支持向量机
支持向量机概览
支撑向量机(SVM)算法在分类问题中有着重要地位,其主要思想是最大化两类之间的间隔。按照数据集的特点:
- 线性可分问题,如之前的感知机算法处理的问题
- 线性可分,只有一点点错误点,如感知机算法发展出来的 Pocket 算法处理的问题
- 非线性问题,完全不可分,如在感知机问题发展出来的多层感知机和深度学习
这三种情况对于 SVM 分别有下面三种处理手段:
- hard-margin SVM
- soft-margin SVM
- kernel Method
L2范数的平方:
若,则
SVM 的求解中,大量用到了 Lagrange 乘子法,首先对这种方法进行介绍。
约束优化问题

一般地,约束优化问题(原问题)可以写成: 定义 Lagrange 函数: 那么原问题可以等价于无约束形式: 这是由于,当满足原问题的不等式约束的时候, 才能取得最大值,直接等价于原问题,如果不满足原问题的不等式约束,那么最大值就为 ,由于需要取最小值,于是不会取到这个情况。
这个问题的对偶形式: 对偶问题是关于 的最大化问题。
由于:
证明:显然有 ,于是显然有 ,且 。
对偶问题的解小于原问题,有两种情况:
- 强对偶:可以取等于号
- 弱对偶:不可以取等于号
其实这一点也可以通过一张图来说明:
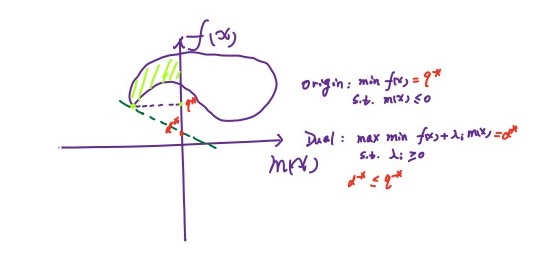
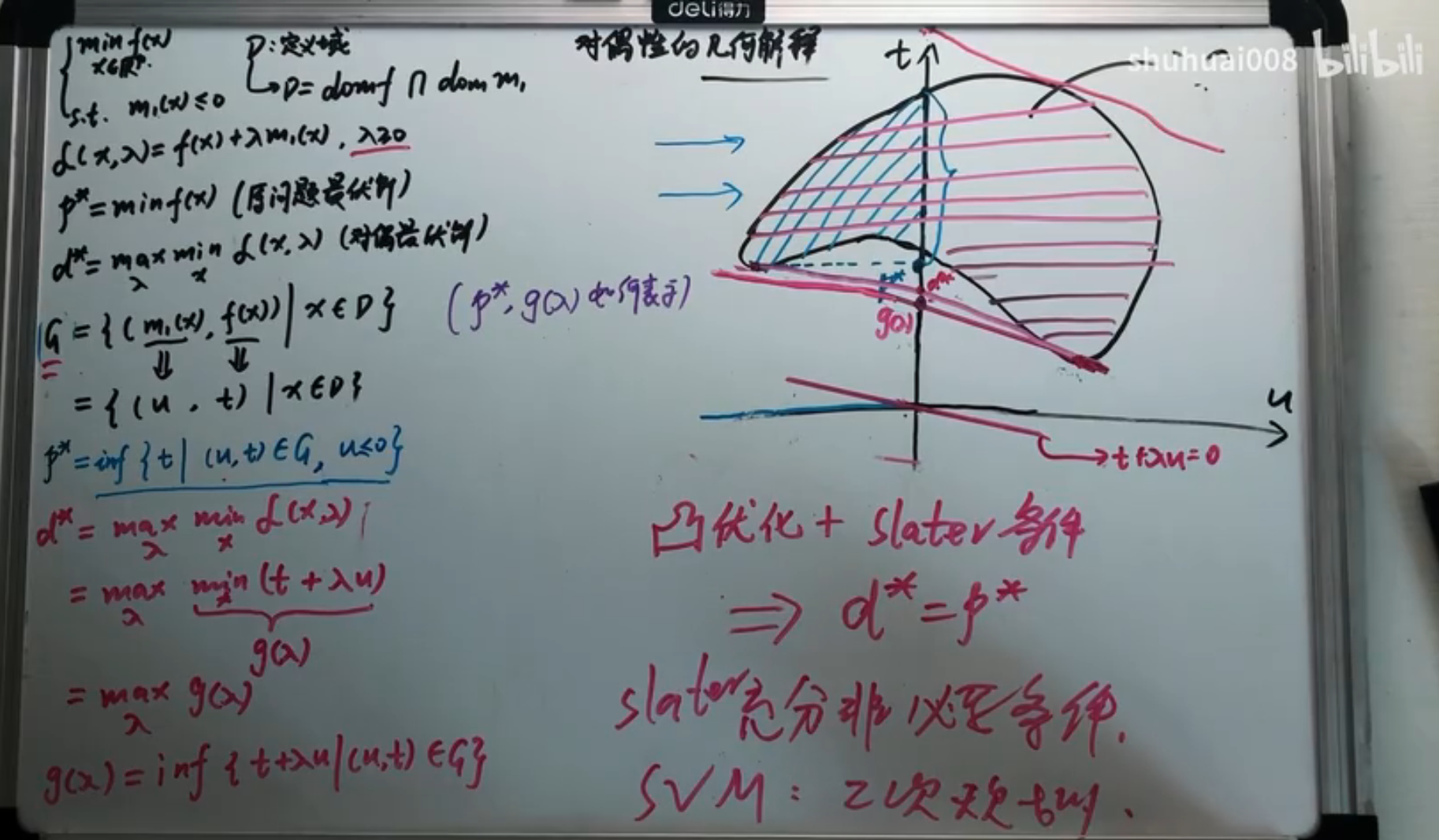
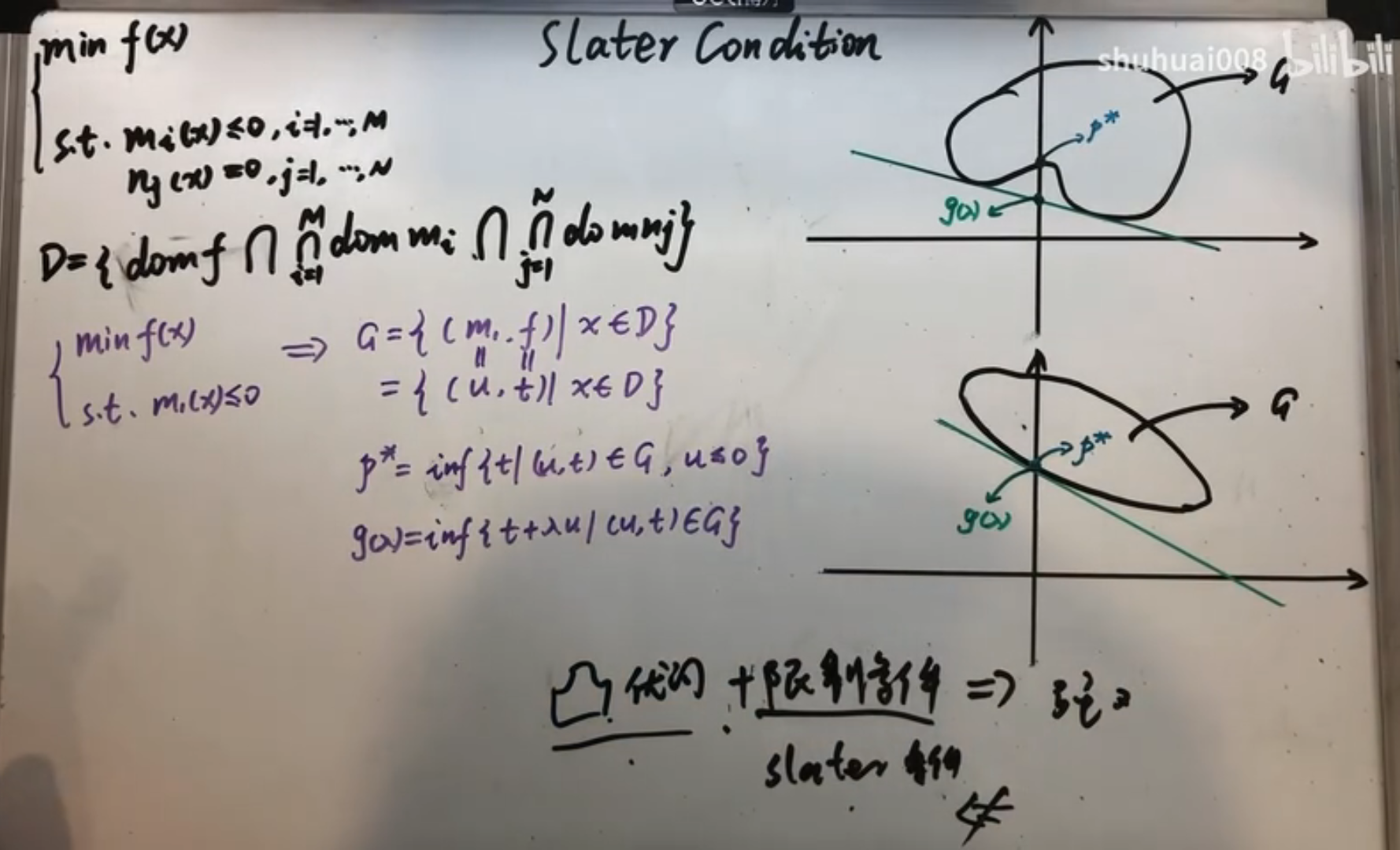

对于一个凸优化问题,有如下定理:
如果凸优化问题满足某些条件如 Slater 条件,那么它和其对偶问题满足强对偶关系。记问题的定义域为:。于是 Slater 条件为: 其中 Relint 表示相对内部(不包含边界的内部)。
- 对于大多数凸优化问题,Slater 条件成立。
- 松弛 Slater 条件,如果 M 个不等式约束中,有 K 个函数为仿射函数,那么只要其余的函数满足 Slater 条件即可。

上面介绍了原问题和对偶问题的对偶关系,但是实际还需要对参数进行求解,求解方法使用 KKT 条件进行:
KKT 条件和强对偶关系是等价关系。KKT 条件对最优解的条件为:
可行域:
互补松弛 ,对偶问题的最佳值为 ,原问题为 为了满足相等,两个不等式必须成立,于是,对于第一个不等于号,需要有梯度为0条件,对于第二个不等于号需要满足互补松弛条件。
梯度为0:
Hard-margin SVM

支撑向量机也是一种硬分类模型,在之前的感知机模型中,我们在线性模型的基础上叠加了符号函数,在几何直观上,可以看到,如果两类分的很开的话,那么其实会存在无穷多条线可以将两类分开。在 SVM 中,我们引入最大化间隔这个概念,间隔指的是数据和直线的距离的最小值,因此最大化这个值反映了我们的模型倾向。
