虚拟内存
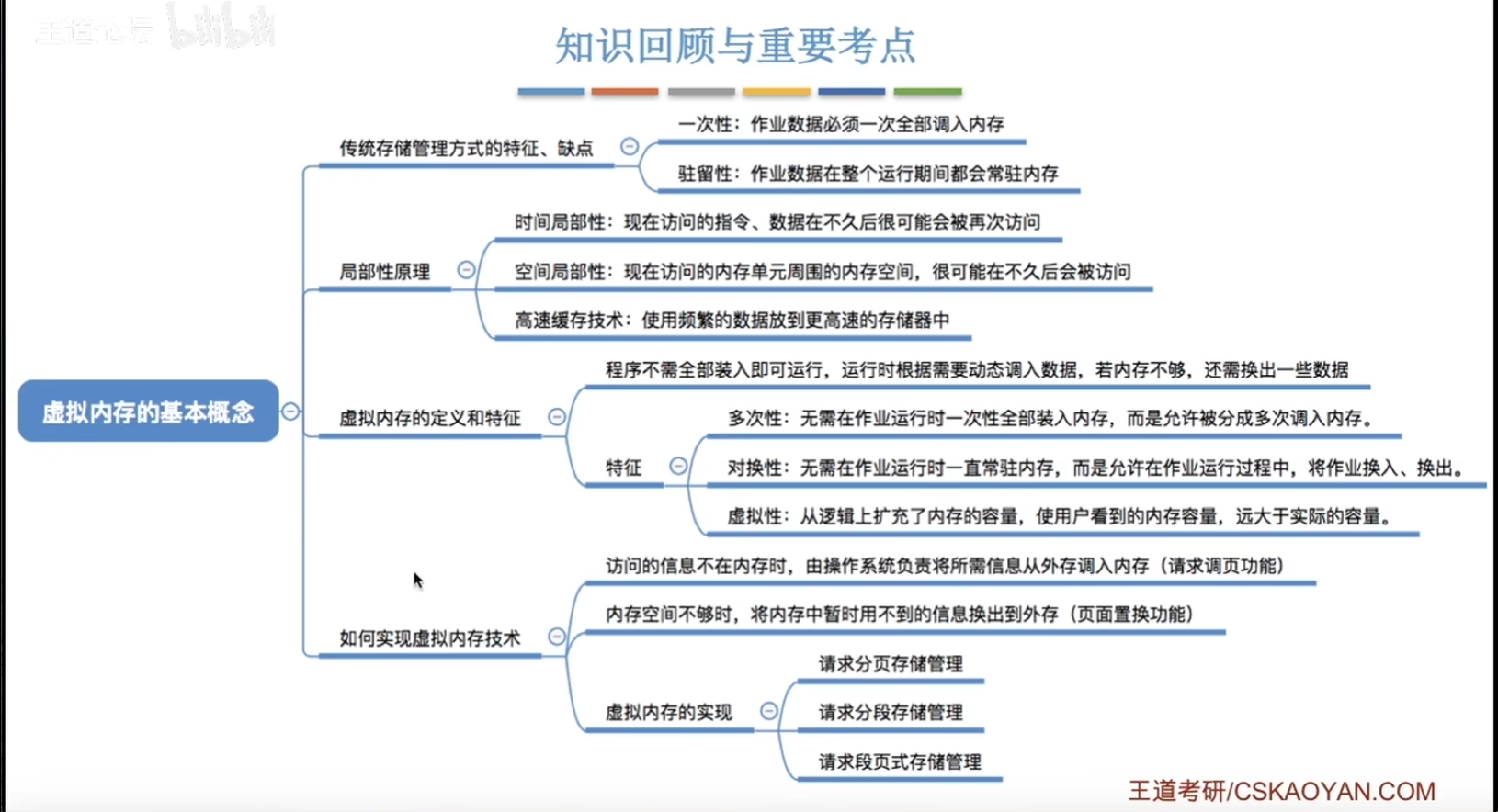
虚拟内存的基本概念
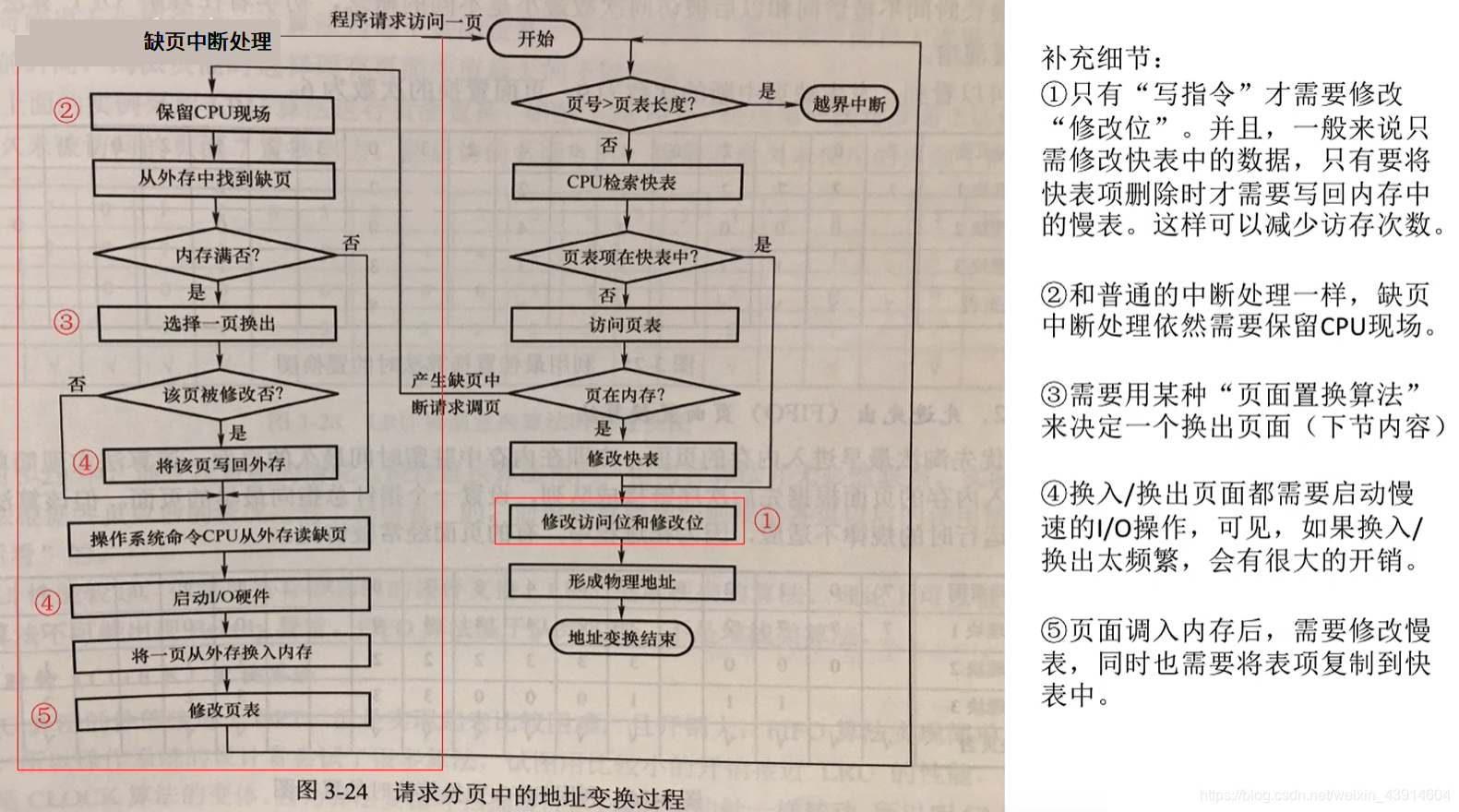
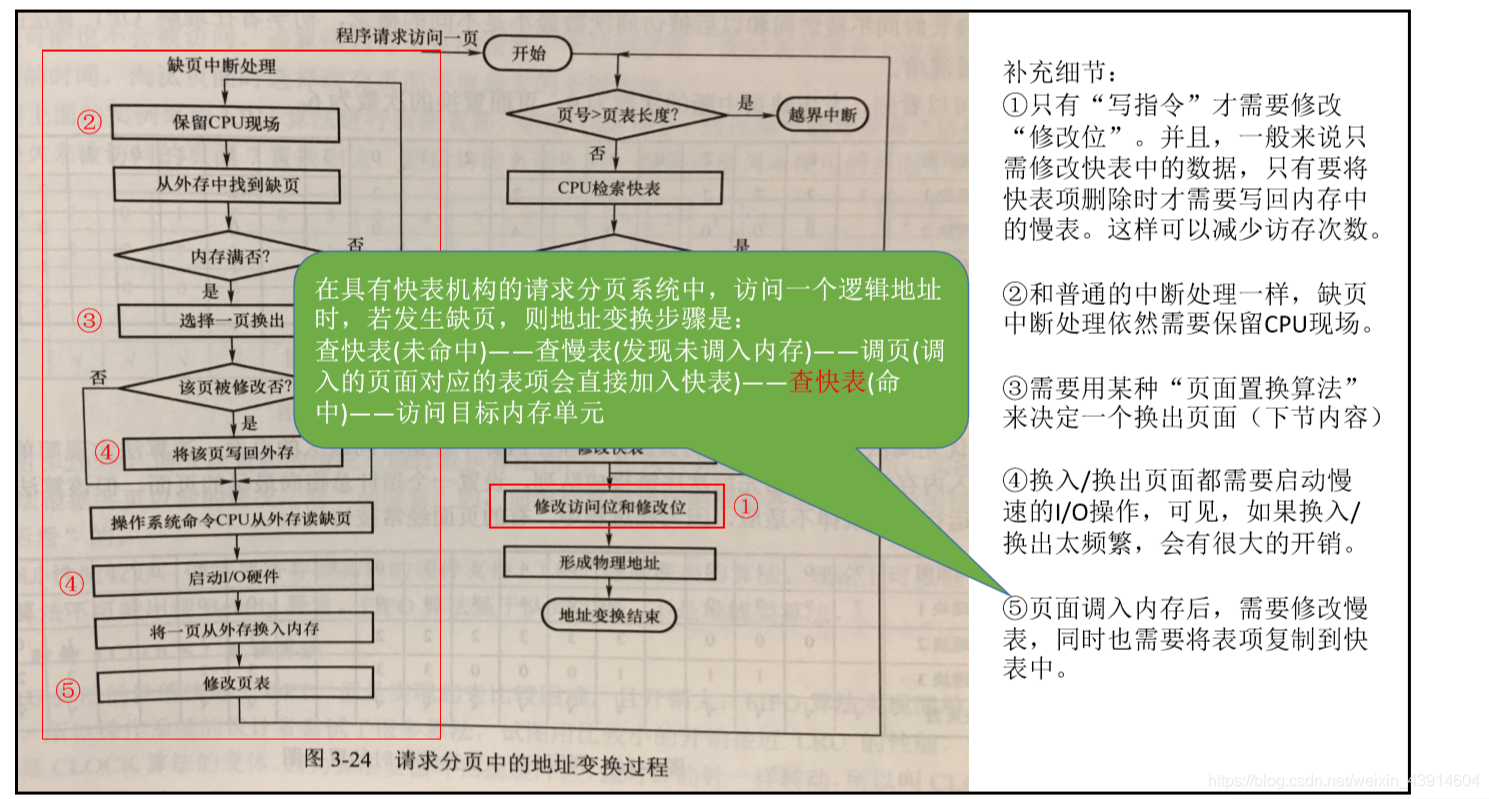
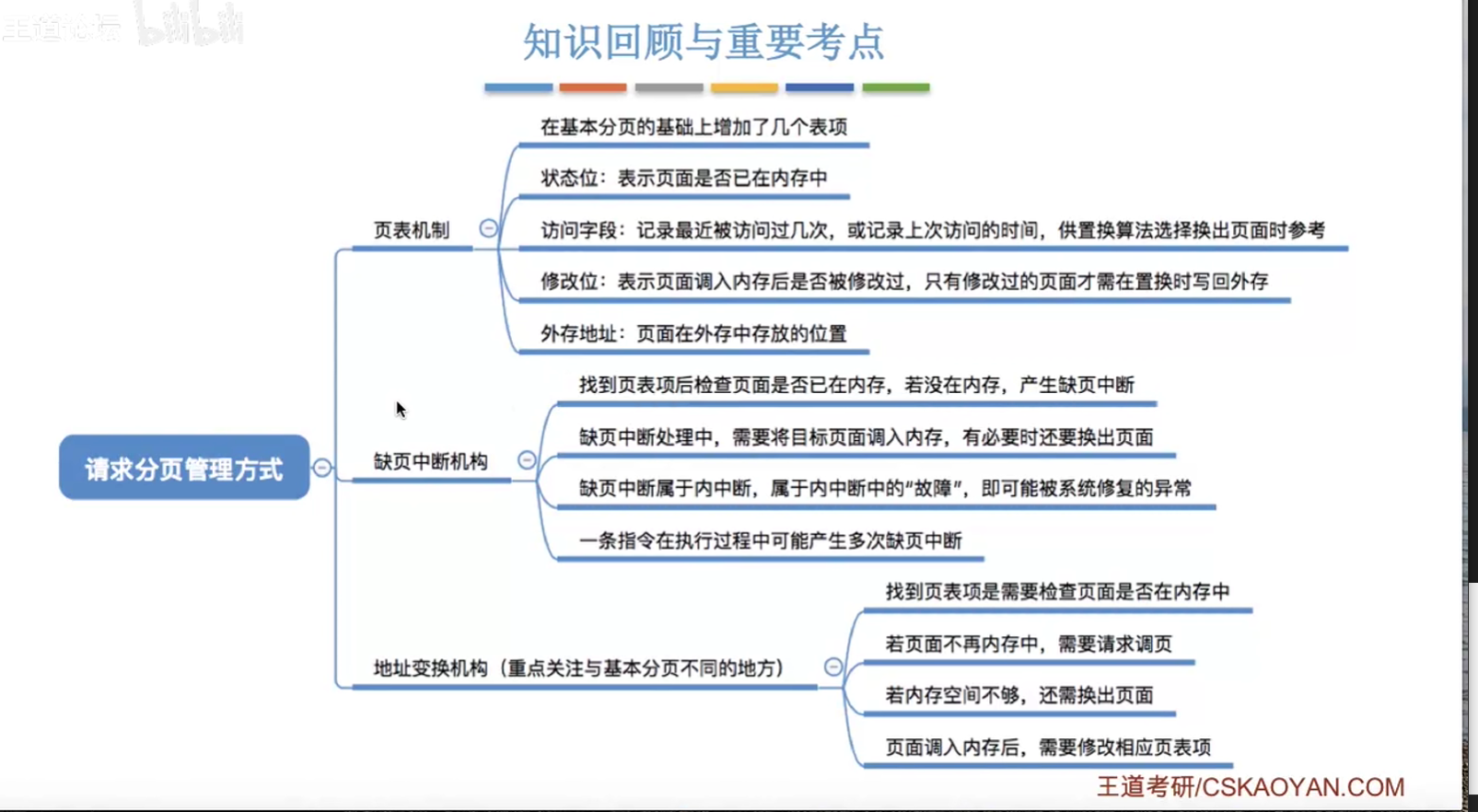
请求分页管理方式
页面置换算法
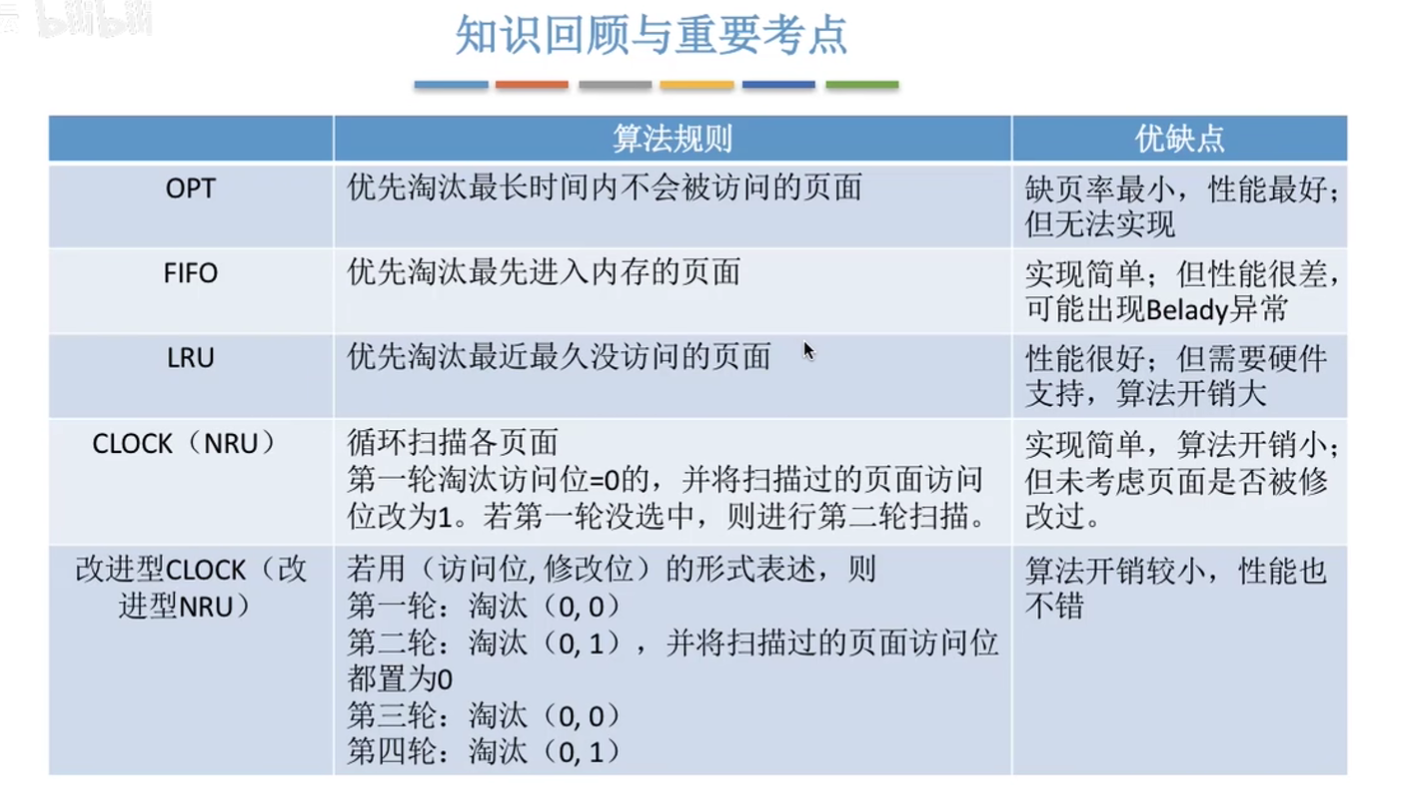
页面分配策略、抖动、工作集
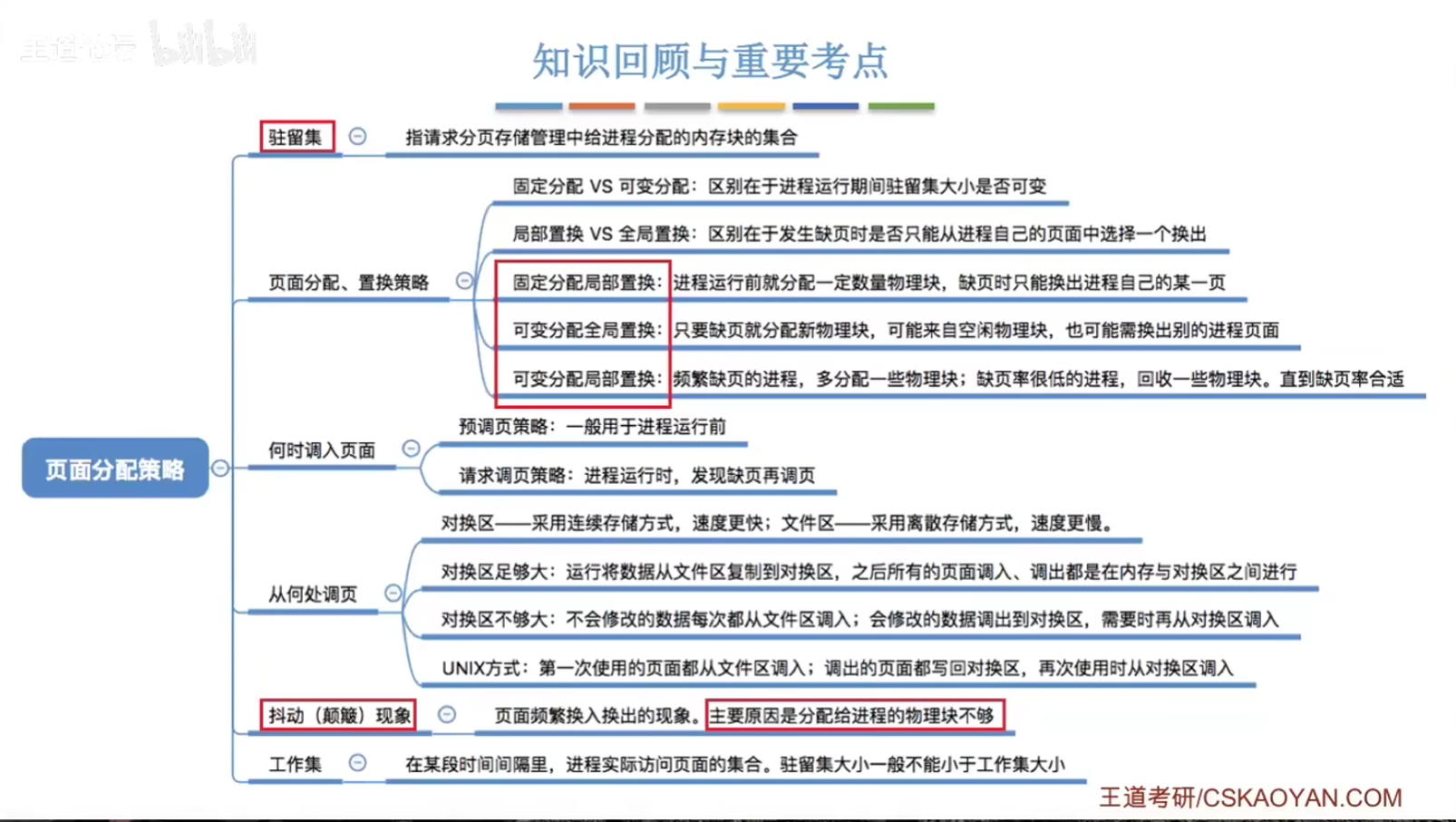
内存映射文件
LRU调度机制实现
问题描述
请你设计并实现一个满足 LRU (最近最少使用) 缓存 约束的数据结构。
实现 LRUCache 类:
LRUCache(int capacity) 以 正整数 作为容量 capacity 初始化 LRU 缓存
int get(int key) 如果关键字 key 存在于缓存中,则返回关键字的值,否则返回 -1 。
void put(int key, int value) 如果关键字 key 已经存在,则变更其数据值 value ;如果不存在,则向缓存中插入该组 key-value 。如果插入操作导致关键字数量超过 capacity ,则应该 逐出 最久未使用的关键字。
函数 get 和 put 最好以 O(1) 的平均时间复杂度运行。
输入说明
输入若干行:
第一行输入一个整数capacity表示LRU缓存的容量。
后面每行输入为put或get:
如果指令为put类型,后面需要输入两个整数表示key和value。
