编辑距离
- 392. Is Subsequence
- 115. Distinct Subsequences
- 583. Delete Operation for Two Strings
- 72. Edit Distance
392. Is Subsequence
Given two strings s and t, return true if s is a subsequence of t, or false otherwise.
A subsequence of a string is a new string that is formed from the original string by deleting some (can be none) of the characters without disturbing the relative positions of the remaining characters. (i.e., "ace" is a subsequence of "abcde" while "aec" is not).
Example 1:
Input: s = "abc", t = "ahbgdc"
Output: true
Example 2:
Input: s = "axc", t = "ahbgdc"
Output: false
Constraints:
0 <= s.length <= 1000 <= t.length <= 10^4sandtconsist only of lowercase English letters.
Follow up: Suppose there are lots of incoming s, say s1, s2, ..., sk where k >= 109, and you want to check one by one to see if t has its subsequence. In this scenario, how would you change your code?
思路
(这道题也可以用双指针的思路来实现,时间复杂度也是O(n))
这道题应该算是编辑距离的入门题目,因为从题意中我们也可以发现,只需要计算删除的情况,不用考虑增加和替换的情况。
所以掌握本题的动态规划解法是对后面要讲解的编辑距离的题目打下基础。
动态规划五部曲分析如下:
- 确定dp数组(dp table)以及下标的含义
dp[i][j] 表示以下标i-1为结尾的字符串s,和以下标j-1为结尾的字符串t,相同子序列的长度为dp[i][j]。
注意这里是判断s是否为t的子序列。即t的长度是大于等于s的。
有同学问了,为啥要表示下标i-1为结尾的字符串呢,为啥不表示下标i为结尾的字符串呢?
为什么这么定义我在 718. 最长重复子数组 中做了详细的讲解。
其实用i来表示也可以!
但我统一以下标i-1为结尾的字符串来计算,这样在下面的递归公式中会容易理解一些,如果还有疑惑,可以继续往下看。
- 确定递推公式
在确定递推公式的时候,首先要考虑如下两种操作,整理如下:
-
if (s[i - 1] == t[j - 1])
- t中找到了一个字符在s中也出现了
-
if (s[i - 1] != t[j - 1])
- 相当于t要删除元素,继续匹配
if(s[i - 1] == t[j - 1]),那么dp[i][j] = dp[i - 1][j - 1] + 1;,因为找到了一个相同的字符,相同子序列长度自然要在dp[i-1][j-1]的基础上加1(如果不理解,在回看一下dp[i][j]的定义)
if(s[i - 1] != t[j - 1]),此时相当于t要删除元素,t如果把当前元素t[j - 1]删除,那么dp[i][j] 的数值就是 看s[i - 1]与 t[j - 2]的比较结果了,即:dp[i][j] = dp[i][j - 1];
其实这里大家可以发现和 1143.最长公共子序列 的递推公式基本那就是一样的,区别就是本题如果删元素一定是字符串t,而 1143.最长公共子序列是两个字符串都可以删元素。
- dp数组如何初始化
从递推公式可以看出dp[i][j]都是依赖于dp[i - 1][j - 1] 和 dp[i][j - 1],所以dp[0][j]和dp[i][0]是一定要初始化的。
这里大家已经可以发现,在定义dp[i][j]含义的时候为什么要表示以下标i-1为结尾的字符串s,和以下标j-1为结尾的字符串t,相同子序列的长度为dp[i][j]。
因为这样的定义在dp二维矩阵中可以留出初始化的区间,如图:
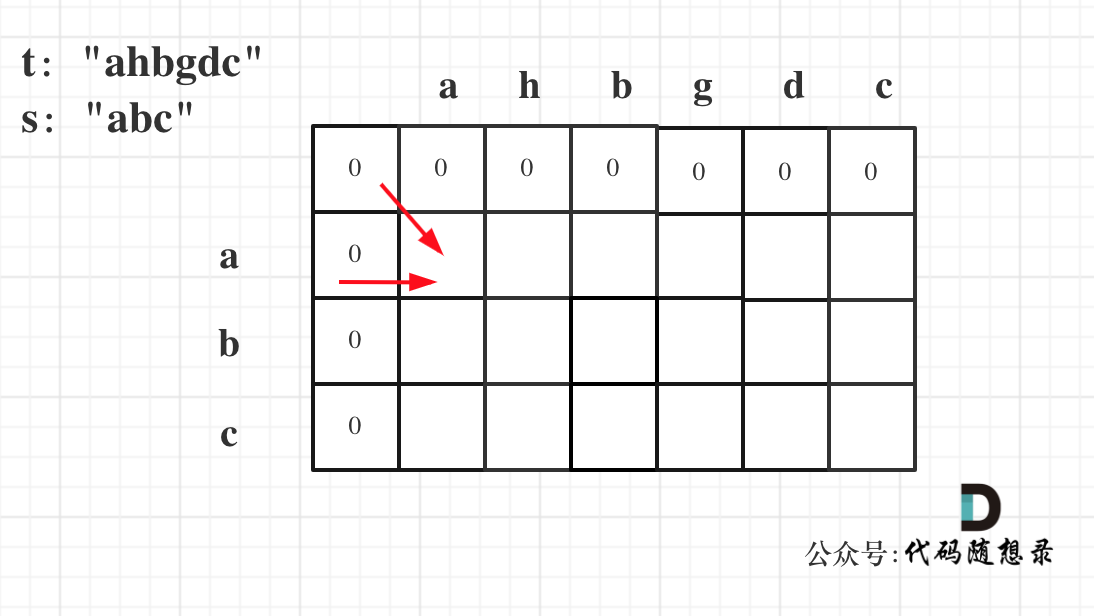
如果要是定义的dp[i][j]是以下标i为结尾的字符串s和以下标j为结尾的字符串t,初始化就比较麻烦了。
dp[i][j] 表示以下标i-1为结尾的字符串,与空字符串的相同子序列长度,所以为0. dp[0][j]同理。
vector<vector<int>> dp(s.size() + 1, vector<int>(t.size() + 1, 0));
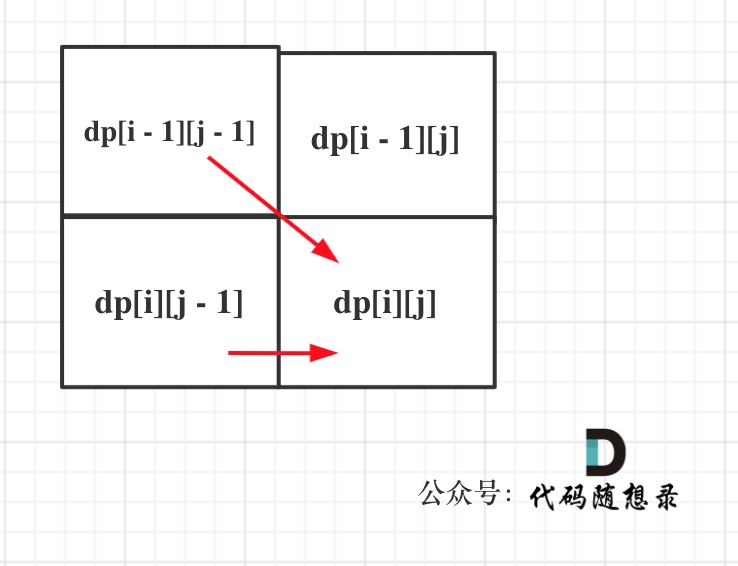
- 确定遍历顺序
同理从递推公式可以看出dp[i][j]都是依赖于dp[i - 1][j - 1] 和 dp[i][j - 1],那么遍历顺序也应该是从上到下,从左到右
如图所示:
- 举例推导dp数组
以示例一为例,输入:s = "abc", t = "ahbgdc",dp状态转移图如下:
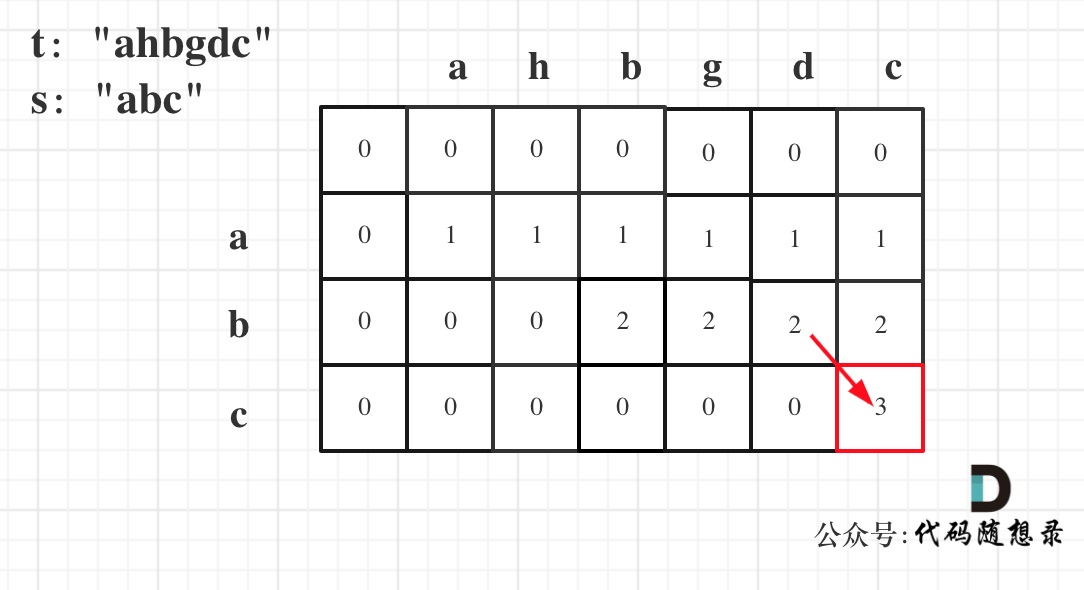
dp[i][j]表示以下标i-1为结尾的字符串s和以下标j-1为结尾的字符串t 相同子序列的长度,所以如果dp[s.size()][t.size()] 与 字符串s的长度相同说明:s与t的最长相同子序列就是s,那么s 就是 t 的子序列。
图中dp[s.size()][t.size()]=3, 而s.size() 也为3。所以s是t 的子序列,返回true。
C++解法
动规五部曲分析完毕,C++代码如下:
class Solution {
public:
bool isSubsequence(string s, string t) {
vector<vector<int>> dp(s.size() + 1, vector<int>(t.size() + 1, 0));
for (int i = 1; i <= s.size(); i++) {
for (int j = 1; j <= t.size(); j++) {
if (s[i - 1] == t[j - 1]) dp[i][j] = dp[i - 1][j - 1] + 1;
else dp[i][j] = dp[i][j - 1];
}
}
if (dp[s.size()][t.size()] == s.size()) return true;
return false;
}
};
- 时间复杂度:O(n × m)
- 空间复杂度:O(n × m)
Java解法
class Solution {
public boolean isSubsequence(String s, String t) {
int length1 = s.length(); int length2 = t.length();
int[][] dp = new int[length1+1][length2+1];
for(int i = 1; i <= length1; i++){
for(int j = 1; j <= length2; j++){
if(s.charAt(i-1) == t.charAt(j-1)){
dp[i][j] = dp[i-1][j-1] + 1;
}else{
dp[i][j] = dp[i][j-1];
}
}
}
if(dp[length1][length2] == length1){
return true;
}else{
return false;
}
}
}
> 修改遍历顺序后,可以利用滚动数组,对dp数组进行压缩
class Solution {
public boolean isSubsequence(String s, String t) {
// 修改遍历顺序,外圈遍历t,内圈遍历s。使得dp的推算只依赖正上方和左上方,方便压缩。
int[][] dp = new int[t.length() + 1][s.length() + 1];
for (int i = 1; i < dp.length; i++) { // 遍历t字符串
for (int j = 1; j < dp[i].length; j++) { // 遍历s字符串
if (t.charAt(i - 1) == s.charAt(j - 1)) {
dp[i][j] = dp[i - 1][j - 1] + 1;
} else {
dp[i][j] = dp[i - 1][j];
}
}
System.out.println(Arrays.toString(dp[i]));
}
return dp[t.length()][s.length()] == s.length();
}
}
> 状态压缩
class Solution {
public boolean isSubsequence(String s, String t) {
int[] dp = new int[s.length() + 1];
for (int i = 0; i < t.length(); i ++) {
// 需要使用上一轮的dp[j - 1],所以使用倒序遍历
for (int j = dp.length - 1; j > 0; j --) {
// i遍历的是t字符串,j遍历的是dp数组,dp数组的长度比s的大1,因此需要减1。
if (t.charAt(i) == s.charAt(j - 1)) {
dp[j] = dp[j - 1] + 1;
}
}
}
return dp[s.length()] == s.length();
}
}
> 将dp定义为boolean类型,dp[i]直接表示s.substring(0, i)是否为t的子序列
class Solution {
public boolean isSubsequence(String s, String t) {
boolean[] dp = new boolean[s.length() + 1];
// 表示 “” 是t的子序列
dp[0] = true;
for (int i = 0; i < t.length(); i ++) {
for (int j = dp.length - 1; j > 0; j --) {
if (t.charAt(i) == s.charAt(j - 1)) {
dp[j] = dp[j - 1];
}
}
}
return dp[dp.length - 1];
}
}
115. Distinct Subsequences
Given two strings s and t, return the number of distinct subsequences of s which equals t.
The test cases are generated so that the answer fits on a 32-bit signed integer.
Example 1:
Input: s = "rabbbit", t = "rabbit"
Output: 3
Explanation:
As shown below, there are 3 ways you can generate "rabbit" from s.
`**rabb**b**it**`
`**ra**b**bbit**`
`**rab**b**bit**`
Example 2:
Input: s = "babgbag", t = "bag"
Output: 5
Explanation:
As shown below, there are 5 ways you can generate "bag" from s.
`**ba**b**g**bag`
`**ba**bgba**g**`
`**b**abgb**ag**`
`ba**b**gb**ag**`
`babg**bag**`
Constraints:
1 <= s.length, t.length <= 1000sandtconsist of English letters.
思路
这道题目如果不是子序列,而是要求连续序列的,那就可以考虑用KMP。
这道题目相对于72. 编辑距离,简单了不少,因为本题相当于只有删除操作,不用考虑替换增加之类的。
但相对于刚讲过的动态规划:392.判断子序列就有难度了,这道题目双指针法可就做不了了,来看看动规五部曲分析如下:
- 确定dp数组(dp table)以及下标的含义
dp[i][j]:以i-1为结尾的s子序列中出现以j-1为结尾的t的个数为dp[i][j]。
为什么i-1,j-1 这么定义我在 718. 最长重复子数组 中做了详细的讲解。
- 确定递推公式
这一类问题,基本是要分析两种情况
- s[i - 1] 与 t[j - 1]相等
- s[i - 1] 与 t[j - 1] 不相等
当s[i - 1] 与 t[j - 1]相等时,dp[i][j]可以有两部分组成。
一部分是用s[i - 1]来匹配,那么个数为dp[i][j]。即不需要考虑当前s子串和t子串的最后一位字母,所以只需要dp[i][j]。
一部分是不用s[i - 1]来匹配,个数为dp[i - 1][j]。
这里可能有录友不明白了,为什么还要考虑不用s[i - 1]来匹配,都相同了指定要匹配啊。
例如: s:bagg 和 t:bag ,s[3] 和 t[2]是相同的,但是字符串s也可以不用s[3]来匹配,即用s[0]s[1]s[2]组成的bag。
当然也可以用s[3]来匹配,即:s[0]s[1]s[3]组成的bag。
所以当s[i - 1] 与 t[j - 1]相等时,dp[i][j] = dp[i - 1][j - 1] + dp[i - 1][j];
当s[i - 1] 与 t[j - 1]不相等时,dp[i][j]只有一部分组成,不用s[i - 1]来匹配(就是模拟在s中删除这个元素),即:dp[i - 1][j]
所以递推公式为:dp[i][j] = dp[i - 1][j];
这里可能有录友还疑惑,为什么只考虑 “不用s[i - 1]来匹配” 这种情况, 不考虑 “不用t[j - 1]来匹配” 的情况呢。
这里大家要明确,我们求的是 s 中有多少个 t,而不是 求t中有多少个s,所以只考虑 s中删除元素的情况,即 不用s[i - 1]来匹配 的情况。
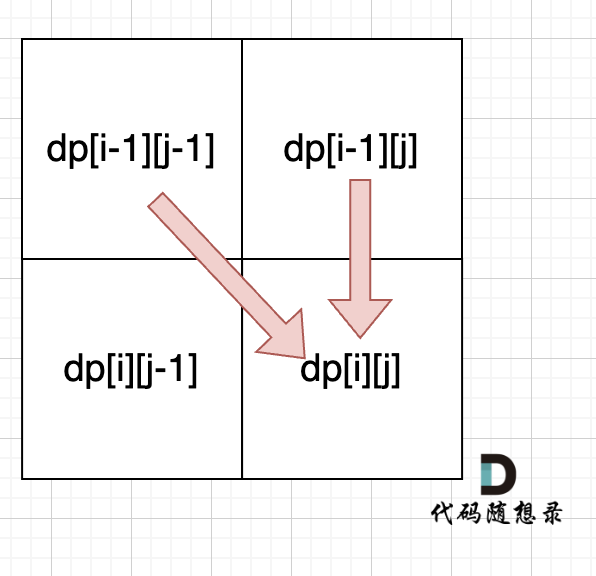
- dp数组如何初始化
从递推公式dp[i][j] = dp[i - 1][j] + dp[i - 1][j]; 和 dp[i][j] = dp[i - 1][j]; 中可以看出dp[i][j] 是从上方和左上方推导而来,如图:,那么 dp[i][j] 和dp[0][j]是一定要初始化的。
每次当初始化的时候,都要回顾一下dp[i][j]的定义,不要凭感觉初始化。
dp[i][0]表示什么呢?
dp[i][0] 表示:以i-1为结尾的s可以随便删除元素,出现空字符串的个数。
那么dp[i][0]一定都是1,因为也就是把以i-1为结尾的s,删除所有元素,出现空字符串的个数就是1。
再来看dp[0][j],dp[0][j]:空字符串s可以随便删除元素,出现以j-1为结尾的字符串t的个数。
那么dp[0][j]一定都是0,s如论如何也变成不了t。
最后就要看一个特殊位置了,即:dp[0][0] 应该是多少。
dp[0][j]应该是1,空字符串s,可以删除0个元素,变成空字符串t。
初始化分析完毕,代码如下:
vector<vector<long long>> dp(s.size() + 1, vector<long long>(t.size() + 1));
for (int i = 0; i <= s.size(); i++) dp[i][0] = 1;
for (int j = 1; j <= t.size(); j++) dp[0][j] = 0;
// 其实这行代码可以和dp数组初始化的时候放在一起,但我为了凸显初始化的逻辑,所以还是加上了。
4. 确定遍历顺序
从递推公式dp[i][j] = dp[i - 1][j] + dp[i - 1][j]; 和 dp[i][j] = dp[i - 1][j]; 中可以看出dp[i][j]都是根据左上方和正上方推出来的。
所以遍历的时候一定是从上到下,从左到右,这样保证dp[i][j]可以根据之前计算出来的数值进行计算。
代码如下:
for (int i = 1; i <= s.size(); i++) {
for (int j = 1; j <= t.size(); j++) {
if (s[i - 1] == t[j - 1]) {
dp[i][j] = dp[i - 1][j - 1] + dp[i - 1][j];
} else {
dp[i][j] = dp[i - 1][j];
}
}
}
- 举例推导dp数组
以s:"baegg",t:"bag"为例,推导dp数组状态如下:
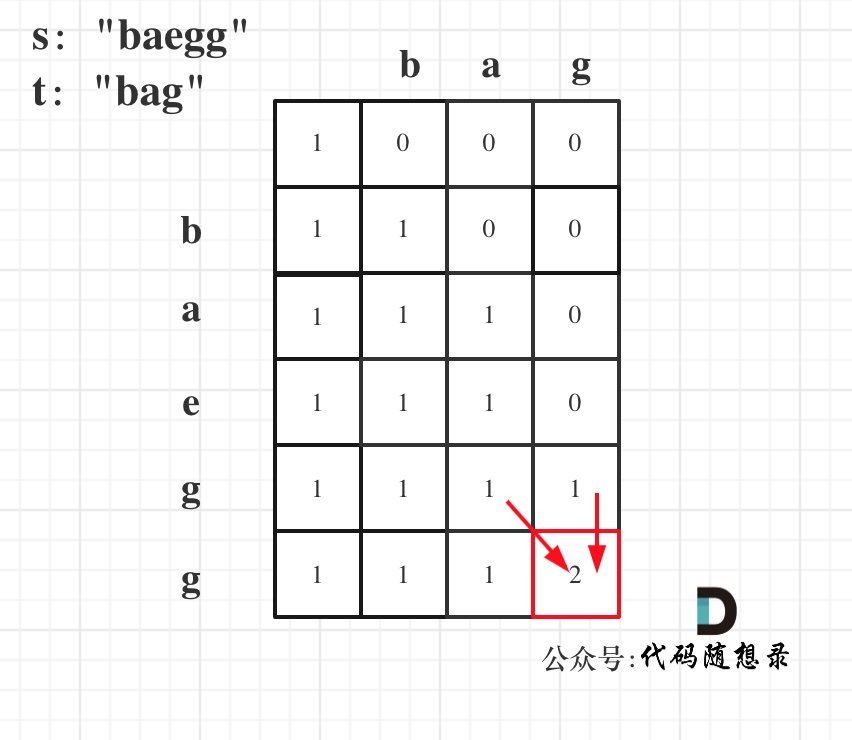
如果写出来的代码怎么改都通过不了,不妨把dp数组打印出来,看一看,是不是这样的。
C++解法
动规五部曲分析完毕,代码如下:
class Solution {
public:
int numDistinct(string s, string t) {
vector<vector<uint64_t>> dp(s.size() + 1, vector<uint64_t>(t.size() + 1));
for (int i = 0; i < s.size(); i++) dp[i][0] = 1;
for (int j = 1; j < t.size(); j++) dp[0][j] = 0;
for (int i = 1; i <= s.size(); i++) {
for (int j = 1; j <= t.size(); j++) {
if (s[i - 1] == t[j - 1]) {
dp[i][j] = dp[i - 1][j - 1] + dp[i - 1][j];
} else {
dp[i][j] = dp[i - 1][j];
}
}
}
return dp[s.size()][t.size()];
}
};
- 时间复杂度: O(n * m)
- 空间复杂度: O(n * m)
Java解法
class Solution {
public int numDistinct(String s, String t) {
int[][] dp = new int[s.length() + 1][t.length() + 1];
for (int i = 0; i < s.length() + 1; i++) {
dp[i][0] = 1;
}
for (int i = 1; i < s.length() + 1; i++) {
for (int j = 1; j < t.length() + 1; j++) {
if (s.charAt(i - 1) == t.charAt(j - 1)) {
dp[i][j] = dp[i - 1][j - 1] + dp[i - 1][j];
}else{
dp[i][j] = dp[i - 1][j];
}
}
}
return dp[s.length()][t.length()];
}
}
583. Delete Operation for Two Strings
Given two strings word1 and word2, return the minimum number of steps required to make word1 and word2 the same.
In one step, you can delete exactly one character in either string.
Example 1:
Input: word1 = "sea", word2 = "eat"
Output: 2
Explanation: You need one step to make "sea" to "ea" and another step to make "eat" to "ea".
Example 2:
Input: word1 = "leetcode", word2 = "etco"
Output: 4
Constraints:
1 <= word1.length, word2.length <= 500word1andword2consist of only lowercase English letters.
思路
本题和动态规划:115.不同的子序列相比,其实就是两个字符串都可以删除了,情况虽说复杂一些,但整体思路是不变的。
这次是两个字符串可以相互删了,这种题目也知道用动态规划的思路来解,动规五部曲,分析如下:
- 确定dp数组(dp table)以及下标的含义
dp[i][j]:以i-1为结尾的字符串word1,和以j-1位结尾的字符串word2,想要达到相等,所需要删除元素的最少次数。
这里dp数组的定义有点点绕,大家要撸清思路。
- 确定递推公式
- 当word1[i - 1] 与 word2[j - 1]相同的时候
- 当word1[i - 1] 与 word2[j - 1]不相同的时候
当word1[i - 1] 与 word2[j - 1]相同的时候,dp[i][j] = dp[i - 1][j - 1];
当word1[i - 1] 与 word2[j - 1]不相同的时候,有三种情况:
情况一:删word1[i - 1],最少操作次数为dp[i - 1][j] + 1
情况二:删word2[j - 1],最少操作次数为dp[i][j - 1] + 1
情况三:同时删word1[i - 1]和word2[j - 1],操作的最少次数为dp[i - 1][j - 1] + 2
那最后当然是取最小值,所以当word1[i - 1] 与 word2[j - 1]不相同的时候,递推公式:dp[i][j] = min({dp[i - 1][j - 1] + 2, dp[i - 1][j] + 1, dp[i][j - 1] + 1});
因为 dp[i][j] + 1 = dp[i - 1][j] + 2,所以递推公式可简化为:dp[i][j] = min(dp[i - 1][j] + 1, dp[i][j - 1] + 1);
这里可能不少录友有点迷糊,从字面上理解 就是 当同时删word1[i - 1]和word2[j - 1],dp[i][j] 本来就不考虑 word2[j - 1]了,那么我在删 word1[i - 1],是不是就达到两个元素都删除的效果,即 dp[i][j] + 1。
- dp数组如何初始化
从递推公式中,可以看出来,dp[i][j] 和 dp[0][j]是一定要初始化的。
dp[i][j]:word2为空字符串,以i-1为结尾的字符串word1要删除多少个元素,才能和word2相同呢,很明显dp[i][j] = i。
dp[0][j]的话同理,所以代码如下:
vector<vector<int>> dp(word1.size() + 1, vector<int>(word2.size() + 1));
for (int i = 0; i <= word1.size(); i++) dp[i][0] = i;
for (int j = 0; j <= word2.size(); j++) dp[0][j] = j;
- 确定遍历顺序
从递推公式 dp[i][j] = min(dp[i - 1][j - 1] + 2, min(dp[i - 1][j], dp[i][j - 1]) + 1); 和dp[i][j] = dp[i - 1][j - 1]可以看出dp[i][j]都是根据左上方、正上方、正左方推出来的。
所以遍历的时候一定是从上到下,从左到右,这样保证dp[i][j]可以根据之前计算出来的数值进行计算。
- 举例推导dp数组
以word1:"sea",word2:"eat"为例,推导dp数组状态图如下:
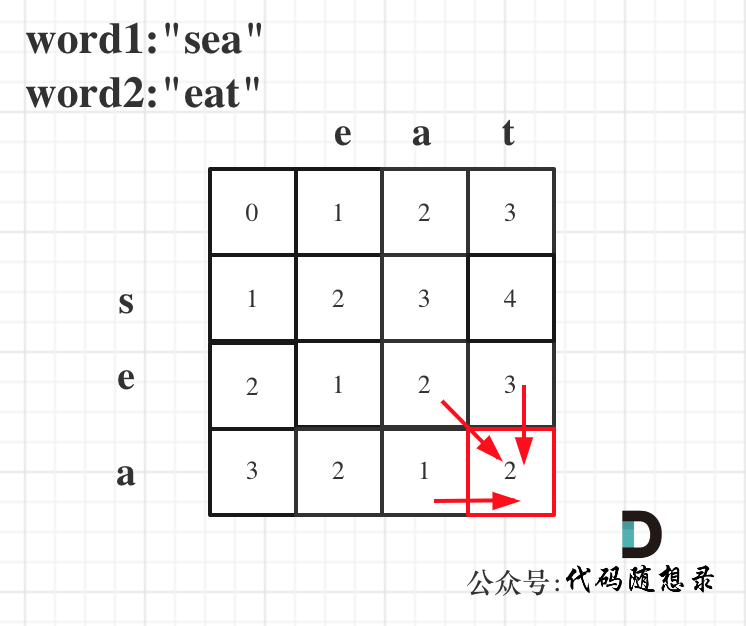
C++解法
以上分析完毕,代码如下:
class Solution {
public:
int minDistance(string word1, string word2) {
vector<vector<int>> dp(word1.size() + 1, vector<int>(word2.size() + 1));
for (int i = 0; i <= word1.size(); i++) dp[i][0] = i;
for (int j = 0; j <= word2.size(); j++) dp[0][j] = j;
for (int i = 1; i <= word1.size(); i++) {
for (int j = 1; j <= word2.size(); j++) {
if (word1[i - 1] == word2[j - 1]) {
dp[i][j] = dp[i - 1][j - 1];
} else {
dp[i][j] = min(dp[i - 1][j] + 1, dp[i][j - 1] + 1);
}
}
}
return dp[word1.size()][word2.size()];
}
};
- 时间复杂度: O(n * m)
- 空间复杂度: O(n * m)
本题和动态规划:1143.最长公共子序列基本相同,只要求出两个字符串的最长公共子序列长度即可,那么除了最长公共子序列之外的字符都是必须删除的,最后用两个字符串的总长度减去两个最长公共子序列的长度就是删除的最少步数。
代码如下:
class Solution {
public:
int minDistance(string word1, string word2) {
vector<vector<int>> dp(word1.size()+1, vector<int>(word2.size()+1, 0));
for (int i=1; i<=word1.size(); i++){
for (int j=1; j<=word2.size(); j++){
if (word1[i-1] == word2[j-1]) dp[i][j] = dp[i-1][j-1] + 1;
else dp[i][j] = max(dp[i-1][j], dp[i][j-1]);
}
}
return word1.size()+word2.size()-dp[word1.size()][word2.size()]*2;
}
};
- 时间复杂度: O(n * m)
- 空间复杂度: O(n * m)
Java解法
class Solution {
public int minDistance(String word1, String word2) {
int[][] dp = new int[word1.length() + 1][word2.length() + 1];
for(int i = 0; i <= word1.length(); i++){
dp[i][0] = i;
}
for(int j = 0; j <= word2.length(); j++){
dp[0][j] = j;
}
dp[0][0] = 0;
for(int i = 1; i <= word1.length(); i++){
for(int j = 1; j <= word2.length(); j++){
if(word1.charAt(i - 1) != word2.charAt(j - 1)){
dp[i][j] = Math.min(dp[i - 1][j], dp[i][j - 1]) + 1;
}else{
dp[i][j] = dp[i - 1][j - 1];
}
}
}
return dp[word1.length()][word2.length()];
}
}
// dp数组中存储word1和word2最长相同子序列的长度
class Solution {
public int minDistance(String word1, String word2) {
int len1 = word1.length();
int len2 = word2.length();
int[][] dp = new int[len1 + 1][len2 + 1];
for (int i = 1; i <= len1; i++) {
for (int j = 1; j <= len2; j++) {
if (word1.charAt(i - 1) == word2.charAt(j - 1)) {
dp[i][j] = dp[i - 1][j - 1] + 1;
} else {
dp[i][j] = Math.max(dp[i - 1][j], dp[i][j - 1]);
}
}
}
return len1 + len2 - dp[len1][len2] * 2;
}
}
// dp数组中存储需要删除的字符个数
class Solution {
public int minDistance(String word1, String word2) {
int[][] dp = new int[word1.length() + 1][word2.length() + 1];
for (int i = 0; i < word1.length() + 1; i++) dp[i][0] = i;
for (int j = 0; j < word2.length() + 1; j++) dp[0][j] = j;
for (int i = 1; i < word1.length() + 1; i++) {
for (int j = 1; j < word2.length() + 1; j++) {
if (word1.charAt(i - 1) == word2.charAt(j - 1)) {
dp[i][j] = dp[i - 1][j - 1];
}else{
dp[i][j] = Math.min(dp[i - 1][j - 1] + 2,
Math.min(dp[i - 1][j] + 1, dp[i][j - 1] + 1));
}
}
}
return dp[word1.length()][word2.length()];
}
}
//DP - longest common subsequence (用最長公共子序列反推)
class Solution {
public int minDistance(String word1, String word2) {
char[] char1 = word1.toCharArray();
char[] char2 = word2.toCharArray();
int len1 = char1.length;
int len2 = char2.length;
int dp[][] = new int [len1 + 1][len2 + 1];
for(int i = 1; i <= len1; i++){
for(int j = 1; j <= len2; j++){
if(char1[i - 1] == char2[j - 1])
dp[i][j] = dp[i - 1][j - 1] + 1;
else
dp[i][j] = Math.max(dp[i - 1][j], dp[i][j - 1]);
}
}
return len1 + len2 - (2 * dp[len1][len2]);//和leetcode 1143只差在這一行。
}
}
72. Edit Distance
Given two strings word1 and word2, return the minimum number of operations required to convert word1 to word2.
You have the following three operations permitted on a word:
- Insert a character
- Delete a character
- Replace a character
Example 1:
Input: word1 = "horse", word2 = "ros"
Output: 3
Explanation:
horse -> rorse (replace 'h' with 'r')
rorse -> rose (remove 'r')
rose -> ros (remove 'e')
Example 2:
Input: word1 = "intention", word2 = "execution"
Output: 5
Explanation:
intention -> inention (remove 't')
inention -> enention (replace 'i' with 'e')
enention -> exention (replace 'n' with 'x')
exention -> exection (replace 'n' with 'c')
exection -> execution (insert 'u')
Constraints:
0 <= word1.length, word2.length <= 500word1andword2consist of lowercase English letters.
思路
编辑距离是用动规来解决的经典题目,这道题目看上去好像很复杂,但用动规可以很巧妙的算出最少编辑距离。
接下来我依然使用动规五部曲,对本题做一个详细的分析:
- 确定dp数组(dp table)以及下标的含义
dp[i][j] 表示以下标i-1为结尾的字符串word1,和以下标j-1为结尾的字符串word2,最近编辑距离为dp[i][j]。
有同学问了,为啥要表示下标i-1为结尾的字符串呢,为啥不表示下标i为结尾的字符串呢?
为什么这么定义我在 718. 最长重复子数组 中做了详细的讲解。
其实用i来表示也可以! 用i-1就是为了方便后面dp数组初始化的。
- 确定递推公式
在确定递推公式的时候,首先要考虑清楚编辑的几种操作,整理如下:
if (word1[i - 1] == word2[j - 1]) 不操作
if (word1[i - 1] != word2[j - 1]) 增、删、换
也就是如上4种情况。
if (word1[i - 1] == word2[j - 1]) 那么说明不用任何编辑,dp[i][j] 就应该是 dp[i - 1][j - 1],即dp[i][j] = dp[i - 1][j - 1];
此时可能有同学有点不明白,为啥要即dp[i][j] = dp[i - 1][j - 1]呢?
那么就在回顾上面讲过的dp[i][j]的定义,word1[i - 1] 与 word2[j - 1]相等了,那么就不用编辑了,以下标i-2为结尾的字符串word1和以下标j-2为结尾的字符串word2的最近编辑距离dp[i - 1][j - 1]就是 dp[i][j]了。
在下面的讲解中,如果哪里看不懂,就回想一下dp[i][j]的定义,就明白了。
在整个动规的过程中,最为关键就是正确理解dp[i][j]的定义!
if (word1[i - 1] != word2[j - 1]),此时就需要编辑了,如何编辑呢?
- 操作一:word1删除一个元素,那么就是以下标i - 2为结尾的word1 与 j-1为结尾的word2的最近编辑距离 再加上一个操作。
即 dp[i][j] = dp[i - 1][j] + 1;
- 操作二:word2删除一个元素,那么就是以下标i - 1为结尾的word1 与 j-2为结尾的word2的最近编辑距离 再加上一个操作。
即 dp[i][j] = dp[i][j - 1] + 1;
这里有同学发现了,怎么都是删除元素,添加元素去哪了。
word2添加一个元素,相当于word1删除一个元素,例如 word1 = "ad" ,word2 = "a",word1删除元素'd' 和 word2添加一个元素'd',变成word1="a", word2="ad", 最终的操作数是一样! dp数组如下图所示意的:
a a d
+-----+-----+ +-----+-----+-----+
| 0 | 1 | | 0 | 1 | 2 |
+-----+-----+ ===> +-----+-----+-----+
a | 1 | 0 | a | 1 | 0 | 1 |
+-----+-----+ +-----+-----+-----+
d | 2 | 1 |
+-----+-----+
操作三:替换元素,word1替换word1[i - 1],使其与word2[j - 1]相同,此时不用增删加元素。
可以回顾一下,if (word1[i - 1] == word2[j - 1])的时候我们的操作 是 dp[i][j] = dp[i - 1][j - 1] 对吧。
那么只需要一次替换的操作,就可以让 word1[i - 1] 和 word2[j - 1] 相同。
所以 dp[i][j] = dp[i - 1][j - 1] + 1;
综上,当 if (word1[i - 1] != word2[j - 1]) 时取最小的,即:dp[i][j] = min({dp[i - 1][j - 1], dp[i - 1][j], dp[i][j - 1]}) + 1;
递归公式代码如下:
if (word1[i - 1] == word2[j - 1]) {
dp[i][j] = dp[i - 1][j - 1];
}
else {
dp[i][j] = min({dp[i - 1][j - 1], dp[i - 1][j], dp[i][j - 1]}) + 1;
}
- dp数组如何初始化
再回顾一下dp[i][j]的定义:
dp[i][j] 表示以下标i-1为结尾的字符串word1,和以下标j-1为结尾的字符串word2,最近编辑距离为dp[i][j]。
那么dp[i][j] 和 dp[0][j] 表示什么呢?
