第五周Cache替换算法和写策略
- 第1讲 Cache替换算法
- 第2讲 Cache写策略(一致性问题)
- 第3讲 Cache实现的几个因素(5m49s)
- 第4讲 Cache实现举例(8m25s)
- 第5讲 Cache综合计算举例(12m49s)
- 第五周小测验
第1讲 Cache替换算法
替换算法概述(3m09s)

先进先出(FIFO)算法(6m08s)
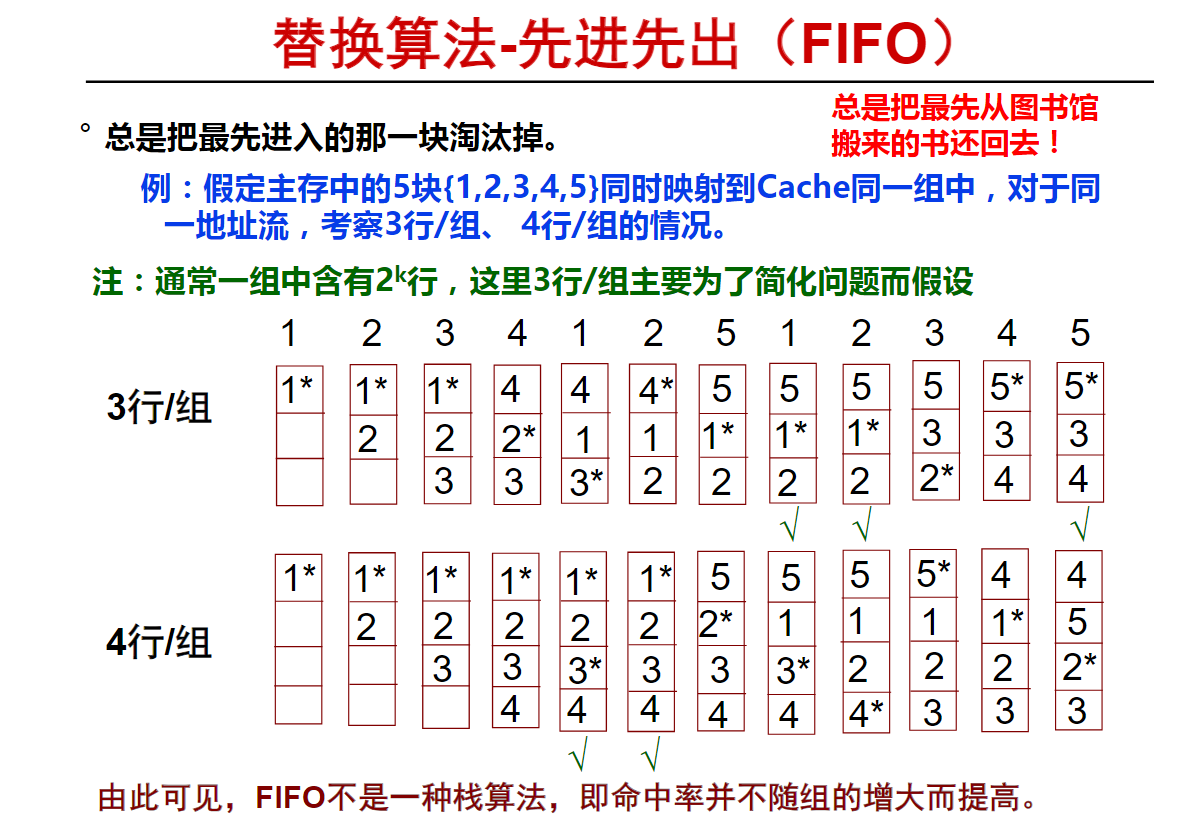
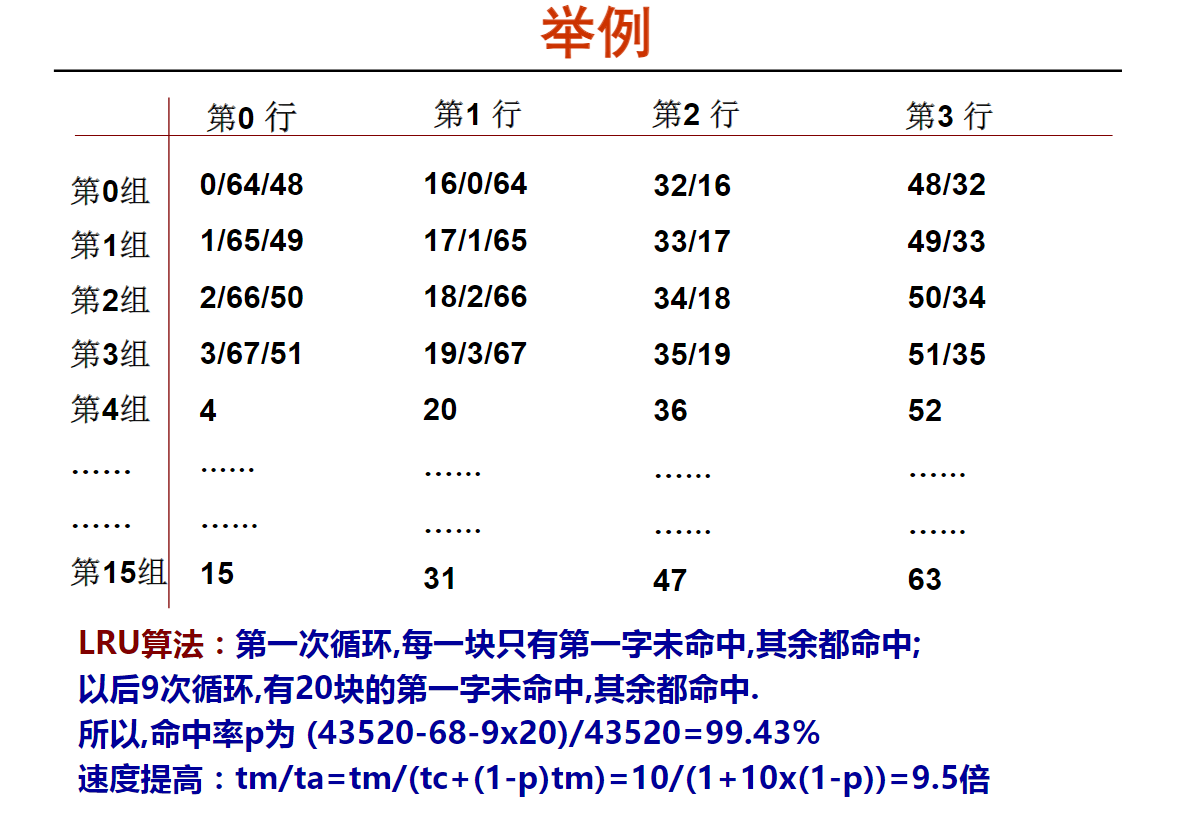
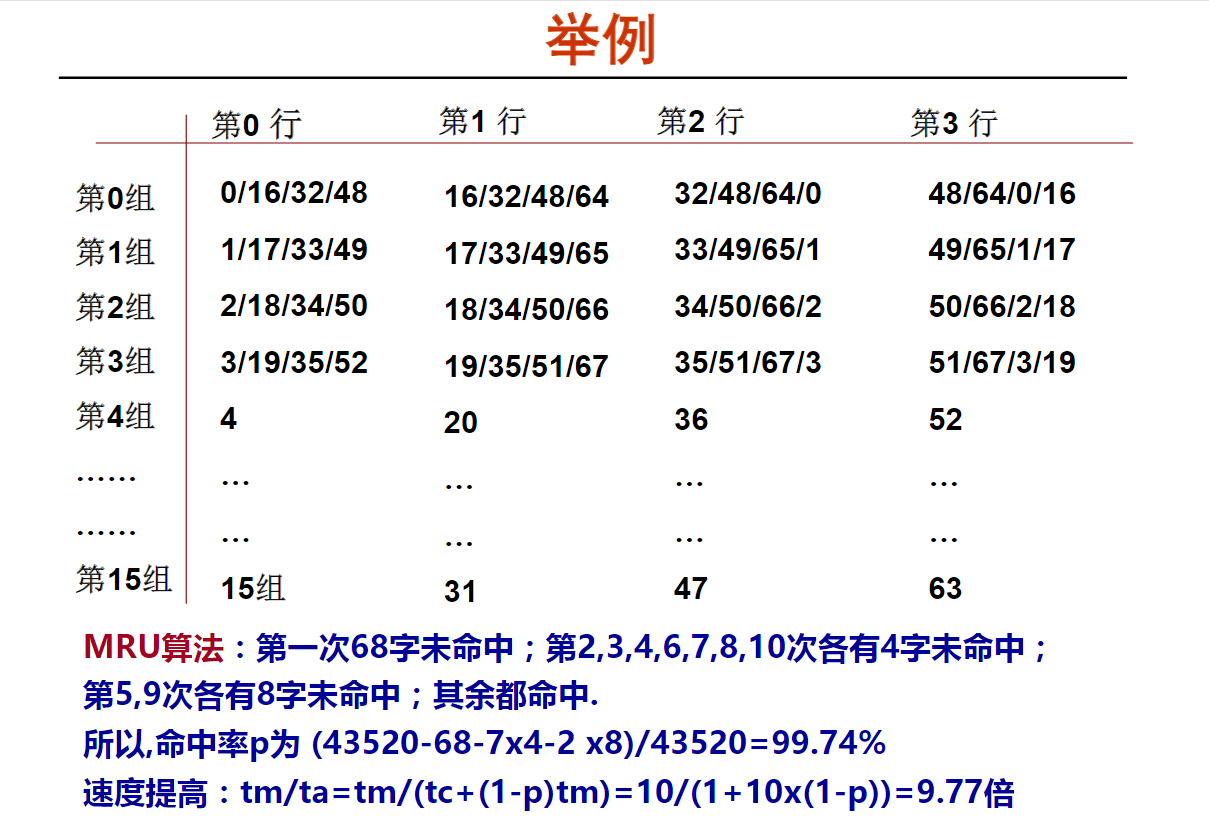
最近最少用(LRU)算法(10m06s)
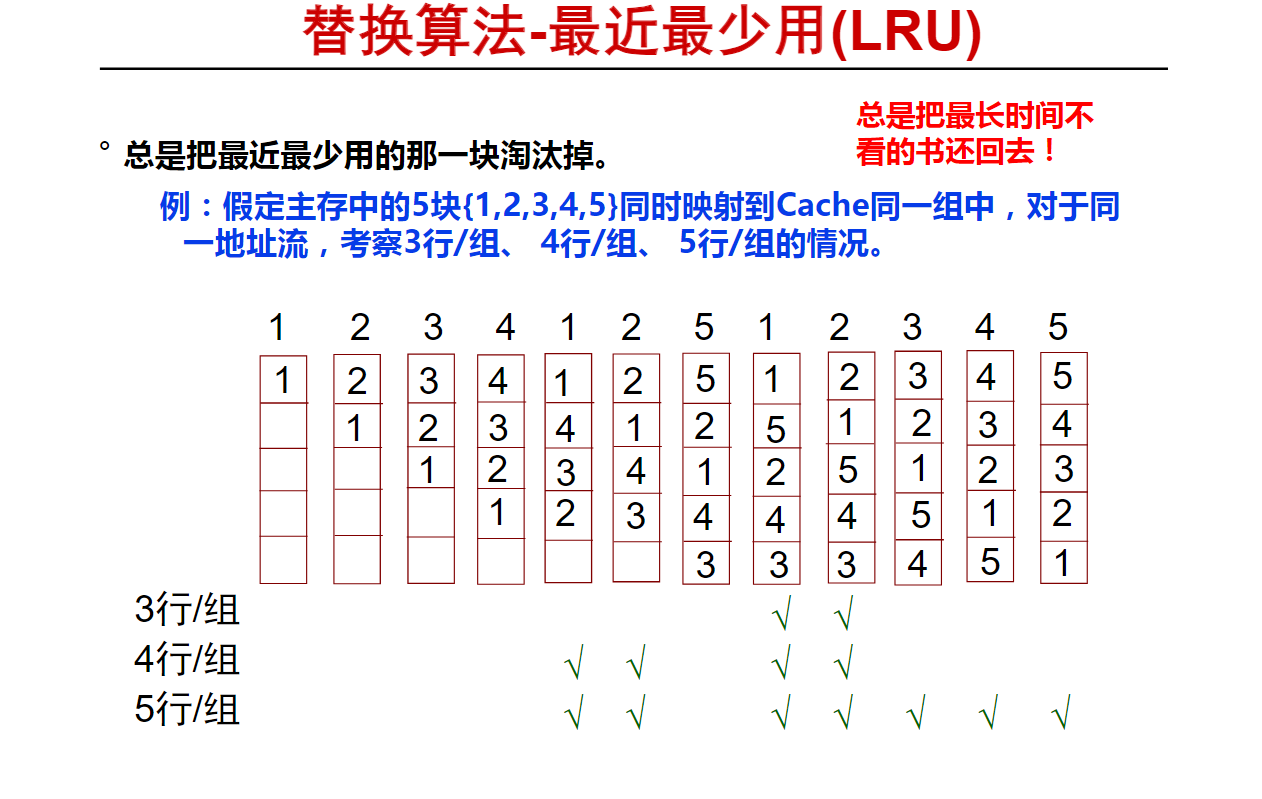

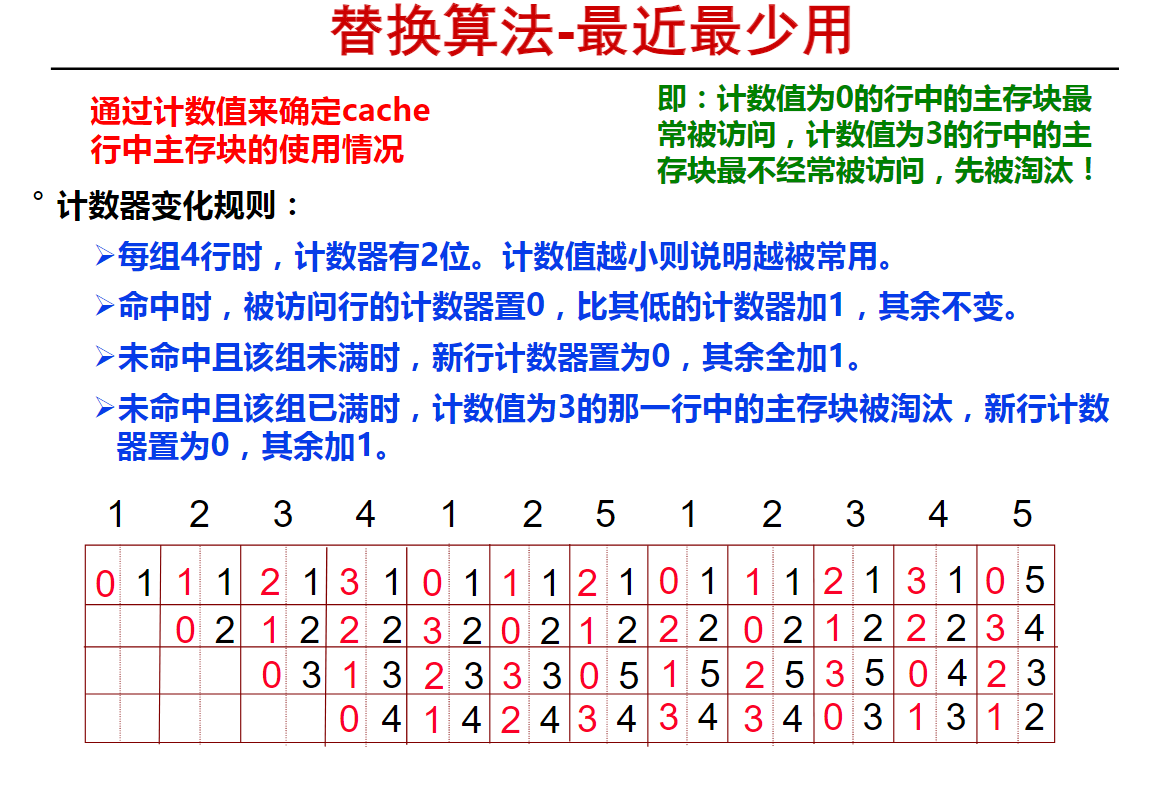

Cache举例(15m05s)

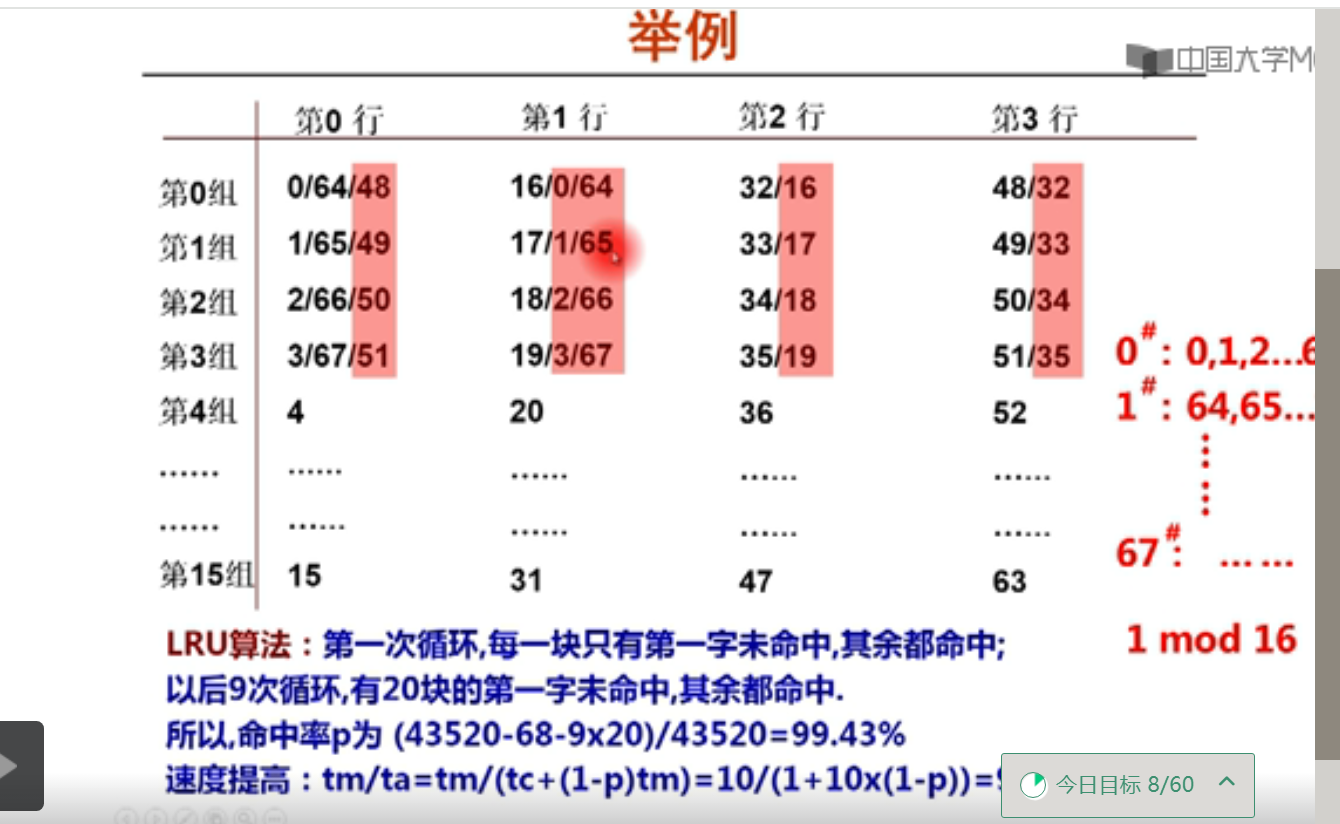
0/64/48
淘汰0,写入64;淘汰64写入48
后写入的比先写入的多更近
第2讲 Cache写策略(一致性问题)
写策略概述(11m11s)