分割的超平面可以写为: 那么最大化间隔(约束为分类任务的要求): 对于这个约束 ,不妨固定 ,这是由于分开两类的超平面的系数经过比例放缩不会改变这个平面,这也相当于给超平面的系数作出了约束。化简后的式子可以表示为: 这就是一个包含 个约束的凸优化问题,有很多求解这种问题的软件。
但是,如果样本数量或维度非常高,直接求解困难甚至不可解,于是需要对这个问题进一步处理。引入 Lagrange 函数: 我们有原问题就等价于: 我们交换最小和最大值的符号得到对偶问题:


由于不等式约束是仿射函数,对偶问题和原问题等价:
-
:
-
:首先将 代入: 所以:
-
将上面两个参数代入:
因此,对偶问题就是:

从 KKT 条件得到超平面的参数:
原问题和对偶问题满足强对偶关系的充要条件为其满足 KKT 条件:
根据这个条件就得到了对应的最佳参数: 于是这个超平面的参数 就是数据点的线性组合,最终的参数值就是部分满足 向量的线性组合(互补松弛条件给出),这些向量也叫支撑向量。
Soft-margin SVM

Hard-margin 的 SVM 只对可分数据可解,如果不可分的情况,我们的基本想法是在损失函数中加入错误分类的可能性。错误分类的个数可以写成: 这个函数不连续,可以将其改写为: 求和符号中的式子又叫做 Hinge Function。
将这个错误加入 Hard-margin SVM 中,于是: 这个式子中,常数 可以看作允许的错误水平,同时上式为了进一步消除 符号,对数据集中的每一个观测,我们可以认为其大部分满足约束,但是其中部分违反约束,因此这部分约束变成 ,其中 ,进一步的化简:
Kernel Method

核方法可以应用在很多问题上,在分类问题中,对于严格不可分问题,我们引入一个特征转换函数将原来的不可分的数据集变为可分的数据集,然后再来应用已有的模型。往往将低维空间的数据集变为高维空间的数据集后,数据会变得可分(数据变得更为稀疏):
Cover theorem:高维空间比低维空间更易线性可分。
应用在 SVM 中时,观察上面的 SVM 对偶问题: 在求解的时候需要求得内积,于是不可分数据在通过特征变换后,需要求得变换后的内积。我们常常很难求得变换函数的内积。于是直接引入内积的变换函数: 称 为一个正定核函数,其中 是 Hilbert 空间(完备的线性内积空间),如果去掉内积这个条件我们简单地称为核函数。
是一个核函数。
证明:


正定核函数有下面的等价定义:
如果核函数满足:
- 对称性
- 正定性(非负性)
那么这个核函数是正定核函数。
证明:
- 对称性 ,显然满足内积的定义
- 正定性 ,对应的 Gram Matrix 是半正定的。
要证: 半正定+对称性。
:首先,对称性是显然的,对于正定性: 任意取 ,即需要证明 : 这个式子就是内积的形式,Hilbert 空间满足线性性,于是正定性的证。
