数据预处理
获取数据
!wget https://raw.githubusercontent.com/Rosefinch-Midsummer/Rosefinch-Midsummer.github.io/main/content/posts/file/bankpep.csv
读入数据并以id为索引,展示前五个数据
| |
把字符型数据替换成数值型数据
| |
 利用dummmies矩阵处理多个离散值的特征项如把children分成children1,children2,children3
利用dummmies矩阵处理多个离散值的特征项如把children分成children1,children2,children3
| |
| |
| |
可视化
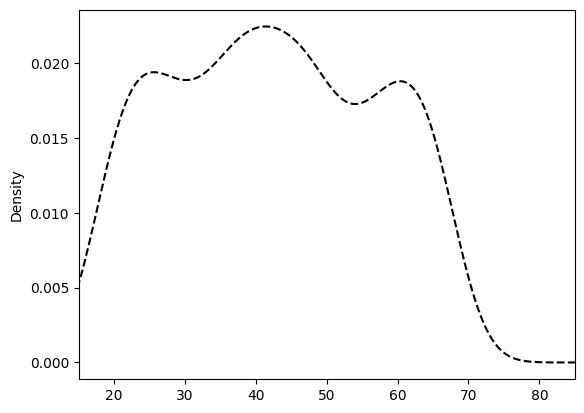
1.客户年龄分布的直方图和密度图
| |
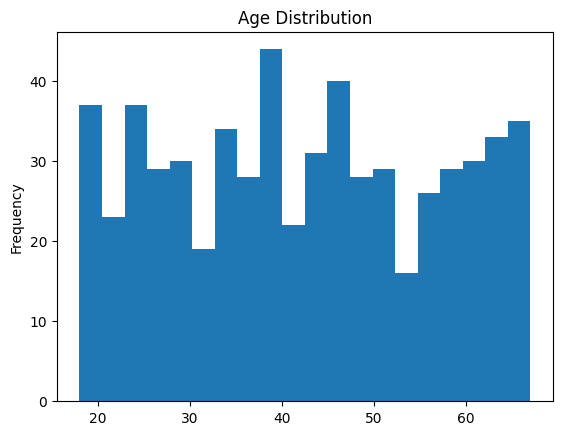
| |
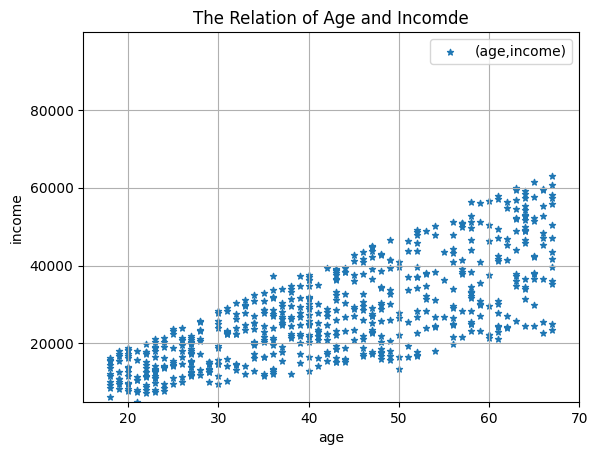
2.客户年龄和收入关系的散点图
| |
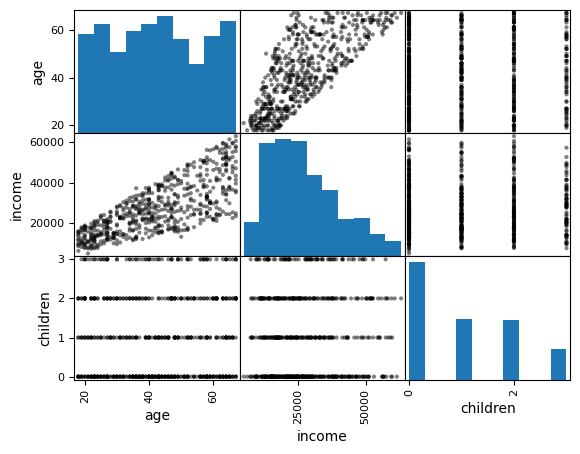
3.绘制散点图矩阵观察客户各项信息之间的关系
如研究银行客户的年龄、收入和孩子数之间的关系,对角线显示直方图
| |
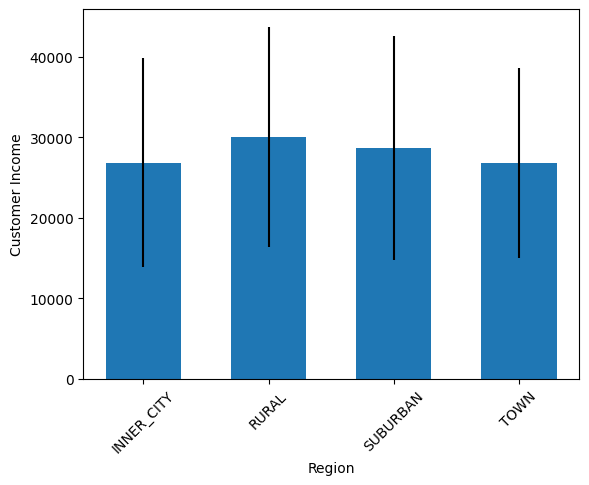
4.按区域展示平均收入的柱状图,并显示标准差
| |
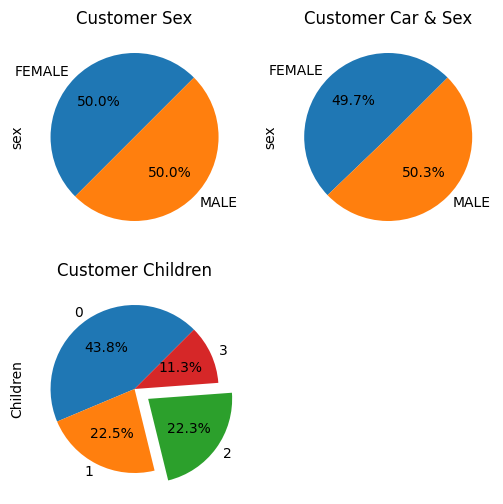
