使用Python把MP4文件批量转换为MP3文件#
前提:本地安装ffmpeg,可以选择安装pydub或是moviepy
使用Python调用ffmpeg需要安装ffmpeg-python
使用PyDub#
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
| import os
from pydub import AudioSegment
def convert_mp4_to_mp3(directory):
for filename in os.listdir(directory):
if filename.endswith('.mp4'):
mp4_file_path = os.path.join(directory, filename)
mp3_file_path = os.path.splitext(mp4_file_path)[0] + '.mp3'
try:
# 使用 pydub 转换 mp4 为 mp3
audio = AudioSegment.from_file(mp4_file_path, format='mp4')
audio.export(mp3_file_path, format='mp3')
# 删除原有的 mp4 文件
os.remove(mp4_file_path)
print(f"Converted {mp4_file_path} to {mp3_file_path} and deleted original mp4 file.")
except Exception as e:
print(f"Error processing {mp4_file_path}: {e}")
# 设置你的目标目录
target_directory = r'E:\Entertainment\100s'
convert_mp4_to_mp3(target_directory)
|
使用MoviePy#
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
| import os
from moviepy.editor import VideoFileClip
def convert_mp4_to_mp3(directory):
# 遍历目录
for filename in os.listdir(directory):
if filename.endswith('.mp4'):
mp4_file_path = os.path.join(directory, filename)
mp3_file_path = os.path.splitext(mp4_file_path)[0] + '.mp3'
try:
# 使用 moviepy 转换视频为音频
video_clip = VideoFileClip(mp4_file_path)
video_clip.audio.write_audiofile(mp3_file_path)
