二叉搜索树
- 700. Search in a Binary Search Tree
- 98. Validate Binary Search Tree
- 530. Minimum Absolute Difference in BST
- 783. Minimum Distance Between BST Nodes(同上)
- 501. Find Mode in Binary Search Tree
- 235. Lowest Common Ancestor of a Binary Search Tree
- 701. Insert into a Binary Search Tree
- 450. Delete Node in a BST
- 669. Trim a Binary Search Tree
- 108. Convert Sorted Array to Binary Search Tree
- 109. Convert Sorted List to Binary Search Tree
- 538. Convert BST to Greater Tree
- 1038. Binary Search Tree to Greater Sum Tree(同上)
700. Search in a Binary Search Tree
You are given the root of a binary search tree (BST) and an integer val.
Find the node in the BST that the node's value equals val and return the subtree rooted with that node. If such a node does not exist, return null.
Example 1:
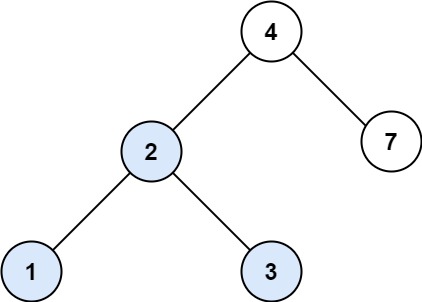
Input: root = [4,2,7,1,3], val = 2
Output: [2,1,3]
Example 2:
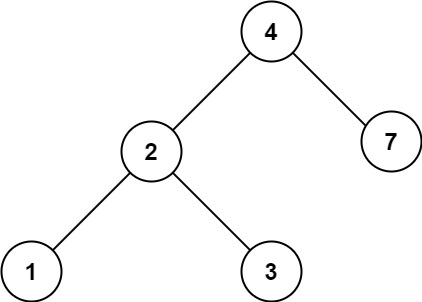
Input: root = [4,2,7,1,3], val = 5
Output: []
Constraints:
- The number of nodes in the tree is in the range
[1, 5000]. 1 <= Node.val <= 10^7rootis a binary search tree.1 <= val <= 10^7
思路
二叉搜索树是一个有序树:
- 若它的左子树不空,则左子树上所有结点的值均小于它的根结点的值;
- 若它的右子树不空,则右子树上所有结点的值均大于它的根结点的值;
- 它的左、右子树也分别为二叉搜索树
这就决定了,二叉搜索树,递归遍历和迭代遍历和普通二叉树都不一样。
本题,其实就是在二叉搜索树中搜索一个节点。那么我们来看看应该如何遍历。
递归法
- 确定递归函数的参数和返回值
递归函数的参数传入的就是根节点和要搜索的数值,返回的就是以这个搜索数值所在的节点。
- 确定终止条件
如果root为空,或者找到这个数值了,就返回root节点。
- 确定单层递归的逻辑
看看二叉搜索树的单层递归逻辑有何不同。
因为二叉搜索树的节点是有序的,所以可以有方向的去搜索。
如果root->val > val,搜索左子树,如果root->val < val,就搜索右子树,最后如果都没有搜索到,就返回NULL。
很多录友写递归函数的时候 习惯直接写 searchBST(root->left, val),却忘了递归函数还有返回值。
递归函数的返回值是什么? 是 左子树如果搜索到了val,要将该节点返回。 如果不用一个变量将其接住,那么返回值不就没了。
所以要 result = searchBST(root->left, val)。
迭代法
一提到二叉树遍历的迭代法,可能立刻想起使用栈来模拟深度遍历,使用队列来模拟广度遍历。
对于二叉搜索树可就不一样了,因为二叉搜索树的特殊性,也就是节点的有序性,可以不使用辅助栈或者队列就可以写出迭代法。
对于一般二叉树,递归过程中还有回溯的过程,例如走一个左方向的分支走到头了,那么要调头,在走右分支。
而对于二叉搜索树,不需要回溯的过程,因为节点的有序性就帮我们确定了搜索的方向。
例如要搜索元素为3的节点,我们不需要搜索其他节点,也不需要做回溯,查找的路径已经规划好了。
中间节点如果大于3就向左走,如果小于3就向右走,如图:
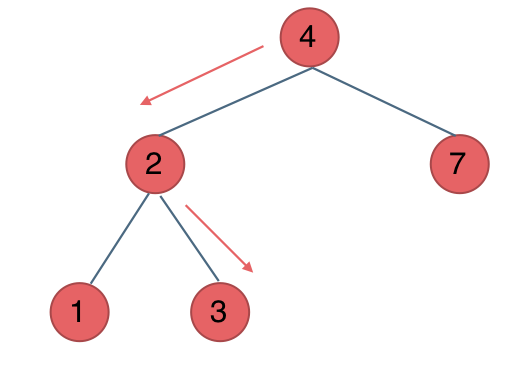
C++解法
递归法整体代码如下:
class Solution {
public:
TreeNode* searchBST(TreeNode* root, int val) {
if (root == NULL || root->val == val) return root;
TreeNode* result = NULL;
if (root->val > val) result = searchBST(root->left, val);
if (root->val < val) result = searchBST(root->right, val);
return result;
}
};
或者我们也可以这么写
class Solution {
public:
TreeNode* searchBST(TreeNode* root, int val) {
if (root == NULL || root->val == val) return root;
if (root->val > val) return searchBST(root->left, val);
if (root->val < val) return searchBST(root->right, val);
return NULL;
}
};
迭代法代码如下:
class Solution {
public:
TreeNode* searchBST(TreeNode* root, int val) {
while (root != NULL) {
if (root->val > val) root = root->left;
else if (root->val < val) root = root->right;
else return root;
}
return NULL;
}
};
Java解法
class Solution {
// 迭代,利用二叉搜索树特点,优化,可以不需要栈
public TreeNode searchBST(TreeNode root, int val) {
while (root != null)
if (val < root.val) root = root.left;
else if (val > root.val) root = root.right;
else return root;
return null;
}
}
Python3解法
class Solution:
def searchBST(self, root: TreeNode, val: int) -> TreeNode:
# 为什么要有返回值:
# 因为搜索到目标节点就要立即return,
# 这样才是找到节点就返回(搜索某一条边),如果不加return,就是遍历整棵树了。
if not root or root.val == val:
return root
if root.val > val:
return self.searchBST(root.left, val)
if root.val < val:
return self.searchBST(root.right, val)
Go解法
//递归法
func searchBST(root *TreeNode, val int) *TreeNode {
if root == nil || root.Val == val {
return root
}
if root.Val > val {
return searchBST(root.Left, val)
}
return searchBST(root.Right, val)
}
//迭代法
func searchBST(root *TreeNode, val int) *TreeNode {
for root != nil {
if root.Val > val {
root = root.Left
} else if root.Val < val {
root = root.Right
} else {
return root
}
}
return nil
}
98. Validate Binary Search Tree
Given the root of a binary tree, determine if it is a valid binary search tree (BST).
A valid BST is defined as follows:
- The left subtree of a node contains only nodes with keys less than the node's key.
- The right subtree of a node contains only nodes with keys greater than the node's key.
- Both the left and right subtrees must also be binary search trees.
Example 1:

Input: root = [2,1,3]
Output: true
Example 2:

Input: root = [5,1,4,null,null,3,6]
Output: false
Explanation: The root node's value is 5 but its right child's value is 4.
Constraints:
- The number of nodes in the tree is in the range
[1, 10^4]. -2^31 <= Node.val <= 2^31 - 1
思路
要知道中序遍历下,输出的二叉搜索树节点的数值是有序序列。
有了这个特性,验证二叉搜索树,就相当于变成了判断一个序列是不是递增的了。
递归法
可以递归中序遍历将二叉搜索树转变成一个数组,代码如下:
vector<int> vec;
void traversal(TreeNode* root) {
if (root == NULL) return;
traversal(root->left);
vec.push_back(root->val); // 将二叉搜索树转换为有序数组
traversal(root->right);
}
然后只要比较一下,这个数组是否是有序的,注意二叉搜索树中不能有重复元素。
traversal(root);
for (int i = 1; i < vec.size(); i++) {
// 注意要小于等于,搜索树里不能有相同元素
if (vec[i] <= vec[i - 1]) return false;
}
return true;
以上代码中,我们把二叉树转变为数组来判断,是最直观的,但其实不用转变成数组,可以在递归遍历的过程中直接判断是否有序。
这道题目比较容易陷入两个陷阱:
- 陷阱1
不能单纯的比较左节点小于中间节点,右节点大于中间节点就完事了。
写出了类似这样的代码:
if (root->val > root->left->val && root->val < root->right->val) {
return true;
} else {
return false;
}
我们要比较的是 左子树所有节点小于中间节点,右子树所有节点大于中间节点。所以以上代码的判断逻辑是错误的。
例如: [10,5,15,null,null,6,20] 这个case:
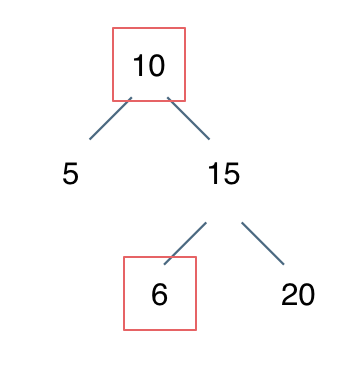
节点10大于左节点5,小于右节点15,但右子树里出现了一个6 这就不符合了!
- 陷阱2
样例中最小节点 可能是int的最小值,如果这样使用最小的int来比较也是不行的。
此时可以初始化比较元素为longlong的最小值。
问题可以进一步演进:如果样例中根节点的val 可能是longlong的最小值又要怎么办呢?文中会解答。
了解这些陷阱之后我们来看一下代码应该怎么写:
递归三部曲:
- 确定递归函数,返回值以及参数
要定义一个longlong的全局变量,用来比较遍历的节点是否有序,因为后台测试数据中有int最小值,所以定义为longlong的类型,初始化为longlong最小值。
注意递归函数要有bool类型的返回值, 我们在二叉树:递归函数究竟什么时候需要返回值,什么时候不要返回值? (opens new window)中讲了,只有寻找某一条边(或者一个节点)的时候,递归函数会有bool类型的返回值。
其实本题是同样的道理,我们在寻找一个不符合条件的节点,如果没有找到这个节点就遍历了整个树,如果找到不符合的节点了,立刻返回。
代码如下:
long long maxVal = LONG_MIN; // 因为后台测试数据中有int最小值
bool isValidBST(TreeNode* root)
- 确定终止条件
如果是空节点是不是二叉搜索树呢?
是的,二叉搜索树也可以为空!
代码如下:
if (root == NULL) return true;
- 确定单层递归的逻辑
中序遍历,一直更新maxVal,一旦发现maxVal >= root->val,就返回false,注意元素相同时候也要返回false。
代码如下:
bool left = isValidBST(root->left); // 左
// 中序遍历,验证遍历的元素是不是从小到大
if (maxVal < root->val) maxVal = root->val; // 中
else return false;
bool right = isValidBST(root->right); // 右
return left && right;
以上代码是因为后台数据有int最小值测试用例,所以都把maxVal改成了longlong最小值。
如果测试数据中有 longlong的最小值,怎么办?
不可能在初始化一个更小的值了吧。 建议避免初始化最小值,如下方法取到最左面节点的数值来比较。代码如下:
class Solution {
public:
TreeNode* pre = NULL; // 用来记录前一个节点
bool isValidBST(TreeNode* root) {
if (root == NULL) return true;
bool left = isValidBST(root->left);
if (pre != NULL && pre->val >= root->val) return false;
pre = root; // 记录前一个节点
bool right = isValidBST(root->right);
return left && right;
}
};
最后这份代码看上去整洁一些,思路也清晰。
迭代法
可以用迭代法模拟二叉树中序遍历,对前中后序迭代法生疏的同学可以看这两篇二叉树:听说递归能做的,栈也能做! (opens new window),二叉树:前中后序迭代方式统一写法(opens new window)
迭代法中序遍历稍加改动就可以了,代码如下:
class Solution {
public:
bool isValidBST(TreeNode* root) {
stack<TreeNode*> st;
TreeNode* cur = root;
TreeNode* pre = NULL; // 记录前一个节点
while (cur != NULL || !st.empty()) {
if (cur != NULL) {
st.push(cur);
cur = cur->left; // 左
} else {
cur = st.top(); // 中
st.pop();
if (pre != NULL && cur->val <= pre->val)
return false;
pre = cur; //保存前一个访问的结点
cur = cur->right; // 右
}
}
return true;
}
};
在二叉树:二叉搜索树登场! (opens new window)中我们分明写出了痛哭流涕的简洁迭代法,怎么在这里不行了呢,因为本题是要验证二叉搜索树啊。
总结
这道题目是一个简单题,但对于没接触过的同学还是有难度的。
所以初学者刚开始学习算法的时候,看到简单题目没有思路很正常,千万别怀疑自己智商,学习过程都是这样的,大家智商都差不多。
只要把基本类型的题目都做过,总结过之后,思路自然就开阔了,加油💪
C++解法
将二叉搜索树转换为有序数组整体代码如下:
class Solution {
private:
vector<int> vec;
void traversal(TreeNode* root) {
if (root == NULL) return;
traversal(root->left);
vec.push_back(root->val); // 将二叉搜索树转换为有序数组
traversal(root->right);
}
public:
bool isValidBST(TreeNode* root) {
vec.clear(); // 不加这句在leetcode上也可以过,但最好加上
traversal(root);
for (int i = 1; i < vec.size(); i++) {
// 注意要小于等于,搜索树里不能有相同元素
if (vec[i] <= vec[i - 1]) return false;
}
return true;
}
};
不转变成数组,可以在递归遍历的过程中直接判断是否有序。整体代码如下:
class Solution {
public:
long long maxVal = LONG_MIN; // 因为后台测试数据中有int最小值
bool isValidBST(TreeNode* root) {
if (root == NULL) return true;
bool left = isValidBST(root->left);
// 中序遍历,验证遍历的元素是不是从小到大
if (maxVal < root->val) maxVal = root->val;
else return false;
bool right = isValidBST(root->right);
return left && right;
}
};
不可能在初始化一个更小的值了吧。 建议避免初始化最小值,如下方法取到最左面节点的数值来比较。代码如下:
class Solution {
public:
TreeNode* pre = NULL; // 用来记录前一个节点
bool isValidBST(TreeNode* root) {
if (root == NULL) return true;
bool left = isValidBST(root->left);
if (pre != NULL && pre->val >= root->val) return false;
pre = root; // 记录前一个节点
bool right = isValidBST(root->right);
return left && right;
}
};
最后这份代码看上去整洁一些,思路也清晰。
Java解法
// 简洁实现·中序遍历
class Solution {
private long prev = Long.MIN_VALUE;
public boolean isValidBST(TreeNode root) {
if (root == null) {
return true;
}
if (!isValidBST(root.left)) {
return false;
}
if (root.val <= prev) { // 不满足二叉搜索树条件
return false;
}
prev = root.val;
return isValidBST(root.right);
}
}
Python3解法
递归法(版本三)直接取该树的最小值
# Definition for a binary tree node.
# class TreeNode:
# def __init__(self, val=0, left=None, right=None):
# self.val = val
# self.left = left
# self.right = right
class Solution:
def __init__(self):
self.pre = None # 用来记录前一个节点
def isValidBST(self, root):
if root is None:
return True
left = self.isValidBST(root.left)
if self.pre is not None and self.pre.val >= root.val:
return False
self.pre = root # 记录前一个节点
right = self.isValidBST(root.right)
return left and right
Go解法
// 中序遍历解法
func isValidBST(root *TreeNode) bool {
// 保存上一个指针
var prev *TreeNode
var travel func(node *TreeNode) bool
travel = func(node *TreeNode) bool {
if node == nil {
return true
}
leftRes := travel(node.Left)
// 当前值小于等于前一个节点的值,返回false
if prev != nil && node.Val <= prev.Val {
return false
}
prev = node
rightRes := travel(node.Right)
return leftRes && rightRes
}
return travel(root)
}
530. Minimum Absolute Difference in BST
Given the root of a Binary Search Tree (BST), return the minimum absolute difference between the values of any two different nodes in the tree.
