调试及性能分析
代码不能完全按照您的想法运行,它只能完全按照您的写法运行,这是编程界的一条金科玉律。
让您的写法符合您的想法是非常困难的。在这节课中,我们会传授给您一些非常有用技术,帮您处理代码中的 bug 和程序性能问题。
调试代码
打印调试法与日志
“最有效的 debug 工具就是细致的分析,配合恰当位置的打印语句” — Brian Kernighan, Unix 新手入门。
调试代码的第一种方法往往是在您发现问题的地方添加一些打印语句,然后不断重复此过程直到您获取了足够的信息并找到问题的根本原因。
另外一个方法是使用日志,而不是临时添加打印语句。日志较普通的打印语句有如下的一些优势:
- 您可以将日志写入文件、socket 或者甚至是发送到远端服务器而不仅仅是标准输出;
- 日志可以支持严重等级(例如 INFO, DEBUG, WARN, ERROR等),这使您可以根据需要过滤日志;
- 对于新发现的问题,很可能您的日志中已经包含了可以帮助您定位问题的足够的信息。
这里 是一个包含日志的例程序:
import logging
import sys
class CustomFormatter(logging.Formatter):
"""Logging Formatter to add colors and count warning / errors"""
grey = "\x1b[38;21m"
yellow = "\x1b[33;21m"
red = "\x1b[31;21m"
bold_red = "\x1b[31;1m"
reset = "\x1b[0m"
format = "%(asctime)s - %(name)s - %(levelname)s - %(message)s (%(filename)s:%(lineno)d)"
FORMATS = {
logging.DEBUG: grey + format + reset,
logging.INFO: grey + format + reset,
logging.WARNING: yellow + format + reset,
logging.ERROR: red + format + reset,
logging.CRITICAL: bold_red + format + reset
}
def format(self, record):
log_fmt = self.FORMATS.get(record.levelno)
formatter = logging.Formatter(log_fmt)
return formatter.format(record)
# create logger with 'spam_application'
logger = logging.getLogger("Sample")
# create console handler with a higher log level
ch = logging.StreamHandler()
ch.setLevel(logging.DEBUG)
if len(sys.argv)> 1:
if sys.argv[1] == 'log':
ch.setFormatter(logging.Formatter('%(asctime)s : %(levelname)s : %(name)s : %(message)s'))
elif sys.argv[1] == 'color':
ch.setFormatter(CustomFormatter())
if len(sys.argv) > 2:
logger.setLevel(logging.__getattribute__(sys.argv[2]))
else:
logger.setLevel(logging.DEBUG)
logger.addHandler(ch)
# logger.debug("debug message")
# logger.info("info message")
# logger.warning("warning message")
# logger.error("error message")
# logger.critical("critical message")
import random
import time
for _ in range(100):
i = random.randint(0, 10)
if i <= 4:
logger.info("Value is {} - Everything is fine".format(i))
elif i <= 6:
logger.warning("Value is {} - System is getting hot".format(i))
elif i <= 8:
logger.error("Value is {} - Dangerous region".format(i))
else:
logger.critical("Maximum value reached")
time.sleep(0.3)
$ python logger.py
# Raw output as with just prints
$ python logger.py log
# Log formatted output
$ python logger.py log ERROR
# Print only ERROR levels and above
$ python logger.py color
# Color formatted output
有很多技巧可以使日志的可读性变得更好,我最喜欢的一个是技巧是对其进行着色。到目前为止,您应该已经知道,以彩色文本显示终端信息时可读性更好。但是应该如何设置呢?
ls 和 grep 这样的程序会使用 ANSI escape codes,它是一系列的特殊字符,可以使您的 shell 改变输出结果的颜色。例如,执行 echo -e "\e[38;2;255;0;0mThis is red\e[0m" 会打印红色的字符串:This is red 。只要您的终端支持真彩色。如果您的终端不支持真彩色(例如 MacOS 的 Terminal.app),您可以使用支持更加广泛的 16 色,例如:”\e[31;1mThis is red\e[0m”。
下面这个脚本向您展示了如何在终端中打印多种颜色(只要您的终端支持真彩色)
#!/usr/bin/env bash
for R in $(seq 0 20 255); do
for G in $(seq 0 20 255); do
for B in $(seq 0 20 255); do
printf "\e[38;2;${R};${G};${B}m█\e[0m";
done
done
done
第三方日志系统
如果您正在构建大型软件系统,您很可能会使用到一些依赖,有些依赖会作为程序单独运行。如 Web 服务器、数据库或消息代理都是此类常见的第三方依赖。
和这些系统交互的时候,阅读它们的日志是非常必要的,因为仅靠客户端侧的错误信息可能并不足以定位问题。
幸运的是,大多数的程序都会将日志保存在您的系统中的某个地方。对于 UNIX 系统来说,程序的日志通常存放在 /var/log。例如, NGINX web 服务器就将其日志存放于/var/log/nginx。
目前,系统开始使用 system log,您所有的日志都会保存在这里。大多数(但不是全部的)Linux 系统都会使用 systemd,这是一个系统守护进程,它会控制您系统中的很多东西,例如哪些服务应该启动并运行。systemd 会将日志以某种特殊格式存放于/var/log/journal,您可以使用 journalctl 命令显示这些消息。
类似地,在 macOS 系统中是 /var/log/system.log,但是有更多的工具会使用系统日志,它的内容可以使用 log show 显示。
对于大多数的 UNIX 系统,您也可以使用dmesg 命令来读取内核的日志。
如果您希望将日志加入到系统日志中,您可以使用 logger 这个 shell 程序。下面这个例子显示了如何使用 logger并且如何找到能够将其存入系统日志的条目。
不仅如此,大多数的编程语言都支持向系统日志中写日志。
logger "Hello Logs"
# On macOS
log show --last 1m | grep Hello
# On Linux
journalctl --since "1m ago" | grep Hello
正如我们在数据整理那节课上看到的那样,日志的内容可以非常的多,我们需要对其进行处理和过滤才能得到我们想要的信息。
如果您发现您需要对 journalctl 和 log show 的结果进行大量的过滤,那么此时可以考虑使用它们自带的选项对其结果先过滤一遍再输出。还有一些像 lnav 这样的工具,它为日志文件提供了更好的展现和浏览方式。
调试器
当通过打印已经不能满足您的调试需求时,您应该使用调试器。
