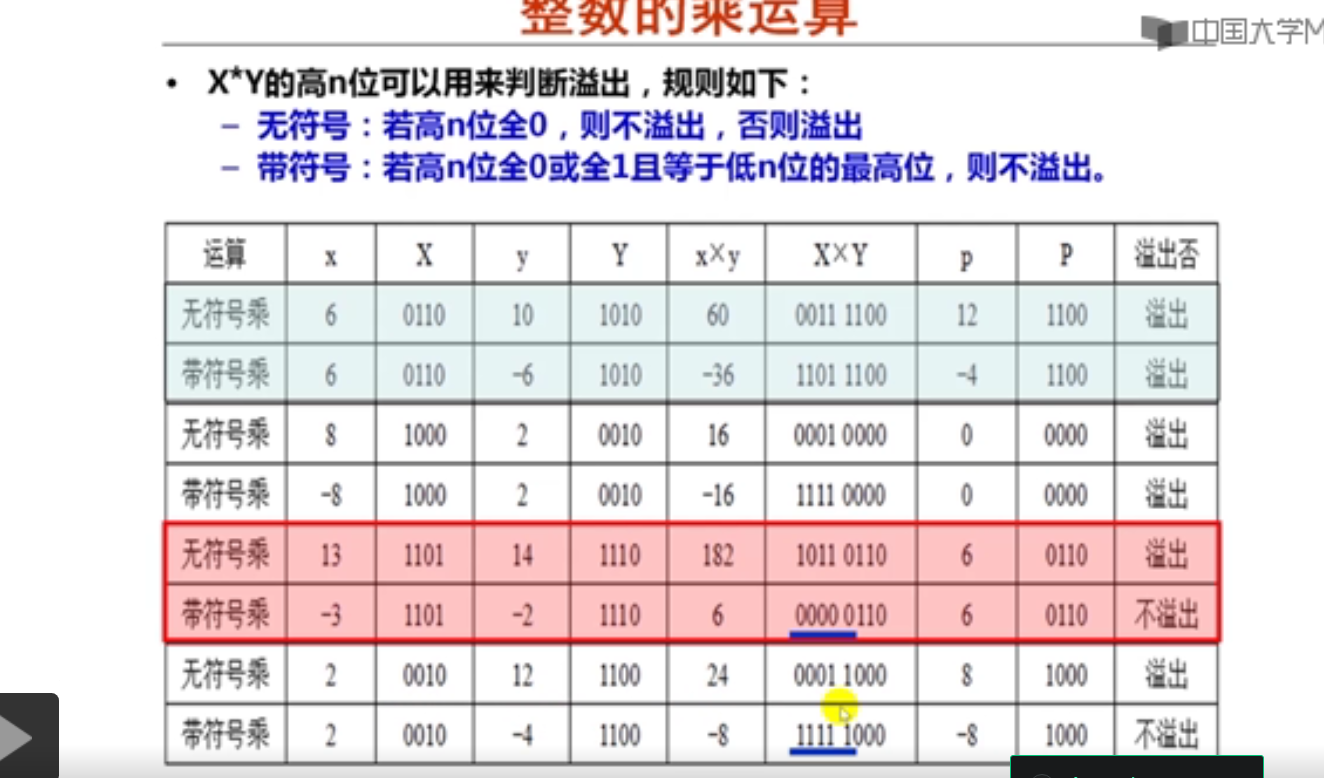

#include <iostream>
#include <cstdio>
using namespace std;
int is_mul_overflow(int a, int b) {
if( a >= 0 && b >=0 ) {
return INT_MAX / a < b;
}
else if( a < 0 && b < 0 ) {
return INT_MAX / a > b;
}
else if( a * b == INT_MIN ) {
return 0;
}
else {
return a < 0 ? is_mul_overflow(-a, b) : is_mul_overflow(a, -b);
}
}
void check(int n1, int n2, int expect_ret, int case_n) {
int ret = is_mul_overflow(n1, n2);
if( expect_ret == is_mul_overflow(n1, n2) )
printf("test pass case:%d\n",case_n);
else
printf("test fail case:%d\n",case_n);
}
int main() {
int case_n = 0;
check(0x00000001, 0x0000000f, 0x0000000f, ++case_n);
printf("%x\n", INT_MIN);
printf("%x\n", INT_MAX);
int result = -1*1;
printf("%d",result);
return 0;
}
test fail case:1
80000000
7fffffff
-1
-1(1111)乘以+1(0001)结果(00001111)溢出????
取负指令neg:各位取反末位加一
判断两int相乘是否溢出,目前找到的最正确方式:
#include <iostream>
#include <cstdio>
using namespace std;
int is_mul_overflow(int a, int b) {
if( a >= 0 && b >=0 ) {
return INT_MAX / a < b;
}
else if( a < 0 && b < 0 ) {
return INT_MAX / a > b;
}
else if( a * b == INT_MIN ) {
return 0;
}
else {
return a < 0 ? is_mul_overflow(-a, b) : is_mul_overflow(a, -b);
}
}
void check(int n1, int n2, int expect_ret, int case_n) {
int ret = is_mul_overflow(n1, n2);
if( expect_ret == is_mul_overflow(n1, n2) )
printf("test pass case:%d\n",case_n);
else
printf("test fail case:%d\n",case_n);
}
int main() {
int case_n = 0;
check(1, 0x80000000, 0, ++case_n);
check(-1, 0x80000000, 1, ++case_n);
check(0x80000000, -1, 1, ++case_n);
check(-1, 0x80000001, 0, ++case_n);
check(0x80000001, -1, 0, ++case_n);
check(1, 0x7fffffff, 0, ++case_n);
check(0x7fffffff, 1, 0, ++case_n);
check(2, 0x7fffffff, 1, ++case_n);
check(0x7fffffff, 2, 1, ++case_n);
check(0x7fffffff, -1, 0, ++case_n);
check(-1, 0x7fffffff, 0, ++case_n);
check(2, 0xc0000000, 0, ++case_n);
check(0xc0000000, 2, 0, ++case_n);
check(0x70000000, 2, 1, ++case_n);
check(2, 0x70000000, 1, ++case_n);
printf("%x\n", INT_MIN);
printf("%x\n", INT_MAX);
return 0;
}
test pass case:1
test pass case:2
test pass case:3
test pass case:4
test pass case:5
test pass case:6
test pass case:7
test pass case:8
test pass case:9
test pass case:10
test pass case:11
test pass case:12
test pass case:13
test pass case:14
test pass case:15
80000000
7fffffff

int copy_array(int* array,int count)
{
int *myarray = (int*)malloc(count*sizeof(int));
if(myarray==NULL)
{
return -1;
}
for(int i=0;i<count;i++)
myarray[i]=array[i];
return count;
}

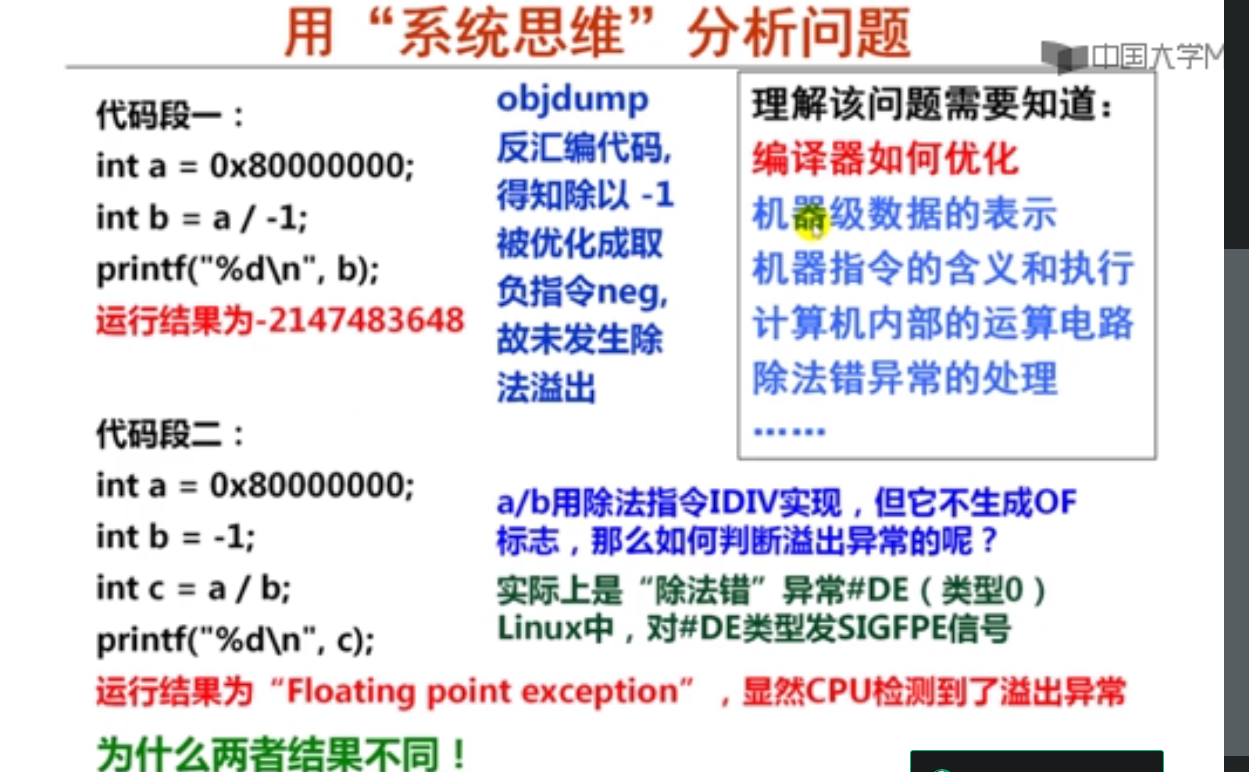
第2讲 整数除法运算


int main() {
int a = 0x80000000;
int b = a/-1;
printf("%d\n",b);//-2147483648
printf("%d\n",-a);//-2147483648
int c = -1;
int d = a/c;
printf("%d",d);//这里无输出结果
return 0;
}


对于C语言程序中的一个char型变量x,若x=-15,则x/4的机器数为( 1111 1101 )。
这里不能整除,需要添加偏置量。

第3讲 浮点数运算
附录float、double类型数据精度范围问题
| 类型 | 比特数 | 有效数字(精度) | 数值范围 |
|---|---|---|---|
| float | 32 | 6~7 | -3.4*10^38~3.4*10^38 |
| double | 64 | 15~16 | -1.79*10^308~1.79*10^308 |
| long double | 128/ | 18~19 | -1.2*10^4932~1.2*10^4932 |
在计算机中,浮点数类型(如 float 和 double)的精度是由其存储格式和位数决定的。
对于 float 类型,它通常使用 IEEE 754 单精度浮点数表示法,占用 32 位(4 字节)存储空间。其中,1 位用于表示符号位,8 位用于指数,剩下的 23 位用于表示尾数。这意味着 float 类型可以提供大约 7 位有效数字的精度。
而对于 double 类型,它通常使用 IEEE 754 双精度浮点数表示法,占用 64 位(8 字节)存储空间。其中,1 位用于表示符号位,11 位用于指数,剩下的 52 位用于表示尾数。这使得 double 类型可以提供大约 15 位有效数字的精度。
需要注意的是,这些数字精度是近似值,因为浮点数的存储和计算都涉及到舍入误差。在进行浮点数计算时,可能会出现舍入误差导致精度损失。因此,在对浮点数进行比较和精确计算时,需要注意处理舍入误差可能引起的问题。
如果需要更高精度的计算,可以考虑使用其他表示方法,如使用任意精度的库(例如 BigDecimal 类型)或进行符号位、指数和尾数的自定义存储。这样可以在需要时灵活调整精度要求。但请注意,这些方法可能会牺牲计算速度和内存开销。
float 类型使用 IEEE 754 单精度浮点数表示法,其中尾数部分占据了 23 位。为了理解为什么 float 类型可以提供大约 7 位有效数字的精度,我们需要了解浮点数的表示方式。
在 IEEE 754 单精度浮点数表示法中,浮点数被分为三个部分:符号位、指数部分和尾数部分。符号位用于表示正数或负数,指数部分用于调整浮点数的大小范围,而尾数部分则表示浮点数的精度。
尾数部分占据了 23 位,其中最高位默认为 1,并且在存储时省略了这个最高位。这意味着尾数部分可以表示 24 个二进制位,即 2^24 = 16,777,216 种不同的值。然而,由于尾数部分只有 23 位,因此只能表示 2^23 = 8,388,608 个不同的值。
有效数字的位数可以通过以下公式计算:log10(2^N),其中 N 表示尾数部分的位数。对于 float 类型,N = 23,因此有效数字的位数为 log10(2^23) ≈ 7.22。所以,float 类型可以提供大约 7 位有效数字的精度。
请注意,这个数字是一个近似值,并且在进行浮点数计算时可能会存在舍入误差。因此,在进行精确计算或比较时,需要考虑舍入误差可能带来的影响。
2^52一共16位,故double类型数据的精度为15~16位。
附录定点小数和浮点小数的区别
定点小数和浮点小数是两种不同的表示和处理实数的方法。
-
定点小数:
- 定点小数使用固定的小数点位置来表示实数。小数点位置在数值中是固定的,通常是在最后一位或者是固定的位置。例如,假设小数点位置固定在整数部分和小数部分之间的某个位置,如 "123.456" 中的小数点位置。
- 定点小数的表示方式更直观和易于理解,因为小数点位置是固定的,有助于对数值的理解和操作。然而,它的范围和精度是固定的,不够灵活。
- 定点小数在计算机中通常使用固定位数的整数表示,其中一个固定的位数表示小数点的位置。这样可以通过位移和固定精度的整数运算来处理定点小数。
-
浮点小数:
- 浮点小数使用科学计数法的形式来表示实数。它由三个部分组成:符号位、尾数部分和指数部分。浮点小数的小数点位置是可变的,通过指数部分来表示。
- 浮点小数的表示方式更适合处理非常大或非常小的数值范围,因为指数部分可以调整小数点的位置,提供了更大的数值范围和灵活性。
- 浮点小数在计算机中通常使用 IEEE 754 标准(单精度或双精度)来表示,其中尾数部分和指数部分以二进制形式存储,并进行特定的规范化处理和舍入操作。
总结: 定点小数和浮点小数是不同的数值表示方式。定点小数使用固定的小数点位置,适合处理小范围和固定精度的数值。浮点小数使用科学计数法,通过指数来调整小数点位置,适合处理较大范围和可变精度的数值。浮点小数的表示方式更复杂,计算也会涉及舍入误差,但提供了更大的数值范围和灵活性。
1. 浮点加减运算(23分钟)



#include <stdio.h>
#include <conio.h>
int main()
{
int a=1,b=0;
printf("Division by zero:%d\n",a/b);
getchar();
return 0;
}
Process returned -1073741676 (0xC0000094) execution time : 0.543 s
整数除0的结果无法用01序列表示
#include <stdio.h>
#include <conio.h>
int main()
{
double x=1.0,y=-1.0,z=0.0;
printf("Division by zero:%f %f\n",x/z,y/z);
getchar();
return 0;
}
Division by zero:1.#INF00 -1.#INF00
浮点数除0可以表示为无穷大



2. 浮点运算的精度(22分钟)


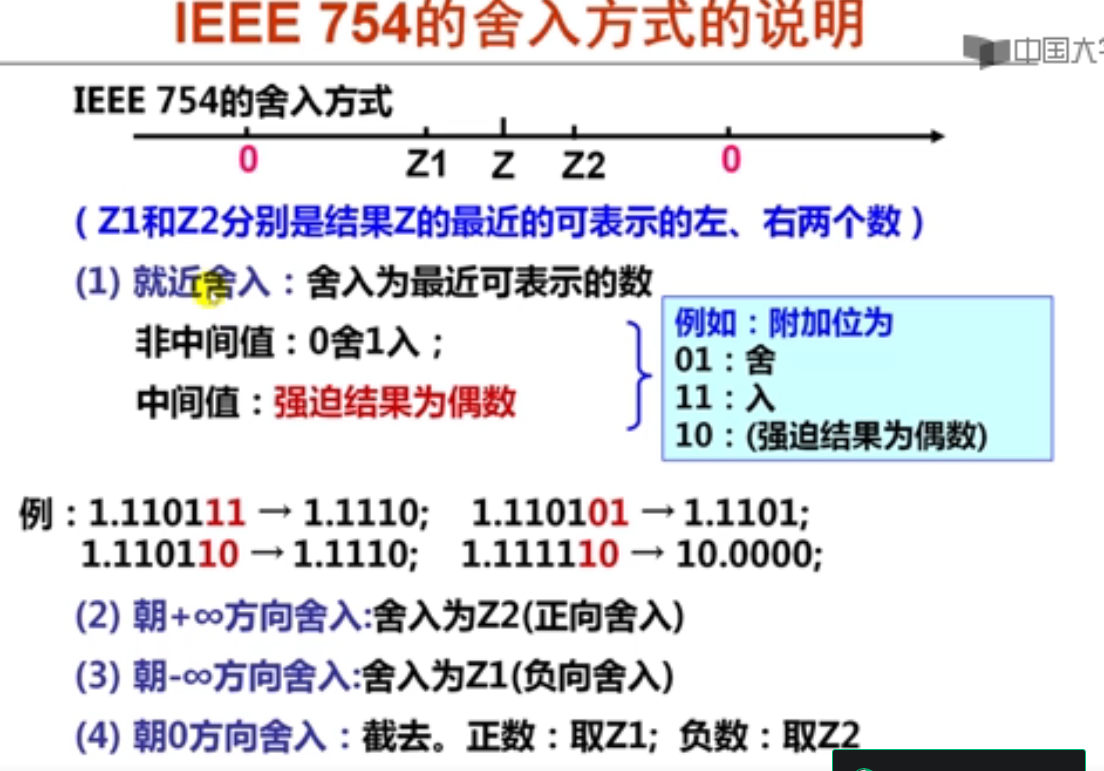
附加位为01时,要强制结果为偶数,末位需要加1




3. 浮点运算精度举例(16分钟)





第四周小测验
1单选(0.5分)
若在一个8位计算机中完成x+2y的运算,假定变量x和y的机器数用补码表示为[x]补=44H,[y]补= DCH,则x+2y的机器数及相应的溢出标志OF分别是( FCH、0)。
解析: x和y的机器数是用补码表示的,分别是0100 0100、1101 1100,因为是做x+2y,所以,先对y算术左移一位,然后和x相加,此时sub=0,即0100 0100 + 1011 1000+0 = 1111 1100(FCH),因为两个加数符号相异,所以不会发生溢出,即OF=0。
2单选(0.5分)
若在一个8位计算机中完成x–2y,假定变量x和y的机器数用补码表示为[x]补=44H,[y]补= DCH,则x–2y的机器数及相应的溢出标志OF分别是(8CH、1 )。
解析: x和y的机器数是用补码表示的,分别是0100 0100、1101 1100,因为是做x–2y,所以,先对y算术左移一位,得1011 1000,然后各位取反,再和x相加,此时sub=1,即0100 0100 + 0100 0111+1 = 1000 1100(8CH),因为两个加数符号都为0,而结果符号为1,所以发生了溢出,即OF=1。
3单选(0.5分)
若在一个8位计算机中完成x/2+2y,假定变量x和y的机器数用补码表示为[x]补=44H,[y]补= DCH,则x/2+2y的机器数及相应的溢出标志OF分别是( DAH、0 )。
解析: x和y的机器数是用补码表示的,分别是0100 0100、1101 1100,因为是做x/2+2y,所以,先对x算术右移一位,得0010 0010;再对y算术左移一位,得1011 1000,两者相加,此时sub=0,即0010 0010 + 1011 1000+0 = 1101 1010(DAH),因为两个加数符号相异,所以不会发生溢出,即OF=0。
4单选(0.5分)
假定变量r1 和r2的机器数用8位补码表示为[r1]补=F5H,[r2]补=EEH。若将运算结果存放在一个8位寄存器中,则下列运算中会发生溢出的是(B )。
A. r1/r2
B. r1× r2
C. r1+ r2
D. r1– r2
正确答案:B你选对了
C. r1(-11)+ r2(-18)结果为1 1110 0011(-29)
5单选(0.5分)
假定整数加法指令、整数减法指令和移位指令所需时钟周期(CPI)都为1,整数乘法指令所需时钟周期为10。若x为整型变量,为了使计算64*x所用时钟周期数最少,编译器应选用的最佳指令序列为(1条左移指令 )。
解析: 因为64*x可以用x左移6位来实现,左移指令比乘法指令快10倍,因此最佳指令序列为1条左移指令,只要一个时钟周期。
6单选(0.5分)
假定整数加法指令、整数减法指令和移位指令所需时钟周期(CPI)都为1,整数乘法指令所需时钟周期为10。若x为整型变量,为了使计算54*x所用时钟周期数最少,编译器应选用的最佳指令序列为(3条左移指令和两条减法指令 )。
解析:一条整数乘法指令需要10个时钟周期。 而54*x=(64-8-2)*x=64*x -8*x -2*x,可用3条左移指令和两条减法指令来实现,共需5个时钟周期。
7单选(0.5分)
假定整数加法指令、逻辑运算指令和移位指令所需时钟周期(CPI)都为1,整数除法指令所需时钟周期为32。若x为整型变量,为了使计算x/64所用时钟周期数最少,编译器应选用的最佳指令序列为(两条右移指令、1条与操作指令、1条加法指令 )。
A. 1条右移指令
B. 两条右移指令、1条与操作指令、1条加法指令
C. 1条加法指令、1条右移指令
D. 1条除法指令
正确答案:B你选对了
解析: A、若x为负数且不能被64整除,则x右移6位和x/64的结果不相等。 B、x/64 = ( x>=0 ? x : (x+63) ) >> 6,因此关键是计算偏移量b,这里,x为正时b=0,x为负时b=63。可从x的符号得到b,x>>31得到32位符号,正数为32位0,负数为32位1,然后通过“与”操作提取低6位,这就是偏移量b。也即:x/64 = ( x+ ( x>>31)&0x3F ) ) >> 6,用2条右移、1条加和1条与指令即可实现,只要4个时钟周期。 C、若x为负数,则x/64=(x+63)>>6,但该公式不适合正数x,因此无法用一条加和一条右移指令实现。 D、一条整数乘法指令需要32个时钟周期。
8单选(0.5分)
已知float型变量用IEEE 754单精度浮点格式表示,float型变量x和y的机器数分别表示为x=40E8 0000H,y=C204 0000H,则在计算x+y时,第一步对阶操作的结果[Ex-Ey]补为(1111 1101 )。
解析: 因为x=40E8 0000H=0100 0000 1110 1000 0...0,y=C204 0000H=1100 0010 0000 0100 0...0,所以x和y的阶码分别为100 0000 1、100 0010 0,对阶时计算过程为 1000 0001 + 0111 1100 = 1111 1101。
9单选(0.5分)
对于IEEE 754单精度浮点数加减运算,只要对阶时得到的两个阶之差的绝对值|ΔE|大于等于(25 ),就无需继续进行后续处理,此时,运算结果直接取阶大的那个数。
解析: 对于IEEE 754单精度浮点格式,当出现“1.bb…b + 0.00…0 01bb…b”情况时会发生“大数吃小数”现象,小数0.00…0 01bb…b中的小数点被左移了25位。
10多选(0.5分)
变量dx、dy和dz的声明和初始化如下:
double dx = (double) x;
double dy = (double) y;
double dz = (double) z;
若float和double分别采用IEEE 754单精度和双精度浮点数格式,sizeof(int)=4,则对于任意int型变量x、y和z,以下哪个关系表达式是永真的?
A. dx*dy*dz == dz*dy*dx
B. (double)(float) x == dx
C. (dx+dy)+dz == dx+(dy+dz)
D. dx*dx >= 0
正确答案:C、D你错选为B、D
解析: A、非永真。相乘的结果可能产生舍入。 B、非永真。当int型数据x的有效位数比float型可表示的最大有效位数24更多时,x强制转换为float型数据时有效位数丢失,而将x转换为double型数据时没有有效位数丢失。也即等式左边可能是近似值,而右边是精确值。 C、永真。因为dx、dy和dz是由32位int型数据转换得到的,而double类型可以精确表示int类型数据,并且对阶时尾数移位位数不会超过52位,因此尾数不会舍入,因而不会发生大数吃小数的情况。但是,如果dx、dy和dz是任意double类型数据,则非永真。 D、永真。double型数据用IEEE 754标准表示,尾数用原码小数表示,符号和数值部分分开运算。不管结果是否溢出都不会影响乘积的符号。
第五周IA-32指令系统概述
第1讲 程序转换概述
1. 程序和指令的关系(15分钟)
指令中包含的信息可能包括(ABC )。
A.操作码,用于指出指令的操作性质
B.立即数,即操作数本身
C.寄存器编号,用于指出操作数所在的寄存器


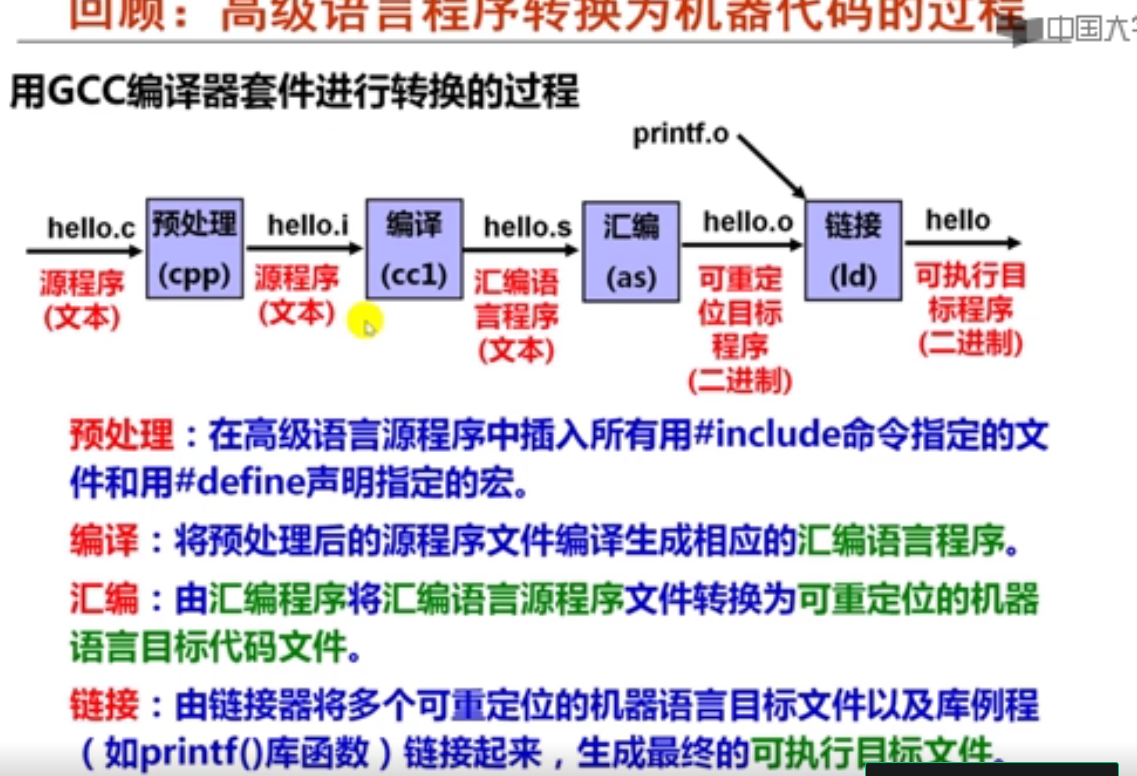
2. 目标代码和ISA(15分钟)
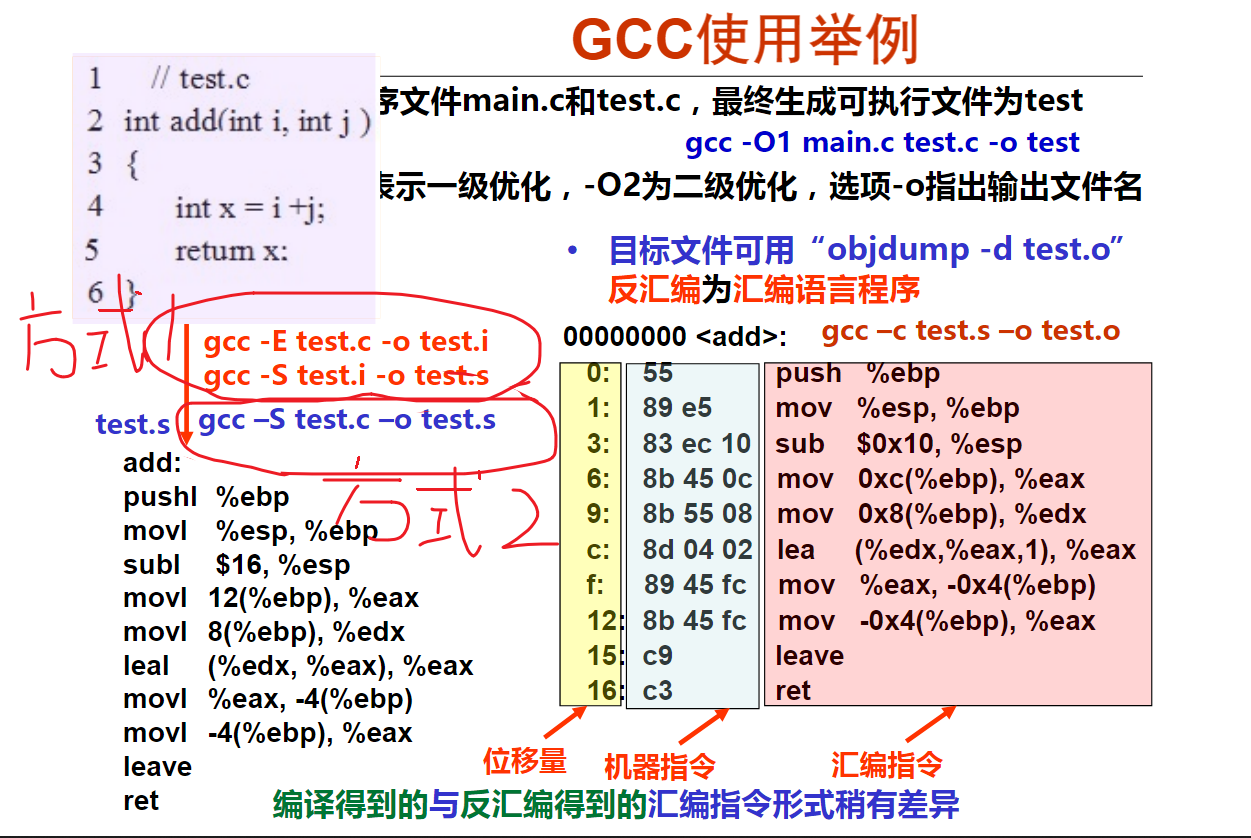
test.c写成下面这样:
int add(int i,int j)
{
int x = i + j;
return x;
}
main.c写成下面这样:
#include <stdio.h>
#include "test.c"
int main()
{
int x = 6, y = 8;
int sum = add(x,y);
printf("%d",sum);
return 0;
}
执行gcc -O1 main.c test.c -o test出现如下的warning
main.c: In function ‘main’:
main.c:5:19: warning: implicit declaration of function ‘add’ [-Wimplicit-function-declaration]
5 | int sum = add(x,y);
一般常见错误原因是先调用了主函数,然后在主函数里调用被定义在主函数之后的函数。解决办法就是调整函数顺序或增加函数声明。
经测试gcc -O1 main.c test.c -o test和gcc -O1 test.c main.c -o test都会报这个warning。
这里出现这个warning的原因是在需要调用该函数的文件中没有声明该函数或声明格式错误。
main.c修改后如下:
#include <stdio.h>
extern int add(int,int);
int main()
{
int x = 6, y = 8;
int sum = add(x,y);
printf("%d",sum);
return 0;
}
再执行gcc -O1 main.c test.c -o test和./test就能出现14这个正确结果了!!
也可以在相应的.h文件中声明函数(这时不要再加extern了。)

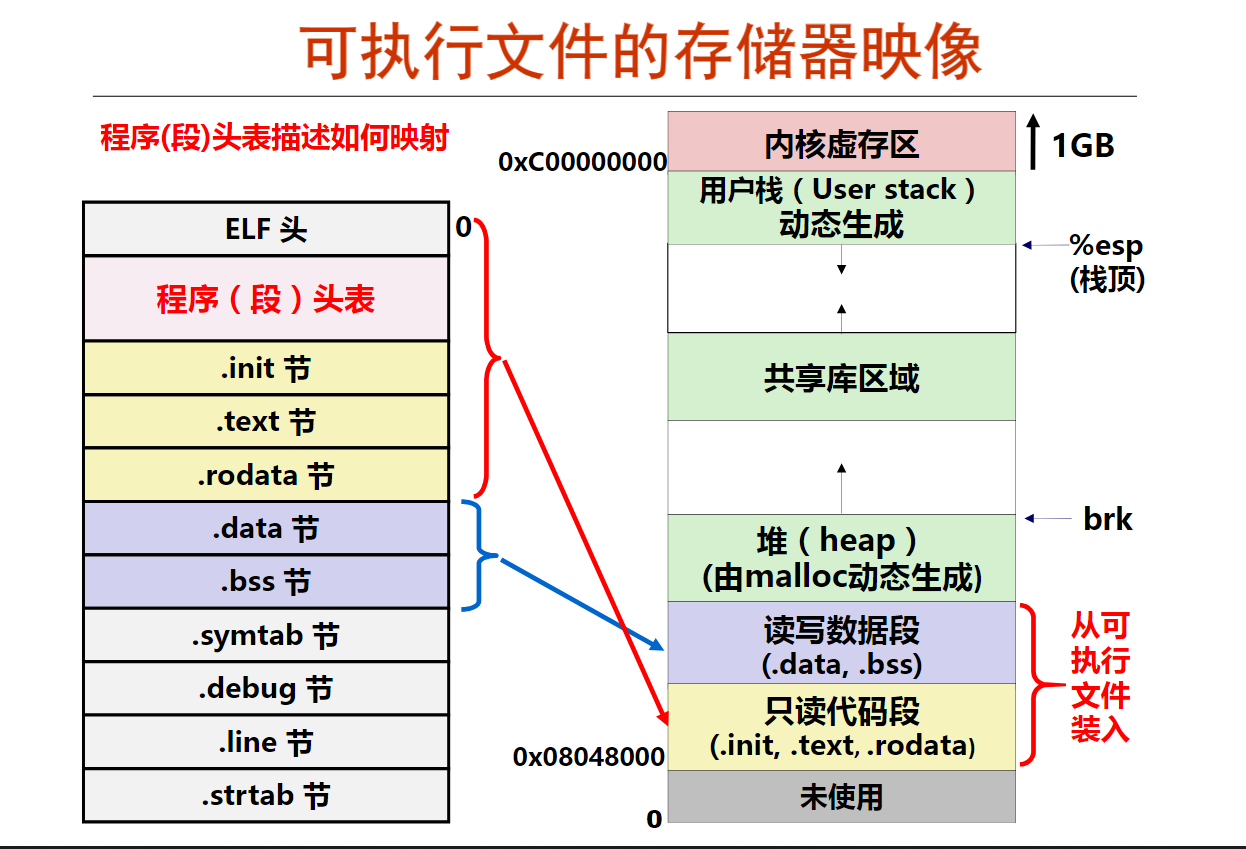
以下是关于用objdump对可重定位目标文件和可执行目标文件反汇编得到结果的叙述,其中错误的是( C )。
A.两者都包含所有的机器指令,用十六进制表示
B.两者都包含机器指令对应的汇编指令,而且汇编指令的形式完全相同
C.可重定位目标文件的反汇编结果中,每条指令的地址是相对于所在函数第一条指令的位移地址
D.可执行目标文件的反汇编结果中,每条指令的地址是一个绝对地址
下面是在WSL2(Ubuntu22.04)上的编译test.c的过程和结果。
gcc -E test.c -o test.i
gcc -S test.i -o test.s
然后执行 cat test.s
.file "test.c"
.text
.globl add
.type add, @function
add:
.LFB0:
.cfi_startproc
endbr64
pushq %rbp
.cfi_def_cfa_offset 16
.cfi_offset 6, -16
movq %rsp, %rbp
.cfi_def_cfa_register 6
movl %edi, -20(%rbp)
movl %esi, -24(%rbp)
movl -20(%rbp), %edx
movl -24(%rbp), %eax
addl %edx, %eax
movl %eax, -4(%rbp)
movl -4(%rbp), %eax
popq %rbp
.cfi_def_cfa 7, 8
ret
.cfi_endproc
.LFE0:
.size add, .-add
.ident "GCC: (Ubuntu 11.3.0-1ubuntu1~22.04) 11.3.0"
.section .note.GNU-stack,"",@progbits
.section .note.gnu.property,"a"
.align 8
.long 1f - 0f
.long 4f - 1f
.long 5
0:
.string "GNU"
1:
.align 8
.long 0xc0000002
.long 3f - 2f
2:
.long 0x3
3:
.align 8
4:
再执行gcc -c test.s -o test.o和objdump -d test.o出现下面的结果:
test.o: file format elf64-x86-64
Disassembly of section .text:
0000000000000000 <add>:
0: f3 0f 1e fa endbr64
4: 55 push %rbp
5: 48 89 e5 mov %rsp,%rbp
8: 89 7d ec mov %edi,-0x14(%rbp)
b: 89 75 e8 mov %esi,-0x18(%rbp)
e: 8b 55 ec mov -0x14(%rbp),%edx
11: 8b 45 e8 mov -0x18(%rbp),%eax
14: 01 d0 add %edx,%eax
16: 89 45 fc mov %eax,-0x4(%rbp)
19: 8b 45 fc mov -0x4(%rbp),%eax
1c: 5d pop %rbp
1d: c3 ret
x86架构汇编指令一般有两种格式:Intel汇编格式和AT&T汇编格式,DOS、Windows使用Intel汇编格式,而Unix、Linux、Mac OS使用AT&T汇编格式。
下面简单列出几个Intel和AT&T汇编格式的区别:
- 第一当然是两个操作数的顺序啦:Intel的第一个操作数是目标操作数,第二个操作数是源操作数;AT&T的第一个操作数是源操作数,第二个操作数是目标操作数。
- 寄存器的表示:Intel的寄存器直接写寄存器的名字就行(eax);AT&T的寄存器需要在前面加一个百分号%修饰(%eax)。
- 立即数表示:Intel的立即数前不用加任何标志(1);AT&T的立即数前需要加
$符号修饰($1)。 - 括号的使用:Intel中寻址时用的括号是中括号
[];AT&T中使用的是小括号()。 - ......
objdump默认的汇编格式是AT&T格式。可以通过-M参数来修改反汇编的格式(具体可以参考man objdump)。
执行objdump -d test.o -M intel |less出现下面的结果:
test.o: file format elf64-x86-64
Disassembly of section .text:
0000000000000000 <add>:
0: f3 0f 1e fa endbr64
4: 55 push rbp
5: 48 89 e5 mov rbp,rsp
8: 89 7d ec mov DWORD PTR [rbp-0x14],edi
b: 89 75 e8 mov DWORD PTR [rbp-0x18],esi
e: 8b 55 ec mov edx,DWORD PTR [rbp-0x14]
11: 8b 45 e8 mov eax,DWORD PTR [rbp-0x18]
14: 01 d0 add eax,edx
16: 89 45 fc mov DWORD PTR [rbp-0x4],eax
19: 8b 45 fc mov eax,DWORD PTR [rbp-0x4]
1c: 5d pop rbp
1d: c3 ret
(END)

ISA是计算机组成的抽象
不同ISA规定的指令集不同,如IA-32、MIPS、ARM等
计算机组成必须能够实现ISA规定的功能,如提供GPR、标志、运算电路等
同一种ISA可以有不同的计算机组成,如乘法指令可用ALU或乘法器实现

第2讲 IA-32指令系统概述
1. Intel处理器概述(6分钟)

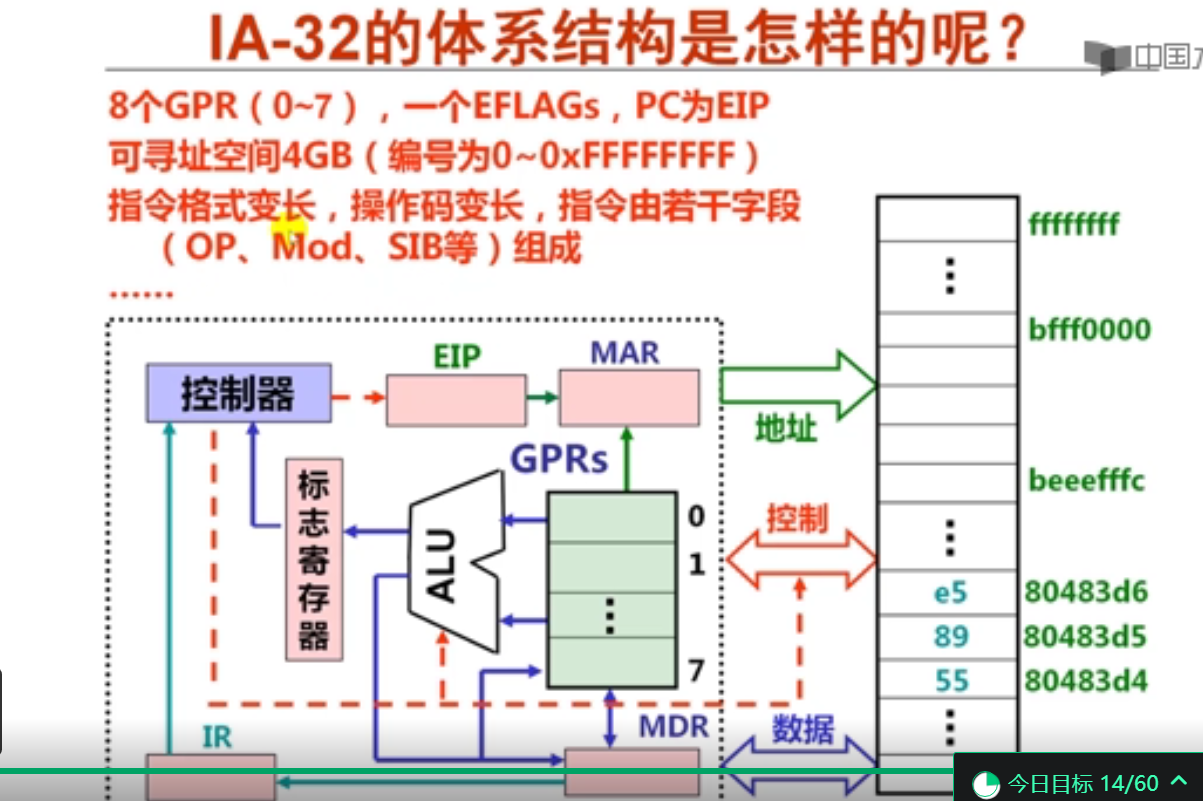
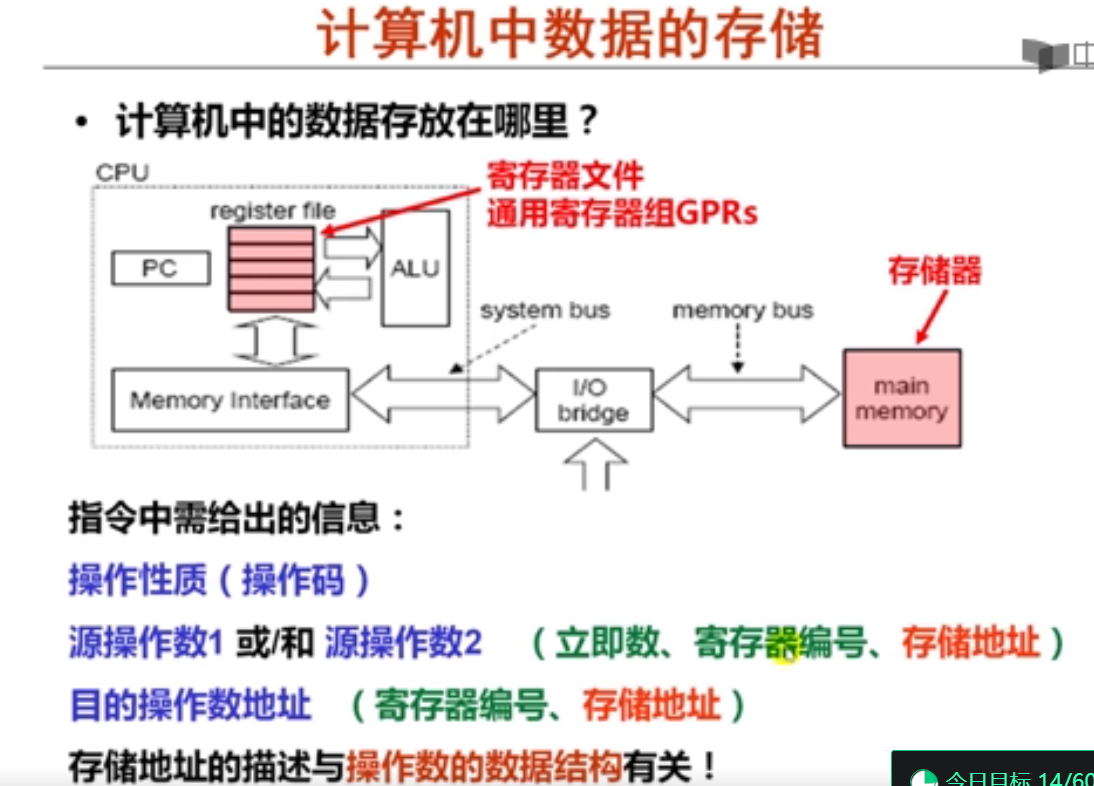
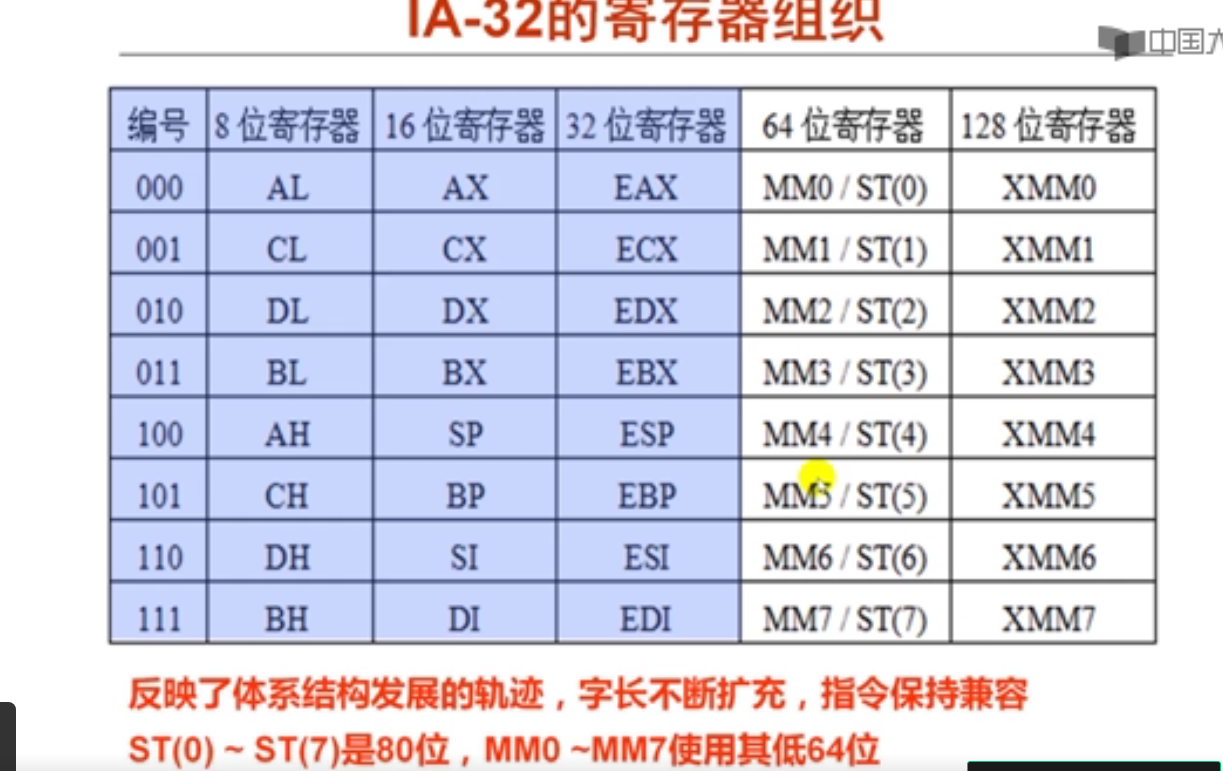
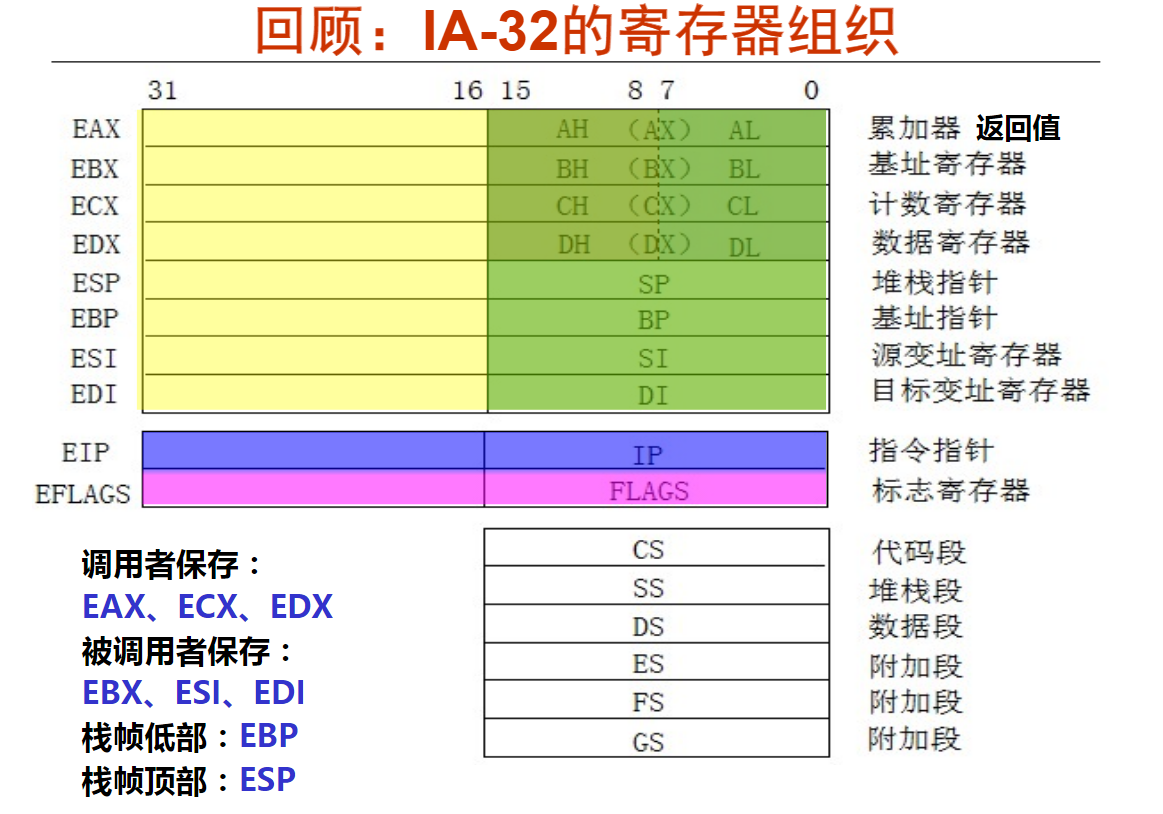
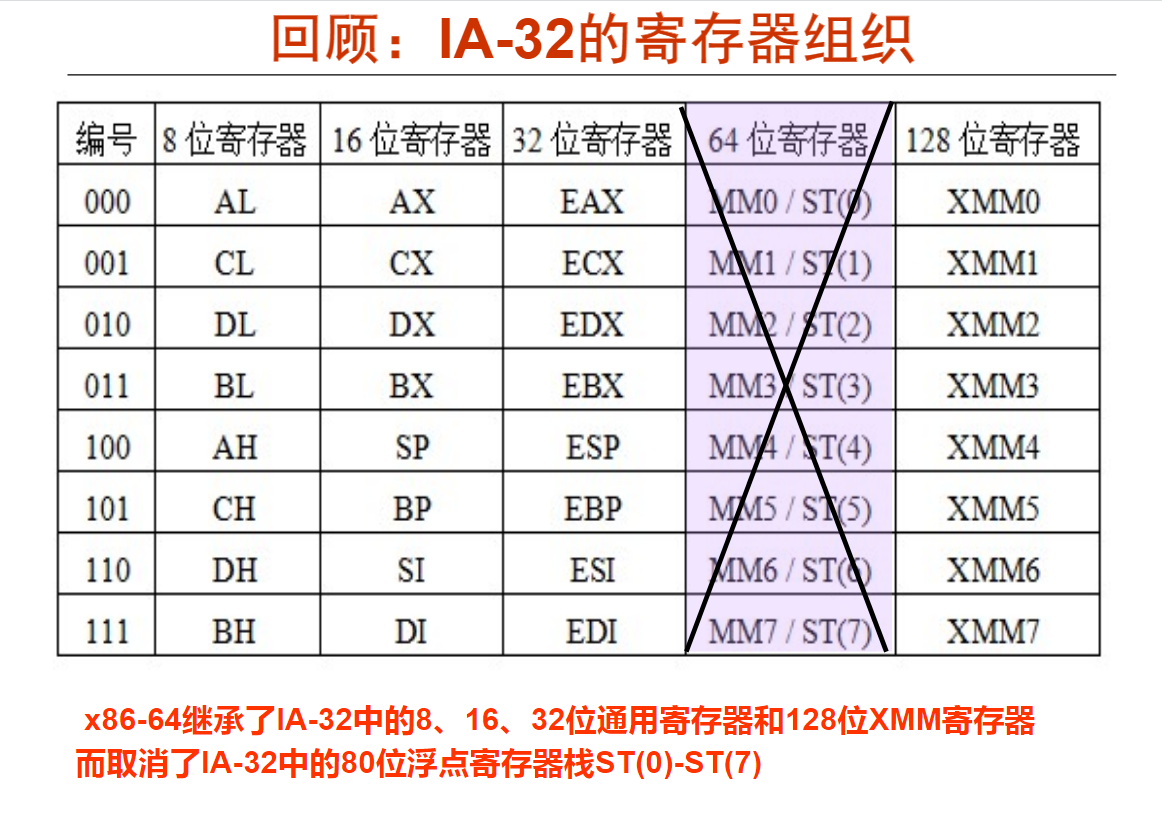
2. IA-32的寄存器组织(7分钟)
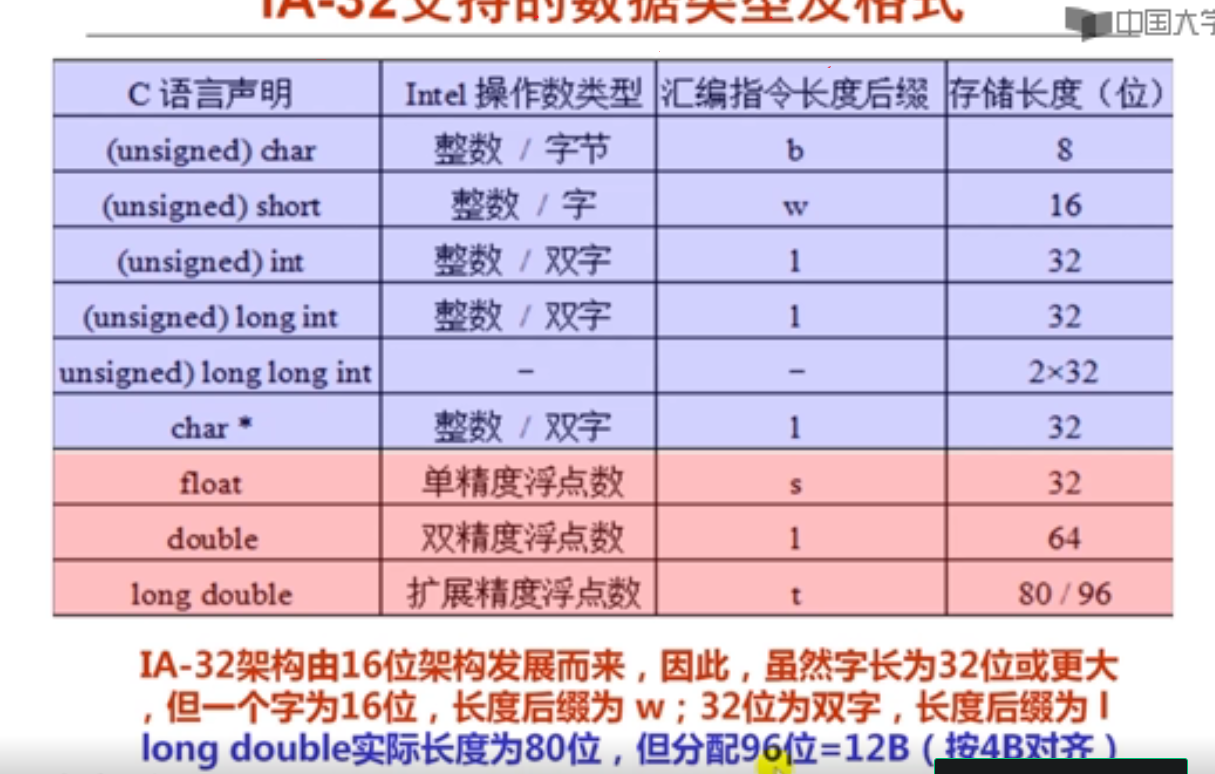
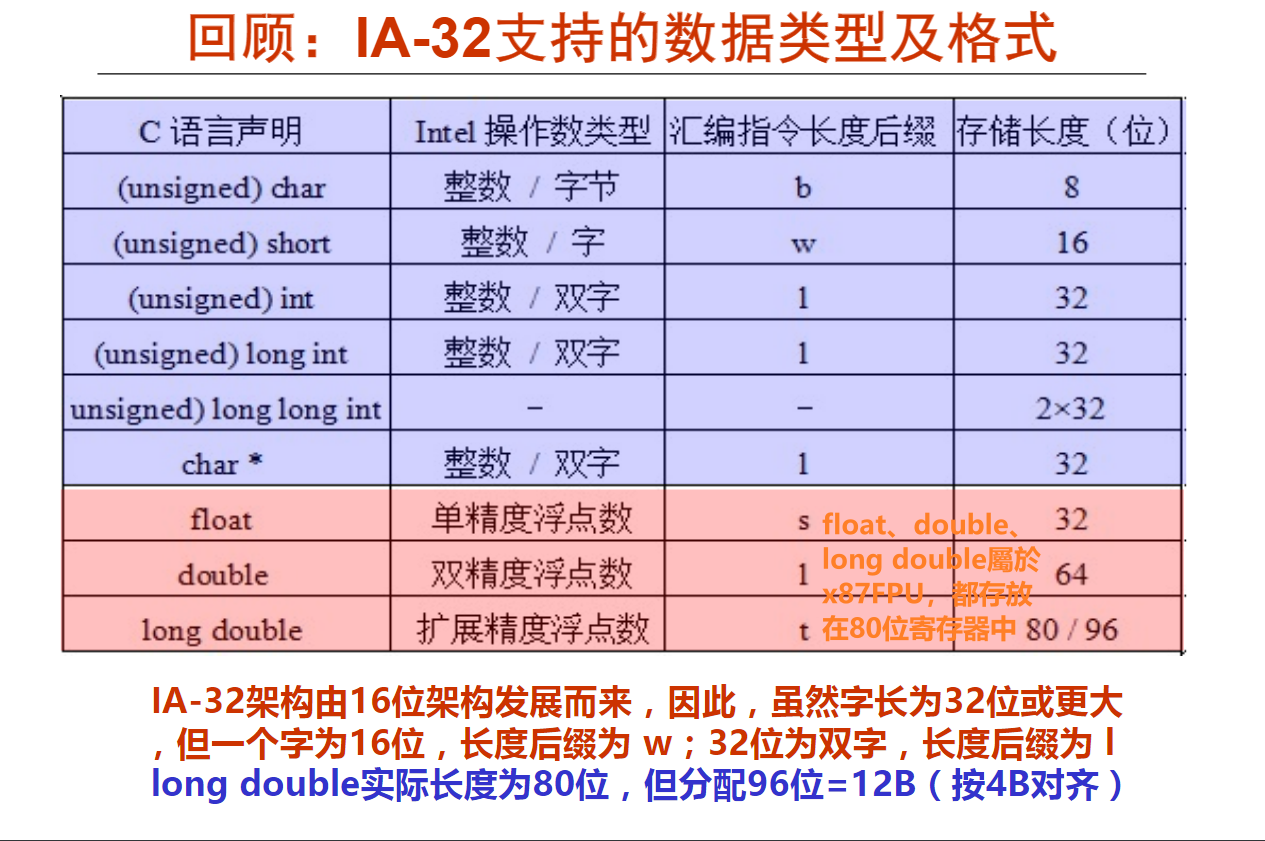
IA-32支持的数据类型及格式如上所示。
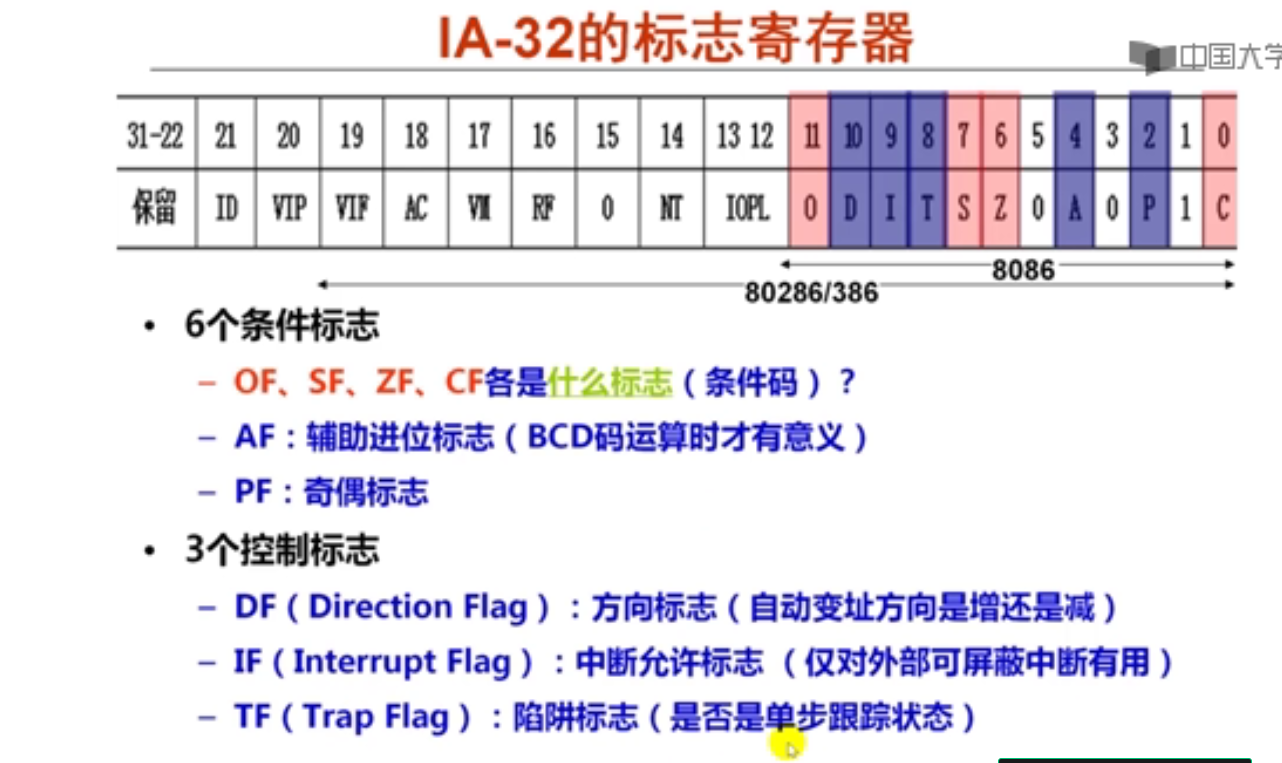
ZF 零标志
SF 符号标志
OF 溢出标志
CF 进/借位标志
3. IA-32的寻址方式(8分钟)

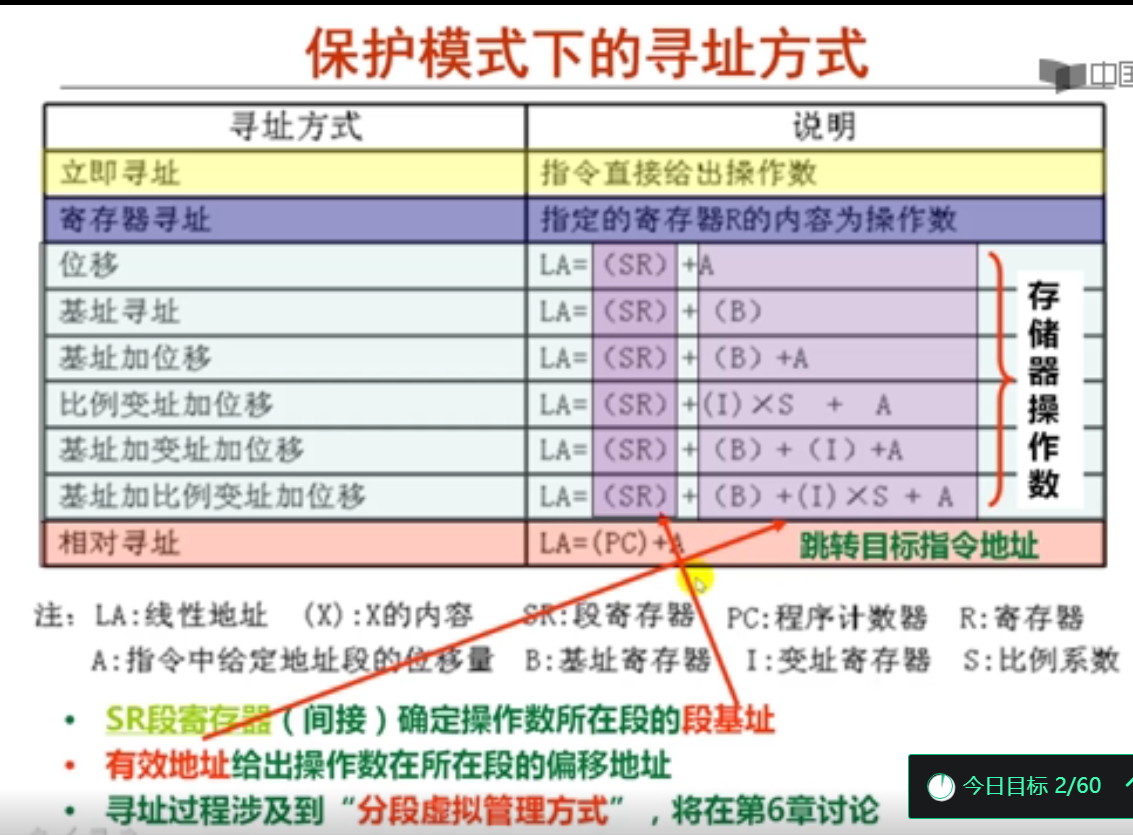
4. 高级语言程序中寻址举例(9分钟)
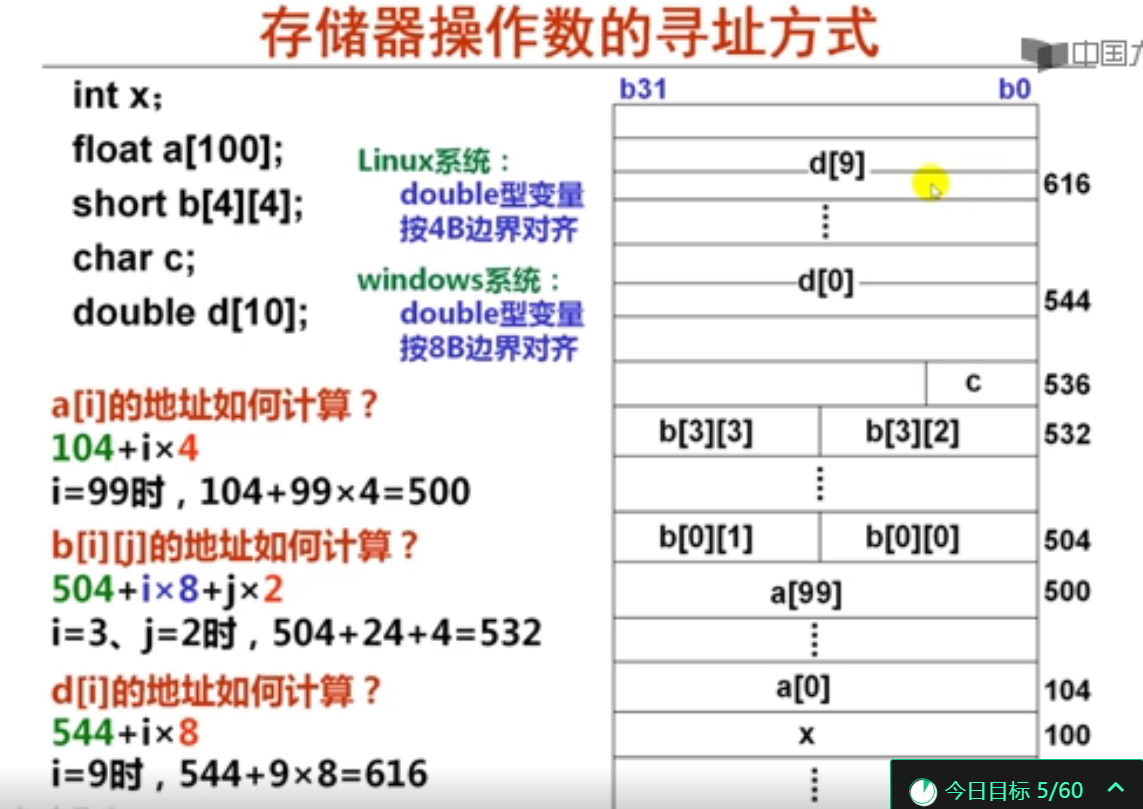
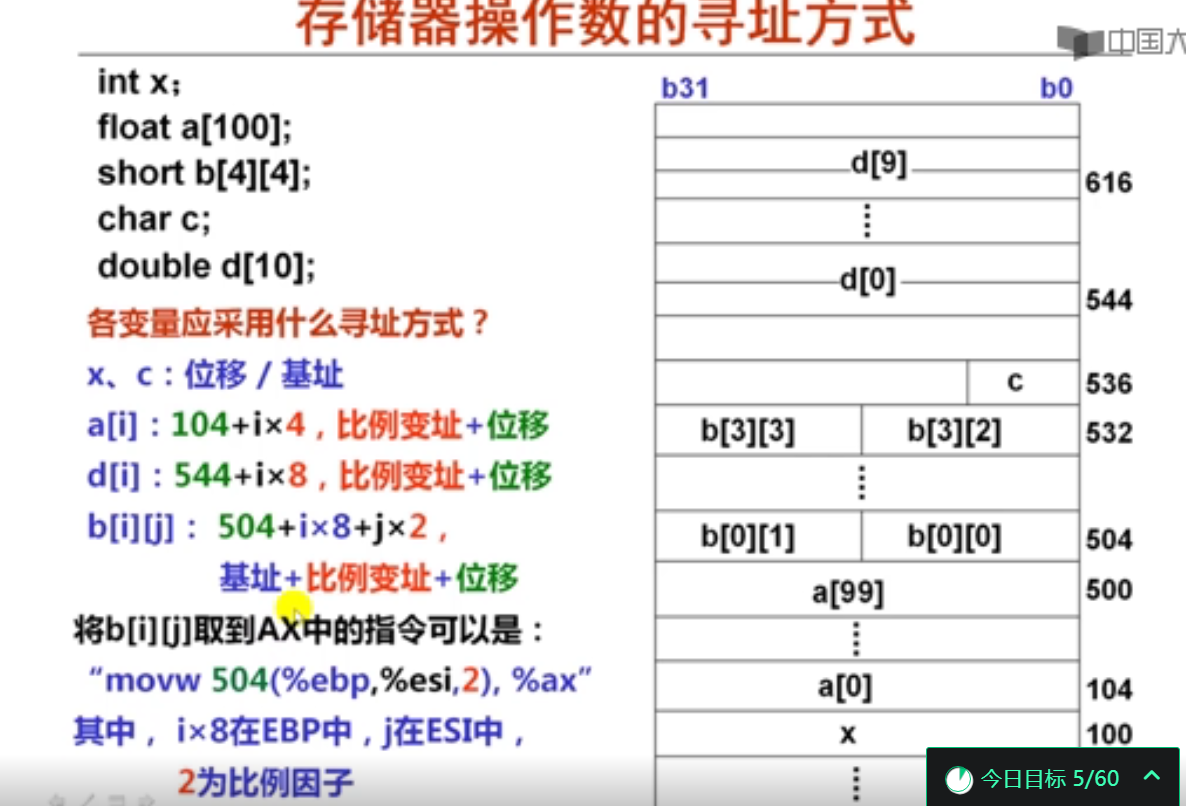
指令集体系结构设计时需要考虑各种寻址方式,这些寻址方式要能够支持高级语言程序的各种数据结构中数据的访问。其中,变址寻址通常用于数组元素的访问。
5. IA-32机器指令格式(10分钟)
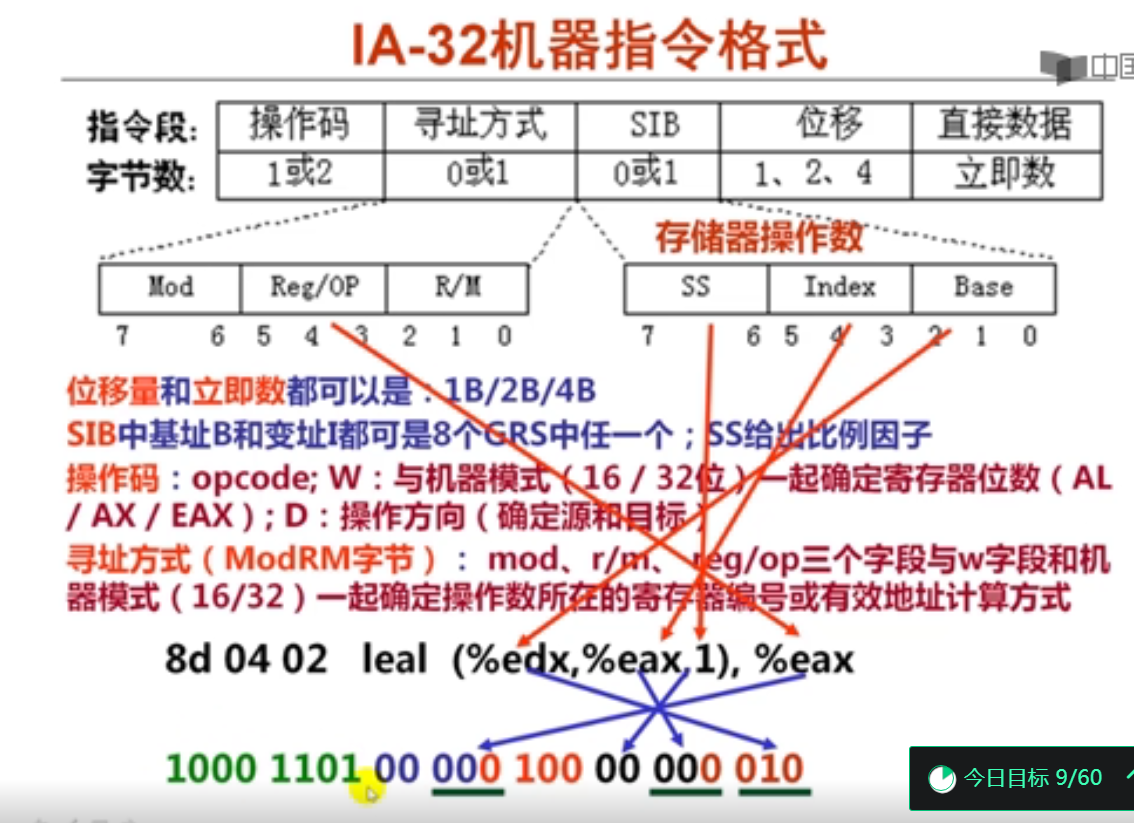
IA-32是变长指令字处理器,其中包含操作码、寻址方式、SIB、位移和立即数等字段。SIB字段用于确定操作数的存储地址,其中SS表示比例因子,占两位(00--1B;01--2B;10--4B;11--8B),Index表示3位变址寄存器编号,Base表示3位基址寄存器编号。

第五周小测验
1单选(0.5分)
以下有关指令的叙述中,错误的是(C )。
A. 伪指令是由若干条机器指令构成的一个指令序列,属于软件范畴
B. 机器指令是用二进制表示的一个0/1序列,CPU能直接执行
C. 汇编指令是机器指令的符号表示,CPU能直接执行
D. 微指令是一条机器指令所包含的控制信号的组合,CPU能直接执行
2单选(0.5分)
一条机器指令通常由多个字段构成。以下选项中,通常(D )不显式地包含在机器指令中。
A. 寄存器编号
B. 操作码
C. 寻址方式
D. 下条指令地址
3单选(0.5分)
对于运算类指令或传送类指令,需要在指令中指出操作数或操作数所在的位置。通常,指令中指出的操作数不可能出现在(A )中。
A. 程序计数器
B. 通用寄存器
C. 存储单元
D. 指令
4单选(0.5分)
令集体系结构(ISA)是计算机系统中必不可少的一个抽象层,它是对硬件的抽象,软件通过它所规定的指令系统规范来使用硬件。以下有关ISA的叙述中,错误的是(D )。
A. ISA规定了指令的操作数类型、寄存器结构、存储空间大小、编址方式和大端/小端方式
B. ISA规定了指令获取操作数的方式,即寻址方式
C. ISA规定了所有指令的集合,包括指令格式和操作类型
D. ISA规定了执行每条指令时所包含的控制信号
5单选(0.5分)
以下选项中,不属于指令集体系结构名称的是(B )。
A. MIPS
B. UNIX
C. IA-32
D. ARM
6单选(0.5分)
以下Intel微处理器中,不兼容IA-32指令集体系结构的是(C )。
A. Pentium (II、III、4)
B. Core(i3、i5、i7)
C. Itanium和Itanium 2
D. 80386和80486
7单选(0.5分)
以下关于IA-32指令格式的叙述中,错误的是(B )。
A. 采用变长指令字格式,指令长度从一个字节到十几个字节不等
B. 指令中给出的操作数所在的通用寄存器的宽度总是32位
C. 采用变长操作码,操作码位数可能是5位到十几位不等
D. 指令中指出的位移量和立即数的长度可以是0、1、2或4个字节
8单选(0.5分)
以下关于IA-32指令寻址方式的叙述中,错误的是( D)。
A. 存储器操作数中最复杂的寻址方式是“基址加比例变址加位移”
B. 操作数可以是指令中的立即数、也可以是通用寄存器或存储单元中的内容
C. 对于寄存器操作数,必须在指令中给出通用寄存器的3位编号
D. 相对寻址的目标地址为“PC内容加位移”,PC内容指当前正在执行指令的地址
9单选(0.5分)(重点)
以下关于IA-32中整数运算指令所支持的操作数的叙述中,错误的是(B )。
A. 参加运算的操作数可以是一个字节(8b)、一个字(16b)或双字(32b)
B. 除乘法指令外,其他运算指令的源操作数和目的操作数的位数相等
C.对于乘除运算指令,操作数一定区分是无符号整数还是带符号整数
D.对于加减运算指令,操作数不区分是无符号整数还是带符号整数
除法运算
10单选(0.5分)(重点)
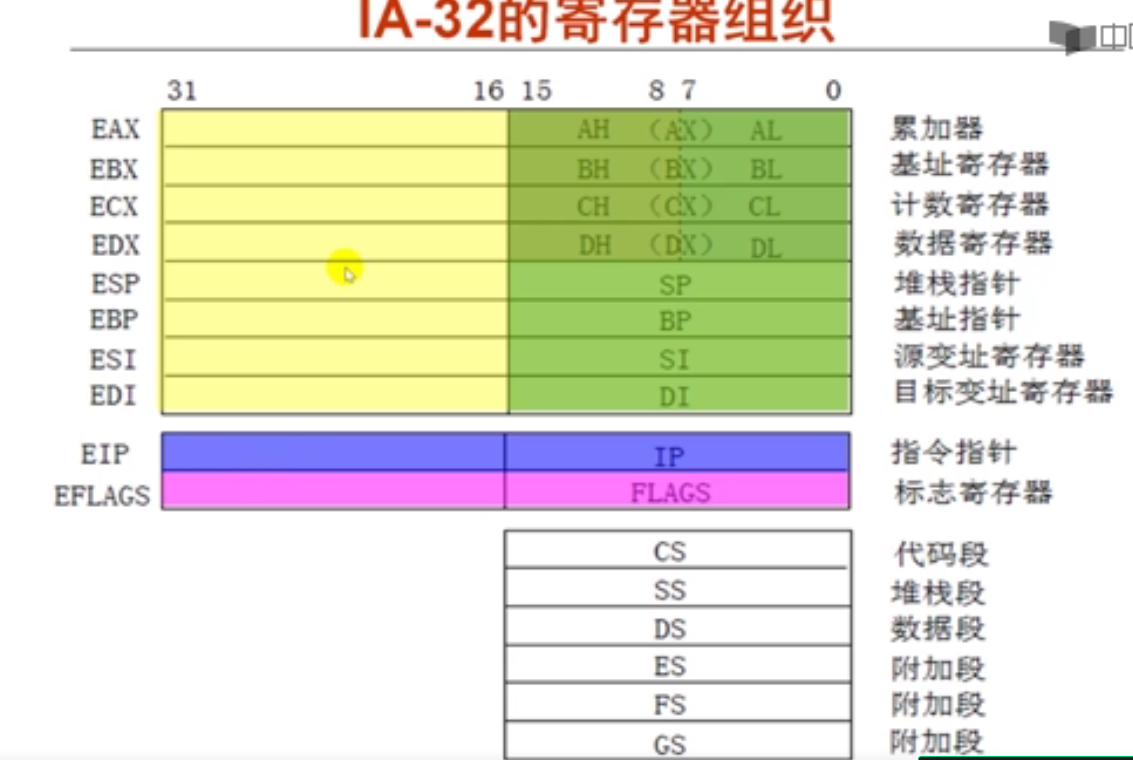
以下关于IA-32的定点寄存器组织的叙述中,错误的是(C)。
A. 寄存器ESP/SP称为栈指针寄存器,EBP/BP称为基址指针寄存器
B. EIP/IP为指令指针寄存器,即PC;EFLAGS/FLAGS为标志寄存器
C. 每个通用寄存器都可作为32位、16位或8位寄存器使用
D. 寄存器EAX/AX/AL称为累加器,ECX/CX/CL称为计数寄存器
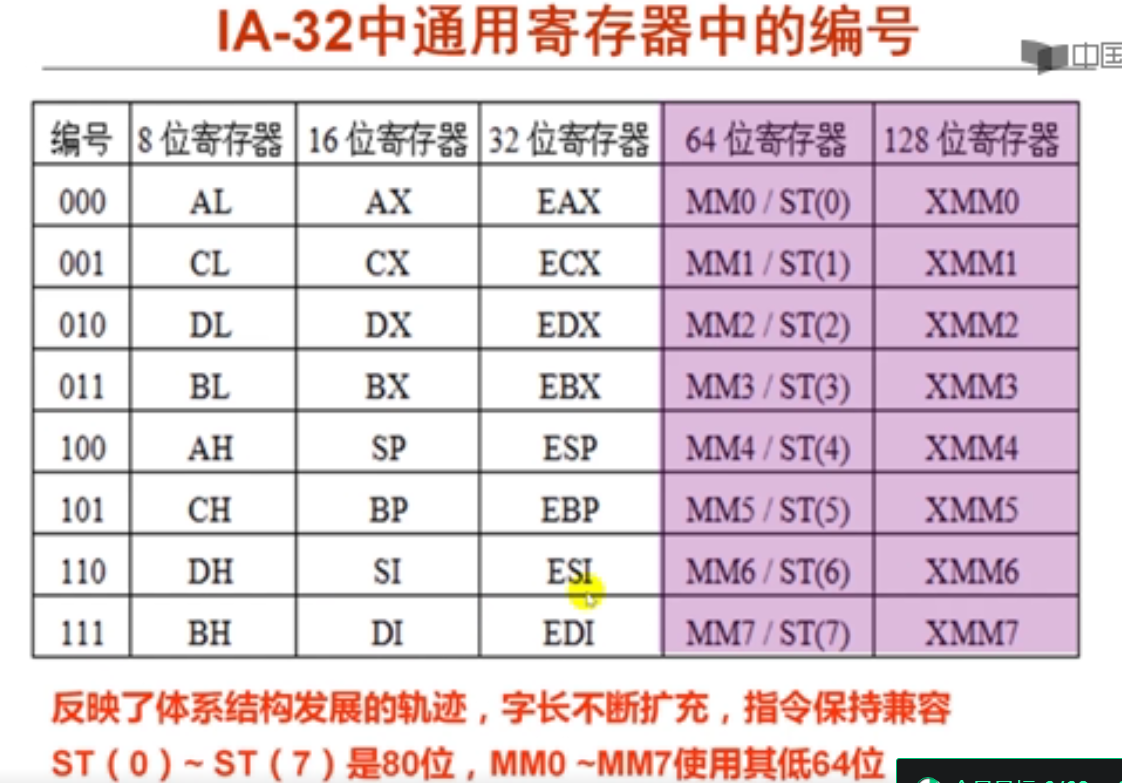
32位处理器中:EAX、ECX、EDX、EBX、ESP、EBP、ESI、EDI这8个寄存器通常存放一般性的数据,被称为通用寄存器。它们都有各自的用途。
EAX、ECX、EDX、EBX为数据寄存器;ESP、EBP为指针寄存器;ESI、EDI变址寄存器。
以EAX为例,寄存器的逻辑结构图如图2-3-1所示。
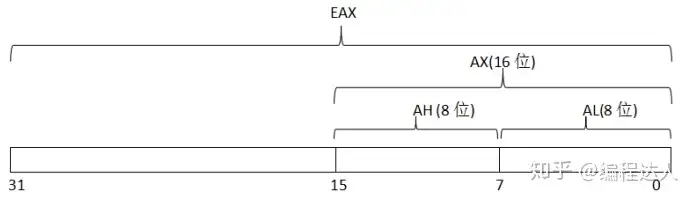
EAX寄存器它本身是一个32位寄存器,那么它可以存储一个32位的数据。EAX寄存器是在32位处理器中工作的,它的上一代处理器是16位处理器,而16位处理器的上一代是8位处理器,为了保证兼容,使之前的处理器经过程序的修改可以在32位处理器上运行。使得EAX寄存器包含了16位、8位的寄存器。
EAX寄存器可分为一个可独立使用的16位寄存器:AX(16位);16位寄存器还可以分为两个可以独立使用的8位寄存器: AH(8位~15位为高8位)、AL(0位~7位为低8位)。
而ESP、EBP、ESI、EDI这四个寄存器是分成了两段。
以ESP为例,寄存器的逻辑结构图如图2-3-2所示。
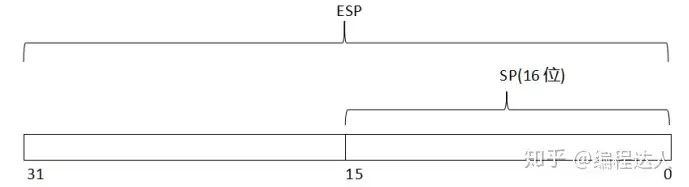
举例介绍了个别的寄存器逻辑结构,接下来我们来画出32位、16位、8位的通用寄存器逻辑结构图
通用寄存器逻辑结构必须记住,对以后学习有帮助
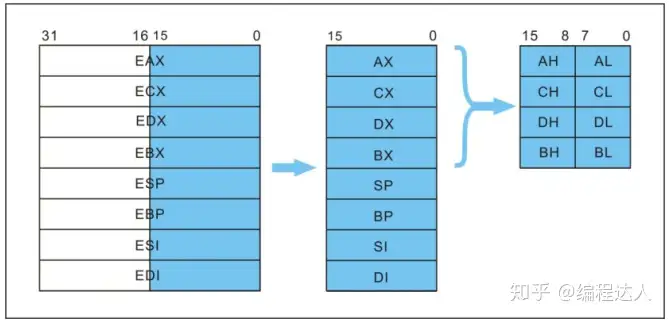
从这里可以看出,不是每个通用寄存器都可以作为8位寄存器使用
第六周IA-32指令类型
指令内容比较繁琐,不需要记忆,只要求能看懂手册会用即可。下面使用的是AT&T指令集,不是Intel80x86指令集。两者差异明显,比如mov指令是否加l,w等以及源操作数和目的操作数的位置不同。
第1讲 传送指令
1.常用传送指令(15分钟)


2.传送指令执行过程(5分钟)
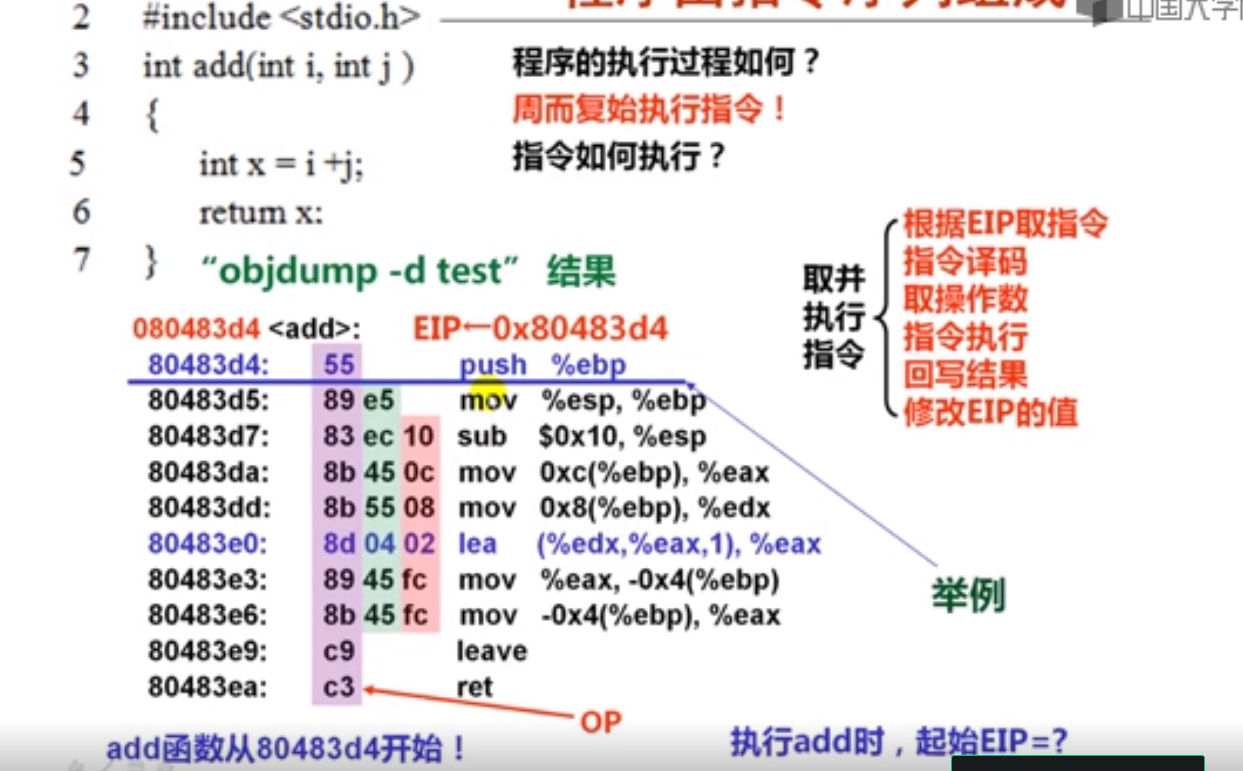
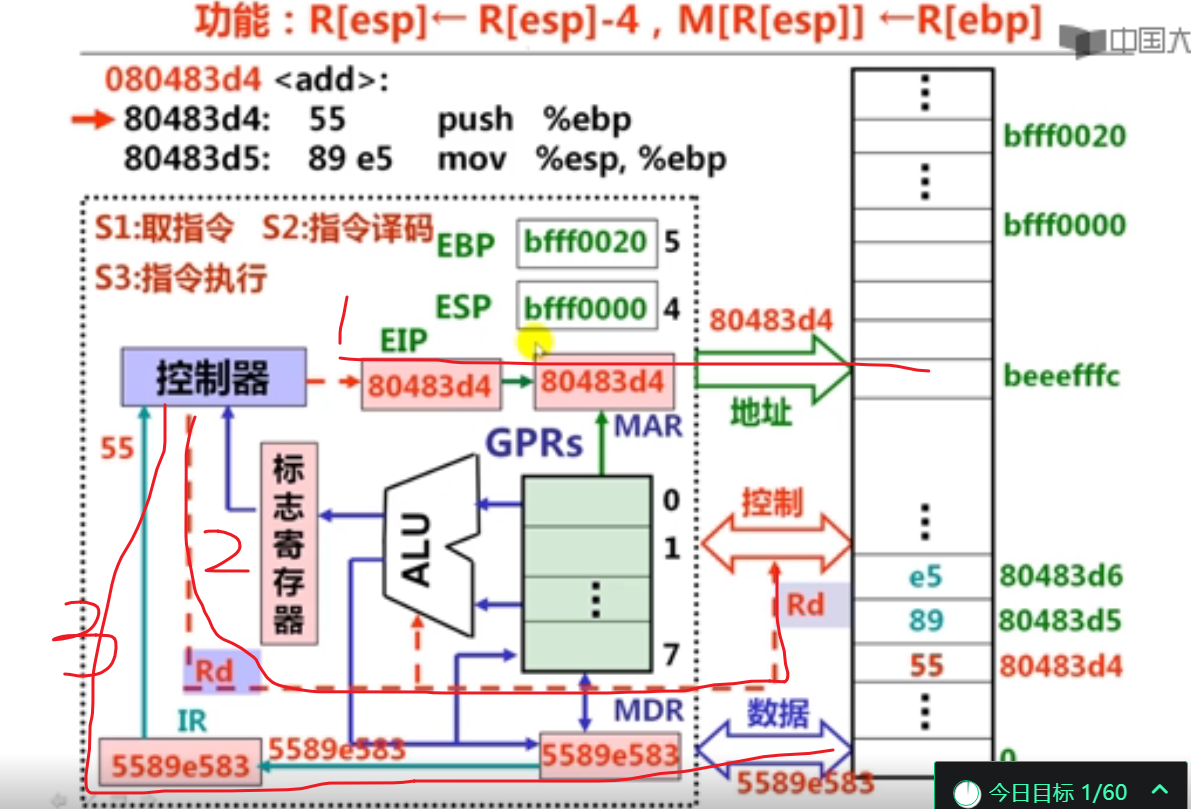
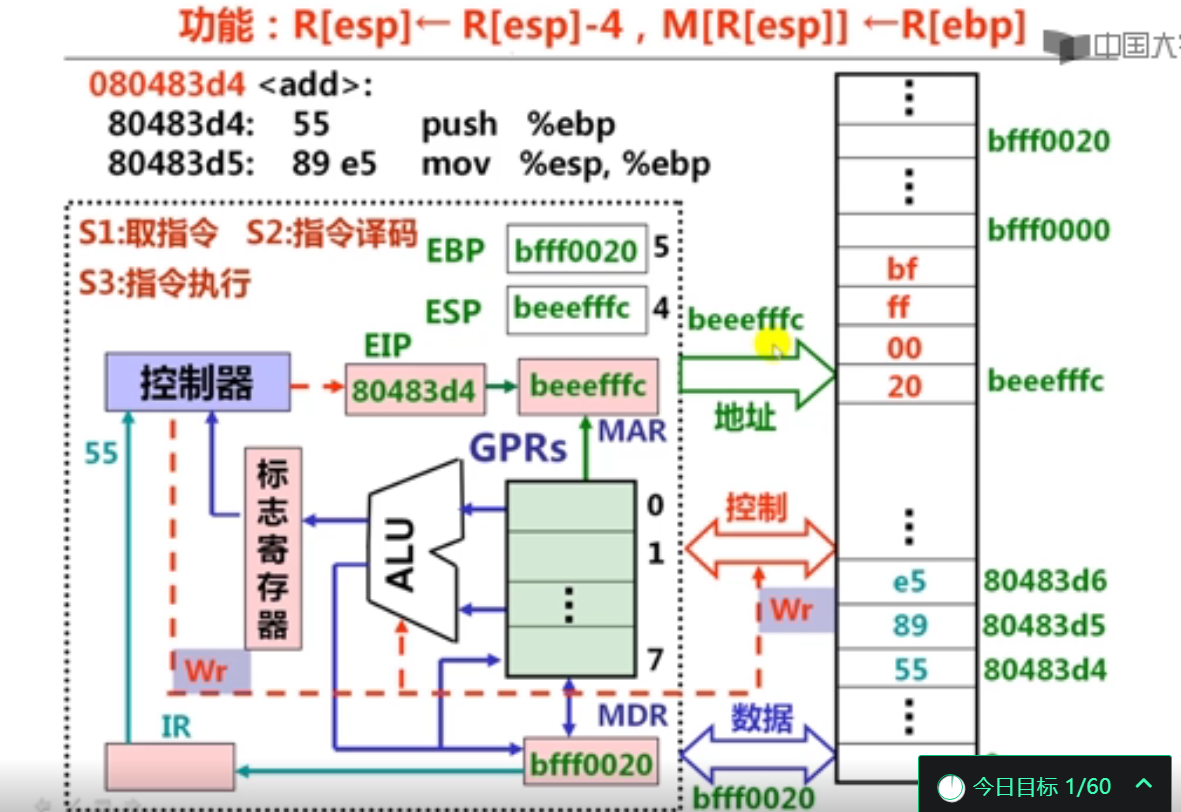
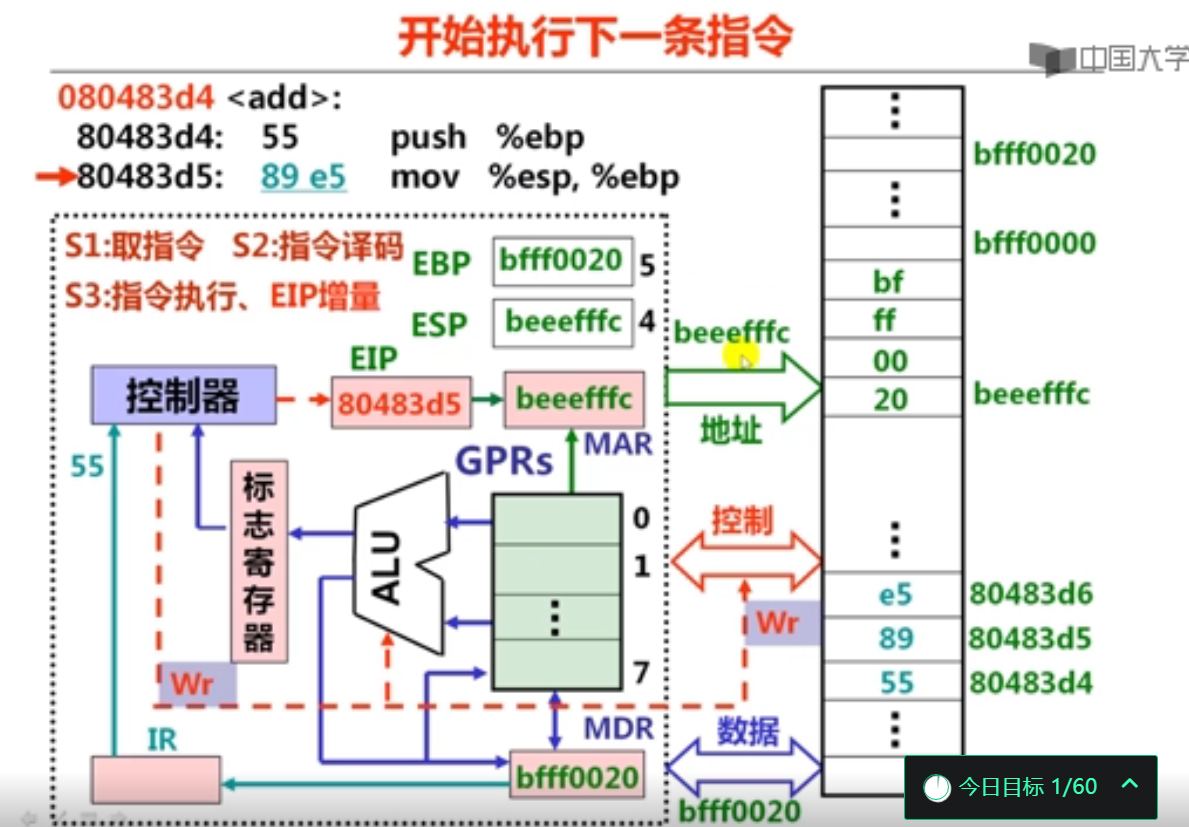
还有一个问题就是因为虽说经常听到 PC 这个词,但是我却没有见到其实体,所以我的理解是 PC 实际上就是 CS:IP 组合的逻辑表示。PC 不是一个实体,真正用来表示 PC 值的是 CS:IP,所谓的 PC 自动增加是指令指针寄存器 IP 在自增?这个理解对吗?
在 x86 体系里是这样。x86 系统中自增的是 IP,用 CS:IP 组合表示正在执行的指令地址,此时 PC 只是一个概念上的说法。在 ARM 体系中 R15 就是 PC,当然 ARM 和 IA-32、x64 都支持高级内存管理,所以「PC」的内容未必是当前指令在内存中的绝对位置。

第2讲 定点算术运算指令
1.常用定点运算指令(9分钟)


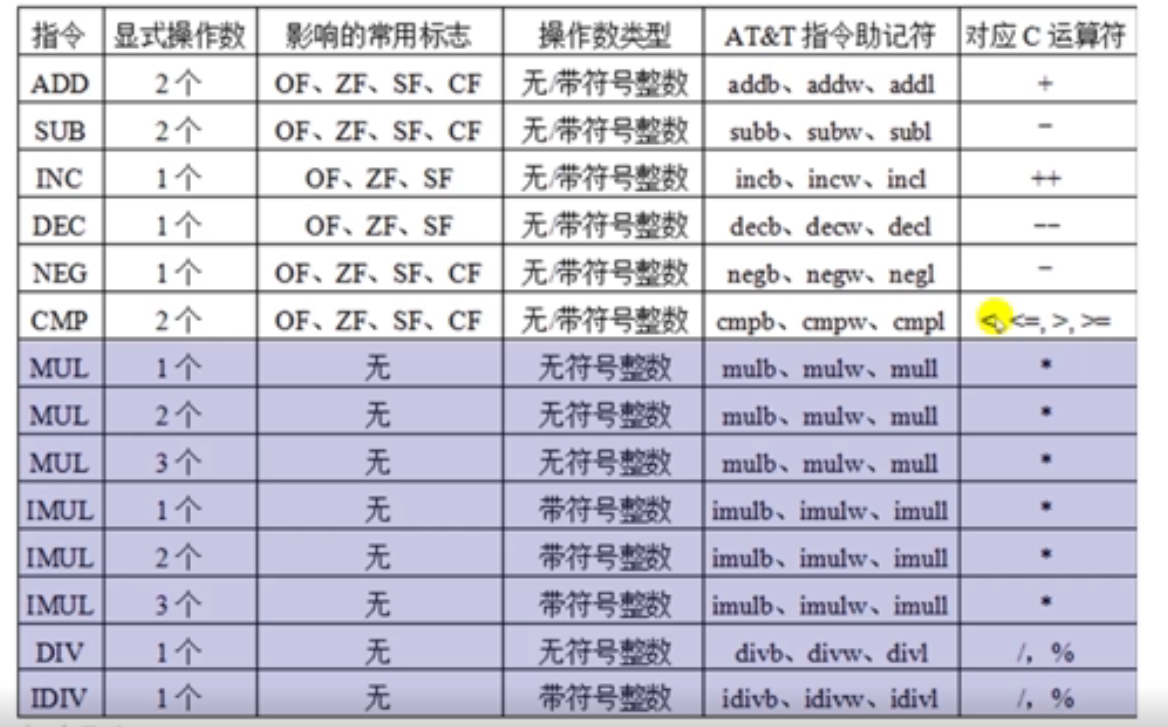
定点算术运算指令汇总
2.加法运算的底层实现举例(15分钟)

#include <iostream>
#include <cstdio>
using namespace std;
int add(int i,int j)
{
int x = i + j;
return x;
}
int main()
{
int t1 = 2147483647;
int t2 = 2;
int sum = add(t1,t2);
printf("sum=%d",sum);
}
sum=-2147483647
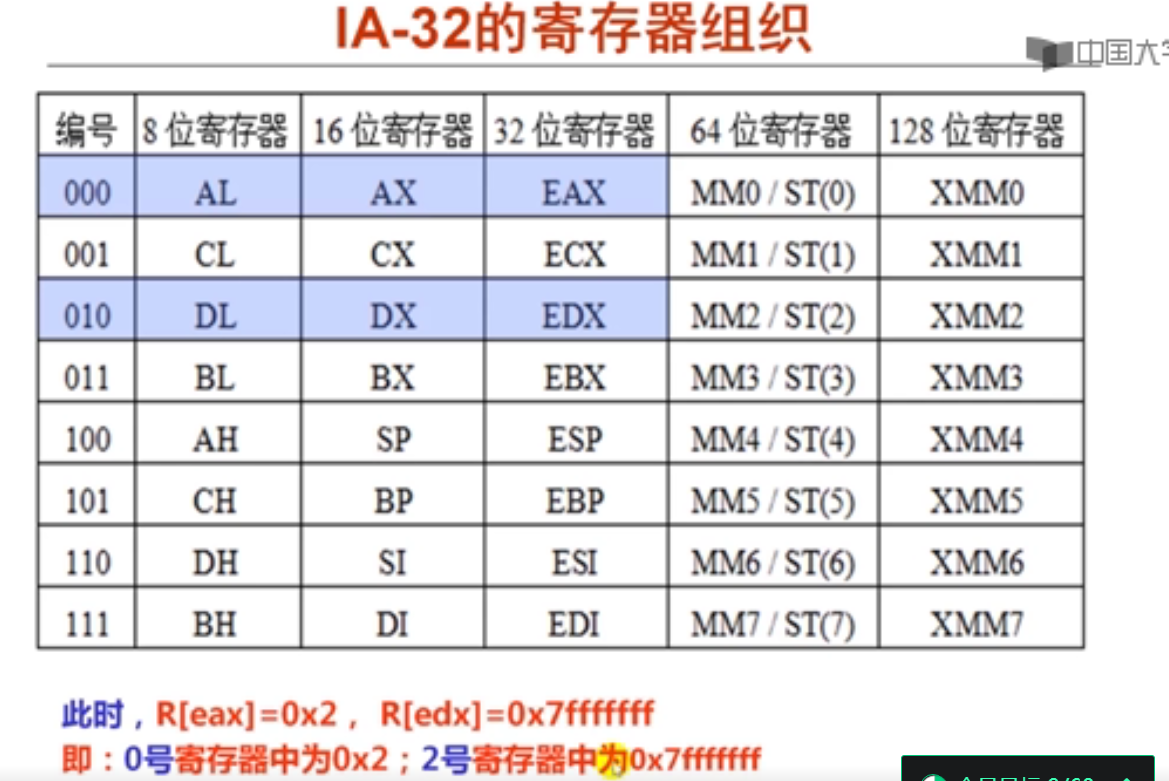
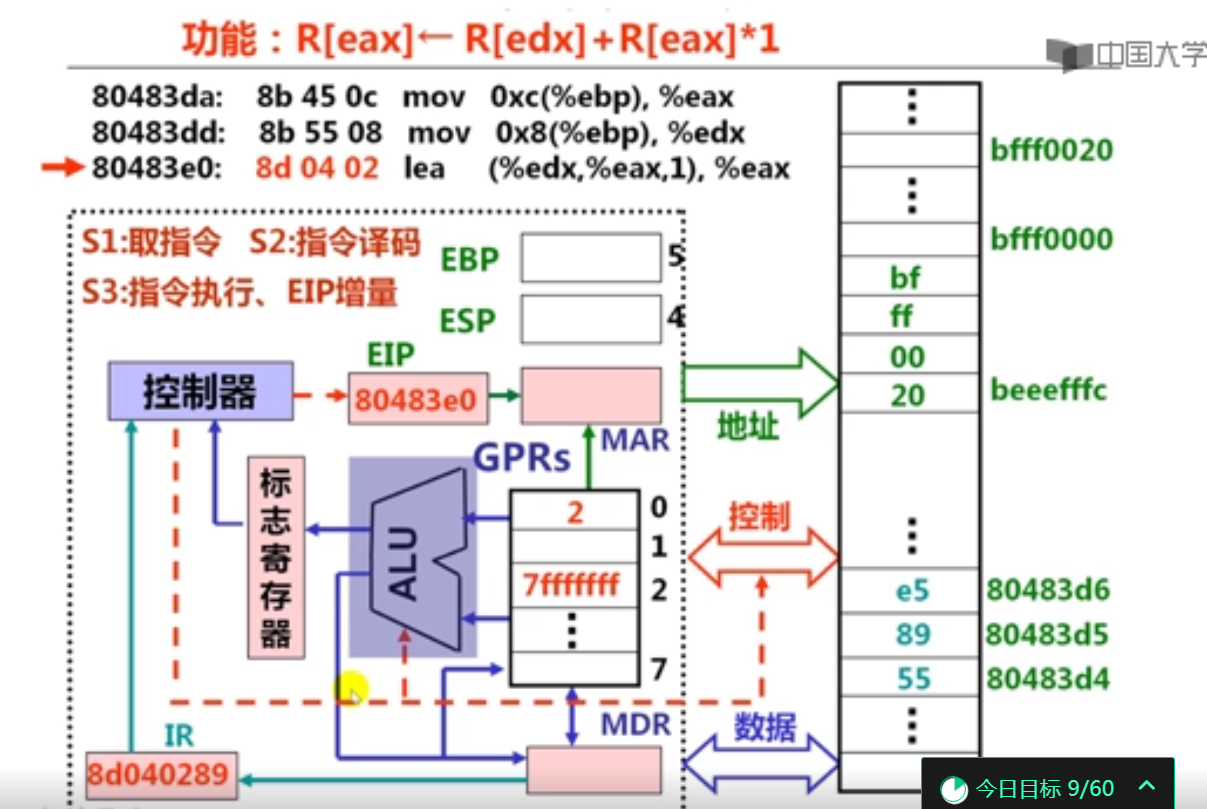