Example 1:
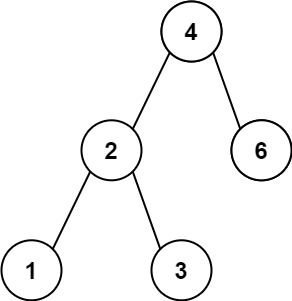
Input: root = [4,2,6,1,3]
Output: 1
Example 2:
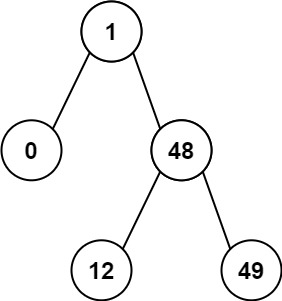
Input: root = [1,0,48,null,null,12,49]
Output: 1
Constraints:
- The number of nodes in the tree is in the range
[2, 10^4]. 0 <= Node.val <= 10^5
Note: This question is the same as 783: https://leetcode.com/problems/minimum-distance-between-bst-nodes/
思路
方法一:中序遍历转为有序数组
方法二:中序遍历,双指针,直接计算差值
题目中要求在二叉搜索树上任意两节点的差的绝对值的最小值。
注意是二叉搜索树,二叉搜索树可是有序的。
遇到在二叉搜索树上求什么最值啊,差值之类的,就把它想成在一个有序数组上求最值,求差值,这样就简单多了。
递归
那么二叉搜索树采用中序遍历,其实就是一个有序数组。
在一个有序数组上求两个数最小差值,这是不是就是一道送分题了。
最直观的想法,就是把二叉搜索树转换成有序数组,然后遍历一遍数组,就统计出来最小差值了。
代码如下:
class Solution {
private:
vector<int> vec;
void traversal(TreeNode* root) {
if (root == NULL) return;
traversal(root->left);
vec.push_back(root->val); // 将二叉搜索树转换为有序数组
traversal(root->right);
}
public:
int getMinimumDifference(TreeNode* root) {
vec.clear();
traversal(root);
if (vec.size() < 2) return 0;
int result = INT_MAX;
for (int i = 1; i < vec.size(); i++) { // 统计有序数组的最小差值
result = min(result, vec[i] - vec[i-1]);
}
return result;
}
};
以上代码是把二叉搜索树转化为有序数组了,其实在二叉搜素树中序遍历的过程中,我们就可以直接计算了。
需要用一个pre节点记录一下cur节点的前一个节点。
如图:
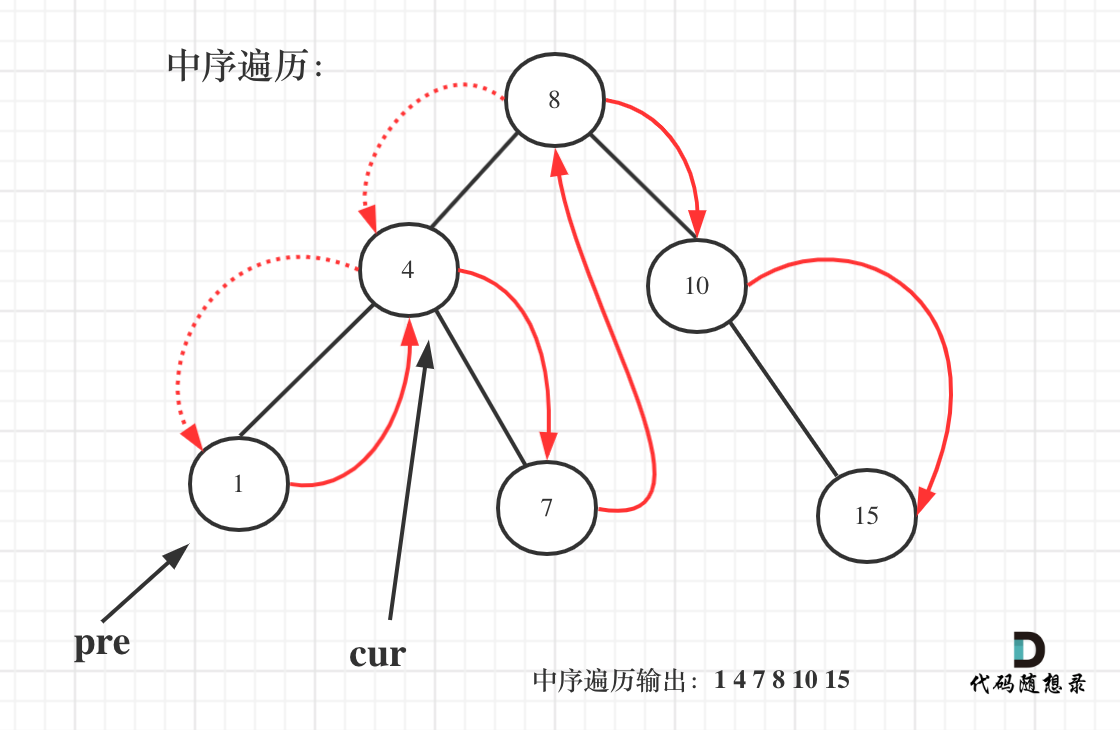
一些同学不知道在递归中如何记录前一个节点的指针,其实实现起来是很简单的,大家只要看过一次,写过一次,就掌握了。
代码如下:
class Solution {
private:
int result = INT_MAX;
TreeNode* pre = NULL;
void traversal(TreeNode* cur) {
if (cur == NULL) return;
traversal(cur->left); // 左
if (pre != NULL){ // 中
result = min(result, cur->val - pre->val);
}
pre = cur; // 记录前一个
traversal(cur->right); // 右
}
public:
int getMinimumDifference(TreeNode* root) {
traversal(root);
return result;
}
};
是不是看上去也并不复杂!
迭代
看过这两篇二叉树:听说递归能做的,栈也能做! (opens new window),二叉树:前中后序迭代方式的写法就不能统一一下么? (opens new window)文章之后,不难写出两种中序遍历的迭代法。
下面我给出其中的一种中序遍历的迭代法,代码如下:
class Solution {
public:
int getMinimumDifference(TreeNode* root) {
stack<TreeNode*> st;
TreeNode* cur = root;
TreeNode* pre = NULL;
int result = INT_MAX;
while (cur != NULL || !st.empty()) {
if (cur != NULL) { // 指针来访问节点,访问到最底层
st.push(cur); // 将访问的节点放进栈
cur = cur->left; // 左
} else {
cur = st.top();
st.pop();
if (pre != NULL) { // 中
result = min(result, cur->val - pre->val);
}
pre = cur;
cur = cur->right; // 右
}
}
return result;
}
};
总结
遇到在二叉搜索树上求什么最值,求差值之类的,都要思考一下二叉搜索树可是有序的,要利用好这一特点。
同时要学会在递归遍历的过程中如何记录前后两个指针,这也是一个小技巧,学会了还是很受用的。
后面我将继续介绍一系列利用二叉搜索树特性的题目。
C++解法
方法二:中序遍历,双指针,直接计算差值
代码如下:
class Solution {
private:
int result = INT_MAX;
TreeNode* pre = NULL;
void traversal(TreeNode* cur) {
if (cur == NULL) return;
traversal(cur->left); // 左
if (pre != NULL){ // 中
result = min(result, cur->val - pre->val);
}
pre = cur; // 记录前一个
traversal(cur->right); // 右
}
public:
int getMinimumDifference(TreeNode* root) {
traversal(root);
return result;
}
};
Java解法
迭代法-中序遍历
class Solution {
TreeNode pre;
Stack<TreeNode> stack;
public int getMinimumDifference(TreeNode root) {
if (root == null) return 0;
stack = new Stack<>();
TreeNode cur = root;
int result = Integer.MAX_VALUE;
while (cur != null || !stack.isEmpty()) {
if (cur != null) {
stack.push(cur); // 将访问的节点放进栈
cur = cur.left; // 左
}else {
cur = stack.pop();
if (pre != null) { // 中
result = Math.min(result, cur.val - pre.val);
}
pre = cur;
cur = cur.right; // 右
}
}
return result;
}
}
Python3解法
递归法(版本二)利用中序递增,找到该树最小值
class Solution:
def __init__(self):
self.result = float('inf')
self.pre = None
def traversal(self, cur):
if cur is None:
return
self.traversal(cur.left) # 左
if self.pre is not None: # 中
self.result = min(self.result, cur.val - self.pre.val)
self.pre = cur # 记录前一个
self.traversal(cur.right) # 右
def getMinimumDifference(self, root):
self.traversal(root)
return self.result
Go解法
中序遍历,然后计算最小差值
// 中序遍历的同时计算最小值
func getMinimumDifference(root *TreeNode) int {
// 保留前一个节点的指针
var prev *TreeNode
// 定义一个比较大的值
min := math.MaxInt64
var travel func(node *TreeNode)
travel = func(node *TreeNode) {
if node == nil {
return
}
travel(node.Left)
if prev != nil && node.Val - prev.Val < min {
min = node.Val - prev.Val
}
prev = node
travel(node.Right)
}
travel(root)
return min
}
783. Minimum Distance Between BST Nodes(同上)
Given the root of a Binary Search Tree (BST), return the minimum absolute difference between the values of any two different nodes in the tree.
Example 1:
Input: root = [4,2,6,1,3]
Output: 1
Example 2:
Input: root = [1,0,48,null,null,12,49]
Output: 1
Constraints:
- The number of nodes in the tree is in the range
[2, 10^4]. 0 <= Node.val <= 10^5
思路
方法一:中序遍历转为有序数组,再计算差值
方法二:中序遍历,双指针,直接计算差值
C++解法
方法一:中序遍历转为有序数组,再计算差值
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode() : val(0), left(nullptr), right(nullptr) {}
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
* };
*/
class Solution {
public:
vector<int> diffs;
void traversal(TreeNode* cur){
if(cur == NULL) return;
traversal(cur->left);
diffs.push_back(cur->val);
traversal(cur->right);
}
int minDiffInBST(TreeNode* root) {
traversal(root);
int result = INT_MAX;
for(int i = 0; i < diffs.size() - 1; i++){
result = min(result, diffs[i + 1] - diffs[i]);
}
return result;
}
};
501. Find Mode in Binary Search Tree
Given the root of a binary search tree (BST) with duplicates, return all the mode(s) (i.e., the most frequently occurred element) in it.
If the tree has more than one mode, return them in any order.
Assume a BST is defined as follows:
- The left subtree of a node contains only nodes with keys less than or equal to the node's key.
- The right subtree of a node contains only nodes with keys greater than or equal to the node's key.
- Both the left and right subtrees must also be binary search trees.
Example 1:
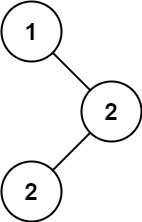
Input: root = [1,null,2,2]
Output: [2]
Example 2:
Input: root = [0]
Output: [0]
Constraints:
- The number of nodes in the tree is in the range
[1, 10^4]. -10^5 <= Node.val <= 10^5
Follow up: Could you do that without using any extra space? (Assume that the implicit stack space incurred due to recursion does not count).
思路
这道题目呢,递归法我从两个维度来讲。
首先如果不是二叉搜索树的话,应该怎么解题,是二叉搜索树,又应该如何解题,两种方式做一个比较,可以加深大家对二叉树的理解。
递归法
如果不是二叉搜索树,最直观的方法一定是把这个树都遍历了,用map统计频率,把频率排个序,最后取前面高频的元素的集合。
具体步骤如下:
- 这个树都遍历了,用map统计频率
至于用前中后序哪种遍历也不重要,因为就是要全遍历一遍,怎么个遍历法都行,层序遍历都没毛病!
这里采用前序遍历,代码如下:
// map<int, int> key:元素,value:出现频率
void searchBST(TreeNode* cur, unordered_map<int, int>& map) { // 前序遍历
if (cur == NULL) return ;
map[cur->val]++; // 统计元素频率
searchBST(cur->left, map);
searchBST(cur->right, map);
return ;
}
- 把统计的出来的出现频率(即map中的value)排个序
有的同学可能可以想直接对map中的value排序,还真做不到,C++中如果使用std::map或者std::multimap可以对key排序,但不能对value排序。
所以要把map转化数组即vector,再进行排序,当然vector里面放的也是pair<int, int>类型的数据,第一个int为元素,第二个int为出现频率。
代码如下:
bool static cmp (const pair<int, int>& a, const pair<int, int>& b) {
return a.second > b.second; // 按照频率从大到小排序
}
vector<pair<int, int>> vec(map.begin(), map.end());
sort(vec.begin(), vec.end(), cmp); // 给频率排个序
- 取前面高频的元素
此时数组vector中已经是存放着按照频率排好序的pair,那么把前面高频的元素取出来就可以了。
代码如下:
result.push_back(vec[0].first);
for (int i = 1; i < vec.size(); i++) {
// 取最高的放到result数组中
if (vec[i].second == vec[0].second) result.push_back(vec[i].first);
else break;
}
return result;
所以如果本题没有说是二叉搜索树的话,那么就按照上面的思路写!
既然是搜索树,它中序遍历就是有序的。
如图:
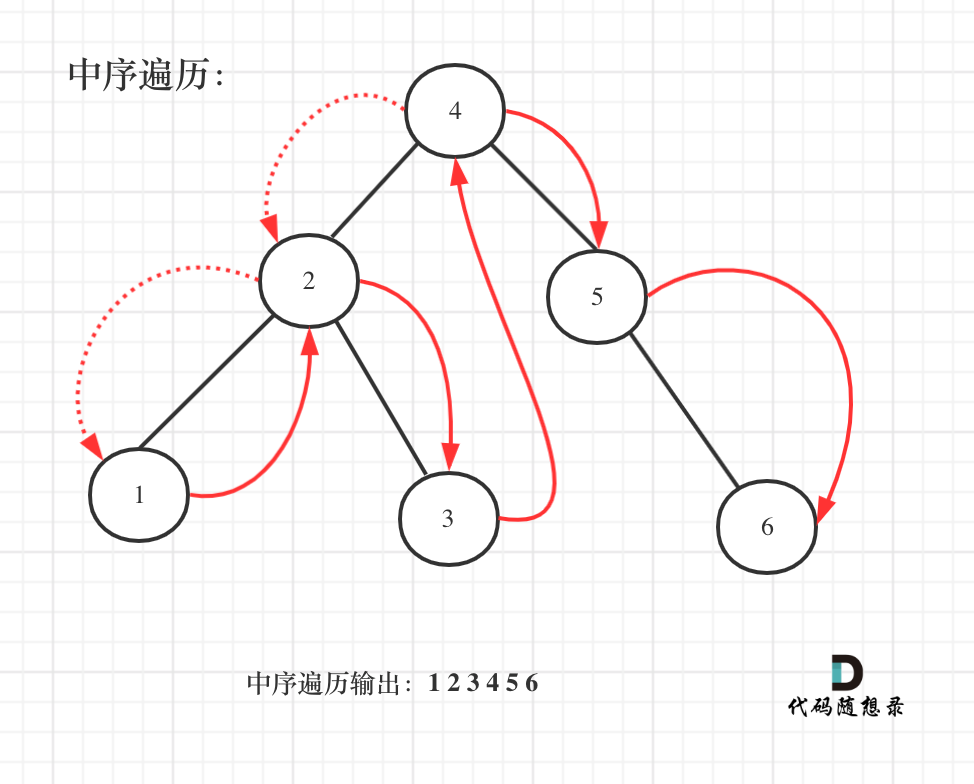
中序遍历代码如下:
void searchBST(TreeNode* cur) {
if (cur == NULL) return ;
searchBST(cur->left); // 左
(处理节点) // 中
searchBST(cur->right); // 右
return ;
}
遍历有序数组的元素出现频率,从头遍历,那么一定是相邻两个元素作比较,然后就把出现频率最高的元素输出就可以了。
关键是在有序数组上的话,好搞,在树上怎么搞呢?