如果指令为get类型,后面需要输入一个整数表示key。
提示:
1 <= capacity <= 3000
0 <= key <= 10000
0 <= value <= 10^5
最多调用 2 * 10^5 次 get 和 put
输出说明
输出若干行:
每行一个整数,表示为get指令的返回值。
示例
输入
2
put 1 1
put 2 2
get 1
put 3 3
get 2
put 4 4
get 1
get 3
get 4
输出
1
-1
-1
3
4
解释
LRUCache lRUCache = new LRUCache(2);//容量为2,即最多只能保存两个关键字
lRUCache.put(1, 1); // 缓存是 {1=1}
lRUCache.put(2, 2); // 缓存是 {1=1, 2=2}
lRUCache.get(1); // 返回 1。注意,这里使用了1
lRUCache.put(3, 3); // 该操作会使得关键字 2 作废(在关键字1和2中,2是最久未被使用的),缓存是 {1=1, 3=3}
lRUCache.get(2); // 返回 -1 (未找到)
lRUCache.put(4, 4); // 该操作会使得关键字 1 作废,缓存是 {4=4, 3=3}
lRUCache.get(1); // 返回 -1 (未找到)
lRUCache.get(3); // 返回 3
lRUCache.get(4); // 返回 4
自己写出的无法处理大规模输入数据的代码
#include <iostream>
#include <vector>
#include <algorithm>