调试器是一种可以允许我们和正在执行的程序进行交互的程序,它可以做到:
- 当到达某一行时将程序暂停;
- 一次一条指令地逐步执行程序;
- 程序崩溃后查看变量的值;
- 满足特定条件时暂停程序;
- 其他高级功能。
很多编程语言都有自己的调试器。Python 的调试器是pdb.
下面对pdb 支持的命令进行简单的介绍:
- l(ist) - 显示当前行附近的11行或继续执行之前的显示;
- s(tep) - 执行当前行,并在第一个可能的地方停止;
- n(ext) - 继续执行直到当前函数的下一条语句或者 return 语句;
- b(reak) - 设置断点(基于传入的参数);
- p(rint) - 在当前上下文对表达式求值并打印结果。还有一个命令是pp ,它使用
pprint打印; - r(eturn) - 继续执行直到当前函数返回;
- q(uit) - 退出调试器。
让我们使用pdb 来修复下面的 Python 代码(参考讲座视频)
def bubble_sort(arr):
n = len(arr)
for i in range(n):
for j in range(n):
if arr[j] > arr[j+1]:
arr[j] = arr[j+1]
arr[j+1] = arr[j]
return arr
print(bubble_sort([4, 2, 1, 8, 7, 6]))
执行python3 -m pdb bubble_sort.py进入pdb调试环境。
注意,因为 Python 是一种解释型语言,所以我们可以通过 pdb shell 执行命令。 ipdb 是一种增强型的 pdb ,它使用IPython 作为 REPL并开启了 tab 补全、语法高亮、更好的回溯和更好的内省,同时还保留了pdb 模块相同的接口。
对于更底层的编程语言,您可能需要了解一下 gdb ( 以及它的改进版 pwndbg) 和 lldb。
它们都对类 C 语言的调试进行了优化,它允许您探索任意进程及其机器状态:寄存器、堆栈、程序计数器等。
专门工具
即使您需要调试的程序是一个二进制的黑盒程序,仍然有一些工具可以帮助到您。当您的程序需要执行一些只有操作系统内核才能完成的操作时,它需要使用 系统调用。有一些命令可以帮助您追踪您的程序执行的系统调用。在 Linux 中可以使用strace ,在 macOS 和 BSD 中可以使用 dtrace。dtrace 用起来可能有些别扭,因为它使用的是它自有的 D 语言,但是我们可以使用一个叫做 dtruss 的封装使其具有和 strace (更多信息参考 这里)类似的接口
下面的例子展现来如何使用 strace 或 dtruss 来显示ls 执行时,对stat 系统调用进行追踪对结果。若需要深入了解 strace,这篇文章 值得一读。
# On Linux
sudo strace -e lstat ls -l > /dev/null
4
# On macOS
sudo dtruss -t lstat64_extended ls -l > /dev/null
有些情况下,我们需要查看网络数据包才能定位问题。像 tcpdump 和 Wireshark 这样的网络数据包分析工具可以帮助您获取网络数据包的内容并基于不同的条件进行过滤。
对于 web 开发, Chrome/Firefox 的开发者工具非常方便,功能也很强大:
- 源码 -查看任意站点的 HTML/CSS/JS 源码;
- 实时地修改 HTML, CSS, JS 代码 - 修改网站的内容、样式和行为用于测试(从这一点您也能看出来,网页截图是不可靠的);
- Javascript shell - 在 JS REPL中执行命令;
- 网络 - 分析请求的时间线;
- 存储 - 查看 Cookies 和本地应用存储。
静态分析
有些问题是您不需要执行代码就能发现的。例如,仔细观察一段代码,您就能发现某个循环变量覆盖了某个已经存在的变量或函数名;或是有个变量在被读取之前并没有被定义。 这种情况下 静态分析 工具就可以帮我们找到问题。静态分析会将程序的源码作为输入然后基于编码规则对其进行分析并对代码的正确性进行推理。
下面这段 Python 代码中存在几个问题。 首先,我们的循环变量foo 覆盖了之前定义的函数foo。最后一行,我们还把 bar 错写成了baz,因此当程序完成sleep (一分钟)后,执行到这一行的时候便会崩溃。
import time
def foo():
return 42
for foo in range(5):
print(foo)
bar = 1
bar *= 0.2
time.sleep(60)
print(baz)
静态分析工具可以发现此类的问题。当我们使用pyflakes 分析代码的时候,我们会得到与这两处 bug 相关的错误信息。mypy 则是另外一个工具,它可以对代码进行类型检查。这里,mypy 会经过我们bar 起初是一个 int ,然后变成了 float。这些问题都可以在不运行代码的情况下被发现。
安装pip命令:sudo apt install python3-pip
安装pyflakes命令:pip3 install pyflakes
$ pyflakes foobar.py
foobar.py:6: redefinition of unused 'foo' from line 3
foobar.py:11: undefined name 'baz'
$ mypy foobar.py
foobar.py:6: error: Incompatible types in assignment (expression has type "int", variable has type "Callable[[], Any]")
foobar.py:9: error: Incompatible types in assignment (expression has type "float", variable has type "int")
foobar.py:11: error: Name 'baz' is not defined
Found 3 errors in 1 file (checked 1 source file)
在 shell 工具那一节课的时候,我们介绍了 shellcheck,这是一个类似的工具,但它是应用于 shell 脚本的。
大多数的编辑器和 IDE 都支持在编辑界面显示这些工具的分析结果、高亮有警告和错误的位置。 这个过程通常称为 code linting 。风格检查或安全检查的结果同样也可以进行相应的显示。
在 vim 中,有 ale 或 syntastic 可以帮助您做同样的事情。 在 Python 中, pylint 和 pep8 是两种用于进行风格检查的工具,而 bandit 工具则用于检查安全相关的问题。
对于其他语言的开发者来说,静态分析工具可以参考这个列表:Awesome Static Analysis (您也许会对 Writing 一节感兴趣) 。对于 linters 则可以参考这个列表: Awesome Linters。
对于风格检查和代码格式化,还有以下一些工具可以作为补充:用于 Python 的 black、用于 Go 语言的 gofmt、用于 Rust 的 rustfmt 或是用于 JavaScript, HTML 和 CSS 的 prettier 。这些工具可以自动格式化您的代码,这样代码风格就可以与常见的风格保持一致。 尽管您可能并不想对代码进行风格控制,标准的代码风格有助于方便别人阅读您的代码,也可以方便您阅读它的代码。
性能分析
即使您的代码能够像您期望的一样运行,但是如果它消耗了您全部的 CPU 和内存,那么它显然也不是个好程序。算法课上我们通常会介绍大O标记法,但却没教给我们如何找到程序中的热点。 鉴于 过早的优化是万恶之源,您需要学习性能分析和监控工具,它们会帮助您找到程序中最耗时、最耗资源的部分,这样您就可以有针对性的进行性能优化。
计时
和调试代码类似,大多数情况下我们只需要打印两处代码之间的时间即可发现问题。下面这个例子中,我们使用了 Python 的 time模块。
import time, random
n = random.randint(1, 10) * 100
# 获取当前时间
start = time.time()
# 执行一些操作
print("Sleeping for {} ms".format(n))
time.sleep(n/1000)
# 比较当前时间和起始时间
print(time.time() - start)
# Output
# Sleeping for 500 ms
# 0.5713930130004883
不过,执行时间(wall clock time)也可能会误导您,因为您的电脑可能也在同时运行其他进程,也可能在此期间发生了等待。 对于工具来说,需要区分真实时间、用户时间和系统时间。通常来说,用户时间+系统时间代表了您的进程所消耗的实际 CPU (更详细的解释可以参照这篇文章)。