dp[i][j] :以下标i-1为结尾的字符串word1,和空字符串word2,最近编辑距离为dp[i][j]。
那么dp[i][j]就应该是i,对word1里的元素全部做删除操作,即:dp[i][j] = i;
同理dp[0][j] = j;
所以C++代码如下:
for (int i = 0; i <= word1.size(); i++) dp[i][0] = i;
for (int j = 0; j <= word2.size(); j++) dp[0][j] = j;
4. 确定遍历顺序
从如下四个递推公式:
dp[i][j] = dp[i - 1][j - 1]dp[i][j] = dp[i - 1][j - 1] + 1dp[i][j] = dp[i][j - 1] + 1dp[i][j] = dp[i - 1][j] + 1
可以看出dp[i][j]是依赖左方,上方和左上方元素的,如图:
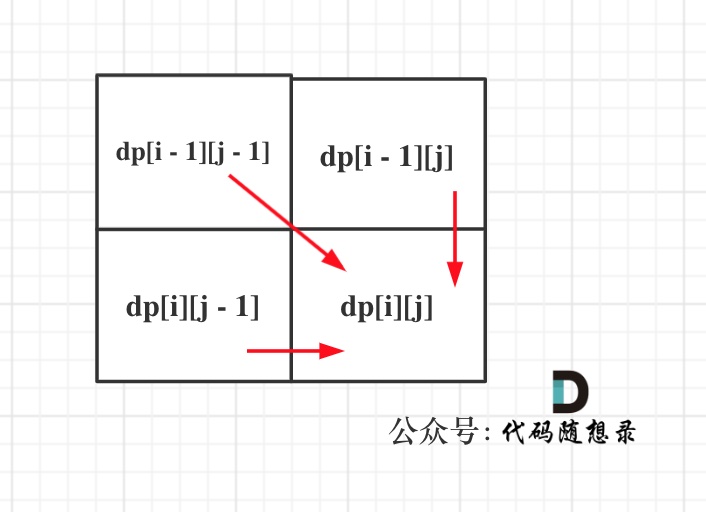
所以在dp矩阵中一定是从左到右从上到下去遍历。
代码如下:
for (int i = 1; i <= word1.size(); i++) {
for (int j = 1; j <= word2.size(); j++) {
if (word1[i - 1] == word2[j - 1]) {
dp[i][j] = dp[i - 1][j - 1];
}
else {
dp[i][j] = min({dp[i - 1][j - 1], dp[i - 1][j], dp[i][j - 1]}) + 1;
}
}
}
- 举例推导dp数组
以示例1为例,输入:word1 = "horse", word2 = "ros"为例,dp矩阵状态图如下:
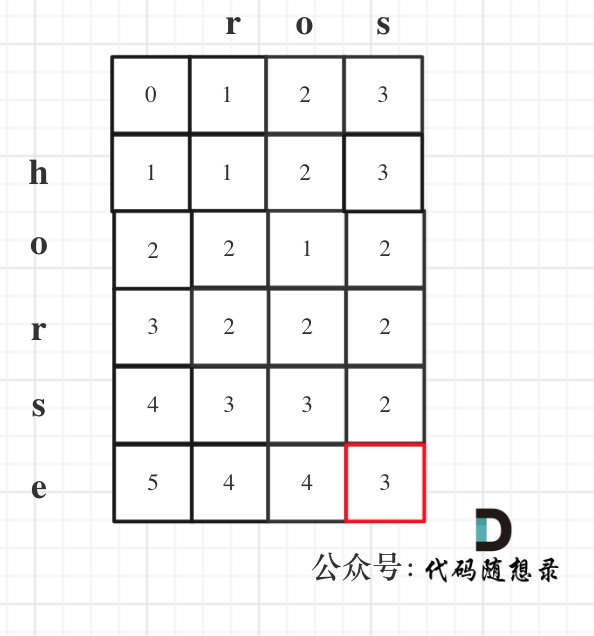
C++解法
以上动规五部分析完毕,C++代码如下:
class Solution {
public:
int minDistance(string word1, string word2) {
vector<vector<int>> dp(word1.size() + 1, vector<int>(word2.size() + 1, 0));
for (int i = 0; i <= word1.size(); i++) dp[i][0] = i;
for (int j = 0; j <= word2.size(); j++) dp[0][j] = j;
for (int i = 1; i <= word1.size(); i++) {
for (int j = 1; j <= word2.size(); j++) {
if (word1[i - 1] == word2[j - 1]) {
dp[i][j] = dp[i - 1][j - 1];
}
else {
dp[i][j] = min({dp[i - 1][j - 1], dp[i - 1][j], dp[i][j - 1]}) + 1;
}
}
}
return dp[word1.size()][word2.size()];
}
};
- 时间复杂度: O(n * m)
- 空间复杂度: O(n * m)
Java解法
public int minDistance(String word1, String word2) {
int m = word1.length();
int n = word2.length();
int[][] dp = new int[m + 1][n + 1];
// 初始化
for (int i = 1; i <= m; i++) {
dp[i][0] = i;
}
for (int j = 1; j <= n; j++) {
dp[0][j] = j;
}
for (int i = 1; i <= m; i++) {
for (int j = 1; j <= n; j++) {
// 因为dp数组有效位从1开始
// 所以当前遍历到的字符串的位置为i-1 | j-1
if (word1.charAt(i - 1) == word2.charAt(j - 1)) {
dp[i][j] = dp[i - 1][j - 1];
} else {
dp[i][j] = Math.min(Math.min(dp[i - 1][j - 1], dp[i][j - 1]), dp[i - 1][j]) + 1;
}
}
}
return dp[m][n];
}