:对于 进行分解,对于对称矩阵 ,那么令 ,其中 是特征向量,于是就构造了
小结
分类问题在很长一段时间都依赖 SVM,对于严格可分的数据集,Hard-margin SVM 选定一个超平面,保证所有数据到这个超平面的距离最大,对这个平面施加约束,固定 ,得到了一个凸优化问题并且所有的约束条件都是仿射函数,于是满足 Slater 条件,将这个问题变换成为对偶的问题,可以得到等价的解,并求出约束参数: 对需要的超平面参数的求解采用强对偶问题的 KKT 条件进行。 解就是: 当允许一点错误的时候,可以在 Hard-margin SVM 中加入错误项。用 Hinge Function 表示错误项的大小,得到: 对于完全不可分的问题,我们采用特征转换的方式,在 SVM 中,我们引入正定核函数来直接对内积进行变换,只要这个变换满足对称性和正定性,那么就可以用做核函数。
SVM实战
支持向量机(Support Vector Machine, SVM)是最受欢迎的机器学习模型之一。它特别适合处理中小型复杂数据集的分类任务。
一、什么是支持向量机
SMV在众多实例中寻找一个最优的决策边界,这个边界上的实例叫做支持向量,它们“支持”(支撑)分离开超平面,所以它叫支持向量机。
那么我们如何保证我们得到的决策边界是最优的呢?
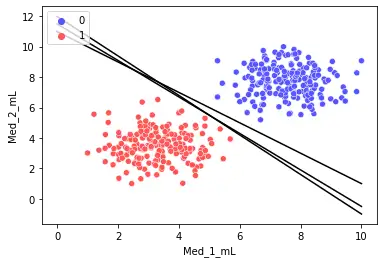
如上图,三条黑色直线都可以完美分割数据集。由此可知,我们仅用单一直线可以得到无数个解。那么,其中怎样的直线是最优的呢?
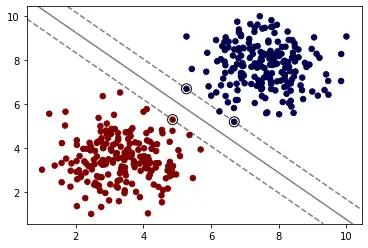
如上图,我们计算直线到分割实例的距离,使得我们的直线与数据集的距离尽可能的远,那么我们就可以得到唯一的解。最大化上图虚线之间的距离就是我们的目标。而上图中重点圈出的实例就叫做支持向量。
这就是支持向量机。
二、观察数据
添加引用:
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
导入数据集(大家不用在意这个域名):
df = pd.read_csv('https://blog.caiyongji.com/assets/mouse_viral_study.csv')
df.head()
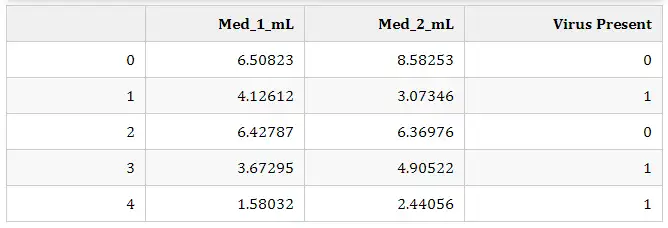
该数据集模拟了一项医学研究,对感染病毒的小白鼠使用不同剂量的两种药物,观察两周后小白鼠是否感染病毒。
- 特征: 1. 药物Med_1_mL 药物Med_2_mL
- 标签:是否感染病毒(1感染/0不感染)
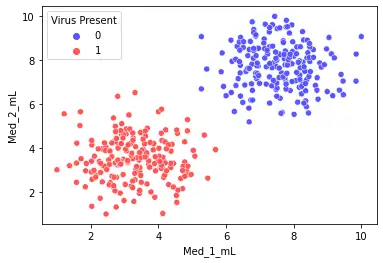