- 真实时间 - 从程序开始到结束流失掉的真实时间,包括其他进程的执行时间以及阻塞消耗的时间(例如等待 I/O或网络);
- User - CPU 执行用户代码所花费的时间;
- Sys - CPU 执行系统内核代码所花费的时间。
例如,试着执行一个用于发起 HTTP 请求的命令并在其前面添加 time 前缀。网络不好的情况下您可能会看到下面的输出结果。请求花费了 2s 才完成,但是进程仅花费了 15ms 的 CPU 用户时间和 12ms 的 CPU 内核时间。
$ time curl https://missing.csail.mit.edu &> /dev/null
real 0m2.561s
user 0m0.015s
sys 0m0.012s
性能分析工具(profilers)
CPU
大多数情况下,当人们提及性能分析工具的时候,通常指的是 CPU 性能分析工具。 CPU 性能分析工具有两种: 追踪分析器(tracing)及采样分析器(sampling)。 追踪分析器 会记录程序的每一次函数调用,而采样分析器则只会周期性的监测(通常为每毫秒)您的程序并记录程序堆栈。它们使用这些记录来生成统计信息,显示程序在哪些事情上花费了最多的时间。如果您希望了解更多相关信息,可以参考这篇 介绍性的文章。
大多数的编程语言都有一些基于命令行的分析器,我们可以使用它们来分析代码。它们通常可以集成在 IDE 中,但是本节课我们会专注于这些命令行工具本身。
在 Python 中,我们使用 cProfile 模块来分析每次函数调用所消耗的时间。 在下面的例子中,我们实现了一个基础的 grep 命令:
#!/usr/bin/env python
import sys, re
def grep(pattern, file):
with open(file, 'r') as f:
print(file)
for i, line in enumerate(f.readlines()):
pattern = re.compile(pattern)
match = pattern.search(line)
if match is not None:
print("{}: {}".format(i, line), end="")
if __name__ == '__main__':
times = int(sys.argv[1])
pattern = sys.argv[2]
for i in range(times):
for file in sys.argv[3:]:
grep(pattern, file)
我们可以使用下面的命令来对这段代码进行分析。通过它的输出我们可以知道,IO 消耗了大量的时间,编译正则表达式也比较耗费时间。因为正则表达式只需要编译一次,我们可以将其移动到 for 循环外面来改进性能。
$ python -m cProfile -s tottime grep.py 1000 '^(import|\s*def)[^,]*$' *.py
[omitted program output]
ncalls tottime percall cumtime percall filename:lineno(function)
8000 0.266 0.000 0.292 0.000 {built-in method io.open}
8000 0.153 0.000 0.894 0.000 grep.py:5(grep)
17000 0.101 0.000 0.101 0.000 {built-in method builtins.print}
8000 0.100 0.000 0.129 0.000 {method 'readlines' of '_io._IOBase' objects}
93000 0.097 0.000 0.111 0.000 re.py:286(_compile)
93000 0.069 0.000 0.069 0.000 {method 'search' of '_sre.SRE_Pattern' objects}
93000 0.030 0.000 0.141 0.000 re.py:231(compile)
17000 0.019 0.000 0.029 0.000 codecs.py:318(decode)
1 0.017 0.017 0.911 0.911 grep.py:3(<module>)
[omitted lines]
关于 Python 的 cProfile 分析器(以及其他一些类似的分析器),需要注意的是它显示的是每次函数调用的时间。看上去可能快到反直觉,尤其是如果您在代码里面使用了第三方的函数库,因为内部函数调用也会被看作函数调用。
更加符合直觉的显示分析信息的方式是包括每行代码的执行时间,这也是_行分析器_的工作。例如,下面这段 Python 代码会向本课程的网站发起一个请求,然后解析响应返回的页面中的全部 URL:
#!/usr/bin/env python
import requests
from bs4 import BeautifulSoup
# 这个装饰器会告诉行分析器
# 我们想要分析这个函数
@profile
def get_urls():
response = requests.get('https://missing.csail.mit.edu')
s = BeautifulSoup(response.content, 'lxml')
urls = []
for url in s.find_all('a'):
urls.append(url['href'])
if __name__ == '__main__':
get_urls()
如果我们使用 Python 的 cProfile 分析器,我们会得到超过2500行的输出结果,即使对其进行排序,我仍然搞不懂时间到底都花在哪了。如果我们使用 line_profiler,它会基于行来显示时间:
$ kernprof -l -v a.py
Wrote profile results to urls.py.lprof
Timer unit: 1e-06 s
Total time: 0.636188 s
File: a.py
Function: get_urls at line 5
Line # Hits Time Per Hit % Time Line Contents
==============================================================
5 @profile
6 def get_urls():
7 1 613909.0 613909.0 96.5 response = requests.get('https://missing.csail.mit.edu')
8 1 21559.0 21559.0 3.4 s = BeautifulSoup(response.content, 'lxml')
9 1 2.0 2.0 0.0 urls = []
10 25 685.0 27.4 0.1 for url in s.find_all('a'):
11 24 33.0 1.4 0.0 urls.append(url['href'])
内存
像 C 或者 C++ 这样的语言,内存泄漏会导致您的程序在使用完内存后不去释放它。为了应对内存类的 Bug,我们可以使用类似 Valgrind 这样的工具来检查内存泄漏问题。
对于 Python 这类具有垃圾回收机制的语言,内存分析器也是很有用的,因为对于某个对象来说,只要有指针还指向它,那它就不会被回收。
下面这个例子及其输出,展示了 memory-profiler 是如何工作的(注意装饰器和 line-profiler 类似)。
@profile
def my_func():
a = [1] * (10 ** 6)
b = [2] * (2 * 10 ** 7)
del b
return a
if __name__ == '__main__':
my_func()
$ python -m memory_profiler example.py
Line # Mem usage Increment Line Contents
==============================================
3 @profile
4 5.97 MB 0.00 MB def my_func():
5 13.61 MB 7.64 MB a = [1] * (10 ** 6)
6 166.20 MB 152.59 MB b = [2] * (2 * 10 ** 7)
7 13.61 MB -152.59 MB del b
8 13.61 MB 0.00 MB return a
事件分析
在我们使用strace调试代码的时候,您可能会希望忽略一些特殊的代码并希望在分析时将其当作黑盒处理。perf 命令将 CPU 的区别进行了抽象,它不会报告时间和内存的消耗,而是报告与您的程序相关的系统事件。