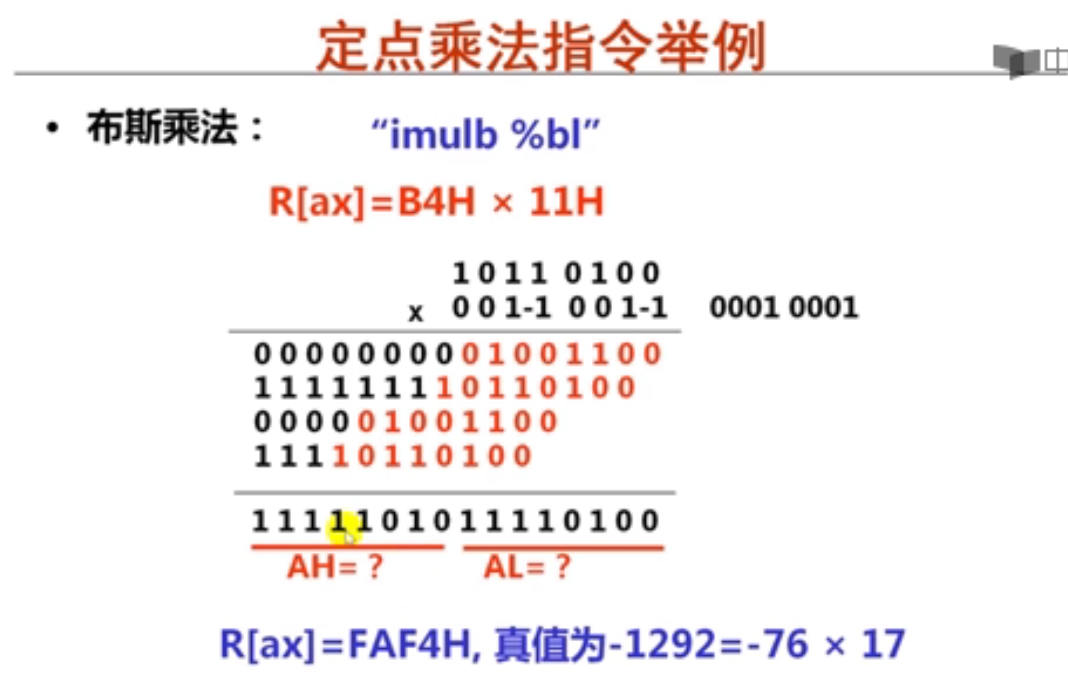
ALU结构原理
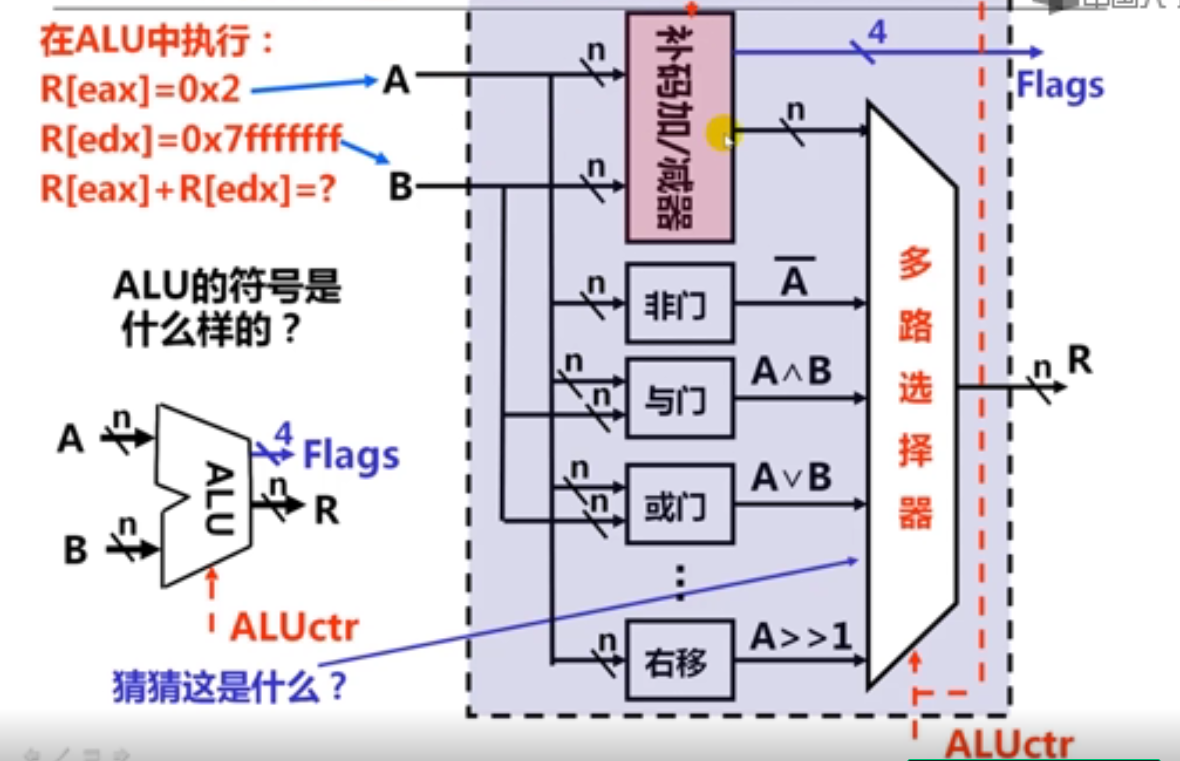
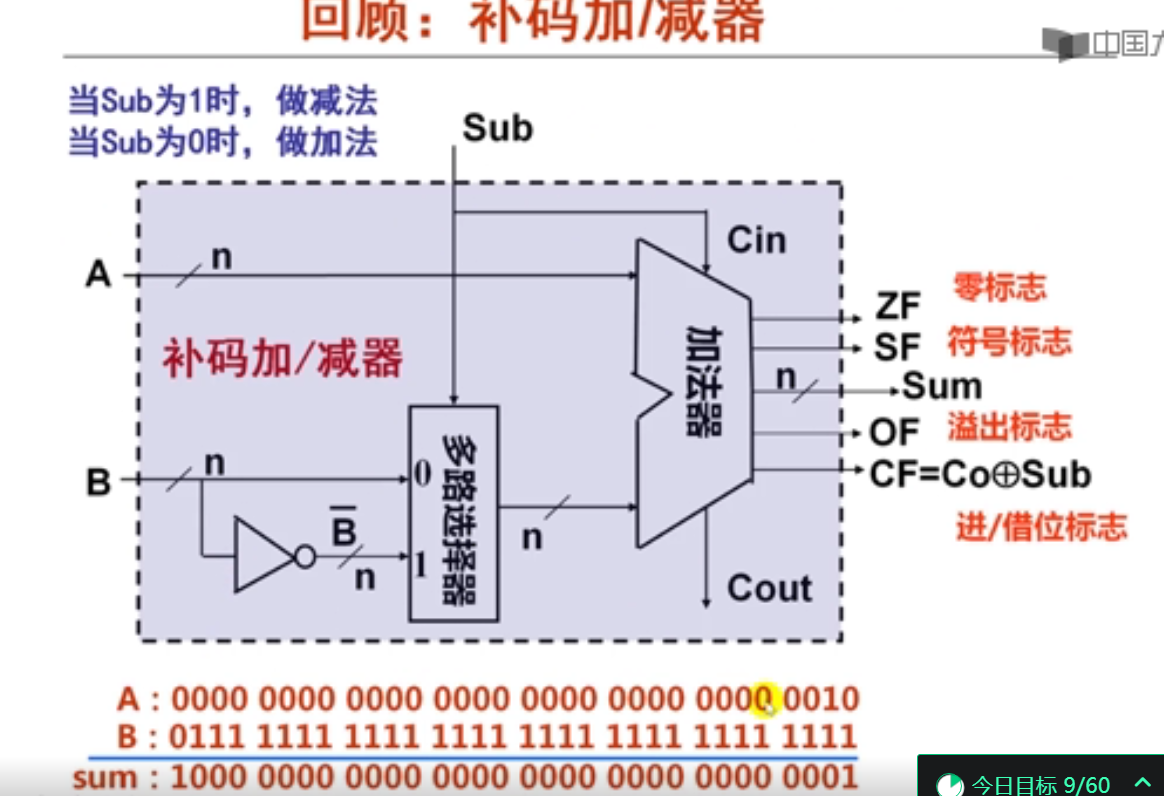
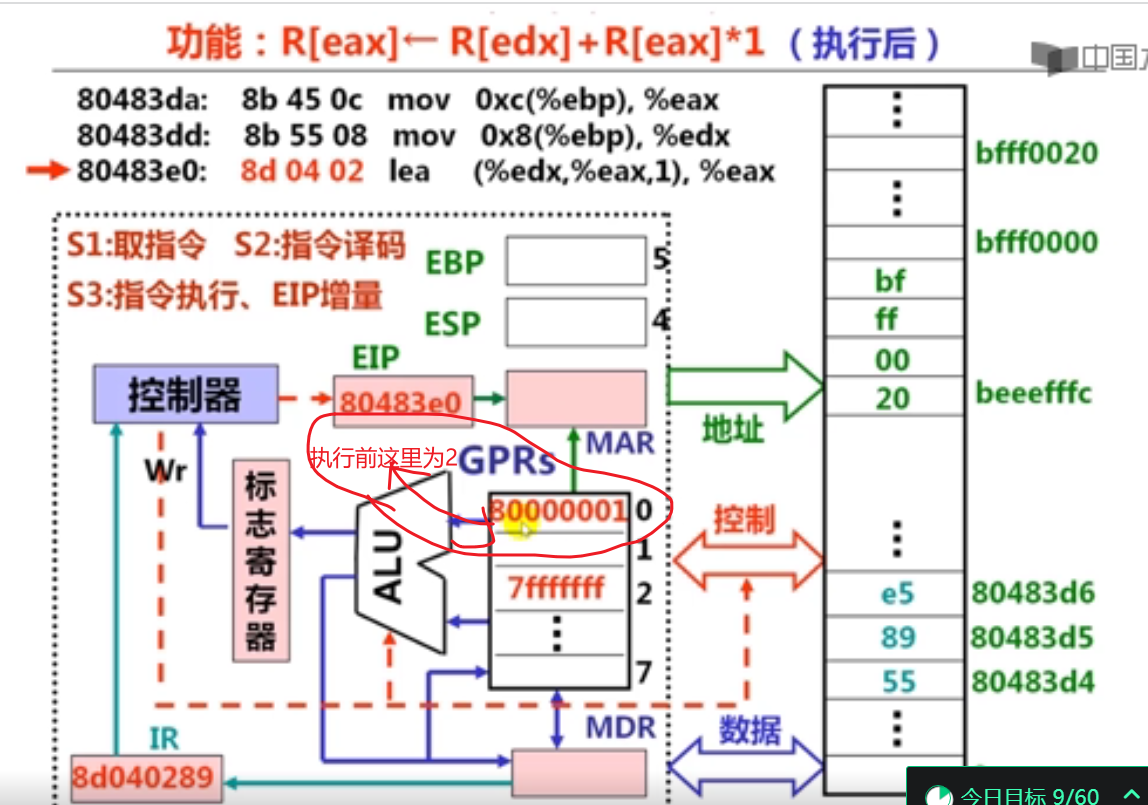

3.加法指令和乘法指令举例(18分钟)

溢出标志OF:在运算过程中,如果操作数或结果超出了机器能表示的范围称为溢出。此时OF位置1,否则置0。简而言之,如果操作数符号相同,而结果与操作数符号不同,则发生了溢出。 上面是负数加负数还是负数,故没有溢出。
符号标志SF:计算运算结果的符号,若最高有效位为1则置为1,最高有效位为0则置为0
零标志ZF:计算结果为0时置为1,否则置为0
进位标志CF:CF=Cout XOR Sub。例如,执行加法指令时,最高有效位有进位时置1,否则置0。


第3讲 按位运算指令
1.逻辑运算和移位指令(12分钟)



2.按位运算指令举例(10分钟)

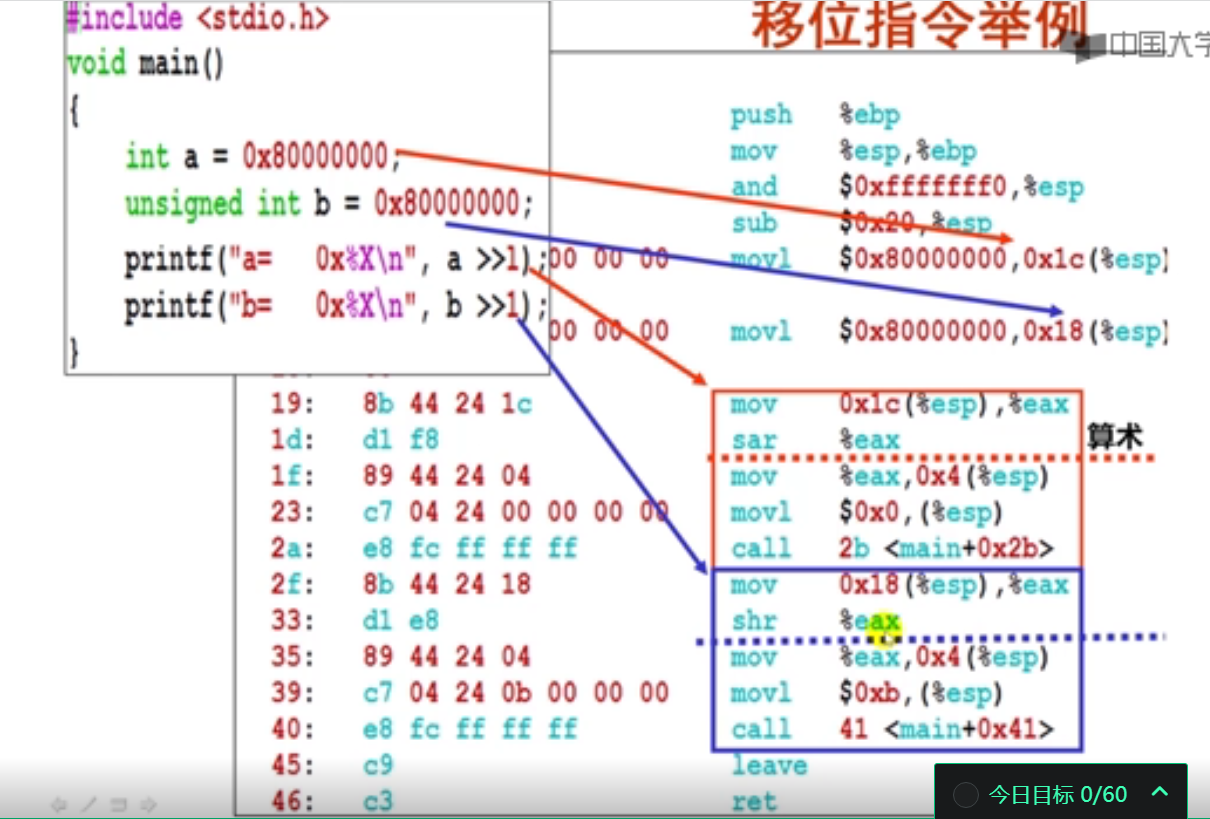
#include <stdio.h>
int main()
{
int a = 0x80000000;
unsigned int b = 0x80000000;
printf("0x%X\n",a>>1);
printf("0x%X\n",b>>1);
return 0;
}
0xC0000000
0x40000000
第4讲 控制转移指令
1.条件转移指令举例(22分钟)


#include <stdio.h>
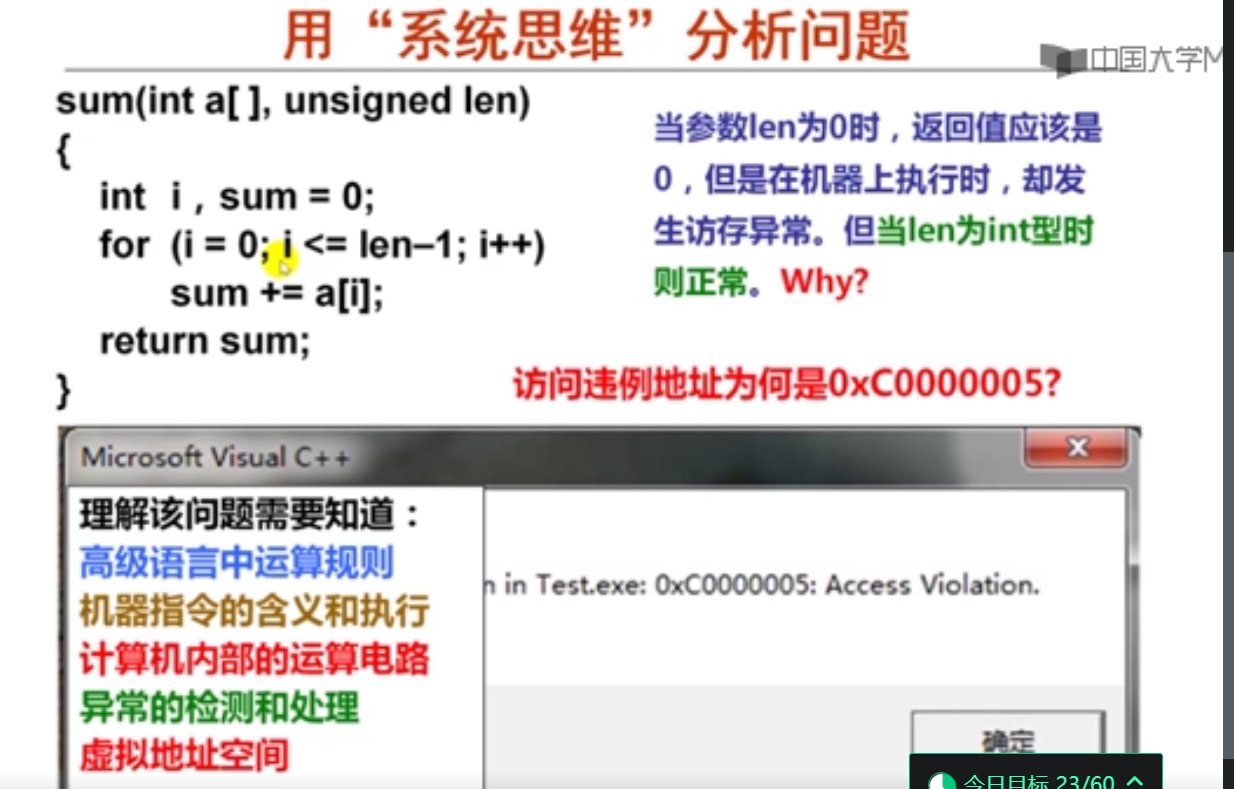
int sum(int a[],unsigned len)
{
int i,sum = 0;
for(i=0;i<=len-1;i++)
sum += a[i];
return sum;
}
int main()
{
int a[4]={1,2,3,4};
unsigned int len = 0;
printf("%d\n",sum(a,len));
return 0;
}
Process returned -1073741819 (0xC0000005) execution time : 0.532 s
Press any key to continue.
这是个死循环。

#include <stdio.h>
int sum(int a[],int len)
{
int i,sum = 0;
for(i=0;i<=len-1;i++)
sum += a[i];
return sum;
}
int main()
{
int a[4]={1,2,3,4};
int len = 0;
printf("%d\n",sum(a,len));
return 0;
}
0
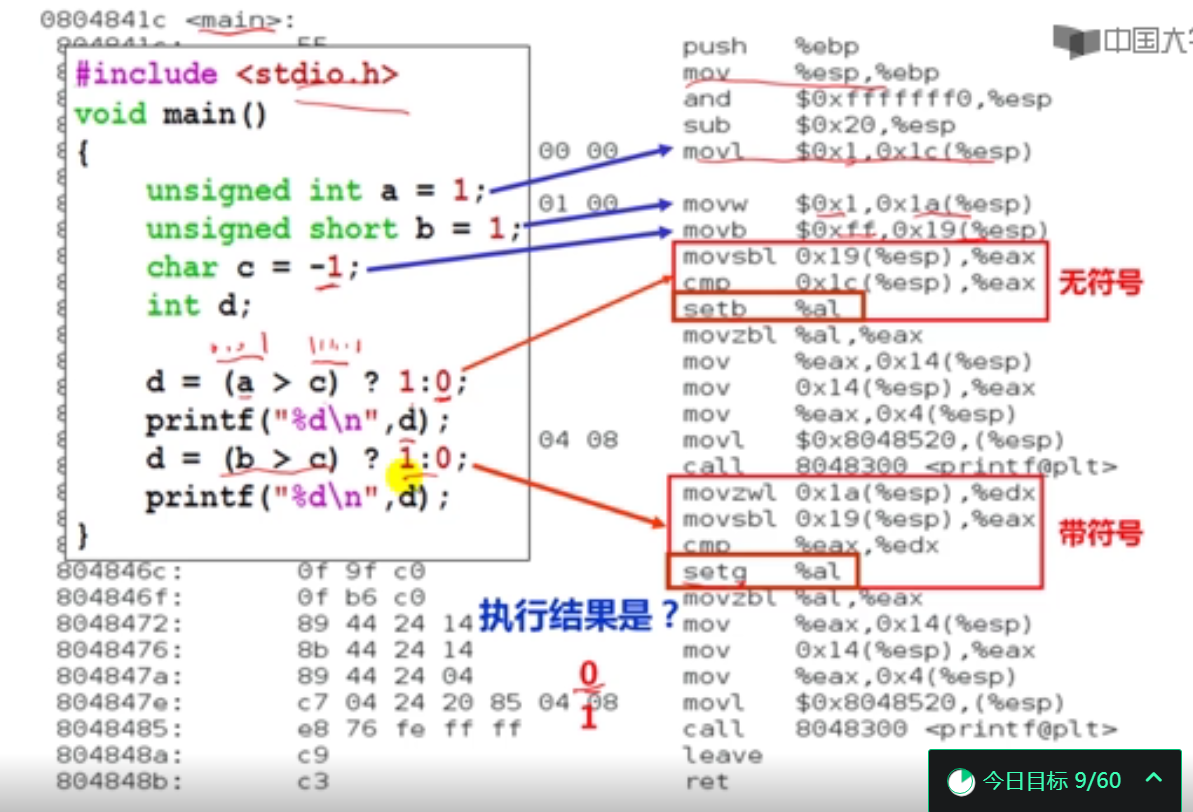
2.条件设置指令举例(5分钟)

#include <stdio.h>
int main()
{
unsigned int a = 1;
unsigned short b = 1;
char c = -1;
int d;
d = (a > c) ? 1 : 0;
printf("%d\n",d);
d = (a == c) ? 1 : 0;
printf("%d\n",d);
d = (b > c) ? 1 : 0;
printf("%d\n",d);
return 0;
}
a:0000 0000 0000 0000 0000 0000 0000 0001
b:0000 0000 0000 0001
c:1111 1111
0
0
1
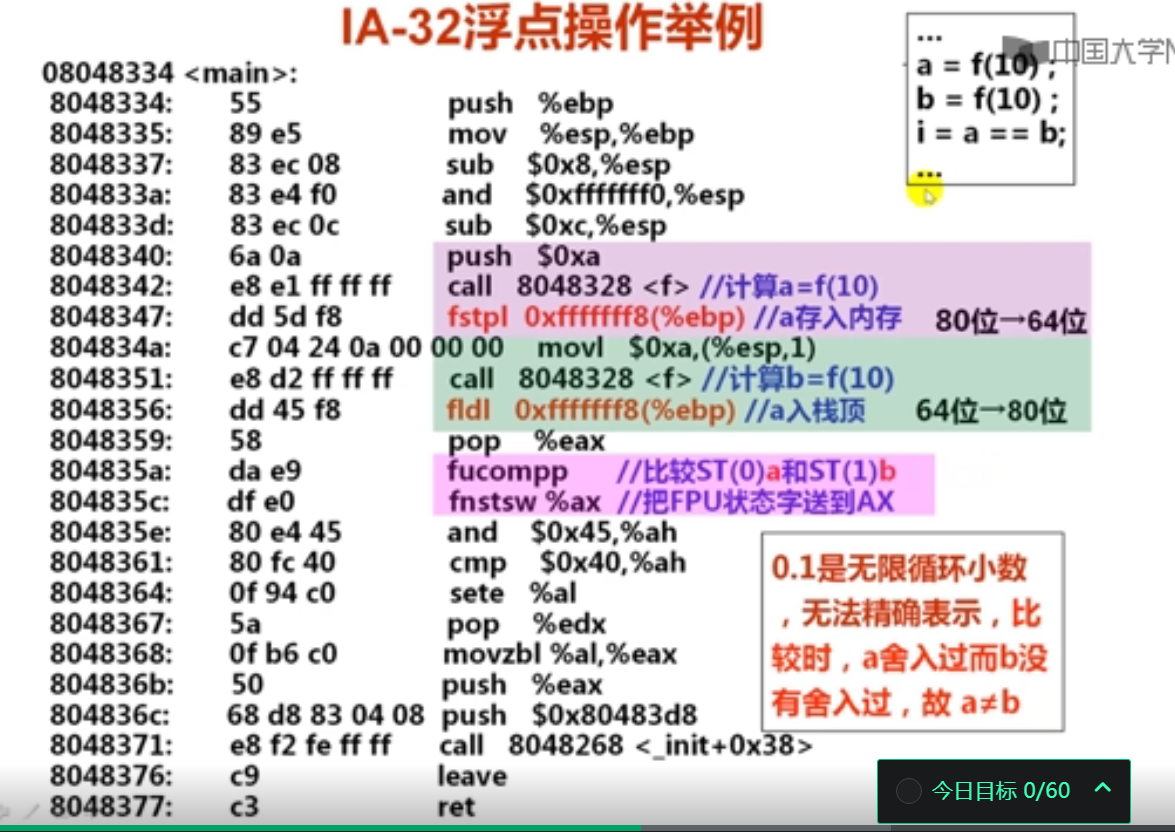
第5讲 x87浮点处理指令
1. x87 FPU常用指令(11分钟)






2. x87浮点处理指令举例(15分钟)



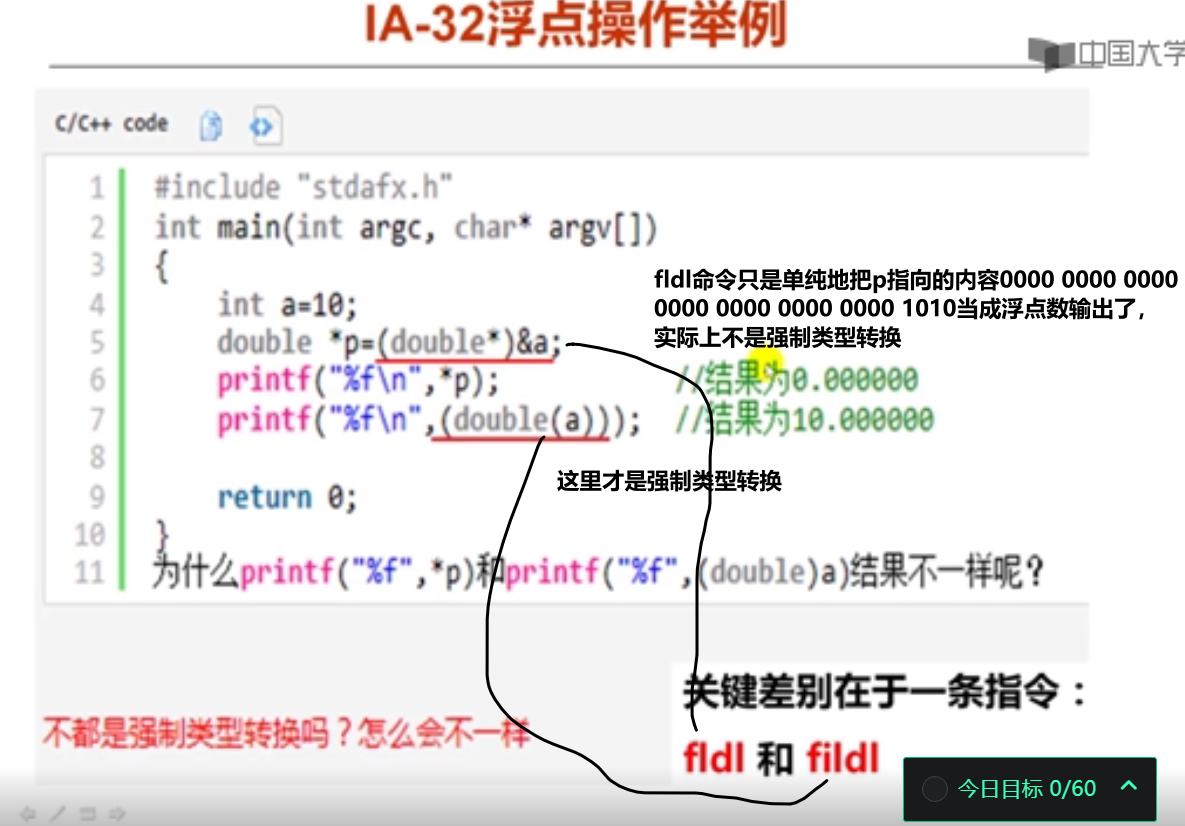

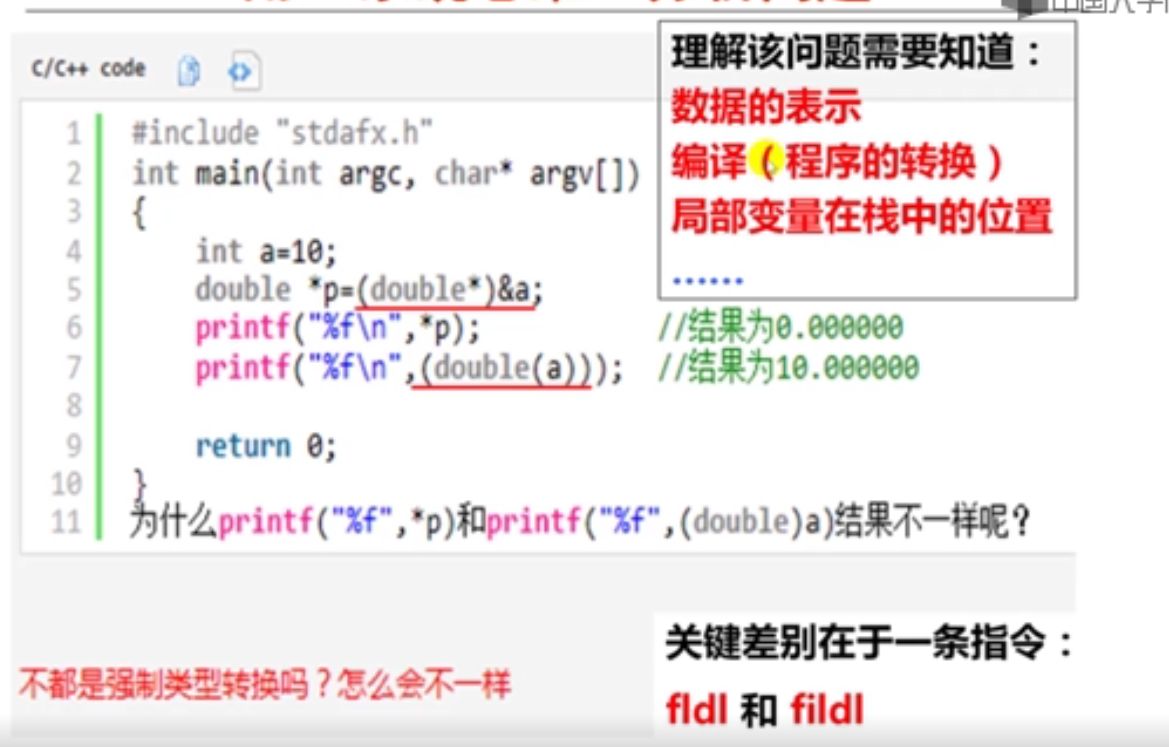
#include <stdio.h>
int main()
{
int a = 10;
double *p = (double*)&a;
printf("%f\n",*p);
printf("%f\n",(double)a);
return 0;
}
0.000000
10.000000
老师说printf("%f\n",*p);实际上会输出个不确定的值。
输出为%d格式会出现更玄乎的结果。
#include <stdio.h>
int main()
{
int a = 10;
double *p = (double*)&a;
printf("%d\n",*p);
printf("%d\n",(double)a);
return 0;
}
10
0
第6讲 MMX及SSE指令集
MMX及SSE指令集(14分钟)




第六周小测验
1单选(相对基址比例变址寻址方式)
某C语言程序中对数组变量b的声明为“int b[10][5];”,有一条for语句如下:
for (i=0; i<10, i++)
for (j=0; j<5; j++)
sum+= b[i][j];
假设执行到“sum+= b[i][j];”时,sum的值在EAX中,b[i][0]所在的地址在EDX中,j在ESI中,则“sum+= b[i][j];”所对应的指令(AT&T格式)可以是( A )。
A.addl 0(%edx, %esi, 4), %eax
B.addl 0(%esi, %edx, 4), %eax
C.addl 0(%edx, %esi, 2), %eax
D.addl 0(%esi, %edx, 2), %eax
2单选(popl指令)
IA-32中指令“popl %ebp”的功能是( D )。
A.R[esp]←R[esp]+4,R[ebp]←M[R[esp]]
B.R[esp]←R[esp]-4,R[ebp]←M[R[esp]]
C.R[ebp]←M[R[esp]],R[esp]←R[esp]-4
D.R[ebp]←M[R[esp]],R[esp]←R[esp]+4
3单选(movl指令)
IA-32中指令“movl 8(%edx, %esi, 4), %edx”的功能是( D )。
A.M[R[esi]+R[edx]*4+8]←R[edx]
B.R[edx]←M[R[esi]+R[edx]*4+8]
C.M[R[edx]+R[esi]*4+8]←R[edx]
D.R[edx]←M[R[edx]+R[esi]*4+8]
4单选(movswl指令)
设SignExt[x]表示对x符号扩展,ZeroExt[x]表示对x零扩展。IA-32中指令“movswl %cx, -20(%ebp)”的功能是( D )。
A.M[R[ebp]-20]←ZeroExt[R[cx]]
B.R[cx]←ZeroExt [M[R[ebp]-20]]
C.R[cx]←SignExt [M[R[ebp]-20]]
D.M[R[ebp]-20]←SignExt[R[cx]]
5单选(subw指令)
假设 R[ax]=FFE8H,R[bx]=7FE6H,执行指令“subw %bx, %ax”后,寄存器的内容和各标志的变化为( A )。
A.R[ax]=8002H,OF=0,SF=1,CF=0,ZF=0
B.R[bx]=8002H,OF=1,SF=1,CF=0,ZF=0
C.R[ax]=8002H,OF=1,SF=1,CF=0,ZF=0
D.R[bx]=8002H,OF=0,SF=1,CF=0,ZF=0
解析: A、指令在补码加减运算部件中执行:1111 1111 1110 1000+1000 0000 0001 1001+1 =(1)1000 0000 0000 0010(8002H),结果无溢出(OF=0)、负数(SF=1)、没有借位(CF= (1 异或 1) =0)、非0(ZF=0)。
6单选(imulw指令)
假设R[eax]=0000B160H,R[ebx]=00FF0110H,执行指令“imulw %bx”后,通用寄存器的内容变化为( D )。
A.R[eax]=FFAC7600H,其余不变
B. R[eax]=00BC7600,其余不变
C.R[eax]=00007600H,R[dx]=00BCH
D.R[eax]=00007600H,R[dx]=FFACH
解析: D、因为一个源操作数为BX寄存器中的内容,所以只要将AX和BX中的内容相乘即可。指令在带符号乘法部件中执行,B160H*0110H=FFFB1600+FFB16000=FFAC7600H,DX寄存器内容为FFACH,AX寄存器内容为7600H,EAX中高16位不变。
7单选(salw指令)
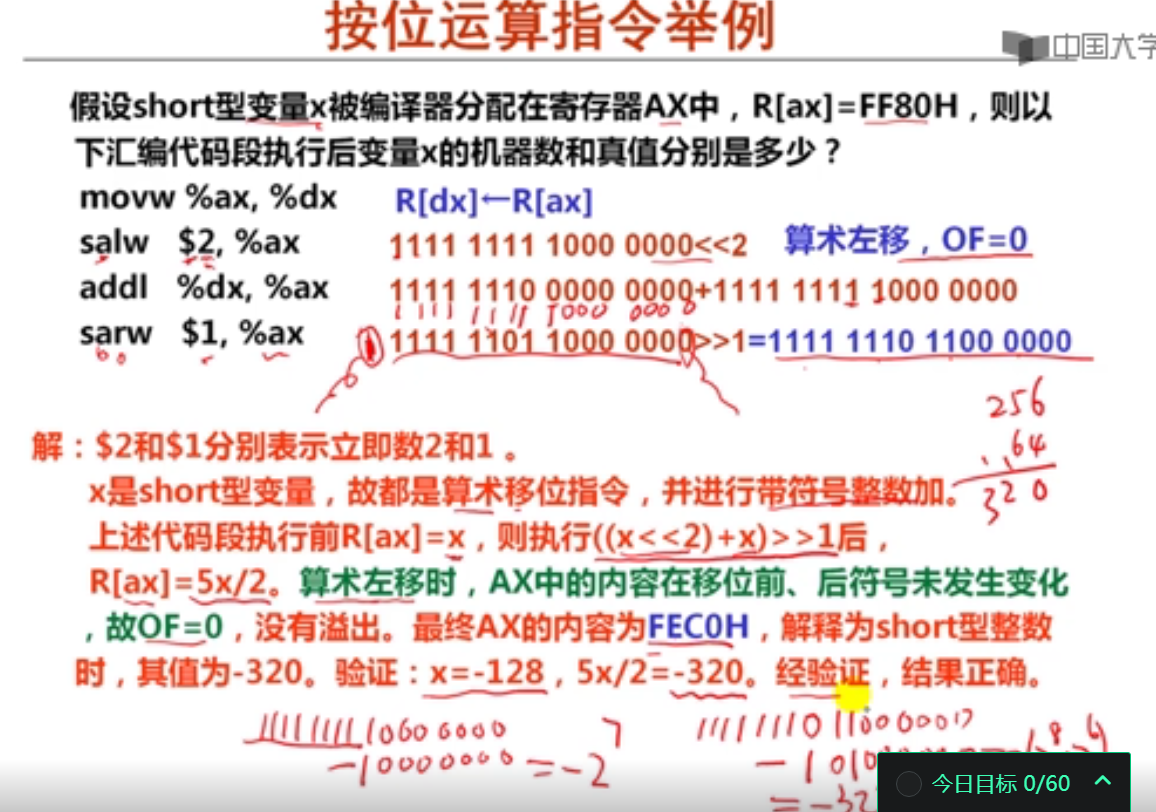
假设short型变量x被分配在寄存器AX中,若R[ax]=FF70H,则执行指令“salw $2, %ax”后,变量x的机器数和真值分别是( C )。
A.3FDC,16348
B. FFDCH,-36
C.FDC0H,-576
D.FDC3H,-573
解析: C、salw指令是算术左移指令,对FF70=1111 1111 0111 0000算术左移2位后,结果为1111 1101 1100 0000(FDC0H),真值为-10 0100 0000B = -(512+64) = -576。
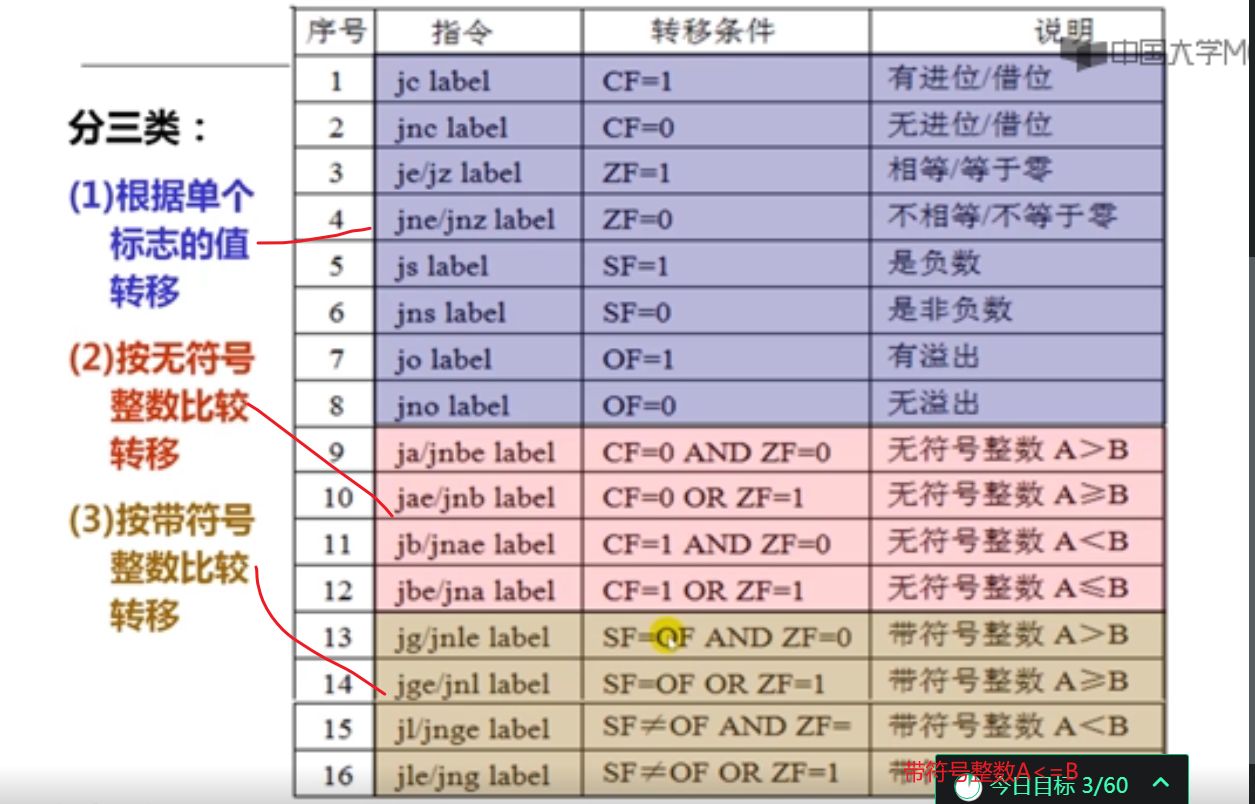
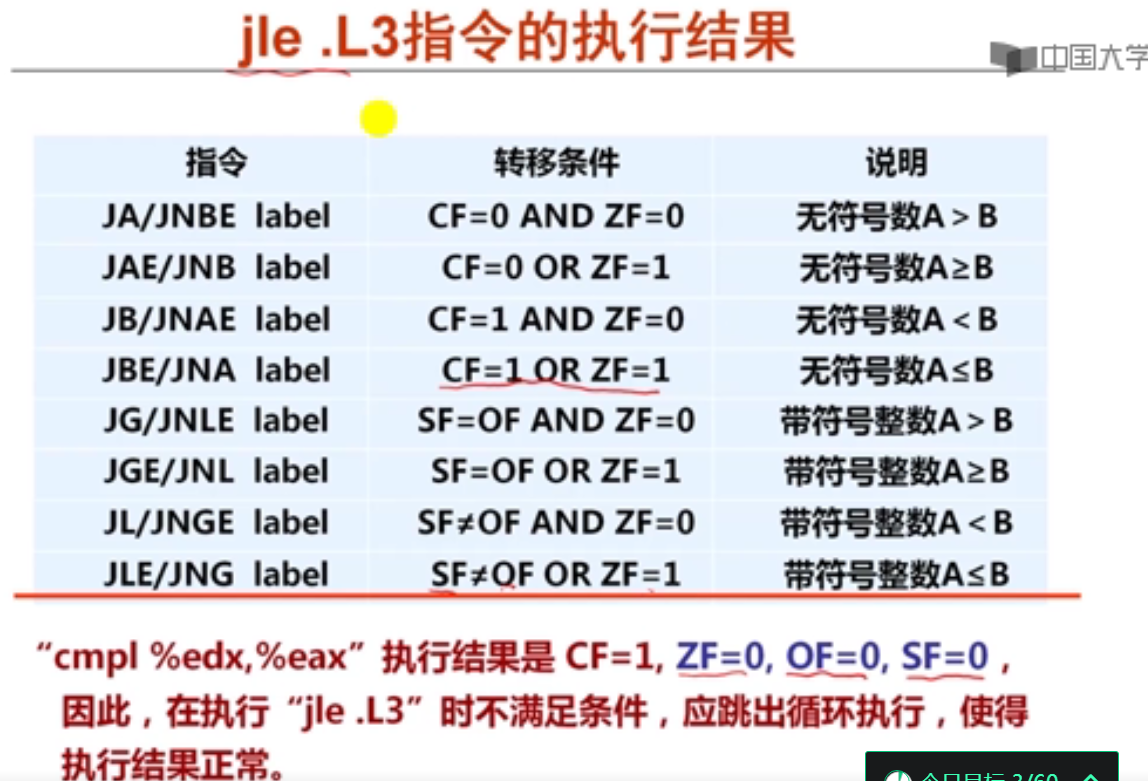
8单选(cmpl比较指令和jle转移指令)(难点)
程序P中有两个变量i和j,被分别分配在寄存器EAX和EDX中,P中语句“if (i<j) { …}”对应的指令序列如下(左边为指令地址,中间为机器代码,右边为汇编指令):
804846a 39 c2 cmpl %eax, %edx
804846c 7e 0d jle xxxxxxxx
若执行到804846a处的cmpl指令时,i=105,j=100,则jle指令执行后将会转到( A )处的指令执行。
A.804847b
B.8048479
C.804846e
D.8048461
解析: A、因为cmpl指令中EDX内容为100,EAX内容为105,对这两个数做减法,显然100<105,满足jle指令小于或等于的条件,执行完jle指令后将转移到PC+偏移量=0x84846c+2+0d=0x804847b去执行。
9单选(x87 FPU浮点处理指令系统)
以下关于x87 FPU浮点处理指令系统的叙述中,错误的是( A )。
A.float和double型数据从主存装入浮点寄存器时有可能发生舍入,造成精度损失
B.提供8个80位浮点寄存器ST(0)~ST(7),采用栈结构,栈顶为ST(0)
C. float、double和long double型数据存入主存时,分别占32位、64位和96位
D.float、double和long double三种类型数据都按80位格式存放在浮点寄存器中
10单选(MMX/SSE指令集)
以下关于MMX/SSE指令集的叙述中,错误的是( D )。
A. SSE指令是一种采用SIMD(单指令多数据)技术的数据级并行指令
B. 同一个微处理器同时支持IA-32指令集与MMX/SSE指令集
C. 目前SSE支持128位整数运算或同时并行处理两个64位双精度浮点数
D. MMX/SSE指令集和IA-32指令集共用同一套通用寄存器
第七周C语言语句的机器级表示
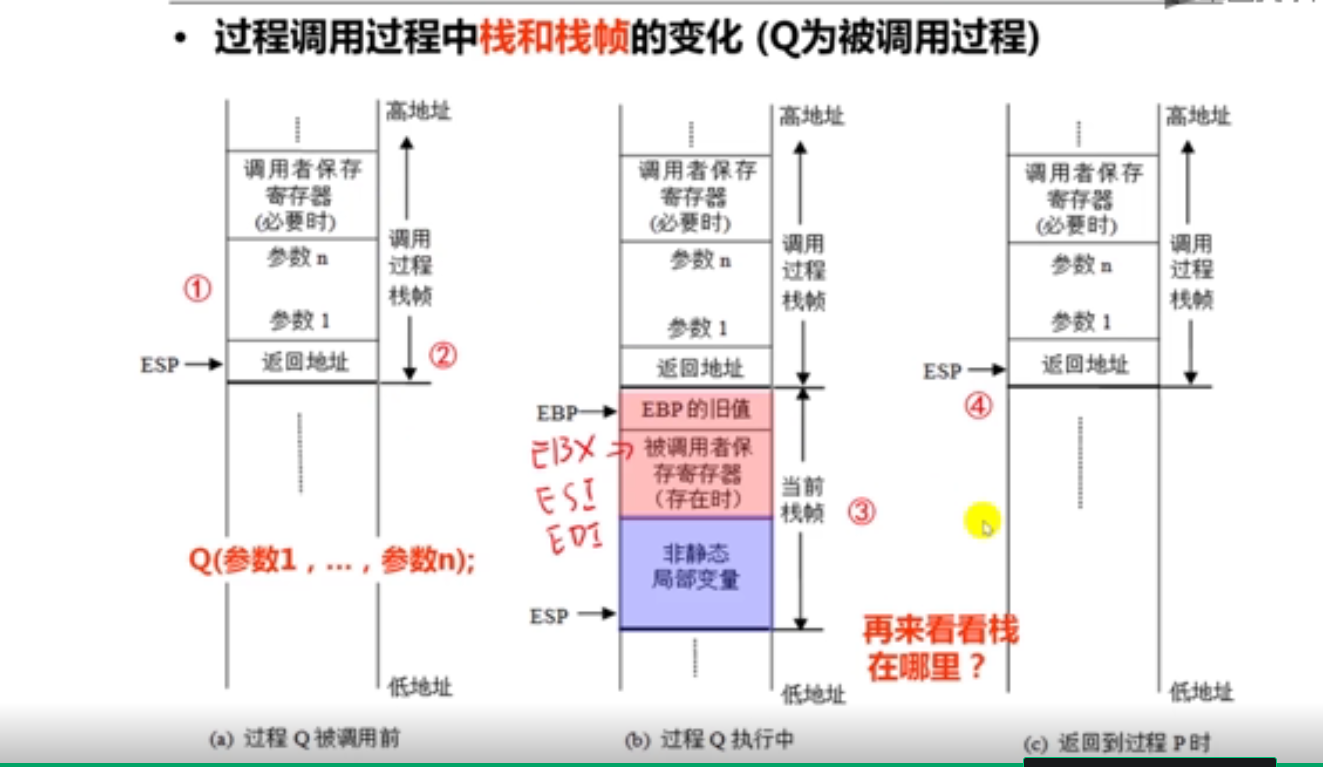
第1讲 过程(函数)调用的机器级表示
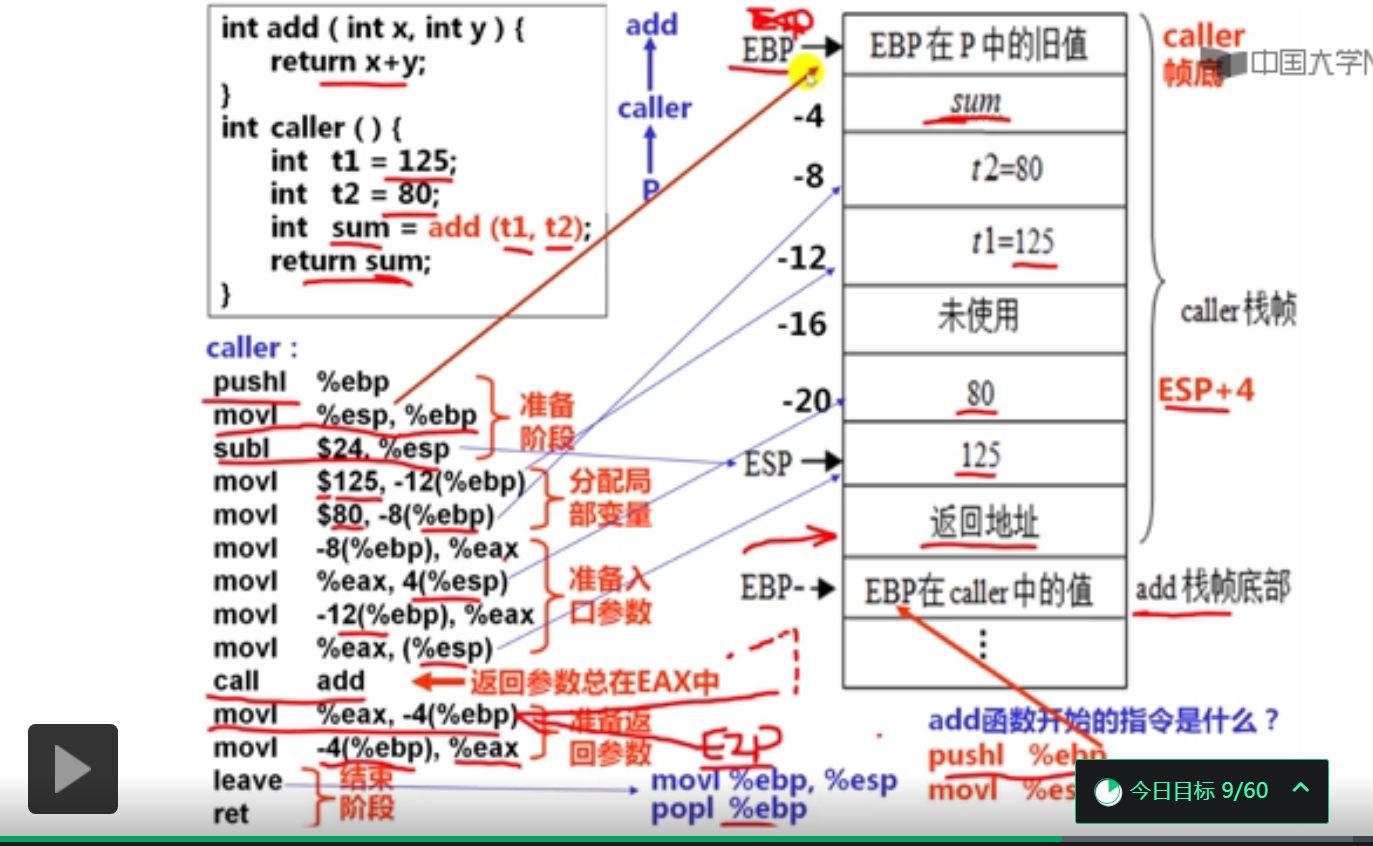
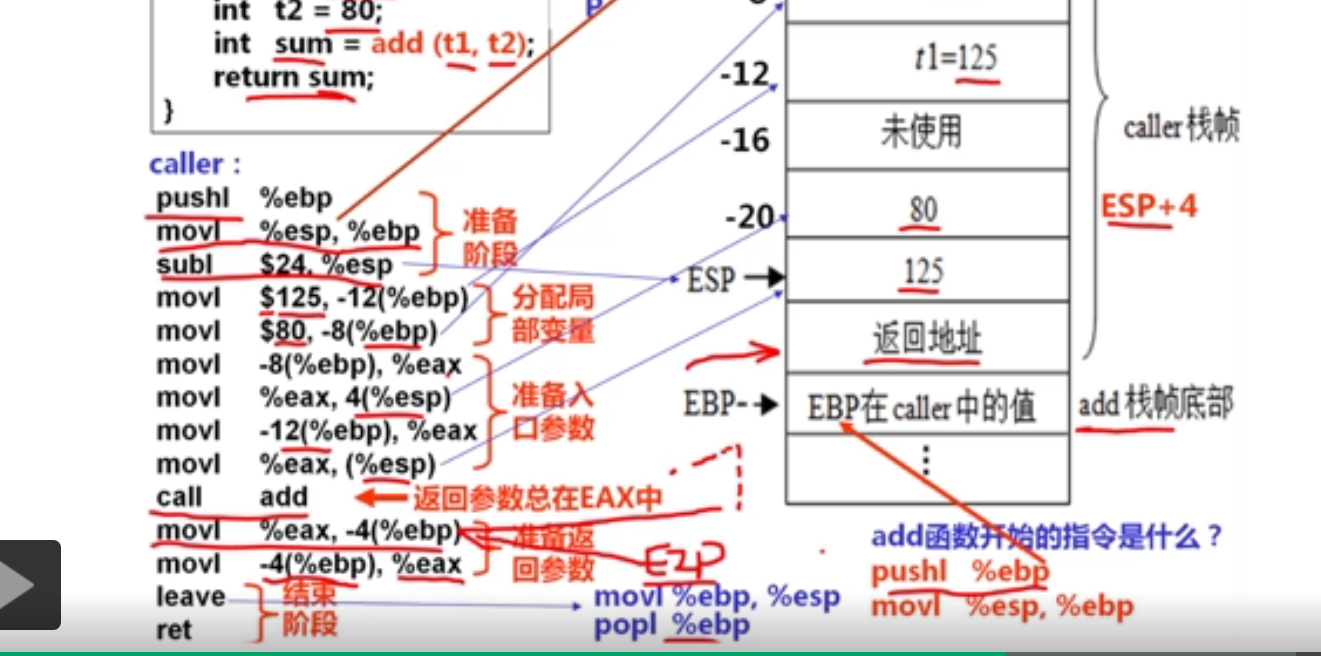
1.过程调用概述(13分钟)

测试程序:
#include <stdio.h>
int add(int x,int y)
{
return x + y;
}
int caller()
{
int t1 = 125;
int t2 = 80;
int sum = add(t1,t2);
return sum;
}
int main()
{
int sum = caller();
printf("%d",sum);
return 0;
}


2.过程(函数)的机器级代码结构(13分钟)

3.过程调用的参数传递(12分钟)
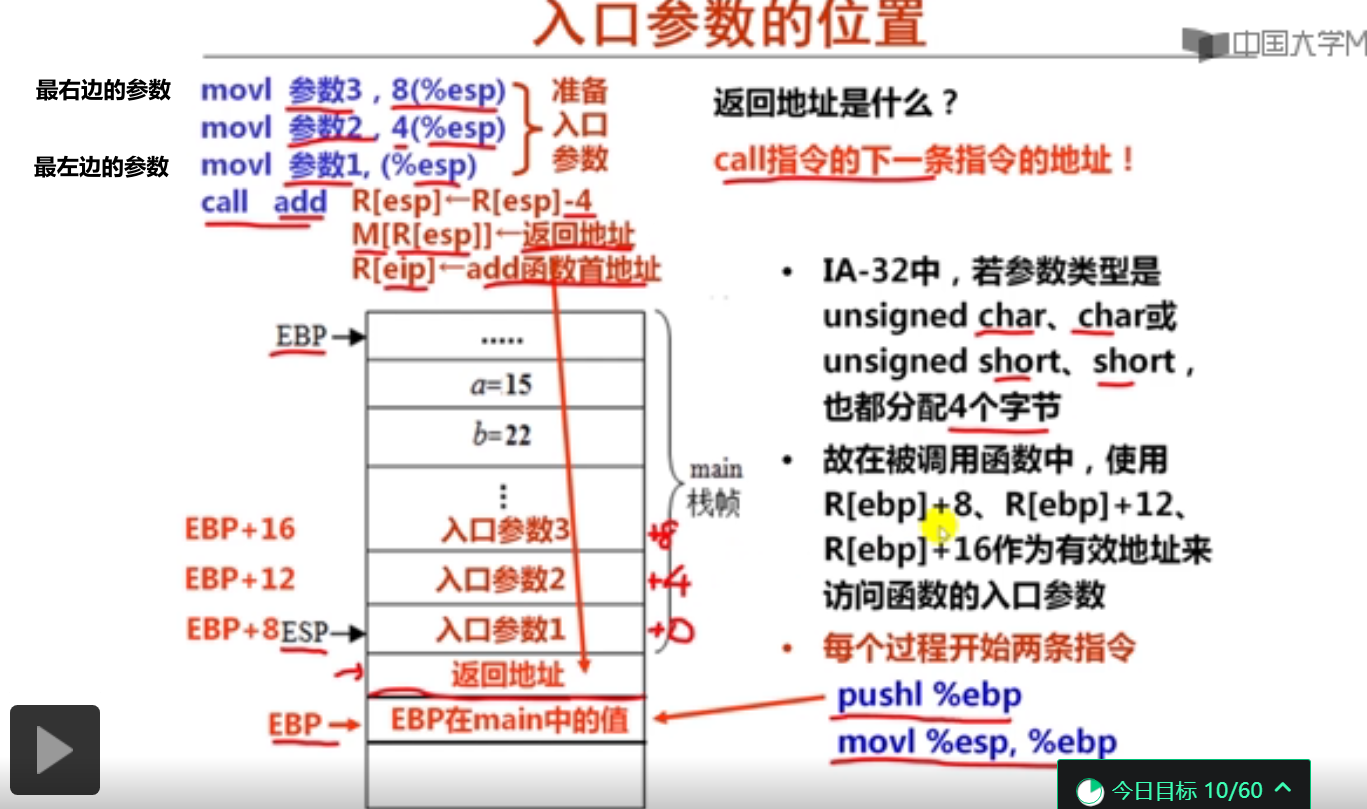

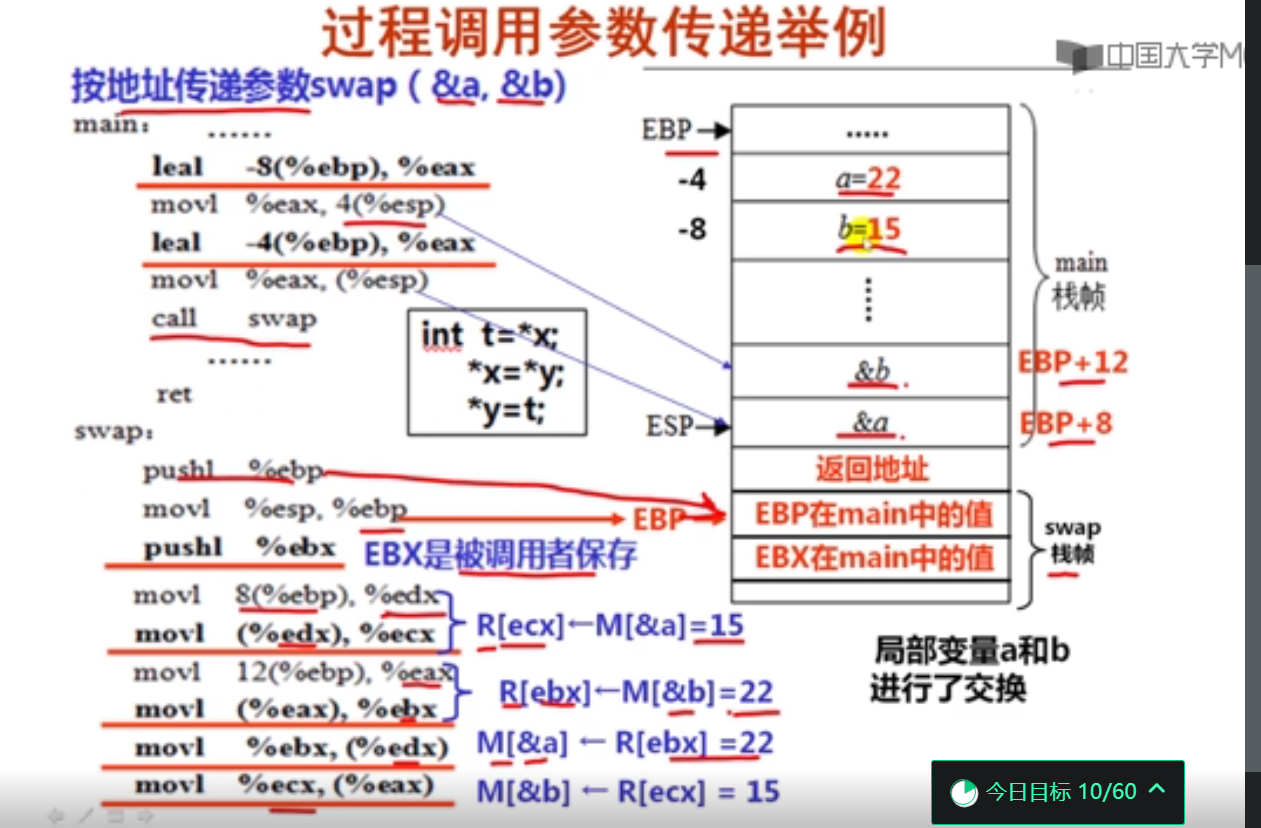
#include <stdio.h>
void swap(int *x, int *y)
{
int temp = *x;
*x = *y;
*y = temp;
}
int main()
{
int a = 15, b = 22;
printf("a=%d\tb=%d\n",a,b);
swap(&a, &b);
printf("a=%d\tb=%d\n",a,b);
return 0;
}
a=15 b=22
a=22 b=15
按地址传递程序汇编结果:
.file "main.c"
.text
.globl swap
.type swap, @function
swap:
.LFB0:
.cfi_startproc
endbr64
pushq %rbp
.cfi_def_cfa_offset 16
.cfi_offset 6, -16
movq %rsp, %rbp
.cfi_def_cfa_register 6
movq %rdi, -24(%rbp)
movq %rsi, -32(%rbp)
movq -24(%rbp), %rax
movl (%rax), %eax
movl %eax, -4(%rbp)
movq -32(%rbp), %rax
movl (%rax), %edx
movq -24(%rbp), %rax
movl %edx, (%rax)
movq -32(%rbp), %rax
movl -4(%rbp), %edx
movl %edx, (%rax)
nop
popq %rbp
.cfi_def_cfa 7, 8
ret
.cfi_endproc
.LFE0:
.size swap, .-swap
.section .rodata
.LC0:
.string "a=%d\tb=%d\n"
.text
.globl main
.type main, @function
main:
.LFB1:
.cfi_startproc
endbr64
pushq %rbp
.cfi_def_cfa_offset 16
.cfi_offset 6, -16
movq %rsp, %rbp
.cfi_def_cfa_register 6
subq $16, %rsp
movq %fs:40, %rax
movq %rax, -8(%rbp)
xorl %eax, %eax
movl $15, -16(%rbp)
movl $22, -12(%rbp)
movl -12(%rbp), %edx
movl -16(%rbp), %eax
movl %eax, %esi
leaq .LC0(%rip), %rax
movq %rax, %rdi
movl $0, %eax
call printf@PLT
leaq -12(%rbp), %rdx
leaq -16(%rbp), %rax
movq %rdx, %rsi
movq %rax, %rdi
call swap
movl -12(%rbp), %edx
movl -16(%rbp), %eax
movl %eax, %esi
leaq .LC0(%rip), %rax
movq %rax, %rdi
movl $0, %eax
call printf@PLT
movl $0, %eax
movq -8(%rbp), %rdx
subq %fs:40, %rdx
je .L4
call __stack_chk_fail@PLT
.L4:
leave
.cfi_def_cfa 7, 8
ret
.cfi_endproc
.LFE1:
.size main, .-main
.ident "GCC: (Ubuntu 11.3.0-1ubuntu1~22.04) 11.3.0"
.section .note.GNU-stack,"",@progbits
.section .note.gnu.property,"a"
.align 8
.long 1f - 0f
.long 4f - 1f
.long 5
0:
.string "GNU"
1:
.align 8
.long 0xc0000002
.long 3f - 2f
2:
.long 0x3
3:
.align 8
4:
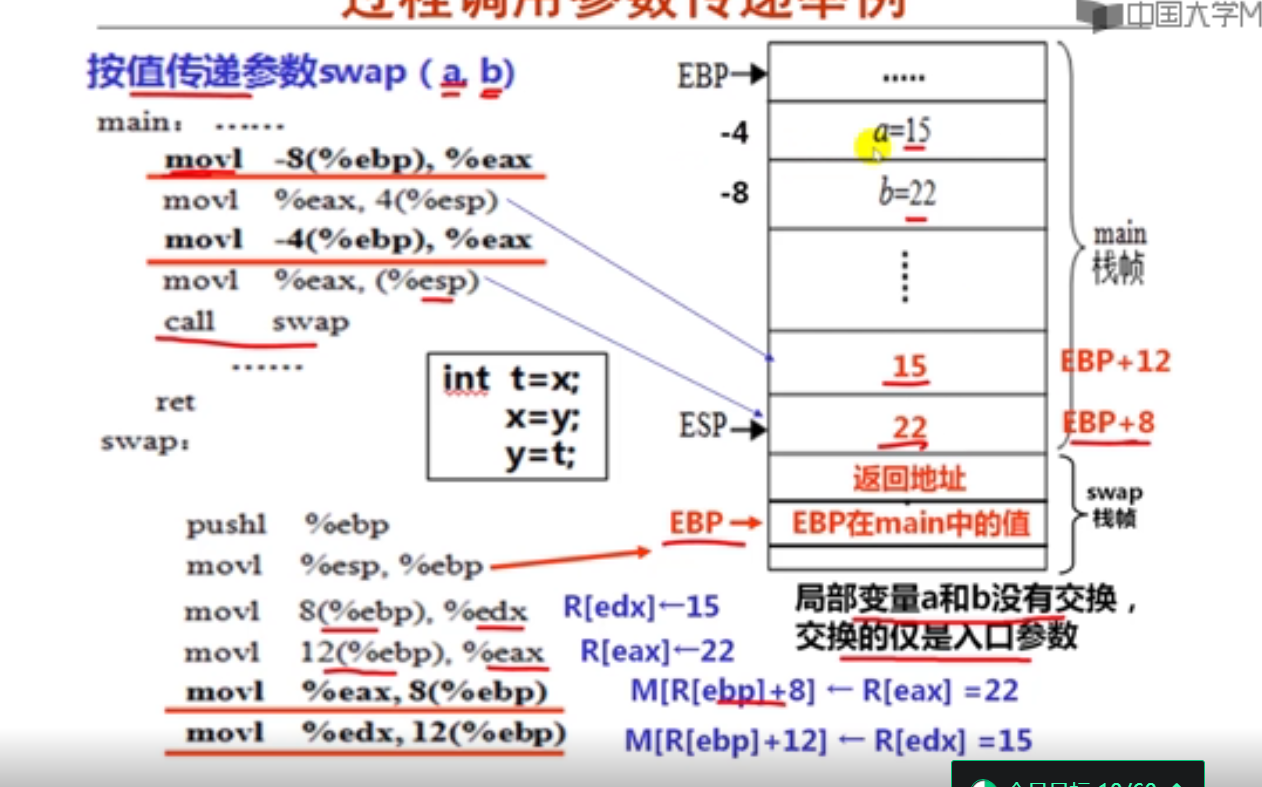
测试程序:
#include <stdio.h>
void swap(int x, int y)
{
int temp = x;
x = y;
y = temp;
}
int main()
{
int a = 15, b = 22;
printf("a=%d\tb=%d\n",a,b);
swap(a, b);
printf("a=%d\tb=%d\n",a,b);
return 0;
}
按值传递程序汇编文件:
.file "main.c"
.text
.globl swap
.type swap, @function
swap:
.LFB0:
.cfi_startproc
endbr64
pushq %rbp
.cfi_def_cfa_offset 16
.cfi_offset 6, -16
movq %rsp, %rbp
.cfi_def_cfa_register 6
movl %edi, -20(%rbp)
movl %esi, -24(%rbp)
movl -20(%rbp), %eax
movl %eax, -4(%rbp)
movl -24(%rbp), %eax
movl %eax, -20(%rbp)
movl -4(%rbp), %eax
movl %eax, -24(%rbp)
nop
popq %rbp
.cfi_def_cfa 7, 8
ret
.cfi_endproc
.LFE0:
.size swap, .-swap
.section .rodata
.LC0:
.string "a=%d\tb=%d\n"
.text
.globl main
.type main, @function
main:
.LFB1:
.cfi_startproc
endbr64
pushq %rbp
.cfi_def_cfa_offset 16
.cfi_offset 6, -16
movq %rsp, %rbp
.cfi_def_cfa_register 6
subq $16, %rsp
movl $15, -8(%rbp)
movl $22, -4(%rbp)
movl -4(%rbp), %edx
movl -8(%rbp), %eax
movl %eax, %esi
leaq .LC0(%rip), %rax
movq %rax, %rdi
movl $0, %eax
call printf@PLT
movl -4(%rbp), %edx
movl -8(%rbp), %eax
movl %edx, %esi
movl %eax, %edi
call swap
movl -4(%rbp), %edx
movl -8(%rbp), %eax
movl %eax, %esi
leaq .LC0(%rip), %rax
movq %rax, %rdi
movl $0, %eax
call printf@PLT
movl $0, %eax
leave
.cfi_def_cfa 7, 8
ret
.cfi_endproc
.LFE1:
.size main, .-main
.ident "GCC: (Ubuntu 11.3.0-1ubuntu1~22.04) 11.3.0"
.section .note.GNU-stack,"",@progbits
.section .note.gnu.property,"a"
.align 8
.long 1f - 0f
.long 4f - 1f
.long 5
0:
.string "GNU"
1:
.align 8
.long 0xc0000002
.long 3f - 2f
2:
.long 0x3
3:
.align 8
4:
注:这里a和b在栈中的位置有误,按后面程序中变量的分布都是上边的变量在下,下边的变量在上。根据别人实验结果和我生成的汇编文件,确实是a在下,b在上。而不是图中画的那样a在上b在下。
注:这里a和b在栈中的位置有误,按后面程序中变量的分布都是上边的变量在下,下边的变量在上。根据别人实验结果和我生成的汇编文件,确实是a在下,b在上。而不是图中画的那样a在上b在下。
注:这里a和b在栈中的位置有误,按后面程序中变量的分布都是上边的变量在下,下边的变量在上。根据别人实验结果和我生成的汇编文件,确实是a在下,b在上。而不是图中画的那样a在上b在下。
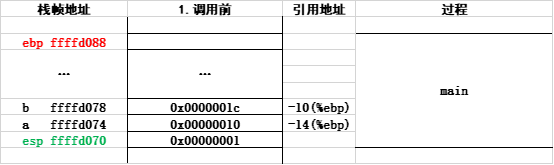
后面小测验内容也可作为参考。
5以下是一个C语言程序代码:
int add(int x, int y)
{
return x+y;
}
int caller( )
{
int t1=100 ;
int t2=200;
int sum=add(t1, t2);
return sum;
}
以下关于上述程序代码在IA-32上执行的叙述中,错误的是( C )。
A.add函数返回时返回值存放在EAX寄存器中
B.变量t1和t2被分配在caller函数的栈帧中
C.传递参数时t1和t2的值从高地址到低地址依次存入栈中
D.变量sum被分配在caller函数的栈帧中
6第5题中的caller函数对应的机器级代码如下:
1 pushl %ebp
2 movl %esp, %ebp
3 subl $24, %esp
4 movl $100, -12(%ebp)
5 movl $200, -8(%ebp)
6 movl -8(%ebp), %eax
7 movl %eax, 4(%esp)
8 movl -12(%ebp), %eax
9 movl %eax, (%esp)
10 call add
11 movl %eax, -4(%ebp)
12 movl -4(%ebp), %eax
13 leave
14 ret
假定caller的调用过程为P,对于上述指令序列,以下叙述中错误的是( B )。
A.从上述指令序列可看出,caller函数没有使用被调用者保存寄存器
B.第3条指令将栈指针ESP向高地址方向移动,以生成当前栈帧
C.第2条指令使BEP内容指向caller栈帧的底部
D.第1条指令将过程P的EBP内容压入caller栈帧
7对于第5题的caller函数以及第6题给出的对应机器级代码,以下叙述中错误的是( D )。
A.参数t1和t2的有效地址分别为R[esp]和R[esp]+4
B.变量t1和t2的有效地址分别为R[ebp]-12和R[ebp]-8
C.参数t1所在的地址低(或小)于参数t2所在的地址
D.变量t1所在的地址高(或大)于变量t2所在的地址
4.过程调用举例(11分钟)
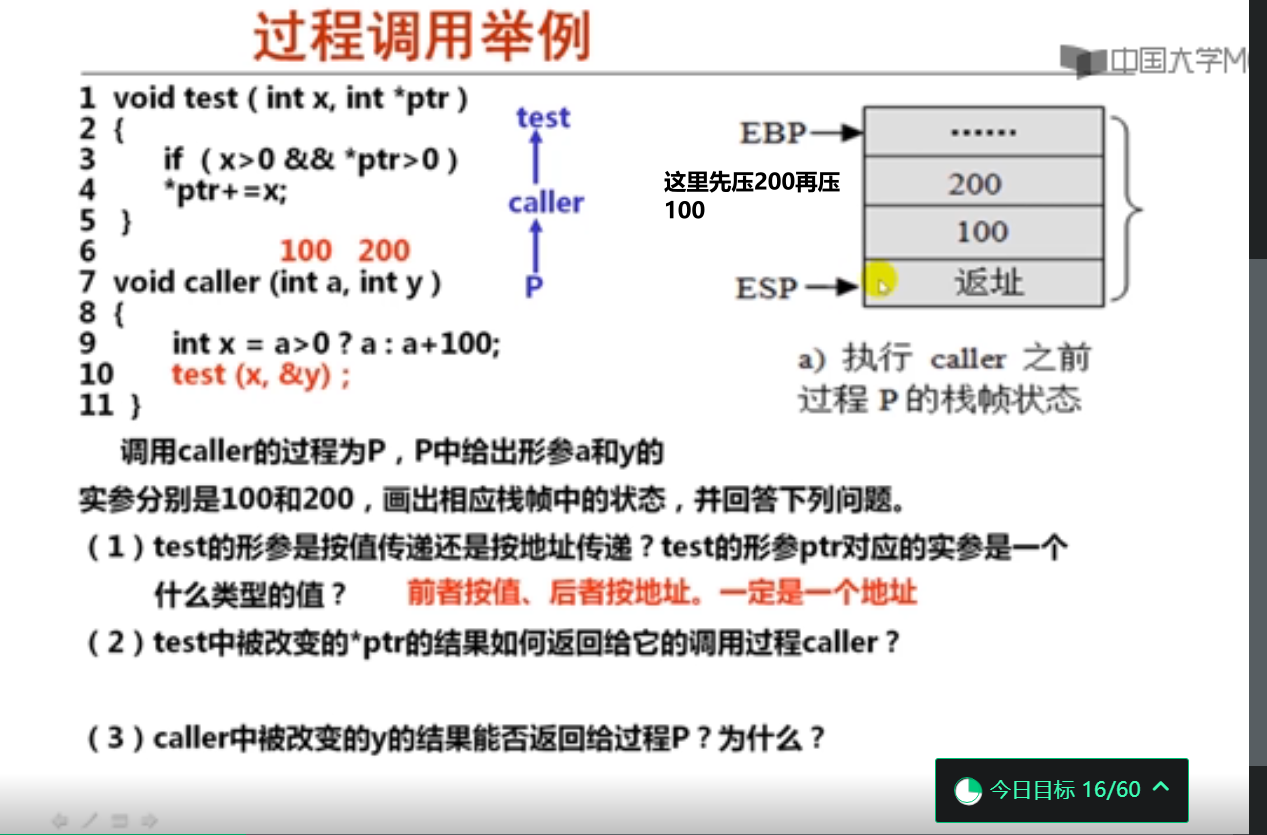


5.递归过程调用举例(11分钟)
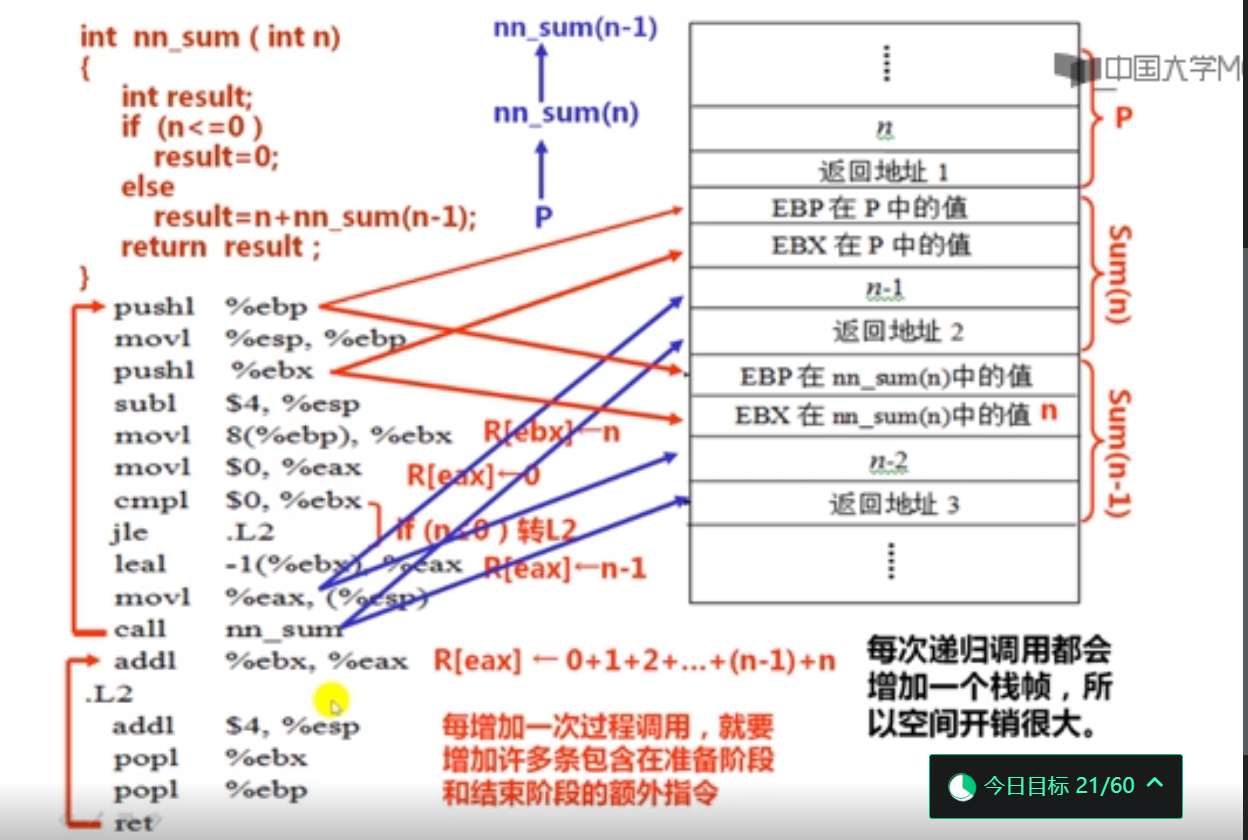
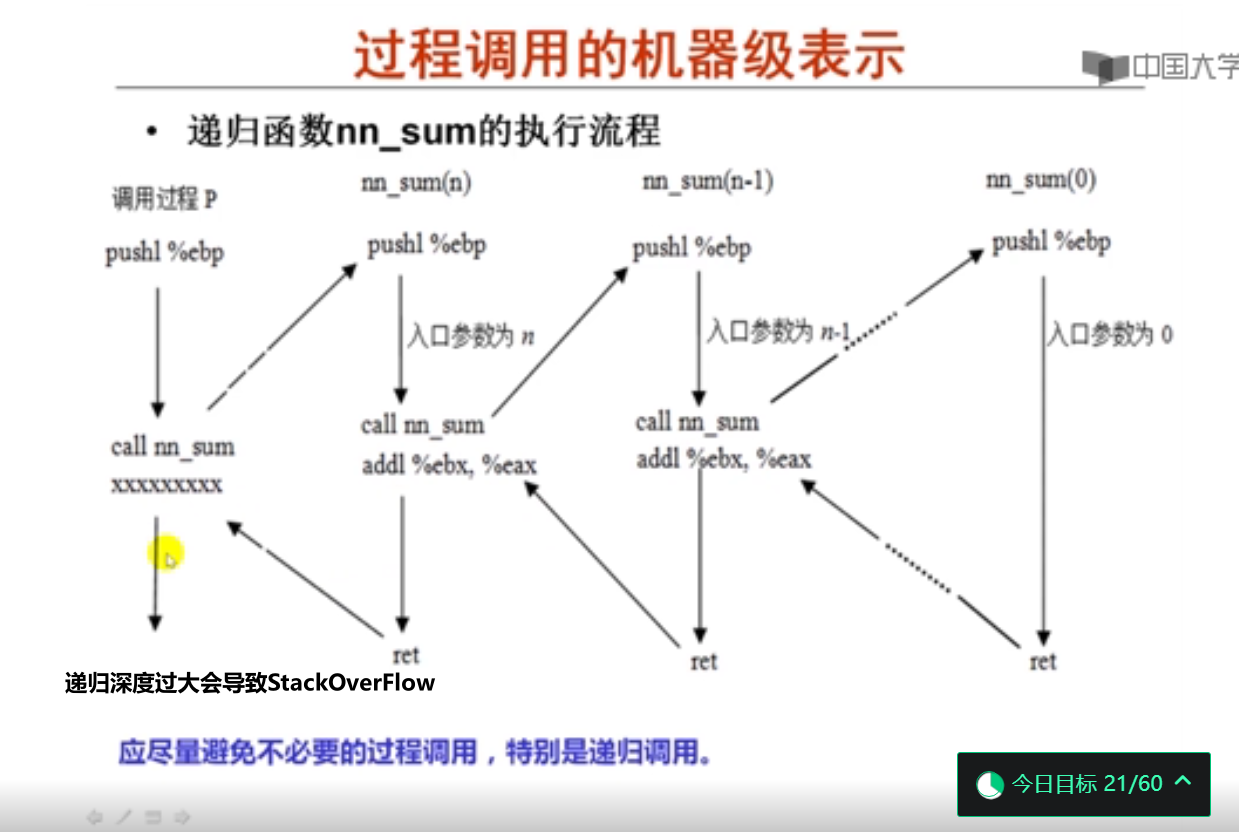
6.过程调用举例(14分钟)

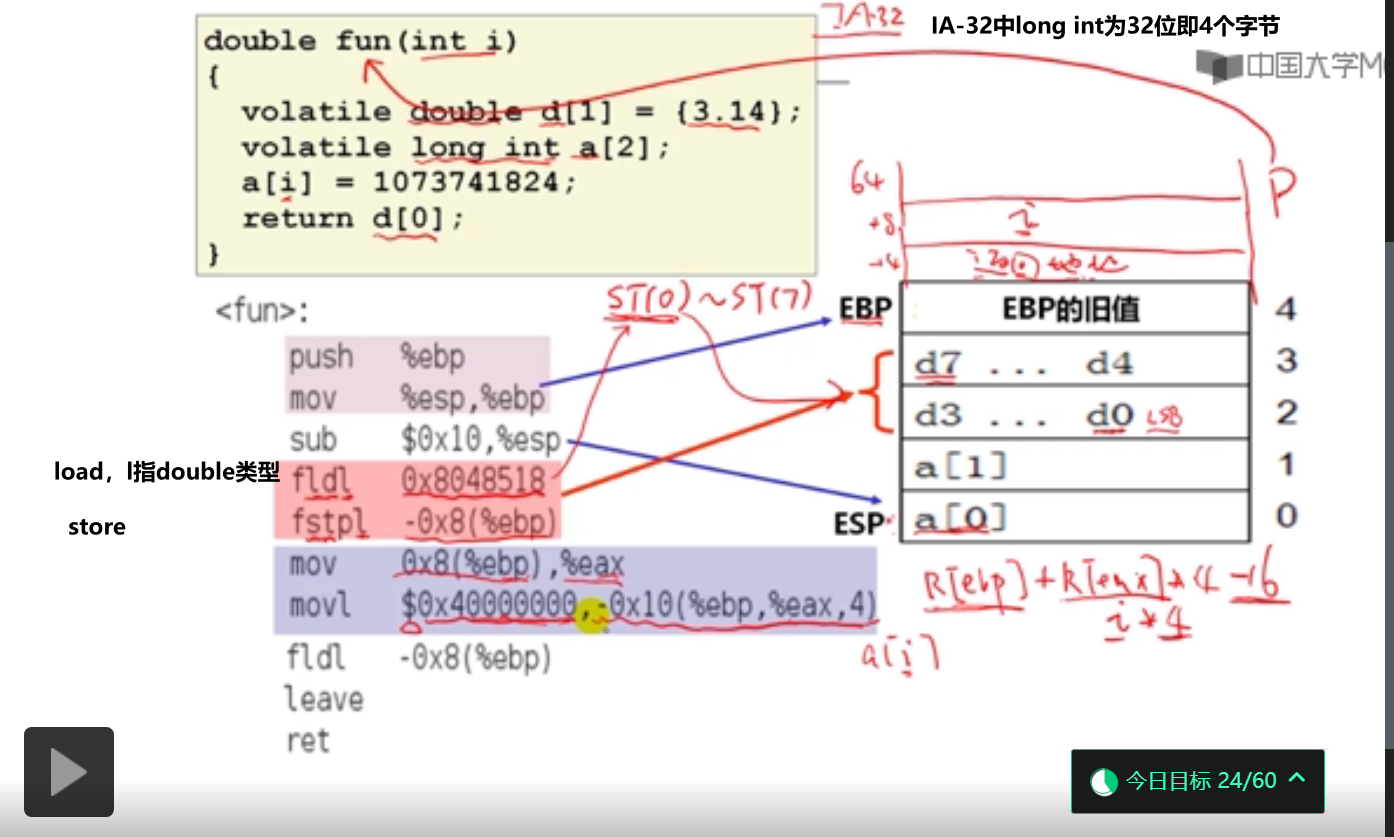
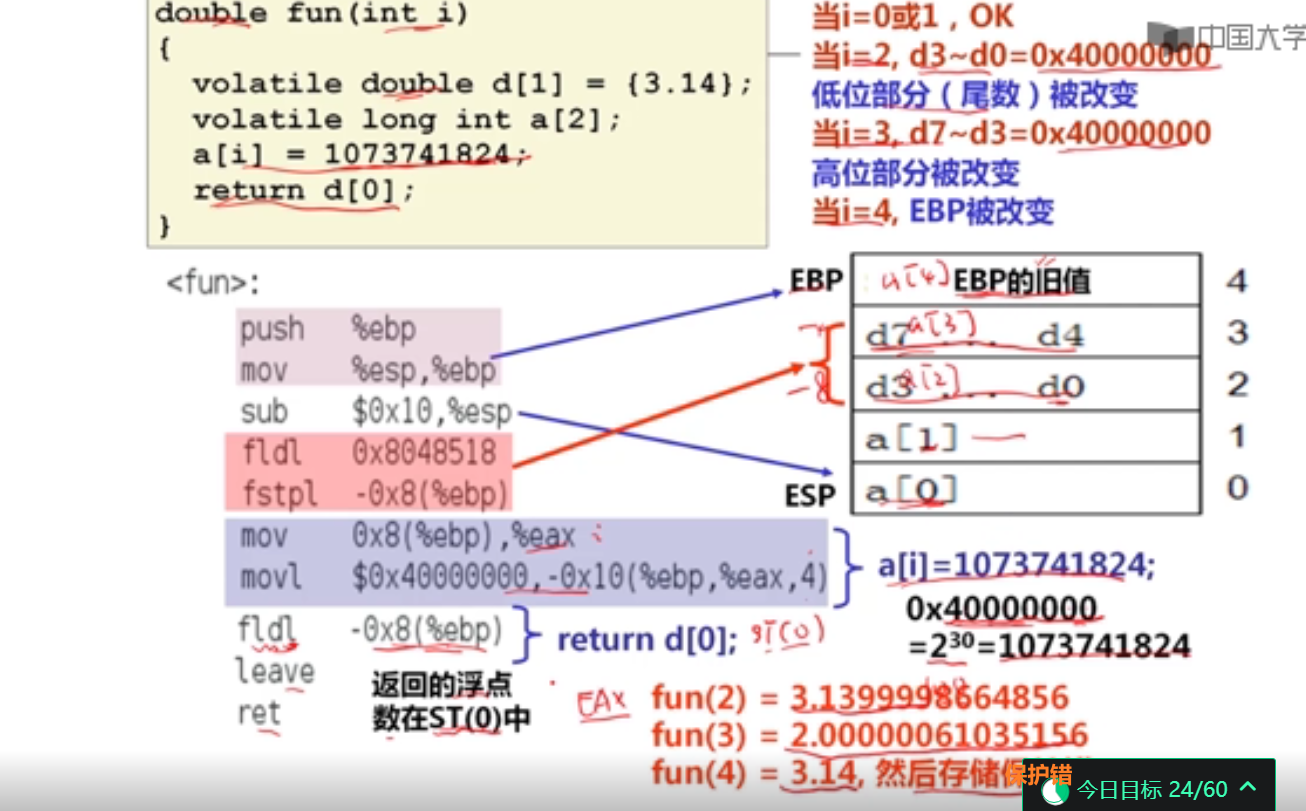
这里的数据按顺序压栈,和函数参数传递不同。
Code::Blocks運行結果如下所示:
#include <stdio.h>
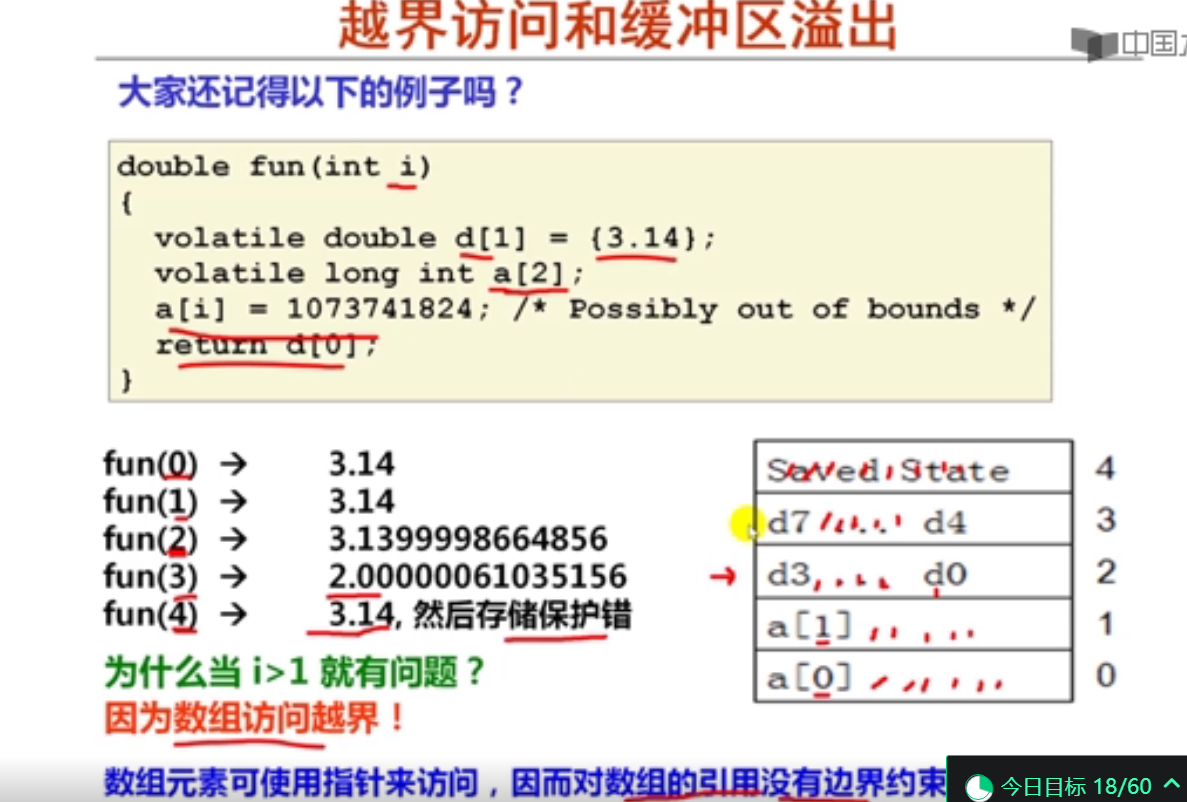
double fun(int i)
{
volatile double d[1] = {3.14};
volatile long int a[2];
a[i] = 1073741824;
return d[0];
}
int main()
{
printf("%f\n",fun(1));
printf("%f\n",fun(2));
printf("%f\n",fun(3));
printf("%f\n",fun(4));
return 0;
}
3.140000
3.140000
3.140000
3.140000
#include <stdio.h>
double fun(int i)
{
volatile double d[1] = {3.14};
volatile long int a[2];
a[i] = 1073741824;
printf("%d\n",&d[0]);
printf("%d\n",&a[0]);
printf("%d\n",&a[2]);
return d[0];
}
int main()
{
fun(3);
return 0;
}
6487520
6487504
6487512
从结果来看,数据确实是按课上所讲的顺序压栈的,不过这里为何是一次+8呢?把volatile long int改为int,结果不变。
#include <stdio.h>
double fun(int i)
{
double d[1] = {3.14};
int a[2];
a[i] = 10;
printf("%d\n",&d[0]);
printf("%d\n",&a[0]);
printf("%d\n",&a[2]);
return d[0];
}
int main()
{
fun(3);
return 0;
}
6487520
6487504
6487512
这和栈帧那块内容很不同。
测试汇编代码的环境:Ubuntu 22.04.2 LTS (GNU/Linux 5.15.90.1-microsoft-standard-WSL2 x86_64)
汇编代码如下:
.file "main.c"
.text
.globl fun
.type fun, @function
fun:
.LFB0:
.cfi_startproc
endbr64
pushq %rbp
.cfi_def_cfa_offset 16
.cfi_offset 6, -16
movq %rsp, %rbp
.cfi_def_cfa_register 6
subq $64, %rsp
movl %edi, -52(%rbp)
movq %fs:40, %rax
movq %rax, -8(%rbp)
xorl %eax, %eax
movsd .LC0(%rip), %xmm0
movsd %xmm0, -40(%rbp)
movl -52(%rbp), %eax
cltq
movq $1073741824, -32(%rbp,%rax,8)
movsd -40(%rbp), %xmm0
movq %xmm0, %rax
movq -8(%rbp), %rdx
subq %fs:40, %rdx
je .L3
call __stack_chk_fail@PLT
.L3:
movq %rax, %xmm0
leave
.cfi_def_cfa 7, 8
ret
.cfi_endproc
.LFE0:
.size fun, .-fun
.section .rodata
.LC1:
.string "%f\n"
.text
.globl main
.type main, @function
main:
.LFB1:
.cfi_startproc
endbr64
pushq %rbp
.cfi_def_cfa_offset 16
.cfi_offset 6, -16
movq %rsp, %rbp
.cfi_def_cfa_register 6
movl $1, %edi
call fun
movq %xmm0, %rax
movq %rax, %xmm0
leaq .LC1(%rip), %rax
movq %rax, %rdi
movl $1, %eax
call printf@PLT
movl $2, %edi
call fun
movq %xmm0, %rax
movq %rax, %xmm0
leaq .LC1(%rip), %rax
movq %rax, %rdi
movl $1, %eax
call printf@PLT
movl $3, %edi
call fun
movq %xmm0, %rax
movq %rax, %xmm0
leaq .LC1(%rip), %rax
movq %rax, %rdi
movl $1, %eax
call printf@PLT
movl $4, %edi
call fun
movq %xmm0, %rax
movq %rax, %xmm0
leaq .LC1(%rip), %rax
movq %rax, %rdi
movl $1, %eax
call printf@PLT
movl $0, %eax
popq %rbp
.cfi_def_cfa 7, 8
ret
.cfi_endproc
.LFE1:
.size main, .-main
.section .rodata
.align 8
.LC0:
.long 1374389535
.long 1074339512
.ident "GCC: (Ubuntu 11.3.0-1ubuntu1~22.04) 11.3.0"
.section .note.GNU-stack,"",@progbits
.section .note.gnu.property,"a"
.align 8
.long 1f - 0f
.long 4f - 1f
.long 5
0:
.string "GNU"
1:
.align 8
.long 0xc0000002
.long 3f - 2f
2:
.long 0x3
3:
.align 8
4:
注:我的写的程序的汇编代码和课程中的汇编代码存在很大差异,这里暂且存疑。等做完(四)中实验再加料。
第2讲 选择和循环语句的机器级表示
1.选择结构的机器级表示(18分钟)



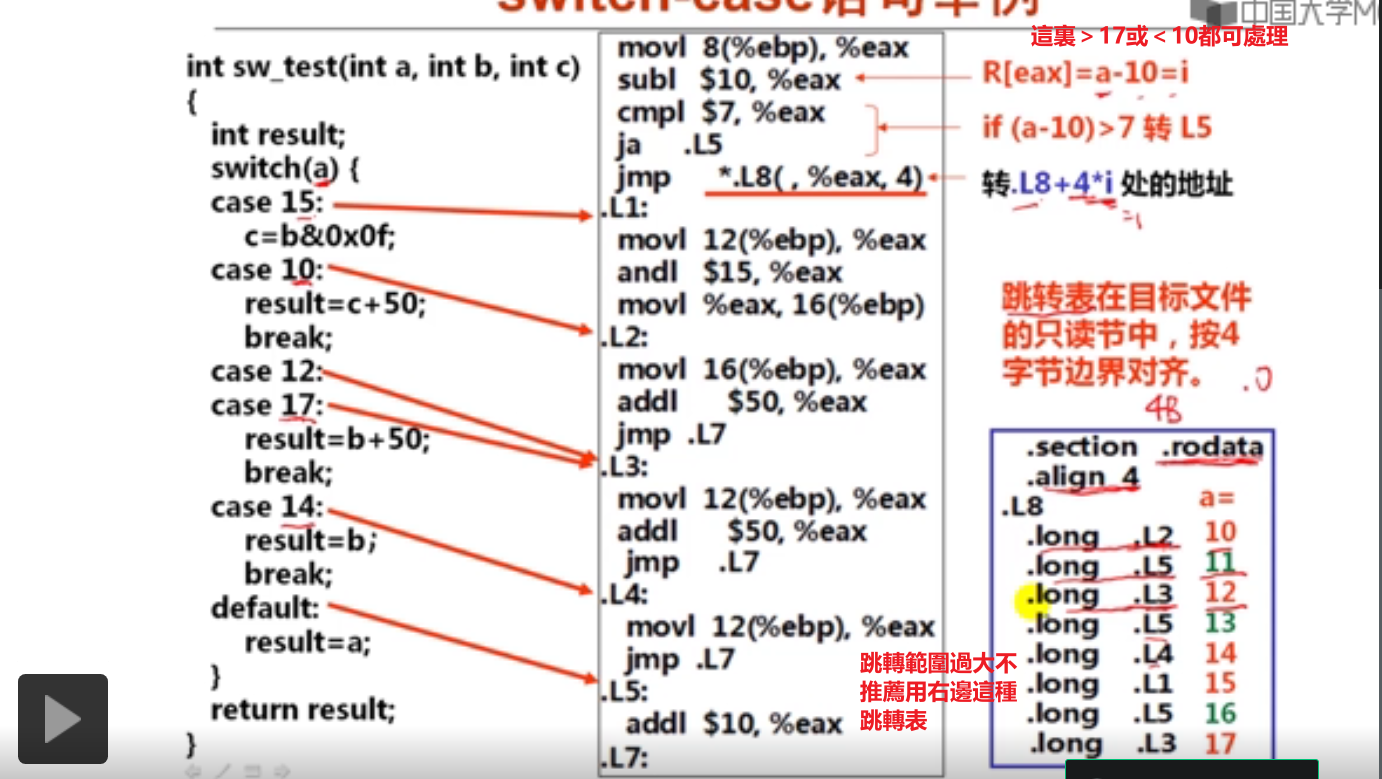
2.循环结构的机器级表示(14分钟)

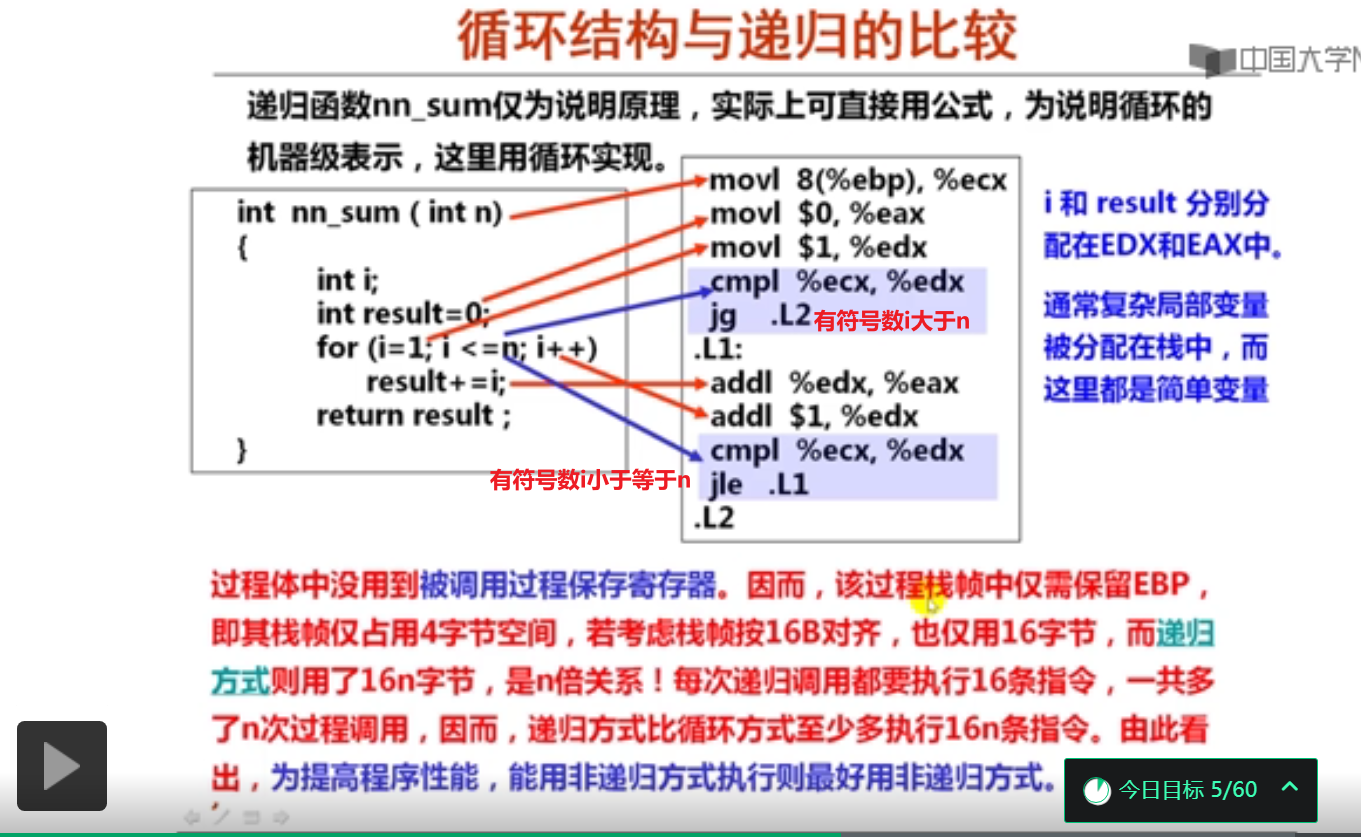


and(&)按位与
&&逻辑与
第七周小测验
1假设P为调用过程,Q为被调用过程,程序在IA-32处理器上执行,以下有关过程调用的叙述中,错误的是( B )。
A.C语言程序中的函数调用就是过程调用
B.从P传到Q的实参无需重新分配空间存放
C.从Q跳回到Q执行应使用RET指令
D.从P跳转到Q执行应使用CALL指令
2以下是有关IA-32的过程调用方式的叙述,错误的是( B )。
A.入口参数使用栈(stack)传递,即所传递的实参被分配在栈中
B.EBX、ESI、EDI、EBP和ESP都是被调用者保存寄存器
C.返回地址是CALL指令下一条指令的地址,被保存在栈中
D.EAX、ECX和EDX都是调用者保存寄存器
3以下是有关IA-32的过程调用所使用的栈和栈帧的叙述,错误的是( A )。
A.只能通过将栈指针ESP作为基址寄存器来访问用户栈中的数据
B.从被调用过程返回调用过程之前,被调用过程会释放自己的栈帧
C.过程嵌套调用深度越深,栈中栈帧个数越多,严重时会发生栈溢出
D.每进行一次过程调用,用户栈从高地址向低地址增长出一个栈帧
4以下是有关C语言程序的变量的作用域和生存期的叙述,错误的是( D )。
A.不同过程中的非静态局部变量可以同名,是因为它们被分配在不同栈帧中
B.非静态局部变量可以和全局变量同名,是因为它们被分配在不同存储区
C.因为非静态局部变量被分配在栈中,所以其作用域仅在过程体内
D.静态(static型)变量和非静态局部(auto型)变量都分配在对应栈帧中
5以下是一个C语言程序代码:
int add(int x, int y)
{
return x+y;
}
int caller( )
{
int t1=100 ;
int t2=200;
int sum=add(t1, t2);
return sum;
}
以下关于上述程序代码在IA-32上执行的叙述中,错误的是( C )。
A.add函数返回时返回值存放在EAX寄存器中
B.变量t1和t2被分配在caller函数的栈帧中
C.传递参数时t1和t2的值从高地址到低地址依次存入栈中
D.变量sum被分配在caller函数的栈帧中
6第5题中的caller函数对应的机器级代码如下:
1 pushl %ebp
2 movl %esp, %ebp
3 subl $24, %esp
4 movl $100, -12(%ebp)
5 movl $200, -8(%ebp)
6 movl -8(%ebp), %eax
7 movl %eax, 4(%esp)
8 movl -12(%ebp), %eax
9 movl %eax, (%esp)
10 call add
11 movl %eax, -4(%ebp)
12 movl -4(%ebp), %eax
13 leave
14 ret
假定caller的调用过程为P,对于上述指令序列,以下叙述中错误的是( B )。
A.从上述指令序列可看出,caller函数没有使用被调用者保存寄存器
B.第3条指令将栈指针ESP向高地址方向移动,以生成当前栈帧
C.第2条指令使BEP内容指向caller栈帧的底部
D.第1条指令将过程P的EBP内容压入caller栈帧
7对于第5题的caller函数以及第6题给出的对应机器级代码,以下叙述中错误的是( D )。
A.参数t1和t2的有效地址分别为R[esp]和R[esp]+4
B.变量t1和t2的有效地址分别为R[ebp]-12和R[ebp]-8
C.参数t1所在的地址低(或小)于参数t2所在的地址
D.变量t1所在的地址高(或大)于变量t2所在的地址
8以下有关递归过程调用的叙述中,错误的是( A )。
A.每次递归调用在栈帧中保存的返回地址都不相同
B.可能需要执行递归过程很多次,因而时间开销大
C.每次递归调用都会生成一个新的栈帧,因而空间开销大
D.递归过程第一个参数的有效地址为R[ebp]+8
9以下关于if (cond_expr) then_statement else else_statement选择结构对应的机器级代码表示的叙述中,错误的是( D )。
A.计算cond_expr的代码段一定在条件转移指令之前
B.一定包含一条条件转移指令(分支指令)
C.一定包含一条无条件转移指令
D.对应then_statement的代码一定在对应else_statement的代码之前
10以下关于循环结构语句的机器级代码表示的叙述中,错误的是( A )。
A.循环体内执行的指令不包含条件转移指令
B.一定至少包含一条条件转移指令
C.循环结束条件通常用一条比较指令CMP来实现
D.不一定包含无条件转移指令
第八周复杂数据类型的机器级表示
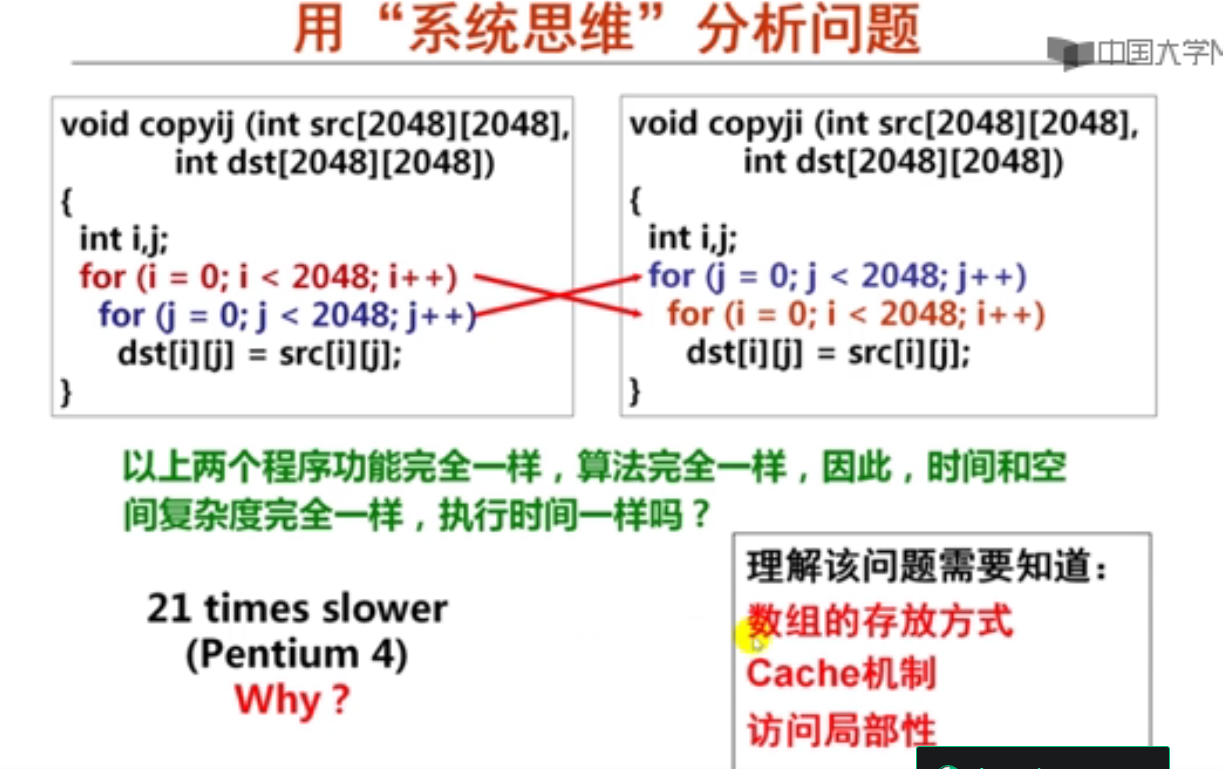
第1讲 数组和指针类型的分配和访问
1.数组的分配与访问(19分钟)

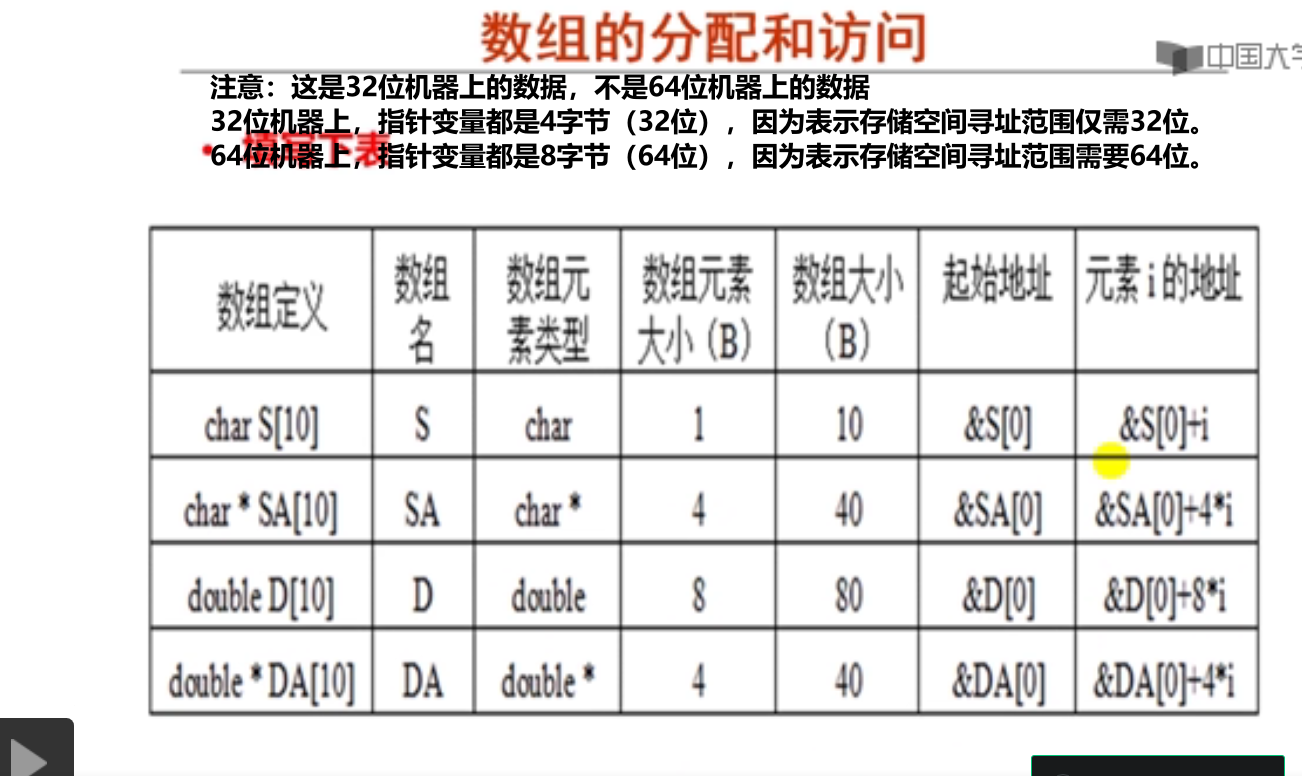


注:这里如果使用mov指令,则会把ebx寄存器中内容10传送到edx寄存器。
2.数组与指针的关系(9分钟)
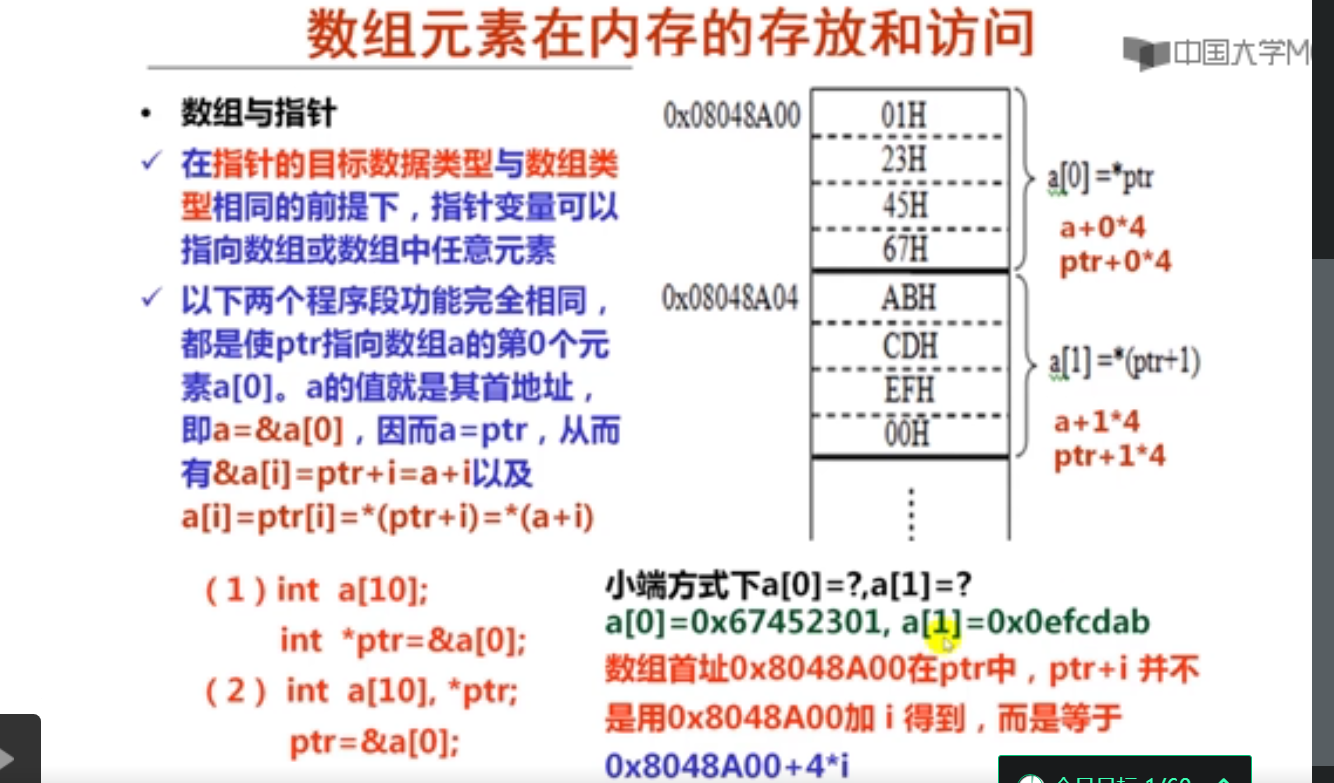
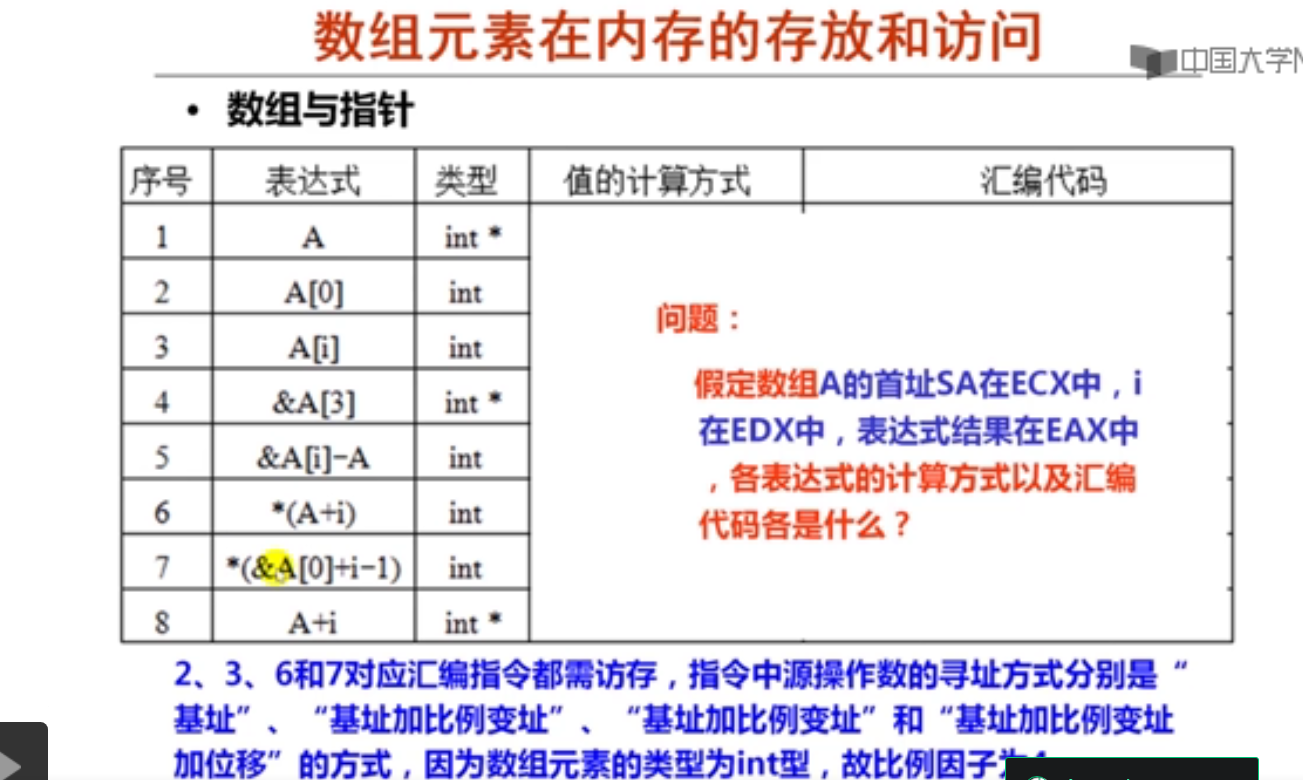
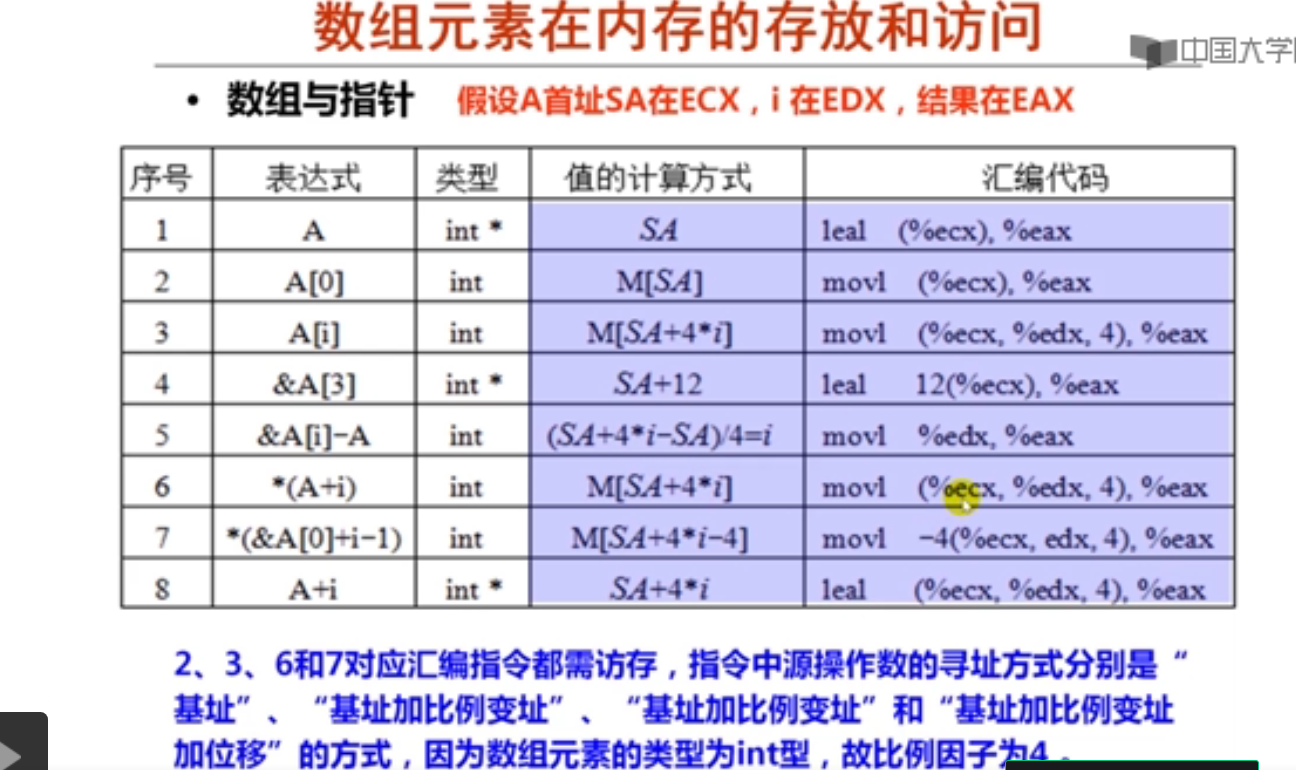
movl 传送内容,leal 传送地址
其中第5个不好理解,测试程序及结果如下:
#include <stdio.h>
int main()
{
int A[10] = {1,2,3,4,5,6,7,8,9,10};
printf("%d",&A[7]-A);
return 0;
}
7
第5条也可以用leal指令实现。
3.指针数组和多维数组(19分钟)


