前言
这是我对三周“超级兴趣课程”的一个总结。坦白说,只有当我不是真正学生物专业的时候,才不会觉得生物是个“天坑”——毕竟它是个劳动密集型学科。
我对各种新技术一直很感兴趣,生物信息学和基因测序自然也不例外。
这一切的起点源于寒假读的一本书《可不可以不变老》,书中关于长寿基因的内容重新点燃了我对自身基因序列的兴趣。
再加上我长期关注分子生物学和族源相关的知识(更准确地说,是进化树),我对自己作为“黄帝后裔”的身份几乎毫无疑问。但我也清楚,深入了解基因信息,有助于提前识别和规避某些遗传疾病的风险。
遗憾的是,按照课程讲义上的操作步骤,我得到的基因测序结果只展示了一些最常见、直观的特征,比如瞳孔颜色、头发颜色、耳垢类型等。更深入的、有价值的信息还需要我自己学习生物信息学的知识,进行进一步分析和探索。
总之,这段学习经历既让我重新审视了生物学的挑战,也坚定了我对基因领域更深入探索的决心。
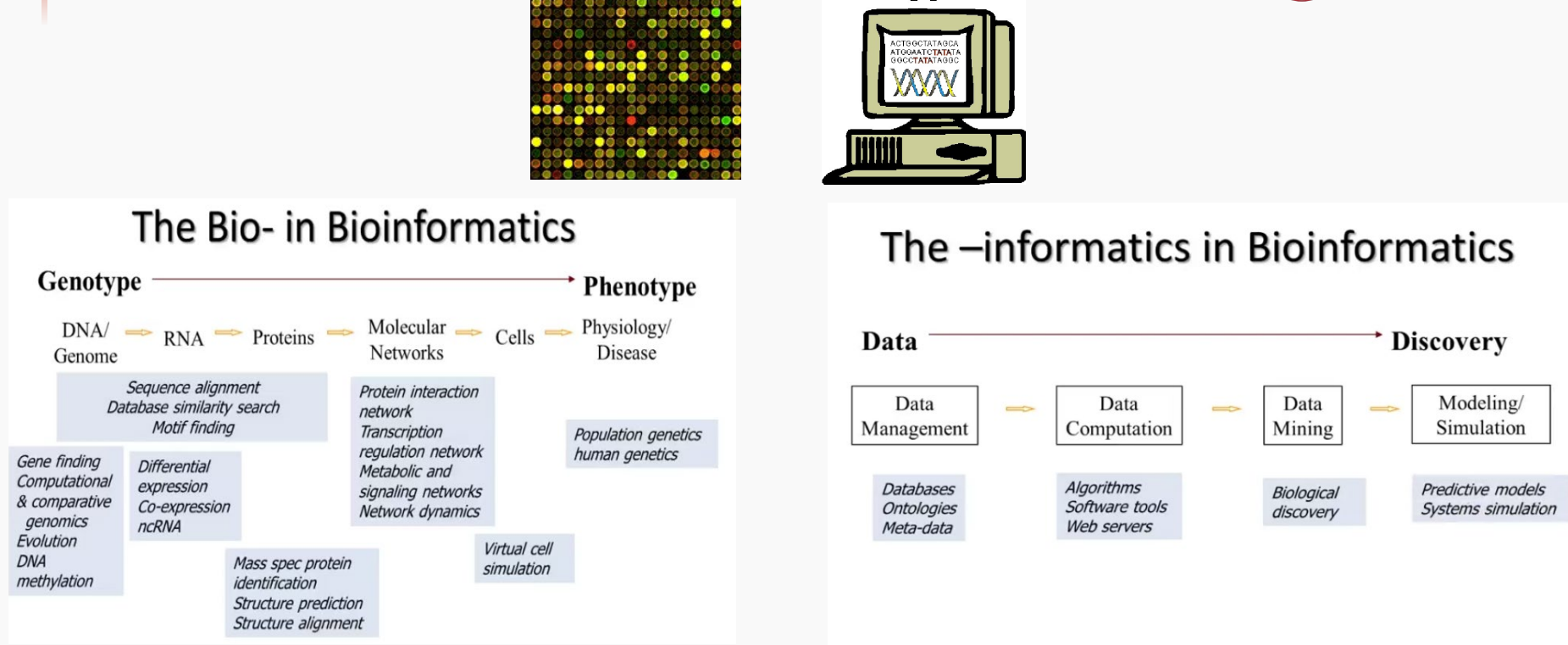
AI与生物医药的融合:AlphaFold与分子设计的未来
AI在生物医药领域的崛起
背景
生物数据的爆炸式增长
随着基因组学、蛋白质组学等技术的飞速发展,生物数据呈现指数级增长。传统的数据分析方法已难以应对如此庞大且复杂的数据规模。计算能力的大幅提升
现代计算硬件的进步,尤其是GPU和云计算的兴起,为AI提供了强劲的计算支持,使得复杂的机器学习算法能够高效处理海量生物数据。
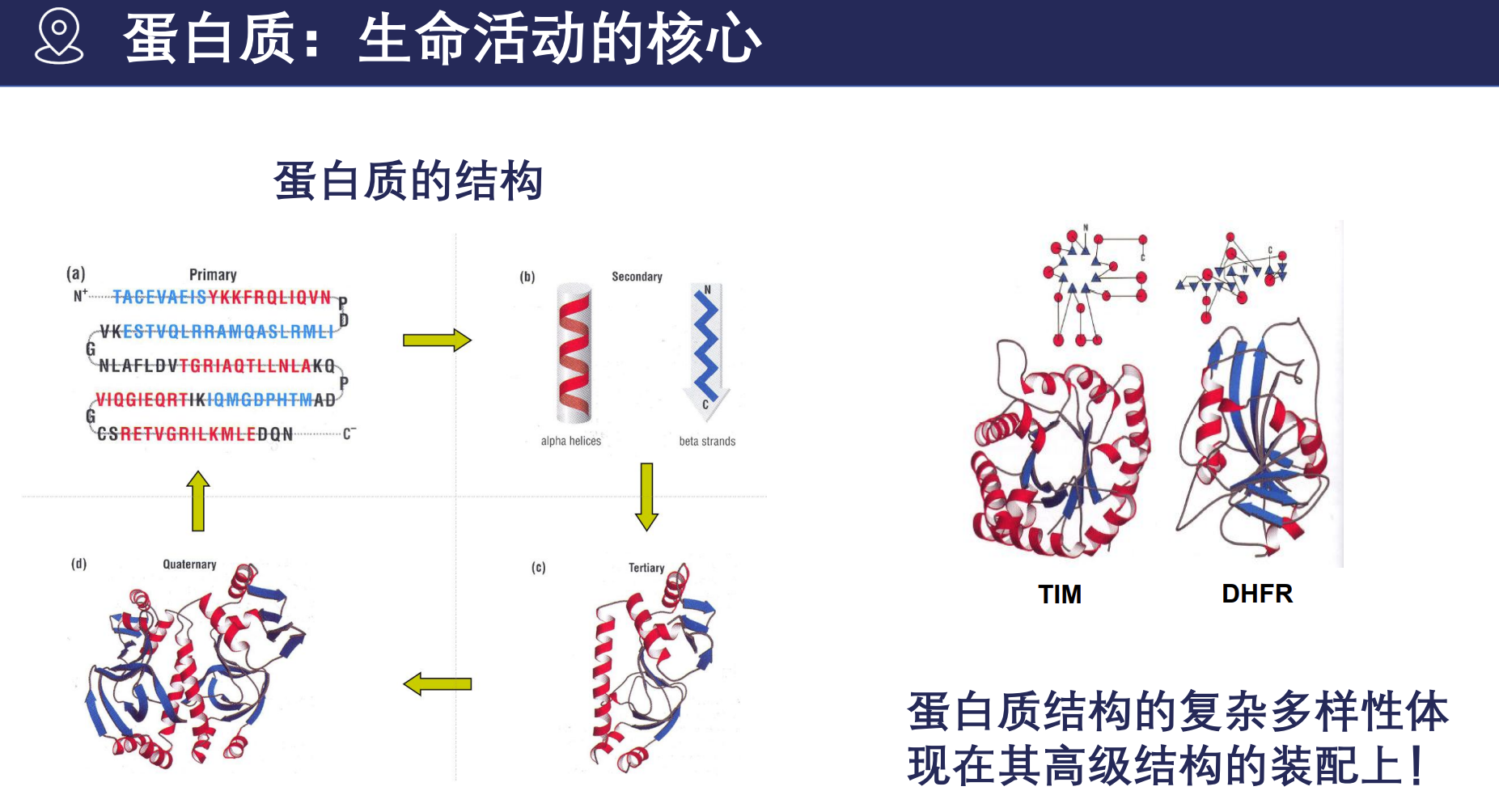
蛋白质:生命活动的核心
蛋白质不仅是生命体内众多生理功能的执行者,更是药物研发的重要靶点及创新药物的源泉。
蛋白质的五大功能区域:免疫、防御、结构支撑、催化反应、调节信号与物质运输。
AlphaFold:蛋白质结构预测的革命性突破
CASP(Critical Assessment of Structure Prediction)是由马里兰大学John Moult教授和Krzysztof Fidelis教授于1994年发起的一项蛋白质结构预测评测,该评测采用严格的双盲机制,被视为蛋白质结构预测技术的“奥林匹克竞赛”,是该领域的金标准。
AlphaFold技术应用范围:
- 蛋白质单体结构预测:预测单个蛋白质的三维空间构象。
- 蛋白质复合物结构预测:模拟蛋白质之间的相互作用及复合体形成。
- RNA结构预测:揭示RNA分子的三维结构。
- 蛋白质-配体结合预测:预测蛋白质与小分子配体的结合模式。
- 蛋白质多构象预测:识别蛋白质在不同环境或功能状态下的多种构象。
评价指标GDT(Global Distance Test)范围为0到100,体现预测结构与真实结构的近似程度,数值越高越准确。
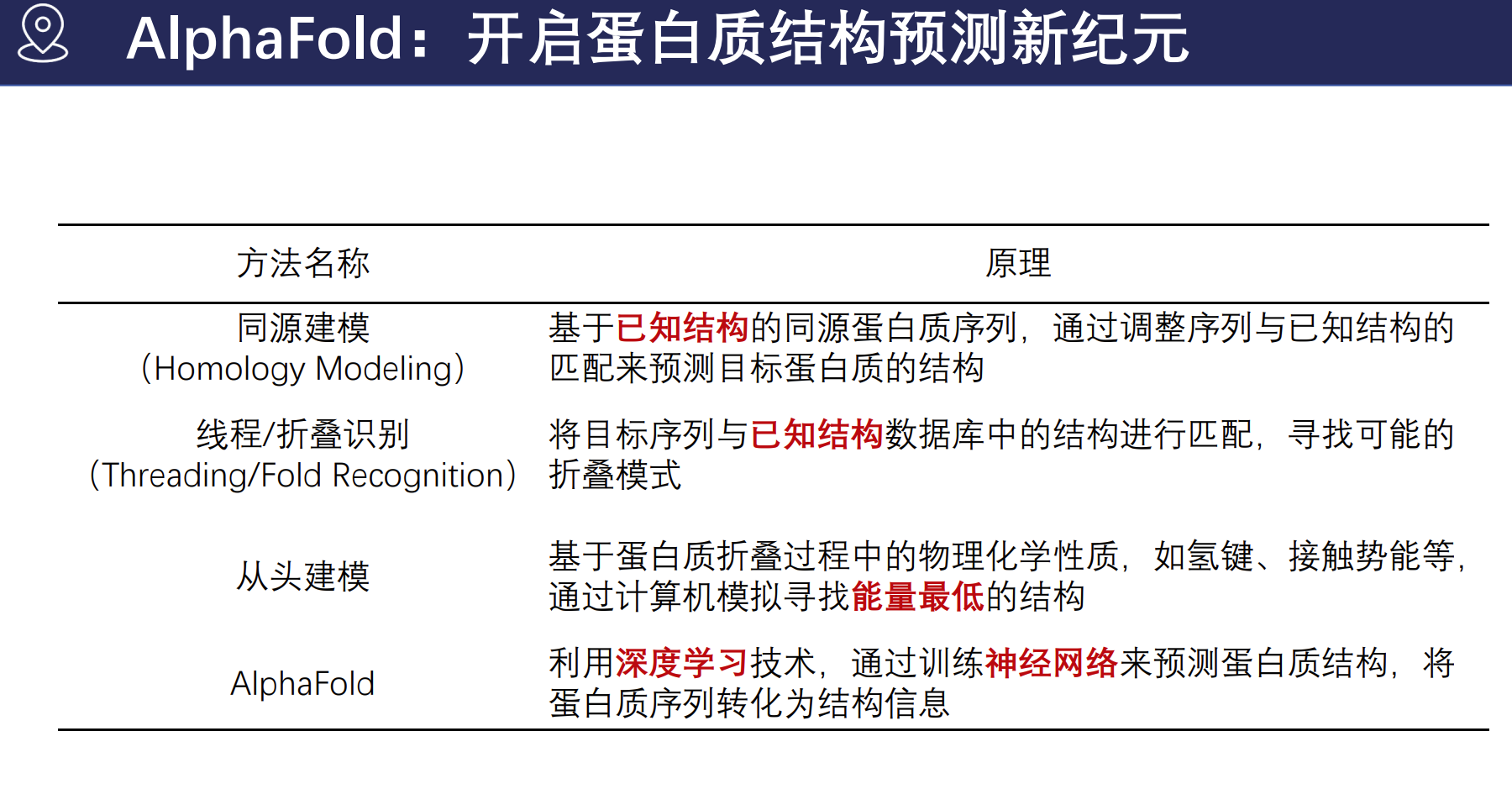
蛋白质结构预测历程简述
- 1980年代:同源建模(Homology Modeling)
- 1990年代:折叠识别/线程法(Threading/Fold Recognition)、从头预测(Ab Initio Modeling)以及分子动力学模拟(Molecular Dynamics)
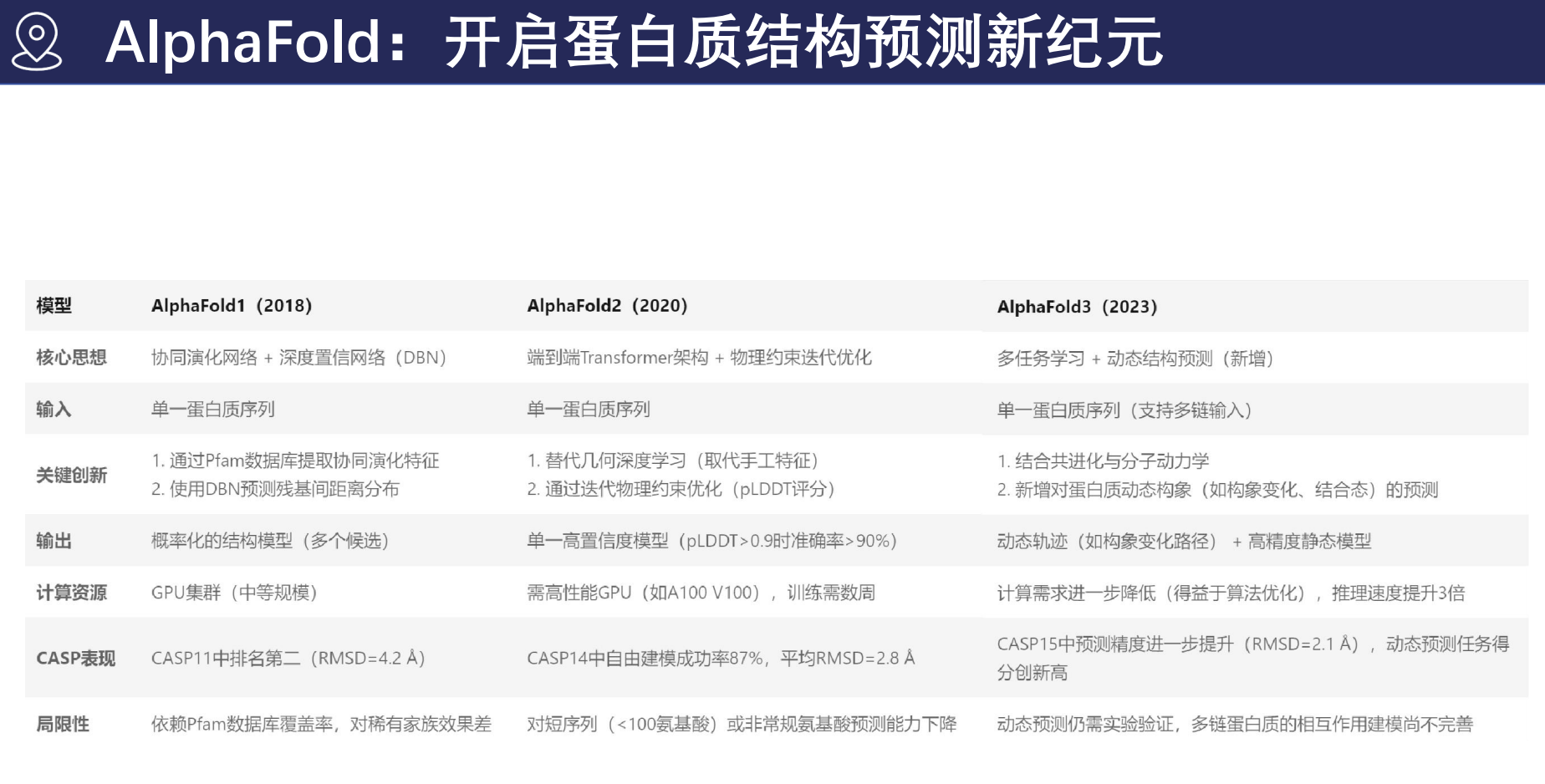
- 2018年:AlphaFold首次亮相 (CASP13)
- 2020年:AlphaFold2在CASP14中大放异彩,约三分之二的目标蛋白预测准确度媲美实验结构,平均偏差仅0.8埃(Å)。
AlphaFold发展历程
AlphaFold的诞生
2018年,DeepMind投入大量资源,利用深度学习技术开发AlphaFold,成功解决蛋白质结构预测难题。AlphaFold2的突破成绩
2020年AlphaFold2凭借卓越的预测准确度引爆业界,其成果被《自然》杂志赞誉为“改变世界的突破”。AlphaFold3最新进展
由DeepMind与Isomorphic Labs联合开发,AlphaFold3不仅进一步提升预测精准度,还具备细胞过程模拟和复杂分子相互作用预测能力。
AlphaFold与未来分子设计
加速药物研发
通过准确预测蛋白质结构,AlphaFold帮助科研人员快速筛选潜在药物分子,大幅缩短药物研发周期,降低研发成本。优化药物分子设计
基于蛋白质高精度结构,药物分子可以被精准调控与优化,提高活性与选择性,减少副作用,实现更安全有效的治疗方案。推动个性化医疗
利用个体蛋白质结构的差异性,AlphaFold支持定制化药物设计,促进精准医学与个性化治疗的发展,大幅提升治疗效果。
AI助力生物医药文献分析:效率与伦理的平衡
传统的生物医药文献检索方式
- 图书馆检索:通过实体或数字图书馆查找相关资料。
- 数据库检索:利用PubMed、Web of Science、.science等专业数据库,采用关键词、布尔运算符(AND、OR、NOT)以及高级筛选功能进行检索。
- 参考文献回溯:追踪核心文献的引文和被引文献,拓展研究范围。
- 期刊浏览:逐个浏览目标期刊,发现最新或相关研究内容。
这些方法虽然传统,却存在一些明显的问题:
- 效率低下:检索和筛选大量文献耗时费力。
- 筛选困难:需要人工检视每篇文献,难以快速锁定高质量或高度相关的内容。
- 检索准确率不足:主要依赖关键词匹配,难以理解用户的实际需求,导致结果中夹杂大量不相关资料。
- 信息覆盖不足:对跨学科、前沿或新兴领域文献的发现有限,尤其是非英语文献的覆盖相对较弱。
- 智能支持缺失:缺乏自动化、智能化的检测和推荐机制。
基于生成式AI(GenAI)的文献辅助工具
近年来,人工智能,特别是大规模生成式模型,开始应用于文献的检索与阅读、综述写作及引用管理,显著提升科研效率。例如:
- Elicit(https://elicit.com/)
利用Semantic Scholar的语义理解能力,自动生成科研问题的相关文献综述,提取核心信息。 - Semantic Scholar(https://www.semanticscholar.org/)
提供文章摘要、引用和相关论文,支持快速信息获取。 - Consensus(https://consensus.app/)
汇集多个论文中的关键观点,提供可信的科学结论。 - Undermind(https://undermind.ai/)
实现智能文献推荐与交互,为科研人员提供助力。
这些工具的共同特点:
- 支持输入自然语言问题,免去繁琐的关键词拼接。
- 提供详细的摘要、引用关系和相关文献,帮助快速理解研究内容。
- 构建知识图谱,帮助科学家洞察研究之间的关联。
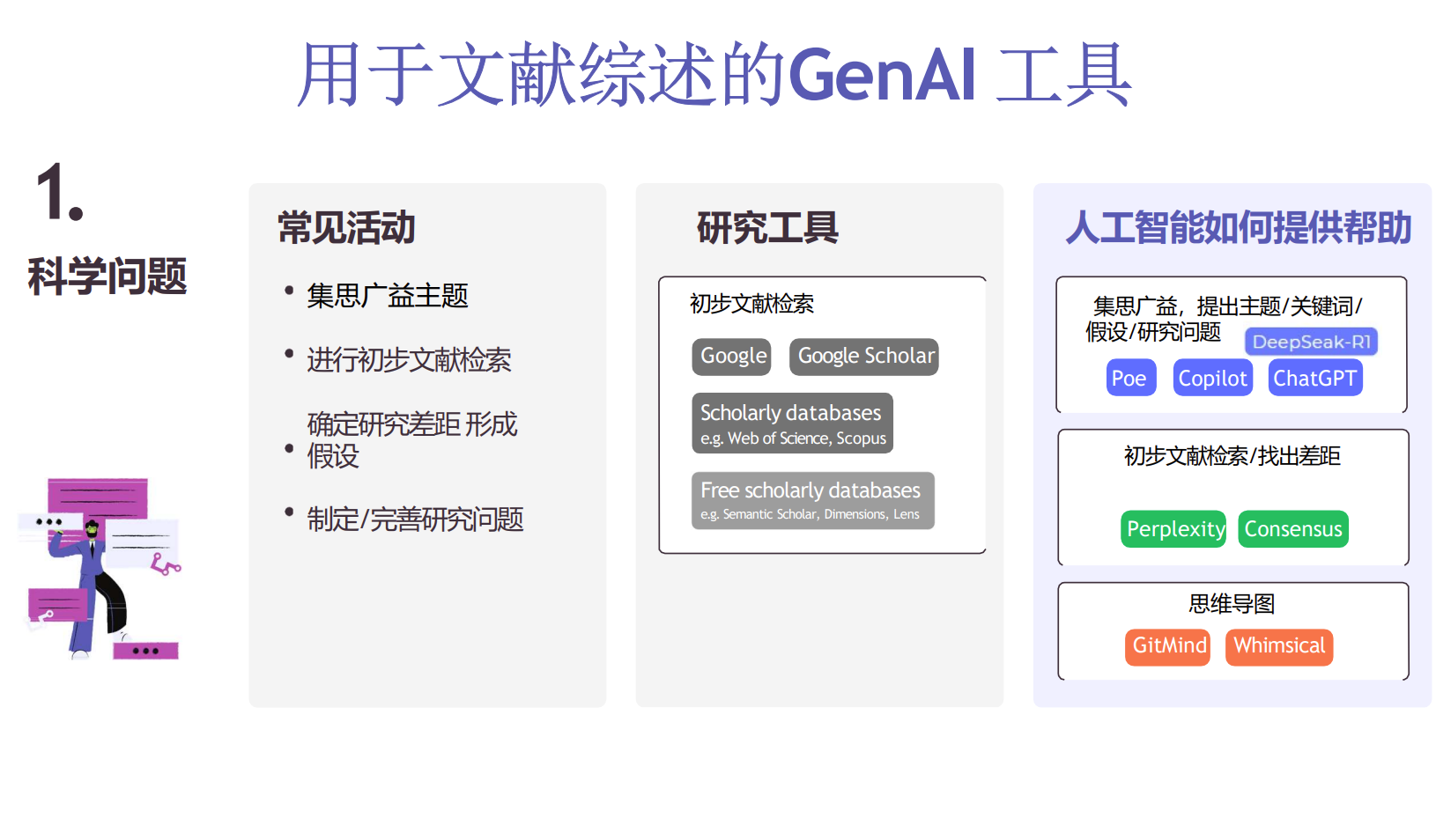
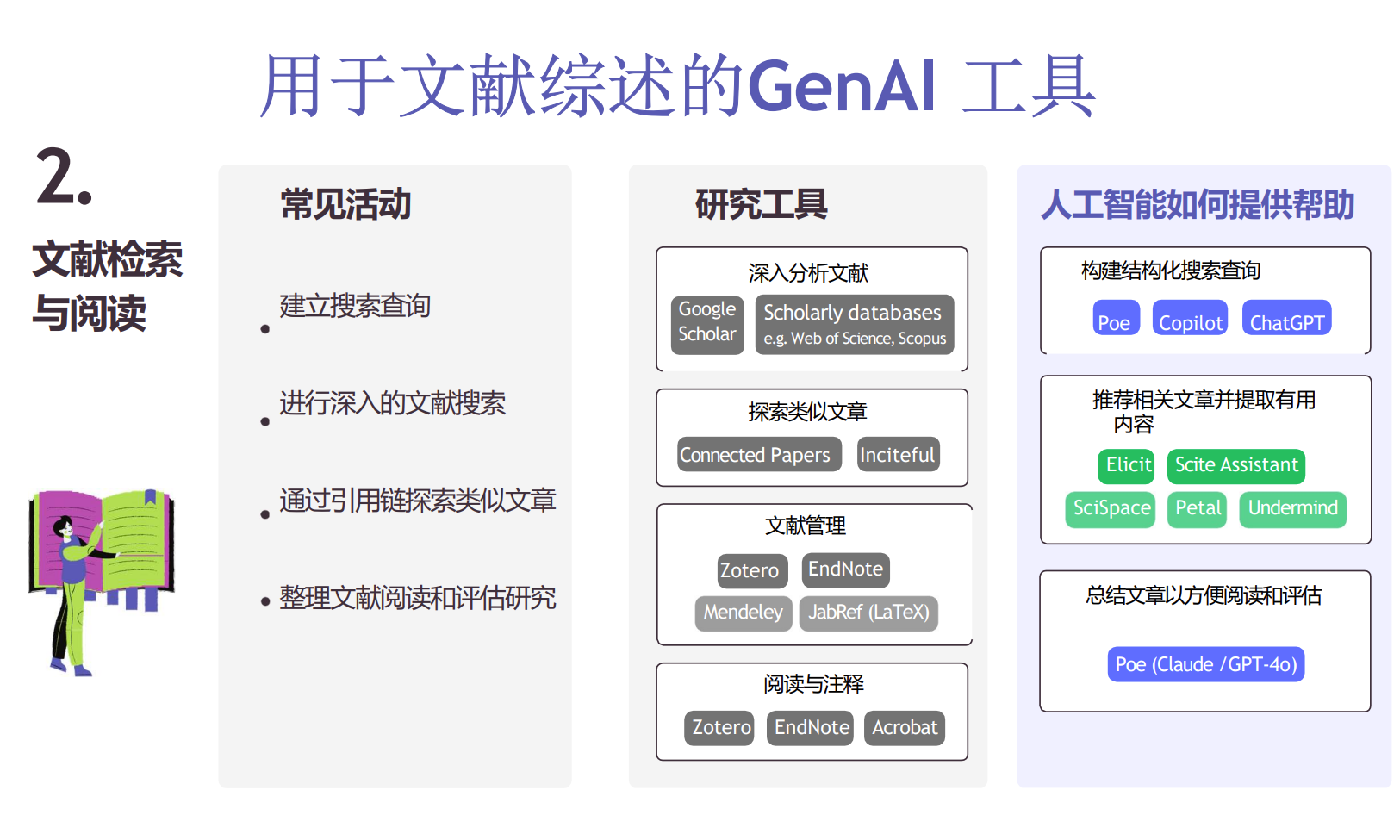

场景演示:传统检索与AI驱动的文献探索
场景一:传统检索
背景:你是一名大学生,正在为毕业论文查找“反式剪接技术在蛋白质定点标记和修饰中的应用”的相关文献。
操作流程:
- 打开数据库,输入关键词“protein trans-splicing”与“protein site-specific modification”。
- 反馈:检索结果繁多,但大部分与主题不符。
- 尝试使用高级筛选(例如,时间、文献类型),但依然难以找到理想文献。
问题点:
- 搜索结果数量庞杂,筛选耗时长。
- 精准匹配困难,容易遗漏关键文献或引入大量噪声。
场景二:AI驱动的文献检索
背景:你使用一款基于AI的文献检索工具,来进行同样的研究。
操作流程:
- 输入自然语言查询:“How is protein trans-splicing used in protein site-specific modification?”
- 反馈:搜索结果更精准,相关性明显提高,排序优先显示最相关的文献。
- 可利用筛选工具,按时间、作者、期刊等精细过滤。
- 点击文献,系统会自动呈现摘要、关键词、引用文献、相关论文等详细信息。
优势总结:
- 检索方式由关键词转变为自然语言,更贴合用户需求。
- 搜索结果:数量显著减少,相关性大幅提升。
- 功能丰富:推荐相关文章、构建知识图谱、文本内容分析,全面提升科研效率。
结语
随着AI技术的发展,生物医药文献分析正逐步走向智能化、便捷化。传统检索表现出一定的局限性,而AI赋能的检索工具不仅极大提高了效率,还在一定程度上为科研伦理保护提供新的思路。例如,通过自动过滤偏见或歧视性内容、确保数据来源透明等方式,助力科研的公平与责任。
未来,如何在快速便捷的同时,确保可靠性、隐私和伦理的平衡,将成为AI推动生物医药科研的重要课题。
AI辅助智慧诊疗用柔性电子材料设计
什么是智慧诊疗用柔性电子
中国科学院院士黄维曾指出:柔性电子是一门结合有机材料、无机材料及其复合材料,在柔性基底上沉积制备电子元器件和集成系统的新兴交叉学科。它以其灵活、轻薄、可弯曲的特性,在医疗、穿戴、智能设备等领域展现出巨大潜力。
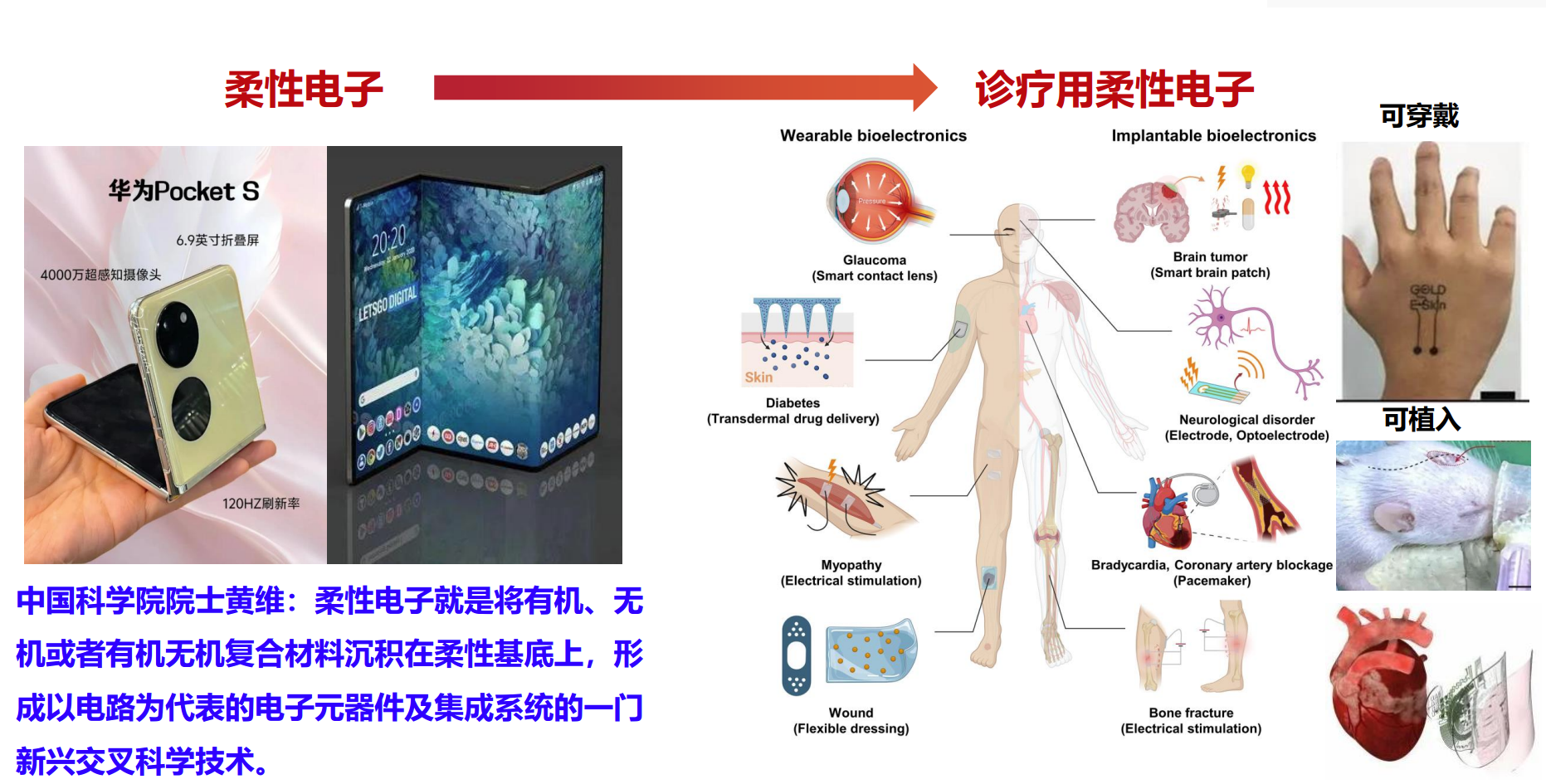
智能材料中,主要包括两大类:
- 感知材料(传感器):用于检测环境或身体的各种信号,比如热、电、光、声等。
- 响应/驱动材料(执行器):在感知信号作用下,实现自愈合、运动或能量转换等功能,包括:
- 自愈合材料
- 磁流变体、电流变体
- 热电材料
- 压电材料
这些材料的结合与创新,为智慧医疗提供了坚实的材料基础,使得多种诊疗设备具有更高的柔韧性、智能化和个性化能力。
诊疗用柔性电子材料案例分析
一、智慧诊疗用热电材料——概念与原理
热电材料是一类能够利用温差直接转换为电能的材料,其核心原理基于塞贝克效应:由德国物理学家Seebeck在19世纪发现。当材料两端存在温差时,热端的空穴(或电子)比冷端更具能量,沿温差方向迁移,在冷端堆积,形成电势差。与此同时,电荷的漂移流与扩散流达到动态平衡后,材料两端稳定地产生电动势,从而实现温差到电能的直接转换。
二、智慧诊疗中热电材料的应用(肿瘤治疗)
通过在肿瘤区域内引入热电材料产生的微电场,可以激活氧气形成活性氧(ROS),这是一种强效的细胞氧化剂,能够选择性地杀死癌细胞,达到微创、靶向的肿瘤治疗效果。
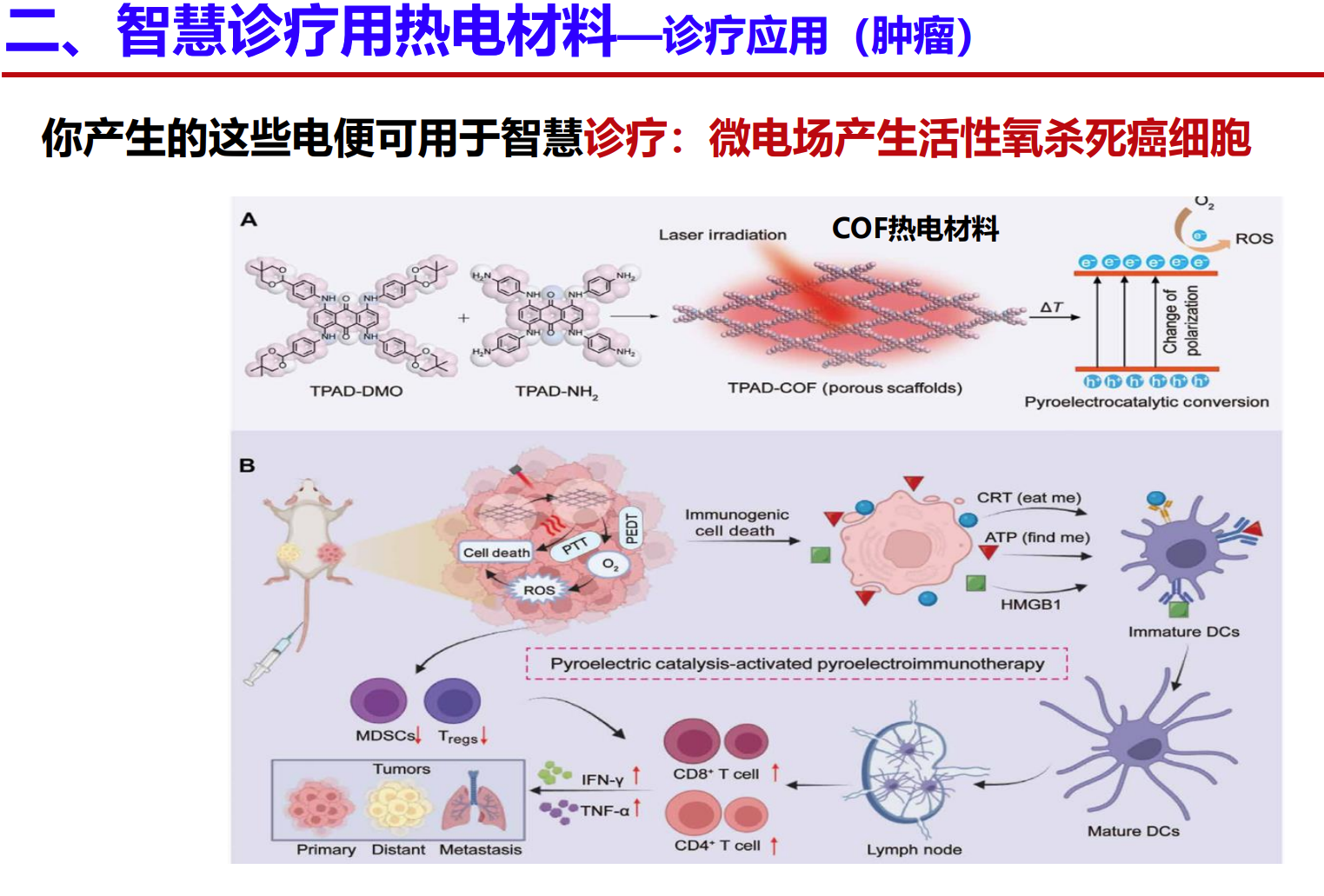
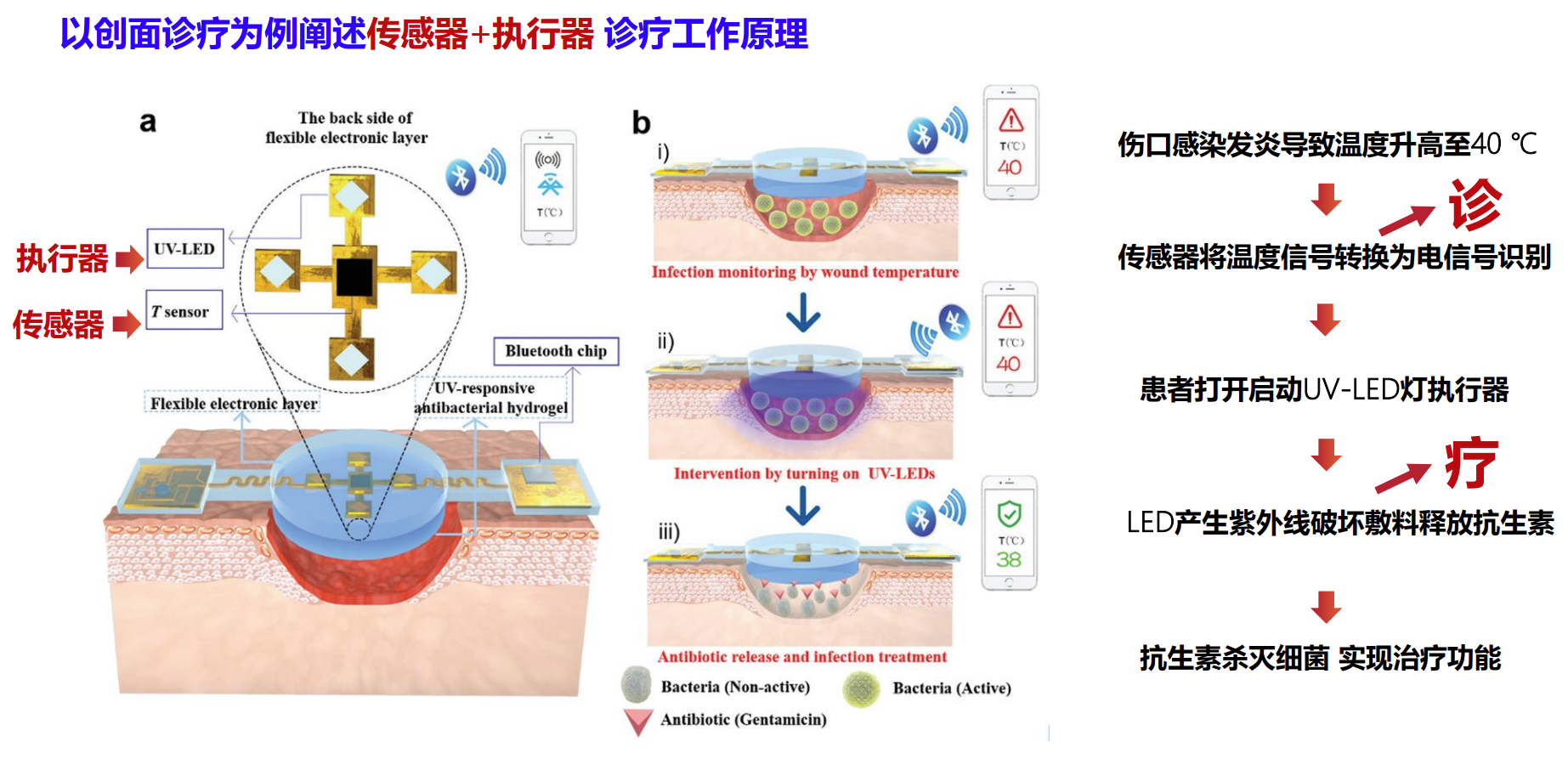
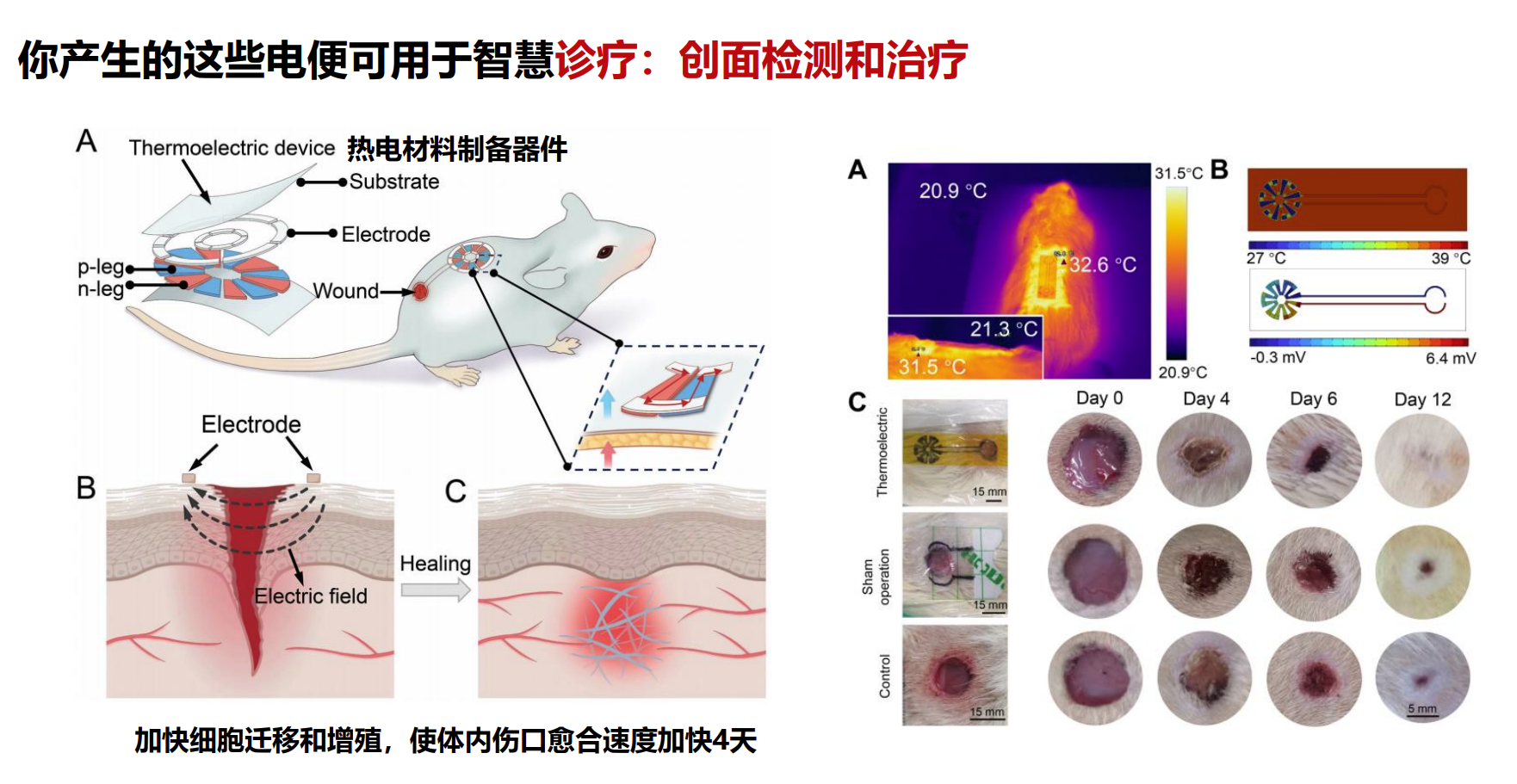
三、应用于创面检测和治疗的智慧热电材料
在创面监测与治疗中,热电材料可以实时检测伤口环境的温度变化,及时反馈创面状况,还能利用热电效应提供局部能量,用于促进血液循环或药物释放,提升愈合效率。
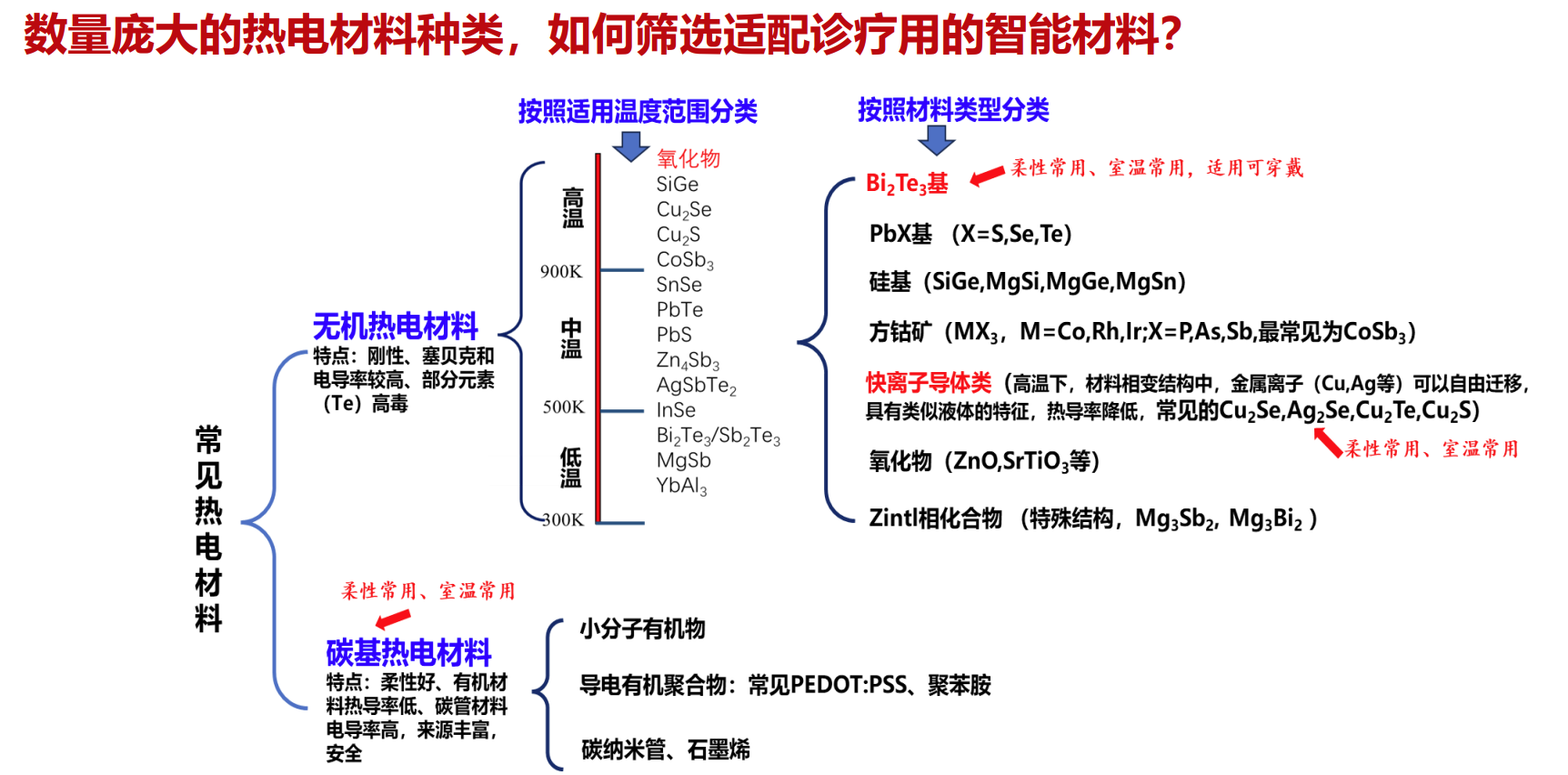
四、热电材料的分类与筛选挑战
面对丰富多样的热电材料,如何快速筛选出最适合医疗应用的高性能“智能材料”成为关键。不同材料在灵敏度、稳定性、生物兼容性等方面各有优势和局限,精准匹配诊疗需求需依赖科学的设计与筛选方法。
AI如何辅助诊疗材料的智能设计
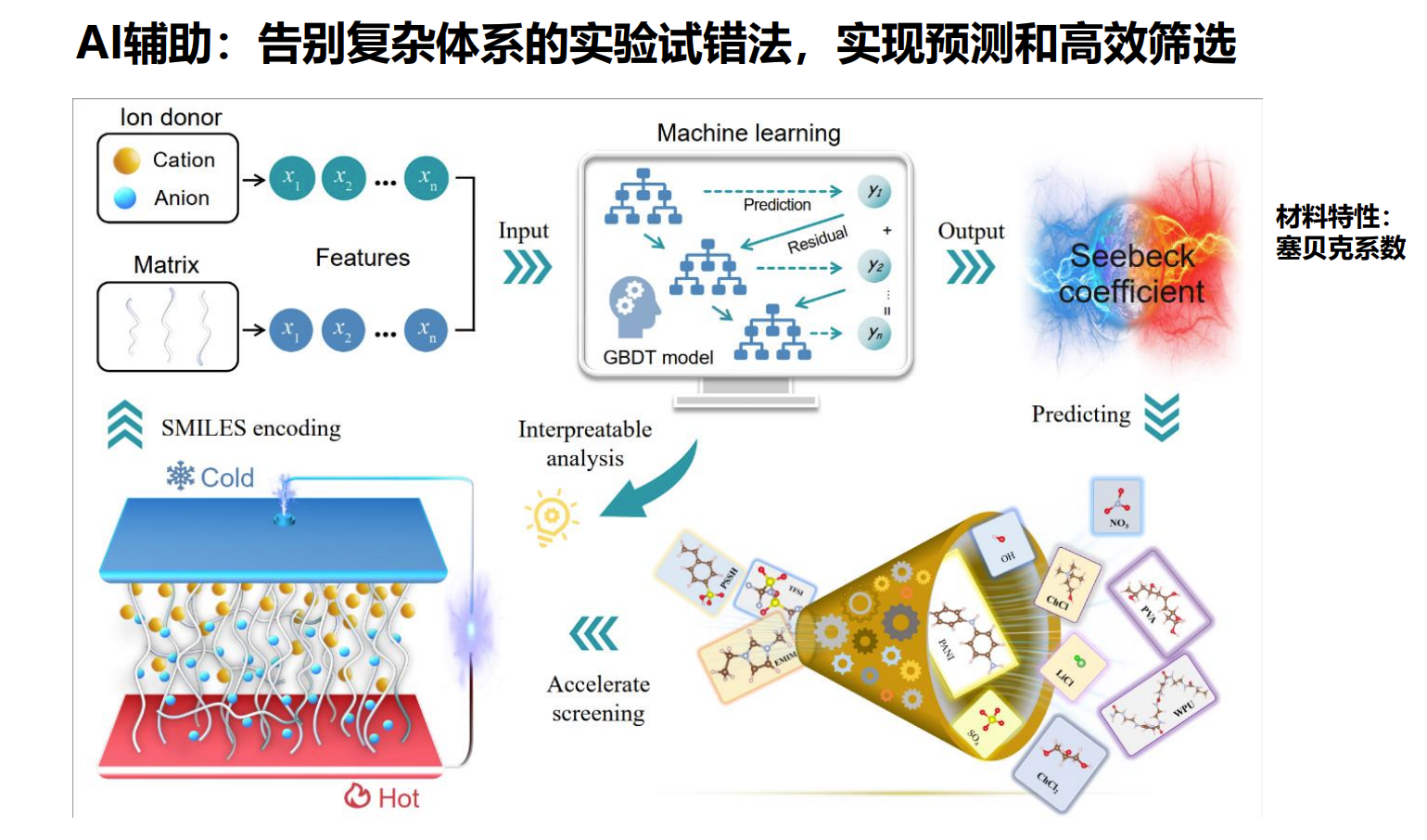
传统的材料优化依赖大量的实验试错,耗时且成本高。而AI技术的引入,为新材料的设计提供了革命性的方法:
- 性能预测:通过将热电材料的化学成分和结构转化为机器学习算法可理解的“特征数据”,实现快速性能预测,例如塞贝克系数、导电性能等关键参数。
- 高通量筛选:利用AI模型对海量潜在材料进行快速筛选,锁定候选“隐形宝藏”,大大缩短研发周期。
- 闭环优化:结合分子模拟和机器学习预测结果,形成实验-模拟-预测的闭环系统,不断优化材料性能。
- 可解释性分析:揭示影响热电性能的关键因素,例如键长、电子态密度、缺陷浓度等,为材料设计提供可操作的科学依据。
通过量子化学模拟、分子动力学等先进技术,验证AI预测的高潜力材料,为实现个性化、智能化的智慧诊疗设备提供坚实的材料基础。
单分子技术透视生命之谜
生命科学为何需要进行单分子研究?
著名物理学家理查德·费曼曾深刻指出:“如果要用一句话描述我们掌握的最重要科学知识,那就是:所有物质都是由原子组成。”原子在宇宙中无处不在,但单纯的原子世界极其单调,无生命、无情感。正是原子之间的相互作用,促使分子形成,分子参与化学反应,合成出更加复杂的结构,最终赋予生命的奇迹与多样性。
如果要用一句话来总结过去半个多世纪生命科学的核心成就,我认为是:生命的奥秘可以在分子水平上得到揭示。 通过研究单个分子,我们逐步破解了生命的基本编码,从蛋白质、核酸到各种生物大分子,深入理解了生命的本质,也为疾病诊断和新药开发提供了坚实基础。
单分子研究使我们摆脱“平均效应”的局限,观察到单个分子在生命过程中的真实动态,从而更全面地揭示生命复杂性、变异性及其调控机制。
常见的单分子研究工具有哪些?
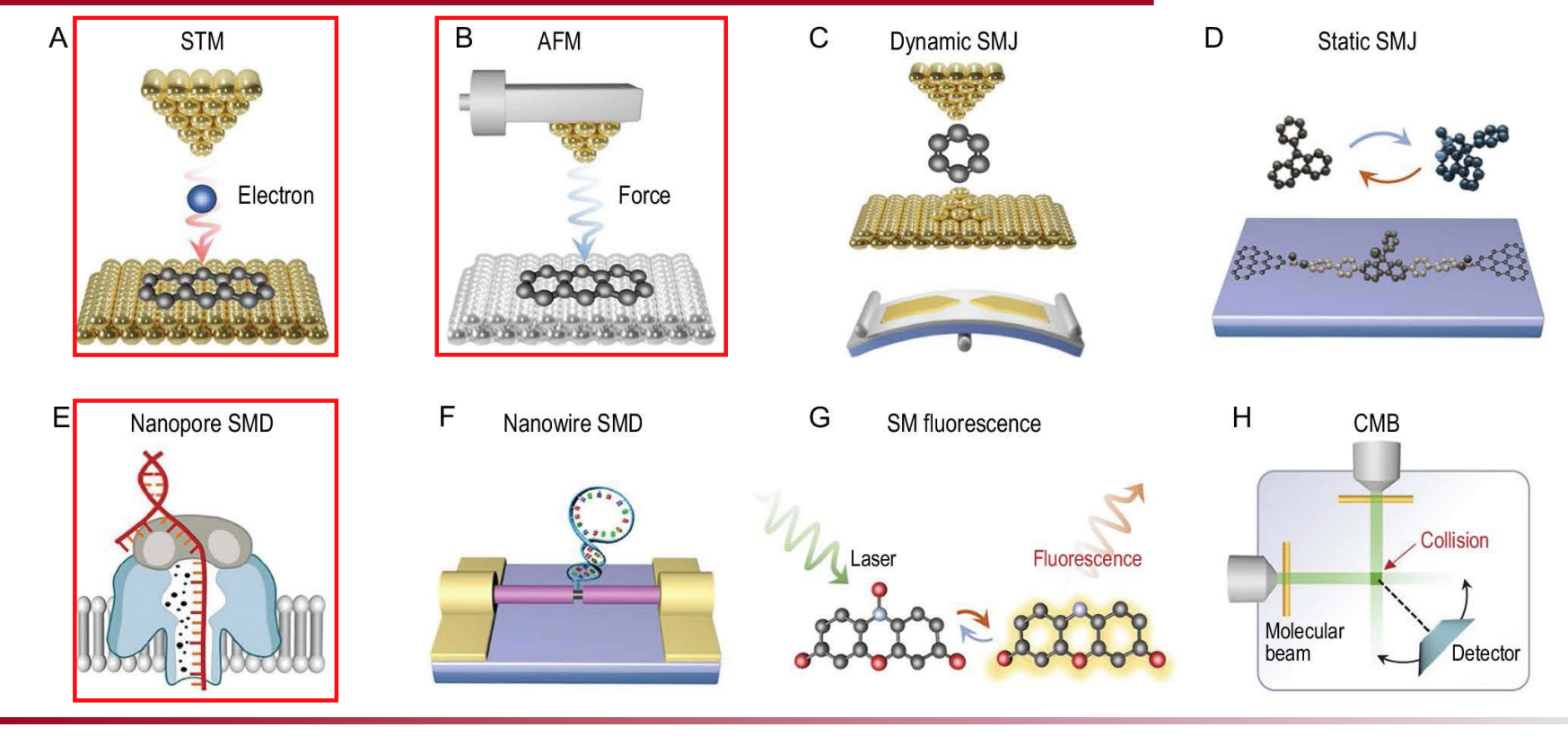
一、扫描隧道显微镜(STM)
原理简介:
扫描隧道显微镜(Scanning Tunneling Microscopy, STM)依赖于量子力学中的隧道效应。当一根极细的金属探针极接近导电样品(距离约0.1-1纳米)但未接触时,在探针与样品之间施加微小的电压(通常在毫伏到伏特范围)。
此时,由于电子具有波动性,能穿越能垒产生隧道电流。这个隧道电流的大小极度依赖于探针与样品的距离和局部电子态密度(LDOS)。由于隧道电流对距离极为敏感,因此STM能够实现原子级别的空间成像,揭示材料表面甚至单个原子的精细结构。
应用:
- 原子级表面结构分析
- 纳米材料界面研究
- 单分子性质检测
二、原子力显微镜(AFM)
原理简介:
原子力显微镜(Atomic Force Microscope, AFM)使用一根尖锐的探针(多由硅或氮化硅制成)紧贴样品表面,通过扫描探针在微米到纳米尺度上的变化,以获取材料表面的三维形貌与物理性质。
AFM的核心在于探针与样品之间的作用力,主要包括:
- 范德华力: 分子间的吸引作用
- 库伦力: 带电粒子之间的静电作用
- 弹性力: 探针-样品变形引起的弹性反作用
- 化学键力: 化学键或共价键的作用
通过调节探针偏压力,AFM能测量出样品的力学性质、粘附能、刚度等参数,还能实现非接触式和接触式扫描,广泛应用于生物材料、纳米结构研究和细胞力学分析。
三、纳米孔技术(Nanopore)
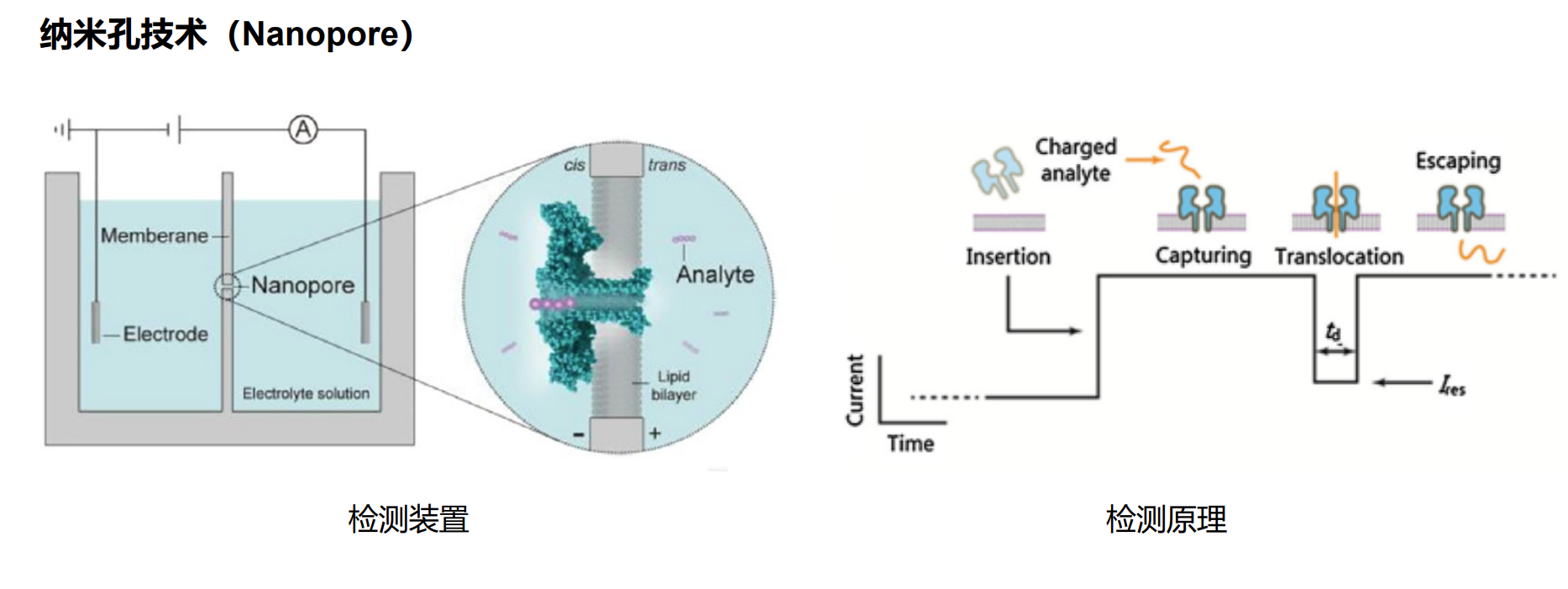
用途:
- 核酸测序:通过单个DNA或RNA分子通过纳米孔时引起的电流变化,实现高通量、长读取长度的序列分析。
- 蛋白质测序:利用纳米孔识别不同氨基酸簇的特征,逐步解码蛋白质序列。
- 糖类分析:检测糖链的结构和变化。
原理:
在一个纳米尺度的孔道两侧施加电压,带电的生物大分子(如DNA、蛋白质)在电场作用下穿过孔道,分子在孔中的运动引起的电流变化,便成为识别和分析的信号。纳米孔技术具有操作简便、成本低廉、信息丰富等优点。
人工智能助力单分子研究的新机遇
随着单分子检测技术的不断成熟,融合人工智能(AI)技术,为提升单分子分析的效率、精度和功能提供了巨大潜力。
AI在单分子研究中的应用前景
- 数据分析与解读:单分子检测会产生海量高维数据,AI算法(如深度学习、机器学习)能从噪声中提取有效信号,实现实时分析,提高识别准确性。
- 结构预测与建模:基于单分子信号,结合AI的结构预测模型,可以快速推断分子结构、动力学行为及其与环境的相互作用。
- 自动识别与提升通量:AI技术可以自动识别特定的信号特征,实现高通量筛选和疾病标志物的快速检测,大幅增长研究效率。
- 预测与设计新材料:通过AI辅助的材料设计,可以精准筛选出最优的单分子传感材料或特定功能分子,推动纳米传感、生物标志物开发。
AI赋能单分子研究的意义
- 缩短研发周期:传统试错耗费巨大,而AI让材料筛选、信号解析变得更迅速、更智能。
- 促进基础科学突破:AI能够揭示单分子动态、相互作用中的隐秘规律,揭示细胞内复杂网络的真实运行机制。
- 推动精准医疗:单分子传感器结合AI诊断算法,支持早期疾病筛查、个性化治疗方案的制定。
展望未来:单分子技术与AI的深度融合
在未来,单分子技术将和AI技术深度融合,推动生命科学向更微观、更智能的方向发展。具体表现为:
- 高通量单分子平台的智能化:实现全自动、高速、精准的单分子检测和分析系统,为临床诊断和药物筛选提供实时、可靠的支持。
- 跨学科的融合创新:材料科学、计算科学、生命科学和工程技术的合作,将催生更多突破性技术,如智能纳米机器人、实时监控细胞过程的单分子装置。
- 个性化生命医学的实现:通过单分子检测个体差异信息,结合AI分析,定制专属精准治疗方案。

总之,单分子技术的不断创新及其与AI的深度结合,将共同推动生命科学的巨大飞跃,逐步解开生命之谜,造福人类健康。
单细胞测序技术:揭示细胞世界动态演变的利器
English: Single-cell Sequencing Technology: Insights into the Dynamic Evolution of the Cellular World
如何探索人体内“细胞演变”的动态变化?
细胞作为生命体的基本单元,其功能和状态会随时间和环境不断变化。基因表达水平的动态改变是细胞行为和命运调控的核心,通过对单个细胞基因表达的精准捕获与分析,能深入理解细胞在发育、疾病进展及治疗过程中呈现的异质性与演变轨迹。这为解析细胞异质性、细胞命运决定以及组织微环境的复杂相互作用提供全新视角。
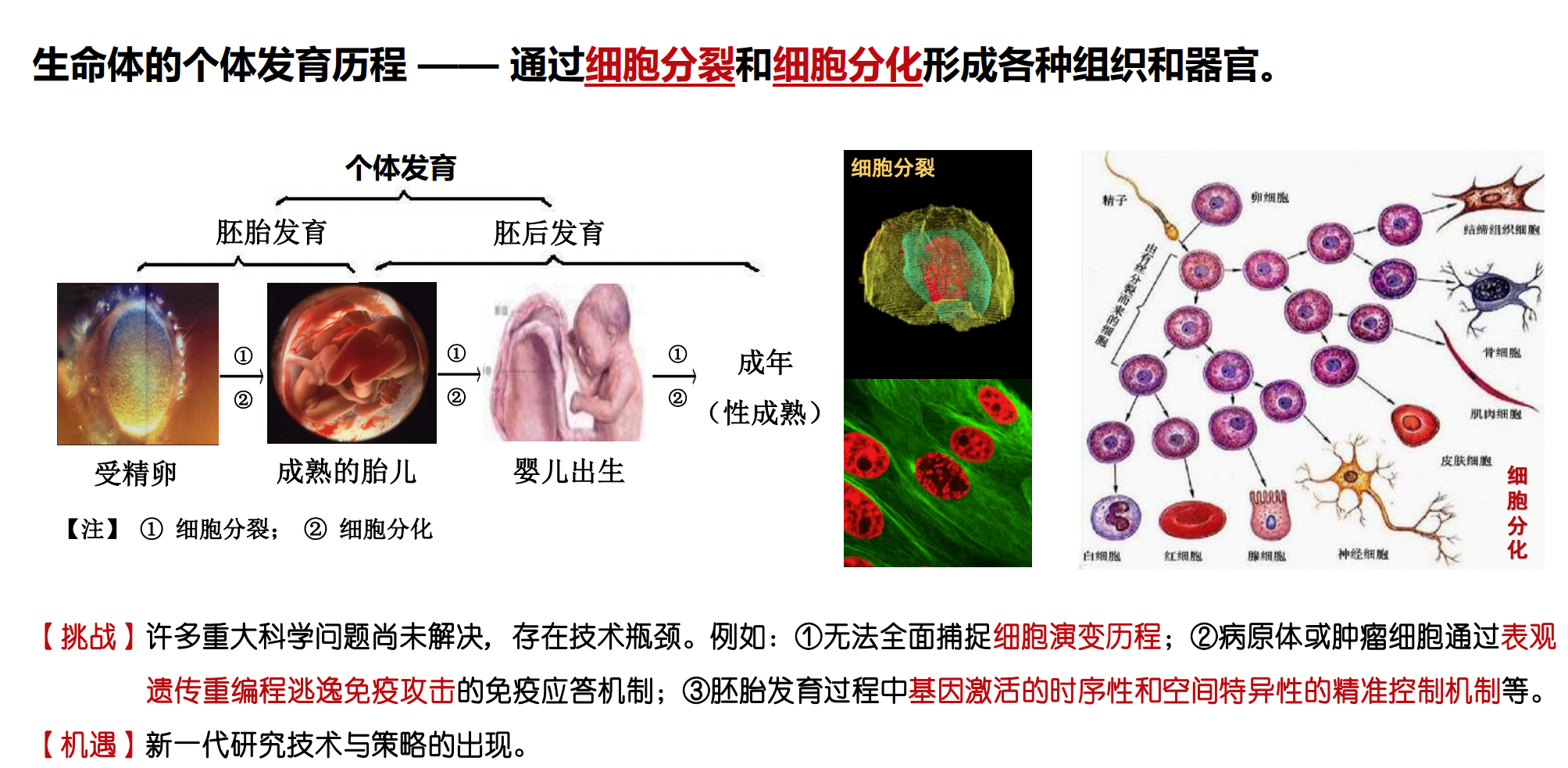
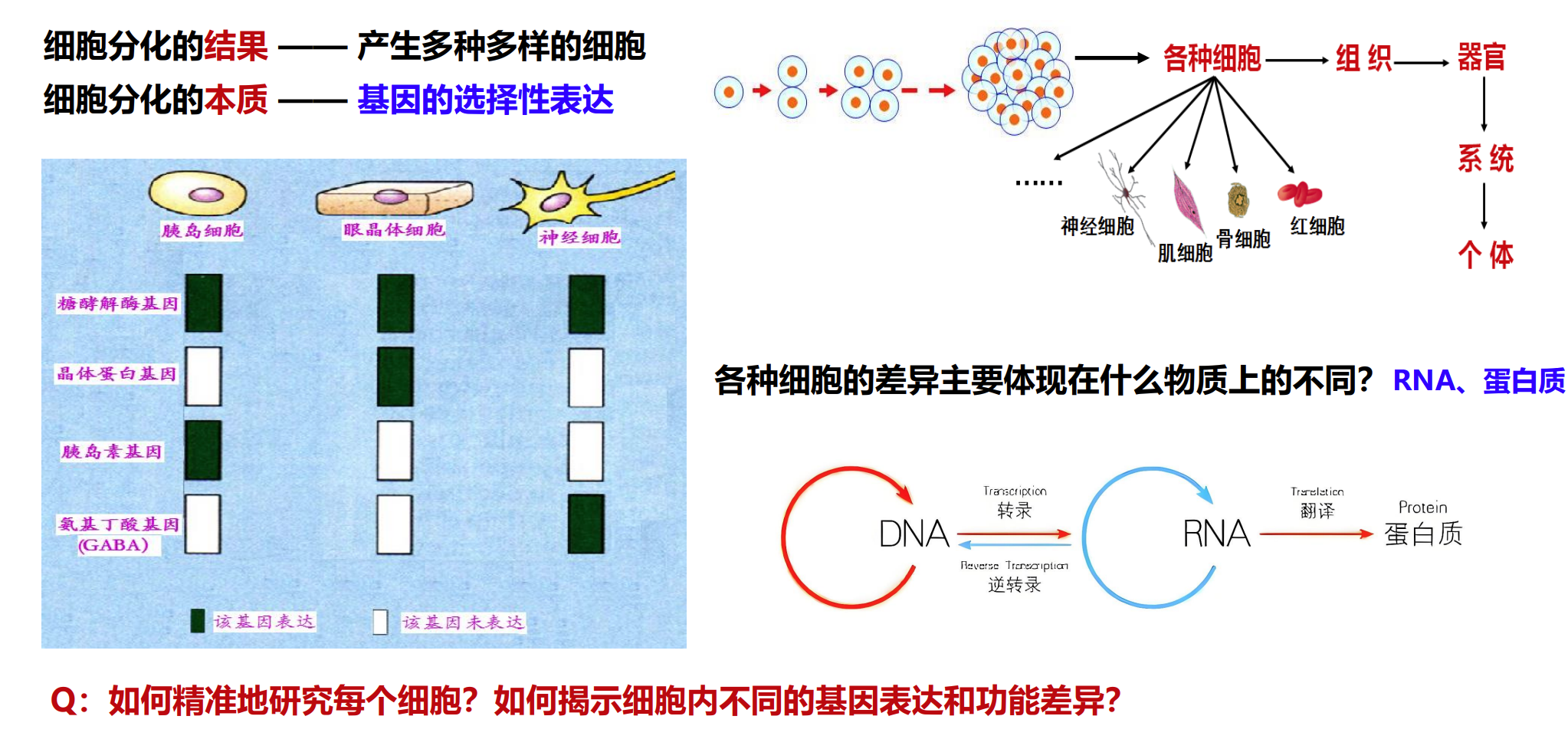
单细胞测序技术的原理
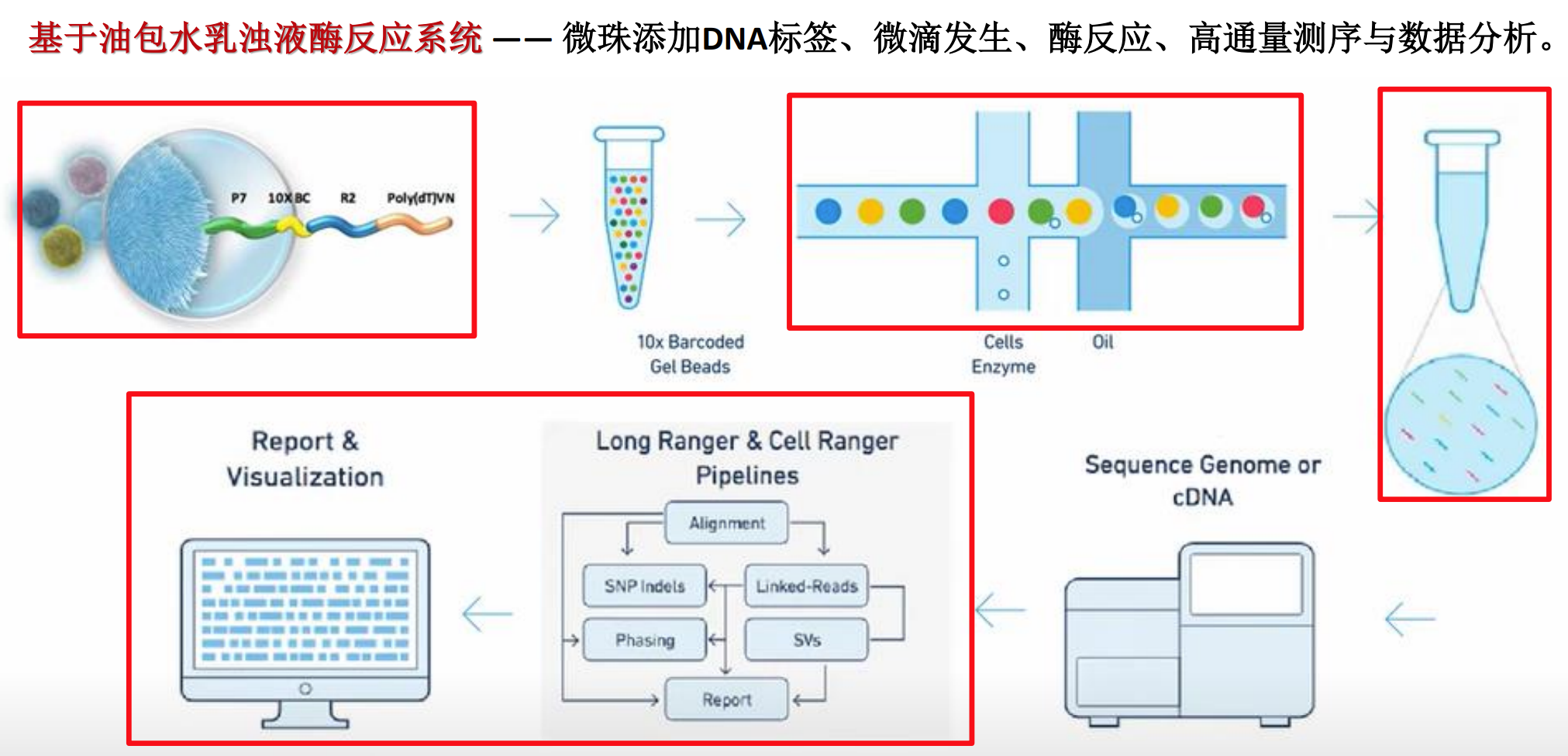
单细胞测序技术以高通量测序为基础,采用基于油包水的乳滴微液滴系统,实现单细胞的分离与独立分析。具体原理包括:
- 微珠DNA标签系统:通过设计独特的DNA条形码(Barcode)标记每个细胞,确保测序数据的单细胞来源可追溯。
- 微滴生成与酶反应:将单细胞与带有标签的微珠包裹于微小液滴中,进行逆转录生成cDNA,获得各细胞特异性的转录组信息。
- 高通量测序与大数据分析:随后对cDNA文库进行测序,并通过生物信息学方法进行基因表达量的定量、细胞类型的分群与动态路径推断。
10x Genomics系统的工作流程解析
微珠DNA标签设计
- 采用高度特异性的引物设计,确保每个微珠带有唯一条形码,用于细胞识别和批次区分。
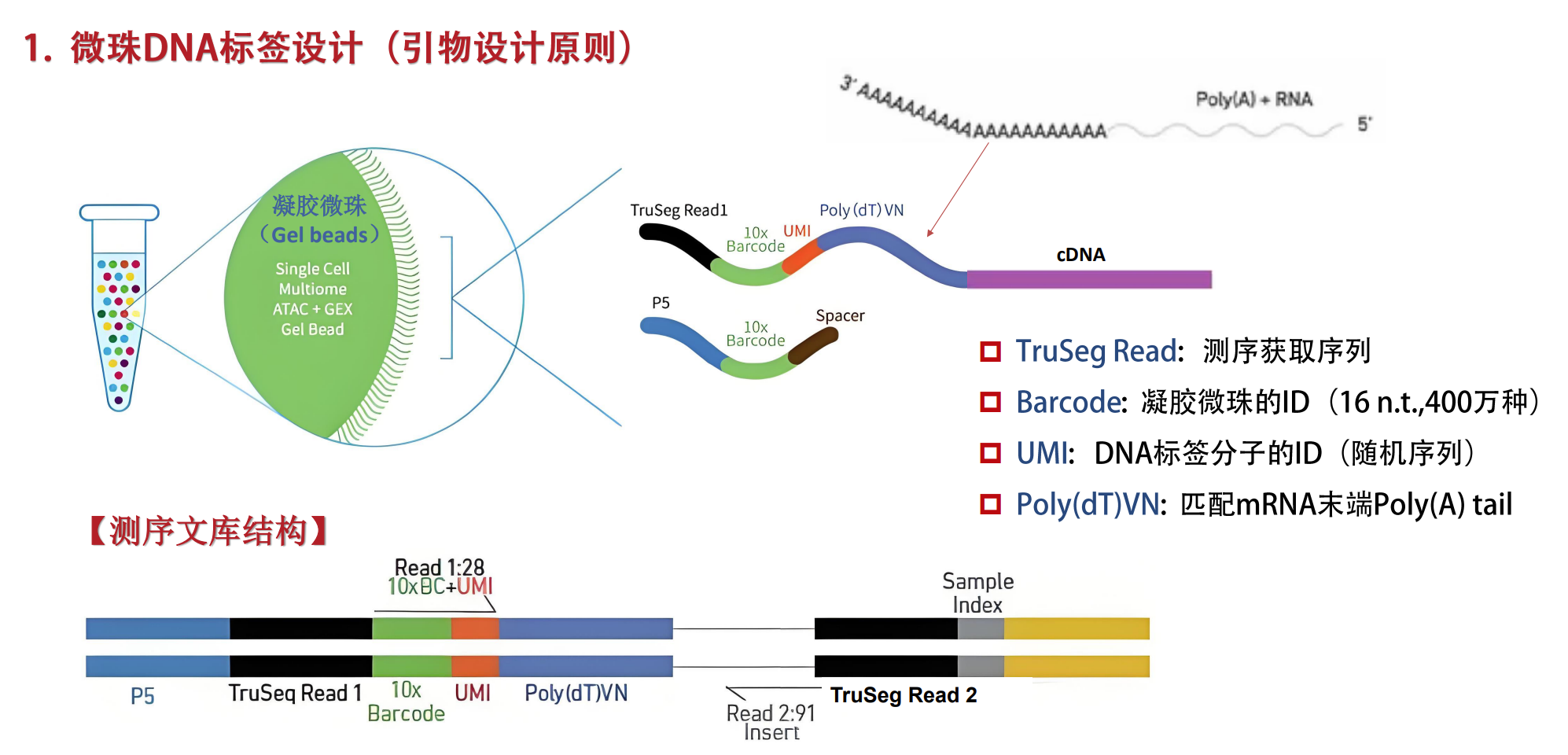
芯片液流管路控制
- 精密的微流控技术使细胞、酶液和微珠在芯片中按照设计方案准确汇合,生成独立的液滴。
cDNA文库构建及测序
- 细胞内mRNA经过逆转录合成cDNA,构建成文库后进行高通量测序,获得细胞内各基因的表达数据。
数据处理与细胞分群
- 通过数据降维、聚类分析等算法,精准区分不同细胞亚型,揭示细胞异质性和发育轨迹。
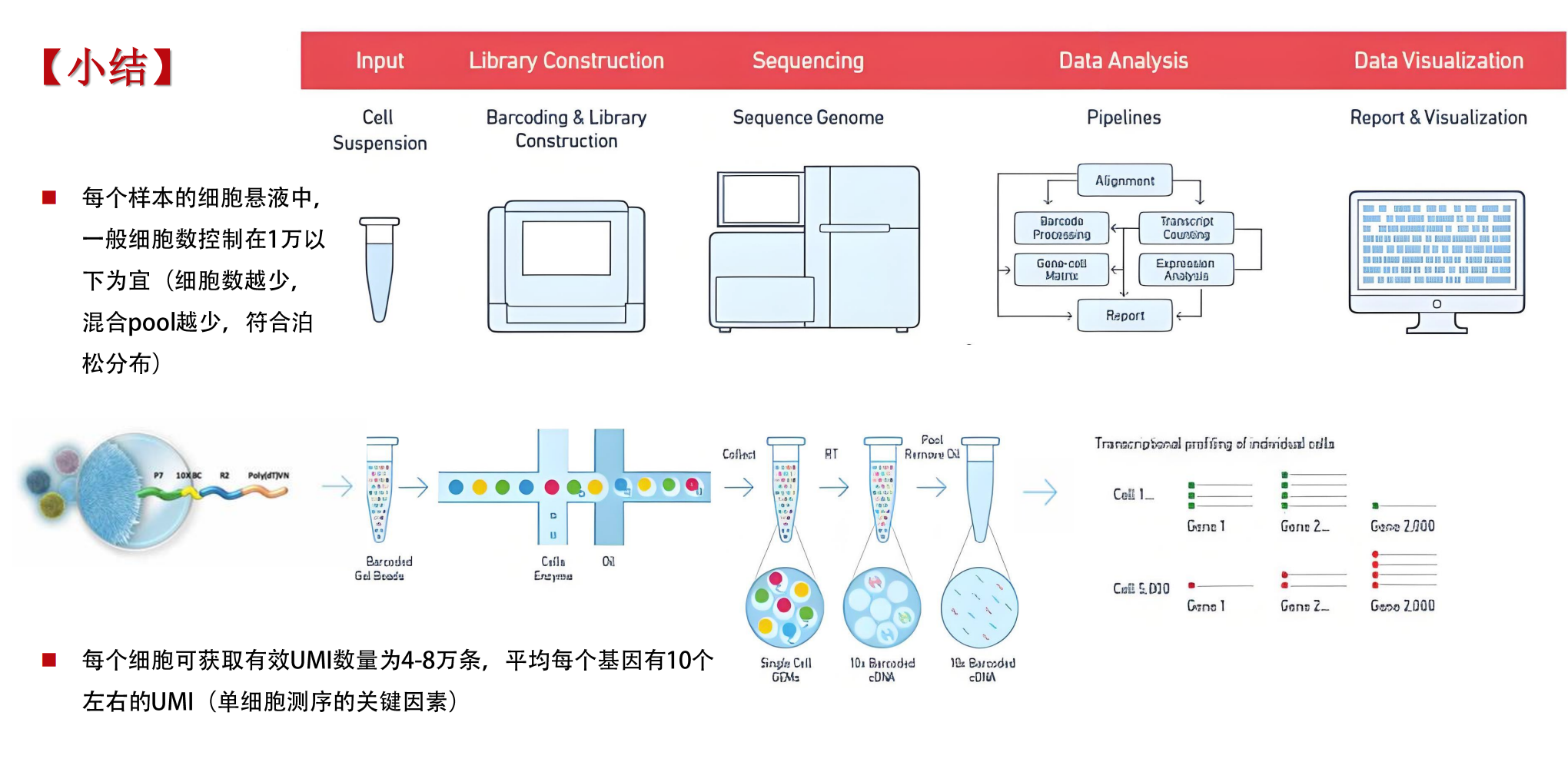
单细胞测序技术平台简介
目前,主流单细胞测序平台包括10x Genomics Chromium、Drop-seq、SMART-seq等各具优势,支持不同的实验设计与研究需求,涵盖高通量细胞捕获、全转录组覆盖、空间信息结合等多种功能,推动细胞生物学和临床研究的深度融合。
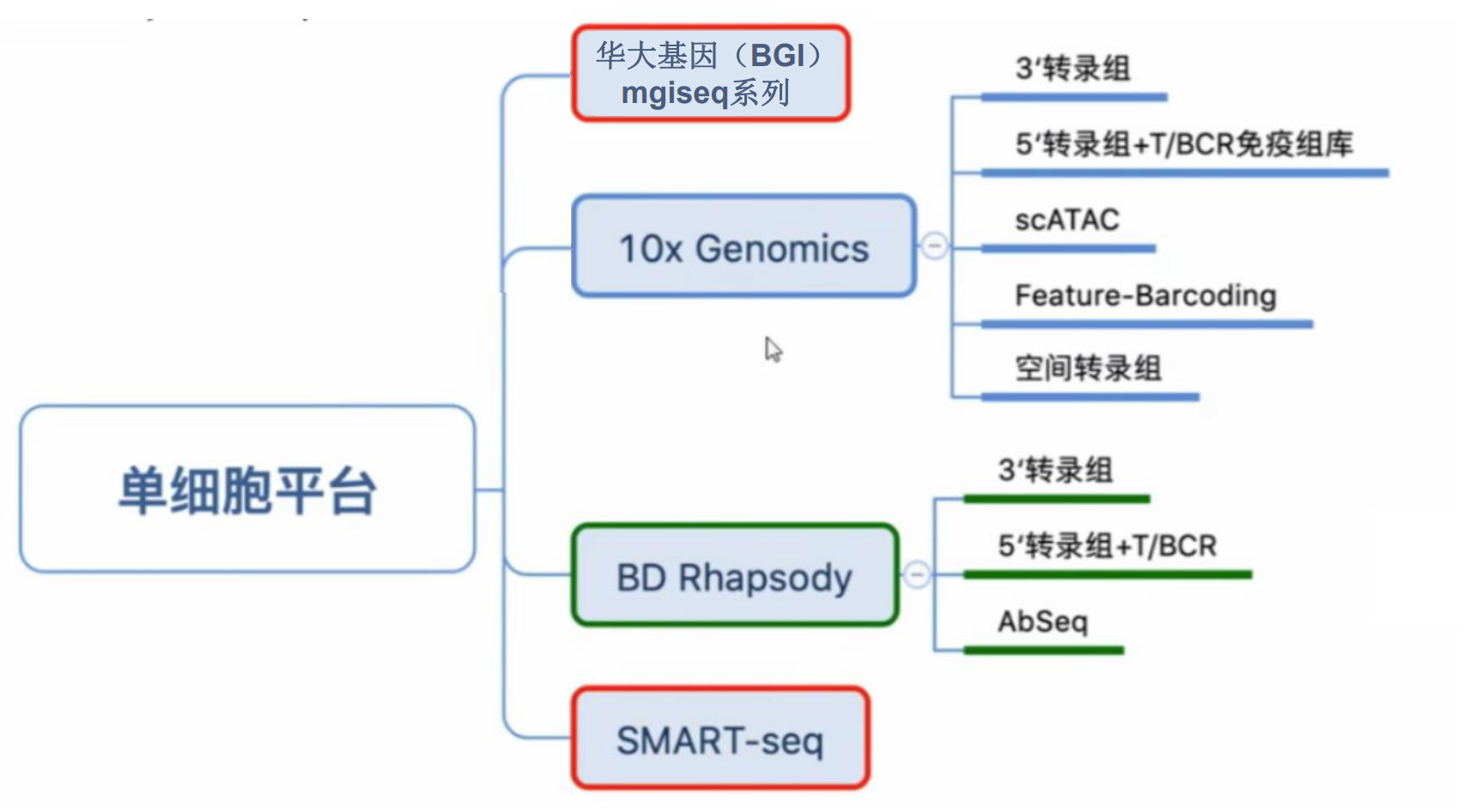
单细胞测序技术的主要应用领域
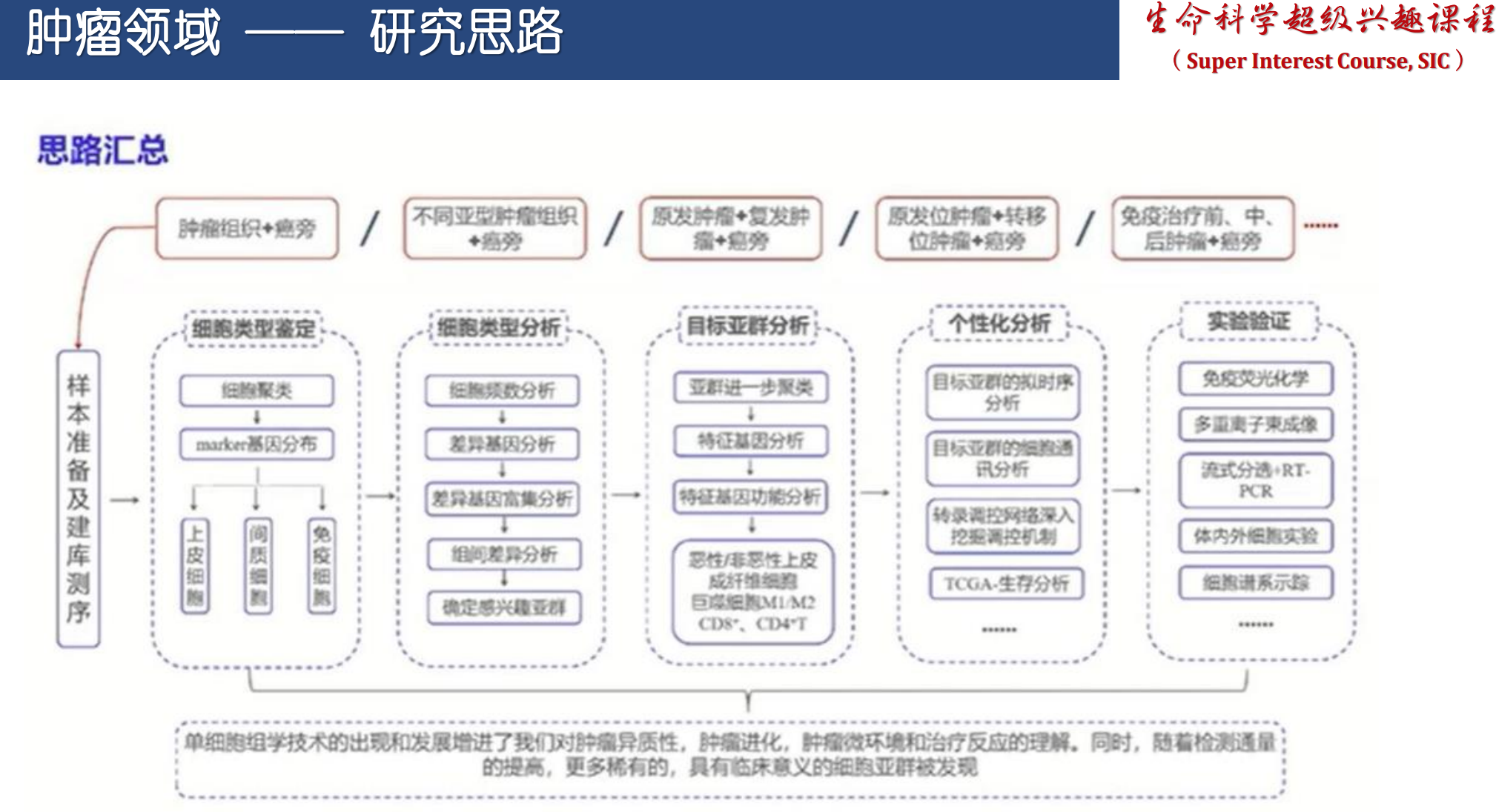
肿瘤研究
肿瘤异质性解析
利用单细胞转录组测序精准揭示原发性胃腺癌内各细胞的转录异质性,解析不同细胞亚群的功能状态,助力个性化治疗策略设计。肿瘤微环境与细胞互作
通过解析肿瘤微环境中不同细胞类型的转录谱,揭示肝内胆管细胞癌中基质细胞与免疫细胞之间的复杂交互,推动肿瘤免疫环境的理解。肿瘤转移与复发机制探究
单细胞测序技术深入探讨早期复发性肝癌的细胞演变路径与潜在分子机制,为复发预测和精准干预提供依据。肿瘤起源与演化研究
揭示神经母细胞瘤的发育起源,阐明肿瘤发生过程中的细胞命运转变;同时解析肿瘤免疫治疗副作用相关分子机制,指导安全性优化。
肺动脉高压(PAH)
肺动脉高压是一种因多种病因导致肺血管重构和肺动脉压力持续升高的疾病,最终可能导致心力衰竭及死亡。其发病机制尚未完全明晰,诊治面临重大挑战,未被有效治疗的患者中位生存期仅约2.8年。
肺动脉高压诊疗面临的难题
发病机制复杂且模糊
肺动脉高压包含五大类,其中第一类肺动脉高压(PAH)和第四类慢性血栓栓塞性肺高压(CTEPH)均为罕见病,缺乏系统的病理机制阐释。临床和生物数据匮乏
由于研究起步较晚,缺少完善的临床队列和生物学数据,限制了对疾病的深入理解和精准治疗方案的制定。预后影响因素及模型尚不清晰
现有研究对影响患者生存的关键因素和机制尚未建立有效模型,阻碍了疾病管理和预后评估。
单细胞测序技术(scRNA-seq)在PAH研究中的应用进展
单细胞转录组测序(scRNA-seq)作为揭示细胞异质性的重要工具,能够在单细胞层面捕获肺血管组织的基因表达差异,为解析PAH的细胞组成和分子机制提供了前所未有的细节。
现有研究多集中于PAH和CTEPH患者的组织样本,揭示肺血管壁细胞、免疫细胞等多种细胞群落的动态变化。
目前单细胞测序在PAH领域主要用于发现疾病相关细胞亚型和信号通路,实际应用验证与临床转化仍处于探索阶段。
未来发展方向与技术前沿
为了更全面和精细地解析PAH及其他复杂疾病的细胞动态,单细胞测序技术正朝着多维度、高通量与空间解析能力方向发展:
ATAC-seq技术
解析染色质开放状态、转录因子结合位点和核小体位置,揭示基因调控层面的表观遗传机制。单细胞蛋白组测序
通过检测细胞表面蛋白,补充转录组信息,精准描绘细胞表型和功能状态。单细胞免疫组测序
深入分析复杂组织中的免疫应答,探索免疫细胞的异质性和功能动态。空间转录组测序
保留细胞空间位置信息,连接基因表达与组织微环境的空间分布,实现细胞-组织多尺度整合分析。单细胞全基因组测序(PanoCell)
在全基因组范围内分析细胞的所有基因,推动细胞命运、基因突变和结构变异的深度研究。
总结
单细胞测序技术通过精准捕获单个细胞的基因表达及表观遗传景观,极大提升了我们对人体细胞动态演变的认识。在肿瘤、肺动脉高压等复杂疾病领域,scRNA-seq已经成为揭示细胞异质性、发病机制及治疗靶点的重要工具。未来,结合蛋白组、免疫组及空间组学的多组学整合,将进一步推动疾病机制的精准解析及临床转化,助力个性化医学的发展,最终实现对人体细胞世界动态演进的全面洞察。
骨骼密码:从漫威金刚狼到生物3D打印的再生革命
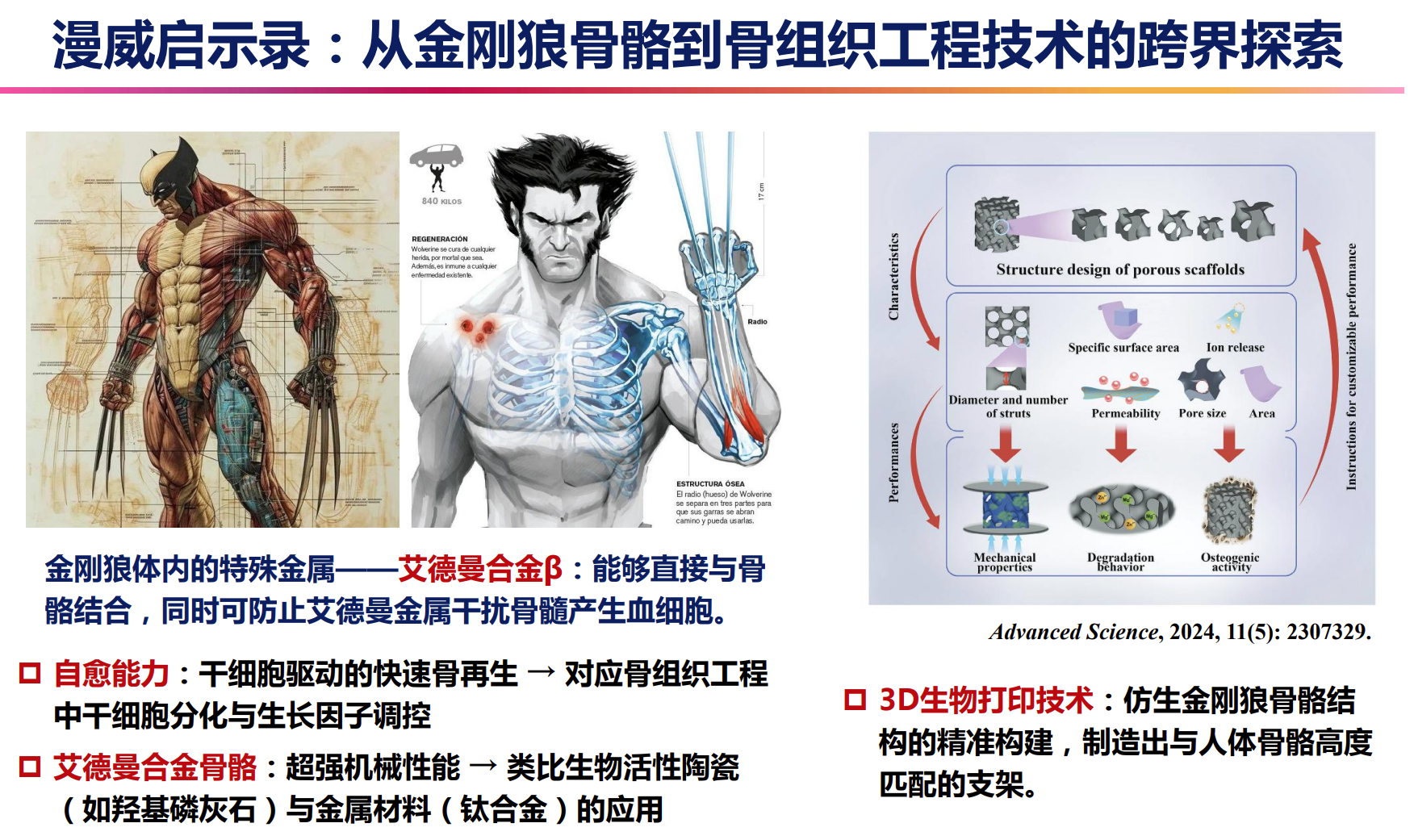
漫威启示录:从金刚狼骨骼到骨组织工程技术的跨界启发
漫威中的金刚狼骨骼由虚构的特殊金属——艾德曼合金β构成,这种合金不仅能够与骨骼直接结合,还避免了对骨髓造血功能的干扰,展现了超强的机械性能和生物相容性。其快速自愈能力,源于干细胞驱动的骨再生过程,启发了现实中的骨组织工程技术,聚焦于干细胞分化与生长因子的精准调控。通过3D生物打印技术,科学家能够仿生金刚狼骨骼的复杂结构,制造出与人体骨骼高度匹配的支架材料,推动骨再生从幻想走向现实。
支架材料
组织工程中的支架材料指那些能与活体细胞结合,且可植入生物体内,辅助替代和修复具体组织功能的材料。该支架相当于人工细胞外基质,为种子细胞的增殖和分化提供三维微环境。支架材料广泛应用于骨、软骨、血管、神经、皮肤及人工器官(如肝、脾、肾、膀胱)等组织的再生。
应用背景
- 由于创伤、肿瘤及骨病的增多,骨缺损、骨不连和骨髓炎患者对骨移植的需求不断上升。
- 外伤、肿瘤、炎症与先天畸形引起的牙槽骨缺损,常伴随牙槽骨吸收,影响种植效果,必须选择合适骨替代品以重建牙槽骨。
- 骨组织工程提供了一种创新治疗方法,支架材料作为组织构建的核心,为细胞提供所需的微结构、水分、营养物质及多种生长因子,保障细胞存活和功能发挥。
骨组织工程三要素
- 种子细胞
- 信号因子
- 支架材料
工程过程包括:种子细胞接种于支架 → 新骨生成 → 支架逐步降解 → 骨缺损修复完成。
支架性能要求
生物相容性与表面活性
支架材料应促进细胞黏附,无毒无害,不致畸、不引发炎症,营造良好微环境,安全用于人体。骨传导性与骨诱导性
- 骨传导性材料能适应降解速度,支持骨组织生长。
- 骨诱导性指材料可诱导间充质干细胞分化为成骨细胞,促进骨再生。
可降解性
支架应逐渐被体内组织替代,降解速率匹配新组织生长速度,支持逐步替代过程。孔径与孔隙率
理想孔径约为223微米,与人体骨单位大小相近。高孔隙率及连通孔隙结构有利于细胞黏附、生长和营养交换。机械强度与可塑性
支架需具备良好机械稳定性,且能加工成符合骨缺损形状的支架,植入后保持结构完整。
支架材料分类
- 人工合成材料
- 天然衍生材料
- 复合支架材料
骨组织再生中的生物背景
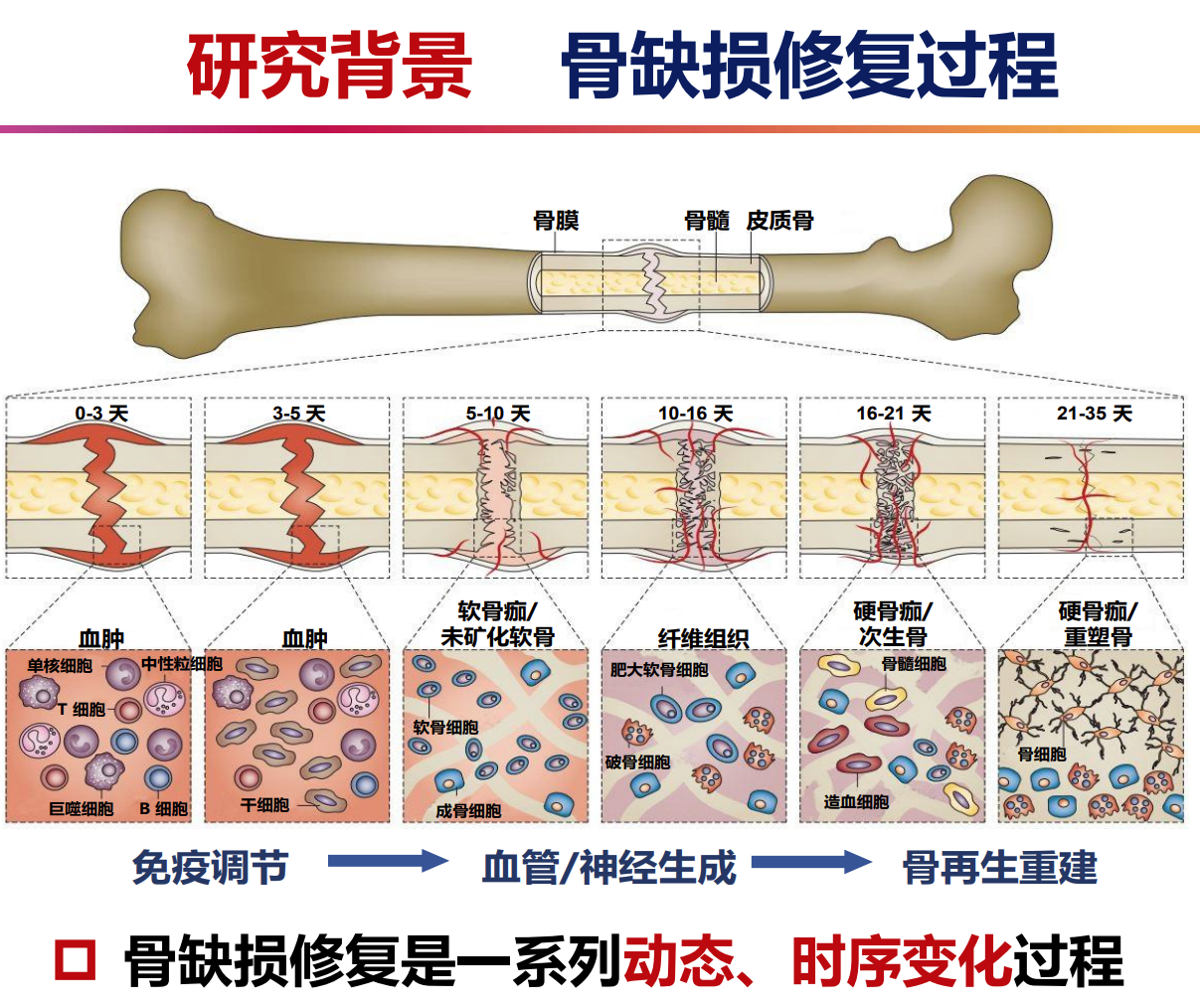
血供的重要性
血管新生确保细胞获得充足营养,促使新陈代谢活跃,血管生成与成骨过程密切耦合,共同促进骨再生。
神经支配作用
骨组织中神经与血管伴生,神经通过神经肽调控成骨,感觉神经维持骨稳态,神经与血管的相互作用形成骨再生的调节网络。
骨-血管-神经的交互作用(crosstalk)
神经通过旁分泌作用调节骨再生,神经生长因子(NGF)和信号蛋白Sema3A促进神经再生,神经细胞释放的神经递质及小胞外囊泡(SEV)则调节血管生成及成骨过程,三者之间形成复杂而关键的交互网络,协同推动骨组织的功能恢复和结构重建。
3D打印技术在骨再生中的创新应用
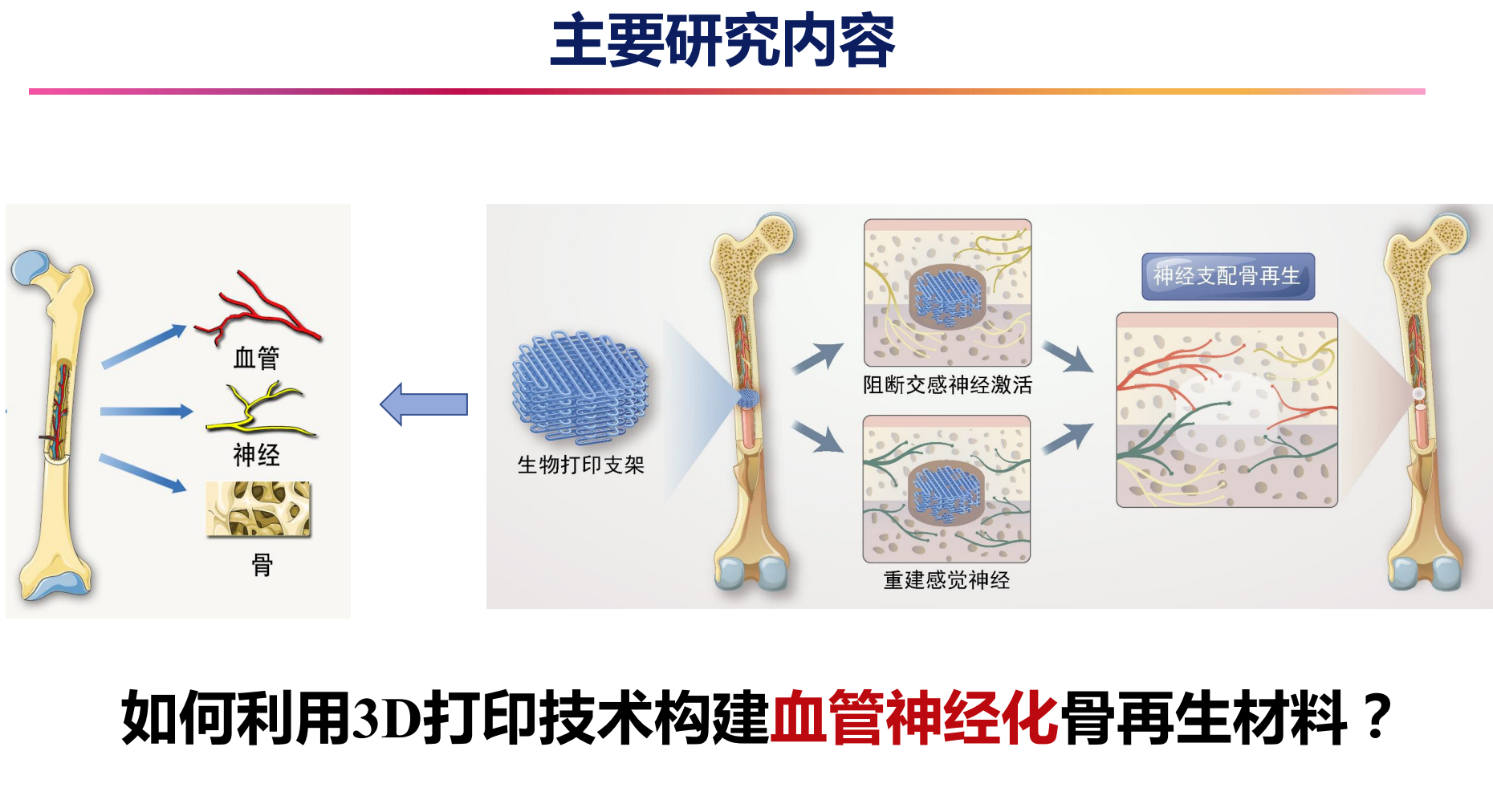
多维度仿生支架构建
随着3D打印技术的飞速发展,其在骨组织工程中的应用不断深化,尤其体现在血管重建和神经支配的集成方面。通过高精度打印技术,科研人员能够制造出精细的微/纳米结构支架,提供细胞迁移和生长的理想微环境,显著提升再生效率。
低氧环境诱导血管生成机制
- HIF-1α(低氧诱导因子):作为调控血管内皮生长因子(VEGF)表达的关键因素,HIF-1α不仅促进血管生成,还介导骨血管生成的耦合。
- 低氧模拟剂:如去铁胺(DFO)和二甲基草酰甘氨酸(DMOG)等化学物质,能够增强HIF-1α表达,进而促进血管新生和骨组织修复,为骨缺损治疗提供新的思路。
典型研究成果汇总
“Flowerbed”灵感的血管化微/纳复合支架
利用3D打印结合静电纺技术,成功制备局部递送DMOG和锶离子(Sr)的复合支架,显著促进组织内生血管化及骨组织再生。3D打印血管网络构建
通过微通道设计,重现骨组织内复杂的血管网络结构,提升支架的血管化效率和细胞营养供给。
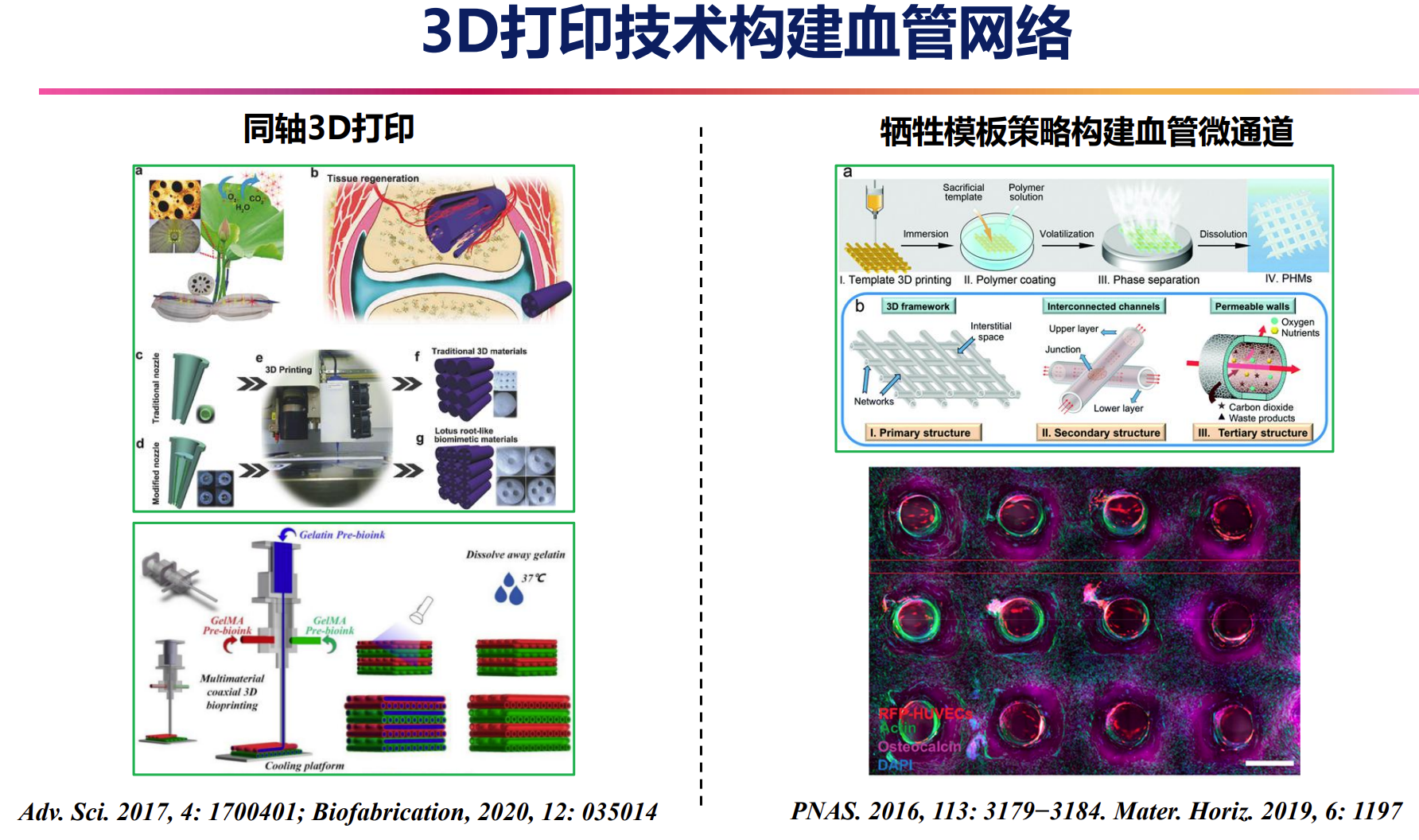
仿生骨微结构纳米纤维支架
结合纳米纤维细胞外基质结构和微通道血管网络,实现双因子缓释功能,支持细胞多维度生长和功能实现。丝素基水凝胶助力血管化骨修复
丝素蛋白基底的生物相容性和机械性能优异,提升支架的整体功能,促进新骨和血管的同步形成。吉兰糖胶基水凝胶支架的应用探索
利用吉兰糖胶的生物活性及可降解特性,构建具有良好生物相容性的骨再生支架。3D打印载支架调控交感神经,促进骨再生
通过调控交感神经的激活状态,改善骨组织微环境,增强骨修复能力,揭示神经对骨再生的调节机制。荧光与磁共振双模态成像技术的整合
实现对骨组织工程的实时可视化监控,提升支架及细胞在体内功能表现的追踪能力,大幅加快临床转化进程。
总结与展望
从漫威金刚狼的想象,到现实中依托干细胞生物学及先进3D打印技术的骨组织工程革命,骨骼再生的未来广阔而充满可能。通过不断优化支架材料的生物活性、机械性能及微结构设计,结合血管神经的协调调控,骨组织工程将逐步实现临床上骨缺损的高效、精准修复。未来,随着多功能智能材料和可视化技术的进一步发展,骨再生技术必将更加个性化和智能化,为患者带来前所未有的康复体验和生活质量提升。
纳米尺度上的生命:智能纳米颗粒在生物医药领域的革命性进展
纳米尺度上的生命:探索细微世界中的医学奇迹
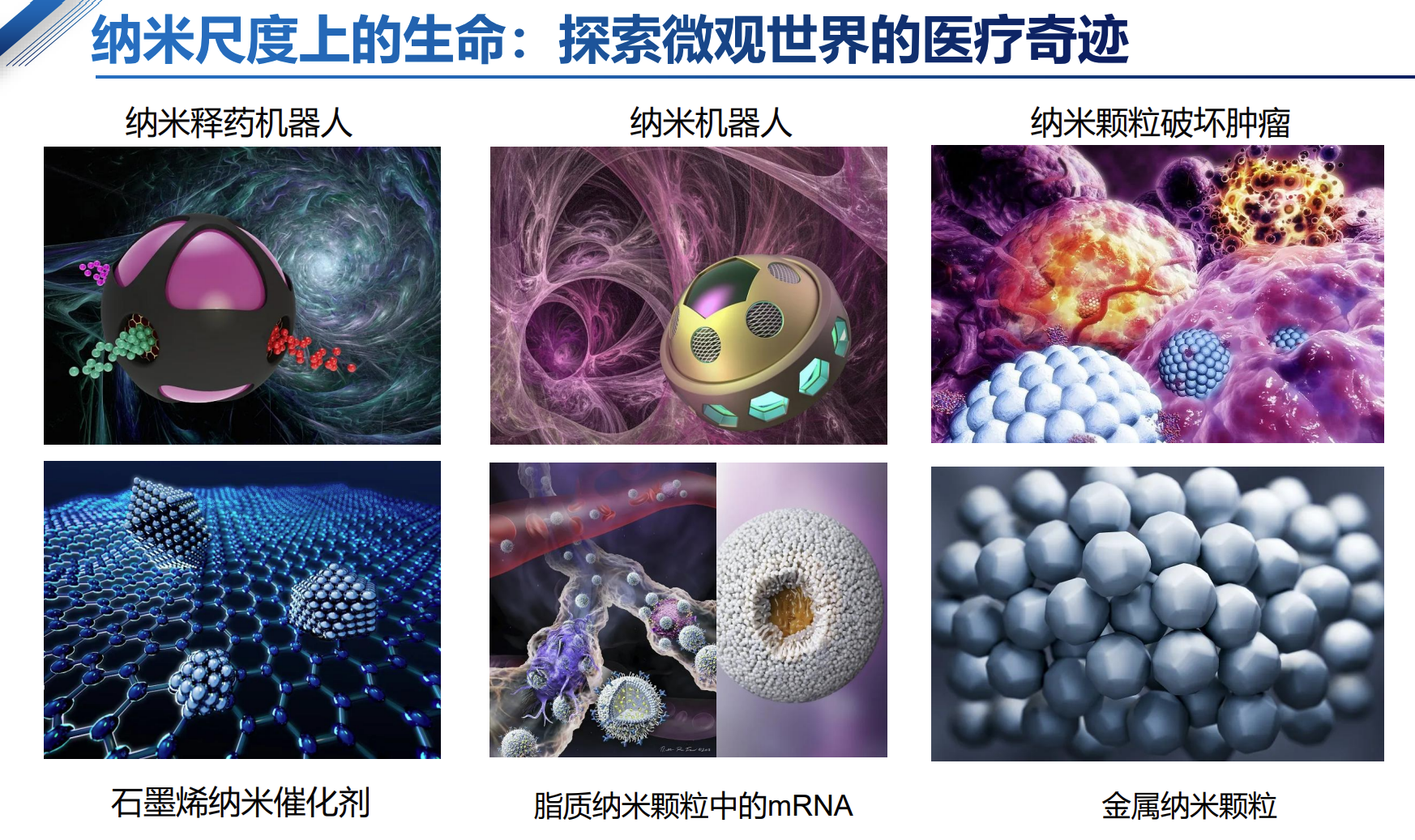
在纳米尺度(1-100纳米)这个极其微小的世界里,智能纳米颗粒作为生命科学和医学的“微观工匠”,正引发一场医疗技术的变革。典型的应用包括:
- 纳米释药机器人:智能调控药物释放,实现精准治疗。
- 纳米机器人:执行细胞级操作,促进疾病诊断与治疗。
- 纳米颗粒破坏肿瘤:通过靶向聚集并释放治疗药物,有效破坏癌细胞。
- 石墨烯纳米催化剂:利用石墨烯的独特性质促进神经修复和抗菌。
- 脂质纳米颗粒中的mRNA:成功应用于新冠疫苗,开启纳米递送技术新纪元。
- 金属纳米颗粒:在抗菌、影像增强及光热治疗中发挥重要作用。
这些技术不仅推动了精准医疗的发展,也带来了前所未有的治疗效果和患者体验提升。
纳米技术简介
纳米材料是指其任意一维尺寸处于纳米尺度范围(1纳米至100纳米)的材料,或以这样的纳米单元构成的复合结构。由于尺寸微小,纳米材料表现出普通物质不具备的物理、化学特性,例如更高的表面能、更优异的光学和电学性能,成为生物医药领域理想的功能载体。
智能纳米颗粒的定义与特性
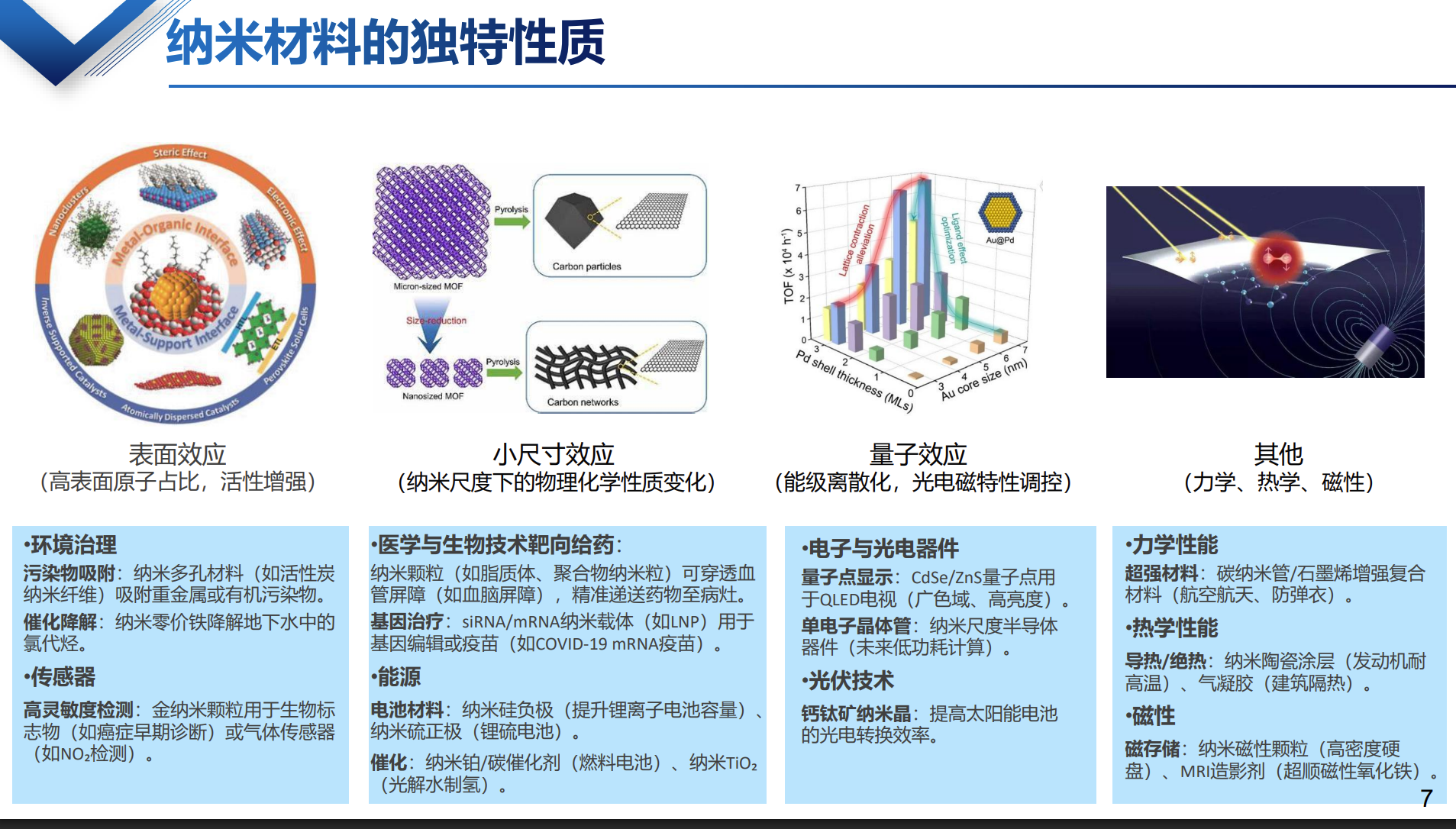
智能纳米颗粒是纳米技术与智能响应机制的结合体,能够感知并响应环境变化(如pH值、温度、酶的存在等),从而执行精准的功能任务,例如:
- 靶向性:识别特定细胞或组织,实现定点治疗。
- 药物缓释:根据环境条件控制药物释放节奏,使治疗更持久有效。
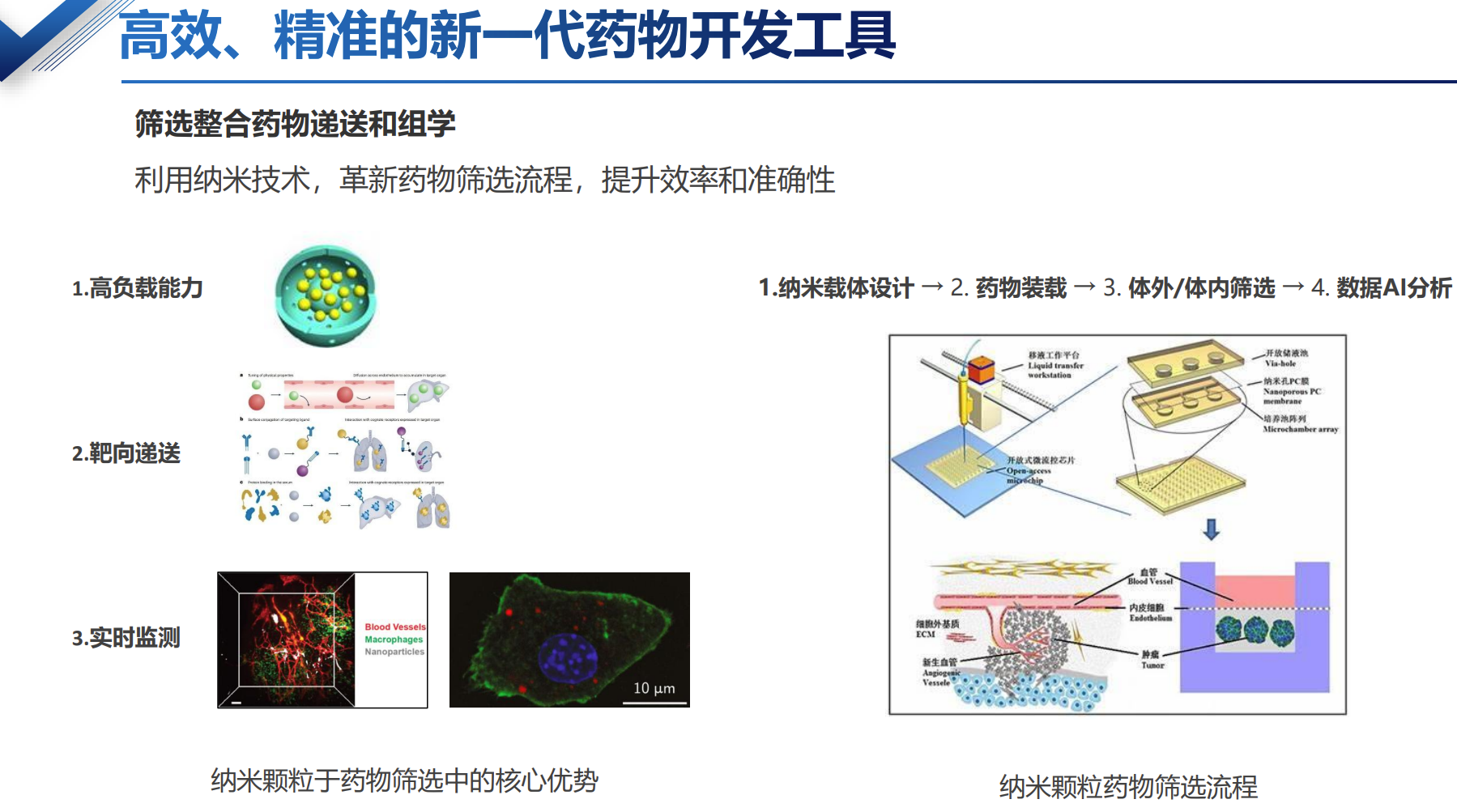
智能纳米颗粒递送药物的主要优势
改善药物溶解度与稳定性
- 提高溶解度:纳米颗粒能够将疏水性药物包裹,使其在水中更好溶解。
- 增强稳定性:防止药物在体内被快速降解,延长药物半衰期。
这一优势显著提升药物的生物利用度和治疗效果。
高靶向性与精准递送
- 被动靶向:利用肿瘤组织的血管高通透性和滞留效应,使药物自然富集。
- 主动靶向:通过表面修饰抗体或配体,将药物精准递送至目标细胞或组织,减少对正常组织的影响和副作用。
响应性释放与环境适应性
- 受环境因素(pH、温度、酶)诱导,实现药物的按需释放。
- 可整合多重刺激(光、磁、化学)响应,实现更复杂、精准的治疗控制和时空药物释放。
多功能性
- 可同步携带药物、成像剂和诊断分子,支持“诊疗一体化”。
- 实现疾病的早期诊断与个性化治疗,提高疗效并减轻患者负担。
生物医药中的应用领域
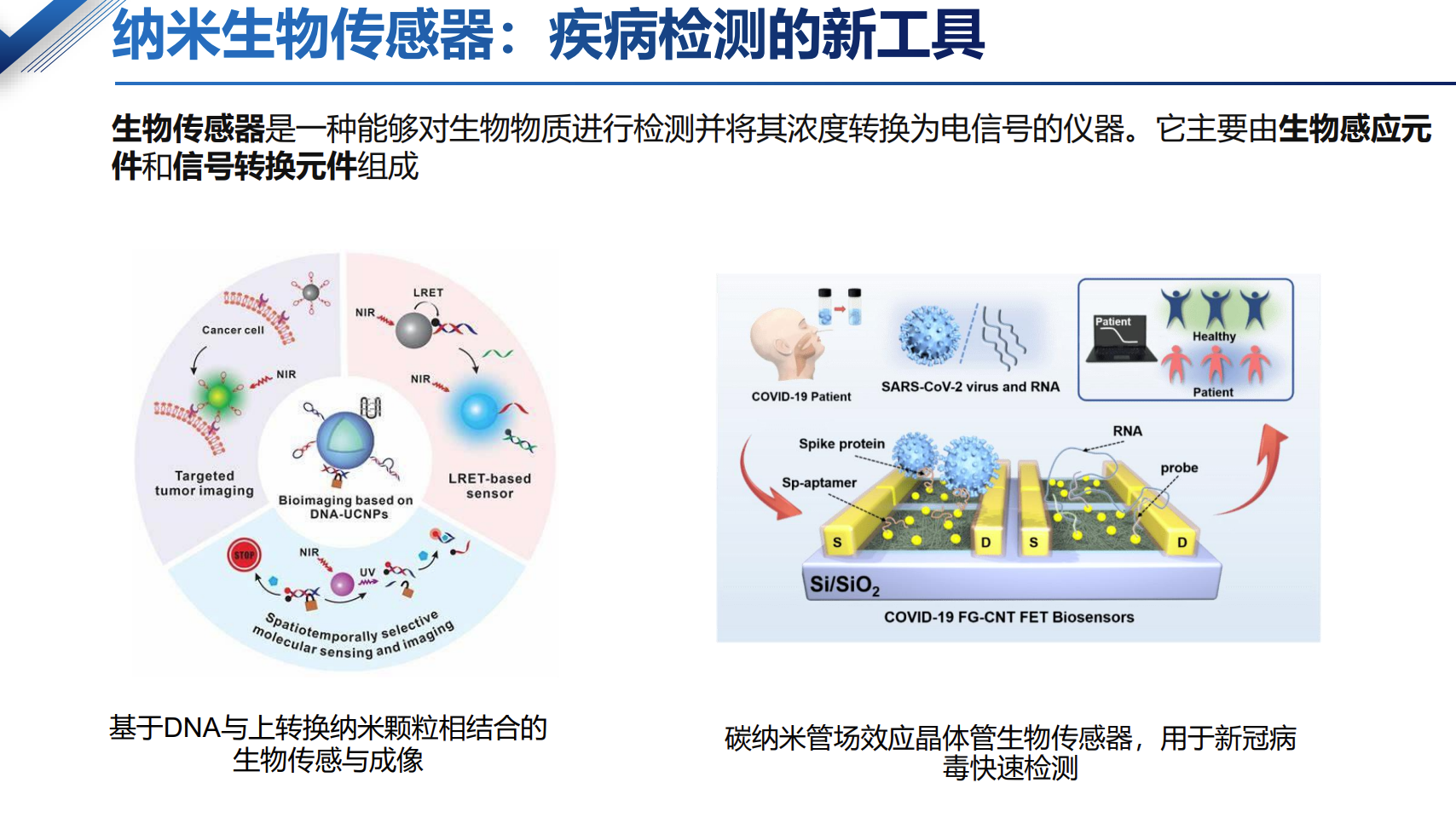
疾病诊断:点亮微观世界的“探照灯”
智能纳米颗粒增强传统医学成像技术(如CT、MRI、PET、超声成像和荧光成像)的灵敏度和分辨率,使得疾病如癌症、脑部疾病等能被更早、更准确地检测到。
药物递送:推进精准医疗革命
通过靶向、精准而高效地递送药物,智能纳米颗粒提高治疗疗效并大大减少传统药物的系统性副作用,成为个体化医疗的重要工具。
增强自身免疫
肿瘤微环境往往抑制免疫系统,使免疫治疗难以奏效。纳米载体能够携带免疫调节剂、特异性抗体,联合作用于免疫治疗、化疗和放疗,激活免疫细胞,提升肿瘤清除能力。比如,利用CAR或TCR mRNA-纳米颗粒结合T细胞输注,实现对疾病的更有效控制。
基因治疗:解锁生命密码的钥匙
通过纳米颗粒递送基因编辑工具(如CRISPR/Cas9),实现对遗传基因的精准修复,纳米技术显著提升基因治疗的靶向性、细胞摄取率和安全性,减少免疫反应,对癌症等疾病展现巨大治疗潜力。
组织工程:修复生命的“建筑师”
纳米支架结合细胞和生物活性分子,可模拟体内微环境,促进组织修复和再生。例如,在骨愈合过程中持续释放生长因子,创造有利于骨再生的环境,推动组织工程向临床应用迈进。
心血管疾病的“疏通工”
设计具有多模态成像功能的靶向纳米颗粒精准递送药物至血栓或动脉粥样硬化斑块,实现高效治疗并最小化副作用。例如,血小板膜包覆的纳米颗粒携带阿替普酶用于广谱溶栓治疗,以及多模态成像引导的高强度聚焦超声(HIFU)技术辅助血栓溶解,提高治疗的安全性与精准度。
未来发展方向与挑战
展望未来,智能纳米颗粒将在精准医疗、个性化治疗、实时多功能诊疗等领域发挥更大潜力,但仍面临诸多挑战:
- 生物相容性与安全性:长期体内稳定性及潜在毒性需系统评估。
- 制造标准化与规模化:实现高质量、可控批量生产。
- 临床转化:从实验室走向临床治疗,需满足严格的法规与伦理要求。
- 成本控制与普及应用:降低制造成本,促进技术在全球的广泛应用。
智能纳米颗粒代表了未来医疗的新方向,融合纳米科技、生物学与信息科学,将推动医药科学实现跨越式发展,助力构筑更为精准、高效、安全的医疗体系。
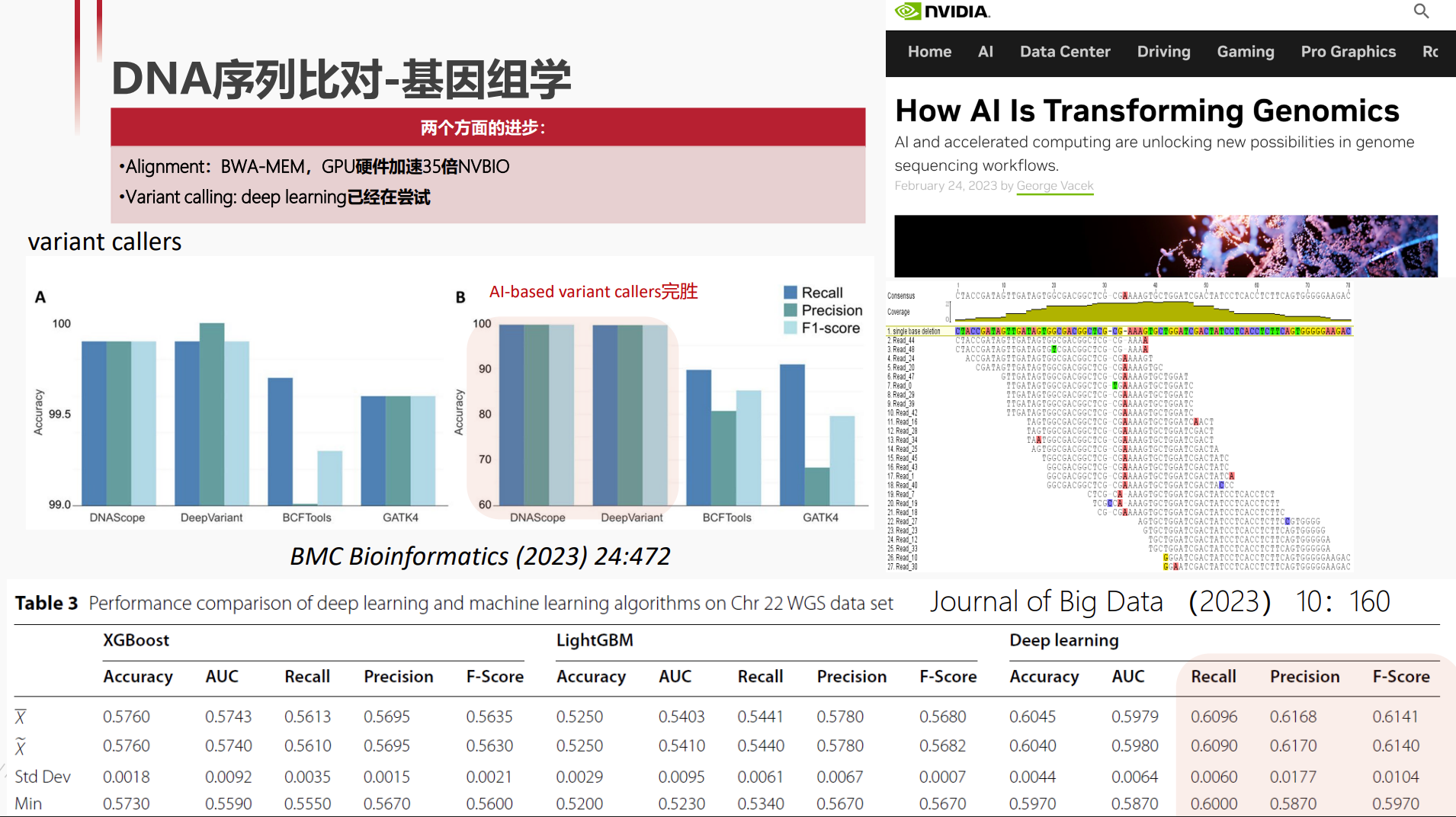
生物序列数据中的AI魔法:从数据到发现
生命的密码:DNA究竟意味着什么?
生命的基本密码是什么?答案是DNA。DNA携带着生命的遗传信息,定义了生命的结构、功能以及演化路径。通过解码这些生物序列,我们可以揭示生命的本质,理解疾病机制,甚至设计新型的生物材料和药物。在这个信息爆炸的时代,生物学数据正以指数级速度增长,带领我们进入“数据驱动的生命科学”新时代。


生物学的数据膨胀:增长的曲线与挑战
随着高通量测序技术的飞速发展,生物学产生的数据呈现出爆炸式增长。每年产生的基因组、转录组、蛋白质组等海量数据,远远超出传统分析能力。

假设:
我们有一组长度为50残基的序列(L=50),在序列比较中,每两个残基的比对耗时1秒,那么为了比对N条序列,所需时间为:
$$ (2L)^{N-2} = (2 \times 50)^{N-2} = 100^{N-2} $$
例如,4条序列的完全比对,需耗费$100^{2} = 10,000$秒(约2.8小时)。
如果计算资源无限,且愿意等待50亿年(地球生命的演化时间),那么最大能比对的序列条数为多少?
实际上,这样的计算已经超越了任何实用的范围。这个例子直观显示:传统的串行比对在海量数据面前无能为力,人工智能的介入成为解决“规模瓶颈”的关键。
人工智能在生物学中的魔法:从分子到个体
现代AI技术,尤其是深度学习,正赋予我们前所未有的能力,从海量的生物序列中挖掘“智慧的宝藏”。
以全球最大规模的蛋白质序列数据库——VenusFactory为例,我们能够利用AI模型进行“功能预测”、结构推断和工程设计。
VenusFactory:蛋白质“功能预测”的典范
在全球范围内,VenusFactory已经成为最大的蛋白质序列数据集之一。该平台专注于蛋白质“功能预测”,通过AI技术训练出“六边形战士”,为生物工程领域带来了革命性的变化。
VenusFactory在蛋白质工程中的实际应用主要集中在以下几个方面:
- 单域抗体的耐碱性改造:上海交通大学的洪亮团队运用Venus模型,对国内生长激素龙头企业金赛药业的单域抗体进行了耐碱性改造。在不到一年的时间里,成功将普通单域抗体的耐碱性提升了4倍,每年为金赛药业节省了上千万元的成本。
- 碱性磷酸酶(ALP)的优化:Venus系列模型还被应用于优化某家体外诊断头部公司的碱性磷酸酶(ALP),使其分子活性超过国际领先企业的产品3倍。这一成果对于超敏检测诊断(如心肌梗塞、阿尔茨海默症等)具有重要的临床意义,目前改造后的ALP已进入200L规模放大生产阶段。
- PET降解酶的设计:Venus模型成功设计出一种活性卓越、稳定性强且产品纯净的PET降解酶,展示了其在工业生产中的广泛应用潜力。
AI在酶工程中的应用——新质生产力的体现
通过结合高通量测序(NGS)与AI模型,我们可以高效筛选新酶、设计新蛋白,从而推动医药、农业、工业等多个领域的创新。
典型应用:
- 目标区域捕获测序: 用于疾病相关基因的突变检测和个体化药物研发。
- 全基因组/外显子组测序: 理解遗传变异与疾病的关联。
- 转录组/表观遗传测序: 揭示基因表达和调控机制。
- ChIP-Seq、甲基化测序: 捕获调控元件与染色质状态。
后续分析:
测序数据的质量控制、比对、变异检测、注释整合,为疾病机理、药物靶点的发现提供丰富信息。
NGS(高通量测序)应用
高通量测序技术被广泛应用于分子生物学、遗传学等多个领域,其中目标区域捕获测序是最主要的应用之一。具体包括:
- 全基因组测序
- 外显子组测序
- 目标区域测序
- 转录组测序
- 表达谱测序
- 小RNA测序
- 宏基因组测序
- ChIP-Seq
- 甲基化测序
在下机数据分析中,涉及到数据质量评估、测序数据的序列比对以及变异检测分析等重要环节。
人工智能在生命科学中的未来展望
随着技术的不断发展,AI将在生物学研究中发挥更加核心的作用,推动“新质生产力”的飞跃。
展望未来,人工智能将继续在生物学中发挥重要作用,包括但不限于:
- 精确的序列比对
- 药物靶点的识别与开发
- 合成生物学的创新与应用
- 蛋白质结构的预测与分析
- 文本处理、多模态数据的整合与注释
更准确地说,未来,我们可以期待在以下几个关键领域取得突破:
1. 高级序列比对与比对算法优化
传统的序列比对算法在面对海量数据时效率不足,深度学习模型将开发出更智能、更快速的序列比对工具,实现快速筛选和相似性识别,助力基因组、蛋白质数据库的智能分析。
2. 药物靶点的精准识别与个性化药物设计
结合大规模生物序列和结构信息,AI可预测蛋白质-药物相互作用,辅助发现新药靶点,设计个性化、低副作用的药物方案。
3. 合成生物学的智能设计
利用AI模拟生物合成途径,设计新型代谢路径和合成菌株,实现绿色生产、药物制造乃至新材料的快速开发。
4. 蛋白质结构预测革命
深度学习模型(如AlphaFold)已实现蛋白质三维结构的高精度预测,将彻底改变蛋白质功能研究与新药开发的格局。
5. 多模态数据的整合与深度注释
结合基因组、转录组、蛋白质组、影像等多源信息,AI能实现全方位、多角度的生物学理解,推动系统生物学的快速发展。
6. 多样化应用的深度融合:
- 文本与知识图谱: 自动抽取生物医学文献信息,构建知识网络,快速更新科研成果。
- 影像与序列的协同分析: 结合细胞影像与基因序列,实现更精准的疾病预测和机制解析。
结语:AI赋予生命科学无限可能
人工智能已由辅助工具转变为推动创新的核心力量。从序列比对、结构预测到药物发现、合成设计,AI正深刻改变着生命科学的面貌。随着算法的不断优化、数据的持续积累,以及跨学科的协作,未来的生命科学将走向“智能生命”的新时代。
我们正站在一场“智慧之门”的开启之际,AI在生命科学的舞台上,将为人类探索生命奥秘、改善健康、推动可持续发展带来前所未有的机遇。让我们共同期待这个充满希望与创新的未来!
让肿瘤细胞无所遁形——基于深度学习方法的病理图像识别
AI图像识别在肿瘤诊断中的应用
随着人工智能(AI)技术的不断发展,图像识别已成为肿瘤病理诊断的重要工具。深度学习模型,特别是卷积神经网络(CNN),能够自动学习和提取复杂的影像特征,从而实现高速、精准的肿瘤细胞检测与分类。当前,利用AI对病理切片、医学影像进行自动标注、肿瘤区域识别、病理特征提取,为早期筛查、诊断和疗效评估提供了有力支持,大大提高了诊断效率和准确性。
图像生物标记物
**生物标记物(Biomarker)**是指可以客观测量和评价正常生物过程、疾病发生发展或药物反应的指标。根据NIH(美国国家卫生研究院)生物标志物工作组的定义,生物标记物广泛应用于临床诊断、疾病预后、疗效监测以及风险评估中。它们的检测可以帮助早期识别病变、评估治疗效果和指导个体化治疗策略。
常见的图像生物标记物包括:
- 肿瘤边界和形态特征
- 细胞核或细胞质的特定荧光或组织结构变化
- 微血管网络的血流特征
- 特定的免疫染色标记物
这些影像特征作为“数字化的生物标记物”,在疾病诊断与预后评价中扮演重要角色。
生物标记物识别与疾病诊断
基于影像组学(Radiomics)的生物标记物识别,已成为计算机视觉的重要应用领域。通过高通量提取医学影像中的大量特征信息,结合AI模型进行分析,可实现疾病的早期筛查、病理状态的细粒度识别。
关键技术流程包括:
- 图像获取:高质量的影像数据采集(如CT、MRI、病理切片)
- 图像预处理:噪声滤除、标准化、增强等步骤
- 图像分割:自动或半自动提取感兴趣区域(ROI)
- 特征提取:形状、纹理、强度等多维特征
- 图像配准:多模态影像配准,实现数据融合
- 目标识别:分类、检测出肿瘤区域或病理改变
AI辅助诊断模型:
- 传统机器学习算法:Logistic回归、支持向量机(SVM)、随机森林(Random Forest)、XGBoost等
- 深度学习模型:卷积神经网络(CNN)、循环神经网络(RNN)、Transformer架构
- 模型渲染和可视化:通过可解释性分析,增强模型的临床信赖度
这些技术的结合,提高了影像信息的利用率,为精准医疗提供了可量化的支持。
计算机视觉的理论基础
计算机视觉涉及模型、算法与工具,用于模拟人类视觉识别能力,从复杂的图像数据中自动提取有用信息。其基础理论包括:
- 图像特征提取与表示
- 图像分类与检测算法
- 深度学习的卷积层设计
- 图像分割与目标识别技术
- 多模态数据融合方法
掌握这些基础,为深入开展生物标记物识别与疾病诊断提供理论支撑。
AI辅助图像生物标记物识别流程
一般流程包括:
- 数据的获取:从病理切片、影像设备或公共数据库采集数据
- 预处理:去噪、标准化、增强,提高模型鲁棒性
- 打标签(标注):由专家标注感兴趣区域或已知类别,作为训练数据
- 数据划分:训练集、验证集、测试集的合理划分,确保模型泛化能力
- 模型训练:利用深度学习或机器学习模型进行特征学习与分类
- 结果验证:利用验证集调整模型参数,避免过拟合;利用测试集评价模型性能,包括准确率、灵敏度、特异性等指标。
- 模型部署与应用:将训练好的模型集成到临床辅助平台,实现自动化、高效化的生物标记物识别与疾病诊断。
相关实例:肿瘤放疗后CRT切片分析
例如,通过深度学习模型分析肿瘤放疗(CRT)切片,可以量化肿瘤细胞的形态学变化以及坏死区域的比例,从而判断放疗效果。自动识别肿瘤细胞和坏死区域,不仅节省了人工阅片时间,还能提供定量指标,为个性化放疗方案提供科学依据。
生物信息学实验:从个体基因到群体遗传的研究流程
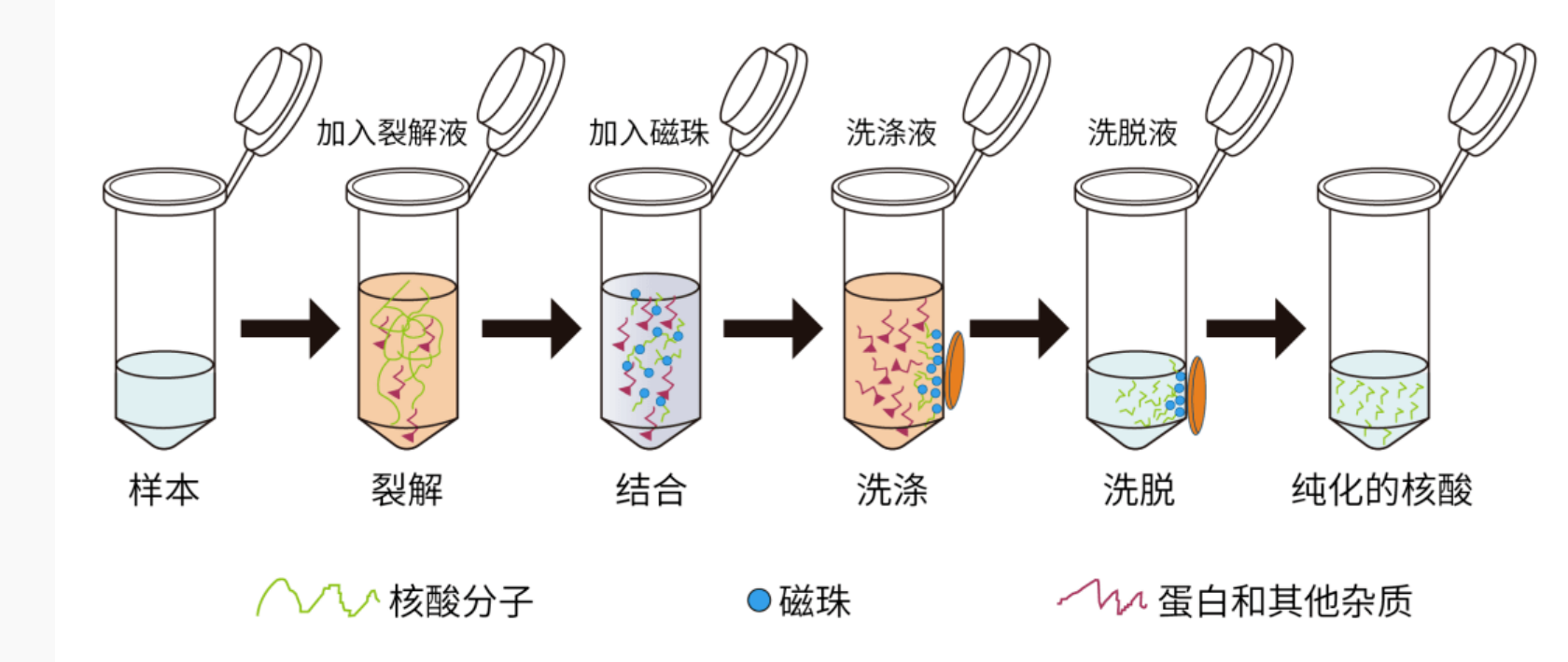
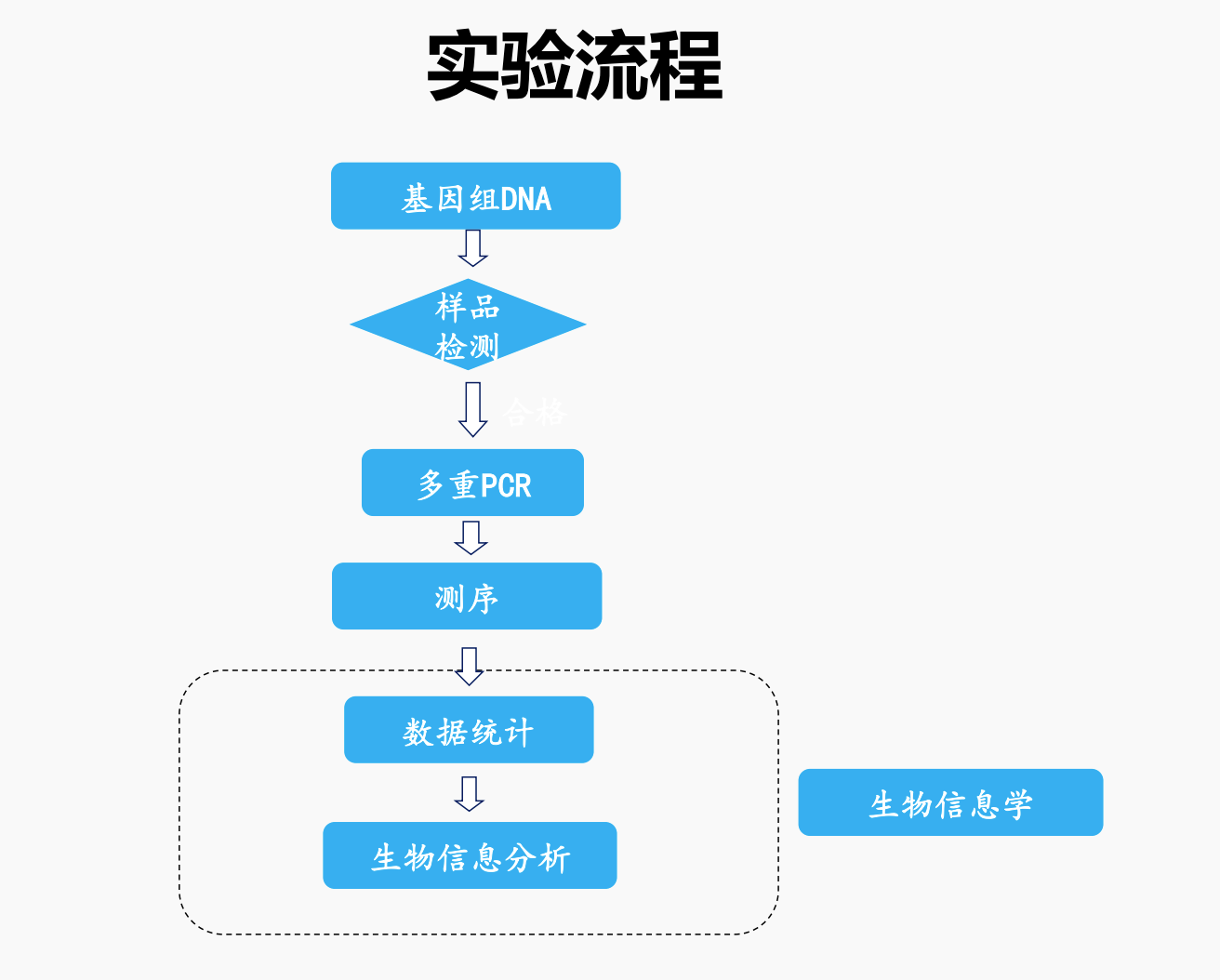
实验一:唾液采集与DNA提取
- 采集无菌唾液样本,确保样本纯净无污染
- 利用商业化DNA提取试剂盒,提取高纯度DNA
- 测定DNA浓度与纯度(如A260/A280比值)
实验二:文库制备
- 片段化DNA,获得目标片段长度(如200-500 bp)
- 连接测序接头,准备测序文库
- 纯化、定量后进行PCR扩增,确保文库浓度满足上机要求
实验三:高通量测序
- 将准备好的文库加载到测序平台(如Illumina、BGISEQ等)
- 进行高通量测序,获得大量原始序列数据
- 质量控制、过滤低质量reads,为后续分析奠定基础
总结
这套流程涉及从样本采集、DNA纯化到测序平台运行,为基因组、转录组或表观遗传学研究提供关键数据基础。通过现代生物信息学分析,可以解码个体遗传信息,识别遗传变异,为疾病风险评估、药物靶点发现和群体遗传结构研究打下坚实基础。
附录
BWV(Biological Weighting Vector)
在生物信息学中,BWV 通常指的是 Biological Weighting Vector(生物加权向量)。BWV 在基因组研究与分析中广泛应用,特别是在机器学习和生物信息学的应用中。
BWV 的主要用途
- 特征选择:在基因组数据中,BWV 可用于评估不同基因或特征的重要性,从而帮助选择与生物过程相关的关键特征。
- 模型训练:在机器学习模型中,BWV 提供特定数据特征的权重,从而改进分类或预测的性能。
- 数据整合:将不同来源的数据整合为统一的分析框架,通常涉及对不同特征施加不同的权重。
应用示例
- 在转录组学分析中,BWV 可以用于定义基因表达水平的重要性,从而影响疾病的预测模型。
- 在生态学中,BWV 可用于评估环境变量对于某些物种分布的影响。
BWA(Burrows-Wheeler Aligner)
在生物信息学中,BWA 指的是 Burrows-Wheeler Aligner,这是一种广泛使用的工具,旨在对高通量测序数据进行快速和高效的基因组比对。BWA 特别适用于短序列数据,如 Illumina 测序数据。
BWA 的主要功能
比对短序列:BWA 能够将短读段(通常在 70 到 150 碱基之间)比对到参考基因组中,帮助研究人员识别变异(如 SNPs 和插入/缺失)。
比对速度:由于使用了 Burrows-Wheeler 变换(BWT)和 FM-index,BWA 拥有较高的比对速度,适合处理大规模测序数据。
多种比对模式:
- BWA-MEM:适用于较长的读取序列(如 70bp 以上),提供准确的比对结果,广泛应用于新的测序平台。
- BWA-SW:适用于较短的读取或进行全局比对,精确度较高但速度较慢。
- BWA-backtrack:适用于 35bp 到 100bp 的短序列。
BWA 的优势
- 快速:在处理数百万至数十亿个读取时,能保持较高的比对速度。
- 内存效率高:在设计上减少了内存占用,适合计算资源有限的环境。
- 支持的文件格式:BWA 可以处理 FASTQ 格式的输入,并生成 BAM 格式的输出,便于后续分析。
常见应用
- 变异检测:通过比对样本序列与参考基因组的差异,识别潜在的基因组变异。
- 二次分析:在基因组组装后,常常需要将测序数据与已知基因组进行比对,BWA 是这个过程中常用的工具。
- 转录组测序数据分析:在 RNA-seq 分析中,BWA 也可用于比对转录本数据。
使用示例
以下是一个简单的 BWA 命令示例:
| |
构建系统进化树的流程
构建系统进化树的流程主要包括以下几个步骤,假设你已拥有用于分析的序列数据(如fq格式的测序数据):
1. 数据预处理
- 质量控制:使用工具如 FastQC 检查fq文件的质量,并根据需要进行去噪或修剪(如使用 Trimmomatic 或 Cutadapt)。
- 去除污染序列:可以利用 Bowtie 或 BWA 等工具比对到参考基因组,以去除可能的污染序列。
2. 序列组装
- 组装方法:如果需要从短序列中组装完整的基因组,可以使用 SPAdes、Velvet 等组装工具。若目标是特定基因片段,可能不需要这一步。
3. 序列比对
- 生成序列比对文件:使用工具如 MAFFT、Clustal Omega 或 Muscle 对多个序列进行比对,生成比对的序列数据。
4. 选择进化模型
- 模型测试:根据比对结果,可以使用 jModelTest 或 ModelTest-NG 选择合适的进化模型。
5. 构建系统进化树
- 树构建方法:常用方法包括:
- 邻接法(Neighbor-Joining, NJ):使用工具如 MEGA 或 PHYLIP。
- 最大似然法(Maximum Likelihood, ML):可以用 RAxML 或 IQ-TREE 构建树。
- 贝叶斯法(Bayesian Inference, BI):使用如 MrBayes 工具构建贝叶斯进化树。
6. 树的评估
- 重采样和支持值: 对构建的树进行重采样,例如使用自助法(Bootstrap)进行树的支持值评估。
7. 树的可视化
- 可视化工具:使用 FigTree、iTOL 或 TreeView 等工具可视化和编辑进化树。
8. 结果分析
- 解释树的结果,包括各个物种或样本的进化关系,以及可能的生物学含义。
参考文献和资源
- 为了深入理解和使用这些工具,可以访问相关的文档和手册,或查阅具体的研究文章。
Q30
在基因测序中,Q30 指的是测序质量的一个指标,特别是在下一代测序(NGS)中常用。具体来说,它表示测序数据中碱基调用的质量值,使用质量评分(Phred score)来量化。
Q值的含义
- Q值:表示测序碱基的准确性。Q值可以用以下公式计算: $Q = -10 \log_{10}(P)$ 其中,( P ) 是碱基错误的概率。
- Q30:表示每个碱基的错误概率为 1/1000,即99.9%的准确性。换句话说,Q30意味着该碱基被正确调用的概率非常高。
为什么Q30重要?
- 准确性:高Q值(如Q30)代表高质量的数据,能够用于下游分析,如变异检测、基因组组装等。
- 数据可靠性:许多生物信息学分析工具和算法对输入数据的质量有要求,通常需要Q值至少达到Q30。
评估测序质量
在基因测序完成后,通常会生成质量控制报告,通过对测序数据中的碱基质量值进行统计,可以评估整体的测序质量。
SNP(单核苷酸多态性,Single Nucleotide Polymorphism)
SNP(单核苷酸多态性,Single Nucleotide Polymorphism)是指在基因组中一个单一的核苷酸(A、T、C或G)发生变异的情况。具体来说,SNP是位于同一基因组位置的不同个体间存在的核苷酸变异。SNP是最常见的遗传变异类型,通常是个体遗传差异的基础。
SNP的特征
- 变异类型:SNP可以是替换(替换一个核苷酸为另一种)或缺失(缺少一个核苷酸)。
- 频率:SNP在一般人群中的频率通常达到1%以上,才能称为多态性。
- 位置:许多SNP位于基因内或基因的调控区,有些则位于非编码区域。
SNP在生物信息学中的应用
SNP具有重要的生物学意义,广泛应用于以下领域:
遗传研究:
- SNP用于研究与遗传疾病、性状相关的基因,帮助识别疾病相关的基因区域。
个体化医学:
- 通过分析个体的SNP信息,可以评估对药物的反应、潜在的副作用等,从而实现个体化治疗。
人群遗传学:
- SNP分析用于研究人群的遗传结构和演化历史,帮助追踪人类的迁徙模式。
群体基因组学:
- SNP用于描述和分析不同个体或种群之间的遗传变异,是群体遗传学研究的基础。
关联研究:
- SNP常用于全基因组关联研究(GWAS),通过统计方法寻找与特定性状或疾病相关的SNP标记。
CNV(拷贝数变异,Copy Number Variation)
CNV(拷贝数变异,Copy Number Variation)是指在基因组中某一特定区域的DNA拷贝数发生变化的现象。这种变化可以是基因组中一段DNA的拷贝数增多或减少。CNV是遗传变异的一个重要类型,并可能对个体的基因组功能、基因表达以及疾病易感性产生影响。
CNV的特征
- 变异类型:CNV可以分为两种主要类型:
- 增益(Duplication):DNA片段的拷贝数增加,可能导致基因表达量的增加。
- 缺失(Deletion):DNA片段的拷贝数减少,可能导致基因丧失或表达降低。
- 大小范围:CNV的大小可以从几百碱基对(bp)到几兆碱基对(Mb)不等。
CNV在生物信息学中的应用
CNV在多个领域中具有重要的生物学和医学意义,包括:
遗传研究:
- CNV有助于理解与遗传疾病相关的基因组结构变异,并可能揭示疾病的遗传基础。
肿瘤基因组学:
- 在癌症研究中,CNV的检测可以揭示肿瘤细胞的基因组不稳定性,与肿瘤的发生、发展和预后相关。
个体化医学:
- 通过检测个体的CNV,可以评估其对某些药物或环境因素的反应,有助于实现个体化治疗。
群体遗传学:
- CNV用于研究不同人群之间的遗传多样性,帮助理解人类迁徙和进化的历史。
全基因组关联研究:
- CNV可以与性状相关联,帮助鉴定与疾病或性状表现相关的基因区域。
CNV的检测方法
CNV可以通过多种技术进行检测,包括:
- 微阵列CGH(Comparative Genomic Hybridization)
- 全基因组测序(Whole Genome Sequencing)
- 聚合酶链反应(PCR)和实时PCR
- 高通量测序技术