这就考察对树的操作了。
在二叉树:搜索树的最小绝对差 (opens new window)中我们就使用了pre指针和cur指针的技巧,这次又用上了。
弄一个指针指向前一个节点,这样每次cur(当前节点)才能和pre(前一个节点)作比较。
而且初始化的时候pre = NULL,这样当pre为NULL时候,我们就知道这是比较的第一个元素。
代码如下:
if (pre == NULL) { // 第一个节点
count = 1; // 频率为1
} else if (pre->val == cur->val) { // 与前一个节点数值相同
count++;
} else { // 与前一个节点数值不同
count = 1;
}
pre = cur; // 更新上一个节点
此时又有问题了,因为要求最大频率的元素集合(注意是集合,不是一个元素,可以有多个众数),如果是数组上大家一般怎么办?
应该是先遍历一遍数组,找出最大频率(maxCount),然后再重新遍历一遍数组把出现频率为maxCount的元素放进集合。(因为众数有多个)
这种方式遍历了两遍数组。
那么我们遍历两遍二叉搜索树,把众数集合算出来也是可以的。
但这里其实只需要遍历一次就可以找到所有的众数。
那么如何只遍历一遍呢?
如果 频率count 等于 maxCount(最大频率),当然要把这个元素加入到结果集中(以下代码为result数组),代码如下:
if (count == maxCount) { // 如果和最大值相同,放进result中
result.push_back(cur->val);
}
是不是感觉这里有问题,result怎么能轻易就把元素放进去了呢,万一,这个maxCount此时还不是真正最大频率呢。
所以下面要做如下操作:
频率count 大于 maxCount的时候,不仅要更新maxCount,而且要清空结果集(以下代码为result数组),因为结果集之前的元素都失效了。
if (count > maxCount) { // 如果计数大于最大值
maxCount = count; // 更新最大频率
result.clear(); // 很关键的一步,不要忘记清空result,之前result里的元素都失效了
result.push_back(cur->val);
}
迭代法
只要把中序遍历转成迭代,中间节点的处理逻辑完全一样。
二叉树前中后序转迭代,传送门:
下面我给出其中的一种中序遍历的迭代法,其中间处理逻辑一点都没有变(我从递归法直接粘过来的代码,连注释都没改)
代码如下:
class Solution {
public:
vector<int> findMode(TreeNode* root) {
stack<TreeNode*> st;
TreeNode* cur = root;
TreeNode* pre = NULL;
int maxCount = 0; // 最大频率
int count = 0; // 统计频率
vector<int> result;
while (cur != NULL || !st.empty()) {
if (cur != NULL) { // 指针来访问节点,访问到最底层
st.push(cur); // 将访问的节点放进栈
cur = cur->left; // 左
} else {
cur = st.top();
st.pop(); // 中
if (pre == NULL) { // 第一个节点
count = 1;
} else if (pre->val == cur->val) { // 与前一个节点数值相同
count++;
} else { // 与前一个节点数值不同
count = 1;
}
if (count == maxCount) { // 如果和最大值相同,放进result中
result.push_back(cur->val);
}
if (count > maxCount) { // 如果计数大于最大值频率
maxCount = count; // 更新最大频率
result.clear(); // 很关键的一步,不要忘记清空result,之前result里的元素都失效了
result.push_back(cur->val);
}
pre = cur;
cur = cur->right; // 右
}
}
return result;
}
};
总结
本题在递归法中,我给出了如果是普通二叉树,应该怎么求众数。
知道了普通二叉树的做法时候,我再进一步给出二叉搜索树又应该怎么求众数,这样鲜明的对比,相信会对二叉树又有更深层次的理解了。
在递归遍历二叉搜索树的过程中,我还介绍了一个统计最高出现频率元素集合的技巧, 要不然就要遍历两次二叉搜索树才能把这个最高出现频率元素的集合求出来。
为什么没有这个技巧一定要遍历两次呢? 因为要求的是集合,会有多个众数,如果规定只有一个众数,那么就遍历一次稳稳的了。
最后我依然给出对应的迭代法,其实就是迭代法中序遍历的模板加上递归法中中间节点的处理逻辑,分分钟就可以写出来,中间逻辑的代码我都是从递归法中直接粘过来的。
求二叉搜索树中的众数其实是一道简单题,但大家可以发现我写了这么一大篇幅的文章来讲解,主要是为了尽量从各个角度对本题进剖析,帮助大家更快更深入理解二叉树。
需要强调的是 leetcode上的耗时统计是非常不准确的,看个大概就行,一样的代码耗时可以差百分之50以上,所以leetcode的耗时统计别太当回事,知道理论上的效率优劣就行了。
C++解法
普通二叉树处理方式完整代码如下所示:
class Solution {
private:
void searchBST(TreeNode* cur, unordered_map<int, int>& map) { // 前序遍历
if (cur == NULL) return ;
map[cur->val]++; // 统计元素频率
searchBST(cur->left, map);
searchBST(cur->right, map);
return ;
}
bool static cmp (const pair<int, int>& a, const pair<int, int>& b) {
return a.second > b.second;
}
public:
vector<int> findMode(TreeNode* root) {
unordered_map<int, int> map; // key:元素,value:出现频率
vector<int> result;
if (root == NULL) return result;
searchBST(root, map);
vector<pair<int, int>> vec(map.begin(), map.end());
sort(vec.begin(), vec.end(), cmp); // 给频率排个序
result.push_back(vec[0].first);
for (int i = 1; i < vec.size(); i++) {
// 取最高的放到result数组中
if (vec[i].second == vec[0].second) result.push_back(vec[i].first);
else break;
}
return result;
}
};
双指针处理方式完整代码如下:(只需要遍历一遍二叉搜索树,就求出了众数的集合)
class Solution {
private:
int maxCount = 0; // 最大频率
int count = 0; // 统计频率
TreeNode* pre = NULL;
vector<int> result;
void searchBST(TreeNode* cur) {
if (cur == NULL) return ;
searchBST(cur->left); // 左
// 中
if (pre == NULL) { // 第一个节点
count = 1;
} else if (pre->val == cur->val) { // 与前一个节点数值相同
count++;
} else { // 与前一个节点数值不同
count = 1;
}
pre = cur; // 更新上一个节点
if (count == maxCount) { // 如果和最大值相同,放进result中
result.push_back(cur->val);
}
if (count > maxCount) { // 如果计数大于最大值频率
maxCount = count; // 更新最大频率
result.clear(); // 很关键的一步,不要忘记清空result,之前result里的元素都失效了
result.push_back(cur->val);
}
searchBST(cur->right); // 右
return ;
}
public:
vector<int> findMode(TreeNode* root) {
count = 0;
maxCount = 0;
pre = NULL; // 记录前一个节点
result.clear();
searchBST(root);
return result;
}
};
Java解法
迭代法
class Solution {
public int[] findMode(TreeNode root) {
TreeNode pre = null;
Stack<TreeNode> stack = new Stack<>();
List<Integer> result = new ArrayList<>();
int maxCount = 0;
int count = 0;
TreeNode cur = root;
while (cur != null || !stack.isEmpty()) {
if (cur != null) {
stack.push(cur);
cur =cur.left;
}else {
cur = stack.pop();
// 计数
if (pre == null || cur.val != pre.val) {
count = 1;
}else {
count++;
}
// 更新结果
if (count > maxCount) {
maxCount = count;
result.clear();
result.add(cur.val);
}else if (count == maxCount) {
result.add(cur.val);
}
pre = cur;
cur = cur.right;
}
}
return result.stream().mapToInt(Integer::intValue).toArray();
}
}
Python3解法
递归法(版本二)利用二叉搜索树性质
class Solution:
def __init__(self):
self.maxCount = 0 # 最大频率
self.count = 0 # 统计频率
self.pre = None
self.result = []
def searchBST(self, cur):
if cur is None:
return
self.searchBST(cur.left) # 左
# 中
if self.pre is None: # 第一个节点
self.count = 1
elif self.pre.val == cur.val: # 与前一个节点数值相同
self.count += 1
else: # 与前一个节点数值不同
self.count = 1
self.pre = cur # 更新上一个节点
if self.count == self.maxCount: # 如果与最大值频率相同,放进result中
self.result.append(cur.val)
if self.count > self.maxCount: # 如果计数大于最大值频率
self.maxCount = self.count # 更新最大频率
self.result = [cur.val] # 很关键的一步,不要忘记清空result,之前result里的元素都失效了
self.searchBST(cur.right) # 右
return
def findMode(self, root):
self.count = 0
self.maxCount = 0
self.pre = None # 记录前一个节点
self.result = []
self.searchBST(root)
return self.result
Go解法
计数法,不使用额外空间,利用二叉树性质,中序遍历
func findMode(root *TreeNode) []int {
res := make([]int, 0)
count := 1
max := 1
var prev *TreeNode
var travel func(node *TreeNode)
travel = func(node *TreeNode) {
if node == nil {
return
}
travel(node.Left)
if prev != nil && prev.Val == node.Val {
count++
} else {
count = 1
}
if count >= max {
if count > max && len(res) > 0 {
res = []int{node.Val}
} else {
res = append(res, node.Val)
}
max = count
}
prev = node
travel(node.Right)
}
travel(root)
return res
}
235. Lowest Common Ancestor of a Binary Search Tree
Given a binary search tree (BST), find the lowest common ancestor (LCA) node of two given nodes in the BST.
According to the definition of LCA on Wikipedia: “The lowest common ancestor is defined between two nodes p and q as the lowest node in T that has both p and q as descendants (where we allow a node to be a descendant of itself).”
Example 1:
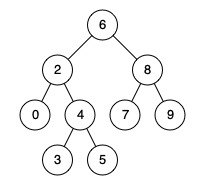
Input: root = [6,2,8,0,4,7,9,null,null,3,5], p = 2, q = 8
Output: 6
Explanation: The LCA of nodes 2 and 8 is 6.
Example 2:
Input: root = [6,2,8,0,4,7,9,null,null,3,5], p = 2, q = 4
Output: 2
Explanation: The LCA of nodes 2 and 4 is 2, since a node can be a descendant of itself according to the LCA definition.
Example 3:
Input: root = [2,1], p = 2, q = 1
Output: 2
Constraints:
- The number of nodes in the tree is in the range
[2, 10^5]. -10^9 <= Node.val <= 10^9- All
Node.valare unique. p != qpandqwill exist in the BST.
思路
做过二叉树:公共祖先问题 (opens new window)题目的同学应该知道,利用回溯从底向上搜索,遇到一个节点的左子树里有p,右子树里有q,那么当前节点就是最近公共祖先。
那么本题是二叉搜索树,二叉搜索树是有序的,那得好好利用一下这个特点。
在有序树里,如果判断一个节点的左子树里有p,右子树里有q呢?
因为是有序树,所以 如果 中间节点是 q 和 p 的公共祖先,那么 中节点的数组 一定是在 [p, q]区间的。即 中节点 > p && 中节点 < q 或者 中节点 > q && 中节点 < p。
那么只要从上到下去遍历,遇到 cur节点是数值在[p, q]区间中则一定可以说明该节点cur就是p 和 q的公共祖先。 那问题来了,一定是最近公共祖先吗?
如图,我们从根节点搜索,第一次遇到 cur节点是数值在[q, p]区间中,即 节点5,此时可以说明 q 和 p 一定分别存在于 节点 5的左子树,和右子树中。
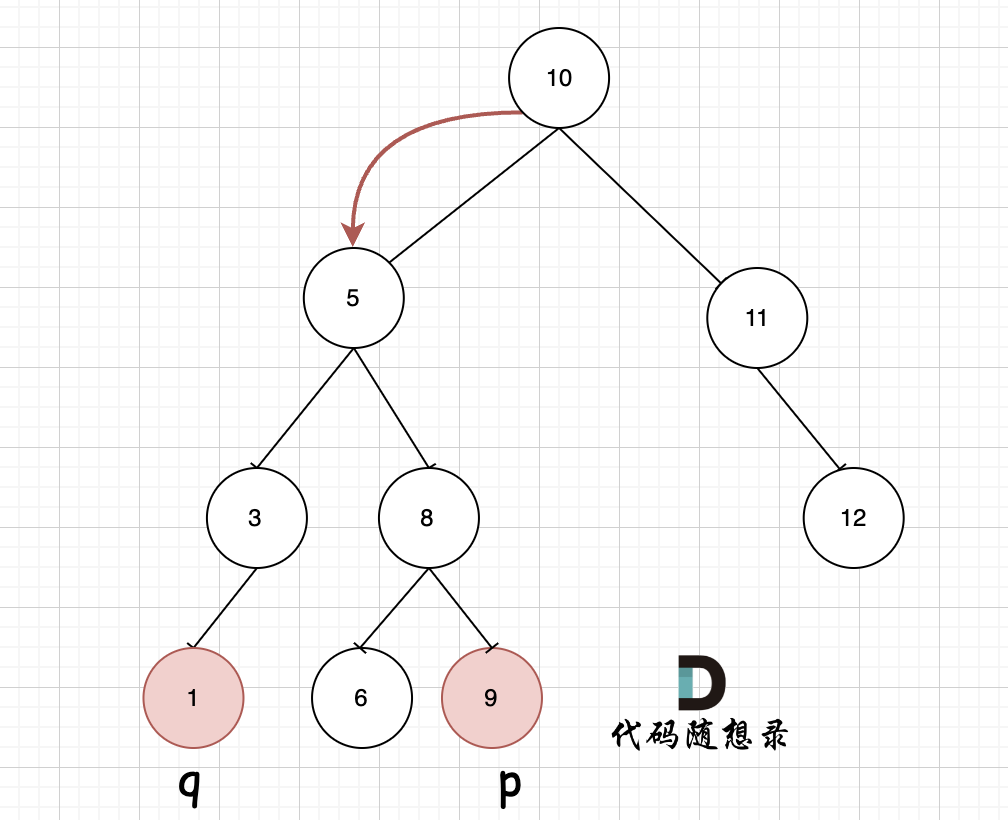
此时节点5是不是最近公共祖先? 如果 从节点5继续向左遍历,那么将错过成为p的祖先, 如果从节点5继续向右遍历则错过成为q的祖先。
所以当我们从上向下去递归遍历,第一次遇到 cur节点是数值在[q, p]区间中,那么cur就是 q和p的最近公共祖先。
理解这一点,本题就很好解了。
而递归遍历顺序,本题就不涉及到 前中后序了(这里没有中节点的处理逻辑,遍历顺序无所谓了)。
如图所示:p为节点6,q为节点9
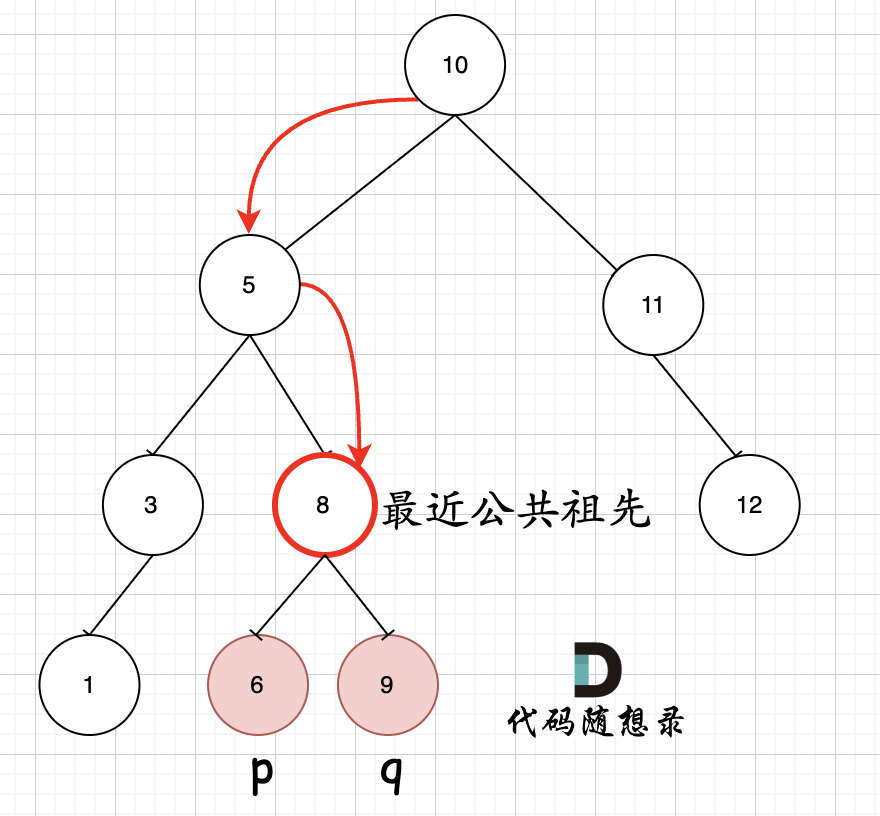
可以看出直接按照指定的方向,就可以找到节点8,为最近公共祖先,而且不需要遍历整棵树,找到结果直接返回!