例如,perf 可以报告不佳的缓存局部性(poor cache locality)、大量的页错误(page faults)或活锁(livelocks)。下面是关于常见命令的简介:
perf list- 列出可以被 pref 追踪的事件;perf stat COMMAND ARG1 ARG2- 收集与某个进程或指令相关的事件;perf record COMMAND ARG1 ARG2- 记录命令执行的采样信息并将统计数据储存在perf.data中;perf report- 格式化并打印perf.data中的数据。
可视化
使用分析器来分析真实的程序时,由于软件的复杂性,其输出结果中将包含大量的信息。人类是一种视觉动物,非常不善于阅读大量的文字。因此很多工具都提供了可视化分析器输出结果的功能。
对于采样分析器来说,常见的显示 CPU 分析数据的形式是 火焰图,火焰图会在 Y 轴显示函数调用关系,并在 X 轴显示其耗时的比例。火焰图同时还是可交互的,您可以深入程序的某一具体部分,并查看其栈追踪(您可以尝试点击下面的图片)。

调用图和控制流图可以显示子程序之间的关系,它将函数作为节点并把函数调用作为边。将它们和分析器的信息(例如调用次数、耗时等)放在一起使用时,调用图会变得非常有用,它可以帮助我们分析程序的流程。 在 Python 中您可以使用 pycallgraph 来生成这些图片。

资源监控
有时候,分析程序性能的第一步是搞清楚它所消耗的资源。程序变慢通常是因为它所需要的资源不够了。例如,没有足够的内存或者网络连接变慢的时候。
有很多很多的工具可以被用来显示不同的系统资源,例如 CPU 占用、内存使用、网络、磁盘使用等。
- 通用监控 - 最流行的工具要数
htop,了,它是top的改进版。htop可以显示当前运行进程的多种统计信息。htop有很多选项和快捷键,常见的有:<F6>进程排序、t显示树状结构和h打开或折叠线程。 还可以留意一下glances,它的实现类似但是用户界面更好。如果需要合并测量全部的进程,dstat是也是一个非常好用的工具,它可以实时地计算不同子系统资源的度量数据,例如 I/O、网络、 CPU 利用率、上下文切换等等; - I/O 操作 -
iotop可以显示实时 I/O 占用信息而且可以非常方便地检查某个进程是否正在执行大量的磁盘读写操作; - 磁盘使用 -
df可以显示每个分区的信息,而du则可以显示当前目录下每个文件的磁盘使用情况( disk usage)。-h选项可以使命令以对人类(human)更加友好的格式显示数据;ncdu是一个交互性更好的du,它可以让您在不同目录下导航、删除文件和文件夹; - 内存使用 -
free可以显示系统当前空闲的内存。内存也可以使用htop这样的工具来显示; - 打开文件 -
lsof可以列出被进程打开的文件信息。 当我们需要查看某个文件是被哪个进程打开的时候,这个命令非常有用; - 网络连接和配置 -
ss能帮助我们监控网络包的收发情况以及网络接口的显示信息。ss常见的一个使用场景是找到端口被进程占用的信息。如果要显示路由、网络设备和接口信息,您可以使用ip命令。注意,netstat和ifconfig这两个命令已经被前面那些工具所代替了。 - 网络使用 -
nethogs和iftop是非常好的用于对网络占用进行监控的交互式命令行工具。
如果您希望测试一下这些工具,您可以使用 stress 命令来为系统人为地增加负载。
专用工具
有时候,您只需要对黑盒程序进行基准测试,并依此对软件选择进行评估。 类似 hyperfine 这样的命令行可以帮您快速进行基准测试。例如,我们在 shell 工具和脚本那一节课中我们推荐使用 fd 来代替 find。我们这里可以用hyperfine来比较一下它们。
例如,下面的例子中,我们可以看到fd 比 find 要快20倍。
$ hyperfine --warmup 3 'fd -e jpg' 'find . -iname "*.jpg"'
Benchmark #1: fd -e jpg
Time (mean ± σ): 51.4 ms ± 2.9 ms [User: 121.0 ms, System: 160.5 ms]
Range (min … max): 44.2 ms … 60.1 ms 56 runs
Benchmark #2: find . -iname "*.jpg"
Time (mean ± σ): 1.126 s ± 0.101 s [User: 141.1 ms, System: 956.1 ms]
Range (min … max): 0.975 s … 1.287 s 10 runs
Summary
'fd -e jpg' ran
21.89 ± 2.33 times faster than 'find . -iname "*.jpg"'
和 debug 一样,浏览器也包含了很多不错的性能分析工具,可以用来分析页面加载,让我们可以搞清楚时间都消耗在什么地方(加载、渲染、脚本等等)。 更多关于 Firefox 和 Chrome的信息可以点击链接。
课后练习
调试
-
使用 Linux 上的
journalctl或 macOS 上的log show命令来获取最近一天中超级用户的登录信息及其所执行的指令。如果找不到相关信息,您可以执行一些无害的命令,例如sudo ls然后再次查看。 -
安装
shellcheck并尝试对下面的脚本进行检查。这段代码有什么问题吗?请修复相关问题。在您的编辑器中安装一个linter插件,这样它就可以自动地显示相关警告信息。#!/bin/sh ## Example: a typical script with several problems for f in $(ls *.m3u) do grep -qi hq.*mp3 $f \ && echo -e 'Playlist $f contains a HQ file in mp3 format' done
性能分析
-
这里 有一些排序算法的实现。请使用
cProfile和line_profiler来比较插入排序和快速排序的性能。两种算法的瓶颈分别在哪里?然后使用memory_profiler来检查内存消耗,为什么插入排序更好一些?然后再看看原地排序版本的快排。附加题:使用perf来查看不同算法的循环次数及缓存命中及丢失情况。 -
这里有一些用于计算斐波那契数列 Python 代码,它为计算每个数字都定义了一个函数:
#!/usr/bin/env python def fib0(): return 0 def fib1(): return 1 s = """def fib{}(): return fib{}() + fib{}()""" if __name__ == '__main__': for n in range(2, 10): exec(s.format(n, n-1, n-2)) # from functools import lru_cache # for n in range(10): # exec("fib{} = lru_cache(1)(fib{})".format(n, n)) print(eval("fib9()"))将代码拷贝到文件中使其变为一个可执行的程序。首先安装
pycallgraph和graphviz(如果您能够执行dot, 则说明已经安装了 GraphViz.)。并使用pycallgraph graphviz -- ./fib.py来执行代码并查看pycallgraph.png这个文件。fib0被调用了多少次?我们可以通过记忆法来对其进行优化。将注释掉的部分放开,然后重新生成图片。这回每个fibN函数被调用了多少次? -
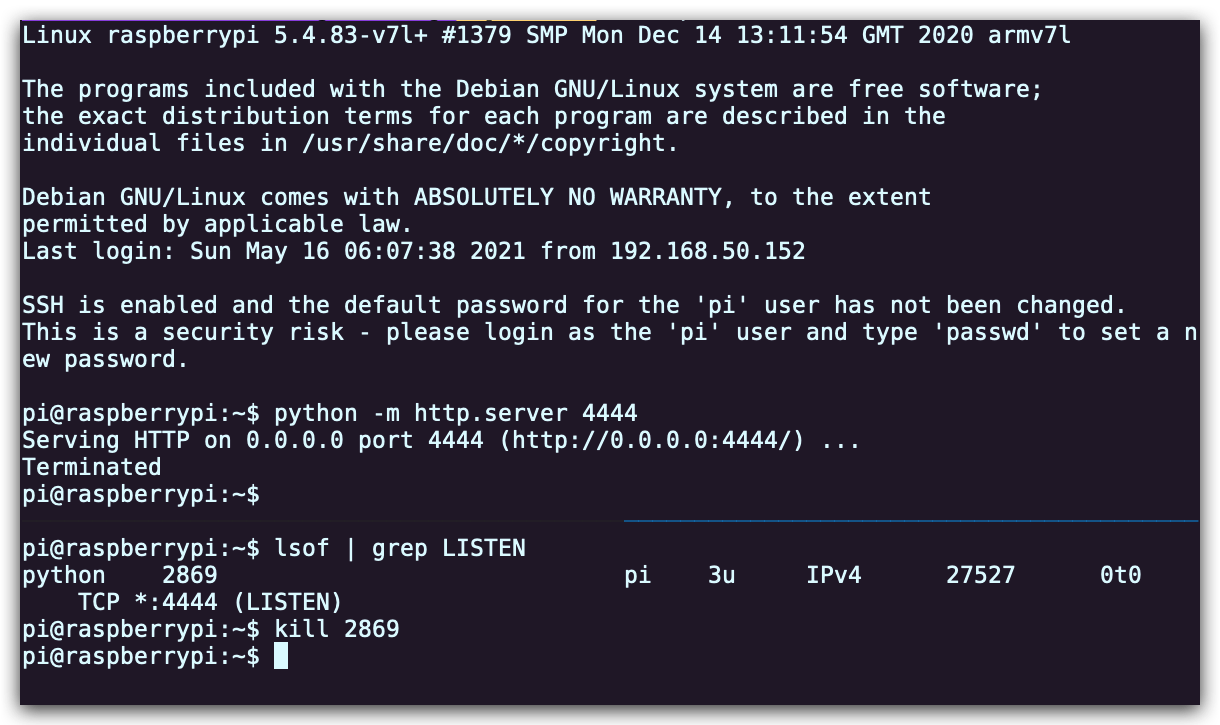
我们经常会遇到的情况是某个我们希望去监听的端口已经被其他进程占用了。让我们通过进程的PID查找相应的进程。首先执行
python -m http.server 4444启动一个最简单的 web 服务器来监听4444端口。在另外一个终端中,执行lsof | grep LISTEN打印出所有监听端口的进程及相应的端口。找到对应的 PID 然后使用kill <PID>停止该进程。 -
限制进程资源也是一个非常有用的技术。执行
stress -c 3并使用htop对 CPU 消耗进行可视化。现在,执行taskset --cpu-list 0,2 stress -c 3并可视化。stress占用了3个 CPU 吗?为什么没有?阅读man taskset来寻找答案。附加题:使用cgroups来实现相同的操作,限制stress -m的内存使用。 -
(进阶题)
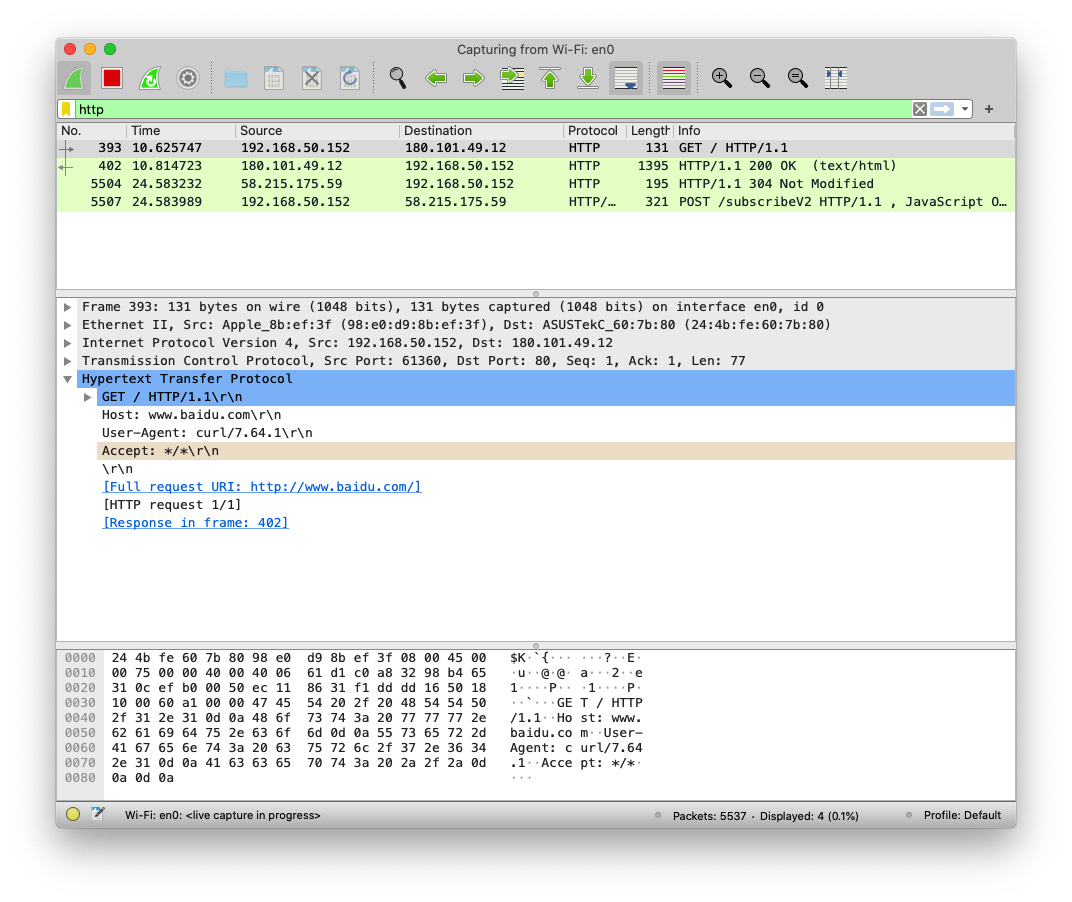
curl ipinfo.io命令或执行 HTTP 请求并获取关于您 IP 的信息。打开 Wireshark 并抓取curl发起的请求和收到的回复报文。(提示:可以使用http进行过滤,只显示 HTTP 报文)
Solution-调试与性能分析
1. 调试
-