5.多子图绘制三种性别占比饼图
账户中性别占比饼图,有车的性别占比饼图,按孩子数的账户占比饼图
| |
| |
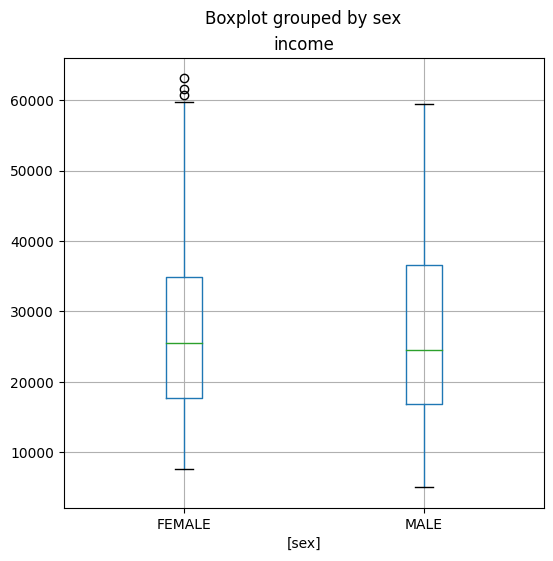
6.各性别收入的箱须图
作用:表达数据的分位数分布,观察异常值
- 将样本居中的50%值域用一个长方形表示
- 较大和较小的25%值域各用一根线表示
- 异常值用’o’表示
| |
训练模型,测试性能
svm
原理:将数据看作多维空间的点,用数学优化的方法求解一个最优的超平面将不同类别的点分开,“越胖越好”。若数据集在低维空间无法使用超平面切割,则可以用核函数将低维数据映射到高维空间,从而实现分割
| |
评估分类器性能
| |
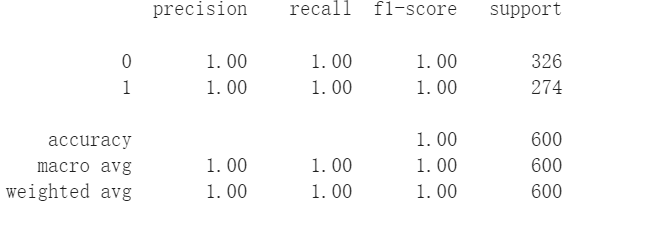
划分训练集和测试集,并在测试集上测试性能
| |

svm样本距离计算,数值型数据需标准化处理,标准化分为StandardScaler(标准化)、MinMaxScaler(归一化也可以写成Normalization)、QuantileTransformer等。
| |

DecisionTree
DecisionTreeClassifier
训练分类器
| |
评估分类器性能
| |
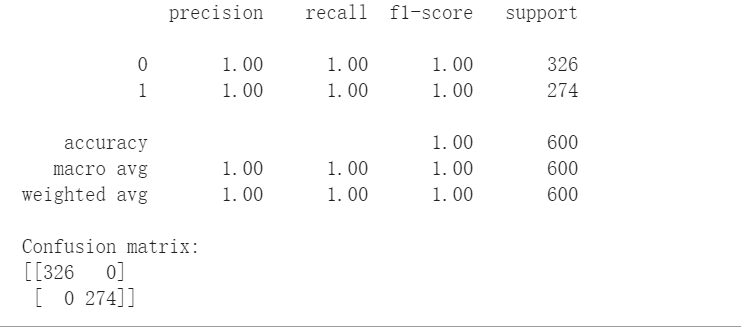
分割训练集训练
| |
GradientBoostingClassifier
| |
MLPClassifier
| |
Naive_Bayes
| |
XGBClassifier
| |