递归法
递归三部曲如下:
- 确定递归函数返回值以及参数
参数就是当前节点,以及两个结点 p、q。
返回值是要返回最近公共祖先,所以是TreeNode * 。
代码如下:
TreeNode* traversal(TreeNode* cur, TreeNode* p, TreeNode* q)
- 确定终止条件
遇到空返回就可以了,代码如下:
if (cur == NULL) return cur;
其实都不需要这个终止条件,因为题目中说了p、q 为不同节点且均存在于给定的二叉搜索树中。也就是说一定会找到公共祖先的,所以并不存在遇到空的情况。
- 确定单层递归的逻辑
在遍历二叉搜索树的时候就是寻找区间[p->val, q->val](注意这里是左闭又闭)
那么如果 cur->val 大于 p->val,同时 cur->val 大于q->val,那么就应该向左遍历(说明目标区间在左子树上)。
需要注意的是此时不知道p和q谁大,所以两个都要判断
代码如下:
if (cur->val > p->val && cur->val > q->val) {
TreeNode* left = traversal(cur->left, p, q);
if (left != NULL) {
return left;
}
}
细心的同学会发现,在这里调用递归函数的地方,把递归函数的返回值left,直接return。
在二叉树:公共祖先问题 (opens new window)中,如果递归函数有返回值,如何区分要搜索一条边,还是搜索整个树。
搜索一条边的写法:
if (递归函数(root->left)) return ;
if (递归函数(root->right)) return ;
搜索整个树写法:
left = 递归函数(root->left);
right = 递归函数(root->right);
left与right的逻辑处理;
本题就是标准的搜索一条边的写法,遇到递归函数的返回值,如果不为空,立刻返回。
如果 cur->val 小于 p->val,同时 cur->val 小于 q->val,那么就应该向右遍历(目标区间在右子树)。
if (cur->val < p->val && cur->val < q->val) {
TreeNode* right = traversal(cur->right, p, q);
if (right != NULL) {
return right;
}
}
剩下的情况,就是cur节点在区间(p->val <= cur->val && cur->val <= q->val)或者 (q->val <= cur->val && cur->val <= p->val)中,那么cur就是最近公共祖先了,直接返回cur。
代码如下:
return cur;
迭代法
对于二叉搜索树的迭代法,大家应该在二叉树:二叉搜索树登场! (opens new window)就了解了。
利用其有序性,迭代的方式还是比较简单的,解题思路在递归中已经分析了。
总结
对于二叉搜索树的最近祖先问题,其实要比普通二叉树公共祖先问题 (opens new window)简单的多。
不用使用回溯,二叉搜索树自带方向性,可以方便的从上向下查找目标区间,遇到目标区间内的节点,直接返回。
最后给出了对应的迭代法,二叉搜索树的迭代法甚至比递归更容易理解,也是因为其有序性(自带方向性),按照目标区间找就行了。
C++解法
那么整体递归代码如下:
class Solution {
private:
TreeNode* traversal(TreeNode* cur, TreeNode* p, TreeNode* q) {
if (cur == NULL) return cur;
// 中
if (cur->val > p->val && cur->val > q->val) { // 左
TreeNode* left = traversal(cur->left, p, q);
if (left != NULL) {
return left;
}
}
if (cur->val < p->val && cur->val < q->val) { // 右
TreeNode* right = traversal(cur->right, p, q);
if (right != NULL) {
return right;
}
}
return cur;
}
public:
TreeNode* lowestCommonAncestor(TreeNode* root, TreeNode* p, TreeNode* q) {
return traversal(root, p, q);
}
};
精简后代码如下:
class Solution {
public:
TreeNode* lowestCommonAncestor(TreeNode* root, TreeNode* p, TreeNode* q) {
if (root->val > p->val && root->val > q->val) {
return lowestCommonAncestor(root->left, p, q);
} else if (root->val < p->val && root->val < q->val) {
return lowestCommonAncestor(root->right, p, q);
} else return root;
}
};
迭代代码如下:
class Solution {
public:
TreeNode* lowestCommonAncestor(TreeNode* root, TreeNode* p, TreeNode* q) {
while(root) {
if (root->val > p->val && root->val > q->val) {
root = root->left;
} else if (root->val < p->val && root->val < q->val) {
root = root->right;
} else return root;
}
return NULL;
}
};
灵魂拷问:是不是又被简单的迭代法感动到痛哭流涕?
Java解法
迭代法
class Solution {
public TreeNode lowestCommonAncestor(TreeNode root, TreeNode p, TreeNode q) {
while (true) {
if (root.val > p.val && root.val > q.val) {
root = root.left;
} else if (root.val < p.val && root.val < q.val) {
root = root.right;
} else {
break;
}
}
return root;
}
}
Python3解法
递归法(版本一)
class Solution:
def traversal(self, cur, p, q):
if cur is None:
return cur
# 中
if cur.val > p.val and cur.val > q.val: # 左
left = self.traversal(cur.left, p, q)
if left is not None:
return left
if cur.val < p.val and cur.val < q.val: # 右
right = self.traversal(cur.right, p, q)
if right is not None:
return right
return cur
def lowestCommonAncestor(self, root, p, q):
return self.traversal(root, p, q)
递归法(版本二)精简
class Solution:
def lowestCommonAncestor(self, root, p, q):
if root.val > p.val and root.val > q.val:
return self.lowestCommonAncestor(root.left, p, q)
elif root.val < p.val and root.val < q.val:
return self.lowestCommonAncestor(root.right, p, q)
else:
return root
Go解法
递归法
func lowestCommonAncestor(root, p, q *TreeNode) *TreeNode {
if root.Val > p.Val && root.Val > q.Val {
return lowestCommonAncestor(root.Left, p, q)
} else if root.Val < p.Val && root.Val < q.Val {
return lowestCommonAncestor(root.Right, p, q)
} else {
return root
}
}
701. Insert into a Binary Search Tree
You are given the root node of a binary search tree (BST) and a value to insert into the tree. Return the root node of the BST after the insertion. It is guaranteed that the new value does not exist in the original BST.
Notice that there may exist multiple valid ways for the insertion, as long as the tree remains a BST after insertion. You can return any of them.
Example 1:
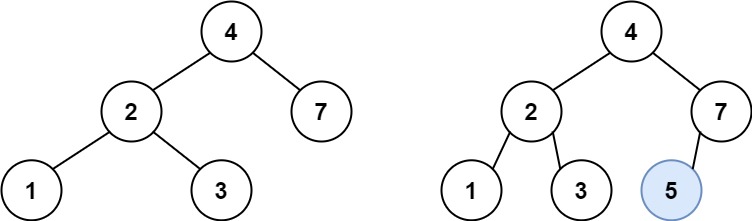
Input: root = [4,2,7,1,3], val = 5
Output: [4,2,7,1,3,5]
Explanation: Another accepted tree is:
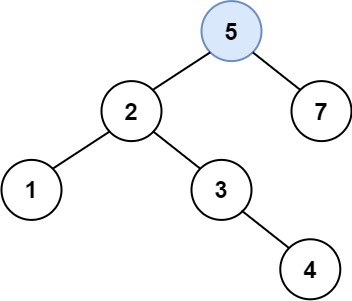
Example 2:
Input: root = [40,20,60,10,30,50,70], val = 25
Output: [40,20,60,10,30,50,70,null,null,25]
Example 3:
Input: root = [4,2,7,1,3,null,null,null,null,null,null], val = 5
Output: [4,2,7,1,3,5]
Constraints:
- The number of nodes in the tree will be in the range
[0, 10^4]. -10^8 <= Node.val <= 10^8- All the values
Node.valare unique. -10^8 <= val <= 10^8- It's guaranteed that
valdoes not exist in the original BST.
思路
这道题目其实是一道简单题目,但是题目中的提示:有多种有效的插入方式,还可以重构二叉搜索树,一下子吓退了不少人,瞬间感觉题目复杂了很多。
其实可以不考虑题目中提示所说的改变树的结构的插入方式。
如下演示视频中可以看出:只要按照二叉搜索树的规则去遍历,遇到空节点就插入节点就可以了。
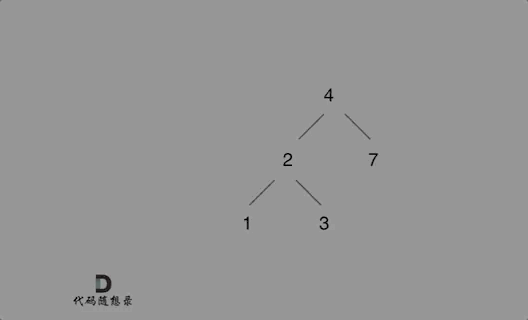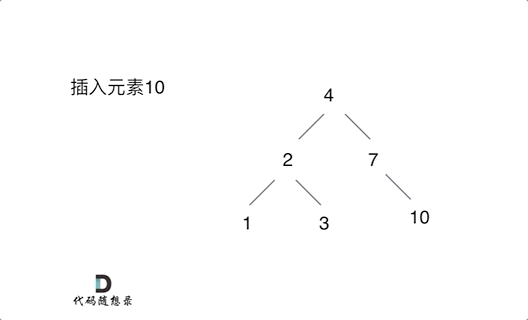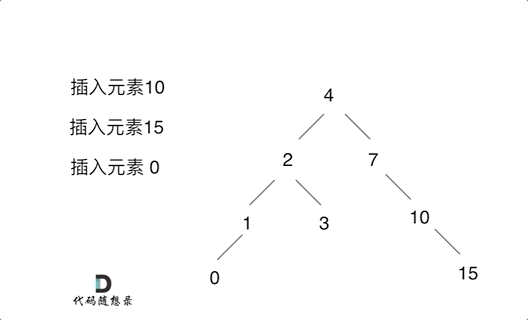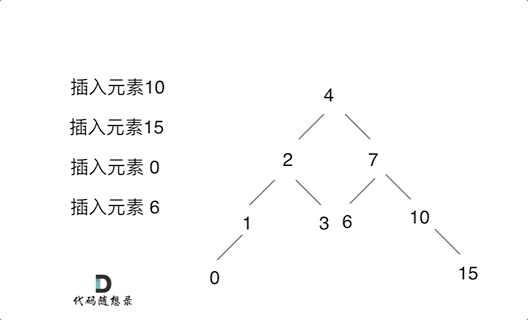
例如插入元素10 ,需要找到末尾节点插入便可,一样的道理来插入元素15,插入元素0,插入元素6,需要调整二叉树的结构么? 并不需要。。
只要遍历二叉搜索树,找到空节点 插入元素就可以了,那么这道题其实就简单了。
接下来就是遍历二叉搜索树的过程了。
递归
递归三部曲:
- 确定递归函数参数以及返回值
参数就是根节点指针,以及要插入元素,这里递归函数要不要有返回值呢?
可以有,也可以没有,但递归函数如果没有返回值的话,实现是比较麻烦的,下面也会给出其具体实现代码。
有返回值的话,可以利用返回值完成新加入的节点与其父节点的赋值操作。(下面会进一步解释)
递归函数的返回类型为节点类型TreeNode * 。
代码如下:
TreeNode* insertIntoBST(TreeNode* root, int val)
- 确定终止条件
终止条件就是找到遍历的节点为null的时候,就是要插入节点的位置了,并把插入的节点返回。
代码如下:
if (root == NULL) {
TreeNode* node = new TreeNode(val);
return node;
}
这里把添加的节点返回给上一层,就完成了父子节点的赋值操作了,详细再往下看。
- 确定单层递归的逻辑
此时要明确,需要遍历整棵树么?