#include <stdio.h>
int main()
{
static short num[][4] = {{2,9,-1,5},{3,8,2,-6}};
static short *pn[2] = {num[0],num[1]};
static short s[2] = {0,0};
int i,j;
for(i=0;i<2;i++)
{
for(j=0;j<4;j++)
s[i] += *pn[i]++;
printf("sum of line %d is %d\n",i,s[i]);
}
return 0;
}
sum of line 0 is 15
sum of line 1 is 7
#include <stdio.h>
int main()
{
static short num[][4] = {{2,9,-1,5},{3,8,2,-6}};
static short *pn[2] = {num[0],num[1]};
static short s[2] = {0,0};
int i,j;
for(i=0;i<2;i++)
{
for(j=0;j<4;j++)
{
s[i] += num[i][j];
printf("0x%x\n",&num[i][j]);
}
printf("sum of line %d is %d\n",i,s[i]);
}
return 0;
}
0x403010
0x403012
0x403014
0x403016
sum of line 0 is 15
0x403018
0x40301a
0x40301c
0x40301e
sum of line 1 is 7
静态区地址是按代码顺序从低地址向高地址增长的,这和栈区不同!!
静态区地址是按代码顺序从低地址向高地址增长的,这和栈区不同!!
静态区地址是按代码顺序从低地址向高地址增长的,这和栈区不同!!
第2讲 结构和联合数据类型的分配和访问
1.结构类型的分配和访问(20分钟)

#include <stdio.h>
int main()
{
int m = 0;
struct cont_info
{
char id[8];
char name [12];
unsigned post;
char address[100];
char phone[20];
};
struct cont_info x = {"0000000","ZhangS",210022,"273 long street,High Building#3015","12345678"};
int n = 1;
printf("0x%x\n",&m);
printf("0x%x\n",&(x.id));
printf("0x%x\n",&(x.name));
printf("0x%x\n",&(x.post));
printf("0x%x\n",&(x.address));
printf("0x%x\n",&(x.phone));
printf("0x%x\n",&n);
printf("%d\n",&m);
printf("%d\n",&(x.id));
printf("%d\n",&(x.name));
printf("%d\n",&(x.post));
printf("%d\n",&(x.address));
printf("%d\n",&(x.phone));
printf("%d\n",&n);
return 0;
}
0x62fe0c
0x62fd70
0x62fd78
0x62fd84
0x62fd88
0x62fdec
0x62fd6c
6487564
6487408
6487416
6487428
6487432
6487532
6487404
这个程序中结构体变量和m、n存储位置相同,都在栈区。
#include <stdio.h>
struct cont_info
{
char id[8];
char name [12];
unsigned post;
char address[100];
char phone[20];
};
struct cont_info x = {"0000000","ZhangS",210022,"273 long street,High Building#3015","12345678"};
int main()
{
printf("0x%x\n",&(x.id));
printf("0x%x\n",&(x.name));
printf("0x%x\n",&(x.post));
printf("0x%x\n",&(x.address));
printf("0x%x\n",&(x.phone));
printf("%d\n",&(x.id));
printf("%d\n",&(x.name));
printf("%d\n",&(x.post));
printf("%d\n",&(x.address));
printf("%d\n",&(x.phone));
return 0;
}
0x62fe1c
0x403020
0x403028
0x403034
0x403038
0x40309c
0x62fe18
6487580
4206624
4206632
4206644
4206648
4206748
6487576
这个程序中结构体变量和m、n存储位置不同,前者在静态区,后者在栈区。



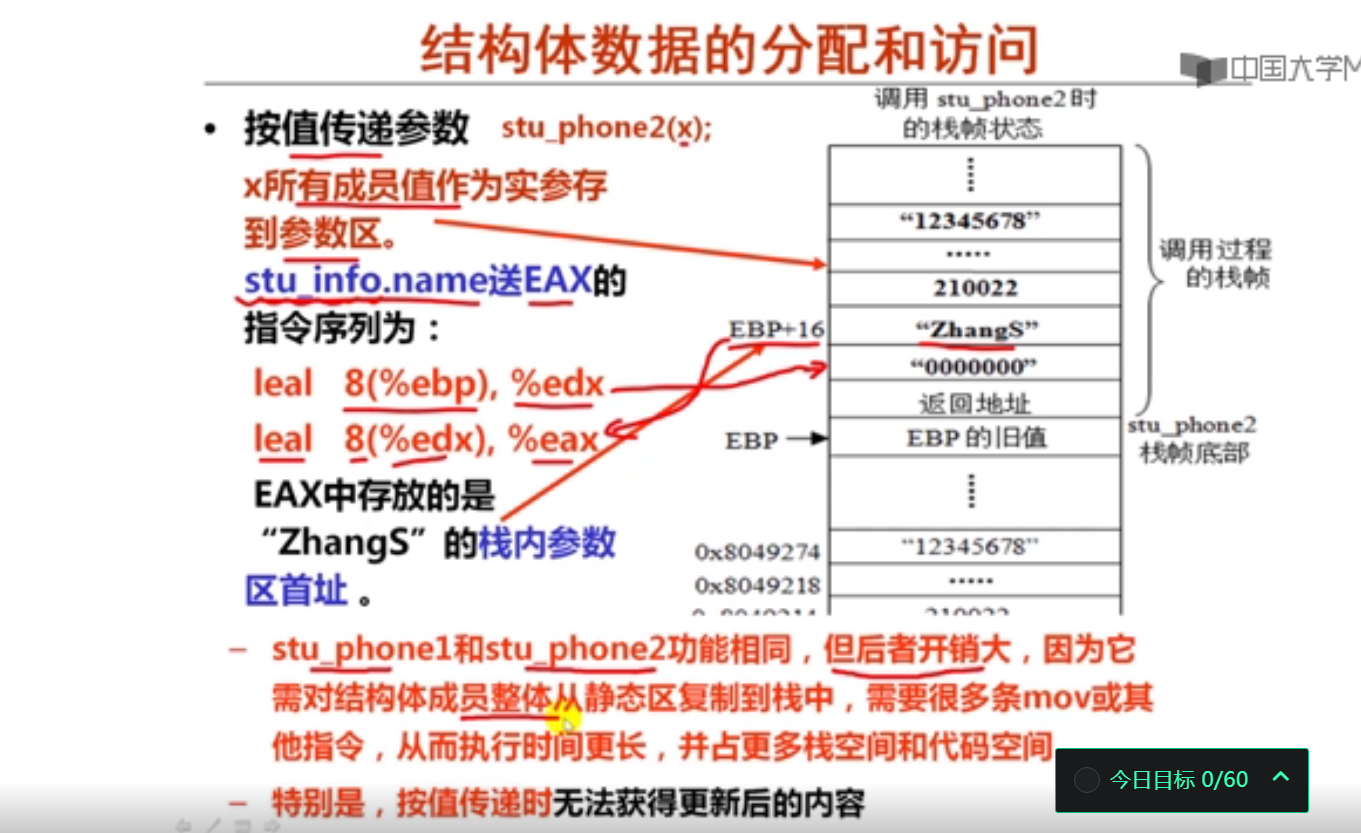
2.联合类型的分配和访问(18分钟)

#include <stdio.h>
int main()
{
union uarea
{
char c_data;
short s_data;
int i_data;
long l_data;
}u;
printf("The size of uarea is %d\n",sizeof(u));
return 0;
}
The size of uarea is 4
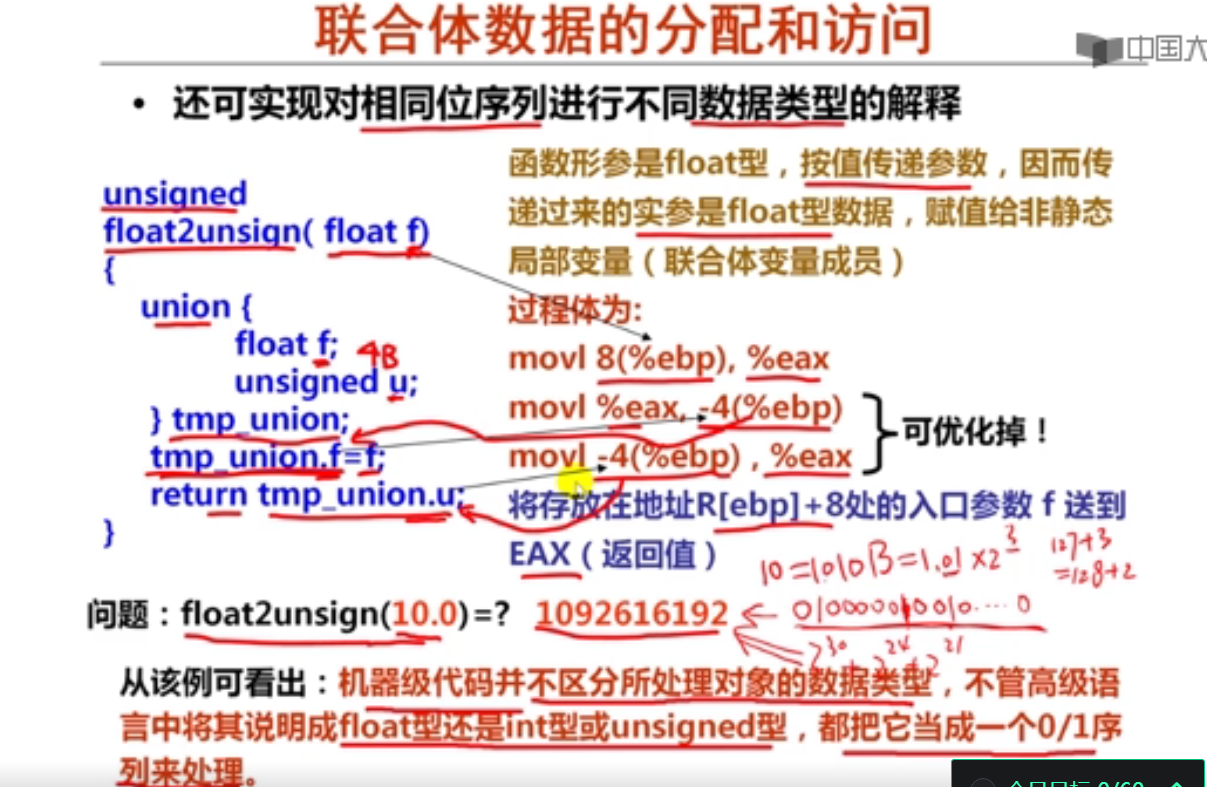
#include <stdio.h>
unsigned float2unsign(float f)
{
union
{
float f;
unsigned u;
}tmp_union;
tmp_union.f = f;
return tmp_union.u;
}
int main()
{
printf("%d",float2unsign(10.0));
return 0;
}
1092616192
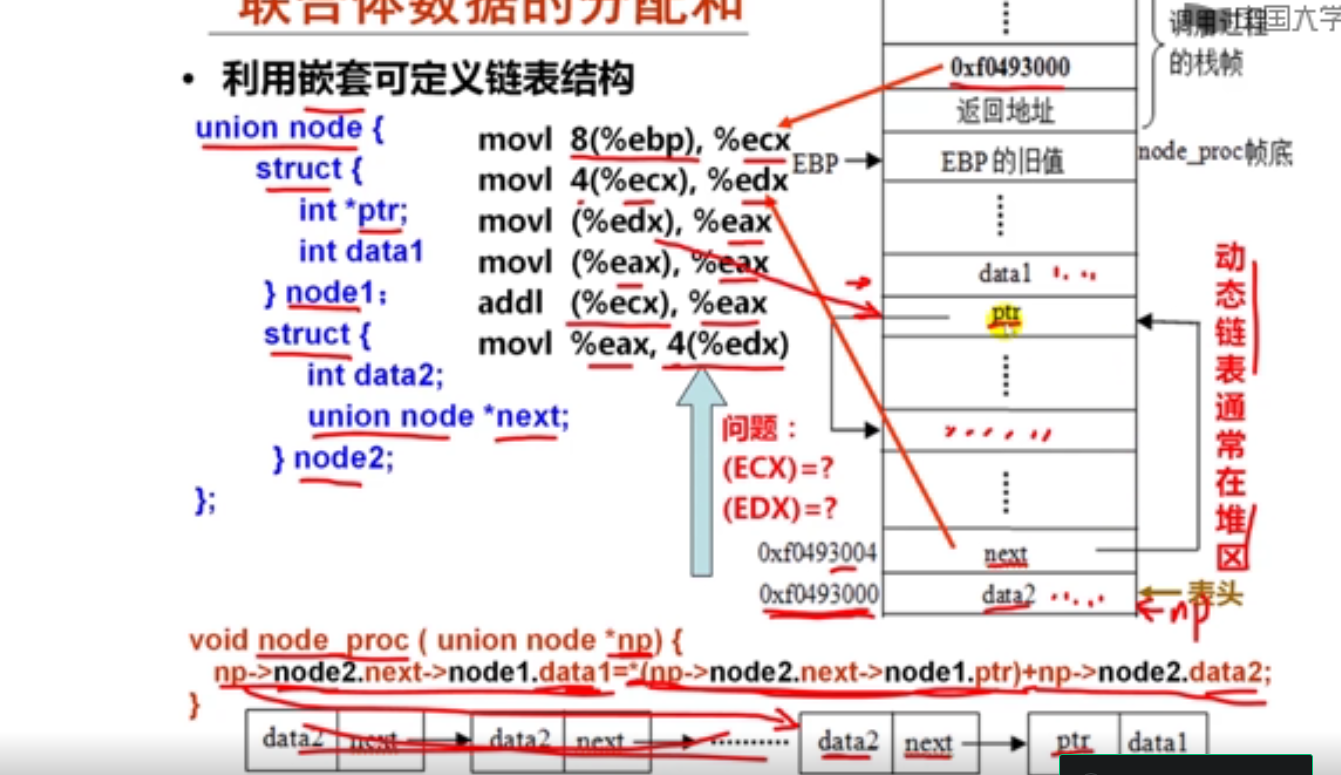
第3讲 数据的对齐存放
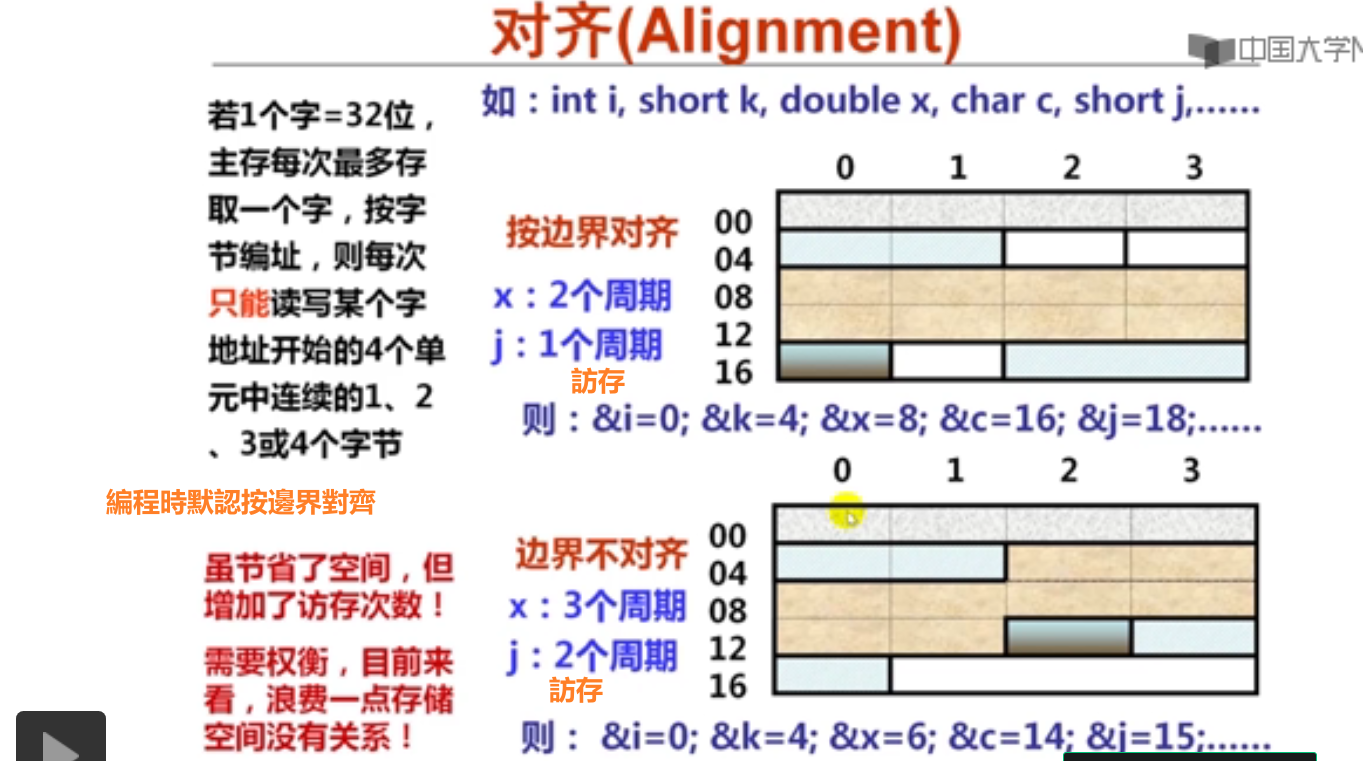
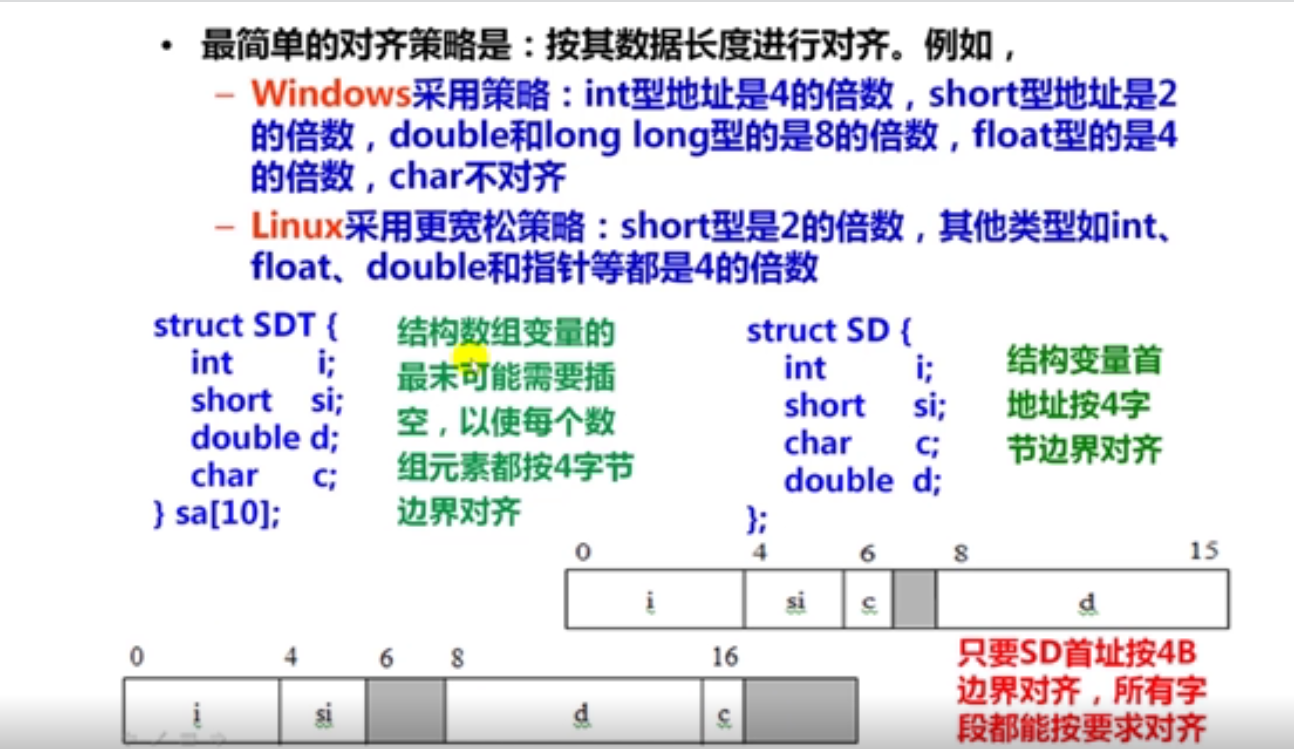
1.数据的对齐方式(14分钟)

#include <stdio.h>
int main()
{
struct cont_info
{
short si;
int i;
char c;
double f;
};
struct cont_info x = {100,9,'A',10.0};
printf("0x%x\n",&(x.si));
printf("0x%x\n",&(x.i));
printf("0x%x\n",&(x.c));
printf("0x%x\n",&(x.f));
printf("%d\n",&(x.si));
printf("%d\n",&(x.i));
printf("%d\n",&(x.c));
printf("%d\n",&(x.f));
return 0;
}
0x62fe00
0x62fe04
0x62fe08
0x62fe10
6487552
6487556
6487560
6487568
6487569/8=810946
Windows系统中double类型确实是按8个字节对齐的即地址是8的倍数!
这种写法太浪费空间了!!
#include <stdio.h>
int main()
{
struct cont_info
{
int i;
short si;
double f;
char c;
}sa[10];
struct cont_info x = {100,9,10.0,'A'};
printf("The size of x is %d\n",sizeof(x));
printf("The size of sa is %d\n",sizeof(sa));
printf("0x%x\n",&(x.i));
printf("0x%x\n",&(x.si));
printf("0x%x\n",&(x.f));
printf("0x%x\n",&(x.c));
printf("%d\n",&(x.i));
printf("%d\n",&(x.si));
printf("%d\n",&(x.f));
printf("%d\n",&(x.c));
return 0;
}
The size of x is 24
The size of sa is 240
0x62fd10
0x62fd14
0x62fd18
0x62fd20
6487312
6487316
6487320
6487328

#include <stdio.h>
int main()
{
struct cont_info
{
int i;
char c;
short si;
double f;
};
struct cont_info x = {100,'A',9,10.0};
printf("0x%x\n",&(x.i));
printf("0x%x\n",&(x.c));
printf("0x%x\n",&(x.si));
printf("0x%x\n",&(x.f));
printf("%d\n",&(x.i));
printf("%d\n",&(x.c));
printf("%d\n",&(x.si));
printf("%d\n",&(x.f));
return 0;
}
0x62fe10
0x62fe14
0x62fe16
0x62fe18
6487568
6487572
6487574
6487576
#include <stdio.h>
int main()
{
struct cont_info
{
int i;
short si;
char c;
double f;
};
struct cont_info x = {100,9,'A',10.0};
printf("0x%x\n",&(x.i));
printf("0x%x\n",&(x.si));
printf("0x%x\n",&(x.c));
printf("0x%x\n",&(x.f));
printf("%d\n",&(x.i));
printf("%d\n",&(x.si));
printf("%d\n",&(x.c));
printf("%d\n",&(x.f));
return 0;
}
0x62fe10
0x62fe14
0x62fe16
0x62fe18
6487568
6487572
6487574
6487576
2.数据对齐方式举例(14分钟)


#include <stdint-gcc.h>
#include <stdio.h>
#pragma pack(4)
typedef struct
{
uint32_t f1;
uint8_t f2;
uint8_t f3;
uint32_t f4;
uint64_t f5;
}__attribute__((aligned(1024))) ts;
int main()
{
printf("Struct size is: %d, aligned on 1024\n",sizeof(ts));
printf("Allocate f1 on address:0x%x\n",&(((ts*)0)->f1));
printf("Allocate f2 on address:0x%x\n",&(((ts*)0)->f2));
printf("Allocate f3 on address:0x%x\n",&(((ts*)0)->f3));
printf("Allocate f4 on address:0x%x\n",&(((ts*)0)->f4));
printf("Allocate f5 on address:0x%x\n",&(((ts*)0)->f5));
return 0;
}
Struct size is: 1024, aligned on 1024
Allocate f1 on address:0x0
Allocate f2 on address:0x4
Allocate f3 on address:0x5
Allocate f4 on address:0x8
Allocate f5 on address:0xc

#include <stdio.h>
//#pragma pack(1)
struct test
{
char x2;
int x1;
short x3;
long long x4;
}__attribute__((packed));
struct test1
{
char x2;
int x1;
short x3;
long long x4;
};
struct test2
{
char x2;
int x1;
short x3;
long long x4;
}__attribute__((aligned(8)));
int main()
{
printf("size=%d\n",sizeof(struct test));
printf("size=%d\n",sizeof(struct test1));
printf("size=%d\n",sizeof(struct test2));
return 0;
}
在Windows10(按8字节对齐)下执行结果:
size=24
size=24
size=24
紧凑方式没起作用。
在WSL2(Ubuntu22.04LTS)上执行结果如下:
size=15
size=24
size=24
中间这个按自然边界对齐的方式所占用字节数和课程中讲到的不同。。
在Ubuntu系统上这个程序执行结果也是上面这样。。
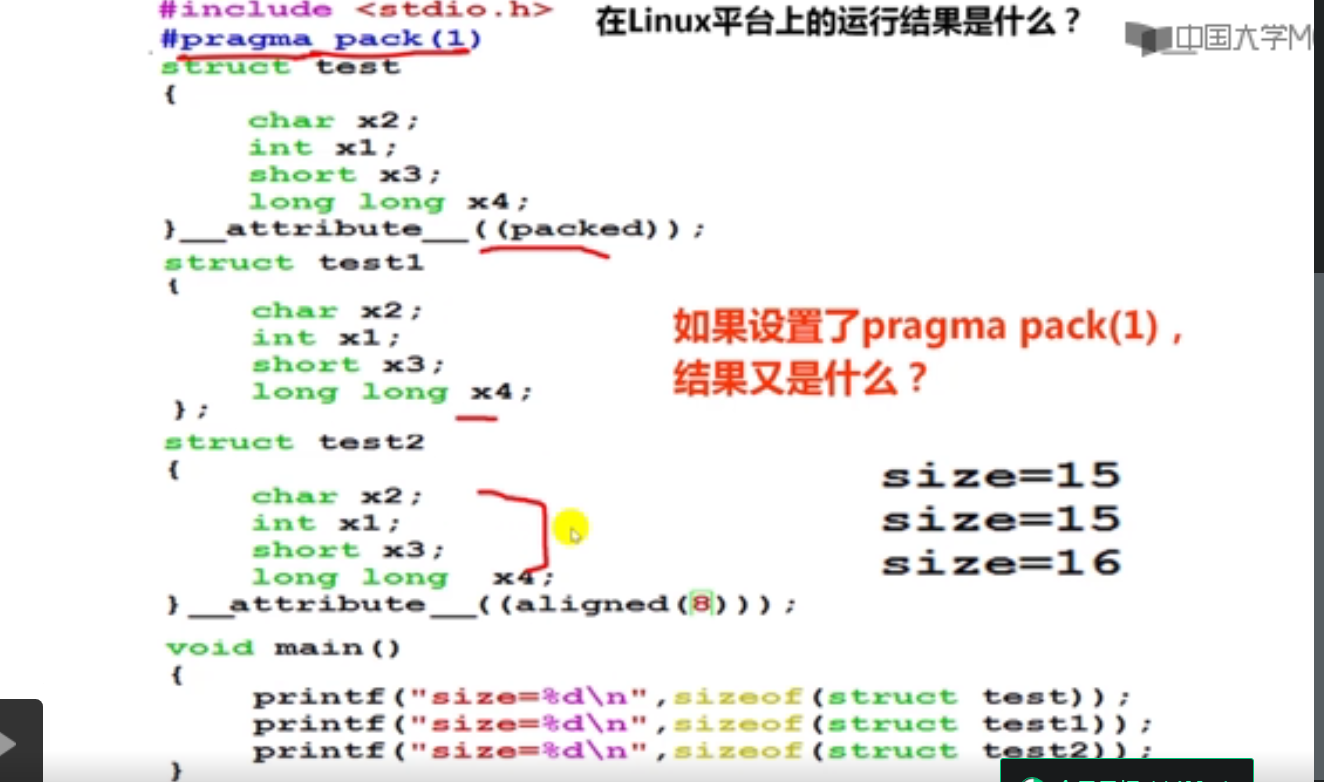
#include <stdio.h>
#pragma pack(1)
struct test
{
char x2;
int x1;
short x3;
long long x4;
}__attribute__((packed));
struct test1
{
char x2;
int x1;
short x3;
long long x4;
};
struct test2
{
char x2;
int x1;
short x3;
long long x4;
}__attribute__((aligned(8)));
int main()
{
printf("size=%d\n",sizeof(struct test));
printf("size=%d\n",sizeof(struct test1));
printf("size=%d\n",sizeof(struct test2));
return 0;
}
size=15
size=15
size=16

#include <stdio.h>
#pragma pack(1)
struct test
{
char x2;
int x1;
short x3;
long long x4;
}__attribute__((packed));
struct test1
{
char x2;
int x1;
short x3;
long long x4;
};
struct test2
{
char x2;
int x1;
short x3;
long long x4;
}__attribute__((aligned(8)));
int main()
{
printf("size=%d\n",sizeof(struct test));
printf("size=%d\n",sizeof(struct test1));
printf("size=%d\n",sizeof(struct test2));
return 0;
}
size=15
size=16
size=16
第4讲 越界访问和缓冲区溢出攻击
越界访问和缓冲区溢出攻击(27分钟)

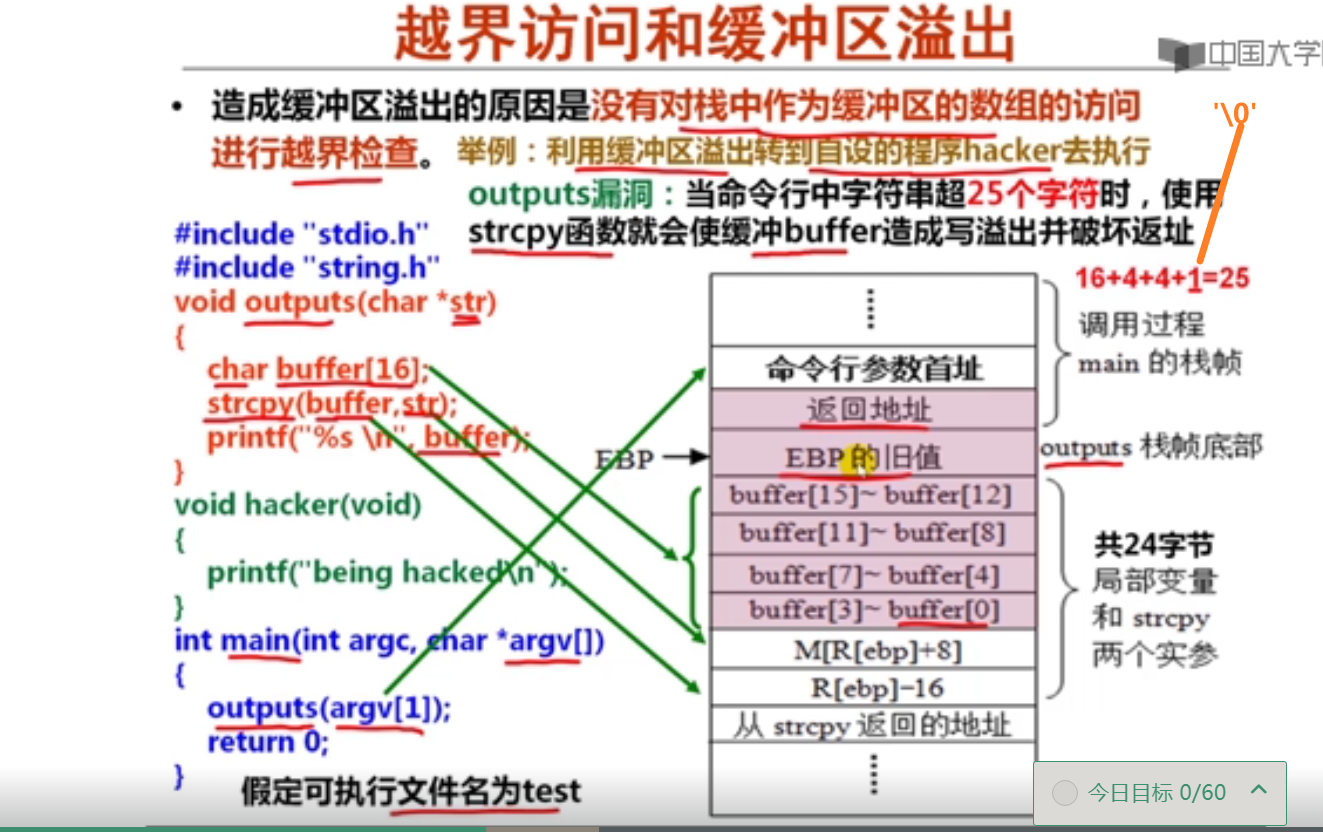



test.c文件内容:
#include <stdio.h>
#include <string.h>
void outputs(char *str)
{
char buffer[16];
strcpy(buffer,str);
printf("%s\n",buffer);
}
void cracker(void)
{
printf("Being cracked\n");
}
int main(int argc,char *argv[])
{
outputs(argv[1]);
return 0;
}
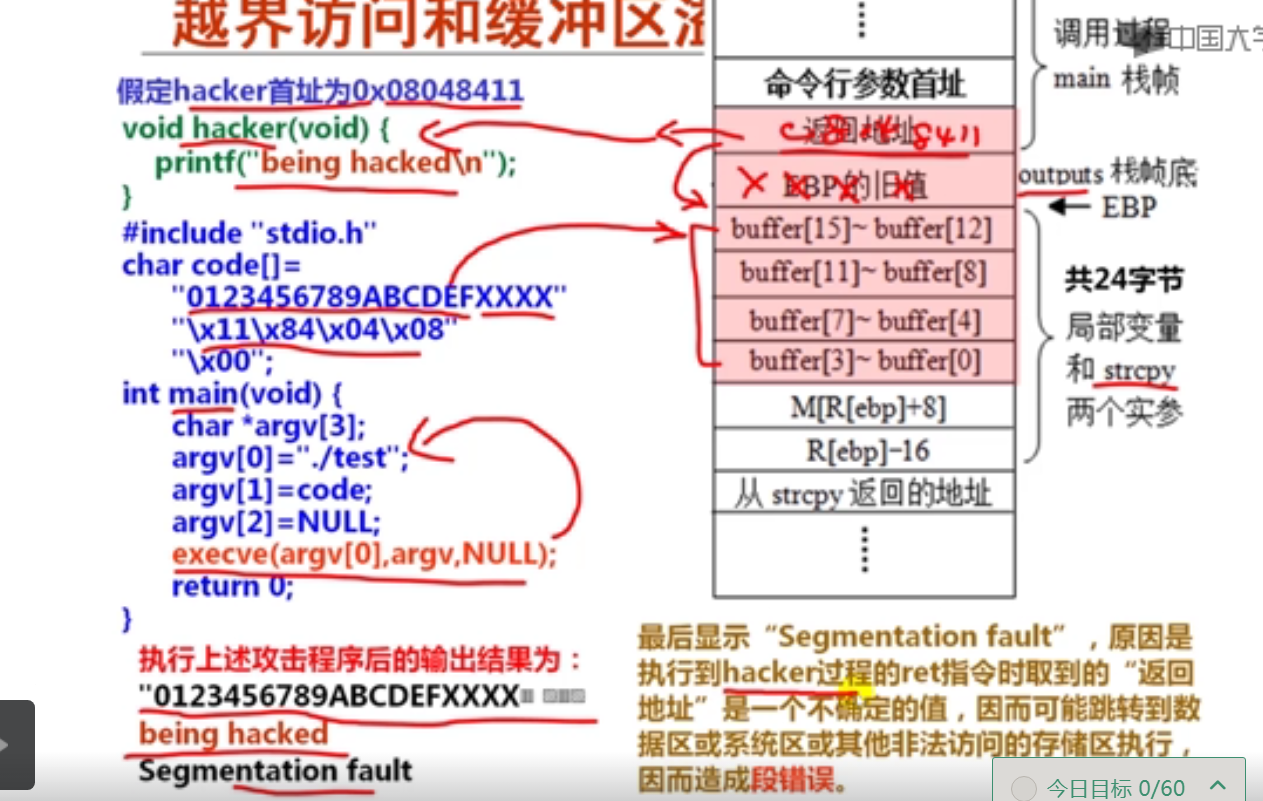
main.c文件内容:
#include <stdio.h>
#define _GNU_SOURCE
#include <unistd.h>
char code[]=
"0123456789ABCDEFXXXX"
"\x11\x84\x04\x08"
"\x00";
int main()
{
char *argv[3];
argv[0]="./test";
argv[1]=code;
argv[2]=NULL;
execve(argv[0],argv,NULL);
return 0;
}
在WSL2Ubuntu上运行结果如下:
xxxx@DESKTOP-xxxx:~/csapp$ ./test1
Segmentation fault
xxxx@DESKTOP-xxxx:~/csapp$ ./hello
0123456789ABCDEFXXXX
这里应该有保护机制,阻止了缓冲区溢出的攻击,直接就输出了Segmentation fault,没能输出"Being cracked"。
当然也可能是没能提供cracker()函数的真正地址。
第八周小测验
1求a[2]地址
假定全局short型数组a的起始地址为0x804908c,则a[2]的地址是( C )。
A.0x8049094
B.0x8049092
C.0x8049090
D.0x804908e
解释:short型的字节大小数为2,&a[0]= 0x804908c,所以0x804908c+2+2=0x8049090
2传值汇编指令
假定全局数组a的声明为char *a[8],a的首地址为0x80498c0,i 在ECX中,现要将a[i]取到EAX相应宽度的寄存器中,则所用的汇编指令是( B )。
A.mov 0x80498c0( , %ecx), %ah
B.mov 0x80498c0( , %ecx, 4), %eax
C.mov (0x80498c0, %ecx), %ah
D.mov (0x80498c0, %ecx, 4), %eax
解释:课程使用IA-32系统,指针型变量的大小为4Byte,%eax为目的寄存器
3传值汇编指令
假定全局数组a的声明为double *a[8],a的首地址为0x80498c0,i 在ECX中,现要将a[i]取到EAX相应宽度的寄存器中,则所用的汇编指令是(D )。
A.mov (0x80498c0, %ecx, 8), %eax
B.mov (0x80498c0, %ecx, 4), %eax
C.mov 0x80498c0( , %ecx, 8), %eax
D.mov 0x80498c0( , %ecx, 4), %eax
解释:IA-32系统不管是什么类型的指针,大小都为4byte
4传送首地址汇编指令
假定局部数组a的声明为int a[4]={0, -1, 300, 20},a的首地址为R[ebp]-16,则将a的首地址取到EDX的汇编指令是( B )。
A.movl -16(%ebp ), %edx
B.leal -16(%ebp), %edx
C.movl -16(%ebp, 4), %edx
D.leal -16(%ebp, 4), %edx
解释:因为是取地址,所以用到加载有效地址leal,又因为是取首地址,无需变址和比例因子。
5详解ptr+i
某C语言程序中有以下两个变量声明:
int a[10];
int *ptr=&a[0];
则ptr+i的值为( B )。
A.&a[0]+8´i
B.&a[0]+4´i
C.&a[0]+2´i
D.&a[0]+i
解释:IA-32系统中不管是什么类型的指针,大小都为4B
6二维数组元素地址
假定静态short型二维数组b的声明如下:
static short b[2][4]={ {2, 9, -1, 5}, {3, 8, 2, -6}};
若b的首地址为0x8049820,则按行优先存储方式下,数组元素“8”的地址是( D )。
A.0x8049824
B.0x8049828
C.0x8049825
D.0x804982a
解释:8前面有5个元素,大小为5*2=10,所以地址为:0x8049820+a=0x804982a
7指针数组元素的值
假定静态short型二维数组b和指针数组pb的声明如下:
static short b[2][4]={ {2, 9, -1, 5}, {3, 1, -6, 2 }};
static short *pb[2]={b[0], b[1]};
若b的首地址为0x8049820,则pb[1]的值是( C )。
A.0x8049824
B.0x8049820
C.0x8049828
D.0x8049822
解释:这里问的是pb[1]这个数组元素的值,显然应该是b[1],而b[1]应该是指二维数组b的第1行(从0开始)的起始地址。b每行有4个元素,每个元素占两个字节(short型),因而每行占8个字节,因而b的第1行首地址为0x8049820+8=0x8049828。
8指针数组元素的地址
假定静态short型二维数组b和指针数组pb的声明如下:
static short b[2][4]={ {2, 9, -1, 5}, {3, 1, -6, 2 }};
static short *pb[2]={b[0], b[1]};
若b的首地址为0x8049820,则&pb[1]的值是( D )。
A.0x8049830
B.0x8049832
C.0x8049838
D.0x8049834
解释:这里问的是pb[1]这个数组元素的地址,通常pb数组直接在b数组后面分配,因为b数组占2x8=16个单元,因此pb数组的首地址为0x8049820+16=0x8049830。而pb数组的每个元素是一个指针,故占4B,所以pb[1]的地址为0x8049830+4=0x8049834。
9结构体元素赋值汇编指令
假定结构体类型cont_info的声明如下:
struct cont_info {
char id[8];
char name [16];
unsigned post;
char address[100];
char phone[20];
} ;
若结构体变量x初始化定义为struct cont_info x={“00000010”, “ZhangS”, 210022, “273 long street, High Building #3015”, “12345678”},x的首地址在EDX中,则“unsigned xpost=x.post;”对应汇编指令为( C )。
A.leal 0x24(%edx), %eax
B.movl 0x24(%edx), %eax
C.movl 0x18(%edx), %eax
D.leal 0x18(%edx), %eax
解释:0x18=24.且为赋值语句,用movl
10对齐方式
以下是关于IA-32处理器对齐方式的叙述,其中错误的是( D )。
A.可以用编译指导语句(如#pragma pack)设置对齐方式
B.不同操作系统采用的对齐策略可能不同
C.对于同一个struct型变量,在不同对齐方式下可能会占用不同大小的存储区
D.总是按其数据宽度进行对齐,例如,double型变量的地址总是8的倍数
第九周x86-64指令系统
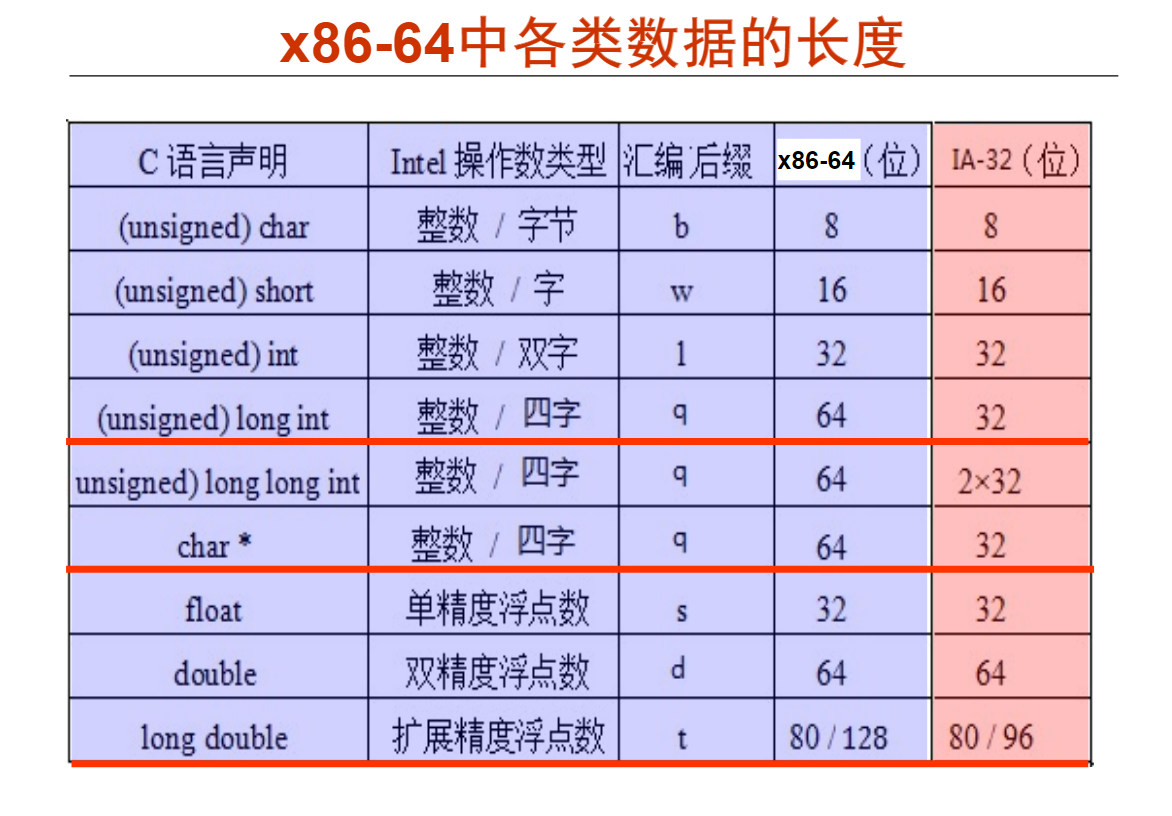
第1讲 x86-64指令系统概述







第2讲 x86-64的基本指令
1.x86-64传送指令(16分钟)

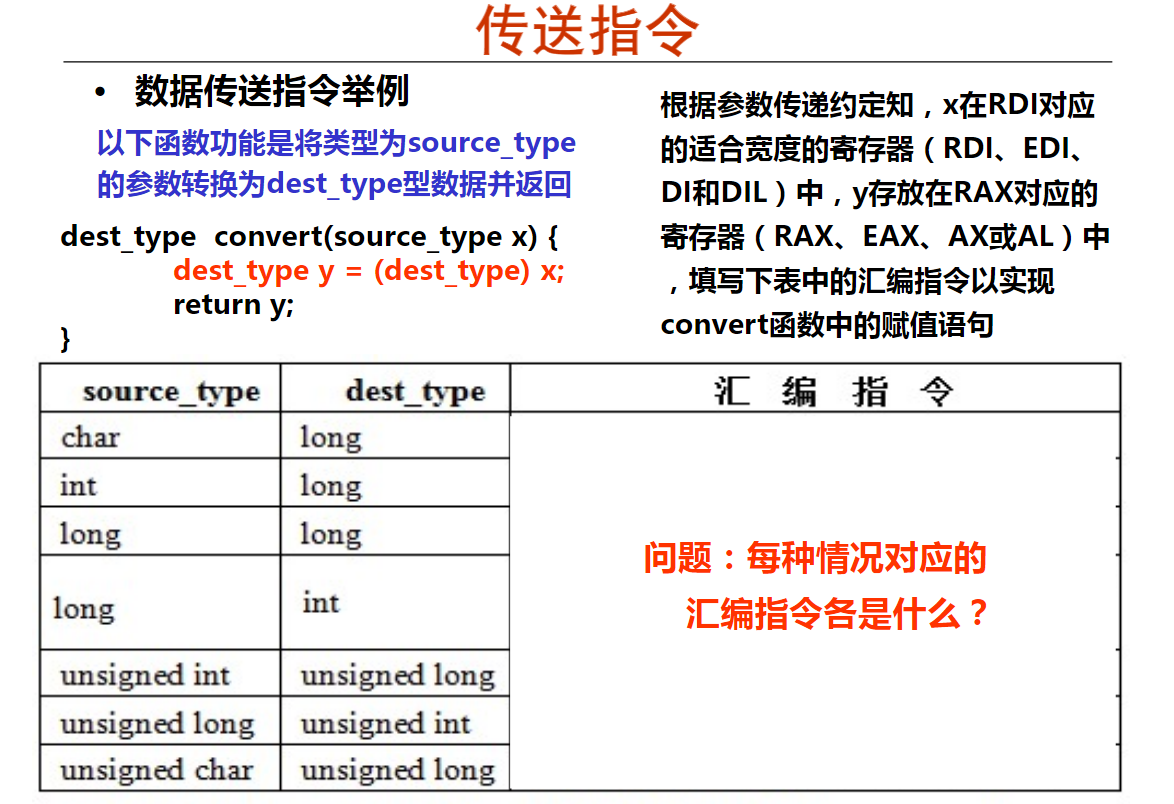
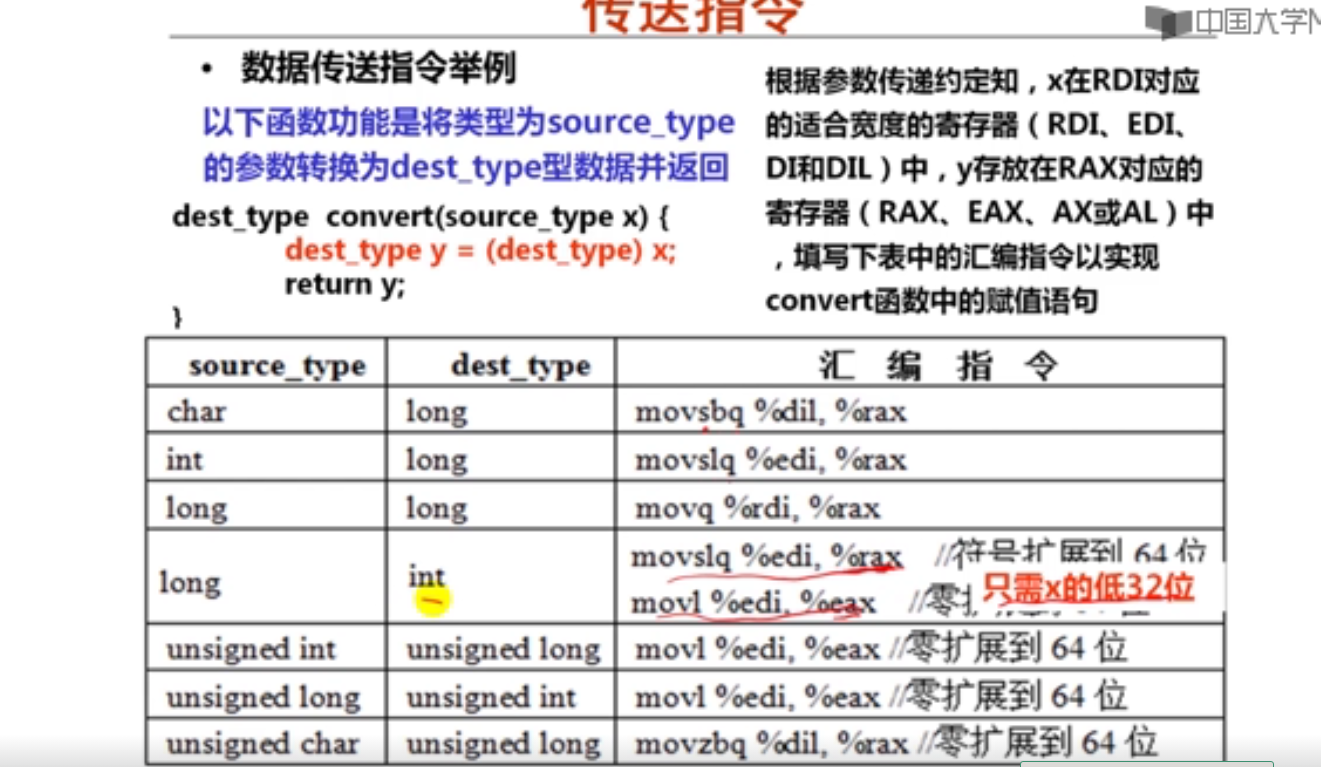
2.x86-64算术、逻辑运算指令(20分钟)





3.x86-64逆向工程举例(17分钟)
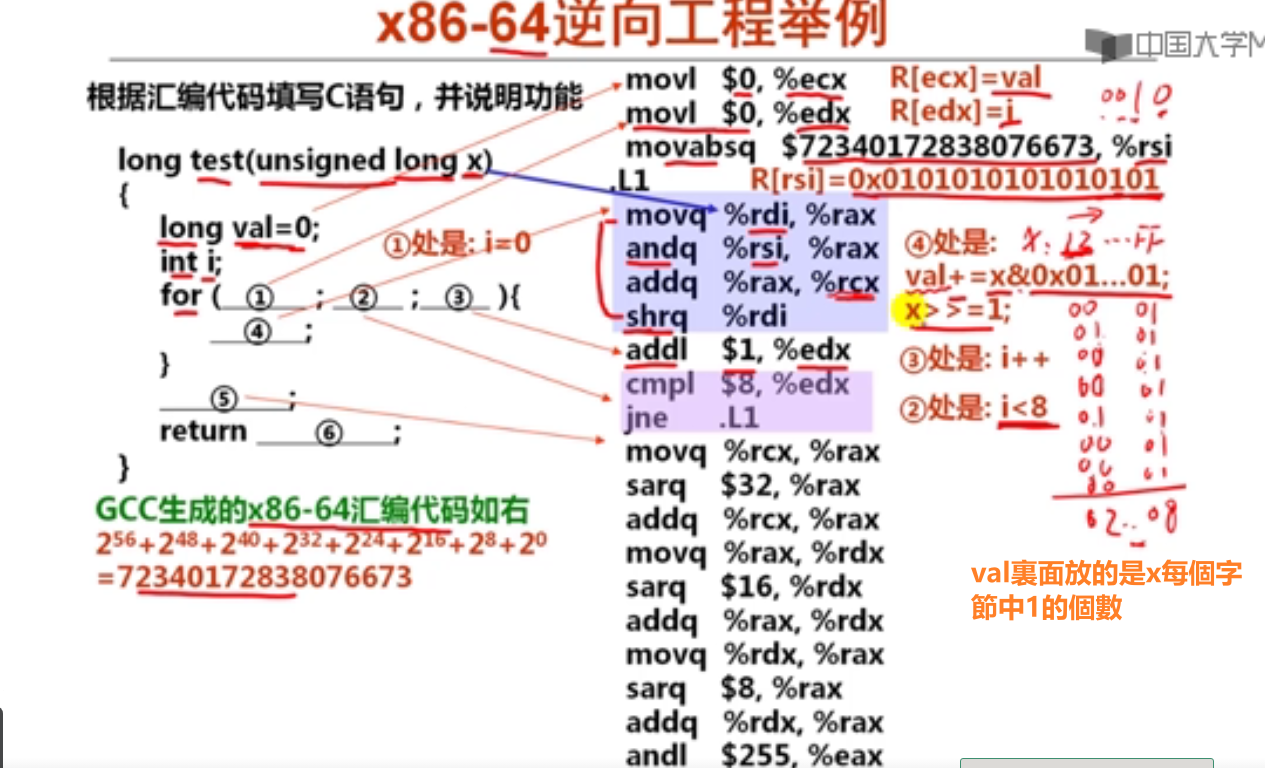

第3讲 x86-64的过程调用
1.x86-64过程调用的参数传递方式(16分钟)
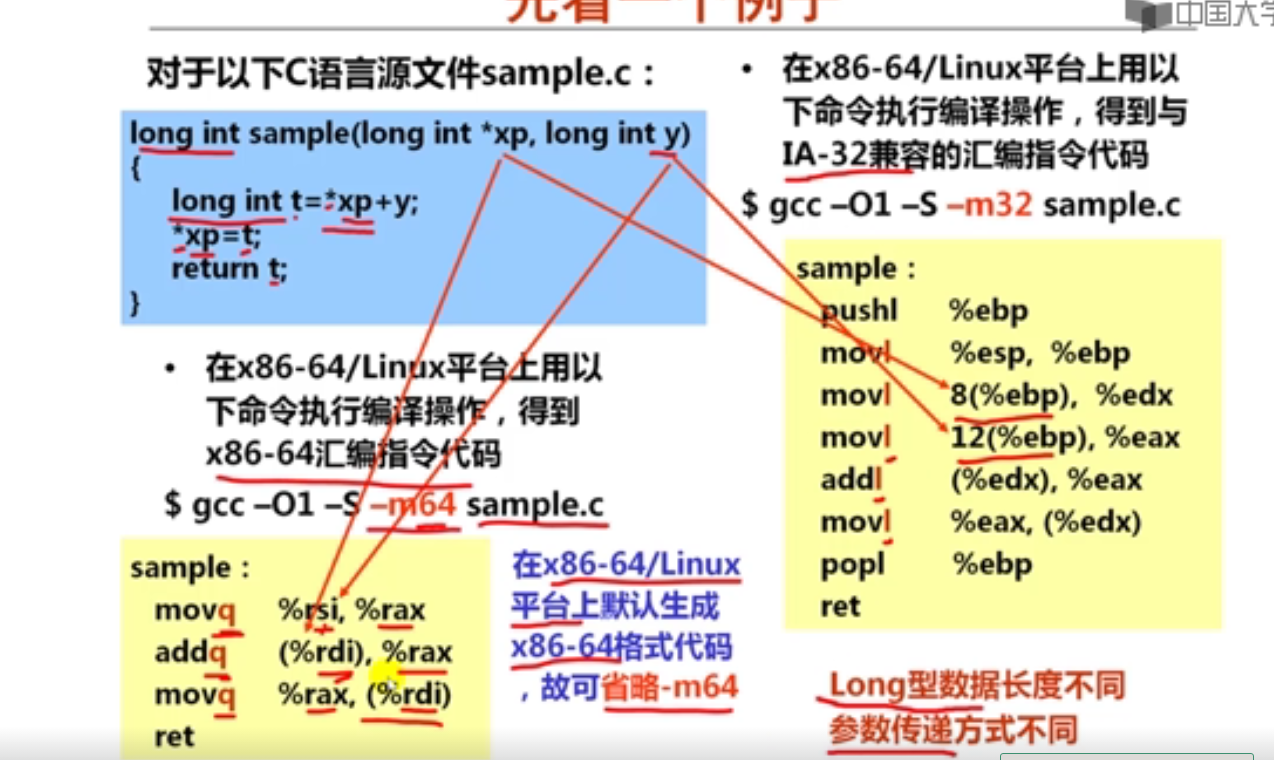
long int sample(long int *xp, long int y)
{
long int t = *xp + y;
*xp = t;
return t;
}
執行gcc -O1 -S -m32 sample.c
.file "sample.c"
.text
.globl sample
.type sample, @function
sample:
.LFB0:
.cfi_startproc
movl 4(%esp), %edx
movl (%edx), %eax
addl 8(%esp), %eax
movl %eax, (%edx)
ret
.cfi_endproc
.LFE0:
.size sample, .-sample
.ident "GCC: (Ubuntu 11.3.0-1ubuntu1~22.04) 11.3.0"
.section .note.GNU-stack,"",@progbits
執行gcc -O1 -S -m64 sample.c
.file "sample.c"
.text
.globl sample
.type sample, @function
sample:
.LFB0:
.cfi_startproc
endbr64
movq %rsi, %rax
addq (%rdi), %rax
movq %rax, (%rdi)
ret
.cfi_endproc
.LFE0:
.size sample, .-sample
.ident "GCC: (Ubuntu 11.3.0-1ubuntu1~22.04) 11.3.0"
.section .note.GNU-stack,"",@progbits
.section .note.gnu.property,"a"
.align 8
.long 1f - 0f
.long 4f - 1f
.long 5
0:
.string "GNU"
1:
.align 8
.long 0xc0000002
.long 3f - 2f
2:
.long 0x3
3:
.align 8
4:
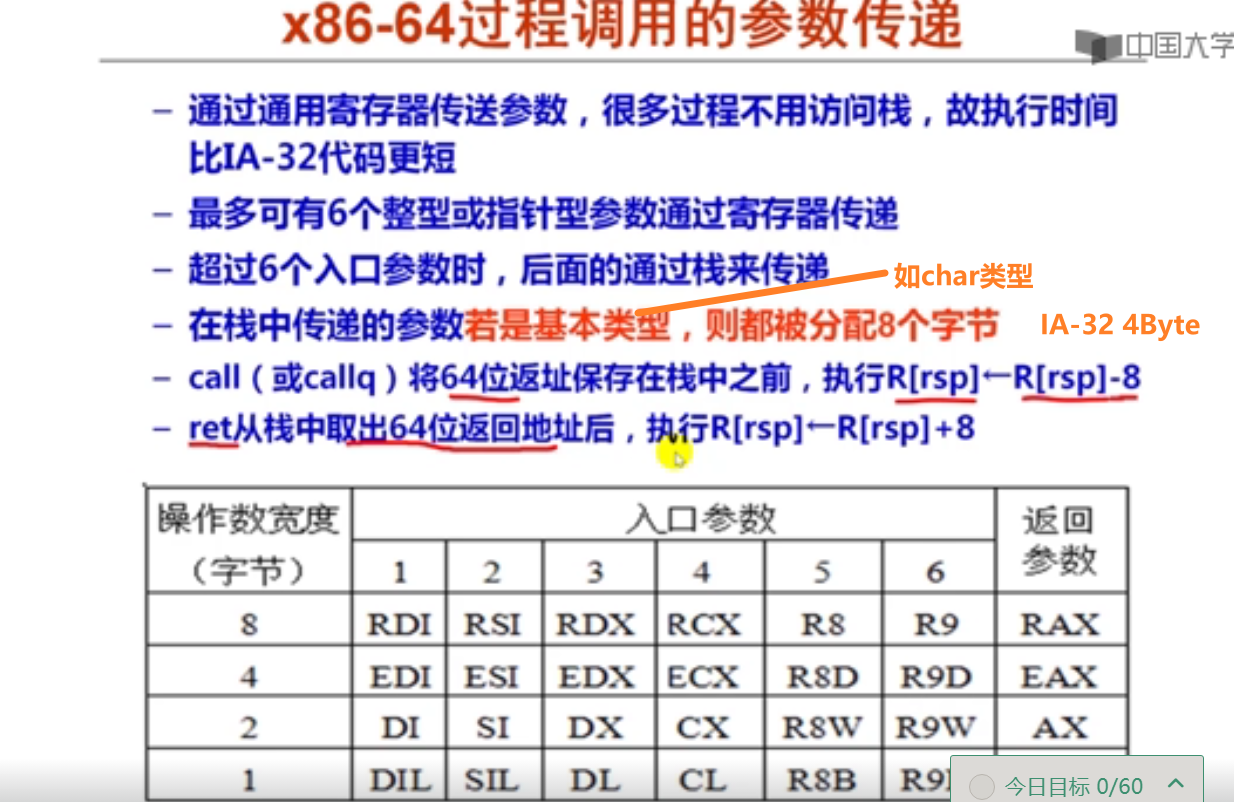

2.x86-64过程调用举例(24分钟)



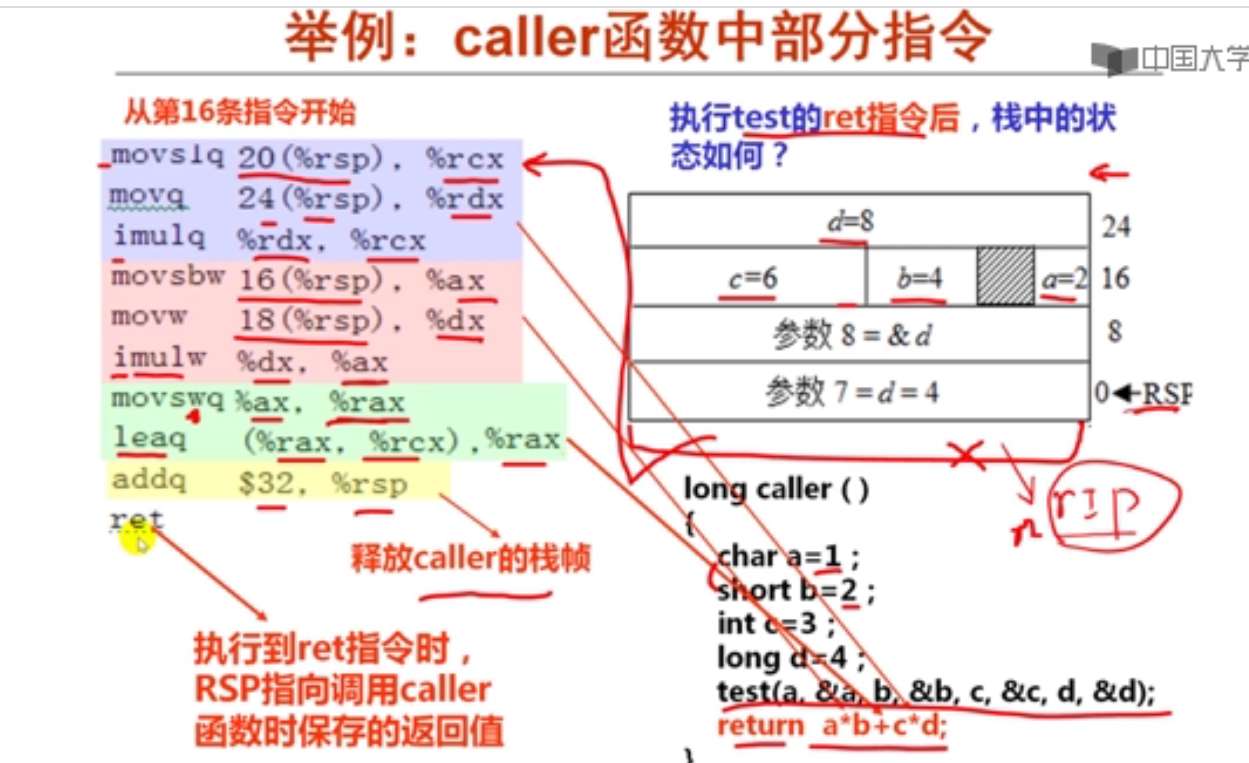
void test(char a,char *ap,short b,short *bp,int c,int *cp,long d,long *dp)
{
*ap += a;
*bp += b;
*cp += c;
*dp += d;
}
long caller()
{
char a =1 ;
short b = 2;
int c = 3;
long d = 4;
test(a,&a,b,&b,c,&c,d,&d);
return a*b+c*d;
}
.file "sample.c"
.text
.globl test
.type test, @function
test:
.LFB0:
.cfi_startproc
endbr64
movq 16(%rsp), %rax
addb %dil, (%rsi)
addw %dx, (%rcx)
addl %r8d, (%r9)
movq 8(%rsp), %rdx
addq %rdx, (%rax)
ret
.cfi_endproc
.LFE0:
.size test, .-test
.globl caller
.type caller, @function
caller:
.LFB1:
.cfi_startproc
endbr64
movl $56, %eax
ret
.cfi_endproc
.LFE1:
.size caller, .-caller
.ident "GCC: (Ubuntu 11.3.0-1ubuntu1~22.04) 11.3.0"
.section .note.GNU-stack,"",@progbits
.section .note.gnu.property,"a"
.align 8
.long 1f - 0f
.long 4f - 1f
.long 5
0:
.string "GNU"
1:
.align 8
.long 0xc0000002
.long 3f - 2f
2:
.long 0x3
3:
.align 8
4:
3.IA-32和x86-64的比较举例(15分钟)

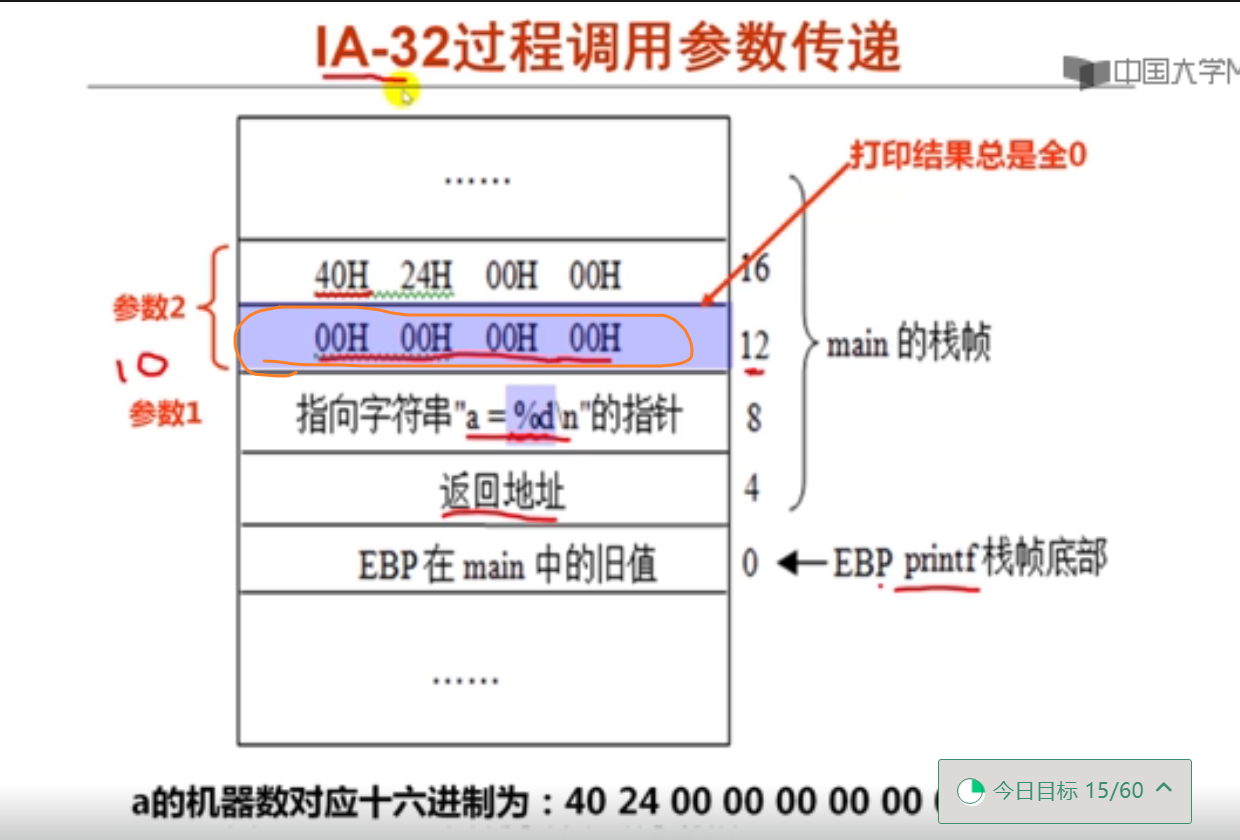


#include <stdio.h>
void test(char a,char *ap,short b,short *bp,int c,int *cp,long d,long *dp)
{
*ap += a;
*bp += b;
*cp += c;
*dp += d;
}
long caller()
{
char a =1 ;
short b = 2;
int c = 3;
long d = 4;
test(a,&a,b,&b,c,&c,d,&d);
return a*b+c*d;
}
int main()
{
double a = 10;
printf("a = %d\n",a);
}
在WSL2Ubuntu22.04LTS系统上输出结果a = -310744488是个随机值
.file "sample.c"
.text
.globl test
.type test, @function
test:
.LFB23:
.cfi_startproc
endbr64
movq 16(%rsp), %rax
addb %dil, (%rsi)
addw %dx, (%rcx)
addl %r8d, (%r9)
movq 8(%rsp), %rdx
addq %rdx, (%rax)
ret
.cfi_endproc
.LFE23:
.size test, .-test
.globl caller
.type caller, @function
caller:
.LFB24:
.cfi_startproc
endbr64
movl $56, %eax
ret
.cfi_endproc
.LFE24:
.size caller, .-caller
.section .rodata.str1.1,"aMS",@progbits,1
.LC1:
.string "a = %d\n"
.text
.globl main
.type main, @function
main:
.LFB25:
.cfi_startproc
endbr64
subq $8, %rsp
.cfi_def_cfa_offset 16
movsd .LC0(%rip), %xmm0
leaq .LC1(%rip), %rsi
movl $1, %edi
movl $1, %eax
call __printf_chk@PLT
movl $0, %eax
addq $8, %rsp
.cfi_def_cfa_offset 8
ret
.cfi_endproc
.LFE25:
.size main, .-main
.section .rodata.cst8,"aM",@progbits,8
.align 8
.LC0:
.long 0
.long 1076101120
.ident "GCC: (Ubuntu 11.3.0-1ubuntu1~22.04) 11.3.0"
.section .note.GNU-stack,"",@progbits
.section .note.gnu.property,"a"
.align 8
.long 1f - 0f
.long 4f - 1f
.long 5
0:
.string "GNU"
1:
.align 8
.long 0xc0000002
.long 3f - 2f
2:
.long 0x3
3:
.align 8
4:
第九周小测验
1以下有关IA-32和x86-64之间比较的叙述中,错误的是(D )。
A.IA-32的通用寄存器有8个,而x86-64的通用寄存器有16个
B.IA-32的字长为32位,x86-64的字长为64位并兼容IA-32
C.IA-32的通用寄存器为8/16/32位,而x86-64的通用寄存器为8/16/32/64位
D.(unsigned) long型变量在IA-32和x86-64中的长度都是64位(四字)
解释:long型变量在IA-32中的长度是32位
2以下有关x86-64寄存器的叙述中,错误的是( D )。
A.128位的XMM寄存器从原来IA-32中的8个增加到16个
B.用来存放将要执行的指令的地址的指令指针寄存器为64位的RIP
C.基址寄存器和变址寄存器都可以是任意一个64位的通用寄存器
D.任何浮点操作数都被分配在浮点寄存器栈(ST(0)~ST(7))中
3以下有关x86-64对齐方式的叙述中,错误的是(B )。
A.int、float型数据必须按4字节边界对齐
B.long double型数据在内存占12字节空间(96位)
C.long、double、指针型数据必须按8字节边界对齐
D.short型数据必须按2字节边界对齐
解释:long double型数据在内存占16字节空间(128位),实际只用80位
4以下有关x86-64传送指令的叙述中,错误的是(B )。
A.movl相当于movzlq,能将目的寄存器高32位清0
B.pushq和popq分别对ESP寄存器减8和加8
C.相比IA-32,增加了movq指令,可传送64位数据
D.movzbq的功能是将8位寄存器内容零扩展为64位
解释:pushq和popq分别对RSP寄存器减8和加8
5假定变量x的类型为int,对于变量y的初始化声明“long y=(long) x;”,其对应的汇编指令是(A )。
A.movslq %edx, %rax
B.movq %rdx, %rax
C.movzlq %edx, %rax
D.movl %edx, %eax
解释:这里进行的是符号扩展,不是零扩展
6假定变量x的类型为long,对于变量y的初始化声明“int y=(int) x;”,其对应的汇编指令不可能是( C)。
A.movl %edx, %eax
B.movzlq %edx, %rax
C.movsql %rdx, %eax
D.movslq %edx, %rax
7以下是C语言赋值语句“x=a*b+c;”对应的x86-64汇编代码:
movslq %edx, %rdx
movsbl %sil, %esi
imull %edi, %esi
movslq %esi, %rsi
leaq (%rdx, %rsi), %rax
已知x、a、b和c分别在RAX、RDI、RSI和RDX对应宽度的寄存器中,根据上述汇编指令序列,推测x、a、b和c的数据类型分别为(D )。
A.x—long, a—long, b—char, c—int
B.x—long, a—long, b—char, c—long
C.x—long, a—int, b—char, c—long
D.x—long, a—int, b—char, c—int
8假定long型变量t、int型变量x和short型变量y分别在RAX、RDI和RSI对应宽度寄存器中,C语言赋值语句“t=(long)(x+y);”对应的x86-64汇编指令序列不可能是( A )。
A.
movswq %si, %rdx
leaq (%rdx, %rdi), %rax
B.
movswq %si, %rax
movslq %edi, %rdx
addq %rdx, %rax
C.
movswq %si, %rsi
movslq %edi, %rdi
leaq (%rsi, %rdi), %rax
D.
movswl %si, %edx
addl %edi, %edx
movslq %edx, %rax
9以下关于x86-64过程调用的叙述中,错误的是( B )。
A.前6个参数采用通用寄存器传递,其余参数通过栈传递
B.在通用寄存器中传递的参数,都存放在64位寄存器中
C.在栈中的参数若是基本类型,则被分配8个字节空间
D.返回参数存放在RAX相应宽度的寄存器中
10以下关于IA-32和x86-64指令系统比较的叙述中,错误的是( D )。
A.对于64位数据,x86-64可用一条指令处理,而IA-32需多条指令处理
B.对于入口参数,x86-64可用通用寄存器传递,而IA-32需用栈来传递
C.对于浮点操作数,x86-64存于128位的XMM中,而IA-32存于80位的ST(i)中
D.对于返回地址,x86-64使用通用寄存器保存,而IA-32使用栈来保存
解释:对于返回地址,x86-64和IA-32都使用栈来保存
第十周链接概述和目标文件格式
第1讲 可执行文件生成概述
可执行文件生成过程概述(21分钟)
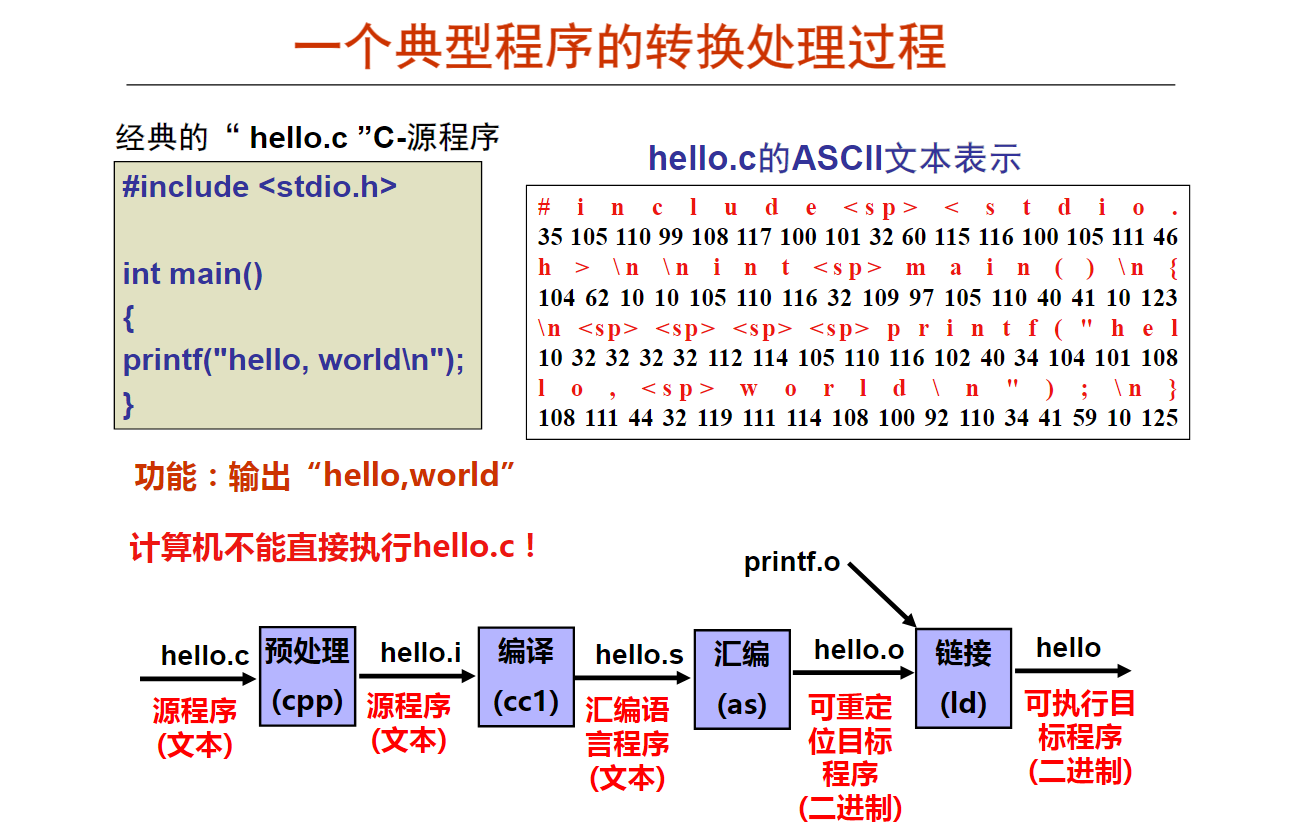


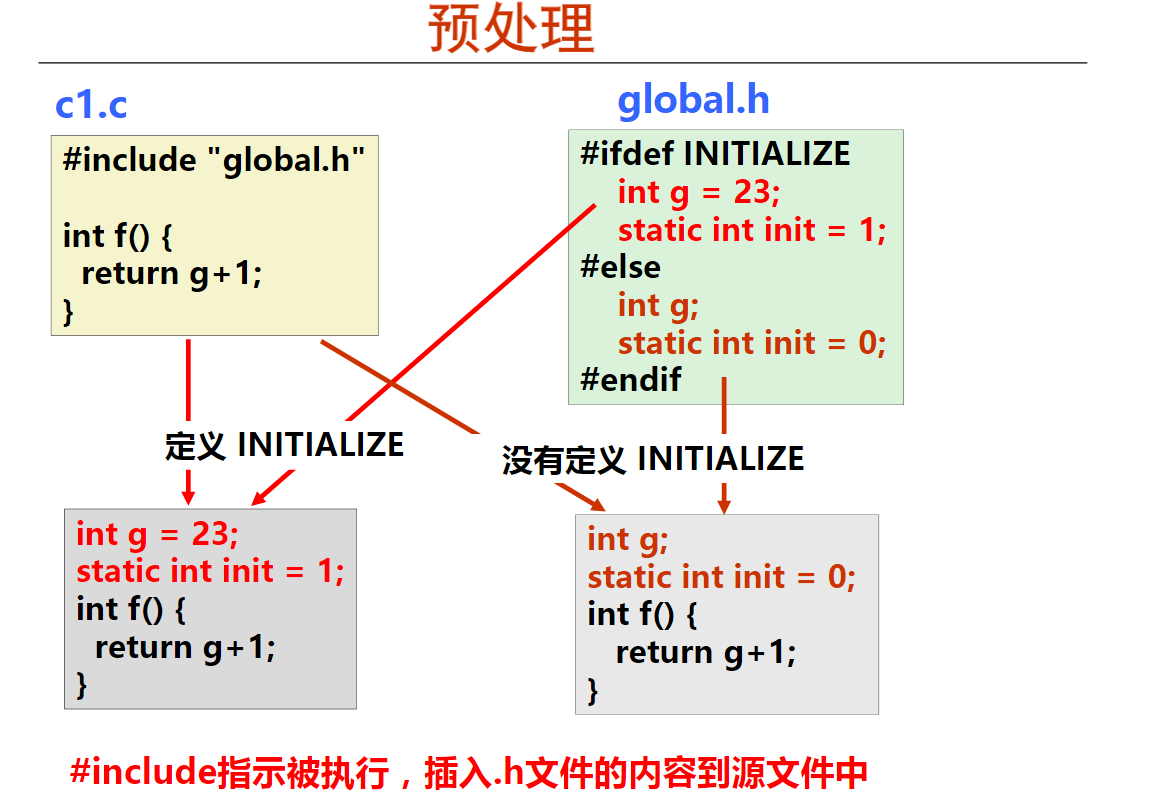



链接器的由来(17分钟)

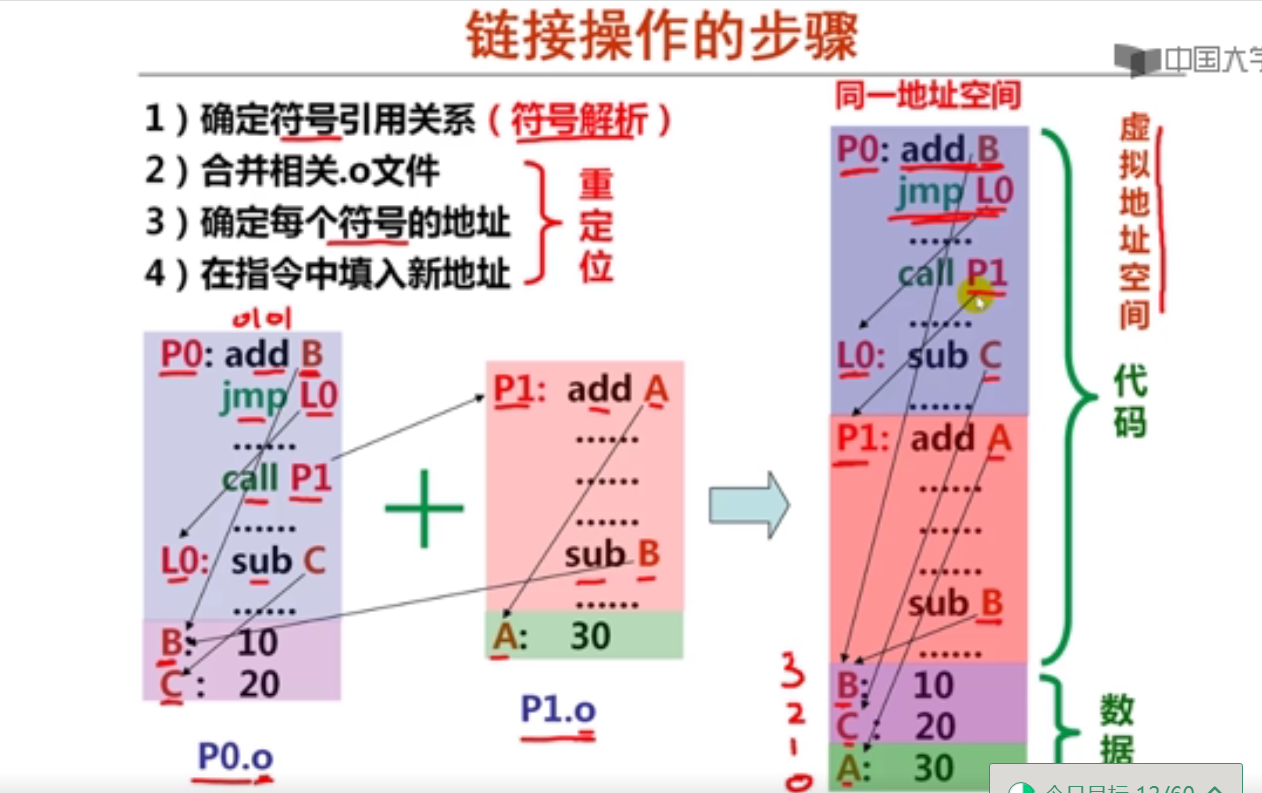

注意:静态链接需要包含所调用函数的代码,而动态链接不需要。
第2讲 目标文件格式概述
链接过程的本质(14分钟)


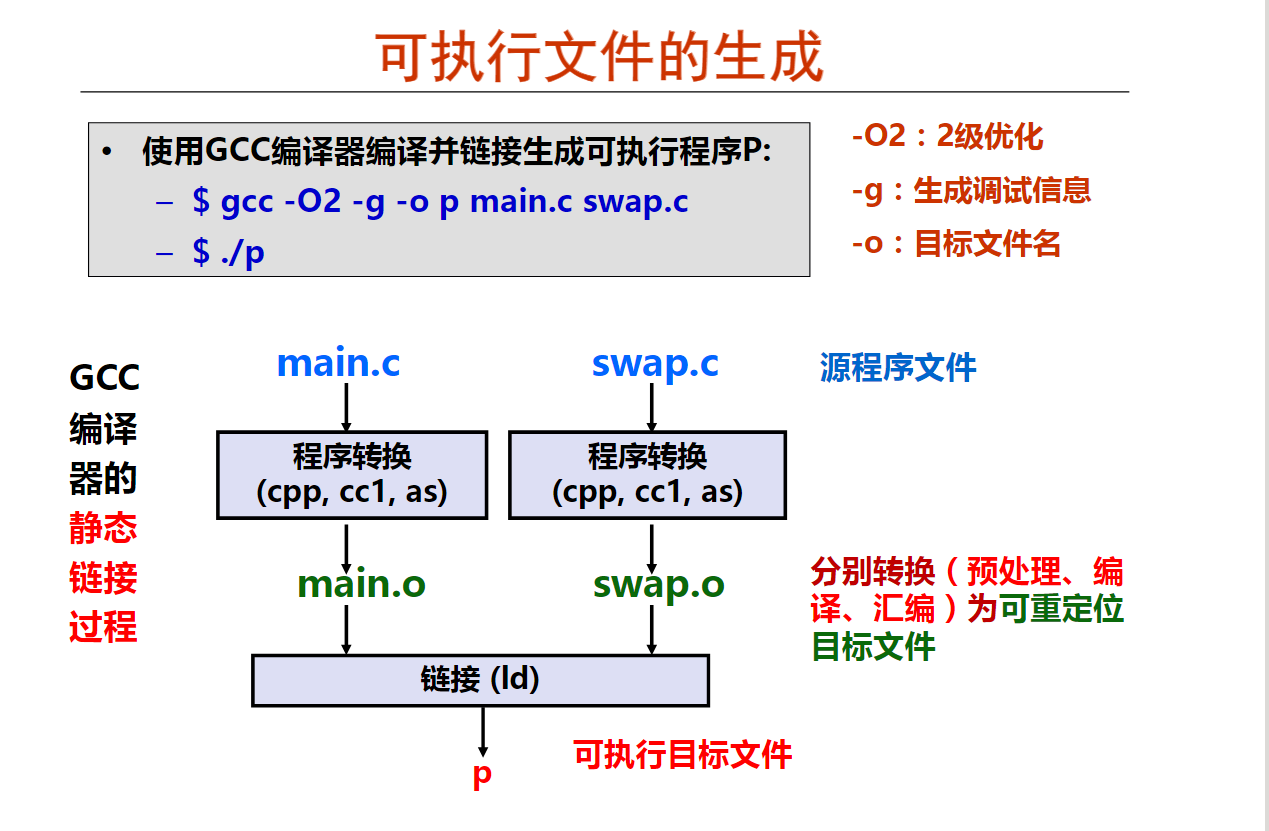
guangwudi@debian:~/csapp$ vim main.c
guangwudi@debian:~/csapp$ vim swap.c
guangwudi@debian:~/csapp$ gcc -O2 -g -o p main.c swap.c
guangwudi@debian:~/csapp$ ./p
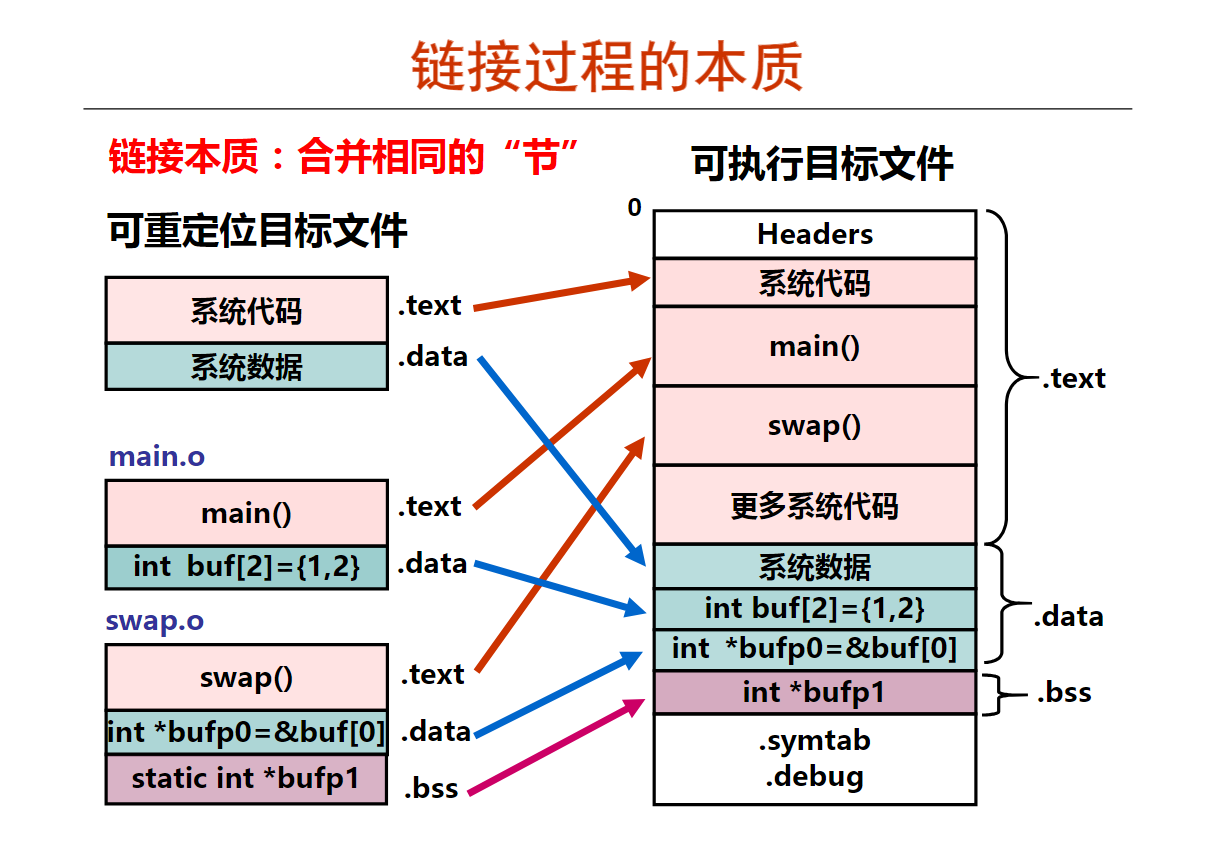
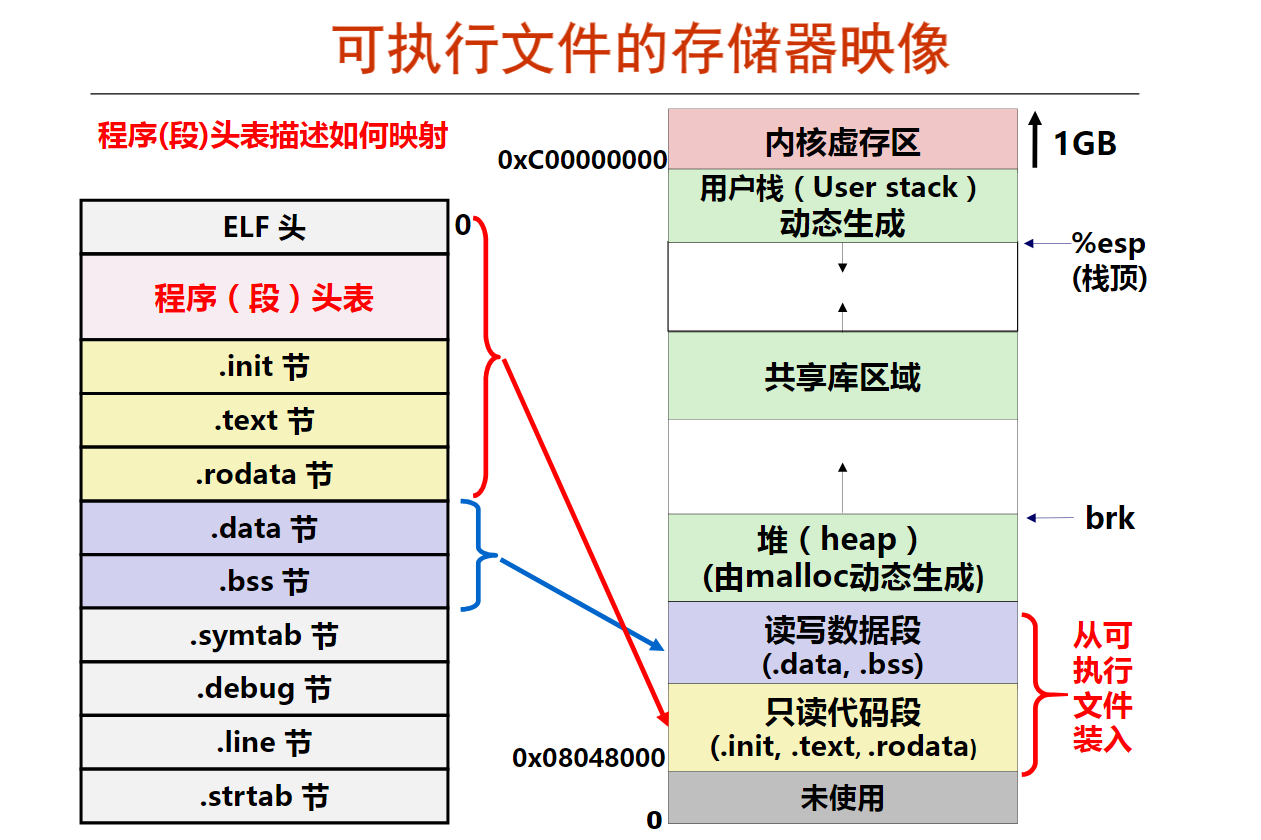
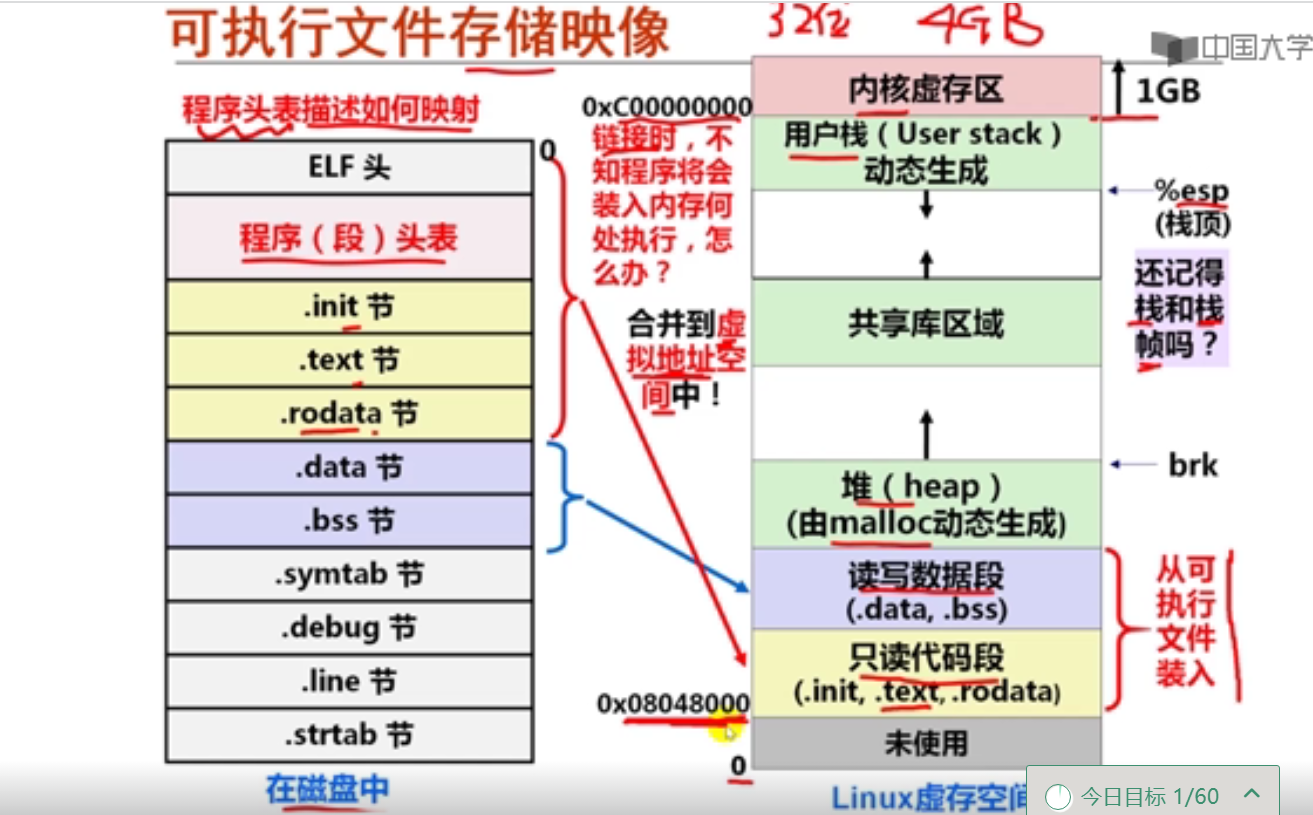
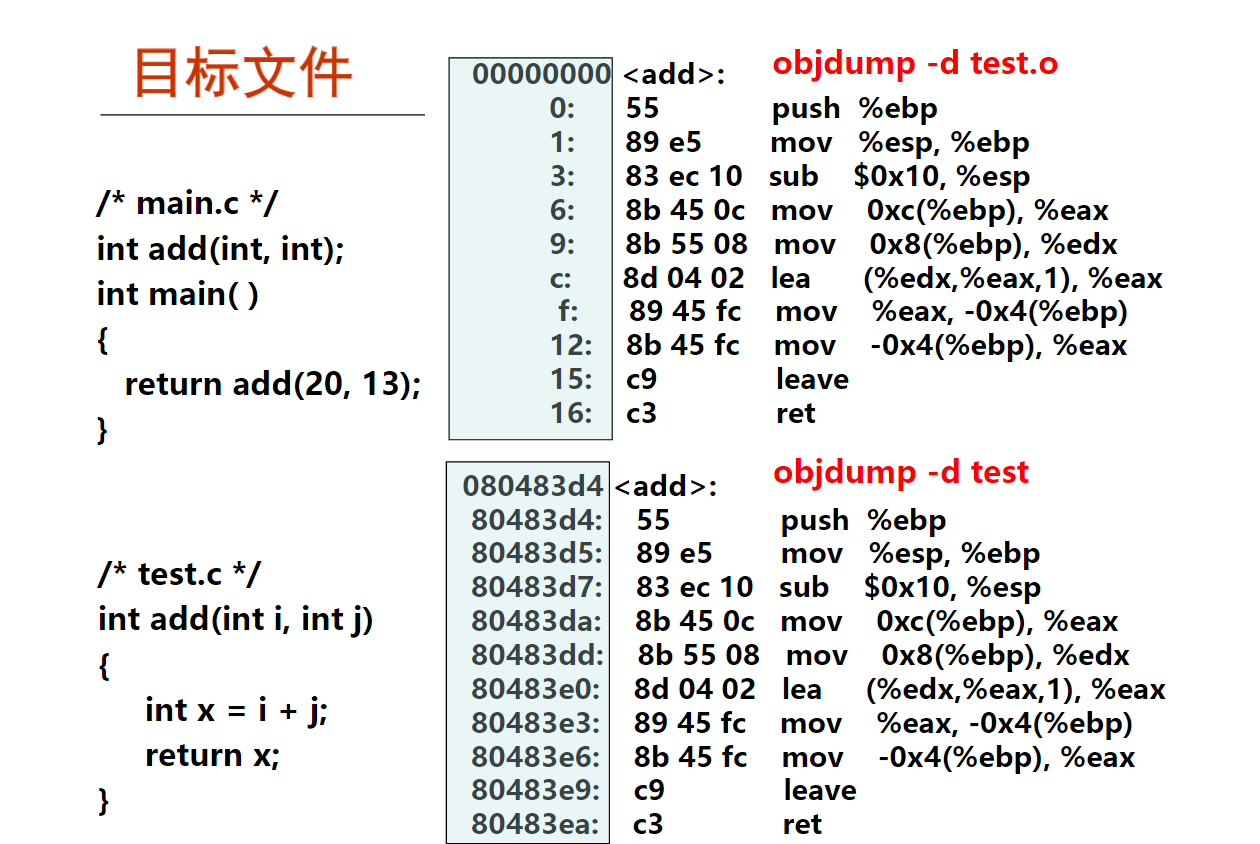
目标文件的两种视图(16分钟)
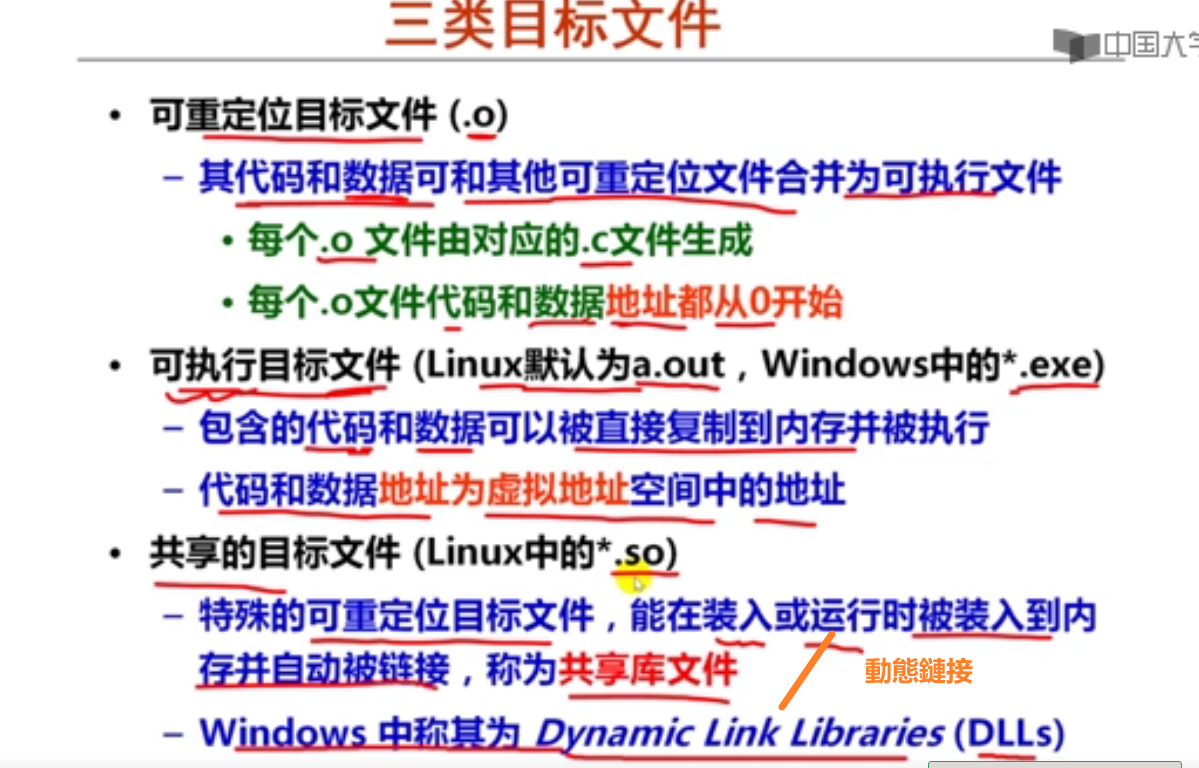

