线性回归——正则方程法求解
假设数据集为: 其中
考虑截距的话,则,此时X、W和Y的表达式如下:
方便起见,后面我们记: 对每一个样本数据,作出如下的线性回归假设:
Least squares revisited
Armed with the tools of matrix derivatives, let us now proceed to find in closed-form the value of θ that minimizes J(θ). We begin by re-writing J in matrix-vectorial notation.
Given a training set, define the design matrix X to be the n-by-d matrix (actually n-by-d + 1, if we include the intercept term) that contains the training examples’ input values in its rows:
Also, let be the -dimensional vector containing all the target values from the training set:
Now, since we can easily verify that
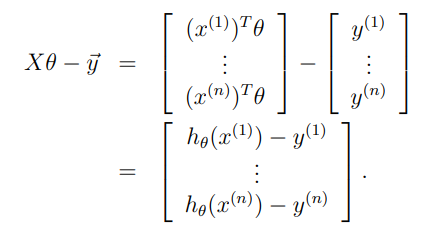
Thus, using the fact that for a vector we have that
Finally, to minimize let's find its derivatives with respect to . Hence,
In the third step, we used the fact that , and in the fifth step used the facts and for symmetric matrix (fon more details, see Section 4.3 of “Linear Algebra Review and Reference”). To minimize we set its derivatives to zero, and obtain the normal equations:
Thus, the value of that minimizes is given in closed form by the equation
最小二乘法
对这个问题,采用二范数定义的平方误差来定义损失函数: 展开得到: 最小化这个值的 : 这个式子中 又被称为伪逆。对于行满秩或者列满秩的 ,可以直接求解,但是对于非满秩的样本集合,需要使用奇异值分解(SVD)的方法,对 求奇异值分解,得到 于是: 在几何上,最小二乘法相当于模型(这里就是直线)和试验值的距离的平方求和,假设我们的试验样本张成一个 维空间(满秩的情况):,而模型可以写成 ,也就是 的某种组合,而最小二乘法就是说希望 和这个模型距离越小越好,于是它们的差应该与这个张成的空间垂直:
噪声为高斯分布的 MLE
对于一维的情况,记 ,那么 。代入极大似然估计中: 这个表达式和最小二乘估计得到的结果一样。
权重先验也为高斯分布的 MAP
取先验分布 。于是: 这里省略了 ,和 没有关系,同时也利用了上面高斯分布的 MLE的结果。
我们将会看到,超参数 的存在和下面会介绍的 Ridge 正则项可以对应,同样的如果将先验分布取为 Laplace 分布,那么就会得到和 L1 正则类似的结果。