别忘了这是搜索树,遍历整棵搜索树简直是对搜索树的侮辱。
搜索树是有方向了,可以根据插入元素的数值,决定递归方向。
代码如下:
if (root->val > val) root->left = insertIntoBST(root->left, val);
if (root->val < val) root->right = insertIntoBST(root->right, val);
return root;
到这里,大家应该能感受到,如何通过递归函数返回值完成了新加入节点的父子关系赋值操作了,下一层将加入节点返回,本层用root->left或者root->right将其接住。
刚刚说了递归函数不用返回值也可以,找到插入的节点位置,直接让其父节点指向插入节点,结束递归,也是可以的。
迭代
再来看看迭代法,对二叉搜索树迭代写法不熟悉,可以看这篇:二叉树:二叉搜索树登场!(opens new window)
在迭代法遍历的过程中,需要记录一下当前遍历的节点的父节点,这样才能做插入节点的操作。
在二叉树:搜索树的最小绝对差 (opens new window)和二叉树:我的众数是多少? (opens new window)中,都是用了记录pre和cur两个指针的技巧,本题也是一样的。
总结
首先在二叉搜索树中的插入操作,大家不用恐惧其重构搜索树,其实根本不用重构。
然后在递归中,我们重点讲了如何通过递归函数的返回值完成新加入节点和其父节点的赋值操作,并强调了搜索树的有序性。
最后依然给出了迭代的方法,迭代的方法就需要记录当前遍历节点的父节点了,这个和没有返回值的递归函数实现的代码逻辑是一样的。
C++解法
递归法整体代码如下:
class Solution {
public:
TreeNode* insertIntoBST(TreeNode* root, int val) {
if (root == NULL) {
TreeNode* node = new TreeNode(val);
return node;
}
if (root->val > val) root->left = insertIntoBST(root->left, val);
if (root->val < val) root->right = insertIntoBST(root->right, val);
return root;
}
};
那么递归函数定义如下:
TreeNode* parent; // 记录遍历节点的父节点
void traversal(TreeNode* cur, int val)
没有返回值,需要记录上一个节点(parent),遇到空节点了,就让parent左孩子或者右孩子指向新插入的节点。然后结束递归。
代码如下:
class Solution {
private:
TreeNode* parent;
void traversal(TreeNode* cur, int val) {
if (cur == NULL) {
TreeNode* node = new TreeNode(val);
if (val > parent->val) parent->right = node;
else parent->left = node;
return;
}
parent = cur;
if (cur->val > val) traversal(cur->left, val);
if (cur->val < val) traversal(cur->right, val);
return;
}
public:
TreeNode* insertIntoBST(TreeNode* root, int val) {
parent = new TreeNode(0);
if (root == NULL) {
root = new TreeNode(val);
}
traversal(root, val);
return root;
}
};
可以看出还是麻烦一些的。
我之所以举这个例子,是想说明通过递归函数的返回值完成父子节点的赋值是可以带来便利的。
网上千篇一律的代码,可能会误导大家认为通过递归函数返回节点 这样的写法是天经地义,其实这里是有优化的!
迭代法代码如下:
class Solution {
public:
TreeNode* insertIntoBST(TreeNode* root, int val) {
if (root == NULL) {
TreeNode* node = new TreeNode(val);
return node;
}
TreeNode* cur = root;
TreeNode* parent = root; // 这个很重要,需要记录上一个节点,否则无法赋值新节点
while (cur != NULL) {
parent = cur;
if (cur->val > val) cur = cur->left;
else cur = cur->right;
}
TreeNode* node = new TreeNode(val);
if (val < parent->val) parent->left = node;// 此时是用parent节点的进行赋值
else parent->right = node;
return root;
}
};
Java解法
递归法
class Solution {
public TreeNode insertIntoBST(TreeNode root, int val) {
if (root == null) // 如果当前节点为空,也就意味着val找到了合适的位置,此时创建节点直接返回。
return new TreeNode(val);
if (root.val < val){
root.right = insertIntoBST(root.right, val); // 递归创建右子树
}else if (root.val > val){
root.left = insertIntoBST(root.left, val); // 递归创建左子树
}
return root;
}
}
Python3解法
递归法(版本二)
class Solution:
def insertIntoBST(self, root: Optional[TreeNode], val: int) -> Optional[TreeNode]:
if root is None or root.val == val:
return TreeNode(val)
elif root.val > val:
if root.left is None:
root.left = TreeNode(val)
else:
self.insertIntoBST(root.left, val)
elif root.val < val:
if root.right is None:
root.right = TreeNode(val)
else:
self.insertIntoBST(root.right, val)
return root
Go解法
递归法
func insertIntoBST(root *TreeNode, val int) *TreeNode {
if root == nil {
root = &TreeNode{Val: val}
return root
}
if root.Val > val {
root.Left = insertIntoBST(root.Left, val)
} else {
root.Right = insertIntoBST(root.Right, val)
}
return root
}
450. Delete Node in a BST
Given a root node reference of a BST and a key, delete the node with the given key in the BST. Return the root node reference (possibly updated) of the BST.
Basically, the deletion can be divided into two stages:
- Search for a node to remove.
- If the node is found, delete the node.
Example 1:
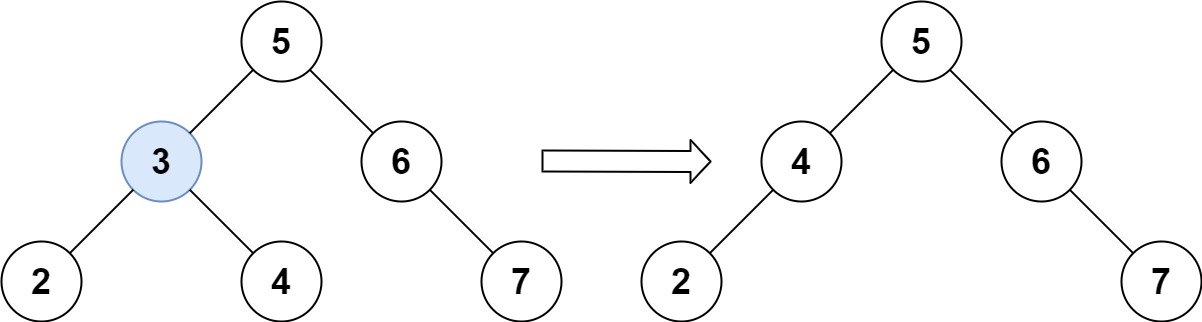
Input: root = [5,3,6,2,4,null,7], key = 3
Output: [5,4,6,2,null,null,7]
Explanation: Given key to delete is 3. So we find the node with value 3 and delete it.
One valid answer is [5,4,6,2,null,null,7], shown in the above BST.
Please notice that another valid answer is [5,2,6,null,4,null,7] and it's also accepted.
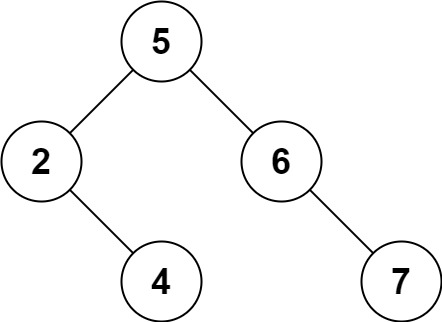
Example 2:
Input: root = [5,3,6,2,4,null,7], key = 0
Output: [5,3,6,2,4,null,7]
Explanation: The tree does not contain a node with value = 0.
Example 3:
Input: root = [], key = 0
Output: []
Constraints:
- The number of nodes in the tree is in the range
[0, 10^4]. -10^5 <= Node.val <= 10^5- Each node has a unique value.
rootis a valid binary search tree.-10^5 <= key <= 10^5
Follow up: Could you solve it with time complexity O(height of tree)?
思路
搜索树的节点删除要比节点增加复杂的多,有很多情况需要考虑,做好心理准备。
递归
递归三部曲:
- 确定递归函数参数以及返回值
说到递归函数的返回值,在二叉树:搜索树中的插入操作 (opens new window)中通过递归返回值来加入新节点, 这里也可以通过递归返回值删除节点。
代码如下:
TreeNode* deleteNode(TreeNode* root, int key)
- 确定终止条件
遇到空返回,其实这也说明没找到删除的节点,遍历到空节点直接返回了
if (root == nullptr) return root;
- 确定单层递归的逻辑
这里就把二叉搜索树中删除节点遇到的情况都搞清楚。
有以下五种情况:
- 第一种情况:没找到删除的节点,遍历到空节点直接返回了
- 找到删除的节点
- 第二种情况:左右孩子都为空(叶子节点),直接删除节点, 返回NULL为根节点
- 第三种情况:删除节点的左孩子为空,右孩子不为空,删除节点,右孩子补位,返回右孩子为根节点
- 第四种情况:删除节点的右孩子为空,左孩子不为空,删除节点,左孩子补位,返回左孩子为根节点
- 第五种情况:左右孩子节点都不为空,则将删除节点的左子树头结点(左孩子)放到删除节点的右子树的最左面节点的左孩子上,返回删除节点右孩子为新的根节点。
第五种情况有点难以理解,看下面动画:
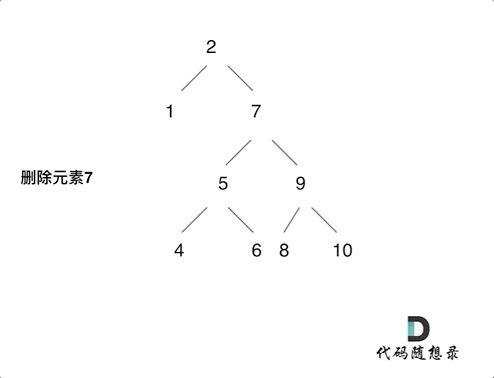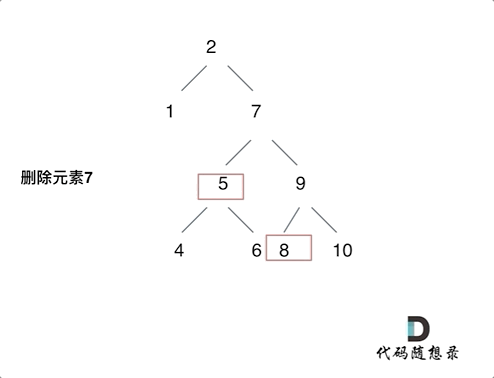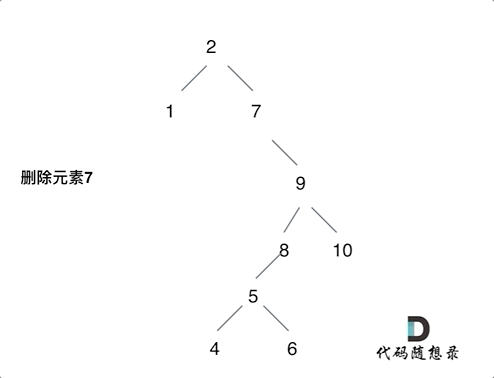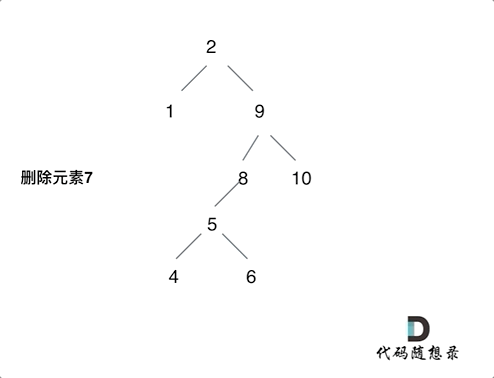
动画中的二叉搜索树中,删除元素7, 那么删除节点(元素7)的左孩子就是5,删除节点(元素7)的右子树的最左面节点是元素8。
将删除节点(元素7)的左孩子放到删除节点(元素7)的右子树的最左面节点(元素8)的左孩子上,就是把5为根节点的子树移到了8的左孩子的位置。
要删除的节点(元素7)的右孩子(元素9)为新的根节点。.
这样就完成删除元素7的逻辑,最好动手画一个图,尝试删除一个节点试试。
代码如下:
if (root->val == key) {
// 第二种情况:左右孩子都为空(叶子节点),直接删除节点, 返回NULL为根节点
// 第三种情况:其左孩子为空,右孩子不为空,删除节点,右孩子补位 ,返回右孩子为根节点
if (root->left == nullptr) return root->right;
// 第四种情况:其右孩子为空,左孩子不为空,删除节点,左孩子补位,返回左孩子为根节点
else if (root->right == nullptr) return root->left;
// 第五种情况:左右孩子节点都不为空,则将删除节点的左子树放到删除节点的右子树的最左面节点的左孩子的位置
// 并返回删除节点右孩子为新的根节点。
else {
TreeNode* cur = root->right; // 找右子树最左面的节点
while(cur->left != nullptr) {
cur = cur->left;
}
cur->left = root->left; // 把要删除的节点(root)左子树放在cur的左孩子的位置
TreeNode* tmp = root; // 把root节点保存一下,下面来删除
root = root->right; // 返回旧root的右孩子作为新root
delete tmp; // 释放节点内存(这里不写也可以,但C++最好手动释放一下吧)
return root;
}
}
这里相当于把新的节点返回给上一层,上一层就要用 root->left 或者 root->right接住,代码如下:
if (root->val > key) root->left = deleteNode(root->left, key);
if (root->val < key) root->right = deleteNode(root->right, key);
return root;
普通二叉树的删除方式
这里我在介绍一种通用的删除,普通二叉树的删除方式(没有使用搜索树的特性,遍历整棵树),用交换值的操作来删除目标节点。
代码中目标节点(要删除的节点)被操作了两次:
- 第一次是和目标节点的右子树最左面节点交换。
- 第二次直接被NULL覆盖了。
思路有点绕,感兴趣的同学可以画图自己理解一下。
代码如下:(关键部分已经注释)
class Solution {
public:
TreeNode* deleteNode(TreeNode* root, int key) {
if (root == nullptr) return root;
if (root->val == key) {
if (root->right == nullptr) { // 这里第二次操作目标值:最终删除的作用
return root->left;
}
TreeNode *cur = root->right;
while (cur->left) {
cur = cur->left;
}
swap(root->val, cur->val); // 这里第一次操作目标值:交换目标值其右子树最左面节点。
}
root->left = deleteNode(root->left, key);
root->right = deleteNode(root->right, key);
return root;
}
};
这个代码是简短一些,思路也巧妙,但是不太好想,实操性不强,推荐第一种写法!