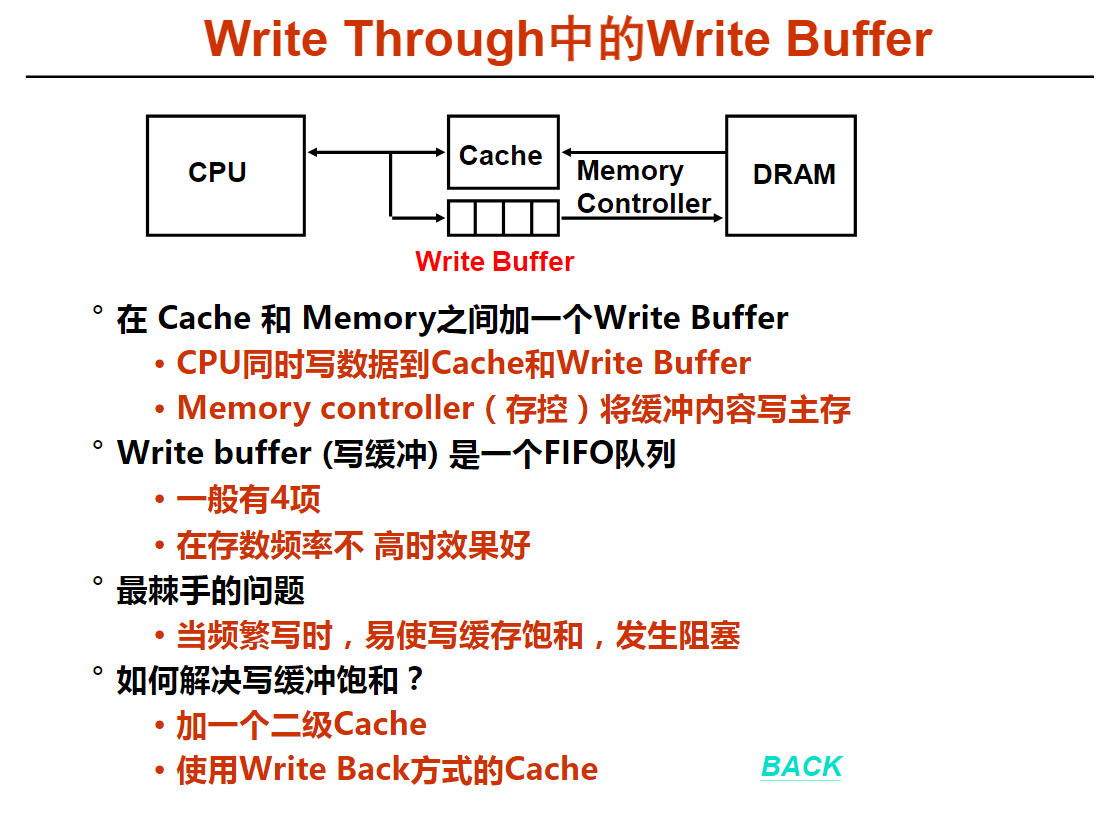
写策略算法描述(8m28s)



第3讲 Cache实现的几个因素(5m49s)
系统中的Cache数目

Harvard结构:指令数据分开存储
分立是为了方便并行,避免阻塞
第4讲 Cache实现举例(8m25s)
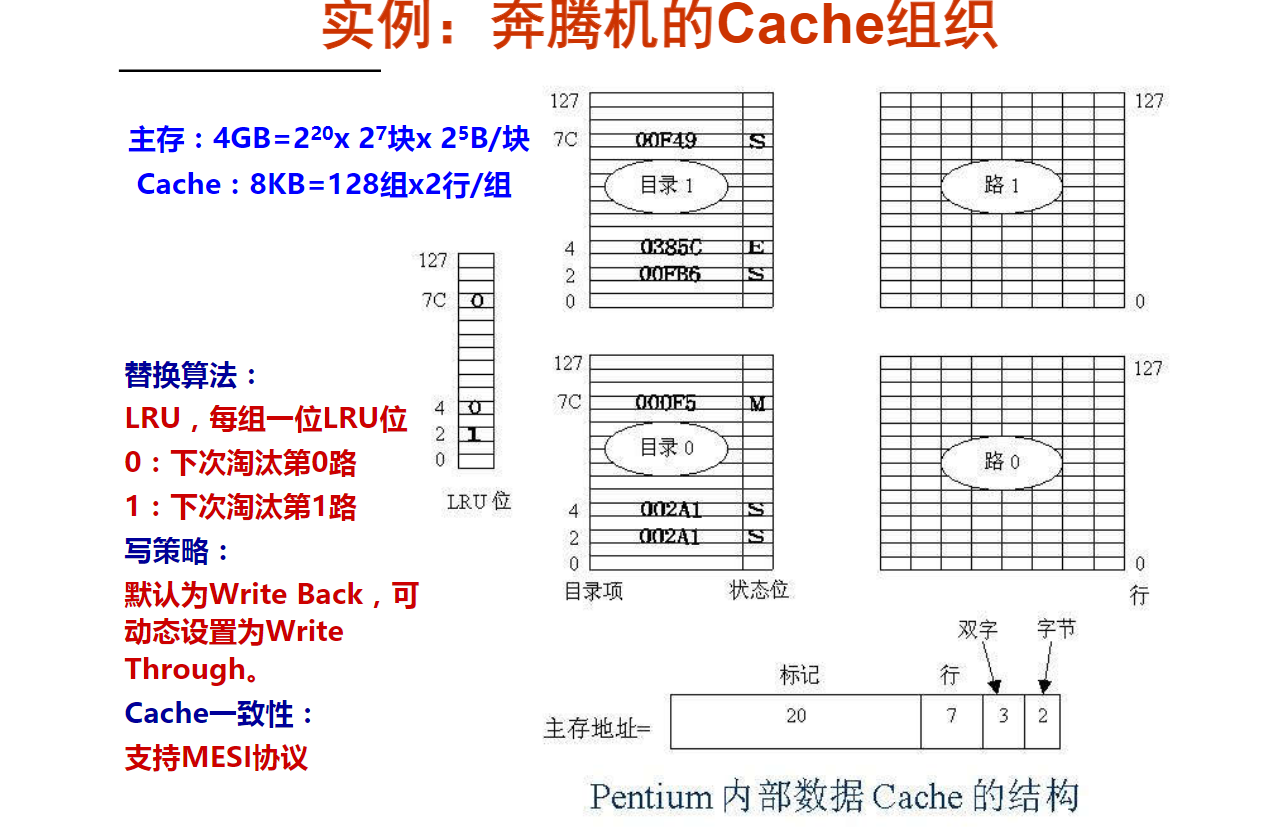
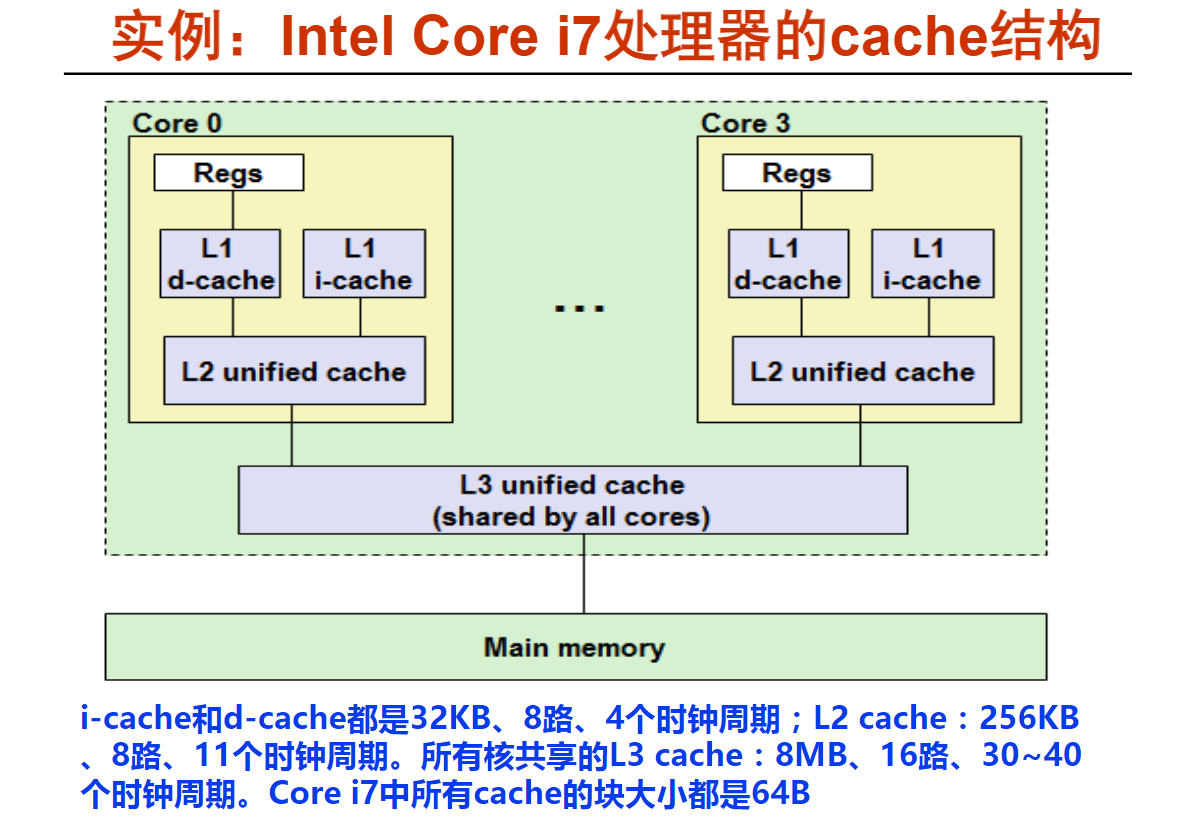
第5讲 Cache综合计算举例(12m49s)

(1)只算数据Cache


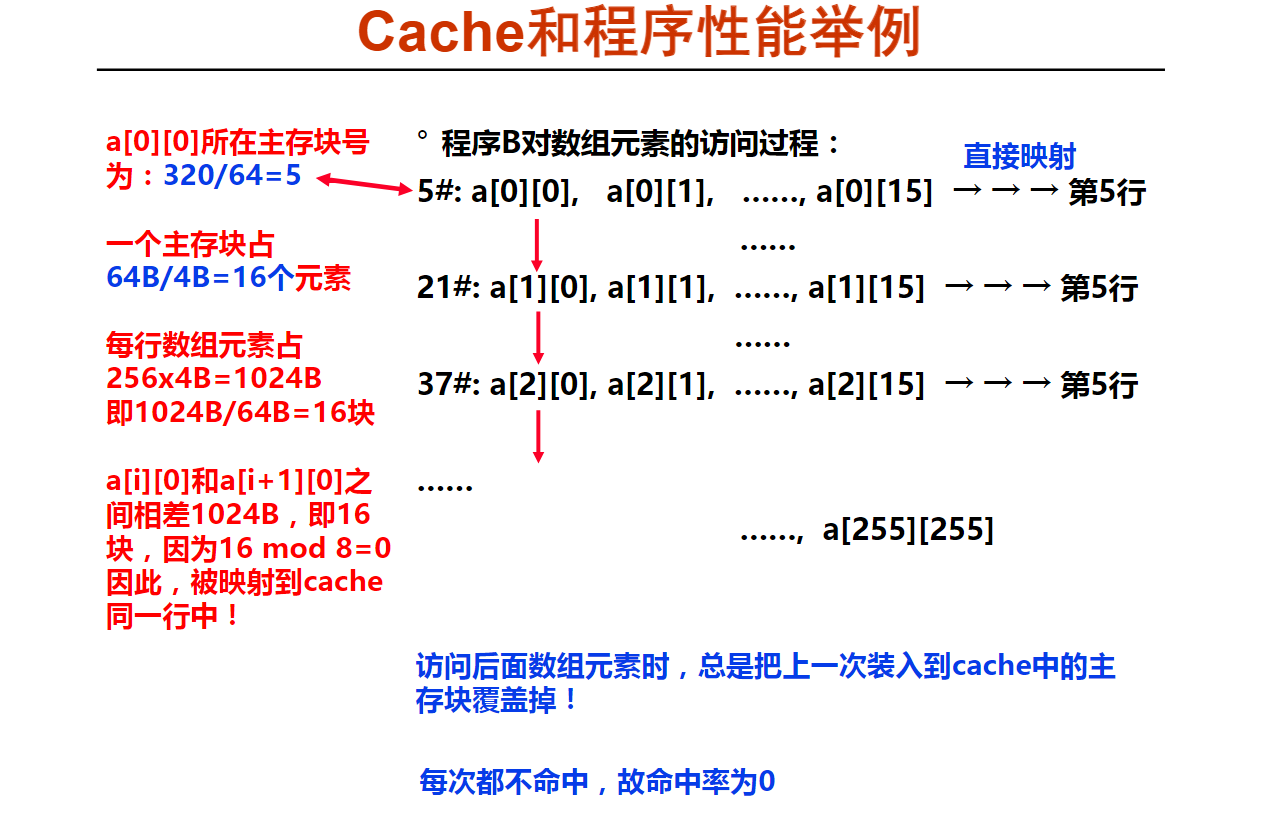
第五周小测验
错题序号:4、9
1以下关于cache替换算法的叙述中,错误的是( C )。
A.组相联和全相联映射都必须考虑如何进行替换
B.LRU算法需要对每个cache行记录替换信息,即LRU位
C.先进先出算法无需对每个cache行记录替换信息
D.直接映射方式是多对一映射,无需考虑替换问题
解析: C、先进先出算法需要对每个cache行打一个时间戳,记录何时装入了一个新的主存块。
2以下关于LRU替换算法的叙述中,错误的是(B )。