video_clip.close()
# 删除原有的 mp4 文件
os.remove(mp4_file_path)
print(f"Converted {mp4_file_path} to {mp3_file_path} and deleted original mp4 file.")
except Exception as e:
print(f"Error processing {mp4_file_path}: {e}")
# 设置你的目标目录
target_directory = r'E:\Entertainment\北流嘉措'
convert_mp4_to_mp3(target_directory)
|
【最新】windows电脑FFmpeg安装教程手把手详解#
windows电脑FFmpeg安装教程手把手详解教程来源
本文以 Windows 64 位操作系统为例演示
一、下载&解压
打开 FFmpeg 官网,选择下载。
选择 Windows 平台,下面有两个链接,都是可以的,选择其一。

本文以点击第一个链接为例,进去以后,选择左边的 release builds ,右边出现如下内容:
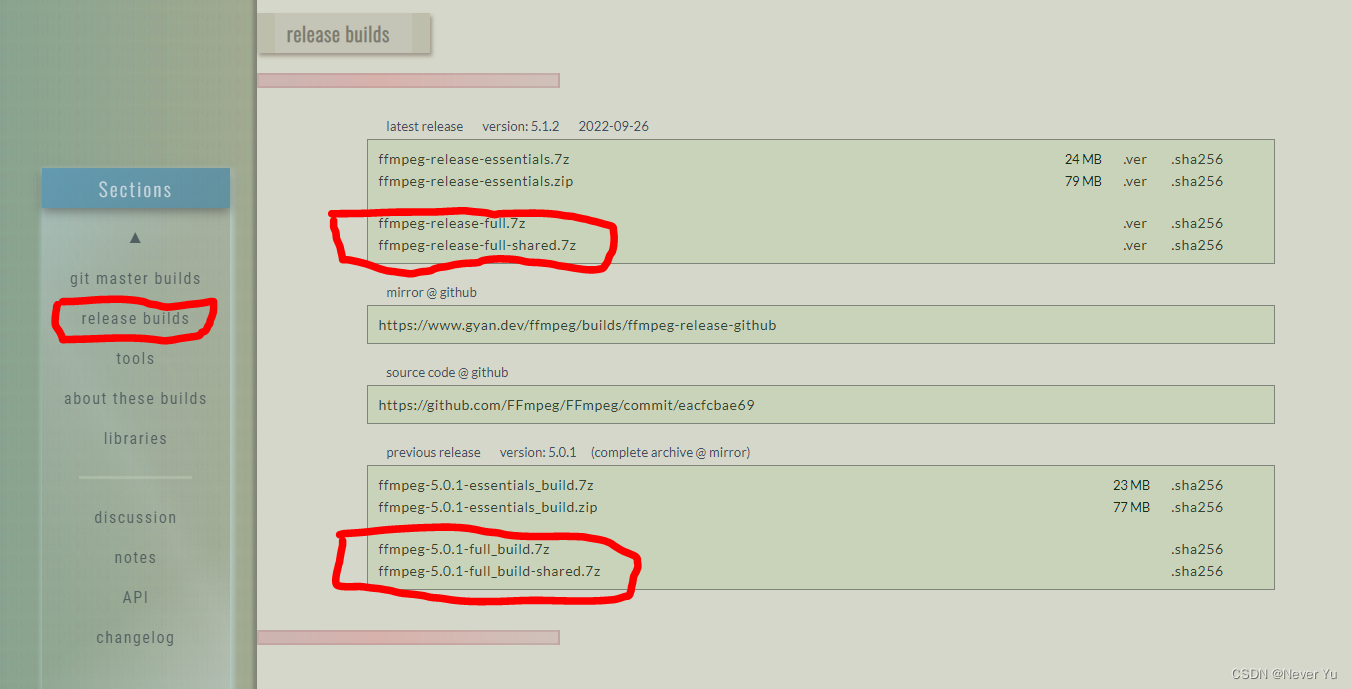
你可以选择下载上面红色圈中的 release-full 版本,或者选择下面红色圈中的前一个稳定版本 xxx-full_build。
release-full 版本会比下面的 xxx-full_build 版本更新,选择哪一个都可以,看你个人喜好。
至于你是想选择带 shared 的还是不带 shared 的版本,其实都是可以的。因为同一个版本带 shared 的和不带 shared 的,功能是完全一样的。
带 shared 的里面,多了 include、lib 目录。把 FFmpeg 依赖的模块包单独的放在的 lib 目录中。ffmpeg.exe,ffplay.exe,ffprobe.exe 作为可执行文件的入口,文件体积很小,他们在运行的时候,如果需要,会到 lib 中调用相应的功能。
不带 shared 的里面,bin 目录中有 ffmpeg.exe,ffplay.exe,ffprobe.exe 三个可执行文件,每个 exe 的体积都稍大一点,因为它已经把相关的需要用的模块包编译到exe里面去了。
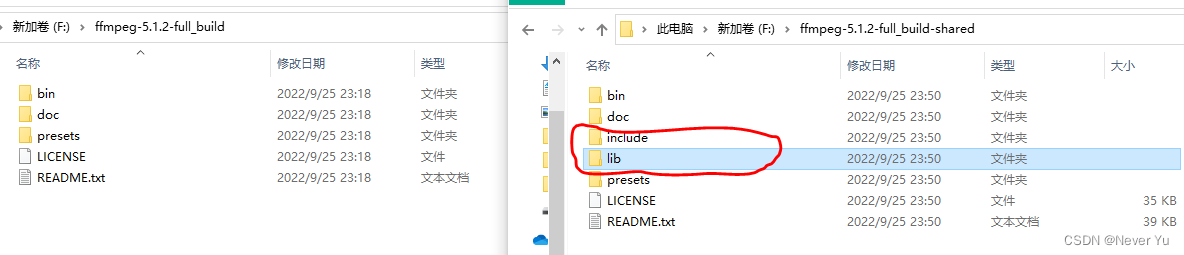
解压以后的内容,如上图所示;进入 bin 目录,复制 bin 目录路径。

二、配置环境变量
1、配置系统环境变量
1、在电脑桌面上,打开我的电脑
2、在空白处,右键,选择属性
3、选择 高级系统设置 -> 高级 -> 环境变量
4、在系统变量中,选择 Path,然后编辑:
5、然后在出来的编辑环境变量表中,新建一个,将刚才复制的 bin 目录路径粘贴进去,保存即可。
三、验证
重新打开一个命令行窗口,输入: ffmpeg -version,有版本信息输出,则证明配置成功!!