sns.scatterplot(x='Med_1_mL',y='Med_2_mL',hue='Virus Present',data=df)
我们用seaborn绘制两种药物在不同剂量特征对应感染结果的散点图。
sns.pairplot(df,hue='Virus Present')
我们通过pairplot方法绘制特征两两之间的对应关系。
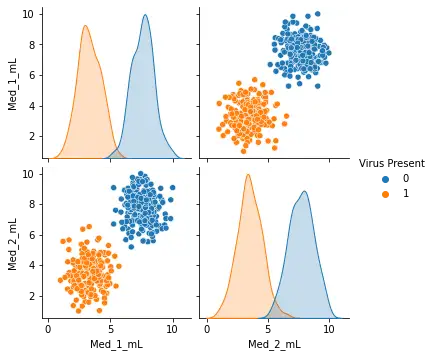
我们可以做出大概的判断,当加大药物剂量可使小白鼠避免被感染。
使用SVM训练数据集
#SVC: Supprt Vector Classifier支持向量分类器
from sklearn.svm import SVC
#准备数据
y = df['Virus Present']
X = df.drop('Virus Present',axis=1)
#定义模型
model = SVC(kernel='linear', C=1000)
#训练模型
model.fit(X, y)
# 绘制图像
# 定义绘制SVM边界方法
def plot_svm_boundary(model,X,y):
X = X.values
y = y.values
# Scatter Plot
plt.scatter(X[:, 0], X[:, 1], c=y, s=30,cmap='coolwarm')
# plot the decision function
ax = plt.gca()
xlim = ax.get_xlim()
ylim = ax.get_ylim()
# create grid to evaluate model
xx = np.linspace(xlim[0], xlim[1], 30)
yy = np.linspace(ylim[0], ylim[1], 30)
YY, XX = np.meshgrid(yy, xx)
xy = np.vstack([XX.ravel(), YY.ravel()]).T
Z = model.decision_function(xy).reshape(XX.shape)
# plot decision boundary and margins
ax.contour(XX, YY, Z, colors='k', levels=[-1, 0, 1], alpha=0.5,
linestyles=['--', '-', '--'])
# plot support vectors
ax.scatter(model.support_vectors_[:, 0], model.support_vectors_[:, 1], s=100,
linewidth=1, facecolors='none', edgecolors='k')
plt.show()
plot_svm_boundary(model,X,y)
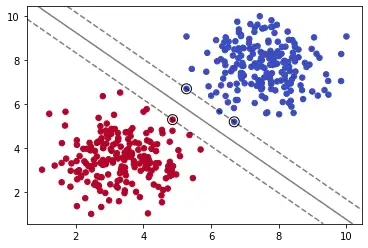 注:这里会报UserWarning: X does not have valid feature names, but SVC was fitted with feature names
注:这里会报UserWarning: X does not have valid feature names, but SVC was fitted with feature names
warnings.warn(
我们导入sklearn下的SVC(Supprt Vector Classifier)分类器,它是SVM的一种实现。
其实在工具 sklearn 中,已经封装了多种 SVM 模型,这里我们重点介绍下 SVC,该模型既可以训练线性可分的数据,也可以训练线性不可分数据。
SVC相关参数
| 参数名 | 含义 |
|---|---|
| C | 惩罚系数,默认为1.0。当 C 越大时,分类器的准确性越高,但是泛化能力越低。反之,泛化能力强,但是准确性会降低。 |
| kernel | 核函数类型,默认为 rbf。主要的核函数类型如下: liner:线性核函数,在数据为线性可分的情况下使用 poly:多项式核函数,可以将数据从低维空间映射到高维空间,但是参数较多,计算量大 rbf:高斯核函数,同样可以将数据从低维空间映射到高维空间,相比 poly,参数较少,通用性较好 sigmoid:当使用 sigmoid 核函数时,SVM 实现的是一个多层神经网络 |
| gamma | 核函数系数,默认为样本特征数的倒数,即 gamma = 1/ n_features |
| max_iter | 最大迭代次数,默认为-1,不做限制 |
| class_weight | 类别权重,dict 类型或 str 类型,可选参数,默认为 None。如果给定参数'balance',则使用 y 的值自动调整为与输入数据中的类频率成反比的权重。 |
SVC参数C
SVC方法参数C代表L2正则化参数,正则化的强度与C的值成反比,即C值越大正则化强度越弱,其必须严格为正。
model = SVC(kernel='linear', C=0.05)
model.fit(X, y)
plot_svm_boundary(model,X,y)
我们减少C的值,可以看到模型拟合数据的程度减弱。
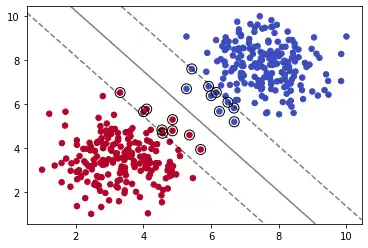
核技巧
SVC方法的kernel参数可取值{'linear', 'poly', 'rbf', 'sigmoid', 'precomputed'}。像前文中所使用的那样,我们可以使kernel='linear'进行线性分类。那么如果我们像进行非线性分类呢?