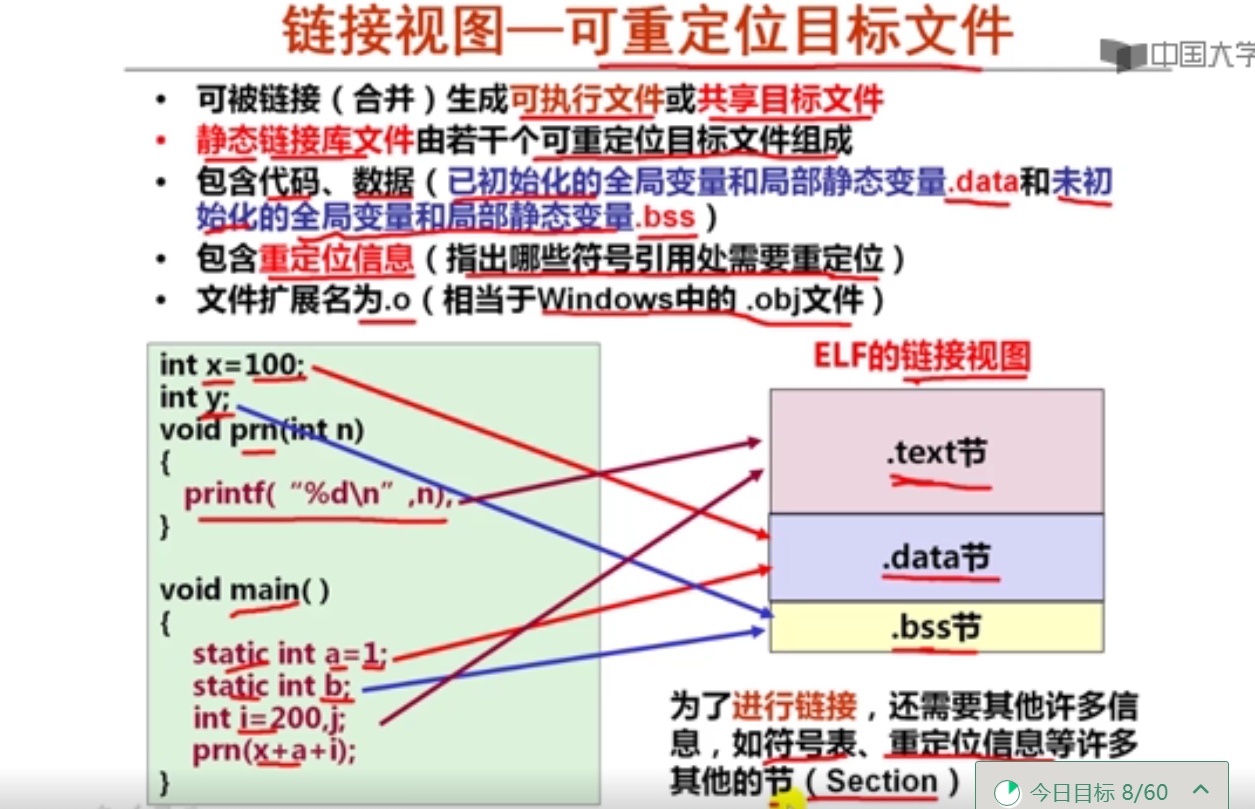
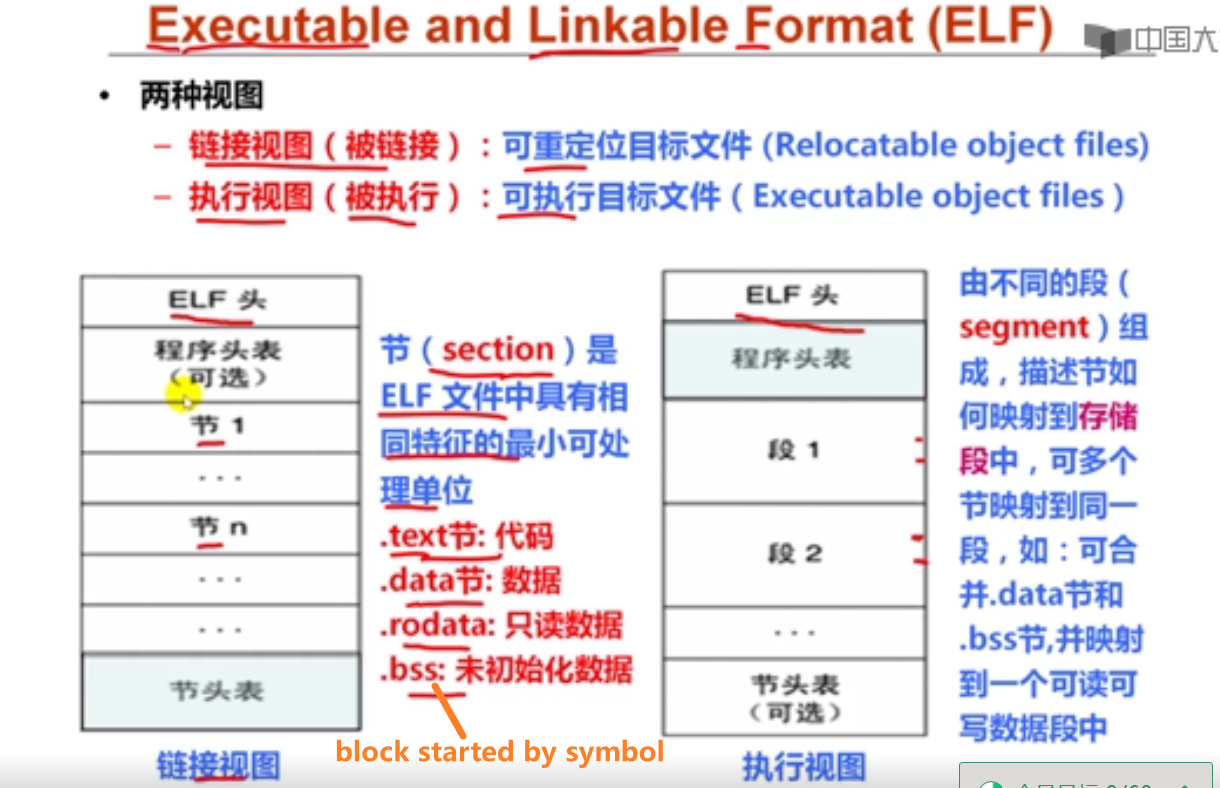
第3讲 ELF可重定位目标文件
可重定位文件概述(10分钟)
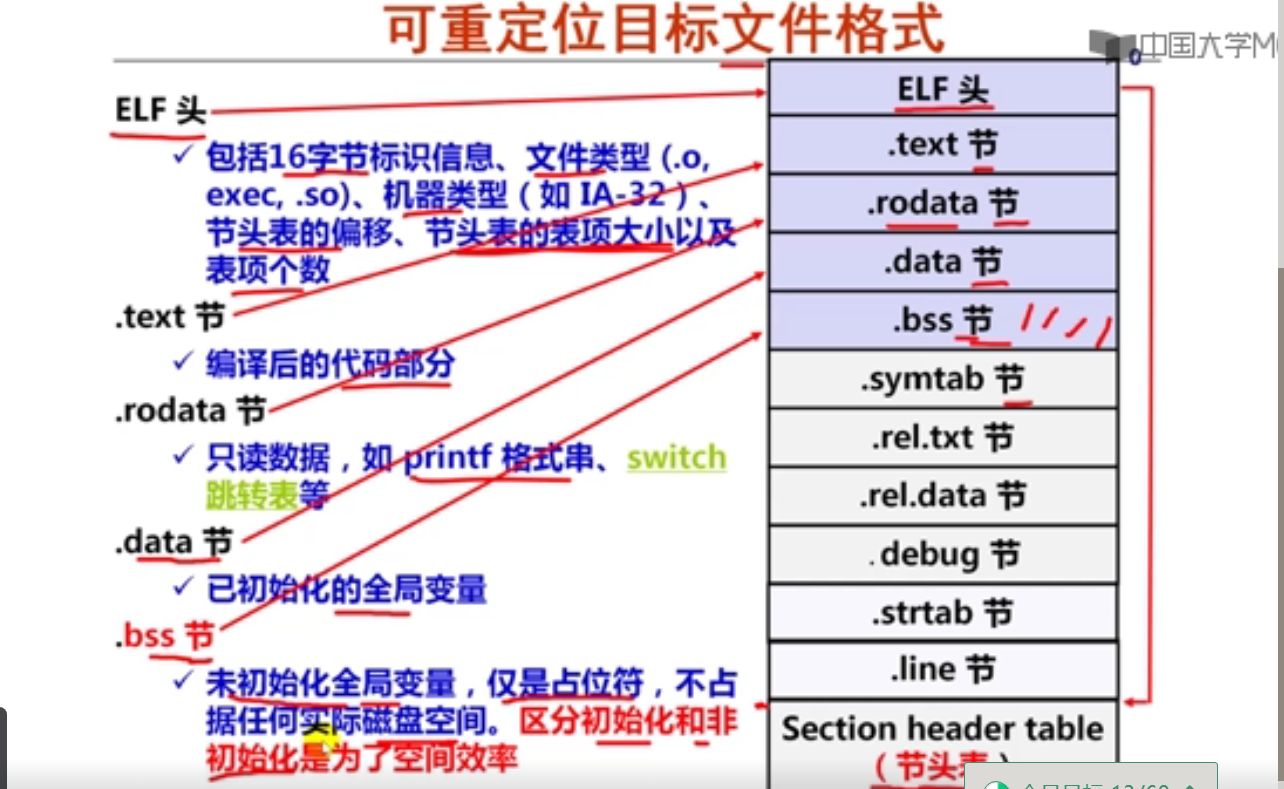

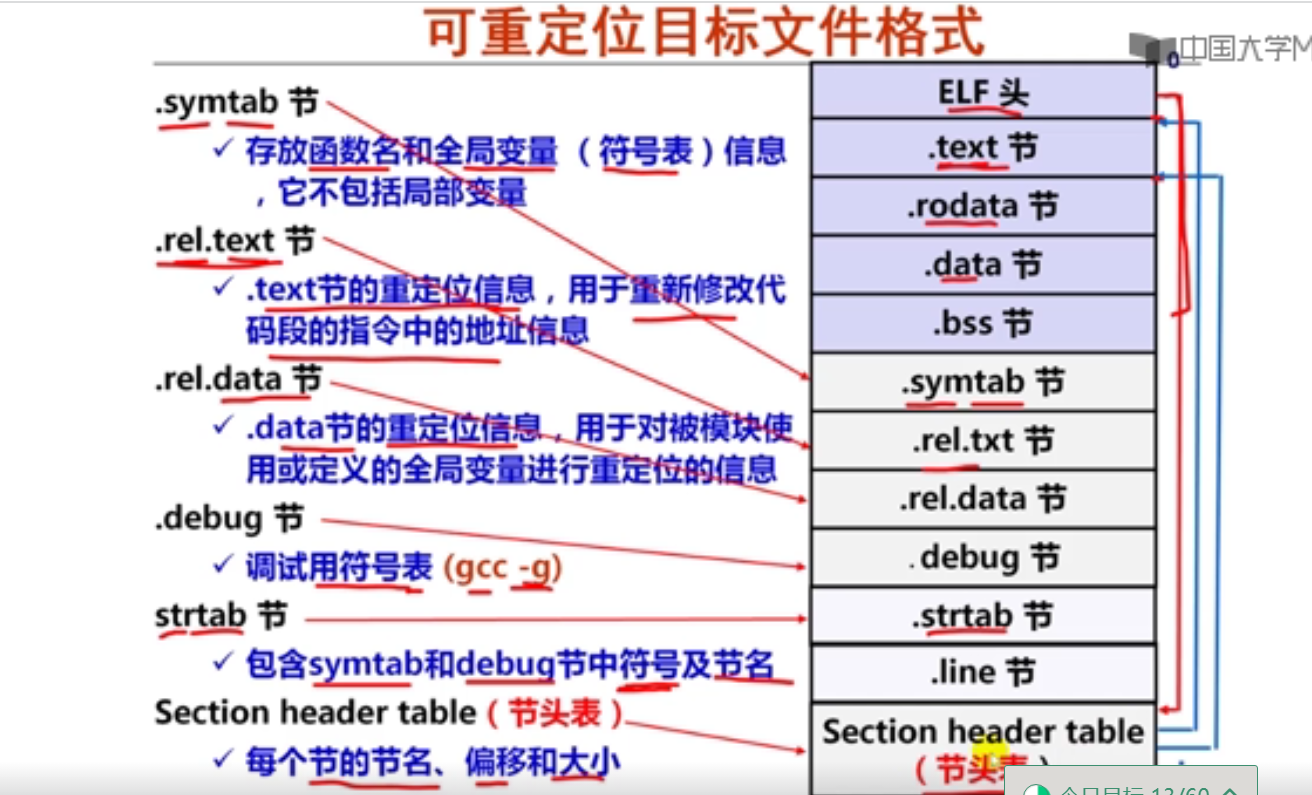
ELF头和节头表(26分钟)
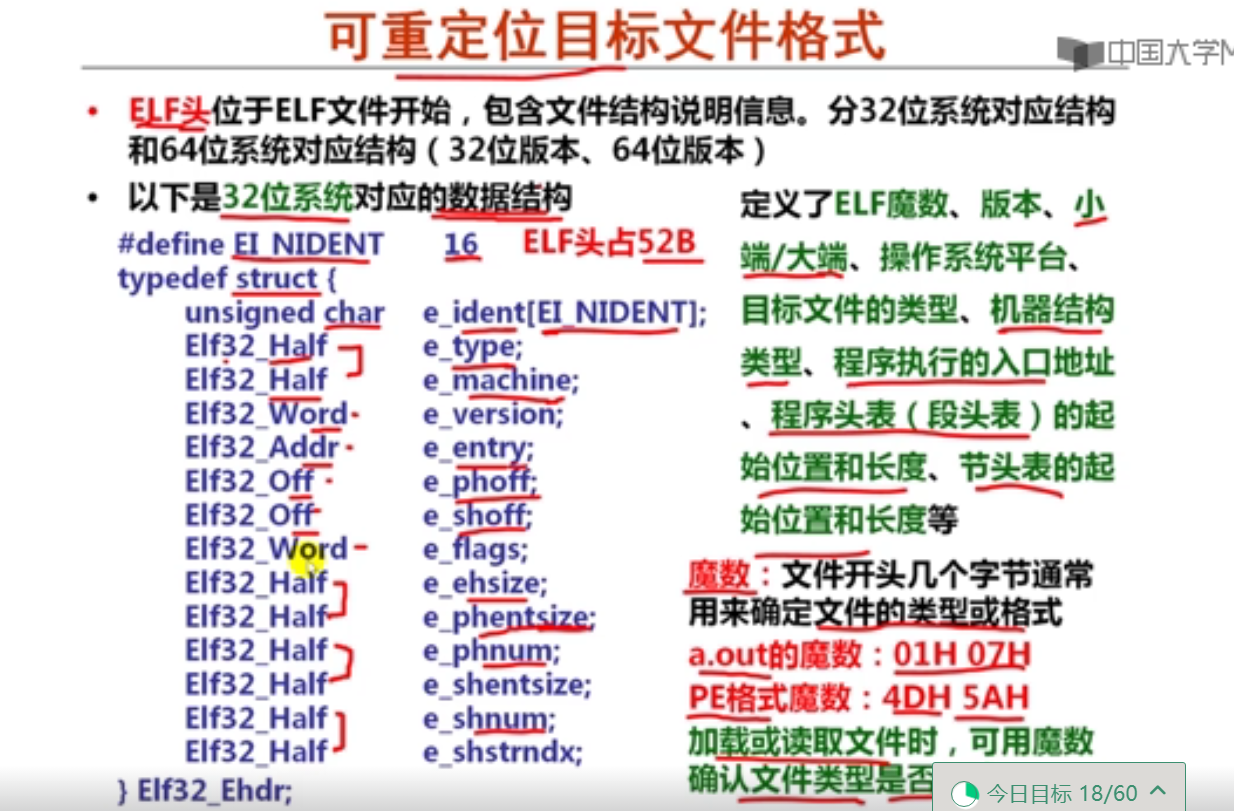

Usage: readelf <option(s)> elf-file(s)
Display information about the contents of ELF format files
Options are:
-a --all Equivalent to: -h -l -S -s -r -d -V -A -I
-h --file-header Display the ELF file header
-l --program-headers Display the program headers
--segments An alias for --program-headers
-S --section-headers Display the sections' header
--sections An alias for --section-headers
-g --section-groups Display the section groups
-t --section-details Display the section details
-e --headers Equivalent to: -h -l -S
-s --syms Display the symbol table
--symbols An alias for --syms
--dyn-syms Display the dynamic symbol table
--lto-syms Display LTO symbol tables
--sym-base=[0|8|10|16]
Force base for symbol sizes. The options are
mixed (the default), octal, decimal, hexadecimal.
-C --demangle[=STYLE] Decode mangled/processed symbol names
STYLE can be "none", "auto", "gnu-v3", "java",
"gnat", "dlang", "rust"
--no-demangle Do not demangle low-level symbol names. (default)
--recurse-limit Enable a demangling recursion limit. (default)
--no-recurse-limit Disable a demangling recursion limit
-U[dlexhi] --unicode=[default|locale|escape|hex|highlight|invalid]
Display unicode characters as determined by the current locale
(default), escape sequences, "<hex sequences>", highlighted
escape sequences, or treat them as invalid and display as
"{hex sequences}"
-n --notes Display the core notes (if present)
-r --relocs Display the relocations (if present)
-u --unwind Display the unwind info (if present)
-d --dynamic Display the dynamic section (if present)
-V --version-info Display the version sections (if present)
-A --arch-specific Display architecture specific information (if any)
-c --archive-index Display the symbol/file index in an archive
-D --use-dynamic Use the dynamic section info when displaying symbols
-L --lint|--enable-checks
Display warning messages for possible problems
-x --hex-dump=<number|name>
Dump the contents of section <number|name> as bytes
-p --string-dump=<number|name>
Dump the contents of section <number|name> as strings
-R --relocated-dump=<number|name>
Dump the relocated contents of section <number|name>
-z --decompress Decompress section before dumping it
-w --debug-dump[a/=abbrev, A/=addr, r/=aranges, c/=cu_index, L/=decodedline,
f/=frames, F/=frames-interp, g/=gdb_index, i/=info, o/=loc,
m/=macro, p/=pubnames, t/=pubtypes, R/=Ranges, l/=rawline,
s/=str, O/=str-offsets, u/=trace_abbrev, T/=trace_aranges,
U/=trace_info]
Display the contents of DWARF debug sections
-wk --debug-dump=links Display the contents of sections that link to separate
debuginfo files
-P --process-links Display the contents of non-debug sections in separate
debuginfo files. (Implies -wK)
-wK --debug-dump=follow-links
Follow links to separate debug info files (default)
-wN --debug-dump=no-follow-links
Do not follow links to separate debug info files
--dwarf-depth=N Do not display DIEs at depth N or greater
--dwarf-start=N Display DIEs starting at offset N
--ctf=<number|name> Display CTF info from section <number|name>
--ctf-parent=<name> Use CTF archive member <name> as the CTF parent
--ctf-symbols=<number|name>
Use section <number|name> as the CTF external symtab
--ctf-strings=<number|name>
Use section <number|name> as the CTF external strtab
--sframe[=NAME] Display SFrame info from section NAME, (default '.sframe')
-I --histogram Display histogram of bucket list lengths
-W --wide Allow output width to exceed 80 characters
-T --silent-truncation If a symbol name is truncated, do not add [...] suffix
@<file> Read options from <file>
-H --help Display this information
-v --version Display the version number of readelf
#include <stdio.h>
int main()
{
printf("guangfuzhonghua!\n");
return 0;
}
guangwudi@debian:~/csapp$ readelf -h hello.o
ELF Header:
Magic: 7f 45 4c 46 01 01 01 00 00 00 00 00 00 00 00 00
Class: ELF32
Data: 2's complement, little endian
Version: 1 (current)
OS/ABI: UNIX - System V
ABI Version: 0
Type: REL (Relocatable file)
Machine: Intel 80386
Version: 0x1
Entry point address: 0x0
Start of program headers: 0 (bytes into file)
Start of section headers: 660 (bytes into file)
Flags: 0x0
Size of this header: 52 (bytes)
Size of program headers: 0 (bytes)
Number of program headers: 0
Size of section headers: 40 (bytes)
Number of section headers: 15
Section header string table index: 14
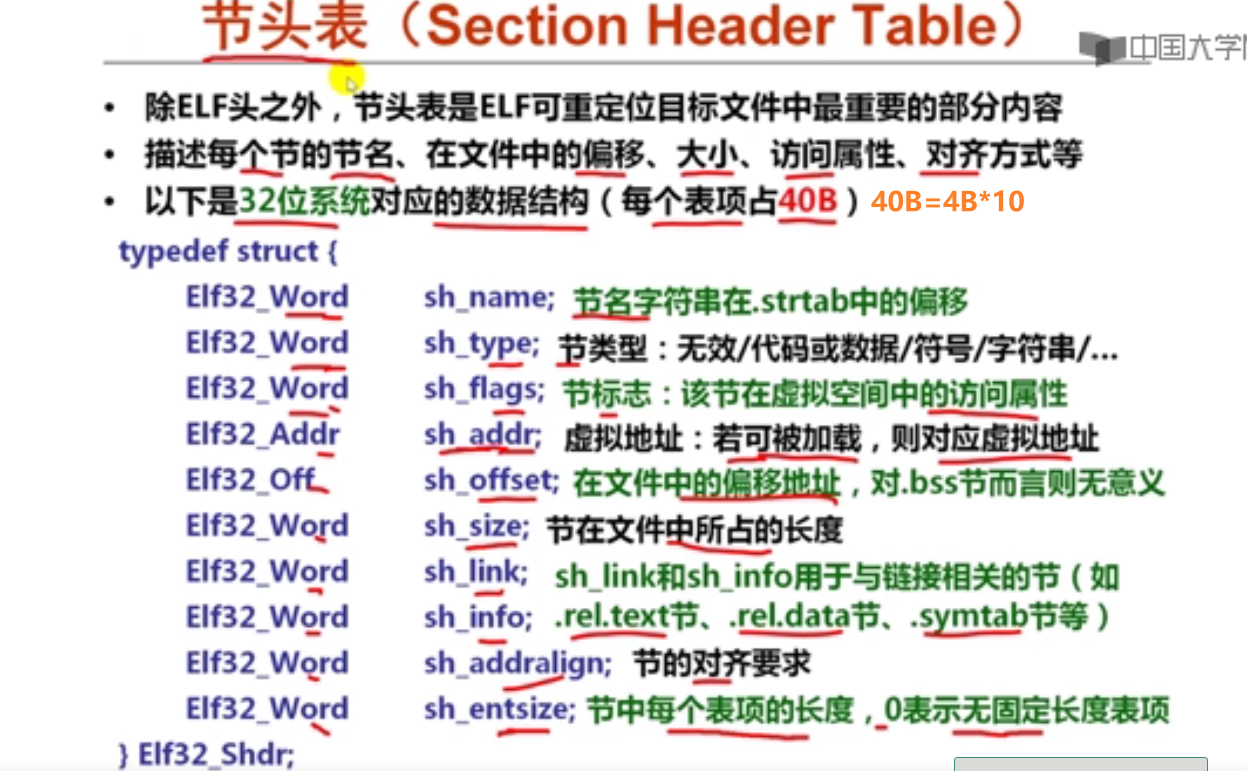
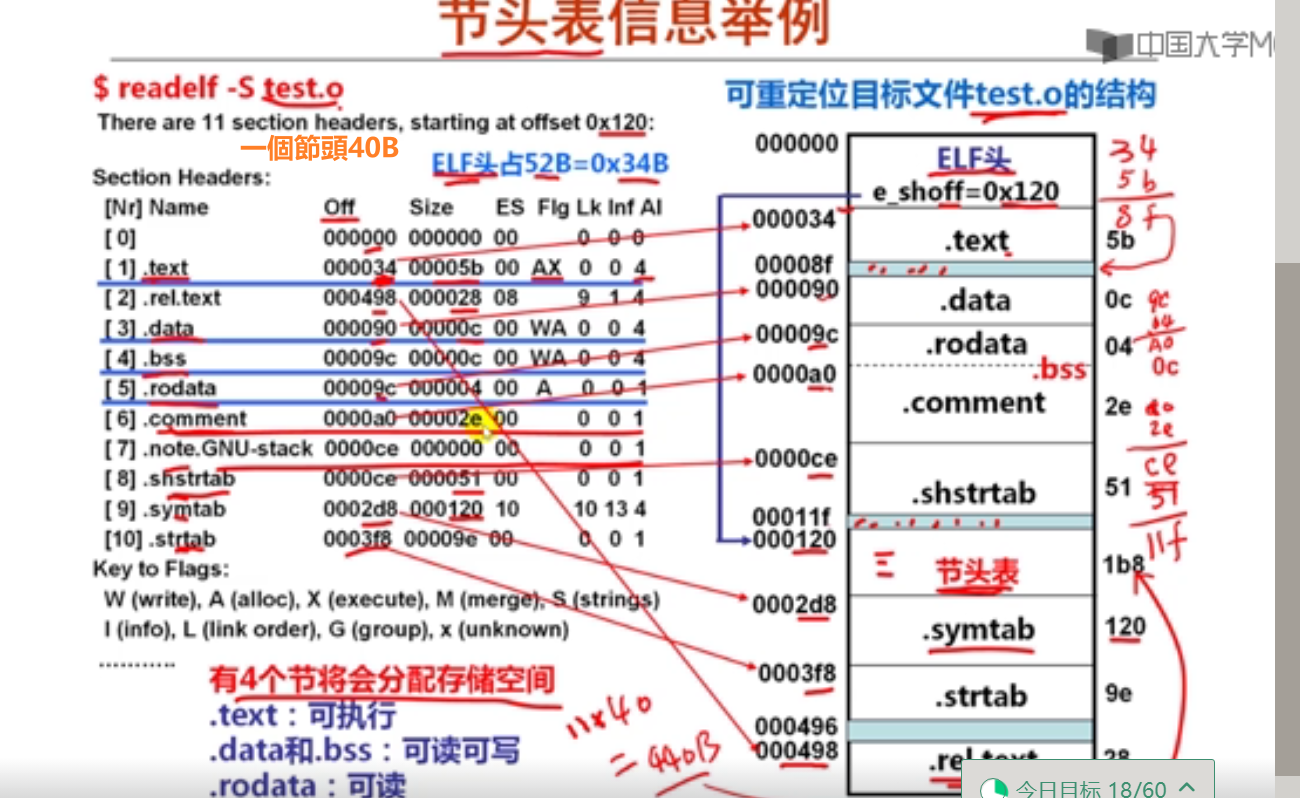
-S輸出節頭表
guangwudi@debian:~/csapp$ readelf -S hello.o
There are 15 section headers, starting at offset 0x294:
Section Headers:
[Nr] Name Type Addr Off Size ES Flg Lk Inf Al
[ 0] NULL 00000000 000000 000000 00 0 0 0
[ 1] .group GROUP 00000000 000034 000008 04 12 6 4
[ 2] .text PROGBITS 00000000 00003c 00003c 00 AX 0 0 1
[ 3] .rel.text REL 00000000 0001e0 000020 08 I 12 2 4
[ 4] .data PROGBITS 00000000 000078 000000 00 WA 0 0 1
[ 5] .bss NOBITS 00000000 000078 000000 00 WA 0 0 1
[ 6] .rodata PROGBITS 00000000 000078 000011 00 A 0 0 1
[ 7] .text.__x86.[...] PROGBITS 00000000 000089 000004 00 AXG 0 0 1
[ 8] .comment PROGBITS 00000000 00008d 000020 01 MS 0 0 1
[ 9] .note.GNU-stack PROGBITS 00000000 0000ad 000000 00 0 0 1
[10] .eh_frame PROGBITS 00000000 0000b0 000060 00 A 0 0 4
[11] .rel.eh_frame REL 00000000 000200 000010 08 I 12 10 4
[12] .symtab SYMTAB 00000000 000110 000090 10 13 5 4
[13] .strtab STRTAB 00000000 0001a0 00003f 00 0 0 1
[14] .shstrtab STRTAB 00000000 000210 000082 00 0 0 1
Key to Flags:
W (write), A (alloc), X (execute), M (merge), S (strings), I (info),
L (link order), O (extra OS processing required), G (group), T (TLS),
C (compressed), x (unknown), o (OS specific), E (exclude),
D (mbind), p (processor specific)
-s輸出符號表
guangwudi@debian:~/csapp$ readelf -s hello.o
Symbol table '.symtab' contains 9 entries:
Num: Value Size Type Bind Vis Ndx Name
0: 00000000 0 NOTYPE LOCAL DEFAULT UND
1: 00000000 0 FILE LOCAL DEFAULT ABS hello.c
2: 00000000 0 SECTION LOCAL DEFAULT 2 .text
3: 00000000 0 SECTION LOCAL DEFAULT 6 .rodata
4: 00000000 0 SECTION LOCAL DEFAULT 7 .text.__x86.get_[...]
5: 00000000 60 FUNC GLOBAL DEFAULT 2 main
6: 00000000 0 FUNC GLOBAL HIDDEN 7 __x86.get_pc_thunk.ax
7: 00000000 0 NOTYPE GLOBAL DEFAULT UND _GLOBAL_OFFSET_TABLE_
8: 00000000 0 NOTYPE GLOBAL DEFAULT UND puts
第4讲 ELF可执行目标文件
可执行文件概述(13分钟)
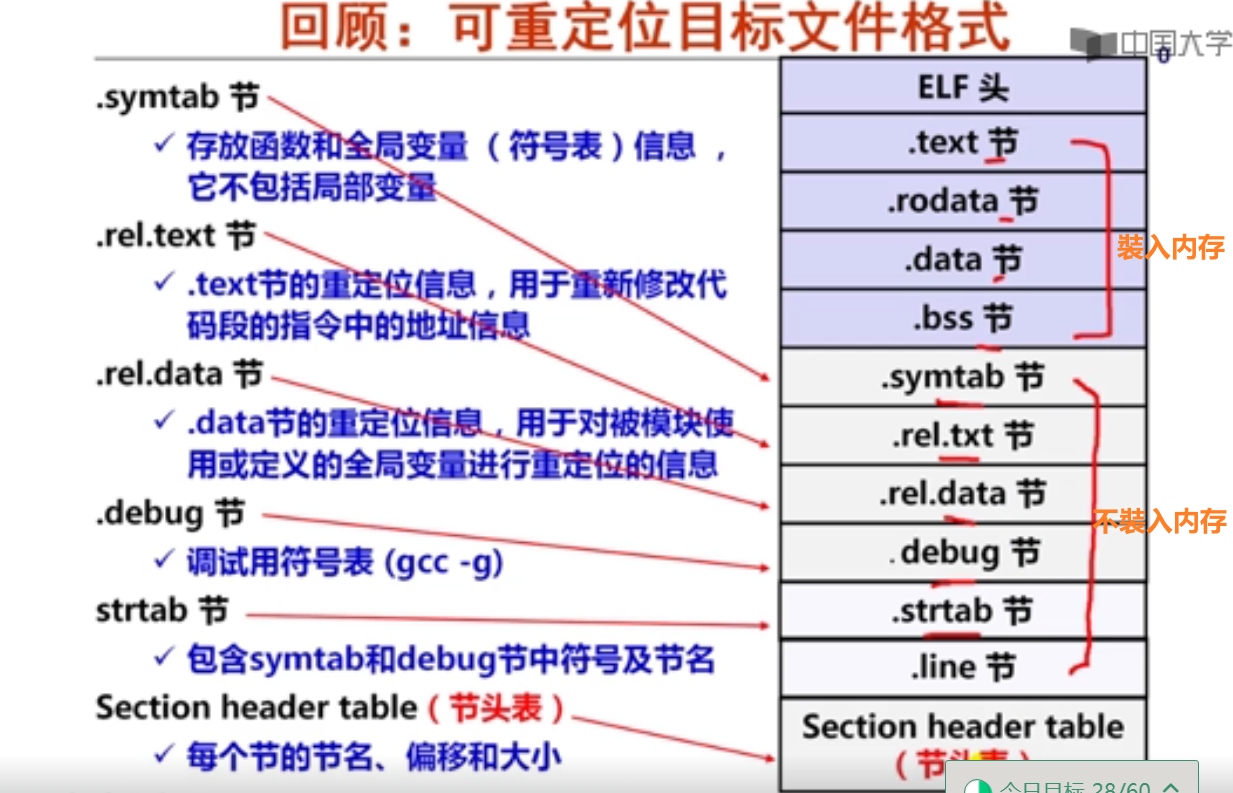
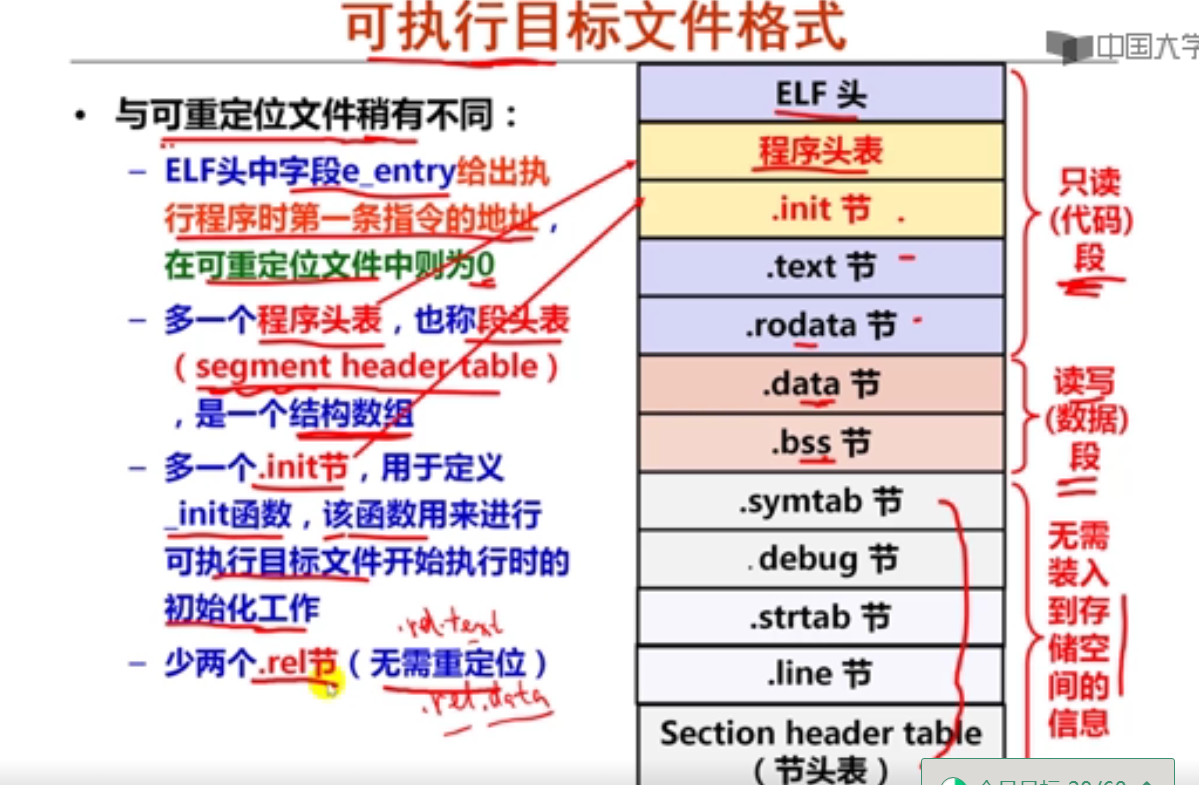

guangwudi@debian:~/csapp$ readelf -h hello
ELF Header:
Magic: 7f 45 4c 46 01 01 01 00 00 00 00 00 00 00 00 00
Class: ELF32
Data: 2's complement, little endian
Version: 1 (current)
OS/ABI: UNIX - System V
ABI Version: 0
Type: DYN (Position-Independent Executable file)
Machine: Intel 80386
Version: 0x1
Entry point address: 0x1060
Start of program headers: 52 (bytes into file)
Start of section headers: 13784 (bytes into file)
Flags: 0x0
Size of this header: 52 (bytes)
Size of program headers: 32 (bytes)
Number of program headers: 11
Size of section headers: 40 (bytes)
Number of section headers: 30
Section header string table index: 29
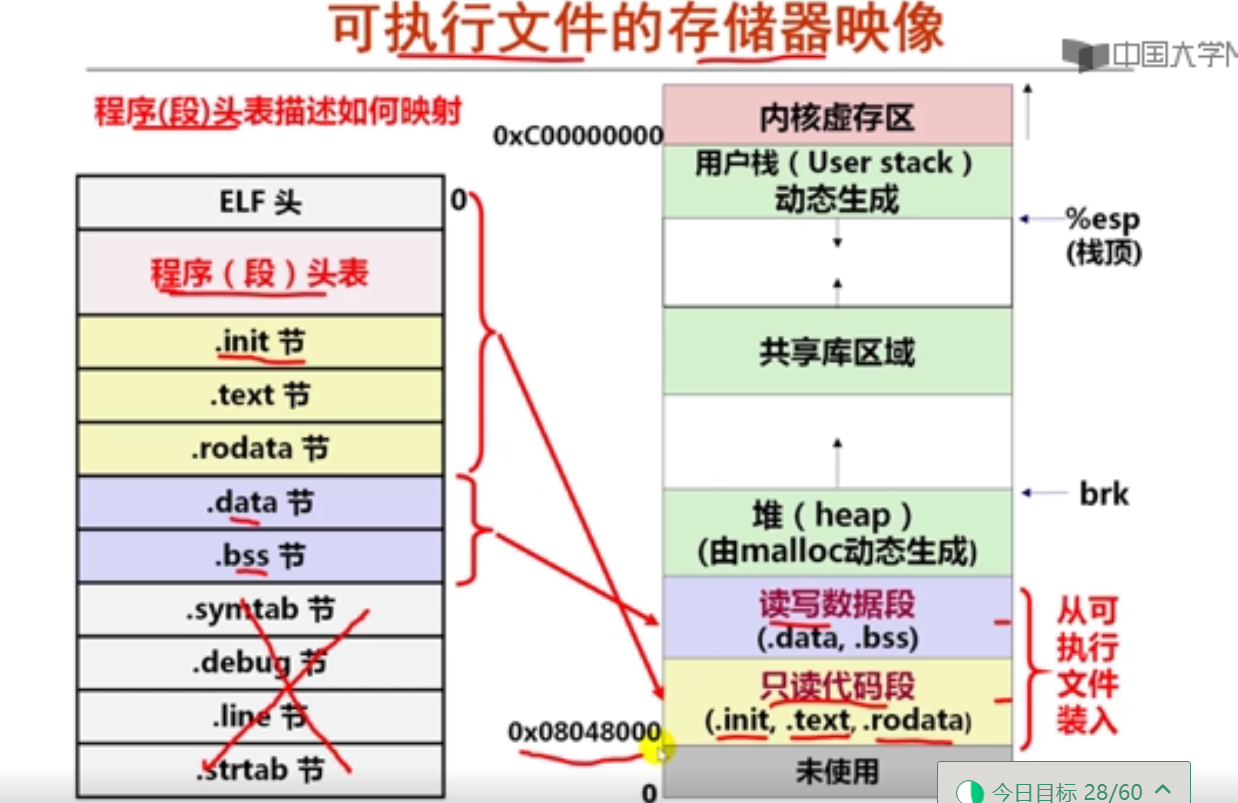
程序头表和存储器映像(21分钟)
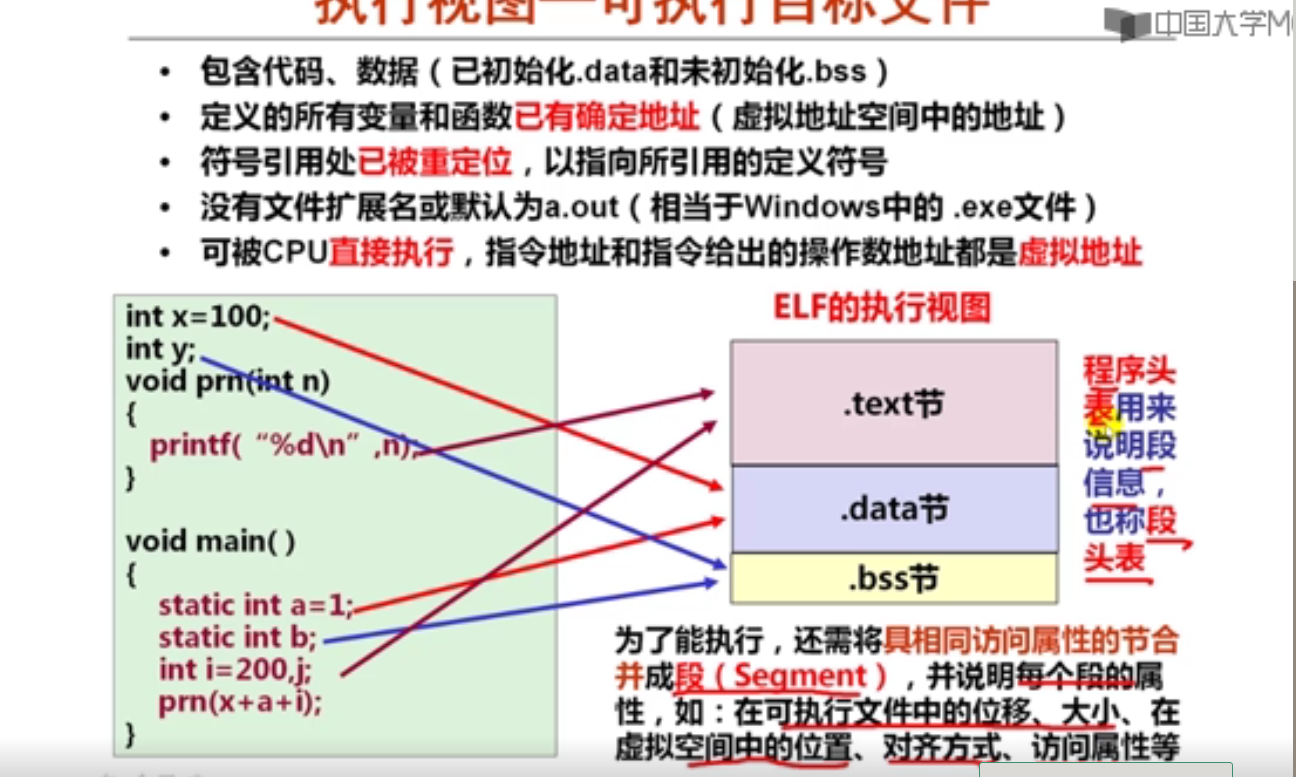
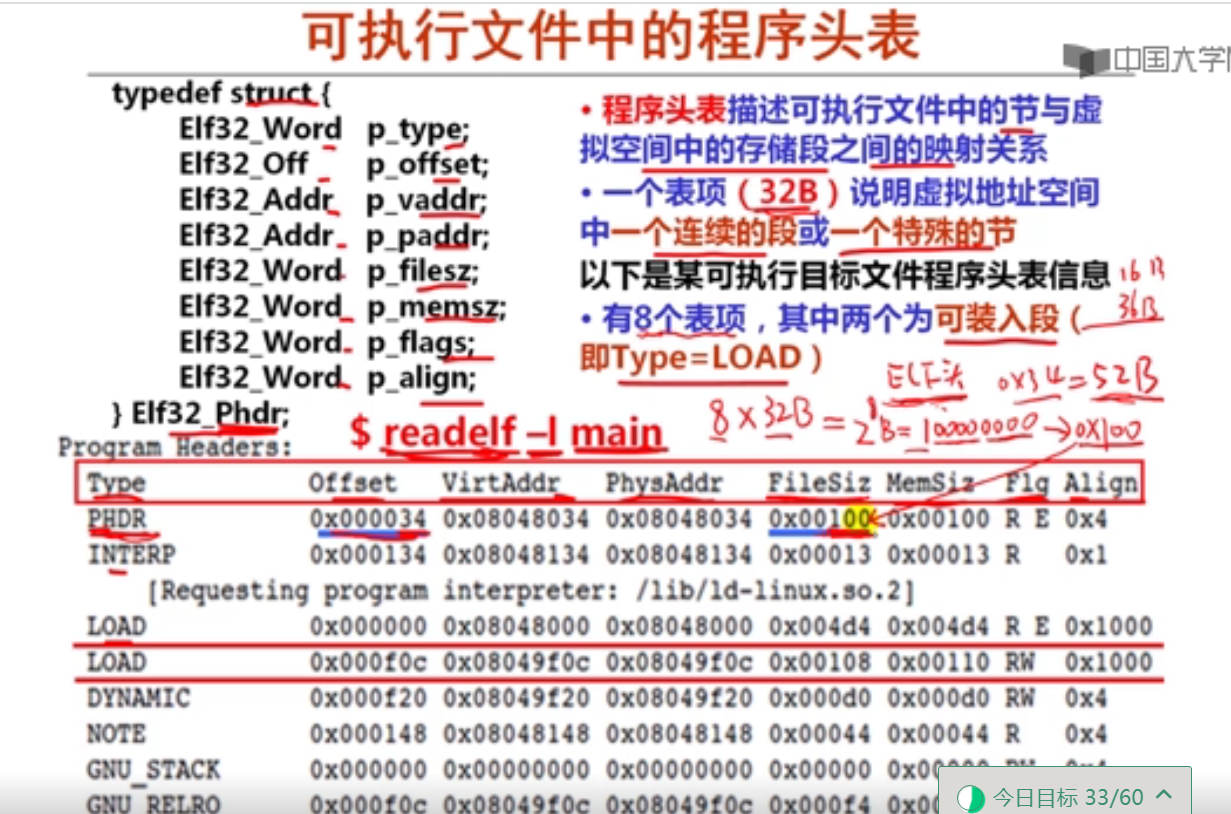
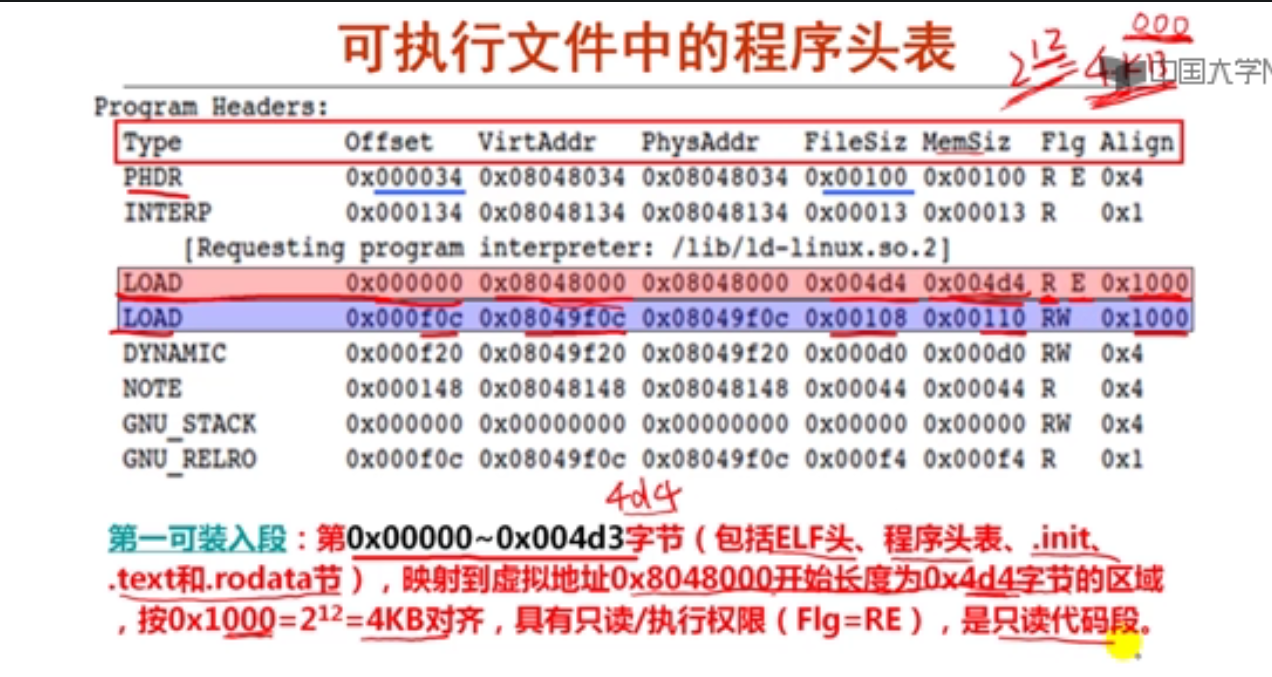
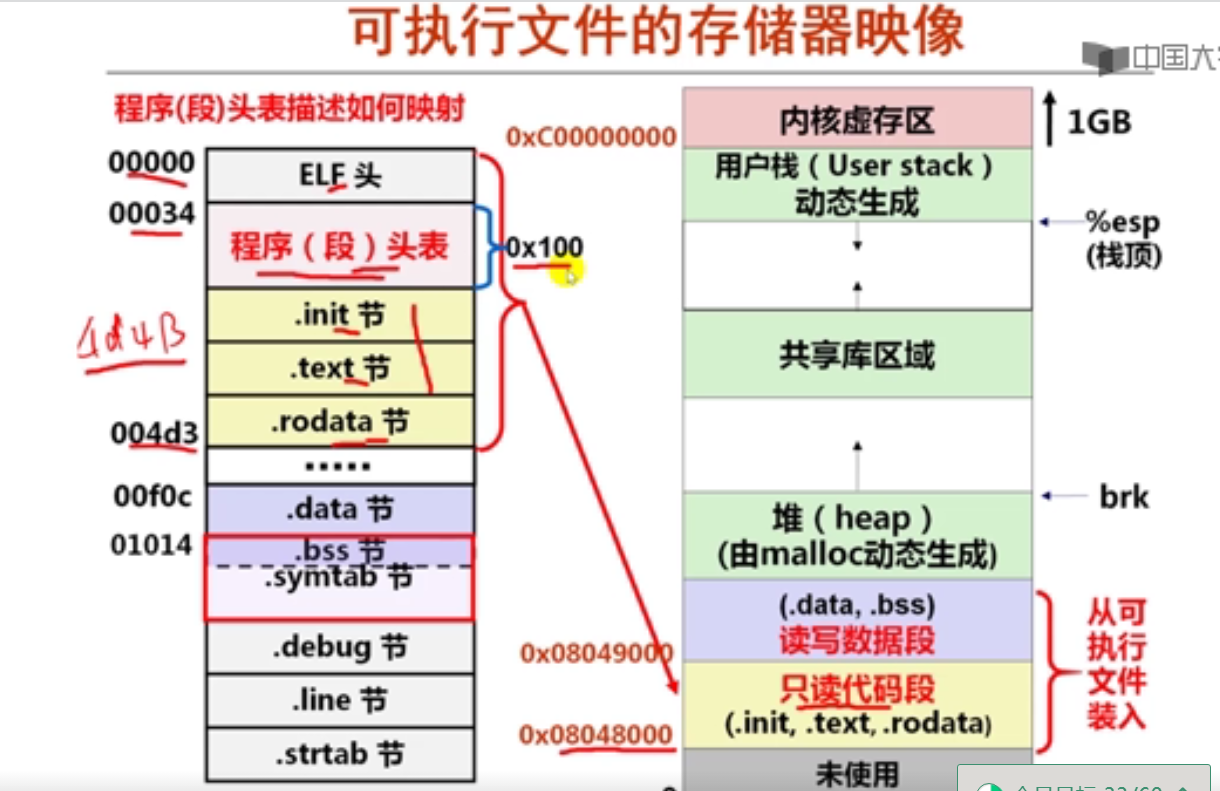
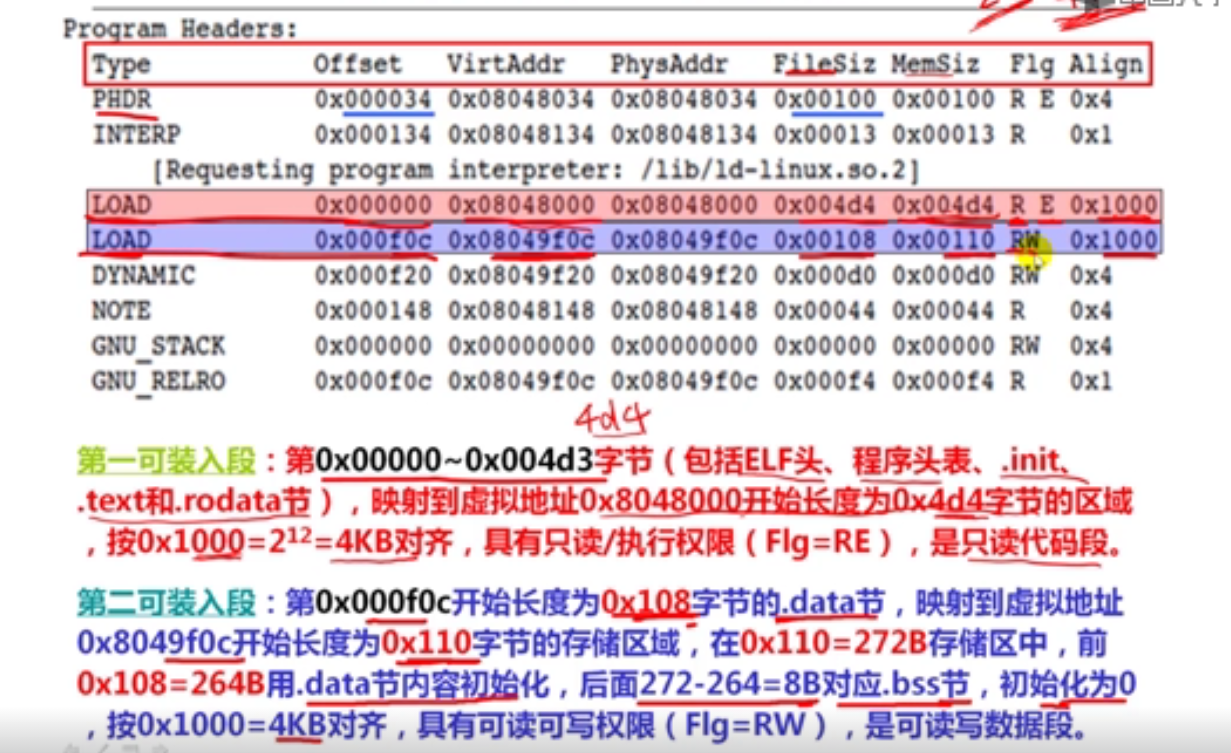
guangwudi@debian:~/csapp$ readelf -l hello
Elf file type is DYN (Position-Independent Executable file)
Entry point 0x1060
There are 11 program headers, starting at offset 52
Program Headers:
Type Offset VirtAddr PhysAddr FileSiz MemSiz Flg Align
PHDR 0x000034 0x00000034 0x00000034 0x00160 0x00160 R 0x4
INTERP 0x000194 0x00000194 0x00000194 0x00013 0x00013 R 0x1
[Requesting program interpreter: /lib/ld-linux.so.2]
LOAD 0x000000 0x00000000 0x00000000 0x003d4 0x003d4 R 0x1000
LOAD 0x001000 0x00001000 0x00001000 0x001e0 0x001e0 R E 0x1000
LOAD 0x002000 0x00002000 0x00002000 0x00118 0x00118 R 0x1000
LOAD 0x002ee8 0x00003ee8 0x00003ee8 0x00128 0x0012c RW 0x1000
DYNAMIC 0x002ef0 0x00003ef0 0x00003ef0 0x000f0 0x000f0 RW 0x4
NOTE 0x0001a8 0x000001a8 0x000001a8 0x00044 0x00044 R 0x4
GNU_EH_FRAME 0x00201c 0x0000201c 0x0000201c 0x00034 0x00034 R 0x4
GNU_STACK 0x000000 0x00000000 0x00000000 0x00000 0x00000 RW 0x10
GNU_RELRO 0x002ee8 0x00003ee8 0x00003ee8 0x00118 0x00118 R 0x1
Section to Segment mapping:
Segment Sections...
00
01 .interp
02 .interp .note.gnu.build-id .note.ABI-tag .gnu.hash .dynsym .dynstr .gnu.version .gnu.version_r .rel.dyn .rel.plt
03 .init .plt .plt.got .text .fini
04 .rodata .eh_frame_hdr .eh_frame
05 .init_array .fini_array .dynamic .got .got.plt .data .bss
06 .dynamic
07 .note.gnu.build-id .note.ABI-tag
08 .eh_frame_hdr
09
10 .init_array .fini_array .dynamic .got
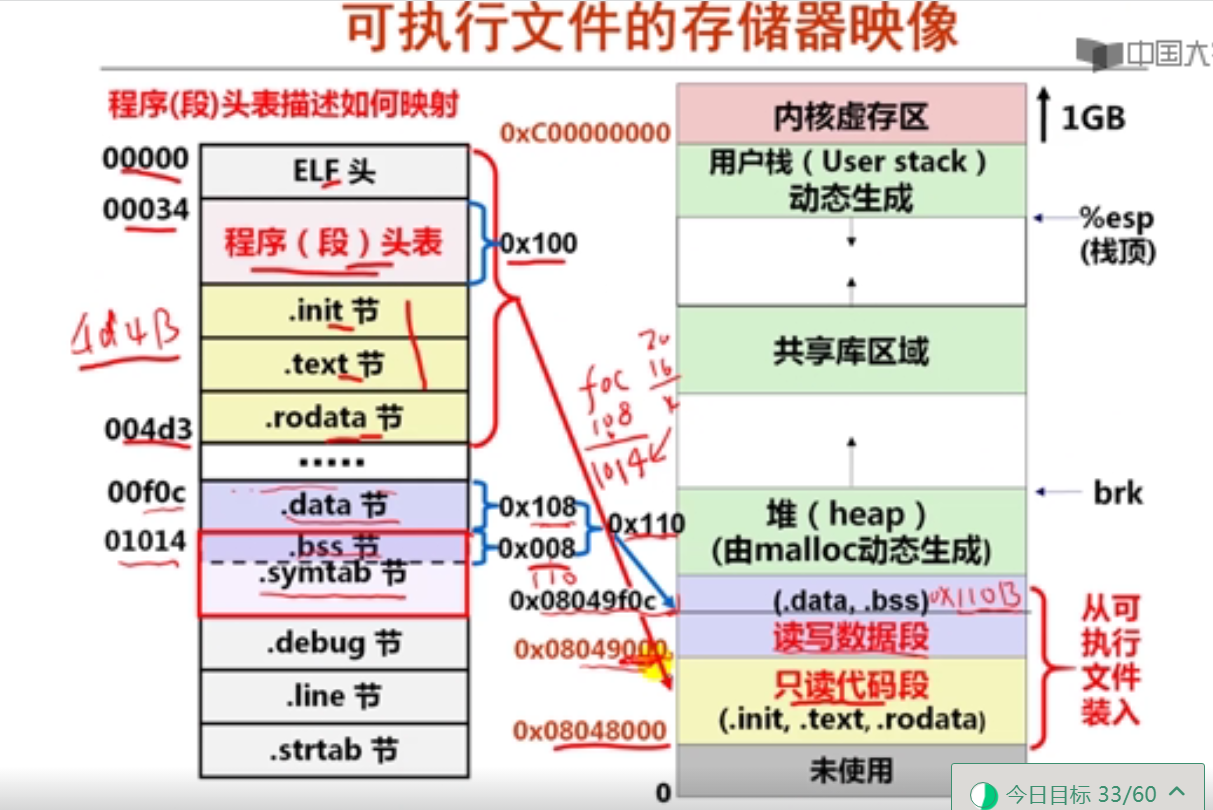
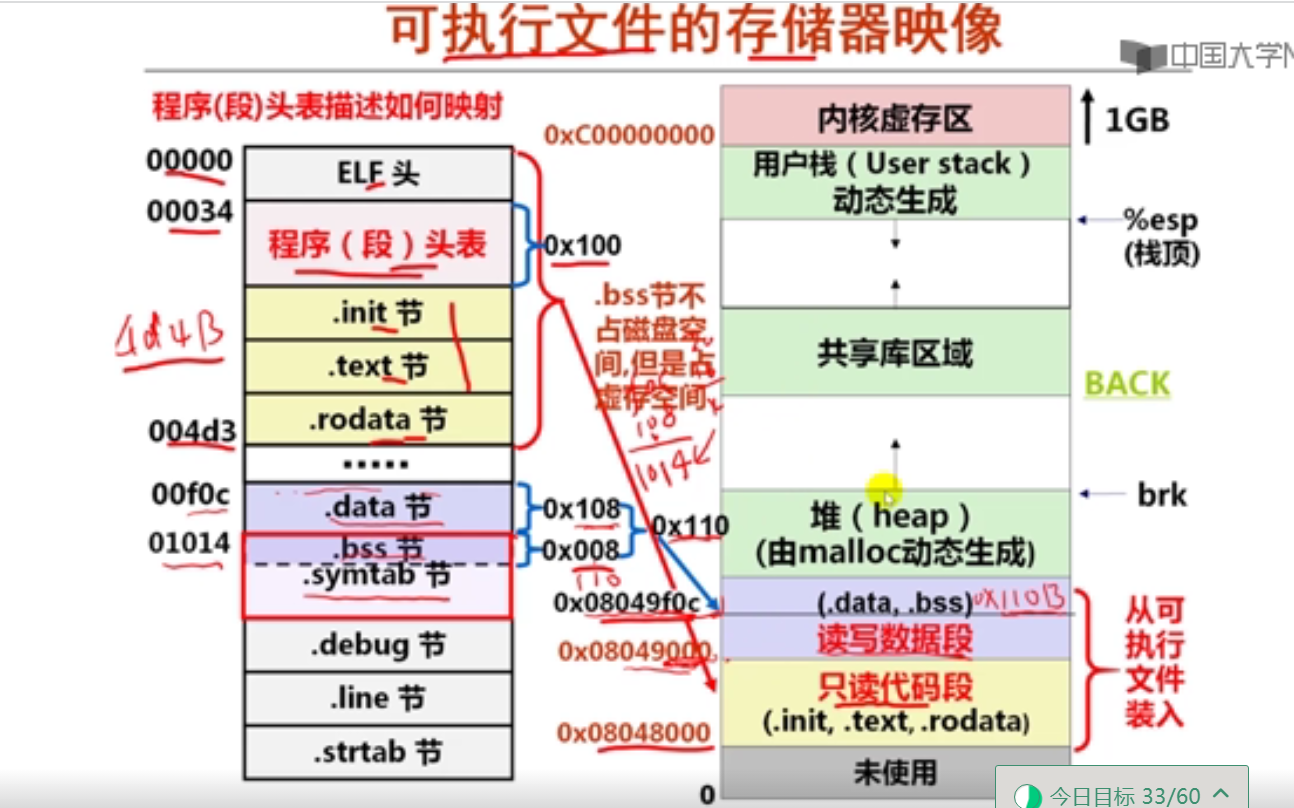
第十周小测验
1以下是有关使用GCC生成C语言程序的可执行文件的叙述,其中错误的是(D )。
A.第三步汇编,将汇编语言代码汇编转换为机器指令表示的机器语言代码
B.第四步链接,将多个模块的机器语言代码链接生成可执行目标程序文件
C.第一步预处理,对#include、#define、#ifdef等预处理命令进行处理
D.第二步编译,将预处理结果编译转换为二进制形式的汇编语言程序代码
解釋:第二步编译,将预处理结果编译转换为文本形式的汇编语言程序代码
2以下是有关使用GCC生成C语言程序的可执行文件的叙述,其中错误的是(B )。
A.预处理的结果还是一个C语言源程序文件,属于可读的文本文件
B.只要在链接命令中指定所有的相关可重定位目标文件就能生成可执行文件
C.经过预处理、编译和汇编处理的结果是一个可重定位目标文件
D.每个C语言源程序文件生成一个对应的可重定位目标文件
解释:只要……就……
3以下是有关链接所带来的好处和不足的叙述,错误的是( A )。
A.使得所生成的可执行目标代码中包含了更多公共库函数代码,所占空间大
B.使得公共函数库可以为所有程序共享使用,有利于代码重用和提高效率
C.使得程序员仅需重新编译修改过的源程序模块,从而节省程序开发时间
D.使得程序员可以分模块开发程序,有利于提高大规模程序的开发效率
解释:所生成的可执行目标代码不包含公共库函数代码
4以下关于ELF目标文件格式的叙述中,错误的是( D )。
A.可重定位和可执行两种目标文件中的代码都是二进制表示的指令形式
B.可执行目标文件是ELF格式的执行视图,由不同的段组成
C.可重定位目标文件是ELF格式的链接视图,由不同的节组成
D.可重定位和可执行两种目标文件中的数据都是二进制表示的补码形式
解释:可重定位和可执行两种目标文件中的数据都是十六进制表示的补码形式
5以下关于链接器基本功能的叙述中,错误的是( C )。
A.将每个.o文件中的.data节、.text节和.bss节合并
B.根据所定义符号的首地址对符号的引用进行重定位
C.确定每个符号(包括全局变量和局部变量)的首地址
D.将每个符号引用与唯一的一个符号定义进行关联
解释:局部变量不属于符号定义
6以下关于可重定位目标文件的叙述中,错误的是( B )。
A.在.rodata节中包含相应模块内所有只读数据
B.在.data节中包含相应模块内所有变量的初始值
C.在.rel.text节和.rel.data节中包含相应模块内所有可重定位信息
D.在.text节中包含相应模块内所有机器代码
解释:.data节只包括已初始化的全局变量或静态局部变量,不包括已初始化的非静态局部变量和未初始化的变量。
7以下关于ELF目标文件的ELF头的叙述中,错误的是( D )。
A.数据结构在可重定位和可执行两种目标文件中完全一样
B.包含了节头表和程序头表各自的起始位置和长度
C.包含了操作系统版本和机器结构类型等信息
D.包含了ELF头本身的长度和目标文件的长度
解释:不包含目标文件的长度
8以下关于ELF目标文件的节头表的叙述中,错误的是( B )。
A.通过节头表可获得节的名称、类型、起始地址和长度
B.每个表项用来记录某个节的内容以及相关描述信息
C.数据结构在可重定位和可执行两种目标文件中完全一样
D.描述了每个可装入节的起始虚拟地址、对齐和存取方式
解释:没有记录某个节的内容
9以下关于ELF可重定位和可执行两种目标文件格式比较的叙述中,错误的是( B )。
A.可执行目标文件的ELF头中有具体程序入口地址,而在可重定位目标文件中则为0
B.可重定位目标文件中有初始化程序段.init节,而在可执行目标文件中则没有
C.可执行目标文件中有程序头表(段头表),而在可重定位目标文件中则没有
D.可重定位目标文件中有可重定位节.rel.text和.rel.data,而在可执行目标文件中则没有
解释:可执行目标文件中有初始化程序段.init节,而可重定位目标文件中没有
10以下关于ELF可执行目标文件的程序头表(段头表)的叙述中,错误的是( C )。
A..text节和.rodata节都包含在只读代码段,而.data节和.bss节都包含在读写数据段
B.通过段头表可获得可装入段或特殊段的类型、在文件中的偏移位置及长度
C.用于描述可执行文件中的节与主存中的存储段之间的映射关系
D.描述了每个可装入段的起始虚拟地址、存储长度、存取方式和对齐方式
解释:ELF可执行目标文件的程序头表(段头表)用于描述可执行文件中的节与虚拟空间中的存储段之间的映射关系
第十一周符号及符号解析
第1讲 符号及符号表
符号和符号表的基本概念(27分钟)
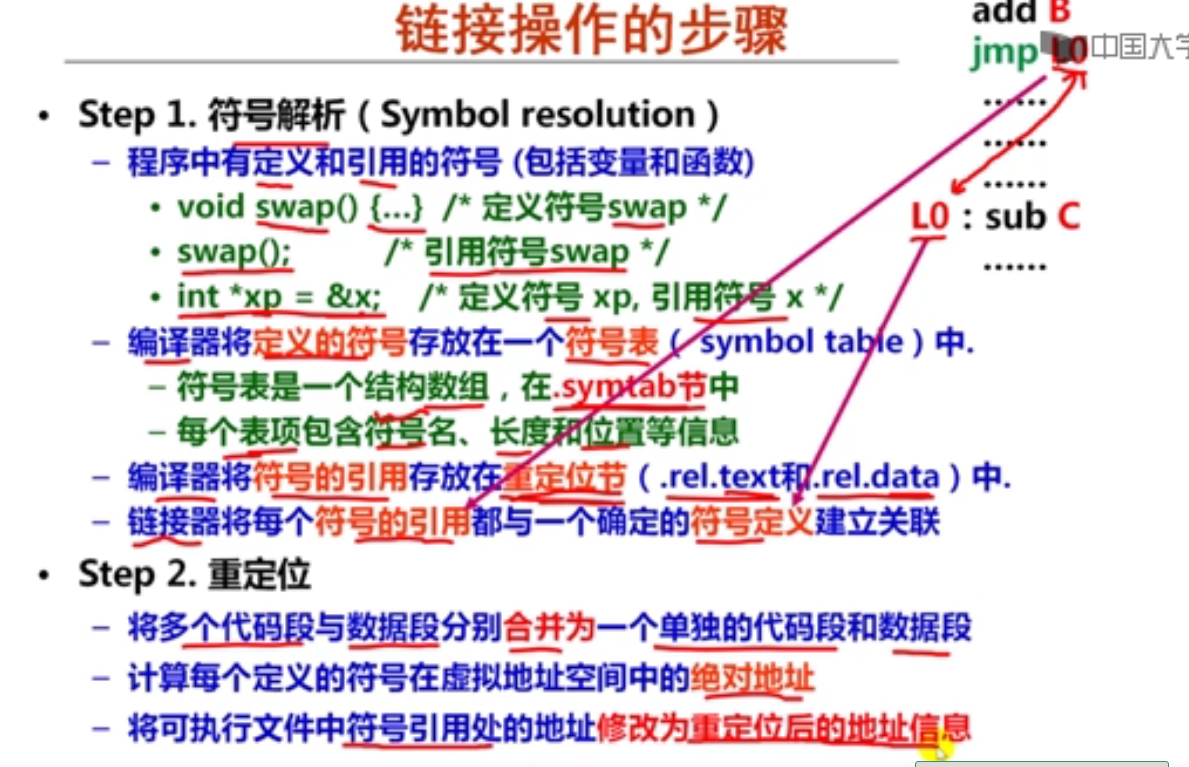
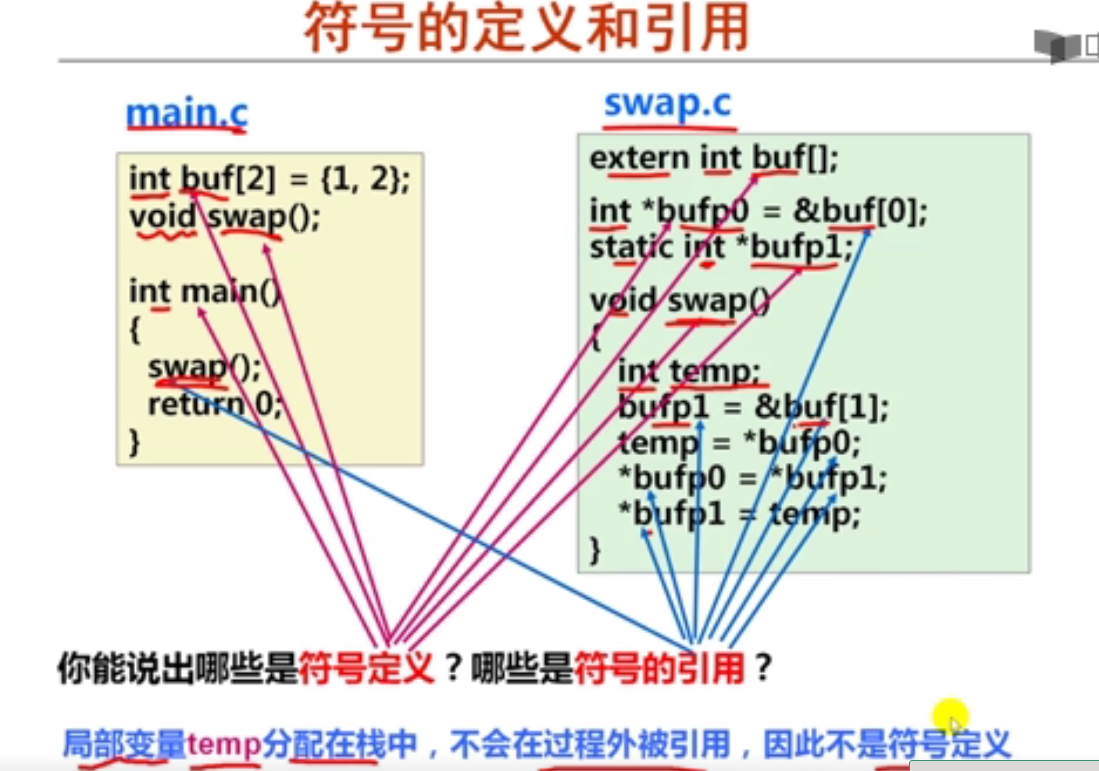

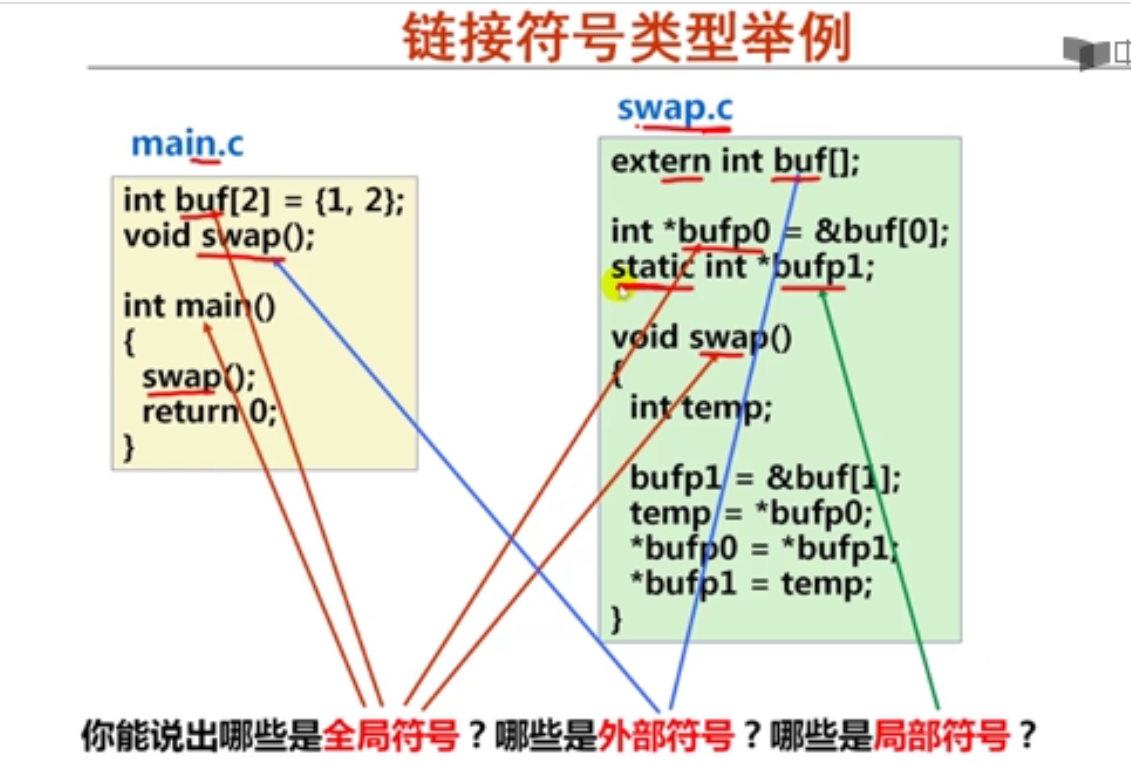

main.c文件内容如下:
int buf[2] = {1,2};
void swap();
int main()
{
swap();
return 0;
}
swap.c文件内容如下:
extern int buf[];
int *bufp0 = &buf[0];
static int *bufp1;
void swap()
{
int temp;
bufp1 = &buf[1];
temp = *bufp0;
*bufp0 = *bufp1;
*bufp1 = temp;
}
guangwudi@debian:~/csapp$ readelf -s p
Symbol table '.dynsym' contains 7 entries:
Num: Value Size Type Bind Vis Ndx Name
0: 00000000 0 NOTYPE LOCAL DEFAULT UND
1: 00000000 0 FUNC GLOBAL DEFAULT UND _[...]@GLIBC_2.34 (2)
2: 00000000 0 NOTYPE WEAK DEFAULT UND _ITM_deregisterT[...]
3: 00000000 0 FUNC WEAK DEFAULT UND [...]@GLIBC_2.1.3 (3)
4: 00000000 0 NOTYPE WEAK DEFAULT UND __gmon_start__
5: 00000000 0 NOTYPE WEAK DEFAULT UND _ITM_registerTMC[...]
6: 00002004 4 OBJECT GLOBAL DEFAULT 16 _IO_stdin_used
Symbol table '.symtab' contains 43 entries:
Num: Value Size Type Bind Vis Ndx Name
0: 00000000 0 NOTYPE LOCAL DEFAULT UND
1: 00000000 0 FILE LOCAL DEFAULT ABS Scrt1.o
2: 000001cc 32 OBJECT LOCAL DEFAULT 3 __abi_tag
3: 00000000 0 FILE LOCAL DEFAULT ABS main.c
4: 00000000 0 FILE LOCAL DEFAULT ABS crtstuff.c
5: 000010b0 0 FUNC LOCAL DEFAULT 14 deregister_tm_clones
6: 000010f0 0 FUNC LOCAL DEFAULT 14 register_tm_clones
7: 00001140 0 FUNC LOCAL DEFAULT 14 __do_global_dtors_aux
8: 00004018 1 OBJECT LOCAL DEFAULT 25 completed.0
9: 00003eec 0 OBJECT LOCAL DEFAULT 20 __do_global_dtor[...]
10: 00001190 0 FUNC LOCAL DEFAULT 14 frame_dummy
11: 00003ee8 0 OBJECT LOCAL DEFAULT 19 __frame_dummy_in[...]
12: 00000000 0 FILE LOCAL DEFAULT ABS swap.c
13: 00000000 0 FILE LOCAL DEFAULT ABS crtstuff.c
14: 00002114 0 OBJECT LOCAL DEFAULT 18 __FRAME_END__
15: 00000000 0 FILE LOCAL DEFAULT ABS
16: 00003ef0 0 OBJECT LOCAL DEFAULT 21 _DYNAMIC
17: 00002008 0 NOTYPE LOCAL DEFAULT 17 __GNU_EH_FRAME_HDR
18: 00003ff4 0 OBJECT LOCAL DEFAULT 23 _GLOBAL_OFFSET_TABLE_
19: 00000000 0 FUNC GLOBAL DEFAULT UND __libc_start_mai[...]
20: 00000000 0 NOTYPE WEAK DEFAULT UND _ITM_deregisterT[...]
21: 000010a0 4 FUNC GLOBAL HIDDEN 14 __x86.get_pc_thunk.bx
22: 00004004 0 NOTYPE WEAK DEFAULT 24 data_start
23: 00004018 0 NOTYPE GLOBAL DEFAULT 24 _edata
24: 000011c8 0 FUNC GLOBAL HIDDEN 15 _fini
25: 00001195 0 FUNC GLOBAL HIDDEN 14 __x86.get_pc_thunk.dx
26: 00000000 0 FUNC WEAK DEFAULT UND __cxa_finalize@G[...]
27: 00004004 0 NOTYPE GLOBAL DEFAULT 24 __data_start
28: 00004014 4 OBJECT GLOBAL DEFAULT 24 bufp0
29: 00000000 0 NOTYPE WEAK DEFAULT UND __gmon_start__
30: 00004008 0 OBJECT GLOBAL HIDDEN 24 __dso_handle
31: 00002004 4 OBJECT GLOBAL DEFAULT 16 _IO_stdin_used
32: 0000401c 0 NOTYPE GLOBAL DEFAULT 25 _end
33: 00001070 44 FUNC GLOBAL DEFAULT 14 _start
34: 00002000 4 OBJECT GLOBAL DEFAULT 16 _fp_hw
35: 0000400c 8 OBJECT GLOBAL DEFAULT 24 buf
36: 00004018 0 NOTYPE GLOBAL DEFAULT 25 __bss_start
37: 00001050 30 FUNC GLOBAL DEFAULT 14 main
38: 000011c3 0 FUNC GLOBAL HIDDEN 14 __x86.get_pc_thunk.ax
39: 00004018 0 OBJECT GLOBAL HIDDEN 24 __TMC_END__
40: 00000000 0 NOTYPE WEAK DEFAULT UND _ITM_registerTMC[...]
41: 000011a0 35 FUNC GLOBAL DEFAULT 14 swap
42: 00001000 0 FUNC GLOBAL HIDDEN 11 _init
guangwudi@debian:~/csapp$ readelf -s hello.o
Symbol table '.symtab' contains 9 entries:
Num: Value Size Type Bind Vis Ndx Name
0: 00000000 0 NOTYPE LOCAL DEFAULT UND
1: 00000000 0 FILE LOCAL DEFAULT ABS hello.c
2: 00000000 0 SECTION LOCAL DEFAULT 2 .text
3: 00000000 0 SECTION LOCAL DEFAULT 6 .rodata
4: 00000000 0 SECTION LOCAL DEFAULT 7 .text.__x86.get_[...]
5: 00000000 60 FUNC GLOBAL DEFAULT 2 main
6: 00000000 0 FUNC GLOBAL HIDDEN 7 __x86.get_pc_thunk.ax
7: 00000000 0 NOTYPE GLOBAL DEFAULT UND _GLOBAL_OFFSET_TABLE_
8: 00000000 0 NOTYPE GLOBAL DEFAULT UND puts
使用nm obj_file列出目標文件obj_file的符號表
guangwudi@debian:~/csapp$ nm hello.o
U _GLOBAL_OFFSET_TABLE_
00000000 T main
U puts
00000000 T __x86.get_pc_thunk.ax
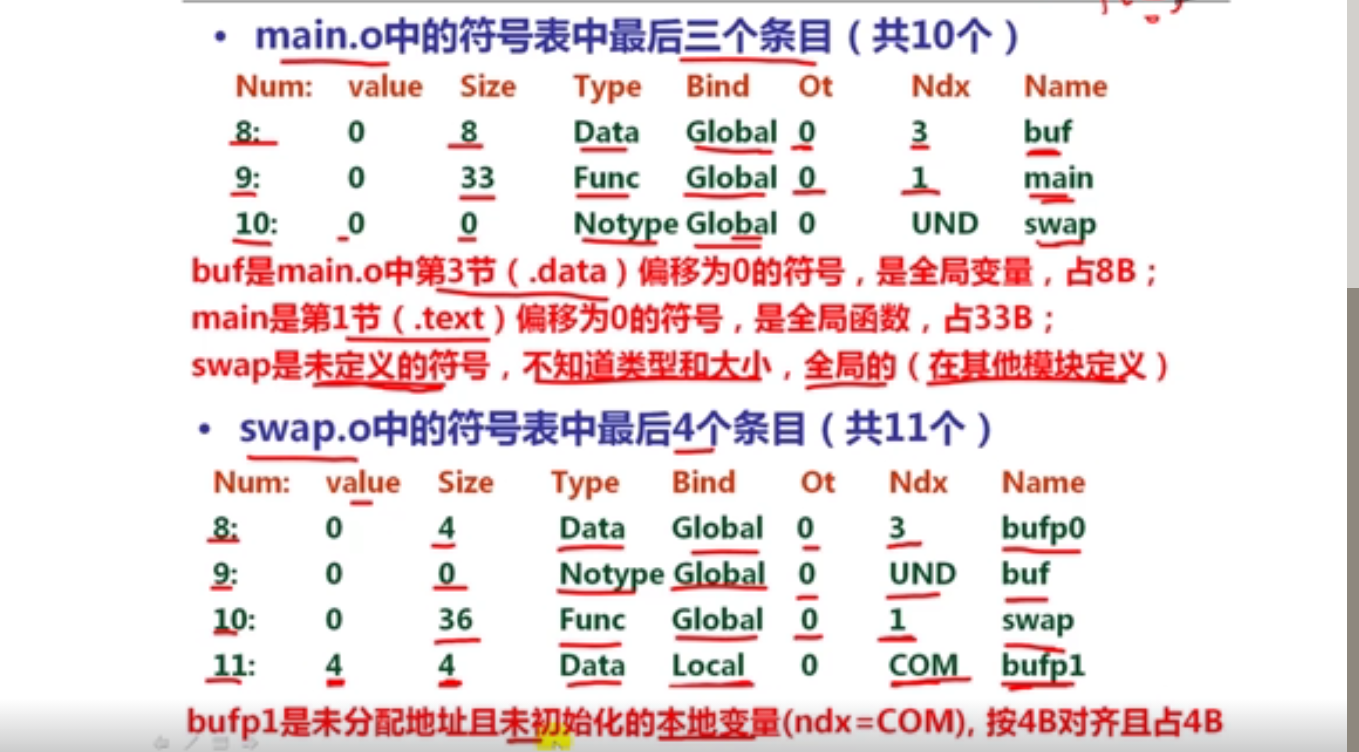
这里提到偏移量是0时,在“Ot”属性下的“0”处划了红线。这里老师把“Ot”看成了“of”,想当然认为是offset,表示偏移量,实际上应该是“Other”属性。正确的做法应该是在( value )属性下的取值处划线呢?
全局符号的强弱特性(8分钟)

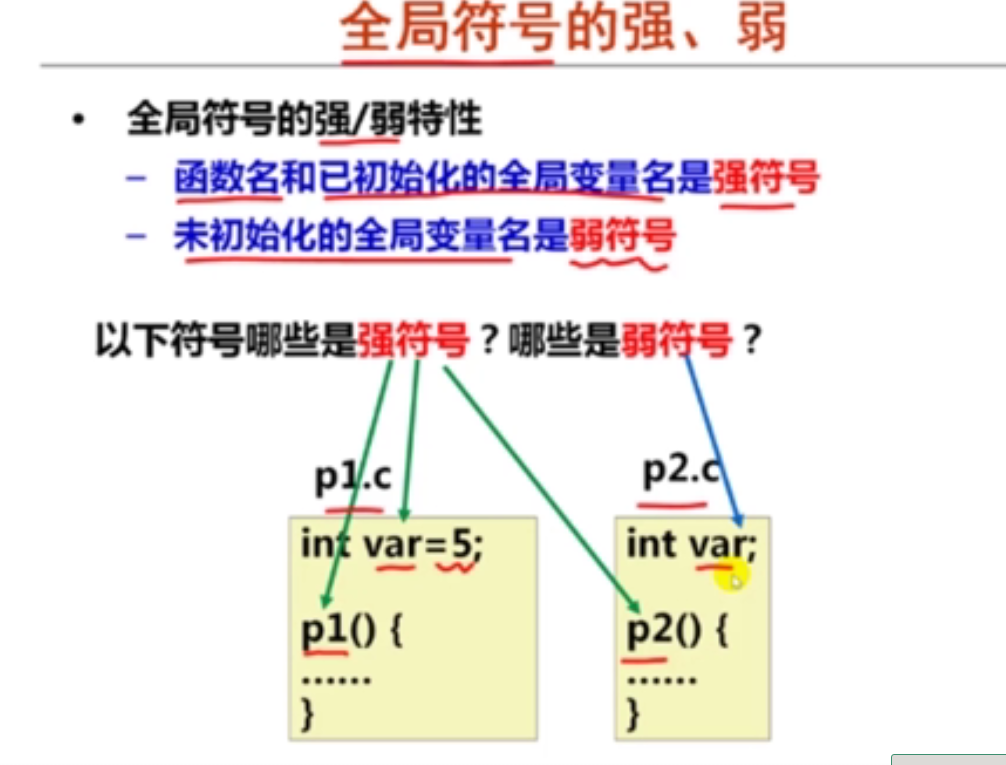
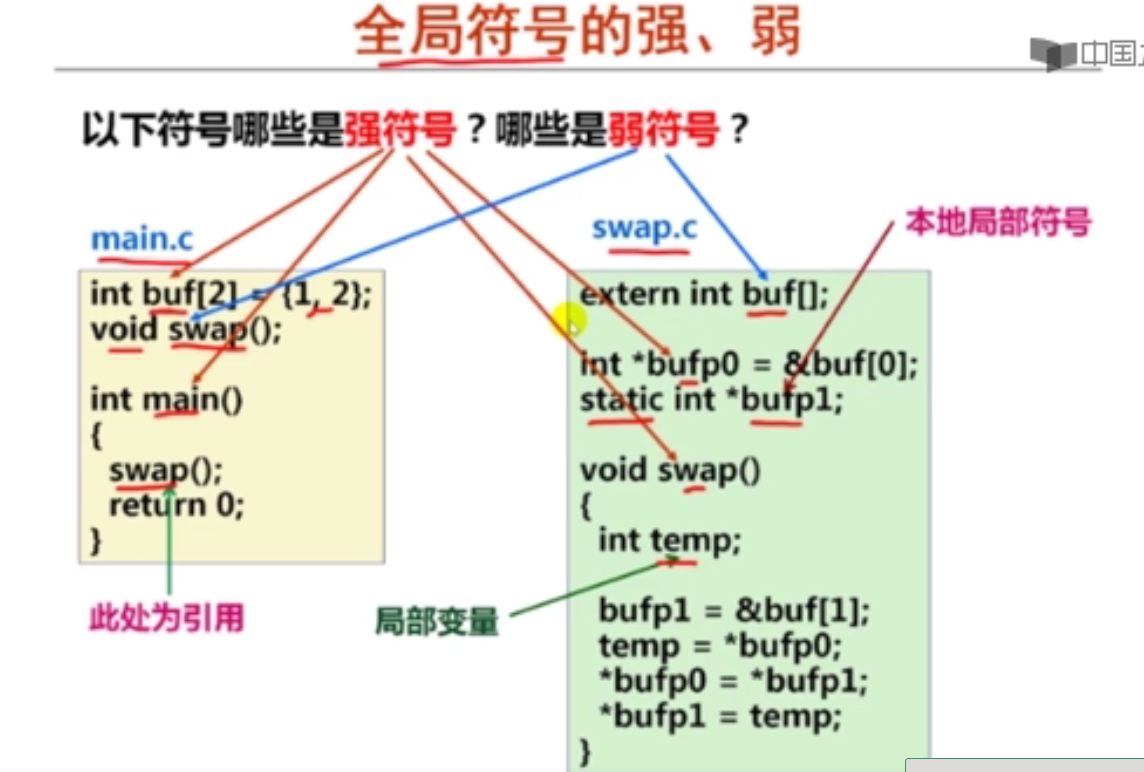

多重符号定义举例(21分钟)

/*main.c*/
int x = 10;
int p1(void);
int main()
{
x = p1();
return x;
}
/*p1.c*/
int x = 20;
int p1()
{
return x;
}
guangwudi@debian:~/csapp$ gcc -static -o myproc main.c p1.c
/usr/bin/ld: /tmp/ccIGgPqC.o:(.data+0x0): multiple definition of `x'; /tmp/ccskziV9.o:(.data+0x0): first defined here
collect2: error: ld returned 1 exit status
在Code::Blocks中报错error: ld returned 1 exit status

/*main.c*/
#include <stdio.h>
int y = 100;
int z;
void p1(void);
int main()
{
z = 1000;
p1();
printf("y=%d,z=%d\n",y,z);
return 0;
}
/*p1.c*/
int y;
int z;
void p1()
{
y = 200;
z = 2000;
}
在Code::Blocks中能正常输出结果:
y=200,z=2000
但在Debian32-bit虚拟机中一直报错multiple definition,暂时无力解决。
guangwudi@debian:~/csapp$ gcc -c p1.c
guangwudi@debian:~/csapp$ ar rcs mylib.a p1.o
guangwudi@debian:~/csapp$ gcc -c main.c
guangwudi@debian:~/csapp$ gcc -static -o myproc main.o ./mylib.a
/usr/bin/ld: ./mylib.a(p1.o):(.bss+0x0): multiple definition of `y'; main.o:(.data+0x0): first defined here
/usr/bin/ld: ./mylib.a(p1.o):(.bss+0x4): multiple definition of `z'; main.o:(.bss+0x0): first defined here
collect2: error: ld returned 1 exit status


/*main.c*/
#include <stdio.h>
int d = 100;
int x = 200;
void p1(void);
int main()
{
p1();
printf("d=%d,x=%d\n",d,x);
return 0;
}
/*p1.c*/
double d;
void p1()
{
d = 1.0;
}
在Code::Blocks中能正常输出结果:
d=0,x=1072693248

第2讲 静态链接和符号解析
静态共享库的创建(15分钟)


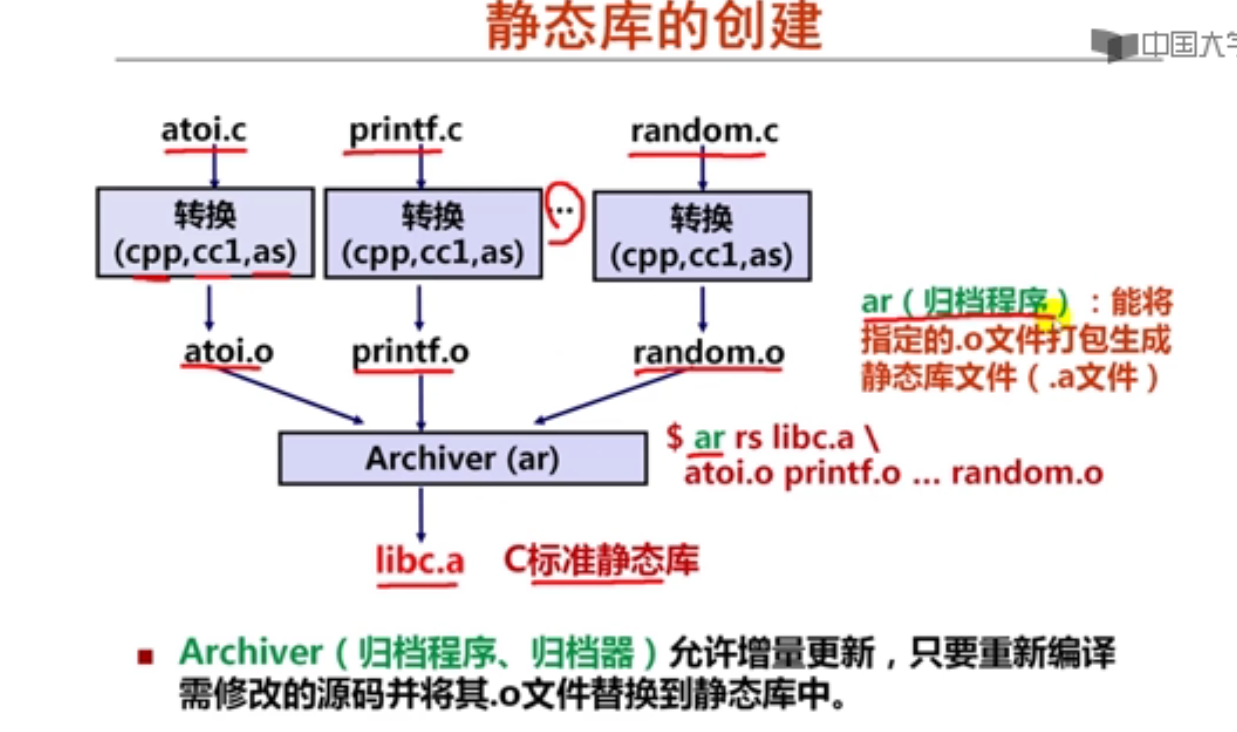
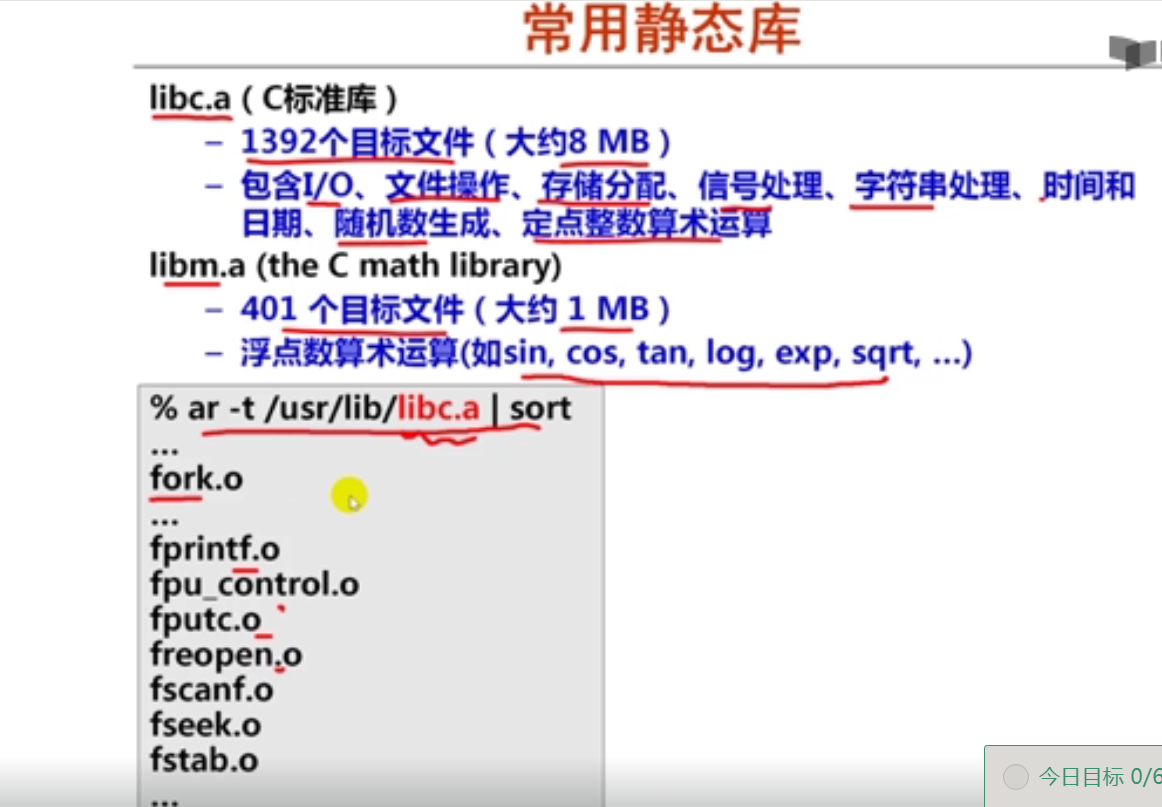
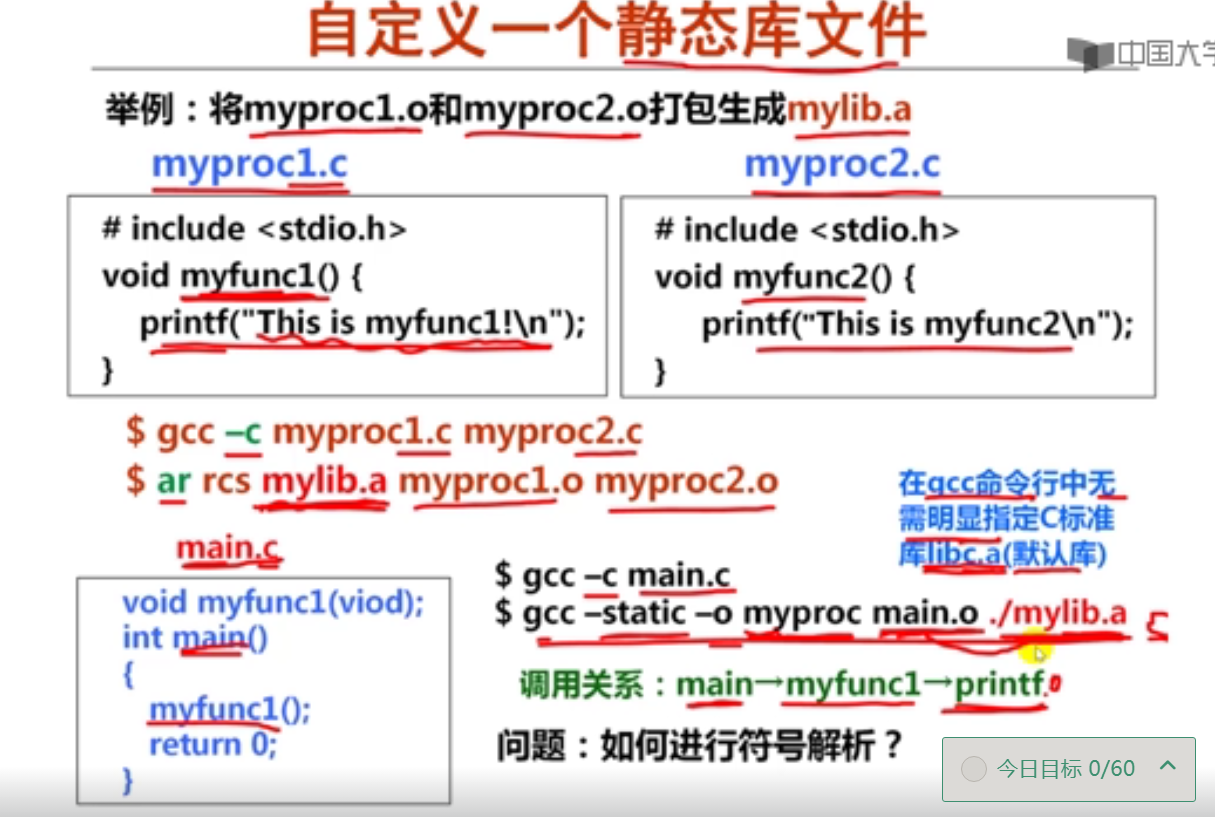
/*myproc1.c*/
#include<stdio.h>
void myfunc1()
{
printf("This is myfunc1!\n");
}
/*myproc2.c*/
#include<stdio.h>
void myfunc2()
{
printf("This is myfunc2!\n");
}
/*main.c*/
void myfunc1(void);
int main()
{
myfunc1();
return 0;
}
guangwudi@debian:~/csapp$ vim myproc1.c
guangwudi@debian:~/csapp$ vim myproc2.c
guangwudi@debian:~/csapp$ gcc -c myproc1.c myproc2.c
guangwudi@debian:~/csapp$ ar rcs mylib.a myproc1.o myproc2.o
guangwudi@debian:~/csapp$ vim main.c
guangwudi@debian:~/csapp$ gcc -c main.c
guangwudi@debian:~/csapp$ gcc -static -o myproc main.o ./mylib.a
guangwudi@debian:~/csapp$ ./myproc
This is myfunc1!
符号解析过程(13分钟)

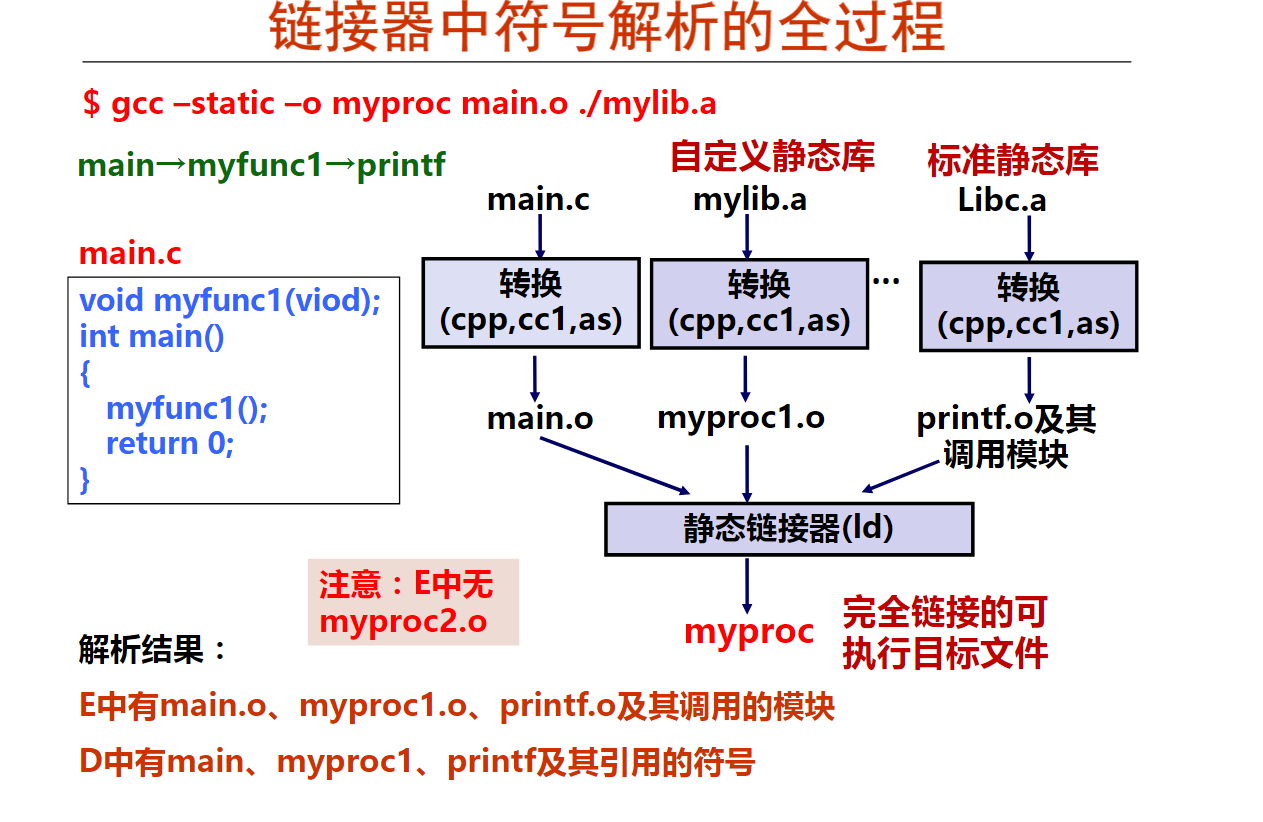
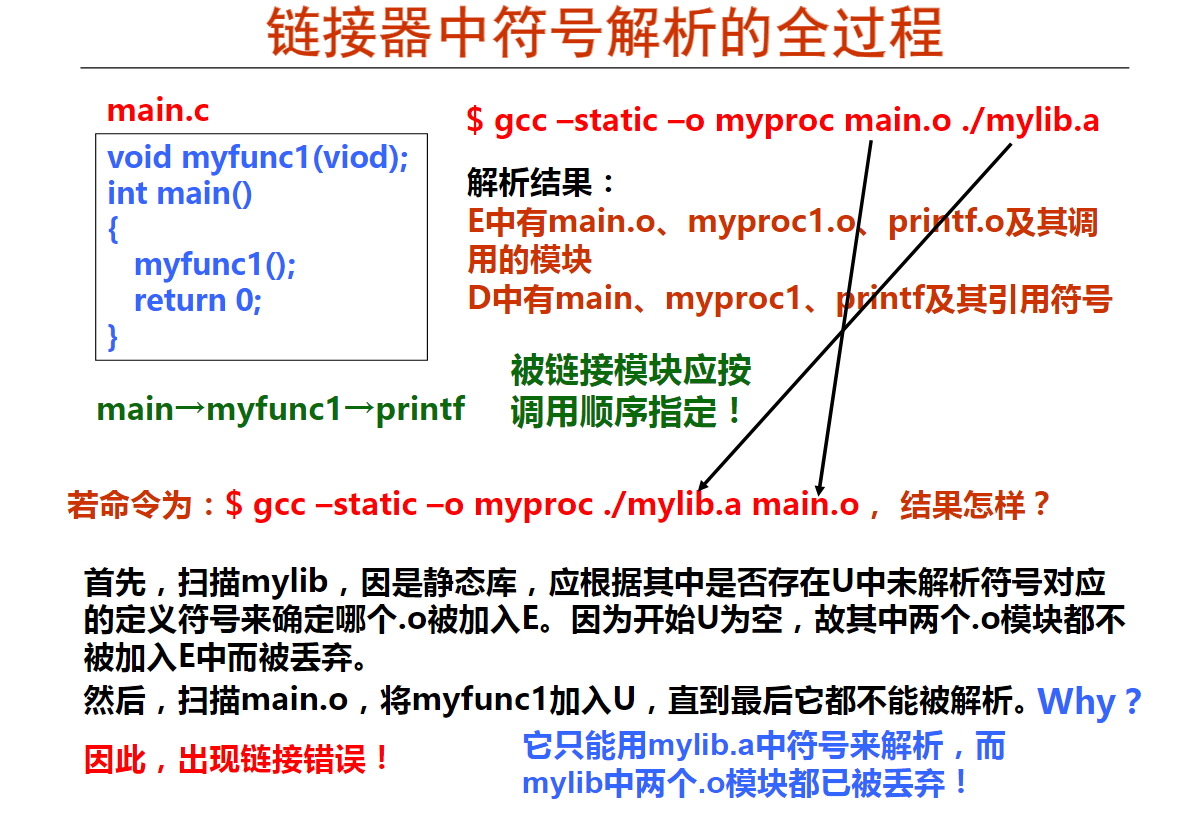
链接顺序问题(10分钟)


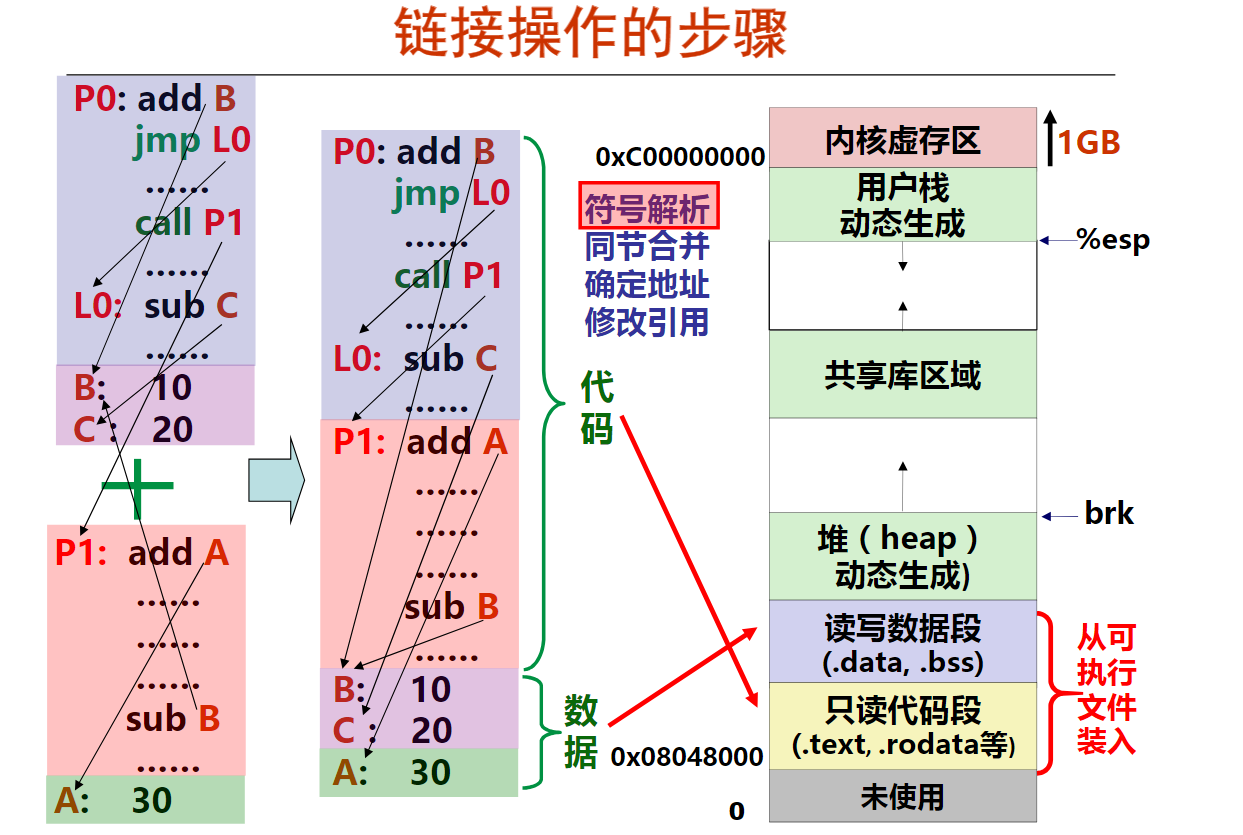
第十一周小测验
1以下是链接过程中对符号定义的判断,其中错误的是( A )。
A.全局变量声明“int *xp=&x;”中,xp和x都是符号的定义
B.函数内的局部变量声明“short x=200;”中,x不是符号的定义
C.静态局部变量声明“static int x=*xp;”中,x是符号的定义
D.全局变量声明“int x, y;”中,x和y都是符号的定义
解释:局部变量不是符号,静态全局变量是局部符号。
2.若x为局部变量,xp、y和z是全局变量,则以下判断中错误的是(A )。
A.赋值语句“int y=x+z;”中,y和z都是符号的引用
B.赋值语句“y=x+*xp;”中,y和xp都是符号的引用
C.静态局部变量声明“static int x=*xp;”中,xp是符号的引用
D.赋值语句“y=x+z;”中,y和z都是符号的引用
3以下有关ELF目标文件的符号表的叙述中,错误的是(C )。
A.符号表定义在.symtab节中,每个表项描述某个符号的相应信息
B.通过符号表可获得符号的名称、所在节及在节中偏移地址和长度
C.符号表中包含了所有定义符号的描述信息,包括局部变量的相关信息
D.可重定位和可执行两种目标文件中都有符号表且数据结构一样
4以下是有关链接过程中符号解析(符号绑定)的叙述,其中错误的是( B )。
A.全局符号(包括外部全局符号)需将模块内的引用与模块外的定义符号绑定
B.同一个符号名可能在多个模块中有定义,每个定义处的符号都须分配空间
C.符号解析的目的是将符号引用与某目标模块中定义的符号建立关联
D.本地符号的解析比较简单,只要与本模块内定义的符号关联即可
解释:一个符号变量只能有一个地址
5以下有关强符号和弱符号的符号解析的叙述中,错误的是( C )。
A.一个符号名只能有一个强符号,否则符号解析失败
B.一个符号名可以有多个弱符号,任选一个为其定义
C.一个符号名可以仅出现在引用处或仅出现在定义处
D.一个符号名可以有一个强符号和多个弱符号,强符号为其定义
6以下是两个源程序文件:
/* m1.c */
int p1(viod);
int main()
{
int p1= p1();
return p1;
}
/* m2.c */
static int main=1;
int p1()
{
main++;
}
对于上述两个源程序文件链接时的符号解析,错误的是( D )。
A.在m1中,定义了一个强符号main和一个弱符号p1
B.在m2中,定义了一个强符号p1和一个局部符号main
C.在m1中,对m2中定义的强符号p1的引用只有一处
D.因为出现了两个强符号main,所以会发生链接错误
7以下是两个源程序文件:
/* m1.c */
int p1;
int main()
{
int p1= p1();
return p1;
}
/* m2.c */
int main=1;
int p1()
{
int p1=main++;
return main;
}
对于上述两个源程序文件链接时的符号解析,错误的是( C )。
A.在m1中,定义了一个强符号main和一个弱符号p1
B.在m2中,定义了一个强符号p1和一个强符号main
C.在模块m1的所有语句中,对符号p1的引用一共有三处
D.因为出现了两个强符号main,所以会发生链接错误
8以下是两个源程序文件:
/* m1.c */
int x=100;
int p1(void);
int main()
{
x = p1();
return x;
}
/* m2.c */
float x;
static main=1;
int p1()
{
int p1=main + (int)x;
return p1;
}
对于上述两个源程序文件链接时的符号解析,错误的是( C )。
A.m1中对x的两处引用都与m1中对x的定义绑定
B.m2中的变量p1与函数p1被分配在不同存储区
C.m2中对x的引用与m2中对x的定义绑定
D.虽然x、main和p1都出现了多次定义,但不会发生链接错误
解释:从这里可以看出,return x不是对x的引用。。。
9以下是两个源程序文件:
/* m1.c */
#include <stdio.h>
int x=100;
short y=1, z=2;
int main()
{
p1();
printf("x=%d, z=%d\n",x,z);
}
/* m2.c */
double x;
void p1()
{
x= -1.0;
}
上述程序执行的结果是( B )。提示:1074790400=2^30+2^20,16400=2^14+2^4。
A.x=100, z=2
B.x=0, z=-16400
C.x=-1, z=2
D.x=-1074790400, z=0
解析: B、该题中变量x在m1.c中为强符号,在m2.c中为弱符号。在调用p1函数后,x处原来存放的100被替换,-1.0的double类型表示为1 0111 1111 111 00…0,十六进制表示为BFF0 0000 0000 0000。因为x、y和z都是初始化变量,同在.data节中,链接后空间被分配在一起,x占4B,随后y和z各占2B。因为IA-32为小端方式,所以,x的机器数为全0,y的机器数也为全0,z的机器数为BFF0H。执行printf函数后x=0, z=-(2^14+2^4)=-16400。
10假设调用关系如下:func.o→libx.a和liby.a中的函数,libx.a→libz.a中的函数,libx.a和liby.a之间、liby.a和libz.a相互独立,则以下几个命令行中,静态链接发生错误的命令是( B )。
A.gcc -static –o myfunc func.o libx.a libz.a liby.a
B.gcc -static –o myfunc func.o liby.a libz.a libx.a
C.gcc -static –o myfunc func.o liby.a libx.a libz.a
D.gcc -static –o myfunc func.o libx.a liby.a libz.a
第十二周重定位及动态链接
<a href="https://rosefinch-midsummer.github.io/book/file/cs/course1-week12.pdf" target="_blank">在线阅读PDF文档</a>
第1讲 符号的重定位
重定位的基本概念(12分钟)
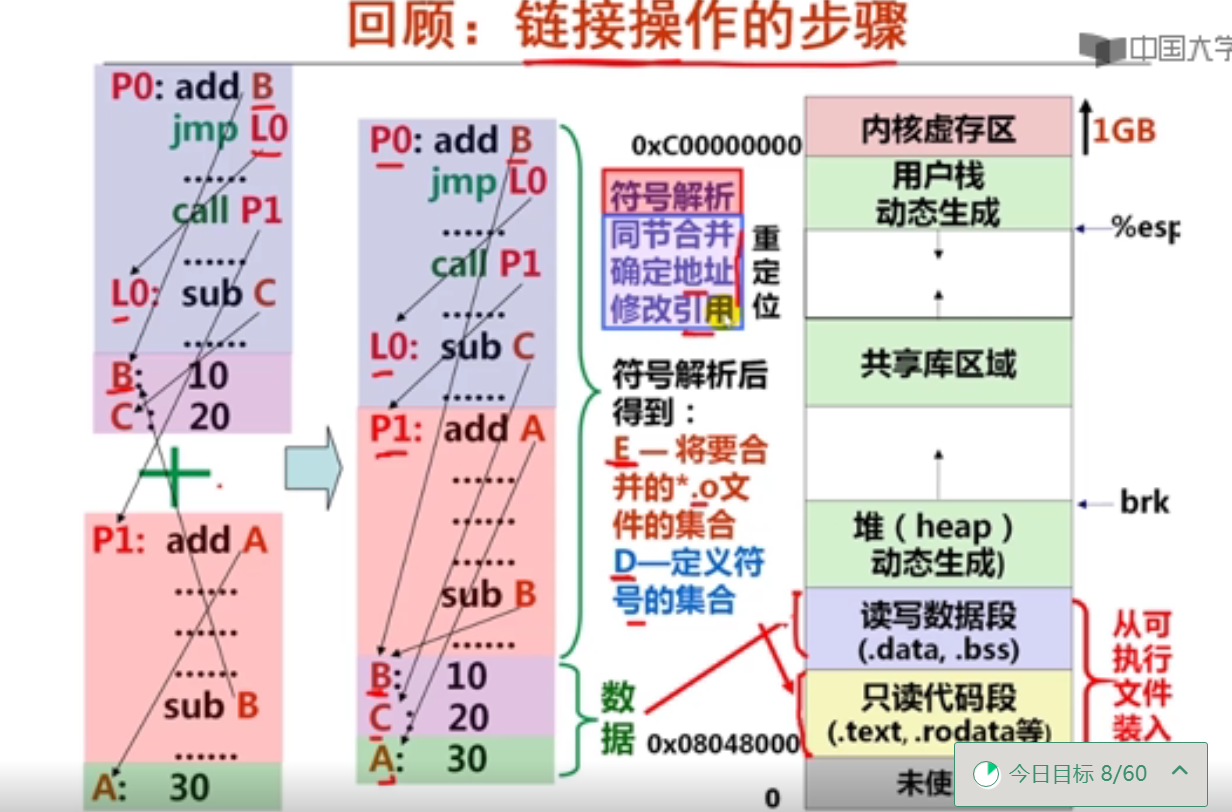