迭代法
删除节点的迭代法还是复杂一些的,但其本质我在递归法里都介绍了,最关键就是删除节点的操作(动画模拟的过程)
总结
读完本篇,大家会发现二叉搜索树删除节点比增加节点复杂的多。
因为二叉搜索树添加节点只需要在叶子上添加就可以的,不涉及到结构的调整,而删除节点操作涉及到结构的调整。
这里我们依然使用递归函数的返回值来完成把节点从二叉树中移除的操作。
这里最关键的逻辑就是第五种情况(删除一个左右孩子都不为空的节点),这种情况一定要想清楚。
而且就算想清楚了,对应的代码也未必可以写出来,所以这道题目既考察思维逻辑,也考察代码能力。
递归中我给出了两种写法,推荐大家学会第一种(利用搜索树的特性)就可以了,第二种递归写法其实是比较绕的。
最后我也给出了相应的迭代法,就是模拟递归法中的逻辑来删除节点,但需要一个pre记录cur的父节点,方便做删除操作。
迭代法其实不太容易写出来,所以如果是初学者的话,彻底掌握第一种递归写法就够了。
C++解法
递归法整体代码如下:(注释中:情况1,2,3,4,5和上面分析严格对应)
class Solution {
public:
TreeNode* deleteNode(TreeNode* root, int key) {
if (root == nullptr) return root; // 第一种情况:没找到删除的节点,遍历到空节点直接返回了
if (root->val == key) {
// 第二种情况:左右孩子都为空(叶子节点),直接删除节点, 返回NULL为根节点
if (root->left == nullptr && root->right == nullptr) {
///! 内存释放
delete root;
return nullptr;
}
// 第三种情况:其左孩子为空,右孩子不为空,删除节点,右孩子补位 ,返回右孩子为根节点
else if (root->left == nullptr) {
auto retNode = root->right;
///! 内存释放
delete root;
return retNode;
}
// 第四种情况:其右孩子为空,左孩子不为空,删除节点,左孩子补位,返回左孩子为根节点
else if (root->right == nullptr) {
auto retNode = root->left;
///! 内存释放
delete root;
return retNode;
}
// 第五种情况:左右孩子节点都不为空,则将删除节点的左子树放到删除节点的右子树的最左面节点的左孩子的位置
// 并返回删除节点右孩子为新的根节点。
else {
TreeNode* cur = root->right; // 找右子树最左面的节点
while(cur->left != nullptr) {
cur = cur->left;
}
cur->left = root->left; // 把要删除的节点(root)左子树放在cur的左孩子的位置
TreeNode* tmp = root; // 把root节点保存一下,下面来删除
root = root->right; // 返回旧root的右孩子作为新root
delete tmp; // 释放节点内存(这里不写也可以,但C++最好手动释放一下吧)
return root;
}
}
if (root->val > key) root->left = deleteNode(root->left, key);
if (root->val < key) root->right = deleteNode(root->right, key);
return root;
}
};
迭代法代码如下:
class Solution {
private:
// 将目标节点(删除节点)的左子树放到 目标节点的右子树的最左面节点的左孩子位置上
// 并返回目标节点右孩子为新的根节点
// 是动画里模拟的过程
TreeNode* deleteOneNode(TreeNode* target) {
if (target == nullptr) return target;
if (target->right == nullptr) return target->left;
TreeNode* cur = target->right;
while (cur->left) {
cur = cur->left;
}
cur->left = target->left;
return target->right;
}
public:
TreeNode* deleteNode(TreeNode* root, int key) {
if (root == nullptr) return root;
TreeNode* cur = root;
TreeNode* pre = nullptr; // 记录cur的父节点,用来删除cur
while (cur) {
if (cur->val == key) break;
pre = cur;
if (cur->val > key) cur = cur->left;
else cur = cur->right;
}
if (pre == nullptr) { // 如果搜索树只有头结点
return deleteOneNode(cur);
}
// pre 要知道是删左孩子还是右孩子
if (pre->left && pre->left->val == key) {
pre->left = deleteOneNode(cur);
}
if (pre->right && pre->right->val == key) {
pre->right = deleteOneNode(cur);
}
return root;
}
};
Java解法
// 解法1(最好理解的版本)
class Solution {
public TreeNode deleteNode(TreeNode root, int key) {
if (root == null) return root;
if (root.val == key) {
if (root.left == null) {
return root.right;
} else if (root.right == null) {
return root.left;
} else {
TreeNode cur = root.right;
while (cur.left != null) {
cur = cur.left;
}
cur.left = root.left;
root = root.right;
return root;
}
}
if (root.val > key) root.left = deleteNode(root.left, key);
if (root.val < key) root.right = deleteNode(root.right, key);
return root;
}
}
Python3解法
递归法(版本二)
class Solution:
def deleteNode(self, root, key):
if root is None: # 如果根节点为空,直接返回
return root
if root.val == key: # 找到要删除的节点
if root.right is None: # 如果右子树为空,直接返回左子树作为新的根节点
return root.left
cur = root.right
while cur.left: # 找到右子树中的最左节点
cur = cur.left
root.val, cur.val = cur.val, root.val # 将要删除的节点值与最左节点值交换
root.left = self.deleteNode(root.left, key) # 在左子树中递归删除目标节点
root.right = self.deleteNode(root.right, key) # 在右子树中递归删除目标节点
return root
Go解法
// 递归版本
func deleteNode(root *TreeNode, key int) *TreeNode {
if root == nil {
return nil
}
if key < root.Val {
root.Left = deleteNode(root.Left, key)
return root
}
if key > root.Val {
root.Right = deleteNode(root.Right, key)
return root
}
if root.Right == nil {
return root.Left
}
if root.Left == nil{
return root.Right
}
minnode := root.Right
for minnode.Left != nil {
minnode = minnode.Left
}
root.Val = minnode.Val
root.Right = deleteNode1(root.Right)
return root
}
func deleteNode1(root *TreeNode)*TreeNode {
if root.Left == nil {
pRight := root.Right
root.Right = nil
return pRight
}
root.Left = deleteNode1(root.Left)
return root
}
669. Trim a Binary Search Tree
Given the root of a binary search tree and the lowest and highest boundaries as low and high, trim the tree so that all its elements lies in [low, high]. Trimming the tree should not change the relative structure of the elements that will remain in the tree (i.e., any node's descendant should remain a descendant). It can be proven that there is a unique answer.
Return the root of the trimmed binary search tree. Note that the root may change depending on the given bounds.
Example 1:
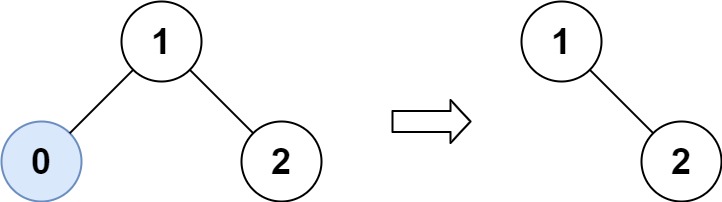
Input: root = [1,0,2], low = 1, high = 2
Output: [1,null,2]
Example 2:
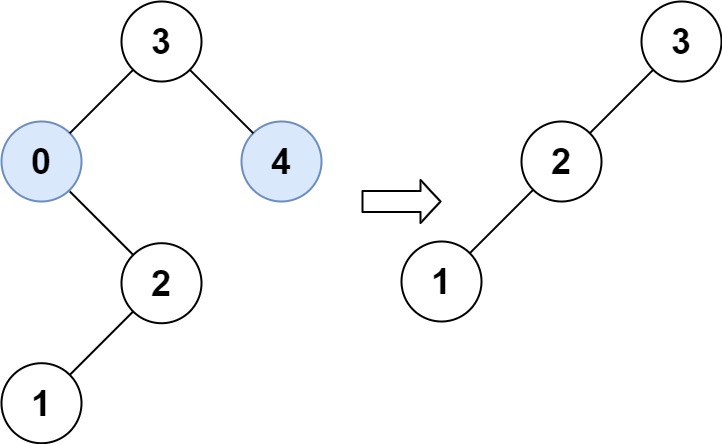
Input: root = [3,0,4,null,2,null,null,1], low = 1, high = 3
Output: [3,2,null,1]
Constraints:
- The number of nodes in the tree is in the range
[1, 10^4]. 0 <= Node.val <= 10^4- The value of each node in the tree is unique.
rootis guaranteed to be a valid binary search tree.0 <= low <= high <= 10^4
思路
相信看到这道题目大家都感觉是一道简单题(事实上leetcode上也标明是简单)。
但还真的不简单!
递归法
直接想法就是:递归处理,然后遇到 root->val < low || root->val > high 的时候直接return NULL,一波修改,赶紧利落。
不难写出如下代码:
class Solution {
public:
TreeNode* trimBST(TreeNode* root, int low, int high) {
if (root == nullptr || root->val < low || root->val > high) return nullptr;
root->left = trimBST(root->left, low, high);
root->right = trimBST(root->right, low, high);
return root;
}
};
然而[1, 3]区间在二叉搜索树的中可不是单纯的节点3和左孩子节点0就决定的,还要考虑节点0的右子树。
我们在重新关注一下第二个示例,如图:
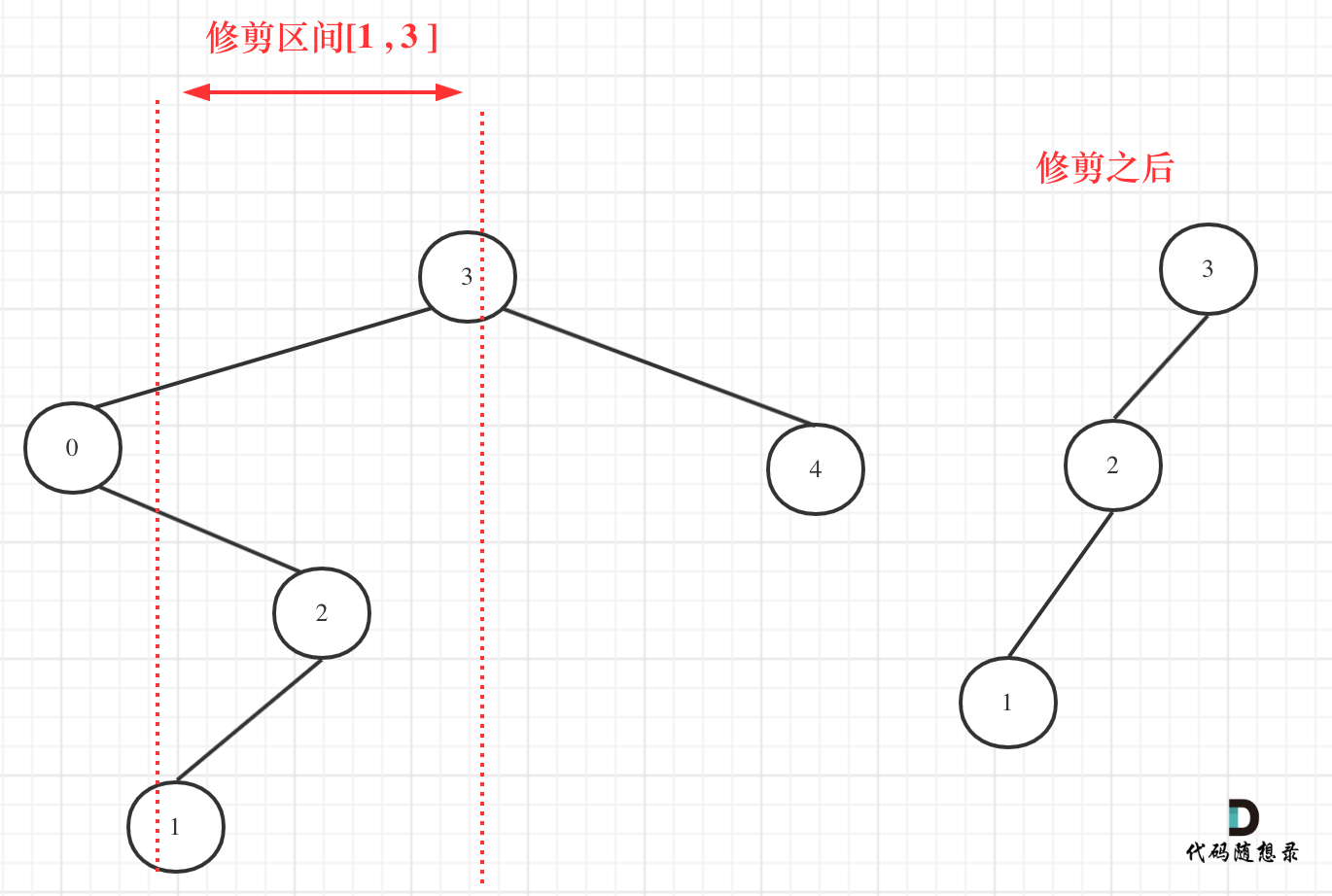
所以以上的代码是不可行的!
从图中可以看出需要重构二叉树,想想是不是本题就有点复杂了。
其实不用重构那么复杂。
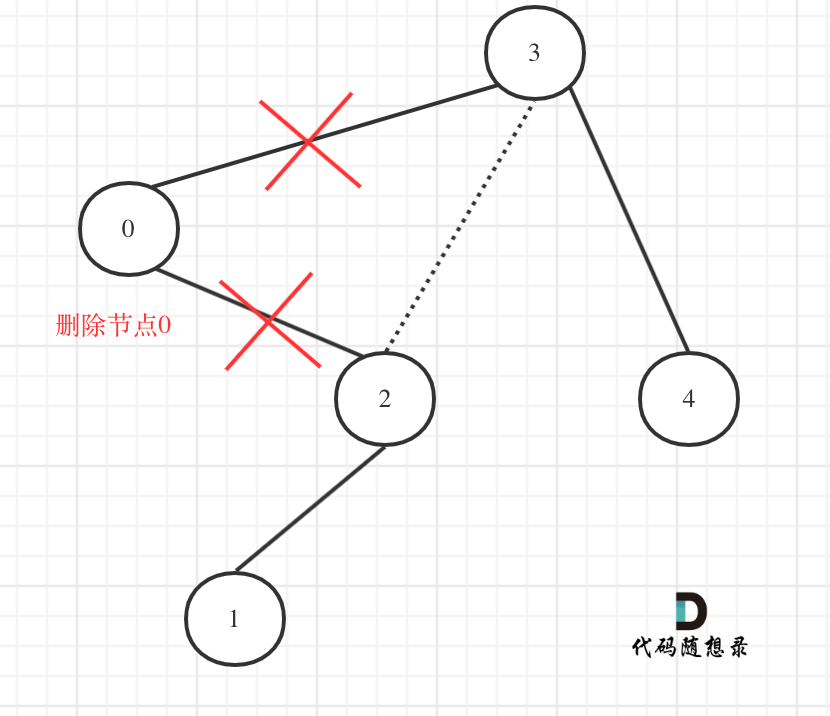
在上图中我们发现节点0并不符合区间要求,那么将节点0的右孩子 节点2 直接赋给 节点3的左孩子就可以了(就是把节点0从二叉树中移除),如图:
理解了最关键部分了我们再递归三部曲:
- 确定递归函数的参数以及返回值
这里我们为什么需要返回值呢?
因为是要遍历整棵树,做修改,其实不需要返回值也可以,我们也可以完成修剪(其实就是从二叉树中移除节点)的操作。
但是有返回值,更方便,可以通过递归函数的返回值来移除节点。
这样的做法在二叉树:搜索树中的插入操作 (opens new window)和二叉树:搜索树中的删除操作 (opens new window)中大家已经了解过了。
代码如下:
TreeNode* trimBST(TreeNode* root, int low, int high)
- 确定终止条件
修剪的操作并不是在终止条件上进行的,所以就是遇到空节点返回就可以了。
if (root == nullptr ) return nullptr;
- 确定单层递归的逻辑
如果root(当前节点)的元素小于low的数值,那么应该递归右子树,并返回右子树符合条件的头结点。
代码如下:
if (root->val < low) {
TreeNode* right = trimBST(root->right, low, high); // 寻找符合区间[low, high]的节点
return right;
}
如果root(当前节点)的元素大于high的,那么应该递归左子树,并返回左子树符合条件的头结点。
代码如下:
if (root->val > high) {
TreeNode* left = trimBST(root->left, low, high); // 寻找符合区间[low, high]的节点
return left;
}
接下来要将下一层处理完左子树的结果赋给root->left,处理完右子树的结果赋给root->right。
最后返回root节点,代码如下:
root->left = trimBST(root->left, low, high); // root->left接入符合条件的左孩子
root->right = trimBST(root->right, low, high); // root->right接入符合条件的右孩子
return root;
此时大家是不是还没发现这多余的节点究竟是如何从二叉树中移除的呢?