#include <map>
#include <string>
#include <sstream>
#include <utility>
using namespace std;
struct item{
int new_count = 0;
pair<int, int> kv = {0, 0};
};
class LRUCache{
public:
int capacity = 0;
vector<item> Cache;
LRUCache(int capacity){
this->capacity = capacity;
}
int get(int key){
int size = Cache.size();
for(int i = 0; i < size; i++){
if(Cache[i].kv.first == key){
for(int j = 0; j < size; j++){
if(Cache[j].new_count < Cache[i].new_count)
Cache[j].new_count++;
}
Cache[i].new_count = 1;
return Cache[i].kv.second;
}
}
return -1;
}
void put(int key, int value){
int size = Cache.size();
bool exist = false;
if(size < capacity){
for(int i = 0; i < size; i++){
if(Cache[i].kv.first == key){
Cache[i].kv.second = value;
exist = true;
}
}
if(!exist){
item temp = {1, {key, value}};
Cache.push_back(temp);
for(int i = 0; i < size; i++){
Cache[i].new_count++;
}
}
}else{
int maxCount = 0;
int index = 0;
for(int i = 0; i < size; i++){
if(Cache[i].new_count > maxCount){
maxCount = Cache[i].new_count;
index = i;
}
Cache[i].new_count++;
}
Cache[index].new_count = 1;
Cache[index].kv = {key, value};
}
}
};
int main() {
int n;
cin >> n;
LRUCache lRUCache = LRUCache(n);
string operation;
int key, value;
string line;
while (getline(cin, line)) {
istringstream iss(line);
iss >> operation;
if (operation == "put") {
iss >> key >> value;
lRUCache.put(key, value);
} else if (operation == "get") {
iss >> key;
cout << lRUCache.get(key) << endl;