执行Python代码需要重启PyCharm。
额外补充
对于 windows 电脑可以将解压文件放到系统的 system32 目录中去,就不用配置环境变量了。
PyDub入门教程#
Python音频处理利器:pydub详解
Pydub 是一个用 Python 编写的音频处理库,它可以方便地处理许多音频文件,诸如分割、合并、格式转换、音量调节等。它具有以下特点:
- 主要使用 ffmpeg 和 libav 模块来实现音频的读取、处理和输出。
- 支持的音频格式非常广泛,包括 MP3、WAV、FLAC、MP4 等。
- API 简单易用,可以方便地进行常用的音频处理操作。
Pydub 是一个轻量级、快速且易于使用的库。silence库是pydub的一个扩展库,可以在音频文件中根据静默部分进行分割,非常方便。
1 pydub安装#
安装 Pydub 的最简单方法是使用 pip,只需在命令行下运行以下命令即可:
依赖:需安装ffmpeg或者libav
如果 ffmpeg 或 libav 未安装,则还需要在系统中安装相关依赖库。
2 pydub模块使用#
读取音频文件非常简单,只需使用 AudioSegment.from_file() 函数即可。以下示例演示了如何读取名为 “soundfile.mp3” 的 MP3 文件:
2.1 打开音频文件#
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| from pydub import AudioSegment
# 打开wav格式音频文件
sound = AudioSegment.from_wav('./soundfile.wav')
# 打开mp3音频文件,AudioSegment原生只支持wav,raw文件,安装ffmpeg可支持其所有格式
sound = AudioSegment.from_mp3('./soundfile.mp3')
# 打开音频文件,生成AudioSegment对象
sound = AudioSegment.from_file('./soundfile.mp3') # format默认值为"mp3"
sound = AudioSegment.from_file('./soundfile.wav', format='wav')
# 打开raw文件需要额外参数,sample_width(采样位数),frame_rate(采样频率),channels(声通道)
# sample_width: 1、8bit,2、16bit,3、32bit
# frame_rate: 44100(44.1kHz CD audio), 48000(48kHz DVD audio)
# channels: 1、单声道,2、立体声
sound = AudioSegment.from_file('./soundfile.raw', format='raw', frame_rate=44100, channels=2, sample_width=2)
|
2.2 导出音频文件#
要将 AudioSegment 对象保存为音频文件,可以使用 export() 函数。以下示例将上述读取的音频输出为名为 “outputsoundfile.mp3” 的 mp3文件:
1
2
3
4
| sound = AudioSegment.from_file('./soundfile.wav', format='wav')
# 导出音频文件
sound.export('./outputsoundfile.mp3', format='mp3')
|
2.3 创建音频文件#
1
2
3
4
5
6
| # 生成一个时间长度为0秒的AudioSegment对象,一般用于多个音频合并
sound = AudioSegment.empty()
# 生成一个时间长度为5秒的无声AduioSegment对象
# 参数duration:时间长度(毫秒),frame_rate:频率,默认为11025Hz
sound = AudioSegment.silent(duration=50000)
|
2.4 合并音频文件#
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
| # 两个单声道音频合并为一个多声道音频
left_channel = AudioSegment.from_wav('sound_left.wav')
right_channel = AudioSegment.from_wav('sound_right.wav')
stereo_sound = AudioSegment.from_mono_auidosegments(left_channel,right_channel)
# 将多声道音频分解成两个单声道
sound = AudioSegment.from_wav('sound.wav')
sound.split_to_mono()
# 两个音频文件合并为一个音频文件
sound1 = AudioSegment.from_file('sound1.wav', format='wav')
sound2 = AudioSegment.from_file('sound2.wav', format='wav')
# 无交叉淡入淡出
sound = sound1 + sound2
# OR
sound = sound1.append(sound2, crossfade=0)
# 淡入淡出,参数crossfade:效果持续时间,默认100毫秒
sound = sound1.append(sound2, crossfade=100)
# 两个音频文件叠加为一个音频文件
# 例,长音频sound1,30s
sound1 = AudioSegment.from_file('sound1.wav', format='wav')
# 例,短音频sound2,10s
sound2 = AudioSegment.from_file('sound2.wav', format='wav')
# 将sound2叠加至sound1上,参数postions:从sound1音频10秒处开始叠加,默认为0,得到的音频文件,会从10秒处开始出现sound2音频,20秒处sound2音频结束,只余sound1音频
sound = sound1.overlay(sound2, postions=10000)
# 将sound2叠加至sound1上,参数loop:开启循环,默认为Fasle,得到的音频文件sound2将会循环播放至sound1结束
sound = sound1.overlay(sound2, loop=true)
# 将sound2叠加至sound1上,参数times:重复次数,默认为1,得到的音频文件sound2将会重复两次,在两个sound2的时间结束sound2音频
sound = sound1.overlay(sound2, times=2)
# 将sound1叠加至sound2上,10秒后sound2音频结束,sound1音频截断至10s结束,最终该音频长度只有10s,即
sound = sound2.overlay(sound1)
len(sound) == sound2
|
2.5 音频文件信息#