在回顾一下上面的代码,针对下图中二叉树的情况:
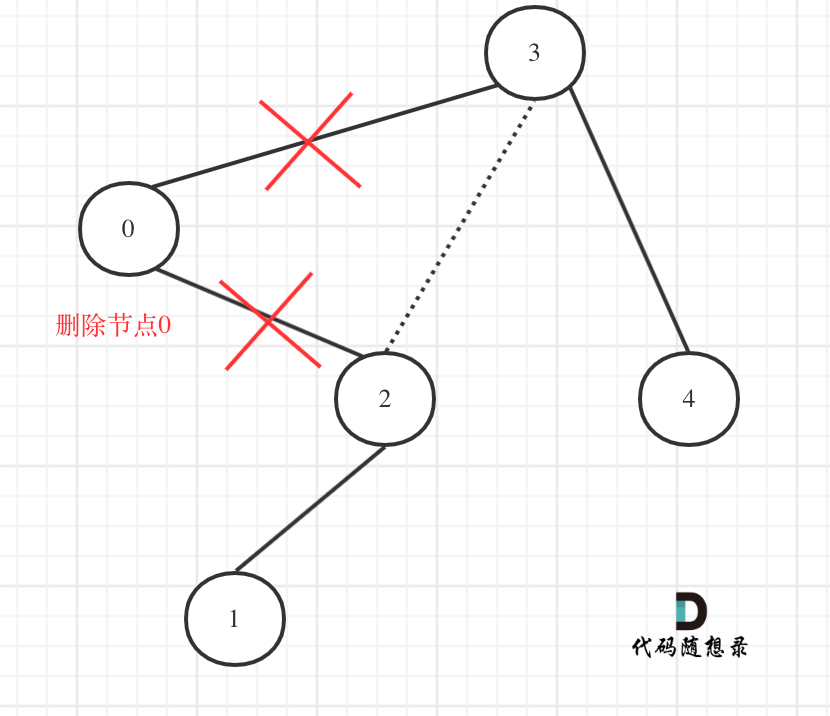
如下代码相当于把节点0的右孩子(节点2)返回给上一层,
if (root->val < low) {
TreeNode* right = trimBST(root->right, low, high); // 寻找符合区间[low, high]的节点
return right;
}
然后如下代码相当于用节点3的左孩子 把下一层返回的 节点0的右孩子(节点2) 接住。
root->left = trimBST(root->left, low, high);
此时节点3的左孩子就变成了节点2,将节点0从二叉树中移除了。
迭代法
因为二叉搜索树的有序性,不需要使用栈模拟递归的过程。
在剪枝的时候,可以分为三步:
- 将root移动到
[L, R]范围内,注意是左闭右闭区间 - 剪枝左子树
- 剪枝右子树
总结
修剪二叉搜索树其实并不难,但在递归法中大家可看出我费了很大的功夫来讲解如何删除节点的,这个思路其实是比较绕的。
最终的代码倒是很简洁。
如果不对递归有深刻的理解,这道题目还是有难度的!
本题我依然给出递归法和迭代法,初学者掌握递归就可以了,如果想进一步学习,就把迭代法也写一写。
C++解法
递归法最后整体代码如下:
class Solution {
public:
TreeNode* trimBST(TreeNode* root, int low, int high) {
if (root == nullptr ) return nullptr;
if (root->val < low) {
TreeNode* right = trimBST(root->right, low, high); // 寻找符合区间[low, high]的节点
return right;
}
if (root->val > high) {
TreeNode* left = trimBST(root->left, low, high); // 寻找符合区间[low, high]的节点
return left;
}
root->left = trimBST(root->left, low, high); // root->left接入符合条件的左孩子
root->right = trimBST(root->right, low, high); // root->right接入符合条件的右孩子
return root;
}
};
精简之后代码如下:
class Solution {
public:
TreeNode* trimBST(TreeNode* root, int low, int high) {
if (root == nullptr) return nullptr;
if (root->val < low) return trimBST(root->right, low, high);
if (root->val > high) return trimBST(root->left, low, high);
root->left = trimBST(root->left, low, high);
root->right = trimBST(root->right, low, high);
return root;
}
};
只看代码,其实不太好理解节点是如何移除的,这一块大家可以自己再模拟模拟!
迭代法代码如下:
class Solution {
public:
TreeNode* trimBST(TreeNode* root, int L, int R) {
if (!root) return nullptr;
// 处理头结点,让root移动到[L, R] 范围内,注意是左闭右闭
while (root != nullptr && (root->val < L || root->val > R)) {
if (root->val < L) root = root->right; // 小于L往右走
else root = root->left; // 大于R往左走
}
TreeNode *cur = root;
// 此时root已经在[L, R] 范围内,处理左孩子元素小于L的情况
while (cur != nullptr) {
while (cur->left && cur->left->val < L) {
cur->left = cur->left->right;
}
cur = cur->left;
}
cur = root;
// 此时root已经在[L, R] 范围内,处理右孩子大于R的情况
while (cur != nullptr) {
while (cur->right && cur->right->val > R) {
cur->right = cur->right->left;
}
cur = cur->right;
}
return root;
}
};
Java解法
递归法
class Solution {
public TreeNode trimBST(TreeNode root, int low, int high) {
if (root == null) {
return null;
}
if (root.val < low) {
return trimBST(root.right, low, high);
}
if (root.val > high) {
return trimBST(root.left, low, high);
}
// root在[low,high]范围内
root.left = trimBST(root.left, low, high);
root.right = trimBST(root.right, low, high);
return root;
}
}
Python3解法
递归法
class Solution:
def trimBST(self, root: TreeNode, low: int, high: int) -> TreeNode:
if root is None:
return None
if root.val < low:
# 寻找符合区间 [low, high] 的节点
return self.trimBST(root.right, low, high)
if root.val > high:
# 寻找符合区间 [low, high] 的节点
return self.trimBST(root.left, low, high)
root.left = self.trimBST(root.left, low, high) # root.left 接入符合条件的左孩子
root.right = self.trimBST(root.right, low, high) # root.right 接入符合条件的右孩子
return root
Go解法
// 递归
func trimBST(root *TreeNode, low int, high int) *TreeNode {
if root == nil {
return nil
}
if root.Val < low { //如果该节点值小于最小值,则该节点更换为该节点的右节点值,继续遍历
right := trimBST(root.Right, low, high)
return right
}
if root.Val > high { //如果该节点的值大于最大值,则该节点更换为该节点的左节点值,继续遍历
left := trimBST(root.Left, low, high)
return left
}
root.Left = trimBST(root.Left, low, high)
root.Right = trimBST(root.Right, low, high)
return root
}
108. Convert Sorted Array to Binary Search Tree
Given an integer array nums where the elements are sorted in ascending order, convert it to a height-balanced binary search tree.
Example 1:
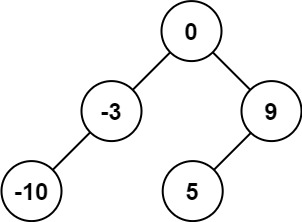
Input: nums = [-10,-3,0,5,9]
Output: [0,-3,9,-10,null,5]
Explanation: [0,-10,5,null,-3,null,9] is also accepted:

Example 2:
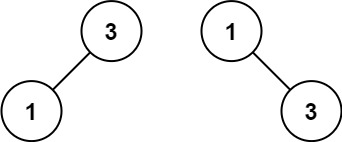
Input: nums = [1,3]
Output: [3,1]
Explanation: [1,null,3] and [3,1] are both height-balanced BSTs.
Constraints:
1 <= nums.length <= 10^4-10^4 <= nums[i] <= 10^4numsis sorted in a strictly increasing order.
思路
题目中说要转换为一棵高度平衡二叉搜索树。为什么强调要平衡呢?
因为只要给我们一个有序数组,如果不强调平衡,都可以以线性结构来构造二叉搜索树。
上图中,是符合二叉搜索树的特性吧,如果要这么做的话,是不是本题意义就不大了,所以才强调是平衡二叉搜索树。
其实数组构造二叉树,构成平衡树是自然而然的事情,因为大家默认都是从数组中间位置取值作为节点元素,一般不会随机取。所以想构成不平衡的二叉树是自找麻烦。
在二叉树:构造二叉树登场! (opens new window)和二叉树:构造一棵最大的二叉树 (opens new window)中其实已经讲过了,如果根据数组构造一棵二叉树。
本质就是寻找分割点,分割点作为当前节点,然后递归左区间和右区间。
本题其实要比二叉树:构造二叉树登场! (opens new window)和 二叉树:构造一棵最大的二叉树 (opens new window)简单一些,因为有序数组构造二叉搜索树,寻找分割点就比较容易了。
分割点就是数组中间位置的节点。
那么为问题来了,如果数组长度为偶数,中间节点有两个,取哪一个?
取哪一个都可以,只不过构成了不同的平衡二叉搜索树。
例如:输入:[-10,-3,0,5,9]
如下两棵树,都是这个数组的平衡二叉搜索树:
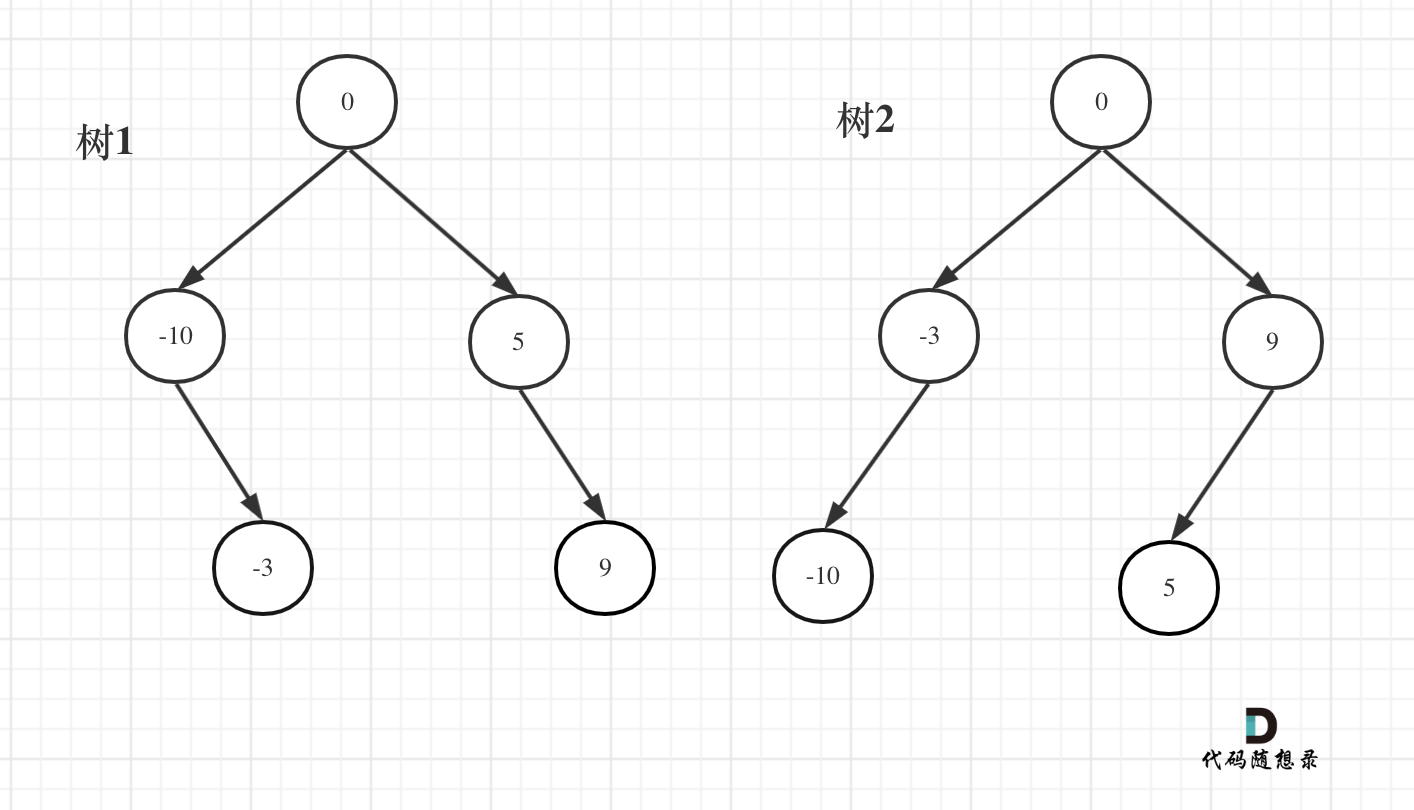
如果要分割的数组长度为偶数的时候,中间元素为两个,是取左边元素 就是树1,取右边元素就是树2。
这也是题目中强调答案不是唯一的原因。 理解这一点,这道题目算是理解到位了。
递归
递归三部曲:
- 确定递归函数返回值及其参数
删除二叉树节点,增加二叉树节点,都是用递归函数的返回值来完成,这样是比较方便的。
相信大家如果仔细看了二叉树:搜索树中的插入操作 (opens new window)和二叉树:搜索树中的删除操作 (opens new window),一定会对递归函数返回值的作用深有感触。
那么本题要构造二叉树,依然用递归函数的返回值来构造中节点的左右孩子。
再来看参数,首先是传入数组,然后就是左下标left和右下标right,我们在二叉树:构造二叉树登场! (opens new window)中提过,在构造二叉树的时候尽量不要重新定义左右区间数组,而是用下标来操作原数组。
所以代码如下:
// 左闭右闭区间[left, right]
TreeNode* traversal(vector<int>& nums, int left, int right)
这里注意,我这里定义的是左闭右闭区间,在不断分割的过程中,也会坚持左闭右闭的区间,这又涉及到我们讲过的循环不变量。
在二叉树:构造二叉树登场! (opens new window),35.搜索插入位置 (opens new window)和59.螺旋矩阵II (opens new window)都详细讲过循环不变量。
- 确定递归终止条件
这里定义的是左闭右闭的区间,所以当区间 left > right的时候,就是空节点了。
代码如下:
if (left > right) return nullptr;
- 确定单层递归的逻辑
首先取数组中间元素的位置,不难写出int mid = (left + right) / 2;,这么写其实有一个问题,就是数值越界,例如left和right都是最大int,这么操作就越界了,在二分法 (opens new window)中尤其需要注意!
所以可以这么写:int mid = left + ((right - left) / 2);
但本题leetcode的测试数据并不会越界,所以怎么写都可以。但需要有这个意识!