A.是一种栈算法,其命中率随组的增大而提高
B.全相联映射方式特别适合采用LRU替换算法
C.基于cache行有多久没有被访问来进行替换
D.LRU是Least-Recently Used的缩写,表示最近最少用
解析: B、LRU替换算法需要为每个cache行设置一个计数器,用于记录对应行的使用情况。计数器的位数与组的大小有关,例如,对于2-路组相联,每组有两个cache行,计数器为1位;对于4-路组相联,计数器为2位。对于全相联,则组的大小等于cache行数,因而计数器的位数等于cache行号的位数,这样,不仅计数器所占容量开销大,而且对计数器进行修改的时间开销也大。因而LRU算法不适合应用于全相联映射方式。
3以下关于写策略的叙述中,错误的是( A )。
A.只有在写命中时才需考虑写策略问题,在写不命中时无需考虑
B.对于写命中,有直写(Write Through)和回写(Write Back)两种写策略
C.多个带cache的CPU共享主存时会出现写策略问题
D.写策略问题也是cache一致性问题
解析: A、写命中指要写的单元已经在cache中,写不命中指要写的单元不在cache中。不管是写命中还是写不命中,都需要考虑写策略问题。在写命中时,可以采用直写(Write Through)或回写(Write Back)方式。前者在写cache的同时也写主存;后者仅写cache,在被替换出去时再将整个主存块写入主存。在写不命中时,可以采用写分配方式,把主存块装入cache,然后采用写命中时的直写或回写策略进行处理,也可以采用非写分配(Not Write Allocate)方式,直接写主存而不写cache。
4以下关于直写(Write Through)策略的叙述中,错误的是(C )。
A.通常在cache和主存之间设置写缓冲,以加快写操作速度
B.在写不命中时,若采用非写分配(Not Write Allocate)方式,则只能用直写替换策略
C.通常在cache行中加“dirty bit”,以标识对应行是否被修改过
D.每次写操作都会写cache中的内容和在主存中的副本
解析: C、因为直写(Write Through)策略会同时写cache和主存,因此,总能保持cache和主存的一致性,无需用“dirty bit”来标识cache行是否被修改。而回写(Write Back)策略仅写cache,在被替换出去时,需要根据dirty bit是否为1,以了解cache行中的主存块是否被修改,若被修改,则说明发生了cache和主存的不一致,需要将整个主存块写入主存。