多项式内核
多项式内核kernel='poly'的原理简单来说就是,用单一特征生成多特征来拟合曲线。比如我们拓展X到y的对应关系如下:
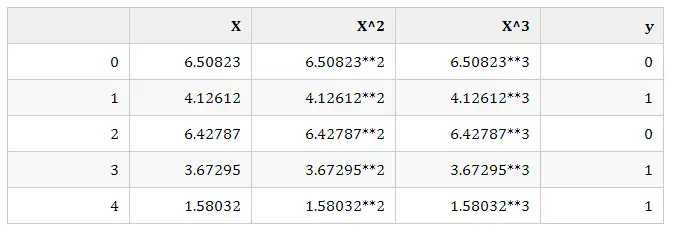
这样我们就可以用曲线来拟合数据集。
model = SVC(kernel='poly', C=0.05,degree=5)
model.fit(X, y)
plot_svm_boundary(model,X,y)
我们使用多项式内核,并通过degree=5设置多项式的最高次数为5。我们可以看出分割出现了一定的弧度。
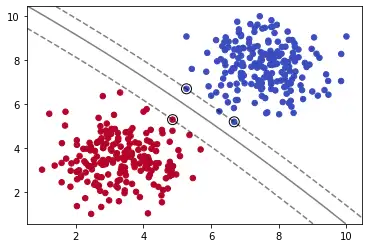
高斯RBF内核
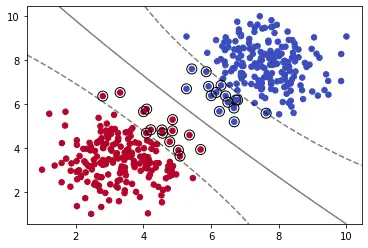
SVC方法默认内核为高斯RBF,即Radial Basis Function(径向基函数)。这时我们需要引入gamma参数来控制钟形函数的形状。增加gamma值会使钟形曲线变得更窄,因此每个实例影响的范围变小,决策边界更不规则。减小gamma值会使钟形曲线变得更宽,因此每个实例的影响范围变大,决策边界更平坦。
model = SVC(kernel='rbf', C=1,gamma=0.01)
model.fit(X, y)
plot_svm_boundary(model,X,y)
调参技巧:网格搜索
from sklearn.model_selection import GridSearchCV
svm = SVC()
param_grid = {'C':[0.01,0.1,1],'kernel':['rbf','poly','linear','sigmoid'],'gamma':[0.01,0.1,1]}
grid = GridSearchCV(svm,param_grid)
grid.fit(X,y)
print("grid.best_params_ = ",grid.best_params_,", grid.best_score_ =" ,grid.best_score_)
我们可以通过GridSearchCV方法来遍历超参数的各种可能性来寻求最优超参数。这是通过算力碾压的方式暴力调参的手段。当然,在分析问题阶段,我们必须限定了各参数的可选范围才能应用此方法。
因为数据集太简单,我们在遍历第一种可能性时就已经得到100%的准确率了,输出如下:
grid.best_params_ = {'C': 0.01, 'gamma': 0.01, 'kernel': 'rbf'} , grid.best_score_ = 1.0
总结
当我们处理线性可分的数据集时,可以使用SVC(kernel='linear')方法来训练数据,当然我们也可以使用更快的方法LinearSVC来训练数据,特别是当训练集特别大或特征非常多的时候。
当我们处理非线性SVM分类时,可以使用高斯RBF内核,多项式内核,sigmoid内核来进行非线性模型的的拟合。当然我们也可以通过GridSearchCV寻找最优参数。