取了中间位置,就开始以中间位置的元素构造节点,代码:TreeNode* root = new TreeNode(nums[mid]);。
接着划分区间,root的左孩子接住下一层左区间的构造节点,右孩子接住下一层右区间构造的节点。
最后返回root节点,单层递归整体代码如下:
int mid = left + ((right - left) / 2);
TreeNode* root = new TreeNode(nums[mid]);
root->left = traversal(nums, left, mid - 1);
root->right = traversal(nums, mid + 1, right);
return root;
这里int mid = left + ((right - left) / 2);的写法相当于是如果数组长度为偶数,中间位置有两个元素,取靠左边的。
迭代法
迭代法可以通过三个队列来模拟,一个队列放遍历的节点,一个队列放左区间下标,一个队列放右区间下标。
总结
在二叉树:构造二叉树登场! (opens new window)和 二叉树:构造一棵最大的二叉树 (opens new window)之后,我们顺理成章的应该构造一下二叉搜索树了,一不小心还是一棵平衡二叉搜索树。
其实思路也是一样的,不断中间分割,然后递归处理左区间,右区间,也可以说是分治。
此时相信大家应该对通过递归函数的返回值来增删二叉树很熟悉了,这也是常规操作。
在定义区间的过程中我们又一次强调了循环不变量的重要性。
最后依然给出迭代的方法,其实就是模拟取中间元素,然后不断分割去构造二叉树的过程。
C++解法
递归整体代码如下:
class Solution {
private:
TreeNode* traversal(vector<int>& nums, int left, int right) {
if (left > right) return nullptr;
int mid = left + ((right - left) / 2);
TreeNode* root = new TreeNode(nums[mid]);
root->left = traversal(nums, left, mid - 1);
root->right = traversal(nums, mid + 1, right);
return root;
}
public:
TreeNode* sortedArrayToBST(vector<int>& nums) {
TreeNode* root = traversal(nums, 0, nums.size() - 1);
return root;
}
};
注意:在调用traversal的时候传入的left和right为什么是0和nums.size() - 1,因为定义的区间为左闭右闭。
迭代法模拟的就是不断分割的过程,C++代码如下:(我已经详细注释)
class Solution {
public:
TreeNode* sortedArrayToBST(vector<int>& nums) {
if (nums.size() == 0) return nullptr;
TreeNode* root = new TreeNode(0); // 初始根节点
queue<TreeNode*> nodeQue; // 放遍历的节点
queue<int> leftQue; // 保存左区间下标
queue<int> rightQue; // 保存右区间下标
nodeQue.push(root); // 根节点入队列
leftQue.push(0); // 0为左区间下标初始位置
rightQue.push(nums.size() - 1); // nums.size() - 1为右区间下标初始位置
while (!nodeQue.empty()) {
TreeNode* curNode = nodeQue.front();
nodeQue.pop();
int left = leftQue.front(); leftQue.pop();
int right = rightQue.front(); rightQue.pop();
int mid = left + ((right - left) / 2);
curNode->val = nums[mid]; // 将mid对应的元素给中间节点
if (left <= mid - 1) { // 处理左区间
curNode->left = new TreeNode(0);
nodeQue.push(curNode->left);
leftQue.push(left);
rightQue.push(mid - 1);
}
if (right >= mid + 1) { // 处理右区间
curNode->right = new TreeNode(0);
nodeQue.push(curNode->right);
leftQue.push(mid + 1);
rightQue.push(right);
}
}
return root;
}
};
Java解法
递归: 左闭右开 [left,right)
class Solution {
public TreeNode sortedArrayToBST(int[] nums) {
return sortedArrayToBST(nums, 0, nums.length);
}
public TreeNode sortedArrayToBST(int[] nums, int left, int right) {
if (left >= right) {
return null;
}
if (right - left == 1) {
return new TreeNode(nums[left]);
}
int mid = left + (right - left) / 2;
TreeNode root = new TreeNode(nums[mid]);
root.left = sortedArrayToBST(nums, left, mid);
root.right = sortedArrayToBST(nums, mid + 1, right);
return root;
}
}
Python3解法
递归 精简(自身调用)
class Solution:
def sortedArrayToBST(self, nums: List[int]) -> Optional[TreeNode]:
if not nums:
return
mid = len(nums) // 2
root = TreeNode(nums[mid])
root.left = self.sortedArrayToBST(nums[:mid])
root.right = self.sortedArrayToBST(nums[mid + 1 :])
return root
Go解法
递归(隐含回溯)
func sortedArrayToBST(nums []int) *TreeNode {
if len(nums) == 0 { //终止条件,最后数组为空则可以返回
return nil
}
idx := len(nums)/2
root := &TreeNode{Val: nums[idx]}
root.Left = sortedArrayToBST(nums[:idx])
root.Right = sortedArrayToBST(nums[idx+1:])
return root
}
109. Convert Sorted List to Binary Search Tree
Given the head of a singly linked list where elements are sorted in ascending order, convert it to aheight-balanced binary search tree.
Example 1:
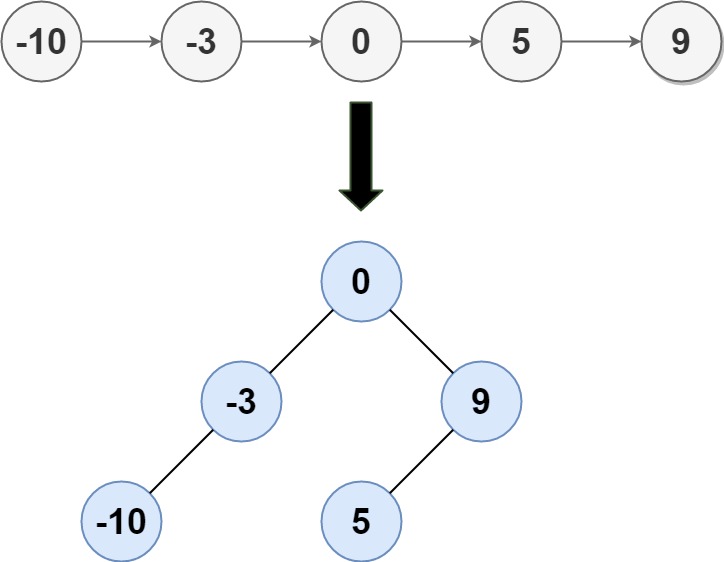
Input: head = [-10,-3,0,5,9]
Output: [0,-3,9,-10,null,5]
Explanation: One possible answer is [0,-3,9,-10,null,5], which represents the shown height balanced BST.
Example 2:
Input: head = []
Output: []
Constraints:
- The number of nodes in
headis in the range[0, 2 * 10^4]. -10^5 <= Node.val <= 10^5
思路
方法一:转为数组然后处理
方法二:双指针找中间位置,再分区处理
Intuition
The problem requires converting a sorted linked list into a height-balanced binary search tree (BST). Since the linked list is sorted, the middle element naturally serves as the root, ensuring balance.
Approach
Find the Middle Node:
Use the slow and fast pointer method to locate the middle element.
This middle node becomes the root of the BST.
Recursively Construct the Left and Right Subtrees:
The left half of the list (before the middle node) forms theleft subtree.
The right half of the list (after the middle node) forms theright subtree.
Base Case:
If head == tail, return nullptr, as there are no elements to process.
Complexity Analysis
Time Complexity:O(nlogn)
Finding the middle element takesO(n), and we perform thislog ntimes.
Space Complexity:O(logn)
Due to recursive stack space.
C++解法
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode() : val(0), next(nullptr) {}
* ListNode(int x) : val(x), next(nullptr) {}
* ListNode(int x, ListNode *next) : val(x), next(next) {}
* };
*/
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode() : val(0), left(nullptr), right(nullptr) {}
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
* };
*/
class Solution {
public:
TreeNode* sortedArrayToBST(vector<int>& nums) {
if(nums.size() == 0){
return NULL;
}
if(nums.size() == 1){
return new TreeNode(nums[0]);
}
int rootVal = nums[nums.size() / 2];
TreeNode* root = new TreeNode(rootVal);
vector<int> left(nums.begin(), nums.begin() + nums.size() / 2);
root->left = sortedArrayToBST(left);
vector<int> right(nums.begin() + nums.size() / 2 + 1 , nums.end());
root->right = sortedArrayToBST(right);
return root;
}
TreeNode* sortedListToBST(ListNode* head) {
vector<int> nums;
ListNode* cur = head;
while(cur){
nums.push_back(cur->val);
cur = cur->next;
}
return sortedArrayToBST(nums);
}
};
方法二:
class Solution {
public:
ListNode* find_middle(ListNode* head, ListNode* tail) {
if (!head)
return nullptr;
ListNode *slow = head, *fast = head;
while (fast != tail && fast->next != tail) {
slow = slow->next;
fast = fast->next->next;
}
return slow;
}
TreeNode* helper(ListNode* head, ListNode* tail) {
if (head == tail)
return nullptr;
ListNode* middle = find_middle(head, tail);
TreeNode* root = new TreeNode(middle->val);
root->left = helper(head, middle);
root->right = helper(middle->next, tail);
return root;
}
TreeNode* sortedListToBST(ListNode* head) {
if (!head)
return nullptr;
return helper(head, nullptr);
}
};
Java解法
Python3解法
Go解法
538. Convert BST to Greater Tree
Given the root of a Binary Search Tree (BST), convert it to a Greater Tree such that every key of the original BST is changed to the original key plus the sum of all keys greater than the original key in BST.
As a reminder, a binary search tree is a tree that satisfies these constraints:
- The left subtree of a node contains only nodes with keys less than the node's key.
- The right subtree of a node contains only nodes with keys greater than the node's key.
- Both the left and right subtrees must also be binary search trees.
Example 1:

Input: root = [4,1,6,0,2,5,7,null,null,null,3,null,null,null,8]
Output: [30,36,21,36,35,26,15,null,null,null,33,null,null,null,8]
Example 2:
Input: root = [0,null,1]
Output: [1,null,1]
Constraints:
- The number of nodes in the tree is in the range
[0, 10^4]. -10^4 <= Node.val <= 10^4- All the values in the tree are unique.
rootis guaranteed to be a valid binary search tree.
Note: This question is the same as 1038: https://leetcode.com/problems/binary-search-tree-to-greater-sum-tree/
思路
一看到累加树,相信很多小伙伴都会疑惑:如何累加?遇到一个节点,然后再遍历其他节点累加?怎么一想这么麻烦呢。
然后再发现这是一棵二叉搜索树,二叉搜索树啊,这是有序的啊。
那么有序的元素如何求累加呢?
其实这就是一棵树,大家可能看起来有点别扭,换一个角度来看,这就是一个有序数组[2, 5, 13],求从后到前的累加数组,也就是[20, 18, 13],是不是感觉这就简单了。
为什么变成数组就是感觉简单了呢?
因为数组大家都知道怎么遍历啊,从后向前,挨个累加就完事了,这换成了二叉搜索树,看起来就别扭了一些是不是。
那么知道如何遍历这个二叉树,也就迎刃而解了,从树中可以看出累加的顺序是右中左,所以我们需要反中序遍历这个二叉树,然后顺序累加就可以了。
递归
遍历顺序如图所示:
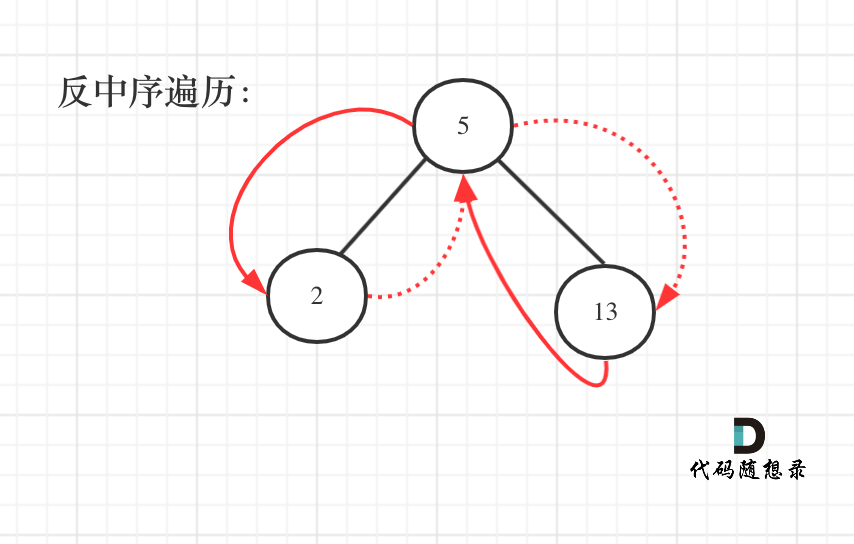
本题依然需要一个pre指针记录当前遍历节点cur的前一个节点,这样才方便做累加。
pre指针的使用技巧,我们在二叉树:搜索树的最小绝对差 (opens new window)和二叉树:我的众数是多少? (opens new window)都提到了,这是常用的操作手段。
- 递归函数参数以及返回值
这里很明确了,不需要递归函数的返回值做什么操作了,要遍历整棵树。
同时需要定义一个全局变量pre,用来保存cur节点的前一个节点的数值,定义为int型就可以了。
代码如下:
int pre = 0; // 记录前一个节点的数值
void traversal(TreeNode* cur)
- 确定终止条件
遇空就终止。
if (cur == NULL) return;
- 确定单层递归的逻辑
注意要右中左来遍历二叉树, 中节点的处理逻辑就是让cur的数值加上前一个节点的数值。
代码如下:
traversal(cur->right); // 右
cur->val += pre; // 中
pre = cur->val;
traversal(cur->left); // 左
迭代法
迭代法其实就是中序模板题了,在二叉树:前中后序迭代法 (opens new window)和二叉树:前中后序统一方式迭代法 (opens new window)可以选一种自己习惯的写法。
C++解法
递归法整体代码如下:
class Solution {
private:
int pre = 0; // 记录前一个节点的数值
void traversal(TreeNode* cur) { // 右中左遍历
if (cur == NULL) return;
traversal(cur->right);
cur->val += pre;
pre = cur->val;
traversal(cur->left);
}
public:
TreeNode* convertBST(TreeNode* root) {
pre = 0;
traversal(root);
return root;
}
};
迭代法的一种代码如下:
class Solution {
private:
int pre; // 记录前一个节点的数值
void traversal(TreeNode* root) {
stack<TreeNode*> st;
TreeNode* cur = root;
while (cur != NULL || !st.empty()) {
if (cur != NULL) {
st.push(cur);
cur = cur->right; // 右
} else {
cur = st.top(); // 中
st.pop();
cur->val += pre;
pre = cur->val;
cur = cur->left; // 左
}
}
}
public:
TreeNode* convertBST(TreeNode* root) {
pre = 0;
traversal(root);
return root;
}
};
Java解法
递归法
class Solution {
int sum;
public TreeNode convertBST(TreeNode root) {
sum = 0;
convertBST1(root);
return root;
}
// 按右中左顺序遍历,累加即可
public void convertBST1(TreeNode root) {
if (root == null) {
return;
}
convertBST1(root.right);
sum += root.val;
root.val = sum;
convertBST1(root.left);
}
}
Python3解法
迭代法(版本一)
class Solution:
def __init__(self):
self.pre = 0 # 记录前一个节点的数值
def traversal(self, root):
stack = []
cur = root
while cur or stack:
if cur:
stack.append(cur)
cur = cur.right # 右
else:
cur = stack.pop() # 中
cur.val += self.pre
self.pre = cur.val
cur = cur.left # 左
def convertBST(self, root):
self.pre = 0
self.traversal(root)
return root
Go解法
弄一个sum暂存其和值
var pre int
func convertBST(root *TreeNode) *TreeNode {
pre = 0
traversal(root)
return root
}
func traversal(cur *TreeNode) {
if cur == nil {
return
}
traversal(cur.Right)
cur.Val += pre
pre = cur.Val
traversal(cur.Left)
}
1038. Binary Search Tree to Greater Sum Tree(同上)
Given the root of a Binary Search Tree (BST), convert it to a Greater Tree such that every key of the original BST is changed to the original key plus the sum of all keys greater than the original key in BST.
As a reminder, a binary search tree is a tree that satisfies these constraints:
- The left subtree of a node contains only nodes with keys less than the node's key.
- The right subtree of a node contains only nodes with keys greater than the node's key.
- Both the left and right subtrees must also be binary search trees.
Example 1:
Input: root = [4,1,6,0,2,5,7,null,null,null,3,null,null,null,8]
Output: [30,36,21,36,35,26,15,null,null,null,33,null,null,null,8]
Example 2:
Input: root = [0,null,1]
Output: [1,null,1]
Constraints:
- The number of nodes in the tree is in the range
[0, 10^4]. -10^4 <= Node.val <= 10^4- All the values in the tree are unique.
rootis guaranteed to be a valid binary search tree.
Note: This question is the same as 538: https://leetcode.com/problems/convert-bst-to-greater-tree/