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
| sound = AudioSegment.from_file('soundfile.wav', format='wav')
# 声道数
schannel = sound.channels
# 采样位数,也称位深度,是指每个采样样本所包含的位数(字节数),通常有8 bit、16 bit
sbytes = sound.sample_width
# 采样频率,也称采样率,是指在单位时间内对声音信号的采样数或样本数,采样频率越能高表现的频率范围越大(电话:8kHZ,无线电广播:22.05kHz,CD:44.1kHz,DVD:48kHZ,蓝光:96kHz,192kHz)
srate = sound.frame_rate
# 帧位数, 帧包含每个声道的采样位数frame_width = channels * sample_width
sframebytes = sound.frame_width
# 音频文件帧数, 可选参数ms:时间长度,默认None
sframe = sound.frame_count()
# 音频文件时长,单位秒
stime = sound.duration_seconds
# OR
stime = (len(sound) / 1000)
|
2.6 处理音频文件#
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
| sound = AudioSegment.from_file('soundfile.wav', format='wav')
# 音频前5秒,pydub中时间以毫秒(ms)为单位
audio_begin = sound[:5000]
# 音频后5秒,pydub中时间以毫秒(ms)为单位
audio_end = sound[-5000:]
# 改变音频幅度,以分贝(dB)为单位
# 调高幅度
raise_via = sound.apply_gain(+5)
raise_via = sound + 5
# 调低音量
lower_via = sound.apply_gain(-5)
lower_via = sound - 5
# 淡入淡出效果
# 淡入,参数duration:持续时间
sound.fade_in(duration=5000)
# 淡出,参数duration:持续时间
sound.fade_out(duration=5000)
# 倒放音频文件
newsound = sound.reverse()
|
2.7 播放音频文件#
1
2
3
4
5
6
7
8
| from pydub import playback
from pydub import AduioSegment
from pydub.playback import play
sound = AduioSegment.from_wav('sound.wav')
# 播放音频
play(sound)
|
2.8 分割音频#
1
2
3
4
5
6
7
8
| from pydub import utils
from pydub import AudioSegment
from pydub.utils import make_chanks
sound = AduioSegment.from_wav('sound.wav')
# 分割音频, 参数chunk_length:一段音频多长时间
make_chanks(sound, chunk_length=5000)
|
3 使用pydub根据静音分割音频#
3.1 静音检测原理#
静音检测原理是通过分析音频信号的能量,判断其是否为静音状态。具体的原理如下:
音频信号通常可以用时域或频域来表示。对于时域表示,可以将音频信号分成一段一段的小块,每个小块称为帧。对于频域表示,可以将音频信号变换为频谱图。
静音的特点是信号的能量较低,通常处于接近零的水平。因此,静音检测可以通过计算每个帧或频谱图的能量来判断是否为静音。
计算能量的方法可以使用绝对能量或相对能量。绝对能量是指计算信号的平方和,即将信号的每个样本取平方后相加。相对能量是指计算信号的功率谱密度,即将信号的功率谱密度求和。
静音检测的阈值是根据实际应用来确定的。通常可以根据经验设置一个合适的阈值,当帧的能量或频谱图的能量低于阈值时,被判断为静音。
静音检测也可以结合其他特征进行判断,例如零交叉率、短时过零率等。这些特征可以提供更准确的静音检测结果。
静音检测原理是通过计算音频信号的能量来判断是否为静音状态,通常通过设置一个阈值来判断。此外,还可以结合其他特征进行判断,提高检测的准确性。
语音和噪声的区别可以体现在他们的能量上,语音段的能量比噪声段的能量大,如果环境噪声和系统输入的噪声比较小,只要计算输入信号的短时能量就能够把语音段和噪声背景区分开,除此之外,用基于能量的算法来检测浊音通常效果也是比较理想的,因为浊音的能量值比清音大得多,可以判断浊音和清音之间过渡的时刻,但对清音来说,效果不是很好,因此还需要借助短时过零率来表征。
短时能量可以近似为互补的情况,短时能量大的地方过零率小,短时能量小的地方过零率较大。
基于短时能量和过零率的检测方法 尽管基于短时能量和过零率的检测方法各有其优缺点,但是若将这两种基本方法相结合起来使用也可以实现对语音信号可靠的端点检测。无声段的短时能量为零,清音段的短时能量又比浊音段的短时能量大,而在过零率方面,理想的情况是无声段的过零率为零,浊音段的过零率比清音段的过零率要大的多,假设有一段语音,如果某部分短时能量和过零率都为零或者为很小的值,就可以认为这部分为无声段。
如果该部分语音短时能量很大但是过零率很小,则认为该部分语音为浊音段。
如果该部分短时能量很小但是过零率很大,则认为该部分语音为清音段。
正如前面提到,语音信号具有短时性,因此在对语音信号进行分析时,需要将语音信号以30ms为一段分为若干帧来进行分析,则两帧起始点之间的间隔为10ms。
短时能量,无声<浊音<清音
过零率,无声<清音<浊音
3.2 使用pydub进行静音检测#
代码首先使用AudioSegment类从audio.mp3文件中读取音频数据,然后设置了分割参数min_silence_len、silence_thresh和keep_silence。min_silence_len是最小静音长度,silence_thresh是静音阈值,keep_silence是保留静音长度。这些参数的具体含义可以根据实际情况进行调整。最后,根据分割参数使用split_on_silence函数对音频文件进行分割。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| from pydub import AudioSegment
from pydub.silence import split_on_silence
# 读取音频文件
audio = AudioSegment.from_file("D:/dataset/lyb01.wav", format="wav")
# 设置分割参数
min_silence_len = 300 # 最小静音长度
silence_thresh = -50 # 静音阈值,越小越严格
keep_silence = 200 # 保留静音长度