使用 Linux 上的
journalctl或 macOS 上的log show命令来获取最近一天中超级用户的登录信息及其所执行的指令。如果找不到相关信息,您可以执行一些无害的命令,例如sudo ls然后再次查看。 这里我在树莓派上查询相关日志pi@raspberrypi:~$ journalctl | grep sudo pi@raspberrypi:~$ sudo ls Bookshelf myconfig project proxy pi@raspberrypi:~$ journalctl | grep sudo May 16 03:06:04 raspberrypi sudo[799]: pi : TTY=pts/0 ; PWD=/home/pi ; USER=root ; COMMAND=/usr/bin/ls May 16 03:06:04 raspberrypi sudo[799]: pam_unix(sudo:session): session opened for user root by pi(uid=0) May 16 03:06:04 raspberrypi sudo[799]: pam_unix(sudo:session): session closed for user root pi@raspberrypi:~$在 Mac 上面使用下面的命令
log show --last 1h | grep sudo -
安装
shellcheck并尝试对下面的脚本进行检查。这段代码有什么问题吗?请修复相关问题。在您的编辑器中安装一个linter插件,这样它就可以自动地显示相关警告信息。#!/bin/sh ## Example: a typical script with several problems for f in $(ls *.m3u) do grep -qi hq.*mp3 $f \ && echo -e 'Playlist $f contains a HQ file in mp3 format' done在 Vim 中可以通过neomake插件来集成 shellcheck,在
~/.vimrc中添加Plug 'neomake/neomake'call plug#begin() Plug 'neomake/neomake' call plug#end()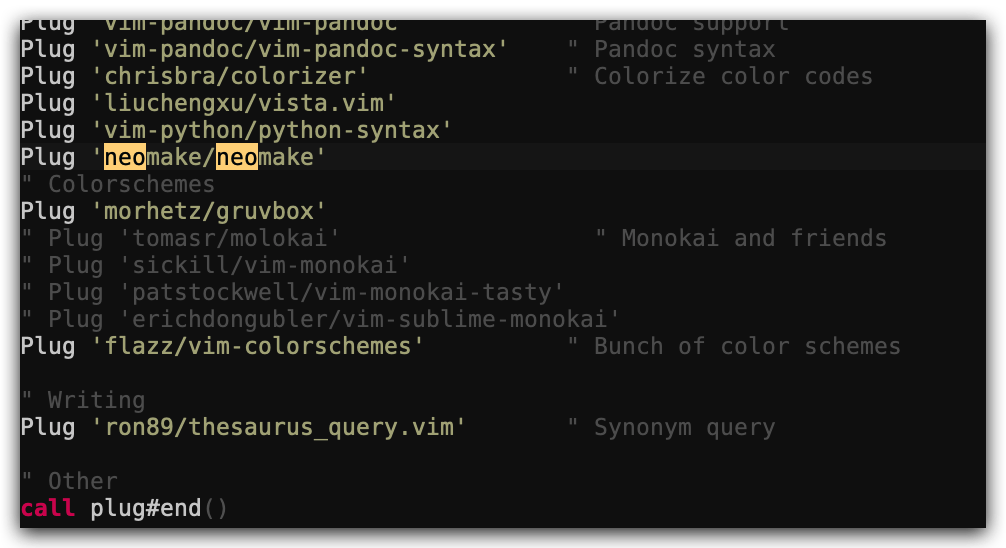 然后在 vim 执行
然后在 vim 执行:PlugInstall安装插件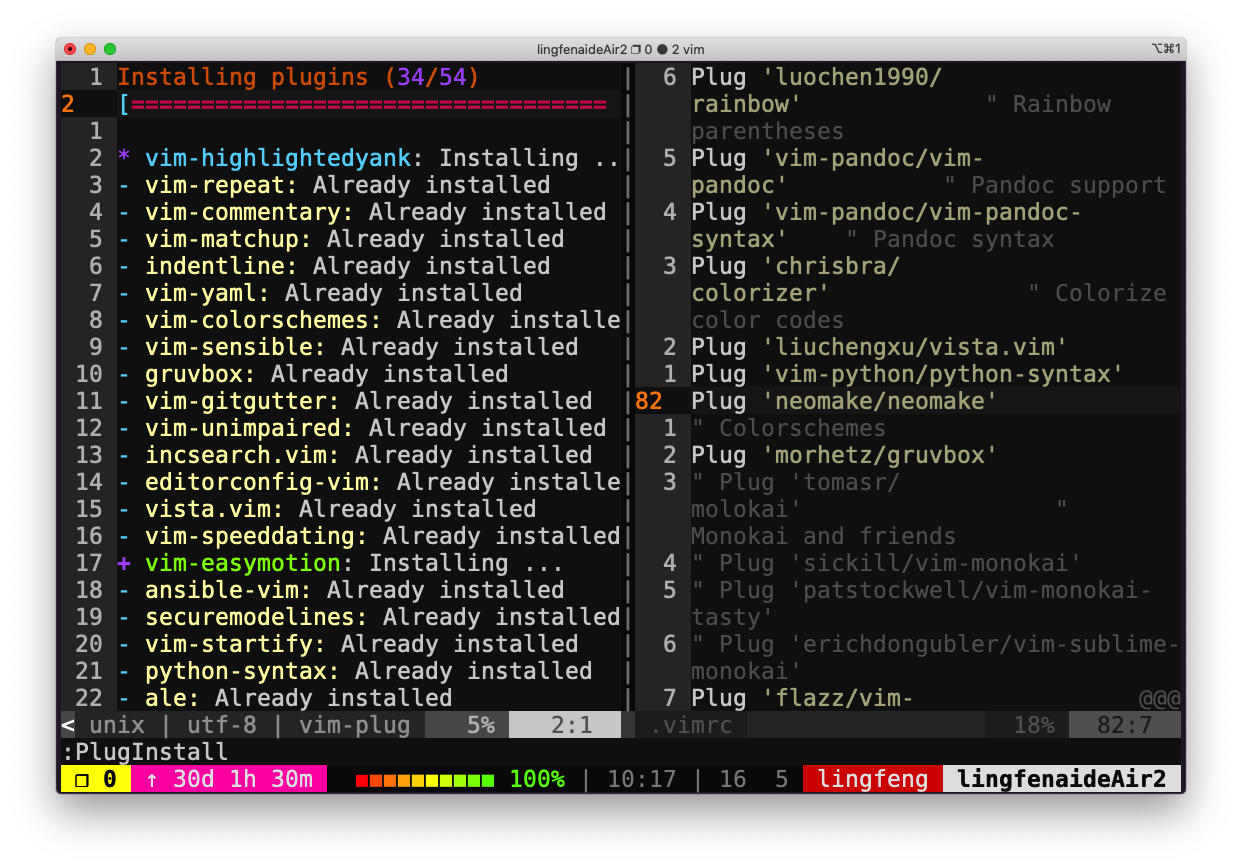 在需要检查的 shell 脚本中,执行
在需要检查的 shell 脚本中,执行:Neomake即可进行 shellcheck 检查。然后光标移动到对应行时可以看到告警或错误。
-
(进阶题) 请阅读 可逆调试 并尝试创建一个可以工作的例子(使用
rr或RevPDB)。此例主要参考了debug-c-and-c++-programs-with-rr,使用的代码是demo.c
# perf内置在linux-tools中,使用rr需要先安装perf ~/debug $ sudo apt install linux-tools-common linux-tools-generic linux-tools-`uname -r` ~/debug $ sudo apt install rr ~/debug $ echo 1 | sudo tee /proc/sys/kernel/perf_event_paranoid ~/debug $ gcc -g demo.c -o demo ~/debug $ ./demo f(0)=0 f(1)=0 f(2)=0 f(3)=0 # 预期输出结果为[0, 2, 4, 6]# -n选项:输出./demo的运行结果 ~/debug $ sudo rr record -n ./demo rr: Saving execution to trace directory `/root/.local/share/rr/deom-1'. f(0)=0 f(1)=0 f(2)=0 f(3)=0 # 进入rr-debugger中调试代码 ~/debug $ sudo rr replay- 在demo.c中,print_array只是打印出stru.a数组的内容,所以出错的地方应该在打印之前,即可能是multiply函数的调用,在此设置断点。
(rr) b multiply # break简写为b Breakpoint 1 at 0x5568214c818c: file demorr.c, line 16. (rr) c # continue简写为c Continuing. Breakpoint 1, multiply (a=0x5568214cb018 <stru> "", size=4, num=0) at demorr.c:16 16 for (i=0; i<size; i++)- 注意到multiply中传入num的值为 0,正常应该是stru.num的初始值 2,使用watch来查看stru.num的值什么时候被改变的。
(rr) watch -l stru.num Hardware watchpoint 2: -location stru.num # reverse-continue简写为rc,回退到watchpoint的值被更改的地方 (rr) rc Continuing. Hardware watchpoint 2: -location stru.num # stru.num的值从 2 变为了 0(注意现在是使用rc反向调试) # stru.num的值的变更发生在initialize函数的调用中 Old value = 0 New value = 2 initialize (a=0x5568214cb018 <stru> "", size=3) at demorr.c:10 10 a[size--] = 0; (rr) q- 观察initialize函数中的语句,发现
size--先返回size值,再执行size=size-1的操作。而且,由于结构体中变量的内存空间是连续的,所以执行a[SIZE]=0时,把stru.num的值置为了 0。为此,将a[size--]=0修改为a[--size]=0,再观察输出结果。
~/debug $ vim demo.c ~/debug $ gcc -g demo.c -o demo ~/debug $ ./demo f(0)=0 f(1)=2 f(2)=4 f(3)=6
2. 性能分析
-
这里 有一些排序算法的实现。请使用
cProfile和line_profiler来比较插入排序和快速排序的性能。两种算法的瓶颈分别在哪里?然后使用memory_profiler来检查内存消耗,为什么插入排序更好一些?然后再看看原地排序版本的快排。附加题:使用perf来查看不同算法的循环次数及缓存命中及丢失情况。python -m cProfile -s time sorts.py #按照执行时间排序python -m cProfile -s time sorts.py | grep sorts.py 33748/1000 0.066 0.000 0.069 0.000 sorts.py:23(quicksort) 34356/1000 0.045 0.000 0.055 0.000 sorts.py:32(quicksort_inplace) 3 0.037 0.012 0.347 0.116 sorts.py:4(test_sorted) 1000 0.031 0.000 0.032 0.000 sorts.py:11(insertionsort) 1 0.007 0.007 0.385 0.385 sorts.py:1(<module>)使用
line_profiler进行分析,需要安装:pip install line_profiler然后为需要分析的函数添加装饰器
@profile,并执行:kernprof -l -v sorts.py首先对快速排序进行分析:
Wrote profile results to sorts.py.lprof Timer unit: 1e-06 s Total time: 0.490021 s File: sorts.py Function: quicksort at line 22 Line # Hits Time Per Hit % Time Line Contents ============================================================== 22 @profile 23 def quicksort(array): 24 32594 91770.0 2.8 18.7 if len(array) <= 1: 25 16797 36674.0 2.2 7.5 return array 26 15797 37626.0 2.4 7.7 pivot = array[0] 27 15797 125796.0 8.0 25.7 left = [i for i in array[1:] if i < pivot] 28 15797 119954.0 7.6 24.5 right = [i for i in array[1:] if i >= pivot] 29 15797 78201.0 5.0 16.0 return quicksort(left) + [pivot] + quicksort(right)然后对插入排序进行分析:
Total time: 1.33387 s File: sorts.py Function: insertionsort at line 11 Line # Hits Time Per Hit % Time Line Contents ============================================================== 11 @profile 12 def insertionsort(array): 13 14 26801 44242.0 1.7 3.3 for i in range(len(array)): 15 25801 43372.0 1.7 3.3 j = i-1 16 25801 41950.0 1.6 3.1 v = array[i] 17 234763 434280.0 1.8 32.6 while j >= 0 and v < array[j]: 18 208962 380062.0 1.8 28.5 array[j+1] = array[j] 19 208962 343217.0 1.6 25.7 j -= 1 20 25801 45248.0 1.8 3.4 array[j+1] = v 21 1000 1503.0 1.5 0.1 return array插入排序的耗时更高一些。快速排序的瓶颈在于
left和right的赋值,而插入排序的瓶颈在while循环。
使用memory_profiler进行分析,需要安装:pip install memory_profiler同样需要添加
@profile装饰器。 首先分析快速排序的内存使用情况:pi@raspberrypi:~$ python -m memory_profiler sorts.py Filename: sorts.py Line # Mem usage Increment Occurences Line Contents ============================================================ 22 20.199 MiB 20.199 MiB 32800 @profile 23 def quicksort(array): 24 20.199 MiB 0.000 MiB 32800 if len(array) <= 1: 25 20.199 MiB 0.000 MiB 16900 return array 26 20.199 MiB 0.000 MiB 15900 pivot = array[0] 27 20.199 MiB 0.000 MiB 152906 left = [i for i in array[1:] if i < pivot] 28 20.199 MiB 0.000 MiB 152906 right = [i for i in array[1:] if i >= pivot] 29 20.199 MiB 0.000 MiB 15900 return quicksort(left) + [pivot] + quicksort(right)然后分析插入排序的内存使用情况:
pi@raspberrypi:~$ python -m memory_profiler sorts.py Filename: sorts.py Line # Mem usage Increment Occurences Line Contents ============================================================ 11 20.234 MiB 20.234 MiB 1000 @profile 12 def insertionsort(array): 13 14 20.234 MiB 0.000 MiB 26638 for i in range(len(array)): 15 20.234 MiB 0.000 MiB 25638 j = i-1 16 20.234 MiB 0.000 MiB 25638 v = array[i] 17 20.234 MiB 0.000 MiB 237880 while j >= 0 and v < array[j]: 18 20.234 MiB 0.000 MiB 212242 array[j+1] = array[j] 19 20.234 MiB 0.000 MiB 212242 j -= 1 20 20.234 MiB 0.000 MiB 25638 array[j+1] = v 21 20.234 MiB 0.000 MiB 1000 return array同时对比原地操作的快速排序算法内存情况:
pi@raspberrypi:~$ python -m memory_profiler sorts.py Filename: sorts.py Line # Mem usage Increment Occurences Line Contents ============================================================ 31 20.121 MiB 20.121 MiB 33528 @profile 32 def quicksort_inplace(array, low=0, high=None): 33 20.121 MiB 0.000 MiB 33528 if len(array) <= 1: 34 20.121 MiB 0.000 MiB 42 return array 35 20.121 MiB 0.000 MiB 33486 if high is None: 36 20.121 MiB 0.000 MiB 958 high = len(array)-1 37 20.121 MiB 0.000 MiB 33486 if low >= high: 38 20.121 MiB 0.000 MiB 17222 return array 39 40 20.121 MiB 0.000 MiB 16264 pivot = array[high] 41 20.121 MiB 0.000 MiB 16264 j = low-1 42 20.121 MiB 0.000 MiB 124456 for i in range(low, high): 43 20.121 MiB 0.000 MiB 108192 if array[i] <= pivot: 44 20.121 MiB 0.000 MiB 55938 j += 1 45 20.121 MiB 0.000 MiB 55938 array[i], array[j] = array[j], array[i] 46 20.121 MiB 0.000 MiB 16264 array[high], array[j+1] = array[j+1], array[high] 47 20.121 MiB 0.000 MiB 16264 quicksort_inplace(array, low, j) 48 20.121 MiB 0.000 MiB 16264 quicksort_inplace(array, j+2, high) 49 20.121 MiB 0.000 MiB 16264 return array- 遗憾的是,按照上面的方法使用
memory_profiler给出的结果无法作为这三种排序算法内存消耗对比的依据(从我自己运行的结果来看,insertionsort的43.301MiB甚至还大于quicksort的43.195MiB,与预期结果相反!!) - 另外,观察三组结果中,函数的每一行的
Increment(即执行该行所导致的内存占用的增减变化)均为 0!这是由于test_sorted用于测试的list太小了,长度仅为1~50,导致排序算法中每一行创建的变量内存占用也很小。如果直接使用一个长度为2000的list来测试:l = [random.randint(0,10000) for i in range(0, 2000)],会发现quicksort函数的Left或Right行的Increment数据不为 0(创建的list占用内存较大了)。与此同时,用该list测试insertionsort函数时,发现耗用时间较长。 - 参考python-profiling-memory-profiling这篇文章,使用一个长度为 10 000的list测试冒泡排序的内存消耗,需要将近30分钟才输出结果。(使用memory_profiler要权衡时间与效率)