}
}
return 0;
}
问题分析
- 超出容量处理问题:代码中处理容量达到上限时的逻辑有些问题,特别是如何更新缓存。如果缓存已经满了(即缓存大小等于容量),需要逐出最久未使用的元素,但目前的逻辑没有处理好这些情况。
- 更新 new_count 时未考虑边界情况:当缓存中已经有该元素时,代码没有正确更新
new_count。 - 容量最大时(即 capacity = 3000):代码没有专门处理这个边界值的情况。标准的 LRU 要求 O(1) 时间复杂度,而目前的实现需要 O(n) 时间复杂度。
GPT4给出的正确代码
为了修正这些问题,应该采用另一种更高效的数据结构来优化 LRU 缓存的实现。一个常见的方法是使用 unordered_map和 list相结合来实现 LRU 缓存,以达到 O(1) 时间复杂度。
以下是修正后的实现:
#include <iostream>
#include <unordered_map>
#include <list>
#include <string>
#include <sstream>
#include <utility>
using namespace std;
class LRUCache {
public:
LRUCache(int capacity) : capacity(capacity) {}
int get(int key) {
auto it = cacheMap.find(key);
if (it == cacheMap.end()) {
return -1; // key 不存在
} else {
cacheList.splice(cacheList.begin(), cacheList, it->second); // 移动当前的 (key, value) 对到链表头部
return it->second->second; // 返回 value
}
}
void put(int key, int value) {
auto it = cacheMap.find(key);
if (it != cacheMap.end()) {
cacheList.splice(cacheList.begin(), cacheList, it->second); // 移动当前的 (key, value) 对到链表头部
it->second->second = value; // 更新 value
} else {
if (cacheList.size() == capacity) {
auto last = cacheList.back(); // 取出链表末尾的 (key, value) 对
cacheMap.erase(last.first); // 从 map 中删除该 key
cacheList.pop_back(); // 移除链表末尾的元素
}
cacheList.emplace_front(key, value); // 在链表头部添加新的 (key, value) 对
cacheMap[key] = cacheList.begin(); // 在 map 中记录该 key 对应的 list 迭代器
}
}
private:
int capacity;
list<pair<int, int>> cacheList; // 保存缓存的 (key, value) 对的链表
unordered_map<int, list<pair<int, int>>::iterator> cacheMap; // 保存 key 及其在链表中的位置
};
int main() {
int n;
cin >> n;
LRUCache lRUCache(n);
string operation;
int key, value;
string line;
while (getline(cin, line)) {
if (line.empty()) continue; //忽略空行
istringstream iss(line);
iss >> operation;
if (operation == "put") {
iss >> key >> value;
lRUCache.put(key, value);
} else if (operation == "get") {
iss >> key;
cout << lRUCache.get(key) << endl;
}
}
return 0;
}
修正的关键点
- 使用
list和unordered_map来实现 LRU 缓存,以保证get和put操作都在 O(1) 时间复杂度内完成。 - 每当
get或put操作时,都将相应的(key, value)对移动到链表头部,从而实现 LRU 机制。 - 当缓存达到容量限制时,直接移除链表末尾的元素,并从
unordered_map删除对应的键,这样可以处理容量为 3000 的边界情况。
这段代码解决了之前版本中存在的多个问题,并使得 LRU 缓存能够在效率上达标,且能够有效处理给定的输入限制。