# 分割音频文件
segments = split_on_silence(audio, min_silence_len=min_silence_len, silence_thresh=silence_thresh,
keep_silence=keep_silence)
for idx in range(len(segments)):
segments[idx].export(f'wav_{idx:04}.wav')
|
4 总结#
通过pydub,我们可以方便地进行音频编解码、混音、重采样等操作,进一步扩展了pydub的应用场景。需要注意的是,在进行音频混音操作时,需要保证两个音频文件的采样率、采样位数和声道数相同。
pydub优点:
轻量级:pydub是一个轻量级的音频处理库,安装方便,使用简单。
功能丰富:pydub提供了丰富的音频处理功能,包括切割、合并、转换、调整音量、编解码、混音、重采样等。
应用广泛:pydub的应用场景非常广泛,包括音频处理、铃声制作、音频格式转换、语音识别等等。
pydub缺点:
对格式的兼容性有限:pydub对音频格式的兼容性有限,不支持所有的音频格式,需要先将音频转换为支持的格式后才能进行处理。
性能一般:pydub在处理大文件时,性能可能会比较一般,需要耗费一定的时间和计算资源。
不支持流式处理:pydub不支持流式处理,需要将整个音频文件读取到内存中,导致内存占用较大。
pydub是一个功能丰富、应用广泛的音频处理库。在使用pydub时,需要注意音频格式的兼容性问题,并注意处理大文件时的性能和内存占用。如果需要处理更复杂的音频任务,可以考虑使用其他更专业的音频处理库。
MoviePy入门教程#
Video editing with Python
zulko.github.io/moviepy/
MoviePy (online documentation here) is a Python library for video editing: cuts, concatenations, title insertions, video compositing (a.k.a. non-linear editing), video processing, and creation of custom effects.
MoviePy can read and write all the most common audio and video formats, including GIF, and runs on Windows/Mac/Linux, with Python 3.9+.
Example#
In this example we open a video file, select the subclip between 10 and 20 seconds, add a title at the center of the screen, and write the result to a new file:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| from moviepy import VideoFileClip, TextClip, CompositeVideoClip
# Load file example.mp4 and keep only the subclip from 00:00:10 to 00:00:20
# Reduce the audio volume to 80% of its original volume
clip = (
VideoFileClip("long_examples/example2.mp4")
.subclipped(10, 20)
.with_volume_scaled(0.8)
)
# Generate a text clip. You can customize the font, color, etc.
txt_clip = TextClip(
font="Arial.ttf",
text="Hello there!",
font_size=70,
color='white'
).with_duration(10).with_position('center')
# Overlay the text clip on the first video clip
final_video = CompositeVideoClip([clip, txt_clip])
final_video.write_videofile("result.mp4")
|
How MoviePy works#
Under the hood, MoviePy imports media (video frames, images, sounds) and converts them into Python objects (numpy arrays) so that every pixel becomes accessible, and video or audio effects can be defined in just a few lines of code (see the built-in effects for examples).
The library also provides ways to mix clips together (concatenations, playing clips side by side or on top of each other with transparency, etc.). The final clip is then encoded back into mp4/webm/gif/etc.
This makes MoviePy very flexible and approachable, albeit slower than using ffmpeg directly due to heavier data import/export operations.
Installation#
Intall moviepy with pip install moviepy. For additional installation options, such as a custom FFMPEG or for previewing, see this section. For development, clone that repo locally and install with pip install -e .
Documentation#
The online documentation (here) is automatically built at every push to the master branch. To build the documentation locally, install the extra dependencies via pip install moviepy[doc], then go to the docs folder and run make html.
moviepy,一个超酷的 Python 库!#
文章来源