使用perf检查每个算法的循环次数、缓存命中和丢失:
- insertionsort的结果
~/debug $ vim sorts.py # 修改main函数删除for循环,改为:test_sorted(insertionsort) ~/debug $ sudo perf stat -e cycles,cache-references,cache-misses python3 sorts.py Performance counter stats for 'python3 sorts.py': 187,253,954 cycles 5,023,695 cache-references 891,768 cache-misses # 17.751 % of all cache refs 0.099464106 seconds time elapsed 0.082930000 seconds user 0.016586000 seconds sys- quicksort的结果
~/debug $ vim sorts.py # main函数的内容改为:test_sorted(quicksort) ~/debug $ sudo perf stat -e cycles,cache-references,cache-misses python3 sorts.py Performance counter stats for 'python3 sorts.py': 192,741,421 cycles 6,843,630 cache-references 898,594 cache-misses # 13.130 % of all cache refs 0.057831555 seconds time elapsed 0.057863000 seconds user 0.000000000 seconds sys- quicksort_inplace的结果
~/debug $ vim sorts.py # main函数改为:test_sorted(quicksort_inplace) ~/debug $ sudo perf stat -e cycles,cache-references,cache-misses python3 sorts.py Performance counter stats for 'python3 sorts.py': 179,221,185 cycles 5,700,092 cache-references 892,157 cache-misses # 15.652 % of all cache refs 0.097429528 seconds time elapsed 0.089351000 seconds user 0.008122000 seconds sys - 遗憾的是,按照上面的方法使用
-
这里有一些用于计算斐波那契数列 Python 代码,它为计算每个数字都定义了一个函数:
#!/usr/bin/env python def fib0(): return 0 def fib1(): return 1 s = """def fib{}(): return fib{}() + fib{}()""" if __name__ == '__main__': for n in range(2, 10): exec(s.format(n, n-1, n-2)) # from functools import lru_cache # for n in range(10): # exec("fib{} = lru_cache(1)(fib{})".format(n, n)) print(eval("fib9()"))将代码拷贝到文件中使其变为一个可执行的程序。首先安装
pycallgraph和graphviz(如果您能够执行dot, 则说明已经安装了 GraphViz.)。并使用pycallgraph graphviz -- ./fib.py来执行代码并查看pycallgraph.png这个文件。fib0被调用了多少次?我们可以通过记忆法来对其进行优化。将注释掉的部分放开,然后重新生成图片。这回每个fibN函数被调用了多少次?setuptools版本过高可能导致pycallgraph安装失败
pip install "setuptools<58.0.0" pip install pycallgraph 放开注释内容后,再次执行:
放开注释内容后,再次执行: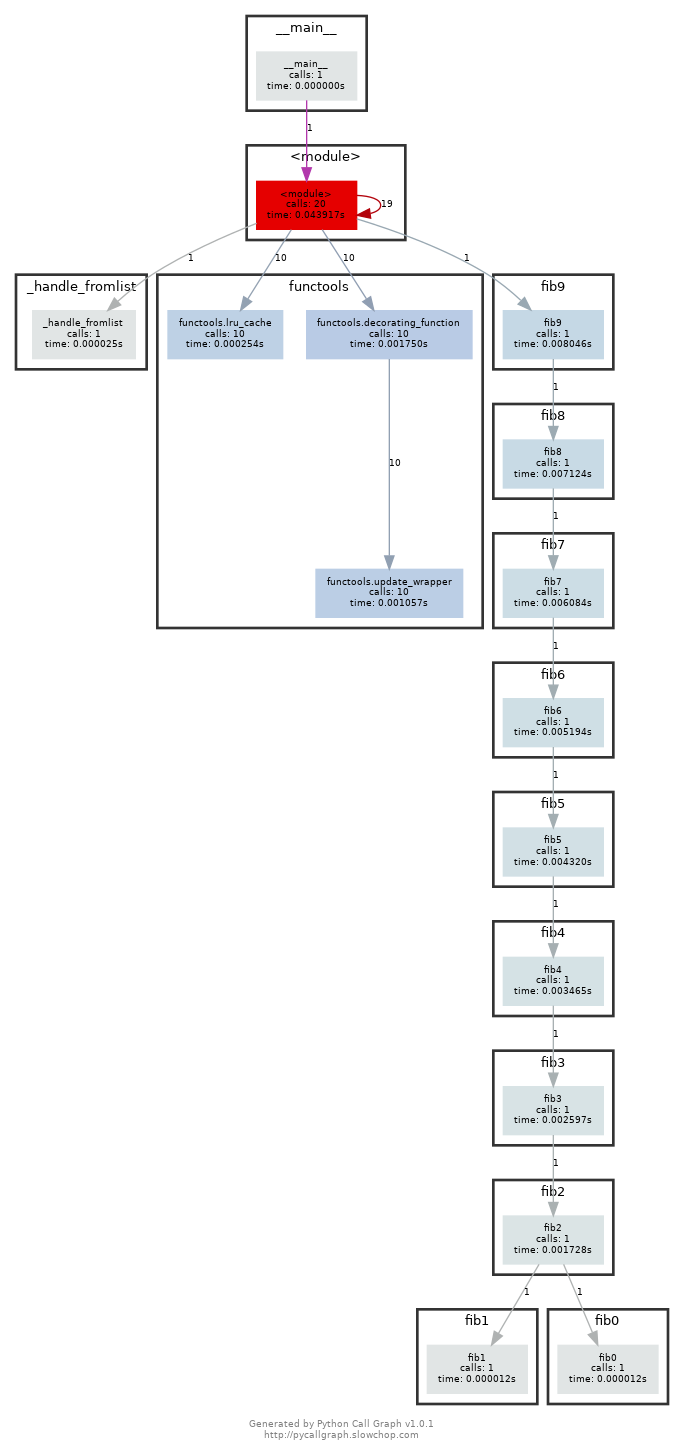 注意:如果你是 Python 2.7的话,需要修改一下注释的内容:
注意:如果你是 Python 2.7的话,需要修改一下注释的内容:from backports.functools_lru_cache import lru_cache不过生成的图片里面会包含很多不相关的内容。
-
我们经常会遇到的情况是某个我们希望去监听的端口已经被其他进程占用了。让我们通过进程的PID查找相应的进程。首先执行
python -m http.server 4444启动一个最简单的 web 服务器来监听4444端口。在另外一个终端中,执行lsof | grep LISTEN打印出所有监听端口的进程及相应的端口。找到对应的 PID 然后使用kill <PID>停止该进程。
-
限制进程资源也是一个非常有用的技术。执行
stress -c 3并使用htop对 CPU 消耗进行可视化。现在,执行taskset --cpu-list 0,2 stress -c 3并可视化。stress占用了3个 CPU 吗?为什么没有?阅读man taskset来寻找答案。附加题:使用cgroups来实现相同的操作,限制stress -m的内存使用。
首先是设备正常运行状态下的资源占用情况: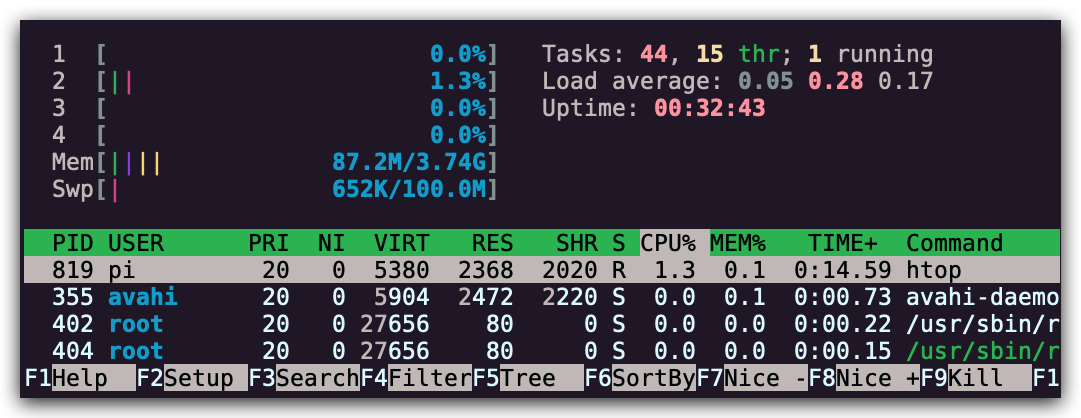 创建负载:
创建负载:stress -c 3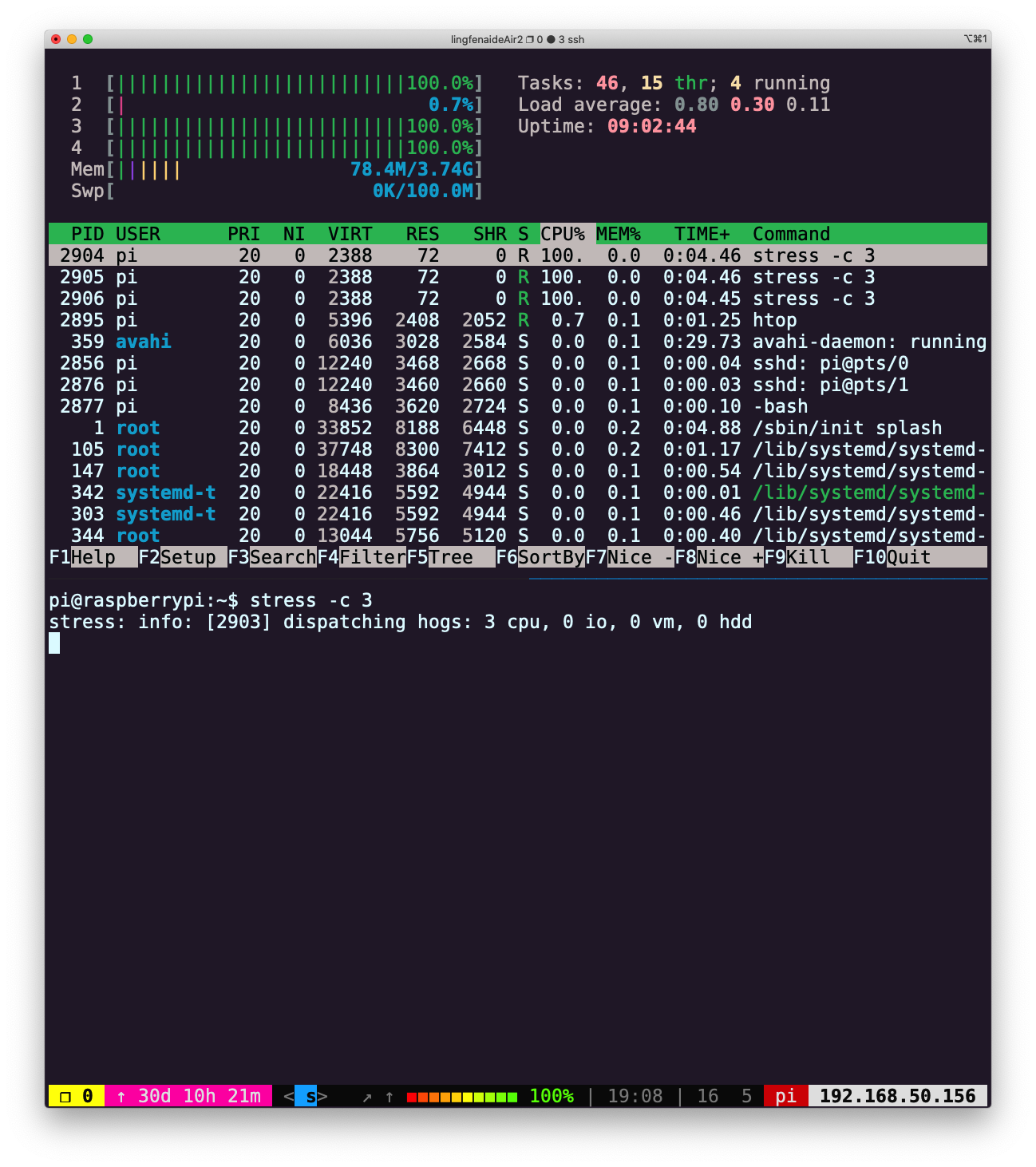 限制资源消耗
限制资源消耗taskset --cpu-list 0,2 stress -c 3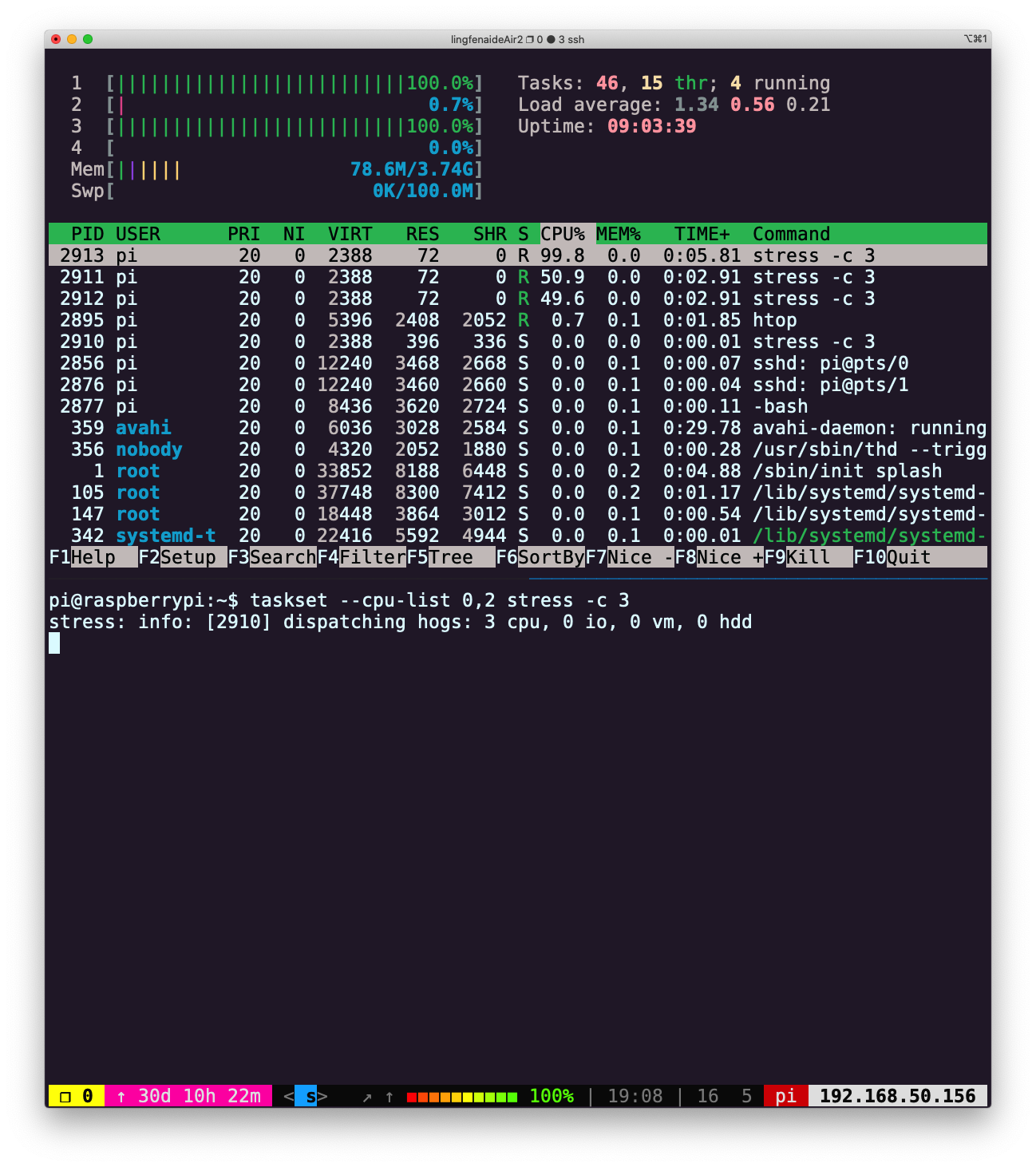 taskset 命令可以将任务绑定到指定CPU核心。
taskset 命令可以将任务绑定到指定CPU核心。
 接下来看
接下来看cgroups是如何工作的,我参考了两篇文章:首先我们看一下如何创建内存负载,这里创建 3 个 worker 来不停的申请释放 512M 内存:
stress -m 3 --vm-bytes 512M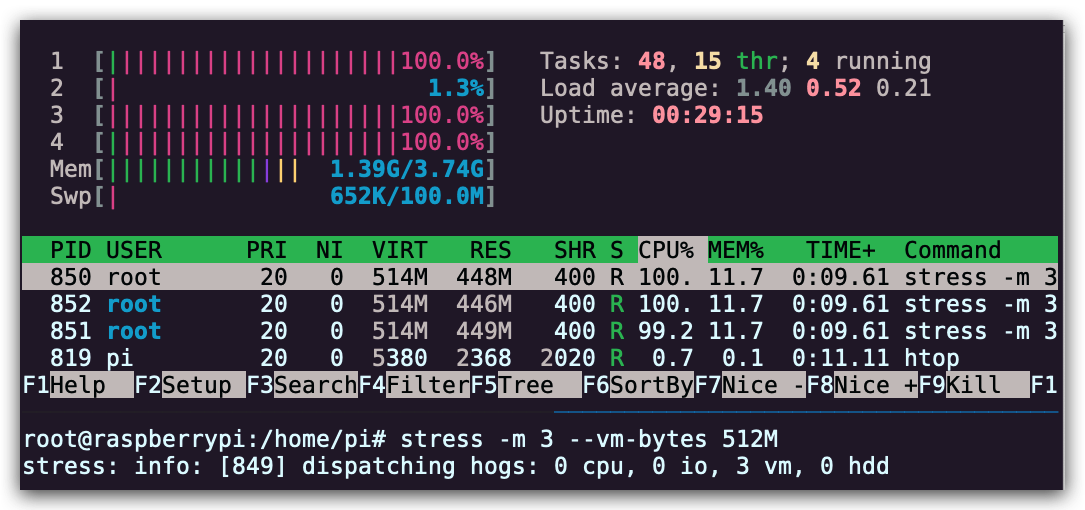 由于题目要求限制内存的使用,首先我们看一下内存设备是否已经挂载:
由于题目要求限制内存的使用,首先我们看一下内存设备是否已经挂载:root@raspberrypi:~# lssubsys -am memory cpuset /sys/fs/cgroup/cpuset cpu,cpuacct /sys/fs/cgroup/cpu,cpuacct blkio /sys/fs/cgroup/blkio devices /sys/fs/cgroup/devices freezer /sys/fs/cgroup/freezer net_cls,net_prio /sys/fs/cgroup/net_cls,net_prio perf_event /sys/fs/cgroup/perf_event pids /sys/fs/cgroup/pids root@raspberrypi:~#内存没挂载的情况下,需要手动挂载:
mount -t cgroup -o memory memory /sys/fs/cgroup/memory我在树莓派上出现了不能挂载的情况,此时需要修改
boot.cmdline.txt,添加:cgroup_enable=memory cgroup_memory=1然后重启,再次查看
pi@raspberrypi:~$ lssubsys -am cpuset /sys/fs/cgroup/cpuset cpu,cpuacct /sys/fs/cgroup/cpu,cpuacct blkio /sys/fs/cgroup/blkio memory /sys/fs/cgroup/memory devices /sys/fs/cgroup/devices freezer /sys/fs/cgroup/freezer net_cls,net_prio /sys/fs/cgroup/net_cls,net_prio perf_event /sys/fs/cgroup/perf_event pids /sys/fs/cgroup/pids pi@raspberrypi:~$已经挂载成功,然后创建组并写入规则(内存限制为128M)