.rel_data和.rel_text保存在.o文件中
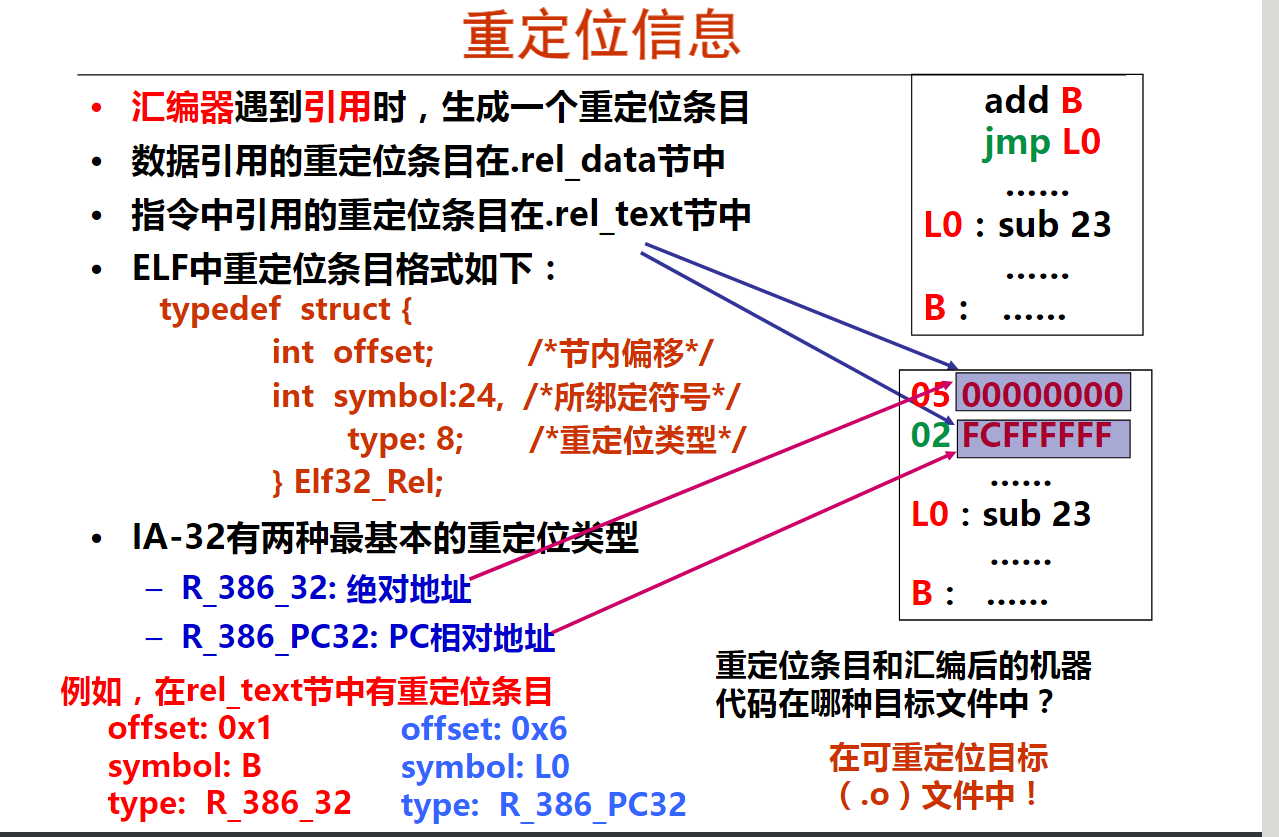
guangwudi@debian:~/csapp$ readelf -r main.o
Relocation section '.rel.text' at offset 0x198 contains 3 entries:
Offset Info Type Sym.Value Sym. Name
00000008 00000502 R_386_PC32 00000000 __x86.get_pc_thunk.ax
0000000d 0000060a R_386_GOTPC 00000000 _GLOBAL_OFFSET_TABLE_
00000014 00000704 R_386_PLT32 00000000 myfunc1
Relocation section '.rel.eh_frame' at offset 0x1b0 contains 2 entries:
Offset Info Type Sym.Value Sym. Name
00000020 00000202 R_386_PC32 00000000 .text
00000044 00000302 R_386_PC32 00000000 .text.__x86.get_p[...]
PC相对地址重定位(20分钟)

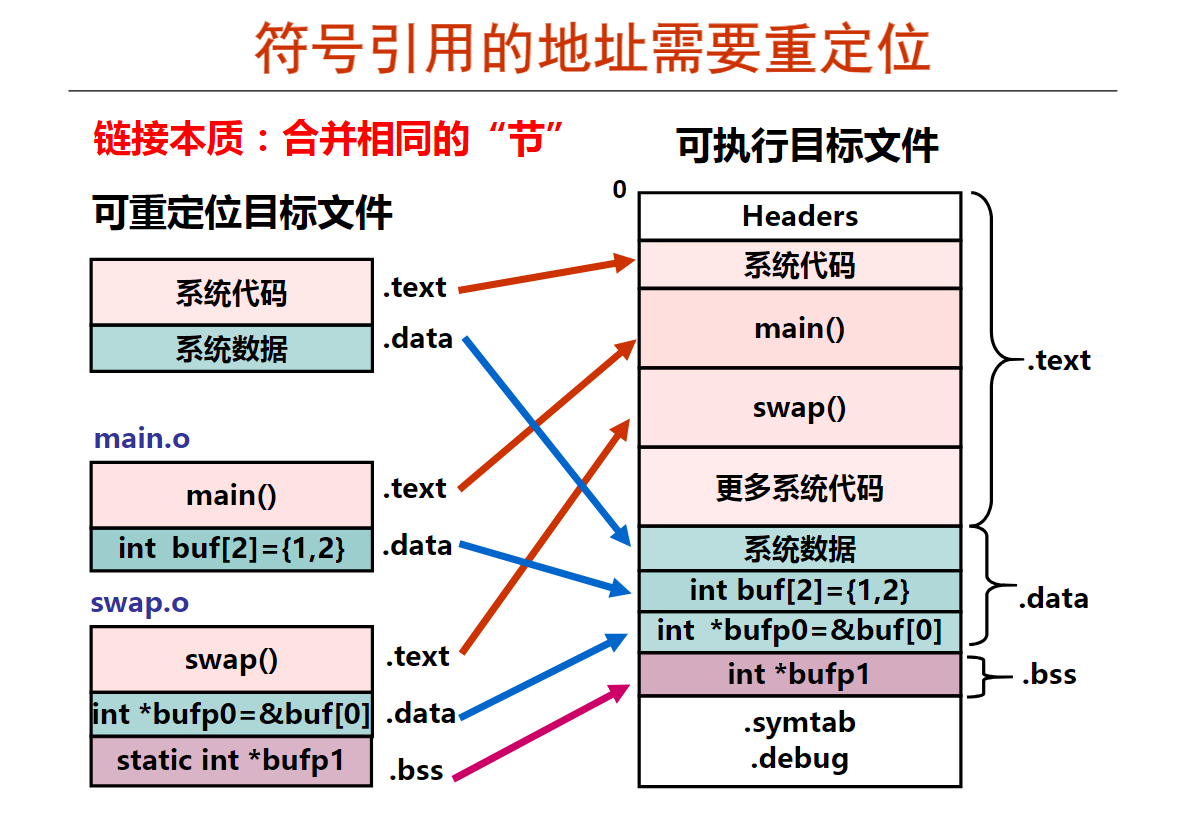

and $0xfffffff0,%esp作用是調整棧頂位置使其為16的倍數(IA-32系統)。
ffff fffc的真值為-4
7:R_386_PC32 swap指swap是從第7個字節單元開始的重定位條目
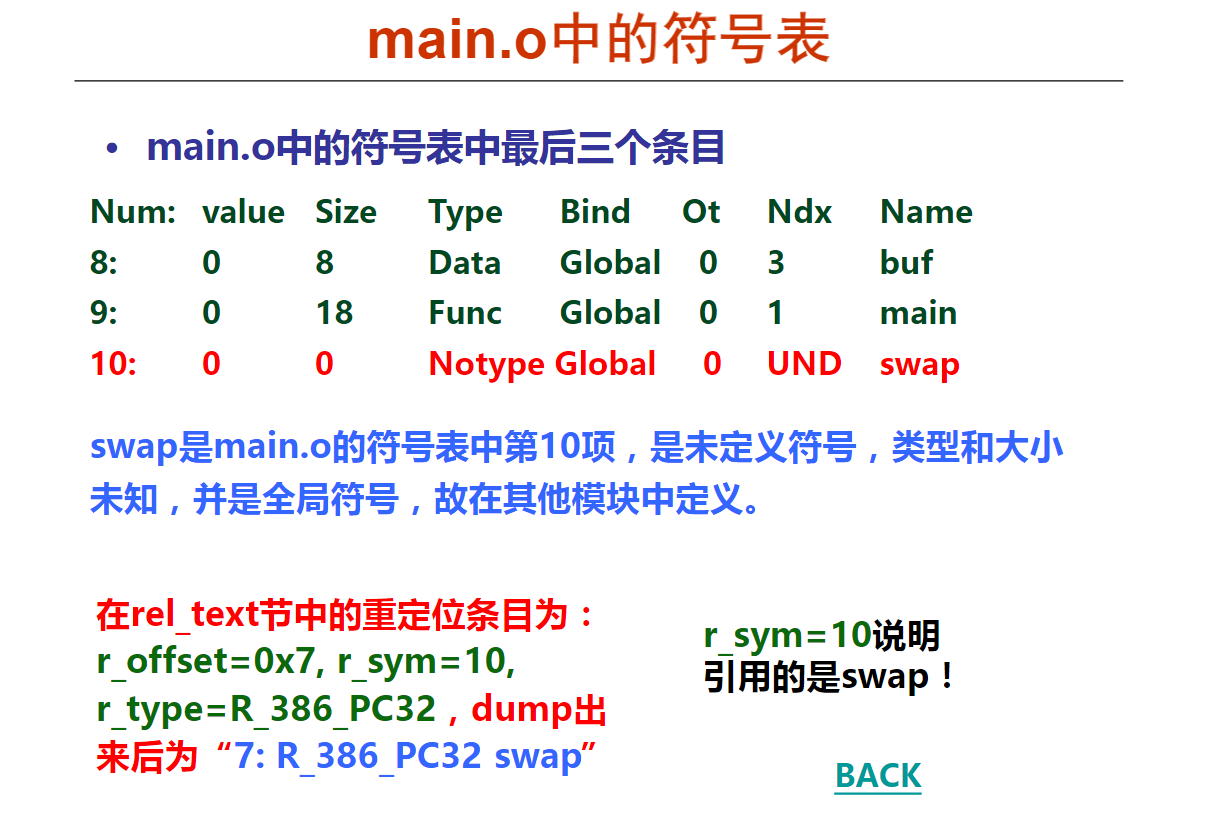


注意:人類和機器計算PC(下一條指令的地址)的方式略有不同。
重定位後call指令的機器代碼為"e8 09 00 00 00"
call指令下條指令地址其實是當前PC的值
绝对地址重定位(11分钟)
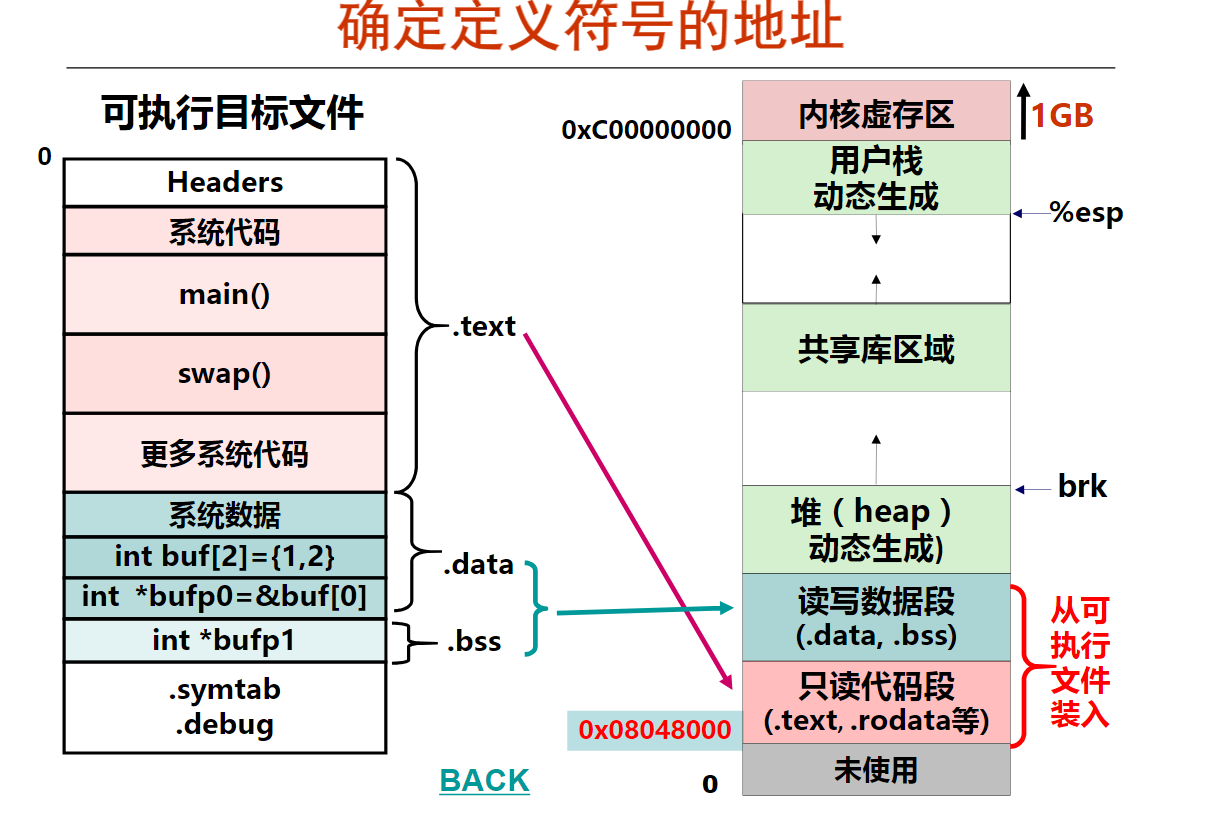
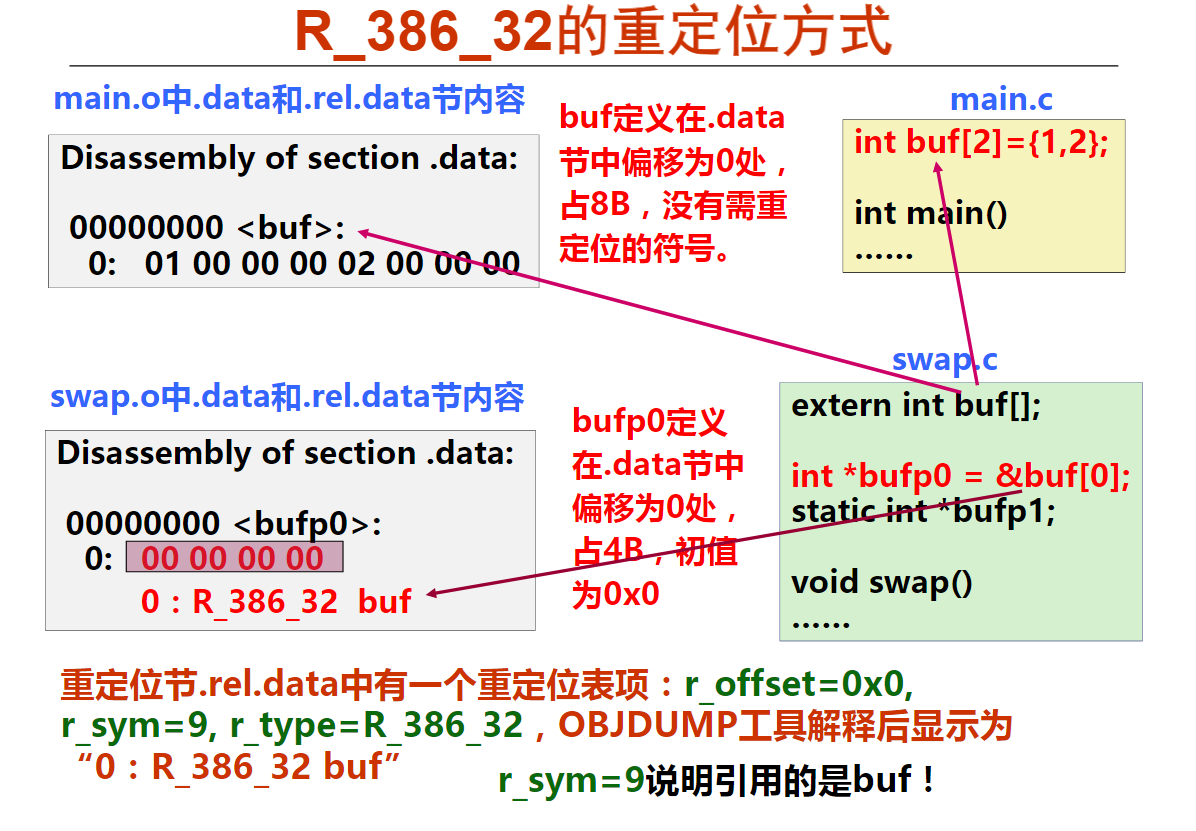
buf的初始值是個確定的值,不需要重定位。


符号重定位举例(13分钟)
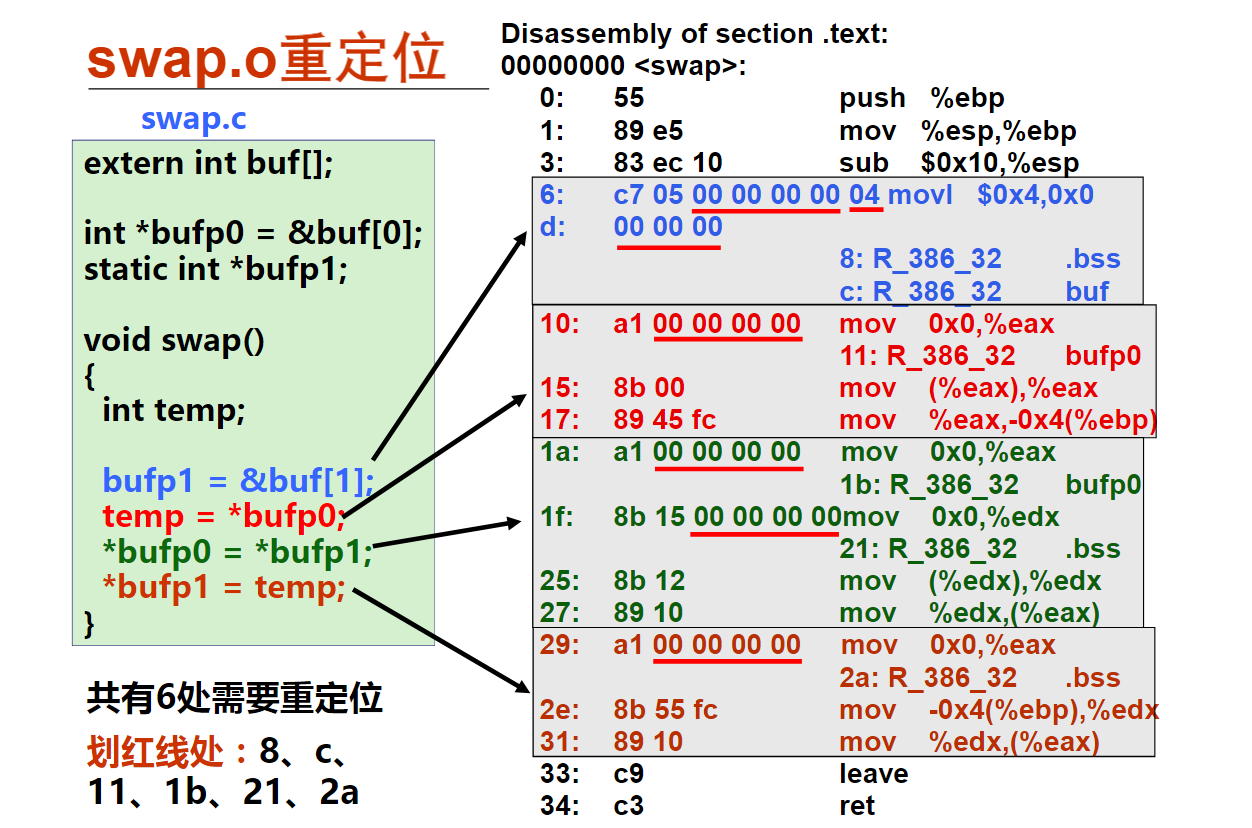
swap()函數裏面除了局部變量temp其餘的變量都是引用。
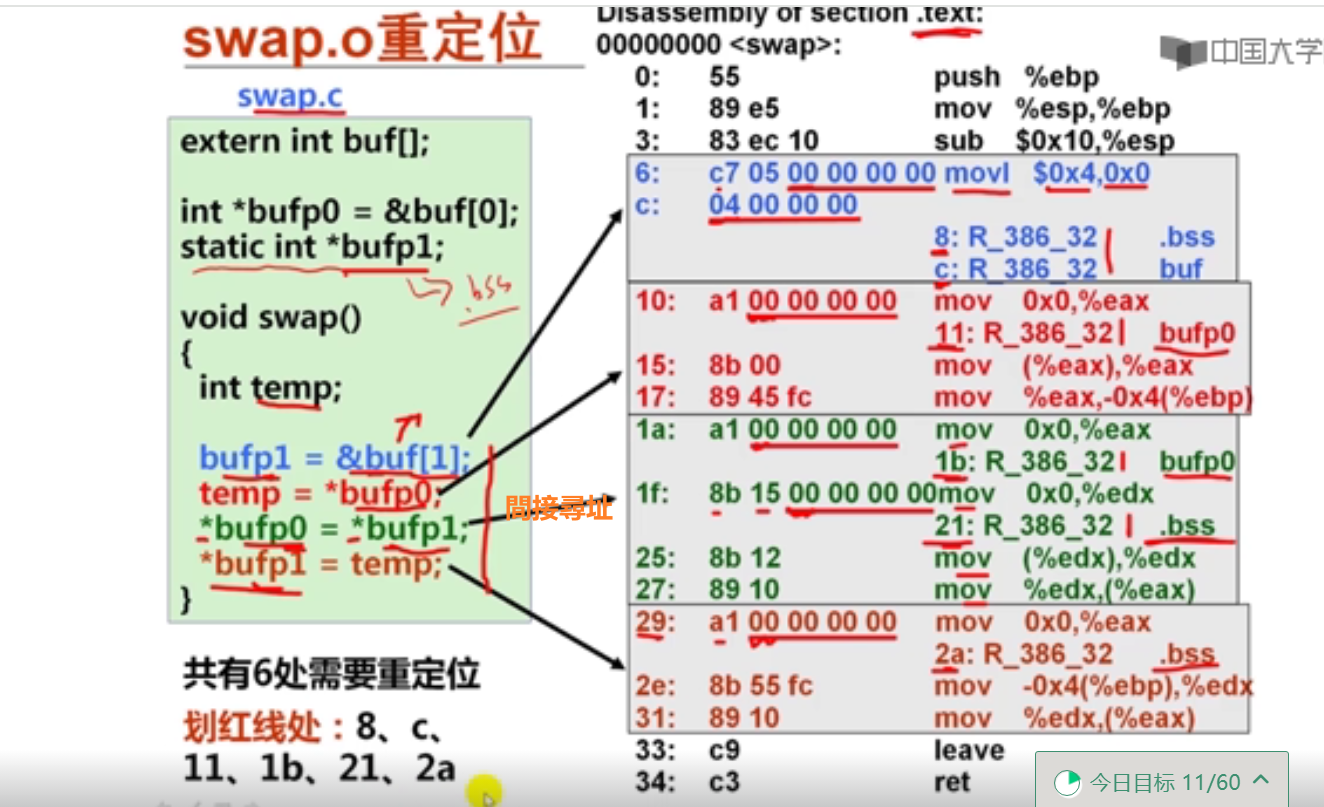
注意:這裏的PPT有錯!!d應該爲c。
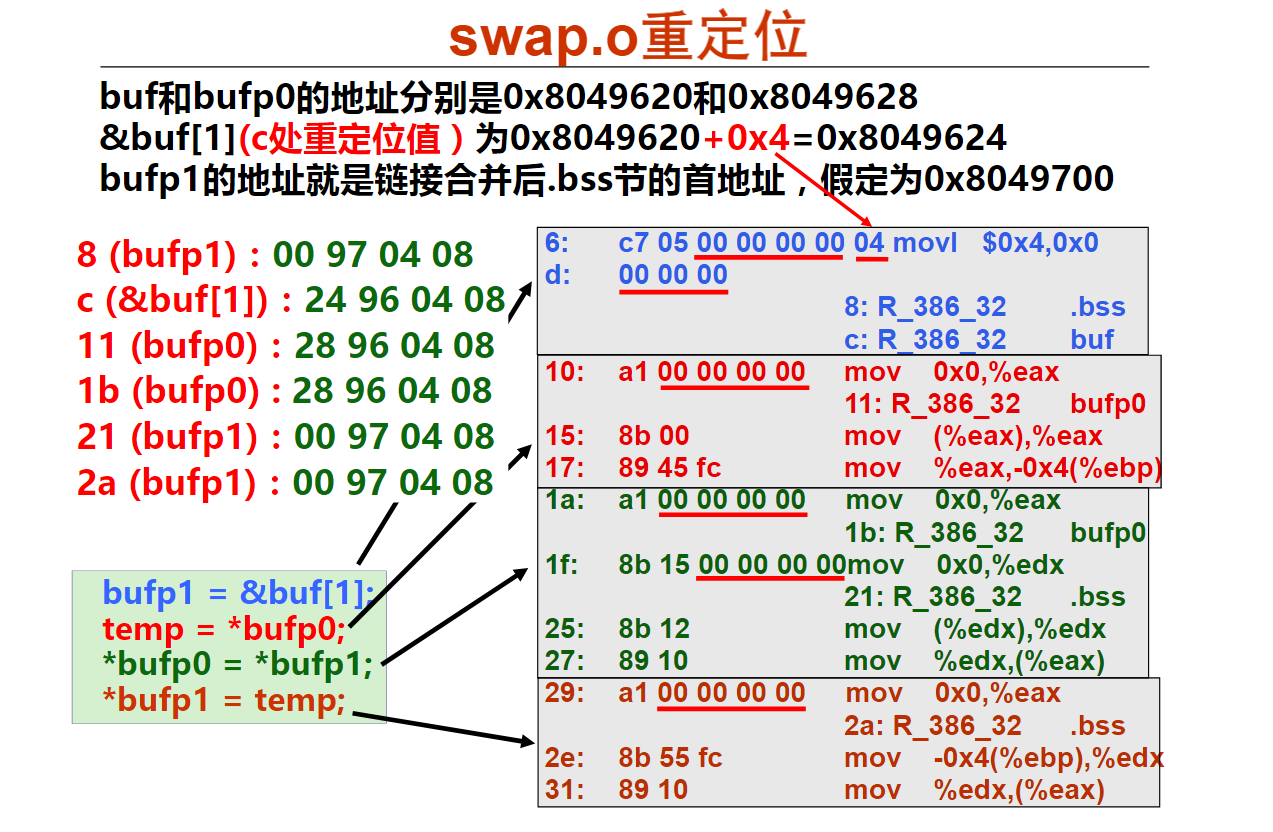
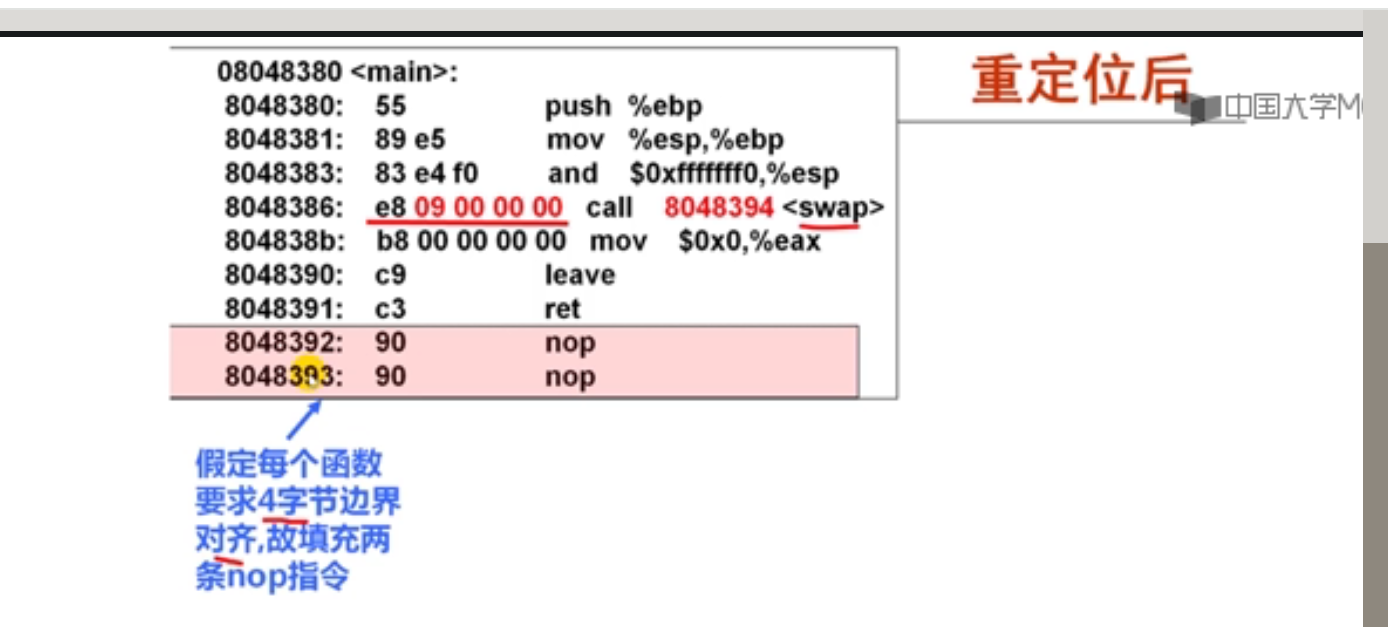
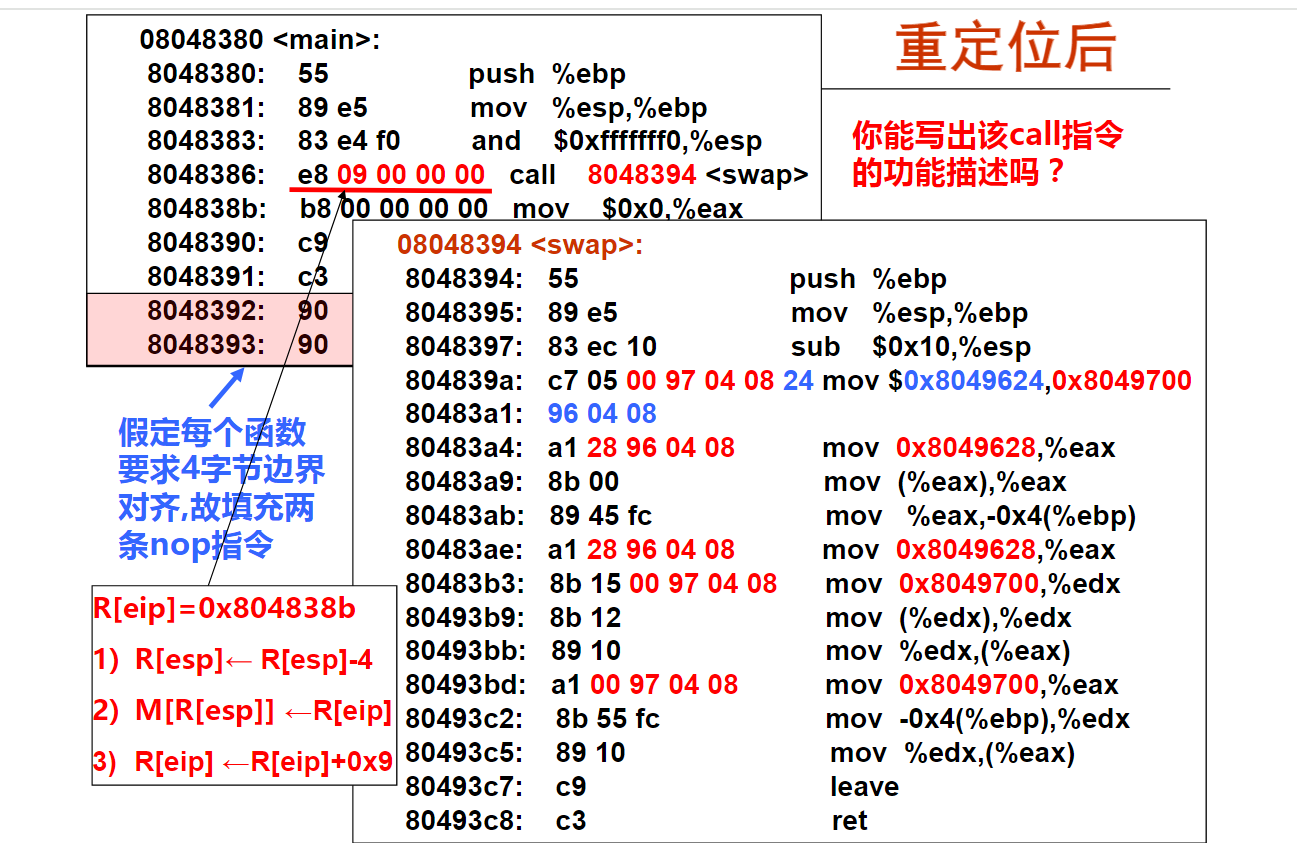
第2讲 可执行文件的加载
可执行文件的加载(15分钟)
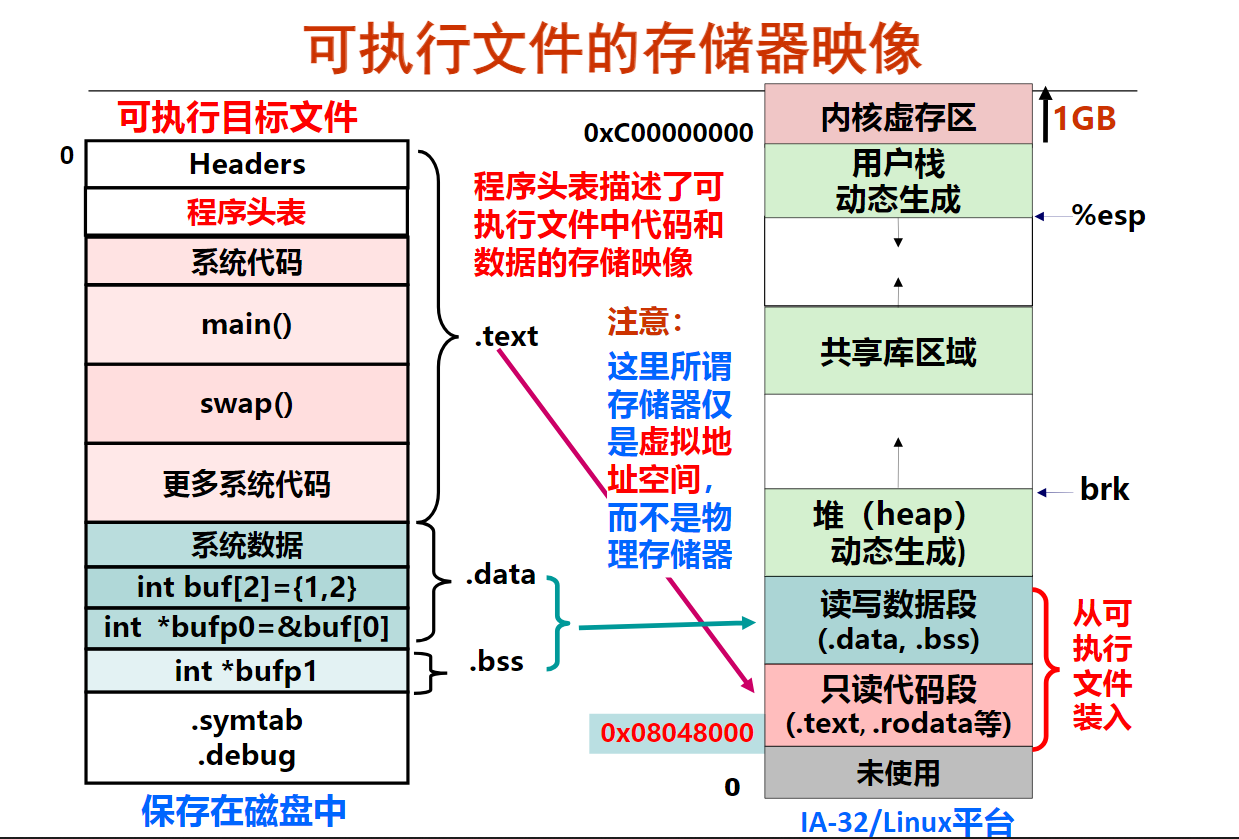

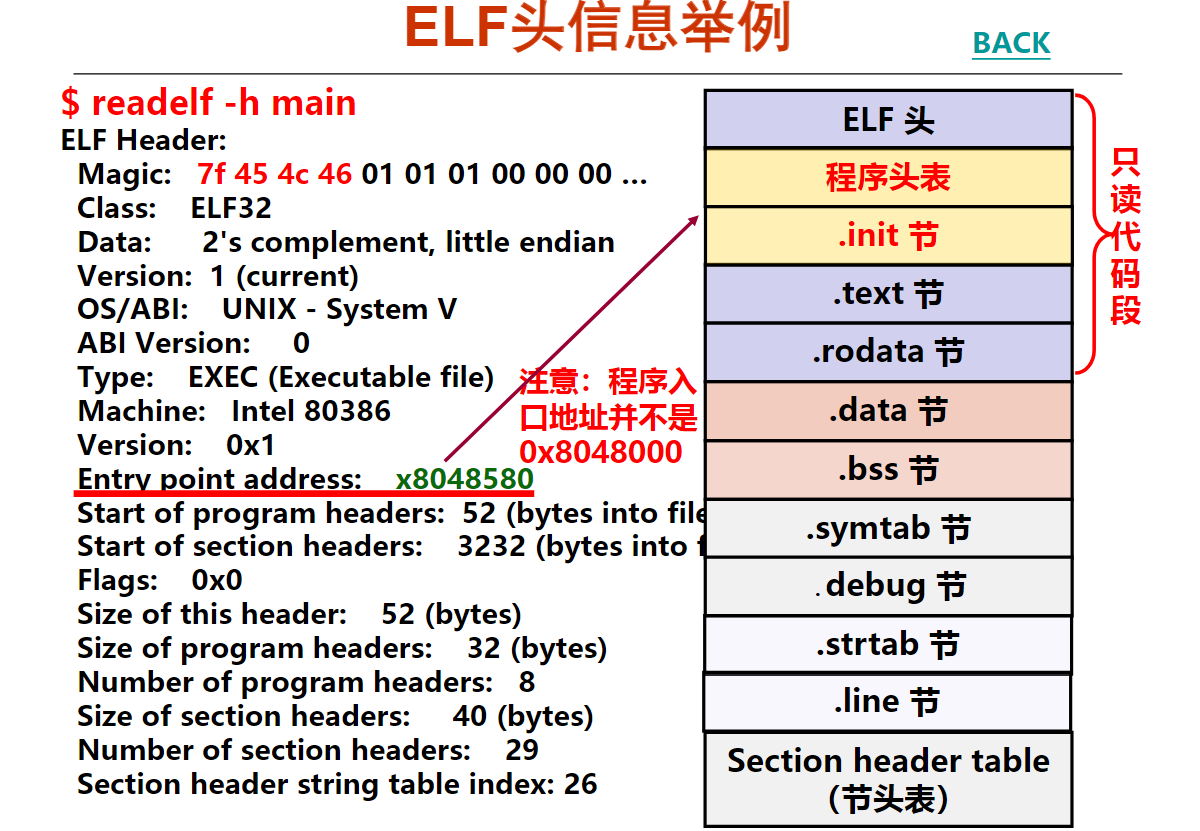


第3讲 共享库和动态链接
共享库和动态链接概述(19分钟)



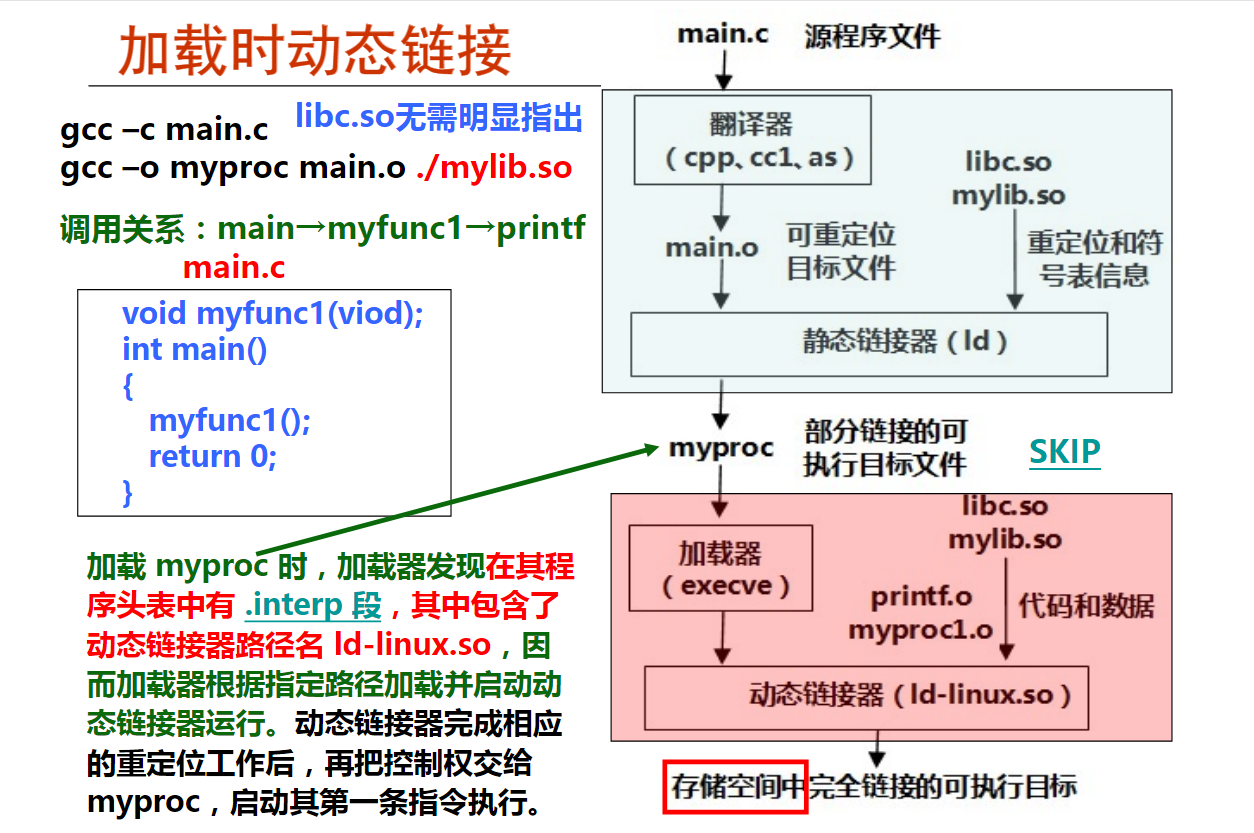
guangwudi@debian:~/csapp$ gcc -c myproc1.c myproc2.c
guangwudi@debian:~/csapp$ gcc -shared -fPIC -o mylib.so myproc1.o myproc2.o
guangwudi@debian:~/csapp$ gcc -c main.c
guangwudi@debian:~/csapp$ gcc -o myproc main.o ./mylib.so
guangwudi@debian:~/csapp$ ./myproc
This is myfunc1!
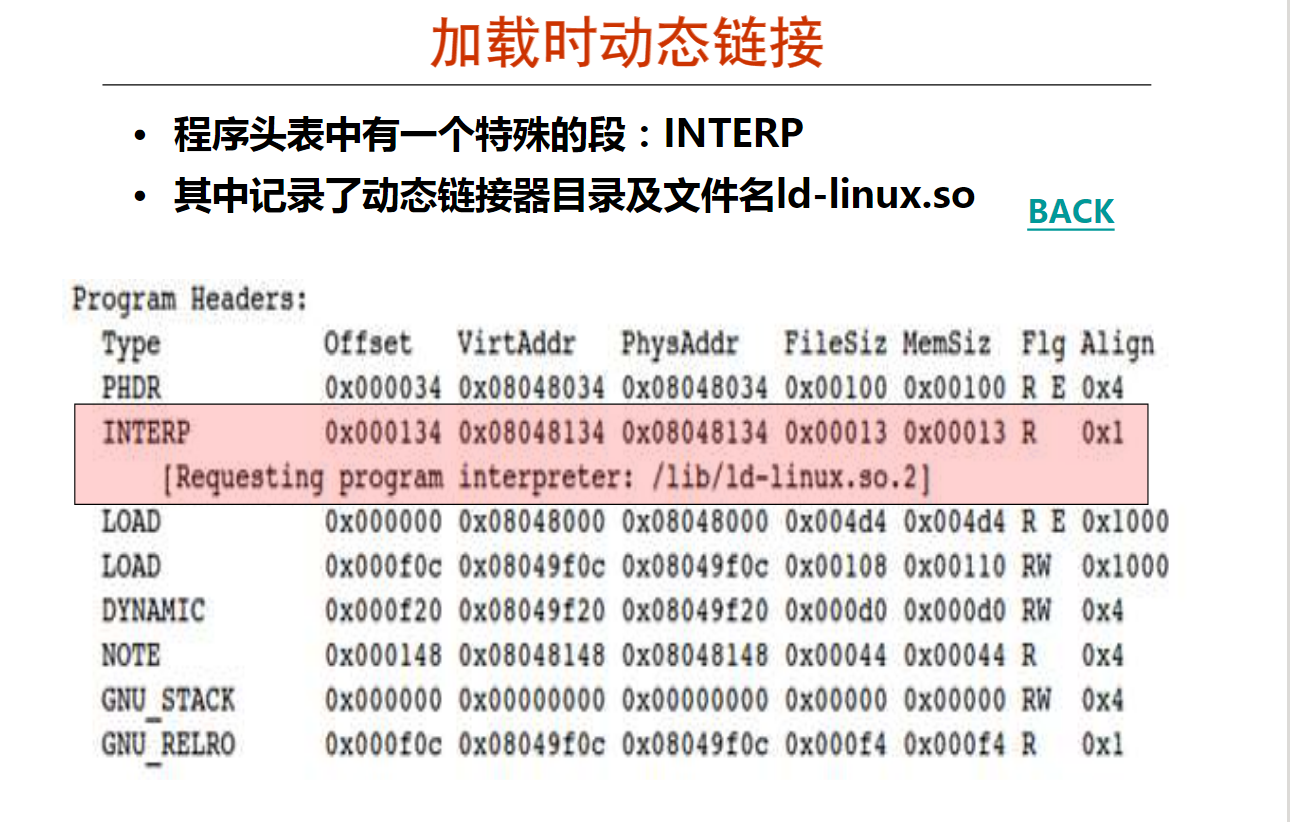

#include <stdio.h>
#include <dlfcn.h>
int main()
{
void *handle;
void *(myfunc1)();
char *error;
handle = dlopen("./mylib.so",RTLD_LAZY);
if(!handle)
{
fprintf(stderr,"%s\n",dlerror());
exit(1);
}
myfunc1 = dlsym(handle,"myfunc1");
if((error = dlerror()) != NULL)
{
fprintf(stderr,"%s\n",dlerror());
exit(1);
}
myfunc1();
if(dlclose(handle) < 0)
{
fprintf(stderr,"%s\n",dlerror());
exit(1);
}
return 0;
}
在Code::Blocks上执行报错fatal error: dlfcn.h: No such file or directory
模块内引用和模块间数据引用(20分钟)


这里的ff ff ff db是偏移地址,运算后得到下一条指令地址8048344
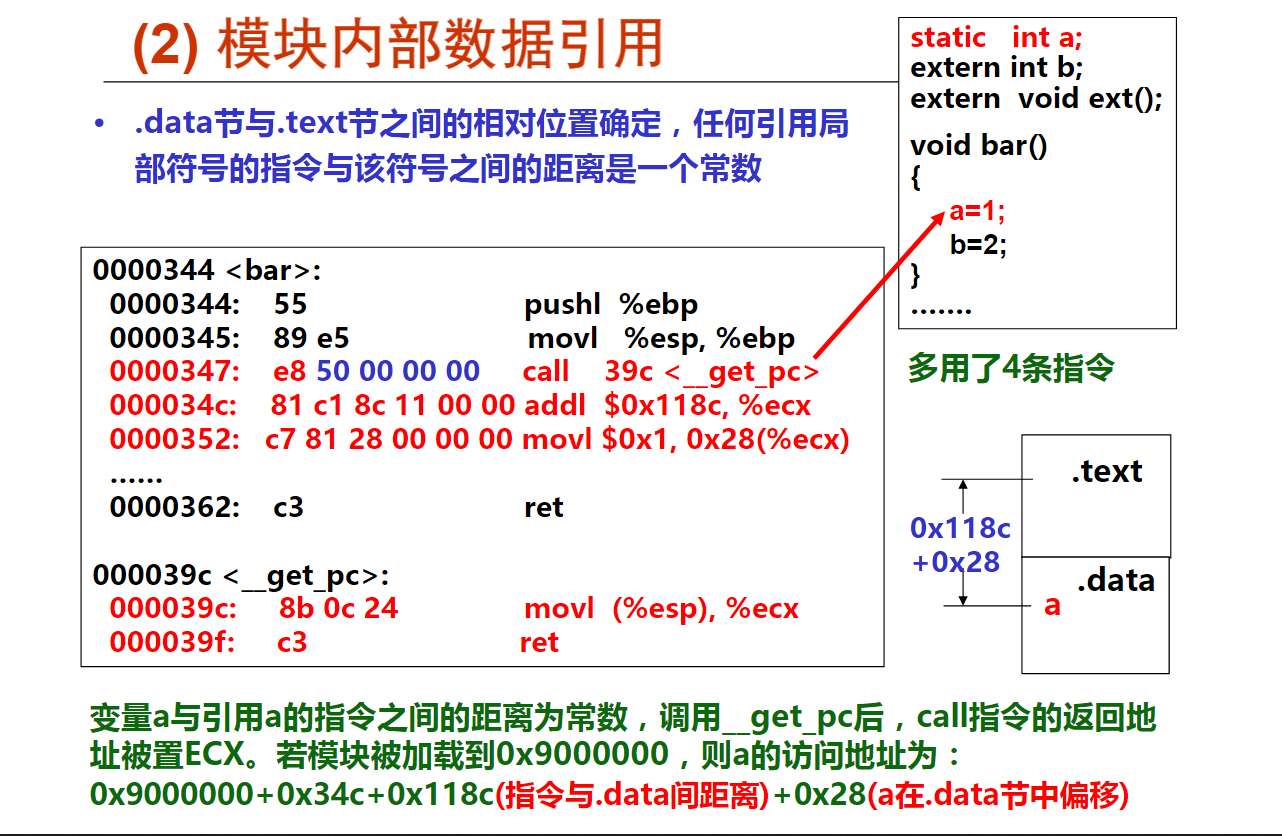
静态链接只需要用1条mov指令,这里用了5条指令。
这里的00 00 00 05是偏移地址,运算后得到下一条指令地址0000 34c
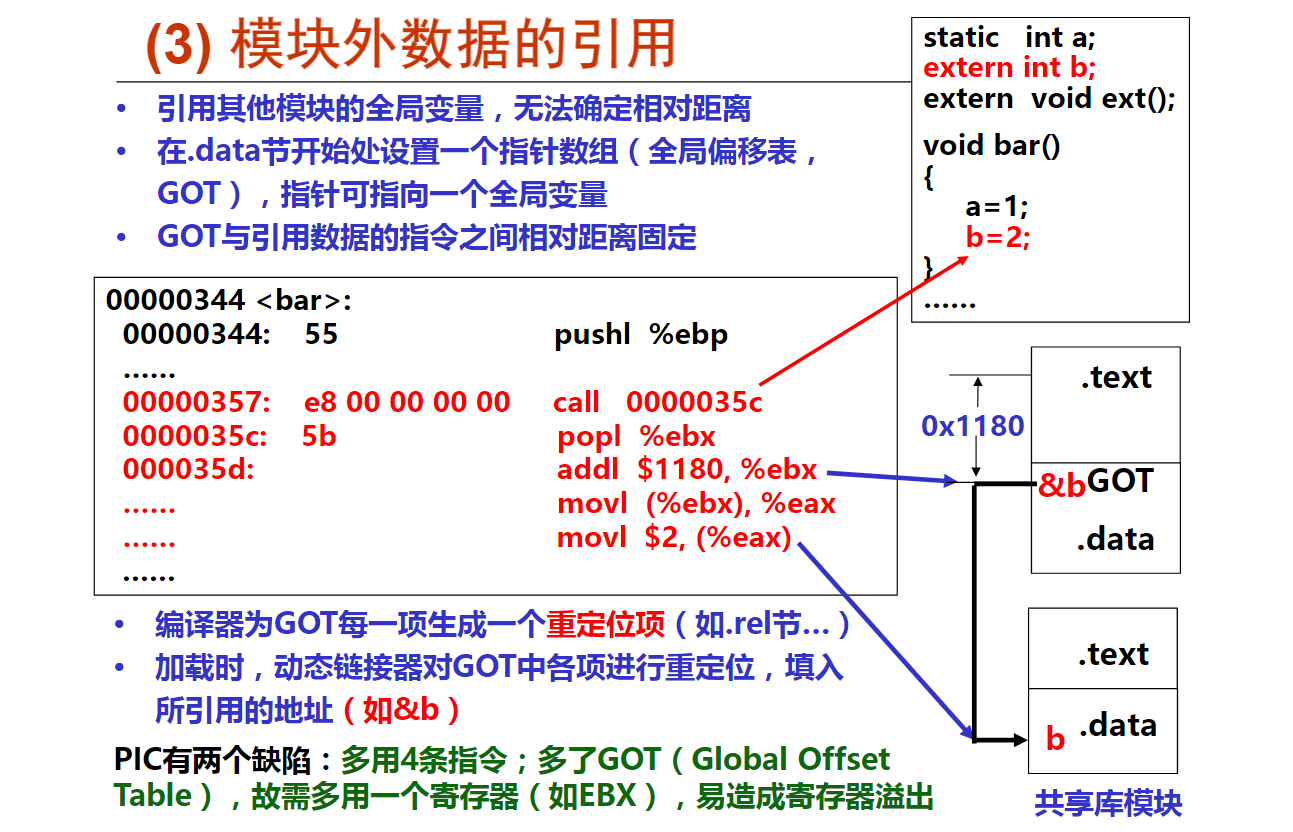
模块间的调用或跳转(19分钟)
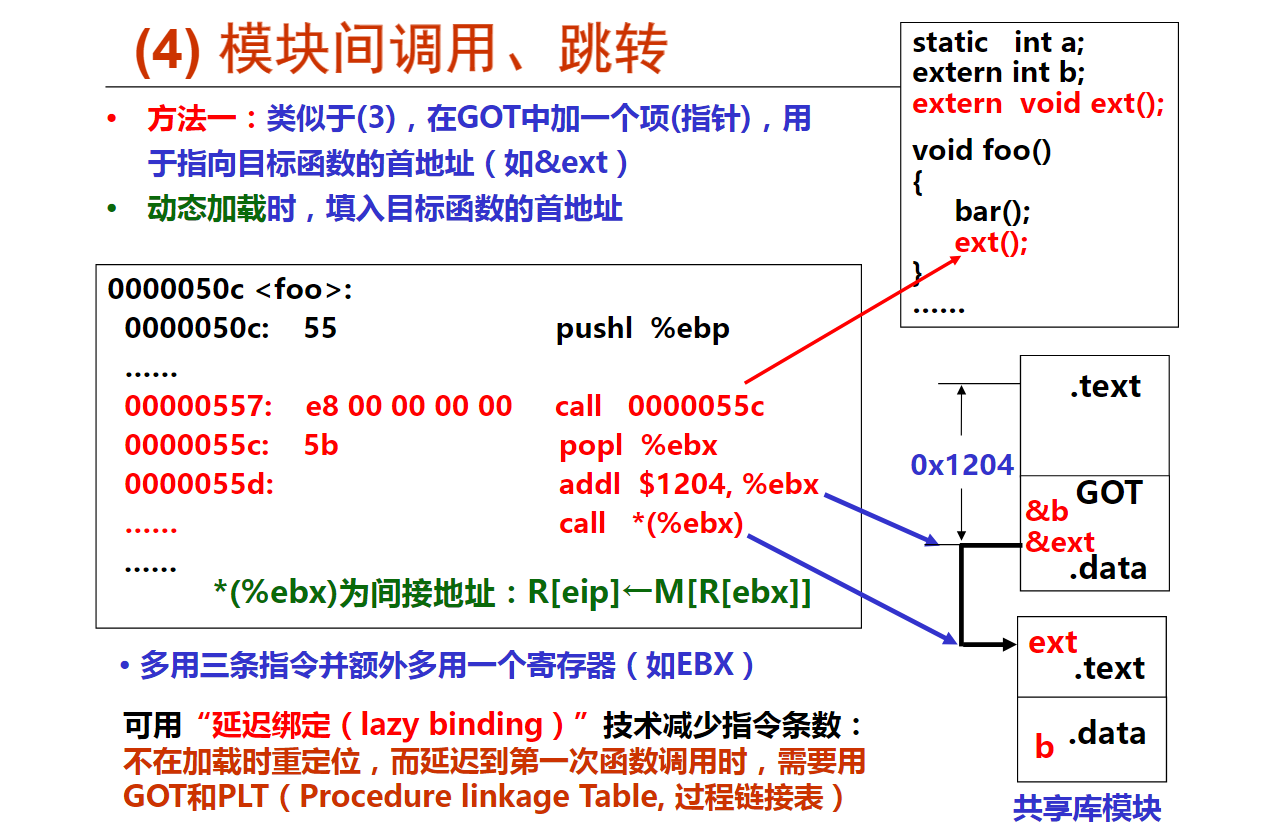
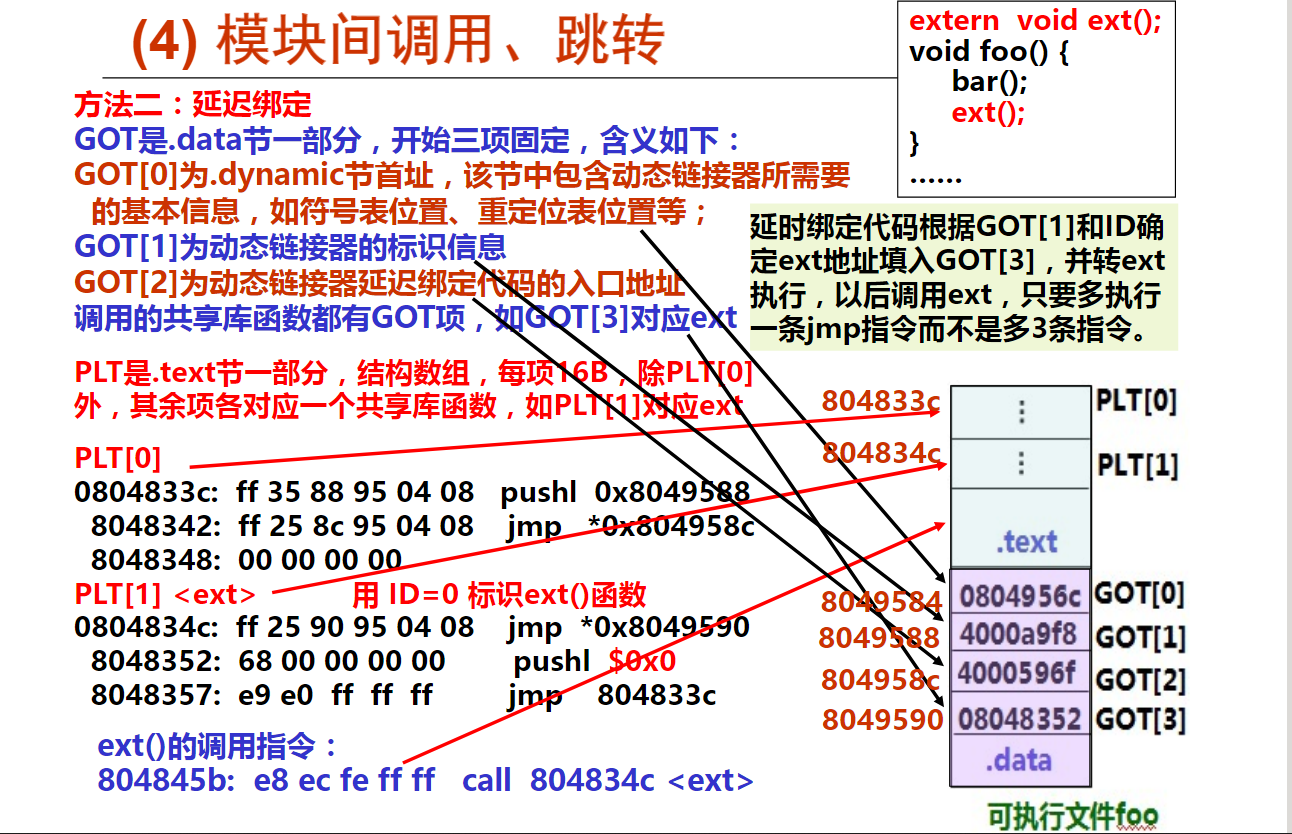
jmp *0x8049590是间接寻址
第一次运行程序时需要重定位,以后运行不需要重定位,只需要call、jmp这两条指令。
第十二周小测验
1以下有关重定位功能的叙述中,错误的是( C )。
A.重定位的最终目标是重新确定各模块合并后每个引用所指向的目标地址
B.重定位的第二步是确定每个段的起始地址,并确定段内每个定义处符号的地址
C.重定位的最后一步是将引用处的地址修改为与之关联(绑定)的定义处的首地址
D.重定位的第一步应先将相同的节合并,且将具有相同存取属性的节合并成段
解析: C、重定位最后一步是对引用处的地址进行重定位,重定位的方式有多种,只有绝对地址方式才是将引用处的地址修改为与之关联(绑定)的定义处的首地址,而对于其他重定位方式,就不一定是这样,例如,对于PC相对地址方式,引用处填写的是一个相对地址。
2以下有关重定位信息的叙述中,错误的是( A )。
A.重定位信息是由编译器在生成汇编指令时产生的
B.重定位信息包含需重定位的位置、绑定的符号和重定位类型
C.数据中的重定位信息在可重定位目标文件的.rel.data节中
D.指令中的重定位信息在可重定位目标文件的.rel.text节中
解析: A、重定位信息应该是在汇编阶段生成的,只有在汇编阶段生成机器指令时才知道需要进行重定位的位置,因为这些需重定位的位置在机器指令中,例如,CALL指令中的偏移地址等。
3假定“int buf[2]={10,50};”所定义的buf被分配在静态数据区,其首地址为0x8048930,bufp1为全局变量,被分配在buf随后的存储空间。以下关于“int *bufp1 = &buf[1];”的重定位的描述中,错误的是( B )。
A.bufp1的地址为0x8048938,重定位前的内容为04H、00H、00H、00H
B.在相应的重定位条目中,对bufp1和buf的引用均采用绝对地址方式
C.在可执行目标文件中,地址0x8048938开始的4个字节为34H、89H、04H、08H
D.在可重定位目标文件的.rel.data节中,有一个引用buf的重定位条目
解析: A、因为buf有2个数组元素,每个元素占4B,因此bufp1的地址为0x8048930+8=0x8048938,重定位时与引用绑定的符号是buf,即绑定的是&buf[0],而真正赋给bufp1的是&buf[1],引用的地址和绑定的地址相差4,所以重定位前的内容为十六进制数04 00 00 00。 B、在重定位条目中只有对buf的引用,没有对bufp1的引用,这里bufp1是一个定义。 C、可执行文件已经进行了重定位,所以,bufp1所在的地址0x8048938处,应该是重定位后的值,显然应该是buf[1]的地址。重定位时通过初始值加上buf的值得到,即4+0x8048930=0x8048934,小端方式下,4个字节分别为34H、89H、04H、08H。 D、因为“int *bufp1 = &buf[1];”是一个声明,也即是对变量bufp1的数据类型的定义和初始化,因此这个需要重定位的初始化值将被存储在.data节中,因而重定位条目在.rel.data节中,并且是绑定buf的一个引用,即引用buf的一个重定位条目。
4假定“int buf[2]={10,50};”所定义的buf被分配在静态数据区,其首地址为0x8048930,bufp1为全局变量,也被分配在静态数据区。以下关于“bufp1 = &buf[1];”的重定位的描述中,错误的是( A )。
A.在可重定位目标文件的.rel.data节中,有一个与bufp1相关的重定位条目
B.在可重定位目标文件的.rel.text节中,有一个与buf相关的重定位条目
C.在相应的重定位条目中,对bufp1和buf的引用均采用绝对地址方式
D.可用一条mov指令实现该赋值语句,该mov指令中有两处需要重定位
解析: A、因为“bufp1 = &buf[1];”是一个赋值语句,而不是一个声明,因而不需要对.data节中的bufp1变量进行重定位,也即重定位条目不在.rel.data节中。 B、赋值语句“ bufp1 = &buf[1];”用movl指令可以实现,所以,对buf的引用出现在机器代码中,即.text节中,因而重定位条目在.rel.text节中。 C、赋值语句“ bufp1 = &buf[1];”用movl指令可以实现,其源操作数和目操作数都是绝对地址方式。 D、赋值语句“ bufp1 = &buf[1];”用movl指令可以实现,其源操作数和目操作数都需要重定位。
“bufp1 = &buf[1];”是一个赋值语句,而不是一个变量声明(定义),因而不需要对.data节中的bufp1变量进行重定位,也即重定位条目不在.rel.data节中。
5以下是有关在Linux系统中启动可执行目标文件执行的叙述,其中错误的是( A )。
A.可在CUI(命令行用户界面)中双击可执行目标文件对应的图标来启动其执行
B.不管是哪种启动执行方式,最终都是通过调用execve()系统调用函数实现的
C.可以通过在一个程序中调用execve()系统调用函数来启动可执行文件执行
D.可在CUI(命令行用户界面)中的命令行提示符后输入对应的命令来启动其执行
解释:CUI(命令行用户界面)中没有可执行目标文件对应的图标
6以下是有关在Linux系统中加载可执行目标文件的叙述,其中错误的是( D )。
A.任何可执行目标文件中的可装入段被映射到一个统一的虚拟地址空间
B.加载器通过可执行目标文件中的程序头表对可装入段进行加载
C.可执行目标文件的加载通过execve()函数调用的加载器来完成
D.在可执行目标文件的加载过程中,其中的指令和数据被读入主存
解释:其中的指令和数据没有被读入主存
7以下是在Linux系统中启动并加载可执行目标文件过程中shell命令行解释程序所做的部分操作:
① 构造构造argv和envp
② 调用fork()系统调用函数
③ 调用execve()系统调用函数
④ 读入命令(可执行文件名)及参数
启动并加载可执行目标文件的正确步骤是( D )。
A.④→①→③→②
B.①→②→③→④
C.②→④→①→③
D.④→①→②→③
8以下是有关动态链接及其所链接的共享库以及动态链接生成的可执行目标文件的叙述,其中错误的是( D )。
A.共享库在Linux下称为动态共享对象(.so),在Windows下称为动态链接库(.dll)
B.可执行目标文件在加载或执行时,系统将会调出动态链接器利用共享库对其进行动态链接
C.生成的可执行目标文件是部分链接的,也即,其中还有部分引用没有进行重定位
D.可执行目标文件由动态链接器对可重定位目标文件和共享库中部分信息进行链接而成
解释:可执行目标文件在加载或执行时,系统将会调出动态链接器利用共享库对其进行动态链接
9以下是有关静态链接和动态链接比较的叙述,其中错误的是( B )。
A.静态库函数更新后需对程序重新编译和链接,而共享库函数更新后程序无需重新编译和链接
B.静态链接情况下静态库函数在加载时被链接,动态链接情况下共享库函数可在加载或运行时被链接
C.静态库函数代码包含在可执行目标文件中,而共享库函数代码不包含在可执行目标文件中
D.静态库函数代码包含在进程代码段中,而共享库函数代码不包含在进程代码段中
解释:
通常情况下,对函数库的链接是放在编译时期(compile time)完成的,所有相关的对象文件(object file)与牵涉到的函数库(library)被链接合成一个可执行文件(executable file)。程序在运行时,与函数库再无瓜葛,因为所有需要的函数已拷贝到自己门下。所以这些函数库被成为静态库(static libaray),通常文件名为“libxxx.a”的形式。
静态库的优点是可以在不用重新编译程序库代码的情况下,进行程序的重新链接,这种方法节省了编译过程的时间(在编译大型程序的时候,需要花费很长的时间)。静态库的另一个优点是开发者可以提供库文件给使用的人员,不用开放源代码,这是库函数提供者经常采用的手段。
动态链接库是程序运行时加载的库,当动态链接库正确安装后,所有的程序都可以使用动态库来运行程序。动态链接库是目标文件的集合,目标文件在动态链接库中的组织方式是按照特殊方式形成的。库中函数和变量的地址是相对地址,不是绝对地址,其真实地址在调用动态库的程序加载时形成。
动态链接库的名称有别名(soname)、真名(realname)和链接名(linker name)。别名由一个前缀 lib,然后是库的名字,再加上一个后缀“.so”构成。真名是动态链接库真实名称,一般总是在别名的基础加上一个小版本号,发布版本等构成。除此之外,还有一个链接名,即程序链接时使用的库的名字。(更详细的内容在第 6 章讲述共享库的版本时展开)
在动态链接库安装的时候,总是复制文件到某个目录下,然后用一个软连接生成别名,在库文件进行更新的时候,仅仅更新软链接即可。
把库函数推迟到程序运行时期载入的好处:
- 可以实现进程之间的资源共享;
- 将一些程序升级变得简单;
- 甚至可以真正做到链接载入完全由程序员在程序代码中控制;
10一个共享库文件(.so文件)由多个模块(.o文件)生成。在生成共享库文件的过程中,需要对.o文件进行处理,以生成位置无关代码。以下有关位置无关代码(PIC)生成的叙述中,错误的是( C )。
A.模块内函数之间的调用可用PC相对地址实现,无需动态链接器进行重定位
B.模块外数据的引用需要动态链接器进行重定位,重定位时在GOT中填入外部数据的地址
C.模块间函数调用需要动态链接器进行重定位,重定位时在GOT和PLT中填入相应内容
D.模块内数据的引用无需动态链接器进行重定位,因为引用与定义间相对位置固定
解释:Lazy Binding才需要在PLT填入相应内容
计算机系统基础一期末考试
错题序号:18、19、22、30
1单选(0.5分)
以下有关指令集体系结构的叙述中,错误的是( )。
得分/总分
A.指令集体系结构在计算机系统层次中必不可少
B.指令集体系结构是对软件的一种抽象
0.50/0.50
C.指令集体系结构是一种规定
D.指令集体系结构位于软件和硬件的交界面
正确答案:B你选对了
2单选(0.5分)
以下有关冯∙诺依曼结构思想的叙述中,错误的是( )。
得分/总分
A.计算机内部以二进制形式表示指令和数据
B.程序由指令构成,计算机能自动执行程序中一条一条指令
C.指令和数据都放在存储器中,两者在形式上有差别
0.50/0.50
D.计算机由运算器、存储器、控制器和I/O设备组成
正确答案:C你选对了
3单选(0.5分)
以下有关机器指令和汇编指令的叙述中,错误的是( )。
得分/总分
A.汇编指令中用十进制或十六进制表示立即数
B.机器指令和汇编指令都能被计算机直接执行
0.50/0.50
C.汇编指令中用符号表示操作码和地址码
D.机器指令和汇编指令一一对应,功能相同
正确答案:B你选对了
4单选(0.5分)
下列数中最小的数为( )。
得分/总分
A.73O
0.50/0.50
B.3FH
C.66D
D.101 0110B
正确答案:A你选对了
5单选(0.5分)
考虑以下C语言代码:
unsigned short usi=65530;
short si=usi;
执行上述程序段后,si的值是( )。
得分/总分
A.–6
0.50/0.50
B.–65530
C.–5
D.65530
正确答案:A你选对了
6单选(0.5分)
在ISO C90标准下执行以下关系表达式,结果为“真”的是( )。
得分/总分
A.(unsigned) –1 > –2
0.50/0.50
B.–1 < 0U
C.2147483647 < (int) 2147483648U
D.2147483647 > –2147483648
正确答案:A你选对了
7单选(0.5分)
已知IA-32采用小端方式,有一个IA-32机器中的可执行文件反汇编后得到的机器级表示如下,其中左边冒号前为指令地址,中间为机器指令,右边为汇编指令。
……
80483d2: 81 ec 10 01 00 00 sub $0x110, %esp
……
80483de: 8b 85 01 ff ff ff mov 0xffffff01(%ebp), %eax
上述划线部分表示的立即数的值分别是( )。
A.268435456,–255
B.272,–255
C.272,33554432
D. 268435456,335544
正确答案:B你选对了
8单选(0.5分)
–1.0625采用IEEE 754单精度浮点数格式表示的结果(十六进制形式)是( )。
A.40080000H
B. C0080000H
C.BF880000H
D.3F880000
正确答案:C你错选为A
9单选(0.5分)
假定某数采用IEEE 754单精度浮点数格式表示为C820 0000H,则该数的值是( )。
得分/总分 A.–1.25×2^144
B.–1.01×2^144
C.–1.25×2^17
D.–1.01×2^17
正确 答案:C.–1.25×2^17
10单选(0.5分)
假定某数采用IEEE 754单精度浮点数格式表示为00000001H,则该数的值是( )。
A.1.00…01×2^(-127)
B.1.0×2^(-149)
C.1.0×2^(-150)
D.NaN(非数)
正确答案:B.1.0×2^(-149)
11单选(0.5分)
若int型变量x的最高有效字节全变0,其余各位不变,则对应C语言表达式为( )。
得分/总分
A. ((unsigned) x >> 8) << 8
B.((unsigned) x << 8) >>8
C.(x << 8) >>8
0.00/0.50
D.( x >> 8) << 8
正确答案:B你错选为C
12单选(0.5分)
假定整数加法指令、整数减法指令和移位指令所需时钟周期都为1,整数乘法指令所需时钟周期为8。若x为整型变量,为了使计算36*x所用时钟周期数最少,编译器应选用的最佳指令序列为( )。
得分/总分
A.4条左移指令和3条减法指令
B.两条左移指令和1条加法指令
0.50/0.50
C.1条乘法指令
D.3条左移指令和两条加法指令
正确答案:B你选对了
13单选(0.5分)
某C语言程序中对数组变量b的声明为“short b[10][5];”,sum为int型,有一条for语句如下:
for (i=0; i<10, i++)
for (j=0; j<5; j++)
sum+= b[i][j];
假设执行到“sum+= b[i][j];”时,sum的值在EAX中,b[i][0]所在的地址在ECX中,j在EDI中,则“sum+= b[i][j];”所对应的指令或指令序列(AT&T格式)可以是( )。
得分/总分
A.
addl 0(%ecx, %edi, 2), %eax
B.
movzwl 0(%edi, %ecx, 2), %edx
addl %edx, %eax
C.
movswl 0(%ecx, %edi, 2), %edx
addl %edx, %eax
D.
addl 0(%edi, %ecx, 2), %eax
正确答案:C.
movswl 0(%ecx, %edi, 2), %edx
addl %edx, %eax
14单选(0.5分)
设SignExt[x]表示对x符号扩展,ZeroExt[x]表示对x零扩展。IA-32中指令“movzwl %cx, -16(%ebp)”的功能是( )。
得分/总分
A.R[cx]←SignExt [M[R[ebp]-16]]
B.M[R[ebp]-16]←SignExt[R[cx]]
C. R[cx]←ZeroExt [M[R[ebp]-16]]
D.M[R[ebp]-16]←ZeroExt[R[cx]]
正确答案:DM[R[ebp]-16]←ZeroExt[R[cx]]
15单选(0.5分)
假设 R[ax]=FFD0H,R[bx]=7FE5H,执行指令“subw %bx, %ax”后,寄存器的内容和各标志的变化为( )。
得分/总分
A.R[ax]=7FEBH,OF=1,SF=0,CF=0,ZF=0
B.R[bx]=7FEBH,OF=0,SF=1,CF=0,ZF=0
C.R[bx]=7FEBH,OF=1,SF=1,CF=1,ZF=0
D.R[ax]=7FEBH,OF=0,SF=0,CF=1,ZF=0
正确答案:A.R[ax]=7FEBH,OF=1,SF=0,CF=0,ZF=0
16单选(0.5分)
以下关于各类控制转移指令的叙述中,错误的是( )。
得分/总分
A.条件转移指令(Jcc)的判断条件可用于整数之间和浮点数之间的大小比较
0.50/0.50
B.调用指令(CALL)和返回指令(RET)都是特殊的无条件转移指令
C.无条件转移指令(JMP)直接将转移目标地址送到EIP寄存器中
D.条件转移指令(Jcc)将根据EFLAGS寄存器中的标志信息进行条件判断
正确答案:A你选对了
17单选(0.5分)
以下是关于IA-32架构的栈帧中所存放信息的叙述,其中错误的是( )。
得分/总分
A.调用过程对应栈帧中最后存放的总是返回地址
B.因为静态变量是局部的,因此被存放在栈帧中
0.50/0.50
C.每个栈帧的底部存放的是EBP寄存器内容
D.每递归调用一次递归过程就生成一个新的栈帧
正确答案:B你选对了
18单选(0.5分)
以下是在IA-32系统上运行的一个程序:
int x= -200;
void main ( )
{
unsigned x;
printf(“x=%d\n”, x);
}
对于程序运行结果的叙述,其中正确的是( )。
得分/总分
A.因为-200被转换成了无符号数,所以打印结果不应该是x= - 200
B.因为x既是全局变量又是局部变量,被定义了两次,所以链接时会出错
C.因为格式符是%d,所以打印出来的结果应是x= - 200
D.因为打印结果是局部变量x的值,而局部变量x未赋初值,所以结果为随机值
0.50/0.50
正确答案:D你选对了
19单选(0.5分)
假定“int buf[4]={100, 20, 1, 8};”所定义的buf被分配在静态数据区,其首地址为0x08048930,“int *bufp1;”为未初始化全局变量。以下关于“bufp1 = &buf[1];”的重定位的描述中,错误的是( )。
得分/总分
A.bufp1被定义在.bss节中,共占4个字节
B.buf被定义在.data节中,共占16个字节
C.bufp1和buf重定位处的初值都是0且都采用绝对地址方式
0.50/0.50
D.bufp1和buf对应的重定位信息都在.rel.text节中
正确答案:C你选对了
20单选(0.5分)
以下有关动态链接的叙述中,错误的是( )。
得分/总分
A.将共享代码从可执行文件中分离出来形成共享库文件,在加载或执行可执行文件时进行动态链接
B.共享库中不同模块之间引用数据或调用函数时,需要使用全局偏移表(GOT)来动态填入地址
C.生成的共享库文件是位置无关代码(PIC),动态链接器可将共享库代码映射到任意地址运行
D.共享库中模块内或不同模块之间引用数据或调用函数时,都需要生成过程链接表(PLT)代码
0.50/0.50
正确答案:D你选对了
21填空(3分)
计算机系统为层次结构,处在软件层次和硬件层次交界面的是指令集体系结构。指令集体系结构的英文缩写为( )。
正确答案:ISA
22填空(3分)
CPU内部数据通路是指CPU内部的数据流经的路径以及路径上的部件,主要是CPU内部进行数据运算、存储和传送的部件,这些部件的宽度基本上要一致,才能相互匹配。所谓( )通常是指CPU内部用于整数运算的数据通路的宽度。
正确答案:字长
23填空(3分)
将数据的最高有效字节MSB存放在高地址而将最低有效字节LSB存放在低地址的方式为( )端方式。该方式下数据的地址就是LSB所在的地址。
正确答案:小
24填空(3分)
若8位带符号整数的补码表示为1001 0101,则右移一位后的结果为( )。
正确答案:1100 1010 或 11001010
25填空(3分)
若8位带符号整数的补码表示为1001 0101,则左移一位后的结果为( )。
正确答案:溢出 或 0010 1010 或 00101010
26填空(3分)
补码乘法运算的情况下,可以通过乘积的高n位和低n位之间的关系来进行溢出判断。判断规则是:若高n位中每一位都与低n位的最高位相同,则( )。
正确答案:不溢出
27填空(3分)
若两个float型变量(用IEEE 754单精度浮点格式表示)x和y的机器数分别表示为x=98737E2FH,y= C03652B3H,则在计算x-y时,第一步对阶操作的结果[Ex-Ey]补为( )。
正确答案:1011 0000 或 10110000
28填空(3分)
用( )指令表示的机器语言程序和用汇编指令表示的汇编语言程序统称为机器级程序,是对应高级语言程序的机器级表示。
正确答案:机器
29填空(3分)
共享库以动态链接的方式被多个加载过程中的或正在执行的应用程序共享,因而共享库的动态链接有两个方面的特点:一是共享性,二是( )。
正确答案:动态性
30填空(3分)
共享库文件是一种特殊的可重定位目标文件,其中记录了相应的代码、数据、重定位和符号表信息,能在可执行目标文件装入或运行时被动态地装入到内存并自动被链接,这个过程称为动态链接(dynamic link),由一个称为( )的程序来完成。
正确答案:动态链接器 或 动态链接程序
计算机系统基础二课程概述
在“计算机系统基础(一):程序的表示、转换与链接"课程中,你学习了可执行文件的生成。接下来,你是否很想知道可执行文件是如何运行、指令和数据是如何存放和被访问的呢?如果是的话,那么就请你参加“计算机系统基础(二):程序的执行和存储访问"课程的学习吧!—— 课程团队
课程概述
本课程主要介绍可执行文件中的代码如何在CPU中执行,如何从存储器中取指令,以及如何从存储器中取数据或存结果。在本课程中,我们主要围绕以下问题进行讲解。
计算机中的CPU是如何执行程序的?
CPU中包含哪些基本的功能部件?
存放代码和数据的主存储器如何构成?
存放文件的磁盘存储器是怎么工作的?
CPU如何把一个虚拟地址转换为主存地址?
如何利用高速缓存技术加快访问存储器的速度?
IA-32/Linux平台如何实现存储访问?
课程大纲
第一周 程序执行概述
第一周 程序执行概述引言
第1讲 程序和指令的关系
第2讲 一条指令的执行过程
第3讲 IA-32指令的大致执行过程
第4讲 CPU的基本功能与结构
课件PPT
第一周小测验
第二周 主存储器组织
第二周 主存储器组织引言
第1讲 存储器基本概念
第2讲 主存的基本结构
第3讲 主存的性能指标
第4讲 半导体存储器组织
第5讲 内存条组织与总线宽度
第6讲 主存模块的连接与读写操作
课件PPT
第二周小测验
第三周 磁盘存储器
第三周磁盘存储器引言
第1讲 磁盘存储器的结构
第2讲 磁盘驱动器以及操作过程
第3讲 磁盘存储器的组成
第4讲 磁盘存储器的连接与操作
课件PPT
第三周小测验
第四周 高速缓存概述
第四周高速缓存概述引言
第1讲 存储器层次结构概述
第2讲 Cache基本概述
第3讲 Cache映射方式
第4讲 Cache命中率和缺失率
第5讲 Cache的关联度
课件PPT
第四周小测验
第五周 Cache替换算法和写策略
第五周 Cache替换算法和写策略引言
第1讲 Cache替换算法
第2讲 Cache写策略(一致性问题)
第3讲 Cache实现的几个因素
第4讲 Cache实现举例
第5讲 Cache综合计算举例
课件PPT
第五周小测验
第六周 虚拟存储器
第六周虚拟存储器引言
第1讲 分页存储管理的基本概念
第2讲 虚拟存储器及虚拟地址空间
第3讲 分页存储管理的实现
第4讲 存储器层次结构及其访问过程
第5讲 段式和段页式虚拟存储管理
第6讲 存储保护
课件PPT
第六周小测验
第七周 IA-32/Linux中的地址转换
第七周IA-32/Linux中的地址转换引言
第1讲 IA-32的地址转换和寻址方式
第2讲 段选择符和段寄存器
第3讲 段描述符和段描述符表
第4讲 逻辑地址向线性地址的转换
第5讲 线性地址向物理地址的转换
第6讲 Intel Core i7/Linux存储系统
课件PPT
第七周小测验
第一周程序执行概述
第1讲 程序和指令的关系

第2讲 一条指令的执行过程
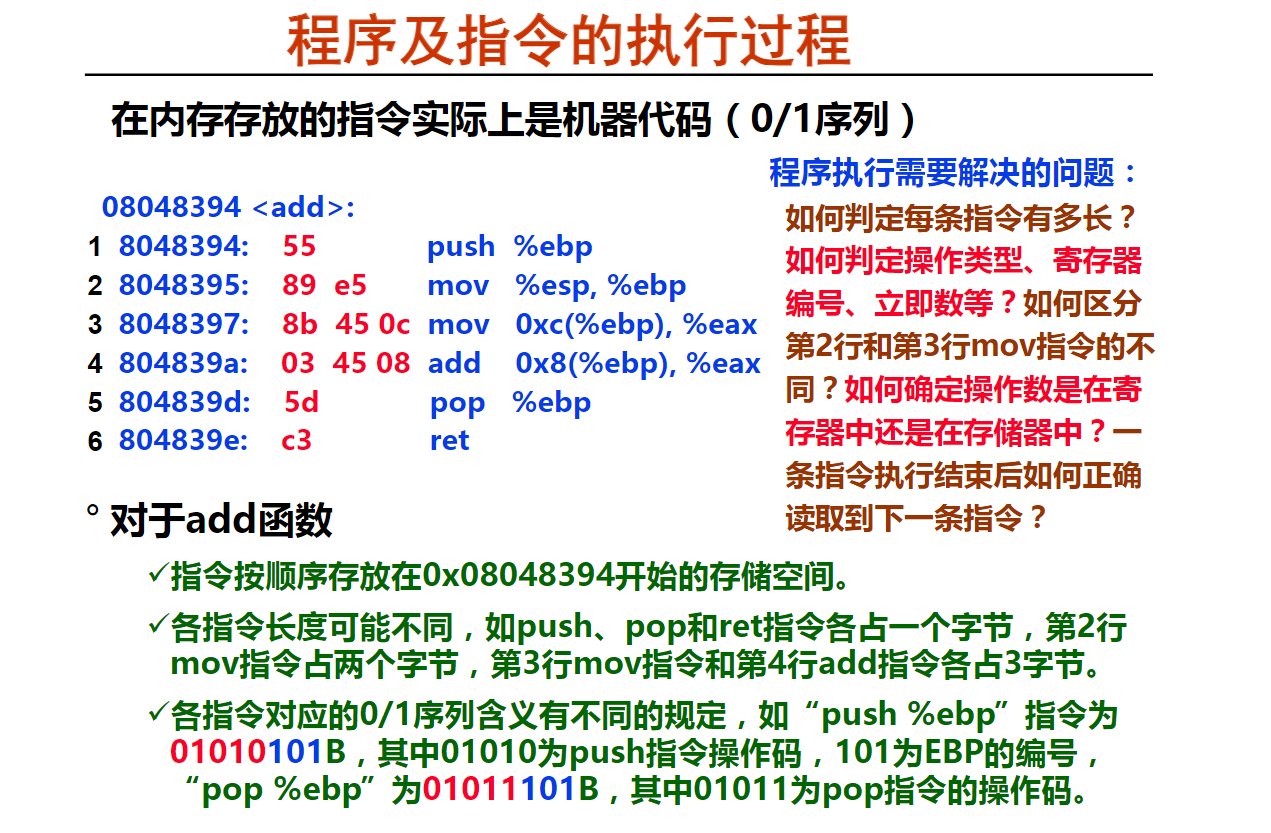
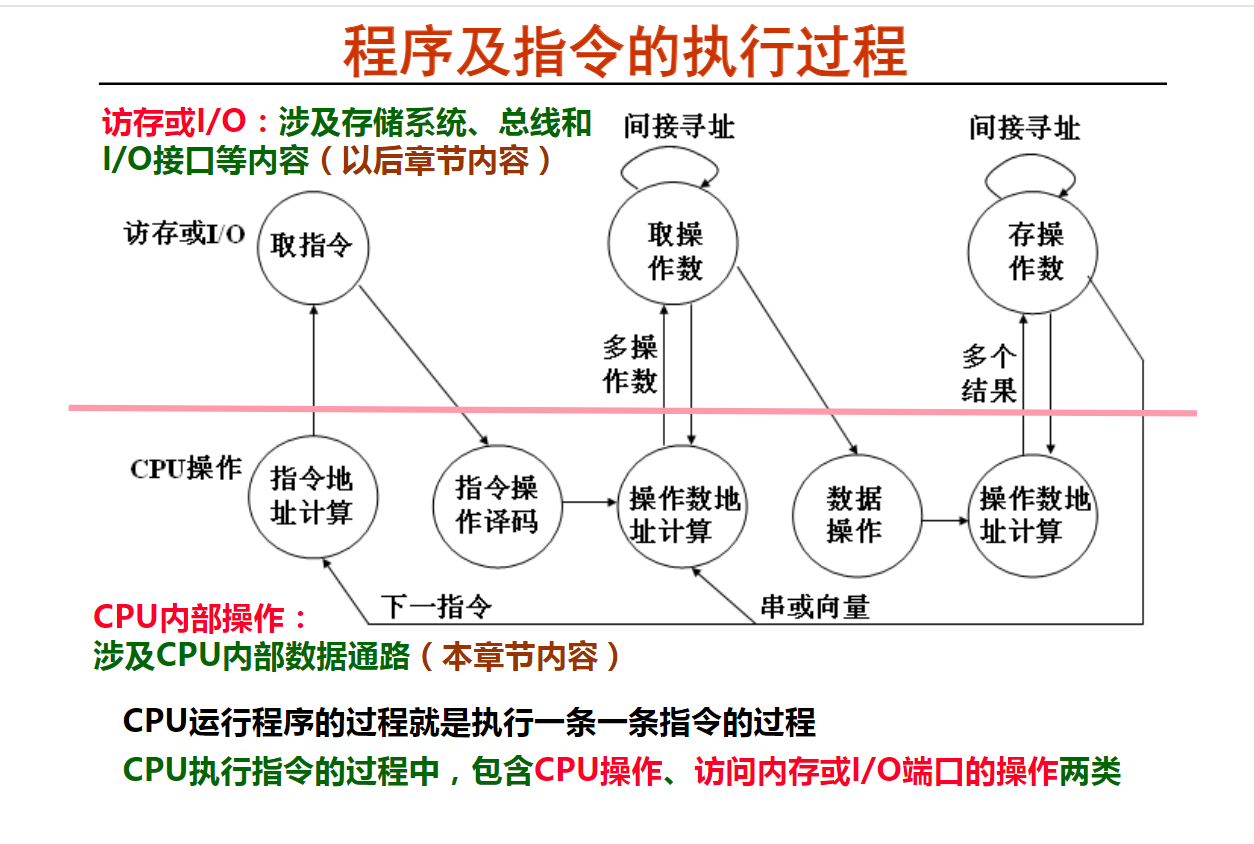
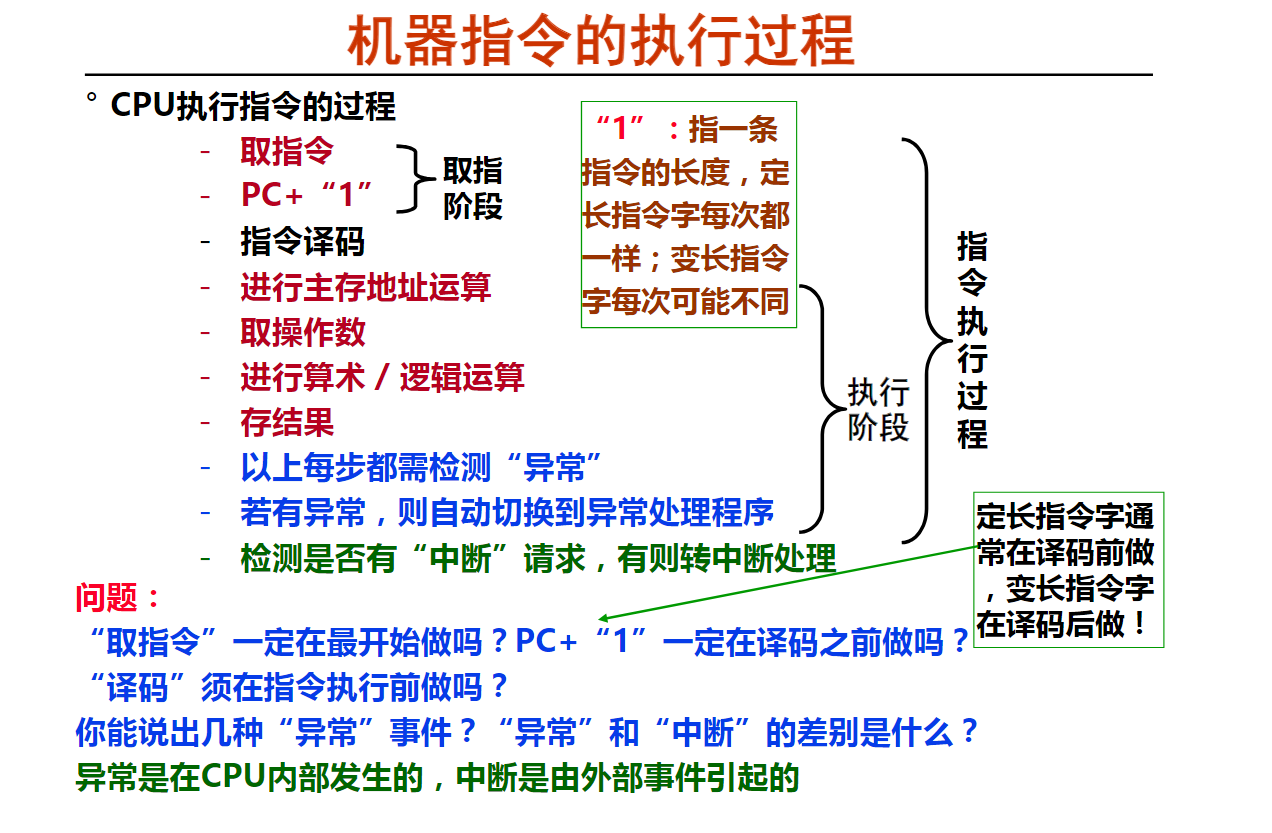

第3讲 IA-32指令的大致执行过程

第4讲 CPU的基本功能与结构

一周小测验
1机器主频的倒数(一个节拍)等于( D )。
A.存储周期
B.机器周期
C.指令周期
D.时钟周期
解析: D、时钟周期是CPU工作的最小时间单位,也称节拍脉冲或T周期,其值等于机器主频的倒数。
指令周期是指读取一条指令并完成执行所用的时间,不同指令的指令周期可能不同。
早期的计算机有机器周期的概念,特指一个指令周期中的不同阶段操作所用时间,例如,取指令、译码、取操作数、执行、送结果等不同阶段分别在一个特定的机器周期内完成。取指令、取操作数和写结果都可能会访问主存,所以这些阶段被称为存储器读或存储器写机器周期。
存储周期是主存的一个指标,指主存进行连续两次独立的读或写操作所需的最小时间间隔。
2CPU中控制器的功能是( A )。
A.完成指令译码,并产生操作控制信号
B.控制从主存取出一条指令
C.产生时序信号
D.完成指令操作码译码
正确答案:A你选对了
3冯·诺依曼计算机中指令和数据均以二进制形式存放在存储器中,CPU依据( C )来区分它们。
A.指令和数据的地址形式不同
B.指令和数据的寻址方式不同
C.指令和数据的访问时点不同
D.指令和数据的表示形式不同
解析: C、指令和数据均以二进制形式存放在存储器中,因而表示形式相同。
指令的寻址很简单,总是根据PC内容访问存储器,而数据的寻址则比较复杂,有立即、寄存器直接、变址、基址寻址等多种寻址方式。不过,CPU并不能根据寻址方式来区分访问的是数据还是指令。
指令周期中的第一个阶段总是取指令阶段,因而CPU根据是否是取指令阶段来区分取到的是指令还是数据。若是指令,则取出后存放在指令寄存器(IR)中。
指令和数据的地址都是二进制形式,因而地址形式相同。
4下列寄存器中,用户可见的(即:机器级代码程序员能感觉其存在的)寄存器是( A )。
A.程序计数器(PC)
B.存储器数据寄存器(MDR)
C.存储器地址寄存器(MAR)
D.指令寄存器(IR)
解析: A、用汇编语言这种机器级语言编写程序的程序员,需要在转移指令中考虑采用什么方式改变PC的值,因而他/她能感觉到PC的存在。而MAR、MDR和IR都是执行指令过程中用到的CPU内部寄存器,汇编程序员在编写程序时不能感觉到有这些寄存器的存在。
5下面是有关CPU中部分部件的描述,其中错误的是( B )。
A.通过将 PC按当前指令长度增量,可实现指令的按序执行
B.IR称为指令寄存器,用来存放当前指令的操作码
C.ALU称为算术逻辑部件,用于进行加、减运算和逻辑运算
D.PC称为程序计数器,用于存放将要执行的指令的地址
解析: B、IR中存放的是整个指令,而不仅仅是指令操作码。
6执行完当前指令后,PC中存放的是后继指令的地址,因此PC的位数和( B )的位数相同。
A.程序状态字寄存器(PSWR)
B.主存地址寄存器(MAR)
C.指令寄存器(IR)
D.指令译码器(ID)
解析: B、PC中存放的是将要读取的指令的主存地址,因而和主存地址寄存器MAR的位数相同。
7通常情况下,下列部件( B )不包含在CPU芯片中。
A.控制器
B.动态随机访问存储器(DRAM)
C.标志(状态)寄存器
D.通用寄存器组
解析: B、CPU中的标志(状态)寄存器用于存放ALU运算得到的各种标志信息等。控制器用于对指令译码产生控制信号。通用寄存器组(General Purpose Registers,GPRs)用于暂存ALU运算所用的操作数或运算结果。通常DRAM用作主存,若干DRAM芯片排列在内存条上,因而不可能在CPU芯片内。
8下列有关程序计数器PC的叙述中,错误的是( D )。
A.无条件转移指令执行后,PC的值一定是转移目标地址
B.每条指令执行后,PC的值都会被改变
C.调用指令执行后,PC的值一定是被调用过程的入口地址
D.指令顺序执行时,PC的值总是自动加1
解析: D、每条指令执行后,PC的值都会被改变,否则会永远执行某一条指令。顺序执行时,PC的值总是自动加上当前指令的长度,而不是1。
9CPU取出一条指令并完成执行所用的时间称为( D )。
A.机器周期
B.CPU周期
C.时钟周期
D.指令周期
正确答案:D你选对了
10下列有关指令周期的叙述中,错误的是( A )。
A.乘法指令和加法指令的指令周期总是一样长
B.任何指令的指令周期中至少有一个存储器访问阶段
C.指令周期的第一个阶段一定是取指令阶段
D.一个指令周期由若干个机器周期或时钟周期组成
解析: A、乘法指令通过执行若干次加减操作和移位操作来完成,因而,乘法指令的指令周期通常比加法指令的指令周期更长,即乘法指令的CPI比加法指令的CPI更大。 B、任何指令周期的第一个阶段都是取指令阶段,需要访问存储器。
第二周主存储器组织
第1讲 存储器基本概念
访存操作和基本术语
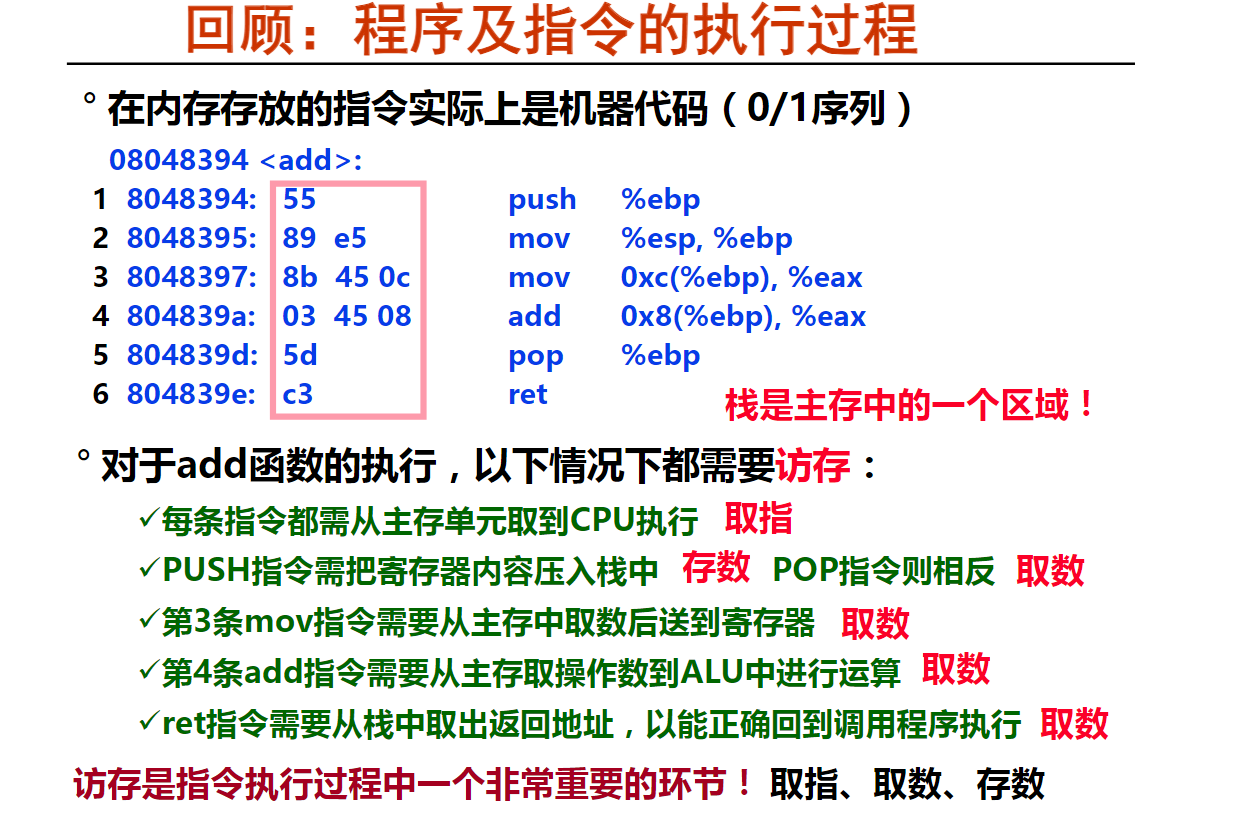

存储器分类




第2讲 主存的基本结构
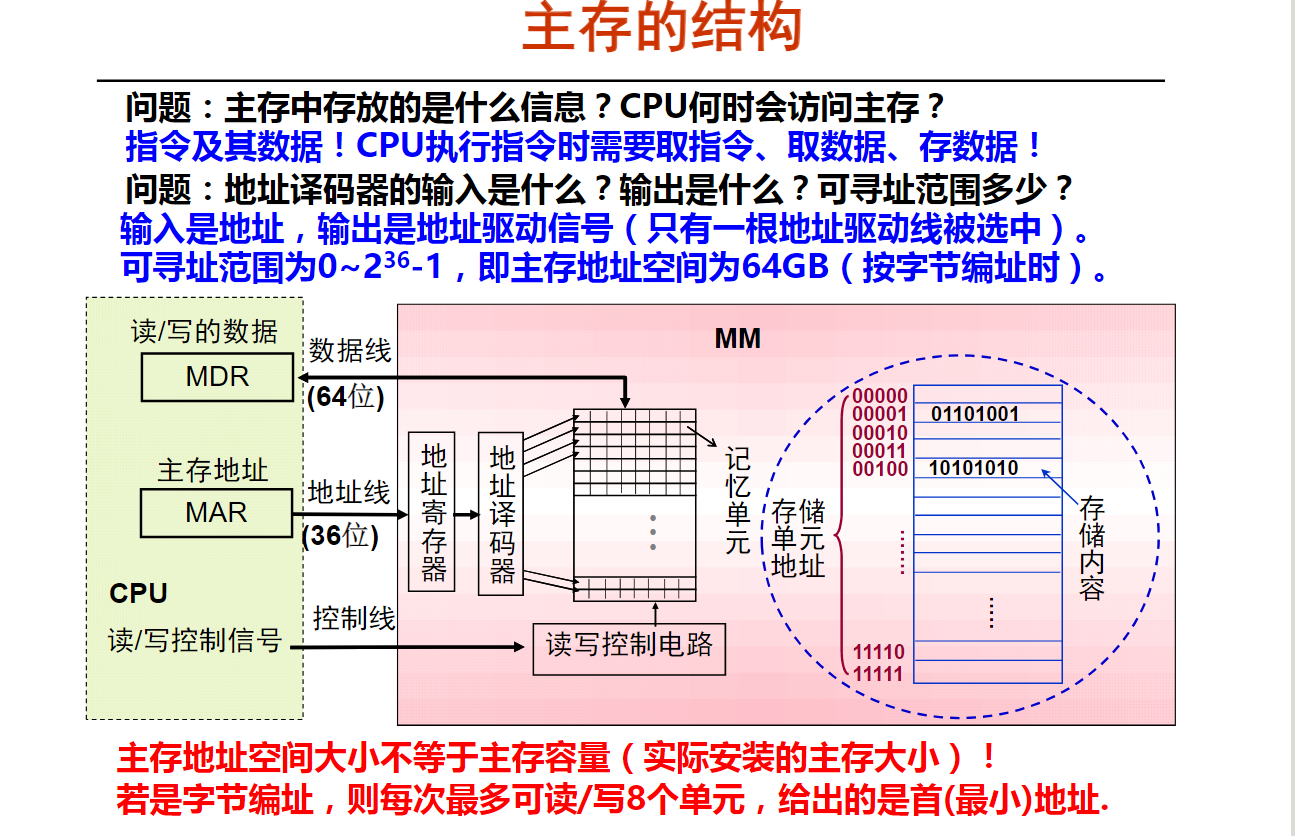
第3讲 主存的性能指标

第4讲 半导体存储器组织
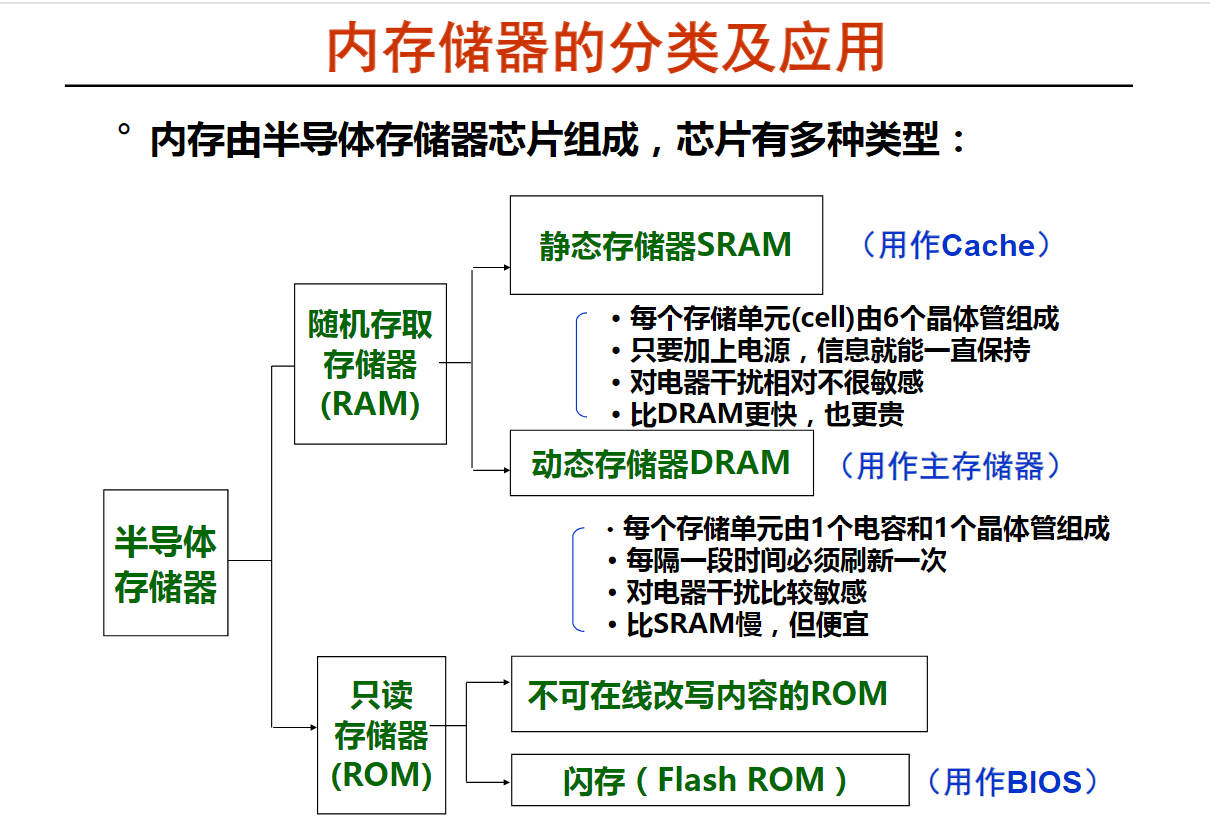
六管静态MOS管电路(4m32s)
单管动态记忆单元电路(3m55s)
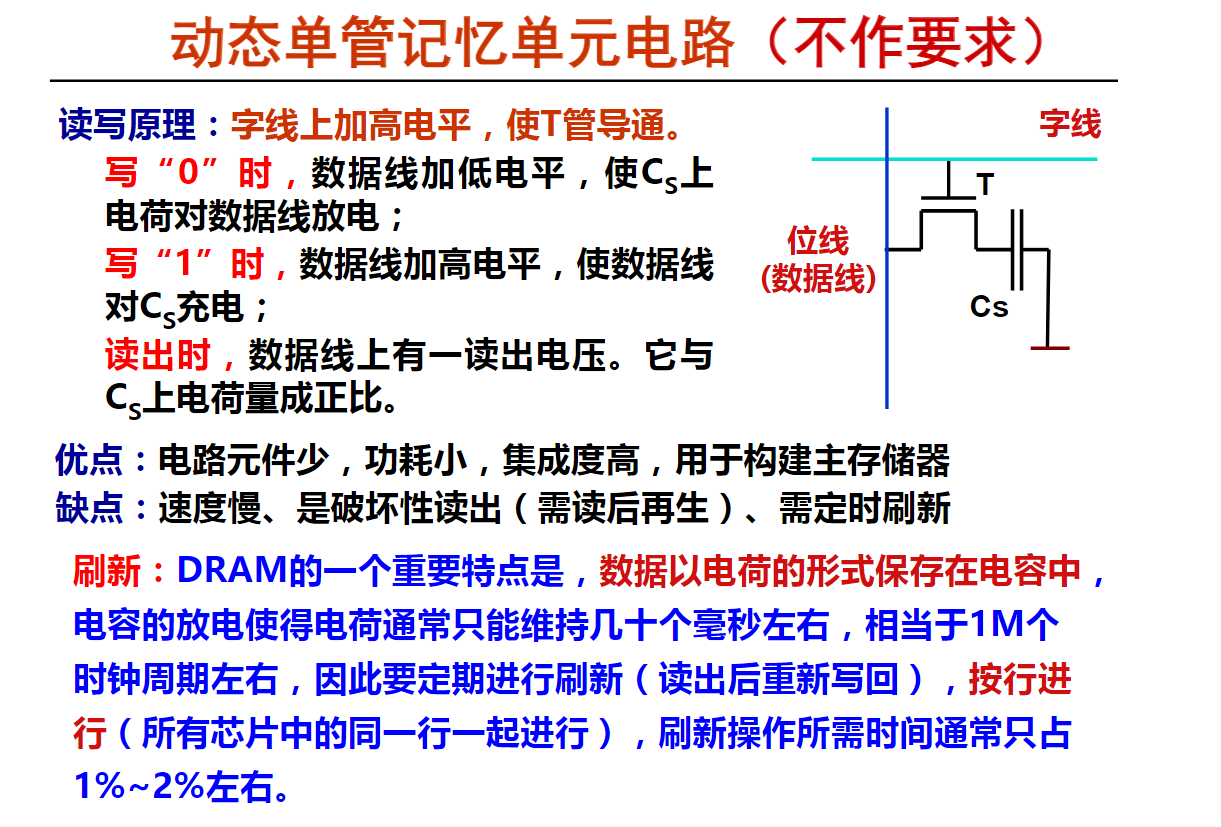
半导体RAM的组织(3m01s)
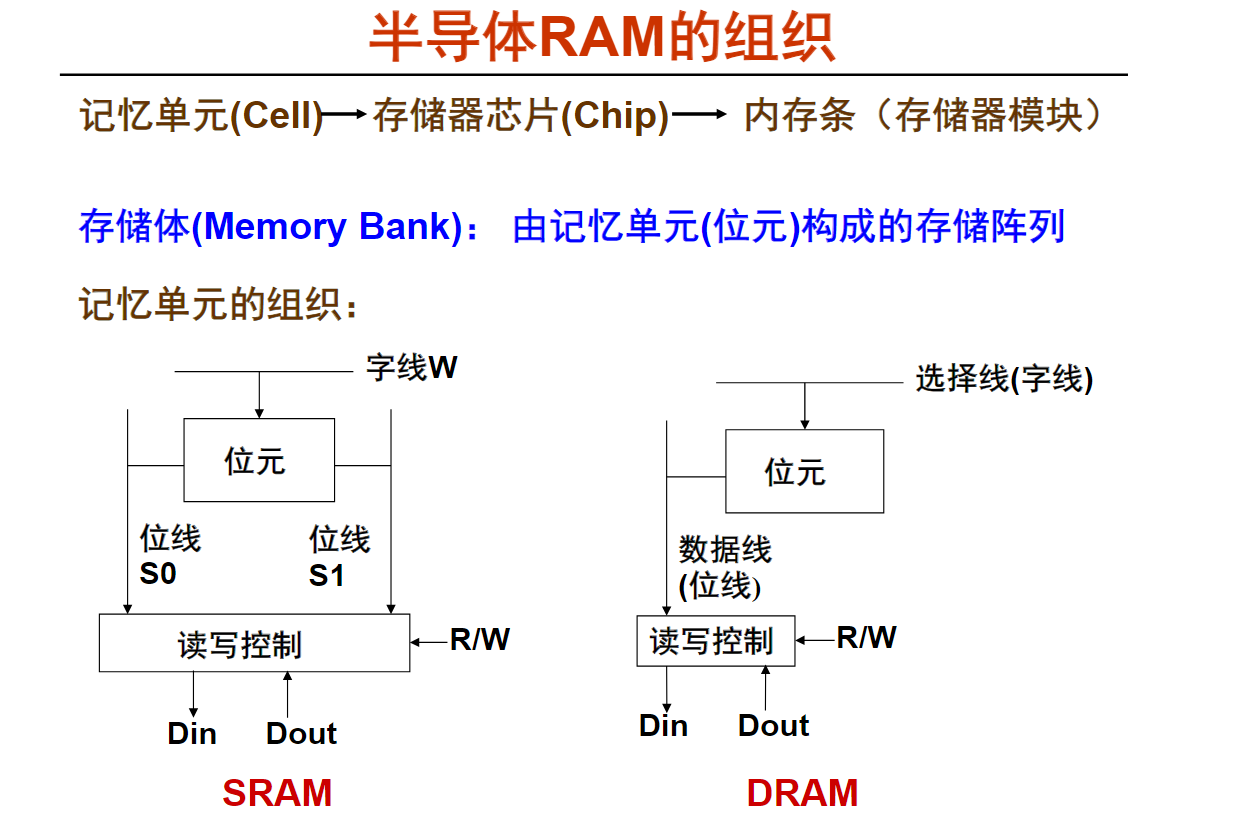
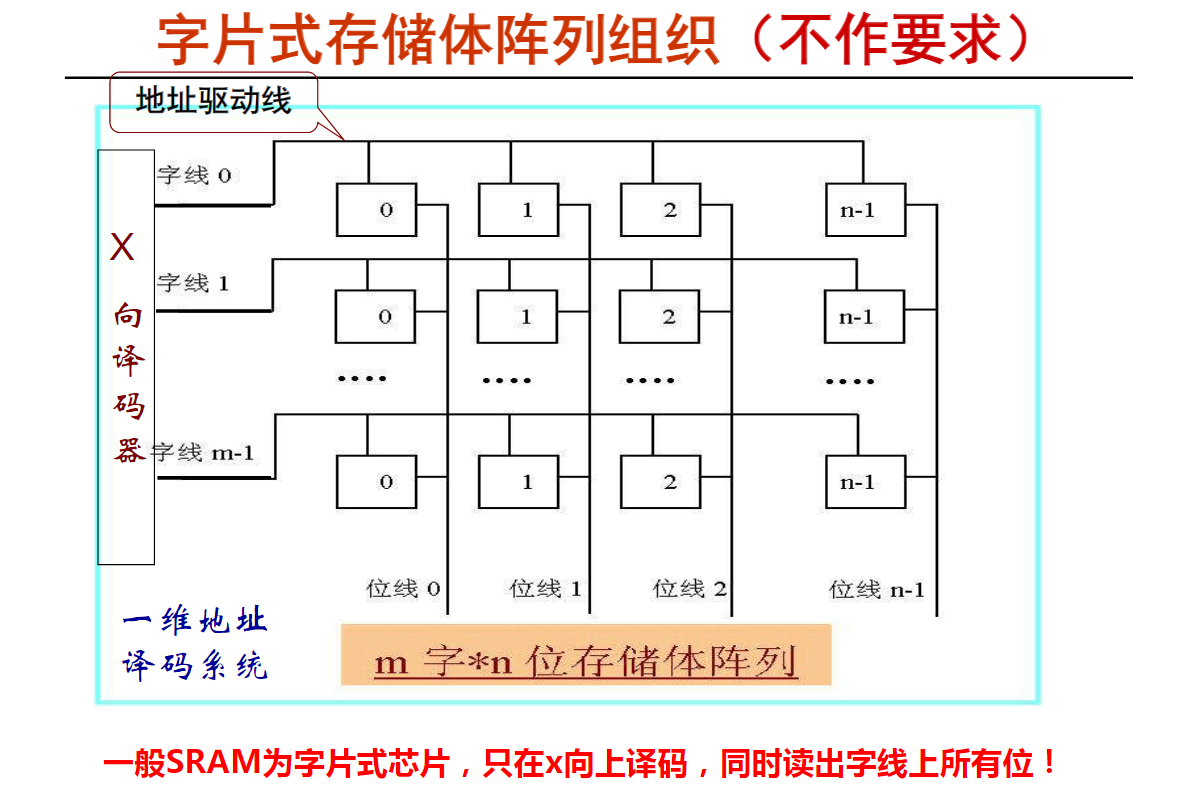
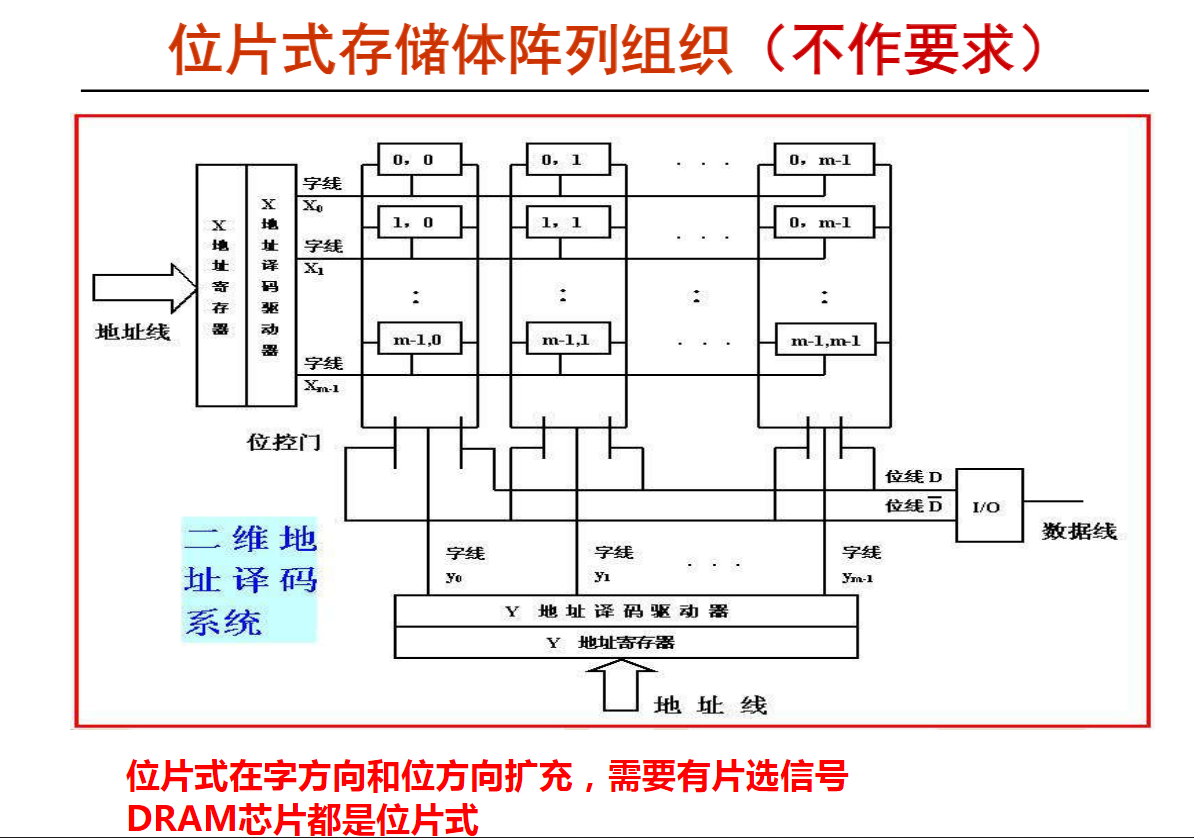
DRAM芯片举例

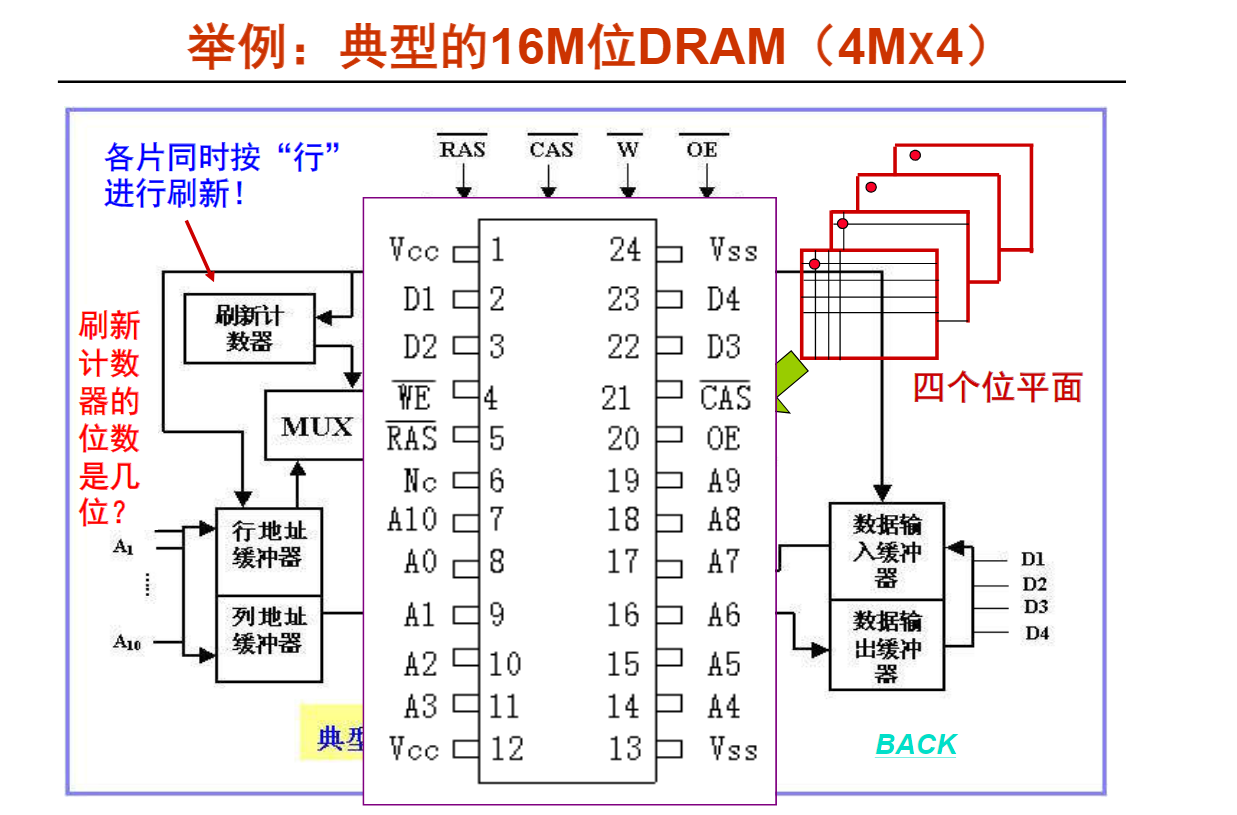
第5讲 内存条组织与总线宽度
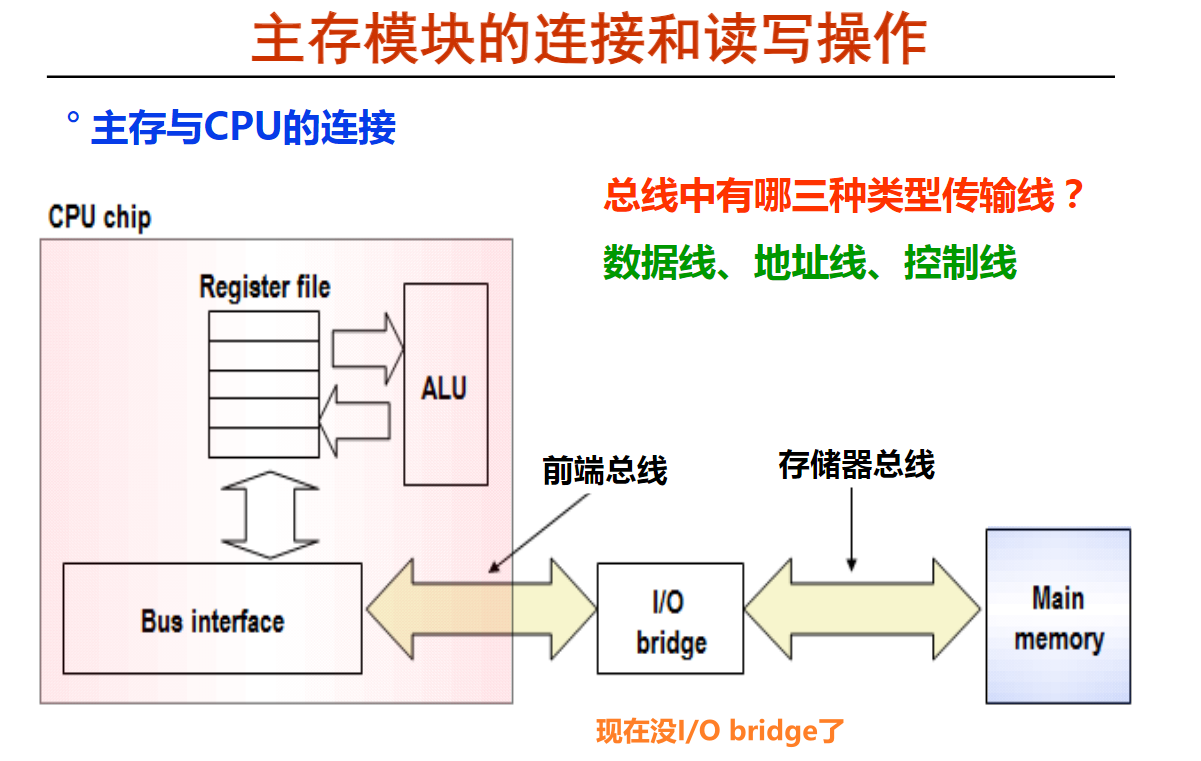
SPARC station 20的内存条(9m59s)
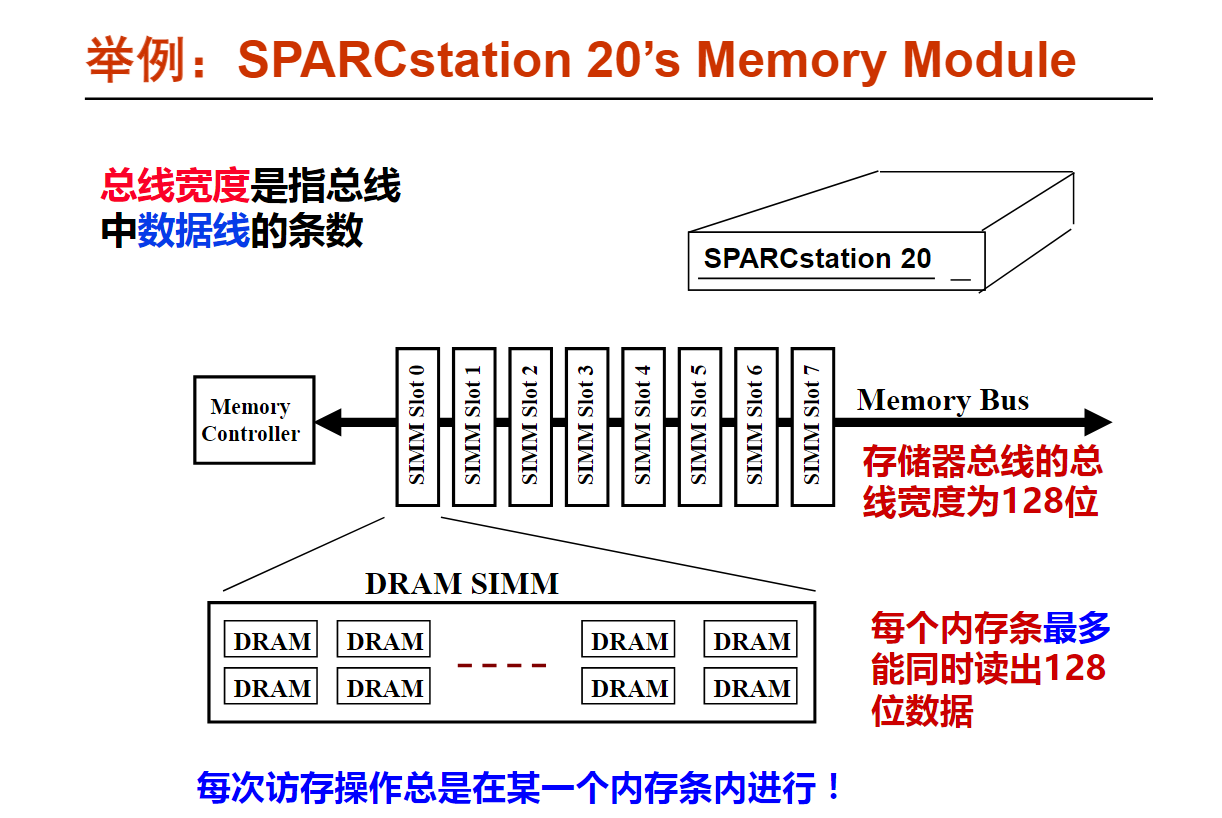


PC中的内存条(4m18s)
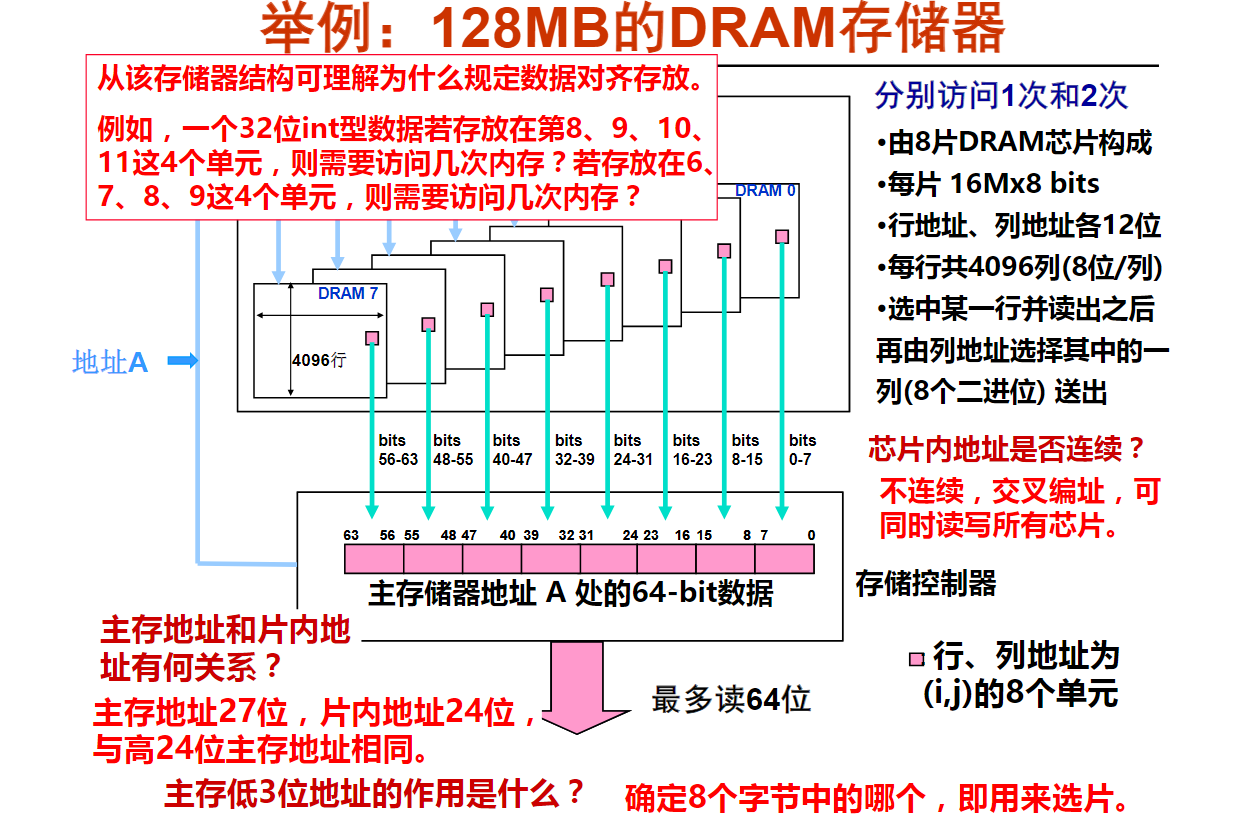
内存条与CPU的连接(6m24s)
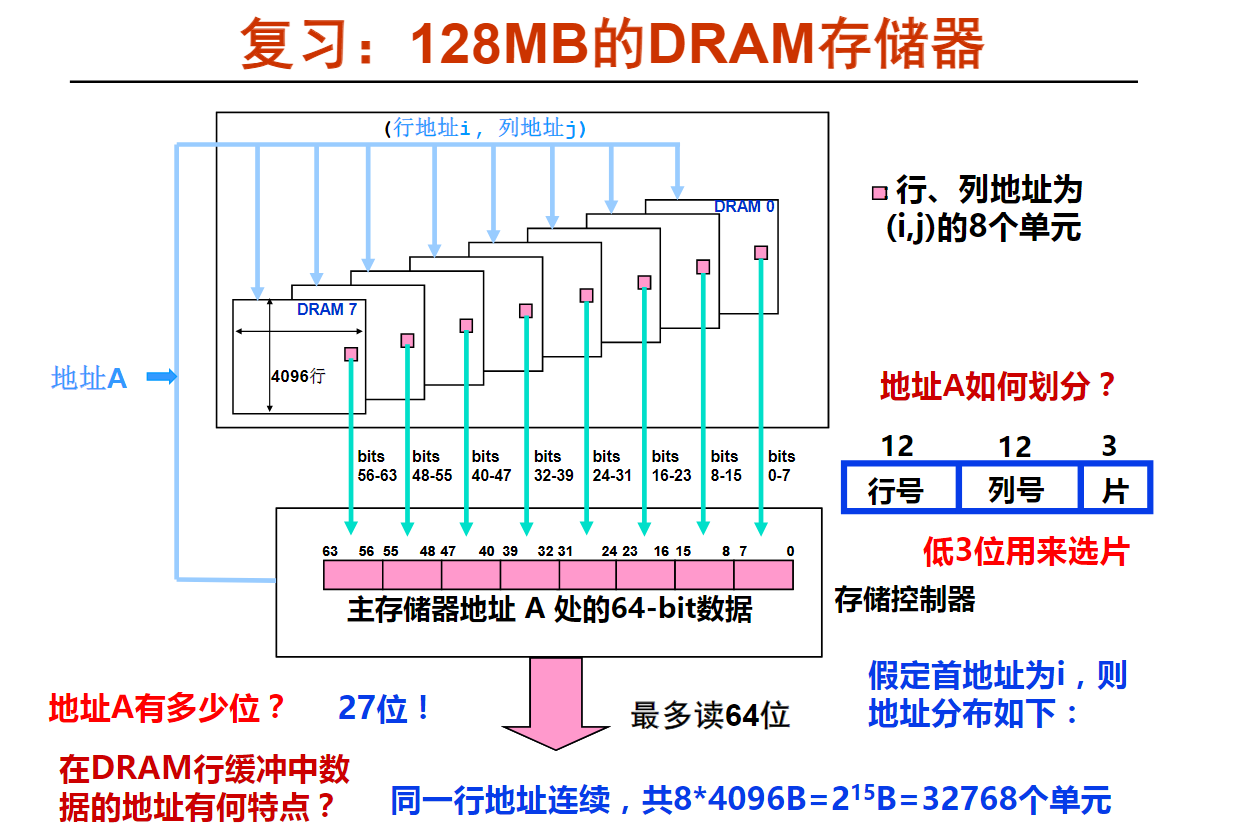
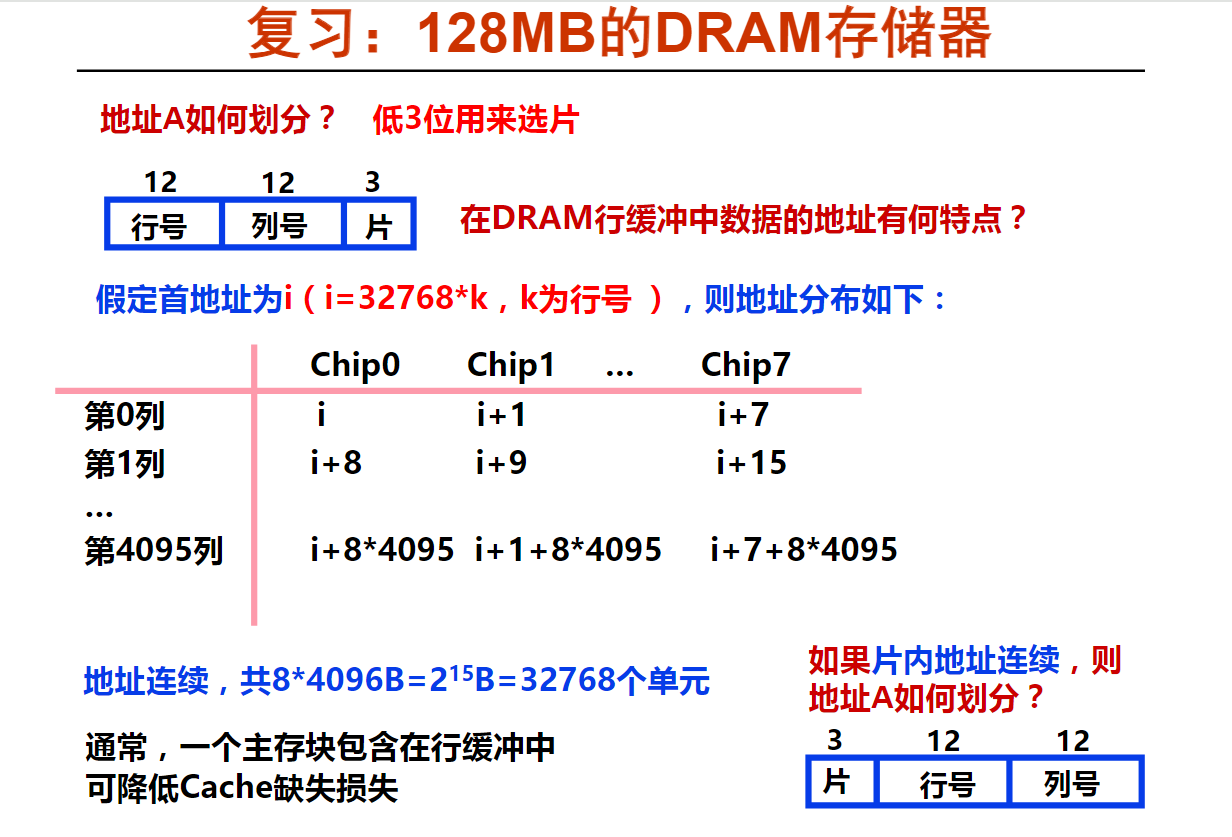

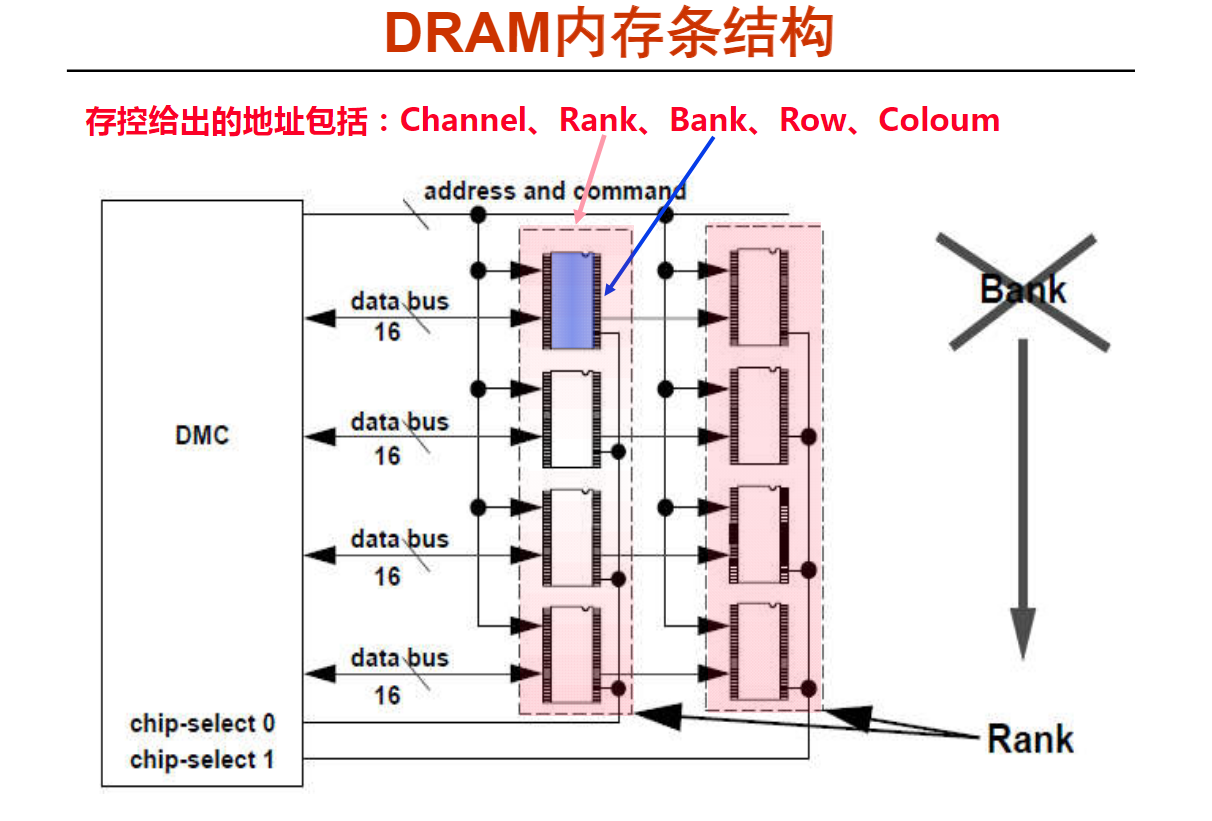


第6讲 主存模块的连接与读写操作(4m08s)
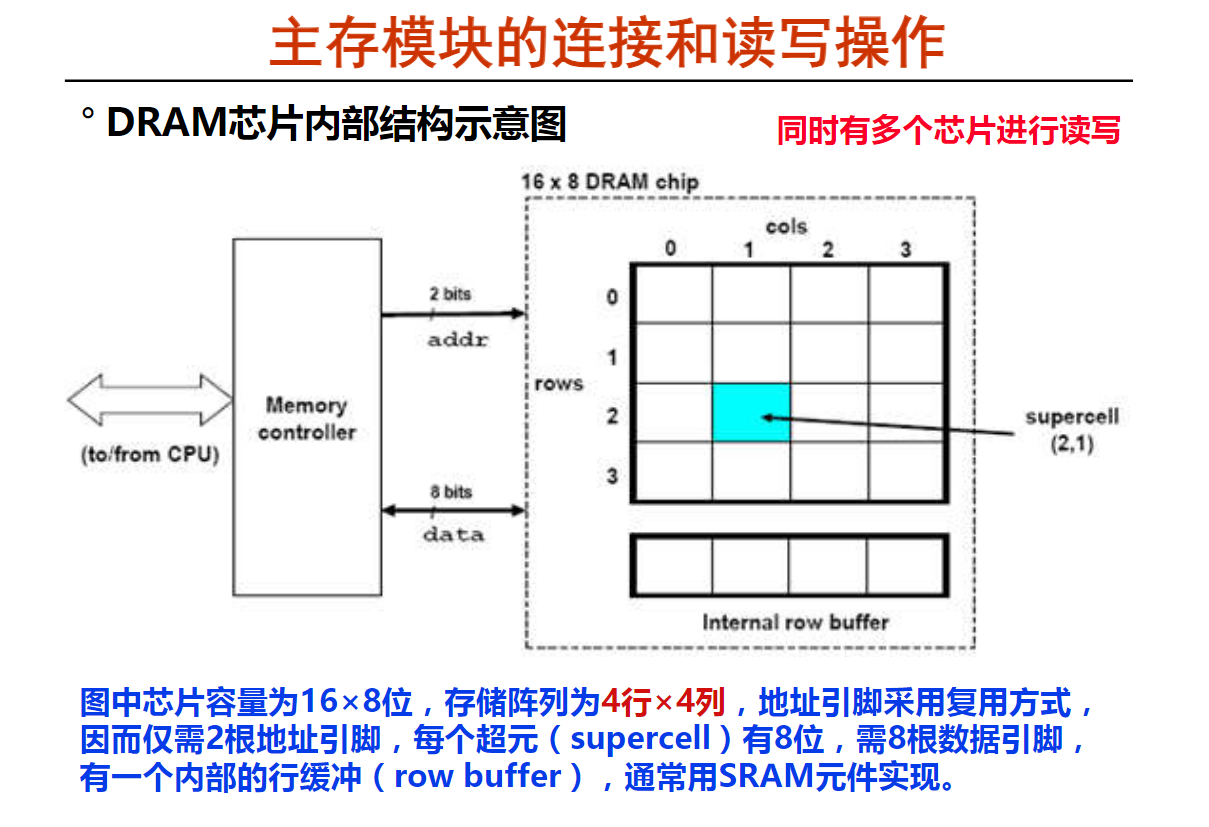
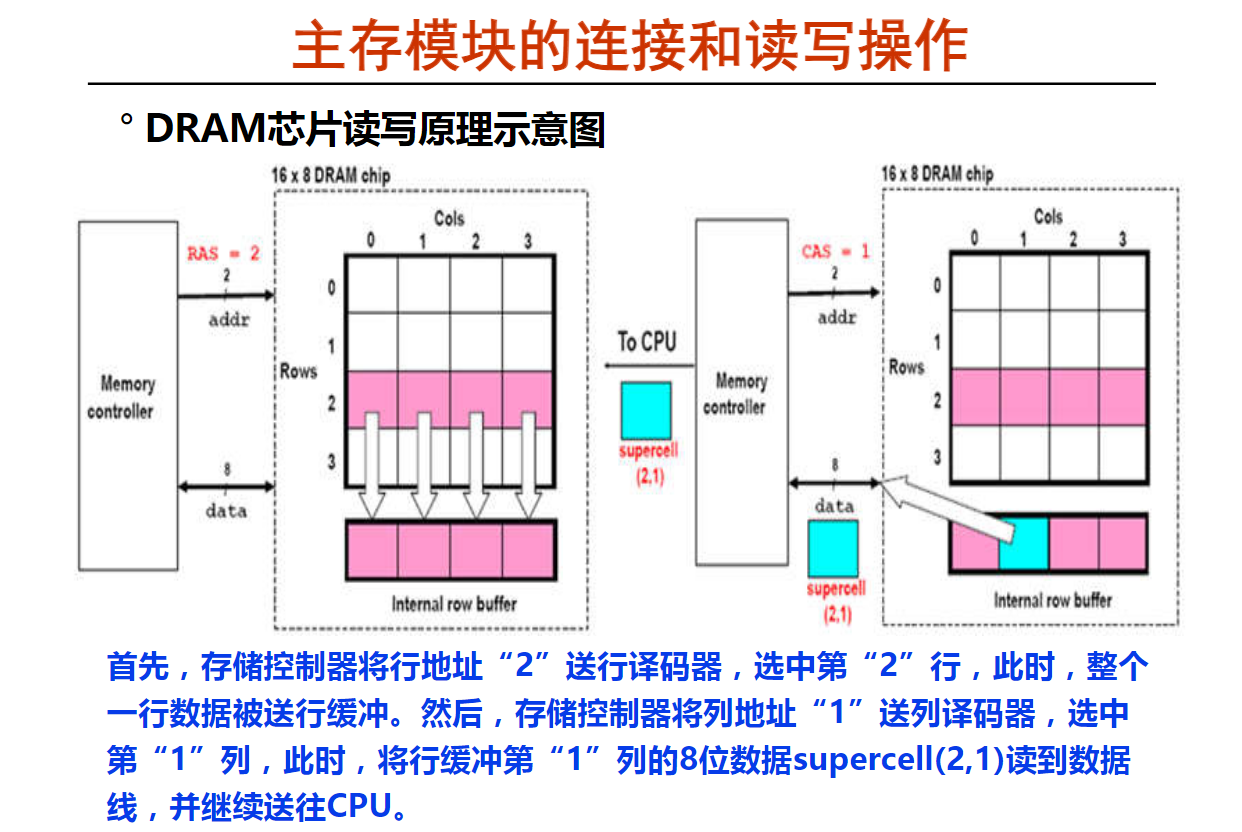
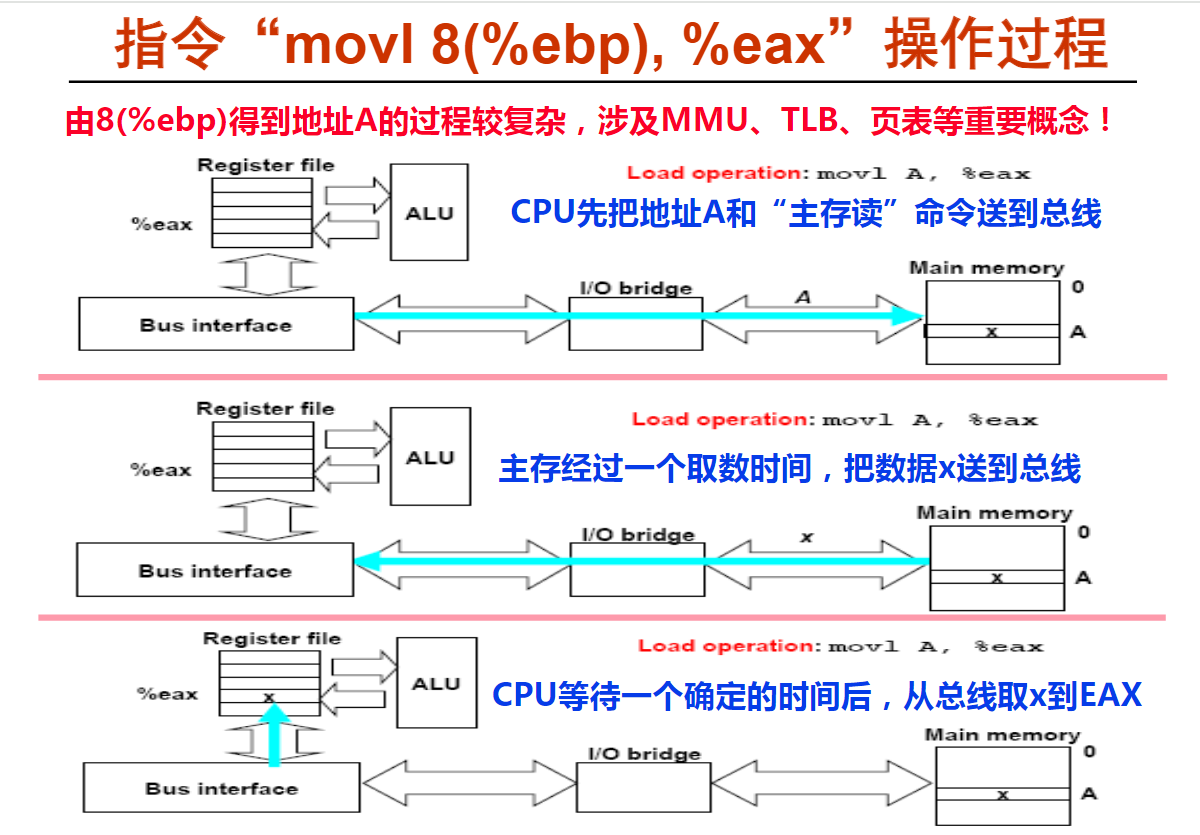
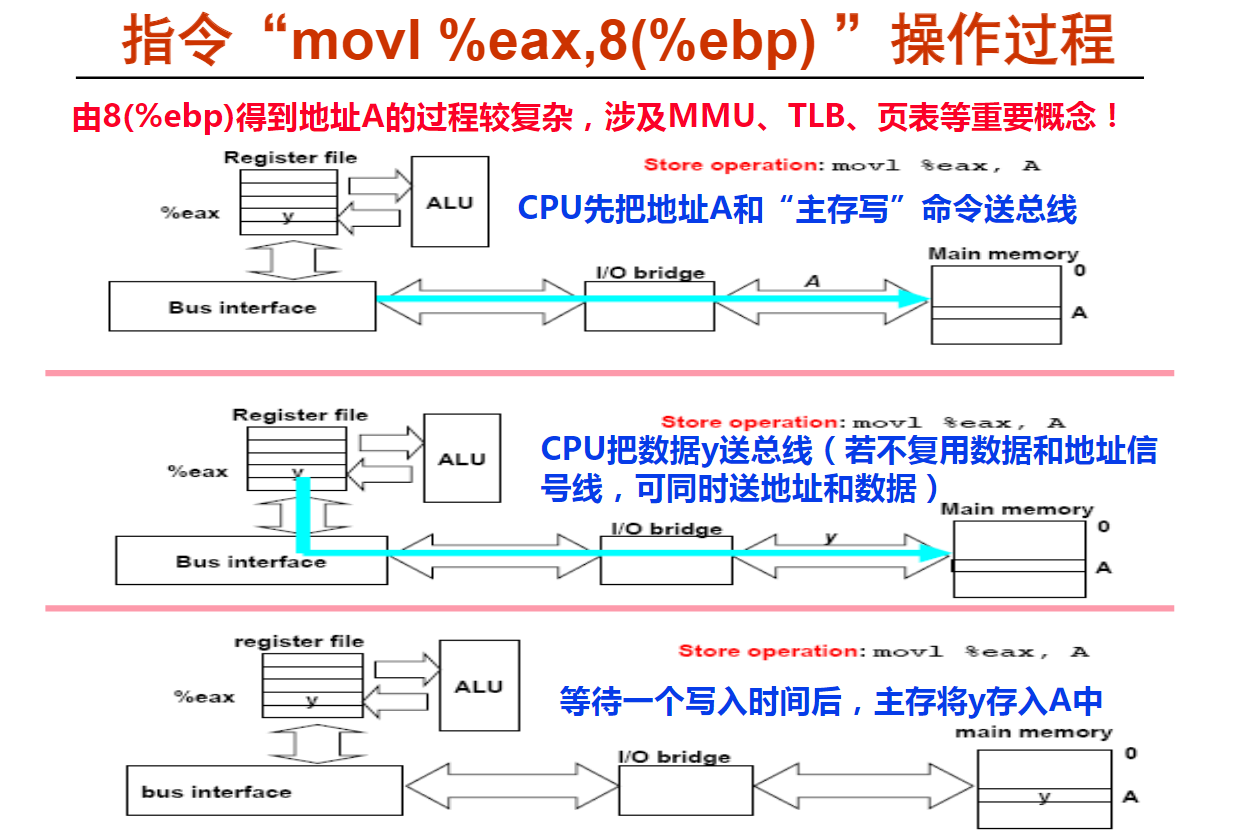

第二周小测验
错题序号:10
1下列几种存储器中,( C )是易失性存储器。
A.CD-ROM
B.Flash Memory
C.cache
D.EPROM
正确答案:C
2下面有关半导体存储器组织的叙述中,错误的是( B )。
A.每个存储单元有一个编号,就是存储单元的地址
B.同一个存储器中,每个存储单元的宽度可以不同
C.存储器的核心部分是存储阵列,由若干存储单元构成
D.存储单元由若干个存放0或1的记忆单元(cell)构成
解析: B、现代计算机的主存储器由半导体存储器构成,其中存放信息的地方称为存储阵列;每个存储阵列包含若干个存储单元,每个存储单元由若干个记忆单元(cell)构成,每个记忆单元存放一位信息(0或1)。
某一台计算机的主存储器编址方式,总是由其对应的指令集体系结构(ISA)确定的;现代通用计算机大多采用按字节编址方式,即主存储器中每个字节有一个地址,也即每个存储单元的宽度都是8位。
3若某个内存条容量为1GB,则说明该内存条中可存储( C )个字节。
A.10^30
B.10^9
C.2^30
D.2^9
正确答案:C你选对了
4某32位计算机,主存地址为32位,按字节编址,则该计算机的主存地址范围是(C )。
A.1~4G
B.1~32G
C.0~(4G-1)
D.0~(32G-1)
解析: C、因为主存地址为32位,所以主存地址空间占2^32=4G个存储单元;因为按字节编址,因此,主存最大可存储的信息量为4GB=32Gbits。主存储器总是从0开始编号,因此存储单元的地址为0、1、2、……、2^32-1=4G-1。这里,4G-1=2^32-1=1 0000 0000 0000 0000 0000 0000 0000 0000 -1 = 1111 1111 1111 1111 1111 1111 1111 1111 = FFFF FFFFH。
5假定主存地址空间大小为1024MB,按字节编址,每次读写操作最多可以一次存取32位。不考虑其它因素,则存储器地址寄存器MAR和存储器数据寄存器MDR的位数至少应分别为( C )。
A.28,32
B.28,8
C.30,32
D.30,8
解析: C、因为1024M=2^30,所以MAR至少为30位。
6采用行、列地址引脚复用的半导体存储器芯片是( B )。
A.SRAM
B.DRAM
C.EPROM
D.Flash Memory
正确答案:B你选对了
7下面有关ROM和RAM的叙述中,错误的是( B )。
A.ROM和RAM都采用随机访问方式进行读写
B.计算机系统的主存都用DRAM芯片实现
C.计算机系统的主存由RAM和ROM组成
D.RAM是可读可写存储器,ROM是只读存储器
正确答案:B你选对了
8下面有关半导体存储器的叙述中,错误的是(A )。
A.半导体存储器都采用随机存取方式进行读写
B.SRAM是半导体静态随机访问存储器,可用作cache
C.ROM芯片属于半导体随机存储器芯片
D.DRAM是半导体动态随机访问存储器,可用作主存
解析: A、有些情况下,可用半导体存储器实现相联存储器,即按内容进行访问,而不是按地址进行随机读写。
9存储容量为16K×4位的DRAM芯片,其地址引脚和数据引脚数各是( B )。
A.14和1
B.7和4
C.7和1
D.14和4
解析: B、因为DRAM芯片存储容量为16K×4位,故该芯片共有16K=2^14个存储单元,应该有14位地址,行、列地址引脚复用后,芯片的地址引脚数为7。每个存储单元占4位,因此芯片的数据引脚数为4。
10假定用若干个16K×8位的存储器芯片组成一个64K×8位的存储器,芯片各单元交叉编址,则地址BFFFH所在的芯片的最小地址为(A )。
A.0003H
B.0000H
C.0001H
D.0002H
解析: A、用若干个16K×8位的存储器芯片构成64K×8位的存储器,需要64K×8位/(16K×8位)= 4个芯片。因为采用交叉编址方式,所以,存储单元地址对4取模后,低两位相同的存储单元在同一个芯片中。BFFFH的最低两位为11,显然,与0003H在同一个芯片中。
第三周磁盘存储器

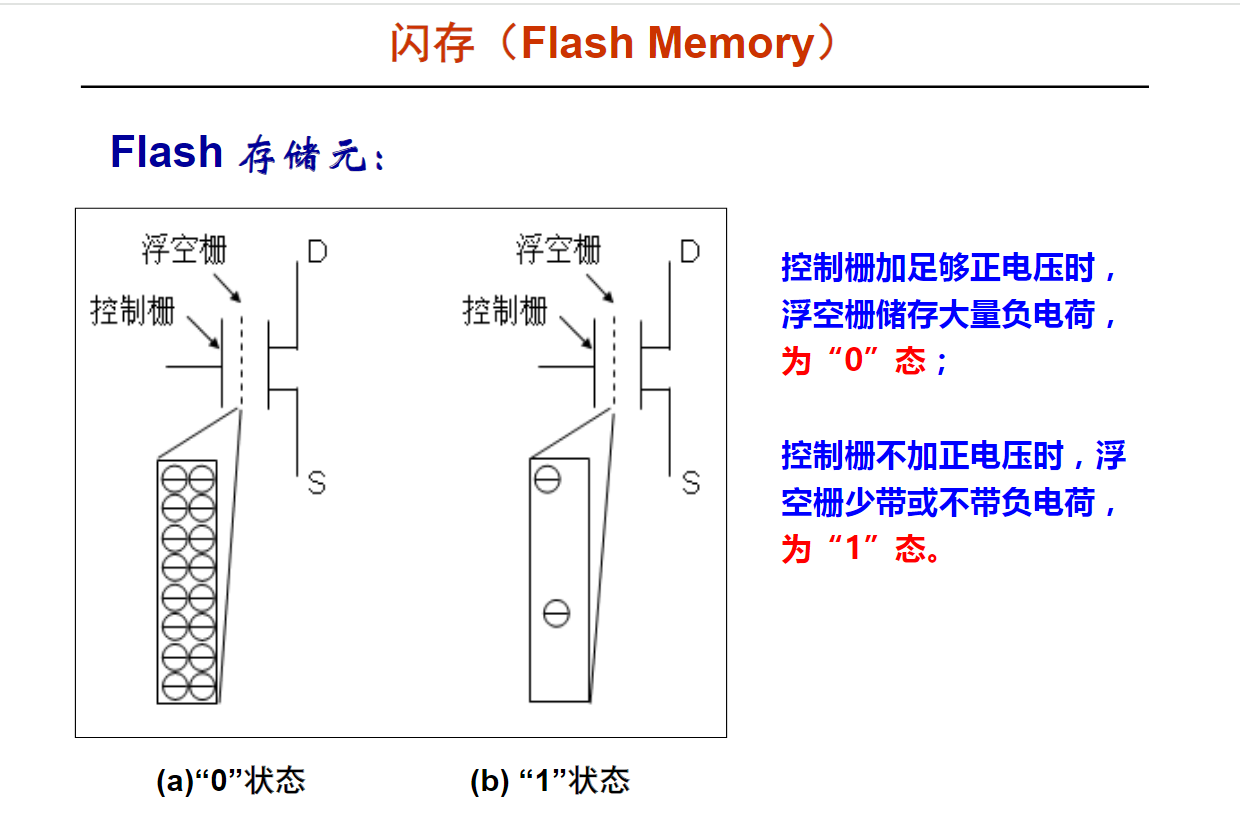
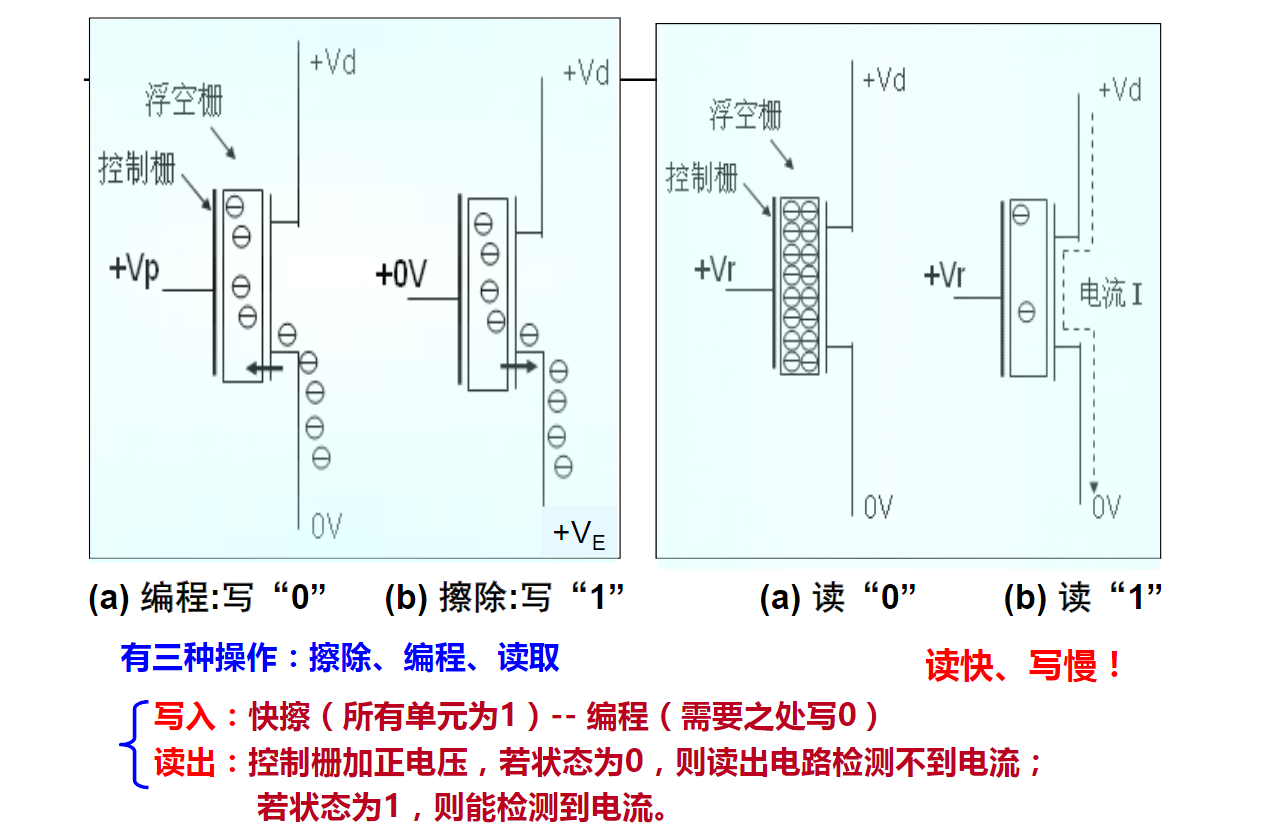

第1讲 磁盘存储器的结构
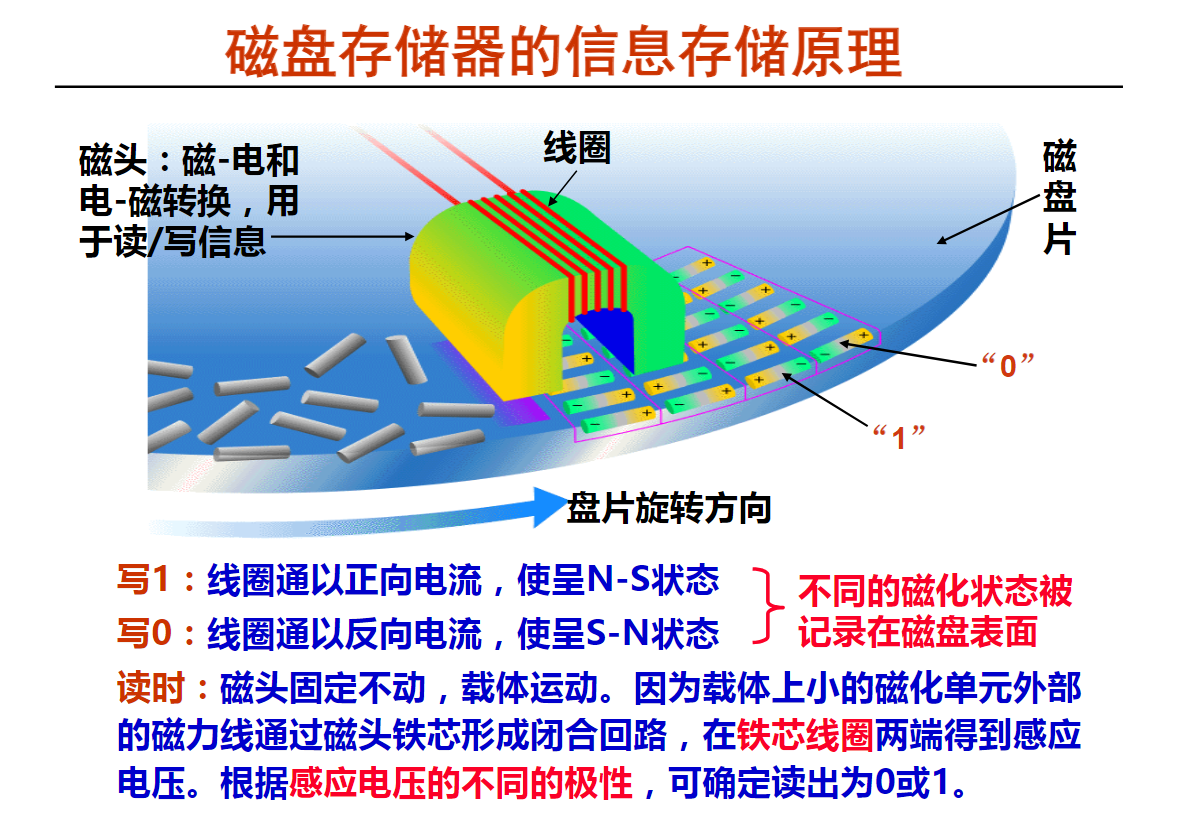
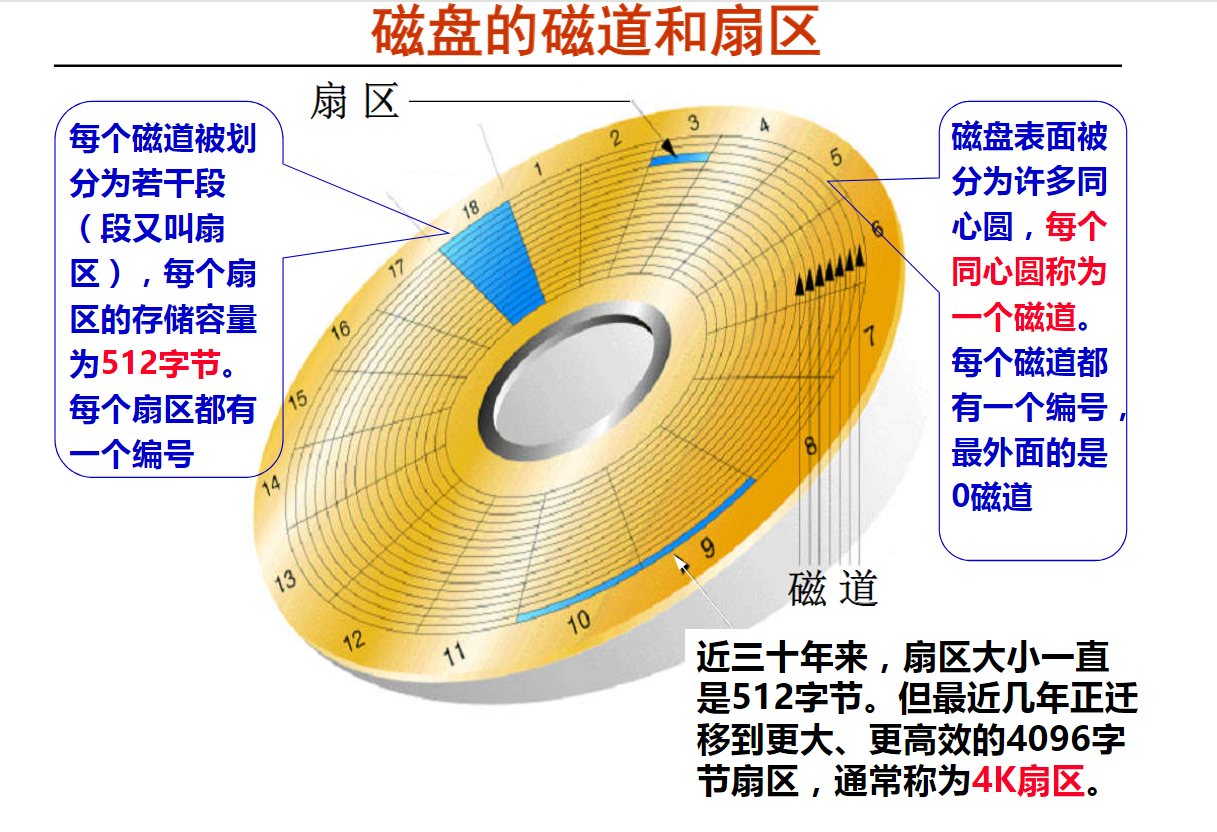
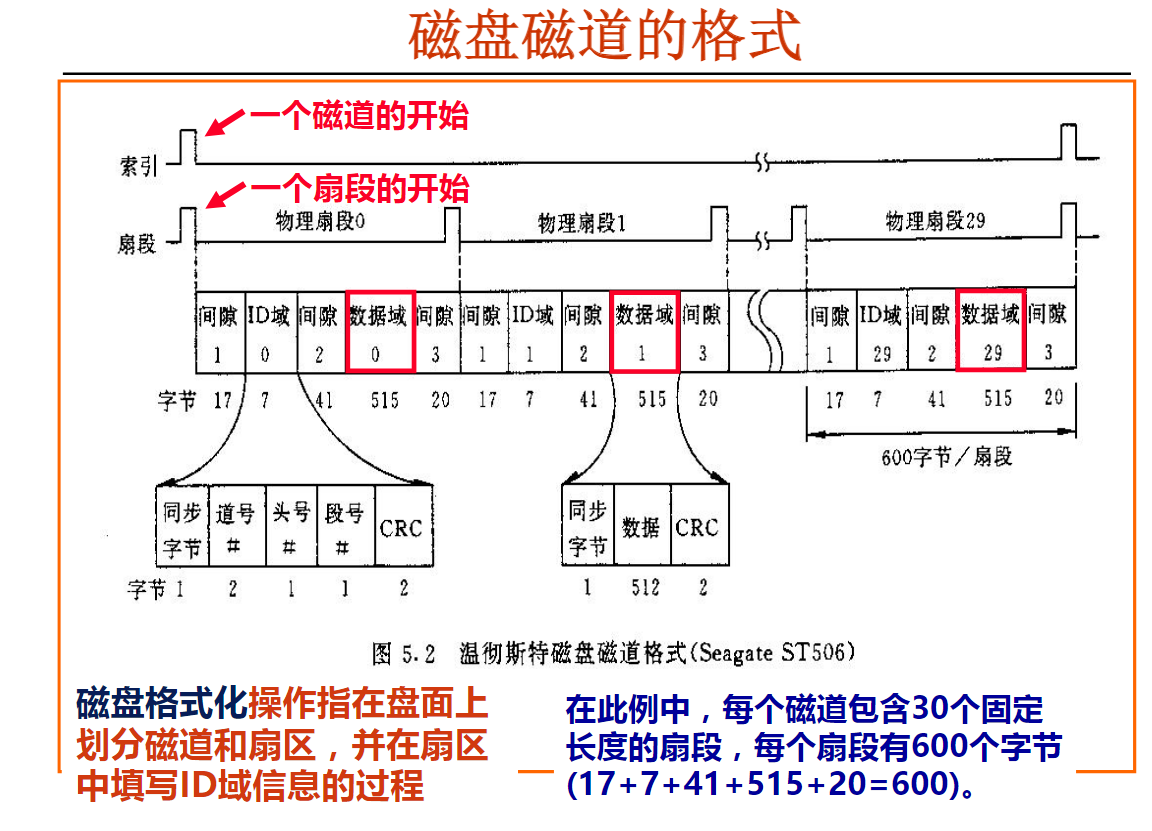
第2讲 磁盘驱动器以及操作过程
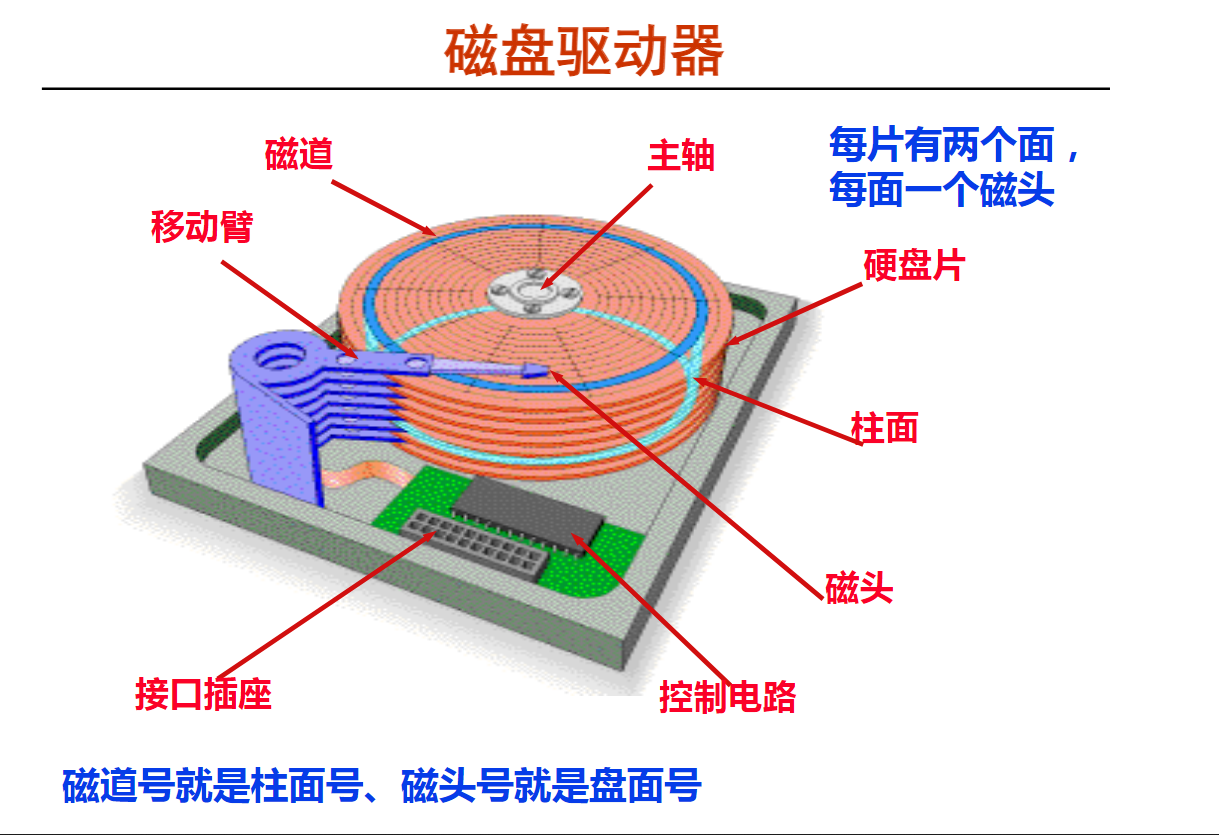
柱面号就是磁道号
盘面号就是磁头号
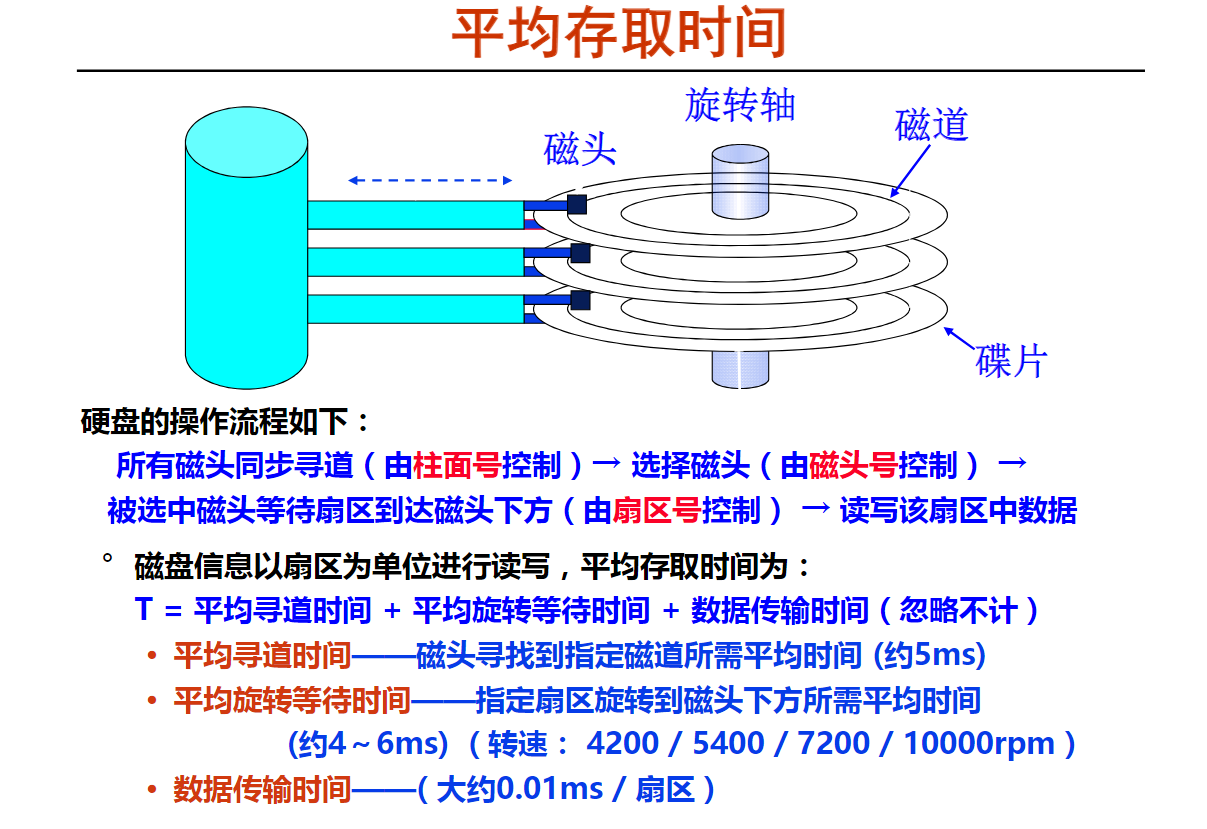

第3讲 磁盘存储器的组成

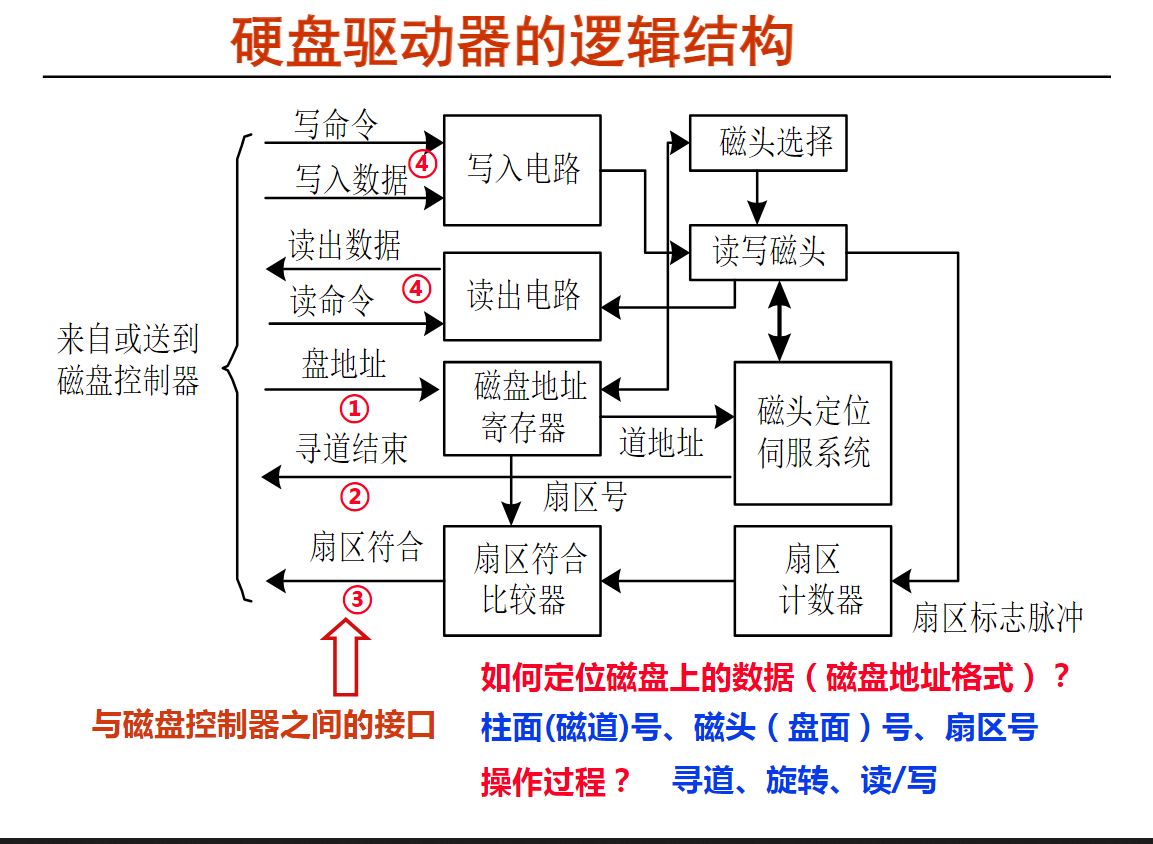
第4讲 磁盘存储器的连接与操作
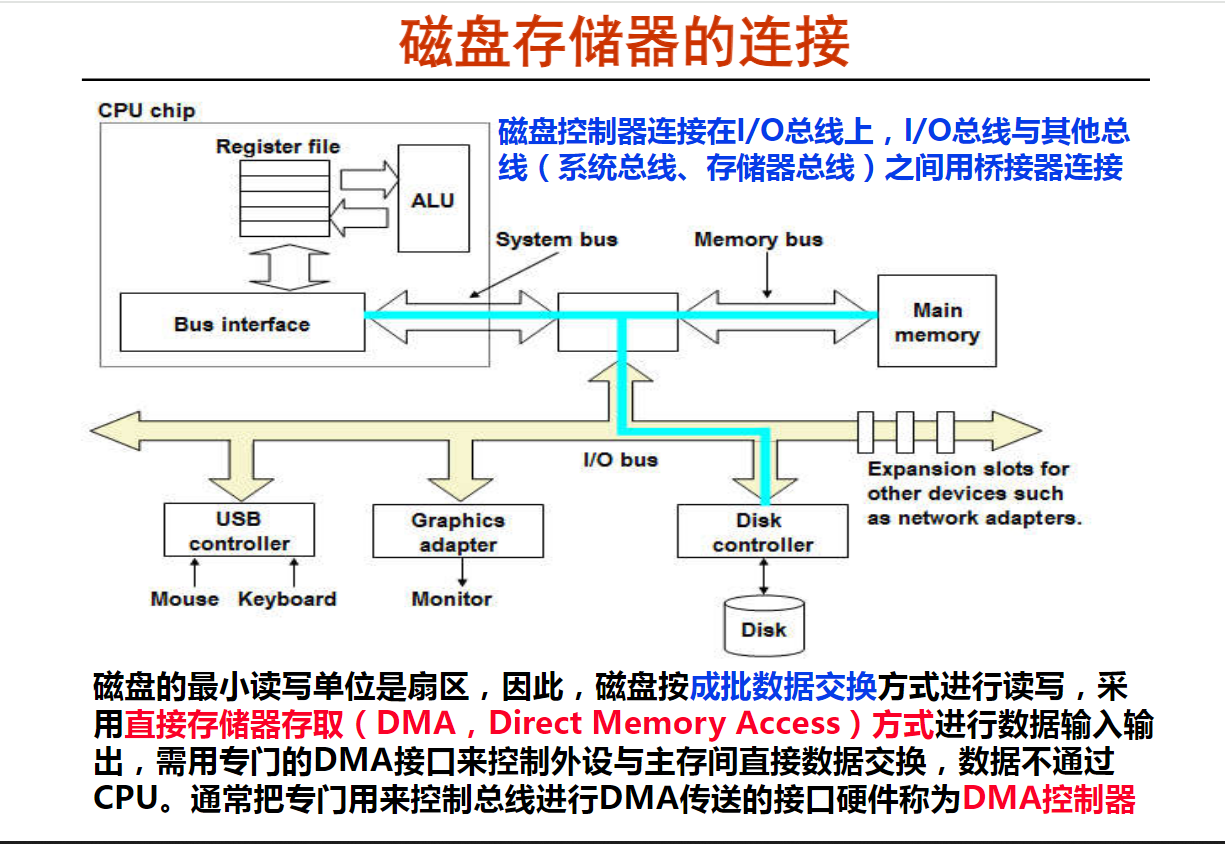
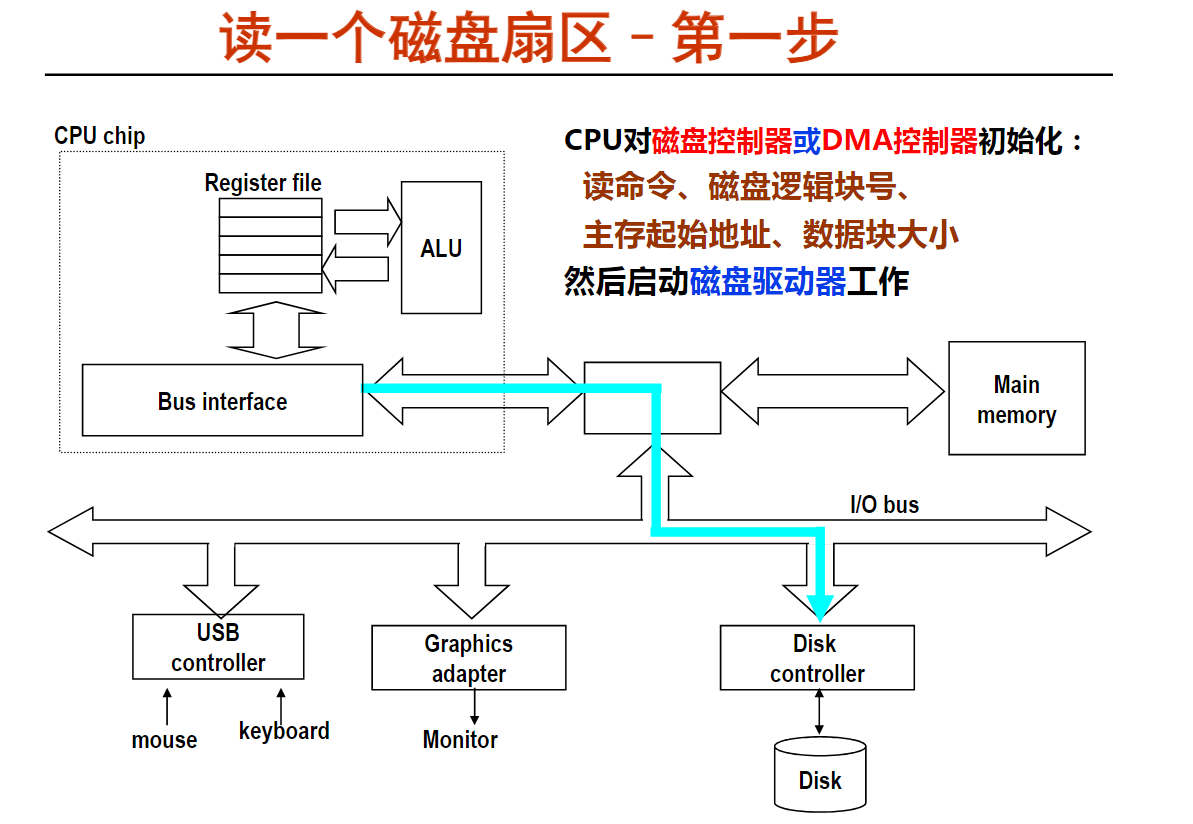
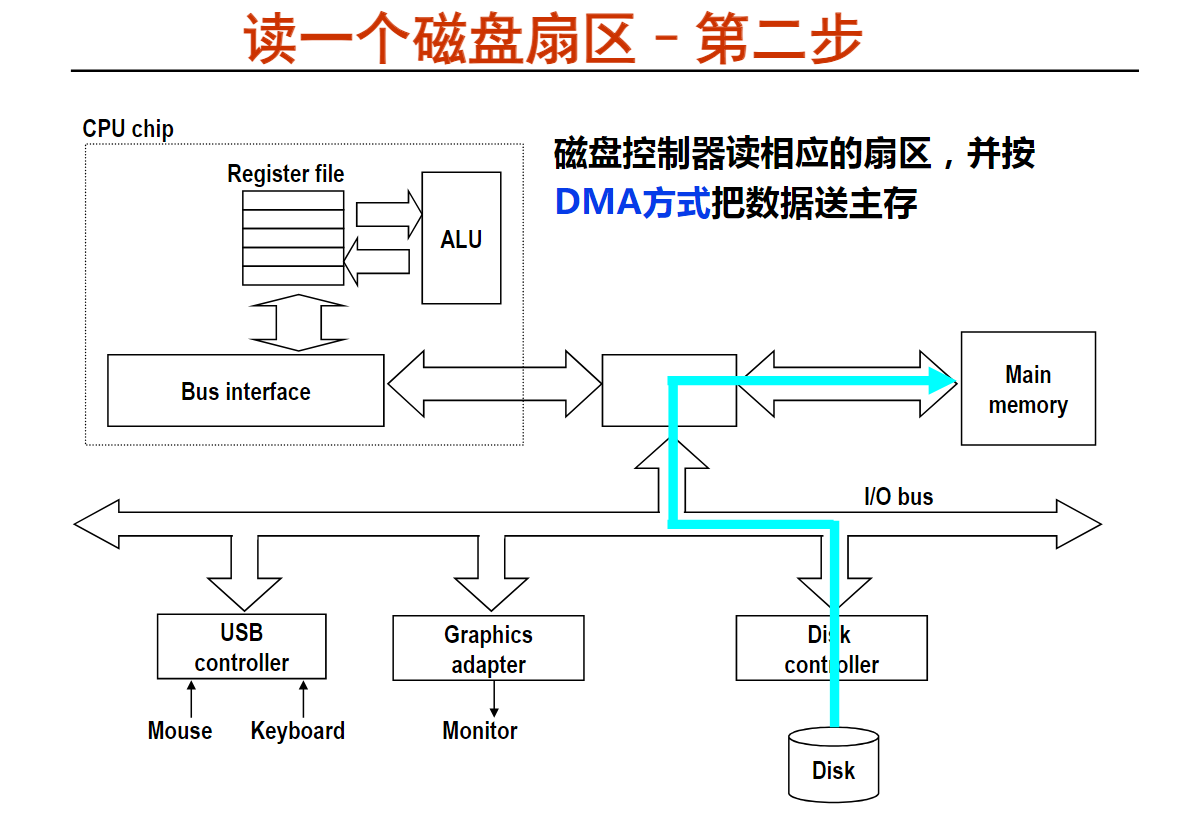
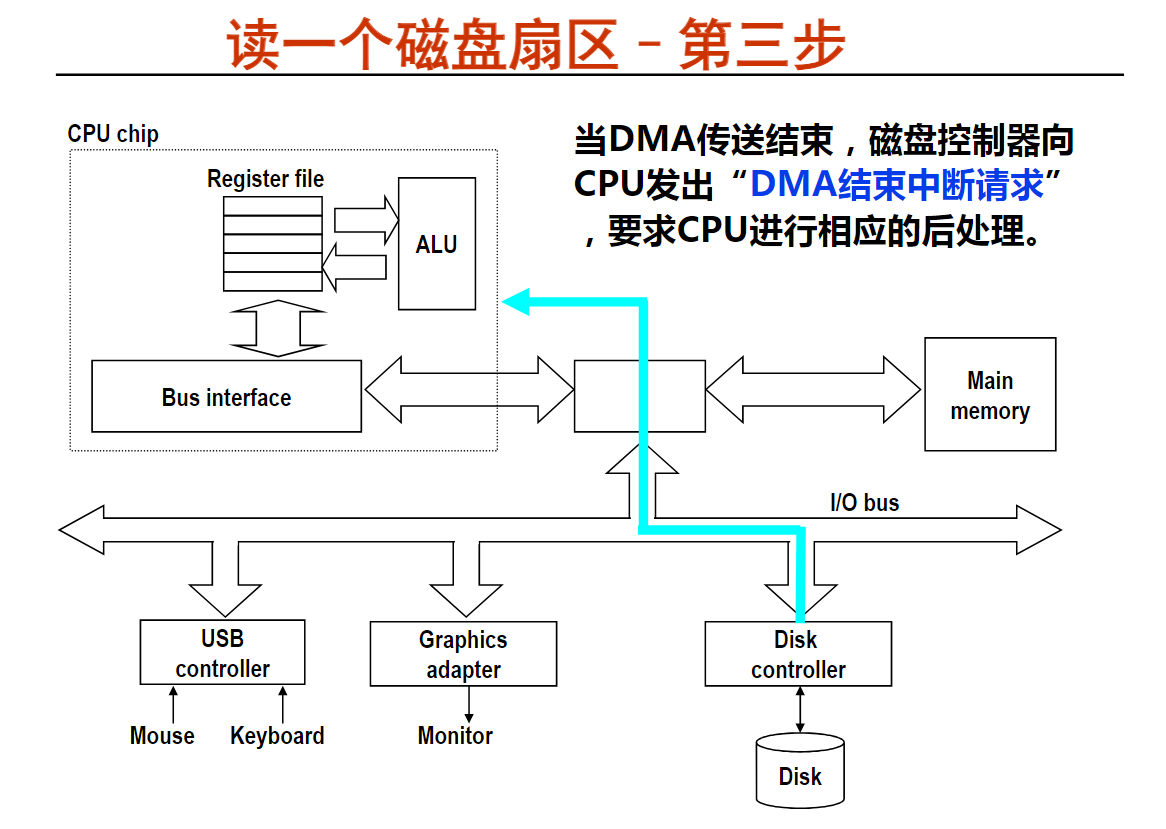
第三周小测验
1以下有关磁盘存储器信息存储原理的叙述中,错误的是( A )。
A.共有三种不同的磁化状态
B.信息在磁盘表面以磁化状态形式存储
C.磁盘片的两个面都可存储信息
D.每个磁化状态对应一位二进制信息
正确答案:A你选对了
2以下有关磁盘存储器结构的叙述中,错误的是( A )。
A.磁盘驱动器的位置介于CPU和磁盘控制器之间
B.磁盘的信息存储介质就是磁盘盘面
C.磁盘操作包括寻道、旋转等待和读写三个步骤
D.由存储介质、磁盘控制器和磁盘驱动器组成
正确答案:A
3以下有关硬磁盘的磁道和扇区的叙述中,错误的是( B )。
A.不同盘面上同一位置的多个磁道构成一个柱面
B.一个磁道由若干扇区构成且磁盘各磁道信息位数总相同
C.每面有一个磁头,寻道过程中所有磁头同时移动
D.磁头和磁盘做相对运动而形成的轨迹即为磁道
解析: B、早期的低密度磁盘中每个磁道信息位数总是一样,但是,现在的磁盘,其外道信息量比内道大
4以下有关磁盘驱动器的叙述中,错误的是( B )。
A.能控制磁头移动到指定磁道,并发回“寻道结束”信号
B.送到磁盘驱动器的盘地址由磁头号、盘面号和扇区号组成
C.能控制磁盘片转过指定的扇区,并发回“扇区符合”信号
D.能对指定盘面的指定扇区进行数据的读或写操作
解析: B、因为每个盘面有一个磁头,所以磁头号就是盘面号。盘地址由柱面号(即磁道号)、盘面号(即磁头号)和扇区号组成。
5假定一个磁盘存储器有10个记录面,用于记录信息的柱面数为5000,每个磁道上记录信息位数相同,磁盘片外径200mm,内径40mm,最内道位密度为200bpm(位/毫米),则该磁盘存储器的容量约为( A )。
A.0.157GB
B.17.7GB
C.4.425GB
D.0.628GB
解析: A、(10×5000×3.14×40×200)/8 B = 0.157GB。
内径、外径都是直径
6假定一个磁盘存储器有4个盘片,用于记录信息的柱面数为2000,每个磁道上有3000个扇区,每个扇区512B,则该磁盘存储器的容量约为( A )。
A.24GB
B.12GB
C.12MB
D.24MB
解析: A、2×4×2000×3000×0.5KB≈24GB。
7假定一个磁盘的转速为7200RPM,磁盘的平均寻道时间为10ms,内部数据传输率为1MB/s,不考虑排队等待时间。那么读一个512字节扇区的平均时间大约为 ( B )。
A.14.17 ms
B.14.67 ms
C.18.83 ms
D.18.33 ms
解析: B、10ms + (1/7200×60×1000)/2 + 0.5KB/1MB×1000≈14.67。
8假定一个磁盘的转速为10000RPM,平均寻道时间为5.5ms,内部数据传输率为4MB/s,磁盘控制器开销为1ms,不考虑排队等待时间。那么读一个4KB扇区的平均时间大约为 ( C )。
A.11.5ms
B.13.5 ms
C.10.5 ms
D.12.5 ms
解析: C、1ms +5.5ms+ (1/10000×60×1000)/2 + 4KB/4MB×1000 = 10.5ms。
9以下有关磁盘存储器读写操作的叙述中,错误的是( C )。
A.最小读写单位可以是一个扇区
B.采用直接存储器存取(DMA)方式进行输入/输出
C.磁盘存储器可与CPU交换盘面上的存储信息
D.按批处理方式进行一个数据块的读写
解析: C、磁盘存储器以成批方式进行数据读写,CPU中没有那么多通用寄存器用于存放交换的数据,所以,磁盘存储器通常直接和主存交换信息
10磁盘存储器进行读写操作之前,CPU需要对磁盘控制器或DMA控制器进行初始化。以下选项中,不包含在初始化信息中的是( D )。
A.传送信息所在的主存起始地址
B.传送数据个数或传送字节数
C.传送方向(即读磁盘还是写磁盘?)
D.传送信息所在的通用寄存器编号
正确答案:D你选对了
第四周高速缓存概述
第1讲 存储器层次结构概述(10m44s)
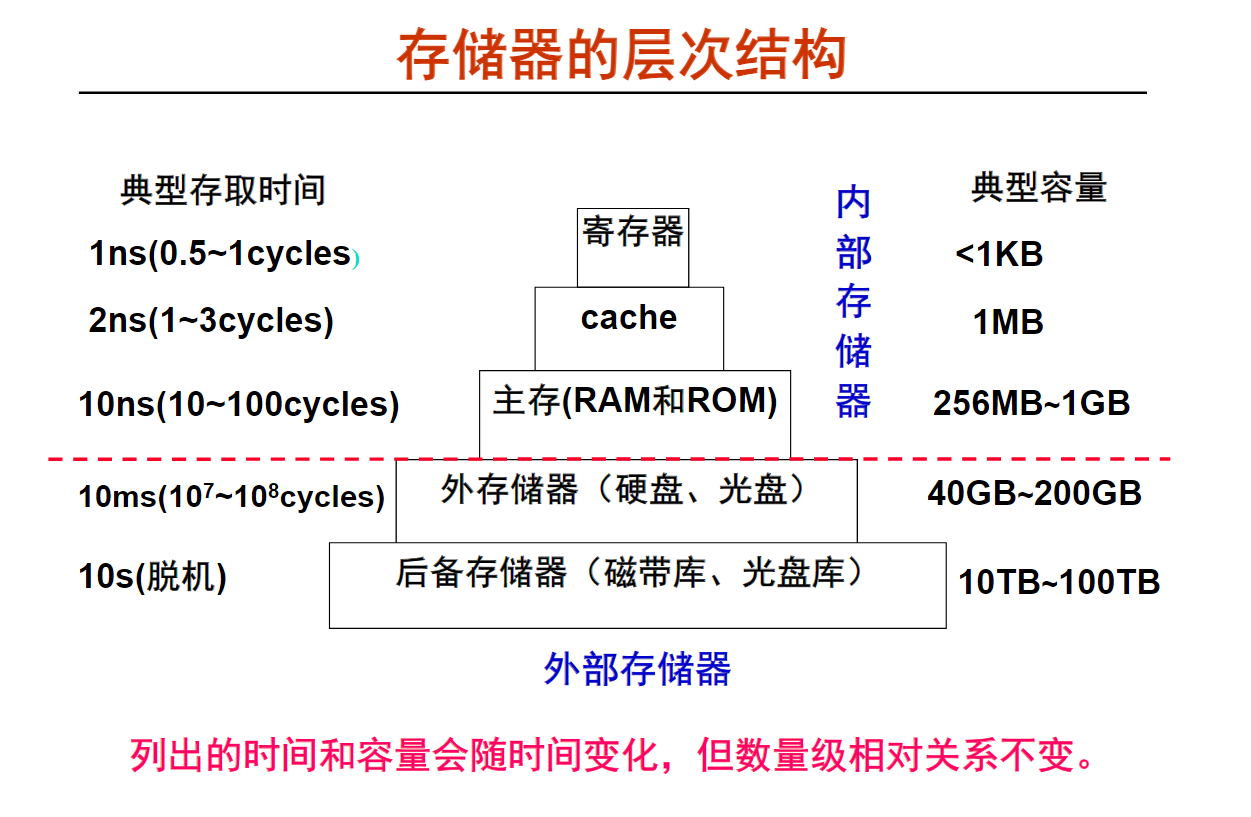
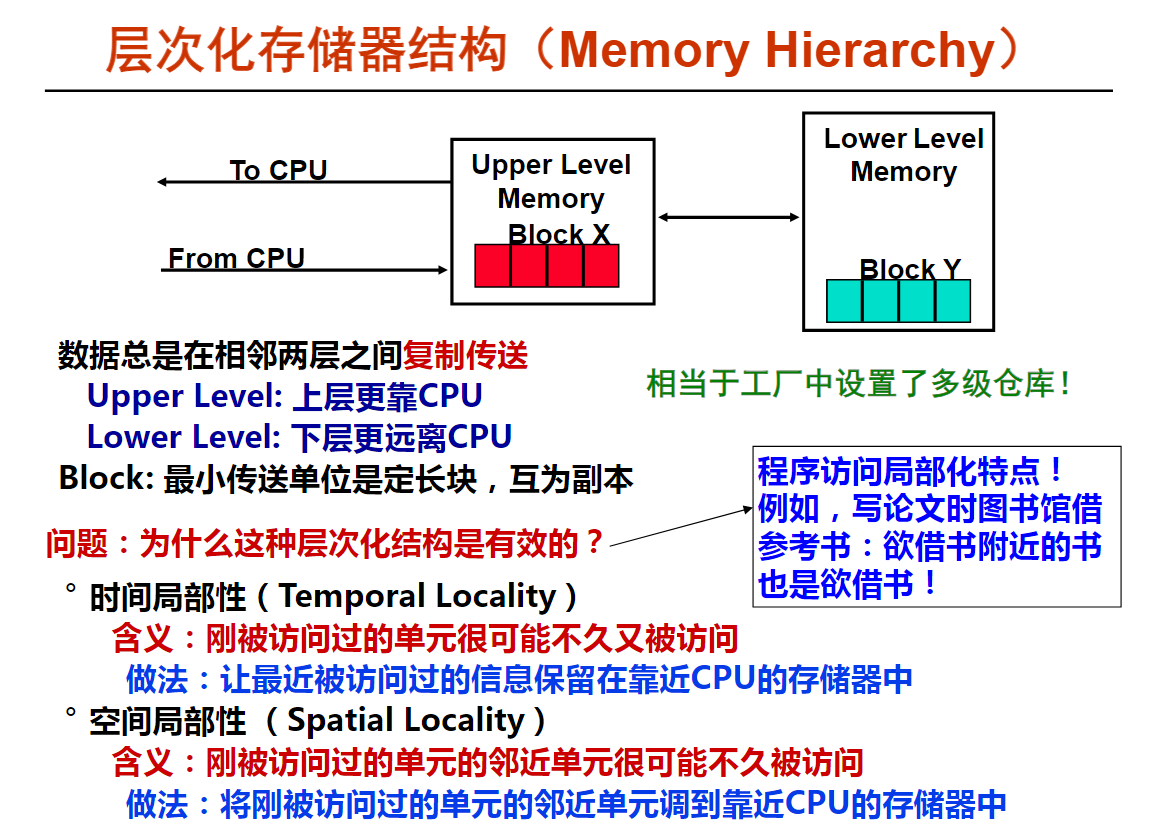
第2讲 Cache基本概述
引入Cache的出发点(7m46s)
加快访存速度措施之三:引入Cache




怎么获得时钟周期???
程序执行时间
21.5倍
Cache和主存的关系(3m43s)
Cache操作过程(4m58s)
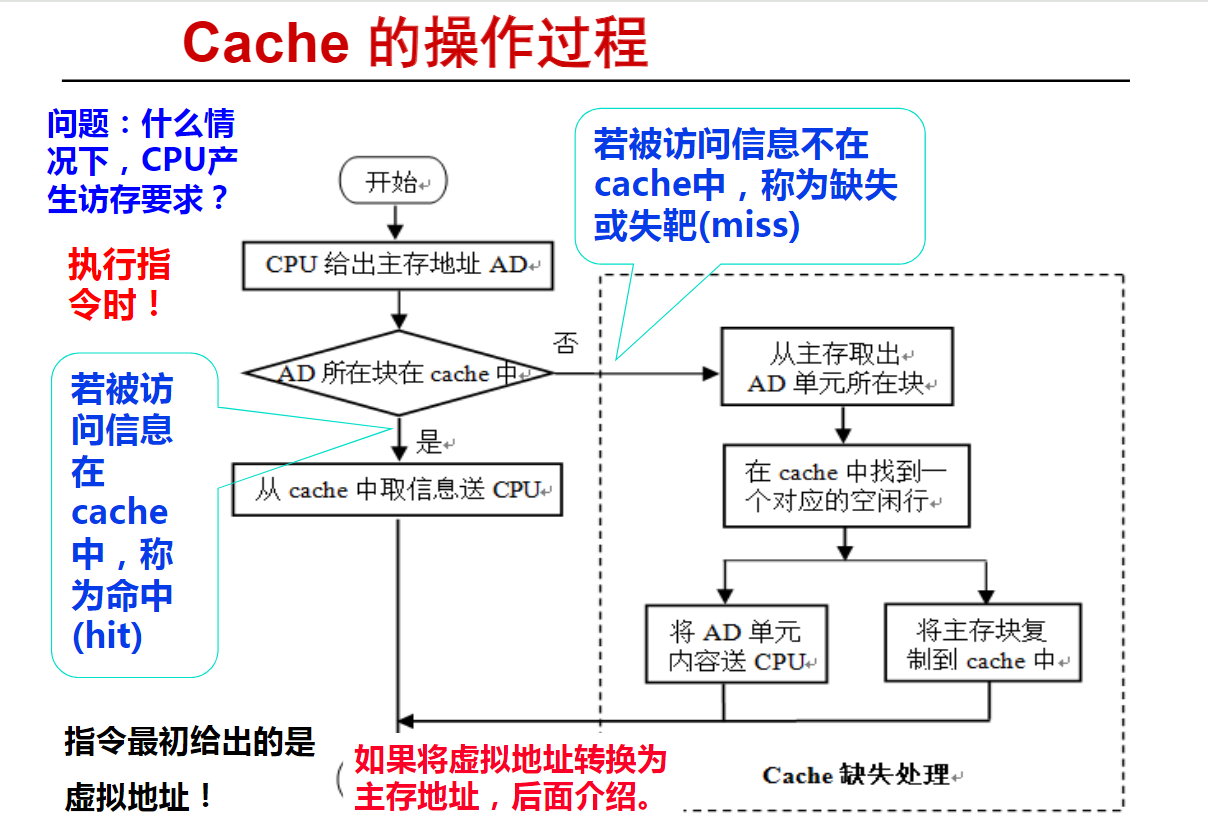
实现Cache需解决的问題(8m06s)

第3讲 Cache映射方式
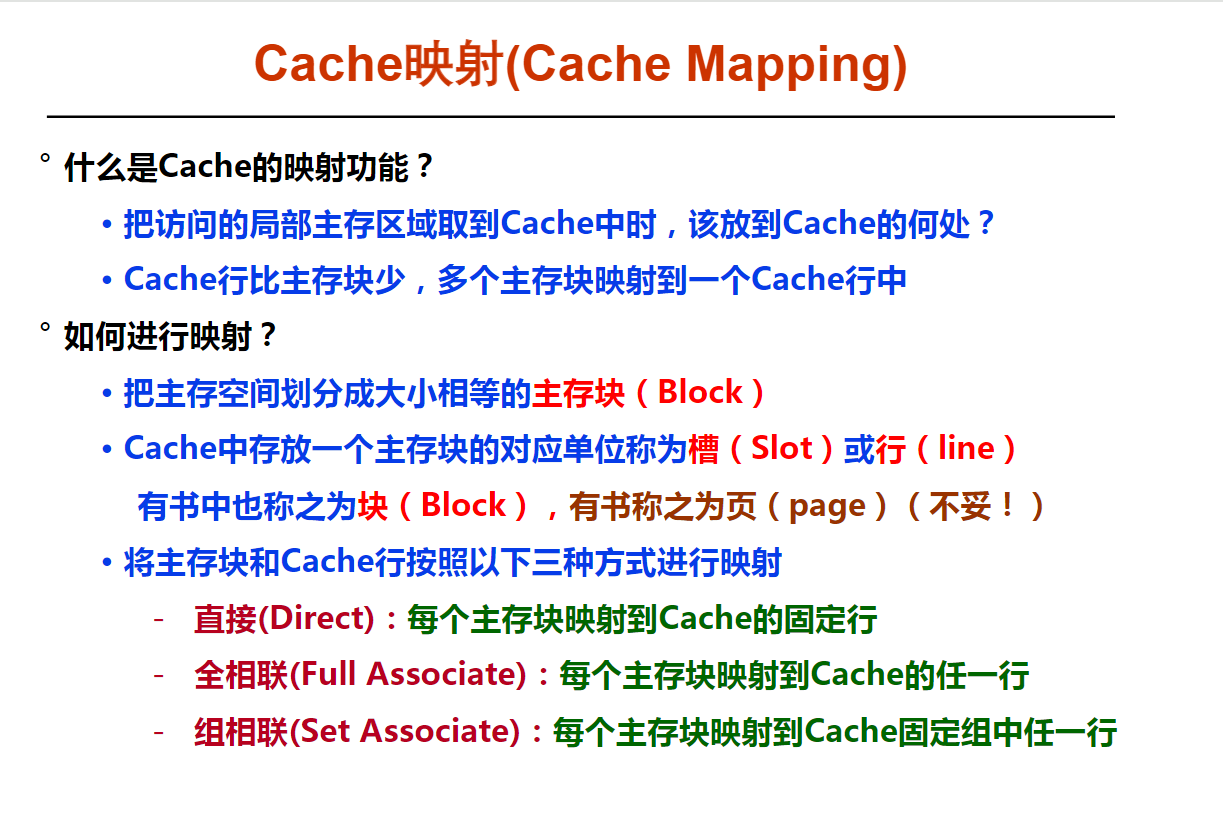
直接映射主存地址划分(14m21s)
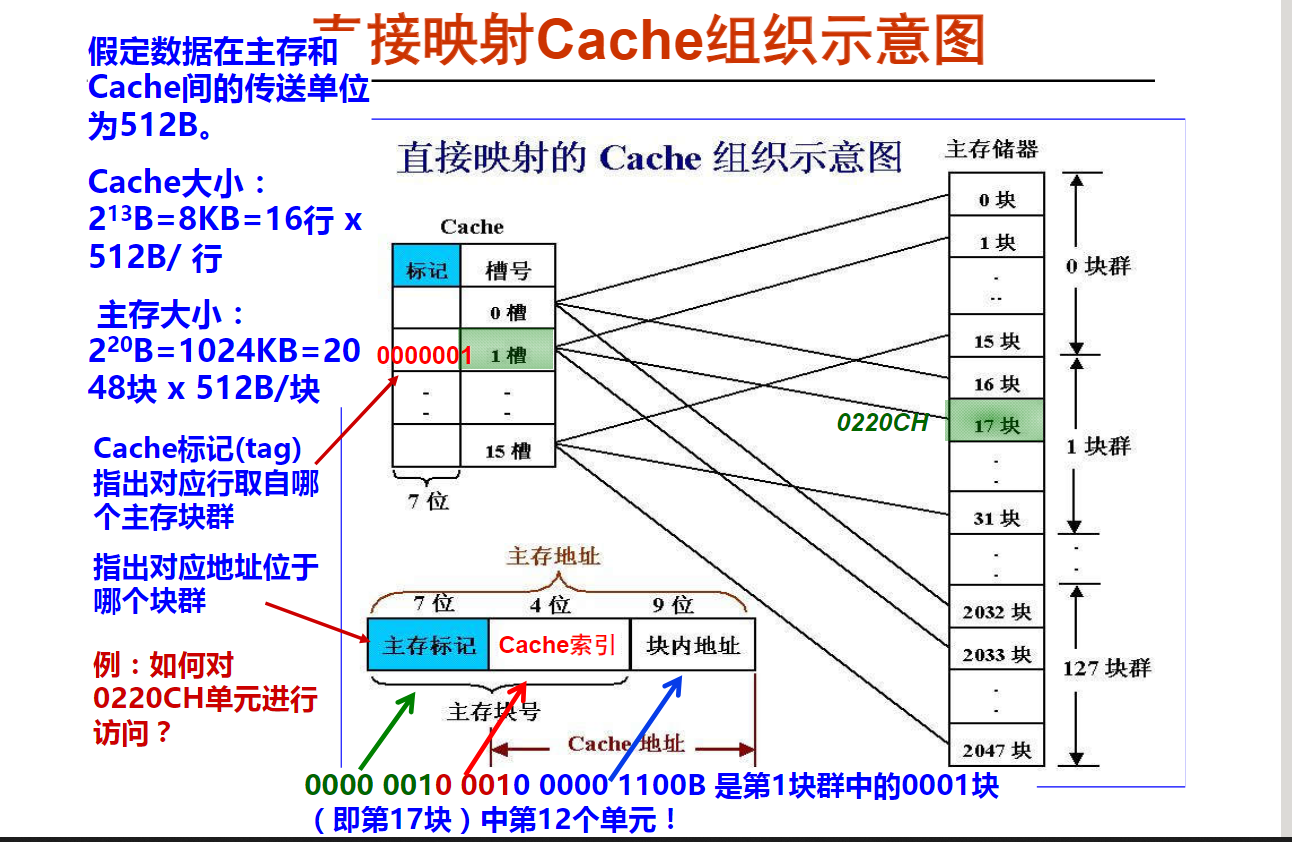
有效位和访存过程(8m59s)
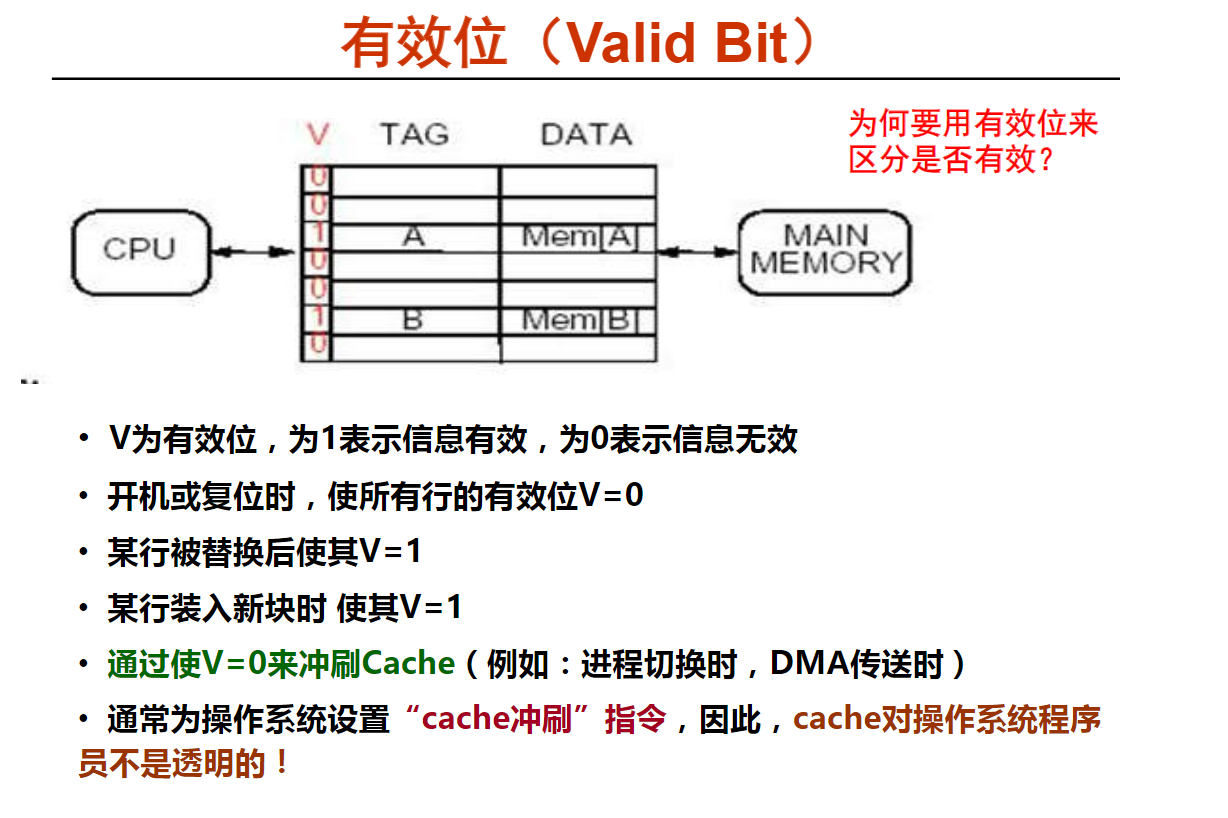
Cache用硬件实现(至多一条指令)
Cache容量的计算(4m48s)
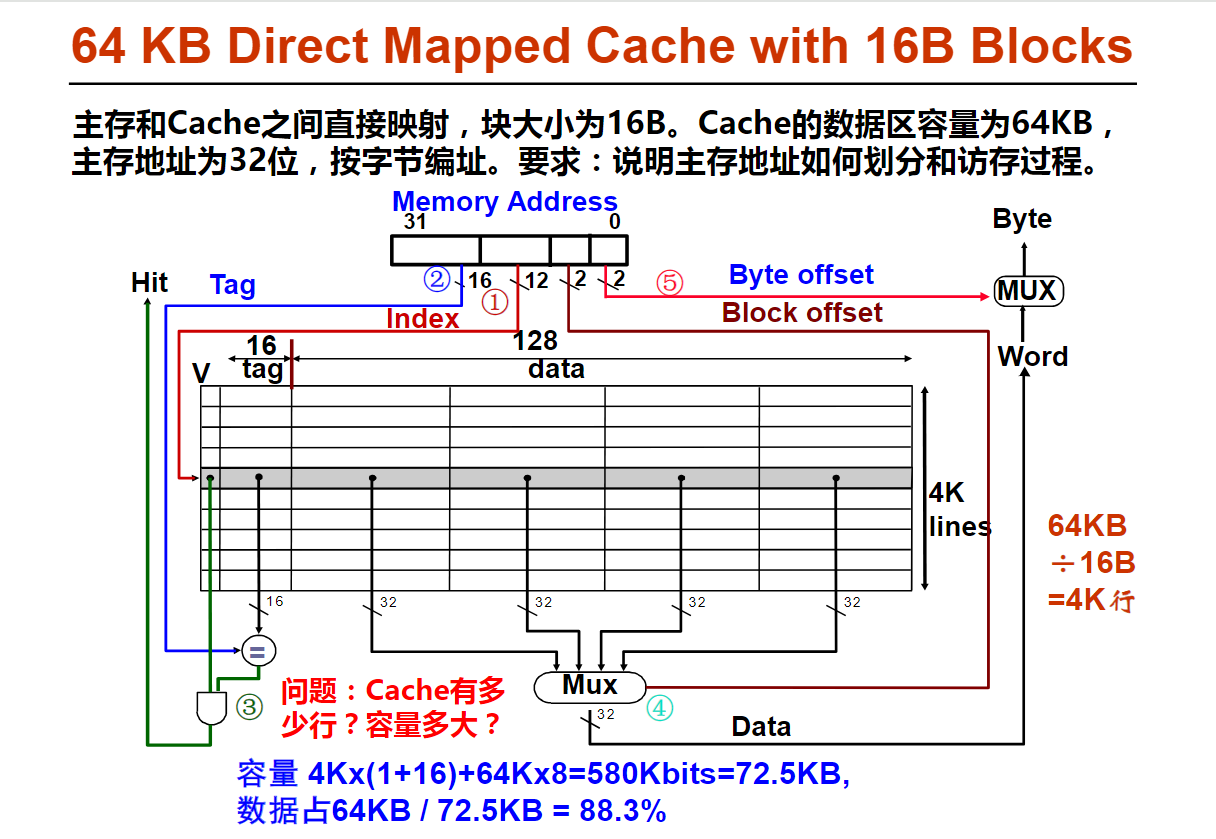

直接映射方式的特点(3m06s)

全相联映射方式(5m35s)
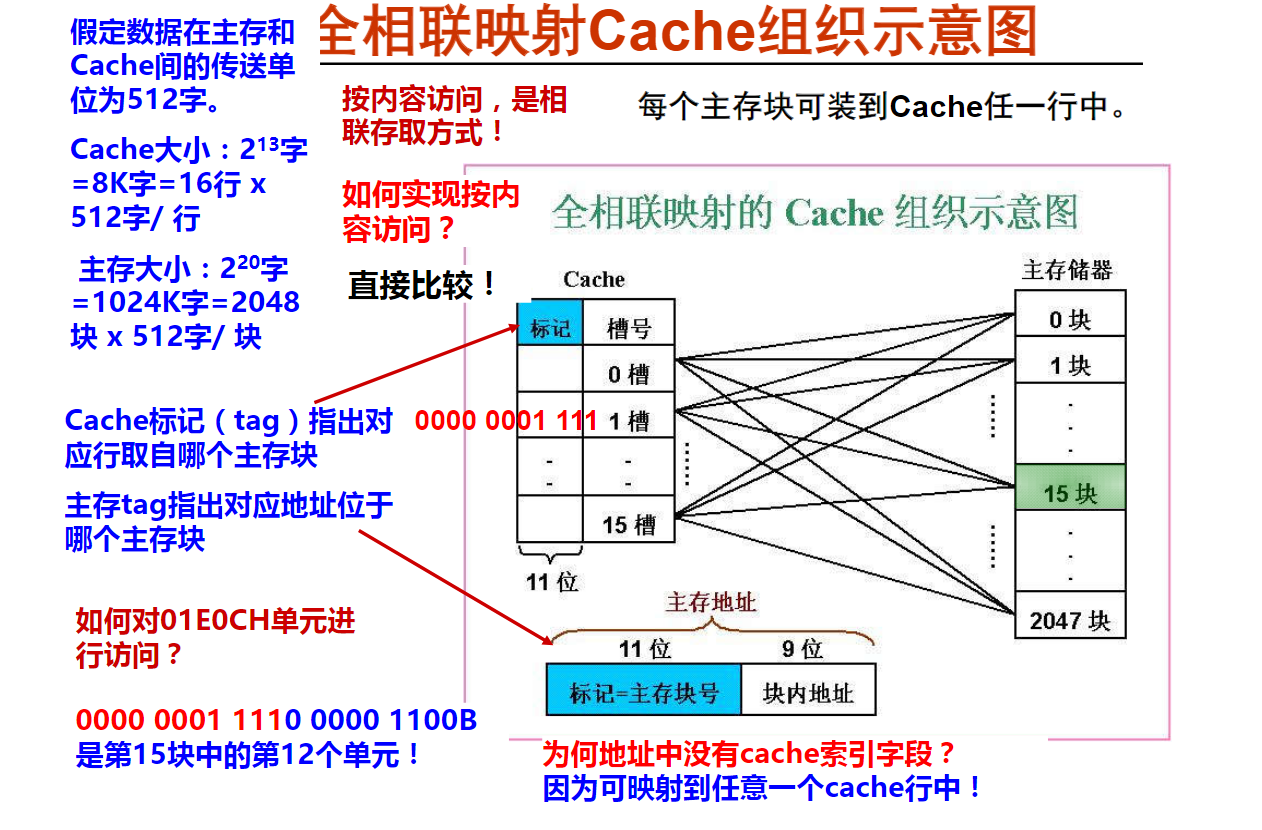
这里的字应为字节。
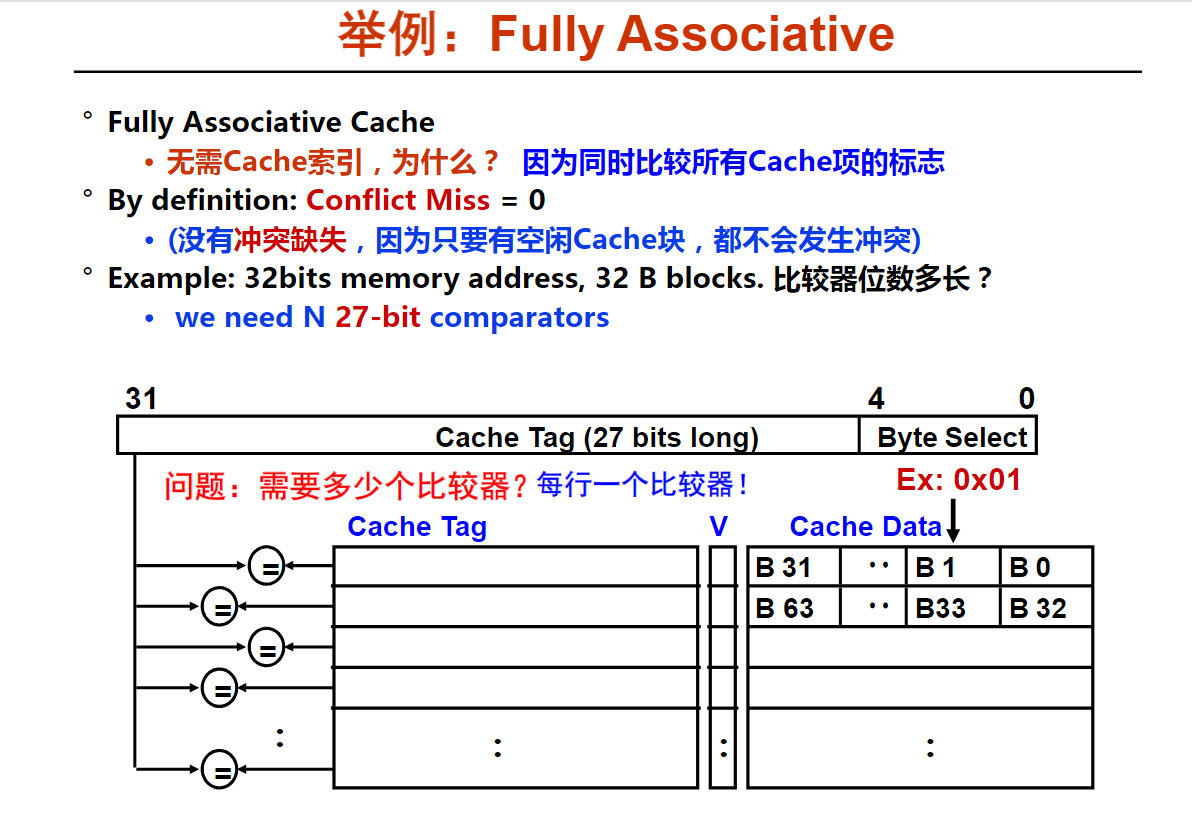
组相联映射方式(7m14s)

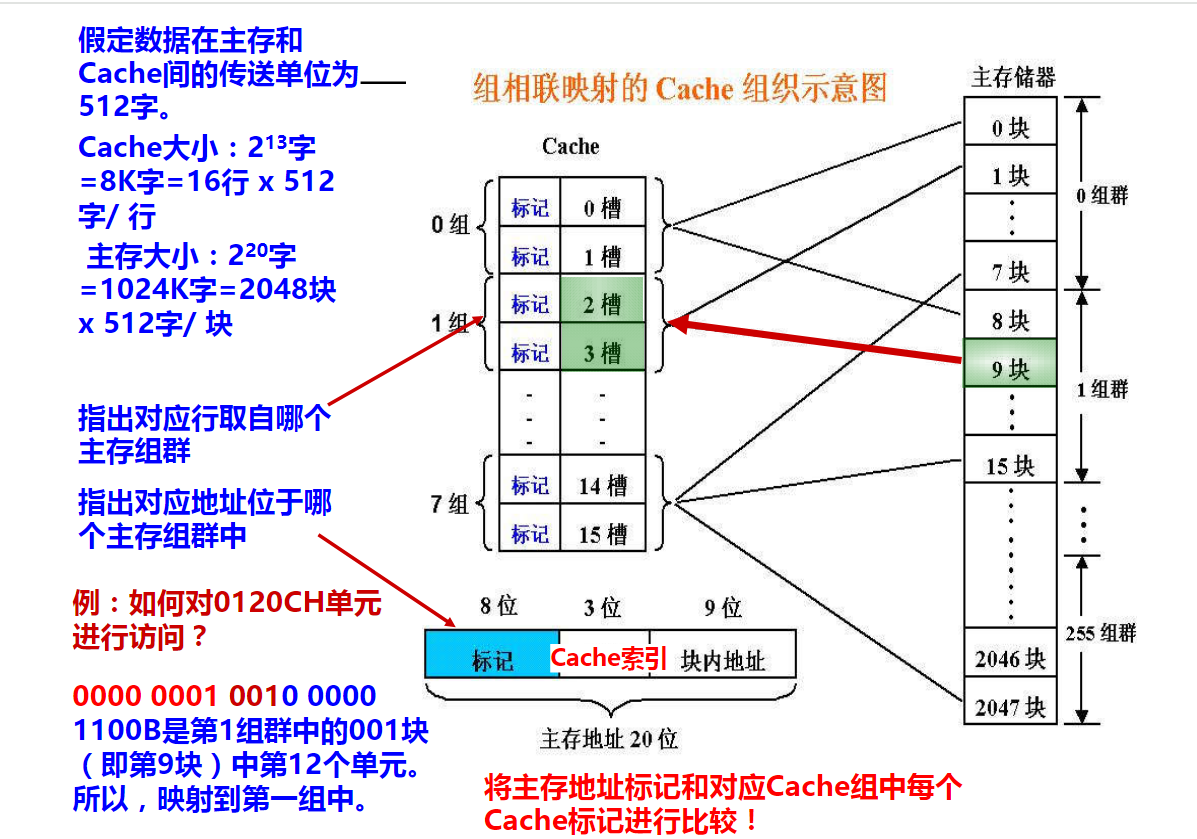
这里的字应为字节。
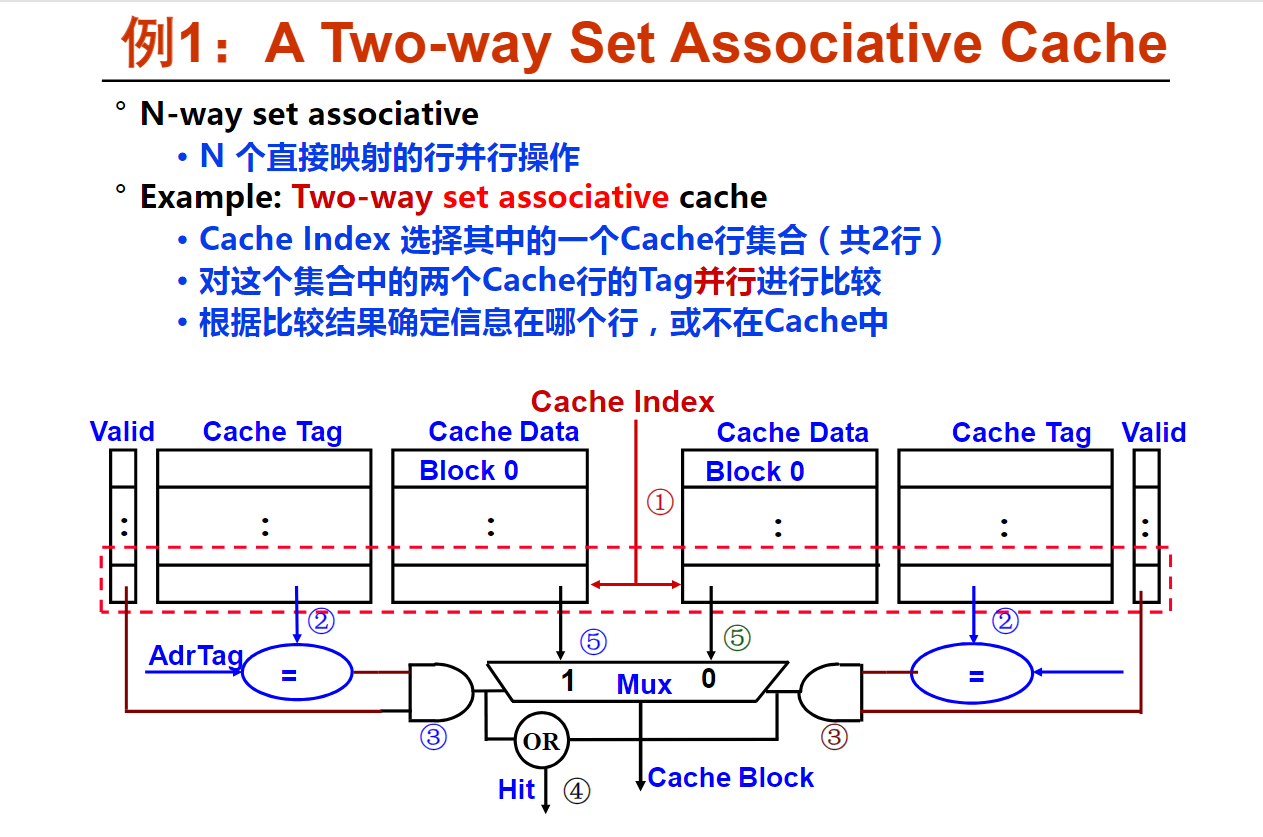
第4讲 Cache命中率和缺失率(5m31s)

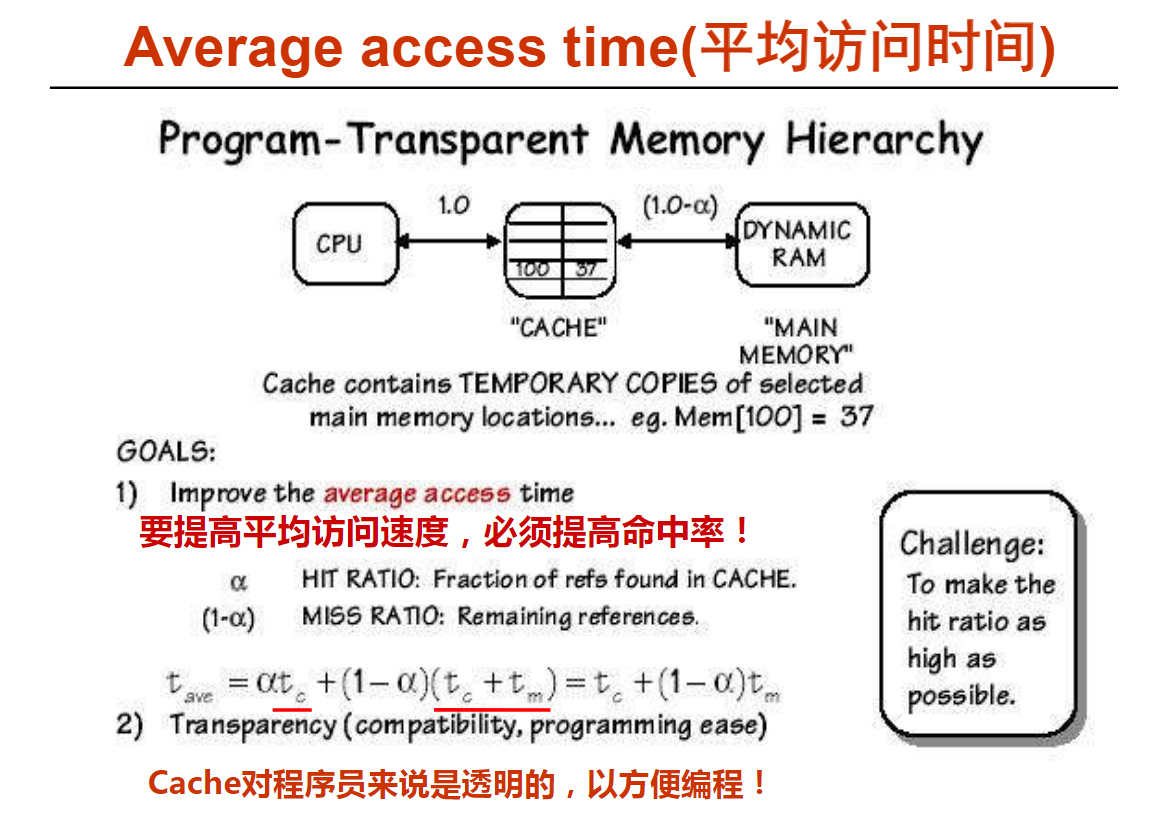

第5讲 Cache的关联度

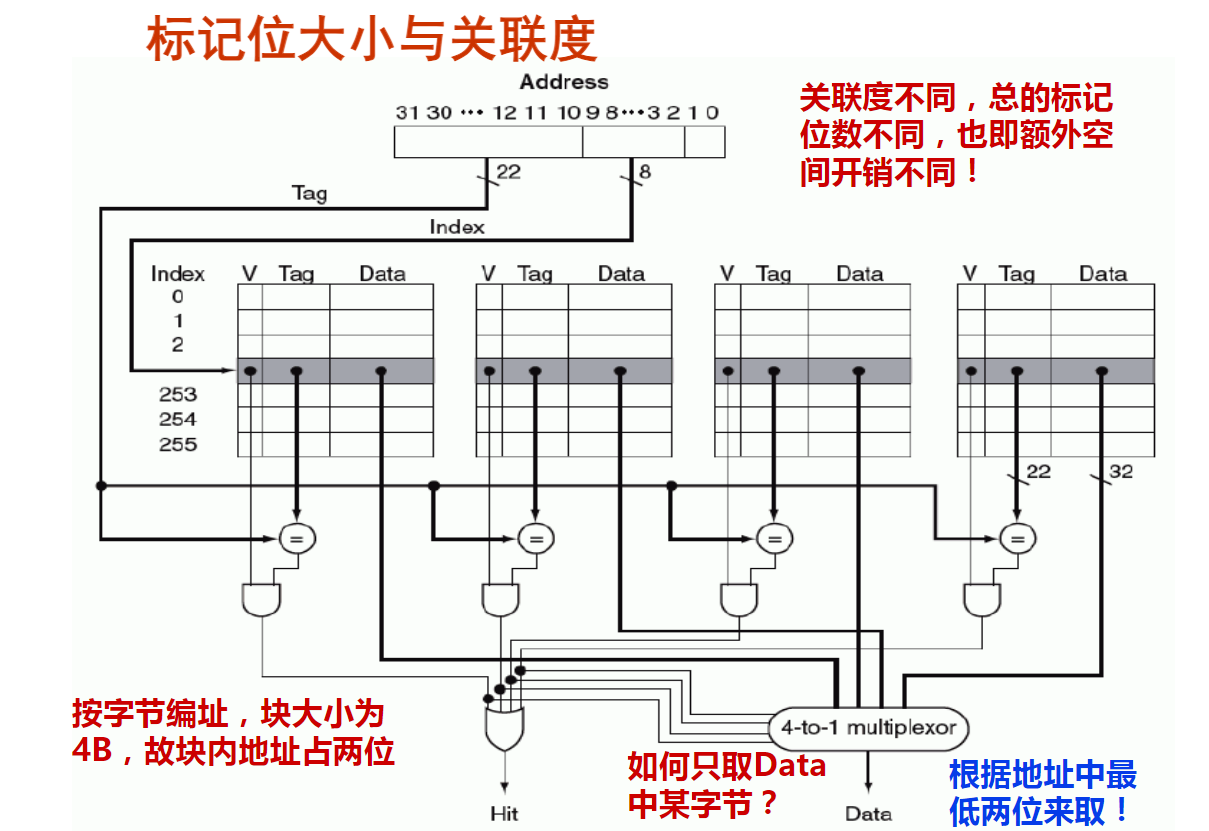

第四周小测验
1在存储器分层体系结构中,存储器速度从最快到最慢的排列顺序是( C )。
A.寄存器-主存-辅存-cache
B.寄存器-主存-cache-辅存
C.寄存器-cache-主存-辅存
D.寄存器-cache-辅存-主存
正确答案:C你选对了
2在存储器分层体系结构中,存储器从容量最大到最小的排列顺序是(C )。
A.辅存-主存-寄存器-cache
B.主存-辅存-cache-寄存器
C.辅存-主存-cache-寄存器
D.辅存-cache-主存-寄存器
正确答案:C你选对了
3在主存和CPU之间增加cache的目的是( B )。
A.提高内存可靠性
B.加快信息访问速度
C.增加内存容量,同时加快访问速度
D.增加内存容量
正确答案:B你选对了
4以下哪一种情况能很好地发挥cache的作用?
A.程序中含有较多的I/O操作
B.程序的大小不超过实际的内存容量
C.程序具有较好的访问局部性
D.程序的指令间相关度不高
正确答案:C你选对了
5假定主存按字节编址,cache共有64行,采用直接映射方式,主存块大小为32字节,所有编号都从0开始。问主存第2593号单元所在主存块对应的cache行号是( D )。
A.81
B.1
C.34
D.17
解析: D、因为按字节编址,主存块大小为32字节,所以块内地址占5位。采用直接映射方式,共64行,故行号占6位。因为2593=2048+512+32+1=0…01 010001 00001B,根据主存地址划分的结果,可以看出2593单元所在主存块对应的cache行号为010001B=17。
6假定主存按字节编址,cache共有64行,采用4路组相联映射方式,主存块大小为32字节,所有编号都从0开始。问主存第2593号单元所在主存块对应的cache组号是( C )。
A.34
B.81
C.1
D.17
解析: C、因为按字节编址,主存块大小为32字节,所以块内地址占5位。采用4路组相联映射方式,共64行,分64/4=16组,故组号占4位。因为2593=2048+512+32+1=0…0101 0001 00001B,根据主存地址划分的结果,可以看出2593单元所在主存块对应的cache组号为0001B=1。
7假定主存地址空间为256MB,按字节编址, cache共有64行,采用8路组相联映射方式,主存块大小为64B,则cache容量至少为( D )字节。
A.4248
B.4216
C.4224
D.4256
解析: D、因为按字节编址,256M=2^28,故主存地址位数为28位。采用8路组相联,共64行,分64/8=8组,故组号占3位。主存块大小为64B,块内地址占6位。因此,标志位占28-3-6=19位。Cache总容量为64×(1+19+64×8)位=4256字节。
8假定CPU通过存储器总线读取数据的过程为:发送地址和读命令需1个时钟周期,存储器准备一个数据需8个时钟周期,总线上每传送1个数据需1个时钟周期。若主存和cache之间交换的主存块大小为64B,存取宽度和总线宽度都为4B,则cache的一次缺失损失至少为多少个时钟周期?D
A.64
B.80
C.72
D.160
解析: D、一次缺失损失需要从主存读出一个主存块(64B),每个总线事务读取4B,因此,需要64B/4B=16个总线事务。每个总线事务所用时间为1+8+1=10个时钟周期,总共需要160个时钟周期。
9假定用作cache的SRAM的存取时间为2ns,用作主存的SDRAM存储器的存取时间为40ns。为使平均存取时间达到3ns,则cache命中率应为(C )左右。
A.85%
B.99.9%
C.97.5%
D.92.5%
解析: C、1-(3-2)/40=97.5%。
10若主存地址32位,按字节编址,块大小为32字节,cache共有2K行,则以下叙述中,错误的是(D )。
A.关联度为8时,标志位共计38K位
B.关联度为2时,标志位共计34K位
C.关联度为1时,标志位共计32K位
D.全相联时,标志位共计64K位
解析: D、全相联时,标志位共计2K×(32-5)=54K位。
第五周Cache替换算法和写策略
- 第1讲 Cache替换算法
- 第2讲 Cache写策略(一致性问题)
- 第3讲 Cache实现的几个因素(5m49s)
- 第4讲 Cache实现举例(8m25s)
- 第5讲 Cache综合计算举例(12m49s)
- 第五周小测验
第1讲 Cache替换算法
替换算法概述(3m09s)

先进先出(FIFO)算法(6m08s)
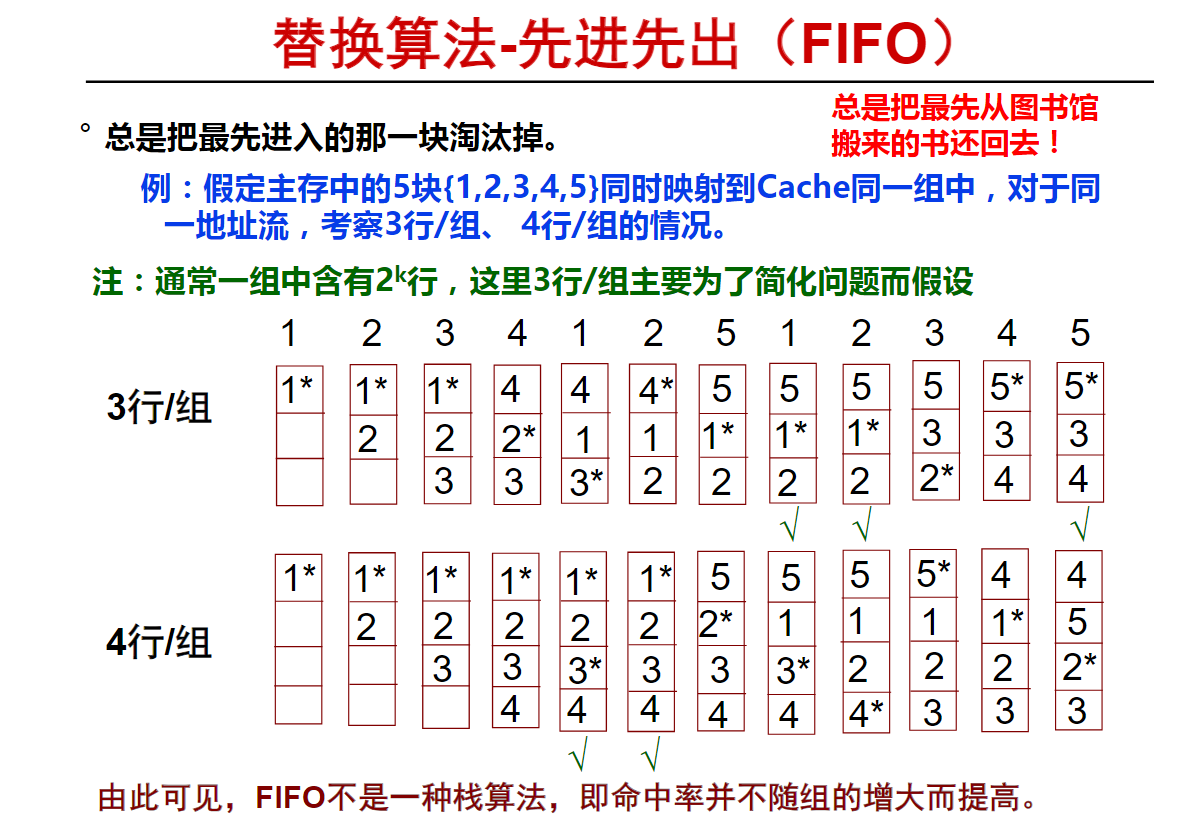
最近最少用(LRU)算法(10m06s)
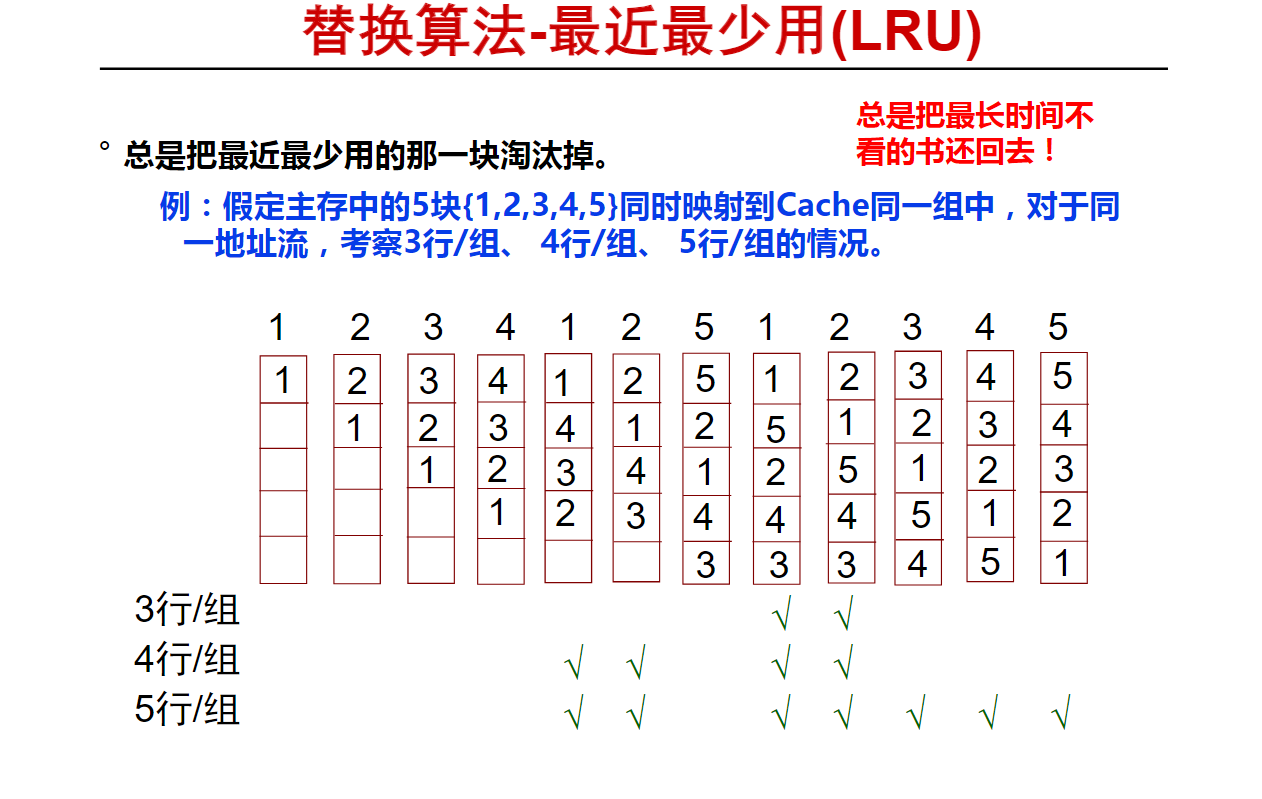

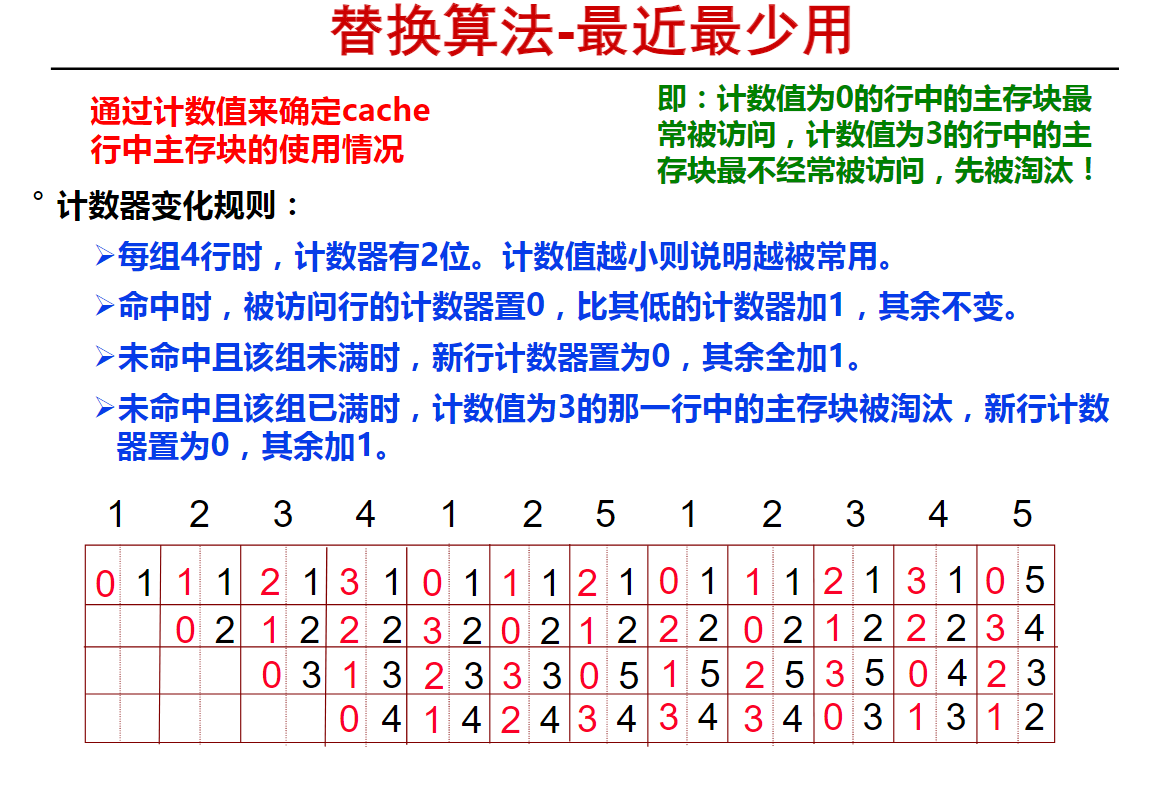

Cache举例(15m05s)

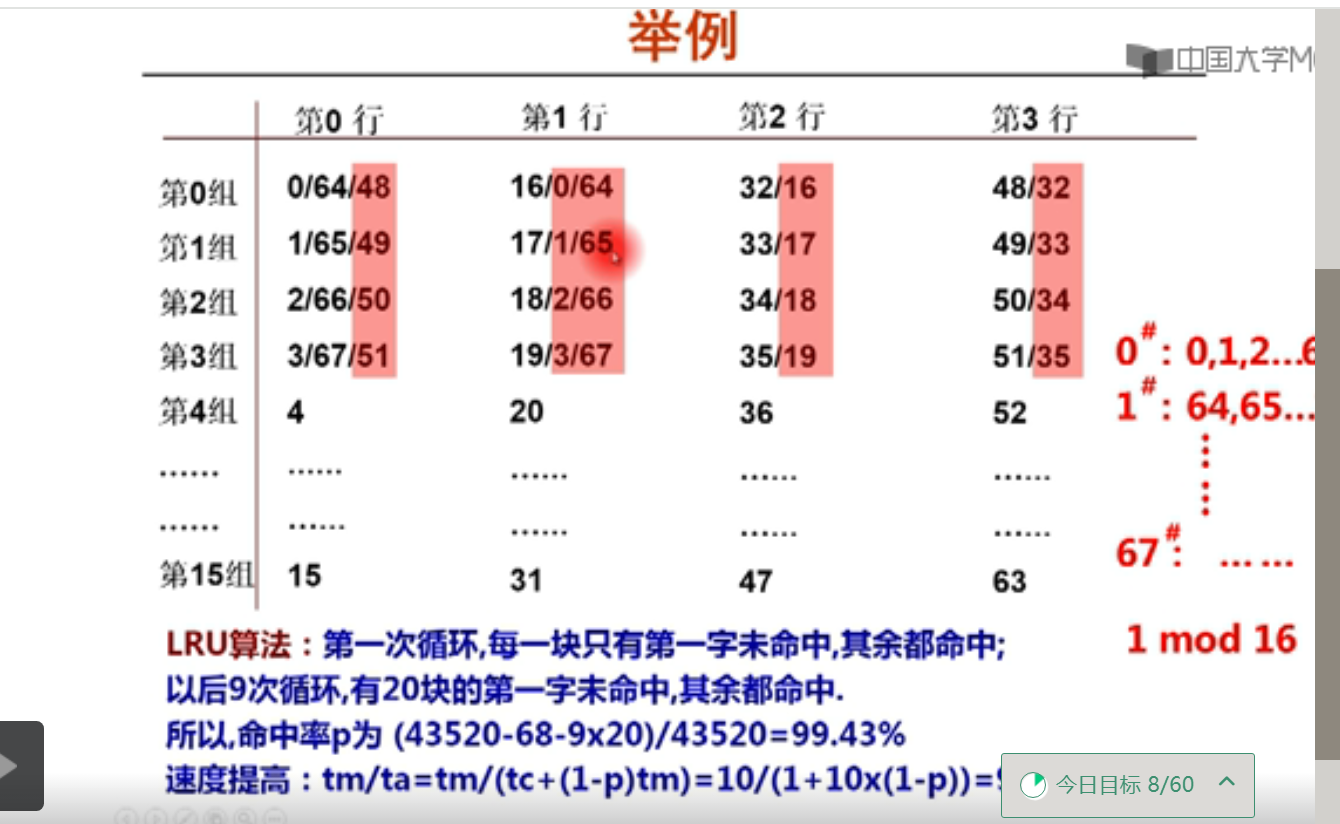
0/64/48
淘汰0,写入64;淘汰64写入48
后写入的比先写入的多更近
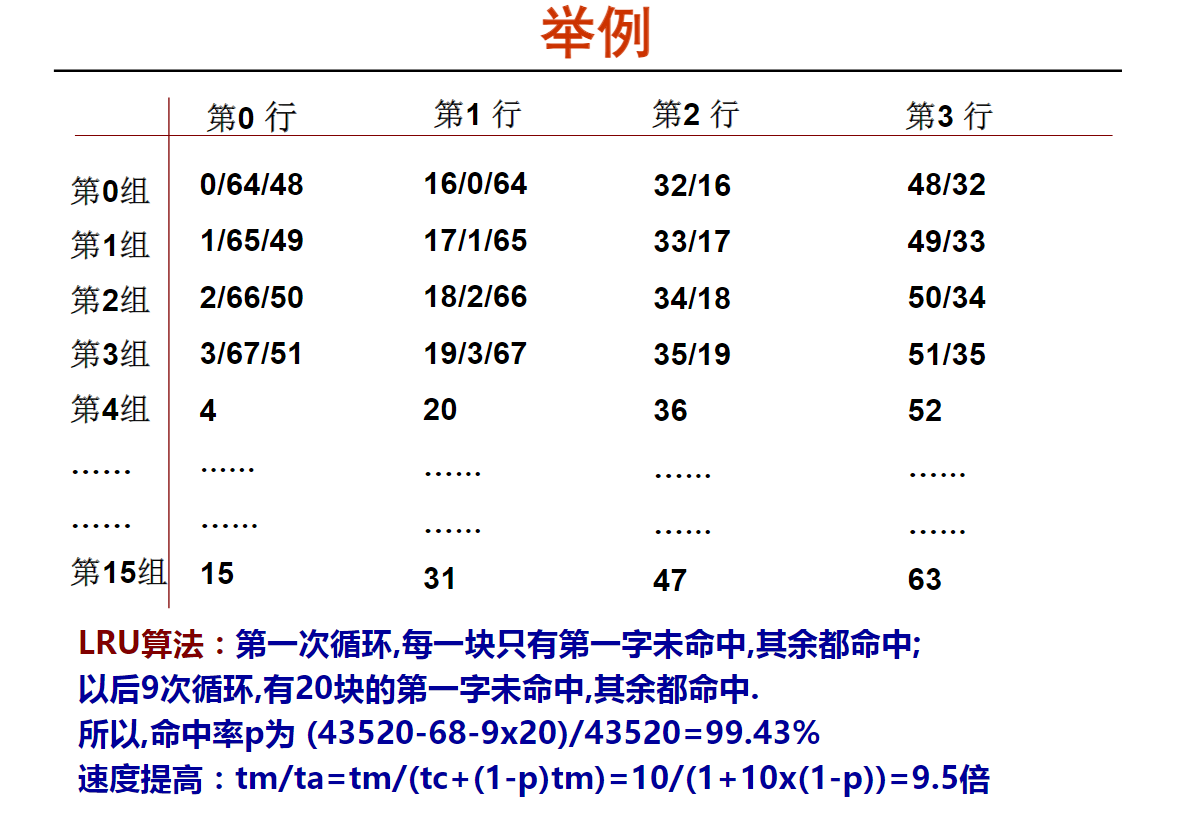
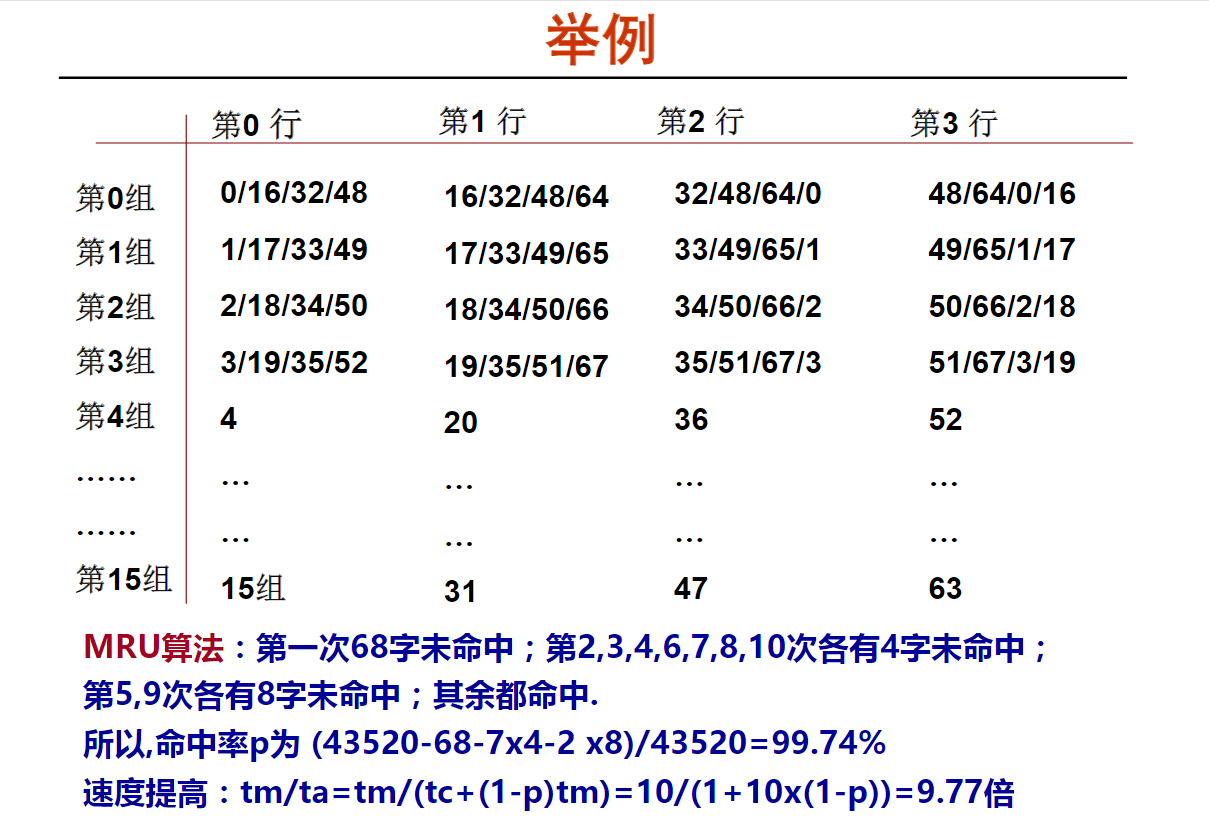
第2讲 Cache写策略(一致性问题)
写策略概述(11m11s)


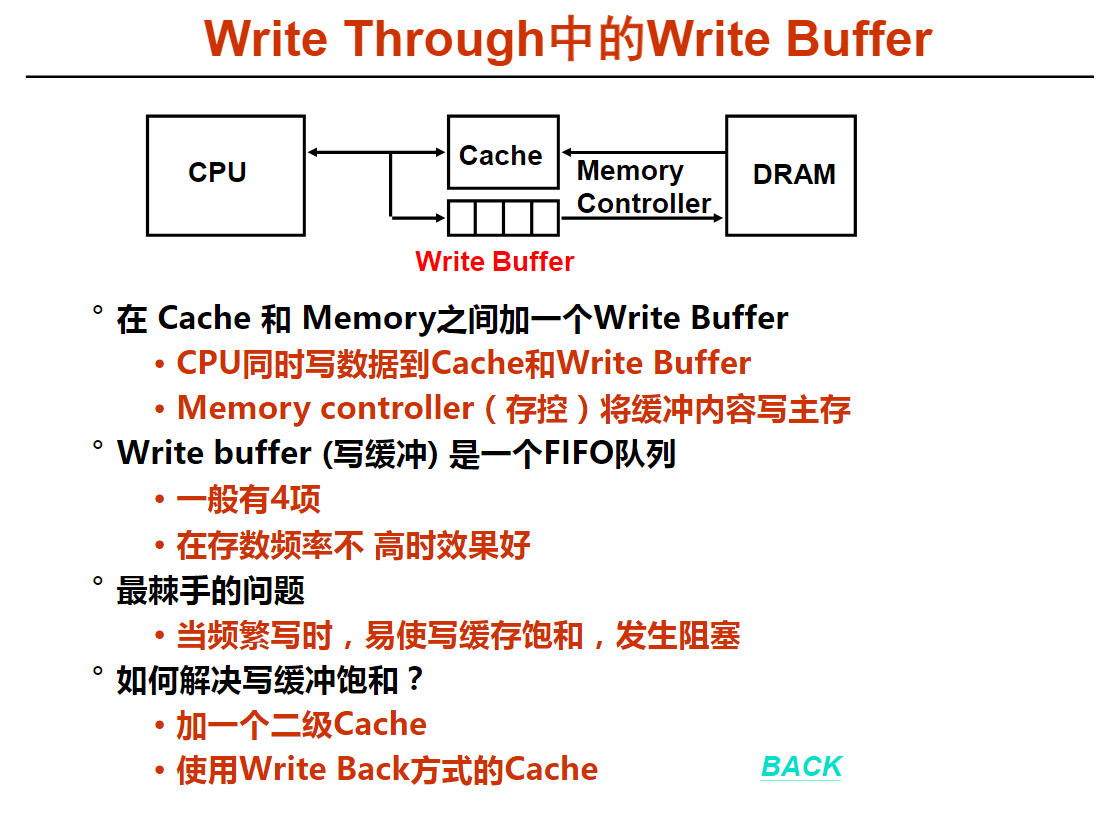
写策略算法描述(8m28s)



第3讲 Cache实现的几个因素(5m49s)
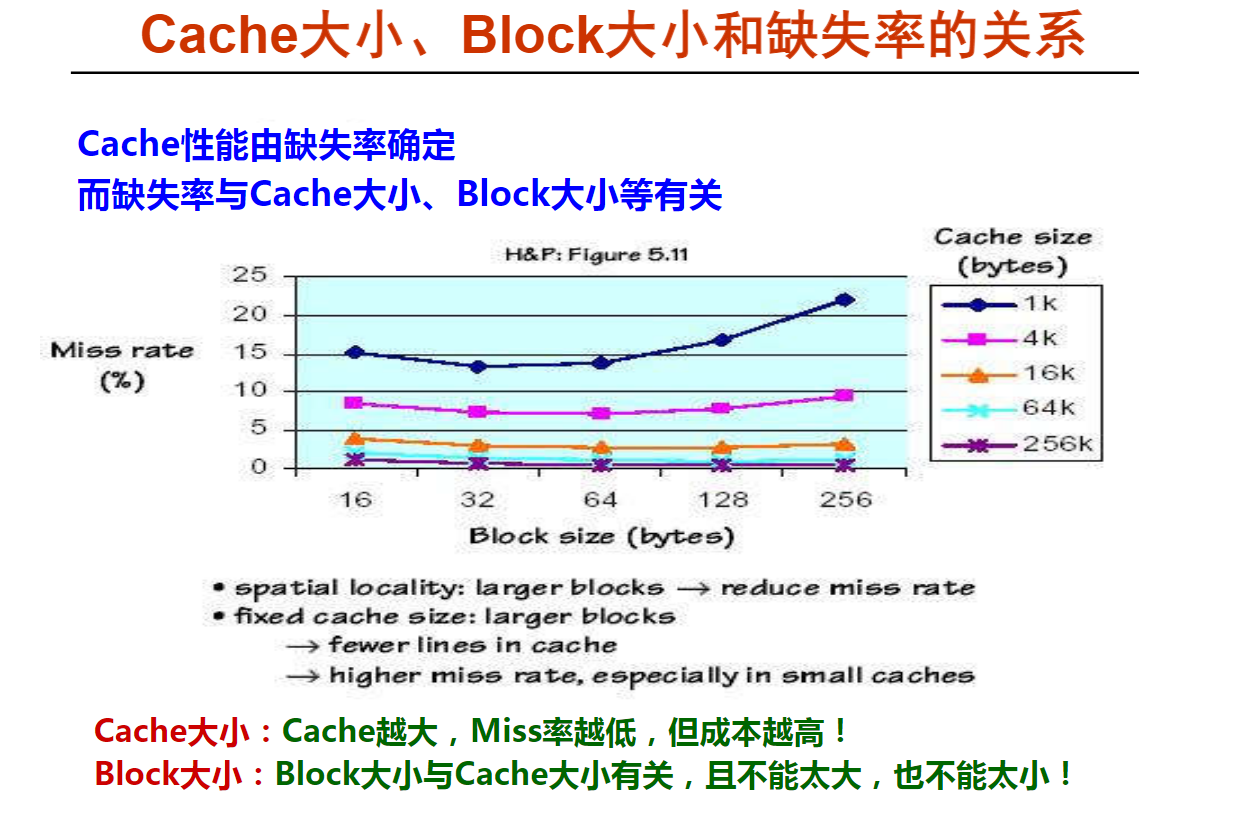
系统中的Cache数目

Harvard结构:指令数据分开存储
分立是为了方便并行,避免阻塞
第4讲 Cache实现举例(8m25s)
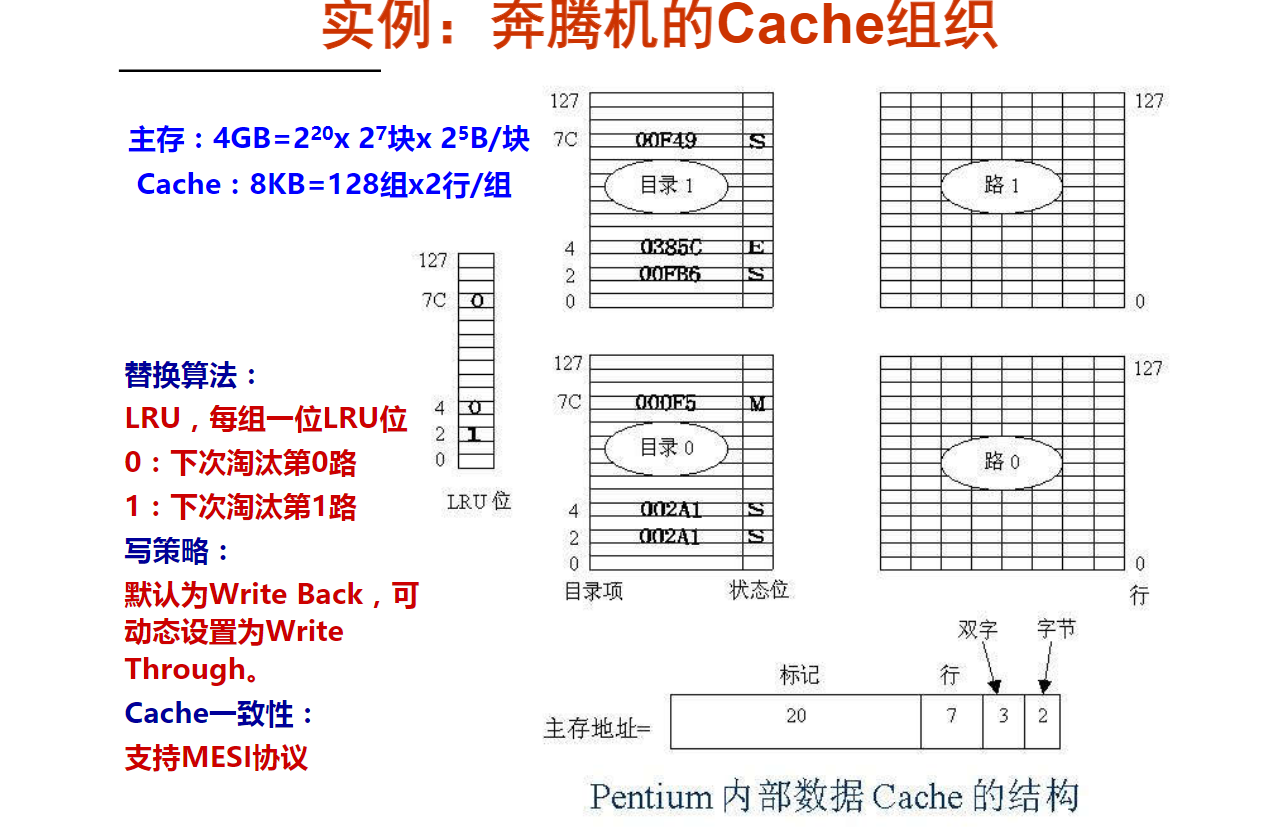
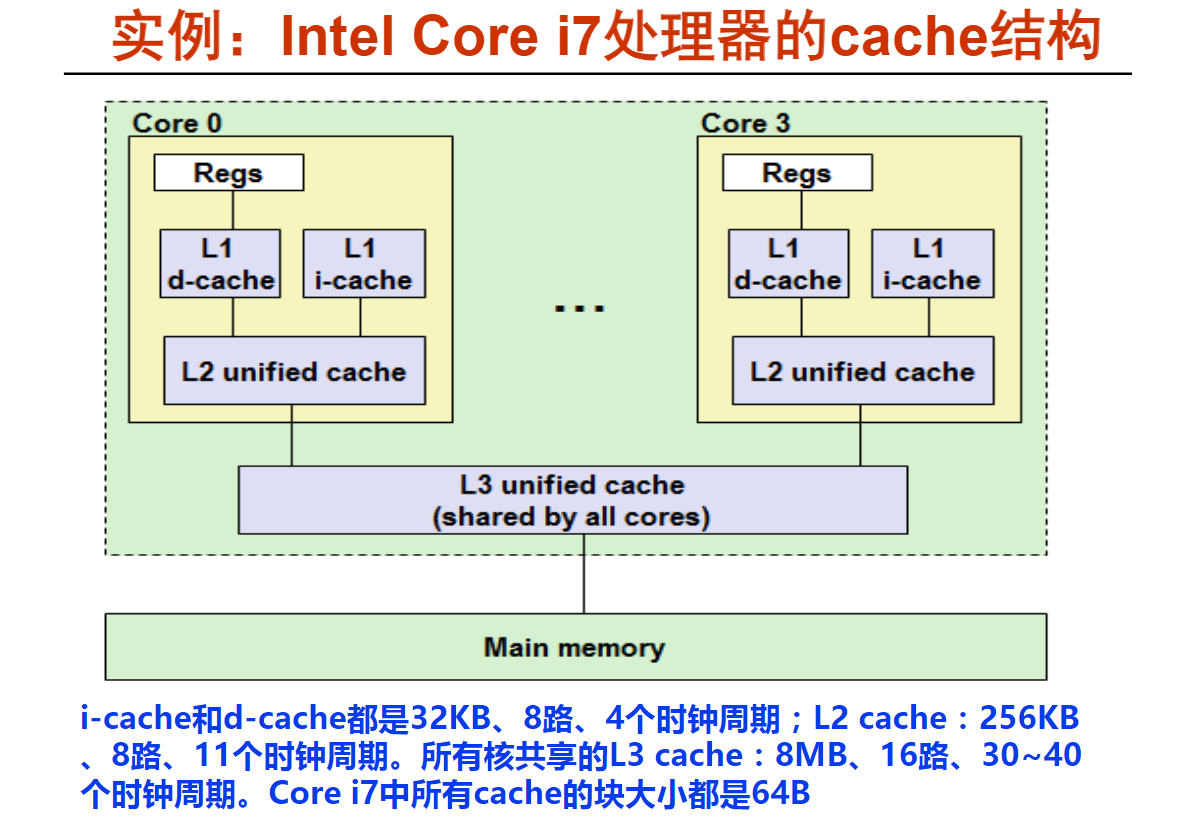
第5讲 Cache综合计算举例(12m49s)

(1)只算数据Cache


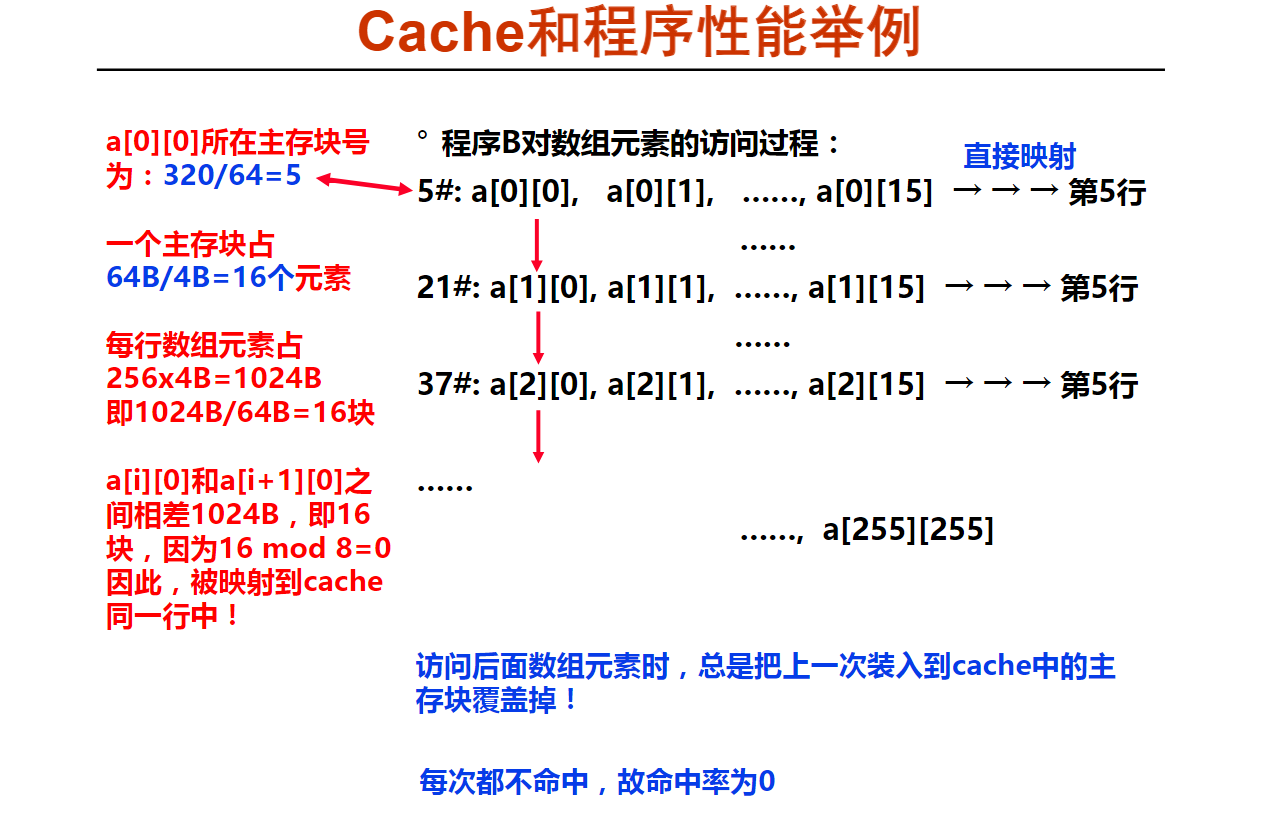
第五周小测验
错题序号:4、9
1以下关于cache替换算法的叙述中,错误的是( C )。
A.组相联和全相联映射都必须考虑如何进行替换
B.LRU算法需要对每个cache行记录替换信息,即LRU位
C.先进先出算法无需对每个cache行记录替换信息
D.直接映射方式是多对一映射,无需考虑替换问题
解析: C、先进先出算法需要对每个cache行打一个时间戳,记录何时装入了一个新的主存块。
2以下关于LRU替换算法的叙述中,错误的是(B )。
A.是一种栈算法,其命中率随组的增大而提高
B.全相联映射方式特别适合采用LRU替换算法
C.基于cache行有多久没有被访问来进行替换
D.LRU是Least-Recently Used的缩写,表示最近最少用
解析: B、LRU替换算法需要为每个cache行设置一个计数器,用于记录对应行的使用情况。计数器的位数与组的大小有关,例如,对于2-路组相联,每组有两个cache行,计数器为1位;对于4-路组相联,计数器为2位。对于全相联,则组的大小等于cache行数,因而计数器的位数等于cache行号的位数,这样,不仅计数器所占容量开销大,而且对计数器进行修改的时间开销也大。因而LRU算法不适合应用于全相联映射方式。
3以下关于写策略的叙述中,错误的是( A )。
A.只有在写命中时才需考虑写策略问题,在写不命中时无需考虑
B.对于写命中,有直写(Write Through)和回写(Write Back)两种写策略
C.多个带cache的CPU共享主存时会出现写策略问题
D.写策略问题也是cache一致性问题
解析: A、写命中指要写的单元已经在cache中,写不命中指要写的单元不在cache中。不管是写命中还是写不命中,都需要考虑写策略问题。在写命中时,可以采用直写(Write Through)或回写(Write Back)方式。前者在写cache的同时也写主存;后者仅写cache,在被替换出去时再将整个主存块写入主存。在写不命中时,可以采用写分配方式,把主存块装入cache,然后采用写命中时的直写或回写策略进行处理,也可以采用非写分配(Not Write Allocate)方式,直接写主存而不写cache。
4以下关于直写(Write Through)策略的叙述中,错误的是(C )。
A.通常在cache和主存之间设置写缓冲,以加快写操作速度
B.在写不命中时,若采用非写分配(Not Write Allocate)方式,则只能用直写替换策略
C.通常在cache行中加“dirty bit”,以标识对应行是否被修改过
D.每次写操作都会写cache中的内容和在主存中的副本
解析: C、因为直写(Write Through)策略会同时写cache和主存,因此,总能保持cache和主存的一致性,无需用“dirty bit”来标识cache行是否被修改。而回写(Write Back)策略仅写cache,在被替换出去时,需要根据dirty bit是否为1,以了解cache行中的主存块是否被修改,若被修改,则说明发生了cache和主存的不一致,需要将整个主存块写入主存。
5假定主存地址位数为32位,按字节编址,主存和cache之间采用直接映射方式,主存块大小为1个字,每字32位,写操作时采用直写(Write Through)方式,则能存放32K字数据的cache的总容量至少应有( A )位。
A.1536K
B.1568K
C.1600K
D.1504K
解析: A、cache共有32K字/1字=32K行,故行号占15位;每个主存块为1字=32位=4B,故块内地址占2位。因此,标志占32-15-2=15位。直接映射方式无需考虑替换算法,故没有替换信息;直写方式无需修改位(dirty bit)。因而cache总容量为32K×(1+15+32)=1536K位。
6假定主存地址位数为32位,按字节编址,主存和cache之间采用直接映射方式,主存块大小为1个字,每字32位,写操作时采用回写(Write Back)方式,则能存放32K字数据的cache的总容量至少应有( D )位。
A.1536K
B.1600K
C.1504K
D.1568K
解析: D、cache共有32K字/1字=32K行,故行号占15位;每个主存块为1字=32位=4B,故块内地址占2位。因此,标志占32-15-2=15位。直接映射方式无需考虑替换算法,故没有替换信息;回写(Write Back)方式需1位修改位(dirty bit)。因而cache总容量为32K×(1+15+1+32)=1568K位。
7假定主存地址位数为32位,按字节编址,主存和cache之间采用全相联映射方式,主存块大小为4个字,每字32位,采用回写(Write Back)方式和随机替换策略,则能存放32K字数据的cache的总容量至少应有( A )位。
A.1264K
B.1256K
C.5024K
D.5056K
解析: A、cache共有32K字/4字=8K行,每个主存块为4字=4×32位=16B,故块内地址占4位。因此,全相联映射方式下,标志占32-4=28位。随机替换算法没有替换信息;回写(Write Back)方式需1位修改位(dirty bit)。因而cache总容量为8K×(1+28+1+4×32)=1264K位。
8假定主存地址位数为32位,按字节编址,主存和cache之间采用4-路组相联映射方式,主存块大小为4个字,每字32位,采用直写(Write Through)方式和LRU替换策略,则能存放32K字数据的cache的总容量至少应有(D )位。
A.1168K
B.4736K
C.4672K
D.1184K
解析: D、cache共有32K字/4字=8K行,因为采用4-路组相联,因而共有8K/4=2K组,组号占11位;每个主存块为4字=4×32位=16B,故块内地址占4位。因此,标志占32-11-4=17位。4路组相联方式下,LRU替换算法需要每行有2位LRU位;直写(Write Through)方式无需修改位(dirty bit)。因而cache总容量为8K×(1+17+2+4×32)=1184K位。
9以下关于cache大小、主存块大小和cache缺失率之间关系的叙述中,错误的是( C )。
A.cache容量越大,cache缺失率越低
B.主存块大小通常为几十到上百个字节
C.主存块越大,cache缺失率越低
D.主存块大小和cache容量无密切关系
解析: C、主存块太小,则不能很好地利用空间局部性,从而导致缺失率变高,但是,主存块太大,也会使得cache行数变少,即cache中可以存放主存块的位置变少,从而降低命中率。因此,主存块不可以太小,也不可以太大,通常为几十到上百个字节。
10某32位机按字节编址。数据cache有16行,主存块大小为64B,采用2-路组相联映射。对于以下程序A,假定编译时i, j, sum均分配在寄存器中,数组a按行优先方式存放,其首址为3200,则a[1][0]所映射的cache组号、程序A的数据cache命中率各是( C )。
short a[256][256];
……
short sum_array()
{
int i, j;
short sum=0;
for (i=0; i < 256; i++)
for (j=0; j < 256; j++)
sum+=a[i][j];
return sum;
}
A.4,31/32
B.4,15/16
C.2,31/32
D.2,15/16
解析: C、a[1][0]所映射的cache组号为[(3200+(1×256+0)×2)/64] mod (16/2) = 2。
程序A的数据cache命中率分析如下:a[0][0]位于主存第3200/64=50块的起始处,按照数组访问顺序a[0][0]、a[0][1]、……、a[0][255]、a[1][0]、a[1][1]、……、a[1][255]、……,总是每64B/2B=32个数组元素组成一个主存块,被轮流装入数据cache的第2、3、……、7、0、1、…….、7、0、……. 组内的cache行中,因而这每一块的32个数组元素中,总是第一次不命中,以后每次都命中,因而命中率为31/32。
第六周虚拟存储器
- 第1讲 分页存储管理的基本概念
- 第2讲 虚拟存储器及虚拟地址空间
- 第3讲 分页存储管理的实现
- 第4讲 存储器层次结构及其访问过程
- 第5讲 段式和段页式虚拟存储管理(8m45s)
- 第6讲 存储保护(6m46s)
- 第六周小测验
第1讲 分页存储管理的基本概念
早期虚拟存储器的概念(7m05s)


分页的基本概念(7m31s)

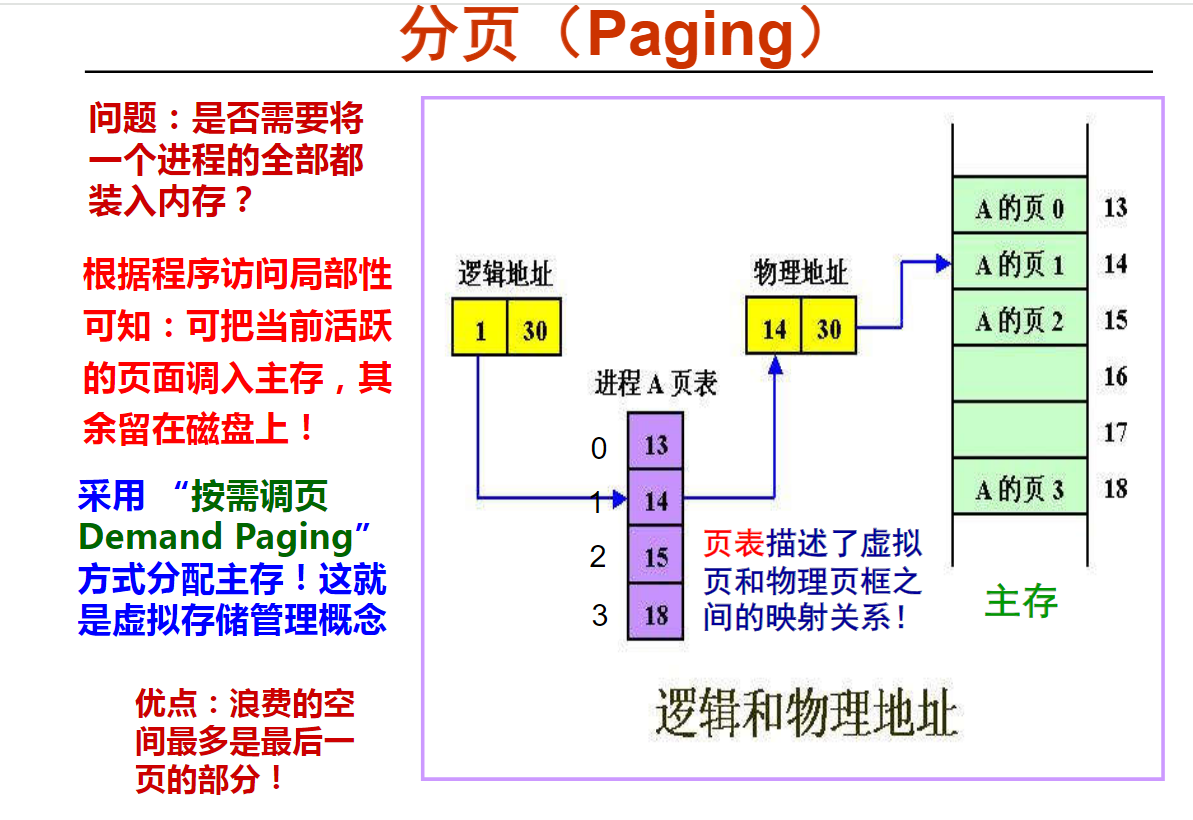
第2讲 虚拟存储器及虚拟地址空间
虚拟存储器的基本概念(5m46s)

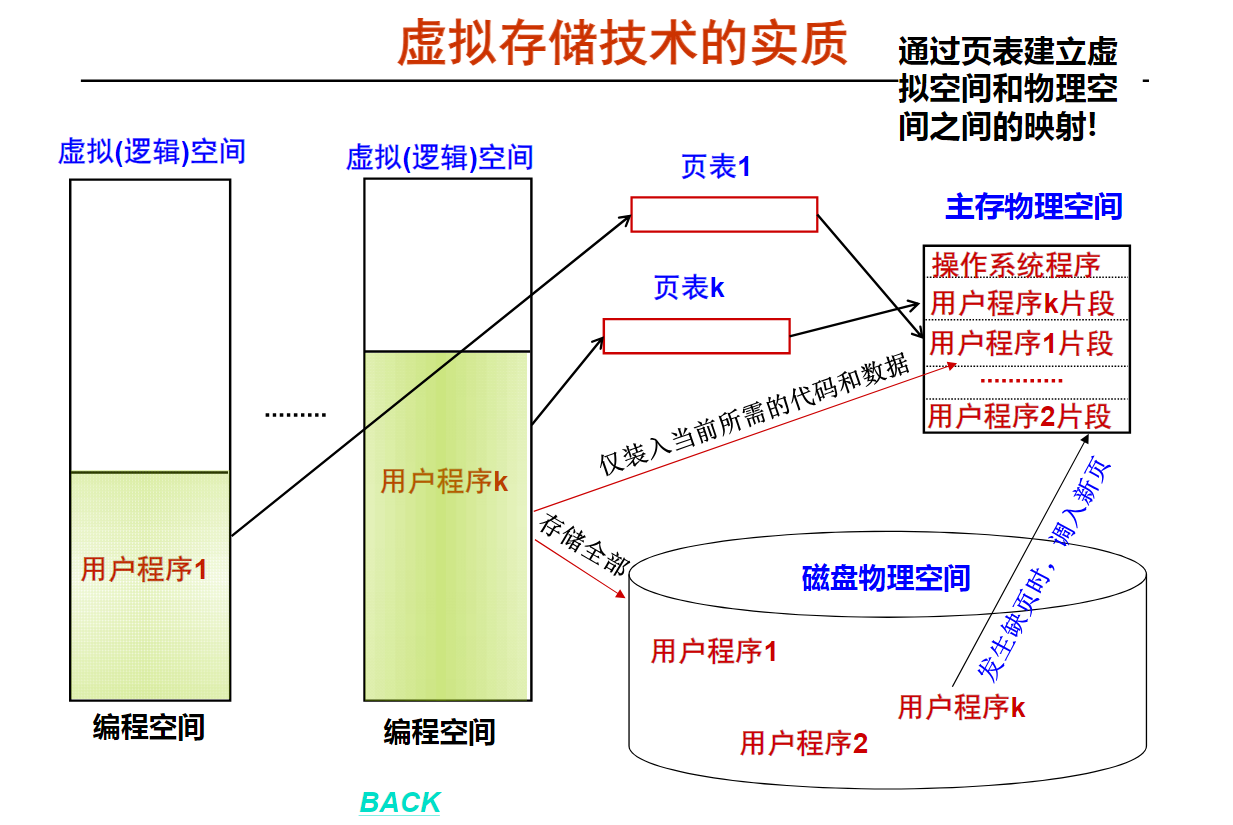
虚拟地址空间(2m57s)
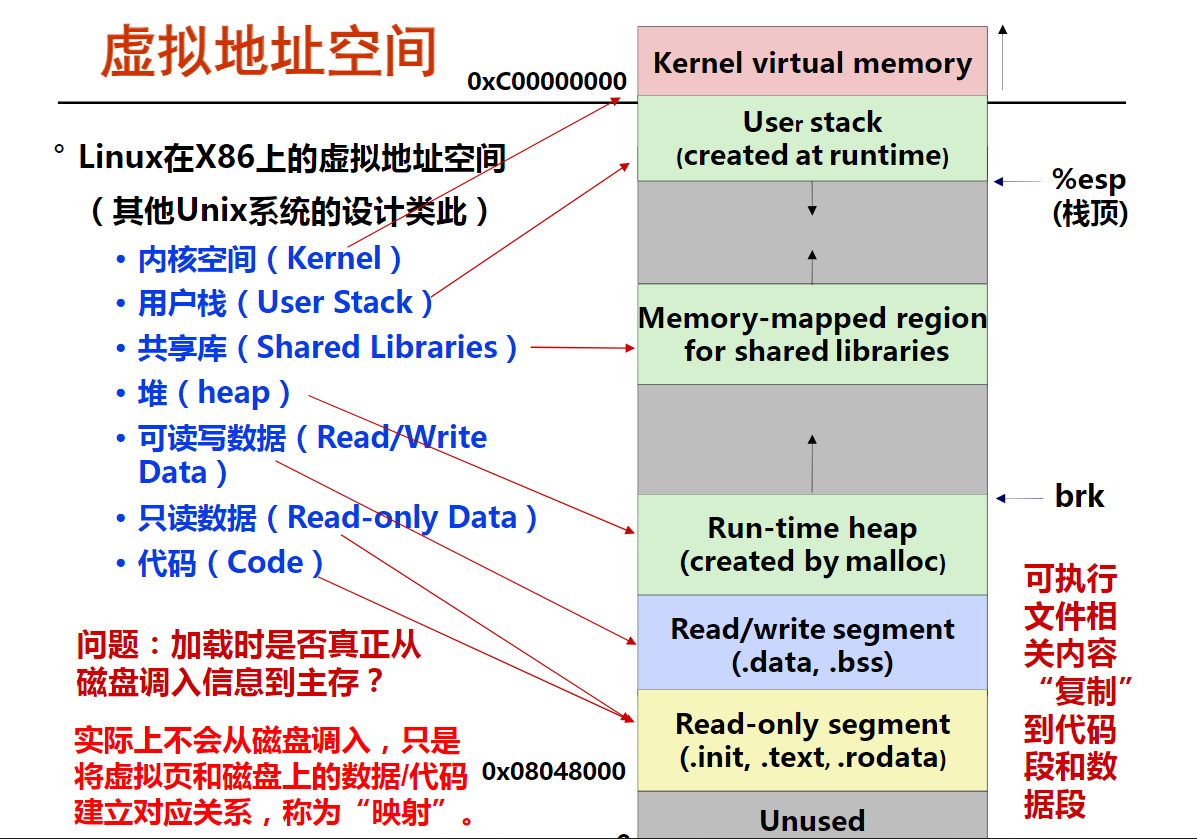
按需调页是由Page fault异常实现的
第3讲 分页存储管理的实现
实现虚拟存储管理需考虑的问题(6m06s)


页表的结构(9m03s)
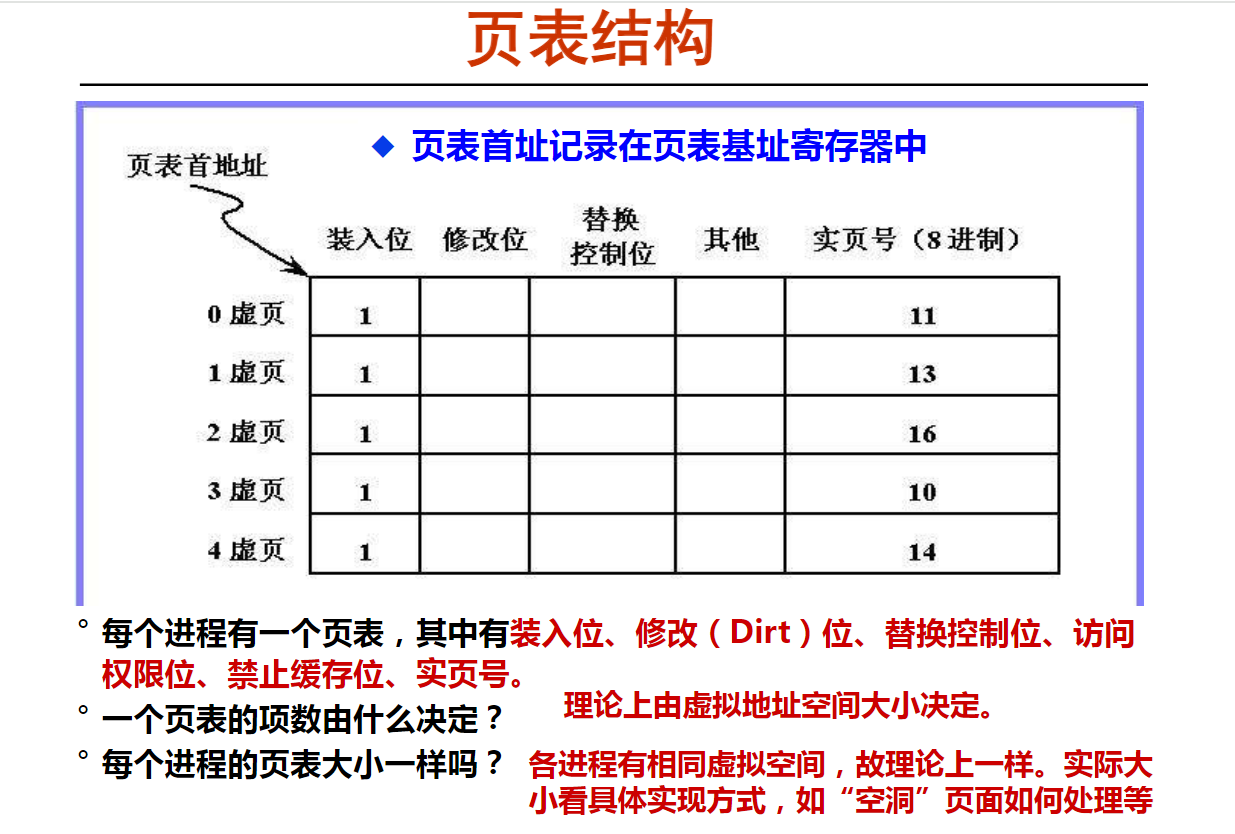
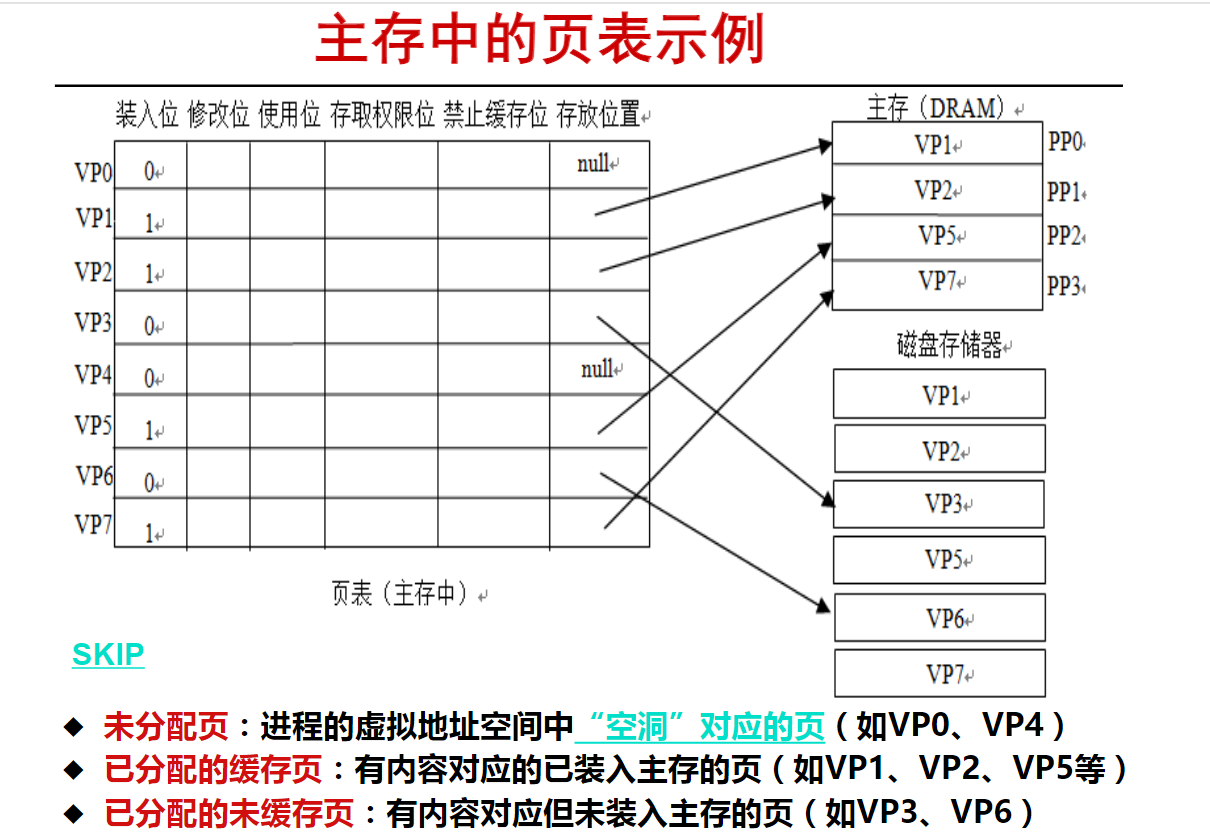
地址转换过程(5m20s)
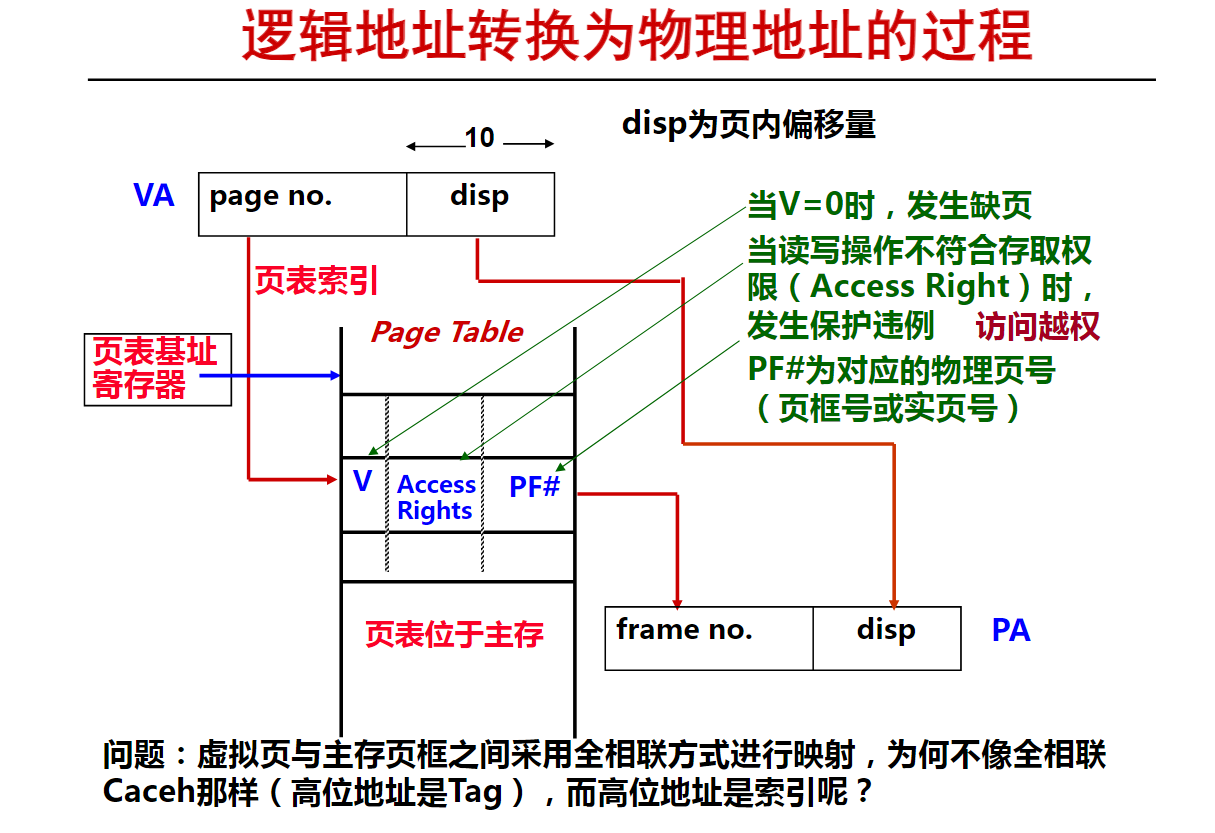

缺页由OS处理
快表(TLB)(8m13s)

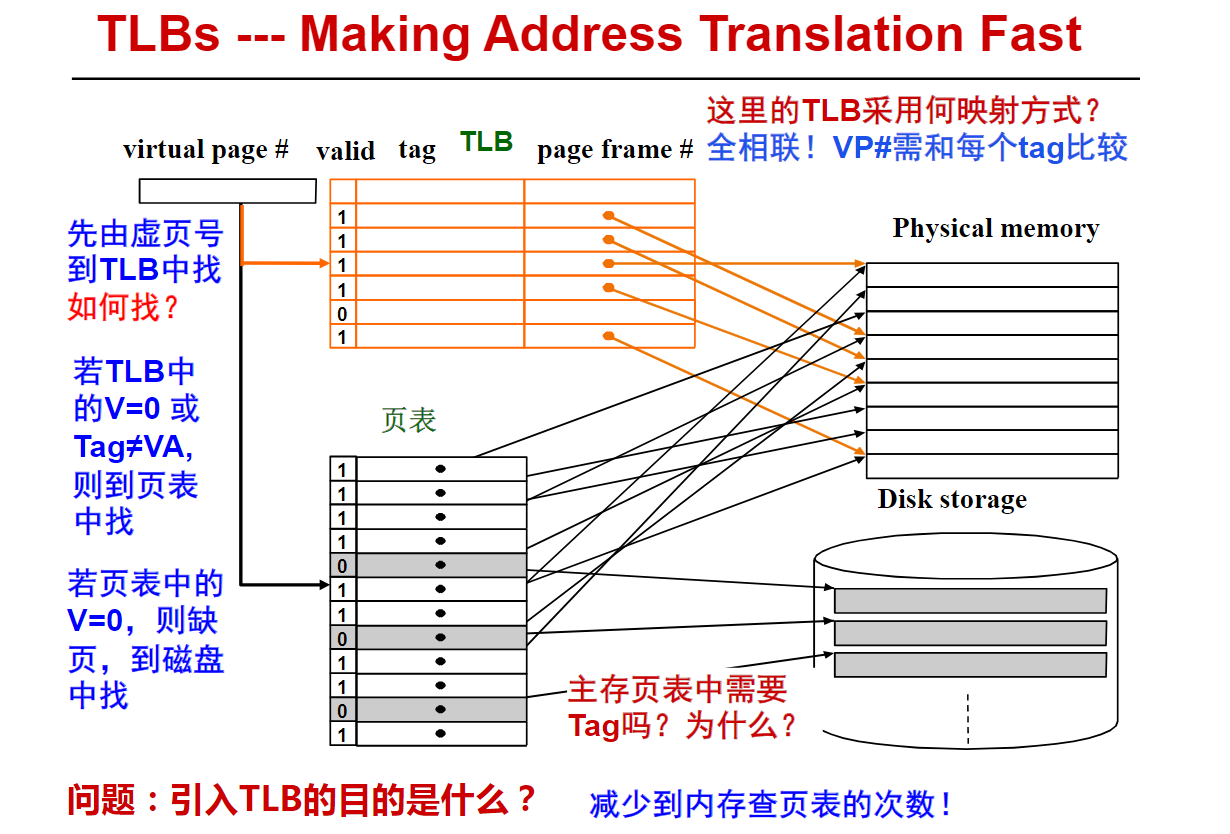
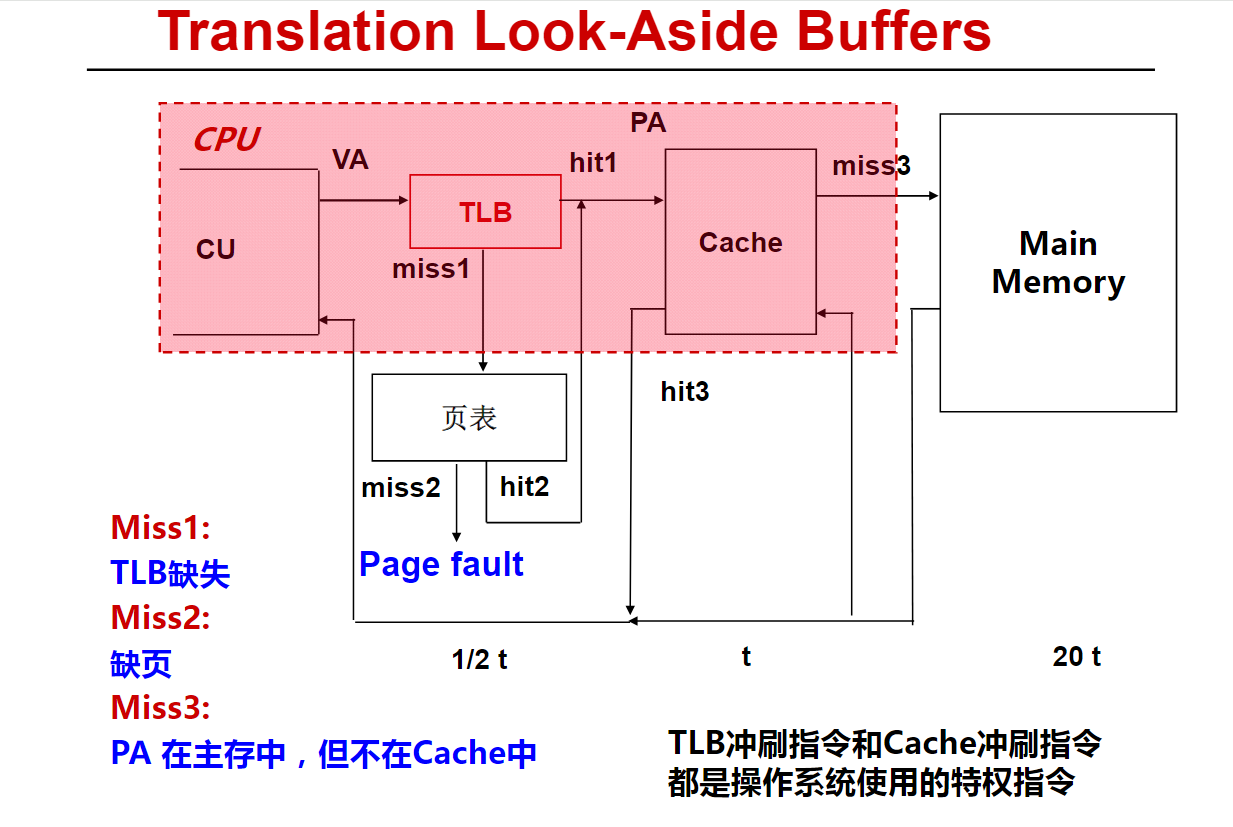
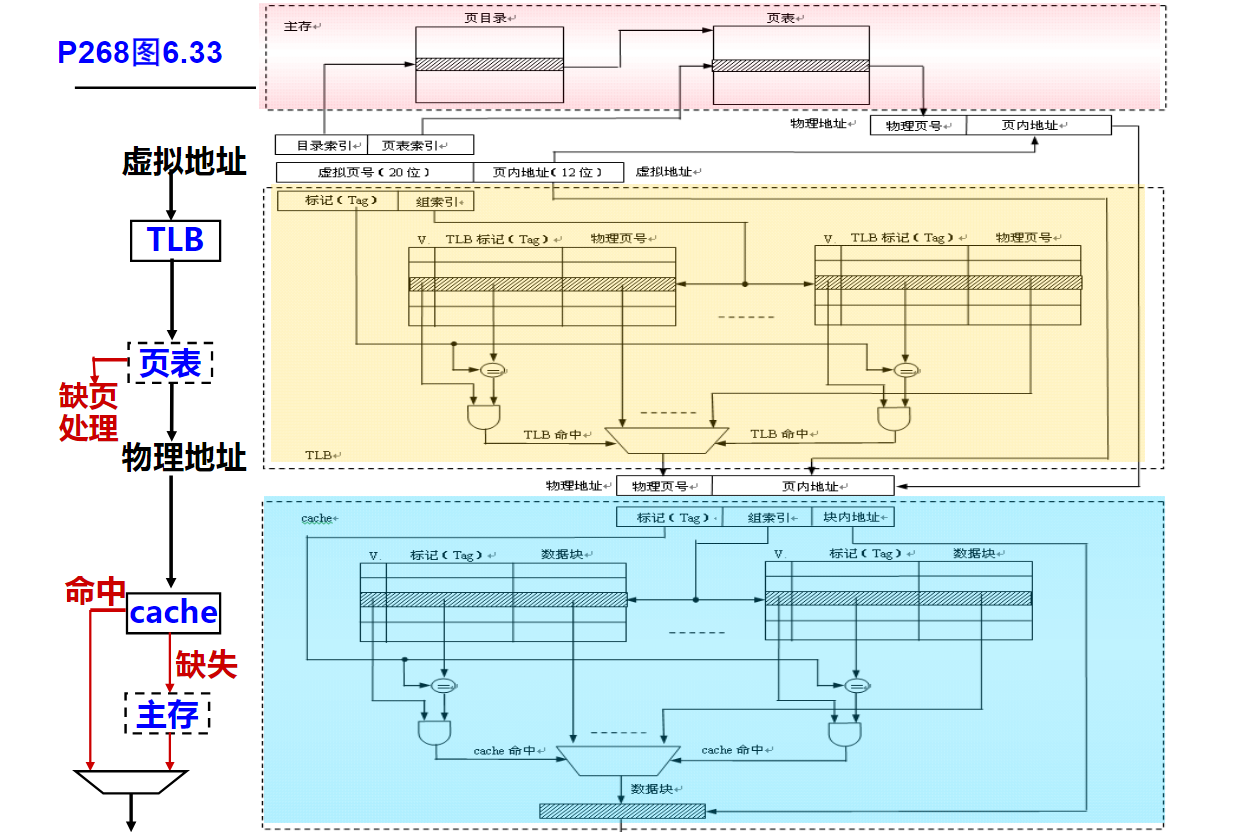
3次:取指令、取操作数、写结果
第4讲 存储器层次结构及其访问过程
存储器访问过程(8m41s)
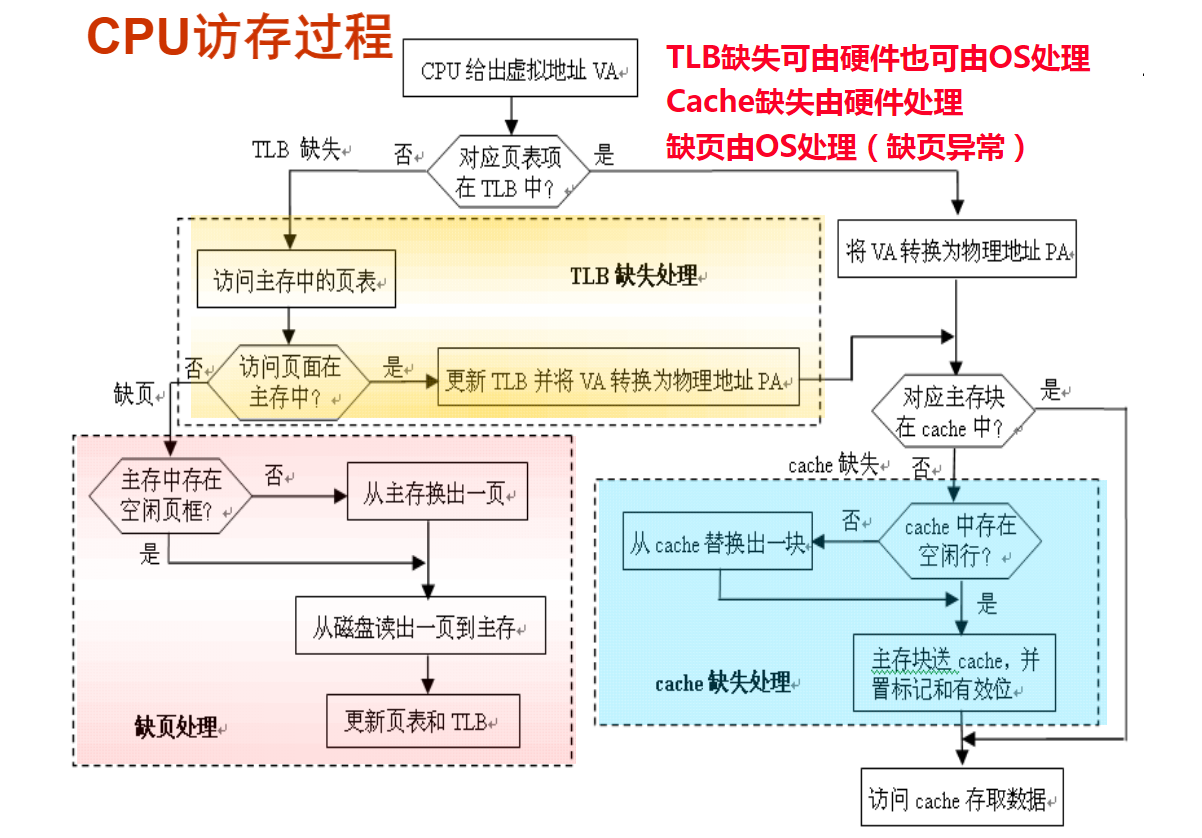
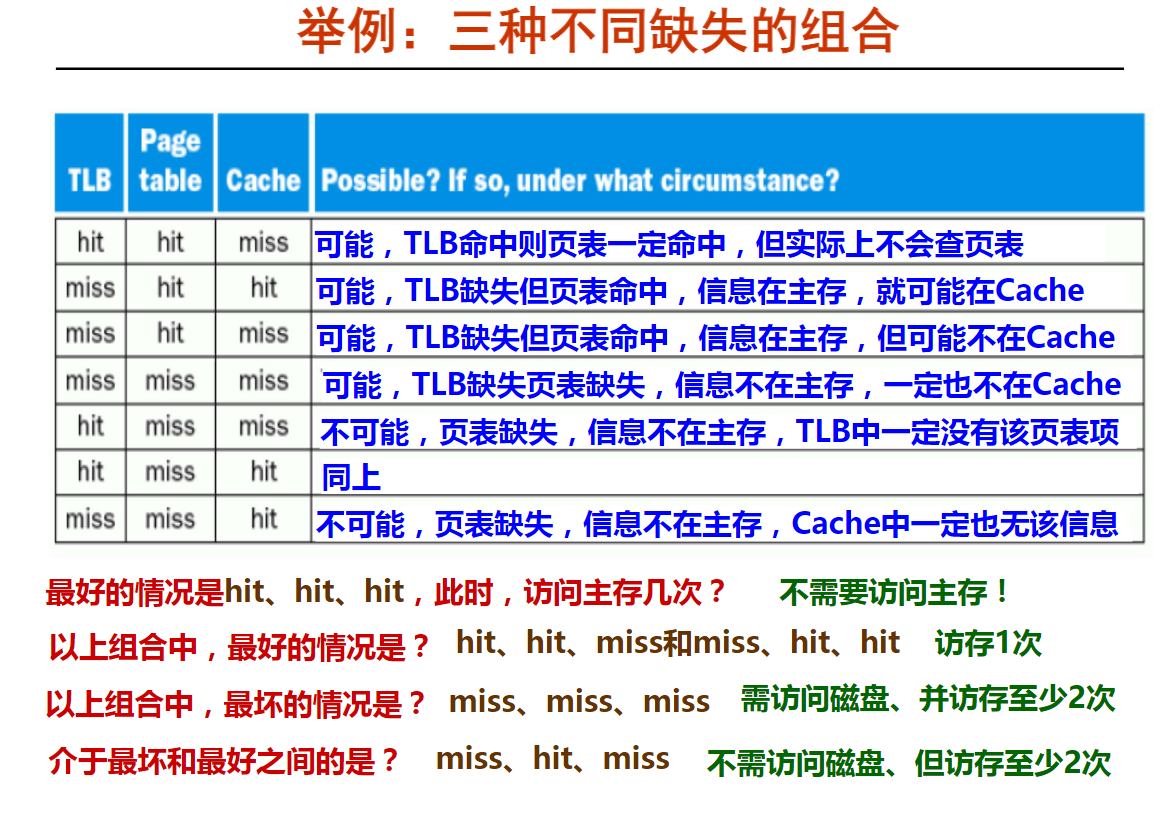
存储器层次结构举例(14m56s)(难点)


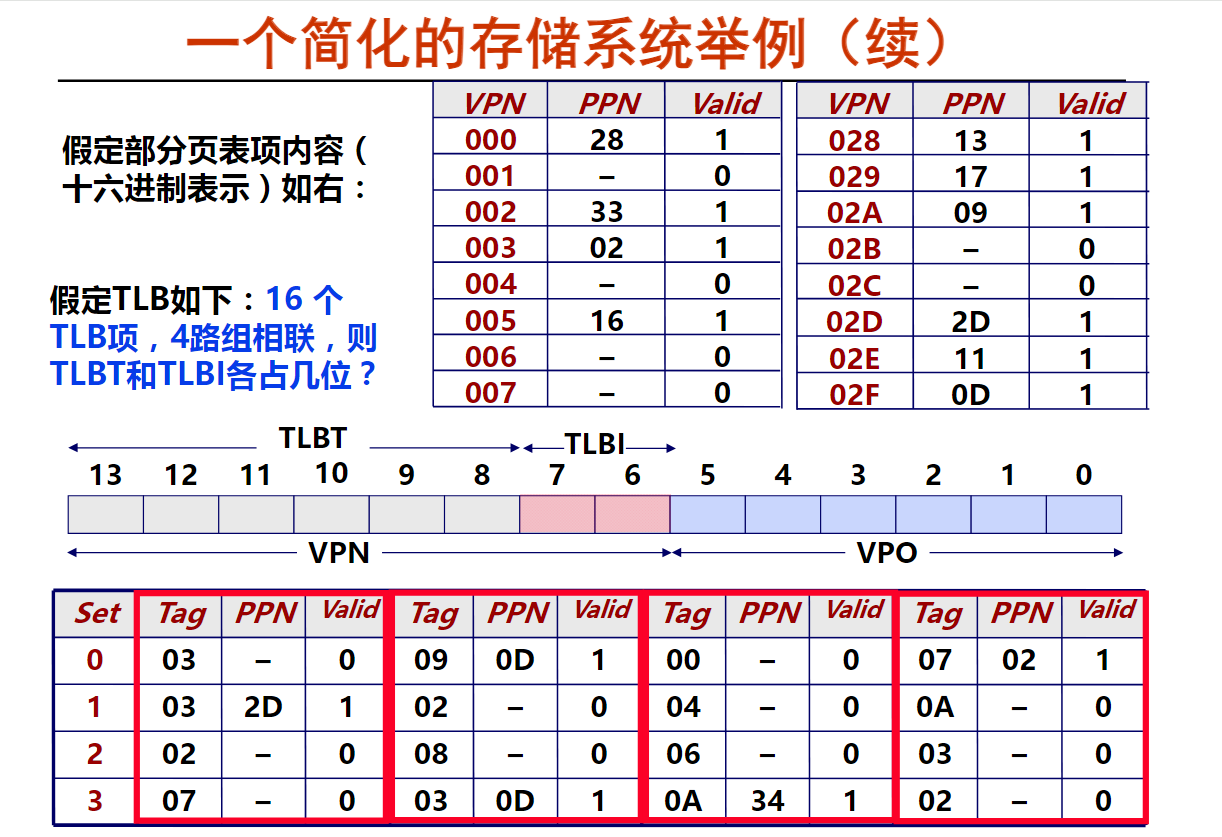
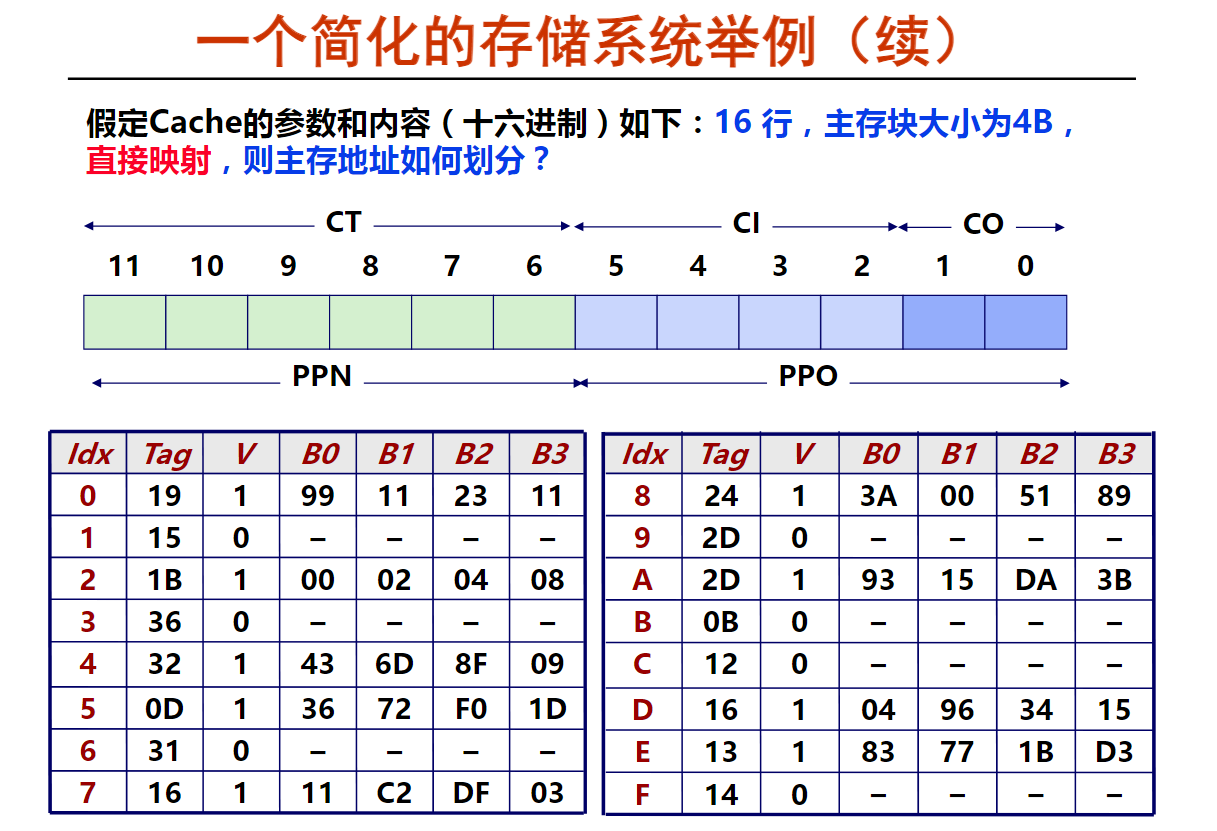
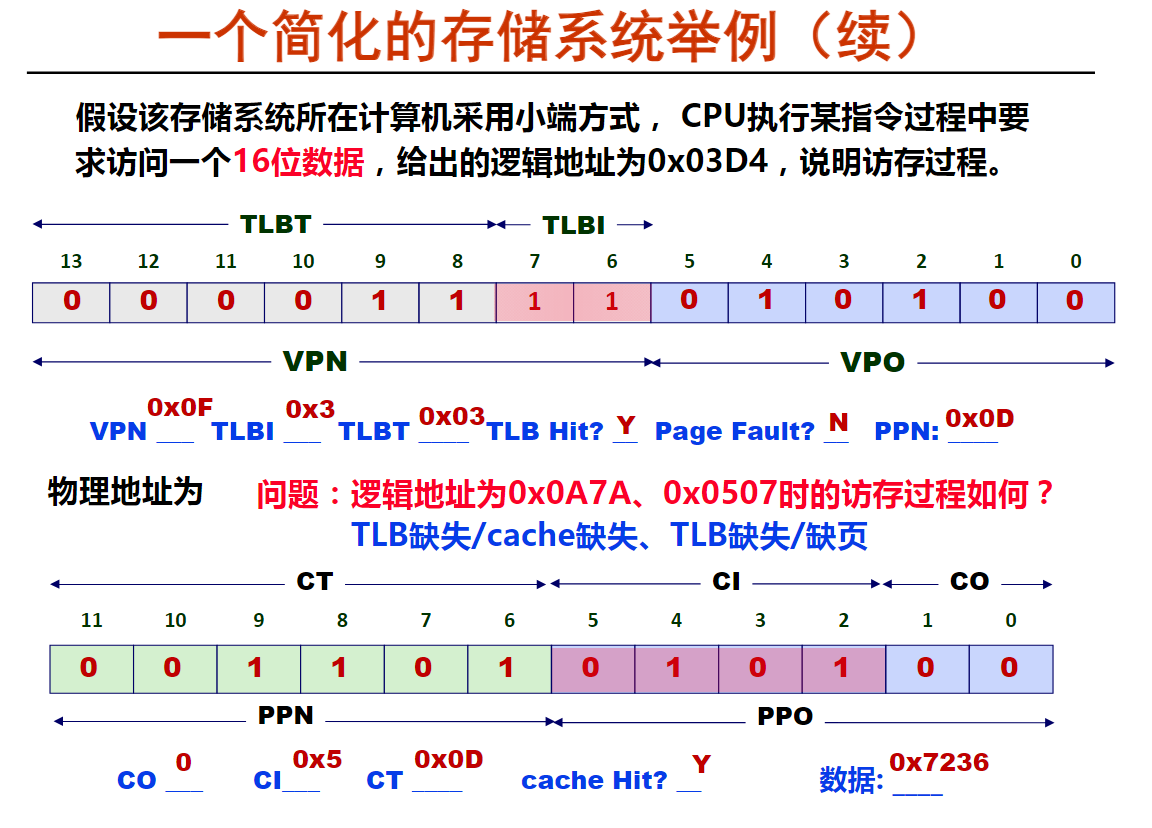
一个一个检查这些随手写的数据发现0A 34 1确实不在主存中,这里有错。
第5讲 段式和段页式虚拟存储管理(8m45s)

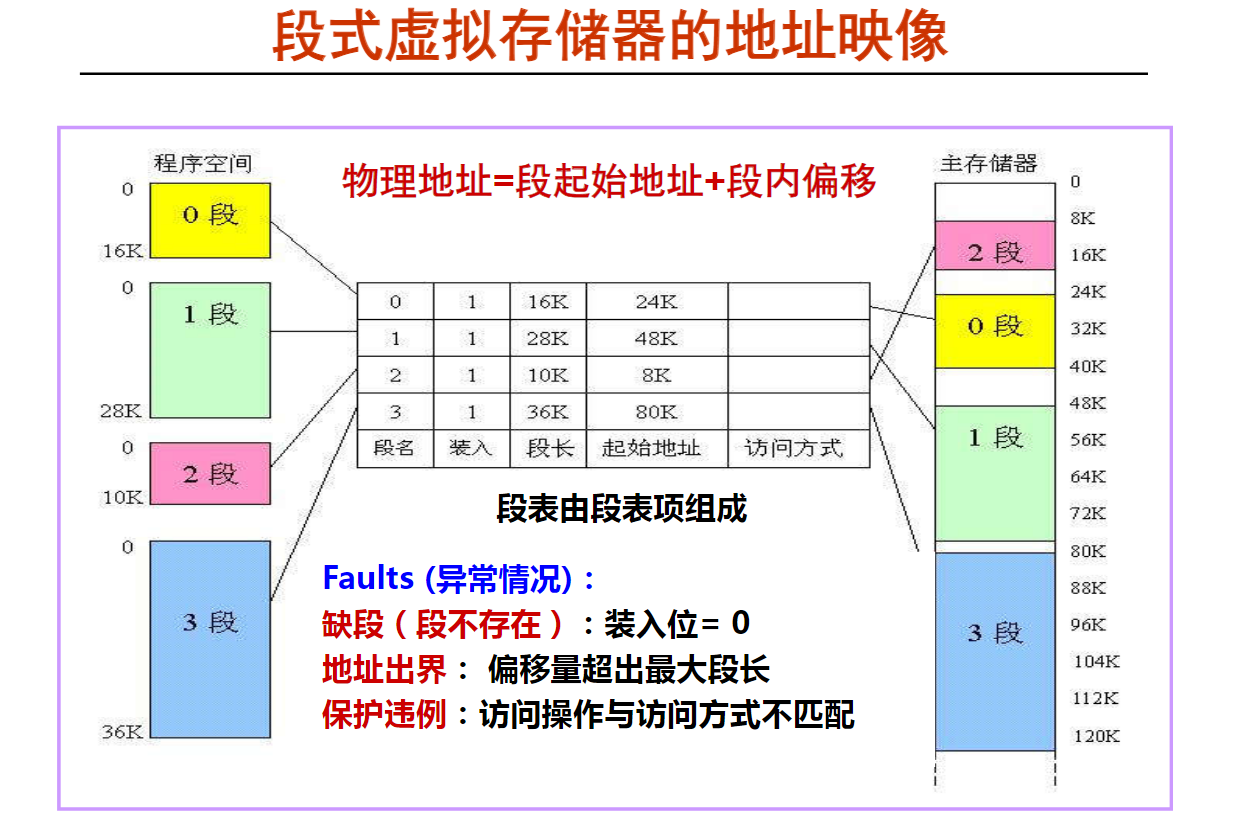

第6讲 存储保护(6m46s)

第六周小测验
错题序号:1、7、8、10
1以下有关早期分页存储管理(自动执行Overlay)方式的叙述中,错误的是( B )。
A.分页方式主要解决程序文件比主存空间大的问题
B.程序员编写程序时应将逻辑地址转换为主存物理地址
C.程序员编写程序所用的地址空间称为逻辑地址空间
D.分页方式可以使程序员编写程序时无需考虑主存容量
解析: B、早期的分页存储管理方式主要解决“程序很大而存放程序的主存很小”的问题。程序员在一个逻辑地址空间中编写程序,不用管主存有多大;运行程序时,由专门的分页管理程序,将程序中的逻辑地址转换为主存的物理地址,并实现程序块在主存的换入和换出操作。因此,地址转换的工作由管理程序自动完成,而不是由编写程序的程序员完成。
2以下有关分页虚拟存储管理方式的叙述中,错误的是( D )。
A.每条指令执行过程中,都需要把指令或数据的虚拟地址转换为物理地址
B.主存地址空间称为物理(实)地址空间,被划分成大小相等的页框
C.每个进程所占的地址空间称为虚拟地址空间,被划分成若干页面
D.程序执行时,必须把程序所包含的所有代码和数据都装入主存中
解析: D、分页虚拟存储管理方式下,每个进程都有一个统一的虚拟地址空间,被划分成大小相等的页面,主存空间被划分成大小相等的页框,程序执行时,主要把正在执行的页面装入主存的页框中,其他还没有执行到的页面可以存放在磁盘中,这样,可以在较小的主存中运行大程序。因此,无需把所有代码和数据都装入主存才能运行程序。
3以下是有关现代虚拟存储管理机制中地址转换的叙述,其中错误的是( A )。
A.整个过程主要由操作系统实现
B.缺页时将转相应异常处理程序执行
C.地址转换过程中要访问页表项
D.地址转换过程中能发现是否缺页
解析: A、虚拟存储管理机制中,地址转换是在指令执行过程中进行的,指令的执行由硬件实现,因而地址转换也由硬件完成,而不是由操作系统软件完成。操作系统生成并修改页表,而由硬件在地址转换过程中查询页表来进行地址转换,并检测是否发生缺页,在发生缺页时,硬件会发出“Page Fault”异常,从而调出相应的异常处理程序进行缺页处理。
4下列命中组合情况中,一次访存过程中不可能发生的是(C )。
A.TLB未命中、cache命中、Page命中
B.TLB命中、cache未命中、Page命中
C.TLB未命中、cache命中、Page未命中
D.TLB未命中、cache未命中、Page命中
解析: C、Page未命中,说明相应信息不在主存,cache中信息是主存信息的副本,因而相应信息肯定不在cache,也就不会cache命中。
5以下是有关虚拟存储管理机制中页表的叙述,其中错误的是( A )。
A.一个页表中的表项可以被所有进程访问
B.每个页表项中都包含装入位(有效位)
C.页表中每个表项与一个虚页对应
D.系统中每个进程有一个页表
解析: A、页表中的每个表项反映的是对应虚拟页面的位置和使用等信息,只能由操作系统和硬件进行访问,不能被任何用户进程访问。
6以下是有关缺页处理的叙述,其中错误的是( A )。
A.缺页是一种外部中断,需要调用操作系统提供的中断服务程序来处理
B.缺页处理过程中需根据页表中给出的磁盘地址去读磁盘数据
C.若对应页表项中的有效位(或存在位)为0,则发生缺页
D.缺页处理完后要重新执行发生缺页的指令
解析: A、外部中断是指CPU以外的中断请求事件,而缺页是由CPU在执行指令过程中进行地址转换时发现的在CPU内部操作时检测到的异常事件,相应的处理工作由操作系统提供的缺页异常处理程序来完成。
7以下是有关分页式存储管理的叙述,其中错误的是( D )。
A.当从磁盘装入的信息不足一页时会产生页内碎片
B.采用全相联映射,每个页可以映射到任何一个空闲的页框中
C.采用回写(Write Back)写策略,每页对应一个修改位(Dirty Bit)
D.相对于段式存储管理,分页式更利于存储保护
解析: D、因为分页方式将地址空间划分成大小相等的页面,因而可能有些页面中的有效信息一部分是代码一部分是数据,或者有效信息不足一页,前者不利于存储保护,后者容易造成页内碎片。而分段方式按代码和数据的不同类信息分段管理,显然易于存储保护。分页方式采用全相联映射方式和Write Back写策略,只要主存中有空闲页框就可以存放任何一个页面,在每次写主存时,都不会同时写磁盘,只有当某一页从主存中替换到磁盘时才可能写磁盘。
8以下有关快表(TLB)的叙述中,错误的是( C )。
A.引入快表的目的是为了加快地址转换速度
B.快表中存放的是当前进程的常用页表项
C.在快表中命中时,在L1 cache中一定命中
D.快表是一种高速缓存,一定在CPU中
解析: C、在快表中命中,是指当前正在进行地址转换的存储单元所在页面对应的页表项在TLB中,因此,可以直接从TLB中取到物理页框号,而立即生成对应的物理地址。不过,这个物理地址所在的主存块不一定在L1 cache中。
9以下是有关段式存储管理的叙述,其中错误的是( C )。
A.每个段表项中必须记录对应段在主存的起始位置和段的长度
B.按程序中实际的段来分配主存,所以分配后的存储块是可变长的
C.段表项中无需有效位(或存在位),因为每个段都在主存中
D.段是逻辑结构上相对独立的程序和数据模块,因此段是可变长的
正确答案:C你选对了
段表项也需要有效位
10以下给出的事件中, 无需通过异常处理程序进行处理的是( C )。
A.缺页故障
B.段不存在
C.cache缺失
D.地址越界
解析: C、cache缺失由硬件处理,无需调出操作系统中的异常处理程序来处理。
第七周IA-32/Linux中的地址转换
- 第1讲 IA-32的地址转换和寻址方式
- 第2讲 段选择符和段寄存器
- 第3讲 段描述符和段描述符表
- 第4讲 逻辑地址向线性地址的转换
- 第5讲 线性地址向物理地址的转换
- 第6讲 Intel Core i7/Linux存储系统
- 第七周小测验

第1讲 IA-32的地址转换和寻址方式

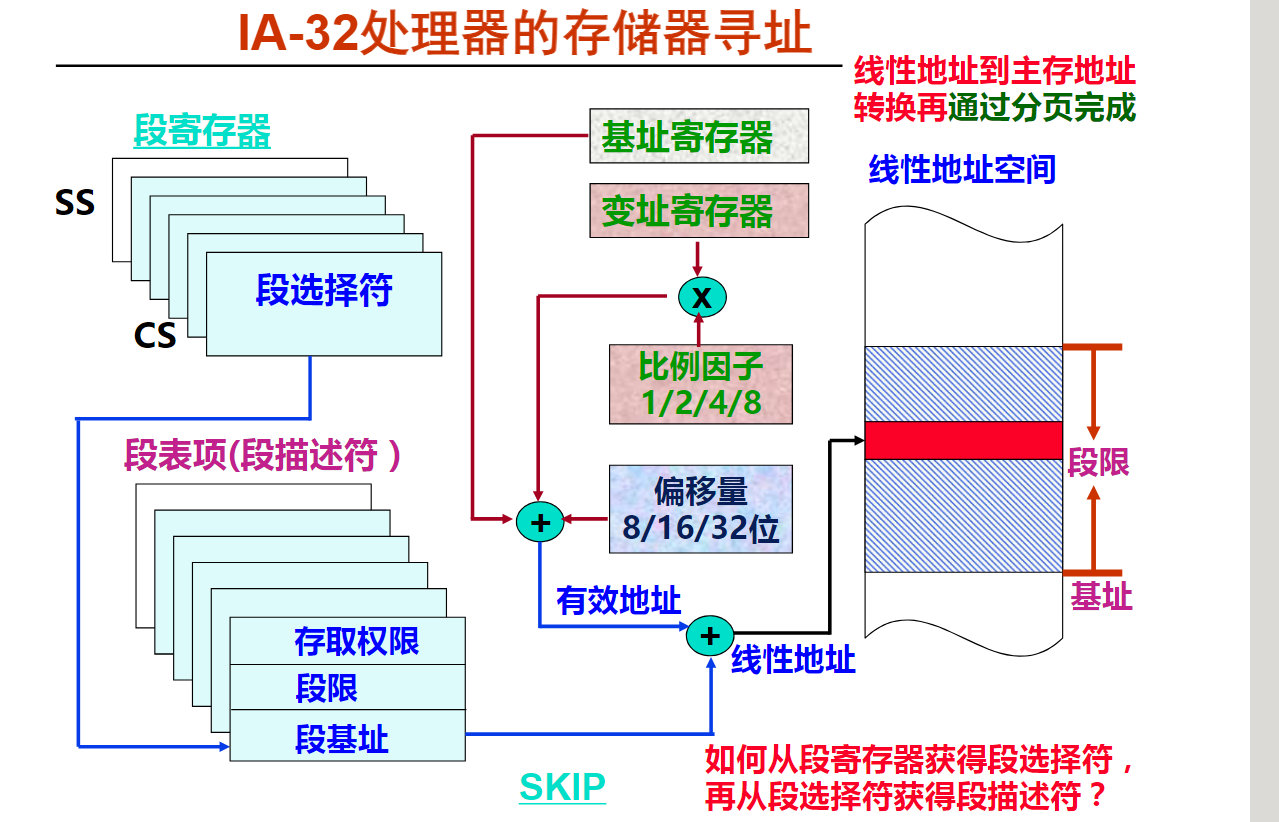
第2讲 段选择符和段寄存器

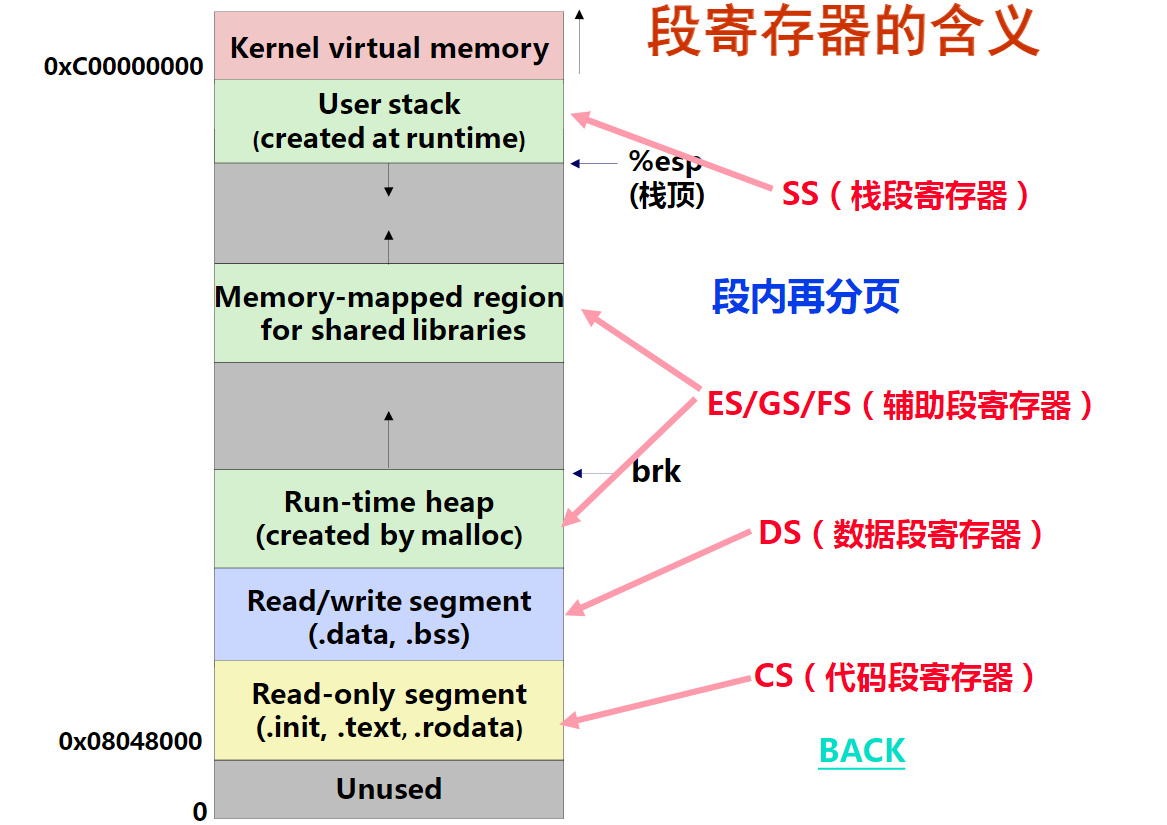
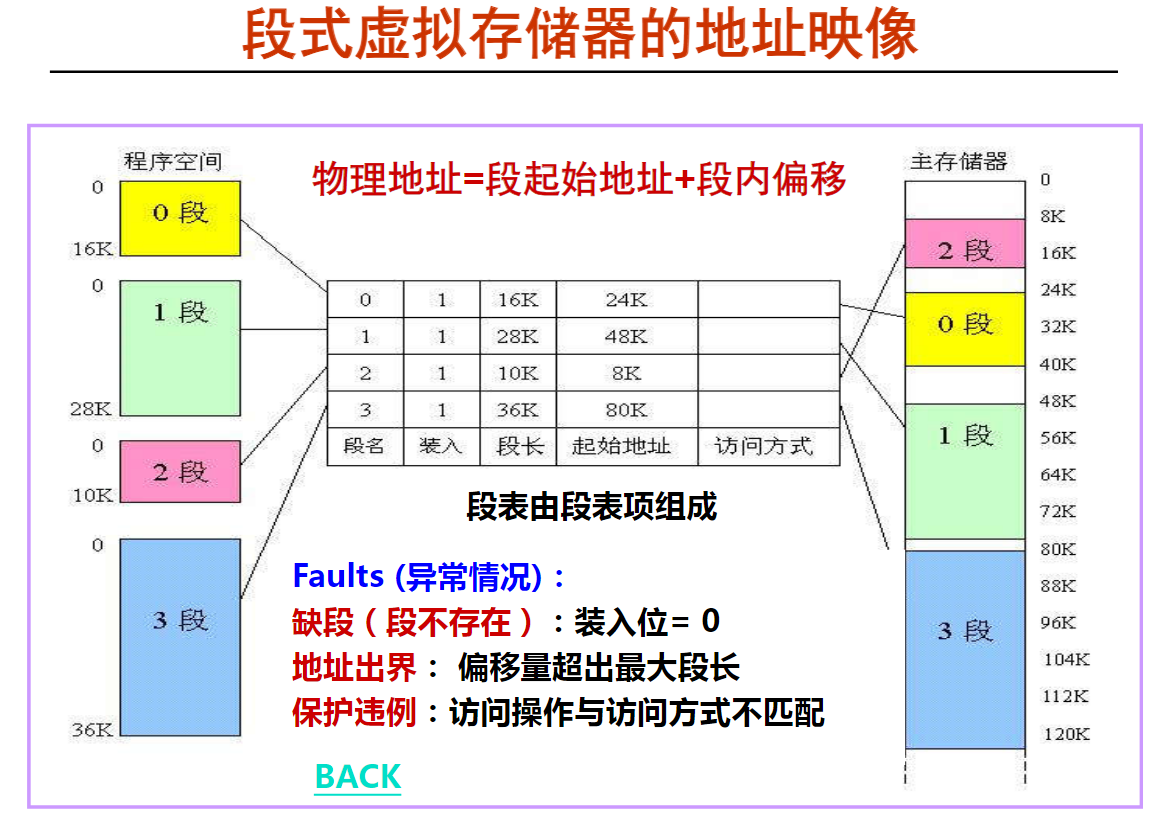
第3讲 段描述符和段描述符表

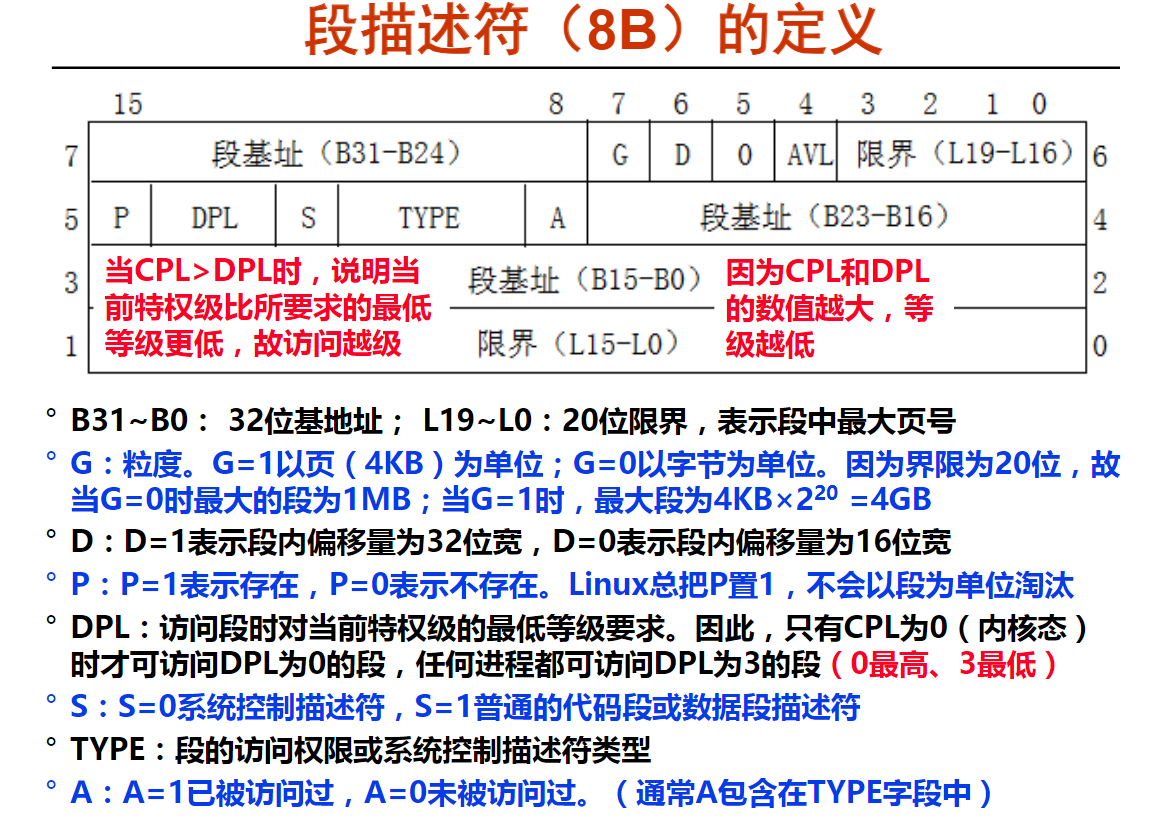

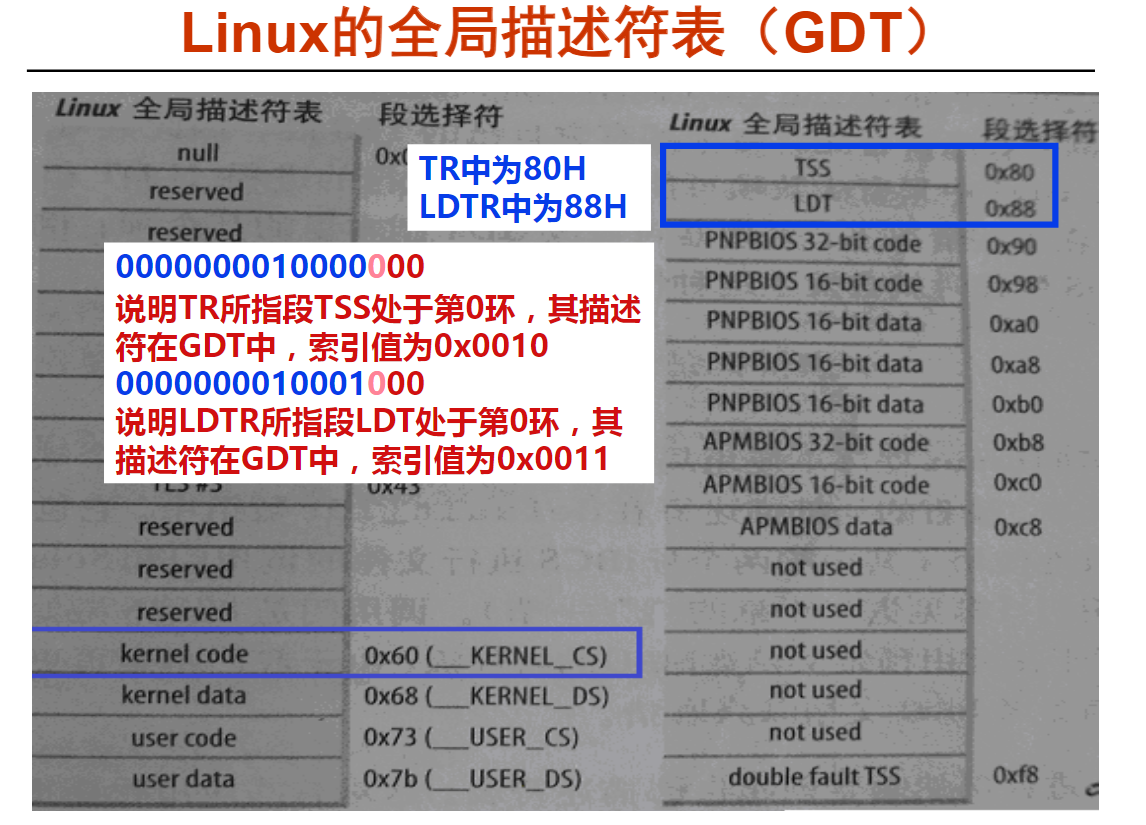
第4讲 逻辑地址向线性地址的转换
逻辑地址向线性地址转换(9m36s)
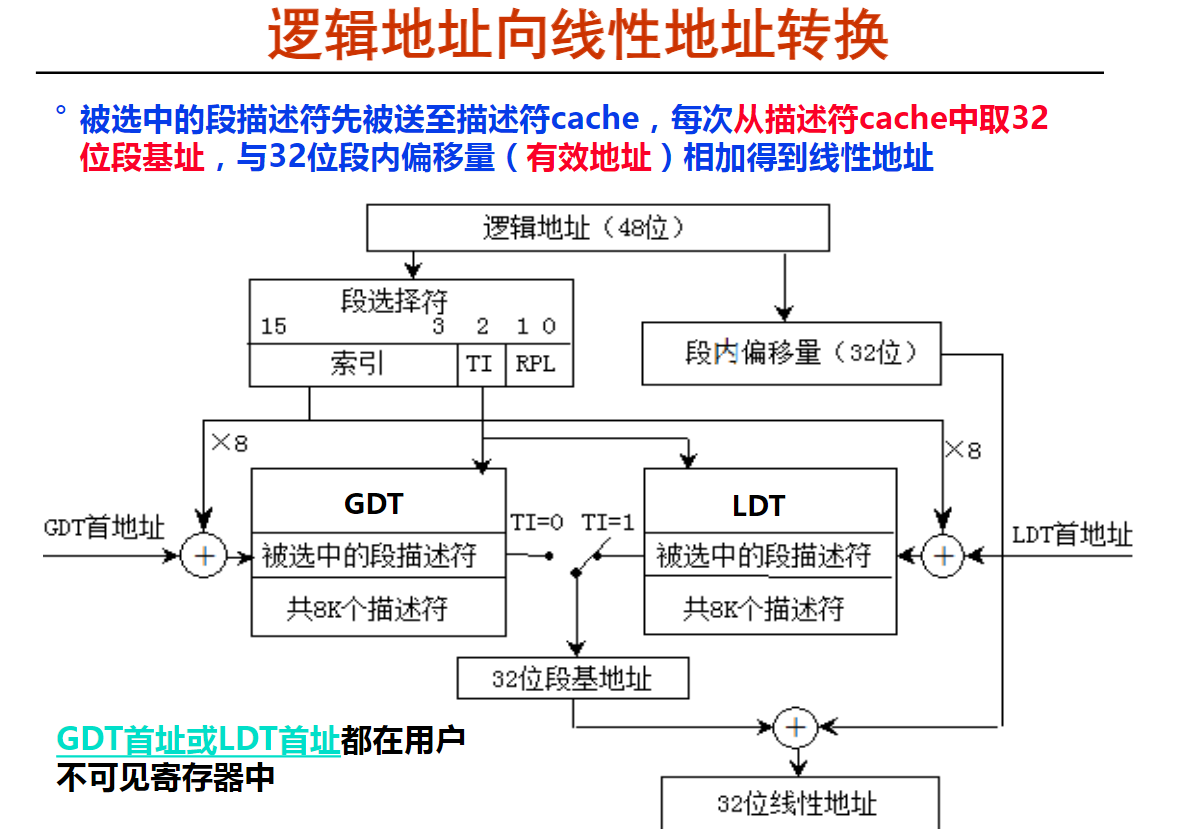
x8
一个段描述符占64位(8个字节)。所以index要x8。
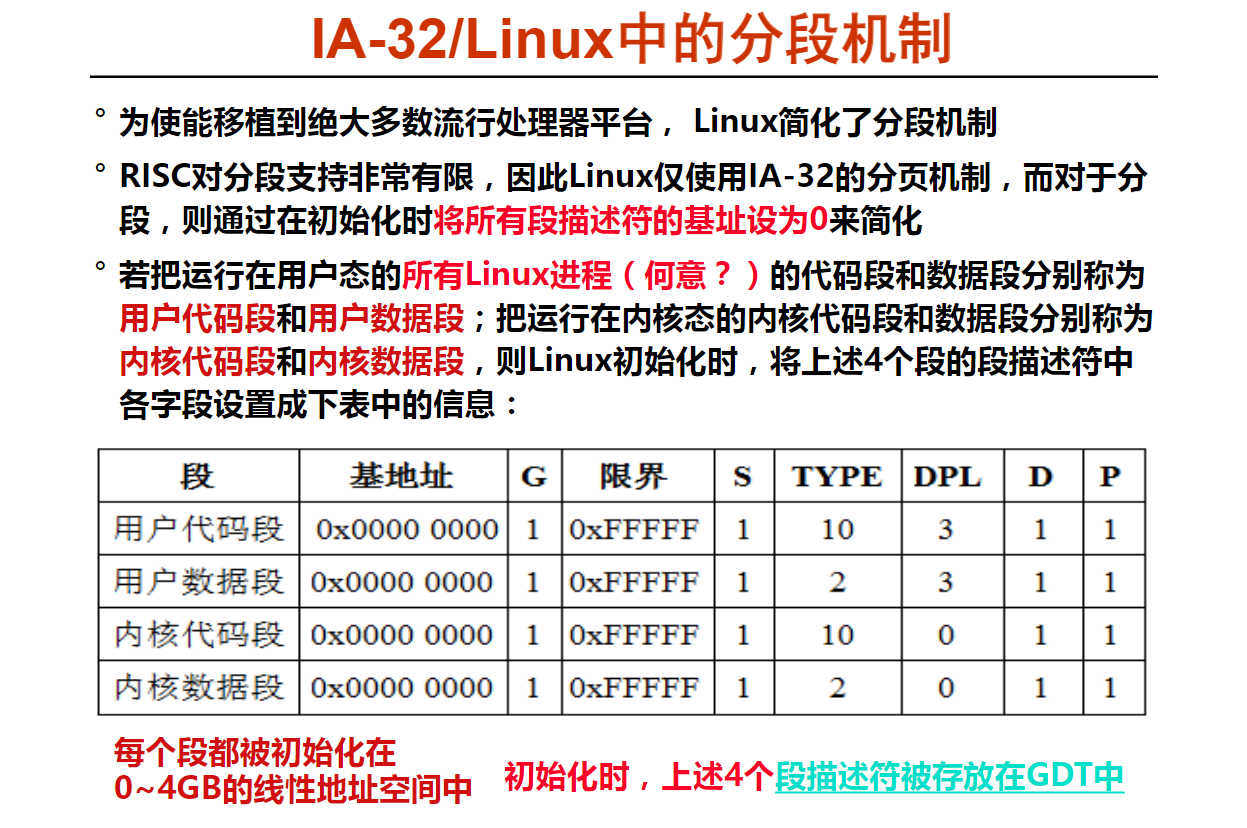
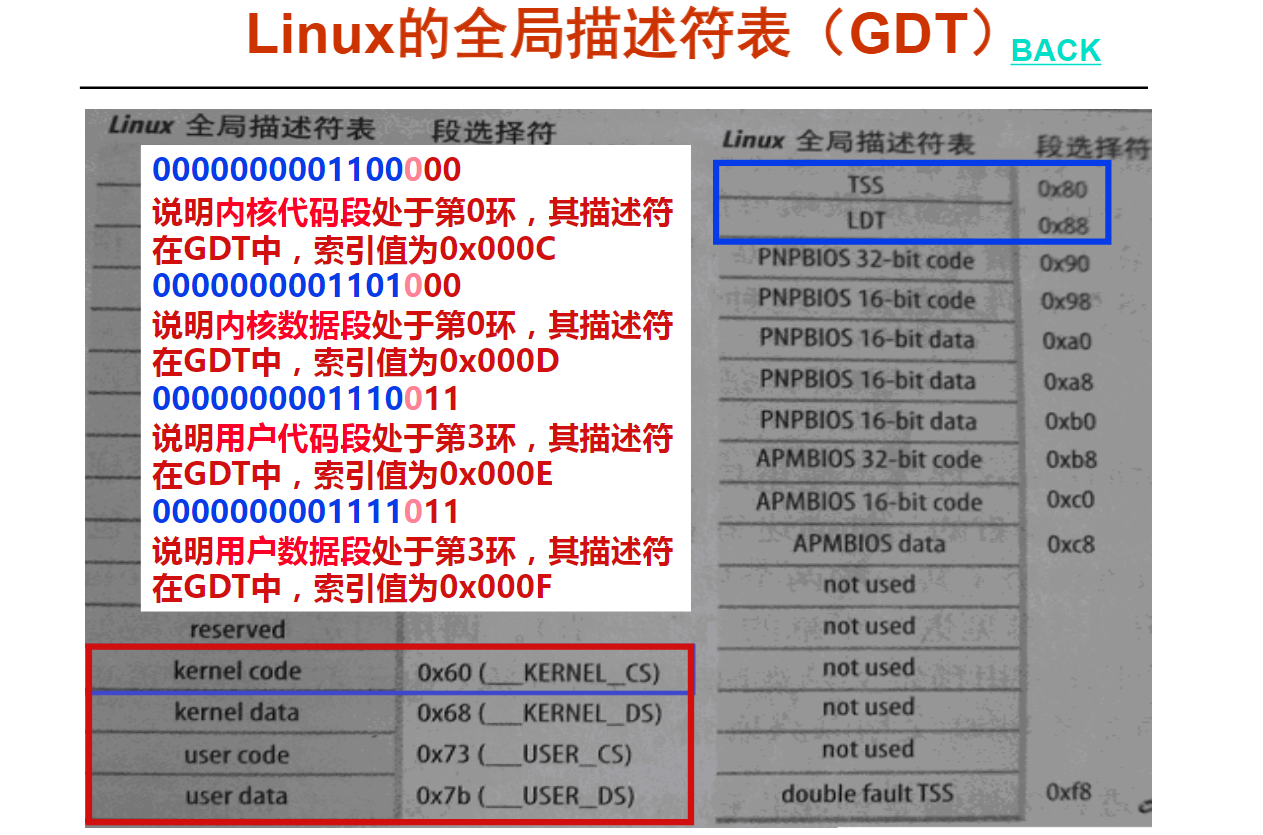
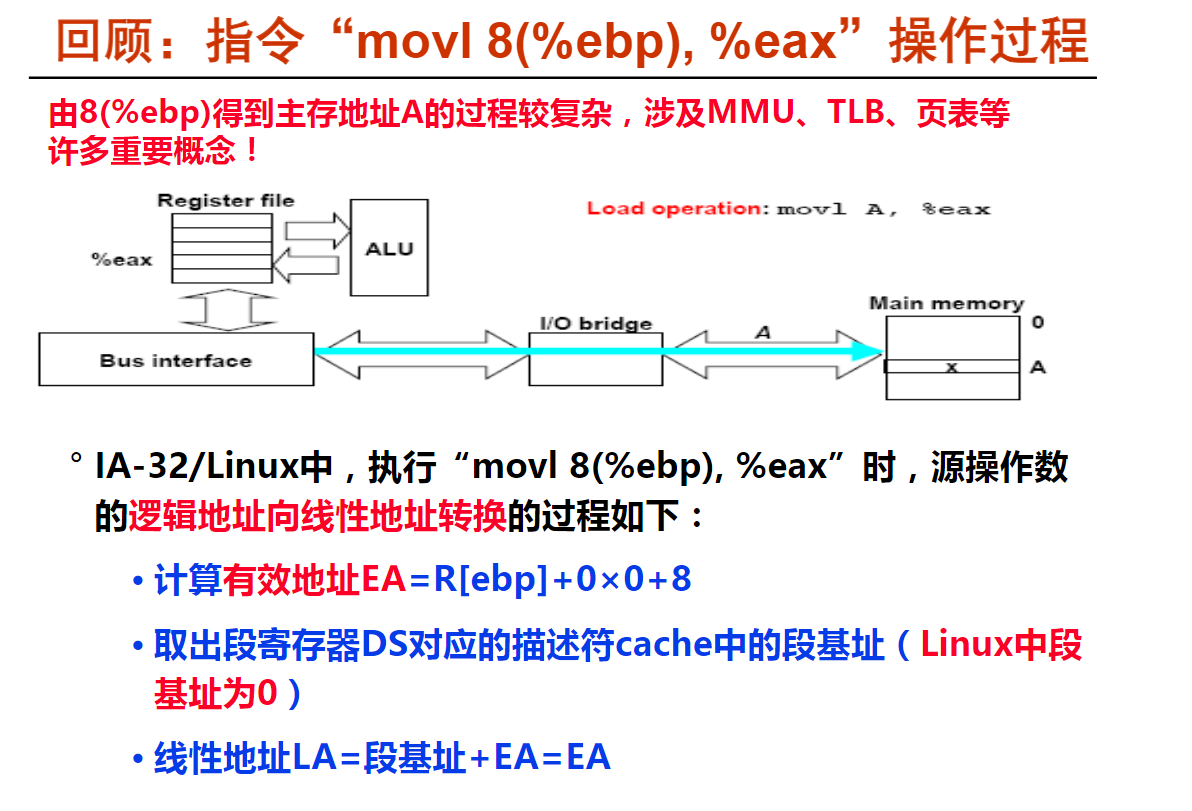
逻辑地址向线性地址转换举例(6m33s)

MMU:存储器管理部件,用于逻辑地址向线性地址转换
第5讲 线性地址向物理地址的转换


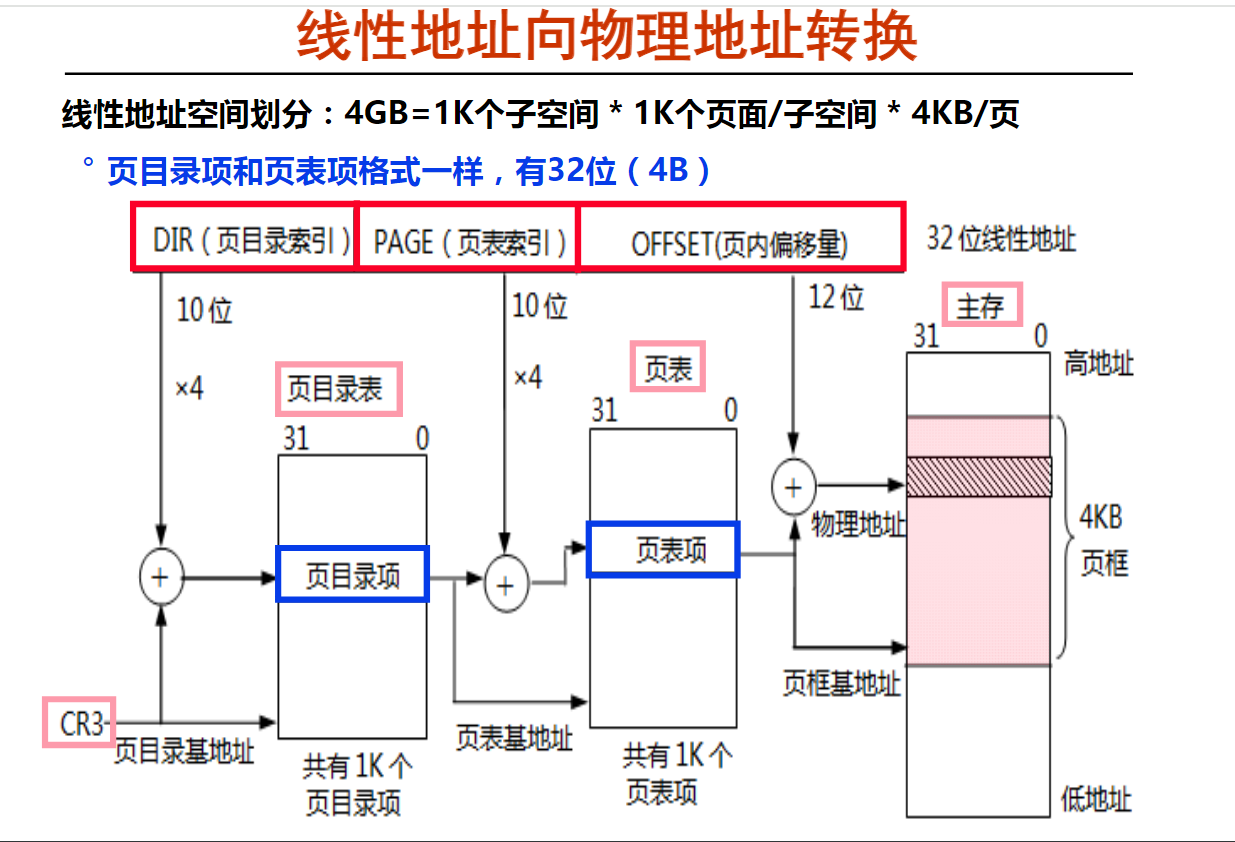

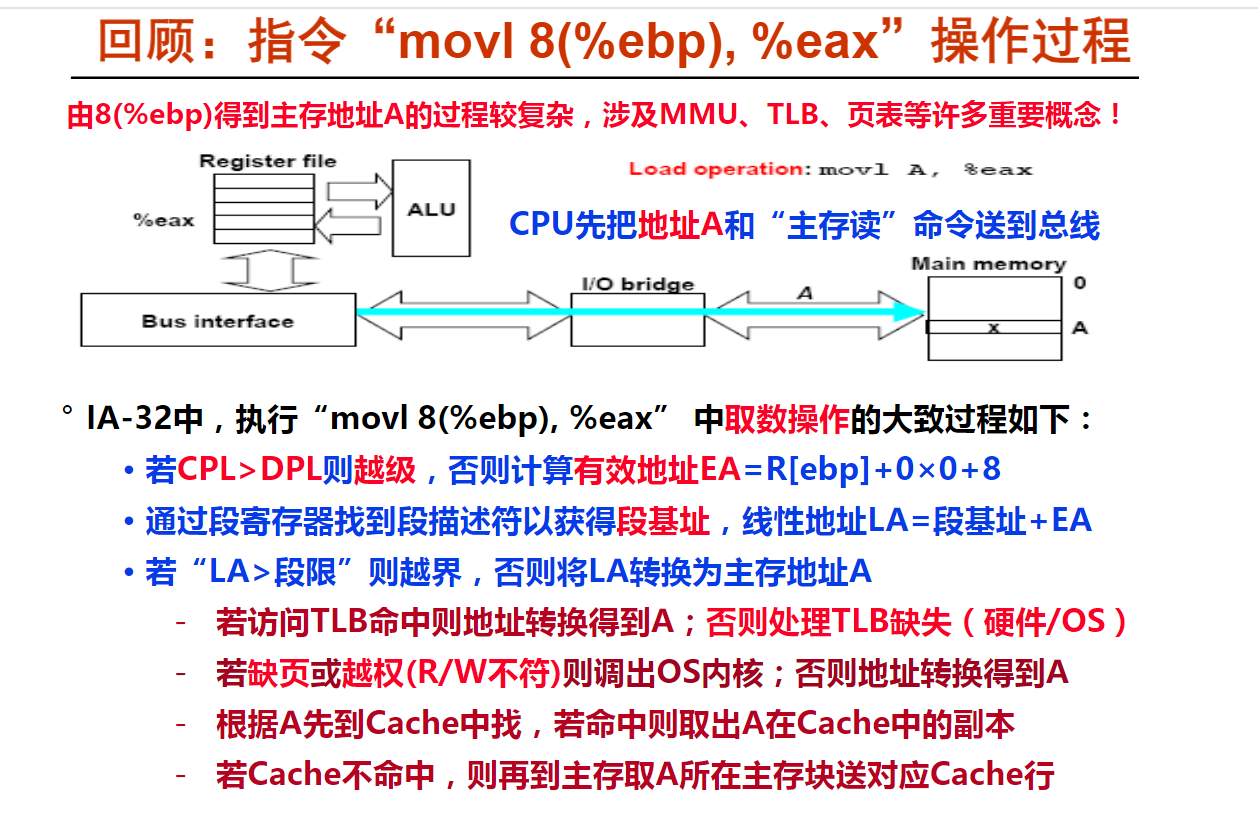
第6讲 Intel Core i7/Linux存储系统
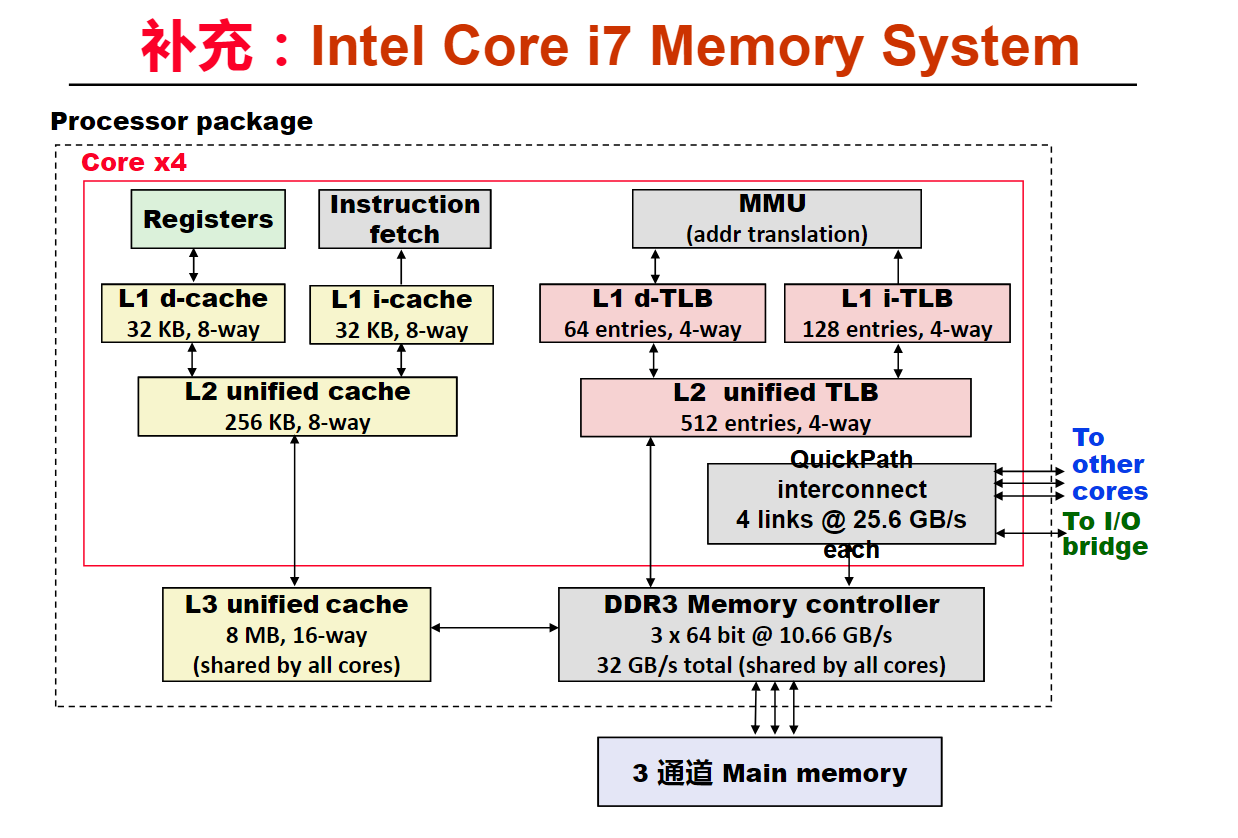
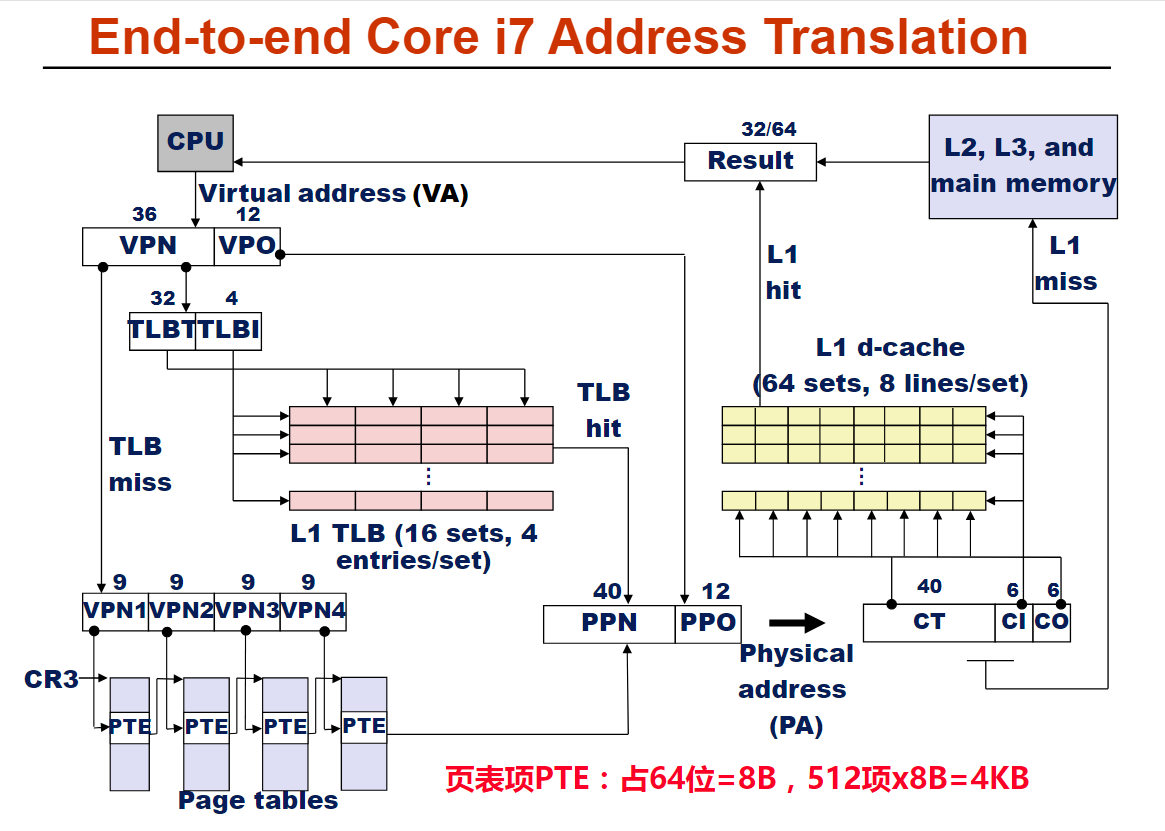
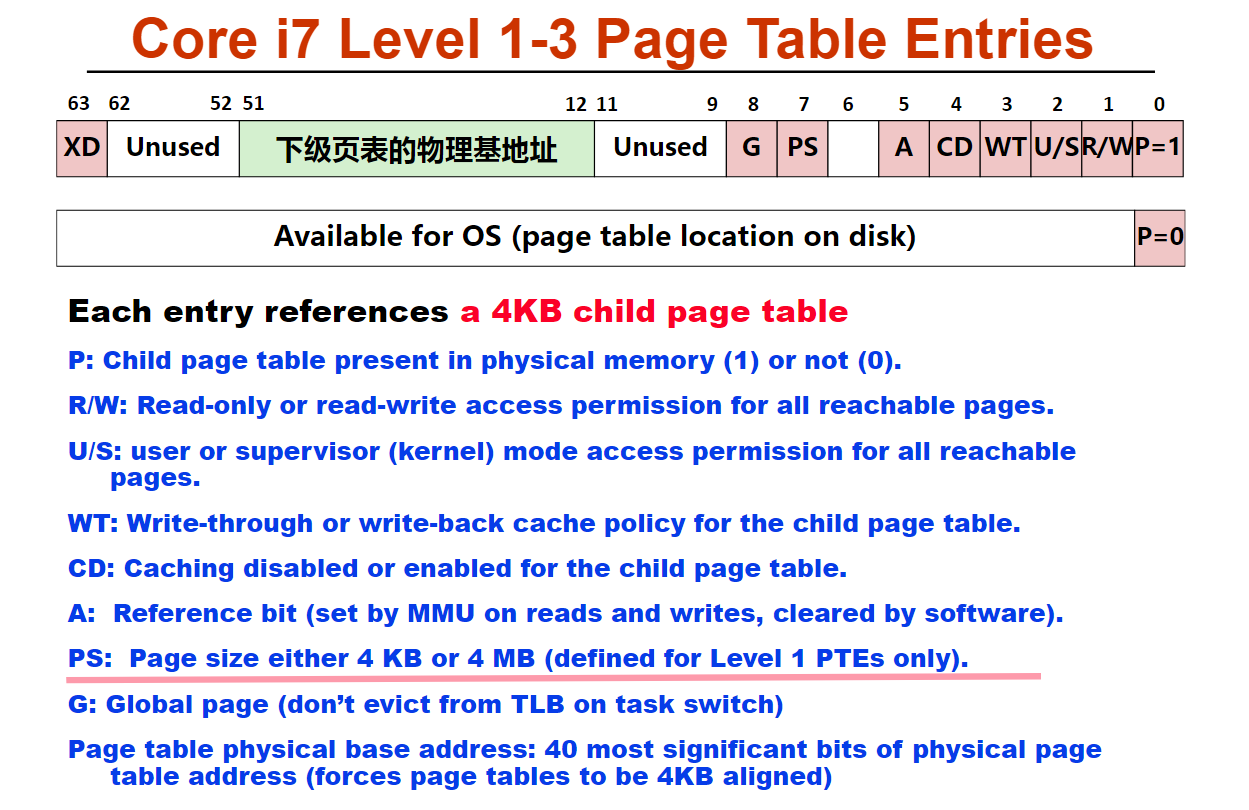
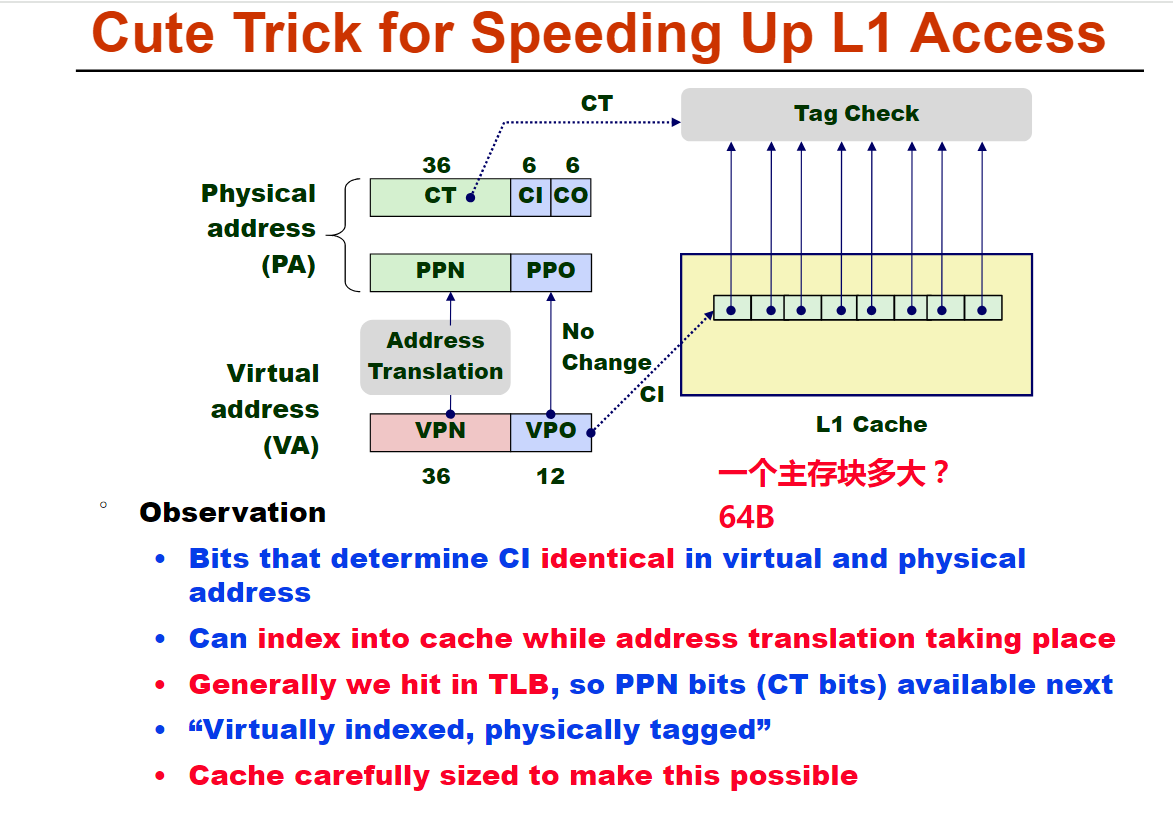
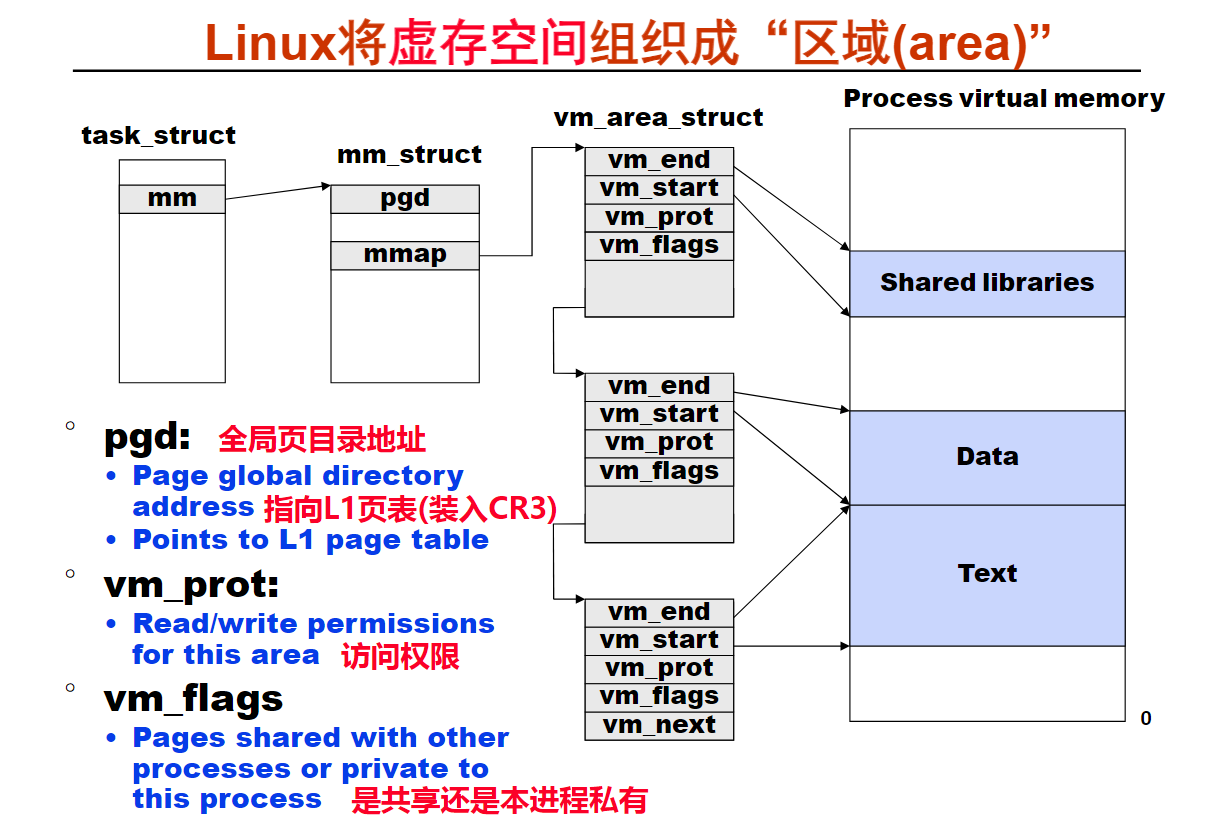
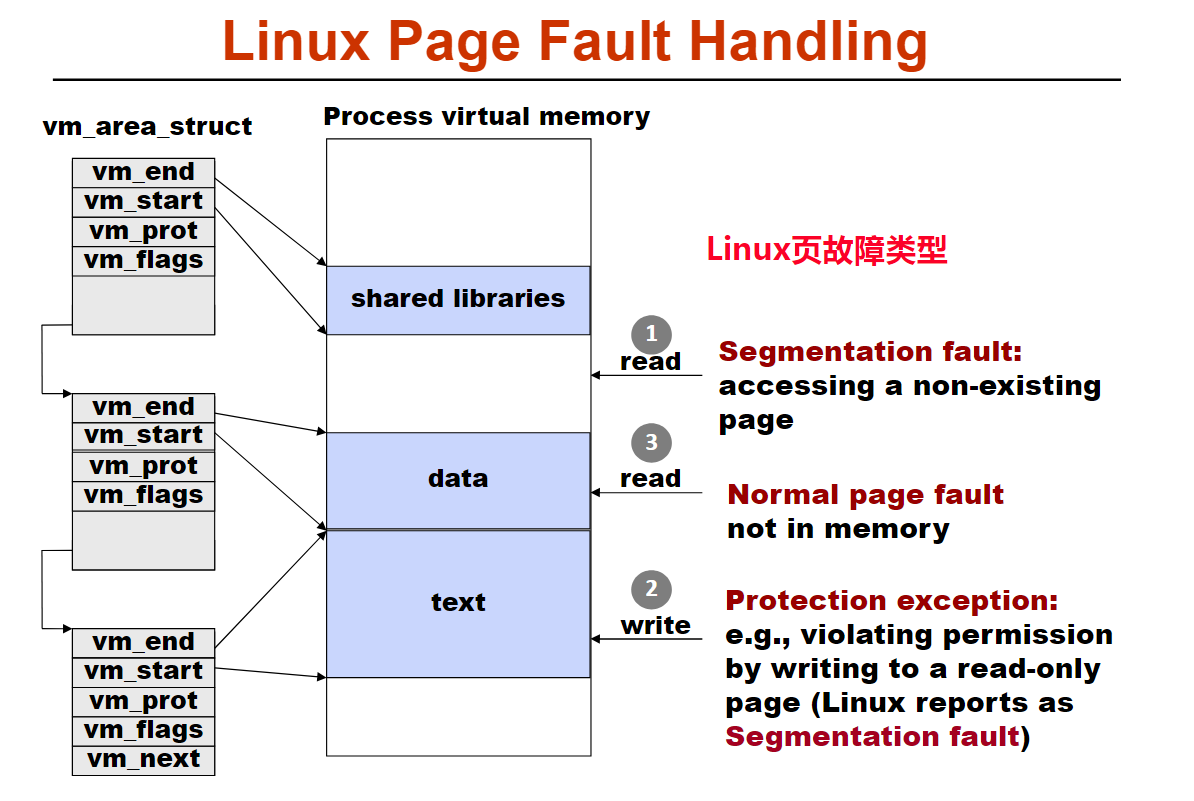
第七周小测验
错题序号:9
1对于IA-32中的指令“movl 8(%edx, %esi, 4), %edx”,若R[edx]=0000 01B6H,R[esi]=0000 0008H,其源操作数的有效地址EA是( A )。
A.0000 01DEH
B.0000 01B6H
C.0000 06E8H
D.0000 01F0H
解析: A、源操作数的有效地址为R[edx]+R[esi]*4+8=0000 01B6H+0000 0008H*4+8=0000 01DEH。
2以下是有关IA-32段页式虚拟存储管理方式的叙述,其中错误的是( C )。
A.指令中隐含给出的32位有效地址就是32位段内偏移量
B.逻辑地址由16位段选择符和32位段内偏移量组成
C.32位线性地址构成的地址空间就是4GB主存地址空间
D.进程的虚拟地址有48位逻辑地址和32位线性地址两种形式
解析: C、32位线性地址空间是4GB的虚拟地址空间,也就是可执行目标程序(即进程)所在的虚拟地址空间,需要对其进一步进行分页存储管理,访问指令和数据时,应根据页面和页框之间的映射关系进行线性地址到物理地址的转换。
3以下是有关IA-32保护模式下地址转换过程的叙述,其中错误的是(B )。
A.顺序为逻辑地址→线性地址→物理地址
B.采用先分页、再分段的地址转换过程
C.32位物理地址就是指32位主存地址
D.地址转换前先计算出32位有效地址
解析: B、地址转换顺序是先通过分段方式将48位逻辑地址转换为32位线性地址,然后再通过分页方式将32位线性地址转换为32位物理地址。
4以下有关IA-32段选择符的叙述中,错误的是( D )。
A.CS寄存器中RPL字段表示当前特权级CPL
B.段选择符存放在一个16位段寄存器中
C.段选择符中的高13位为对应段表项的索引
D.程序的代码段和数据段共用同一个段选择符
解析: D、IA-32中提供了多个段寄存器,如代码段寄存器CS、数据段寄存器DS、堆栈段寄存器SS等,它们可以分别存放代码段、数据段和堆栈段的段选择符。
5以下有关IA-32段描述符和段描述符表的叙述中,错误的是( A )。
A.段基址低12位总是0,因此段描述符中的段基址字段占20位
B.段描述符表就是段表,段描述符就是其中的段表项
C.段描述符分普通段描述符和系统控制段描述符两类
D.段描述符表分GDT(全局)、LDT(局部)和IDT(中断)三类
解析: A、段描述符中的段基址字段B31~B0占32位,而段限界字段L19~L0占20位。
6以下是有关IA-32中逻辑地址向线性地址转换的叙述,其中错误的是( B )。
A.系统启动时操作系统先对GDT和LDT进行初始化
B.每次逻辑地址向线性地址转换都要访问内存中的GDT或LDT
C.GTD和LDT在内存的起始地址分别存放在CPU内不同的地方
D.从对应段描述符中取出段基址与段内偏移量相加可得到线性地址
解析: B、为了加快IA-32的地址转换过程,CPU中专门设置了段描述符cache,对应每个段寄存器(CS、DS、SS、ES、FS和GS)都有相应的描述符cache。每次段寄存器装入新的段选择符时,就会将对应的段描述符装入描述符cache中,在逻辑地址到线性地址转换时,MMU直接用描述符cache中的信息,不必访问内存中的GDT和LDT。
7以下是有关IA-32/Linux系统分段机制的叙述,其中错误的是( C )。
A.将内核代码段和内核数据段的段基址都设为0
B.段描述符中段存在位P为1,故不以段为单位分配内存
C.内核段描述符在GDT中,而用户段描述符在LDT中
D.将用户代码段和用户数据段的段基址都设为0
解析: C、Linux系统中,将内核代码段、内核数据段、用户代码段和用户数据段对应的段描述符都包含在全局描述符表GDT中,分别位于GDT的第12、13、14和15项。
8已知变量y和数组a都是int型,a的首地址为0x8049b00。假设编译器将a的首地址分配在ECX中,数组的下标变量i分配在EDX中,y分配在EAX中,C语言赋值语句“y=a[i];”被编译为指令“movl (%ecx, %edx, 4), %eax”。在IA-32/Linux环境下执行该指令,则当i=150时,得到的存储器操作数的线性地址是( A )。
A.0x8049d58
B.0x8049b9a
C.0x8049b00
D.0x804a100
解析: A、Linux中将所有段的段基址都初始化为0,因而存储器操作数a[150]的线性地址=段基址+有效地址=0+R[ecx]+R[edx]*4=0x8049b00+150*4=0x8049b00+600=0x8049b00+0x258=0x8049d58。
9以下是有关IA-32中线性地址向物理地址转换过程的叙述,其中错误的是( B )。
A.4GB线性地址空间被划分成1M个页面,每个页面大小为4KB
B.每次地址转换都需要先访问页目录表,然后访问页表,根据页表项得到物理地址
C.页目录表中的页目录项和页表中的页表项都占32位,且两者的结构完全相同
D.32位线性地址分成10位页目录索引、10位页表索引和12位页内偏移量三个字段
解析: B、IA-32中有TLB,因此,每次线性地址向物理地址转换时,总是先访问TLB,当TLB命中时,就无需访问主存中的页目录表和页表。
10以下是有关IA-32存储管理控制寄存器的叙述,其中错误的是(C )。
A.CR3控制寄存器用于存放页目录表在主存的起始地址
B.若要启用分页机制,则CR0控制寄存器中的PE和PG都要置1
C.用户进程和操作系统内核都可以访问存储管理控制寄存器
D.CR2控制寄存器用于存放发生页故障(Page Fault)的线性地址
解析: C、IA-32中提供的存储管理控制寄存器用于操作系统内核进行存储管理,访问这些控制寄存器的相关指令都是特权指令,只能在内核态使用,而用户进程中不能使用这些特权指令,因而用户进程不能访问这些控制寄存器。
綜合測驗
计算机系统基础二期末考試
错题序号:2、18、20
1通常( D )的位数和指令位数相同或有关。
A.程序状态字寄存器PSWR
B.指令指针寄存器IP
C.指令译码器ID
D.指令寄存器IR
正确答案:D你选对了
2假定用若干个16K×1位的存储器芯片组成一个64K×8位的存储器,芯片内各单元连续编址,则地址BFF0H所在的芯片的最小地址为( C )。
A.A000H
B.4000H
C.8000H
D.6000H
正确答案:C

附录单选题
用若干片2K*4位的存储芯片组成一个8K*8位的存储器,则地址0B1FH所在的芯片在全局的最大地址是 B
A: 0CFFH
B: 0FFFH
C: 1BFFH
D: 0BFFH
3用存储容量为16K×1位的存储器芯片组成一个64K×8位的存储器,则在字方向和位方向上分别扩展了( B )倍。
A.8和4
B.4和8
C.2和4
D.4和2
正确答案:B你选对了
附录单选题
一个动态存储器芯片的容量是16K×8位, 若采用地址复用技术,则该芯片需要的地址和数据引脚至少分别为(B )。
A: 14,8
B: 7,8
C: 14,1
D: 7,1
附录单选题
某SRAM芯片,其容量为1024×4位,其地址和数据引脚的数目至少分别为(A)。
A: 10,4
B: 5,4
C: 10,8
D: 5,8
附录单选题
动态存储器刷新以 (B) 为单位进行
A: 字节
B: 行
C: 存储单元
D: 列
存储器芯片的容量是有限的,为了满足实际存储器的容量要求,需要对存储器进行扩展。
主存扩展:将存储芯片连在一起组成足够的容量
存储器容量扩展的主要方法有:
- 位扩展:只加大字长,而存储器的字数与存储器芯片字数一致,对所有片子使用共同片选信号;
- 字扩展:仅在字向扩充,而位数不变。需由片选信号来区分各片地址。
- 字位扩展:一个存储器的容量假定为M×N位,若使用l×k 位的芯片(l<M,k<N),需要在字向和位向同时进行扩展。此时共需要(M/l)×(N/k)个存储器芯 片。
位扩展、字扩展、字位扩展通常涉及到所需地址线与数据线的计算问题,先来看一个例题:

log(2,16) = 4
再看一道例题:
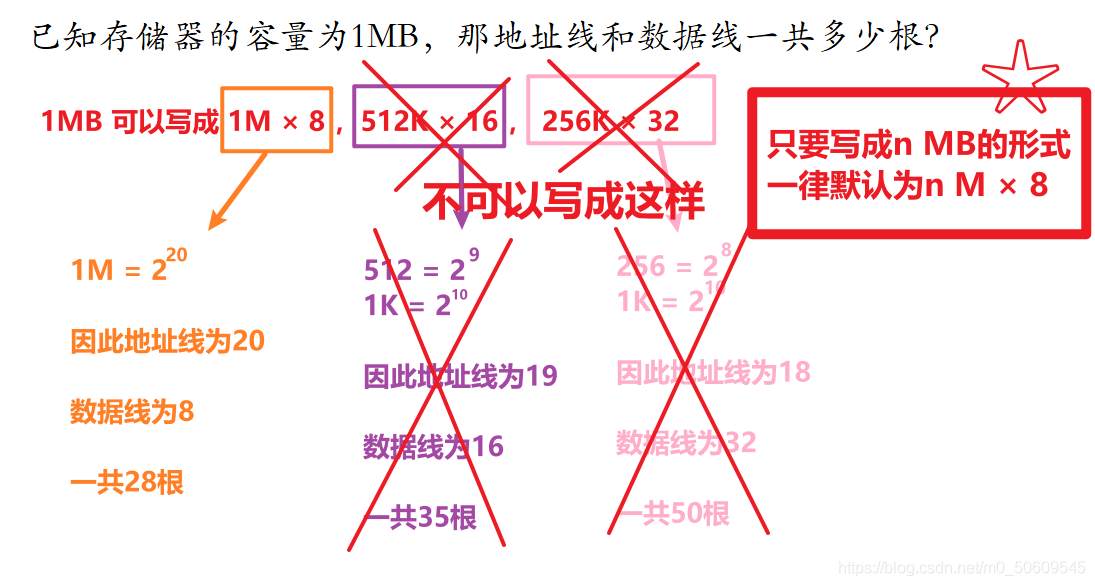
位扩展
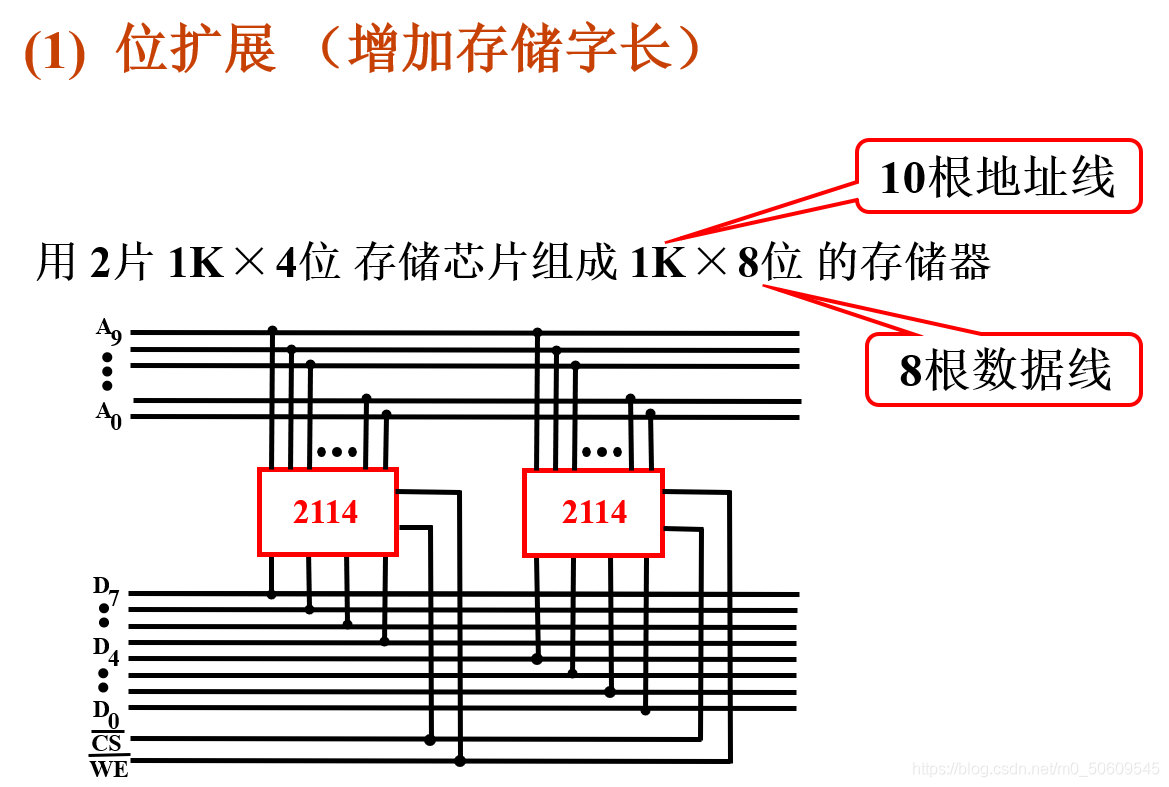
例:2片1K X 4位的芯片,可以组成1K X 8位的存储器(4位→8位)

字扩展
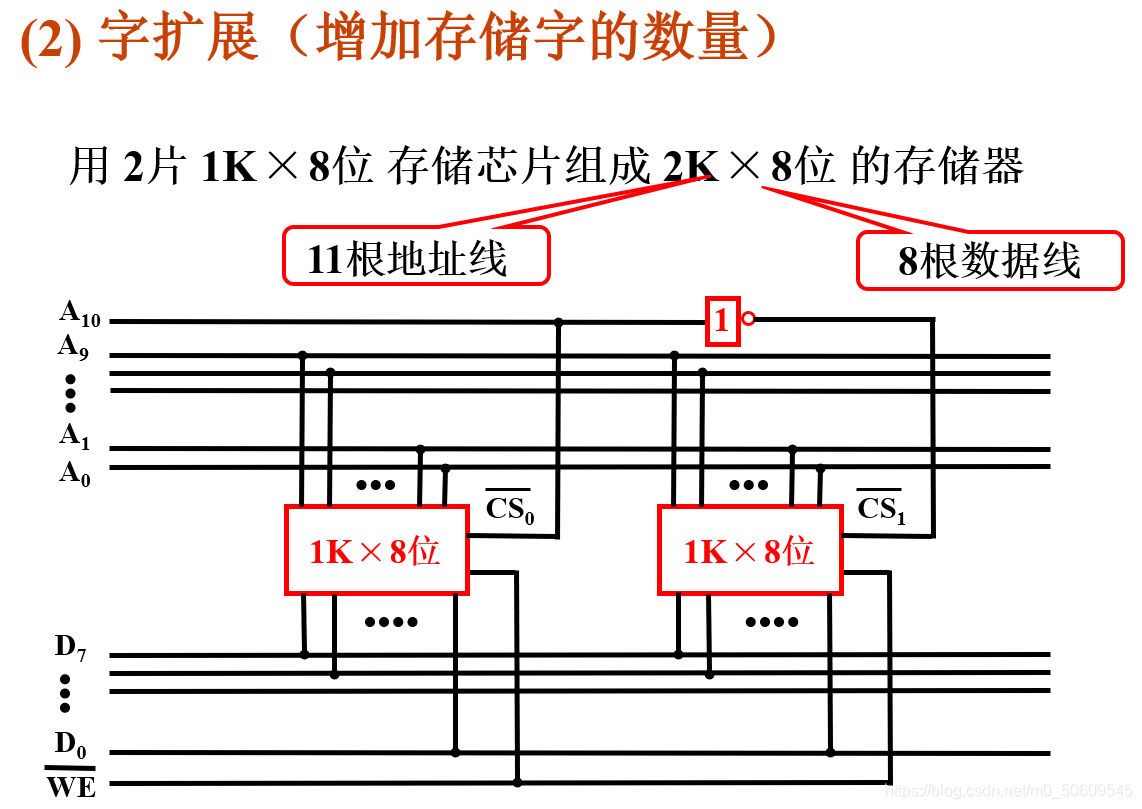
例:2片1K X 8位的芯片,可以组成2K X 8位的存储器(1K→2K)

字位扩展
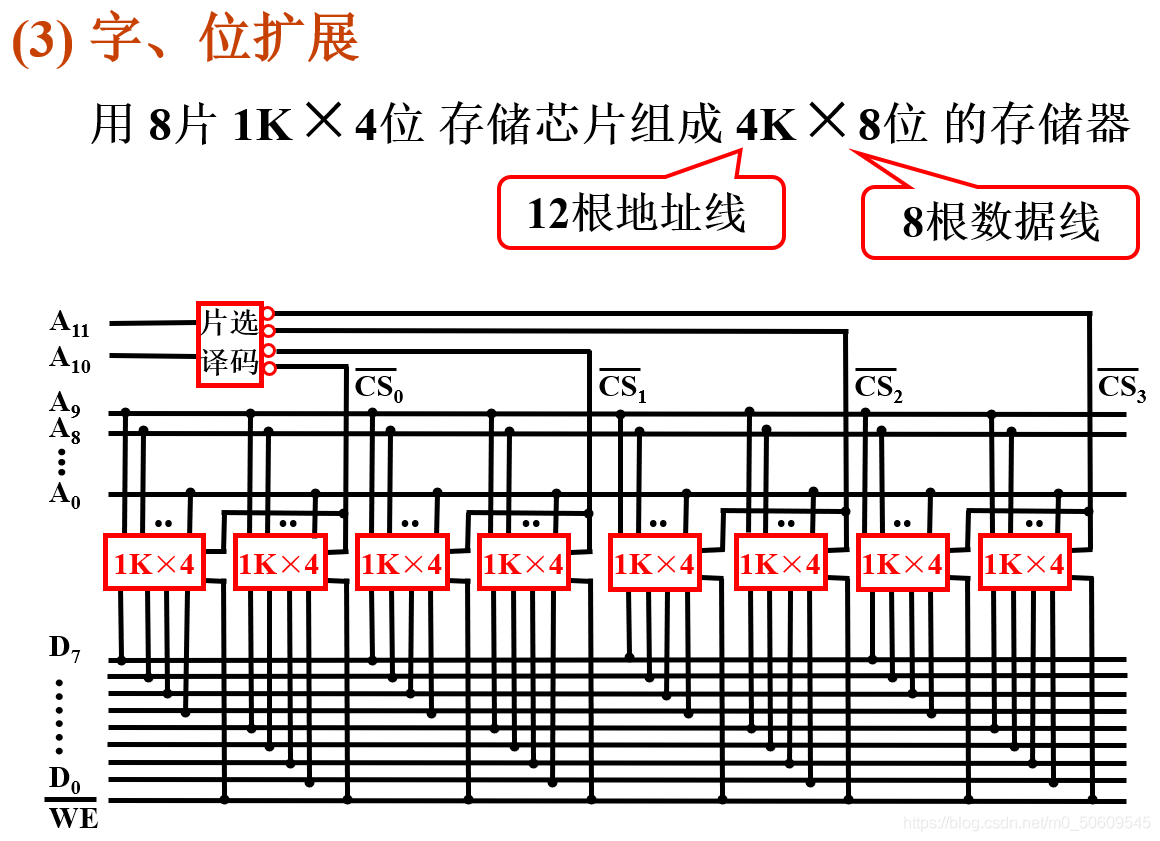
例:1K X 4位的芯片,组成4K X 8位的存储器(1K→4K,4位→8位)

4假定一个磁盘的转速为10000RPM(转/分),磁盘的平均寻道时间为15ms,平均数据传输率为4MB/s,不考虑排队等待时间。那么读一个512字节的扇区的平均存取时间大约为( C )。
A.21.125ms
B.25.625ms
C.18.125ms
D.10.625ms
正确答案:C你选对了
5相联存储器是按( D )进行寻址访问的存储器。
A.堆栈访问方式
B.队列访问方式
C.地址指定方式
D.内容指定方式
正确答案:D你选对了
6假定用作cache的SRAM的存取时间为1.5ns,用作主存的DRAM存储器的存取时间为30ns。为使平均存取时间达到2ns,则cache命中率应为( C )左右。
A.95%
B.93.3%
C.98.33%
D.99.1%
正确答案:C你选对了
7假定主存地址位数为32位,按字节编址,主存和cache之间采用2路相联映射方式,主存块大小为32B,采用回写(Write Back)方式和LRU替换策略,则能存放32KB数据的cache的总容量至少应有多少位?( A )。
A.277K
B.274K
C.276K
D.275K
解析:(1+1+1+32-5-9) X 1Kbits+32K X 8bits=277Kbits
8某32位机按字节编址。数据cache有32行,主存块大小为32B,采用2路组相联映射。对于以下程序A,假定编译时i, j, sum均分配在寄存器中,数组a按行优先方式存放,其首址为3200,则a[1][0]所映射的cache组号、程序A的数据cache命中率各是( B )、( B )。
short a[256][256];
……
short sum_array() {
int i, j;
short sum=0;
for (i=0; i < 256; i++)
for (j=0; j < 256; j++)
sum+=a[i][j];
return sum;
}
A.2, 15/16
B.4, 15/16
C.2, 31/32
D.4,31/32
正确答案:B你选对了
9下列命中组合情况中,一次访存过程中不可能发生的是( C )。
A.TLB命中、cache未命中、Page命中
B.TLB命中、cache命中、Page命中
C.TLB命中、cache命中、Page未命中
D.TLB未命中、cache命中、Page命中
正确答案:C你选对了
10已知变量y和数组a都是int型,a的首地址为0x8049d80。假设编译器将a的首地址分配在ECX中,数组的下标变量i分配在EDX中,y分配在EAX中,C语言赋值语句“y=a[i];”被编译为指令“movl (%ecx, %edx, 4), %eax”。在IA-32/Linux环境下执行该指令,则当i=200时,得到的存储器操作数的线性地址是( A )。
A.0x804a0a0
B.0x8049d80
C.0x8049e4c
D.0x804a580
正确答案:A
0x8049d80+0x320=0x804a0a0
11以下关于指令基本执行过程的叙述中,正确的是( A )。
A.读取指令→指令译码→读取操作数→运算→存结果→查询中断
B.读取指令→读取操作数→指令译码→运算→存结果→查询中断
C.读取指令→查询中断→指令译码→读取操作数→运算→存结果
D.指令译码→读取指令→读取操作数→运算→存结果→查询中断
正确答案:A你选对了
12以下有关CPU基本组成的叙述中,错误的是( A )。
A.若支持乘法和除法指令,则数据通路中一定包含乘法器和除法器
B.ALU和通用寄存器组都属于数据通路部分
C.控制器会产生控制信号,其中主要包含指令译码器
D.CPU主要包含数据通路和控制器两大部分
正确答案:A你选对了
13以下关于存储器分类的叙述中,错误的是( C )。
A.SRAM和DRAM都属于半导体随机存取存储器
B.随机访问存储器采用地址译码方式选中被读/写单元
C.磁带和磁盘都是采用直接存取方式的磁表面存储器
D.磁带、磁盘、光盘和优盘都属于非易失性存储介质
正确答案:C
14以下关于主存储器容量的叙述中,错误的是( B )。
A.主存地址空间是指地址总线和编址单位所确定的最大可配置主存容量
B.主存容量指计算机内所有ROM和RAM存储器容量总和
C.在不考虑其他因素变化的情况下,主存容量越大程序性能越好
D.主存容量的大小主要取决于计算机内实际配置的内存条的容量
正确答案:B
15以下关于cache命中率叙述中,错误的是( D )。
A.cache命中率与cache容量有关
B. cache命中率和程序访问局部性有关
C.cache命中率与cache和主存之间的映射方式有关
D.cache命中率与cache写策略有关
正确答案:D
16假定某32位计算机按字节编址,其L1 data cache数据区容量为32KB,主存块大小为64B,采用8路组相联方式。假定某变量的主存地址为4090,则该变量所在主存块应该映射到的cache行号为( C)。
A.58
B.7
C.63
D.2
正确答案:C
512行,64组
4090/64=63...
注:题目在cache行号应该是cache组号
17以下关于分页存储管理方式的叙述中,错误的是( C )。
A.虚拟页和主存页框之间采用Write Back写策略
B.虚拟页和主存页框之间采用全相联映射
C.虚拟页面大小和主存页框大小两者之间可以不一致
D.虚拟页和主存页框之间的映射关系由页表记录
正确答案:C你选对了
18以下关于IA-32/Linux虚拟地址空间的叙述中,错误的是( D )。
A.每个进程只读代码段总是从0x8048000开始
B.每个进程的虚拟地址空间大小和布局一致
C.虚拟地址空间中栈和堆都是动态存储区
D.每个进程可读可写数据段总是从0x8049000开始
正确答案:D你选对了
19对于IA-32/Linux系统中的指令“movl 16(%edx, %esi, 4), %edx”,若R[edx]=0804 9200H,R[esi]=0000 0010H,则源操作数的线性地址LA是( B )。
A.0804 9238H
B.0804 9250H
C.0804 923EH
D.0804 9256H
正确答案:B你选对了
20在IA-32的分页方式中,若页大小为4KB,某指令的线性地址为0x8048380,该指令所在页面被分配的主存页框号为126,则该指令的主存物理地址为( C )。
A.0012 6380H
B.0804 807EH
C.0007 E380H
D.0804 8126H
解析:
页内偏移量380H
主存页框号126 = 7EH
21根据半导体存储器中记忆单元结构的不同,分为( SRAM )和DRAM两种随机访问存储器,前者用于实现DRAM芯片中的行缓存(row buffer)。
22若一个内存条中有16个DRAM芯片,每个芯片中有4个位平面,每个位平面的存储阵列为4096行×4096列,则内存条的容量为( 128 )MB。
23若计算机按字节编址,主存地址为32位,主存块大小为64B,cache共有64K行,采用16路组相联映射方式,则标志(Tag)字段为( 14 )位。
24TLB(快表)是CPU中的一个高速缓存,主要用于存放活跃页面的( 页表项 )。
25若虚拟地址为32位,页大小为4KB,TLB采用全相联映射方式,则TLB标记应占( 20 )位。
第6章层次结构存储系统平时小测验
本次得分为:37.00/53.00, 本次测试的提交时间为:2023-11-25。
错题序号:2、7、15、23、26、30、31、33、35
1单选(1分)
下列几种存储器中,属于非易失性存储器的是(B )。
A.Cache
B.ROM
C.DRAM
D.SRAM
2单选(1分)
以下有关主存储器组成的叙述中,错误的是( D )。
A. 有通用寄存器堆,用于缓存读写的数据信息 B. 有地址译码器,用于选中要访问的主存单元 C.有存储阵列,用于存储主存中的所有数据信息 D.有地址寄存器,用于存放存储器总线传送的主存地址
正确答案:A你错选为D
3单选(1分)
以下关于存储器层次结构的叙述中,错误的是( B )。
A.Cache是位于寄存器和主存之间的一级存储器
B.CPU可直接访问所有层次的存储器
C.越靠近CPU的存储器层次,其速度越快
D.寄存器是速度最快的一级存储器
4单选(1分)
以下关于半导体存储器分类及应用的叙述中,错误的是( D )。
A.DRAM有漏电和破坏性读出现象,需定时刷新和读后再生
B.SRAM比DRAM集成度更低、价格更贵,但速度更快
C.只读存储器(ROM)和RAM一样,都采用随机存取方式访问
D.固态硬盘(SSD)由NADN闪存实现,它不属于半导体存储器
5单选(1分)
以下关于DRAM芯片的叙述中,错误的是( D )。
A.用作主存的内存条通常由DRAM芯片级联而成
B. 行地址和列地址分时复用地址引脚传送
C.存储体阵列采用二维地址译码方式
D.每增加一个地址引脚,芯片容量提高到原来的2倍
6单选(1分)
以下关于访存指令(装入指令和存储指令)执行过程的叙述中,错误的是(C )。
A.访存开始时CPU总是先将主存地址送给存储控制器 B.DRAM芯片中的行译码器会对行地址译码,被选中行的信息会被送到内部行缓冲中 C.由存储控制器将主存地址分成行地址和列地址,并分时传给DRAM芯片 D.DRAM芯片中的列译码器会对列地址译码,从被选中行中指定的列将数据读出或写入
7单选(1分)
以下有关主存与CPU互连的叙述中,错误的是( A )。
A.主存与CPU之间通过存储器总线互连,内存条插槽就是存储器总线 B.存储器的访问过程由内存条中的存储控制器来进行控制 C.可将内存条插入内存条插槽中,以扩大主存储器的容量 D.CPU与主存之间互连的信号线分为地址线、数据线和控制线三类
正确答案:B你错选为A
解析: B、内存条上只有若干个DRAM芯片,而不包含存储控制器。存储控制器(简称存控)一般在桥接器(如北桥芯片)或者CPU芯片中。
8单选(1分)
以下有关磁盘存储器的叙述中,错误的是( D )。
A.磁盘存储器包含磁盘驱动器和磁盘控制器等组成部分
B.磁盘存储器采用DMA方式进行输入/输出
C.磁盘存储器按批处理方式读写,一次读写一个数据块
D. 磁盘存储器的地址格式为磁道号、柱面号和扇区号
解析: D、磁道号就是柱面号,应该把柱面号改成磁头号(或盘面号)。
9单选(1分)
以下关于高速缓存(Cache)的叙述中,错误的是( D )。
A.Cache对于程序员来说是透明的,但程序员可利用Cache机制编写高效代码
B. 在主存和Cache之间交换数据以一个主存块为单位
C.Cache是主存储器的高速缓存,Cache中的数据在主存中有备份
D.在CPU和主存之间加入Cache的目的是为了扩大主存的容量
10单选(1分)
假设主存按字节编址,cache共有16行,采用直接映射方式,主存块大小为64字节,所有编号都从0开始。主存第641号单元所在主存块对应的cache行号是( A )。
A.10
B. 2
C.11
D. 1
11单选(1分)
假设主存按字节编址,cache共有32行,采用4路组相联映射方式,主存块大小为64字节,所有编号都从0开始。主存第641号单元所在主存块对应的cache组号是( A )。
A.2
B. 10
C. 5
D.1
12单选(1分)
假定主存地址空间为256MB,按字节编址, cache共有64行,采用全相联映射方式,主存块大小为64B,不考虑替换策略和写策略的控制位,则cache容量至少为( A )字节。
A.4280
B.4272
C.4224
D.4232
13单选(1分)
以下关于Cache映射方式特点的叙述中,错误的是( A ) 。
A.全相联映射方式是一种模映射方式
B.直接映射方式不需要考虑替换策略
C.采用什么一致性写策略通常与映射方式无关
D.组相联映射方式比直接映射方式需要更多的比较器
14单选(1分)
以下关于Cache命中率的叙述中,错误的是( B )。
A.Cache命中率与编程设计有关
B.Cache命中率与缺失损失大小有关
C.Cache命中率与映射方式有关
D.Cache命中率与Cache容量有关
15单选(1分)
以下关于虚拟存储器基本概念的叙述中,错误的是( B )。 A.虚拟存储器技术可以解决编程空间受物理内存大小限制的问题
B.实时性要求高的嵌入式系统大多不采用虚拟存储器技术
C.采用虚拟存储器技术的系统中OS必须进行虚实地址转换
D.虚拟存储器技术的实现需要系统软件和硬件两方面协作完成
正确答案:C你错选为B
解析: C、虚实地址转换是由硬件实现的,而不是由OS实现的。
16单选(1分)
以下关于IA-32+Linux系统虚拟地址空间的叙述中,错误的是( B )。
A. 内核空间是用户程序不可见区域,只能由OS访问
B.用户空间中的栈区和堆区都从高地址向低地址增长
C.用户空间中的静态区包括只读代码段和可读可写数据段
D.内核空间在高地址区域,用户空间在低地址区域
17单选(1分)
以下关于分页虚拟存储管理机制的叙述中,错误的是( D )。
A.每个进程都有一个页表,页表也被划分成页面
B.每个进程的虚拟地址空间被划分成若干页面
C.物理主存空间被划分成若干个页面大小的页框
D.页面大小与Cache机制中的主存块大小相同
18单选(1分)
若R[edx]=0000 01B6H,R[esi]=0000 0008H,则IA-32+Linux系统中“movl 8(%edx, %esi, 4), %edx”指令的源操作数的线性地址是( C )。
A.0000 06E8H
B.0000 01F0H
C.0000 01DEH
D.0000 01B6H
正确答案:C你选对了
解析: C、源操作数的有效地址为R[edx]+R[esi]*4+8=0000 01B6H+0000 0008H*4+8=0000 01DEH,在Linux中线性地址就是有效地址。
19单选(1分)
以下是有关IA-32保护模式的叙述,其中错误的是( A )。
A.分段过程实现32位逻辑地址转换为32位线性地址
B.分页采用二级页表方式,包括页目录表和页表
C.采用先分段后分页的段页式存储管理方式
D.分段过程需要用到段描述符表(即段表)
20单选(1分)
已知变量y和数组a都是int型,a的首地址为0x8049b00。假设编译器将a的首地址分配在ECX中,数组的下标变量i分配在EDX中,y分配在EAX中,C语言赋值语句“y=a[i];”被编译为指令“movl (%ecx, %edx, 4), %eax”。在IA-32/Linux环境下执行该指令,则当i=100时,得到的存储器操作数的线性地址是( B )。
A. 0x8049c00
B. 0x8049c90
C. 0x8049f00
D.0x8049b00
正确答案:B你选对了
解析: B、Linux中将所有段的段基址都初始化为0,因而存储器操作数a[150]的线性地址=段基址+有效地址=0+R[ecx]+R[edx]*4=0x8049b00+100*4=0x8049b00+400=0x8049b00+0x190=0x8049c90。
21单选(1分)
以下是有关IA-32中线性地址向物理地址转换过程的叙述,其中错误的是( A )。
A.转换前后的线性地址和物理地址位数不同
B.CR3的内容为页目录表的起始物理地址
C.地址转换时,总是先查TLB中的快表
D.线性地址空间就是虚拟地址空间
正确答案:A你选对了
解析: A、转换前后的线性地址和物理地址位数相同,都是32位。
22单选(1分)
以下是有关IA-32中逻辑地址向线性地址转换过程的叙述,其中错误的是( A )。
A.每次地址转换都要访问主存中的段描述符表
B.逻辑地址包含段选择符和段内偏移量两部分
C.线性地址等于段基址加段内偏移量
D.该转换过程由存储器管理部件MMU实现
正确答案:A你选对了
解析: A、在第一次地址转换时,段描述符表被装入CPU中的描述符cache中,以后就不需要访问主存中的段描述符表了
23多选(3分)
采用虚存机制的系统中,每个进程都有统一的虚拟地址空间,因而带来了很多好处。这些好处包括( ABCD )。
A.可使主存空间得到有效利用
B.可简化程序的加载过程
C.可加快程序运行速度
D.有利于实现存储保护
正确答案:A、B、D你错选为A、B、C、D
解析: C、事实相反,因为虚拟存储机制带来了许多额外的时间和空间开销,反而速度更慢。例如,需要查页表并进行地址转换,使指令执行时间更长。
24判断(2分)
for循环语句的循环体对应的指令序列既具有空间局部性,也具有时间局部性。✔
25判断(2分)
深度递归调用过程对应的指令序列既具有空间局部性,也具有时间局部性✔
26判断(2分)
按行优先方式对数组中各元素按序访问时,该数组既具有空间局部性,也具有时间局部性。❌
解析:只是按序访问数组元素,并没有访问多次,因而这个数组只具有空间局部性,而没有时间局部性。
27判断(2分)
一个过程在短时间内被连续调用时,对应指令序列既具有空间局部性,也具有时间局部性。✔
28判断(2分)
现代计算机都采用多级Cache方式,L1 Cache多采用数据Cache和代码Cache分离设置,而L2 Cache和L3 Cache则为联合Cache,即数据和代码放在同一个Cache中。✔
29判断(2分)
在一个进程的虚拟地址空间中,在栈区和堆区中间的一些区域是没有内容的“空洞”页面,它们被称为未分配页。✔
30判断(2分)
在一个进程的虚拟地址空间中,只读代码段和可读可写数据段与可执行文件中的内容关联,它们被划分成若干页面。在程序执行过程中,这些页面有的没有从磁盘调入主存空间,有的则已经装入主存页框,前者称为未缓存页,后者称为缓存页。✔
31判断(2分)
任何时刻,一个进程中的所有页面都被划分成以下三个不相交的页面集合:已分配页集合、未缓存页集合、缓存页集合。❌
应该是:未分配页集合、未缓存页集合、缓存页集合。
32判断(2分)
在分页虚拟存储管理系统中,某一时刻物理内存中可能同时存在多个进程的页面和页表。✔
33判断(2分)
在一个程序被加载执行的开始,一旦CPU执行指令,在第一次CPU访存过程中,一定会发生TLB缺失、缺页和Cache缺失。✔
34假定内存条容量为512MB,由8个64Mx8位的DRAM芯片组成,每个DRAM芯片的存储体阵列有8个位平面,则该DRAM芯片的地址引脚个数为( 13 )。
该DRAM芯片的存储体阵列容量为64Mx8=8Kx8Kx8,也即每个位平面为8Kx8K=2^13 x 2^13 。故行地址和列地址都是13位,分时通过地址引脚传送,需13个地址引脚。
35假定一个磁盘驱动器的转速为7200RPM,平均寻道时间为10ms,则该磁盘驱动器的平均访问时间约为( 14.1或14.2 )ms。(结果取一位小数)
36假设主存地址空间为4GB,按字节编址, cache共有4K行,采用4路组相联映射方式,采用随机替换策略和写回(write back)策略,主存块大小为64B,则cache容量至少为( 265 )KB。
37若cache存取时间为2ns,主存存取时间为50ns,cache命中率为98%,则Cache-主存层次平均访问时间为( 3 )ns。
计算机系统基础三课程概述
在前两门课中你学习了可执行文件的生成、加载和执行。是否所有程序总能按部就班地正常执行到结束呢?如果发生了异常或者外部中断请求,该怎么办?键盘、磁盘等外设操作无法用一条指令完成,该怎么办?如果你想知道这些问题,就请参加“计算机系统基础(三):异常、中断和输入/输出”课程学习吧! —— 课程团队
课程概述
本课程主要介绍可执行文件中的代码在执行过程中,如果发生了内部异常事件或外部中断请求,CPU如何进行异常/中断响应,以调出操作系统内核中的异常处理程序或中断服务程序执行,以及用户程序如何通过陷阱指令调出操作系统提供的系统调用服务例程来实现输入/输出操作。主要包括以下几个问题:
什么是进程的逻辑控制流?
为何会形成进程的异常控制流?
进程上下文切换如何形成异常控制流?
异常和中断如何形成异常控制流?
IA-32/Linux如何进行异常/中断处理?
如何通过系统调用实现程序中的I/O操作?
外部设备如何与主机互连?
基本的输入/输出方式有哪几种?
内核空间I/O软件如何控制I/O硬件?
课程大纲
第一周 进程和进程的上下文切换
第一周引言
第1讲 异常控制流的概念
第2讲 程序和进程
第3讲 进程的逻辑控制流
第4讲 进程的上下文切换
第5讲 进程的存储器映射
第6讲 共享对象和私有的写时拷贝对象
第7讲 用户态和内核态
第8讲 程序的加载和运行
课件PPT
第一周小测验
第二周 异常和中断
第二周引言
第1讲 异常和中断的基本概念
第2讲 异常和中断的基本处理过程
第3讲 异常的分类
第4讲 故障类异常及举例
第5讲 陷阱类和终止类异常
第6讲 中断的概念
第7讲 异常/中断的响应过程
课件PPT
第二周小测验
第三周 IA-32中的异常/中断机制
第三周引言
第1讲 x86实地址模式下异常/中断处理
第2讲 x86保护模式下异常/中断处理
第3讲 IA-32中异常/中断响应过程
第4讲 IA-32中异常/中断返回过程
课件PPT
第三周小测验
第四周 IA-32/Linux中异常/中断处理
第四周引言
第1讲 Linux中对IDT的初始化
第2讲 Linux异常处理举例
第3讲 IA-32/Linux对中断的处理
第4讲 IA-32/Linux的系统调用处理
第5讲 软中断指令int 0x80的执行过程
课件PPT
第四周小测验
第五周 用户空间I/O软件
第五周引言
第1讲 I/O子系统概述
第2讲 用户I/O软件与系统调用
第3讲 文件的基本概念
第4讲 头文件stdio.h内容理解
第5讲 文件操作举例
课件PPT
第五周小测验
第六周 系统总线和系统互连
第六周引言
第1讲 系统总线及互连概述
第2讲 总线的基本概念和性能指标
第3讲 三种系统总线及系统互连
第4讲 外设和外设控制器
课件PPT
第六周小测验
第七周 I/O方式和内核空间I/O软件
第七周引言
第1讲 程序查询方式
第2讲 中断I/O方式
第3讲 中断处理过程
第4讲 中断屏蔽和多重中断
第5讲 程序查询和中断方式的比较
第6讲 DMA方式
第7讲 内核空间I/O软件
课件PPT
第七周小测验
第一周进程和进程的上下文切换
第二周异常和中断
第三周IA-32中的异常及中断机制
第四周IA-32/Linux中异常/中断处理
第五周用户空间I/O软件
第六周系统总线和系统互连
第七周IO方式和内核空间IO软件
計算機系統基礎三:異常、中斷和輸入輸出期末
计算机系统基础三期末考試
错题序号:6、12
1下列选项中,不会引起异常控制流的事件是( B )。
A.访存缺页
B.浮点运算结果为非规格化数
C.鼠标信息输入
D.整数除0
解析: B、除数为0和访存时缺页都是在执行某条指令时CPU发现的异常事件,鼠标信息输入能引起外部中断,因为它们都会导致异常/中断响应,调出相应的异常处理程序或中断服务程序执行,形成异常控制流。而浮点运算结果为非规格化数则是正常的程序执行结果,不会形成异常控制流。
2以下有关CPU响应外部中断请求的叙述中,错误的是( B )。
A.在“中断响应”周期,CPU将中断允许触发器清0,以使CPU关中断
B.每条指令结束后,CPU都会转到“中断响应”周期进行中断响应处理
C.在“中断响应”周期,CPU把取得的中断服务程序的入口地址送PC
D.在“中断响应”周期,CPU把后继指令地址作为返回地址保存在固定地方
解析: B、CPU在每条指令执行结束时检测中断请求信号,若检测到中断请求信号有效,则进入中断响应周期;若检测到中断请求信号无效,则不会进入中断响应周期。
3中断向量地址是指( D )。
A.子程序入口地址
B.中断查询程序的入口地址
C.中断服务程序入口地址
D.中断服务程序入口地址的地址
正确答案:D
4以下是关于I/O空间独立编址方式下设备驱动程序的描述,其中错误的是( C )。
A.一定包含I/O指令,通过执行I/O指令来控制外设
B.设备驱动程序的实现一定与I/O控制方式有关
C.驱动程序执行过程中一定会调度CPU转去其他进程执行
D.一定属于操作系统内核程序,在核心态执行以进行I/O控制
解析: B、通过执行设备驱动程序,CPU可以向控制端口发送控制命令来启动外设,可以从状态端口读取状态来了解外设或设备控制器的状态,也可以从数据端口中读取数据或向数据端口发送数据等。显然,设备驱动程序中包含了许多I/O指令,通过执行I/O指令,CPU可以访问设备控制器中的I/O端口,从而控制外设的I/O操作。 C、设备驱动程序的实现取决于I/O控制方式,在中断方式或DMA方式下,驱动程序执行过程中会执行处理器调度程序使CPU转去其他进程执行。但是,如果是程序直接控制方式,则驱动程序的执行与外设的I/O操作完全串行,驱动程序一直等到全部完成用户程序的I/O请求后结束,期间不会执行处理器调度程序。
5“开中断”和“关中断”两种操作都用于对( B )进行设置。
A.中断向量寄存器
B.中断允许触发器
C.中断屏蔽寄存器
D.中断请求寄存器
正确答案:B你选对了
6以下有关中断I/O方式的叙述中,错误的是( A )。
A.只要有中断请求发生,那么一条指令执行结束后CPU就进入中断响应周期
B.CPU对外部中断的响应不可能发生在一条指令的执行过程中
C.中断I/O方式下,外设接口中的数据和CPU中的寄存器内容直接交换
D.中断请求的是CPU时间,要求CPU执行程序来处理发生的相关事件
解析: A、在以下两种情况下不正确: (1)关中断(禁止中断)时,虽然有中断请求发生,但CPU因为不允许响应中断而不会进入中断响应周期;(2)当有中断请求的请求源被屏蔽(由中断控制器的中断屏蔽字寄存器的相应屏蔽位进行屏蔽)时,因为对应的中断请求源被屏蔽掉了,因此中断控制器无法向CPU发出中断请求信号,因而不会进入中断响应周期。 B、如果可以在一条指令执行的中途响应中断请求,那么,中断返回后该从一条指令执行的中途开始继续执行,这显然是无法做到的。 C、CPU响应中断后会调出中断服务程序,在中断服务程序执行过程中,CPU会执行相应的输入输出指令,实现CPU中的通用寄存器和外设接口(设备控制器)中的I/O端口之间的直接数据交换。 D、中断请求就是要求CPU执行程序来处理发生的相关事件。
7以下关于DMA控制器和CPU关系的叙述中,错误的是( A )。
A.DMA控制器和CPU都要使用总线时,CPU优先级更高
B.CPU可通过执行I/O指令来访问DMA控制器中的I/O端口
C.CPU可通过执行I/O指令来使DMA控制器启动外设工作
D.DMA控制器和CPU都可以作为总线的主控设备
解析: A、DMA控制器比CPU的优先级更高,如果CPU不释放总线给DMA控制器使用,则外设(如磁盘)读出的数据会因为没有及时传送而发生丢失。
8以下I/O控制方式中,主要由硬件而不是软件实现数据传送的方式是( D )。
A.中断I/O方式
B.无条件程序控制方式
C.程序查询方式
D.DMA方式
解析: D、DMA方式下主要是由DMA控制器使用总线进行数据传送的,而其他方式下都是由CPU执行相应的程序(如查询方式下的驱动程序或中断方式下的中断服务程序)来完成数据传送的。
9填空(2分)
进程的系统级上下文由进程标识、进程现场信息、进程控制信息和系统内核栈等组成。处理器中各个寄存器的内容称为寄存器上下文(也称为硬件上下文)。上下文切换时,将会把当前进程的( )上下文保存到当前进程空间的进程现场信息中。
正确答案:寄存器 或 硬件 或 寄存器上下文 或 硬件上下文
10填空(2分)
Intel处理器把内部异常分成( )、陷阱(trap)和终止(abort)三类。用于系统调用的指令是一种陷阱指令。
正确答案:故障 或 fault 或 故障(fault) 或 故障 fault
11填空(2分)
Intel把中断分成不可屏蔽中断和可屏蔽中断两类。在可编程中断控制器(PIC)中,通过对外设向PIC送来的中断请求信号IRQi与( )字中的对应位进行“与”操作来实现中断屏蔽。
正确答案:中断屏蔽 或 中断屏蔽字
12填空(2分)
异常和中断的识别分为软件识别和硬件识别两种方式,硬件识别方式也称为( )方式。
正确答案:向量中断 或 矢量中断 或 向量中断方式 或 矢量中断方式
13填空(2分)
Intel架构采用硬件识别异常和中断的方式。实地址模式下,它采用( )表记录异常处理程序或中断服务程序的首地址。
正确答案:中断向量 或 中断矢量
14填空(2分)
IA-32保护模式下,CPU在进行异常/中断响应过程中,会根据异常/中断类型号,去访问( )表,以得到异常处理程序或中断服务程序的首地址。
正确答案:中断描述符 或 IDT 或 中断描述符表 或 中断描述表 或 IDT表 或 中断描述
15填空(2分)
已知存储器总线64位宽,速度为1333MT/s,则三通道存储器总线的总带宽大约为( 32 )GB/s。(答案要求舍入到整数,不保留小数部分)
16填空(2分)
Intel架构的I/O端口采用独立编址方式,因此,对于设备控制器中各端口的访问由( I/O )指令实现。
17填空(2分)
一旦检测到中断请求,则在开中断的情况下,先后进入中断响应和中断处理两个阶段。中断响应由CPU完成,而中断处理则由CPU执行( )程序完成。
正确答案:中断服务 或 中断处理 或 中断服务程序 或 中断处理程序
18填空(2分)
DMA控制I/O过程包含三个阶段:DMA控制器初始化、DMA传送和DMA传送结束处理。其中,第一和第三阶段由驱动程序或中断服务程序完成,第二阶段则由( )控制器完成。
正确答案:DMA 或 直接存储器存取 或 DMA控制器
第7章和第8章平时小测验
错题序号:7、9、14、15、16、17、19、22、24、26、27、28
1单选(1.25分)
以下关于进程存储器映射的叙述中,错误的是( B )。
A.进程的虚拟地址空间被划分成若干区域,如只读代码区域
B.存储器映射是指进程的虚拟地址空间与主存物理空间之间的映射
C.每个进程都有一个独立的虚拟地址空间
D.可通过mmap()函数进行存储器映射
正确答案:B你选对了
解析: B、存储器映射是指进程的虚拟地址空间中的各个区域与某个文件中的不同区域之间的对应关系。可用mmap()函数进行映射。void *mmap(void *start, size_t length, int prot, int flags, int fd, off_t offset); 将指定文件fd中偏移量offset开始的长度为length个字节的一块信息,映射到虚拟地址空间中起始地址为start、长度为length个字节的一块区域。
2单选(1.25分)
以下选项给出的异常事件中,属于陷阱类的异常事件是( A )。
A.程序调试时被设置了断点
B.整数除法指令中除数为0
C.地址转换时发生缺页
D.指令译码时发生非法操作码
正确答案:A你选对了
3单选(1.25分)
以下选项给出的操作中,不属于CPU在中断响应过程中完成的是( A )。
A.将所有中断请求信号进行排队,选择优先级最高的中断源进行响应
B.保存断点和程序状态字
C.将“中断允许位”设置为0,即关中断
D.识别中断源,并将对应中断服务程序的首地址送PC
正确答案:A你选对了
解析: A、这是在中断控制器发出中断请求信号时在中断控制器中进行的操作。
4单选(1.25分)
以下关于进程和程序的叙述中,错误的是( B )。
A.程序是代码和数据的集合,属于静态层面的概念
B.同一个可执行文件对应的不同进程,其逻辑控制流完全一致
C.进程是程序的一次运行过程,每个进程有自己的生命周期
D.同一个程序在不同的时间被启动执行,得到的是不同的进程
正确答案:B你选对了
解析: B、同一个可执行文件可能处理不同的数据(如用户在键盘上输入的数据或读入的文件数据可能不同),因而在程序运行过程中,执行分支指令时,可能因满足的条件不同而执行不同的程序分支,从而可能得到不同的逻辑控制流。
5单选(1.25分)
以下关于进程和进程上下文切换的叙述中,错误的是( D )。
A. 进程的上下文切换过程中必须将当前换下进程的现场信息保存在内核栈中
B.进程的上下文切换机制保证了不会因进程被打断执行而改变其逻辑控制流
C.每个进程具有独立的虚拟地址空间,这便于编译、链接、共享和加载
D.进程的上下文切换完全由处理器硬件完成,不需要执行任何操作系统内核程序
正确答案:D你选对了
解析: D、操作系统内核程序进行上下文切换,以保存换下进程的上下文并创建换上进程的上下文
6单选(1.25分)
以下关于内核态和用户态的叙述中,错误的是( B )。
A.只有在内核态才能执行内核程序代码,其中可包含特权指令
B.shell命令行解释程序实现程序的加载和运行,因而它运行在内核态
C.IA-32系统中,特权级别由代码段寄存器CS中的最后两位指定
D.用户态也称目标程序状态,用户态下只能执行用户进程
正确答案:B你选对了
解析: B、Shell命令行解释程序本身运行在用户态,它通过调用fork()、execve()等系统调用封装函数实现程序的加载和运行,在执行这些系统调用函数的过程中,会通过int 0x80指令陷入内核,从而在内核态由内核代码实现相应的子进程创建、程序加载等工作。
7单选(1.25分)
以下关于异常/中断机制与进程上下文切换机制比较的叙述中,错误的是( C )。
A.进程上下文切换和异常/中断响应都会产生进程的异常控制流
B.进程上下文切换和异常/中断响应的结果都是切换到内核程序执行
C.进程上下文切换通过执行内核程序实现,而异常/中断响应处理则由硬件实现
D.单步跟踪是一种异常事件,而不是通过进程上下文切换机制实现
正确答案:B你错选为C
解析: B、进程上下文切换后,CPU执行的是另一个进程的代码
8单选(1.25分)
以下关于异常/中断的检测与响应的叙述中,错误的是( C )。
A.在执行指令过程中进行异常事件检测,而在指令执行结束时进行中断请求检测
B.CPU在异常响应过程中会保存断点和程序状态并转相应异常处理程序执行
C. CPU检测到异常事件后所做的处理和检测到中断请求后所做的处理完全一样
D.异常/中断的检测与响应都由硬件完成,无需CPU执行内核程序实现
正确答案:C你选对了
解析: C、异常事件是CPU执行指令过程中发生的与当前执行指令有关的意外事件,而中断请求则是CPU外部的I/O部件或时钟等向CPU发出的与当前执行指令无关的意外事件。CPU对于异常和中断的响应处理在大的方面基本一致,都需要保存断点和程序状态并转到相应的处理程序去执行。但有些细节并不一样,例如,在检测到中断请求后,CPU必须通过“中断回答”信号启动中断控制器进行中断查询,以确定当前发出的优先级最高的中断请求类型,并通过数据线获取相应的中断类型号。而对于内部异常,CPU则无需进行中断回答。
9单选(1.25分)
以下关于向量中断方式的叙述中,错误的是( B )。
A.对每类异常和中断都设置一个对应的类型号,作为中断向量表的索引
B.CPU能根据异常和中断的类型号自动跳转到对应的处理程序去执行
C.向量中断方式下的硬件开销比软件查询方式下的硬件开销更小
D.采用中断向量表存放所有异常处理程序和中断服务程序的首地址
正确答案:C你错选为B
解析: C、软件查询方式不需要中断向量表和硬件判优和查询线路,而只要把异常或中断的原因记录在特定寄存器中,由专门的查询程序读取寄存器内容来识别异常和中断类型。因此,向量中断方式下的硬件开销比软件查询方式下的硬件开销更大,但响应速度更快。
10单选(1.25分)
与计算机系统一样,I/O子系统也采用层次结构,从最上层提出I/O请求的应用程序到最下层的I/O硬件之间的顺序是( C )。
A.应用程序→中断服务程序→与设备无关的I/O软件→设备驱动程序→I/O硬件
B.应用程序→设备驱动程序→中断服务程序→与设备无关的I/O软件→I/O硬件
C.应用程序→与设备无关的I/O软件→设备驱动程序→中断服务程序→I/O硬件
D.应用程序→与设备无关的I/O软件→中断服务程序→设备驱动程序→I/O硬件
正确答案:C你选对了
11单选(1.25分)
以下选项给出的程序中,不在内核态运行的是(B )。
A.设备驱动程序
B. 命令行解释程序
C.中断服务程序
D. 系统调用服务例程
正确答案:B你选对了
12单选(1.25分)
以下选项给出了几个在Linux系统的程序中使用的函数,其中在内核态运行的是( D )。
A.write()
B. fwrite()
C. _flushbuf()
D.sys_write()
正确答案:D你选对了
解析: D、在给出的几个函数中,fwrite()是C语言标准库函数,在用户编写的C语言程序中使用,因而不是在内核态运行的函数。write()函数是对write系统调用进行封装的函数,其中包含若干条用于传递系统调用参数的mov指令和int $0x80指令等,该函数在用户态执行,当执行到int $0x80指令时从用户态陷入内核态。sys_write()函数是write系统调用服务例程,是内核中专门用于进行write系统调用处理的函数,因而是在内核态执行的函数。_flushbuf是实现C语言标准库函数或宏定义时所调用的基本函数,用于将缓冲中的数据写到文件中,因而也是在用户态执行的函数。
13单选(1.25分)
以下选项中,与I/O接口的含义不同的是( D )。
A.I/O模块
B.设备控制器
C.I/O控制器
D. I/O端口
正确答案:D你选对了
解析: D、I/O端口是I/O接口中的数据缓冲寄存器(数据端口)、控制寄存器(控制端口)或状态寄存器(状态端口)的总称。
14单选(1.25分)
下列选项中, 不属于外部中断请求事件的是( C )。
A.按下“ctrl-C”键
B.启动外设工作
C.网络数据包到达
D.DMA传送结束
正确答案:B你错选为C
解析: B、CPU通常通过执行一条I/O指令(如OUT指令)发送一个控制命令字到外设控制器的命令(控制)端口来启动外设工作。这显然不是一种外部中断请求。
15单选(1.25分)
以下是关于IA-32中可编程中断控制器(PIC)的叙述,其中错误的是( D )。
A.PIC中有中断请求寄存器和中断屏蔽寄存器
B.PIC通过总线中的地址线向CPU发送中断类型号
C.PIC中有中断优先级排队线路和编码器
D.所有外设的中断请求信号IRQ都会送到PIC
正确答案:B你错选为D
解析: B、总线中的地址线是单向的,只能从CPU送出地址信号,而不能向CPU发送地址信息,因此,不可能通过地址线向CPU发送中断类型号。实际上,中断类型号可看成是PIC向CPU发送的数据,通过总线中的数据线传送
16单选(1.25分)
以下是关于DMA控制I/O方式的叙述,其中错误的是( C )。
A.数据传送前的初始化工作由CPU执行内核程序完成
B.数据传送过程由DMA控制器控制完成
C.外设数据直接和主存进行交换
D.数据传送结束后的工作由CPU直接完成,无需执行任何程序
正确答案:D你错选为C
解析: D、DAM方式下,数据传送结束时,DMA控制器会通过中断控制器(PIC)向CPU发送“DMA结束”中断请求信号,从而使CPU调出相应的“DMA结束”中断服务程序来执行。由此可见,数据传送结束后的工作是由CPU执行专门的“DMA结束”中断服务程序来完成的。
17多选(3分)
以下选项中,可以引起异常控制流的有( ABCD )。
A.发生Cache缺失
B.执行陷阱指令,如int $0x80
C.发生缺页异常
D.进程的上下文切换
正确答案:B、C、D你错选为A、B、C、D
18判断(2分)
异常事件是由CPU在执行指令过程中检测到的,而中断请求事件则是由外部设备通过中断控制器向CPU发出中断请求信号后,由CPU在每条指令执行结束时采样中断请求线而检测到的。✔
19判断(2分)
陷阱(也称自陷或陷入)是一种通过专门的“陷阱指令”插入在特定的指令序列中来事先安排的一种异常事件。单步跟踪和断点设置等程序调试功能可以用陷阱方式实现,过程调用也是通过陷阱方式实现的。❌
解析: 过程调用直接使用调用指令call实现,而系统调用则通过陷阱方式实现,例如,IA-32+Linux系统中的系统调用陷阱指令为int $0x80。
20判断(2分)
在IA-32中,不可屏蔽中断请求通过专门的不可屏蔽中断请求信号线NMI向CPU申请,一旦CPU采样该信号有效,则立即响应并处理。 ✔
21判断(2分)
在IA-32中,关中断操作就是将EFLAGS中的IF这一位清0。关中断操作可以由硬件直接实现,也可以在中断服务程序中执行cli指令通过软件来实现。✔
22判断(2分)
在IA-32+Linux系统中,执行int $0x80指令后,处理器将从用户态陷入内核态,在内核态完成相应的系统调用服务后,通过ret指令从内核态回到用户态执行。❌
解析: 完成相应的系统调用服务后,应该通过 iret 指令从内核态返回用户态。ret指令是过程调用call指令对应的返回指令。
23判断(2分)
在类UNIX系统中,除了stdin、stdout和stderr三个标准文件外,所有文件在读写之前都必须通过creat系统调用或open系统调用进行创建或打开。✔
24判断(2分)
在类UNIX系统中,C标准I/O库函数fprintf()、fwrite()和fread()最终都需要调用系统调用封装函数write()来实现。write()函数中一定有一条系统调用陷阱指令。❌
解析: fprintf()和fwrite()最终都需要调用系统调用封装函数write()来实现,而fread()则调用read()系统调用封装函数实现。
25判断(2分)
在系统级I/O函数中,采用int类型的文件描述符fd或用字符串描述的文件名来标识文件,而在C标准I/O库函数中,则用指向FILE结构类型的指针fp来标识文件。 ✔
26判断(2分)
在计算机中,I/O地址空间大小远远大于主存地址空间大小,前者在物理上位于各个I/O接口中,主要用于存放外设或I/O接口与主机之间交换的数据、命令和状态信息。 ❌
解析: I/O地址空间主要用于存放外设或I/O接口与主机之间交换的数据、命令和状态信息。因而其大小远远小于主存地址空间大小。
27判断(2分)
在中断控制I/O方式下,由CPU执行软件来实现对I/O过程的控制;而在DMA控制I/O方式下,则完全由硬件(DMA控制器)控制I/O过程。✔
28填空(2分)
若存储器总线宽度为64位,工作频率为1333MT/s,即每秒传输1333M次,则该存储器总线的带宽为( 10.41 )GB/s(结果至少取两位小数)。
正确答案:10.66 或 10.664
解析: 1333M/sx64/8=10.664GB/s。
29填空(2分)
已知PCI-Express总线带宽计算公式是2.5Gb/s x 2 x 通路数 / (10b/B),则PCI-Express x16的总带宽为( 8 )GB/s。 正确答案:8