5假定主存地址位数为32位,按字节编址,主存和cache之间采用直接映射方式,主存块大小为1个字,每字32位,写操作时采用直写(Write Through)方式,则能存放32K字数据的cache的总容量至少应有( A )位。
A.1536K
B.1568K
C.1600K
D.1504K
解析: A、cache共有32K字/1字=32K行,故行号占15位;每个主存块为1字=32位=4B,故块内地址占2位。因此,标志占32-15-2=15位。直接映射方式无需考虑替换算法,故没有替换信息;直写方式无需修改位(dirty bit)。因而cache总容量为32K×(1+15+32)=1536K位。
6假定主存地址位数为32位,按字节编址,主存和cache之间采用直接映射方式,主存块大小为1个字,每字32位,写操作时采用回写(Write Back)方式,则能存放32K字数据的cache的总容量至少应有( D )位。
A.1536K
B.1600K
C.1504K
D.1568K
解析: D、cache共有32K字/1字=32K行,故行号占15位;每个主存块为1字=32位=4B,故块内地址占2位。因此,标志占32-15-2=15位。直接映射方式无需考虑替换算法,故没有替换信息;回写(Write Back)方式需1位修改位(dirty bit)。因而cache总容量为32K×(1+15+1+32)=1568K位。
7假定主存地址位数为32位,按字节编址,主存和cache之间采用全相联映射方式,主存块大小为4个字,每字32位,采用回写(Write Back)方式和随机替换策略,则能存放32K字数据的cache的总容量至少应有( A )位。
A.1264K
B.1256K
C.5024K
D.5056K
解析: A、cache共有32K字/4字=8K行,每个主存块为4字=4×32位=16B,故块内地址占4位。因此,全相联映射方式下,标志占32-4=28位。随机替换算法没有替换信息;回写(Write Back)方式需1位修改位(dirty bit)。因而cache总容量为8K×(1+28+1+4×32)=1264K位。
8假定主存地址位数为32位,按字节编址,主存和cache之间采用4-路组相联映射方式,主存块大小为4个字,每字32位,采用直写(Write Through)方式和LRU替换策略,则能存放32K字数据的cache的总容量至少应有(D )位。
A.1168K
B.4736K
C.4672K
D.1184K
解析: D、cache共有32K字/4字=8K行,因为采用4-路组相联,因而共有8K/4=2K组,组号占11位;每个主存块为4字=4×32位=16B,故块内地址占4位。因此,标志占32-11-4=17位。4路组相联方式下,LRU替换算法需要每行有2位LRU位;直写(Write Through)方式无需修改位(dirty bit)。因而cache总容量为8K×(1+17+2+4×32)=1184K位。
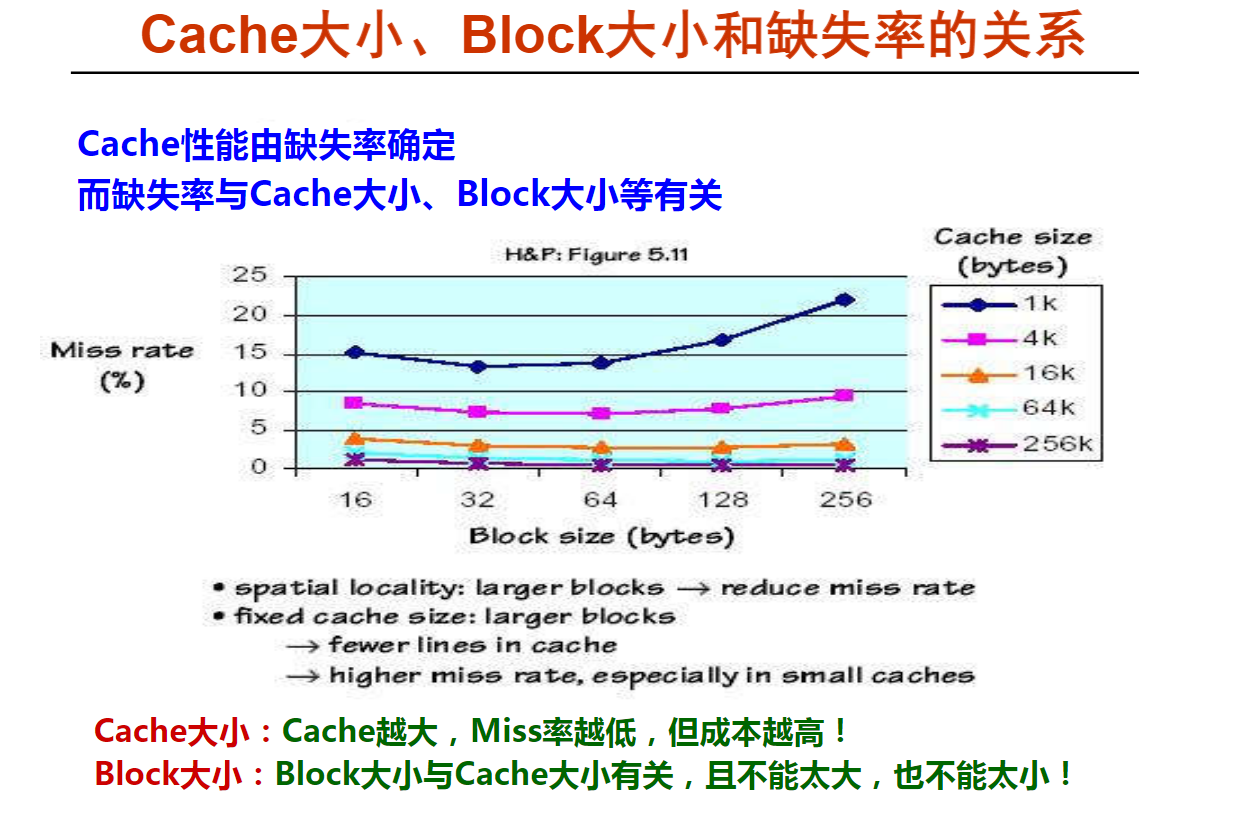
9以下关于cache大小、主存块大小和cache缺失率之间关系的叙述中,错误的是( C )。
A.cache容量越大,cache缺失率越低
B.主存块大小通常为几十到上百个字节
C.主存块越大,cache缺失率越低
D.主存块大小和cache容量无密切关系
解析: C、主存块太小,则不能很好地利用空间局部性,从而导致缺失率变高,但是,主存块太大,也会使得cache行数变少,即cache中可以存放主存块的位置变少,从而降低命中率。因此,主存块不可以太小,也不可以太大,通常为几十到上百个字节。
10某32位机按字节编址。数据cache有16行,主存块大小为64B,采用2-路组相联映射。对于以下程序A,假定编译时i, j, sum均分配在寄存器中,数组a按行优先方式存放,其首址为3200,则a[1][0]所映射的cache组号、程序A的数据cache命中率各是( C )。
short a[256][256];
……
short sum_array()
{
int i, j;
short sum=0;
for (i=0; i < 256; i++)
for (j=0; j < 256; j++)
sum+=a[i][j];
return sum;
}
A.4,31/32
B.4,15/16
C.2,31/32
D.2,15/16
解析: C、a[1][0]所映射的cache组号为[(3200+(1×256+0)×2)/64] mod (16/2) = 2。
程序A的数据cache命中率分析如下:a[0][0]位于主存第3200/64=50块的起始处,按照数组访问顺序a[0][0]、a[0][1]、……、a[0][255]、a[1][0]、a[1][1]、……、a[1][255]、……,总是每64B/2B=32个数组元素组成一个主存块,被轮流装入数据cache的第2、3、……、7、0、1、…….、7、0、……. 组内的cache行中,因而这每一块的32个数组元素中,总是第一次不命中,以后每次都命中,因而命中率为31/32。