root@raspberrypi:/home/pi# cgcreate -g memory:cgroup_test_group root@raspberrypi:/home/pi# echo 128M > /sys/fs/cgroup/memory/cgroup_test_group/memory.limit_in_bytes然后在控制组中运行
stress,创建 3 个 worker 申请 512M 内存:oot@raspberrypi:/home/pi# cgexec -g memory:cgroup_test_group stress -m 3 --vm-bytes 512M stress: info: [832] dispatching hogs: 0 cpu, 0 io, 3 vm, 0 hdd stress: FAIL: [832] (415) <-- worker 833 got signal 9 stress: WARN: [832] (417) now reaping child worker processes stress: FAIL: [832] (451) failed run completed in 5s执行失败。
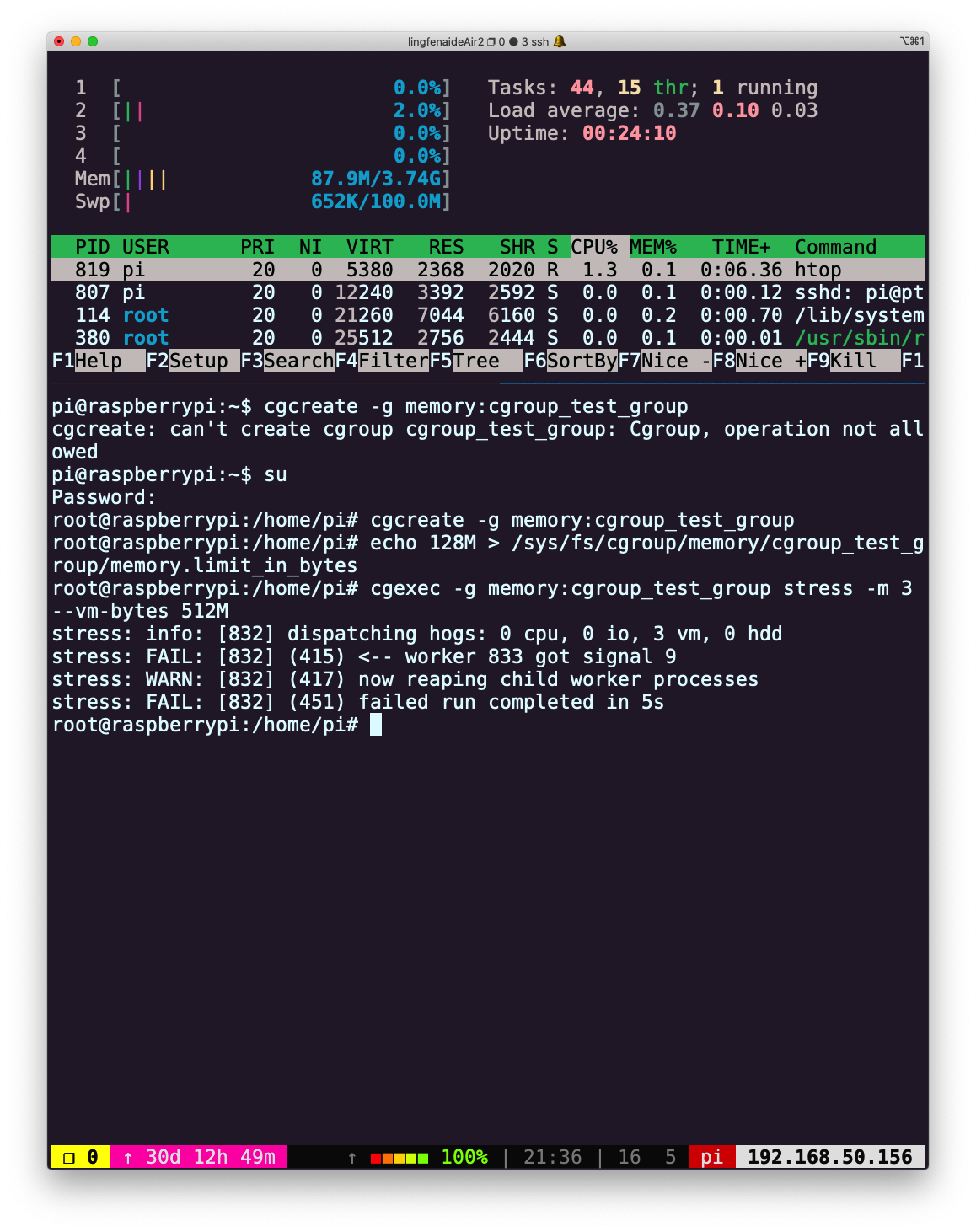
如果是申请 1M 内存,则可以成功运行:cgexec -g memory:cgroup_test_group stress -m 3 --vm-bytes 1M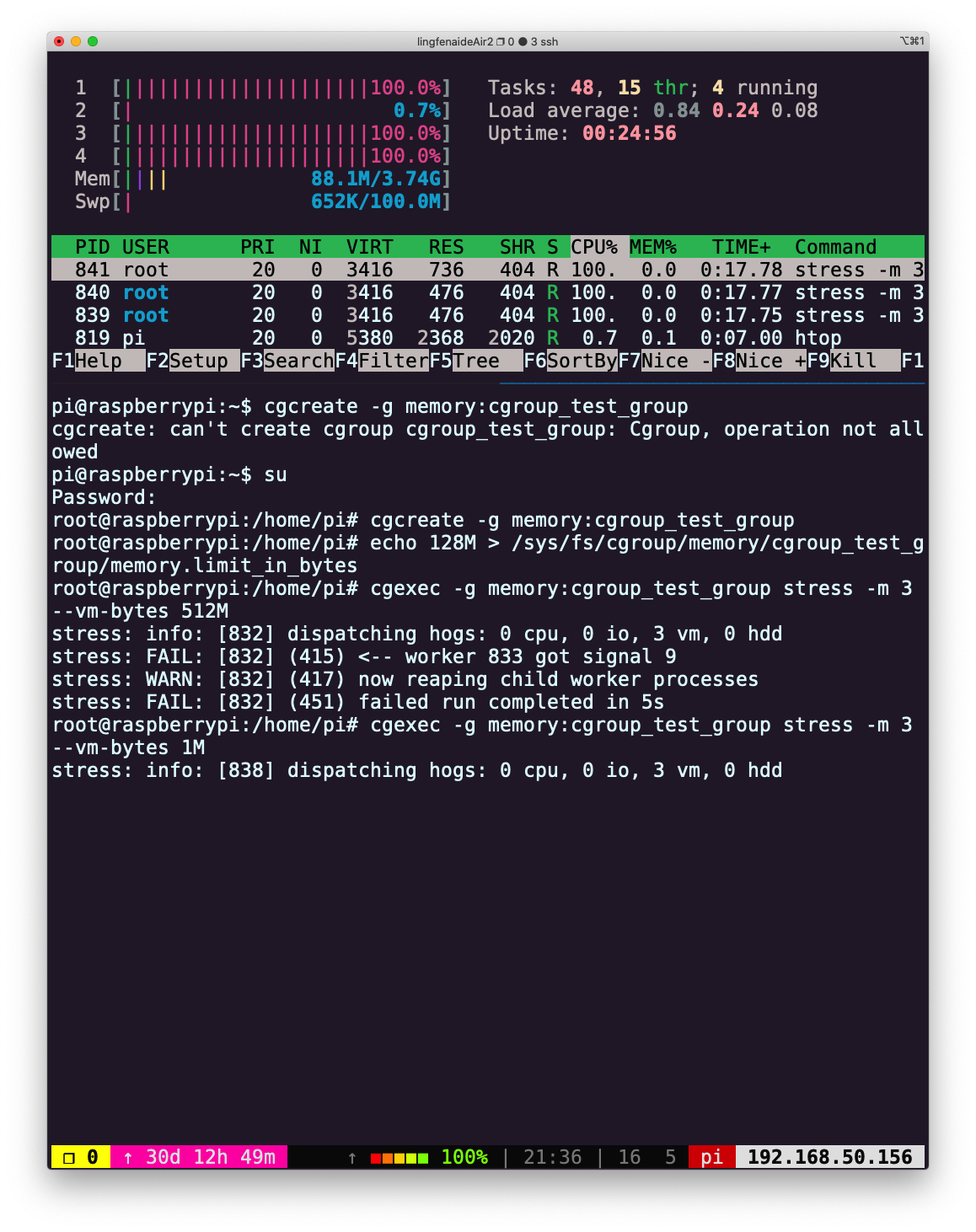
下面是使用cgroupV2限制stress命令内存的示例:比较新版本的Ubuntu默认安装
cgroup v2,可以参考Ubuntu激活cgroupv2。下面,将使用cgroupv2实现限制进程内存消耗的操作,更多信息可参考详解CgroupV2。设置,使用cgroup2
~ $ grep cgroup /proc/filesystems nodev cgroup nodev cgroup2 # 输出结果有cgroup2,说明当前系统支持cgroup2 ~ $ sudo vim /etc/default/grub # 查找变量GRUB_CMDLINE_LINUX_DEFAULT,将原来的行注释掉 # 新增一行:GRUB_CMDLINE_LINUX_DEFAULT="systemd.unified_cgroup_hierarchy=1" ~ $ sudo update-grub ~ $ reboot重启后,检查:
~ $ cat /sys/fs/cgroup/cgroup.controllers cpuset cpu io memory hugetlb pids rdma misc # 这些是cgroup挂载的控制器 ~ $ sudo su root@laihj:~# cd /sys/fs/cgroup # 该目录为cgroup的根root,在其下创建的子目录是其节点 root@laihj:/sys/fs/cgroup# mkdir -p test test/cg root@laihj:/sys/fs/cgroup# ls test cg cgroup.type memory.numa_stat cgroup.controllers cpu.pressure memory.oom.group cgroup.events cpu.stat memory.pressure cgroup.freeze io.pressure memory.stat cgroup.kill memory.current memory.swap.current cgroup.max.depth memory.events memory.swap.events cgroup.max.descendants memory.events.local memory.swap.high cgroup.procs memory.high memory.swap.max cgroup.stat memory.low pids.current cgroup.subtree_control memory.max pids.events cgroup.threads memory.min pids.max root@laihj:/sys/fs/cgroup# ls test/cg cgroup.controllers cgroup.max.descendants cgroup.type cgroup.events cgroup.procs cpu.pressure cgroup.freeze cgroup.stat cpu.stat cgroup.kill cgroup.subtree_control io.pressure cgroup.max.depth cgroup.threads memory.pressure # test节点挂载了memory控制器,所以目录下出现了"memory.*"文件为test/cg挂载memory控制器,并设置memory的使用大小
root@laihj:/sys/fs/cgroup# cd test root@laihj:/sys/fs/cgroup/test# cat cgroup.subtree_control root@laihj:/sys/fs/cgroup/test# echo "+memory" > cgroup.subtree_control root@laihj:/sys/fs/cgroup/test# cat cgroup.subtree_control memory root@laihj:/sys/fs/cgroup/test# echo 100M > memory.max root@laihj:/sys/fs/cgroup/test# echo 0 > memory.swap.max # 设置memory的最大使用量为 100M,同时,必须限制内存交换空间的使用将当前的
bash session pid写入cg中,接下来在bash中执行的所有命令会受到刚才的memory设置的影响(注意,除了根,进程只能驻留在叶节点(没有子cgroup目录的cgroup目录echo $$ > test/cgroup.procs会报错))root@laihj:/sys/fs/cgroup/test# echo $$ > cg/cgroup.procs root@laihj:/sys/fs/cgroup/test# stress -m 3 --vm-bytes 200M stress: info: [5018] dispatching hogs: 0 cpu, 0 io, 3 vm, 0 hdd stress: FAIL: [5018] (416) <-- worker 5020 got signal 9 stress: WARN: [5018] (418) now reaping child worker processes stress: FAIL: [5018] (452) failed run completed in 0s root@laihj:/sys/fs/cgroup/test# stress -m 3 --vm-bytes 40M # 3 个 worker 各分配 40M,总的 120M,仍超过了设置的100M上限 stress: info: [5030] dispatching hogs: 0 cpu, 0 io, 3 vm, 0 hdd stress: FAIL: [5030] (416) <-- worker 5032 got signal 9 stress: WARN: [5030] (418) now reaping child worker processes stress: FAIL: [5030] (452) failed run completed in 0s root@laihj:/sys/fs/cgroup/test# stress -m 3 --vm-bytes 20M stress: info: [5034] dispatching hogs: 0 cpu, 0 io, 3 vm, 0 hdd ^C # 正常执行,按下ctrl+C终止stress命令删除cgroup下的节点,需要从叶节点开始(最内层的目录)
# 确保test/cg中的进程全部停止,这里需要退出当前bash session,即关闭终端,然后,重新开启 ~ $ sudo rmdir /sys/fs/cgroup/test/cg ~ $ sudo rmdir /sys/fs/cgroup/test -
(进阶题)
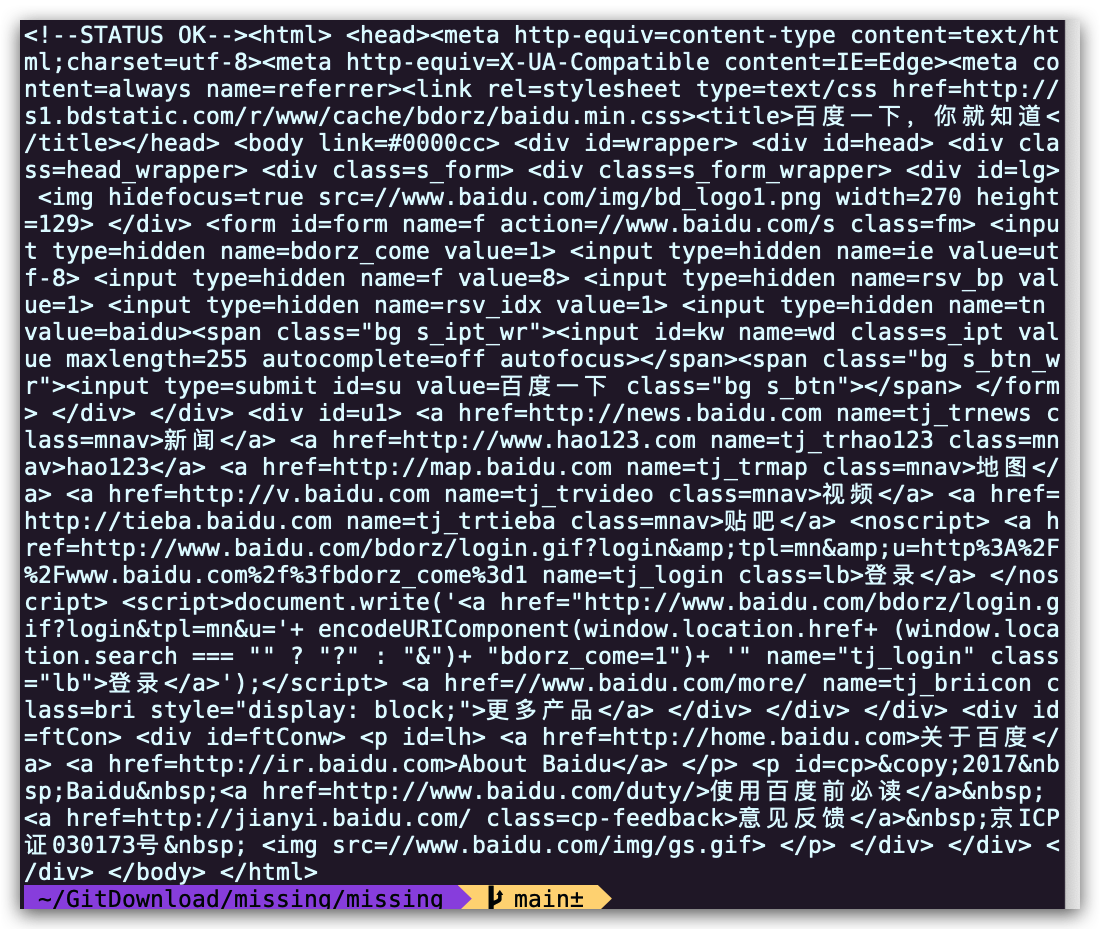
curl ipinfo.io命令或执行 HTTP 请求并获取关于您 IP 的信息。打开 Wireshark 并抓取curl发起的请求和收到的回复报文。(提示:可以使用http进行过滤,只显示 HTTP 报文) 这里我使用的是curl www.baidu.com,请求百度的首页并过滤了除 HTTP 之外的其他报文: